Abstract
The generation of unprecedented amounts of data brings new challenges in data management, but also an opportunity to accelerate the identification of processes of multiple science disciplines. One of these challenges is the harmonization of high-dimensional unbalanced and heterogeneous data. In this manuscript, we propose a statistical approach to combine incomplete and partially-overlapping pieces of covariance matrices that come from independent experiments. We assume that the data are a random sample of partial covariance matrices sampled from Wishart distributions and we derive an expectation-maximization algorithm for parameter estimation. We demonstrate the properties of our method by (i) using simulation studies and (ii) using empirical datasets. In general, being able to make inferences about the covariance of variables not observed in the same experiment is a valuable tool for data analysis since covariance estimation is an important step in many statistical applications, such as multivariate analysis, principal component analysis, factor analysis, and structural equation modeling.
Keywords:
imputation; covariance estimation; expectation-maximization; multi-view data; heterogeneous databases MSC:
62H12; 62h20; 62P10
1. Introduction
High-throughput measurement technologies have revolutionized many scientific disciplines by decreasing the time and cost of analyzing multiple samples and generating huge amounts of data, which has created great opportunities single degreesbut also brought new challenges, especially in data cleaning, normalization, dimension reduction, data harmonization, and data storage. The challenge we want to address in this manuscript is the integration of data from different sources by making inferences about the covariance of variables not observed in the same experiment. Covariance estimation is an important step in many statistical applications, such as multivariate analysis, principal component analysis, factor analysis, structural equation modeling, and statistical genomics.
Harmonization of the increasing amounts of datasets that accumulate in databases has great potential to accelerate our understanding of scientific processes. One of the challenges that still needs to be addressed is the incompleteness inherent in scientific data, in other words, each dataset that is the result of an experimental or observational study can address a limited number of variables with a limited number of samples. The lack of a large sample size reduces the reproducibility of the study [1], and the lack of a large number of measured variables narrows the scope of the study. The integration of information from different datasets is required to accelerate the identification of significant scientific outcomes.
Modern data integration approaches include feature imputation, conventional meta-analysis [2,3,4,5] and many other new methods based on machine learning and statistical methods [6,7,8,9,10,11]. Detailed reviews and classifications of some promising statistical approaches for data integration can be found in [12,13,14]. The results in these studies demonstrate the advantage of integrating multiple diverse datasets.
This work describes a method for learning the covariances among a set of variables by combining multiple covariance matrices from independent experiments. Our method is closely related to meta-analytic structural equation modeling (MASEM). MASEM is a two-stage approach to estimating the parameters of a structural equation model (SEM) using covariance matrices from different studies [15,16]. The first stage of MASEM is to pool the covariance matrices from the different studies, and the second stage is to estimate the parameters of the SEM using the pooled covariance matrix. Our method can be used in the first stage of MASEM to pool the covariance matrices from the different studies.
The main advantage of our method over the existing techniques for pooling covariances is that we use the expectation-maximization algorithm to maximize the likelihood function, leading to an analytical solution for each iteration of the algorithm. This makes our algorithm computationally efficient and suitable for combining covariance matrices involving many variables. In contrast, the existing MASEM methods for pooling covariances are based on iterative algorithms, which directly maximize the likelihood function over the parameters of the covariance matrix. Since the number of parameters in the covariance matrix is quadratic in the number of variables, these methods become more computationally demanding for large numbers of variables. We compared the performance of our method to the performance of the first stage of two-stage MASEM approaches in the Illustrations section with a simulated data set. The results of this comparison demonstrate that our method is computationally more efficient and more accurate than the existing MASEM approaches for pooling covariances. Our algorithm can be used to combine covariance matrices involving thousands of variables, unlike current implementations of the two-stage MASEM approaches, which are unable to handle such large data sets [17]. Another benefit of our method is that, when used with partially overlapping covariance matrices (i.e., when there are pairs of variables that were not observed within any one of the sample covariance matrices), the two-stage MASEM models resulted in a pooled covariance matrix where all these missing values were imputed with the same estimated mean population correlation value. This is not the case for our method, since our method does not make any assumptions about the covariance structure, as these methods do.
The covariance-based approach of combining data can be contrasted with feature imputation-based approaches, which are the preferred method for dealing with incomplete data sets. Popular approaches for imputation include random forest [18], expectation-maximization [19,20], and low-rank matrix factorization [21], among others. The main advantage of the covariance-based method is that it can infer the relationship of variables that are not observed in the same experiment without using feature imputation. This is useful in many applications. For example, the covariance-based approach can be used to infer the relationship between individuals by combining pedigree relationships with genomic relationship matrices calculated from other omics data [17]. A pedigree-based relationship matrix is calculated based on the known ancestorial relationships between individuals; however, there is no straightforward way to impute this ancestorial information for individuals not in the pedigree. Additionally, in many studies involving meta-analytical covariance estimation based on multiple datasets, the only data available are the covariance matrices, so the imputation of features is not an option.
