
SARS-CoV-2 Genomic Epidemiology Dashboards: A Review of Functionality and Technological Frameworks for the Public Health Response
 , ,
, ,
Abstract
:1. Introduction
2. SARS-CoV-2 Genomic Epidemiology Dashboards
3. Data on Genomic Epidemiology Dashboards
3.1. Data Sources
3.2. Data Processing
3.3. Geographic Level
3.4. Key Performance Indicators
4. Visual and Functional Features
4.1. Analyses
4.2. Filtering Options
5. Technologies behind Genomic Epidemiology Dashboards
5.1. Computational Architecture
5.2. Data Storage and Management
5.3. Open-Source and Adaptability
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Holmes, B.J. Communicating about emerging infectious disease: The importance of research. Health Risk Soc. 2008, 10, 349–360. [Google Scholar] [CrossRef]
- M’ikanatha, N.M.; Lynfield, R.; Julian, K.G.; Van Beneden, C.A.; Valk, H.d. Infectious disease surveillance: A cornerstone for prevention and control. In Infectious Disease Surveillance; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2013; pp. 1–20. [Google Scholar]
- Friede, A.; Blum, H.L.; McDonald, M. Public health informatics: How information-age technology can strengthen public health. Annu. Rev. Public Health 1995, 16, 239–252. [Google Scholar] [CrossRef] [PubMed]
- Thacker, S.B.; Stroup, D.F. Origins and progress in surveillance systems. In Infectious Disease Surveillance; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2013; pp. 21–31. [Google Scholar]
- Walker, D.M.; Yeager, V.A.; Lawrence, J.; McAlearney, A.S. Identifying Opportunities to Strengthen the Public Health Informatics Infrastructure: Exploring Hospitals’ Challenges with Data Exchange. Milbank Q. 2021, 99, 393–425. [Google Scholar] [CrossRef] [PubMed]
- Aziz, H.A. A review of the role of public health informatics in healthcare. J. Taibah Univ. Med. Sci. 2017, 12, 78–81. [Google Scholar] [CrossRef] [PubMed]
- Matheus, R.; Janssen, M.; Maheshwari, D. Data science empowering the public: Data-driven dashboards for transparent and accountable decision-making in smart cities. Gov. Inf. Q. 2020, 37, 101284. [Google Scholar] [CrossRef]
- Ivanković, D.; Barbazza, E.; Bos, V.; Brito Fernandes, Ó.; Jamieson Gilmore, K.; Jansen, T.; Kara, P.; Larrain, N.; Lu, S.; Meza-Torres, B.; et al. Features Constituting Actionable COVID-19 Dashboards: Descriptive Assessment and Expert Appraisal of 158 Public Web-Based COVID-19 Dashboards. J. Med. Internet Res. 2021, 23, e25682. [Google Scholar] [CrossRef] [PubMed]
- Vahedi, A.; Moghaddasi, H.; Asadi, F.; Hosseini, A.S.; Nazemi, E. Applications, features and key indicators for the development of COVID-19 dashboards: A systematic review study. Inform. Med. Unlocked 2022, 30, 100910. [Google Scholar] [CrossRef]
- Deng, X.; Gu, W.; Federman, S.; du Plessis, L.; Pybus, O.G.; Faria, N.R.; Wang, C.; Yu, G.; Bushnell, B.; Pan, C.-Y.; et al. Genomic surveillance reveals multiple introductions of SARS-CoV-2 into Northern California. Science 2020, 369, 582–587. [Google Scholar] [CrossRef]
- Tegally, H.; Wilkinson, E.; Giovanetti, M.; Iranzadeh, A.; Fonseca, V.; Giandhari, J.; Doolabh, D.; Pillay, S.; San, E.J.; Msomi, N.; et al. Detection of a SARS-CoV-2 variant of concern in South Africa. Nature 2021, 592, 438–443. [Google Scholar] [CrossRef]
- Wilkinson, E.; Giovanetti, M.; Tegally, H.; San, J.E.; Lessells, R.; Cuadros, D.; Martin, D.P.; Rasmussen, D.A.; Zekri, A.-R.N.; Sangare, A.K.; et al. A year of genomic surveillance reveals how the SARS-CoV-2 pandemic unfolded in Africa. Science 2021, 374, 423–431. [Google Scholar] [CrossRef]
- Dong, E.; Du, H.; Gardner, L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect. Dis. 2020, 20, 533–534. [Google Scholar] [CrossRef]
- World Health Organization. WHO COVID-19 Dashboard. Available online: https://data.who.int/dashboards/covid19/cases?n=c (accessed on 1 March 2024).
