1. Introduction
In the real world, most of the data or information we get is often discrete and unregulated data. In order to solve such problems, the grey theory was was put forward by professor Deng [
1]; this method is particularly suitable for prediction. Professor Deng thinks that the majority of current systems are “generalized energy systems”, noting that non-negative smooth discrete functions may be turned into sequences with approximate exponential laws, referred to as the “grey exponential law” [
2]. However, GM(1,1) relies too much on historical data, and the prediction accuracy is not high when the data dispersion is large. The present GM(1,1) model cannot be utilized to accurately forecast the behavior of many practical systems, because system behavior is influenced by a variety of other factors, and its eigenvalues have never completely followed the grey index law [
3].
Because of the limitations of GM(1,1) model prediction, different scholars have proposed different improvement measures, ref. [
4] proposed an adaptive GM(1,1) model, and combined with back propagation grey model and support vector machine. By comparison, it is found that the improved grey model has better prediction effect. Zhu and Cao [
5] successfully predicted the occurrence of El Nino events with annual data from 1980 to 1986. Tien proposed a grey model with convolution integral to indirectly measure the tensile strength of the material [
6]. Then, Chen and Tien proposed different improved grey models, all of which got better prediction results [
7,
8,
9,
10,
11,
12,
13,
14]. Wu et al. [
15,
16] used the idea of fractional order accumulation to get a better short-term prediction model. However, they all only discussed the prediction accuracy in short-term situations.
In our work, we use Caputo fractional derivative instead of grey index effect and use time series data to analyze the economic development trend of the Group of Seven and predict the GDP growth trend. Then the fractional grey prediction model is used for medium and long-term prediction. The research shows that the proposed GM(,1) model has high performance not only in model fitting, but also in prediction.
The Group of Seven (G7)
The G7 is a platform for major industrial countries such as the United States (USA), the United Kingdom (GBR), Germany (DEU), France (FRA), Japan (JPN), Italy (ITA), Canada (CAN), and the European Union (EU) to meet and discuss policies (EUU). After the first oil crisis hit the western economy in the early 1970s, the six major industrial countries—the United States, the United Kingdom, Germany, France, Japan, and Italy—formed the G6 in November 1975, at the proposal of France. Since then, Canada has become a member of the Group of Seven (G7), which was formed the following year. In 1997, Russia was included to the G7, making it the G8. The Group of Seven (G7) was formed before the Group of Eight (G8). On the evening of 4 June 2014, the G7 leaders summit sponsored by the European Union began in Brussels, Belgium. Since joining the organization in 1997, Russia has been expelled for the first time. Foreign policy, economic, trade, and energy security problems will be discussed at the summit.
The G7 countries are the seven wealthiest advanced countries in the world. Consequently, studying the evolution of the GDP of these countries is interesting.
We collect data for the G7 countries for a total of 44 years, from 1973 to 2016, and use the data of GDP to create different grey models that characterize GDP changes in different countries.
2. Model Describes
2.1. GM(1,1) Prediction Model
Grey prediction refers to a forecast based on a grey system [
1]. This method has no strict requirements on the sample size and data distribution. It requires single data, simple principle and strong applicability. It is suited not only for short-term data prediction, but also for medium and long-term data prediction, and may work effectively.
Set nonnegative sequence , use data sequence to build grey GM(1,1) model, the general steps of the grey GM(1,1) model are as follows:
Step 1: Generating accumulative sequence
First-order accumulated of
is as follows
where
.
Step 2: Constructing background value, and solving parameters .
The background value sequence is
where
.
The following is the whitening differential equation for the GM(1,1) model
Equation (
3) is discretized and the differential becomes difference, as reflected in the Equation (
4)
The least square approach is then used to calculate the parameter
.
where
and
Step 3: To create the GM(1,1) grey prediction formula. To solve the differential Equation (
4), use
to get the time response formula of the grey GM(1,1) model.
