
A Combination of Fuzzy Techniques and Chow Test to Detect Structural Breaks in Time Series



Abstract
:1. Introduction
2. Preliminaries
2.1. Chow Test
- RSS1 which is the residual of squares before the break:
- RSS2 is the residual of squares after the break:
- RSS3 is the residual of squares of the general regression model:
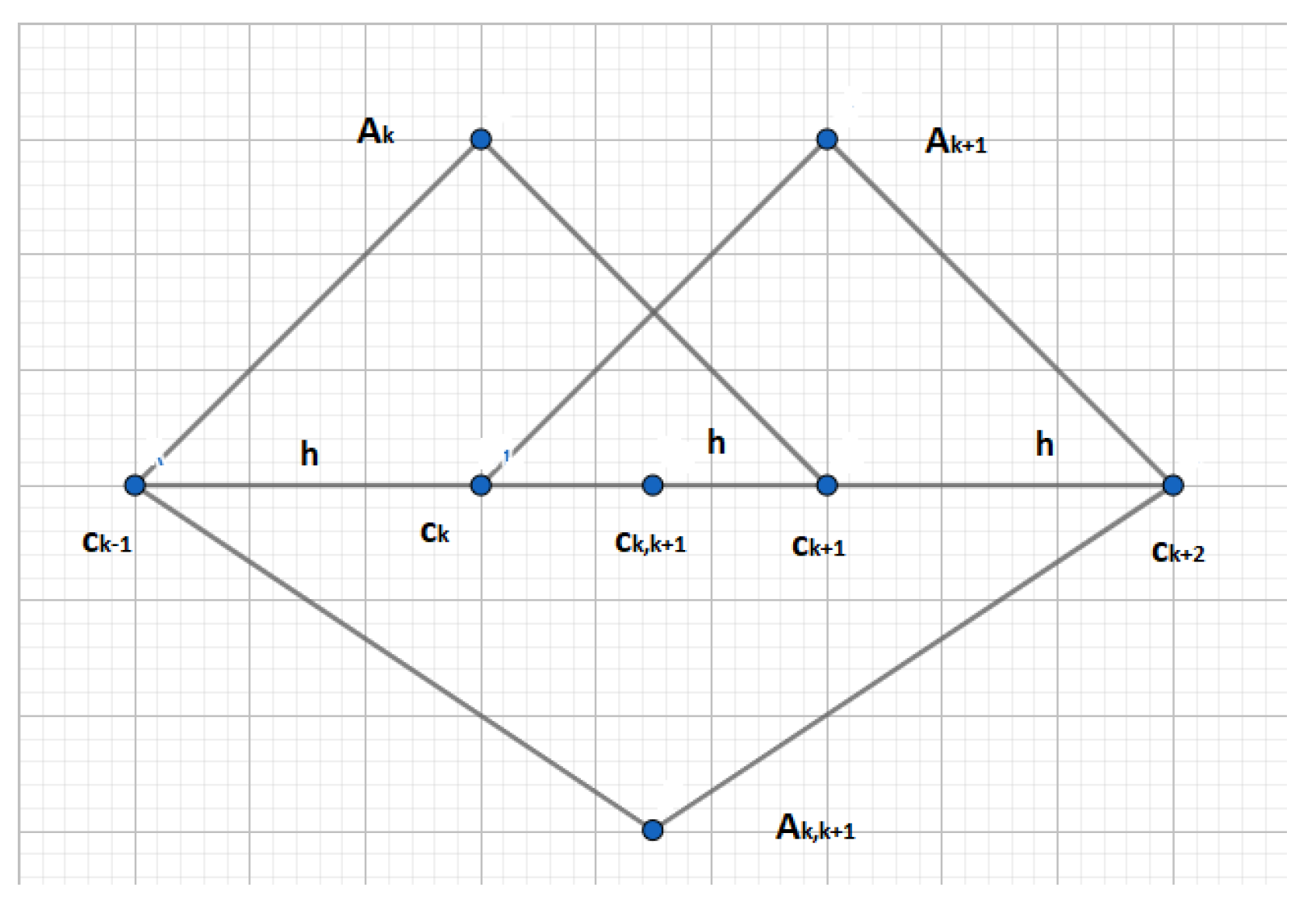
2.2. Fuzzy Transform (F-Transform)
- , ;
- if (for and );
- is continuous;
- strictly increases on for and strictly decreases on for ;
- for all;
- If, where, then fuzzy partitionis called uniform and the following holds for the fuzzy sets forming it:, , , whereand.