- Lo, S.W.; Jamrozy, D. Genomics and epidemiological surveillance. Nat. Rev. Microbiol. 2020, 18, 478. [Google Scholar] [CrossRef]
- Tegally, H.; Moir, M.; Everatt, J.; Giovanetti, M.; Scheepers, C.; Wilkinson, E.; Subramoney, K.; Makatini, Z.; Moyo, S.; Amoako, D.G.; et al. Emergence of SARS-CoV-2 Omicron lineages BA.4 and BA.5 in South Africa. Nat. Med. 2022, 28, 1785–1790. [Google Scholar] [CrossRef]
- GISAID. Available online: https://gisaid.org/ (accessed on 1 March 2024).
- Inzaule, S.C.; Tessema, S.K.; Kebede, Y.; Ogwell Ouma, A.E.; Nkengasong, J.N. Genomic-informed pathogen surveillance in Africa: Opportunities and challenges. Lancet Infect. Dis. 2021, 21, e281–e289. [Google Scholar] [CrossRef]
- Gardy, J.L.; Loman, N.J. Towards a genomics-informed, real-time, global pathogen surveillance system. Nat. Rev. Genet. 2018, 19, 9–20. [Google Scholar] [CrossRef]
- Chen, C.; Nadeau, S.; Yared, M.; Voinov, P.; Xie, N.; Roemer, C.; Stadler, T. CoV-Spectrum: Analysis of globally shared SARS-CoV-2 data to identify and characterize new variants. Bioinformatics 2021, 38, 1735–1737. [Google Scholar] [CrossRef]
- Kalinich, C.C.; Jensen, C.G.; Neugebauer, P.; Petrone, M.E.; Peña-Hernández, M.; Ott, I.M.; Wyllie, A.L.; Alpert, T.; Vogels, C.B.F.; Fauver, J.R.; et al. Real-time public health communication of local SARS-CoV-2 genomic epidemiology. PLoS Biol. 2020, 18, e3000869. [Google Scholar] [CrossRef]
- Fareed, N.; Swoboda, C.M.; Chen, S.; Potter, E.; Wu, D.T.Y.; Sieck, C.J. U.S. COVID-19 State Government Public Dashboards: An Expert Review. Appl. Clin. Inform. 2021, 12, 208–221. [Google Scholar] [CrossRef]
- Dixit, R.A.; Hurst, S.; Adams, K.T.; Boxley, C.; Lysen-Hendershot, K.; Bennett, S.S.; Booker, E.; Ratwani, R.M. Rapid development of visualization dashboards to enhance situation awareness of COVID-19 telehealth initiatives at a multihospital healthcare system. J. Am. Med. Inform. Assoc. 2020, 27, 1456–1461. [Google Scholar] [CrossRef]
- Mathieu, E.; Ritchie, H.; Rodés-Guirao, L.; Appel, C.; Giattino, C.; Hasell, J.; Macdonald, B.; Dattani, S.; Beltekian, D.; Ortiz-Ospina, E.; et al. Coronavirus Pandemic (COVID-19). Available online: https://ourworldindata.org/coronavirus (accessed on 15 February 2024).
