1. Introduction
The first distribution in the Luria–Delbrück (LD) distribution family was proposed by Delbrück [
1] to provide a mathematical foundation for a trailblazing experimental protocol proposed by Luria. Their joint paper, now a classic in genetics research, ushered in an 80-year period of relentless progress in the experimental determination of microbial mutation rates. The experimental protocol is variously referred to as the fluctuation test, the fluctuation experiment, or the Luria–Delbrück experiment. The data generated by such an experiment are called fluctuation assay data, which is a sequence of nonnegative integers representing the numbers of mutants found by the experimentalist in a series of cultures. (For details about the experimental protocol, see Ref. [
2].) Today, despite rapid advances in sequencing technology, the LD experimental protocol remains a widely favored tool for studying microbial mutation rates in the laboratory. While there has been little alteration to the experimental protocol, the LD distribution family has been augmented considerably.
The first addition to the LD distribution family was made by Lea and Coulson [
3] to overcome an important drawback of the distribution proposed by Delbrück. Note that Delbrück used a continuous distribution to model the number of bacterial mutants observed in Luria’s experiments. However, the numbers of mutants in those experiments were small random numbers, and they rarely exceeded 1000. Seeing that a continuous distribution was not an efficient tool to model the number of mutants, Lea and Coulson employed a stochastic birth process to construct a new discrete distribution. The distribution constructed by Lea and Coulson is uniquely determined by a single parameter
m, which is the expected number of mutations. Lea and Coulson defined their new distribution by giving the probability generating function of the form
along with its more compact form
(see Equation (15) in Ref. [
3]). This distribution is now widely referred to as the Luria–Delbrück distribution mainly due to historical reasons, as the original distribution proposed by Delbrück fell into disuse soon after the work of Lea and Coulson.
Further augmentation of the LD distribution family was effected by laboratory needs and theoretical considerations. Mandelbrot [
4] and Koch [
5] independently extended the Lea–Coulson distribution to accommodate distinctive cell growth rates between mutants and nonmutants. The resulting distribution has a fitness parameter
w, which is the ratio of the mutant growth rate to the nonmutant growth rate. Another driving force in the augmentation of the LD distribution is the fact that the number of mutants in a culture is often too large to count. This laboratory difficulty clamors for the study of distributions having a plating efficiency parameter
that indicates how large a portion of each culture is actually plated to ease the counting burden. After a brief initial study of this kind of distribution by Armitage ([
6], p. 14), several investigators explored these distributions more thoroughly in the 1990s [
7,
8,
9,
10,
11]. More recently, further impetus for augmenting the LD distribution family comes from work on mathematical modeling of tumor progression. Antal and Krapivsky [
12] studied the joint distribution of the numbers of both mutants and nonmutants. They allowed not only distinct cell growth rates between mutants and nonmutants, but also distinct cell death rates for both types of cells. In addition, Kessler and Levine [
13] proposed a unified approach for computing mutant probabilities.
Efficient algorithms for computing various LD distributions are key to meaningful inference of microbial mutation rates. An algorithm must satisfy two practical requirements to be useful in the analysis of fluctuation assay data. First, it should remain operational for a wide range of key parameter values that an experimentalist might encounter in the laboratory. Among such parameters are
and
. Second, it should be capable of computing
(the probability of
k mutants) reasonably fast for
for some meaningful
K (e.g.,
K = 2000). In the past 30 years, an idea introduced by Ma et al. [
14] to compute the Lea–Coulson distribution has served as the backbone of several algorithms for computing a variety of extensions of the Lea–Coulson distribution. In 2013, Kessler and Levine [
15] outlined a new, unified approach that relied on numerical integration to compute a much wider class of LD distributions. More details were given later by the same authors [
13]. Mazoyer et al. [
16] employed a possibly similar integration-based approach to compute a wide assortment of LD distributions in the R package flan. For the most part, the implementation in flan achieved impressive accuracy and computing speed. However, there are situations where this universal approach may not be optimal, convenient, or practical, as shown by the following example.
