
Some Probabilistic Generalizations of the Cheney–Sharma and Bernstein Approximation Operators




Abstract
:1. Introduction
2. A Probabilistic Representation and Derivation of the Cheney–Sharma Operator
3. A Generalization of the Bernstein Operator
4. Another Probabilistic Representation of the Cheney–Sharma Operator
5. Cheney–Sharma Operator as Average of Szász–Mirakyan Operator
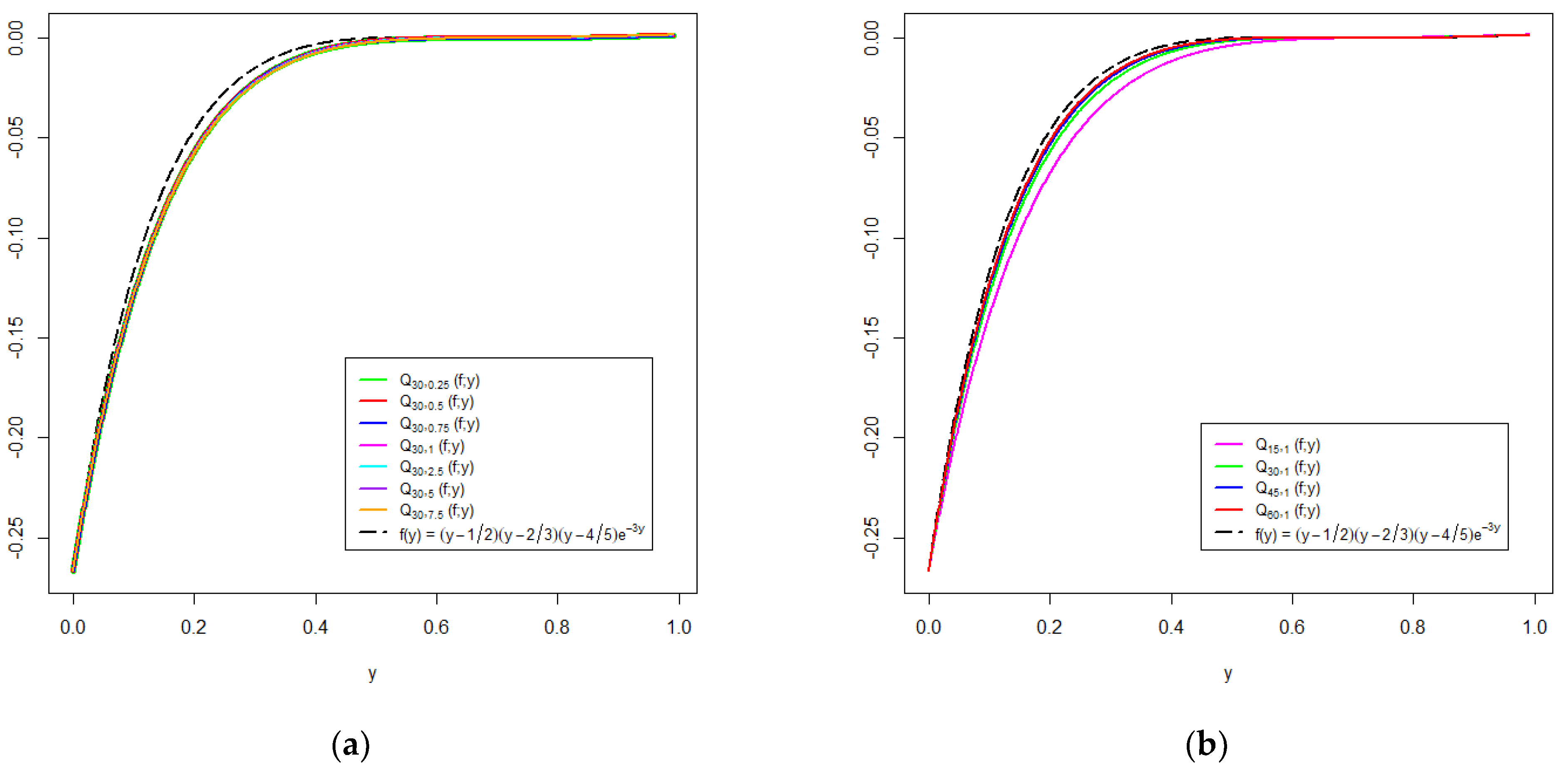
6. Graphical Analysis
7. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Szegö, G. Orthogonal Polynomials; American Mathematical Society Colloquium Publications; American Mathematical Society: Providence, RL, USA, 1959; Volume 23. [Google Scholar]
- Srivastava, H.M.; Manocha, H.L. A Treatise on Generating Functions; Halsted Press: Sydney, Australia; Ellis Horwood Limited: Chichester, UK; John Wiley and Sons: New York, NY, USA; Chichester, UK; Brisbane, Australia; Toronto, ON, Canada, 1984. [Google Scholar]
- Cheney, E.W.; Sharma, A. Bernstein power series. Canad. J. Math. 1964, 16, 241–252. [Google Scholar] [CrossRef]
- Khan, R.A. Some probabilistic methods in the theory of approximation operators. Acta Math. Hung. 1980, 35, 193–203. [Google Scholar] [CrossRef]
