
A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms

 ,
,
Abstract
:1. Introduction
2. Methods Used
2.1. Geostatistical Technique
2.1.1. Ordinary Kriging
2.1.2. Indicator Kriging
2.2. Machine Learning Algorithms in Resource Prediction
2.2.1. Gaussian Process Regression (GPR)
2.2.2. Support Vector Regression (SVR)
2.2.3. Decision Tree Ensemble (DTE)
2.2.4. Fully Connected Neural Network (FCNN)
2.2.5. K-Nearest Neighbors (K-NN)
2.3. Marine Predators Optimization Algorithm (MPA)
- Prey is faster than a predator.
- The predator is faster than the prey.
- Predator and prey have similar speeds.
2.4. Model Validation and Performance Evaluation
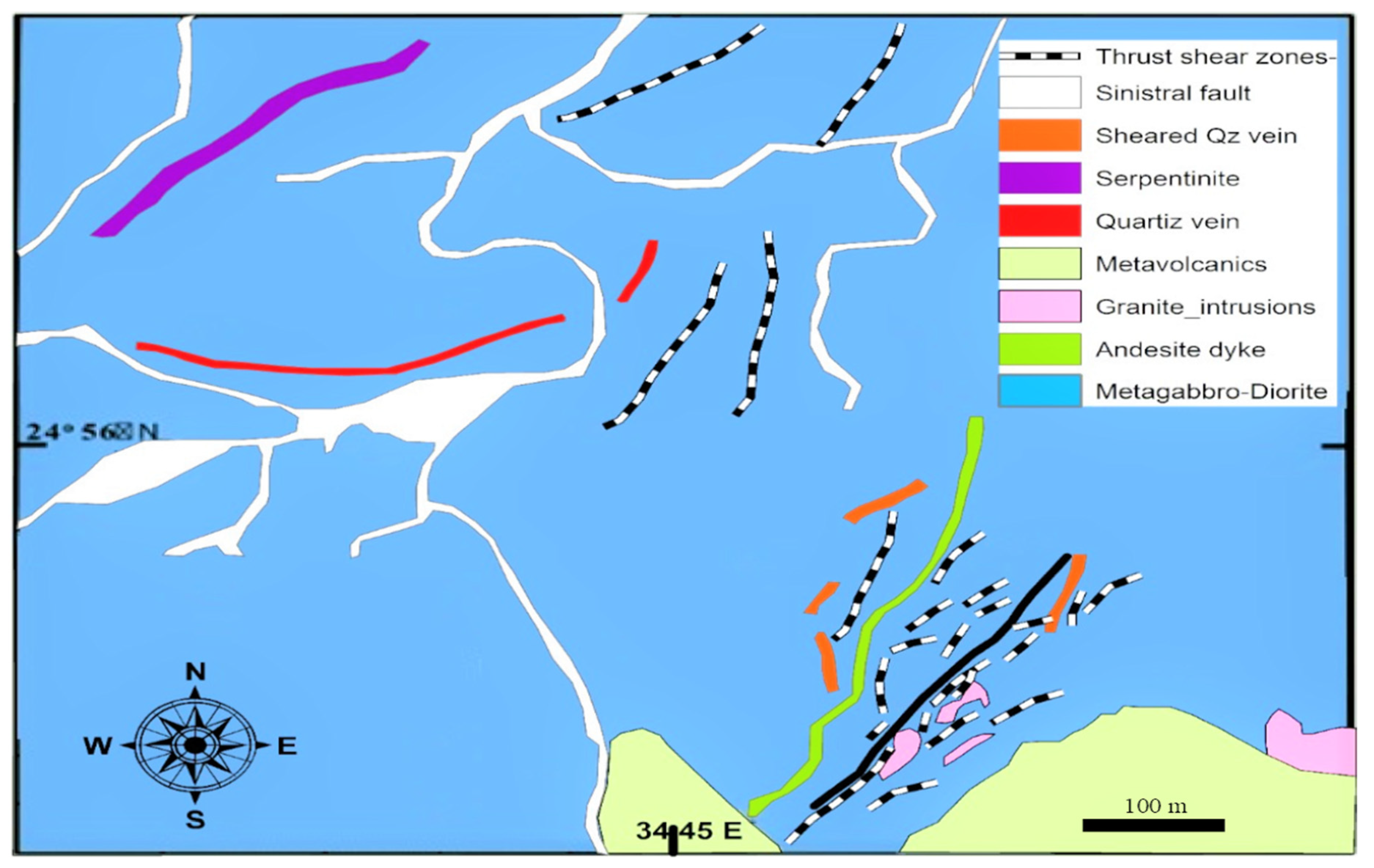
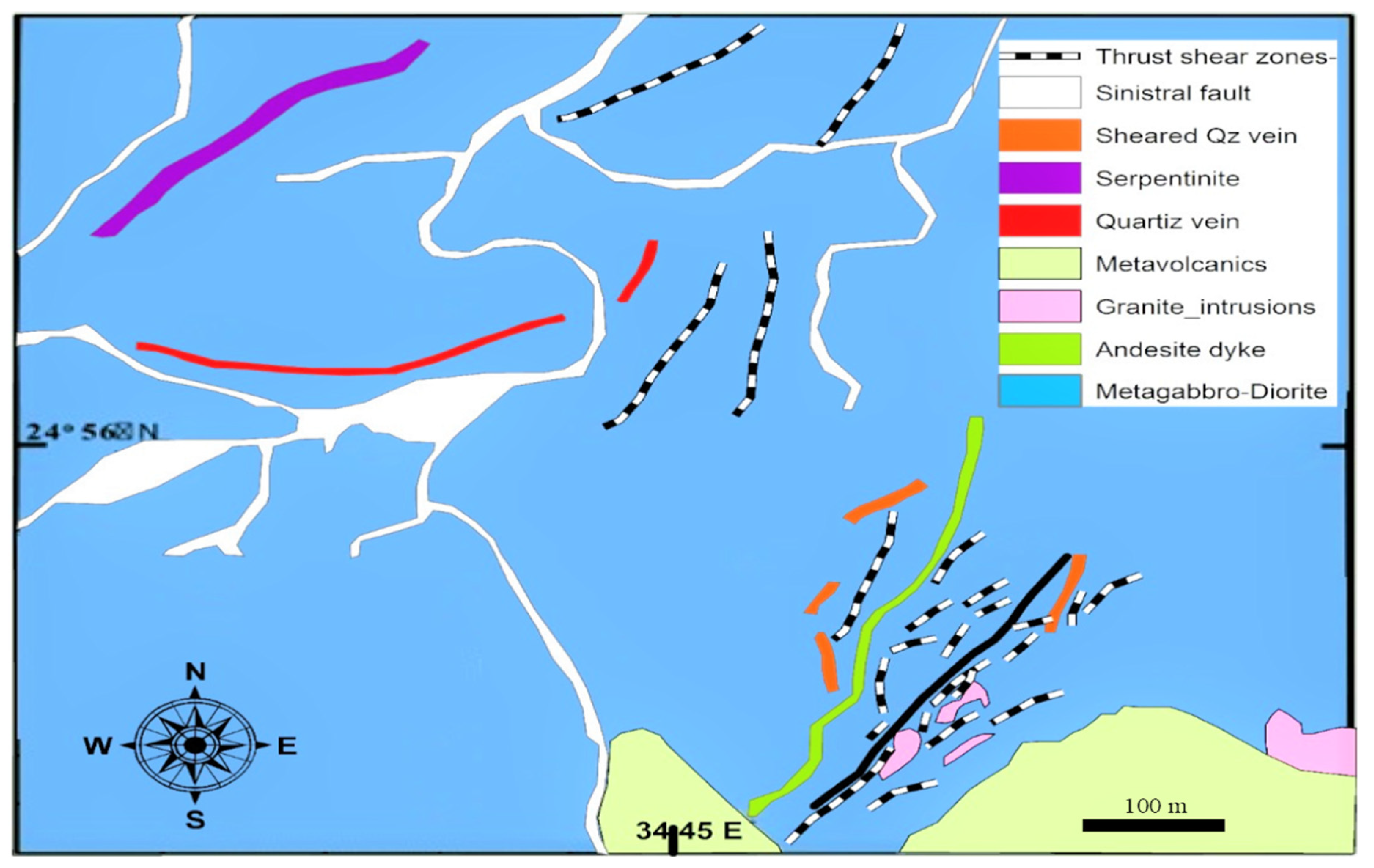
3. Case Study Area
The Quartz Ridge Vein Deposit
4. Results and Discussion
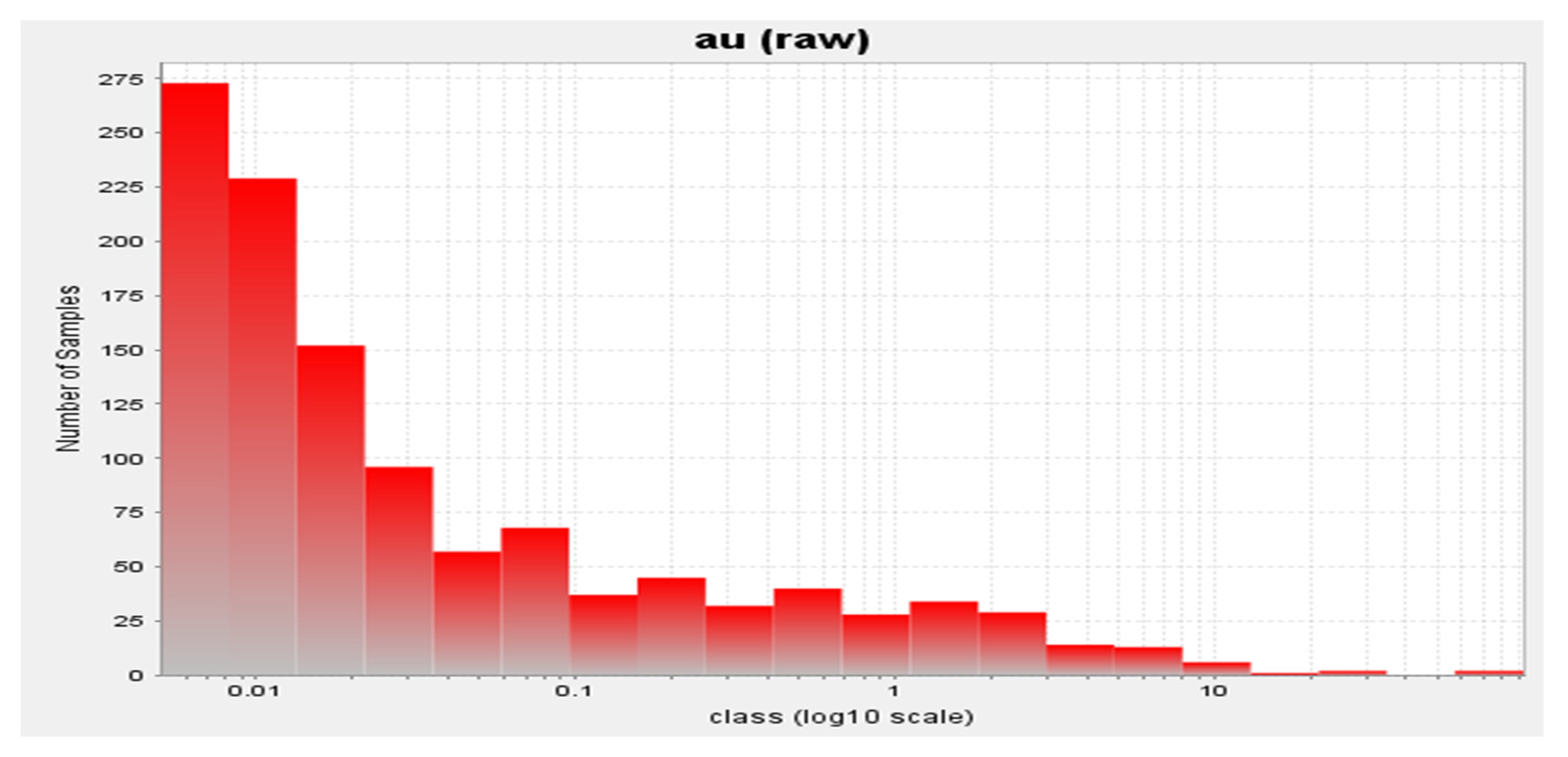
4.1. Data Analysis and Descriptive Statistics
4.2. Variographic Study
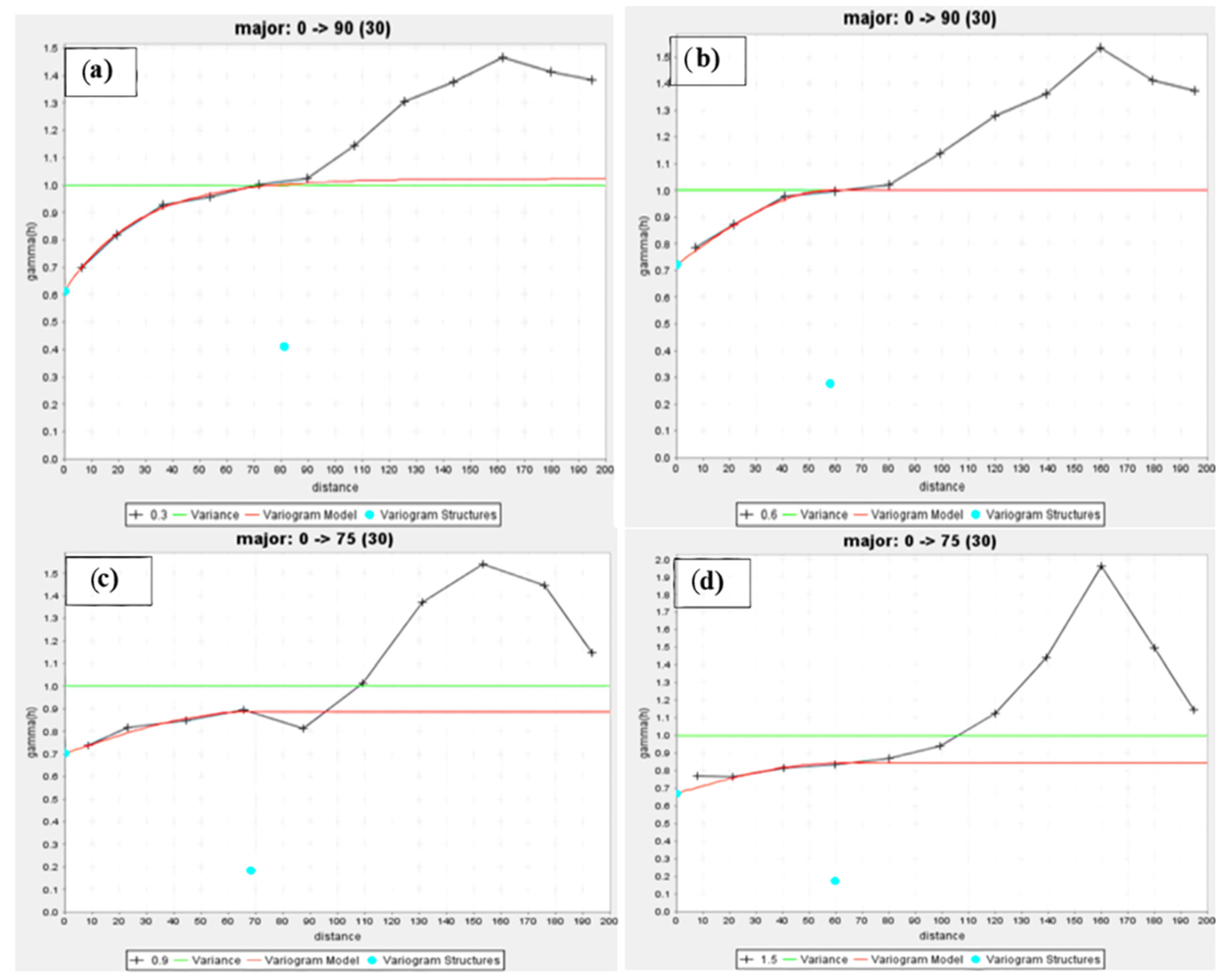
4.2.1. Grade Variography Analysis for OK
4.2.2. Indicator Variography Analysis and Modeling
4.3. Block Modeling for Resource Estimation
4.4. Preparing Data for Machine Learning Approaches and Training Specifications
4.5. Comparative Performance of the All Models
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Sinclair, A.J.; Blackwell, G.H. Applied Mineral Inventory Estimation; Cambridge University Press: Cambridge, UK, 2006; ISBN 1139433598. [Google Scholar]
- Kaplan, U.E.; Topal, E. A new ore grade estimation using combine machine learning algorithms. Minerals 2020, 10, 847. [Google Scholar] [CrossRef]
