This section discusses about the proposed model for preliminary classifying OSA patients. The first subsection talks about the image registration method based on a 3D morphable model and Teichmüller map. Then, geometric distortions of the specific landmarks are calculated based on quasiconformal geometry to generate a feature vector for each subject, which is discussed in the second subsection. With the discriminating feature vectors, an OSA classification model is proposed in the last subsection.
3.1. The 3D Surface Reconstruction from 2D Images
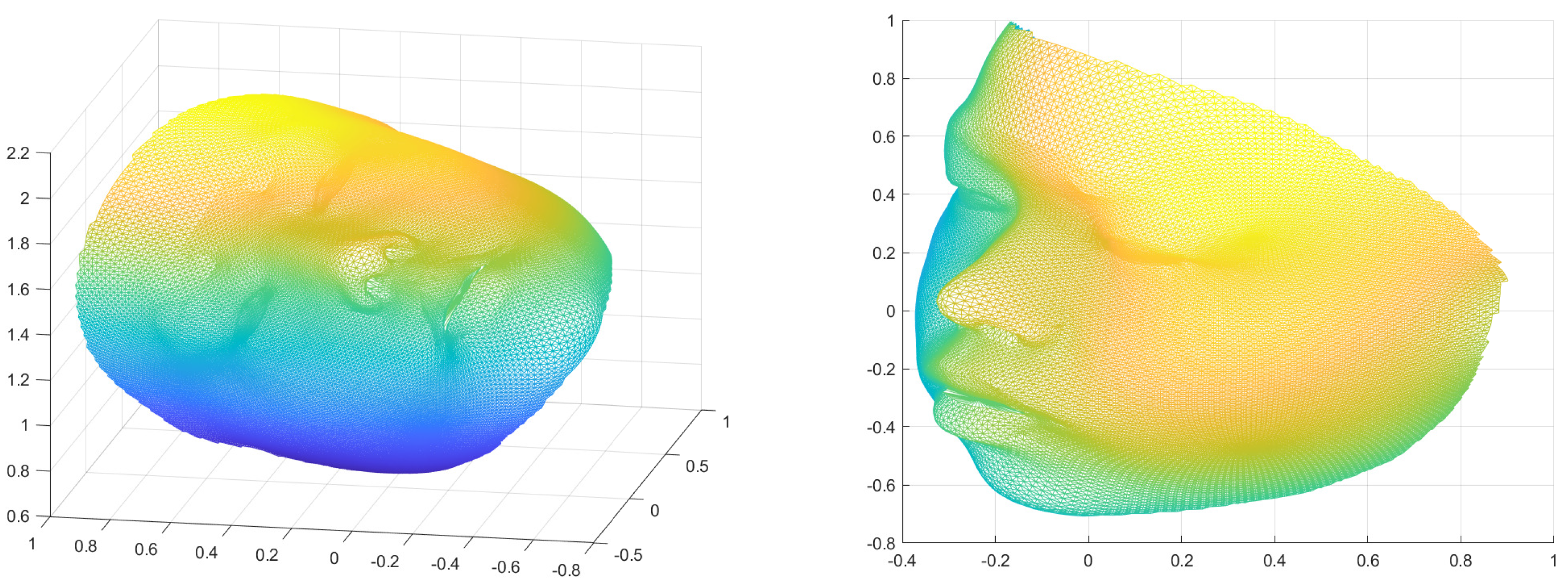
The 3D surface reconstruction from 2D images captured from multiple angles is a crucial step in accurate shape analysis. This process provides a more comprehensive representation of the object’s shape, including its depth and three-dimensional structure, which is essential for analysing and understanding its geometric patterns. The use of multiple images captured from different angles helps to overcome the limitations of 2D imaging, such as occlusions, and provides a more complete representation of the surface. Furthermore, 3D surface reconstruction enables the use of advanced shape analysis techniques, such as surface registration and shape comparison. As such, the first step of our proposed model is to convert 2D images capturing the human face from multiple angles into one 3D facial surface. This procedure is carried out using a deep neural network that regresses the coefficients of the 3DMM face model.
