
Genome-Wide Identification and Analysis of the Hsp40/J-Protein Family Reveals Its Role in Soybean (Glycine max) Growth and Development

 , , ,
, , ,  ,
,  ,
,  , and
, and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Identification of J-Protein Members in Soybean
2.2. Ancestral and Multiple Sequence Analysis
2.3. Domain Association, Motif Analysis, and Gene Structure
2.4. Chromosomal Localization
2.5. Patterns of Gene Expression
3. Results
3.1. Detection and Study of J-Proteins in Soybean
3.2. Multi-Gene Clades: Clades I, IV, IX, and XII
3.3. Oligo-gene clades: Clade II, III, VI, VII, VIII, XI
3.4. Unspecified Clades: Mono-Gene Clades V and X
3.5. Chromosomal Position of J-Protein Genes in Soybean
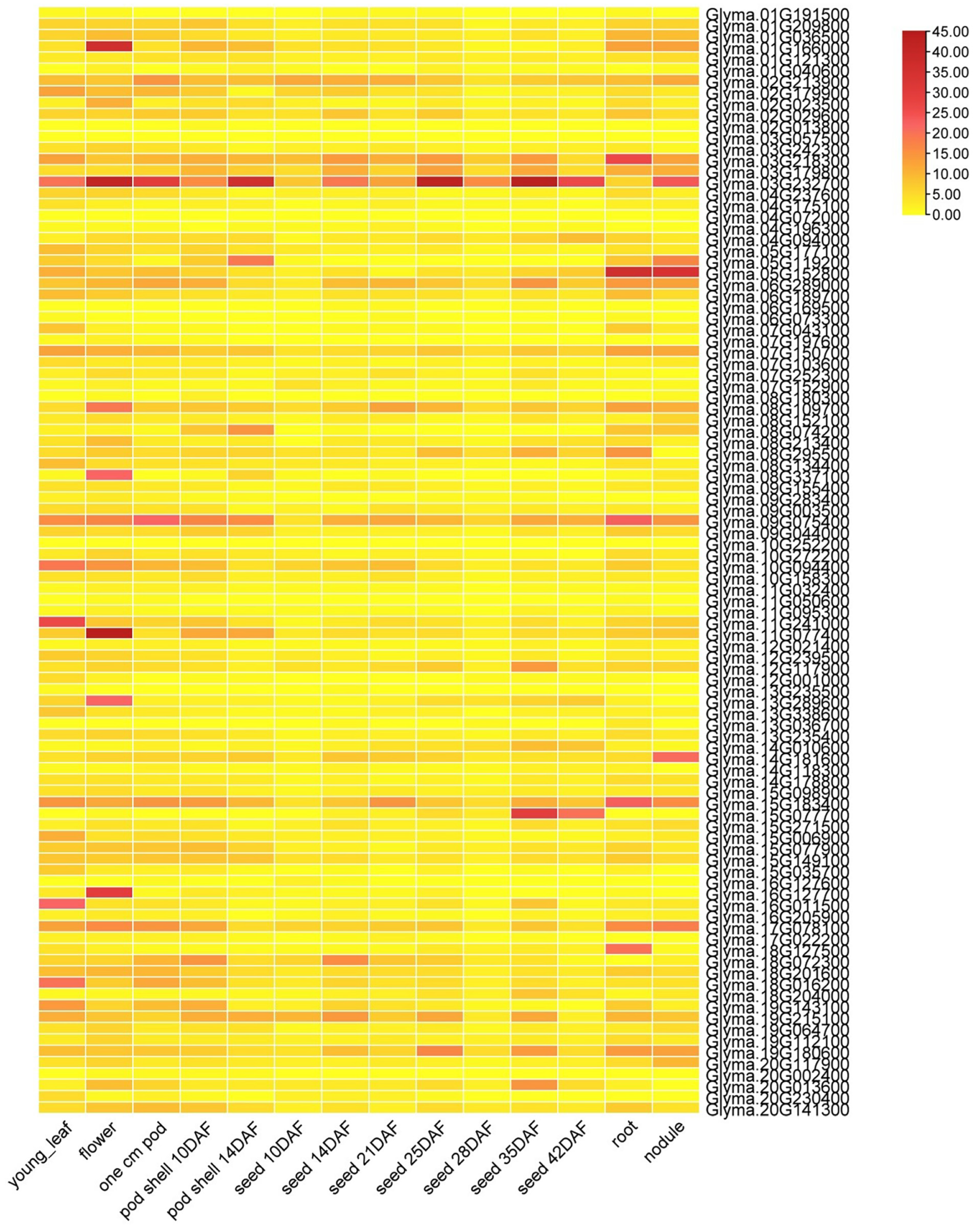
3.6. Soybean J-Protein Gene Expression Rates in Various Tissues
4. Discussion
4.1. Role of DnaJ in Plant Growth and Development
4.2. Detected Soybean J-Proteins Differ from Those Reported in Other Crops
4.3. J-Proteins Are Involved in Their Associated Networks during Soybean Growth and Development
5. Conclusions and Future Perspective
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Hayat, F.; Iqbal, S.; Coulibaly, D.; Razzaq, M.K.; Nawaz, M.A.; Jiang, W.; Shi, T.; Gao, Z. An insight into dwarfing mechanism: Contribution of scion-rootstock interactions toward fruit crop improvement. Fruit Res. 2021, 1, 3. [Google Scholar] [CrossRef]
- Razzaq, M.K.; Akhter, M.; Ahmad, R.M.; Cheema, K.L.; Hina, A.; Karikari, B.; Raza, G.; Xing, G.; Gai, J.; Khurshid, M. CRISPR-Cas9 based stress tolerance: New hope for abiotic stress tolerance in chickpea (Cicer arietinum). Mol. Biol. Rep. 2022, 49, 8977–8985. [Google Scholar] [CrossRef] [PubMed]
- Razzaq, M.K.; Aleem, M.; Mansoor, S.; Khan, M.A.; Rauf, S.; Iqbal, S.; Siddique, K.H. Omics and CRISPR-Cas9 approaches for molecular insight, functional gene analysis, and stress tolerance development in crops. Int. J. Mol. Sci. 2021, 22, 1292. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Chen, L.; Zeng, J.; Razzaq, M.K.; Xu, X.; Xu, Y.; Wang, W.; He, J.; Xing, G.; Gai, J. Identification of additive–epistatic QTLs conferring seed traits in soybean using recombinant inbred lines. Front. Plant Sci. 2020, 11, 566056. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, X.; Zhang, A.; Jiang, Z.; Chen, L.; Zhang, X. Genome-wide dynamic network analysis reveals a critical transition state of flower development in Arabidopsis. BMC Plant Biol. 2019, 19, 11. [Google Scholar] [CrossRef] [Green Version]
- Shen, L.; Kang, Y.G.G.; Liu, L.; Yu, H. The J-domain protein J3 mediates the integration of flowering signals in Arabidopsis. Plant Cell 2011, 23, 499–514. [Google Scholar] [CrossRef] [Green Version]
