
A Sketch-Based Fine-Grained Proportional Integral Queue Management Method


Abstract
:1. Introduction
2. Related Works
3. System Model
3.1. Traffic Statistics
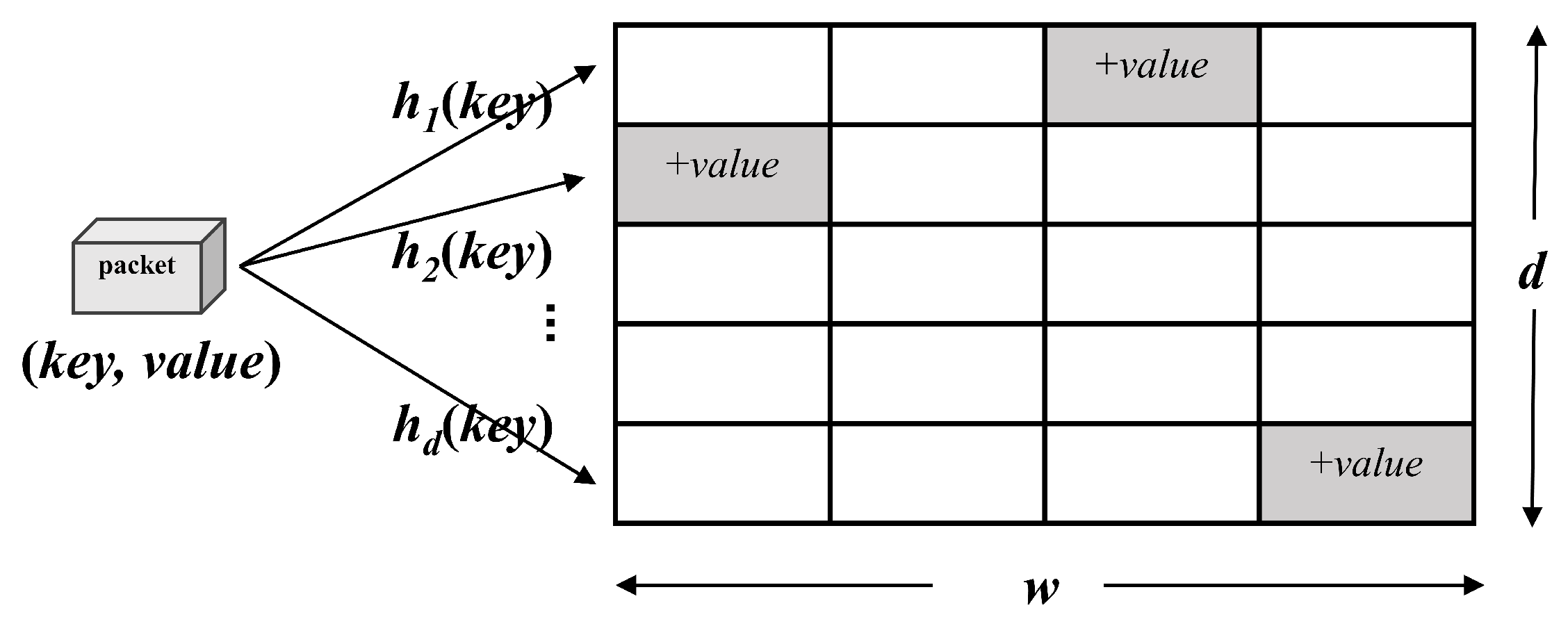
3.1.1. Sketch Structure
3.1.2. Basic Operations
- (1)
- Item mapping: when a packet arrives, it is mapped to store the count in the form of (, ). where uniquely represents the data stream from which the packet came, and is used to count the packet frequency value of that stream in a two-dimensional array.
- (2)
- Hash table update: during the execution of the algorithm, the arrival of new packets (, ), d a separate hash function that does the same for is calculated separately and the count operation is updated for the counter in the corresponding hash table. For example, the hash function h with index value i updates the counter, as shown in Equation (1). When the data stream to be calculated is passed and updated, statistics on the frequency of occurrence of the inserted data can be obtained.
- (3)
- Result query: the Sketch query for packet occurrence frequency estimation. However, because collisions are predicted, the number was potentially incremented by occurrences of other items that were mapped to the same position. Given a collection of counters having the desired count plus noise, the best estimate of the true count of the desired item is to choose the smallest count of Mincount of these counters [30], as shown in Equation (2).