Accumulating and restoring
, the prediction formula of
is
The pseudocode of GM(1,1) is given by Algorithm 1, as shown below:
| Algorithm 1: GM(1,1) model. |
![Axioms 11 00155 i001]() |
2.2. Grey Model of Caputo Type Fractional Derivative
The fractional form of grey model was proposed by Liu et al. [
15] in 2013. The goal of this model is to address several of the flaws in classic grey prediction models. For example, the existing GM(1,1) model cannot be utilized to accurately predict many real-world systems since the system behavior is influenced by other factors, and its eigenvalues do not fully obey the grey exponential law. To compare economic growth in Nigeria and Kenya, Awe et al. [
16] use a fractional integration approach.
Let us take a quick look at the grey model’s fractional order accumulation.
Set nonnegative sequence
, the grey model of the
order equation with one variable GM(
, 1) is
where
,
represents the
-order difference of
. The least square estimation of GM(
, 1) model parameters satisfies
where
and
The whitening equation of GM(
,1) model is
Let
, by fractional Laplace transform, the solution of Formula (
9) is
Thus the fitting value of GM(
,1) model is
The pseudocode of GM(
,1) is given by Algorithm 2, as shown below:
| Algorithm 2: GM(,1) model. |
![Axioms 11 00155 i002]() |
2.3. Accuracy Testing of GM(1,1) and GM(0.95,1)
Extrapolating the projected value can be done using a model with excellent fitting accuracy. If this is not the case, residual correction must be performed first. To verify the accuracy of GM(1,1) and GM(,1), the posterior error detection approach is usually utilized. The posterior error ration (C) and small error probability (P) are two fitting testing measures.
The ratio of residual standard deviation (
) to data standard deviation (
) is known as the posterior error ration (
C). Obviously, the prediction accuracy improves as the residual standard deviation decreases. The following is the exact formula:
The small error probability is shown in (
13), for a given
, when
, the model is called a qualified model with small error probability:
According to the above two indicators, the forecast level is divided into four levels (see
Table 1).
To make it easier to compare GDP between years, the GDP used here was transformed into an unchangeable local currency. The training sample consisted of data from 1973 to 2011, whereas the test sample consisted of data from 2012 to 2016. Furthermore, we evaluated the model using the average absolute deviation (MAD) and the coefficient of determination (
), and we compared the model’s prediction effect using the absolute error criterion. Keep the following definitions in mind:
and
and
To compare the quality of models, we commonly utilize the Akaike information criterion (AIC) and Bayesian information criterion (BIC). The better the model, the lower the AIC and BIC values. AIC criterion has an overfitting problem when compared to BIC criterion. As a result, we use the following BIC standards:
3. Main Results
The data in this section comes from the World Bank’s records from 1973 to 2016. Calculate the MAD,
, and BIC index values in the training sample set (see
Table 2).
As can be seen from
Table 2, the
value and
value of fractional grey prediction models in various countries are smaller than those of traditional grey prediction models, and
is closer to 1, so the fitting effect is better.
Table 3 indicates that the grade of prediction accuracy is first-level for all posterior error ratios
and tiny error probabilities
. As a result, the constructed model can be utilized to forecast in the medium and long future.
