1. Introduction
In order to create adaptable models for data analysis, a significant area of statistics seeks to create distributions with novel traits. In fact, a new distribution can present a fresh modeling viewpoint and a clearer picture of the underlying mechanisms generating the data. As a result, a number of new distributions have been introduced recently, including those in [
1,
2,
3].
Among the famous lifetime distributions, the Teissier (T) distribution (also called the Muth (M) distribution) was established in [
4] to simulate the frequency of death related to aging. Laurent [
5] investigated its classification based on life expectancy and demonstrated its applicability to demographic datasets. Muth [
6] employed this distribution to analyze dependability. Reference [
7] determined the main features of the T distribution. They referred to it as the M distribution, although they might have overlooked publications [
4,
5]. As a matter of fact, scientists have paid little consideration to the T distribution. However, it is of interest because it may be preferable to the one-parameter exponential distribution when modeling data with a subordinate increasing hazard rate function (HRF). Among the existing developments based on the T distribution, let us mention the power M distribution studied in [
8], transmuted M-generated class of distributions proposed in [
9], new M-generated class of distributions elaborated in [
10], exponentiated power M distribution discussed in [
11], inverse power M distribution investigated in [
12] and the truncated M generated family of distributions emphasized in [
13]. More recently, Krishna et al. [
14] used the T distribution for creating an intriguing unit distribution, i.e., a distribution with support as
, the unit T distribution (UTD). This work has motivated the present paper as explained later. Basically, the UTD is the distribution of the random variable
, where
Z is a random variable that follows the T distribution. The cumulative distribution function (CDF) of the UTD is indicated as follows:
which is completed with
for
and
for
, with a shape parameter
such that
, and the corresponding probability density function (PDF) is given by
with
for
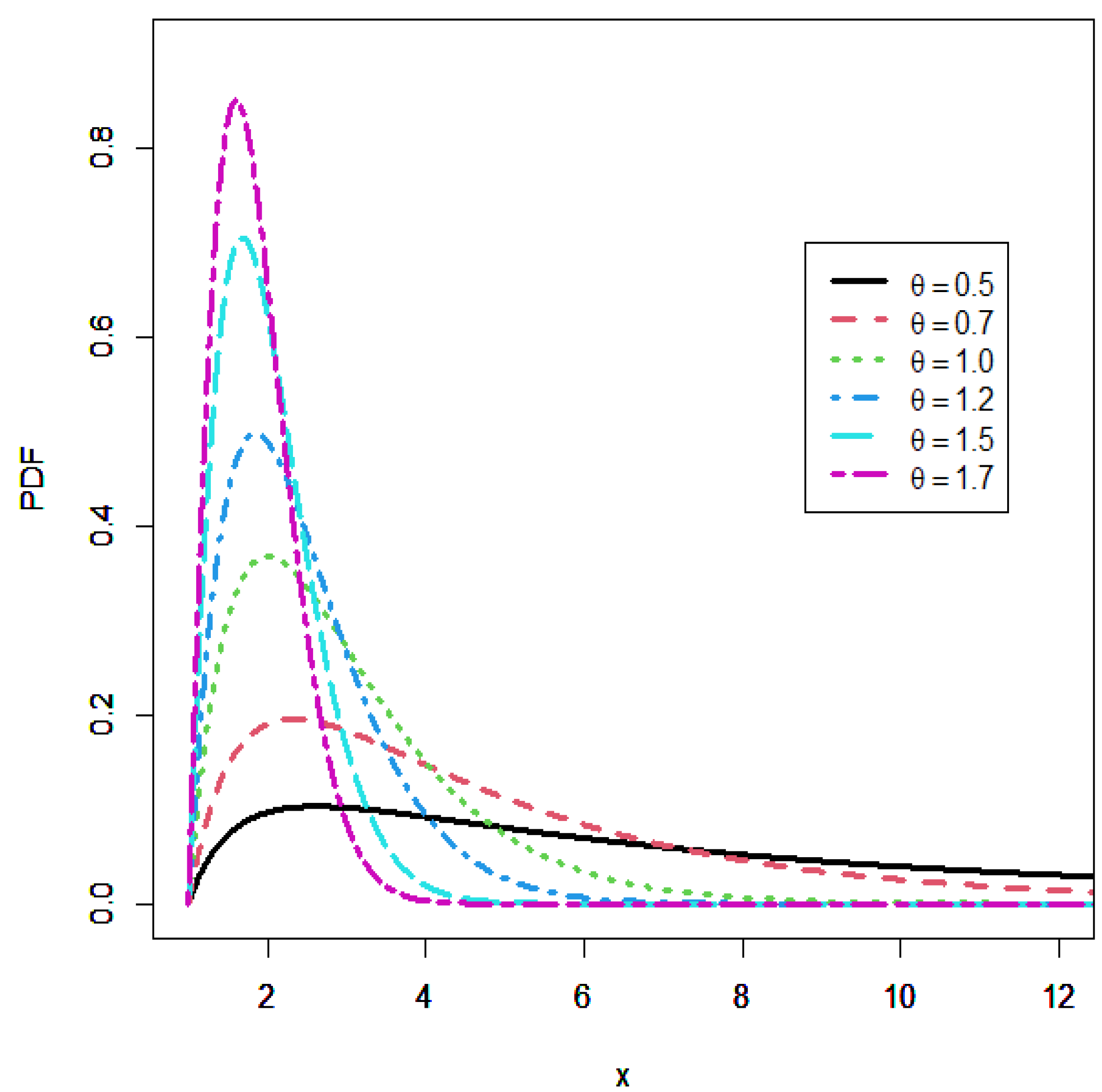
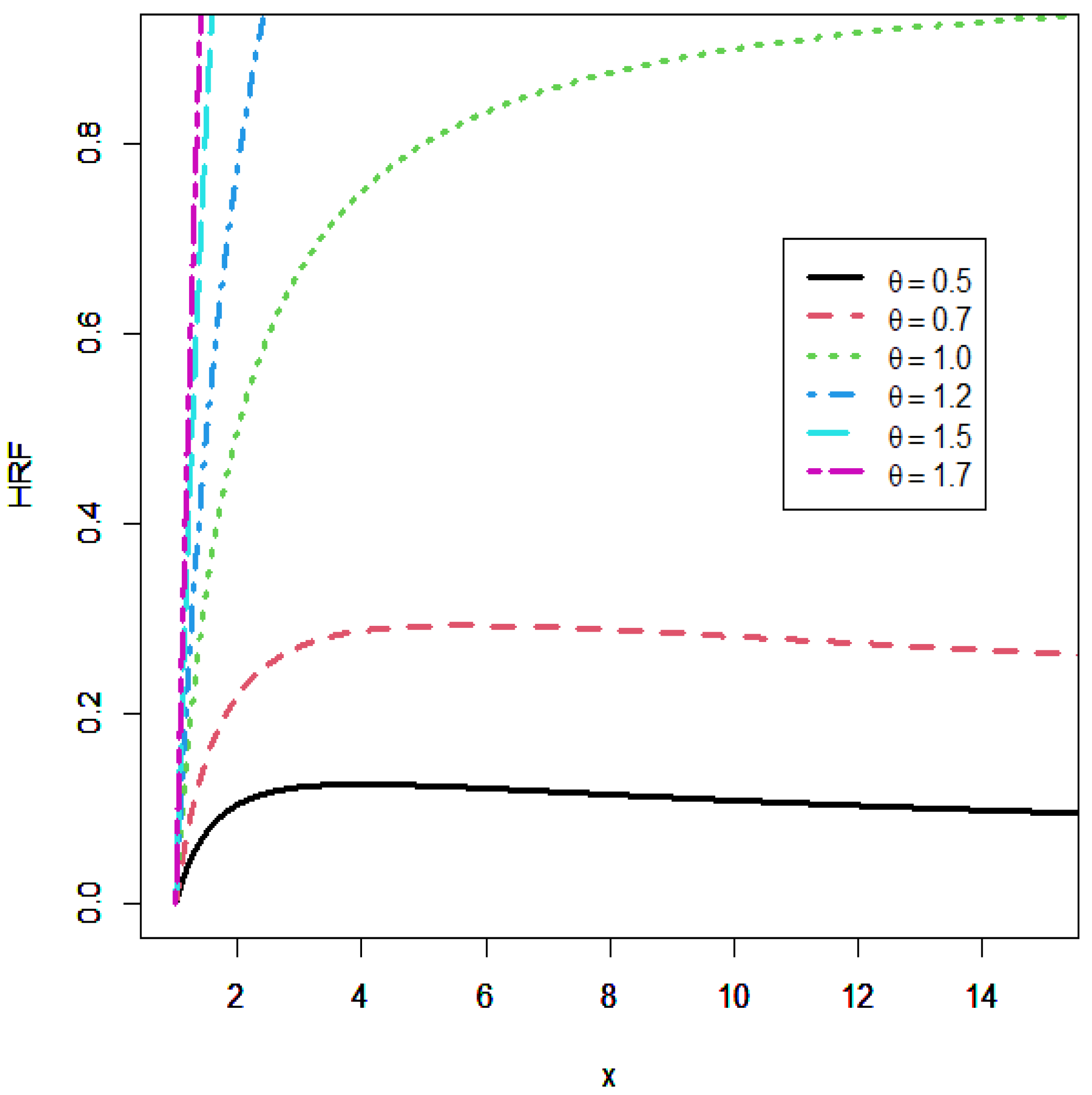
. The UTD stands out from the other unit distributions because of the following combined advantages: (i) It depends on only one parameter. (ii) It possesses closed-form expressions for the PDF, CDF, HRF, moments, inequality-type functions, and entropy measures. (iii) It has flexible PDF and HRF, with a HRF presenting non-monotone shapes, including the bathtub shape and N-shapes.