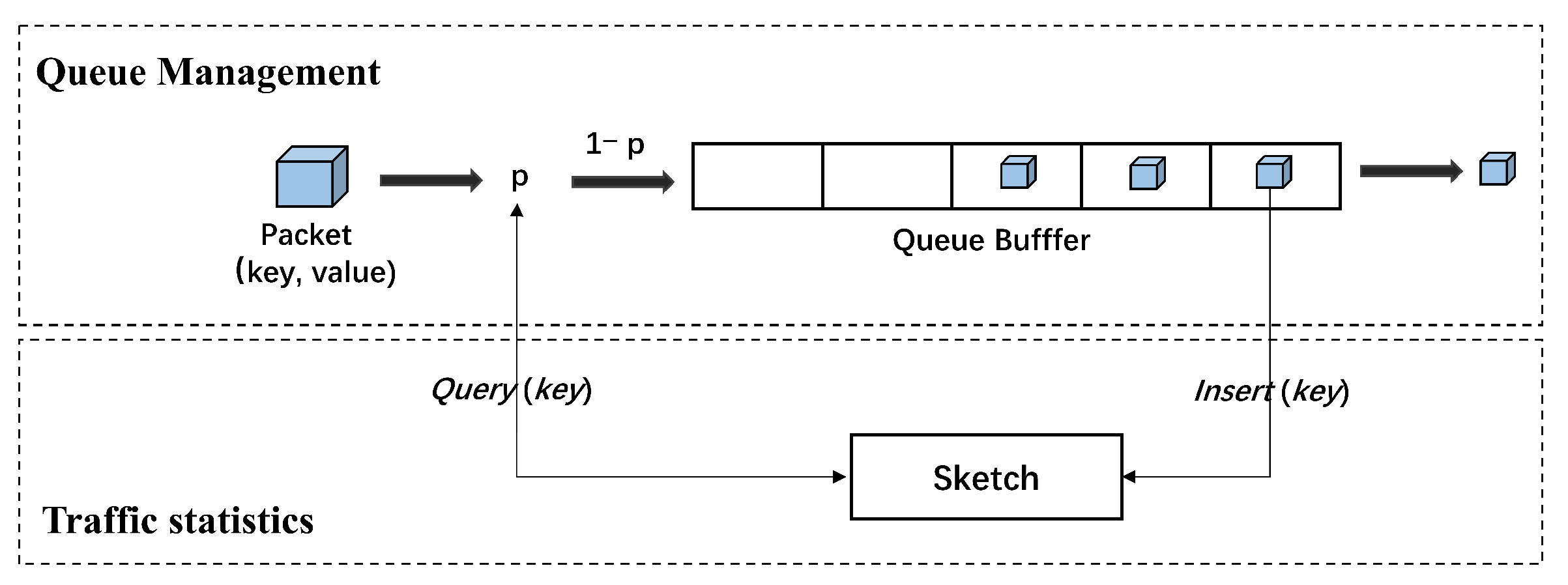
3.2. Queue Management
- Dequeue: after the packet is queued, the function of Sketch is called to calculate the mapping position of the packet based on the hash function in the form of (, ). The bucket corresponding to the value is selected for updating, that is, the is added to the of the packet, and Sketch’s total mapped packet counter is updated. After the packet is out of queue, the drop probability is calculated and updated periodically according to the function , as shown in Equation (3), according to the working mode of PIE, where is the packet drop probability obtained in the previous calculation cycle. and denote the current queuing delay and the last estimate of the queuing delay, respectively, and denotes the reference value of the delay. and are two adjustment parameters. The parameter determines how the deviation of the from the affects the drop probability; the parameter makes an additional adjustment to the drop probability depending on whether the trend of the delay change is increasing or decreasing. is calculated as in Equation (4), where is the current queue length and is the calculated average departure rate, as in Equations (5) and (6), where indicates the number of packets left since the last measurement, and is the average parameter. In addition, to prevent short, non-persistent packet bursts that lead to empty queues and render the off-queue rate measurement less accurate, the algorithm sets a threshold value that reduces the off-queue rate when the queue length exceeds the threshold value. The flow of the S-PIE algorithm is shown in Algorithm 1.