The 3D reconstruction model is based on the 3D morphable face model, commonly referred to as a 3DMM. The 3DMM is a statistical model of the shape and appearance of human faces. The model is created by analysing a large number of 3D scans of human faces, which are then used to generate a set of parameters that can be used to generate an infinite number of 3D faces. With the 3DMM, the face shape
and the texture
can be represented as:
where
and
are the average face shape and texture;
,
, and
are the PCA bases of identity, expression, and texture, respectively;
,
, and
are the corresponding coefficient vectors for generating a 3D face. The Basel Face Model [
17] is used for
,
,
, and
, and the expression bases
in [
18] is used. In order to train the backbone deep neural network for obtaining the 3D face from a 2D image, every 3D face in the training data set is matched with a corresponding 2D image. These 2D images are taken from different angles, including 0 degree (frontal view), 30 degrees, 45 degrees, −30 degrees, and −45 degrees. A subset of the bases is selected based on the five images, resulting in
,
and
. Given the training data with pairs of 2D images and their associated 3D shapes, a deep neural network regresses the coefficient vector
. In this work, we adopt the method in [
19] to obtain the coefficient vector
associated with an image
capturing the human face from one angle.
Now, to integrate all images from multiple angles to obtain a more accurate 3D model, the following procedure is carried out. For each image
, the spatial dependent weight
is assigned. The weight depends on how informative the image
for the 3D reconstruction of the 3D model. For images of poor image quality, we assign a smaller weight. The weight of each image is determined by its sharpness and information content. Specifically, the weight for each image is represented as a vector with the same size as the number of vertices on the 3D reconstructed surface. Therefore, each vertex on the 3D surface is assigned a weight associated with each image. The image sharpness
of an image
I is calculated using the Laplacian operator, which is defined as
, where
represents the Laplacian kernel. By convolving
I with the Laplacian kernel,
captures the features and edges of objects in the image. The magnitude of
is higher for sharper images, resulting in a larger value of
for sharper images. In addition to image sharpness, the image information content is also taken into account. The image information refers to the reliability of the 2D image in providing information for determining the 3D coordinates of a point on the reconstructed face. For example, a frontal image (captured at 0 degree) provides reliable information for the central region of the 3D face. Therefore, the image information weights associated with vertices of the central region are defined as 1. However, if an image cannot capture a region of the 3D face, the image information weights associated with vertices of the occluded region are defined as 0. The final weight for each vertex associated with each image is calculated as the product of its image sharpness and image information weight. For spatial position with a poor quality, such as the existence of occlusions, a smaller weight associated with that particular position can be assigned. The final 3D reconstructed model is given by:
where ⊙ refers to the pointwise multiplication of two vectors and
N is the number of images from multiple angles.
Figure 1 gives an illustration of the 3D reconstruction from 2D images.
3.2. Landmark-Based Teichmüller Curvature Distance (LTCD)
In order to train a three-class classification machine, the distances of each data from each classes have to be defined. The choice of distances play an important role for the classification accuracy. Computing distances between data and classes is important for classification because it provides a way to measure the similarity between each datapoint and each class. This information is crucial for assigning each datapoint to the most appropriate class, and can be used to determine the class membership of each datapoint based on the closest match. Furthermore, the computation of distances between data and classes can also provide valuable insights into the underlying structure and relationships between the data and the classes, which can be useful for developing better classification models and improving accuracy.
In this work, our choice of distances is based on surface geometry on selected feature landmarks, which will be described in this subsection.
3.2.1. Surface Registration
First of all, LTCD is defined as the distance of each data to each class. In order to define distances between different data, a one-to-one correspondence between data must be obtained. In this work, a landmark-matching registration model by computing the Teichmüller mapping that matches facial landmark features is adopted to compute the mutual correspondence between subjects [
14]. The Teichmüller mapping can be formulated as an extremal mapping minimizing the local geometric distortion. As such, the problem of computing the Teichmüller mapping can be converted into an optimization problem
subject to: (i)
and
; (ii)
for some constant
k and holomorphic function
; and (iii)
f satisfies certain boundary condition and/or landmark constraints. The optimization problem can be solved by the Quasiconformal Iteration (QC) using the Linear Beltrami Solver (LBS).
