

CNN2D-SENet-Based Prospecting Prediction Method: A Case Study from the Cu Deposits in the Zhunuo Mineral Concentrate Area in Tibet

Abstract
1. Introduction
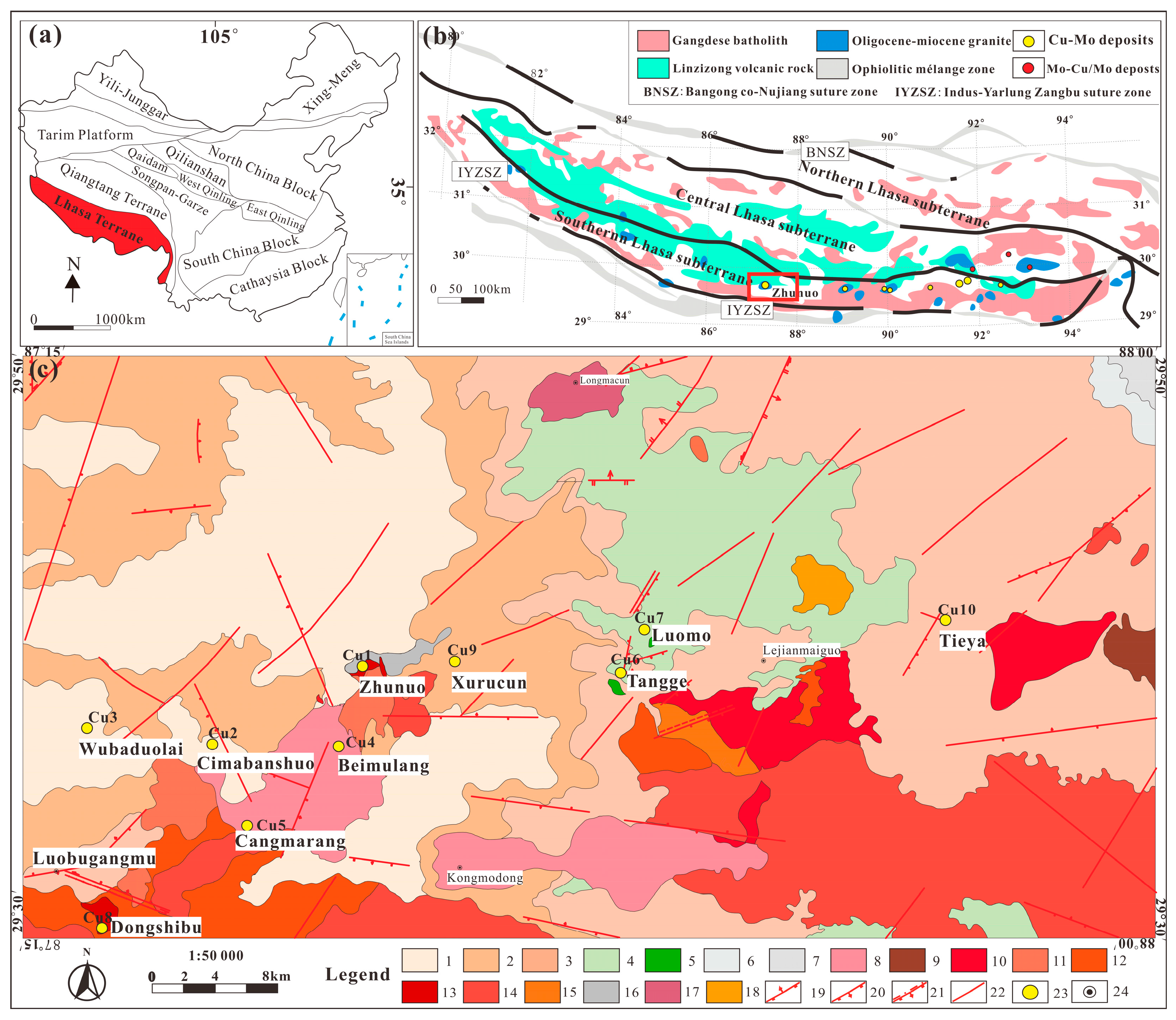
2. Regional Geological Background
3. Methods
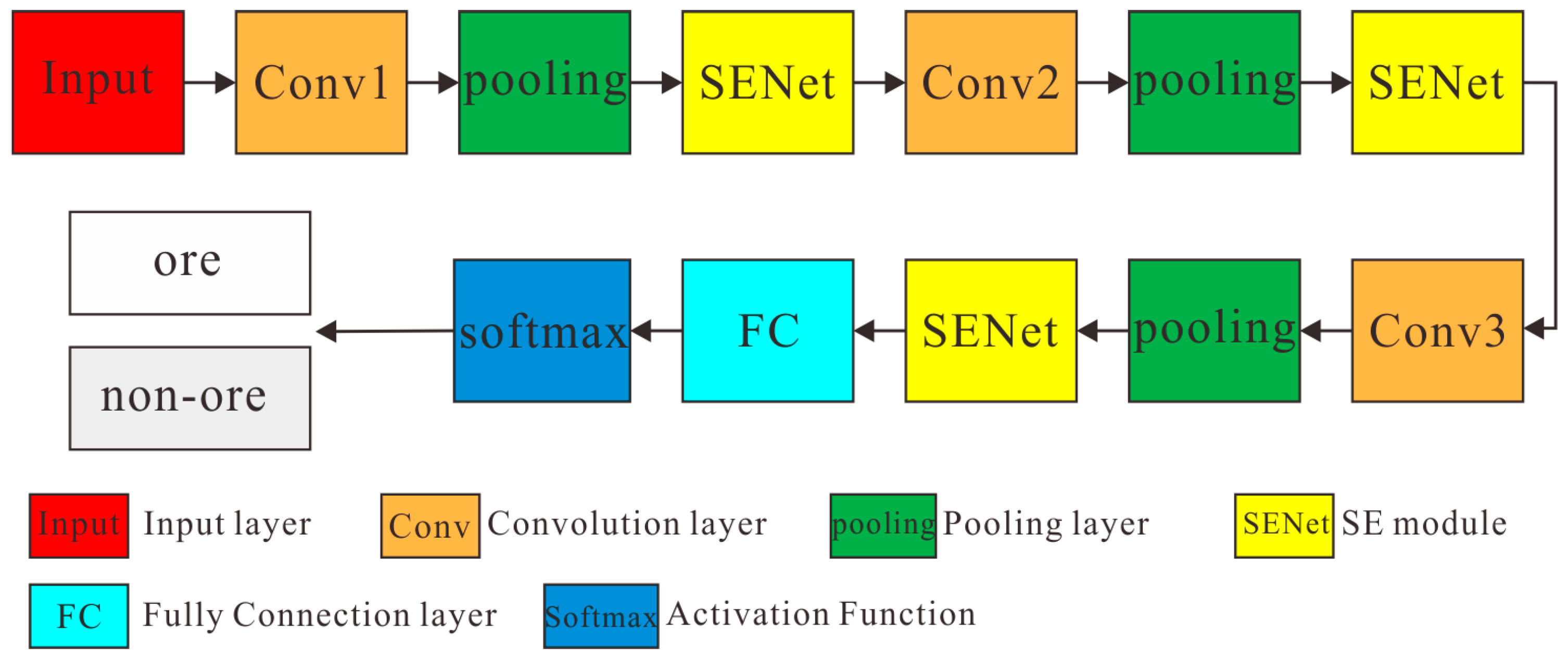
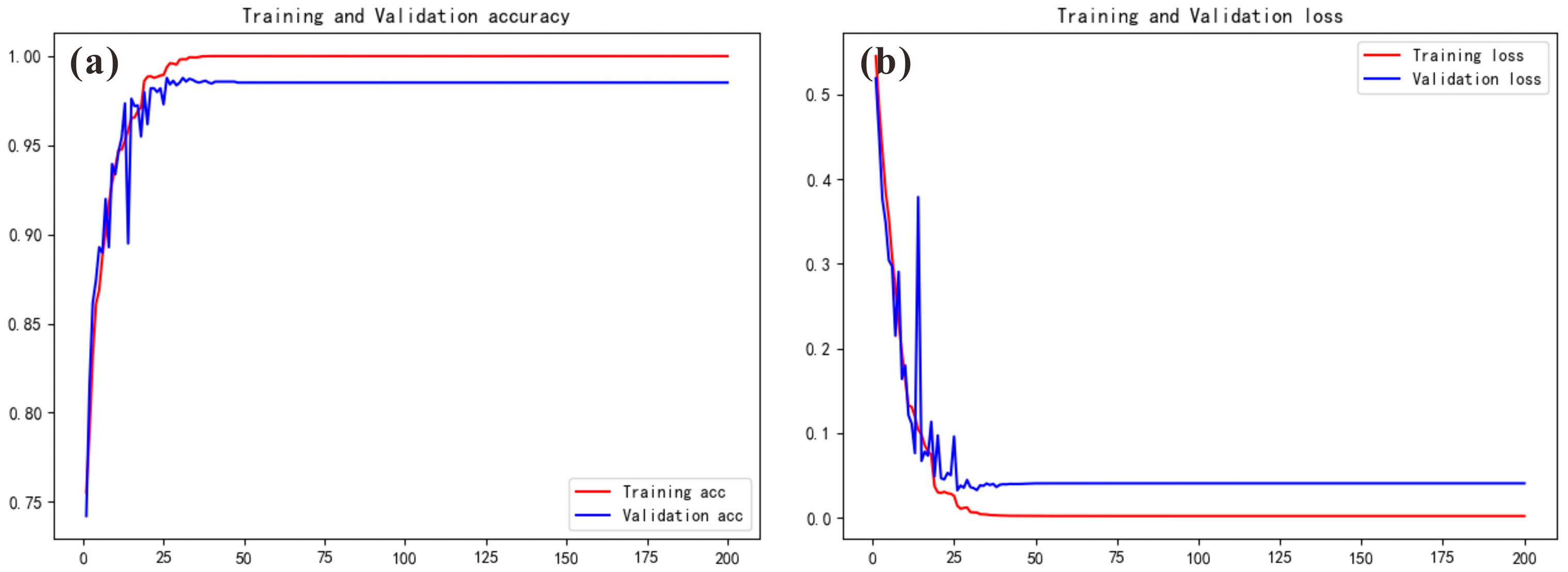
3.1. CNN2D-SENet Model
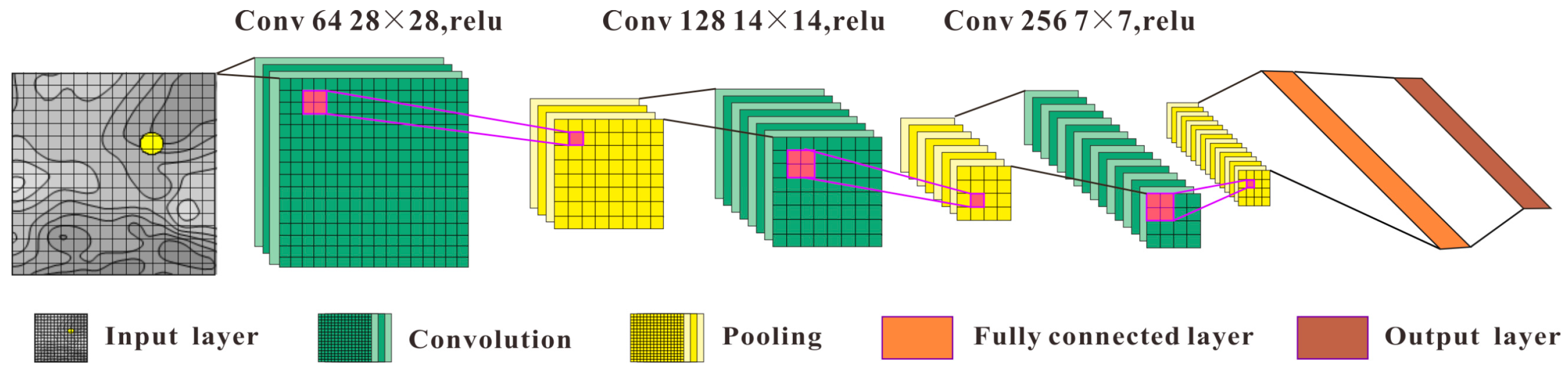
3.1.1. CNN2D
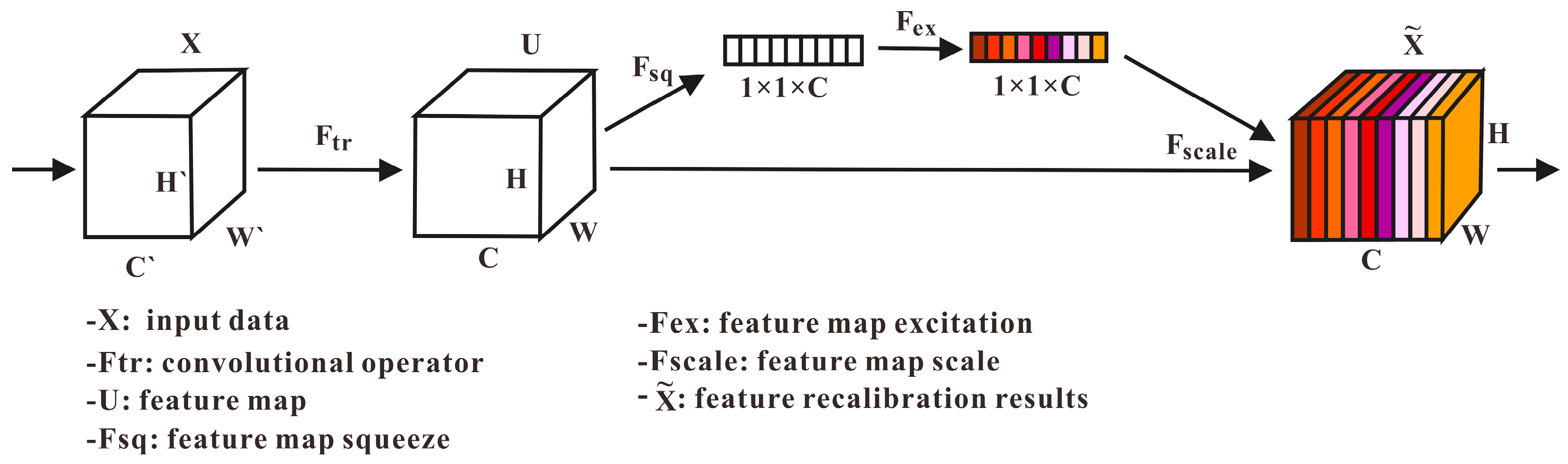
3.1.2. Squeeze-and-Excitation Network
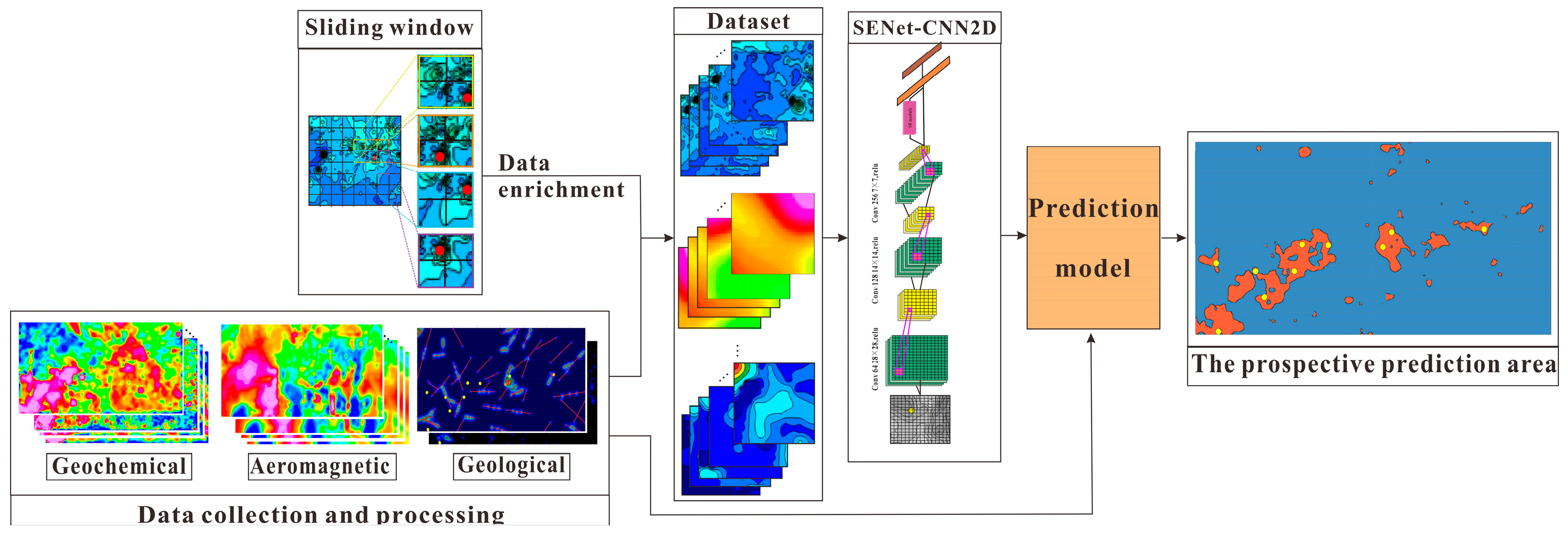
3.2. Method and Steps of Prospecting Prediction Based on the CNN2D-SENet Model
- (1)
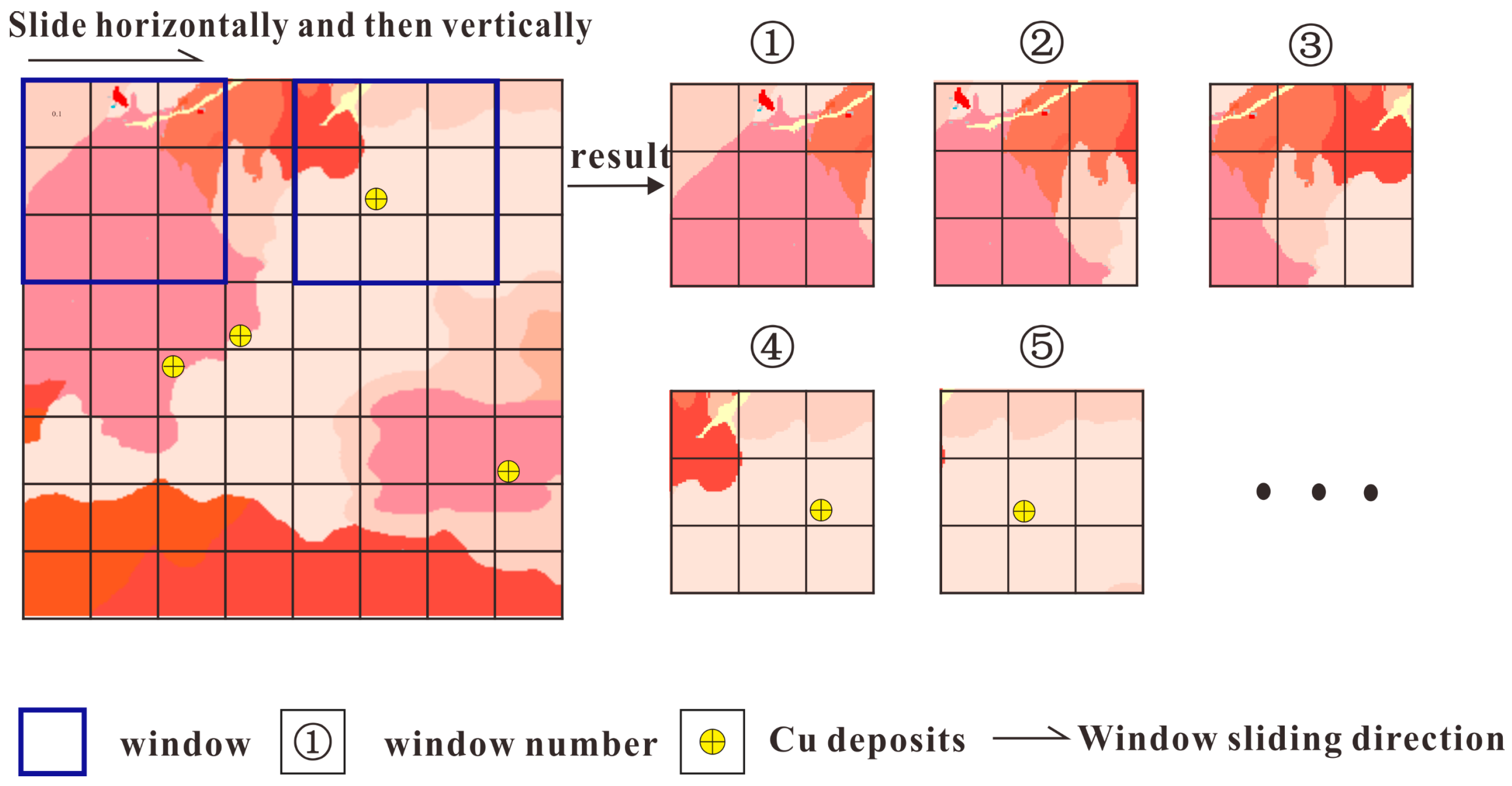
- Data preparation and processing
- (2)
- Construction of the training sample dataset
- (3)
- Construction of the CNN2D-SENet model