Our method and results are unique to our knowledge, although it has been inspired by similar methods such as conditional iterative proportional fitting for the Gaussian distribution [22,23] and a method for updating a pedigree relationship matrix and a genotypic matrix relationship matrix that includes a subset of genotypes from the pedigree-based matrix [24] (the H-matrix).
In the following, we will first formally define and describe the statistical problem. We will provide a detailed description of the derivation of the algorithm for the case where all samples are assumed to have the same known degrees of freedom and the asymptotic standard errors for this case. Then, we generalize the algorithm to the case where the degrees of freedom are different for the different samples. We include a discussion on sparse covariance estimation and parametrized covariance models. Consequently, we present three simulation studies to study the properties of the algorithm such as convergence, dependence on initial estimates, and compare the performance against two MASEM methods. We also demonstrate the use of our method with an empirical case study where we combine data from 50 agricultural phenotypic trials to obtain the combined covariance matrix for 37 traits. This is followed by our conclusions and final comments.
2. Methods
In this section, we describe the use of the EM algorithm for the maximum likelihood estimation of parameters in a Wishart distribution for combining a sample of partially overlapping covariance matrices. The data are assumed to be a random sample of partial covariance matrices, and the EM algorithm is used to estimate the parameters of this distribution. EM is a popular iterative algorithm that alternates between two steps: the expectation step, which computes the expectation of the log-likelihood function with respect to the current estimates of the parameters, and the maximization step, which maximizes the expectation of the log-likelihood function with respect to the current estimates of the parameters. The EM algorithm is guaranteed to converge to a local maximum of the log-likelihood function, and this circumvents many of the difficulties related to the direct maximization of the observed data likelihood function. This is especially advantageous when the number of variables in the covariance matrix is large, as the number of parameters to estimate increases quadratically with the number of variables. In such cases, numerical methods such as the Gradient-Descent and Newton–Raphson methods are not effective.
2.1. Preliminary Results about Normal and Wishart Distributions
We use the following standard matrix notation: denotes the trace of matrix A and denotes the determinant of matrix For two matrices, A and B, denotes the Hadamard product (element-wise matrix product) of A and B and denotes the Kronecker product of A and B.
We will write to say that a random vector has a multivariate normal distribution with mean and covariance matrix . We will write to denote a Wishart distribution with degrees of freedom and scale matrix . The Wishart and the multivariate normal random variables are related by the following formula:
where X is a matrix of independent and identically distributed random variables with mean and covariance matrix . The Wishart distribution is the natural distribution for covariance matrices since the sample covariance matrix obtained from a multivariate normal sample has a Wishart distribution.
We use to say that a random matrix X has a matrix variate normal distribution with mean M, row covariance matrix and column covariance matrix . If , then where is the vectorization of X by stacking the columns of X on top of each other.
The following results about the normal and Wishart distributions and their derivations are given in classic multivariate statistics textbooks such as [25,26,27] and are used in the derivation of the EM-Algorithm, so we will not provide the proofs here.
Theorem 1.
[27] (Theorem 2.2.9) Let Then,
Theorem 2.
[27] (Theorem 2.4.12) Let with Ψ and Then, the following holds:
- 1.
- The probability density function for Y is given by
- 2.
- , .
- 3.
- If we assume Y is partitioned aswhere is and is and Ψ is partitioned aswith the corresponding components to Y, then
- is independent of
- The conditional distribution of given is multivariate Gaussianwhere
- 4.
- Similarly, by changing the order of the indices, we can show that
- is independent of
- The conditional distribution of given is multivariate Gaussianwhere
2.2. Combining Covariance Matrices with EM-Algorithm for the Wishart Distribution
2.2.1. Problem Definition
Let be the set of partially overlapping subsets of variables covering a set of K (i.e., ) with total n variables. Let be the covariance matrices for variables in sets the sizes of the sets are given by We want to estimate the overall covariance parameter using the sample
We will discuss two different algorithms for the estimation of using the sample covariance matrices One of the algorithms is based on the Wishart distribution with a single degree of freedom parameter and the other algorithm is based on the Wishart distribution with sample-specific degrees of freedom parameters. The choice between the two algorithms depends on the knowledge about the degrees of freedom of the sample covariance matrices. If all of the covariance matrices were obtained from similar experiments with similar precision, then the EM-Algorithm for the Wishart distribution with a single degree of freedom parameter should be preferred. If there are multiple degrees of freedom parameters, i.e., the precision of the sample covariance matrices varies significantly, then the EM-Algorithm for the Wishart distribution with sample-specific degrees of freedom values should be used.
2.2.2. EM Algorithm for Wishart Distribution with a Single Degree of Freedom
Given let be independent but partial realizations from a Wishart distribution with a known degree of freedom and a shape parameter We want to estimate the overall covariance matrix after observing In the remainder, if we focus on a sample covariance matrix , we drop the subscript and write for notational economy (we perform the same with .
