
Genome-Wide Identification of the Whirly Gene Family and Its Potential Function in Low Phosphate Stress in Soybean (Glycine max)

 and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Identification of Putative GmWHY Genes in Soybean
2.2. Analysis of the Genomic Position, Arrangement, and Distribution of Conserved Domains in GmWHYs
2.3. Phylogenetic Investigations and Categorizations of the GmWHY Proteins
2.4. Analysis of cis-Regulatory Elements in GmWHYs for Promoter Identification
2.5. Expression Analysis of GmWHYs in Tissues and under Low Phosphate Stress
2.6. RNA Isolation and Reverse Transcription Quantitative PCR (RT-qPCR) Analysis
2.7. Haplotype Analysis of WHYs
3. Results
3.1. Identification of WHY Gene Family in Soybean
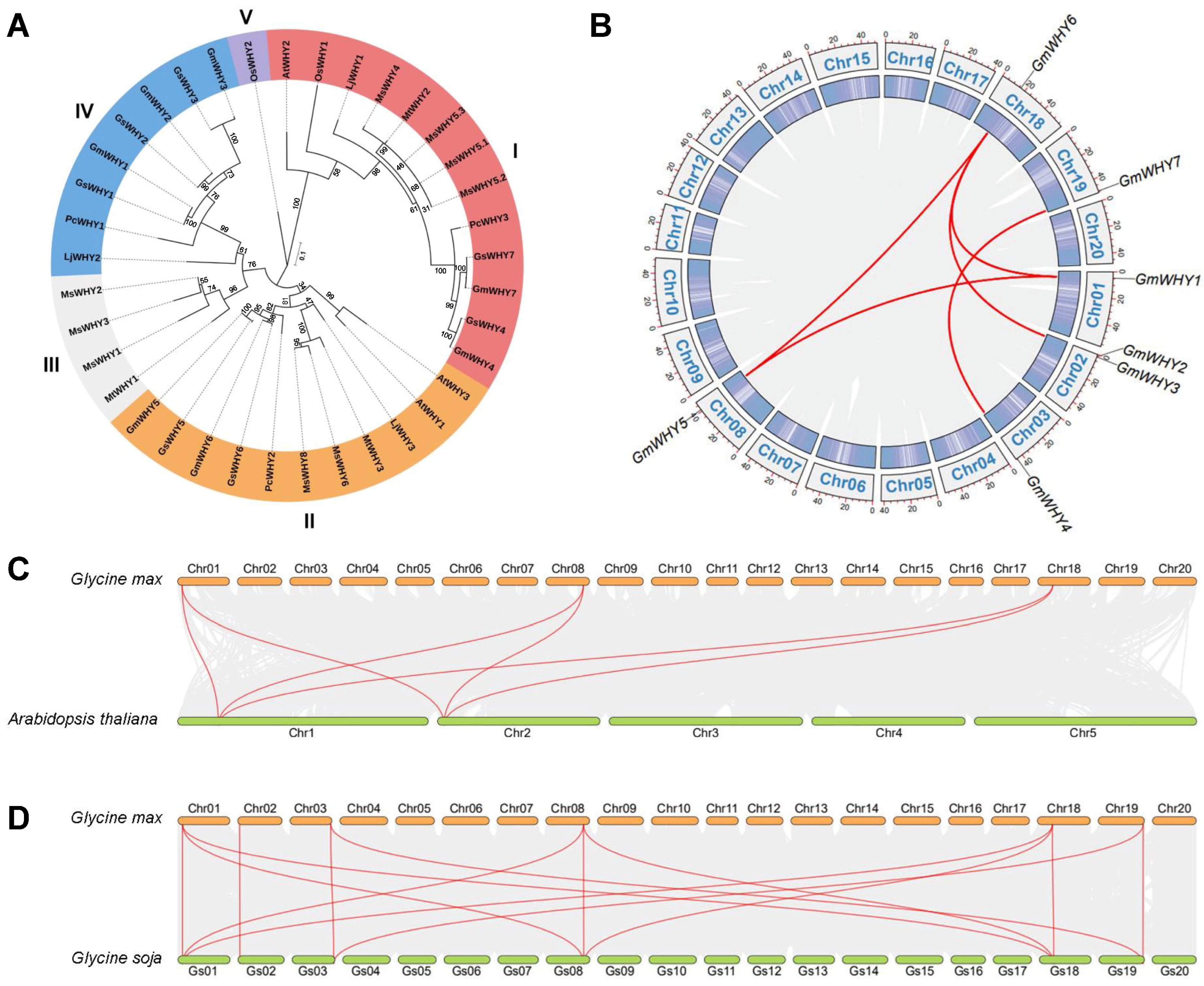
3.2. Phylogenetic Analyses of GmWHYs
3.3. Chromosome Localization and Collinear Relationship Analysis of GmWHY Genes
3.4. The Structure, Conserved Domain, and Motif Analyses of the GmWHYs
3.5. Analysis of cis-Regulatory Elements in GmWHYs
3.6. The Genetic Diversity of GmWHY Genes among Soybean Accessions
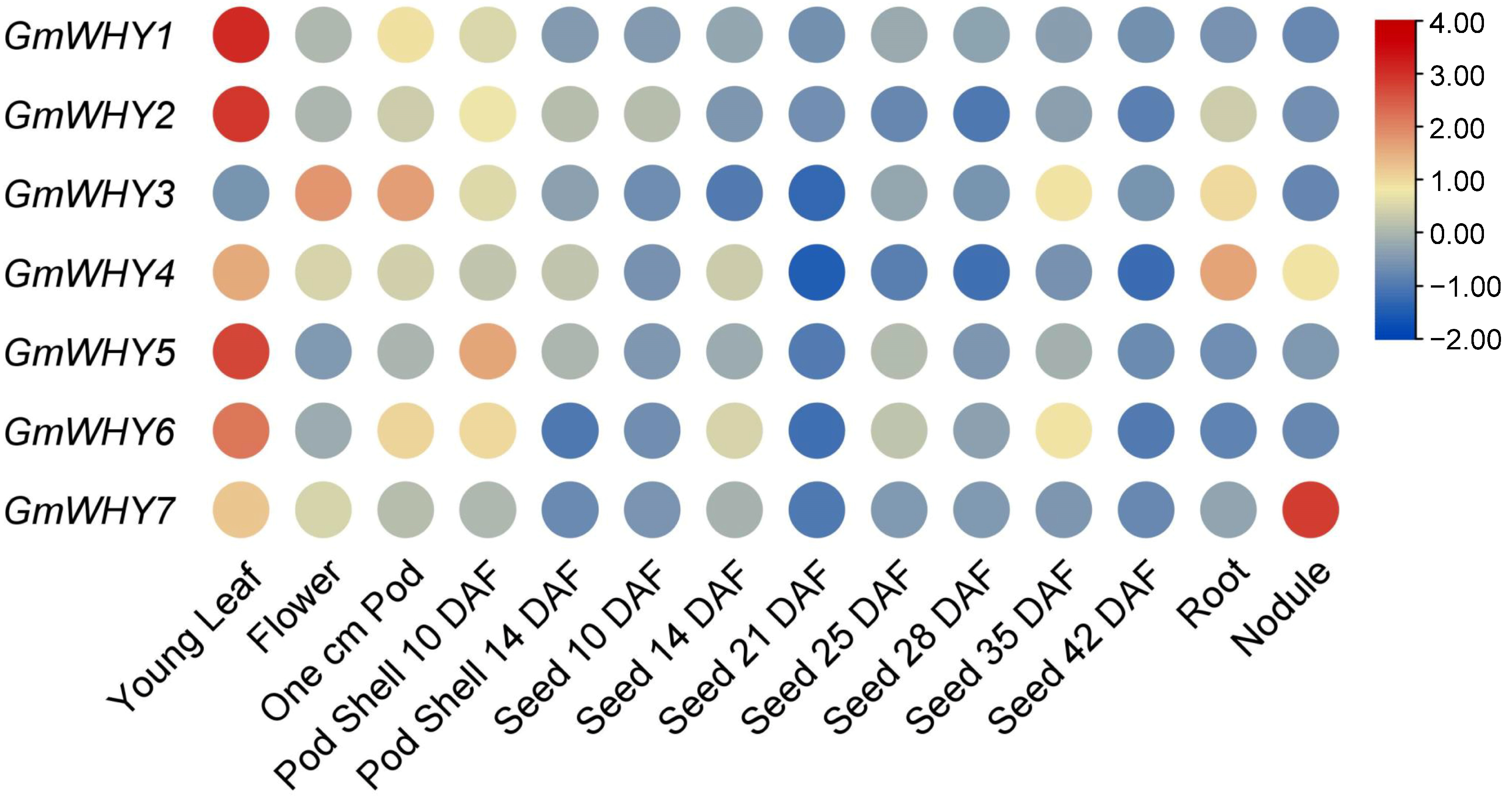
3.7. Tissue Expression Pattern Analysis of GmWHY Genes
3.8. Expression Profiles of GmWHY Genes under Low Phosphate Stress
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krupinska, K.; Desel, C.; Frank, S.; Hensel, G. WHIRLIES are multifunctional DNA-binding proteins with impact on plant development and stress resistance. Front. Plant Sci. 2022, 13, 880423. [Google Scholar] [CrossRef]
- Ruan, Q.; Wang, Y.; Xu, H.; Wang, B.; Zhu, X.; Wei, B.; Wei, X. Genome-wide identification, phylogenetic, and expression analysis under abiotic stress conditions of Whirly (WHY) gene family in Medicago sativa L. Sci. Rep. 2022, 12, 18676. [Google Scholar] [CrossRef]
- Krause, K.; Kilbienski, I.; Mulisch, M.; Rödiger, A.; Schäfer, A.; Krupinska, K. DNA-binding proteins of the Whirly family in Arabidopsis thaliana are targeted to the organelles. FEBS Lett. 2005, 579, 3707–3712. [Google Scholar] [CrossRef] [PubMed]
- Krause, K.; Krupinska, K. Nuclear regulators with a second home in organelles. Trends Plant Sci. 2009, 14, 194–199. [Google Scholar] [CrossRef] [PubMed]
