1. Introduction
The sources of noise and incompleteness in video streams are manifold and diverse. Captured objects may be non-uniformly illuminated, physically damaged, obscured by dirt or dust, etc. [
1]. The human operator capturing a video stream may be negligent, physically affected (e.g., suffering from a tremor), or working under time constraints, which in turn reduces the number of quality image frames, etc. Thus, handling uncertainty caused by noise and incompleteness in video streams represents an important research task. This paper addresses a particular aspect of this research question—it introduces a cognitively economical heuristic for multiple sequence alignment aimed at improving real-time object recognition in short video streams with uncertainties.
Machine learning approaches have already been recognized to be able to outperform human observers in visual recognition tasks with static frame input involving low signal-to-noise ratio (e.g., noise robust convolutional neural networks for image classification [
2,
3,
4], etc.). However, these approaches are not necessarily tailored to the task of object sequence recognition from a limited number of frames of incomplete data recorded in a dynamic scene situation. One way to overcome this problem is to introduce a pre-processing step devoted to image reconstruction from incomplete frames (cf. [
5]). In contrast to this, the heuristic proposed in this paper is based on post-processing of the recognition hypotheses and allows for avoiding time-consuming image reconstruction.
One of the assumptions underlying this heuristic procedure is that there is an object recognition system that is independent and agnostic of the proposed approach. For the purpose of easier representation, let
S be a set of object classes that can be detected and recognized by the given system. Without a loss of generality, the result of processing a single image frame is a recognition hypothesis that can be represented as follows:
where
m is a nonnegative integer (),
sequence
represents recognized objects, i.e.,
and the order of elements in
is determined by the spatial order of recognized objects in the image reference system,
sequence contains the corresponding real-valued recognition confidences for objects in .
For example, recognition hypothesis
can be interpreted as follows: the sequence of recognized objects contains three digits, 4, 7, and 7 (i.e., sequence
), and their recognition confidences are
,
, and
, respectively, (i.e., sequence
).
The second assumption is that multiple image frames are captured for each given spatial scene; i.e., multiple recognition attempts are performed, each of which generates a recognition hypothesis as described in Equation (
1). For example,
Figure 1 shows a set of image frame segments derived from a video stream captured by a mobile phone application. Each frame is processed separately by the external number recognition system introduced in [
1,
6]. In
Table 1, for each frame, a recognition hypothesis is provided.
It is the task of the heuristic proposed in this paper to post-process a set of recognition hypotheses and derive a single recognition result. To demonstrate the applicability of the proposed heuristic, it is extrinsically evaluated in a specific, real-life scenario of the automatic reading of electricity meters. The prototype system for multiple sequence alignment based on the proposed heuristic is engaged to post-process recognition hypotheses obtained from the external number-recognition subsystem (introduced in [
1,
6]). However, it should be noted that the prototype system for multiple sequence alignment is completely agnostic and independent of the underlying number recognition subsystem. This is in line with our commitment to introduce a heuristic that is not intended for a particular object recognition system or a specific recognition task, but rather for addressing the more general problem of the real-time recognition of spatially ordered objects in short video streams. An additional characteristic of our approach is that it is cognitively economical [
7] and has a reduced computational complexity in comparison to optimal multiple sequence alignment.
The rest of this paper is organized as follows.
Section 2 provides an overview of background and related work. The heuristic procedure is introduced in
Section 3, and evaluated and discussed in
Section 4.
Section 5 concludes the paper.
2. Background and Related Work
Uncertainty management in cognitive agents is an important research question in the field of artificial intelligence [
8,
9]. This paper focuses on a particular aspect of this question, i.e., uncertainties in automatic object recognition in short video streams and addresses this research problem by means of multiple sequence alignment.
Under the alignment of two sequences
and
over alphabet
S, it is usually meant that the sequences are modified by adding spaces, so that the resulting sequences
and
are of equal length
L. The value of the alignment is defined as
where
is the score of two opposing symbols at position
k in sequences
and
, respectively. An optimal alignment minimizes the value given in Equation (
4) [
10].