- Parolini, N.; Ardenghi, G.; Dede’, L.; Quarteroni, A. A mathematical dashboard for the analysis of Italian COVID-19 epidemic data. Int. J. Numer. Methods Biomed. Eng. 2021, 37, e3513. [Google Scholar] [CrossRef]
- Stevens, J.S.; Toma, K.; Tanzi-Pfeifer, S.; Rao, M.K.; Mohan, S.; Gharavi, A.G.; Radhakrishnan, J. Dashboards to Facilitate Nephrology Disaster Planning in the COVID-19 Era. Kidney Int. Rep. 2020, 5, 1298–1302. [Google Scholar] [CrossRef]
- Attwood, S.W.; Hill, S.C.; Aanensen, D.M.; Connor, T.R.; Pybus, O.G. Phylogenetic and phylodynamic approaches to understanding and combating the early SARS-CoV-2 pandemic. Nat. Rev. Genet. 2022, 23, 547–562. [Google Scholar] [CrossRef]
- Chen, Z.; Azman, A.S.; Chen, X.; Zou, J.; Tian, Y.; Sun, R.; Xu, X.; Wu, Y.; Lu, W.; Ge, S.; et al. Global landscape of SARS-CoV-2 genomic surveillance and data sharing. Nat. Genet. 2022, 54, 499–507. [Google Scholar] [CrossRef]
- Wang, R.; Chen, J.; Gao, K.; Hozumi, Y.; Yin, C.; Wei, G.W. Analysis of SARS-CoV-2 mutations in the United States suggests presence of four substrains and novel variants. Commun. Biol. 2021, 4, 228. [Google Scholar] [CrossRef]
- Makowski, E.K.; Schardt, J.S.; Smith, M.D.; Tessier, P.M. Mutational analysis of SARS-CoV-2 variants of concern reveals key tradeoffs between receptor affinity and antibody escape. PLoS Comput. Biol. 2022, 18, e1010160. [Google Scholar] [CrossRef]
- Nijkamp, P.; Kourtit, K. Place-Specific Corona Dashboards for Health Policy: Design and Application of a ‘Dutchboard’. Sustainability 2022, 14, 836. [Google Scholar] [CrossRef]
- Clark, K.; Karsch-Mizrachi, I.; Lipman, D.J.; Ostell, J.; Sayers, E.W. GenBank. Nucleic Acids Res. 2016, 44, D67–D72. [Google Scholar] [CrossRef]
- Shu, Y.; McCauley, J. GISAID: Global initiative on sharing all influenza data-from vision to reality. Euro Surveill. 2017, 22, 30494. [Google Scholar] [CrossRef]
- Bedford, T.; Hadfield, J.; Hodcroft, E.; Huddleston, J.; Neher, R.; Sibley, T. Extension of SARS-CoV-2 Data Processing to Incorporate Open Data through GenBank. 2021. Available online: https://dev.nextstrain.org/blog/2021-07-08-ncov-open-announcement (accessed on 5 March 2024).
- Blaxter, M.; Danchin, A.; Savakis, B.; Fukami-Kobayashi, K.; Kurokawa, K.; Sugano, S.; Roberts, R.J.; Salzberg, S.L.; Wu, C.I. Reminder to deposit DNA sequences. Science 2016, 352, 780. [Google Scholar] [CrossRef]
- Xavier, J.S.; Moir, M.; Tegally, H.; Sitharam, N.; Abdool Karim, W.; San, J.E.; Linhares, J.; Wilkinson, E.; Ascher, D.B.; Baxter, C.; et al. SARS-CoV-2 Africa dashboard for real-time COVID-19 information. Nat. Microbiol. 2023, 8, 1–4. [Google Scholar] [CrossRef]
- Argimón, S.; Abudahab, K.; Goater, R.J.E.; Fedosejev, A.; Bhai, J.; Glasner, C.; Feil, E.J.; Holden, M.T.G.; Yeats, C.A.; Grundmann, H.; et al. Microreact: Visualizing and sharing data for genomic epidemiology and phylogeography. Microb. Genom. 2016, 2, e000093. [Google Scholar] [CrossRef]
- Wellcome Sanger Institute. COVID-19 Genomic Surveillance. Available online: https://covid19.sanger.ac.uk/lineages/raw (accessed on 1 March 2024).
- McBroome, J.; Martin, J.; de Bernardi Schneider, A.; Turakhia, Y.; Corbett-Detig, R. Identifying SARS-CoV-2 regional introductions and transmission clusters in real time. Virus Evol. 2022, 8, veac048. [Google Scholar] [CrossRef]
- Lechner, B.; Fruhling, A. Towards public health dashboard design guidelines. In Proceedings of the Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Heraklion, Greece, 2014; pp. 49–59. [Google Scholar]
- Cahyadi, A.; Prananto, A. Reflecting design thinking: A case study of the process of designing dashboards. J. Syst. Inf. Technol. 2015, 17, 286–306. [Google Scholar] [CrossRef]
- Maury, E.; Boldi, M.-O.; Greub, G.; Chavez, V.; Jaton, K.; Opota, O. An Automated Dashboard to Improve Laboratory COVID-19 Diagnostics Management. Front. Digit. Health 2021, 3, 773986. [Google Scholar] [CrossRef]
- Mattern, S. Mission Control: A History of the Urban Dashboard. 2015. Available online: https://placesjournal.org/article/mission-control-a-history-of-the-urban-dashboard/ (accessed on 25 March 2024).