- Golin, S.; Negroni, Y.L.; Bennewitz, B.; Klosgen, R.B.; Mulisch, M.; La Rocca, N.; Cantele, F.; Vigani, G.; Lo Schiavo, F.; Krupinska, K.; et al. WHIRLY2 plays a key role in mitochondria morphology, dynamics, and functionality in Arabidopsis thaliana. Plant Direct 2020, 4, e00229. [Google Scholar] [CrossRef]
- Desveaux, D.; Després, C.; Joyeux, A.; Subramaniam, R.; Brisson, N. PBF-2 is a novel single-stranded DNA binding factor implicated in PR-10a gene activation in potato. Plant Cell 2000, 12, 1477–1489. [Google Scholar] [CrossRef] [PubMed]
- Desveaux, D.; Allard, J.; Brisson, N.; Sygusch, J. A new family of plant transcription factors displays a novel ssDNA-binding surface. Nat. Struct. Biol. 2002, 9, 512–517. [Google Scholar] [CrossRef] [PubMed]
- Cappadocia, L.; Parent, J.S.; Sygusch, J.; Brisson, N. A family portrait: Structural comparison of the Whirly proteins from Arabidopsis thaliana and Solanum tuberosum. Acta Crystallogr. Sect. F Struct. Biol. Cryst. Commun. 2013, 69, 1207–1211. [Google Scholar] [CrossRef]
- Desveaux, D.; Subramaniam, R.; Després, C.; Mess, J.N.; Lévesque, C.; Fobert, P.R.; Dangl, J.L.; Brisson, N. A “Whirly” transcription factor is required for salicylic acid-dependent disease resistance in Arabidopsis. Dev. Cell 2004, 6, 229–240. [Google Scholar] [CrossRef]
- Akbudak, M.A.; Filiz, E. Whirly (Why) transcription factors in tomato (Solanum lycopersicum L.): Genome-wide identification and transcriptional profiling under drought and salt stresses. Mol. Biol. Rep. 2019, 46, 4139–4150. [Google Scholar] [CrossRef]
- Maréchal, A.; Parent, J.S.; Sabar, M.; Véronneau-Lafortune, F.; Abou-Rached, C.; Brisson, N. Overexpression of mtDNA-associated AtWhy2 compromises mitochondrial function. BMC Plant Biol. 2008, 8, 42. [Google Scholar] [CrossRef] [PubMed]
- Prikryl, J.; Watkins, K.P.; Friso, G.; van Wijk, K.J.; Barkan, A. A member of the Whirly family is a multifunctional RNA- and DNA-binding protein that is essential for chloroplast biogenesis. Nucleic Acids Res. 2008, 36, 5152–5165. [Google Scholar] [CrossRef]
- Maréchal, A.; Parent, J.S.; Véronneau-Lafortune, F.; Joyeux, A.; Lang, B.F.; Brisson, N. Whirly proteins maintain plastid genome stability in Arabidopsis. Proc. Natl. Acad. Sci. USA 2009, 106, 14693–14698. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.F.; Hou, M.M.; Tan, B.C. The requirement of WHIRLY1 for embryogenesis is dependent on genetic background in maize. PLoS ONE 2013, 8, e67369. [Google Scholar] [CrossRef] [PubMed]