On a more general level, several methods exist to transform a known distribution into a new distribution. Among the most significant of them is the inverse transformation method based on the standard inverse (or ratio) function. More precisely, a new distribution is obtained by performing the transformation
, where
Y represents a random variable that follows an existing distribution. Many flexible new distributions are derived by this method, such as the inverse Student (IT) distribution, inverse exponential (IE) distribution, inverse Cauchy (IC) distribution, inverse Fisher (IF) distribution, inverse chi-squared (ICS) distribution (see [
15]), inverse Lindley (IL) distribution (see [
16]), inverse Xgamma (IXG) distribution (see [
17]), inverse power Lindley (IPL) distribution (see [
18]), inverted Kumaraswamy (IK) distribution (see [
19]), inverted exponentiated Weibull (IEW) distribution (see [
20]), inverse Weibull generator (IW-G) of distributions (see [
21]), inverted Nadarajah-Haghighi (INH) distribution (see [
22]), inverse power Lomax (IP) distribution (see [
23]), inverted Topp–Leone (ITL) distribution (see [
24]), inverse Maxwell (IM) distribution (see [
25]), inverse Nakagami-m (IN-m) distribution (see [
26]), inverse Pareto (IP) distribution (see [
27]), etc. In full generality, the inverse distributions are especially beneficial when working with variables having a limited range of values, such as time or distance measurements. They are often used in practice to model the lifetime of a particular product or the distribution of insurance claims.
On the other hand, we recall that the Pareto (P) distribution is a distribution that describes the occurrence of extreme events, also known as the power law distribution. It was introduced by the Italian economist Vilfredo Pareto to explain the distribution of wealth in society. The P distribution is characterized by a shape parameter, which determines the rate at which the distribution decays and has the support
in its basic definition. The larger the value of this parameter, the faster the distribution decays. This means that the P distribution has a heavy tail, with a few very large values and many small values. The P distribution has applications in various fields, such as finance, physics, and biology, among others. In particular, it is used quite successfully to model the frequency of occurrence of events that follow a power law (a priori), such as earthquakes, city populations, or income distributions. Modern references on this topic are [
28,
29,
30].
In this paper, using the above information as the motor, a new inverse distribution based on the UTD is introduced, and we name it the inverse UTD (IUTD). As a basic presentation, it constitutes a new one-parameter distribution with support as . It provides a solid alternative to the P distribution as described above. We will emphasize that the IUTD has the same possibility of applications as the P distribution but with more perspective in terms of functionalities and modeling. In the first part, we explore the main functions and properties of the IUTD. In particular, we show that the corresponding PDF can be unimodal and the HRF can be unimodal or increasing. This functional flexibility is an advantage in a modeling sense. We determine its quantile function (QF) from which we derive the quantiles, stochastic dominance, heavy-tailed nature, moments (incomplete and complete), etc. The second part is statistically oriented. Ten estimation methods are developed and employed to estimate the unique parameter involved. We prove their efficiency through a classical simulation approach. Finally, using two real-world data sets as examples, the application demonstrates the superiority of the IUTD over other well-known distributions, including the T and P distributions.
The current paper is organized as follows: In
Section 2, we formulate the mathematical foundations of the IUTD, mainly by presenting and studying the PDF, CDF, and HRF. Its mathematical properties are investigated in
Section 3. In
Section 4, the estimation methods are examined to find the estimates of the unique parameter, and a Monte Carlo simulation is conducted to observe their behavior. In
Section 5, the Bayesian estimation method using the informative gamma prior distribution with the squared error loss function is discussed. In
Section 6, two practical examples are carried out. The conclusion of this study is included in
Section 7.
3. Mathematical Properties
In this section, we drive some important properties of the IUTD, such as the QF along with its use to have randomly generated datasets, the heavy-tailed nature, stochastic dominance, and moments (incomplete and complete), along with two important inequality curves and asymmetry and flatness measures.
3.1. Quantile Function
The QF of the IUTD is defined as the inverse function of the CDF in (
3). It is indicated in the next result.
Proposition 3. The QF of the IUTD is expressed aswhere is the Lambert function, i.e., defined as . Proof. As the definition of an inverse function,
must satisfy the following functional equation:
for any
. Based on it, the following equivalence holds:
The desired expression is obtained. □
By considering this QF, we can determine many quantile characteristics of the IUTD (median, i.e.,
, quartiles, i.e.,
,
, whiskers, etc.). Furthermore, we can easily generate random values from a random variable
X that follows the IUTD distribution using the inversion method. Indeed, by considering
n values from a random variable
P that follows the uniform distribution over
, say
, then
n values from
X are
, where
3.2. Heavy-Tailed Nature
The following result is about the heavy-tailed nature of the IUTD.