- Dominy, S.C.; Noppé, M.A.; Annels, A.E. Errors and uncertainty in mineral resource and ore reserve estimation: The importance of getting it right. Explor. Min. Geol. 2002, 11, 77–98. [Google Scholar] [CrossRef]
- Haldar, S.K. Mineral Exploration: Principles and Applications; Elsevier: Amsterdam, The Netherlands, 2018; ISBN 0128140232. [Google Scholar]
- Allard, D.J.-P.; Chilès, P. Delfiner: Geostatistics: Modeling Spatial Uncertainty; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Samanta, B.; Ganguli, R.; Bandopadhyay, S. Comparing the predictive performance of neural networks with ordinary kriging in a bauxite deposit. Trans. Inst. Min. Metall. Sect. A Min. Technol. 2005, 114, 129–140. [Google Scholar] [CrossRef]
- Chatterjee, S.; Bhattacherjee, A.; Samanta, B.; Pal, S.K. Ore grade estimation of a limestone deposit in India using an artificial neural network. Appl. GIS 2006, 2, 1–2. [Google Scholar] [CrossRef]
- Li, X.L.; Xie, Y.L.; Guo, Q.J.; Li, L.H. Adaptive ore grade estimation method for the mineral deposit evaluation. Math. Comput. Model. 2010, 52, 1947–1956. [Google Scholar] [CrossRef]
- Singh, R.K.; Ray, D.; Sarkar, B.C. Recurrent neural network approach to mineral deposit modelling. In Proceedings of the 2018 4th International Conference on Recent Advances in Information Technology (RAIT), Dhanbad, India, 15–17 March 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Hezarkhani, A. Application of Adaptive Neuro-Fuzzy Inference System for Grade Estimation; Case Study, Sarcheshmeh Porphyry Copper Deposit, Kerman, Iran. Aust. J. Basic Appl. Sci. 2010, 4, 408–420. [Google Scholar]
- Jafrasteh, B.; Fathianpour, N.; Suárez, A. Comparison of machine learning methods for copper ore grade estimation. Comput. Geosci. 2018, 22, 1371–1388. [Google Scholar] [CrossRef]