- Krupinska, K.; Braun, S.; Nia, M.S.; Schäfer, A.; Hensel, G.; Bilger, W. The nucleoid-associated protein WHIRLY1 is required for the coordinate assembly of plastid and nucleus-encoded proteins during chloroplast development. Planta 2019, 249, 1337–1347. [Google Scholar] [CrossRef] [PubMed]
- Miao, Y.; Jiang, J.; Ren, Y.; Zhao, Z. The single-stranded DNA-binding protein WHIRLY1 represses WRKY53 expression and delays leaf senescence in a developmental stage-dependent manner in Arabidopsis. Plant Physiol. 2013, 163, 746–756. [Google Scholar] [CrossRef] [PubMed]
- Fang, C.; Kong, F. Soybean. Curr. Biol. 2022, 32, 902–904. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Wang, L.; Che, Z.; Wang, R.; Cui, R.; Xu, H.; Chu, S.; Jiao, Y.; Zhang, H.; Yu, D.; et al. Novel target sites for soybean yield enhancement by photosynthesis. J. Plant Physiol. 2021, 268, 153580. [Google Scholar] [CrossRef]
- Feng, C.; Gao, H.; Zhou, Y.; Jing, Y.; Li, S.; Yan, Z.; Xu, K.; Zhou, F.; Zhang, W.; Yang, X.; et al. Unfolding molecular switches for salt stress resilience in soybean: Recent advances and prospects for salt-tolerant smart plant production. Front. Plant Sci. 2023, 14, 1162014. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, L.; Zhang, D.; Che, Z.; Wang, Q.; Cui, R.; Zhao, W.; Huang, F.; Zhang, H.; Cheng, H.; et al. Soybean type-B response regulator GmRR1 mediates phosphorus uptake and yield by modifying root architecture. Plant Physiol. 2024, 194, 1527–1544. [Google Scholar] [CrossRef]
- Finn, R.; Clements, J.; Eddy, S. HMMER web server: Interactive sequence similarity searching. Nucleic Acids Res. 2011, 39, 29–37. [Google Scholar] [CrossRef] [PubMed]
- Duvaud, S.; Gabella, C.; Lisacek, F.; Stockinger, H.; Ioannidis, V.; Durinx, C. Expasy, the Swiss Bioinformatics Resource Portal, as designed by its users. Nucleic Acids Res. 2021, 49, 216–227. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Chen, H.; Zhang, Y.; Thomas, H.; Frank, M.; He, Y.; Xia, R. TBtools: An integrative toolkit developed for interactive analyses of big biological data. Mol. Plant 2020, 13, 1194–1202. [Google Scholar] [CrossRef]