The best quasiconformal mapping associated with a given Beltrami coefficient can be obtained with the use of LBS. An algorithm (QC iteration for open surfaces) can be used to obtain the extremal mapping
f [
14]. The main idea of the algorithm is to iteratively search for the optimal Beltrami Coefficient associated with
f. Using the optimal Beltrami coefficient, the desired extremal mapping
f can be easily reconstructed using the LBS. One benefit of the application of the quasiconformal registration is that the effect of global scaling, global rotation, and global translation is minimized.
Two 3D triangular meshes are used as input as well as the expected boundary condition. An optimal Beltrami coefficient v and the Teichmüller mapping f are output as a result. The algorithm follows a three-steps approach.
Firstly, the initial mapping is set
and fix the initial Beltrami coefficient
.
Secondly, we can iteratively compute
where
is the averaging operator,
is the Laplacian operator, and
is the Linear Beltrami Solver. Lastly, this alternating process continues unless
. For more details about the algorithm of the registration model, readers are referred to [
14].
Once the pairwise surface registration is computed, every craniofacial surfaces can be represented by a triangulation mesh with the same connectivity and the same number of vertices with correspondence.
3.2.2. Surface Geometric Feature Vector
Our next step is to obtain a geometric feature vector for each surface, which can be used to define distances between surfaces. The feature vector should comprise the most crucial geometric information that accurately characterizes the surface, as determined by the specific application and its relevant discriminating power. We construct the geometric feature vector for our classification machine as follows. Suppose there are N subjects, in which the first subjects are in the control class (class 0), the second subjects are in the mild OSA class (class 1), and the last subjects are in the moderate-to-severe OSA class (class 2). In this work, a method to construct a feature vector containing Gaussian and Mean curvature data is proposed.
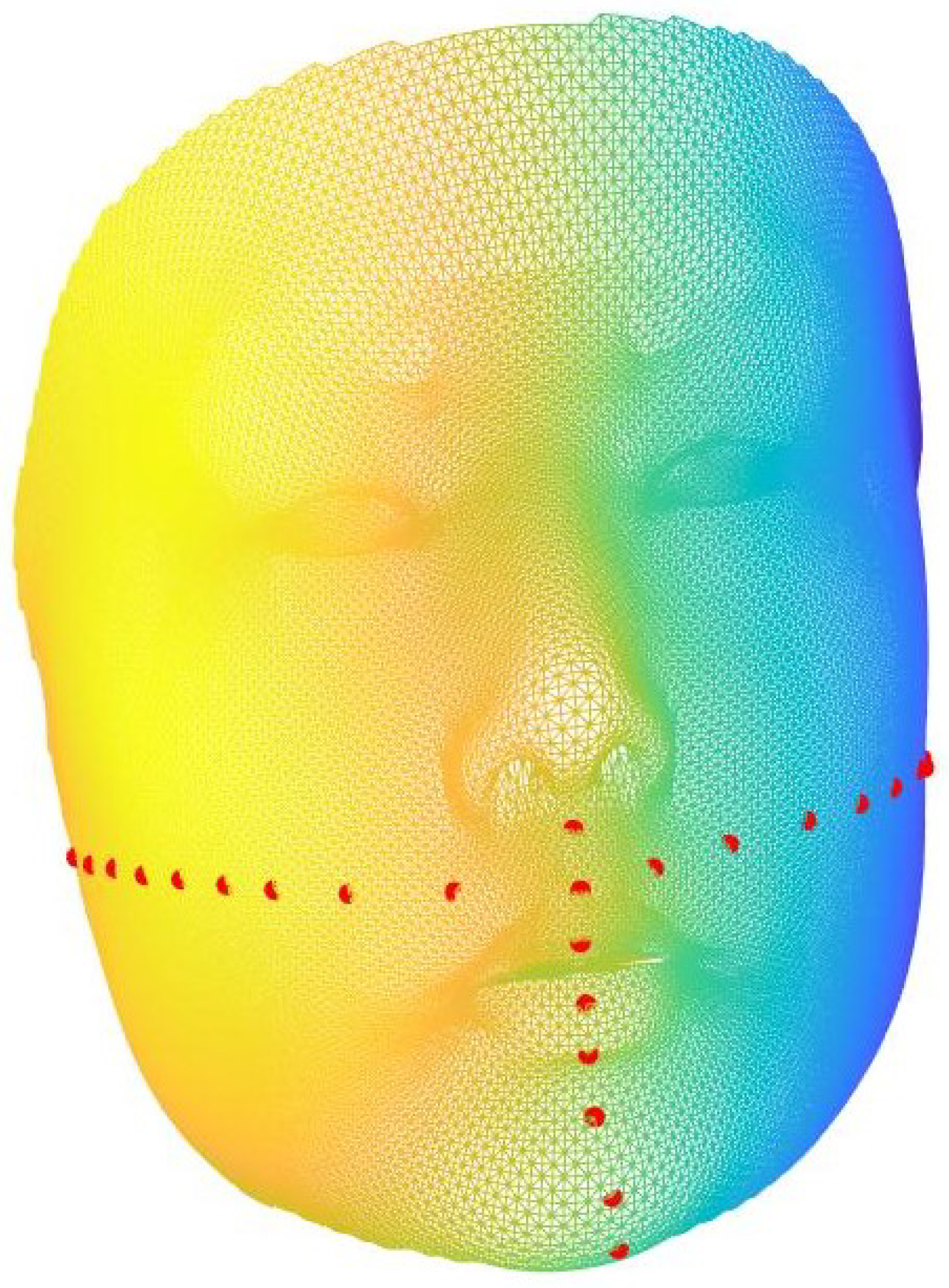
Each of the 3D images is registered to 35,710 indices by the above registration model. In this work, we propose to consider geometric information around some feature landmarks only. This avoids misleading geometric information from unimportant region to interrupt the classification result. Therefore,