- Nextstrain Team. Genomic Epidemiology of SARS-CoV-2 with Subsampling Focused Globally over the Past 6 Months. Available online: https://nextstrain.org/ncov/gisaid/global/6m (accessed on 1 March 2024).
- CoV-Spectrum. Detect and Analyze Variants of SARS-CoV-2. Available online: https://cov-spectrum.org/explore/World/AllSamples/Past6M (accessed on 1 March 2024).
- Persson, M. JavaScript DOM Manipulation Performance: Comparing Vanilla JavaScript and Leading JavaScript Front-End Frameworks. Diploma Thesis, Blekinge Institute of Technology, Karlskrona, Sweden, 2020. [Google Scholar]
- Köster, J.; Rahmann, S. Snakemake—A scalable bioinformatics workflow engine. Bioinformatics 2012, 28, 2520–2522. [Google Scholar] [CrossRef]
- Huddleston, J.; Hadfield, J.; Sibley, T.R.; Lee, J.; Fay, K.; Ilcisin, M.; Harkins, E.; Bedford, T.; Neher, R.A.; Hodcroft, E.B. Augur: A bioinformatics toolkit for phylogenetic analyses of human pathogens. J. Open Source Softw. 2021, 6, 2906. [Google Scholar] [CrossRef]
- Price, M.N.; Dehal, P.S.; Arkin, A.P. FastTree 2—Approximately Maximum-Likelihood Trees for Large Alignments. PLoS ONE 2010, 5, e9490. [Google Scholar] [CrossRef]
- Stamatakis, A. RAxML version 8: A tool for phylogenetic analysis and post-analysis of large phylogenies. Bioinformatics 2014, 30, 1312–1313. [Google Scholar] [CrossRef]
- Katoh, K.; Misawa, K.; Kuma, K.; Miyata, T. MAFFT: A novel method for rapid multiple sequence alignment based on fast Fourier transform. Nucleic Acids Res. 2002, 30, 3059–3066. [Google Scholar] [CrossRef]
- Sagulenko, P.; Puller, V.; Neher, R.A. TreeTime: Maximum-likelihood phylodynamic analysis. Virus Evol. 2018, 4, vex042. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, L.T.; Schmidt, H.A.; von Haeseler, A.; Minh, B.Q. IQ-TREE: A fast and effective stochastic algorithm for estimating maximum-likelihood phylogenies. Mol. Biol. Evol. 2015, 32, 268–274. [Google Scholar] [CrossRef] [PubMed]
- Batini, C.; Lenzerini, M.; Navathe, S. A Comparative Analysis of Methodologies for Database Schema Integration. ACM Comput. Surv. 1986, 18, 323–364. [Google Scholar] [CrossRef]
- Jung, M.G.; Youn, S.A.; Bae, J.; Choi, Y.L. A Study on Data Input and Output Performance Comparison of MongoDB and PostgreSQL in the Big Data Environment. In Proceedings of the 2015 8th International Conference on Database Theory and Application (DTA), Jeju, Republic of Korea, 25–28 November 2015; pp. 14–17. [Google Scholar]
- Győrödi, C.; Gyorodi, R.; Pecherle, G.; Olah, A. A Comparative Study: MongoDB vs. MySQL. In Proceedings of the 13th International Conference on Engineering of Modern Electric Systems (EMES), Oradea, Romania, 11–12 June 2015. [Google Scholar]