- Das Goswami, A.; Mishra, M.K.; Patra, D. Adapting pattern recognition approach for uncertainty assessment in the geologic resource estimation for Indian iron ore mines. In Proceedings of the 2016 International Conference on Signal Processing, Communication, Power and Embedded System (SCOPES), Paralakhemundi, India, 3–5 October 2016; pp. 1816–1821. [Google Scholar] [CrossRef]
- Patel, A.K.; Chatterjee, S.; Gorai, A.K. Development of a machine vision system using the support vector machine regression (SVR) algorithm for the online prediction of iron ore grades. Earth Sci. Inform. 2019, 12, 197–210. [Google Scholar] [CrossRef]
- Dutta, S.; Bandopadhyay, S.; Ganguli, R.; Misra, D. Machine learning algorithms and their application to ore reserve estimation of sparse and imprecise data. J. Intell. Learn. Syst. Appl. 2010, 2, 86. [Google Scholar] [CrossRef] [Green Version]
- Mlynarczuk, M.; Skiba, M. The application of artificial intelligence for the identification of the maceral groups and mineral components of coal. Comput. Geosci. 2017, 103, 133–141. [Google Scholar] [CrossRef]
- Sun, T.; Li, H.; Wu, K.; Chen, F.; Zhu, Z.; Hu, Z. Data-Driven Predictive Modelling of Mineral Prospectivity Using Machine Learning and Deep Learning Methods: A Case Study from Southern Jiangxi Province, China. Miner 2020, 10, 102. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Zuo, R.; Carranza, E.J.M. Mapping mineral prospectivity through big data analytics and a deep learning algorithm. Ore Geol. Rev. 2018, 102, 811–817. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geol. Rev. 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995; ISBN 0198538642. [Google Scholar]