One of the basic algorithms for finding the optimal alignment of two sequences is related to the widely acknowledged edit distance (i.e., the Levenshtein distance) [
11,
12,
13]. The standard minimum edit distance between two sequences is defined as the minimum number of single-symbol edit operations (i.e., deletion of a symbol, insertion of a symbol, and replacement of a symbol by another symbol) required to transform one sequence into the other. In a more general case, the edit operations are weighted, and the calculation of the minimum edit distance can be described as follows. Let
and
be two sequences of lengths
m and
n, respectively, over alphabet
S:
To align these sequences, a distance matrix
D of dimension
is generated. The symbol with index
k in the first sequence, i.e.,
, is assigned the row of matrix
D with index
, while the symbol with index
l in the second sequence, i.e.,
, is assigned the column of matrix
D with index
. The first row and the first column of matrix
D are calculated as:
and the rest of matrix as:
where
,
and
is the cost of deletion of symbol ,
is the cost of insertion of symbol ,
is the cost of replacement of symbol by symbol .
The minimum edit distance between sequences
and
is equal to the bottom right cell of matrix
D, i.e.,
. For example, if we set the costs of all single-symbol edit operations to one, i.e.,
the minimum edit distance between sequences
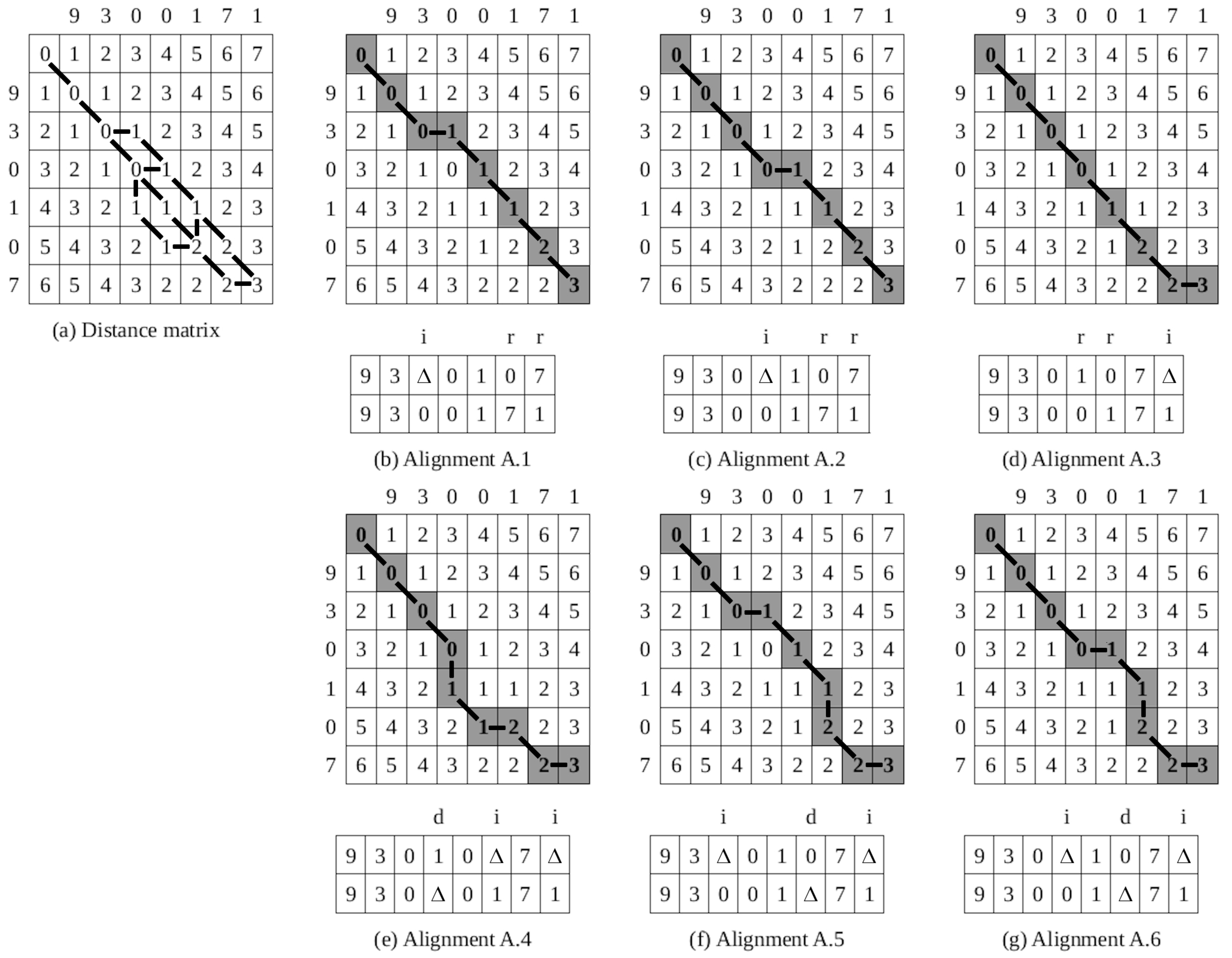
is equal to 3; i.e., three single-symbol edit operations are required to transform one sequence into the other. The underlying distance matrix is given in
Figure 2a.