This example was inspired by an inquiry from a yeast microbiologist. Her group was planning fluctuation experiments to measure the rate of extra-chromosome loss in yeast cells. Due to the high rates of extra-chromosome loss seen in a pilot study, these investigators would like to plate a 0.5% portion of each culture. They also planned to measure cell growth rates to help enhance the accuracy of their rate estimates. Clearly, their data would require an LD distribution involving and . Because , it is sensible to set as a testing value to allow a manageable number of mutants to be observed in the plated portion of a culture. Next, a value for the fitness parameter w is needed. Meaningful values for w lie around , and we here regard all real numbers on the interval as values for w that may be encountered in real-world research. To produce a complete testing example, we set . With this testing example, the latest version of flan (v. 0.9) can compute easily for . However, computing for any would cause flan to stop responding. Perhaps such an annoying problem can be circumvented by tweaking the algorithm on a case-by-case basis. Still, it is worthwhile to seek alternative algorithms to compute this special type of three-parameter LD distributions. In this paper, we offer a more practical algorithm for the three-parameter LD distribution that is crucial to the yeast microbiologist’s investigation and to numerous other investigations. We begin by studying this distribution’s probability generating function.
2. The Probability Generating Function
As just mentioned, sometimes a culture may contain too many mutants for the experimentalist to count. A way of overcoming this difficulty is to count mutants in only a fraction of the whole culture, a practice called partial plating. If an
portion of the whole culture is taken (plated, in microbiology parlance) to count mutants, it is conceptually equivalent to subjecting all mutants in the whole culture to a binomial sampling process with the success probability being
. (The parameter
is called the plating efficiency). Therefore, the distribution of the number of mutants observed by the experimentalist is related to the distribution of the number of mutants in the whole culture. Armitage ([
6], Equation (50)) gave the relation in terms of the two distributions’ generating functions as follows.
Here,
and
are respectively the generating functions of the number of mutants in the whole culture and of the number of mutants in the plated culture, and
is the plating efficiency. A brief proof of Equation (
1) may run as follows.
Let
X be the number of mutants in the whole culture, and let
Y be the number of mutants in the plated culture. From elementary theory of conditional probability it follows that
Now the distribution to be investigated can be assembled by using (
1). The distribution of the number of mutants in the whole culture is the same distribution studied by Mandelbrot [
4] and Koch [
5]. This distribution is known [
17] to have an approximate generating function of the form
where
denotes the beta function. However, an equivalent expression due to Kessler and Levine [
13] would facilitate subsequent development. Setting the two cell death rates to zero and adopting new notation, we reduce Equation (
45) of Kessler and Levine [
13] to
Here, the symbol
is simplified notation for
, which denotes the hypergeometric function as defined in Ref. [
18], p. 238. Note that the generating function
in (
5) is well-defined for
. The adoption of the hypergeometric function to help manipulate the generating function in (
4) has caused the generating function to lose its definition at
, as
is clearly undefined at
. However, this small price paid for mathematical convenience does not compromise the ensuing development. Combining (
1) with (
5) and simplifying, we obtain the desired generating function
of the form
with
3. An Integration-Based Method
Let
be the probability of
k mutants. That is,
. Here, we use the notation
to denote the coefficient of
in the Maclaurin series expansion of
. The integration method is based on Cauchy’s integral formula for derivatives:
Note that
is the pgf in (
6) and
is a circle around the origin with a radius smaller than one. By definition, for any given
, the above integral can be computed by
where
. However, in practice, there are important drawbacks to this idea. First, the integrand is a complex-valued function, which makes implementation and computation needlessly complicated. Second, it is not clear how to choose an appropriate value of
r for a given problem, as a poorly chosen value of
r can lead to a nonsensical result. Kessler and Levine [
13] proposed a clever way of deforming the integration contour
to overcome these difficulties. In this section, we adapt their strategy to devise an improved integration-based algorithm for computing
.