- Stancu, D.D. Approximation of functions by a new class of linear polynomial operators. Rev. Roum. Math. Pures Appl. 1968, 13, 1173–1194. [Google Scholar]
- Cismasiu, C.S. On the Szász-Inverse Beta operators. Stud. Univ. Babeş-Bolyai Math. 2011, 56, 305–313. [Google Scholar]
- Wang, M.L.; Yu, D.S.; Zhou, P. On the approximation by operators of Bernstein-Stancu type. Appl. Math. Comput. 2014, 246, 79–87. [Google Scholar] [CrossRef]
- Acar, T.; Aral, A.; Gupta, V. On approximation properties of a new type Bernstein-Durrmeyer operators. Math. Slovaca 2015, 65, 1107–1122. [Google Scholar] [CrossRef]
- Dong, L.X.; Yu, D.S. Pointwise approximation by a Durrmeyer variant of Bernstein-Stancu operators. J. Inequal. Appl. 2017, 28, 2–13. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwun, Y.C.; Acu, A.M.; Rafiq, A.; Radu, V.A.; Ali, F.; Kang, S.M. Bernstein-Stancu type operators which preserve polynomials. J. Comput. Anal. Appl. 2017, 23, 758–770. [Google Scholar]
- Nasiruzzaman, M.; Srivastava, H.M.; Mohiuddine, S.A. Approximation process based on parametric generalization of Schurer-Kantorovich operators and their bivariate form. Proc. Nat. Acad. Sci. India Sect. A Phys. Sci. 2022, 92, 301–311. [Google Scholar] [CrossRef]
- Braha, N.L.; Mansour, T.; Srivastava, H.M. A parametric generalization of the Baskakov-Schurer-Szász-Stancu approximation operators. Symmetry 2021, 13, 980. [Google Scholar] [CrossRef]
- Srivastava, H.M.; İçöz, G.; Çekim, B. Approximation properties of an extended family of the Szász–Mirakjan Beta-type operators. Axioms 2019, 8, 111. [Google Scholar] [CrossRef] [Green Version]
- Korovkin, P.P. Linear Operators and Approximation Theory; Hindustan Publishing Corporation: Delhi, India, 1960. [Google Scholar]
- Erdélyi, A.; Magnus, W.; Oberhettinger, F.; Tricomi, F.G. Higher Transcendental Functions; McGraw-Hill: New York, NY, USA; London, UK; Toronto, ON, Canada, 1953; Volume 2. [Google Scholar]
- Popoviciu, T. Sur l’approximation des function convexes d’ordre supeŕieur. Mathematica 1935, 10, 49–54. [Google Scholar]
- Slater, L.J. Generalized Hypergeometric Functions; Cambridge University Press: Cambridge, UK, 1966. [Google Scholar]