However, to find all optimal alignments between two sequences, it is necessary to backtrace from cell
to cell
. For each cell in
D (except cell
), it is necessary to keep track of which matrix cell participated in the calculation of the value of the given cell (in accordance with Equations (
5) and (
6)). Each path starting at cell
and ending at cell
represents an optimal alignment. To continue the previous example, there are six possible minimum-cost paths in matrix
D, i.e., six optimal alignments between sequences 930,107 and 9,300,171, as shown in
Figure 2b–g. The minimum-cost paths are marked with a gray background. Horizontal edges in a path determine insertions, vertical edges determine deletions, and diagonal edges determine replacements. The alignments are given under each corresponding matrix. Single-symbol edit operations of insertion, deletion, and replacement are, respectively, denoted by letters
i,
d, and
r. Spaces added to sequences are represented by special symbol △ (i.e., a gap) not belonging to alphabet
S.
This edit distance algorithm can be generalized to multiple sequence alignment [
14]. The basic score scheme applied is the SP-score, which considers the scores of all unordered pairs of opposing symbols at position
k in all aligned sequences [
10]. The sequence alignment is widely applied in computational biology (e.g., aligning protein sequences, cf. [
15,
16]), computational linguistics (e.g., spell correction, speech recognition, machine translation, information extraction, cf. [
11]), and information security (e.g., impersonation attacks detection in cloud computing environments, cf. [
17]), but also in image processing (e.g., scene detection in videos, online signature verification, cf. [
18,
19,
20,
21]). However, there is a practical limitation related to the fact that the problem of finding an optimal multiple sequence alignment is NP-hard [
22]. The complexity of an optimal alignment of
p sequences of average length
n, based on the dynamic programming approach described above, is
.
To address the question of efficiency, a variety of heuristics were introduced [
16,
23] (cf. also [
24]). A popular heuristic in the field of computational biology is so-called progressive alignment [
16,
25]. It works by first performing optimal pairwise sequence alignments and then clustering the sequences, e.g., by applying the mBed or k-means algorithms. In this paper, we introduce a novel cognitively economical heuristic procedure for multiple sequence alignment that builds upon the idea of the progressive alignment. At the methodological level, the novel aspects are as follows:
- (i)
The number of clusters is determined prior to the pairwise sequence alignment. Each distinct maximum-length sequence in a set of recognition hypotheses is declared as a cluster representative. All other non-maximum-length sequences were then assigned to the closest cluster representative, where the distance between two sequences was calculated by means of the adapted edit distance algorithm.
- (ii)
The proposed adaptation of the edit distance approach is inspired by human working memory limitations (cf. [
26]). To reduce the “cognitive load” of our approach, we consider only “economical” sequence alignments that are optimal in terms of the standard minimum edit distance approach and in which no space is inserted into longer sequence. These two requirements for cognitive economy allow for the substantial reduction of the number of sequences derived in the alignment process by means of padding (as detailed in
Section 3).