The basic idea of Kessler and Levine was to transform the complex integral in (
8) to a real integral along the positive real axis. One way to accomplish this task is to deform the contour
into a new contour as depicted in
Figure 1, which has previously been done in Ref. [
19]. We first transform the integral in (
8) to a real integral along the ray
. To facilitate the transformation, we rewrite the hypergeometric function appearing in the pgf in (
6). Applying the transform
via Equation (9.5.9) in Ref. [
18], we obtain
Note that the hypergeometric function appearing in the first term on the right-hand side of (
9) will invalidate this transform when
for
, because
is undefined for
. This kind of drawback of the integration approach has been noticed in a previous study [
19]. The practical implications of this drawback are worth noting. For example, when
, the integration-based algorithm fails altogether. Moreover, for values of
w close to 0.5, the algorithm may produce unreliable results. Nevertheless, the transform in (
9), introduced to the study of the Luria–Delbrück distribution by Kessler and Levine [
13], simplifies the integral in (
8) in two important ways. First, for
,
Therefore, the hypergeometric function appearing in the first term on the right-hand side of (
9) is a single-valued function of
z for
z on both edges of the ray
. Second, because
for all
z, the second term on the right-hand side of (
9) does not involve the hypergeometric function; but it can be a multivalued function, depending on whether
z lies on the upper edge or lower edge of the ray. Therefore, we now focus on the second term on the right-hand side of (
9) with the hypergeometric function removed.
For
z on the upper and lower edges of the the ray
, which are labeled
and
, respectively, in
Figure 1, we have
Therefore, it follows that
Exponentiating (
11) and then taking the imaginary part, we find that one factor of the integrand is
More precisely,
is the imaginary part of the quantity in (
11) when
z lives on the upper edge of the ray
]. If
z is on the lower edge of the ray, the imaginary part of (
11) is
.
In light of (
9), the other factor of the integrand is
It is now necessary to assume that the integral along the small circle
and that long the large circle
vanish as
and
. As shown in Ref. [
19], this kind of claim requires excessive amounts of tedious mathematics to prove, and we do not attempt to prove the two claims here. Assuming the validity of these two claims, we add the integrals on
and
to obtain
Following Kessler and Levine [
13], we recast the above to an integral on the entire positive real axis:
where
Note that the expressions for
and
are expressible as
and
4. A More Practical Algorithm
Unlike the preceding strategy that extracts
directly from the generating function
, the strategy here focuses on the expansion of
after recasting the generating function as
. The success of this strategy relies on an obscure property of the exponential function. Let
and
be functions analytic inside the unit circle. Let
and
. Assume further that
. Then the
sequence can be determined by the
sequence as follows.
Equation (
17) can be established by differentiating the identity
and then equating the coefficients for each separate power of
z. This helpful relation can be traced to a once-popular calculus textbook published in the 1950s ([
20], p. 448). In 1992, Ma et al. [
14] used it to compute the Lea–Coulson distribution.
It follows from (
6) that the generating function can be viewed as
with
A straightforward way to compute the
sequence is to regard
as a composite function
with
The
sequence can then be obtained by Faà di Bruno’s formula [
21]. Theoretically, it seems an easy task. First, applying the Leibniz rule to the function
leads to
Hence,
can be computed by
Third, the derivatives
can be computed from the
and
sequences using Faà di Bruno’s formula (e.g., Equation (2.2) in Ref. [
21]). Finally, note that
and for
we have
. Despite its obvious educational value, this method is of limited use in practice. According to the results of this author’s computational experiments, the computation of
by this method is prohibitively expensive when
.
A more practical algorithm for computing
can be devised by a novel route. Applying Pfaff’s formula (e.g., Equation (9.5.1) in Ref. [
18]) yields
Therefore, we can rewrite the generating function in (
6) as
with
Applying the differentiation formula for the hypergeometric function, e.g., Equation (9.2.3) in Ref. [
18], we have for
It follows from (
23) that
can be computed by
with
The computation of the
sequence can be improved by noting that for
where
and
Furthermore, setting
, we can also compute the
sequence recursively.