- Kityk, R.; Kopp, J.; Mayer, M.P. Molecular mechanism of J-domain-triggered ATP hydrolysis by Hsp70 chaperones. Mol. Cell 2018, 69, 227–237.e4. [Google Scholar] [CrossRef] [Green Version]
- Malinverni, D.; Jost Lopez, A.; De Los Rios, P.; Hummer, G.; Barducci, A. Modeling Hsp70/Hsp40 interaction by multi-scale molecular simulations and coevolutionary sequence analysis. Elife 2017, 6, e23471. [Google Scholar] [CrossRef]
- Liu, T.-T.; Xu, M.-Z.; Gao, S.-Q.; Zhang, Y.; Yang, H.; Peng, J.; Cai, L.-N.; Cheng, Y.; Chen, J.-P.; Jian, Y. Genome-wide identification and analysis of the regulation wheat DnaJ family genes following wheat yellow mosaic virus infection. J. Integr. Agric. 2022, 21, 153–169. [Google Scholar] [CrossRef]
- Yeh, F.L.; Hsu, T. Differential regulation of spontaneous and heat-induced HSP 70 expression in developing zebrafish (Danio rerio). J. Exp. Zool. 2002, 293, 349–359. [Google Scholar] [CrossRef]
- Piecuch, A.; Obłąk, E. Mechanisms of yeast resistance to environmental stress. Adv. Hyg. Exp. Med. 2013, 67, 238–254. [Google Scholar] [CrossRef]
- Mertz-Henning, L.; Pegoraro, C.; Maia, L.; Venske, E.; Rombaldi, C.; de Oliveira, A.C. Expression profile of rice Hsp genes under anoxic stress. Genet. Mol. Res. 2016, 15, gmr.15027954. [Google Scholar] [CrossRef]
- Rampelt, H.; Mayer, M.P.; Bukau, B. Nucleotide exchange factors for Hsp70 chaperones. Mol. Chaperones Methods Protoc. 2011, 787, 83–91. [Google Scholar]
- Liu, Q.; Liang, C.; Zhou, L. Structural and functional analysis of the Hsp70/Hsp40 chaperone system. Protein Sci. 2020, 29, 378–390. [Google Scholar] [CrossRef]
- Zhang, B.; Qiu, H.-L.; Qu, D.-H.; Ruan, Y.; Chen, D.-H. Phylogeny-dominant classification of J-proteins in Arabidopsis thaliana and Brassica oleracea. Genome 2018, 61, 405–415. [Google Scholar] [CrossRef] [Green Version]
- Laufen, T.; Mayer, M.P.; Beisel, C.; Klostermeier, D.; Mogk, A.; Reinstein, J.; Bukau, B. Mechanism of regulation of hsp70 chaperones by DnaJ cochaperones. Proc. Natl. Acad. Sci. USA 1999, 96, 5452–5457. [Google Scholar] [CrossRef] [Green Version]
- Rajan, V.B.V.; D’Silva, P. Arabidopsis thaliana J-class heat shock proteins: Cellular stress sensors. Funct. Integr. Genom. 2009, 9, 433–446. [Google Scholar] [CrossRef]
- Bukau, B.; Horwich, A.L. The Hsp70 and Hsp60 chaperone machines. Cell 1998, 92, 351–366. [Google Scholar] [CrossRef] [Green Version]
- Goffin, L.; Georgopoulos, C. Genetic and biochemical characterization of mutations affecting the carboxy-terminal domain of the Escherichia coli molecular chaperone DnaJ. Mol. Microbiol. 1998, 30, 329–340. [Google Scholar] [CrossRef]