- Fisher, R.A.; Corbet, A.S.; Williams, C.B. The relation between the number of species and the number of individuals in a random sample of an animal population. J. Anim. Ecol. 1943, 12, 42–58. [Google Scholar] [CrossRef]
- Rao, C.R. On discrete distributions arising out of methods of ascertainment. In Classical and Contagious Discrete Distributions; Patil, G.P., Ed.; Statistical Publishing Society: Calcutta, India, 1965; pp. 320–332. [Google Scholar]
- Pethe, S.P.; Jain, G.C. Approximation of functions by a Bernstein-type operator. Can. Math. Bull. 1972, 15, 551–557. [Google Scholar] [CrossRef]
- Haight, F.A. Handbook of the Poisson Distribution; John Wiley: New York, NY, USA, 1967. [Google Scholar]
- Laha, R.G. On some properties of the Bessel function distributions. Bull. Calcutta Math. Soc. 1954, 46, 59–72. [Google Scholar]
- Sneddon, I.N. Special Functions of Mathematical Physics and Chemistry; Oliver and Boyd: Edinburgh, UK, 1961. [Google Scholar]
- Adell, J.A.; de la Cal, J.; Pérez-Palomares, A. On the Cheney and Sharma operator. J. Math. Anal. Appl. 1996, 200, 663–679. [Google Scholar] [CrossRef]