- Chatterjee, S.; Bandopadhyay, S.; Machuca, D. Ore grade prediction using a genetic algorithm and clustering Based ensemble neural network model. Math. Geosci. 2010, 42, 309–326. [Google Scholar] [CrossRef]
- Koike, K.; Matsuda, S.; Suzuki, T.; Ohmi, M. Neural Network-Based Estimation of Principal Metal Contents in the Hokuroku District, Northern Japan, for Exploring Kuroko-Type Deposits. Nat. Resour. Res. 2002, 11, 135–156. [Google Scholar] [CrossRef]
- Samanta, B.; Bandopadhyay, S.; Ganguli, R.; Dutta, S. Sparse data division using data segmentation and kohonen network for neural network and geostatistical ore grade modeling in nome offshore placer deposit. Nat. Resour. Res. 2004, 13, 189–200. [Google Scholar] [CrossRef]
- Zhang, X.; Song, S.; Li, J.; Wu, C. Robust LS-SVM regression for ore grade estimation in a seafloor hydrothermal sulphide deposit. Acta Oceanol. Sin. 2013, 32, 16–25. [Google Scholar] [CrossRef]
- Das Goswami, A.; Mishra, M.K.; Patra, D. Investigation of general regression neural network architecture for grade estimation of an Indian iron ore deposit. Arab. J. Geosci. 2017, 10, 80. [Google Scholar] [CrossRef]
- Afeni, T.B.; Lawal, A.I.; Adeyemi, R.A. Re-examination of Itakpe iron ore deposit for reserve estimation using geostatistics and artificial neural network techniques. Arab. J. Geosci. 2020, 13, 657. [Google Scholar] [CrossRef]
- Arroyo, D.; Emery, X.; Peláez, M. Sequential simulation with iterative methods. In Geostatistics Oslo 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–14. [Google Scholar]