Theorem 3.
EM-Algorithm for the Wishart distribution with a single degree of freedom. Let let be independent but partial realizations from a Wishart distribution with a known degree of freedom and a shape parameter Starting from an initial estimate of the covariance parameter matrix the EM algorithm for Wishart distribution repeatedly updates the estimate of this matrix until convergence. The algorithm is given by:
where a is the set of variables in the given partial covariance matrix, and b is the set difference of K and The matrices are permutation matrices that put each completed covariance in the summation in the same order. The superscripts in parenthesis “” denote the iteration number.
Proof.
We write for the completed version of obtained by complementing each of the observed data with the missing data components and assume is partitioned as
we partition as
where is the part of the matrix that corresponds to the observed variables is the part of the matrix that corresponds to the variables and is the part that corresponds to the covariance of the variables in a and
The likelihood function for the observed data can be written as
The log-likelihood function with the constant terms combined in c is given by
We can write the log-likelihood for the complete data up to a constant term as follows:
The expectation step of the EM-Algorithm involves calculating the expectation of the complete data log-likelihood conditional on the observed data and the value of at iteration t, which we denote by We can write the expectation of the complete data log-likelihood up to a constant term as
The maximization step of the EM algorithm updates to by finding the that maximizes the expected complete data log-likelihood. Using [25] (Lemma 3.3.2), the solution is given by:
We need to calculate for each so we drop the index i in the remaining while deriving a formula for this term.
Firstly, is Secondly, has a matrix-variate normal distribution with mean To calculate the expectation of note that we can write this term as The distribution of the first term is independent of and , and is a Wishart distribution with degrees of freedom and covariance parameter The second term is an inner product The distribution of is a matrix-variate normal distribution with mean and covariance structure given by for the columns and rows, correspondingly. Therefore, the expectation of this inner-product is
This means that the expected value of given and is
Finally, putting and leads to the iterative EM algorithm. □
2.2.3. Asymptotic Standard Errors with a Single Degree of Freedom Parameter
Once the maximizer of has been found, the asymptotic standard errors can be calculated from the information matrix of evaluated at The log-likelihood is given by:
The first derivative with respect to the th element of is given by
The derivative of the above for the th element of is given by
The expected value of the second derivative is given by
Therefore, the information matrix is given by
The asymptotic variance–covariance matrix for is given by
2.2.4. EM-Algorithm for the Wishart Distribution with Sample-Specific Degrees of Freedom Values
Theorem 4.
EM-Algorithm for the Wishart distribution with sample-specific degrees of freedom values. Assume the degrees for the sample of covariance matrices are given by Let Starting from an initial estimate of the genetic relationship matrix the EM-Algorithm repeatedly updates the estimate of the genetic relationship matrix until convergence:
Proof.
The proof is similar to the proof of Theorem 3. The main difference is that the degrees of freedoms for the Wishart distributions are now sample-specific.
We can write the log-likelihood for the complete data up to a constant term as follows:
We can write the expectation of the complete data log-likelihood up to a constant term as
Taking the derivative of the above expression with respect to and setting it to zero, we obtain the following update equation:
The components of can be calculated as before using the same methods as in the proof of Theorem 3. This completes the proof. □
2.2.5. Asymptotic Standard Errors with Sample-Specific Degrees of Freedom Values
The information matrix for the case of sample-specific degrees of freedom values is obtained in a similar fashion as the Wishart distribution with a common degrees of freedom value. The information matrix is given by
2.3. Sparse Estimation of Pooled Covariance Matrices
It is often useful to study the sparsity pattern of covariance and precision matrices. For a multivariate normal random variable, zeros in the covariance matrix correspond to marginal independence between variables, while zeros in the inverse covariance matrix (precision matrix) indicate a conditional independence between variables. An -penalized maximum likelihood approach is a commonly used method for estimating these sparse matrices. This involves adding a term (for sparsity in the covariance matrix) or (for sparsity in the precision matrix) to the likelihood function [28,29,30,31] for a nonnegative scalar value A frequent choice for O is the matrix of all ones, although an alternative is to set for and otherwise, which shrinks the off-diagonal elements to zero.
We can incorporate the sparsity in our algorithm by adding the term to the expectation of the observed data log-likelihood function [32]. The -penalized function that must be maximized in the EM maximization steps becomes
At each iteration of the EM algorithm, this function can be maximized with respect to iteratively by using the methods in [29,31]. For instance, the following iterative algorithm can be used to maximize the -penalized function with (see [31] for more details and caveats):
- 1.
- Set
- 2.
- Set
- 3.
- For each iteration until convergence
- set where is the soft thresholding function defined as is a sign of the value and is the learning rate parameter.
- 4.