- Chou, K.C.; Shen, H.B. Cell-PLoc 2.0: An improved package of web-servers for predicting subcellular localization of proteins in various organisms. Nat. Protoc. 2008, 3, 153–162. [Google Scholar] [CrossRef] [PubMed]
- Yang, M.; Derbyshire, M.K.; Yamashita, R.A.; Marchler-Bauer, A. NCBI’s conserved domain database and tools for protein domain analysis. Curr. Protoc. Bioinform. 2019, 69, e90. [Google Scholar] [CrossRef] [PubMed]
- Bailey, T.L.; Johnson, J.; Grant, C.E.; Noble, W.S. The MEME Suite. Nucleic Acids Res. 2015, 43, 39–49. [Google Scholar] [CrossRef] [PubMed]
- Yang, J.Y.; Yan, R.X.; Roy, A.; Xu, D.; Poisson, J.; Zhang, Y. The I-TASSER Suite: Protein structure and function prediction. Nat. Methods 2015, 12, 7–8. [Google Scholar] [CrossRef] [PubMed]
- Lescot, M.; Déhais, P.; Thijs, G.; Marchal, K.; Moreau, Y.; Van de Peer, Y.; Rouzé, P.; Rombauts, S. PlantCARE, a database of plant cis-acting regulatory elements and a portal to tools for in silico analysis of promoter sequences. Nucleic Acids Res. 2002, 30, 325–327. [Google Scholar] [CrossRef] [PubMed]
- Severin, A.J.; Woody, J.L.; Bolon, Y.T.; Joseph, B.; Diers, B.W.; Farmer, A.D.; Muehlbauer, G.J.; Nelson, R.T.; Grant, D.; Specht, J.E. RNA-Seq Atlas of Glycine max: A guide to the soybean transcriptome. BMC Plant Biol. 2010, 10, 160. [Google Scholar] [CrossRef]
- Yang, Y.; Zhu, X.; Cui, R.; Wang, R.; Li, H.; Wang, J.; Chen, H.; Zhang, D. NCBI’s Identification of soybean phosphorous efficiency QTLs and genes using chlorophyll fluorescence parameters through GWAS and RNA-seq. Planta 2021, 254, 110. [Google Scholar] [CrossRef]
- Livak, K.J.; Schmittgen, T.D. Analysis of relative gene expression data using real-time quantitative PCR and the method. Methods 2001, 25, 402–408. [Google Scholar] [CrossRef]
- Lu, S.J.; Dong, L.D.; Fang, C.; Liu, S.L.; Kong, L.P.; Cheng, Q.; Chen, L.Y.; Su, T.; Nan, H.Y.; Zhang, D.; et al. Stepwise selection on homeologous PRR genes controlling flowering and maturity during soybean domestication. Nat. Genet. 2020, 52, 428–436. [Google Scholar] [CrossRef] [PubMed]
- Guilfoyle, T.J.; Hagen, G. Auxin response factors. Curr. Opin. Plant Biol. 2007, 10, 453–460. [Google Scholar] [CrossRef] [PubMed]