n landmarks around are selected either manually or automatically according to each practical applications (see
Figure 2 for an illustration).
For each landmark point that is selected manually, the closest
points based on Euclidean distances are chosen as feature points as well, where
w is adjusted in the iterations of the algorithm. Therefore,
points are considered for each subject. Some of the points may be duplicate in this process and duplicate entries are removed. After reordering the index in ascending order, a collection of these landmark points can be constructed and denoted as
S, where
represents the
j-th item in the collection
S.
Figure 3 provides a visual representation of the outcome obtained through automatic landmark selection.
To obtain corresponding curvature data, a standard algorithm is used. The normalized Gaussian and Mean curvature are denoted as K and H, respectively, which are combined to form a feature vector for the i-th subject, that is, . More specifically, we normalize both the mean curvature and Gaussian curvatures to be within the interval [0, 1]. Denote the length of the feature vector by L and be the j-th entry of the feature vector.
To augment the discriminating power of the feature vector, a
t-test incorporating the bagging predictors is used to select a certain percentage of features with the highest discriminating power [
11,
20]. In the general
t-test, a probability
called the
p-value is computed for each feature point
which evaluates the power of the feature in discriminating the given three classes. The bagging predictors strategy uses a leave-one-out scheme to improve the stability of the
t-test. Specifically,
N tests are performed, and each test is performed on all the subjects excluding the
i-th one. This gives the
p-value
for feature point
j in the
i-th iteration. After all the tests, the
p-value of each feature is calculated by
. According to the
t-test, the discriminating power of each feature increases as its
p-value decreases. So,
of the features with the highest discriminating power are
of the features with the smallest
p-values, where
is adjusted in the iterations of the algorithm. Based on the
p-values, the features with low discriminating power can be removed from our classification machine by remaining only the
features with the highest discriminating power given a certain percentage.