- Set
2.4. Parametrized Covariance Matrices
In many covariance prediction problems such as SEM, the covariance matrix is assumed to have a certain parametric structure, i.e., the covariance matrix can be written as for a vector of parameters In this case, the EM algorithm can still be used to estimate the parameters of the covariance matrix; however, the maximization step of the EM algorithm needs to be modified. The modified version of the expected likelihood function for the Wishart distribution with sample-specific degrees of freedom values is now expressed as
The maximization step of the EM algorithm now involves the maximization of the expected likelihood function with respect to the parameters , and numerical methods such as the Newton–Raphson method can be used for this purpose.
3. Illustrations
Illustration 1—Simulation study: Inferring the combined covariance matrix from its parts
To establish that a combined covariance can be inferred from realizations of its parts, we have conducted the following simulation study: In each round of the simulation, the true parameter value of the covariance matrix was generated as , where were independently generated as with being a realization from the uniform distribution over was then adjusted by dividing its elements by the mean value of its diagonal elements. This parameter was taken as the covariance parameter of a Wishart distribution with 300 degrees of freedom, and samples from this distribution are generated. After that, each of the realized covariance matrices was made partial by leaving a random sample of 10 to 40 (this number was also selected from the discrete uniform distribution for integers 10 to 40) variables in it. These partial kernel matrices were combined using the EM-Algorithm for the Wishart distribution iterated for 50 rounds (each round cycles through the partial covariance matrices in random order). The resultant combined covariance matrix was compared with the corresponding parts of the parameter . In certain instances, the union of the variables in the parts did not recover all of the variables; therefore, this calculation was based on the recovered part of the full covariance matrix by calculating the mean squared error between the upper diagonal elements of these matrices. This experiment was replicated 10 times for each value of and
The results of this simulation study are summarized in Figure 1. For each covariance size, the MSEs decreased as the number of incomplete samples increased. On the other hand, as the size of the covariance matrix increased, the MSEs also increased.
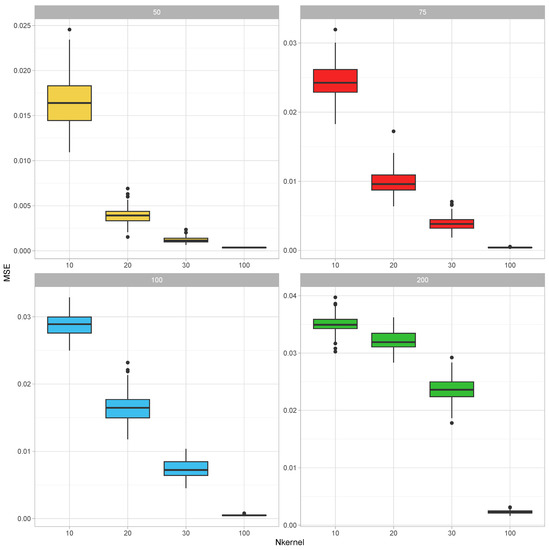
Figure 1.
Illustration 1—Mean square errors (MSE) for estimating correlation parameters based on partial samples for (number of variables in the covariance matrix) and (number of incomplete covariance matrix samples). Each incomplete covariance matrix had a random size between 10 to 40. The MSEs are calculated over 10 replications of the experiment.
Illustration 2—Simulation study: Likelihood Convergence
The EM-Algorithm for the Wishart distribution maximizes the likelihood function for a random sample of incomplete observations from a Wishart distribution. In this application, we explore the convergence of the algorithm for several instances, starting from several different initial estimates.
The example is composed of 10 experiments, each of which starts with a slightly different assumed Wishart covariance parameter , where for are i.i.d. uniform between 0 and 1. For each true assumed covariance matrix, we have generated 10 partial samples including between and variables (random at discrete uniform from to ) each using the Wishart distribution. the total number of variables in the assumed covariance matrix was taken to be 100 or Corresponding to these two matrix sizes, the and are taken as 10 and 25 or 100 and 250. These 10 matrices are combined using the EM-Algorithm for the Wishart distribution 10 different times, each time using a slightly different initial estimate of the covariance parameter where for are i.i.d. uniform between 0 and 1. We record the path of the log-likelihood function for all these examples.
At each instance of the parameter and a particular sample, the likelihood functions converged to the same point (See Figure 2). We have not observed any abnormalities in convergence according to these graphs.
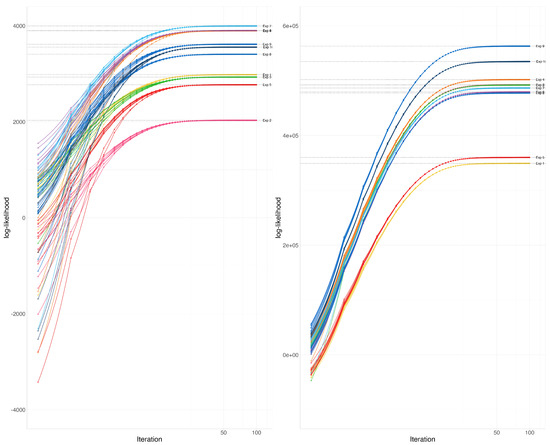
Figure 2.