It follows from (
26) and (
27) that
with
The forgoing development gives the following recipe for computing for .
computing
for
by (
29).
computing
for
by (
28).
computing
for
by (
30) and (
31).
computing
for
by (
17).
5. Asymptotic Behavior of the Mutant Probability
Knowledge of the asymptotic behavior of is of theoretical interest in its own right. Moreover, it plays a helpful role in testing computer implementations of algorithms for computing . A standard tool for fathoming the asymptotic behavior of is classical analysis that relies on so-called transfer theorems in the spirit of the Tauberian method. To seek an asymptotic expression for by this route, we first cite two existing results.
Proposition 1. Let be a complex-valued function analytic in for some and . Assume that as in ,for some constants K and α. If , then On the other hand, if α is a nonnegative integer, then Here, the symbol
defines the close domain
with
and
. This result is due to Flajolet and Odlyzko ([
22], Corollary 2).
The second result has appeared in the classic text of Titchmarsh ([
23], p. 226) as an exercise for students.
Proposition 2. Assume that . As , In Proposition 2 as stated in Ref. [
23],
z approaches 1 only along the real axis within the unit circle. In the following informal process, we assume that (
32) holds for
inside some
. This assumption requires the symbol
in (
32) to represent the analytic continuation of the hypergeometric function defined in the complex plane cut long the segment
.
Now an intuitive derivation of the asymptotic behavior of
can be executed. Begin with the function
defined in (
23). Note that
Therefore, in view of Proposion 2, as
, for
,
Because (
23) can be rewritten as
it follows from (
33) that as
Observe that (
34) is equivalent to
Hence it follows from the relation
that
Let
. Then
satisfies the condition
. Applying Proposition 1 to
and noting the identity
, we obtain the relation
As the constant 1 in (
35) has no effect on the asymptotic behavior of
, we conclude that
The foregoing argument ceases to work when
. However, the case
has been tackled earlier by a slightly different approach [
24], and the result is in agreement with (
36):
It appears an elusive goal to translate the above intuitive argument into a formal mathematical proof of (
36). A perspicacious reviewer has offered a refreshing, rigorous proof that makes ingenious use of elaborate probabilistic machinery. To help the reader focus on the essence of the probabilistic proof, we present separately two results that play an integral role in the proof but that may distract the reader from the main idea if not proved before the proof of (
36). The first result is a special case of a theorem due to Borovkov ([
25], p. 258).
Proposition 3. Let be analytic in a region containing the unit disk. Then If is a probability generating function, then because . Therefore, .
The next result is more elementary.
Proposition 4. Let and be nonnegative continuous functions on . Let be a sequence of nonnegative discrete random variables. Assume that
- 1.
for ;
- 2.
as ;
- 3.
there exists a sequence of positive constants such that and
Proof. Given
, there exists
such that
implies
On the other hand, due to assumption 3, there exists
such that
holds almost everywhere. Therefore, for
,
holds almost everywhere. Note that assumption 1 guarantees the existence of
for
. Taking expectations leads to
which is the desired conclusion. □
Now we proceed to present the probabilistic proof of (
36). Consider the generating function
in (
4). Combining (
1) and (
4) leads to the generating function of interest
where
Let
. Applying the usual binomial-expansion formula and collecting coefficients of
, we have
Now, consider two real-valued functions defined on
:
and
Observe that
as
(see, e.g., p. 15 of Ref. [
18]). Write
where
is a random variable following a negative binomial distribution with parameters
and
. Because
can be viewed as the sum of
independently and identically distributed random variables obeying the geometric distribution with parameter
, it follows from the strong law of large numbers (see, e.g., p. 42 of Ref. [
26]) that
Here, the symbol
signifies convergence almost everywhere. Therefore,
For any
, the random variable
satisfies
Hence it follows from the dominated convergence theorem (see, e.g., p. 42 of Ref. [
26]) and (
40) that
Clearly,
satisfies assumption 1 in Proposition 4. Because
, it follows that
also satisfies assumption 1. Moreover, the random variable sequence
satisfies assumption 3 in Proposition 4 with
. In view of Proposition 4 and (
41), (
39) leads to
This is equivalent to (
36) due to Proposition 3.