- Okushima, Y.; Fukaki, H.; Onoda, M.; Theologis, A.; Tasaka, M. ARF7 and ARF19 regulate lateral root formation via direct activation of LBD/ASL genes in Arabidopsis. Plant Cell 2007, 19, 118–130. [Google Scholar] [CrossRef] [PubMed]
- Wu, F.; Yahaya, B.S.; Gong, Y.; He, B.; Gou, J.; He, Y.; Li, J.; Kang, Y.; Xu, J.; Wang, Q.; et al. ZmARF1 positively regulates low phosphorus stress tolerance via modulating lateral root development in maize. PLoS Genet. 2024, 20, e1011135. [Google Scholar] [CrossRef]
- Xia, T.; Zhu, X.; Zhan, Y.; Liu, B.; Zhou, X.; Zhang, Q.; Xu, W. The white lupin trehalase gene LaTRE1 regulates cluster root formation and function under phosphorus deficiency. Plant Physiol. 2024, kiae290. [Google Scholar] [CrossRef] [PubMed]
- Wang, R.; Liu, X.; Zhu, H.; Yang, Y.; Cui, R.; Fan, Y.; Zhai, X.; Yang, Y.; Zhang, S.; Zhang, J.; et al. Transcription factors GmERF1 and GmWRKY6 synergistically regulate low phosphorus tolerance in soybean. Plant Physiol. 2023, 192, 1099–1114. [Google Scholar] [CrossRef]
- Lin, W.; Huang, D.; Li, M.; Ren, Y.; Zheng, X.; Wu, B.; Miao, Y. WHIRLY proteins, multi-layer regulators linking the nucleus and organelles in developmental and stress-induced senescence of plants. Ann. Bot. 2024, mcae092. [Google Scholar] [CrossRef] [PubMed]
- Taylor, R.E.; West, C.E.; Foyer, C.H. WHIRLY protein functions in plants. Food Energy Secur. 2022, 12, e379. [Google Scholar] [CrossRef] [PubMed]
- Comadira, G.; Rasool, B.; Kaprinska, B.; García, B.M.; Morris, J.; Verrall, S.R.; Bayer, M.; Hedley, P.E.; Hancock, R.D.; Foyer, C.H. WHIRLY1 functions in the control of responses to nitrogen deficiency but not aphid infestation in barley. Plant Physiol. 2015, 168, 1140–1151. [Google Scholar] [CrossRef]
- Lin, W.; Huang, D.; Shi, X.; Deng, B.; Ren, Y.; Lin, W.; Miao, Y. H2O2 as a feedback signal on dual-located WHIRLY1 associates with leaf senescence in Arabidopsis. Cells 2019, 8, 1585. [Google Scholar] [CrossRef]
- Zhao, S.Y.; Wang, G.D.; Zhao, W.Y.; Zhang, S.; Kong, F.Y.; Dong, X.C.; Meng, Q.W. Overexpression of tomato WHIRLY protein enhances tolerance to drought stress and resistance to Pseudomonas solanacearum in transgenic tobacco. Biol. Plant. 2017, 62, 55–68. [Google Scholar] [CrossRef]
- Wang, L.; Zhang, J.; Li, H.; Zhang, G.; Hu, D.; Zhang, D.; Xu, X.; Yang, Y.; Huang, Z. Genome-wide identification of the phytocyanin gene family and its potential function in salt stress in soybean (Glycine max (L.) Merr.). Agronomy 2023, 13, 2484. [Google Scholar] [CrossRef]