- Velmovitsky, P.E.; Bevilacqua, T.; Alencar, P.; Cowan, D.; Morita, P.P. Convergence of Precision Medicine and Public Health Into Precision Public Health: Toward a Big Data Perspective. Front. Public Health 2021, 9, 561873. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Ji, C.; Zhou, H.-Y.; Zheng, H.; Wu, A. Web Resources for SARS-CoV-2 Genomic Database, Annotation, Analysis and Variant Tracking. Viruses 2023, 15, 1158. [Google Scholar] [CrossRef]
- Hill, V.; Githinji, G.; Vogels, C.B.F.; Bento, A.I.; Chaguza, C.; Carrington, C.V.F.; Grubaugh, N.D. Toward a global virus genomic surveillance network. Cell Host Microbe 2023, 31, 861–873. [Google Scholar] [CrossRef]
- Tang, P.; Croxen, M.A.; Hasan, M.R.; Hsiao, W.W.L.; Hoang, L.M. Infection control in the new age of genomic epidemiology. Am. J. Infect. Control 2017, 45, 170–179. [Google Scholar] [CrossRef]
- Hill, V.; Ruis, C.; Bajaj, S.; Pybus, O.G.; Kraemer, M.U.G. Progress and challenges in virus genomic epidemiology. Trends Parasitol. 2021, 37, 1038–1049. [Google Scholar] [CrossRef] [PubMed]
- Jansz, N.; Faulkner, G.J. Viral genome sequencing methods: Benefits and pitfalls of current approaches. Biochem. Soc. Trans. 2024, 52, 1431–1447. [Google Scholar] [CrossRef]
- Hadfield, J.; Megill, C.; Bell, S.M.; Huddleston, J.; Potter, B.; Callender, C.; Sagulenko, P.; Bedford, T.; Neher, R.A. Nextstrain: Real-time tracking of pathogen evolution. Bioinformatics 2018, 34, 4121–4123. [Google Scholar] [CrossRef]
- Wright, D.W.; Harvey, W.T.; Hughes, J.; Cox, M.; Peacock, T.P.; Colquhoun, R.; Jackson, B.; Orton, R.; Nielsen, M.; Hsu, N.S.; et al. Tracking SARS-CoV-2 mutations and variants through the COG-UK-Mutation Explorer. Virus Evol. 2022, 8, veac023. [Google Scholar] [CrossRef]
- Dudas, G.; Carvalho, L.M.; Bedford, T.; Tatem, A.J.; Baele, G.; Faria, N.R.; Park, D.J.; Ladner, J.T.; Arias, A.; Asogun, D.; et al. Virus genomes reveal factors that spread and sustained the Ebola epidemic. Nature 2017, 544, 309–315. [Google Scholar] [CrossRef]
- Faria, N.R.; Azevedo, R.; Kraemer, M.U.G.; Souza, R.; Cunha, M.S.; Hill, S.C.; Thézé, J.; Bonsall, M.B.; Bowden, T.A.; Rissanen, I.; et al. Zika virus in the Americas: Early epidemiological and genetic findings. Science 2016, 352, 345–349. [Google Scholar] [CrossRef]
- Mutreja, A.; Kim, D.W.; Thomson, N.R.; Connor, T.R.; Lee, J.H.; Kariuki, S.; Croucher, N.J.; Choi, S.Y.; Harris, S.R.; Lebens, M.; et al. Evidence for several waves of global transmission in the seventh cholera pandemic. Nature 2011, 477, 462–465. [Google Scholar] [CrossRef]
- Xu, C.; Xu, J.; Wang, L. Long-term effects of climate factors on dengue fever over a 40-year period. BMC Public Health 2024, 24, 1451. [Google Scholar] [CrossRef]
- AXA, UK. AXA to Partner with London School of Hygiene & Tropical Medicine on Dengue Outbreak Forecasting Project. 2023. Available online: https://www.axa.co.uk/newsroom/media-releases/2023/axa-to-partner-with-london-school-of-hygiene-and-tropical-medicine-on-dengue-outbreak-forecasting-project/ (accessed on 30 March 2024).