To show the usefulness of formula (
36), we here employ it as a check on the recursive algorithm given in the preceding section. Consider cases where
and
. For
and selected values of
n,
Table 1,
Table 2 and
Table 3 list exact values of
computed by the recursive algorithm and their corresponding asymptotic values
computed by formula (
36). The relative errors, defined by
, are shown in the last column.
6. Examples and Simulation Results
As alluded to earlier, the foregoing algorithms were motivated by an investigation on chromosome loss in yeast cells. The experimental context of this investigation is similar to that described in a previous study in Refs. [
27,
28]. In this experimental context, the colonies are the equivalent of the parallel cultures in a classic fluctuation experiment [
28].
Table 4 and
Table 5 give two fictitious data sets that mimic the real-world data to highlight several important features of such data. First, as reported by Wu et al. [
28], there is high variation in
, the final total number of viable cells in a culture. Second, there is also high variation in the plating efficiency
. Due to these two challenging features, the mutation rate
should be estimated directly, not via the estimation of
m as is commonly practiced [
2,
29]. Therefore, the log likelihood function is
Here,
is the number of mutants in the
ith culture;
and
are respectively
and
for the
ith culture. The experiment consists of
n cultures and
w is the fitness that is assumed to be constant cross all cultures (or colonies in the present context). The maximum likelihood (ML) estimator of
, denoted by
, is defined by
Many optimization algorithms can be employed to compute
. The golden section search method ([
30], p. 293) is one of the simplest methods for that purpose. The experimentalist starts the computational process by first bracketing the mutation rate via trial and error or by using prior knowledge. Furthermore, the log likelihood function in (
42) can also be used to compute confidence intervals (CIs) for the mutation rates. Specifically, to compute the two boundary points of a
CI for the mutation rate, we solve numerically the following equation:
Here,
denotes the
th quantile of the
distribution with one degree of freedom. The bisection method ([
30], p. 261) can be used to solve (
44). The foregoing work extends previous research [
31].
Assume that the unknown mutation rates in both fictitious experiments lie in the interval . Applying the above ideas to the first experiment yields a mutation rate estimate and a 95% likelihood ratio confidence interval . For the second experiment, the same method yields and a 95% likelihood ratio confidence interval .
Another essential task in microbial mutation research is the comparison of mutation rates under different conditions or between different strains. Let and be mutant data generated by two fluctuation experiments. In particular, the sample sizes are and respectively. Let the symbol and be corresponding values of the parameters and w associated with the mutant count data . Let the two mutation rates be and , respectively. Here, is assumed to be constant for all cultures in experiment , but this assumption can be relaxed without affecting the ensuing discussion.
The preferred method for comparing mutation rates in two independent fluctuation experiments is the likelihood ratio (LR) test [
32]. To perform an LR test, we first compute ML estimates
and
separately using log likelihood functions
and
similarly defined as in (
42). We next construct a combined log likelihood function
from which we compute a combined mutation rate estimate
according to the definition
Finally, we compute an LR statistic
using the definition
The test statistic asymptotically obeys a chi-squared distribution with one degree of freedom. Applying the LR test to the mutation rates in the two fictitious experiments, we obtain and .