- Jeffares, D.C.; Penkett, C.J.; Bähler, J. Rapidly regulated genes are intron poor. Trends Genet. 2008, 24, 375–378. [Google Scholar] [CrossRef] [PubMed]
- Christiaens, J.F.; Van Mulders, S.E.; Duitama, J.; Brown, C.A.; Ghequire, M.G.; De Meester, L.; Michiels, J.; Wenseleers, T.; Voordeckers, K.; Verstrepen, K.J. Functional divergence of gene duplicates through ectopic recombination. Embo Rep. 2012, 13, 1145–1151. [Google Scholar] [CrossRef]
- Hsia, C.C.; McGinnis, W. Evolution of transcription factor function. Curr. Opin. Genet. Dev. 2003, 13, 199–206. [Google Scholar] [CrossRef]
- Chang, Y.N.; Zhu, C.; Jiang, J.; Zhang, H.; Zhu, J.K.; Duan, C.G. Epigenetic regulation in plant abiotic stress responses. J. Integr. Plant Biol. 2020, 62, 563–580. [Google Scholar] [CrossRef]
- Lambers, H. Phosphorus Acquisition and Utilization in Plants. Annu. Rev. Plant Biol. 2022, 73, 17–42. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Zhai, X.; Zhang, L.; Yang, Y.; Zhu, H.; Lü, H.; Xiong, E.; Chu, S.; Zhang, X.; Zhang, D.; et al. Genome-Wide Identification of the Whirly Gene Family and Its Potential Function in Low Phosphate Stress in Soybean (Glycine max). Genes 2024, 15, 833. https://doi.org/10.3390/genes15070833
Li Z, Zhai X, Zhang L, Yang Y, Zhu H, Lü H, Xiong E, Chu S, Zhang X, Zhang D, et al. Genome-Wide Identification of the Whirly Gene Family and Its Potential Function in Low Phosphate Stress in Soybean (Glycine max). Genes. 2024; 15(7):833. https://doi.org/10.3390/genes15070833
Chicago/Turabian StyleLi, Zhimin, Xuhao Zhai, Lina Zhang, Yifei Yang, Hongqing Zhu, Haiyan Lü, Erhui Xiong, Shanshan Chu, Xingguo Zhang, Dan Zhang, and et al. 2024. "Genome-Wide Identification of the Whirly Gene Family and Its Potential Function in Low Phosphate Stress in Soybean (Glycine max)" Genes 15, no. 7: 833. https://doi.org/10.3390/genes15070833
APA StyleLi, Z., Zhai, X., Zhang, L., Yang, Y., Zhu, H., Lü, H., Xiong, E., Chu, S., Zhang, X., Zhang, D., & Hu, D. (2024). Genome-Wide Identification of the Whirly Gene Family and Its Potential Function in Low Phosphate Stress in Soybean (Glycine max). Genes, 15(7), 833. https://doi.org/10.3390/genes15070833