- Enqueue: before the packets enter the queue, it first judges whether the queue is full, and if it is full, the packets are dropped directly. If the queue is not full, the current network state is judged according to the obtained when the packets are out of the queue, and if < /3, the network is considered to be in a relatively uncongested state, and the packets are dropped probabilistically according to the calculated probability p. Otherwise, the network is considered to be in a relatively congested state, and the function of Sketch is called to obtain the frequency of new packets appearing in the current phase , as shown in Equation (7). The percentage of data stream k corresponding to this packet appearing in the queue at the same time was calculated, as shown in Equation (8), where is the total number of packets mapped in Sketch, i.e., the total number of packets passing through the intermediate nodes of the network in the current time period. Then, the threshold is calculated using Equation (9) when the percentage of the stream occupying the router cache space reaches the set threshold , i.e., when the packet percentage of a stream exceeds the weighted average queue percentage, the stream is judged to be a large stream and the packet is dropped. Otherwise, the flow corresponding to the packet is considered to be a small flow and is allowed to enter the queue. The flow of the S-PIE algorithm is shown in Algorithm 2.
| Algorithm 1 DoDequeue for S-PIE |
| 1: if > then |
| 2: CalculateP() for ; |
| 3: whileT > do |
| 4: ClearMemory; |
| Algorithm 2 DoEnqueue for S-PIE |
|
4. Experimental Evaluation
4.1. Simulation Scenario Setup
4.1.1. Network Topology
4.1.2. Evaluation Metrics
- Average queue length: this is a crucial indicator to determine how well network congestion is addressed. The degree of queue fullness and the likelihood of network congestion increase with the average queue-length value. Network congestion is significantly decreased if the AQM algorithm is used for early packet drops.where represents the packet time constant, represents the current time, represents the start time of the idle period, and represent the average queue length, represents the queue weight of the current queue sample, and represents the number of packets entering the queue within a period of time.
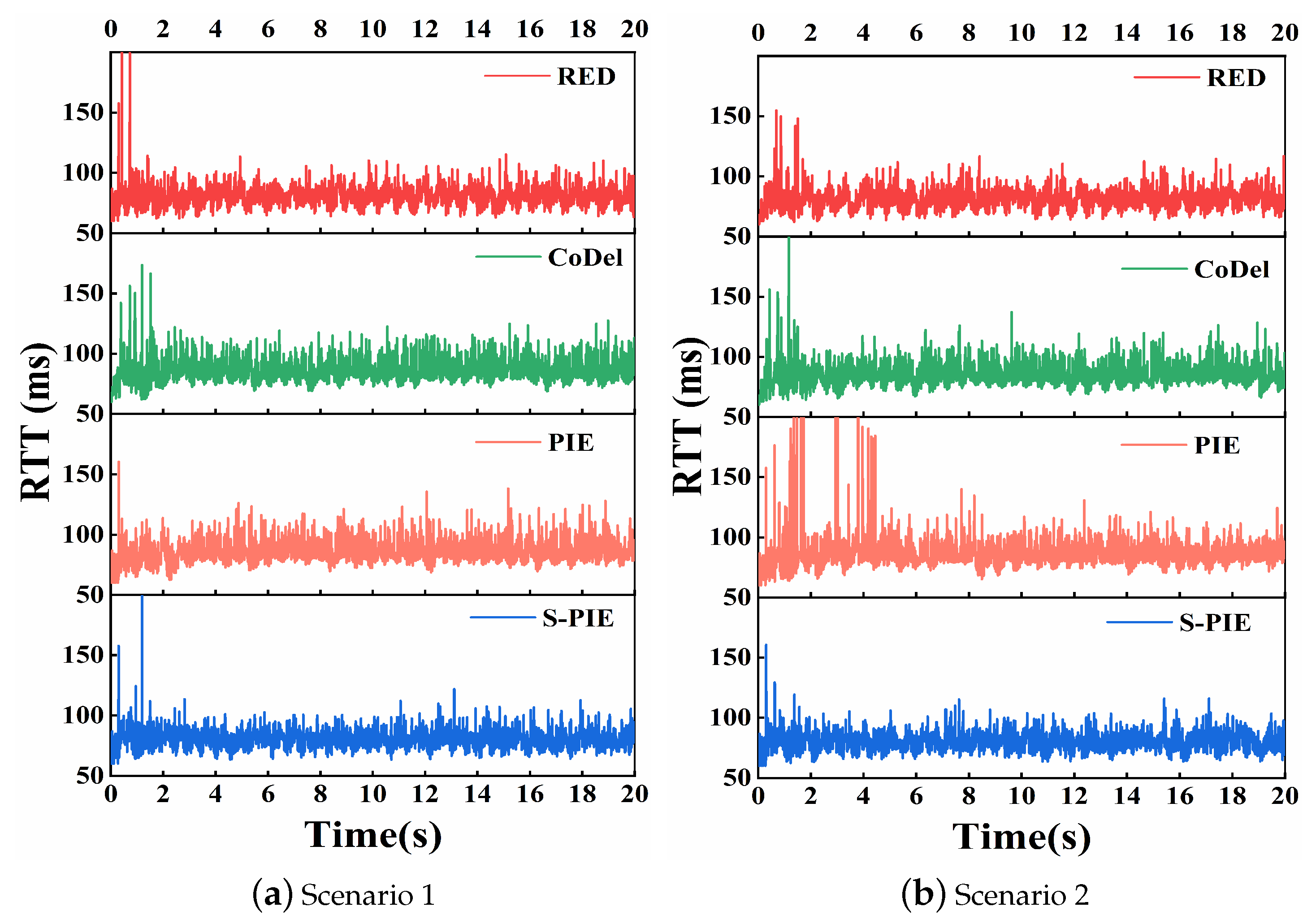