- (4)
- Generating prediction models and model training and verification
4. Application and Experiment
4.1. Data and Data Processing
4.1.1. Geological Data
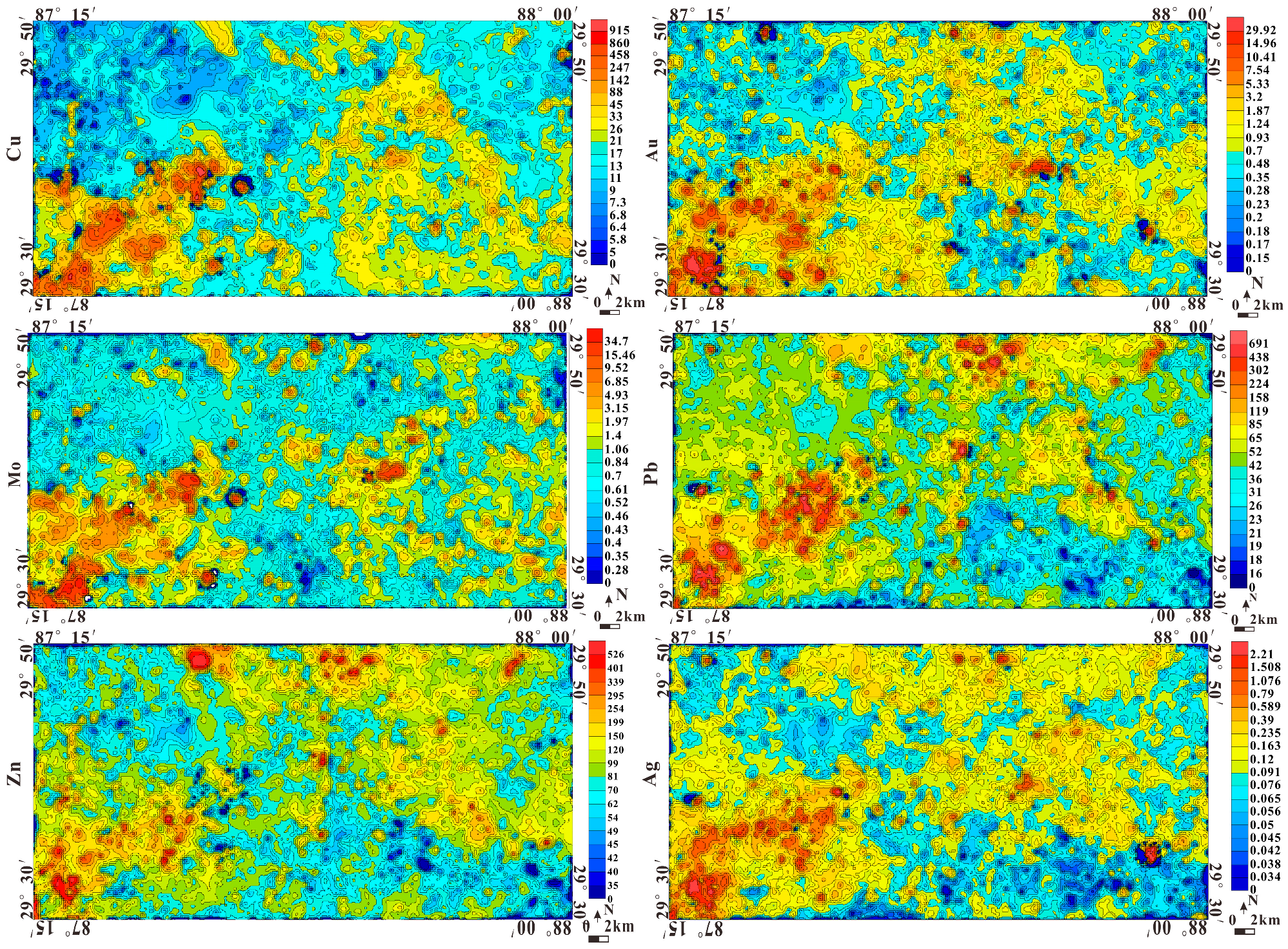
4.1.2. Geochemical Data
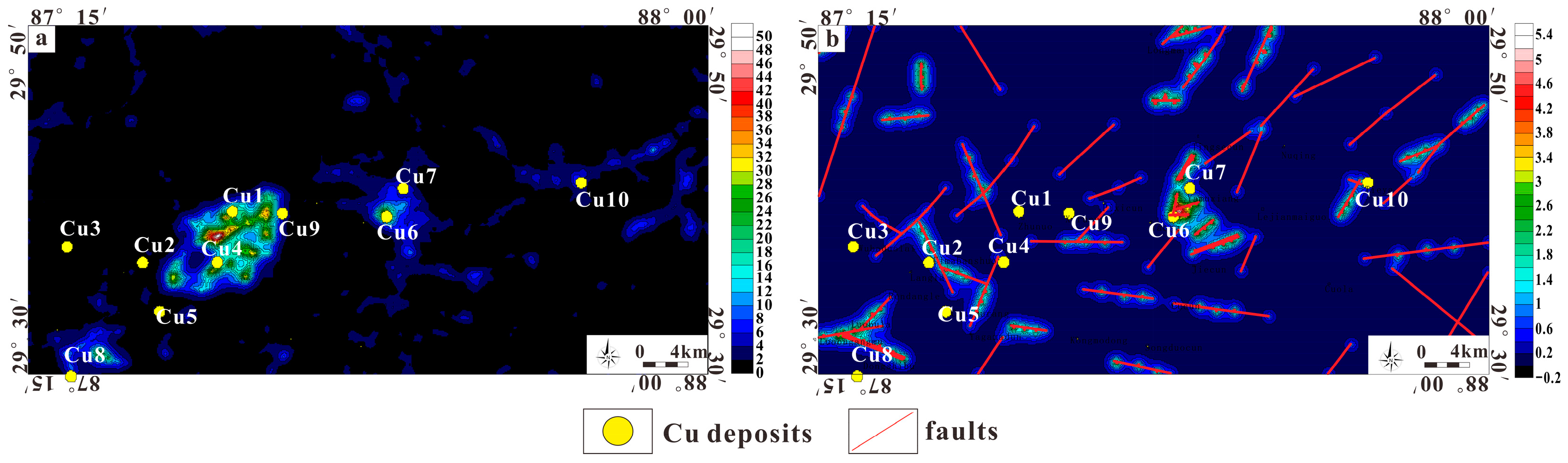
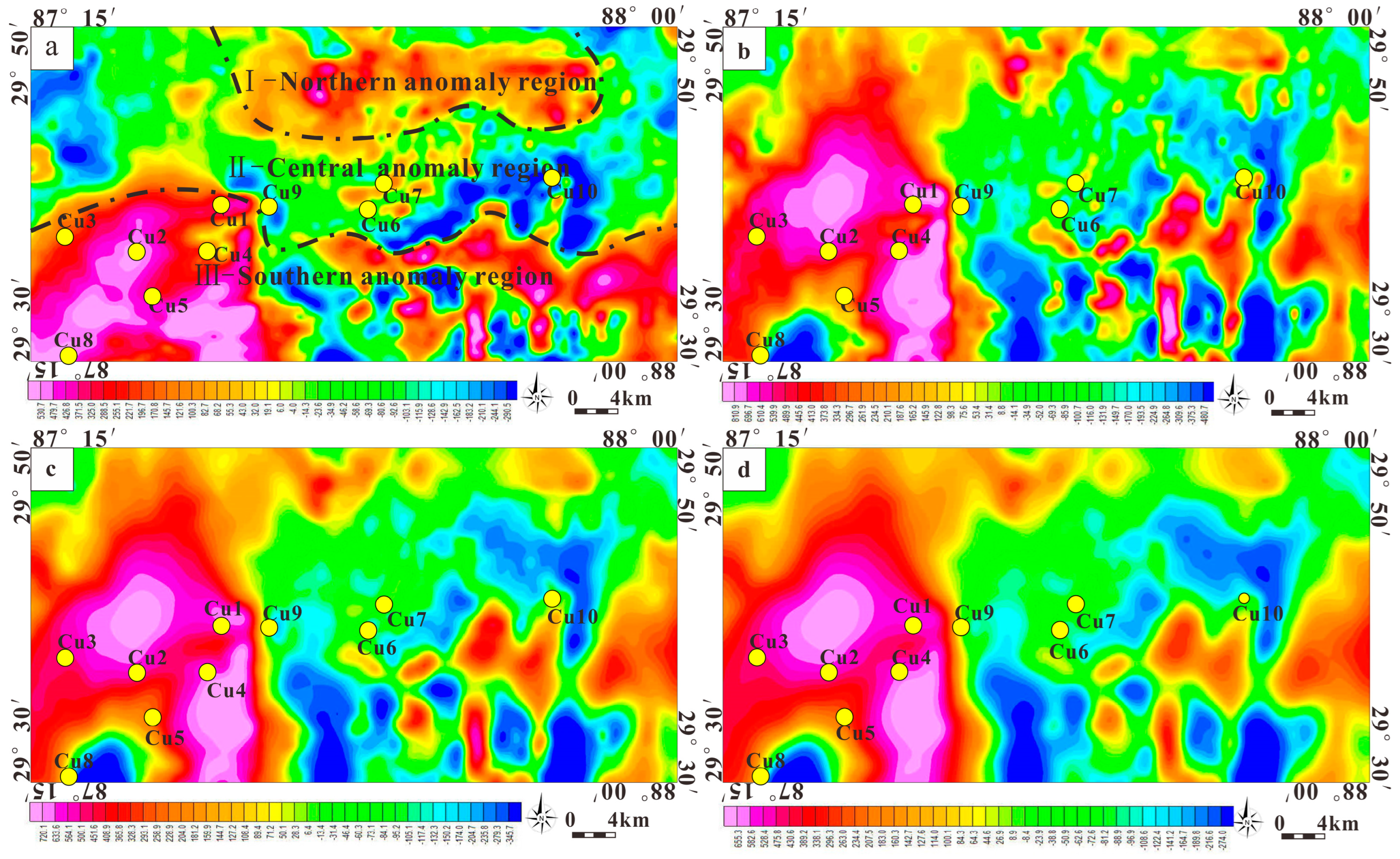
4.1.3. Geophysical Data
4.1.4. Deposits and Mineral Occurrence Data
4.2. Prediction Parameters and Prediction Results
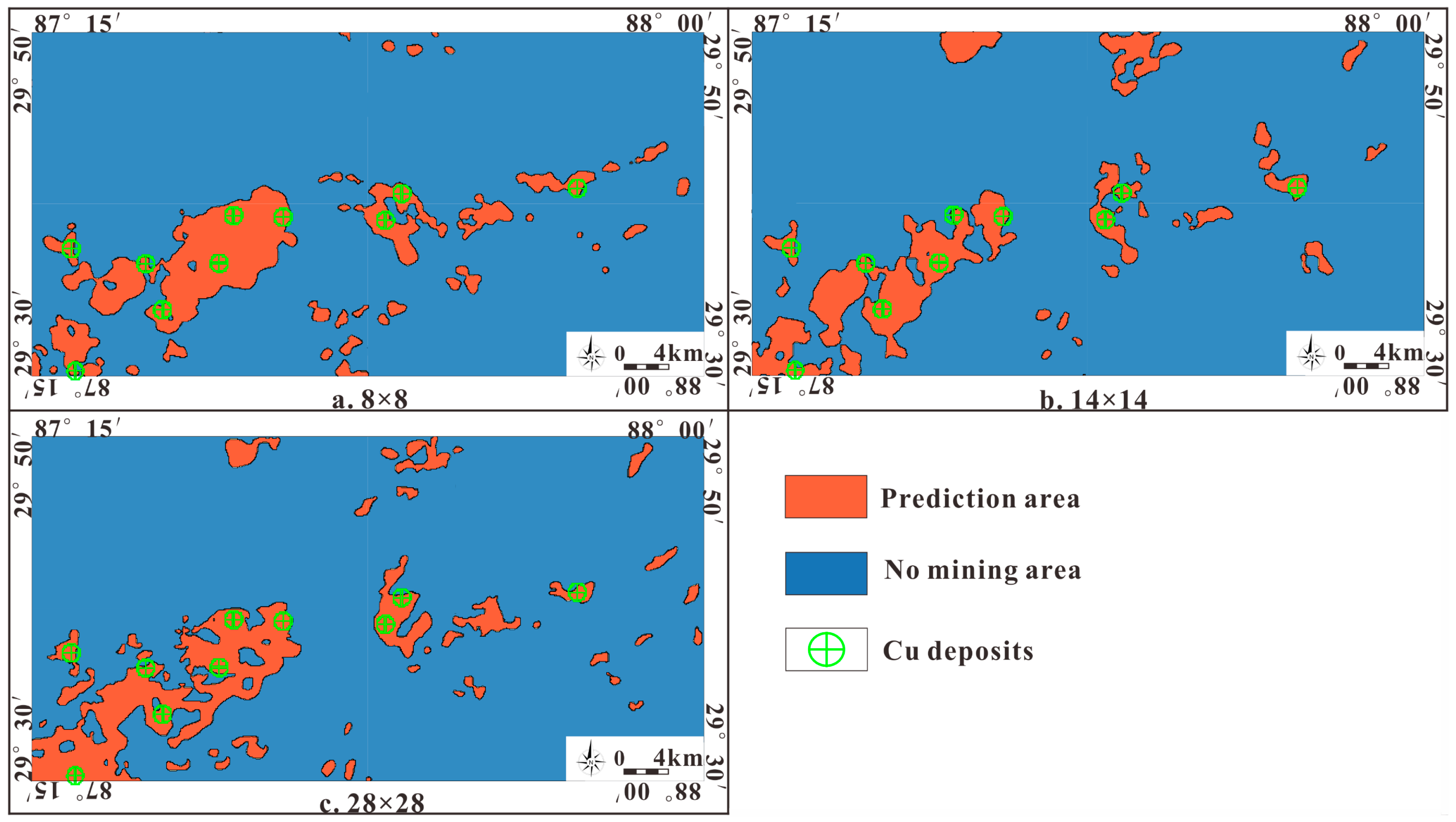
4.2.1. Influence of Window Size on the Prediction Results
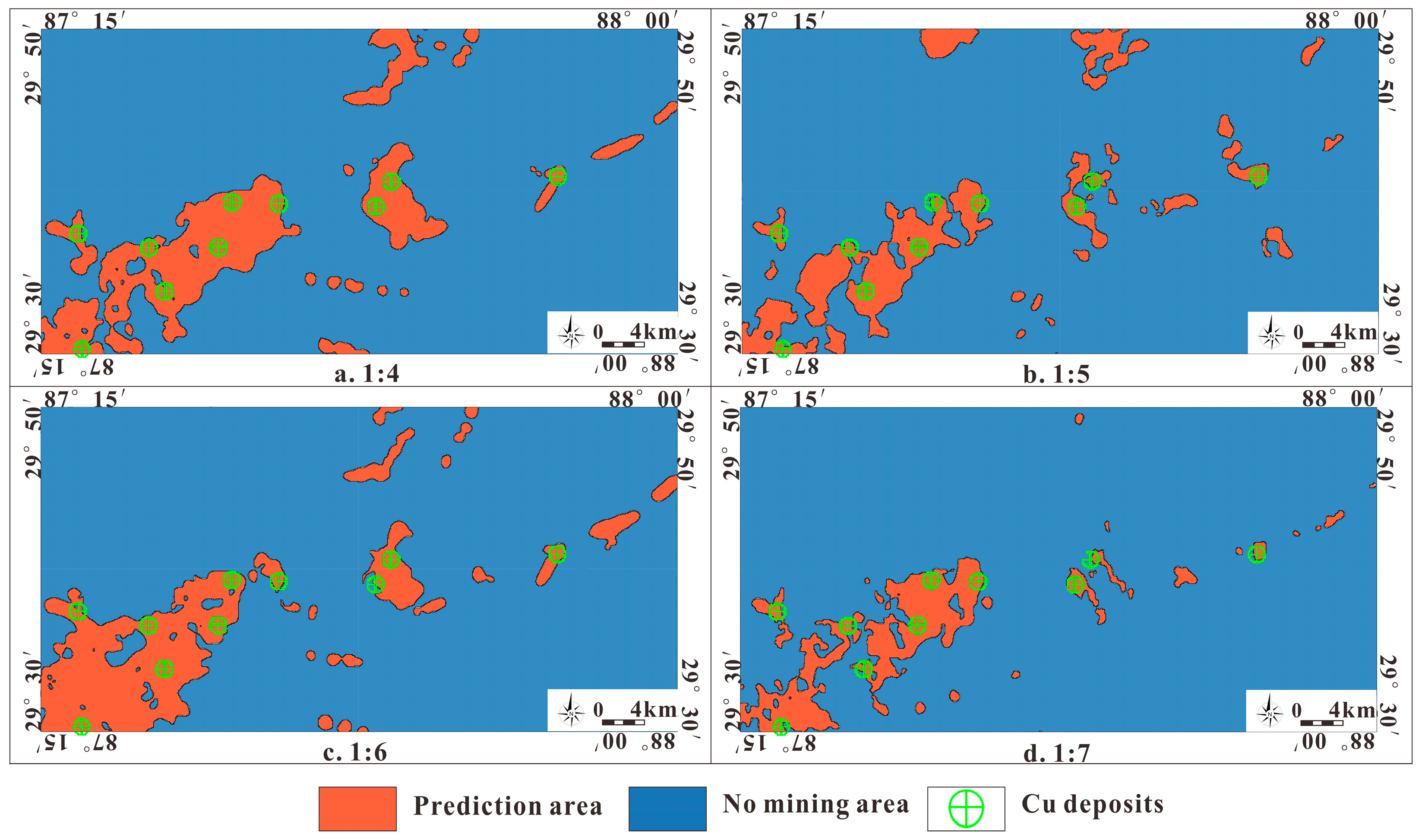
4.2.2. Influence of the Ratio of the Number of Positive and Negative Samples on the Prediction Results
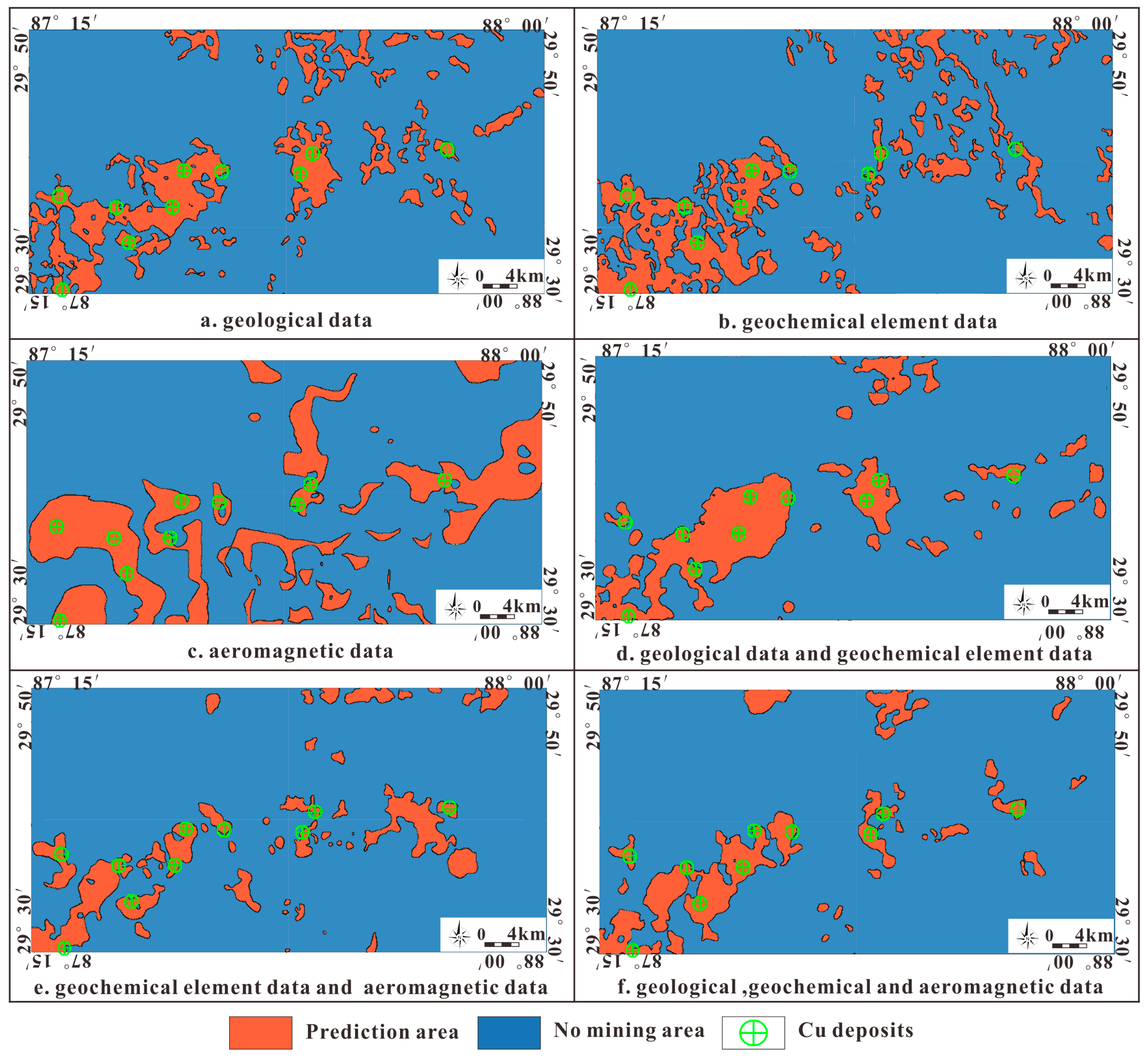
4.2.3. Influence of Different Datasets on the Prediction Results