- The zero-degree fuzzy transform has components of the form
- The first-degree fuzzy transform has components of the formwhere
2.3. Fuzzy Natural Logic
- := stagnating ,
- := increasing ∣ decreasing,
- : = ∅∣ negligibly ∣ slightly ∣ somewhat ∣ clearly ∣ roughly ∣ sharply ∣ quite largely ∣ fairly large∣ hugely∣ significantly.
3. Processing of Time Series Using Methods of Fuzzy Modeling
3.1. Processing of Time Series Using F-transform
3.2. Detection of Structural Breaks in a Time Series
Algorithm for finding structural breaks
- Set the distance and determine a uniform fuzzy partition over the time domain due to Definition 1.
- Set the context for evaluation of the trend in the areas determined by the basic functions.
- Compute the direct first-degree fuzzy transform over the fuzzy partition .
- Localize all pairs of components (,) (cf. (3)) with the following properties:
- –
- , , i.e., the coefficient is close to zero.
- –
- , i.e., the coefficient is unexpectedly big.
Alternatively, k and can be interchanged, i.e., is close to zero and is unexpectedly big. - The interval (or ) which is a support of the basic function (or ) is the area of a structural break due to Definition 4.
3.3. Combination of Fuzzy Techniques and Chow Test
- (a)
- ,
- (b)
- the inequalities (24) hold for some ,
- (c)
- ,
- (d)
- there are minimal such that the following holds:
4. Experiments
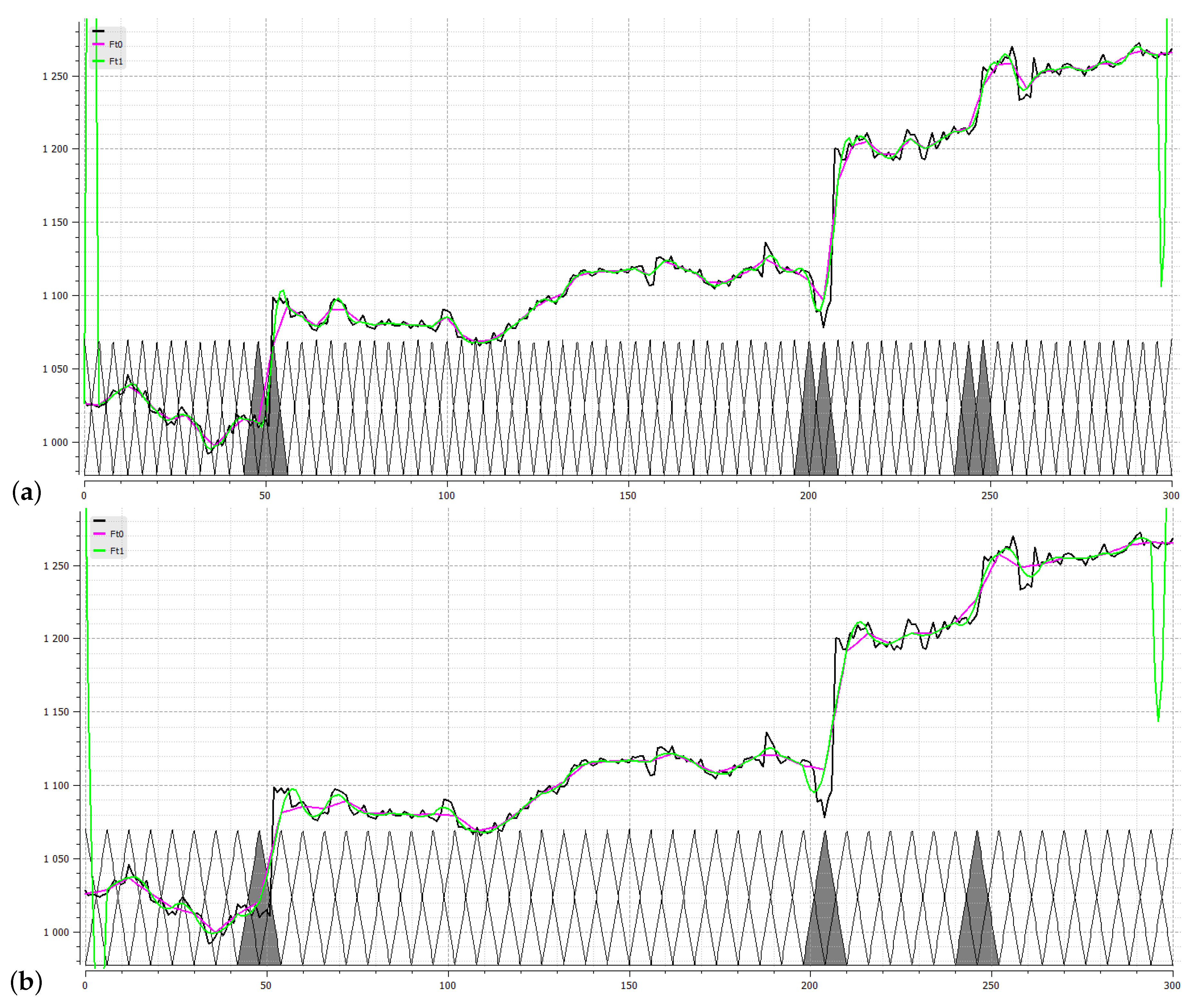
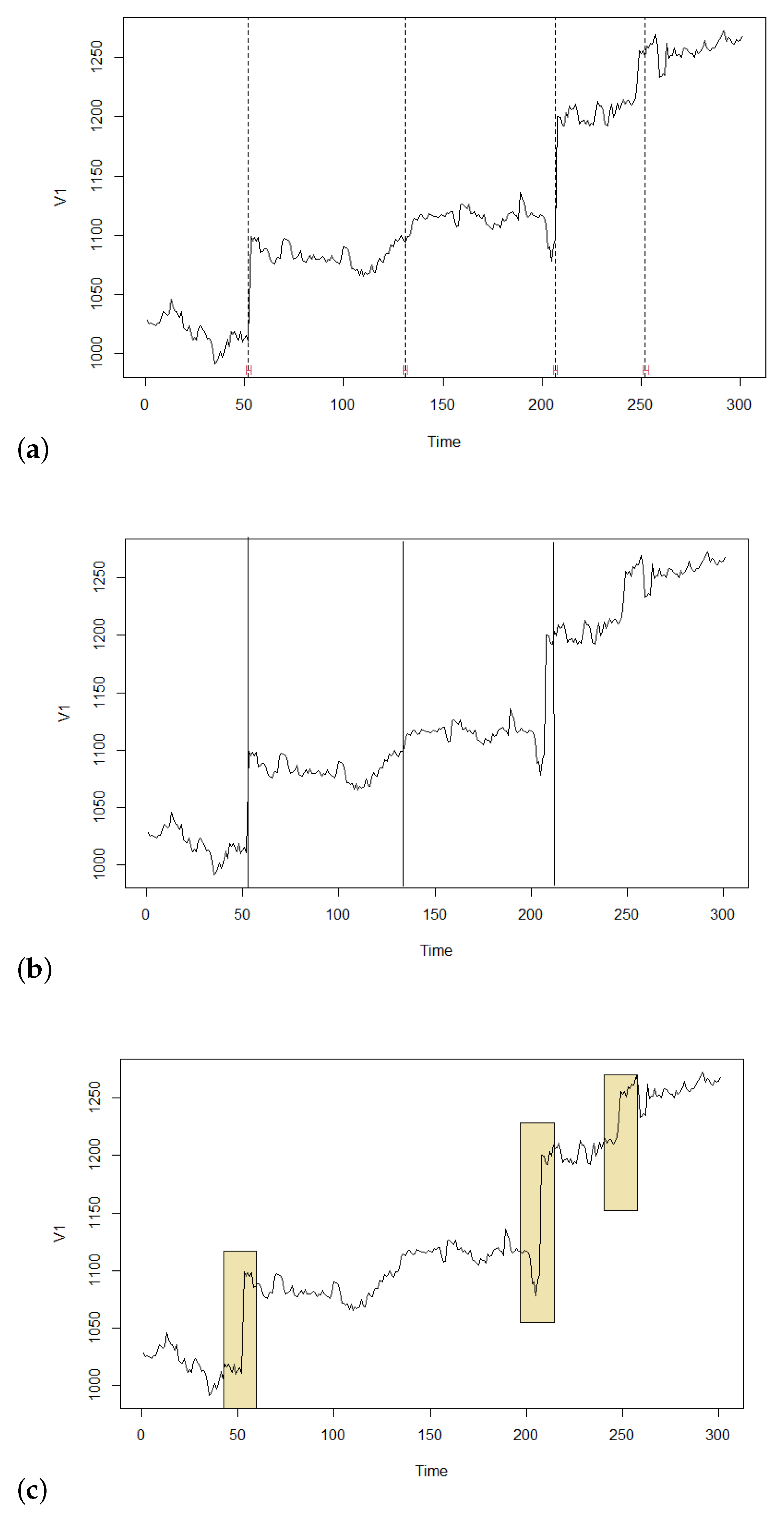
4.1. Detection of Structural Breaks
4.2. When Fuzzy Chow Test Does Not Reject the Null Hypothesis?
4.3. Comparison with Classical Statistical Tests
4.3.1. Pettitt’S Test (1979)
4.3.2. Bai-Perron Test (1998)
4.3.3. Comparison of Statistical Methods with Fuzzy Chow Test
- Statistical methods detect the breaks as if occurring in one time point. However, it is clear from the practice that this rarely happens; the break usually shows in a wider area. Hence, the result of a statistical test should be taken as a point around which the break occurs. But this is equal to what our fuzzy method provides explicitly, and thus we argue that more realistically.
- Statistical methods are less robust and thus, more sensitive to the data. Hence, they are prone to the detection of non-existing breaks. In our example, this happened to all three statistical methods in point () where apparently there is no structural break. Let us emphasize that our fuzzy method ignored this point/area due to its robustness.
- Statistical methods require optimization and therefore, they are computationally expensive. Our method is very simple and computationally effective since the fuzzy transform has linear complexity.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chow, G.C. Tests of Equality Between Sets of Coefficients in Two Linear Regressions. Econometrica 1960, 28, 591–605. [Google Scholar] [CrossRef] [Green Version]
- De Wachter, S.; Tzavalis, D. Detection of structural breaks in linear dynamic panel data models. Comput. Stat. Data Anal. 2012, 56, 3020–3034. [Google Scholar] [CrossRef] [Green Version]
- Fischer, P.; Hilbert, A. Fast detection of structural breaks. In Proceedings of the 21th International Conference on Computational Statistics, Geneva, Switzerland, 19–22 August 2014; pp. 9–16. [Google Scholar]
- Nielsen, B.; Whitby, A. A Joint Chow Test for Structural Instability. Econometrics 2015, 3, 156–186. [Google Scholar] [CrossRef] [Green Version]
- Preuss, P.; Puchstein, R.; Detter, H. Detection of multiple structural breaks in multivariate time series. J. Am. Stat. Assoc. 2015, 110, 654–668. [Google Scholar] [CrossRef] [Green Version]
- Doerr, B.; Fischer, P.; Hilbert, A.; Witt, C. Detecting structural breaks in time series via genetic algorithms. Soft Comput. 2017, 21, 4707–4720. [Google Scholar] [CrossRef]