Proposition 4. The IUTD is a heavy-tailed distribution for , and it is not for .
Proof. To begin, for any
, we have
For , any , and , we have , implying that the term is dominant in the integrated function; by the Riemann integral rules, we have , meaning that the UTD is heavy-tailed.
For and any , the same argument holds: the UTD is heavy-tailed.
For , any , and , we have , implying that the term is dominant in the integrated function; by the Riemann integral rules, we have , meaning that the UTD is not heavy-tailed.
□
This result is important because it makes a strong difference with the P distribution, which is the most famous distribution with support as
. Indeed, the P distribution is exclusively a heavy-tailed distribution for all the values of the involved parameter, whereas the IUTD is more flexible on this aspect, and the modulation of
can make the difference in a data fitting scenario. This point will be illustrated concretely with real-life datasets in
Section 6.
3.3. Stochastic Dominance
The IUTD has comprehensible stochastic dominances (first-order and HRF), which are listed in the proposition below.
Proposition 5. Let us set . Then, for any and , we have Let us set . Then, for any and , we have
Proof. For any
, it is clear that
. Let us investigate the monotonicity of
with respect to
for any
. We have
Therefore, is increasing with respect to , and as a result, for any , we have .
Similarly, for any
, it is clear that
. Let us investigate the monotonicity of
with respect to
for any
. We have
Therefore, is increasing with respect to , and as a result, for any , we have .
This ends the proof. □
The demonstrated stochastic dominances are useful to compare the related models with respect to the parameter
. All the information on this topic can be found in [
31].
3.4. Incomplete and Complete Moments
Incomplete moments are a useful tool in probability and statistics for calculating the moments of a distribution up to a certain order. Unlike complete moments, which are calculated from the entire distribution, incomplete moments are calculated from a truncated distribution that is limited to a specific range or interval. The incomplete moments related to the IUTD are given in the following proposition.
Proposition 6. Let X be a random variable that follows the IUTD distribution, k be a positive integer and . Then the k-th incomplete moment of X at t is defined by , where E represents the mathematical expectation operator and can be expressed aswhere for any and . Proof. By applying an integration by parts without expressing the involved functions, we obtain
We have
. Moreover, by applying the change of variables
, we have
By combining the above identities, we obtain the desired result. □
One of the advantages of the IUTD is that it has a closed-form expression of its incomplete moments. Some consequences of this property are described below.
From the incomplete moments, we immediately derive the complete moments. Indeed, the
k-th complete moment of a random variable
X that follows the IUTD is given by
, and we have
where
for any
and
.
The incomplete moments can be used to determine various residual life functions, and important quantities in survival analysis. In particular, the first incomplete and complete moments are important for expressing the Lorenz and Bonferroni curves, which are, respectively, defined as follows: and . It is also used to establish the mean residual life (), and the mean waiting time ().
Additionally, based on the complete moments, we can calculate the
j-th central moment of
X by utilizing moments around the origin as follows:
Then, the skewness and kurtosis coefficients are given by SK
and KU
. They are crucial to identifying the asymmetry and flatness of the IUTD distribution, respectively.
To end this portion, in
Table 1, we provide a numerical study of the most important quantities presented in the sections above.
From this table, we can note that there is a certain numerical flexibility in the mode, skewness, and kurtosis. In particular, since SK can be negative or positive, we conclude that the IUTD can be left or right skewed, and since KU can be less or greater than 3, all the kurtosis states are reached, i.e., leptokurtic, mesokurtic, and platykurtic.
3.5. Order Statistics
In this subsection, some results on the order statistics of the IUTD are examined. Let
be a random sample from the IUTD and
represent the related order statistics. Let
. Then the CDF and PDF of the
r-th order statistic, that is
, are obtained as
and
where
is the standard beta function, i.e.,
with
and
. For
and
, the CDF and PDF of
and
are achieved, respectively.
6. Real Data Application
In this section, the applicability of the IUTD is realized with two real data analyses. For comparison purposes, the P, T (introduced in [
4]), exponential (E), Lindley (Li), inverse Lindley IL, IP, inverse Rayleigh (IR), and IXG distributions are used. The information on the related PDFs and parameters of these distributions is presented in
Table 9.
The parameter estimation process is carried out based on the MLE method. The estimates of the parameters with standard errors (se), , Akaike information criterion (AIC), Bayesian information criterion (BIC), consistent AIC (CAIC), Hannan–Quinn information criterion (HQIC), Kolmogorov–Smirnov statistic (KS), Anderson–Darling statistics (AD), Cramér–Von Mises statistics (CVM), and the p-values of these statistics (KS p-val, AD p-val, and CVM p-val) are also calculated.