Illustration 2—Convergence of the log-likelihood function: Each color represents a different experiment. In each experiment, a sample of incomplete covariance matrices from a Wishart distribution was combined using the EM-Algorithm for the Wishart distribution starting from 10 slightly different random initial estimates. the total number of variables in the assumed covariance matrix, was taken to be 100 (A) or 1000 (B).
Illustration 3—Simulation study: Comparing the performance with MASEM
In this example, we compare our EM-based approach with the correlation pooling methods from the multivariate MASEM approach. We use the ”tssem1” function contained within the ”metaSEM” [33] R package for pooling covariance matrices using the MASEM approach. We use two different options for the random error structure in the MASEM approach: a diagonal error covariance matrix or a zero covariance matrix (since the variance component of the random effects is zero, the model becomes a fixed-effects model that is equivalent to the Generalized Least Squares (GLS) approach proposed by Becker [34]). When applying our method, we use the correlation matrices as covariance matrices, and before comparing it with the true parameter, we convert this matrix into a correlation matrix. The results are obtained by repeating the following simulation scenario 10 times. A random correlation matrix for 20 variables is generated. Using the random covariance matrix as the covariance parameter of a Wishart distribution with 100 degrees of freedom, we have generated three random covariance matrices. The first of these matrices contained the variables from 1 to 8, the second covariance matrix contained the variables 6 to 15 and the third matrix contained the variables 13 to 20. We have used our method as well as three forms of the MASEM approaches to obtain a complete covariance matrix estimate. We then compared the mean absolute error between the predicted and the true covariance matrix. The results, which are summarized in Figure 3, show that the EM-Algorithm for the Wishart distribution performs much better than the MASEM approaches in terms of the mean absolute errors and especially in terms of computation time. We also note that we could not make the MASEM algorithms produce any results for cases where the number of variables in the covariance matrix was larger than 30 in a reasonable time. This is due to the fact that the MASEM algorithms use a direct numerical optimization of the likelihood function, which becomes very difficult for unstructured covariance matrices. The EM-Algorithm for the Wishart distribution does not have this problem since each iteration of the algorithm depends solely on matrix algebra operations. More importantly, both of the MASEM approaches we have tried resulted in the imputation of previously unobserved correlation values with the same estimated common covariance parameter value.
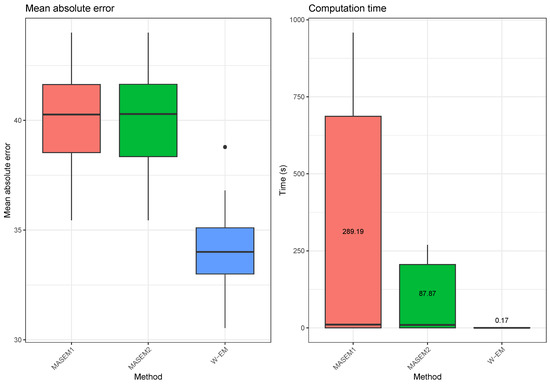
Figure 3.
Illustration 3—Mean absolute errors and computation times for estimating the covariance matrix based on partial samples for two stage MASEM approaches and our EM-Algorithm for the Wishart distribution. The results are calculated over 30 replications of the experiment.
Illustration 4—Empirical study: Cassava data
The need to exploit genomic and statistical tools to harness the total effects of all the genes in the crop genome is gaining traction in most crops. In our illustrations, we used the world’s largest and most updated public database for cassava (CassavaBase) from the Nextgen cassava funded project (http://www.nextgencassava.org). It is estimated that close to a billion people depend on cassava for their dietary needs, particularly in tropical regions of the world. We have accessed the data on 16 November 2019.
The initial data come from 135 phenotypic experiments performed by the East Africa cassava plant breeding programs. The dataset covers 81 traits and contains more than half a million phenotypic records. After filtering the outlier trait values, filtering the traits based on the number of records (at least 200 records per experiment), and trait–trial combinations also based on the number of records (at least 200 records for each trait in a given trial), a subset of 50 of these trials and a total of 37 traits were identified and used for this application (See Figure 4).
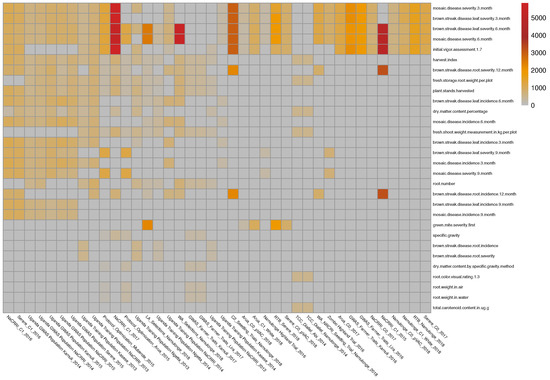
Figure 4.