- Machado, R.S.; Armony, M.; Costa, J.F.C.L. Field Parametric Geostatistics—A Rigorous Theory to Solve Problems of Highly Skewed Distributions. In Geostatistics Oslo 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 383–395. [Google Scholar]
- Samanta, B.; Bandopadhyay, S.; Ganguli, R. Data segmentation and genetic algorithms for sparse data division in Nome placer gold grade estimation using neural network and geostatistics. Explor. Min. Geol. 2002, 11, 69–76. [Google Scholar] [CrossRef]
- Faramarzi, A.; Heidarinejad, M.; Mirjalili, S.; Gandomi, A.H. Marine Predators Algorithm: A nature-inspired metaheuristic. Expert Syst. Appl. 2020, 152, 113377. [Google Scholar] [CrossRef]
- Aytekin, A. Comparative analysis of the normalization techniques in the context of MCDM problems. Decis. Mak. Appl. Manag. Eng. 2021, 4, 1–25. [Google Scholar] [CrossRef]
- David, M. Geostatistical Ore Reserve Estimation; Elsevier: Amsterdam, The Netherlands, 2012; ISBN 0444597611. [Google Scholar]
- Rossi, M.E.; Deutsch, C. V Mineral Resource Estimation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; ISBN 1402057172. [Google Scholar]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2003; ISBN 3540441425. [Google Scholar]
- Hawkins, D.M.; Rivoirard, J. Introduction to Disjunctive Kriging and Nonlinear Geostatistics. J. Am. Stat. Assoc. 1996, 38, 337–340. [Google Scholar] [CrossRef]
- MacKay, D.J.C. Gaussian Processes-a Replacement for Supervised Neural Networks, NIPS Tutorial. 1997. Available online: https://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.47.9170 (accessed on 15 July 2022).