- Qiu, X.-B.; Shao, Y.-M.; Miao, S.; Wang, L. The diversity of the DnaJ/Hsp40 family, the crucial partners for Hsp70 chaperones. Cell. Mol. Life Sci. CMLS 2006, 63, 2560–2570. [Google Scholar] [CrossRef]
- Pulido, P.; Leister, D. Novel DNAJ-related proteins in Arabidopsis thaliana. New Phytol. 2018, 217, 480–490. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kneissl, J.; Wachtler, V.; Chua, N.-H.; Bolle, C. OWL1: An Arabidopsis J-domain protein involved in perception of very low light fluences. Plant Cell 2009, 21, 3212–3225. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Georgopoulos, C.; Lundquist-Heil, A.; Yochem, J.; Feiss, M. Identification of the E. coli dnaJ gene product. Mol. Gen. Genet. MGG 1980, 178, 583–588. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Fang, B.; Wang, W.; Yang, Y.; Rao, L.; Zhang, C. Genome-wide analysis of the rice J-protein family: Identification, genomic organization, and expression profiles under multiple stresses. 3 Biotech 2019, 9, 358. [Google Scholar] [CrossRef] [Green Version]
- Richly, H.; Rocha-Viegas, L.; Ribeiro, J.D.; Demajo, S.; Gundem, G.; Lopez-Bigas, N.; Nakagawa, T.; Rospert, S.; Ito, T.; Di Croce, L. Transcriptional activation of polycomb-repressed genes by ZRF1. Nature 2010, 468, 1124–1128. [Google Scholar] [CrossRef]
- Park, M.Y.; Kim, S.Y. The Arabidopsis J protein AtJ1 is essential for seedling growth, flowering time control and ABA response. Plant Cell Physiol. 2014, 55, 2152–2163. [Google Scholar] [CrossRef] [Green Version]
- Park, H.-Y.; Lee, S.-Y.; Seok, H.-Y.; Kim, S.-H.; Sung, Z.R.; Moon, Y.-H. EMF1 interacts with EIP1, EIP6 or EIP9 involved in the regulation of flowering time in Arabidopsis. Plant Cell Physiol. 2011, 52, 1376–1388. [Google Scholar] [CrossRef] [Green Version]
- Zylicz, M.; Yamamoto, T.; McKittrick, N.; Sell, S.; Georgopoulos, C. Purification and properties of the dnaJ replication protein of Escherichia coli. J. Biol. Chem. 1985, 260, 7591–7598. [Google Scholar] [CrossRef]
- Ueguchi, C.; Kakeda, M.; Yamada, H.; Mizuno, T. An analogue of the DnaJ molecular chaperone in Escherichia coli. Proc. Natl. Acad. Sci. USA 1994, 91, 1054–1058. [Google Scholar] [CrossRef] [Green Version]
- Solana, J.C.; Bernardo, L.; Moreno, J.; Aguado, B.; Requena, J.M. The Astonishing Large Family of HSP40/DnaJ Proteins Existing in Leishmania. Genes 2022, 13, 742. [Google Scholar] [CrossRef]
- Cannon, S.B.; Shoemaker, R.C. Evolutionary and comparative analyses of the soybean genome. Breed. Sci. 2012, 61, 437–444. [Google Scholar] [CrossRef] [Green Version]