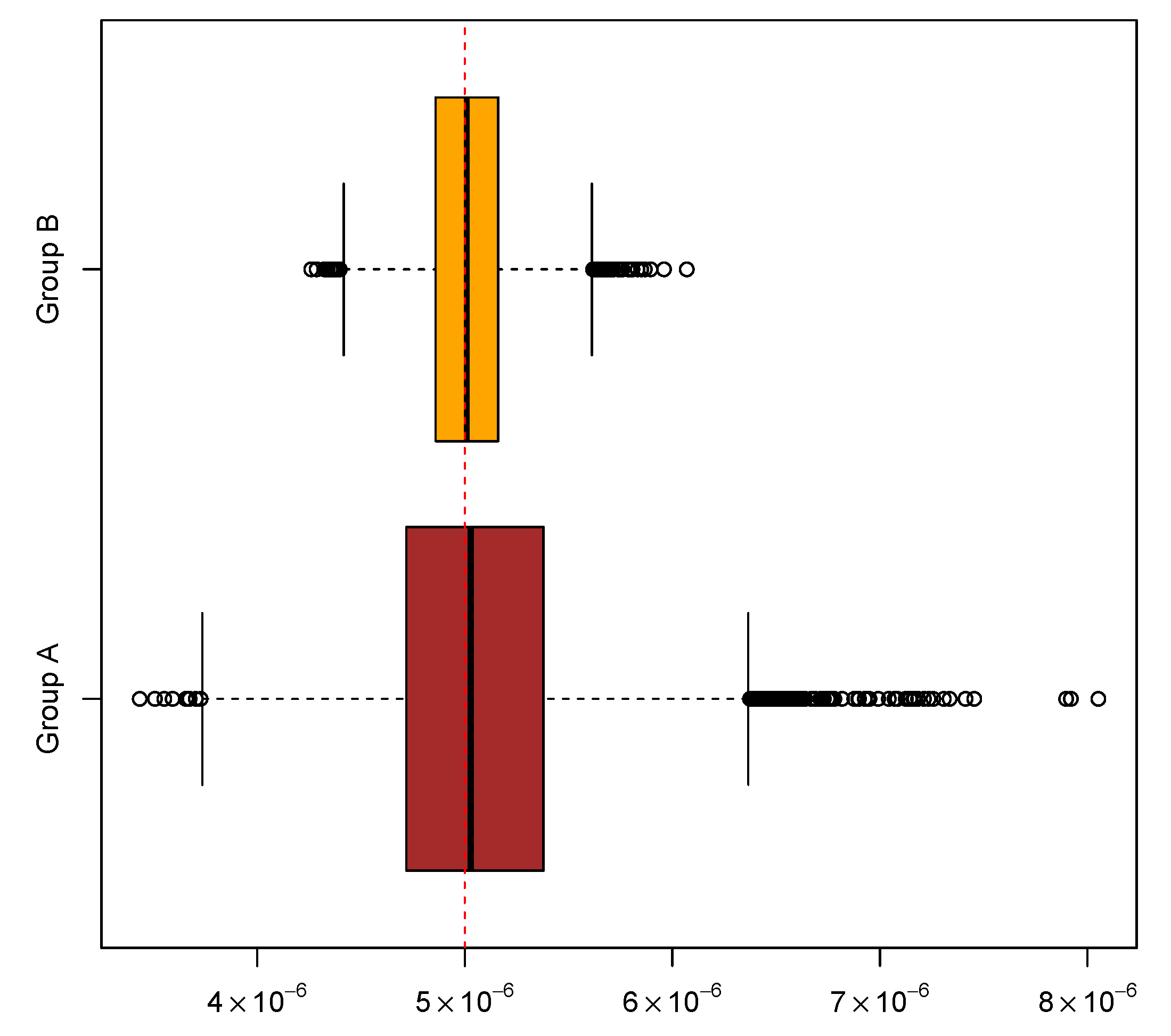
In addition, two groups of experiments were simulated to help assess the performance of the new algorithm. Each group comprises 10,000 experiments with a common mutation rate
, and each experiment comprises 20 cultures. In the first group, the other parameter values were
and
; in the second group,
and
. The above inference methods were applied to the two groups of simulated experiments to gauge the new algorithm for computing mutant distributions. The means and medians of the ML estimates and the coverage rates of the attendant 95% CIs are summarized in