- Haque, M.A.; Halder, A.S.; Hossain, M.J.; Islam, M.R. Prediction of potential public health risk of the recent multicountry monkeypox outbreak: An update after the end declaration of global public health emergency. Health Sci. Rep. 2024, 7, e2136. [Google Scholar] [CrossRef]
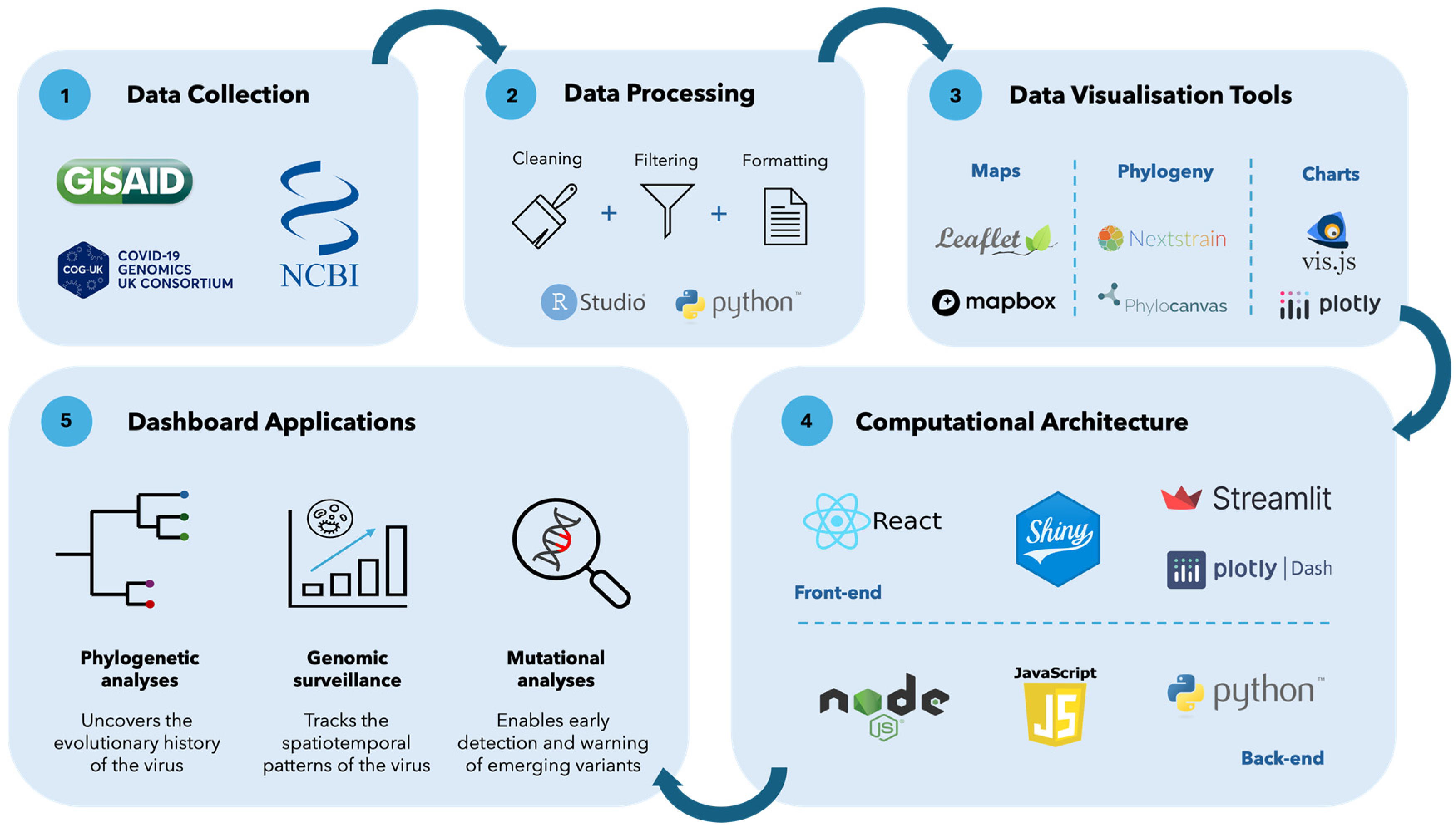
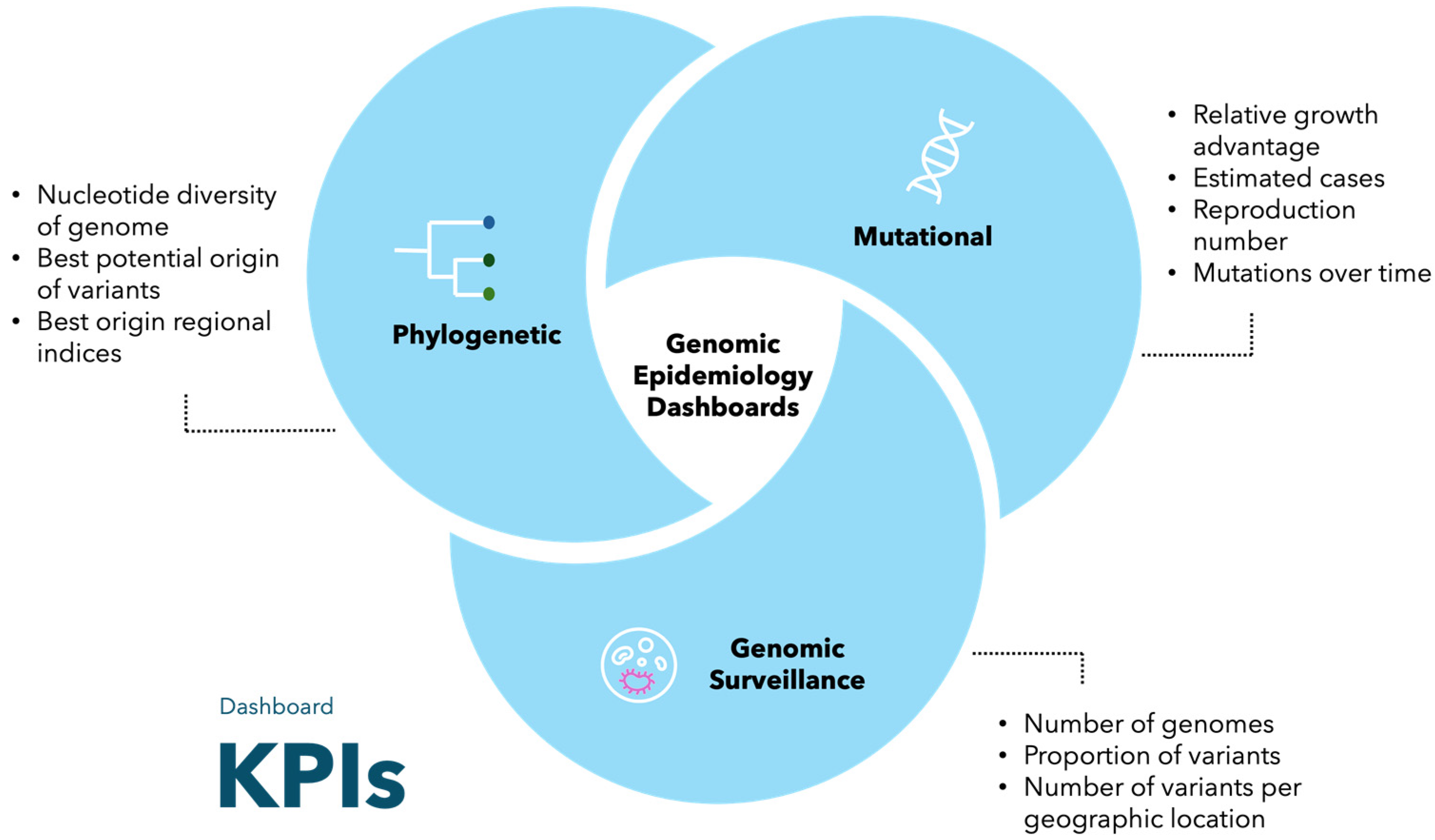

{kind=link}
{kind=link}
| Dashboard Attributes | Nextstrain’s Genomic Epidemiology of SARS-CoV-2 Dashboard 1 | Cluster-Tracker 2 | Global Distribution of SARS-CoV-2 Microreact Dashboard 3 | COVID-19 Genomic Surveillance Dashboard 6 | SARS-CoV-2 Africa Dashboard 8 | CoV-Spectrum 9 |
|---|---|---|---|---|---|---|
| Maintained by | Nextstrain team | Biomolecular Engineering and Genomics Institute, University of California | The Centre for Genomic Pathogen Surveillance | Wellcome Sanger Institute | Centre for Epidemic Response and Innovation | Computational Evolution group at ETH Zurich |
| Main purpose | Presents the genomic epidemiology of SARS-CoV-2 using phylogenetic analyses | Communicates the results of a phylogenetically informed summary heuristic for the USA | Shares the genomic epidemiology of SARS-CoV-2 and enables open data visualization in a collaborative and interdisciplinary effort | Continually evaluates and understands the state of the pandemic and the circulating lineages of SARS-CoV-2 in England | Produces an interactive perspective of the SARS-CoV-2 variants circulating on the African continent | Identifies novel VOCs and tracks the spread of known VOCs |
| Type | Phylogenetic | Phylogenetic | Genomic surveillance | Genomic surveillance | Genomic surveillance | Mutational |
| Update frequency | Every two days | ND | Last updated: 11 February 2022 | Last updated: 20 February 2023 | Every day | Once a week |