- Aleem, M.; Aleem, S.; Sharif, I.; Wu, Z.; Aleem, M.; Tahir, A.; Atif, R.M.; Cheema, H.M.N.; Shakeel, A.; Lei, S. Characterization of SOD and GPX Gene Families in the Soybeans in Response to Drought and Salinity Stresses. Antioxidants 2022, 11, 460. [Google Scholar] [CrossRef]
- Ozyigit, I.I.; Filiz, E.; Vatansever, R.; Kurtoglu, K.Y.; Koc, I.; Öztürk, M.X.; Anjum, N.A. Identification and comparative analysis of H2O2-scavenging enzymes (ascorbate peroxidase and glutathione peroxidase) in selected plants employing bioinformatics approaches. Front. Plant Sci. 2016, 7, 301. [Google Scholar] [CrossRef] [Green Version]
- Tamura, K.; Stecher, G.; Peterson, D.; Filipski, A.; Kumar, S. MEGA6: Molecular evolutionary genetics analysis version 6.0. Mol. Biol. Evol. 2013, 30, 2725–2729. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.L.; Williams, N.; Misleh, C.; Li, W.W. MEME: Discovering and analyzing DNA and protein sequence motifs. Nucleic Acids Res. 2006, 34, W369–W373. [Google Scholar] [CrossRef]
- Fong, J.H.; Marchler-Bauer, A. Protein subfamily assignment using the Conserved Domain Database. BMC Res. Notes 2008, 1, 114. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Chen, H.; Zhang, Y.; Thomas, H.R.; Frank, M.H.; He, Y.; Xia, R. TBtools: An integrative toolkit developed for interactive analyses of big biological data. Mol. Plant 2020, 13, 1194–1202. [Google Scholar] [CrossRef]
- Hara, M. The multifunctionality of dehydrins: An overview. Plant Signal. Behav. 2010, 5, 503–508. [Google Scholar] [CrossRef]
- Iqbal, S.; Pan, Z.; Wu, X.; Shi, T.; Ni, X.; Bai, Y.; Gao, J.; Khalil-ur-Rehman, M.; Gao, Z. Genome-wide analysis of PmTCP4 transcription factor binding sites by ChIP-Seq during pistil abortion in Japanese apricot. Plant Genome 2020, 13, e20052. [Google Scholar] [CrossRef]
- Zeng, J.; Li, M.; Qiu, H.; Xu, Y.; Feng, B.; Kou, F.; Xu, X.; Razzaq, M.K.; Gai, J.; Wang, Y. Identification of QTLs and joint QTL segments of leaflet traits at different canopy layers in an interspecific RIL population of soybean. Theor. Appl. Genet. 2022, 135, 4261–4275. [Google Scholar] [CrossRef]
- Iqbal, S.; Hayat, F.; Mushtaq, N.; Khalil-ur-Rehman, M.; Khan, U.; Yasoob, T.B.; Khan, M.N.; Ni, Z.; Ting, S.; Gao, Z. Bioinformatics Study of Aux/IAA Family Genes and Their Expression in Response to Different Hormones Treatments during Japanese Apricot Fruit Development and Ripening. Plants 2022, 11, 1898. [Google Scholar] [CrossRef] [PubMed]
- Mubarik, M.S.; Wang, X.; Khan, S.H.; Ahmad, A.; Khan, Z.; Amjid, M.W.; Razzaq, M.K.; Ali, Z.; Azhar, M.T. Engineering broad-spectrum resistance to cotton leaf curl disease by CRISPR-Cas9 based multiplex editing in plants. GM Crops Food 2021, 12, 647–658. [Google Scholar] [CrossRef] [PubMed]