- Firat, M.; Gungor, M. Generalized Regression Neural Networks and Feed Forward Neural Networks for prediction of scour depth around bridge piers. Adv. Eng. Softw. 2009, 40, 731–737. [Google Scholar] [CrossRef]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000; ISBN 0521780195. [Google Scholar]
- Steinwart, I.; Christmann, A. Support Vector Machines; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008; ISBN 0387772421. [Google Scholar]
- Tipping, M. Sparse Bayesian Learning and the Relevance Vector Machine. J. Mach. Learn. Res. 2001, 1, 211–244. [Google Scholar]
- Sutton, C.D. Classification and regression trees, bagging, and boosting. Handb. Stat. 2005, 24, 303–329. [Google Scholar]
- Wang, Y.-T.; Zhang, X.; Liu, X.-S. Machine learning approaches to rock fracture mechanics problems: Mode-I fracture toughness determination. Eng. Fract. Mech. 2021, 253, 107890. [Google Scholar] [CrossRef]
- Selmic, R.R.; Lewis, F.L. Neural-network approximation of piecewise continuous functions: Application to friction compensation. IEEE Trans. Neural Netw. 2002, 13, 745–751. [Google Scholar] [CrossRef] [Green Version]
- Sontag, E.D. Feedback Stabilization Using Two-Hidden-Layer Nets. In Proceedings of the 1991 American Control Conference, Boston, MA, USA, 26–28 June 1991; pp. 815–820. [Google Scholar]
- Rokach, L. Pattern Classification Using Ensemble Methods; World Scientific: Singapore, 2009; Volume 75, ISBN 978-981-4271-06-6. [Google Scholar]
- Song, Y.; Liang, J.; Lu, J.; Zhao, X. An efficient instance selection algorithm for k nearest neighbor regression. Neurocomputing 2017, 251, 26–34. [Google Scholar] [CrossRef]
- González-Sanchez, A.; Frausto-Solis, J.; Ojeda, W. Predictive ability of machine learning methods for massive crop yield prediction. SPANISH J. Agric. Res. 2014, 12, 313–328. [Google Scholar] [CrossRef] [Green Version]
- Shrivastava, P.; Shukla, A.; Vepakomma, P.; Bhansali, N.; Verma, K. A survey of nature-inspired algorithms for feature selection to identify Parkinson’s disease. Comput. Methods Programs Biomed. 2017, 139, 171–179. [Google Scholar] [CrossRef] [PubMed]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–73. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics, Orlando, FL, USA, 12–15 October 1997; Volume 5, pp. 4104–4108. [Google Scholar]
- Sahlol, A.T.; Yousri, D.; Ewees, A.A.; Al-Qaness, M.A.A.; Damasevicius, R.; Elaziz, M.A. COVID-19 image classification using deep features and fractional-order marine predators algorithm. Sci. Rep. 2020, 10, 15364. [Google Scholar] [CrossRef] [PubMed]
- Elaziz, M.A.; Ewees, A.A.; Ibrahim, R.A.; Lu, S. Opposition-based moth-flame optimization improved by differential evolution for feature selection. Math. Comput. Simul. 2020, 168, 48–75. [Google Scholar] [CrossRef]
- Lu, X.; Zhou, W.; Ding, X.; Shi, X.; Luan, B.; Li, M. Ensemble Learning Regression for Estimating Unconfined Compressive Strength of Cemented Paste Backfill. IEEE Access 2019, 7, 72125–72133. [Google Scholar] [CrossRef]
- Prasad, K.; Gorai, A.K.; Goyal, P. Development of ANFIS models for air quality forecasting and input optimization for reducing the computational cost and time. Atmos. Environ. 2016, 128, 246–262. [Google Scholar] [CrossRef]
- Samanta, B. Radial basis function network for ore grade estimation. Nat. Resour. Res. 2010, 19, 91–102. [Google Scholar] [CrossRef]
- Hume, W.F. Geology of Egypt: The minerals of economic values associated with the intrusive Precambrian igneous rocks. Ann. Geol. Surv. Egypt 1937, 2, 689–990. [Google Scholar]
- Harraz, H.Z. Primary geochemical haloes, El Sid gold mine, Eastern Desert, Egypt. J. Afr. Earth Sci. 1995, 20, 61–71. [Google Scholar] [CrossRef]
- Klemm, R.; Klemm, D. Gold Production Sites and Gold Mining in Ancient Egypt. In Gold and Gold Mining in Ancient Egypt and Nubia; Springer: Berlin/Heidelberg, Germany, 2013; pp. 51–339. [Google Scholar]
- Eisler, R. Health risks of gold miners: A synoptic review. Environ. Geochem. Health 2003, 25, 325–345. [Google Scholar] [CrossRef]
- Helmy, H.M.; Kaindl, R.; Fritz, H.; Loizenbauer, J. The Sukari Gold Mine, Eastern Desert—Egypt: Structural setting, mineralogy and fluid inclusion study. Miner. Depos. 2004, 39, 495–511. [Google Scholar] [CrossRef]
- Khalil, K.I.; Moghazi, A.M.; El Makky, A.M. Nature and Geodynamic Setting of Late Neoproterozoic Vein-Type Gold Mineralization in the Eastern Desert of Egypt: Mineralogical and Geochemical Constraints; Springer: Berlin/Heidelberg, Germany, 2016; pp. 353–370. [Google Scholar] [CrossRef]
- Botros, N.S. A new classification of the gold deposits of Egypt. Ore Geol. Rev. 2004, 25, 1–37. [Google Scholar] [CrossRef]
- Helba, H.A.; Khalil, K.I.; Mamdouh, M.M.; Abdel Khalek, I.A. Zonation in primary geochemical haloes for orogenic vein-type gold mineralization in the Quartz Ridge prospect, Sukari gold mine area, Eastern Desert of Egypt. J. Geochem. Explor. 2020, 209, 106378. [Google Scholar] [CrossRef]
- Kriewaldt, M.; Okasha, H.; Farghally, M. Sukari Gold Mine: Opportunities and Challenges BT—The Geology of the Egyptian Nubian Shield; Hamimi, Z., Arai, S., Fowler, A.-R., El-Bialy, M.Z., Eds.; Springer International Publishing: Cham, Germany, 2021; pp. 577–591. ISBN 978-3-030-49771-2. [Google Scholar]
- Centamin plc Annual Report 2021. Available online: https://www.centamin.com/media/2529/cent-ar21-full-web-secure.pdf. (accessed on 15 July 2022).