Figure 4 provides a visual depiction of the bagging outcome.
In this work, our model uses the discriminating feature vector for each craniofacial structure.
3.2.3. LTCD Computation
Based on the above preparation, the LTCD can be constructed. In this work, a simple -norm is applied for three-class classification. The idea is that subjects from each class possess an analogous geometrical structure to the skull. The subjects can then be classified by the difference between the template feature vector and subjects. Note that each surface meshes to be analysed are in pairwise correspondence with each others. This ensures that each entry of the feature vector for a given subject can be compared directly to the corresponding entry for another subject, without the need to adjust for point mismatching issues. Evidently, the choice of surface correspondence is critical to the success of this analysis, as it determines the quality of the comparison between subjects. In our model, we use the Teichmüller mapping, which minimizes the conformality distortion and hence, the local geometric distortion. This ensures that the comparison between subjects is accurate and meaningful, with the most important geometric information being captured and considered in the analysis. Since the discriminating feature vector is obtained by bagging, the median of the feature vectors among each class can be generated. The median of each class is used instead of the mean to avoid extreme data. If a larger set of data is adopted, the mean may replace the median to achieve a higher accuracy.
Let
, for
, be the three collections of the trimmed feature vectors belongs to the three classes. Then, the template feature vectors
,
,
of each class can be defined as
for
and
. Since there are 3 classes, the distances to
,
and
are defined for each subject in the
sense as follows.
is called the LTCD of subject
i to the class
j.
If the subject i has a smaller distance to the template vector of class j, it is more likely that the subject belongs to class j. We remark that the choice of landmark points plays a crucial role in the analysis of surface meshes and can greatly affect the definition of geometric features. This in turn affects the landmark-based Teichmüller curvature distance, which is used to quantify the similarity between meshes. The choice of landmarks can be made either manually or automatically, depending on the specific practical application. It is important to carefully consider the choice of landmarks, as it can greatly impact the accuracy and validity of the analysis.
Last but not least, since we have three classes, it is difficult to judge when the magnitude of two of the distance vectors are close. A non-linear balancing term is added to increase the gap between classes, and the details will be discussed in the later section.
3.3. Composite Score Model and Parameter Optimization
In our work, since the length of the feature vector is rather long (usually with at least 500 coordinates), it is not suitable to adapt the commonly used classification algorithm, such as supporting vector machine (SVM) or K-nearest neighbour (KNN) algorithm. These algorithms are sensitive to a small perturbation of the feature vector, and also to outliers. Since medical data on class-1 patient is insufficient, training with outliers is not desirable. In particular, according to the opinion of the medical doctors, it is very difficult for them to distinguish class-0 and class-1 subject. In view of this situation, we need a model that can tolerate a margin of error whilst maintaining overall accuracy.
We propose the following composite score model, with the set of parameter . These composite scores are based on the distance between the subject feature vector and the template feature vectors which can be computed fast and easily across machines.
Definition 7 (Composite Score Model).
For the i-th subject, the set of composite score is defined by The same for the three composition scores instead of for each class since the sample size is small and this can avoid over-fitting. Furthermore, this composition score based on -norm is considering all the coordinates of the feature vector as a whole, and so the influence from a particular extreme coordinate of a feature vector is minimized.
Furthermore, the criterion for classification using the composite scores is defined as follows.
Definition 8 (Criterion for Classification).
Suppose the set contains distinct numbers. The i-th subject is classified into the class p if For the intuition behind the model, it is based on the fact if the i-th subject is closer to the template surface of class k, the value of will be the smallest among . Furthermore, if the i-th subject is of class k, the distance between the subject and the other two classes will be bigger. By considering this two push-and-pull factors, the above composite score model is defined.
We now use the following illustration to help understand the composite score model.