Illustration 4—This figure represents the availability of very unbalanced and heterogeneous phenotypic data for 37 traits in 50 trials in East Africa. The number of phenotypic records in each trial is represented with a colored box at the intersection of the trait (rows) and trial (columns). Gray squares represent unobserved traits and trial combinations. The mean number of traits observed in these studies was . Certain trait combinations were not observed together in these experiments; for example, root weight in water and dry matter content percentage, root number, and total carotenoid content.
Due to the relatively high cost of phenotypic experiments, they typically focus on a limited set of key traits. As a result, when observing multiple phenotypic datasets, the data is typically heterogeneous and incomplete, with certain trait combinations not appearing together in any of the experiments (e.g., root weight in water and dry matter content percentage, root number and total carotenoid content).
Figure 5 includes a heatmap of the resulting covariance matrix for 37 traits was obtained from combining the sample covariance matrices from 50 phenotypic trials. The heatmap indicates that there are three clusters of traits that appear to be positively correlated within each group, but little to no correlation between the groups. Two of these clusters correspond to disease-related traits, and the other is composed primarily of agronomic traits related to yield. The cluster related to cassava mosaic disease is found to be negatively correlated with the other disease traits, which are related to brown streak disease.
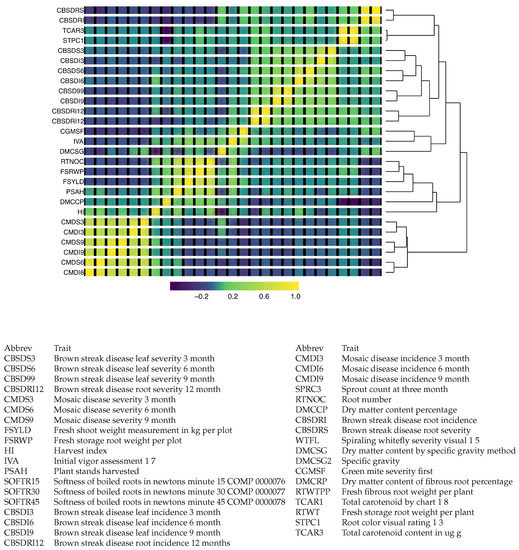
Figure 5.
Illustration 4—Cassava data: The resulting combined covariance matrix for 37 traits obtained by combining the sample covariance matrices from 50 phenotypic trials downloaded from CassavaBase. Abbrev: Abbreviations.
We have used the R Package qgraph [35] to introduce sparsity to the off-diagonal elements of the estimated covariance matrix and graphically present this in Figure 6.
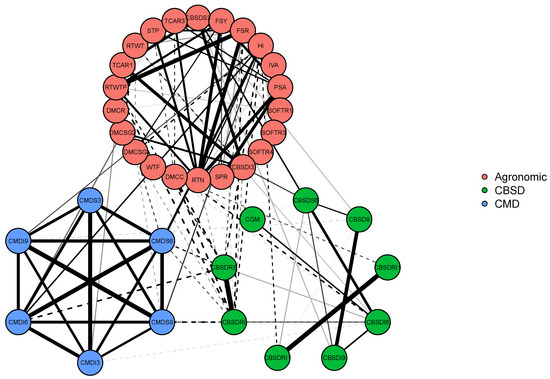
Figure 6.
Illustration 4—Cassava data: A covariance graph for the covariance matrix resulting in a combined covariance matrix for 37 traits obtained by combining the sample covariance matrices from 50 phenotypic trials downloaded from CassavaBase. The green colored lines represent positive trait correlations, red colored lines represent negative trait correlations. The thickness of the line is an indication of the strength of the correlation. The traits that are not connected with any lines are estimated to be marginally independent. The abbreviations for the traits are the same as those given in Figure 5. Similar traits are grouped and have the same color nodes.
4. Conclusions
Analyzing data in large and heterogeneous databases remains a challenge due to the need for new statistical methodologies and tools to make inferences. The EM-Algorithm for the Wishart distribution is one such tool that can be used to solve a very specific problem: combining datasets using covariance matrices (similarly combining relationship or similarity matrices). Our approach is highly beneficial in terms of its statistical formalism and computational efficiency; to the best of our knowledge, this is the first time the EM procedure for pooling covariance matrices has been described, although it has been inspired by similar methods such as (conditional) iterative proportional fitting for the Gaussian distribution [22,23] and a method for combining a pedigree relationship matrix and a genotypic relationship matrix, which includes a subset of genotypes from the pedigree-based matrix [24] (namely, the H-matrix).
Despite the benefits of the proposed framework for combining heterogeneous datasets, certain limitations should be taken into account. Specifically, when combining data using covariance matrices, the original features are not imputed. It is known that the nature of missingness in data can significantly influence the performance of imputation and inference. Consequently, any approaches that disregard the missing data mechanisms are only applicable to data that is missing completely at random (MCAR) or missing at random (MAR). However, such techniques cannot be utilized for data not missing at random (NMAR) [36,37]. Additionally, there could be heterogeneity in covariance matrices to some extent. This can be addressed with a hierarchical distribution (see, e.g., [38]). Furthermore, this structural misspecification can also be accounted for by the method in [39].