- Bedair, M.; Aref, J.; Bedair, M. Automating Estimation Parameters: A Case Study Evaluating Preferred Paths for Optimisation. In Proceedings of the International mining geology Conference, Perth, Australia, 25–26 November 2019. [Google Scholar]
- Vann, J.; Guibal, D.; Harley, M. Multiple Indicator Kriging–Is it suited to my deposit. In Proceedings of the 4th International Mining Geology Conference, Coolum, Australia, 14–17 May 2000. [Google Scholar]
- Davis, J.C.; Sampson, R.J. Statistics and Data Analysis in Geology; Wiley: New York, NY, USA, 1986; Volume 646. [Google Scholar]
- Daya, A.A.; Bejari, H. A comparative study between simple kriging and ordinary kriging for estimating and modeling the Cu concentration in Chehlkureh deposit, SE Iran. Arab. J. Geosci. 2015, 8, 6003–6020. [Google Scholar] [CrossRef]
- Babakhani, M. Geostatistical Modeling in Presence of Extreme Values. Master’s Thesis, University of Alberta, Edmonton, AB, Canada, 2014. [Google Scholar]
- Kim, S.-M.; Choi, Y.; Park, H.-D. New outlier top-cut method for mineral resource estimation via 3D hot spot analysis of Borehole data. Minerals 2018, 8, 348. [Google Scholar] [CrossRef] [Green Version]
- Dunham, S.; Vann, J. Geometallurgy, geostatistics and project value—Does your block model tell you what you need to know. In Proceedings of the Project Evaluation Conference, Melbourne, Australia, 19–20 June 2007; pp. 19–20. [Google Scholar]
- Cambardella, C.A.; Moorman, T.B.; Novak, J.M.; Parkin, T.B.; Karlen, D.L.; Turco, R.F.; Konopka, A.E. Field-scale variability of soil properties in central Iowa soils. Soil Sci. Soc. Am. J. 1994, 58, 1501–1511. [Google Scholar] [CrossRef]
- Vann, J.; Jackson, S.; Bertoli, O. Quantitative kriging neighbourhood analysis for the mining geologist-a description of the method with worked case examples. In Proceedings of the 5th International Mining Geology Conference, Bendigo, Australia, 17–19 November 2003; Australian Inst Mining & Metallurgy: Melbourne, Victoria, 2003; Volume 8, pp. 215–223. [Google Scholar]
- Tercan, A.E.; Sohrabian, B. Multivariate geostatistical simulation of coal quality data by independent components. Int. J. Coal Geol. 2013, 112, 53–66. [Google Scholar] [CrossRef]
- Cuevas, E.; Fausto, F.; González, A. The Locust Swarm Optimization Algorithm BT—New Advancements in Swarm Algorithms: Operators and Applications; Cuevas, E., Fausto, F., González, A., Eds.; Springer International Publishing: Cham, Germany, 2020; pp. 139–159. ISBN 978-3-030-16339-6. [Google Scholar]
- Asadisaghandi, J.; Tahmasebi, P. Comparative evaluation of back-propagation neural network learning algorithms and empirical correlations for prediction of oil PVT properties in Iran oilfields. J. Pet. Sci. Eng. 2011, 78, 464–475. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar]
- Byrd, R.H.; Lu, P.; Nocedal, J.; Zhu, C. A Limited Memory Algorithm for Bound Constrained Optimization. SIAM J. Sci. Comput. 1995, 16, 1190–1208. [Google Scholar] [CrossRef]
- Vafaei, N.; Ribeiro, R.A.; Camarinha-Matos, L.M. Normalization techniques for multi-criteria decision making: Analytical hierarchy process case study. In Proceedings of the Doctoral Conference on Computing, Electrical and Industrial Systems, Costa de Caparica, Portugal, 7–9 July 2021; Springer: Berlin/Heidelberg, Germany, 2016; pp. 261–269. [Google Scholar]
- Corazza, A.; Di Martino, S.; Ferrucci, F.; Gravino, C.; Mendes, E. Applying support vector regression for web effort estimation using a cross-company dataset. In Proceedings of the 2009 3rd International Symposium on Empirical Software Engineering and Measurement, Helsinki, Finland, 19–23 September 2009; pp. 191–202. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Raw Data | Composite Data |
|---|---|---|
| Number of samples | 1158 | 1079 |
| Min value | 0.005 | 0.005 |
| Max value | 93.12 | 10 |
| Mean | 0.525 | 0.4065 |
| Variance | 13.479 | 1.499 |
| Standard Deviation | 3.671 | 1.224 |
| Coefficient of variation | 6.997 | 3.0116 |