Graphical Illustration of the Composite Score Model
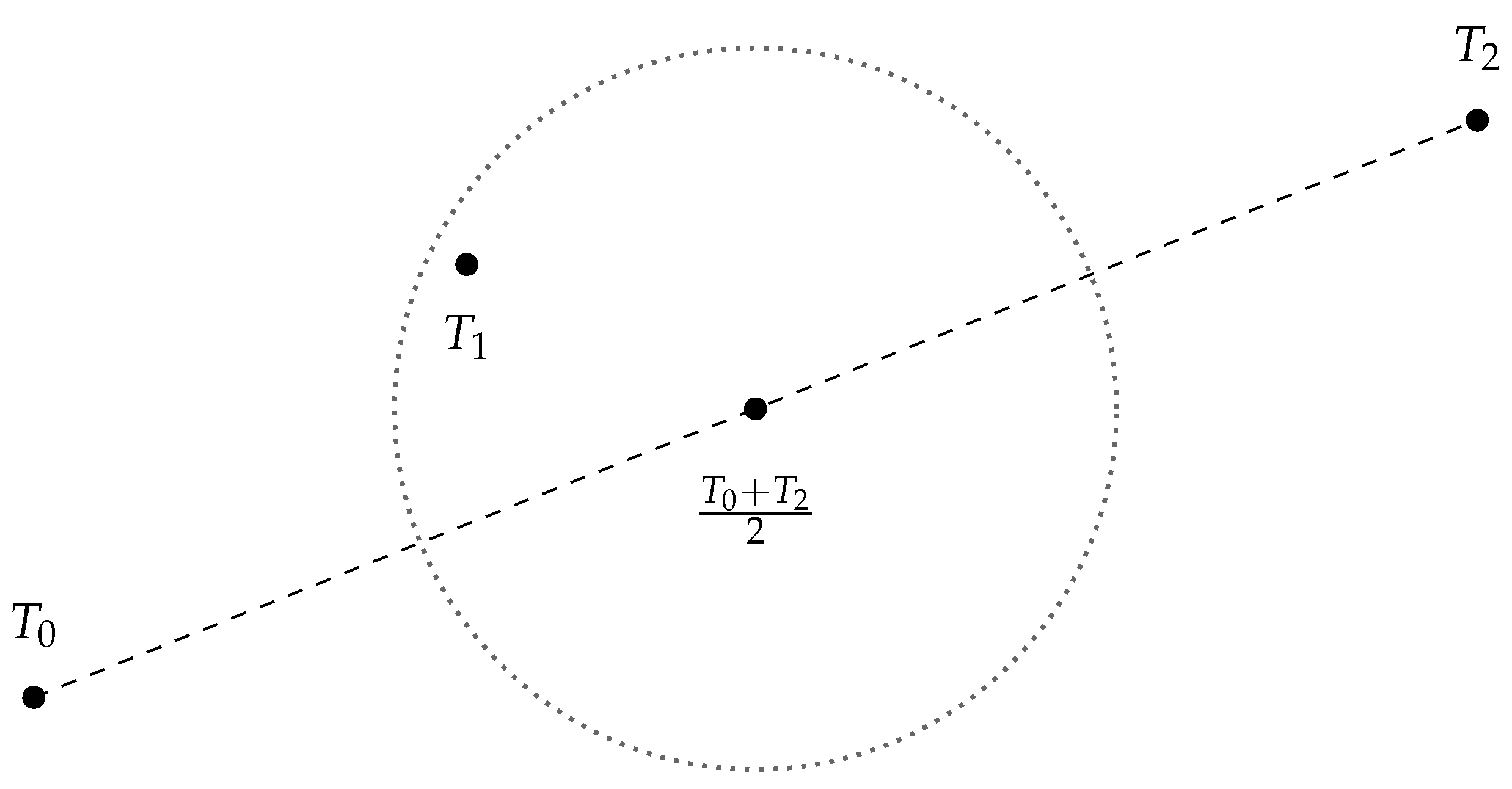
We can interpret the class “0, 1, 2” as the degree of severity of the disease. If we plot the template feature vector
,
,
in
, we should expect that
should be lying on somewhere near the midpoint of
and
, as shown in
Figure 5.