- Shi, T.; Iqbal, S.; Ayaz, A.; Bai, Y.; Pan, Z.; Ni, X.; Hayat, F.; Saqib Bilal, M.; Khuram Razzaq, M.; Gao, Z. Analyzing Differentially Expressed Genes and Pathways Associated with Pistil Abortion in Japanese Apricot via RNA-Seq. Genes 2020, 11, 1079. [Google Scholar] [CrossRef] [PubMed]
- Yan, W.; Craig, E.A. The glycine-phenylalanine-rich region determines the specificity of the yeast Hsp40 Sis1. Mol. Cell. Biol. 1999, 19, 7751–7758. [Google Scholar] [CrossRef] [Green Version]
- Craig, E.; Huang, P.; Aron, R.; Andrew, A. The diverse roles of J-proteins, the obligate Hsp70 co-chaperone. In Reviews of Physiology, Biochemistry and Pharmacology; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Vembar, S.S.; Jonikas, M.C.; Hendershot, L.M.; Weissman, J.S.; Brodsky, J.L. J domain co-chaperone specificity defines the role of BiP during protein translocation. J. Biol. Chem. 2010, 285, 22484–22494. [Google Scholar] [CrossRef] [Green Version]
- Li, K.P.; Wong, C.H.; Cheng, C.C.; Cheng, S.S.; Li, M.W.; Mansveld, S.; Bergsma, A.; Huang, T.; van Eijk, M.J.; Lam, H.M. GmDNJ1, a type-I heat shock protein 40 (HSP40), is responsible for both Growth and heat tolerance in soybean. Plant Direct 2021, 5, e00298. [Google Scholar] [CrossRef]
- Bekh-Ochir, D.; Shimada, S.; Yamagami, A.; Kanda, S.; Ogawa, K.; Nakazawa, M.; Matsui, M.; Sakuta, M.; Osada, H.; Asami, T. A novel mitochondrial DnaJ/Hsp40 family protein BIL2 promotes plant growth and resistance against environmental stress in brassinosteroid signaling. Planta 2013, 237, 1509–1525. [Google Scholar] [CrossRef] [Green Version]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Razzaq, M.K.; Rani, R.; Xing, G.; Xu, Y.; Raza, G.; Aleem, M.; Iqbal, S.; Arif, M.; Mukhtar, Z.; Nguyen, H.T.; et al. Genome-Wide Identification and Analysis of the Hsp40/J-Protein Family Reveals Its Role in Soybean (Glycine max) Growth and Development. Genes 2023, 14, 1254. https://doi.org/10.3390/genes14061254
Razzaq MK, Rani R, Xing G, Xu Y, Raza G, Aleem M, Iqbal S, Arif M, Mukhtar Z, Nguyen HT, et al. Genome-Wide Identification and Analysis of the Hsp40/J-Protein Family Reveals Its Role in Soybean (Glycine max) Growth and Development. Genes. 2023; 14(6):1254. https://doi.org/10.3390/genes14061254
Chicago/Turabian StyleRazzaq, Muhammad Khuram, Reena Rani, Guangnan Xing, Yufei Xu, Ghulam Raza, Muqadas Aleem, Shahid Iqbal, Muhammad Arif, Zahid Mukhtar, Henry T. Nguyen, and et al. 2023. "Genome-Wide Identification and Analysis of the Hsp40/J-Protein Family Reveals Its Role in Soybean (Glycine max) Growth and Development" Genes 14, no. 6: 1254. https://doi.org/10.3390/genes14061254