| Open-source | Yes | Yes | No | Uses open-source framework—CovInce 7 | Uses open-source framework—Genomic Dash | Yes |
| Data source | GenBank and GISAID | GenBank, GISAID, and COG-UK | COG-UK | COG-UK | GISAID | GISAID and Nextstrain open data |
| Data availability | GenBank data only | Yes | Yes | Yes | No | Yes |
| Geographic level | Global | National—USA | Global | National—England | Regional—Africa | Global |
| Key performance indicators | Phylogenetic tree, proportion of variants, nucleotide diversity | Number of clusters and introductions | Number of genomes, proportion of variants, number of cases | Proportion of lineages, estimated cases, number of genomes | Number of genomes, proportion of lineages, proportion of lineages per country over time | Total sequences, overall proportion, descendent lineages, estimated cases, relative growth advantage, reproduction number, age demographics, mutations over time, nucleotide entropy, insertions, substitutions, and deletions |
| Analyses | Phylogenetic and mutational | Phylogenetically informed summary heuristic | Genomic pattern | Genomic pattern | Genomic pattern | Mutational |
| Filtering options | Dataset, time, variant, country, clade, emerging lineage, genotype, etc. | Time | Time and variant | Time, local authorities in England, and lineages | Time, region, country, and lineages | Dataset, time, host, submission dates, and sequence quality |
| Computational architecture | Front-end: Aupice Back-end: Augur | Front-end: Vanilla JavaScript Back-end: Python Figures: Javascript library—Leaflet and jQuery (DataTables) | Front-end: React and Node.js frameworks Back-end: JavaScript, CSS 4 and HTML 5 Figures: JavaScript libraries—Phylocanvas, vis.js, Leaflet, and Mapbox mapping platform | Front-end: React framework Back-end: CovInce framework | Front-end: Streamlit Figures: Python library—Plotly | Front-end: React framework Back-end: TypeScript language Figures: Rechart and Python library—Plotly |