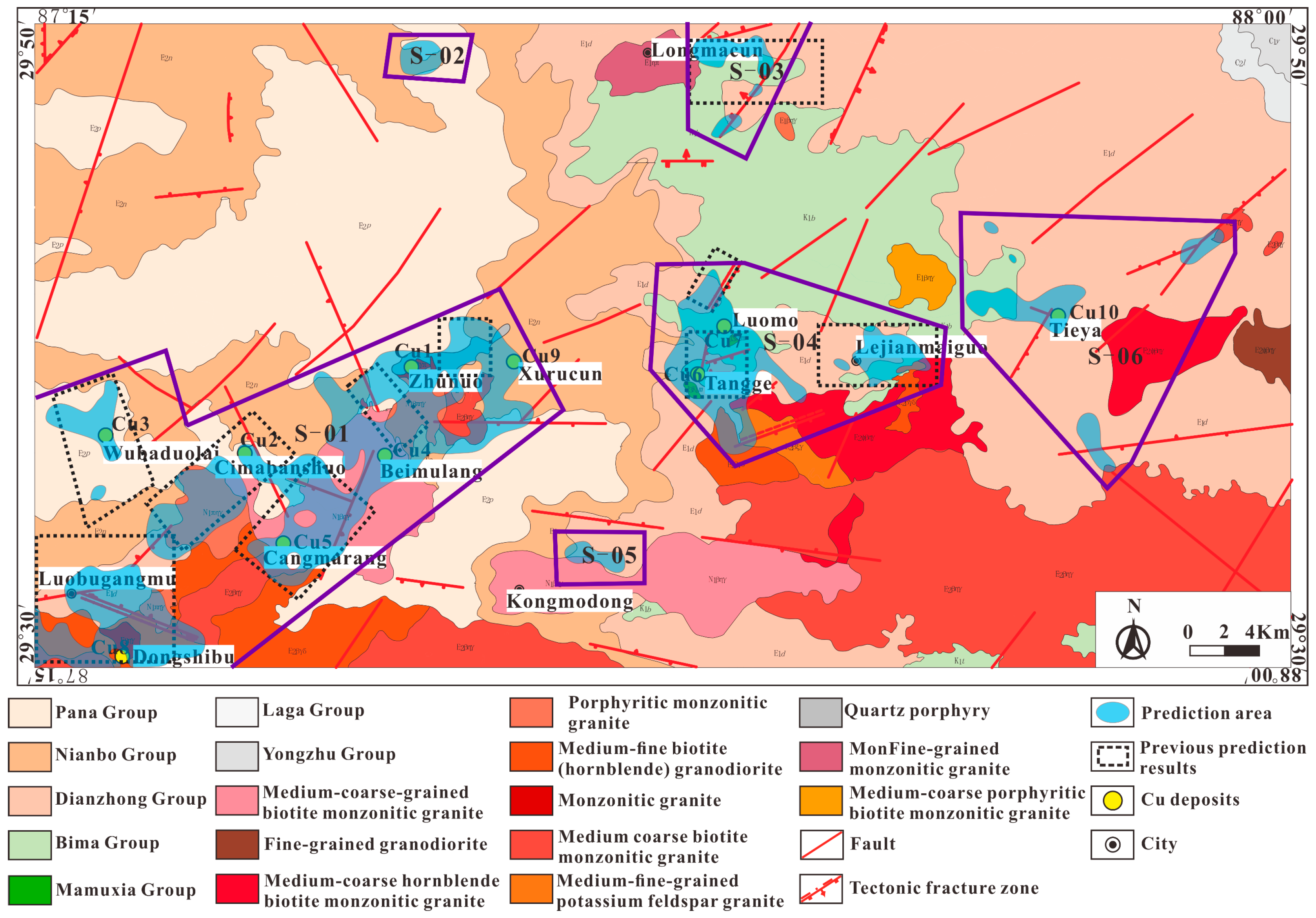
4.2.4. Prediction Results
- The S-01 prediction areas are located in the southwestern corner of the study area, and the prediction area is small. Cu1, Cu2, Cu3, Cu4, Cu5, Cu8, and Cu9 all plot within the prediction area. The main outcrops are the Paleogene Nianbo Group, the Pana Group, and the Dianzhong Group, a large portion of the prediction area was intruded by Eocene granites and Miocene granites, many NE- and NW-trending fault structures are present, porphyry-type Cu mineralization is widespread, Cu anomalies and Cu–Mo anomalies are obvious in the area, and the prediction area has good prospecting prospects for Cu deposits.