- Truong, P.; Novák, V. An Improved Forecasting and Detection of Structural Breaks in Time Series using Fuzzy Techniques. In Theory and Applications of Time Series Analysis and Forecasting; Valenzuela, O., Rojas, F., Herrera, L., Pomares, H., Rojas, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2022. [Google Scholar]
- Perfilieva, I.; Daňková, M.; Bede, B. Towards a Higher Degree F-transform. Fuzzy Sets Syst. 2011, 180, 3–19. [Google Scholar] [CrossRef]
- Novák, V.; Perfilieva, I.; Dvořák, A. Insight into Fuzzy Modeling; Wiley & Sons: Hoboken, NJ, USA, 2016. [Google Scholar]
- Perfilieva, I. Fuzzy Transforms: Theory and applications. Fuzzy Sets Syst. 2006, 157, 993–1023. [Google Scholar] [CrossRef]
- Novák, V.; Mirshahi, S.; Pavliska, V. LFL Forecaster: Analysis, Forecasting and Mining Information from Time Series. In Proceedings of the 2019 IEEE International Conference on Fuzzy Systems, FUZZ-IEEE 2019, New Orleans, LA, USA, 23–26 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Anděl, J. Statistical Analysis of Time Series; SNTL: Praha, Czech Republic, 1976. (In Czech) [Google Scholar]
- Bovas, A.; Ledolter, J. Statistical Methods for Forecasting; Wiley: New York, NY, USA, 2003. [Google Scholar]
- Kedem, B.; Fokianos, K. Regression Models for Time Series Analysis; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Hamilton, J. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 1994. [Google Scholar]
- Nguyen, L.; Novák, V.; Holčapek, M. Gold Price: Trend-cycle Analysis Using Fuzzy Techniques. In Information Processing and Management of Uncertainty in Knowledge-Based Systems, Part III; Lesot, M.-J., Vieira, S., Reformat, M.Z., Carvalho, J.P., Wilbik, A., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer Nature: Cham, Switzerland, 2020; pp. 254–266. [Google Scholar]
- Novák, V. Fuzzy vs. Probabilistic Techniques in Time Series Analysis. In Econometrics for Financial Applications; Anh, L., Dong, L., Kreinovich, V., Thach, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 213–234. [Google Scholar]
- Nguyen, L.; Holčapek, M. Suppression of High Frequencies in Time Series Using Fuzzy Transform of Higher Degree. In Information Processing and Management of Uncertainty in Knowledge-Based Systems: 16th International Conference, IPMU 2016; Carvalho, J., Lesot, M.-J., Kaymak, U., Vieira, S., Bouchon-Meunier, B., Yager, R.R., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 2, pp. 705–716. [Google Scholar]