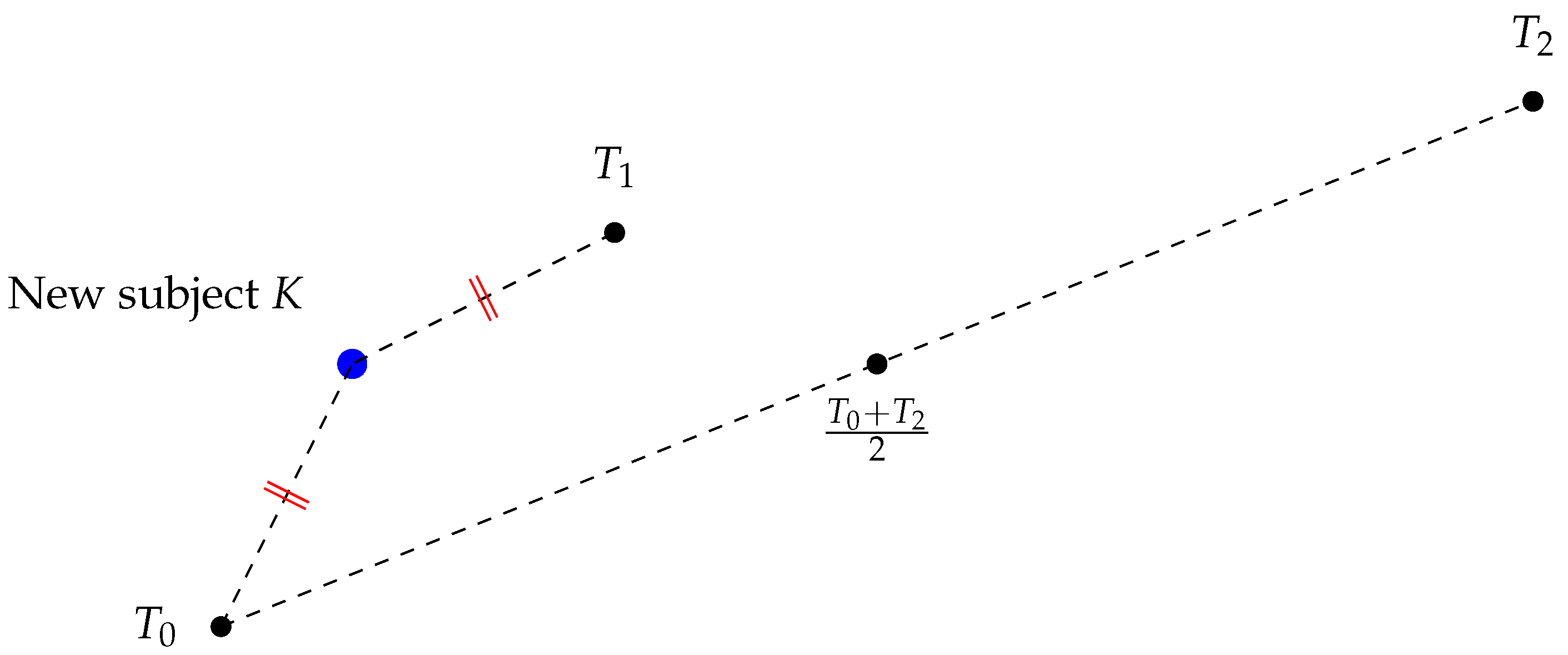
Let us say we have a new subject
K and we want to classify it, as shown in
Figure 6. Suppose
. That means the new subject is equidistant from the template feature vectors
and
.
In this case, it is difficult to classify
K. However, we can consider
as a “push factor”, as shown in
Figure 7. Note that
is large.
For example, we can define , as two “composition scores”. This is a special case of our original composition score model Definition 7 with . Now, since , we can classify the new subject as class 0.
Going back to our original composition score model, to simplify and speed up the process, we fix and iterate in with 0.2 difference each time. The parameters , are used to balance the two push-and-pull factors. Furthermore, to provide a more flexible variation space, and are added for non-linear approximation/optimization. It can provide a different approach for improving accuracy. To avoid over-fitting, and are only chosen in with 0.1 difference each time.