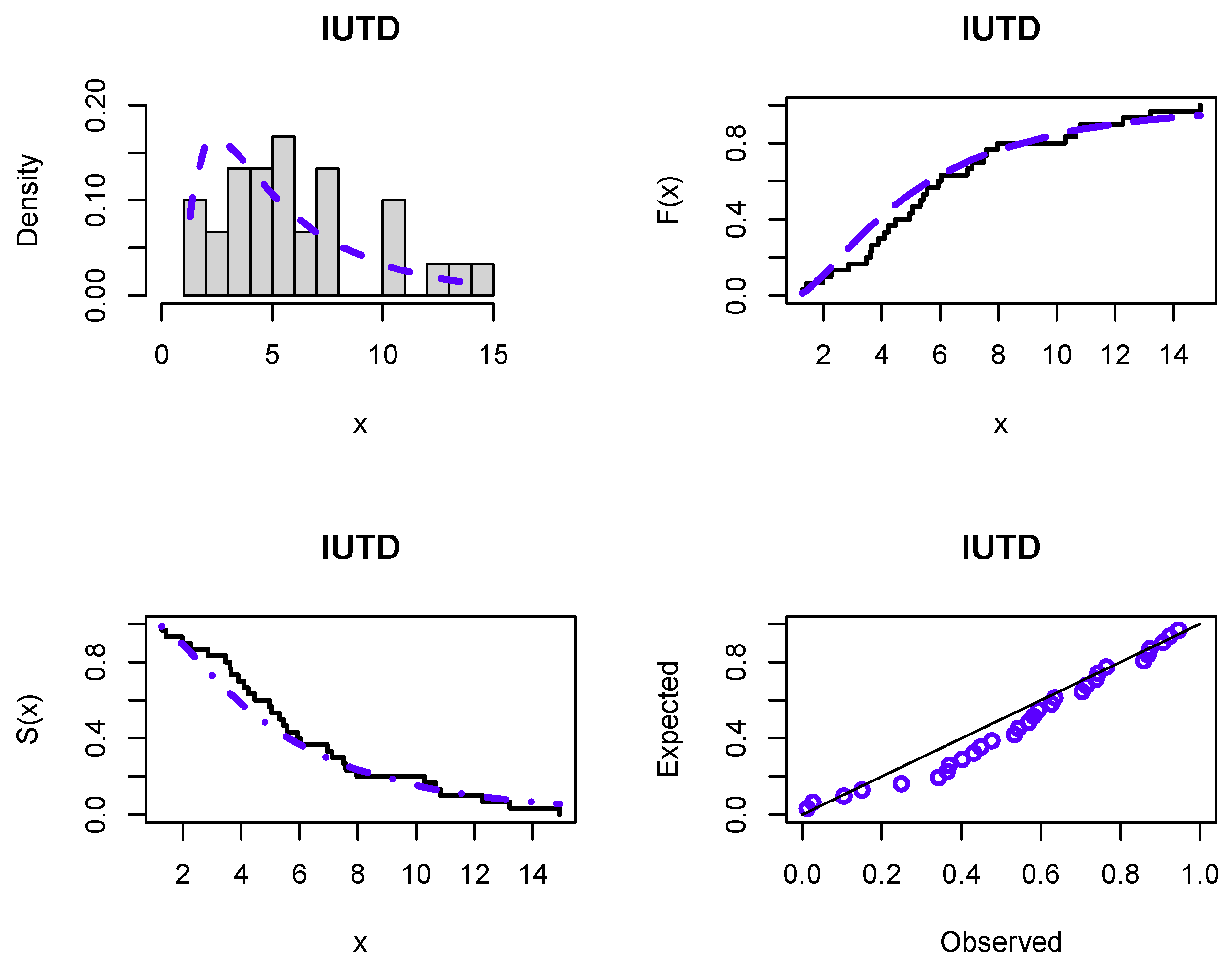
The first dataset represents the rough mortality rate from COVID-19, taken in the Netherlands between 31 March and 30 April 2020. This dataset is taken from [
40] and also studied in [
41]. The data are given as follows: 14.918, 10.656, 12.274, 10.289, 10.832, 7.099, 5.928, 13.211, 7.968, 7.584, 5.555, 6.027, 4.097, 3.611, 4.960, 7.498, 6.940, 5.307, 5.048, 2.857, 2.254, 5.431, 4.462, 3.883, 3.461, 3.647, 1.974, 1.273, 1.416, 4.235. Some descriptive statistics of this dataset are calculated as follows: mean—6.156, median—5.369, standard deviation—3.533, minimum—1.270, maximum—14.920, skewness—0.879, and kurtosis—0.175.