3.1. Fitting Result
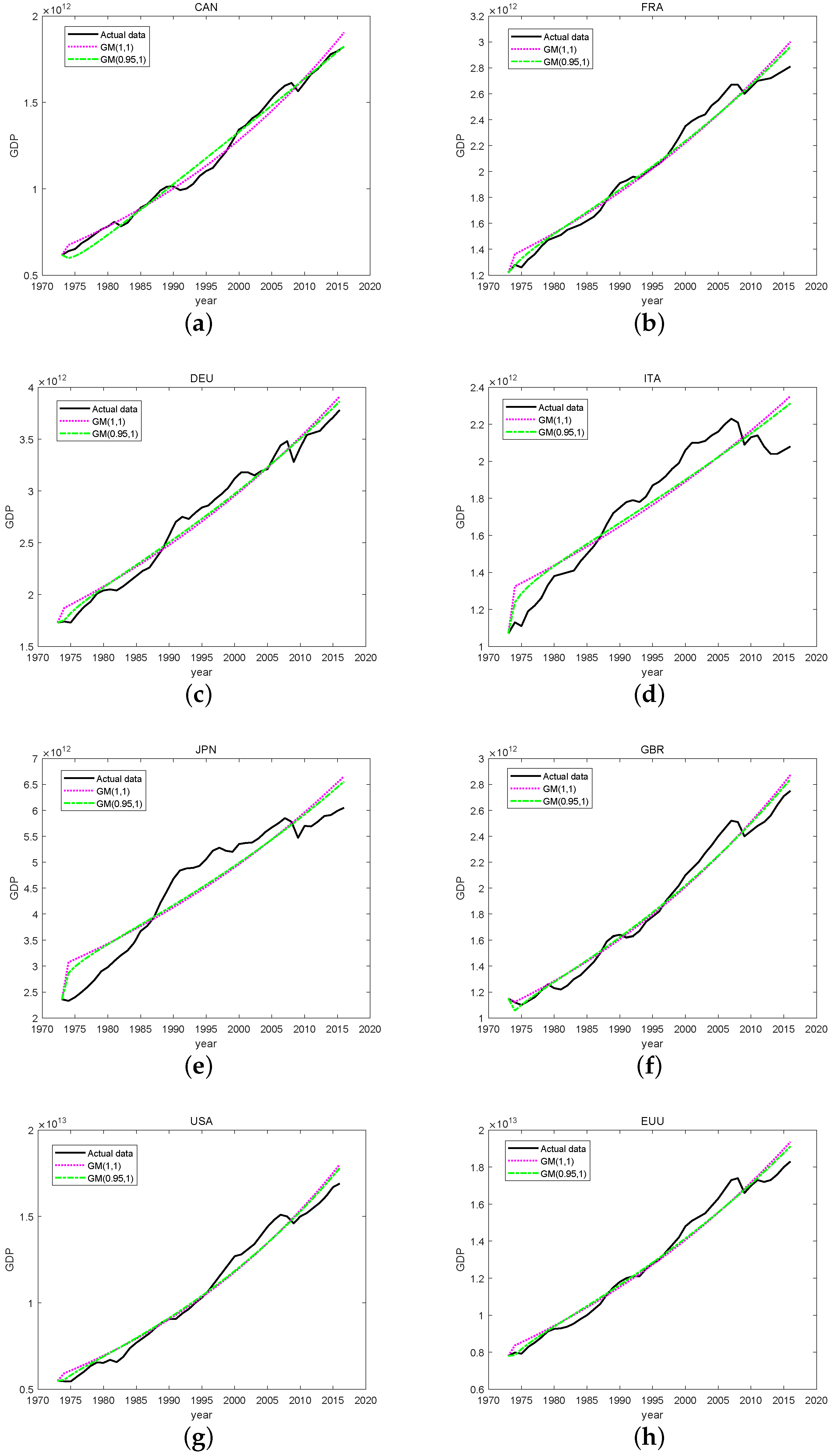
To make it easier to compare the GM(1,1) and GM(0.95,1) models, the prediction results of the two models, as well as the original data, are presented as a line graph using Python and MATLAB, respectively, as shown in
Figure 1. The trends and errors between them can be readily noticed using the graphical comparison.
It can be seen from
Figure 1 that the fractional grey prediction model accurately shows the fluctuation law of data, and the error is small, while the fitting effect of the traditional grey prediction model is poor.
3.2. Predicted Results
The test data in this study is for GDP statistics from G7 countries from 2012 to 2016. The errors of the two prediction models are calculated and the errors are calculated using the absolute error as the error evaluation method.
Table 4 shows the error pair of the prediction model in a summary comparison. The GM(0.95,1) model has a substantially lower prediction error for the data, as can be observed.
4. Conclusions
Because most systems in real life are fractional order, in order to improve the accuracy and application scope of grey prediction, this paper uses fractional order accumulation to replace the traditional grey index effect, and then gives the pseudo codes of the two models, which are applied to the economic growth prediction of the Group of Seven. The results show that, compared with the classical grey prediction model, the fractional prediction model has better prediction effect in medium and long-term prediction. Finally, we give the GDP forecast of G7 countries from 2012 to 2016, and compare it with the actual data to further prove the prediction effect of the fractional grey prediction model.






{kind=link}