- S-02 is located in the northwestern part of the study area and is part of the northern strong magnetic anomaly area, and the predicted area is small. The Nianbo Group and the Pana Group are mainly exposed, and NW-trending faults are developed in the area.
- S-03 is located in the northern part of the study area and is part of the northern strong magnetic anomaly area. The Lower Cretaceous Bima Group and Paleogene Dianzhong Group are mainly exposed. They were intruded by Paleocene granite; several NE-trending faults were mainly developed, which was favorable for ore blending and accommodating mineral precipitation and enrichment; and it was dominated by obvious Pb–Zn anomalies and no Cu anomalies.
- S-04 is located in the middle of the study area and belongs to the central negative magnetic anomaly area. The Lower Cretaceous Bima Group and Paleogene Dianzhong Group are mainly exposed. The predicted area is intruded by Eocene granite, the area contains Cu6 and Cu7, and NE-trending faults are well developed. The geochemical anomalies are dominated by Au–Mo, the Dianzhong Group volcanic rocks are thickly covered, and the Miocene plutons are not exposed. It is very likely that the metallization is deep, the denudation is less, and the deep Cu ore body is buried deeply, resulting in no Cu anomaly on the surface. It is speculated that the area has good prospecting prospects for Cu deposits.
- S-05 is located in the south-central part of the study area. The Paleogene Nianbo Group and Dianzhong Group are mainly exposed at the surface. The strata were intruded by Miocene granites in a large area; the strata developed near E–W-trending faults, showing a certain possibility of mineralization.