3. Heuristic for Multiple Sequence Alignment
In this section, we introduce a heuristic approach to multiple sequence alignment intended for improving real-time object recognition in short video streams under uncertainties. It includes two algorithms:
The gap-minimum alignment algorithm, introduced and illustrated in
Section 3.1, is intended for alignment of two recognition hypotheses.
The cluster-based voting algorithm, introduced and illustrated in
Section 3.2, builds upon the first algorithm and is intended for multiple recognition hypothesis alignment, based on which a single recognition result is derived.
3.1. Gap-Minimum Two Sequence Alignment
Let
and
be two recognition hypotheses, as described in Equation (
1), of lengths
m and
n, respectively:
where
and
are sequences over alphabet
S, and
and
are sequences of the corresponding recognition confidence values. The cognitively economical idea underlying the proposed two-sequence-alignment approach is that we consider only sequence alignments that are optimal in terms of the standard minimum edit distance approach in which no space is inserted into the longer sequence. Thus, when two sequences of unequal lengths are aligned, the longer sequence always remains unchanged, while
spaces are “economically” inserted into the shorter sequence. The algorithm can be described as follows.
Step 1.1: If sequences
and
are of equal length, i.e.,
, then no particular alignment is performed, i.e.:
and the alignment process is terminated.
Step 1.2: Otherwise, if sequences
and
are not of equal length, let us assume, without loss of generality, that the length of
is less than the length of
, i.e.,
. A distance matrix is generated, with the costs of all edit operations set to one, as described in
Section 2. Let
P be a set of all optimal alignments of sequences
and
derived from the distance matrix. We recall that all alignments in set
P are determined by means of the minimal edit distance algorithm (i.e., the Levenshtein algorithm), and thus they contain a minimal number of single-symbol edit operations (i.e., deletion, insertion, and replacement) required to transform sequence
into sequence
. In general, it is easy to show that set
P is never empty (i.e., it is always possible to find at least one alignment).
Step 1.3: From set P, containing all optimal alignments of sequences and , we select only those alignments in which no space is inserted into longer a sequence. Let be a set of selected alignments. If , it is declared that sequences and cannot be economically aligned, and the alignment process is terminated. Otherwise, the algorithm proceeds to the next step.
Step 1.4: The value of each alignment
is calculated as the sum of confidence values of all symbols in a longer sequence
that are opposed to a space, i.e.:
where:
The alignment in
with a minimum value is selected as the most cognitively economical alignment:
The proposed gap-minimum two-sequence alignment algorithm is illustrated by the following examples.
Example 1. Let us consider the alignment of the following recognition hypotheses: Set P, generated in Step 1.2, contains six alignments, i.e., A.1–A.6, shown in Figure 2b–g. Set , generated in Step 1.3, contains only three cognitively economical alignments (A.1–A.3) that satisfy the condition that no space is inserted into longer sequence . The values of these alignments, calculated in Step 1.4 based on confidence values provided in Equation (15), are: The alignment A.3 has the minimum value and thus represents the most cognitively economical alignment: In the selected alignment, an initially longer recognition hypothesis remains unchanged, while initially, the shorter recognition hypothesis was transformed to by inserting a space at the end of sequence .
It should be noted that the confidence value of a space is set to
(cf. Equation (
17), for the following reason. In the external recognition system [
1] applied in this example, digit recognition confidence values are normalized in the
range, and an image segment is considered as potentially containing a digit only if its recognition confidence is beyond the threshold value of
. In the general case, the confidence value of a space is set to the recognition confidence threshold value. By doing so, a space is considered less significant in the post-clustering voting process described in
Section 4.2 than a potentially recognized digit.
Example 2. It should be noted that in the proposed approach, it is possible that two sequences cannot be economically aligned. Let us consider the alignment of the following recognition hypotheses: where the confidence values of particular digits are not specified, since they are irrelevant to this example. The distance matrix generated in Step 1.2 is given in Figure 3. It can be observed that there is only one optimal alignment in set P and that it does not satisfy the condition that no space is inserted into longer sequence . Thus, set is empty, i.e., sequences and cannot be economically aligned. 3.2. Cluster-Based Multiple Sequence Alignment
Let
H be a multiset of nonempty recognition hypotheses produced by an external recognition system, i.e.,
where
. It is important to note that
H is defined as a multiset, i.e., a bag of recognition hypotheses, and not just as a set, in order to emphasize that it may include multiple instances for each of the recognition hypotheses it comprised. The proposed cluster-based multiple sequence alignment can be described as follows.