- Ong, S.H.; Toh, K.K.; Low, Y.C. The non-central negative binomial distribution: Further properties and applications. Commun. Stat.-Theory Methods 2021, 50, 329–344. [Google Scholar] [CrossRef]
- Sofyalıoğlu, M.; Kanat, K.; Çekim, B. Parametric generalization of the Meyer-König-Zeller operators. Chaos Soliton. Fract. 2021, 152, 111417. [Google Scholar] [CrossRef]
- Ong, S.H.; Lee, P.A. On a generalized non-central negative binomial distribution. Commun. Stat.-Theory Methods 1986, 15, 1065–1079. [Google Scholar] [CrossRef]
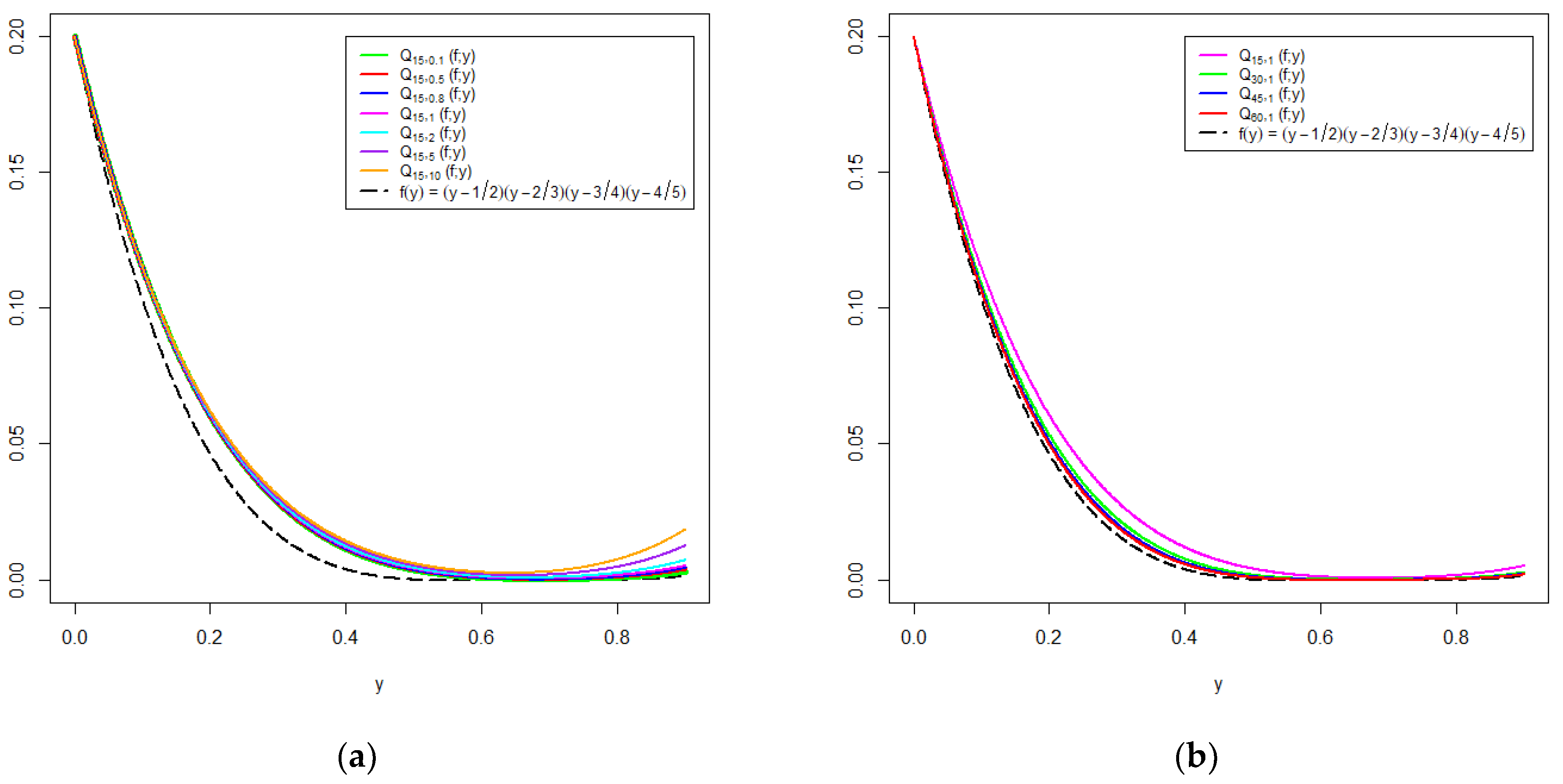

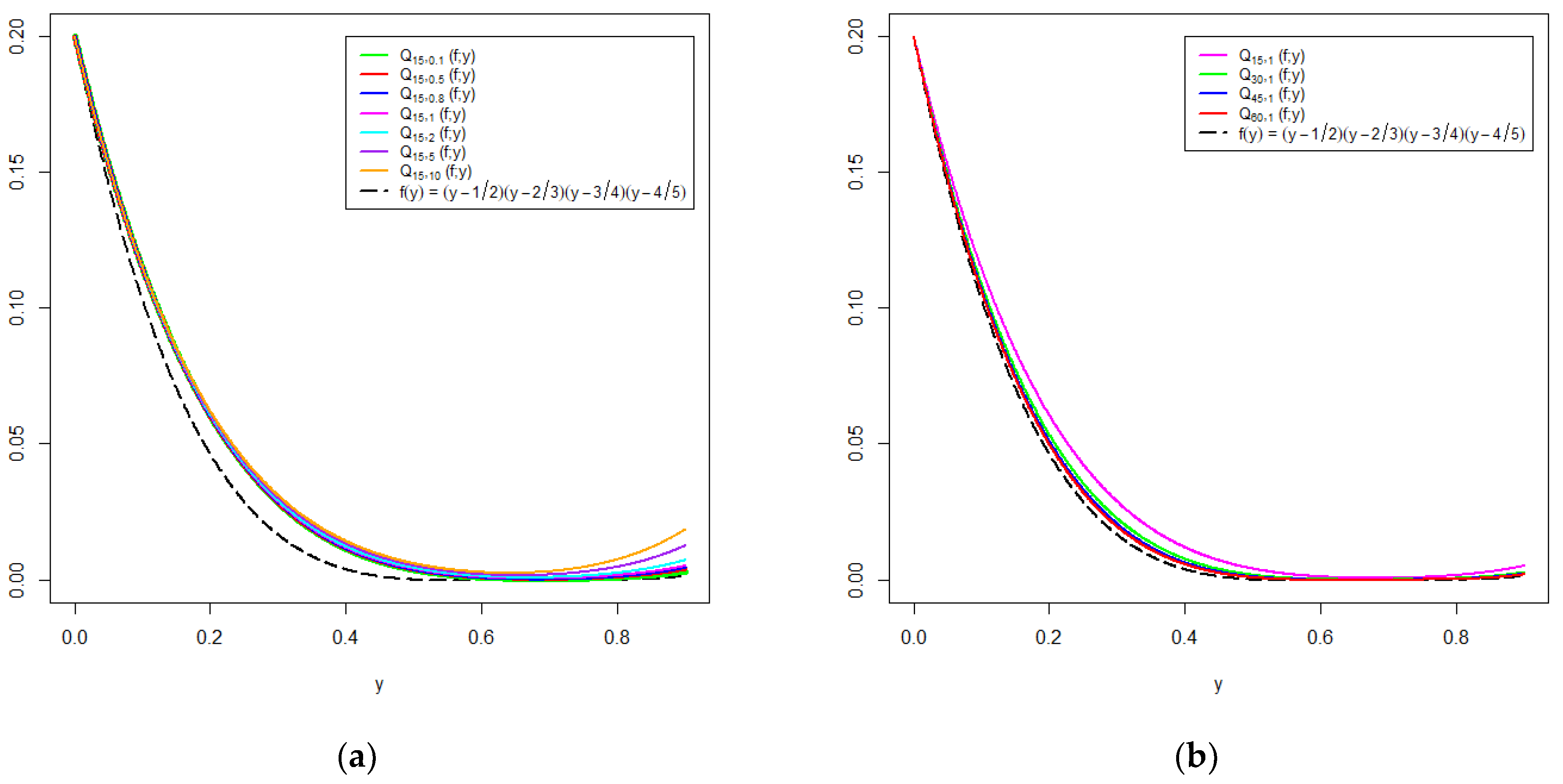{kind=link}
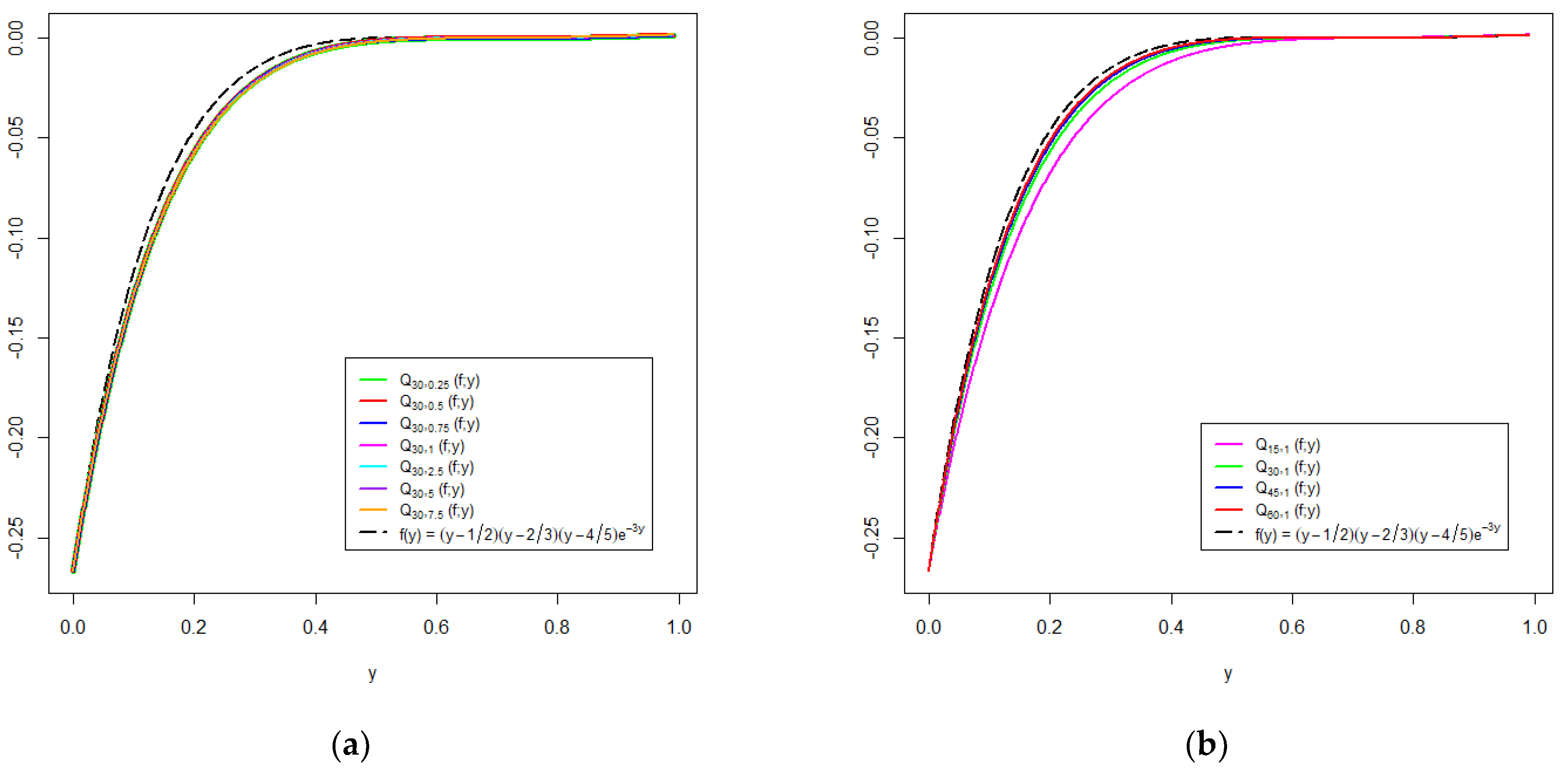{kind=link}
| 0.1 | 0.5 | 0.8 | 1 | 2 | 5 | 10 | |
|---|---|---|---|---|---|---|---|
| 15 | 0.01399 | 0.01414 | 0.01424 | 0.01431 | 0.01461 | 0.01527 | 0.01716 |
| 30 | 0.00711 | 0.00715 | 0.00718 | 0.00720 | 0.00729 | 0.00753 | 0.00781 |
| 45 | 0.00477 | 0.00479 | 0.00480 | 0.00481 | 0.00485 | 0.00497 | 0.00513 |
| 60 | 0.00359 | 0.00360 | 0.00361 | 0.00361 | 0.00364 | 0.00370 | 0.00380 |
| 0.25 | 0.5 | 0.75 | 1 | 2.5 | 5 | 7.5 | |
|---|---|---|---|---|---|---|---|
| 15 | 0.00028 | 0.00030 | 0.00032 | 0.00034 | 0.00043 | 0.00052 | 0.00057 |