- S-06 is located in the eastern part of the study area, and the Lower Cretaceous Bima Group and Paleogene Dianzhong Group are mainly exposed. These strata are mainly intruded by Eocene granites. The faults are well developed, and they are mainly NE-trending, NW-trending, and nearly E–W-trending; no obvious geochemical anomalies were found.
5. Discussion
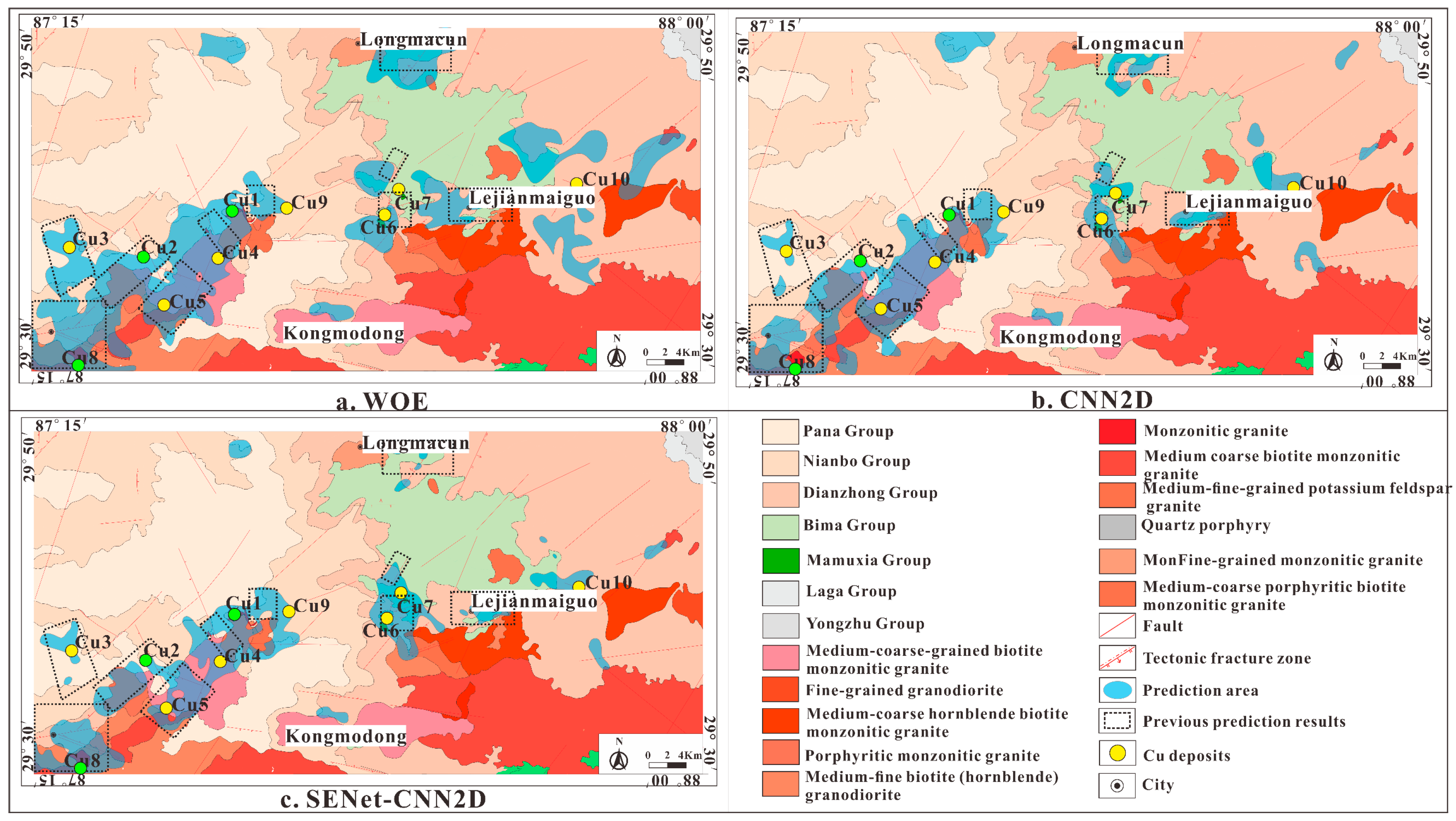
- The prediction area based on the WOE method is relatively large, accounting for 15.3% of the total area; the two methods based on deep learning have a smaller prediction area, such that the prediction area of CNN2D accounts for 9.2%, while the CNN2D-SENet model accounts for only 8.3%.