Step 2.1: Let
be a multiset containing recognition hypotheses from
H with the maximum length, i.e.,
Each hypothesis in represents one cluster. If (i.e., if all recognition hypotheses in H are of equal length), each of the clusters contains exactly one recognition hypothesis from H, and the algorithm jumps to Step 2.3. Otherwise, the algorithm proceeds to Step 2.2.
Step 2.2: If
, each recognition hypothesis from set
is either assigned to exactly one cluster or discarded. More particularly, each hypothesis
is independently aligned—by means of cognitively economical gap-minimum sequence alignment introduced in
Section 3.1—to all hypotheses from set
, producing a set of alignments:
If
, recognition hypothesis
h cannot be economically aligned to any of hypotheses from
, and it is discarded. Otherwise, if
, the alignment from
with minimum value is selected:
(cf. also Equations (
12) and (
13)), and hypothesis
(obtained by transforming observed recognition hypothesis
h in the scope of the selected alignment) is assigned to the cluster represented by recognition hypothesis
. In a special case when there are multiple optimal instances for hypothesis
in multiset
, only one of them is randomly selected in Equation (
22).
Step 2.3: It is easy to show that all recognition hypotheses (some of them being transformed by adding spaces) assigned to the clusters are of equal length . In this step, they are all arrayed in rows, each of which contains columns, and the order or rows is irrelevant. A new sequence containing symbols—one for each column—is generated by means of voting. For each column, a symbol from set with the maximum sum of confidence values in the given column is selected. The final recognition result is obtained by removing all spaces from .
Example 3. To illustrate the proposed algorithm, we consider the set of recognition hypotheses given in Table 1. The algorithm execution is summarized in Table 2. In the given set, there are two recognition hypotheses of the maximum length, and . Therefore, there are two clusters in Step 2.1, which we refer to as and , respectively. In Step 2.2, recognition hypotheses and are economically aligned to and thus assigned to cluster , while recognition hypotheses , , , , and are aligned to and assigned to cluster . After the arraying, voting, and removing spaces from the voting result in Step 2.3, the final recognition result is obtained: 46,777.
It is important to note that although none of the initial recognition hypotheses represents the number given in
Figure 1, the proposed algorithm generated the correct recognition result (we recall that the digit after the decimal point in
Figure 1 is intentionally discarded).
5. Conclusions
In this paper, we introduced a heuristic approach to multiple sequence alignment under uncertainties. The proposed approach was cognitively economical to the extent that it accounted for human working memory limitations and thus had a reduced computational complexity in comparison to the optimal multiple sequence alignment. On the other hand, its relevance was experimentally confirmed.
The evaluation was performed along two lines. First, an extrinsic evaluation conducted in real-life settings demonstrated that the proposed approach improves the accuracy of number recognition in short video streams under uncertainties caused by noise and incompleteness. At the number level (i.e., sequence of digits), the recognition accuracy of a given external recognition system was increased from , obtained prior to the embedding of the introduced heuristic procedure, to , obtained after the embedding. At the digit level, the improved performance is reflected through the recognition accuracy of .
In the second evaluation phase, the proposed heuristic procedure was compared to human performance in the post-processing of recognition hypotheses. A naïve subject was given the same 384 sets of recognition hypotheses to which the post-processing subsystem was confronted in the first evaluation phase. For each of the given sets, the task of the subject was to try to derive the correct recognition result. It was demonstrated that the proposed approach outperformed the human. This indicates that the proposed heuristic for post-processing of the recognition hypotheses may be combined with machine learning approaches, which are typically not tailored for the task of object sequence recognition from a limited number of frames of incomplete data recorded in a dynamic scene situation.

 ,
, 


{kind=link}
{kind=link}
{kind=link}