- Burda, M.; Stěpnička, M. lfl: An R Package for Linguistic Fuzzy Logic. Fuzzy Sets Syst. 2022, 431, 1–38. [Google Scholar] [CrossRef]
- Pettitt, A. A non-parametric approach to the change-point problem. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1979, 28, 126–135. [Google Scholar] [CrossRef]
- Conte, L.; Bayer, D.; Bayer, F. Bootstrap Pettitt test for detecting change points in hydroclimatological data: Case study of Itaipu Hydroelectric Plant, Brazil. Hydrol. Sci. J. 2019, 64, 1312–1326. [Google Scholar] [CrossRef]
- Bai, J.; Perron, P. Estimating and Testing Linear Models with Multiple Structural Changes. Econometrica 1998, 66, 47–78. [Google Scholar] [CrossRef] [Green Version]
- Bai, J.; Perron, P. Computation and Analysis of Multiple Structural Change Models. J. Appl. Econom. 2003, 18, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Hall, A.R.; Han, S.; Boldea, O. Inference regarding multiple structural changes in linear models with endogenous regressors. J. Econom. 1998, 170, 281–302. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| t | Fuzzy Sets | () | Decision | |
|---|---|---|---|---|
| [44,56] | [] | 30.72 | 4.3828 | Reject |
| [200,212] | [] | 26.52 | 4.3828 | Reject |
| [240,252] | [] | 39.77 | 4.3828 | Reject |
| Time Interval | Fuzzy Sets | () | Decision | |
|---|---|---|---|---|
| [112,124] | 2.81 | 4.3828 | is not rejected | |
| [152,164] | 1.46 | 4.3828 | is not rejected | |
| [232,244] | 1.86 | 4.3828 | is not rejected |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Novák, V.; Truong, T.T.P. A Combination of Fuzzy Techniques and Chow Test to Detect Structural Breaks in Time Series. Axioms 2023, 12, 103. https://doi.org/10.3390/axioms12020103
Novák V, Truong TTP. A Combination of Fuzzy Techniques and Chow Test to Detect Structural Breaks in Time Series. Axioms. 2023; 12(2):103. https://doi.org/10.3390/axioms12020103
Chicago/Turabian StyleNovák, Vilém, and Thi Thanh Phuong Truong. 2023. "A Combination of Fuzzy Techniques and Chow Test to Detect Structural Breaks in Time Series" Axioms 12, no. 2: 103. https://doi.org/10.3390/axioms12020103
APA StyleNovák, V., & Truong, T. T. P. (2023). A Combination of Fuzzy Techniques and Chow Test to Detect Structural Breaks in Time Series. Axioms, 12(2), 103. https://doi.org/10.3390/axioms12020103