| Databases/API | ND | None | MongoDB | ND | GISAID API | PostgreSQL and REST APIs |
| Limitations | The pie charts are difficult to read as there are a lot of segments to display for the different variants | This summary heuristic cannot be filtered for by variant | The data presented on the global map are not standardized, which leads to most countries appearing to have produced minimal or no sequences | The dashboard has not been maintained and updated | It has a slower loading time once filters are applied | There are no figures to consolidate the temporal or geographical information of the sequences |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sitharam, N.; Tegally, H.; Silva, D.d.C.; Baxter, C.; de Oliveira, T.; Xavier, J.S. SARS-CoV-2 Genomic Epidemiology Dashboards: A Review of Functionality and Technological Frameworks for the Public Health Response. Genes 2024, 15, 876. https://doi.org/10.3390/genes15070876
Sitharam N, Tegally H, Silva DdC, Baxter C, de Oliveira T, Xavier JS. SARS-CoV-2 Genomic Epidemiology Dashboards: A Review of Functionality and Technological Frameworks for the Public Health Response. Genes. 2024; 15(7):876. https://doi.org/10.3390/genes15070876
Chicago/Turabian StyleSitharam, Nikita, Houriiyah Tegally, Danilo de Castro Silva, Cheryl Baxter, Tulio de Oliveira, and Joicymara S. Xavier. 2024. "SARS-CoV-2 Genomic Epidemiology Dashboards: A Review of Functionality and Technological Frameworks for the Public Health Response" Genes 15, no. 7: 876. https://doi.org/10.3390/genes15070876