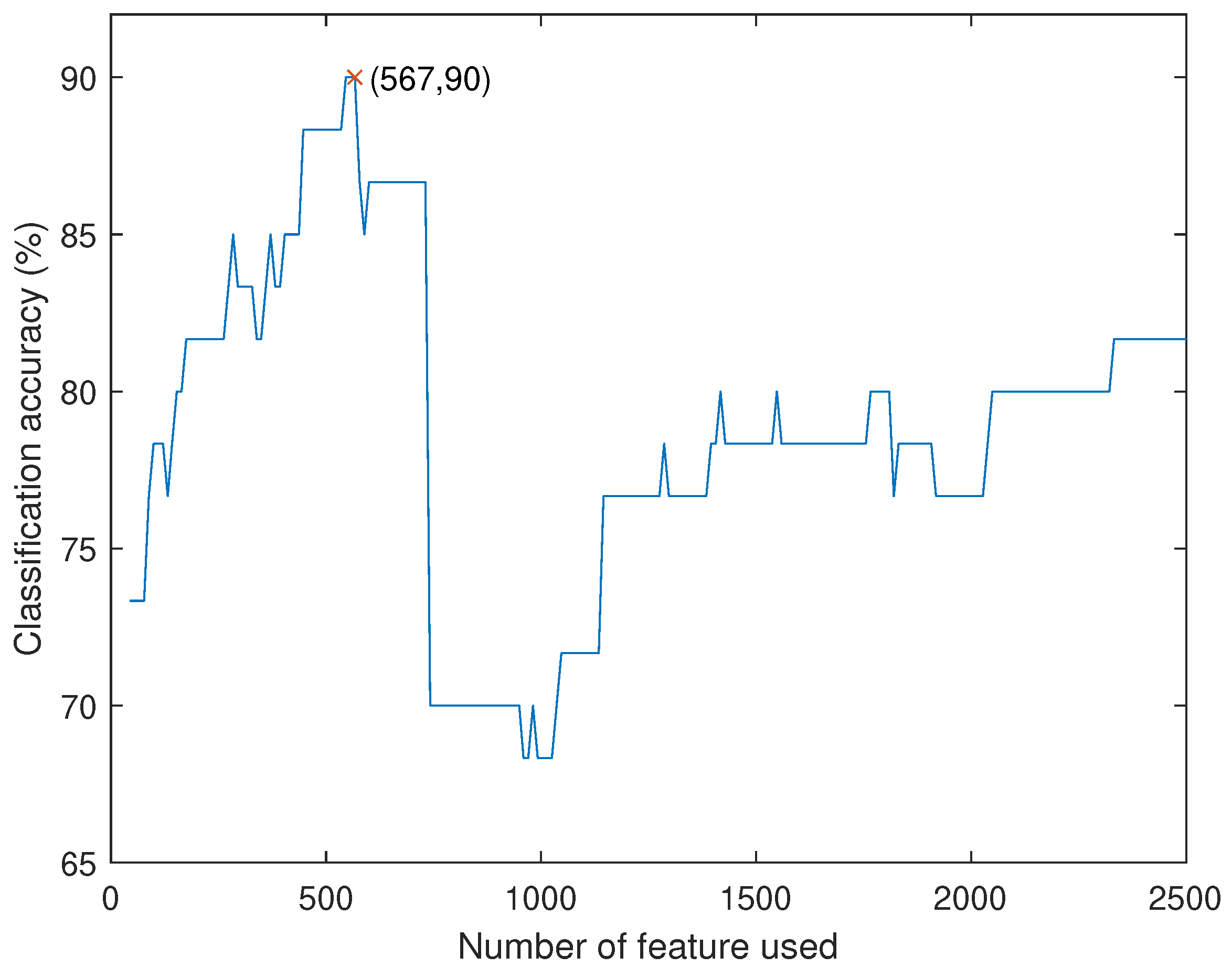
After iteration, we obtain the best result with


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}