| Skewness | 19.653 | 5.1019 |
| Kurtosis | 448.194 | 33.02 |
| Ratio of max to mean value | 117.4 | 24.6 |
| Direction Model | Model Type | Nugget (ppm²) | Range (m) | Sill (ppm²) | Relative Nugget Effect |
|---|---|---|---|---|---|
| Omnidirectional | Exponential | 0.685 | 26.989 | 0.246 | 0.5 |
| Downhole | Spherical | 0.327 | 5.126 | 0.567 | 0.37 |
| Directional | Spherical | 0.758 | 66.102 | 0.238 | 0.56 |
| Cutoffs | Variogram Model | Nugget Effect | Sill | Range | Azimuth | Dip | Relative Nugget Effect Nugget/Sill |
|---|---|---|---|---|---|---|---|
| 0.3 | Exponential | 0.612 | 0.41 | 81.256 | 90 | −75 | 0.6 |
| 0.6 | Spherical | 0.72 | 0.278 | 58.082 | 90 | −75 | 0.72 |
| 0.9 | Spherical | 0.703 | 0.184 | 68.322 | 75 | −75 | 0.79 |
| 1.5 | Spherical | 0.67 | 0.172 | 59.878 | 75 | −45 | 0.79 |
| Measure | X | Y | Z |
|---|---|---|---|
| Min coordinates | 677,083 | 2,760,172 | 202 |
| Max coordinates | 677,703 | 2,760,352 | 342 |
| User block size (parent) | 20 | 20 | 5 |
| Min. block size | 5 | 5 | 1.25 |
| Algorithm | Parameters Settings |
|---|---|
| Common settings | Training process: Cross validation method A five k-folds Algorithm parameters optimization: Bayesian optimization algorithm Iterations: 30 |
| Gaussian Process Regression (GPR) | Basis function is linear Kernel function is rational-quadratic kernel. Kernel parameters: [0.97, 1, 1.5], Sigma is 1.35 × 10−4. |
| Decision Tree Ensembles (DTE) | Ensemble method: Bag, Minimum leaf size: 1, Number of learners: 380, Number of predictors: 2 |
| Fully Connected Neural Network (FCCN) | A fully connected neural network with 290 layers Activation function: Tanh Maximum number of iterations: 1000 The learning rate optimizer: limited-memory Broyden–Fletcher–Goldfarb–Shanno (LBFGS) optimization algorithm. |
| Support Vector Regression (SVR) | Kernel function: gaussian Kernel scale: 0.10 |
| K-Nearest Neighbors (K-NN) | K parameter is 2 Distance metric: Euclidean distance |
| Metric | GPR | DTE | FCNN | K-NN | IK | OK |
|---|---|---|---|---|---|---|
| R | 0.21 | 0.18 | 0.064 | 0.138 | 0.304 | 0.445 |
| R2 | 0.185 | 0.160 | 0.055 | 0.119 | 0.09 | 0.20 |
| MSE | 0.811 | 0.836 | 0.941 | 0.877 | 1.604 | 1.395 |
| RMSE | 0.901 | 0.914 | 0.970 | 0.936 | 1.266 | 1.181 |
| MAE | 0.417 | 0.396 | 0.498 | 0.354 | 0.533 | 0.482 |
| MBE | −0.039 | −0.094 | −0.006 | 0.094 | −0.014 | −0.041 |
| Statistics/Methods | GPR | SVR | DTE | FCNN | K-NN | IK | OK |
|---|---|---|---|---|---|---|---|
| Skill value | 81.88 | - | 84.30 | 94.49 | 89.29 | 92.79 | 81.62 |
| Rank | 2 | 7 | 3 | 6 | 4 | 5 | 1 |
| Metric | GPR | SVR | DTE | FCNN | K-NN |
|---|---|---|---|---|---|
| R | 0.929 | 0.92 | 0.887 | 0.823 | 0.908 |
| R2 | 0.73 | 0.70 | 0.58 | 0.34 | 0.66 |
| RMSE | 1.009 | 1.072 | 1.276 | 1.598 | 1.150 |
| MAE | 0.676 | 0.792 | 0.945 | 1.245 | 0.735 |
| MBE | −0.019 | 0.016 | 0.023 | 0.089 | −0.001 |
| Statistics/Methods | GPR | SVR | DTE | FCNN | K-NN |
|---|---|---|---|---|---|
| Skill value | 27.656 | 30.808 | 42.968 | 67.335 | 35.234 |
| Rank | 1 | 2 | 4 | 5 | 3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaki, M.M.; Chen, S.; Zhang, J.; Feng, F.; Khoreshok, A.A.; Mahdy, M.A.; Salim, K.M. A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms. Minerals 2022, 12, 900. https://doi.org/10.3390/min12070900
Zaki MM, Chen S, Zhang J, Feng F, Khoreshok AA, Mahdy MA, Salim KM. A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms. Minerals. 2022; 12(7):900. https://doi.org/10.3390/min12070900
Chicago/Turabian StyleZaki, M. M., Shaojie Chen, Jicheng Zhang, Fan Feng, Aleksey A. Khoreshok, Mohamed A. Mahdy, and Khalid M. Salim. 2022. "A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms" Minerals 12, no. 7: 900. https://doi.org/10.3390/min12070900
APA StyleZaki, M. M., Chen, S., Zhang, J., Feng, F., Khoreshok, A. A., Mahdy, M. A., & Salim, K. M. (2022). A Novel Approach for Resource Estimation of Highly Skewed Gold Using Machine Learning Algorithms. Minerals, 12(7), 900. https://doi.org/10.3390/min12070900