- The prediction method based on the CNN2D-SENet model successfully predicted three known deposits that were eliminated. However, Cu2 did not successfully fall within the prediction area of the CNN2D model. In addition, although Cu1, Cu2, and Cu8 were successfully predicted using the WOE method, Cu6, Cu7, and Cu10 did not fall within the prediction area. Considering that there is only one “evidence” layer (NE-trending fault) near Cu6 and Cu7, the metallogenic probability is low, and no good metallogenic possibility is shown. There are two “evidence” layers (Dianzhong Group and NE-trending fault) near Cu10, but Cu10 is far from the fault. The WOE method selects features by calculating weights, so breaks that exceed a certain distance have negative weights.
- By comparing the prediction results of the predecessors, it was found that the prediction results of the CNN2D-SENet model and the WOE method have a good fit and consistency with the prediction results of the predecessors. The prediction results of the CNN2D model also have a certain consistency with the prediction results of the predecessors, but the fit is general.
6. Conclusions
- The SENet network can selectively enhance beneficial feature channels while suppressing useless feature channels according to global information and finally achieve adaptive calibration of feature channels. The introduction of SENet to CNN2D helps to achieve a network model with better performance and improve the prediction accuracy.
- To determine the optimal value of the model hyperparameters, a series of preset values were set for each parameter, and a large number of experiments were carried out. The results showed that all the data were selected, the window size was set to 14 × 14, and the ratio of positive to negative samples was set to 1:5 to obtain the optimal prediction result.
- The prospecting and prediction method based on the CNN2D-SENet model successfully delineated six Cu deposit prospecting areas in the Zhunuo mineral concentration area, which is consistent with the previous prediction results. Compared with the traditional WOE method and the typical CNN2D, better prediction results were obtained.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Barik, R.K.; Misra, C.; Lenka, R.K.; Dubey, H.; Mankodiya, K. Hybrid mist-cloud systems for large scale geospatial big data analytics and processing: Opportunities and challenges. Arab. J. Geosci. 2019, 12, 32. [Google Scholar] [CrossRef]
- Cai, H.H.; Xu, Y.Y.; Li, Z.X.; Cao, H.H.; Feng, Y.X.; Chen, S.Q.; Li, Y.S. The division of metallogenic prospective areas based on convolutional neural network model: A case study of the Daqiao gold polymetallic deposit. Geol. Bull. China 2019, 38, 1999–2009, (In Chinese with English abstract). [Google Scholar]
- Chen, L.; Guan, Q.; Xiong, Y.; Liang, J.; Wang, Y.; Xu, Y. A Spatially Constrained Multi-Autoencoder approach for multivariate geochemical anomaly recognition. Comput. Geosci. 2019, 125, 43–54. [Google Scholar] [CrossRef]
- Ran, X.; Xue, L.; Zhang, Y.; Liu, Z.; Sang, X.; He, J. Rock Classification from Field Image Patches Analyzed Using a Deep Convolutional Neural Network. Mathematics 2019, 7, 755. [Google Scholar] [CrossRef]
- Zuo, R.; Xiong, Y. Big Data Analytics of Identifying Geochemical Anomalies Supported by Machine Learning Methods. Nat. Resour. Res. 2017, 27, 5–13. [Google Scholar] [CrossRef]
- Holden, E.-J.; Liu, W.; Horrocks, T.; Wang, R.; Wedge, D.; Duuring, P.; Beardsmore, T. GeoDocA—Fast analysis of geological content in mineral exploration reports: A text mining approach. Ore Geol. Rev. 2019, 111, 102919. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. Recognizing multivariate geochemical anomalies for mineral exploration by combining deep learning and one-class support vector machine. Comput. Geosci. 2020, 140, 104484. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. A positive and unlabeled learning algorithm for mineral prospectivity mapping. Comput. Geosci. 2021, 147, 104667. [Google Scholar] [CrossRef]
- Zhou, Y.Z.; Chen, S.; Zhang, Q.; Xiao, F.; Wang, S.G.; Liu, Y.P.; Jiao, S.T. Progress in Big Data and Mathematical Geosciences—Preface to Topics on Big Data and Mathematical Geoscience. Acta Petrol. Sin. 2018, 34, 255–263, (In Chinese with English abstract). [Google Scholar]
- Li, T.; Zuo, R.; Xiong, Y.; Peng, Y. Random-Drop Data Augmentation of Deep Convolutional Neural Network for Mineral Prospectivity Mapping. Nat. Resour. Res. 2020, 30, 27–38. [Google Scholar] [CrossRef]
- Zhang, S.; Carranza, E.J.M.; Wei, H.; Xiao, K.; Yang, F.; Xiang, J.; Zhang, S.; Xu, Y. Data-driven Mineral Prospectivity Mapping by Joint Application of Unsupervised Convolutional Auto-encoder Network and Supervised Convolutional Neural Network. Nat. Resour. Res. 2021, 30, 1011–1031. [Google Scholar] [CrossRef]
- Zuo, R.G. Deep learning-based mining and integration of deep-level mineralization information. Bull. Mineral. Petrol. Geochem. 2019, 38, 53–60, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Abedi, M.; Norouzi, G.H.; Torabi, S.A. Clustering of mineral prospectivity area as an unsupervised classification approach to explore copper deposit. Arab. J. Geosci. 2012, 6, 3601–3613. [Google Scholar] [CrossRef]
- Paasche, H.; Eberle, D.G. Rapid integration of large airborne geophysical data suites using a fuzzy partitioning cluster algorithm: A tool for geological mapping and mineral exploration targeting. Explor. Geophys. 2009, 40, 277–287. [Google Scholar] [CrossRef]
- Xu, S.T.; Zhou, Y.Z. Experimental study on intelligent identification of ore minerals under the microscope based on deep learning. Chin. J. Petrol. 2018, 34, 3244–3252, (In Chinese with English abstract). [Google Scholar]
- Sang, X.; Xue, L.; Ran, X.; Li, X.; Liu, J.; Liu, Z. Intelligent High-Resolution Geological Mapping Based on SLIC-CNN. ISPRS Int. J. Geo-Informat. 2020, 9, 99. [Google Scholar] [CrossRef]
- Liu, Y.P.; Zhu, L.X.; Zhou, Y.Z. Application of Convolutional Neural Network in Prospecting Prediction of Ore Deposits: Taking the Zhaojikou Pb-Zn Ore Deposit in Anhui Province as a Case. Acta Petrol. Sin. 2018, 34, 3217–3224, (In Chinese with English abstract). [Google Scholar]
- Li, S.; Chen, J.P.; Xiang, J. Prospecting Information Extraction by Text Mining Based on Convolutional Neural Networks—A Case Study of the Lala Copper Deposit, China. IEEE Access 2018, 6, 52286–52297. [Google Scholar] [CrossRef]
- Li, H.; Li, X.; Yuan, F.; Jowitt, S.M.; Zhang, M.; Zhou, J.; Zhou, T.; Li, X.; Ge, C.; Wu, B. Convolutional neural network and transfer learning based mineral prospectivity modeling for geochemical exploration of Au mineralization within the Guandian–Zhangbaling area, Anhui Province, China. Appl. Geochem. 2020, 122, 104747. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A.; Liu, W.; et al. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. In Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef]
- Liu, H.; Peng, C.; Xue, L.; Li, W.; Xu, C.; Jofrisse, C.S. Non-seismic geophysical analysis of potential geothermal resources in the Longgang Block, Northeast China. Earth Planet. Phys. 2022, 6, 576–591. [Google Scholar] [CrossRef]
- Yin, A.; Harrison, T.M. Geologic evolution of the Himalayan-Tibetan orogen. Annu. Rev. Earth Planet. Sci. 2000, 28, 211–280. [Google Scholar] [CrossRef]