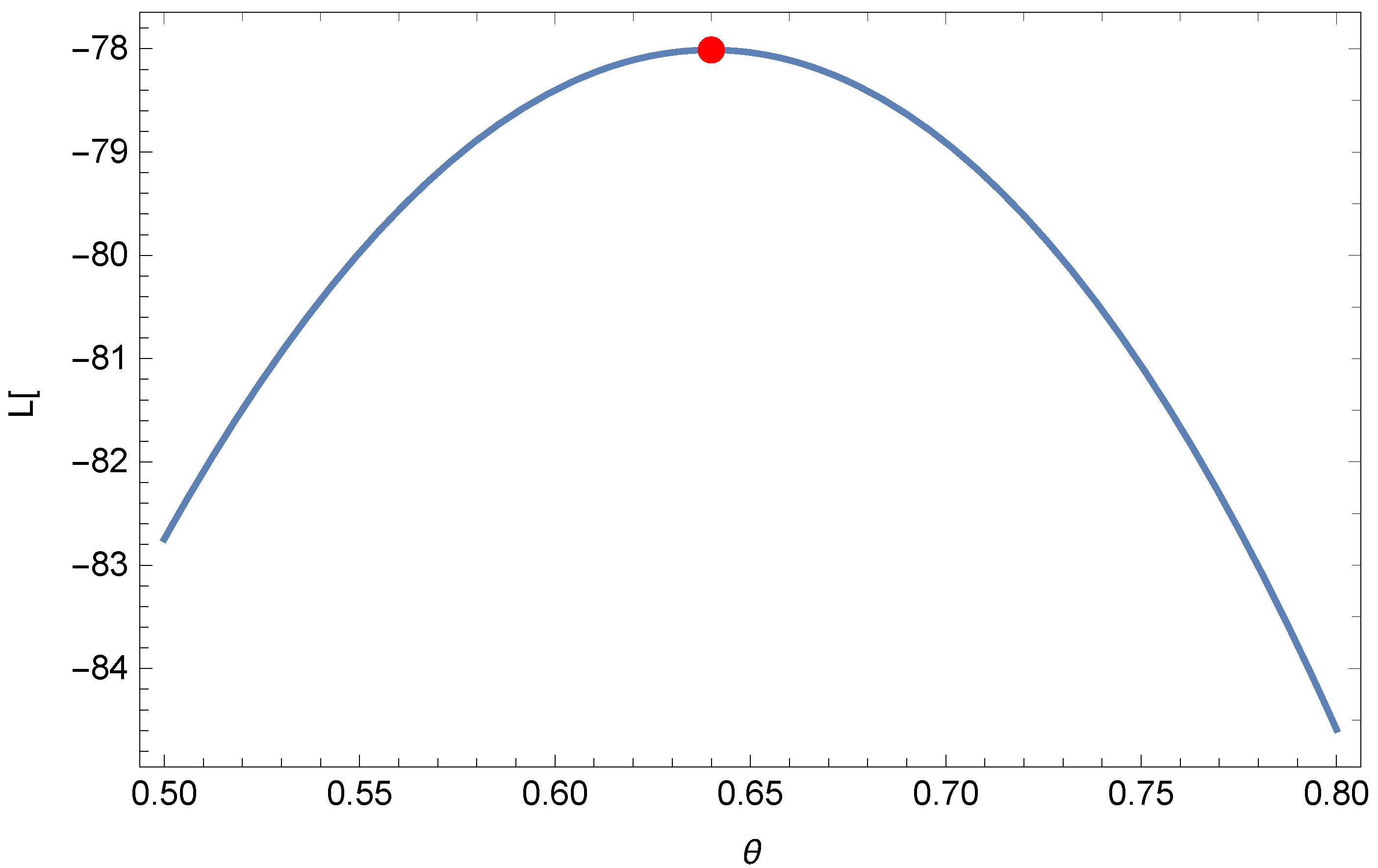
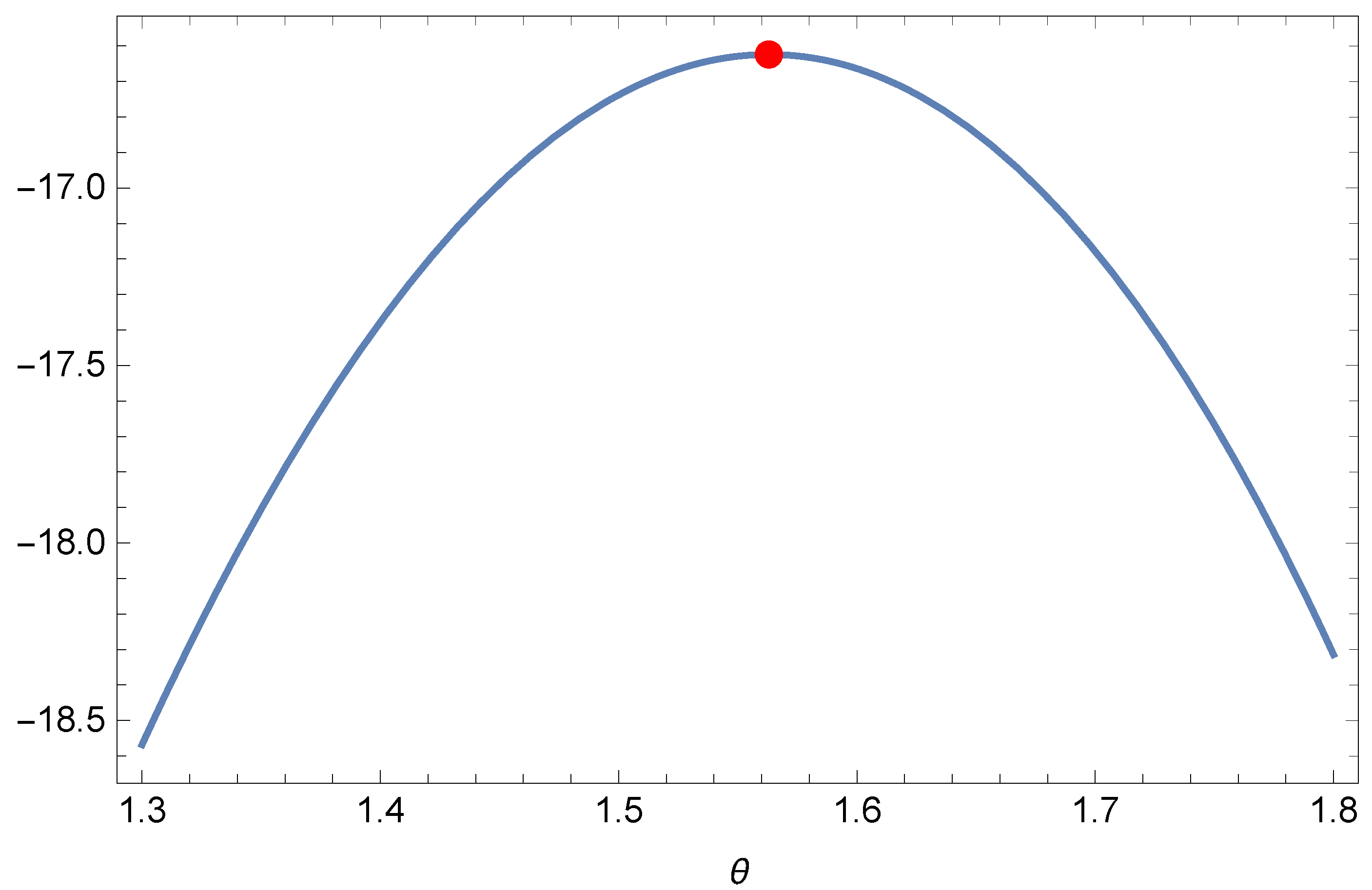
Figure 4 presents the existence and uniqueness of the MLE graphically for this dataset. The goodness-of-fit results are reported in
Table 10.
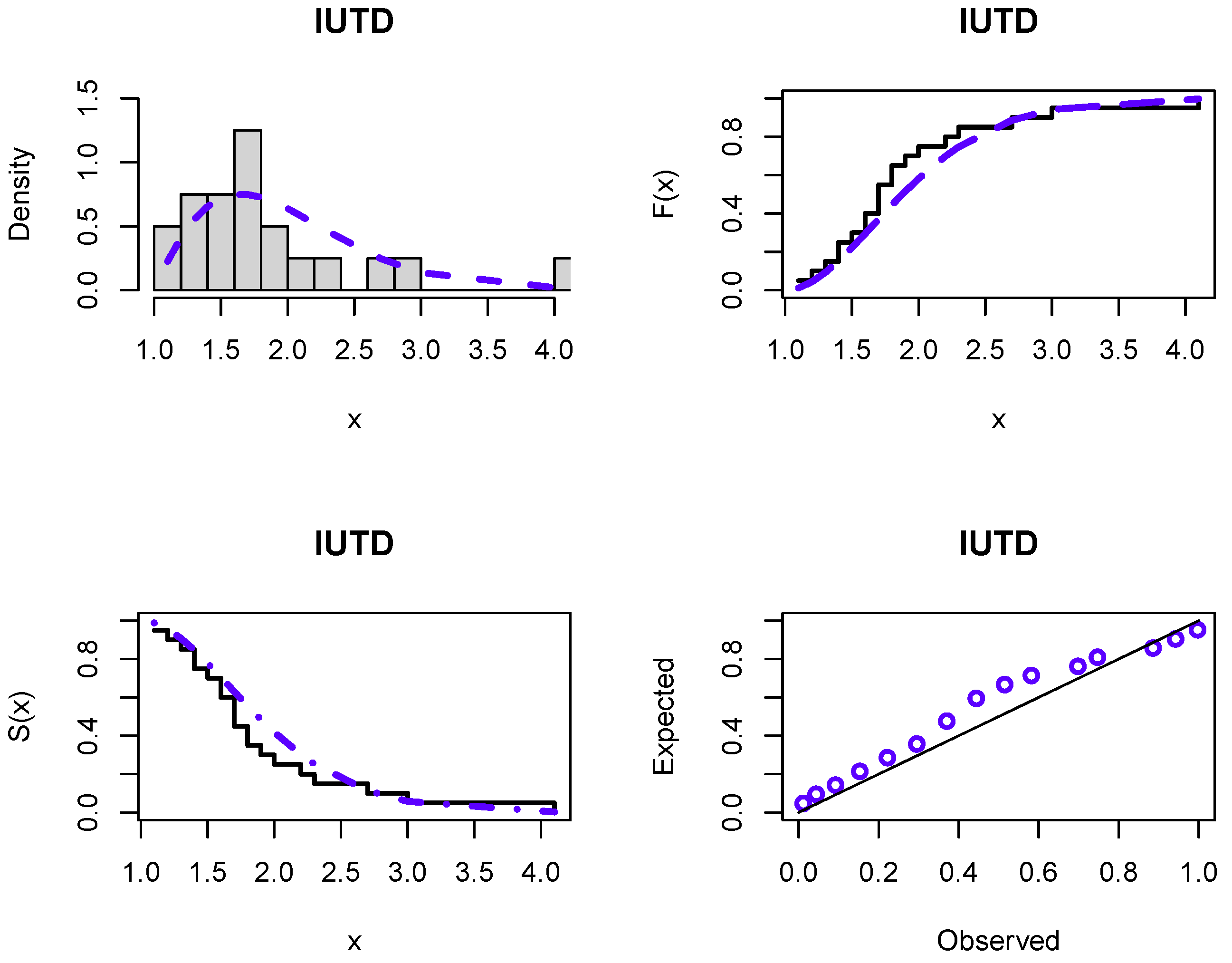
The second dataset represents the minutes of pain relief for 20 patients receiving an analgesic and is taken from [
42]. The data are given as follows: 1.1, 1.4, 1.3, 1.7, 1.9, 1.8, 1.6, 2.2, 1.7, 2.7, 4.1, 1.8, 1.5, 1.2, 1.4, 3.0, 1.7, 2.3, 1.6, 2.0. Some descriptive statistics for this dataset are also computed as follows: mean—1.900, median—1.700, standard deviation—0.704, minimum—1.100, maximum—4.100, skewness—1.862, and kurtosis—4.185.
Figure 5 presents the existence and uniqueness of the MLE graphically for this dataset. The goodness-of-fit results are reported in
Table 11.
From
Table 10 and
Table 11, it is easy to conclude that the new distribution gives the best results for all the criteria. Hence, it is quite suitable for modeling datasets related to health. Furthermore, there exists a limited distribution such as the P distribution that can be used to model data within the range of