| 30 | 0.00016 | 0.00016 | 0.00017 | 0.00018 | 0.00022 | 0.00027 | 0.00031 |
| 45 | 0.00011 | 0.00011 | 0.00012 | 0.00012 | 0.00014 | 0.00017 | 0.00019 |
| 60 | 0.00008 | 0.00009 | 0.00009 | 0.00009 | 0.00010 | 0.00012 | 0.00013 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ong, S.H.; Ng, C.M.; Yap, H.K.; Srivastava, H.M. Some Probabilistic Generalizations of the Cheney–Sharma and Bernstein Approximation Operators. Axioms 2022, 11, 537. https://doi.org/10.3390/axioms11100537
Ong SH, Ng CM, Yap HK, Srivastava HM. Some Probabilistic Generalizations of the Cheney–Sharma and Bernstein Approximation Operators. Axioms. 2022; 11(10):537. https://doi.org/10.3390/axioms11100537
Chicago/Turabian StyleOng, Seng Huat, Choung Min Ng, Hong Keat Yap, and Hari Mohan Srivastava. 2022. "Some Probabilistic Generalizations of the Cheney–Sharma and Bernstein Approximation Operators" Axioms 11, no. 10: 537. https://doi.org/10.3390/axioms11100537
APA StyleOng, S. H., Ng, C. M., Yap, H. K., & Srivastava, H. M. (2022). Some Probabilistic Generalizations of the Cheney–Sharma and Bernstein Approximation Operators. Axioms, 11(10), 537. https://doi.org/10.3390/axioms11100537