- Hou, Z.Q.; Zheng, Y.C.; Yang, Z.M.; Yang, Z.S. Continental Collision Metallogenesis: I. Gangdise Cenozoic Porphyry Metallogenic System. Depos. Geol. 2012, 31, 647–670, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Ji, W.-Q.; Wu, F.-Y.; Chung, S.-L.; Li, J.-X.; Liu, C.-Z. Zircon U–Pb geochronology and Hf isotopic constraints on petrogenesis of the Gangdese batholith, southern Tibet. Chem. Geol. 2009, 262, 229–245. [Google Scholar] [CrossRef]
- Lee, H.-Y.; Chung, S.-L.; Ji, J.; Qian, Q.; Gallet, S.; Lo, C.-H.; Lee, T.-Y.; Zhang, Q. Geochemical and Sr–Nd isotopic constraints on the genesis of the Cenozoic Linzizong volcanic successions, southern Tibet. J. Asian Earth Sci. 2012, 53, 96–114. [Google Scholar] [CrossRef]
- Ge, L.S.; Deng, J.; Yang, L.Q.; Zou, Y.L.; Xing, J.B.; Yuan, S.S.; Wu, Y.H. Meso-Cenozoic mid-acid intrusive magmatism and tectonic evolution in the Gangdise block, Tibet. Geol. Resour. 2016, 15, 1–10, (In Chinese with English abstract). [Google Scholar]
- Hou, Z.Q.; Mo, X.X.; Gao, Y.F.; Qu, X.M.; Meng, X.J. Adakite: A possible important ore-bearing parent rock for porphyry copper deposits—Taking Tibet and Chile porphyry copper deposits for example. Depos. Geol. 2003, 22, 1–12, (In Chinese with English abstract). [Google Scholar]
- Zheng, Y.Y.; Gao, S.B.; Zhang, D.Q.; Fan, Z.H.; Zhang, G.Y.; Ma, G.T. The great significance and enlightenment of the discovery of the Juno porphyry copper deposit in Tibet. Earth Sci. Front. 2006, 13, 233–239, (In Chinese with English abstract). [Google Scholar]
- Zheng, Y.Y.; Duo, J.; Zhang, G.Y.; Gao, S.B.; Fan, Z.H. The discovery process and significance of the Jiru porphyry copper deposit in Tibet. Depos. Geol. 2007, 26, 317–321, (In Chinese with English abstract). [Google Scholar]
- Zheng, Y.Y.; Zhang, G.Y.; Xu, R.K.; Gao, S.B.; Pang, Y.C.; Cao, L. Age constraints of diagenesis and mineralization of the Juno porphyry copper deposit in Gangdise, Tibet. Sci. Bull. 2007, 52, 2542–2548, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Huang, Y.; Ding, J.; Li, G.M.; Dai, J.; Yan, G.Q.; Wang, G.; Liu, X.F. U-Pb age, Hf isotopic composition and mineralization significance of intrusive zircon in copper-molybdenum-gold mining area of Zhunuo porphyry in Tibet. Acta Geol. Sin. 2015, 89, 99–108, (In Chinese with English abstract). [Google Scholar]
- Sun, X.; Lu, Y.; McCuaig, T.C.; Zheng, Y.-Y.; Chang, H.-F.; Guo, F.; Xu, L.-J. Miocene Ultrapotassic, High-Mg Dioritic, and Adakite-like Rocks from Zhunuo in Southern Tibet: Implications for Mantle Metasomatism and Porphyry Copper Mineralization in Collisional Orogens. J. Petrol. 2018, 59, 341–386. [Google Scholar] [CrossRef]
- Peng, C.; Xue, L.-F.; Zhu, M.; Chai, Y.; Liu, W.-Y. The location and evolution of the tectonic boundary between the Paleoproterozoic Jiao-Liao-Ji Belt and the Longgang Block, northeast China. Precambr. Res. 2016, 272, 18–38. [Google Scholar] [CrossRef]
- Wu, S.; Zheng, Y.; Sun, X. Subduction metasomatism and collision-related metamorphic dehydration controls on the fertility of porphyry copper ore-forming high Sr/Y magma in Tibet. Ore Geol. Rev. 2016, 73, 83–103. [Google Scholar] [CrossRef]
- Li, Z.T.; Xue, L.F.; Ran, X.J.; Li, Y.S.; Dong, G.Q.; Li, Y.B.; Dai, J.H. Intelligent prospecting and prediction method based on convolutional neural network—Taking the copper mine in Longshoushan area of Gansu as an example. J. Jilin Univ. 2022, 52, 418–433, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Wang, H.X.; Zhou, J.Q.; Gu, C.H.; Lin, H. Design of activation functions in convolutional neural networks for image classification. J. Zhejiang Univ. 2019, 53, 1363–1373, (In Chinese with English abstract). [Google Scholar] [CrossRef]
- Liu, W.J.; Liang, X.J.; Qu, H.C. Study on the Learning Performance of Convolutional Neural Networks with Different Pooling Models. Chin. J. Image Graph. 2016, 21, 1178–1190, (In Chinese with English abstract). [Google Scholar]
- Ding, K.; Xue, L.; Ran, X.; Wang, J.; Yan, Q. Siamese network based prospecting prediction method: A case study from the Au deposit in the Chongli mineral concentrate area in Zhangjiakou, Hebei Province, China. Ore Geol. Rev. 2022, 148, 105024. [Google Scholar] [CrossRef]
- Li, Y.-S.; Peng, C.; Ran, X.-J.; Xue, L.-F.; Chai, S.-L. Soil geochemical prospecting prediction method based on deep convolutional neural networks-Taking Daqiao Gold Mine in Gansu Province, China as an example. China Geol. 2022, 5, 71–83. [Google Scholar] [CrossRef]
- Xiong, Y.; Zuo, R. Recognition of geochemical anomalies using a deep autoencoder network. Comput. Geosci. 2016, 86, 75–82. [Google Scholar] [CrossRef]
- Agterberg, F.P.; Bonham-Carter, G.F.; Wright, D.F. Statistical Pattern Integration for Mineral Exploration; Geological Survey of Canada Contribution No. 24088. In Computer Applications in Resource Estimation; Prediction and Assessment for Metals and Petroleum; Gaál, G., Merriam, D.F., Eds.; Pergamon Press: Amsterdam, The Netherlands, 1990; pp. 1–21. [Google Scholar] [CrossRef]
- Agterberg, F.P.; Cheng, Q. Conditional Independence Test for Weights-of-Evidence Modeling. Nat. Resour. Res. 2002, 11, 249–255. [Google Scholar] [CrossRef]
- Xiao, K.Y.; Zhang, X.H.; Chen, Z.H.; Song, G.Y.; Ge, Y.; Liu, D.L.; Wang, S.L.; Ning, S.N.; Cao, Y. Evidence weight method and information quantity method and their comparison in metallogenic prediction. Geophys. Geochem. Calc. Technol. 1999, 21, 223–226, (In Chinese with English abstract). [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Coordinates | Minimum/m | Maximum/m | Spacing/m | Unit Number |
|---|---|---|---|---|
| X direction | 524177 | 596768 | 50 | 1453 |
| Y direction | 3,264,867.5 | 3,302,083.5 | 50 | 745 |
| Serial Number | Type | Size of the Deposit |
|---|---|---|
| Cu1 | porphyry type | large |
| Cu2 | porphyry type | ore occurrence |
| Cu3 | porphyry type | ore occurrence |
| Cu4 | porphyry type | ore occurrence |
| Cu5 | porphyry type | ore occurrence |
| Cu6 | skarn type | ore occurrence |
| Cu7 | porphyry type | ore occurrence |
| Cu8 | porphyry type | ore occurrence |
| Cu9 | porphyry type | ore occurrence |
| Cu10 | porphyry type | ore occurrence |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, K.; Xue, L.; Ran, X.; Wang, J.; Yan, Q. CNN2D-SENet-Based Prospecting Prediction Method: A Case Study from the Cu Deposits in the Zhunuo Mineral Concentrate Area in Tibet. Minerals 2023, 13, 730. https://doi.org/10.3390/min13060730
Ding K, Xue L, Ran X, Wang J, Yan Q. CNN2D-SENet-Based Prospecting Prediction Method: A Case Study from the Cu Deposits in the Zhunuo Mineral Concentrate Area in Tibet. Minerals. 2023; 13(6):730. https://doi.org/10.3390/min13060730
Chicago/Turabian StyleDing, Ke, Linfu Xue, Xiangjin Ran, Jianbang Wang, and Qun Yan. 2023. "CNN2D-SENet-Based Prospecting Prediction Method: A Case Study from the Cu Deposits in the Zhunuo Mineral Concentrate Area in Tibet" Minerals 13, no. 6: 730. https://doi.org/10.3390/min13060730
APA StyleDing, K., Xue, L., Ran, X., Wang, J., & Yan, Q. (2023). CNN2D-SENet-Based Prospecting Prediction Method: A Case Study from the Cu Deposits in the Zhunuo Mineral Concentrate Area in Tibet. Minerals, 13(6), 730. https://doi.org/10.3390/min13060730