. The novel distribution could serve as a good alternative for such scenarios.
Figure 6 and
Figure 7 display the fitting of the IUTD to both datasets via estimated PDF, CDF, and SF plots, along with probability-probability (P-P) plots. These plots proved that the new distribution is appropriate for both COVID-19 and analgesic datasets.
7. Conclusions
In this paper, we developed a new one-parameter distribution with support as
, which can be considered an alternative option to the P distribution. To construct it, the unit Teissier distribution introduced in [
14] was utilized as the baseline distribution, and the inversion method was applied. The analysis confirmed that the corresponding PDF exhibits unimodal behavior, and the HRF is observed to be either increasing or unimodal. Some mathematical properties, such as the QF, heavy-tailed nature, stochastic dominance, and incomplete and complete moments, were investigated. In the statistical part, several estimation methods were studied for estimating the unique parameter. The performance of these methods was evaluated through a Monte Carlo simulation, and it was determined that the maximum-likelihood estimation method outperformed the competitors. The Bayesian estimation method using an informative gamma prior distribution under the squared error loss function was discussed. The practical performance of the IUTD is demonstrated via two real datasets. Based on some criteria and goodness-of-fit tests, it exhibits superior performance compared to many inverse and classical distributions, including the P and T distribution.
A natural perspective of this work is the consideration of the distribution of
, where
X is random variable that follows the IUTD and
, with the following CDF:
and
for
. We thus relax the lower bound of 1 into the support; it is now of
. Also, all the available extensions of the P distribution can be applied to the IUTD (exponentiated, transmuted, types II, III, IV, etc.). Bivariate and discrete generalizations of the IUTD are also interesting directions for research.

 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