Overall, the combination of heterogeneous datasets via covariances matrices and the EM-Algorithm for the Wishart distribution is novel, and we expect it to be beneficial in a variety of fields, such as physics, engineering, biology, neuroscience, finance, genomics, and other -omics disciplines.
Author Contributions
Conceptualization, D.A.; methodology, D.A.; software, D.A.; validation, D.A., M.S. and J.I.-S.; formal analysis, D.A.; data curation, D.A., M.S.; writing—original draft preparation, D.A.; writing—review and editing, D.A., M.S. and J.I.-S.; visualization, D.A. and J.I.-S. All authors have read and agreed to the published version of the manuscript.
Funding
D.A.: Support comes from the National Marrow Donor Program/Be The Match, part of a research collaboration that is CIBMTR. CIBMTR support includes funding from Public Health Service U24CA076518 from the National Cancer Institute and N00014-21-1-2954 from the Office of Naval Research. J.I.-S.: Support comes from the Beatriz GalindoProgram (BEAGAL18/00115) from the Ministerio de Educació n y Formació n Profesional of Spain and the Severo Ochoa Program for Centres of Excellence in R&D from the Agencia Estatal de Investigación of Spain, grant SEV-2016-0672 (2017–2021) to the CBGP.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All of the data used in this study is available from cassavabase.org. We have accessed the data on 16 November 2019.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gomez-Cabrero, D.; Abugessaisa, I.; Maier, D.; Teschendorff, A.; Merkenschlager, M.; Gisel, A.; Ballestar, E.; Bongcam-Rudloff, E.; Conesa, A.; Tegnér, J. Data integration in the era of omics: Current and future challenges. BMC 2014, 8, 1–10. [Google Scholar] [CrossRef]
- Rhodes, D.R.; Chinnaiyan, A.M. Integrative analysis of the cancer transcriptome. Nat. Genet. 2005, 37, S31. [Google Scholar] [CrossRef] [PubMed]
- Evangelou, E.; Ioannidis, J.P. Meta-analysis methods for genome-wide association studies and beyond. Nat. Rev. Genet. 2013, 14, 379–389. [Google Scholar] [CrossRef]
- Huttenhower, C.; Hibbs, M.; Myers, C.; Troyanskaya, O.G. A scalable method for integration and functional analysis of multiple microarray datasets. Bioinformatics 2006, 22, 2890–2897. [Google Scholar] [CrossRef]
- Liu, J.; Huang, J.; Xie, Y.; Ma, S. Sparse group penalized integrative analysis of multiple cancer prognosis datasets. Genet. Res. 2013, 95, 68–77. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Gray, J.W.; Parvin, B. Sparse multitask regression for identifying common mechanism of response to therapeutic targets. Bioinformatics 2010, 26, i97–i105. [Google Scholar] [CrossRef]
- Kirk, P.; Griffin, J.E.; Savage, R.S.; Ghahramani, Z.; Wild, D.L. Bayesian correlated clustering to integrate multiple datasets. Bioinformatics 2012, 28, 3290–3297. [Google Scholar] [CrossRef]
- Xiong, Q.; Ancona, N.; Hauser, E.R.; Mukherjee, S.; Furey, T.S. Integrating genetic and gene expression evidence into genome-wide association analysis of gene sets. Genome Res. 2012, 22, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Wu, X.; Jiang, R. Integrating human omics data to prioritize candidate genes. BMC Med. Genom. 2013, 6, 57. [Google Scholar] [CrossRef]
- Troyanskaya, O.G.; Dolinski, K.; Owen, A.B.; Altman, R.B.; Botstein, D. A Bayesian framework for combining heterogeneous data sources for gene function prediction (in Saccharomyces cerevisiae). Proc. Natl. Acad. Sci. USA 2003, 100, 8348–8353. [Google Scholar] [CrossRef]
- Balbin, O.A.; Prensner, J.R.; Sahu, A.; Yocum, A.; Shankar, S.; Malik, R.; Fermin, D.; Dhanasekaran, S.M.; Chandler, B.; Thomas, D.; et al. Reconstructing targetable pathways in lung cancer by integrating diverse omics data. Nat. Commun. 2013, 4, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Bersanelli, M.; Mosca, E.; Remondini, D.; Giampieri, E.; Sala, C.; Castellani, G.; Milanesi, L. Methods for the integration of multi-omics data: Mathematical aspects. BMC Bioinform. 2016, 17, S15. [Google Scholar] [CrossRef]
- Subramanian, I.; Verma, S.; Kumar, S.; Jere, A.; Anamika, K. Multi-omics data integration, interpretation, and its application. Bioinform. Biol. Insights 2020, 14, 1177932219899051. [Google Scholar] [CrossRef]