Table 6. The overall distributional patterns of the ML estimates are displayed in
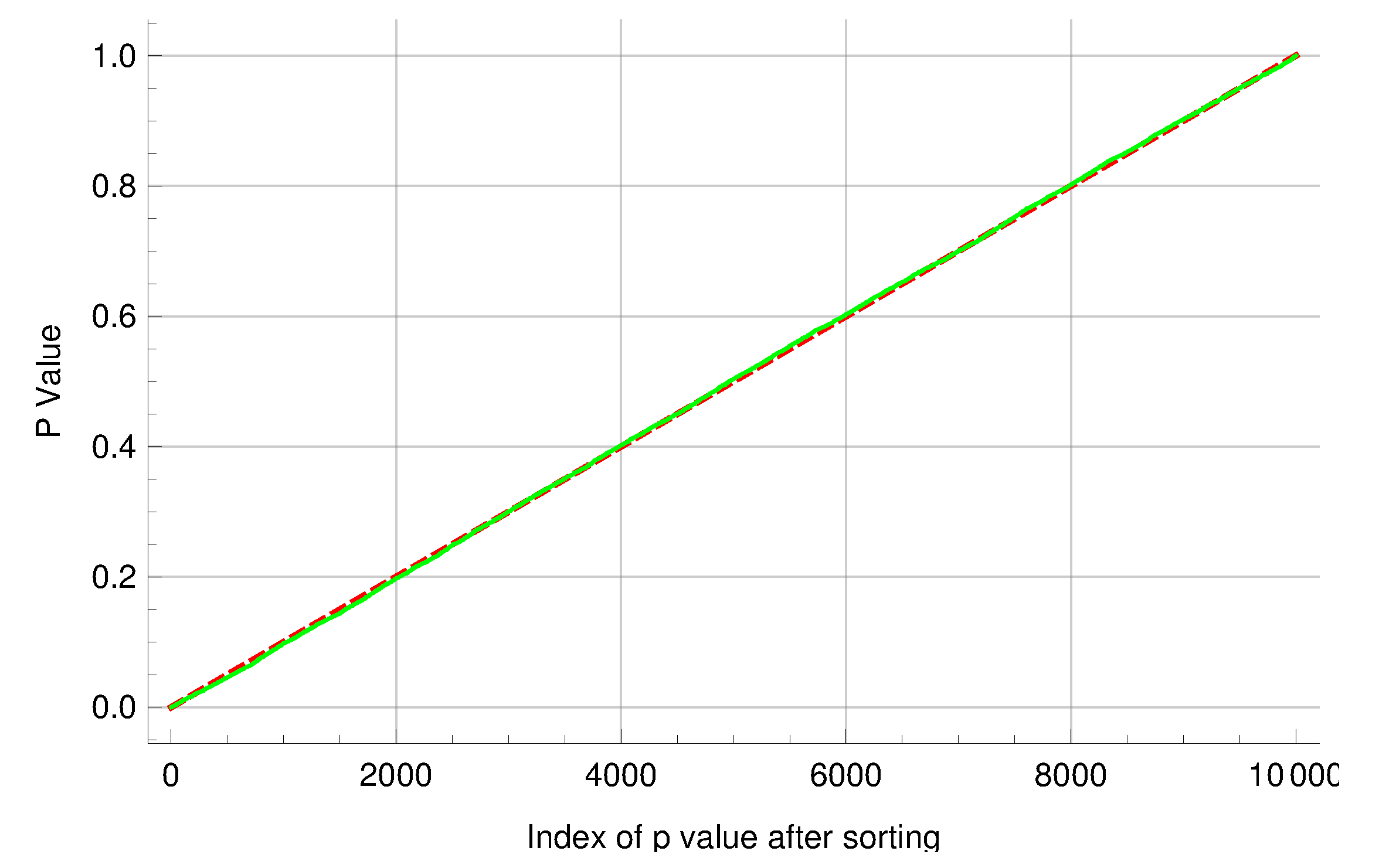
Figure 2. Moreover, experiments in the two groups were paired by their indices and then the LR test was performed on each of the 10,000 pairs of experiments. The sorted
p-values produced by the tests exhibited an expected linear pattern as shown in
Figure 3. Among the
p-values, 545 of them were below 0.05. These results indicate that the new algorithm performed satisfactorily in this simulation study.






{kind=link}
{kind=link}
{kind=link}