- Jiang, D.; Armour, C.R.; Hu, C.; Mei, M.; Tian, C.; Sharpton, T.J.; Jiang, Y. Microbiome multi-omics network analysis: Statistical considerations, limitations, and opportunities. Front. Genet. 2019, 10, 995. [Google Scholar] [CrossRef] [PubMed]
- Cheung, M.W.L.; Chan, W. Meta-analytic structural equation modeling: A two-stage approach. Psychol. Methods 2005, 10, 40. [Google Scholar] [CrossRef] [PubMed]
- Jak, S. Meta-Analytic Structural Equation Modelling; Springer: Berlin, Germany, 2015. [Google Scholar]
- Akdemir, D.; Knox, R.; Isidro y Sánchez, J. Combining partially overlapping multi-omics data in databases using relationship matrices. Front. Plant Sci. 2020, 11, 947. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Dempster, A.P.; Rubin, D.B.; Tsutakawa, R.K. Estimation in covariance components models. J. Am. Stat. Assoc. 1981, 76, 341–353. [Google Scholar] [CrossRef]
- Dempster, A.; Laird, N.; Rubin, D. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–38. [Google Scholar]
- Hastie, T.; Mazumder, R.; Lee, J.D.; Zadeh, R. Matrix completion and low-rank SVD via fast alternating least squares. J. Mach. Learn. Res. 2015, 16, 3367–3402. [Google Scholar]
- Cramer, E. Conditional iterative proportional fitting for Gaussian distributions. J. Multivar. Anal. 1998, 65, 261–276. [Google Scholar] [CrossRef]
- Cramer, E. Probability measure with given marginals and conditionals: I-projections and conditional iterative proportional fitting. Stat. Risk Model. 2000, 18, 311–330. [Google Scholar]
- Legarra, A.; Aguilar, I.; Misztal, I. A relationship matrix including full pedigree and genomic information. J. Dairy Sci. 2009, 92, 4656–4663. [Google Scholar] [CrossRef]
- Anderson, T. An Introduction to Multivariate; Wiley & Sons: Hoboken, NJ, USA, 1984. [Google Scholar]
- Gupta, A.; Nagar, D. Matrix Variate Distributions; Chapman and Hall/CRC Monographs and Surveys in Pure and Applied Mathematics; Chapman and Hall: Boca Raton, FL, USA, 2000. [Google Scholar]
- Kollo, T.; von Rosen, D. Advanced Multivariate Statistics with Matrices; Springer Science & Business Media: Berlin, Germany, 2006; Volume 579. [Google Scholar]
- Bickel, P.J.; Levina, E. Covariance regularization by thresholding. Ann. Stat. 2008, 36, 2577–2604. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.; Hastie, T.; Tibshirani, R. Sparse inverse covariance estimation with the graphical lasso. Biostatistics 2008, 9, 432–441. [Google Scholar] [CrossRef]
- Lam, C.; Fan, J. Sparsistency and rates of convergence in large covariance matrix estimation. Ann. Stat. 2009, 37, 4254. [Google Scholar] [CrossRef]
- Bien, J.; Tibshirani, R.J. Sparse estimation of a covariance matrix. Biometrika 2011, 98, 807–820. [Google Scholar] [CrossRef] [PubMed]
- Green, P.J. On use of the EM algorithm for penalized likelihood estimation. J. R. Stat. Soc. Ser. B 1990, 52, 443–452. [Google Scholar] [CrossRef]
- Cheung, M.W.L. metaSEM: An R package for meta-analysis using structural equation modeling. Front. Psychol. 2015, 5, 1521. [Google Scholar] [CrossRef]
- Becker, B.J. Missing Data and the Synthesis of Correlation Matrices. In Proceedings of the Annual Meeting of the American Educational Research Association, San Francisco, CA, USA, 20–24 April 1992. [Google Scholar]
- Epskamp, S.; Cramer, A.O.J.; Waldorp, L.J.; Schmittmann, V.D.; Borsboom, D. qgraph: Network Visualizations of Relationships in Psychometric Data. J. Stat. Softw. 2012, 48, 1–18. [Google Scholar] [CrossRef]
- Little, R.; Rubin, D. Statistical Analysis with Missing Data; Wiley: New York, NY, USA, 2002. [Google Scholar]
- Rubin, D.B. Inference and missing data. Biometrika 1976, 63, 581–592. [Google Scholar] [CrossRef]
- Ke, Z.; Zhang, Q.; Tong, X. Bayesian meta-analytic SEM: A one-stage approach to modeling between-studies heterogeneity in structural parameters. Struct. Equ. Model. Multidiscip. J. 2019, 26, 348–370. [Google Scholar] [CrossRef]
- Chen, C.F. Bayesian inference for a normal dispersion matrix and its application to stochastic multiple regression analysis. J. R. Stat. Soc. Ser. B 1979, 41, 235–248. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).