- RTT: RTT (round-trip time) indicates the time elapsed from the time a packet is sent by the sender to the time an ACK of that packet is received, and the time measured by RTT includes the transmission time, queuing time, and processing time. Transmission delay refers to the time the packet is used on the link, excluding the waiting time in the device buffer, whereas queuing delay refers to the waiting time of the packet in the device buffer. Therefore, if in the same network, the difference in the RTT of different packets is mainly determined by the queuing delay, which is related to the queue length of the buffer. However, maximizing throughput and minimizing RTT may be orthogonal. High throughput implies utilizing as much link bandwidth as possible, which may increase the queue length and, thus, cause delays.
- Throughput: it is the maximum number of data packets received in a given period. The better the link performance, the higher the throughput.where N denotes the number of packets received by all destination nodes over a period of time, and T denotes the time period.
- Fairness index: Fairness between data streams implies that data streams passing through the bottleneck link can share bandwidth resources equally. The fairness index is used to reflect the fairness between the data streams in this case. The range of the fairness index is [0, 1], as shown in Equation (13); the higher the fairness index, the better the fairness [35].where represents the throughput of each flow.
- Packet drop: active and passive packet drops are two types of packet drops. Active packet drop is the process of identifying and dropping packets before network congestion occurs, using the AQM algorithm. The buffer overflows and must be dropped in the case of passive packet drop. The more active packets that are dropped, the better the performance in predicting network congestion.
4.2. Analysis of Simulation Results
- (1)
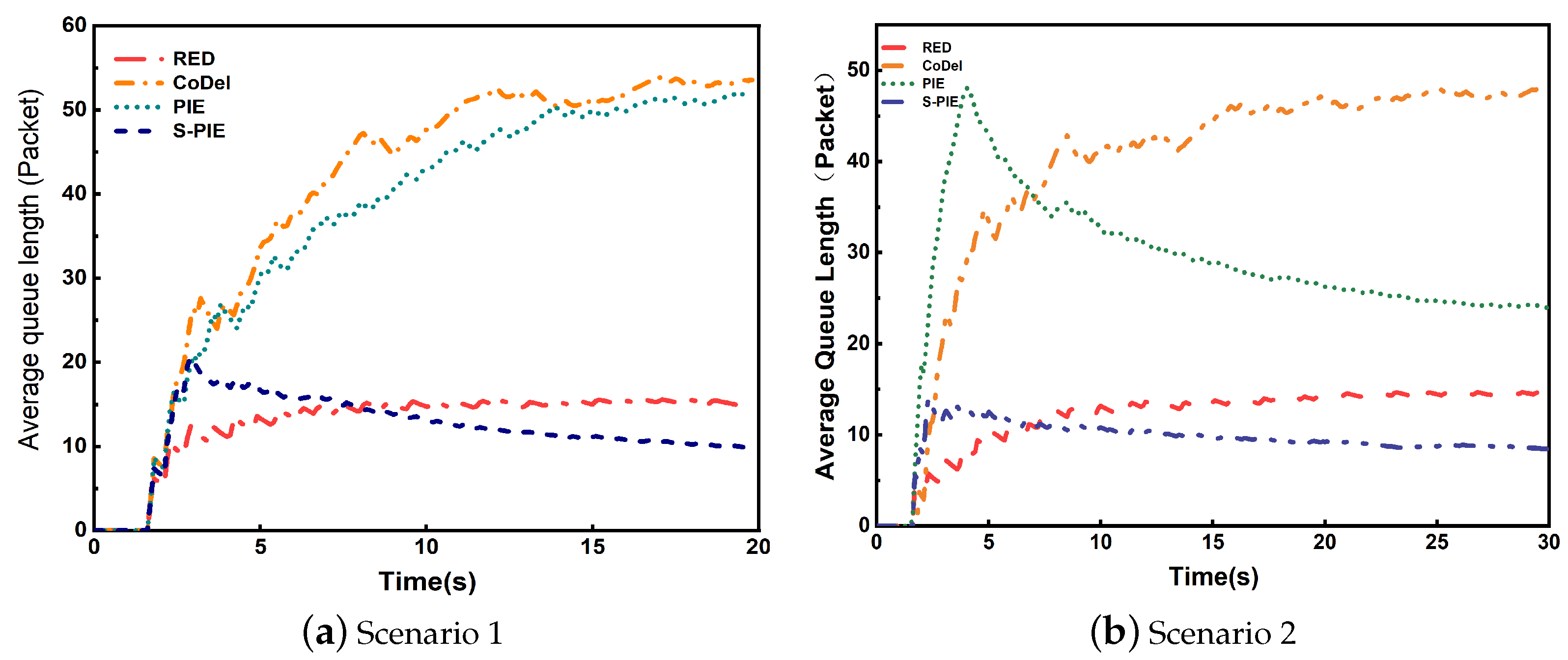
- Average queue length and RTTMaintaining a short average queue length helps to reduce the queuing time of packets forwarded to the route waiting time, which can effectively alleviate the “bufferbloat” problem.
- (2)
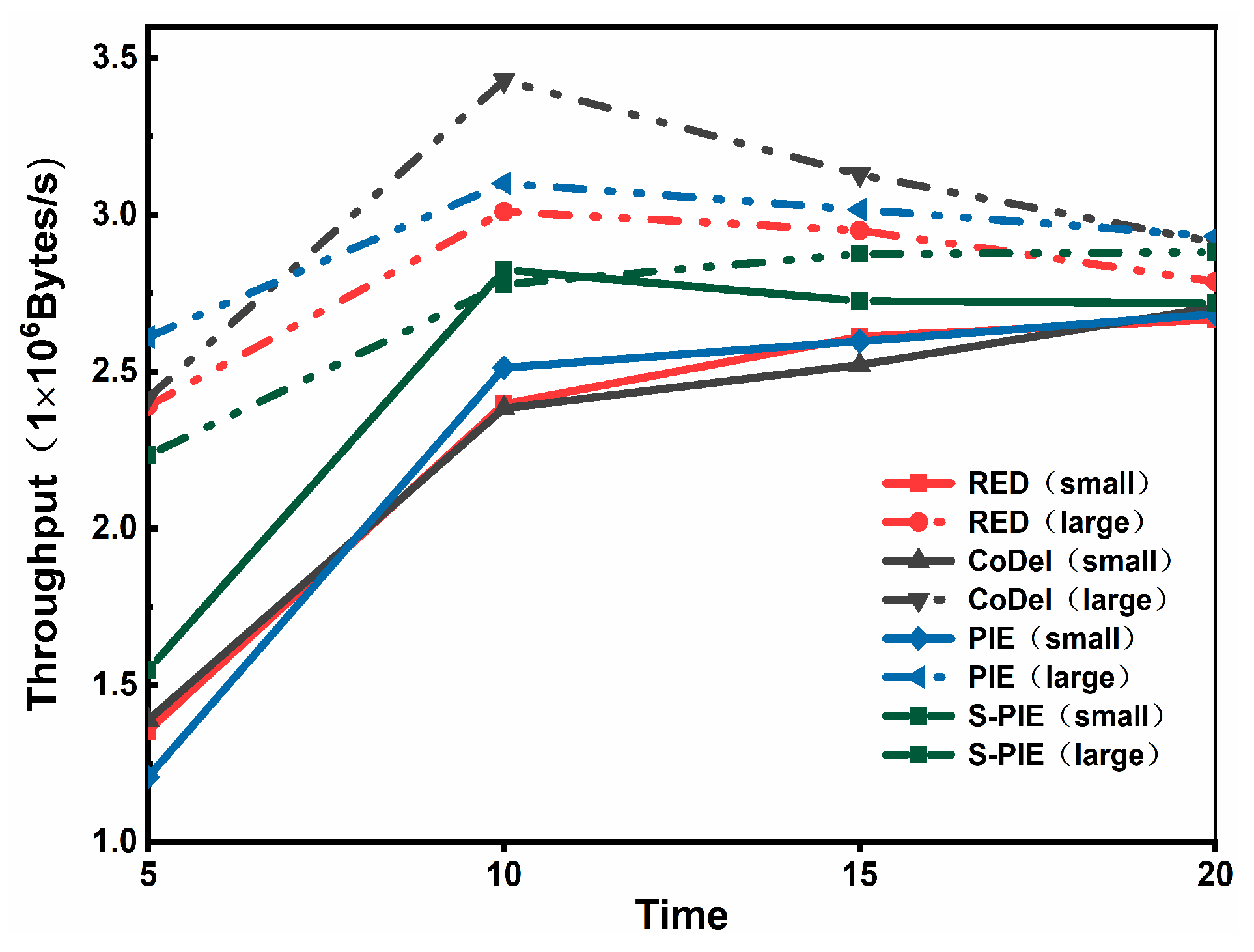
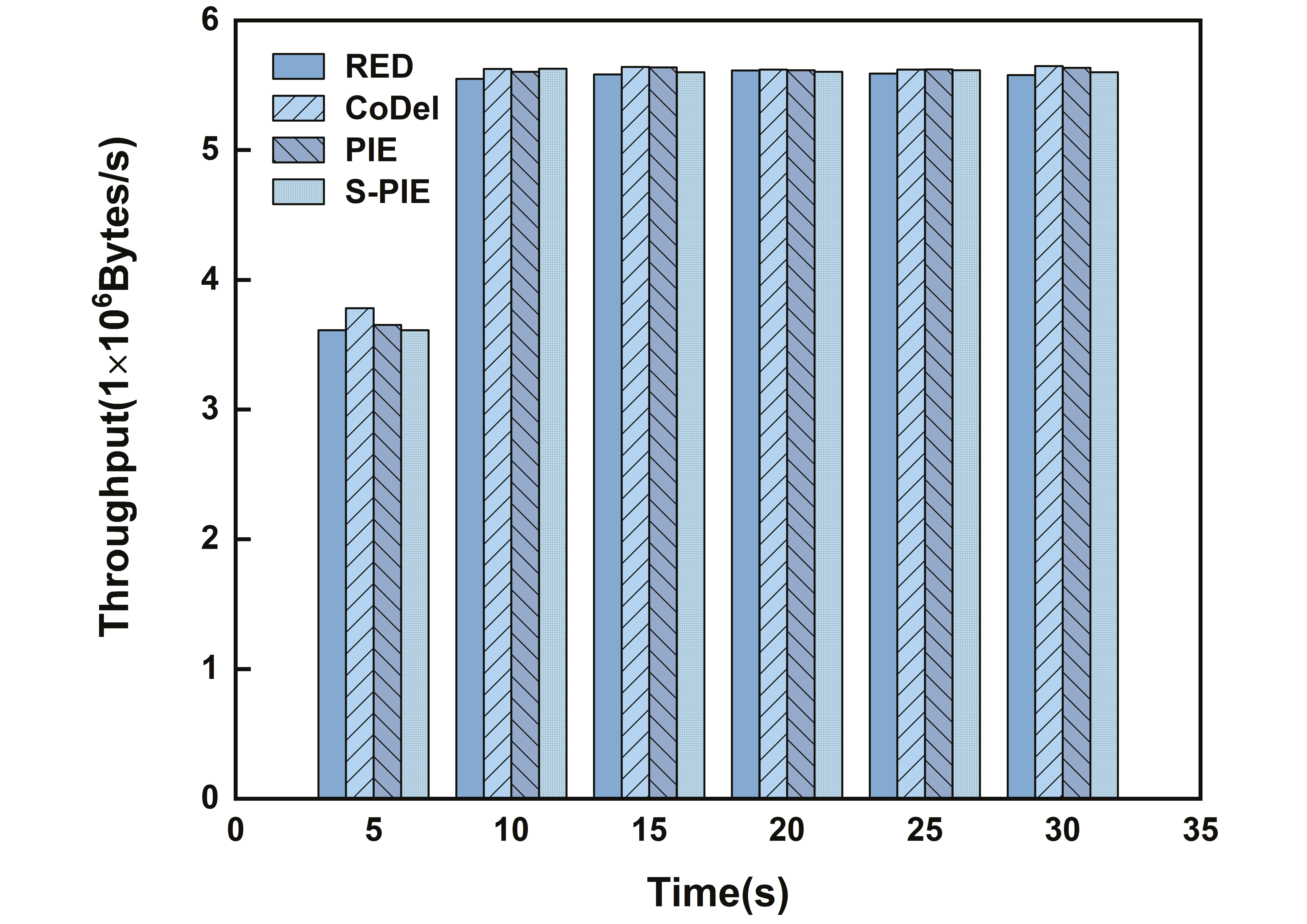
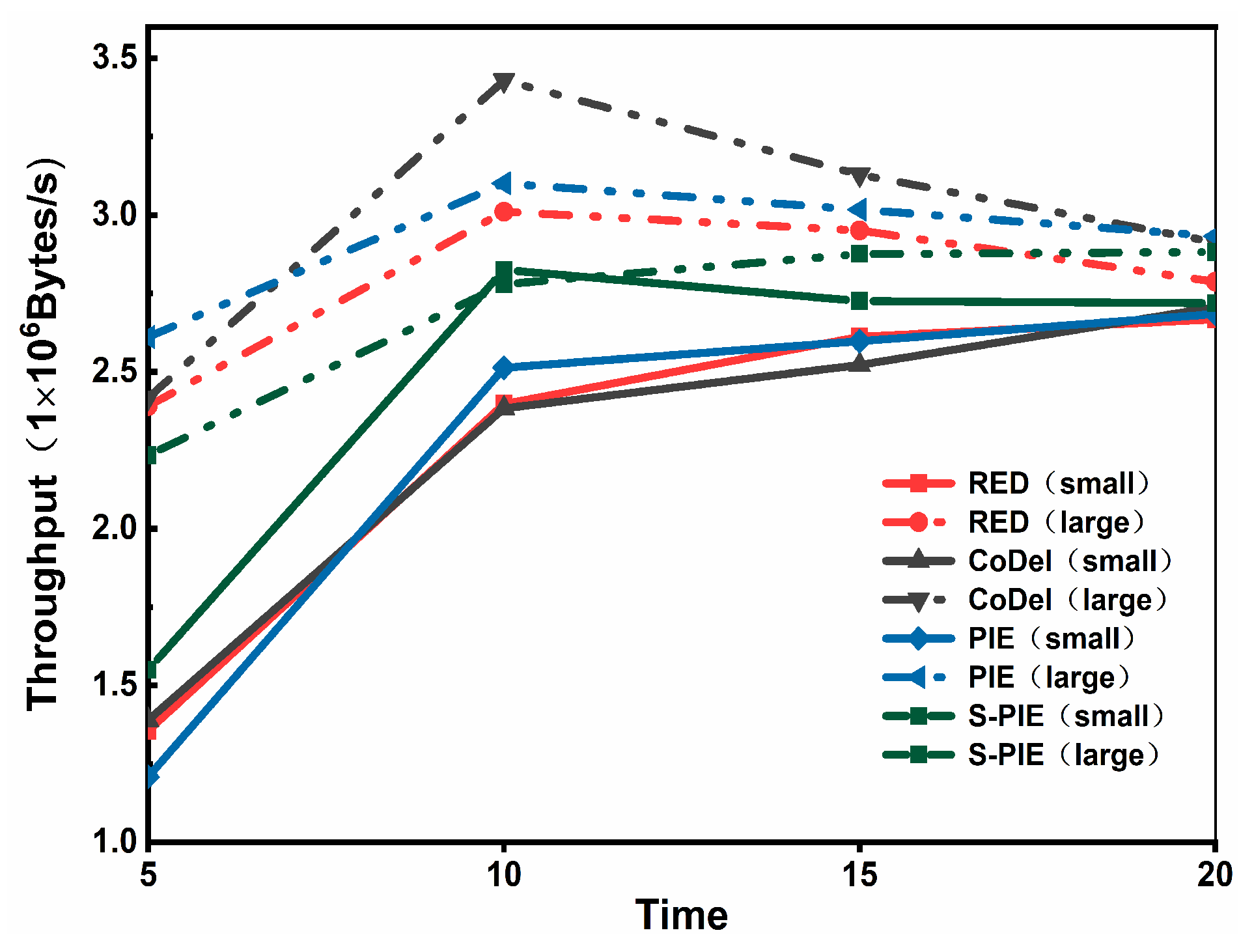
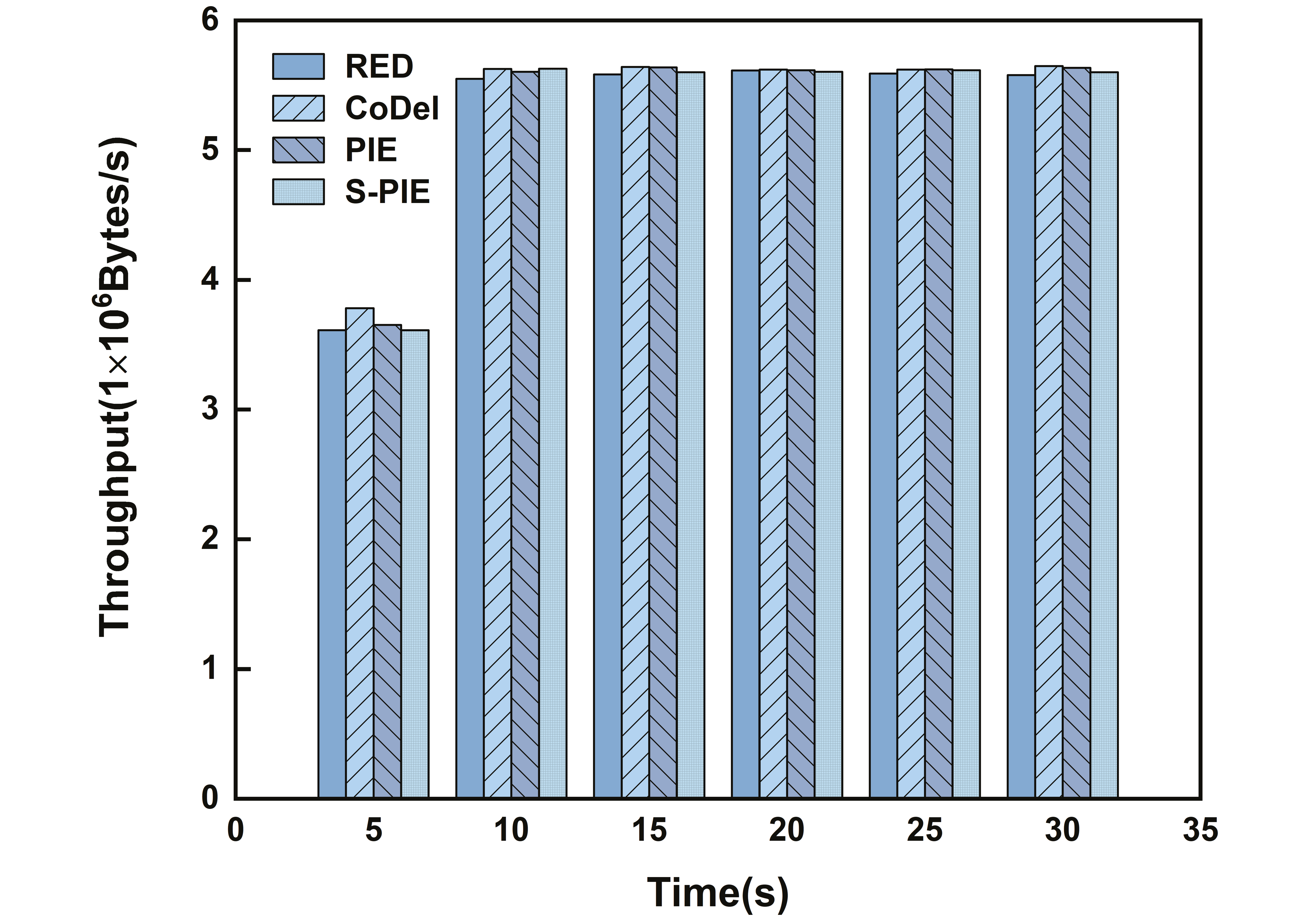
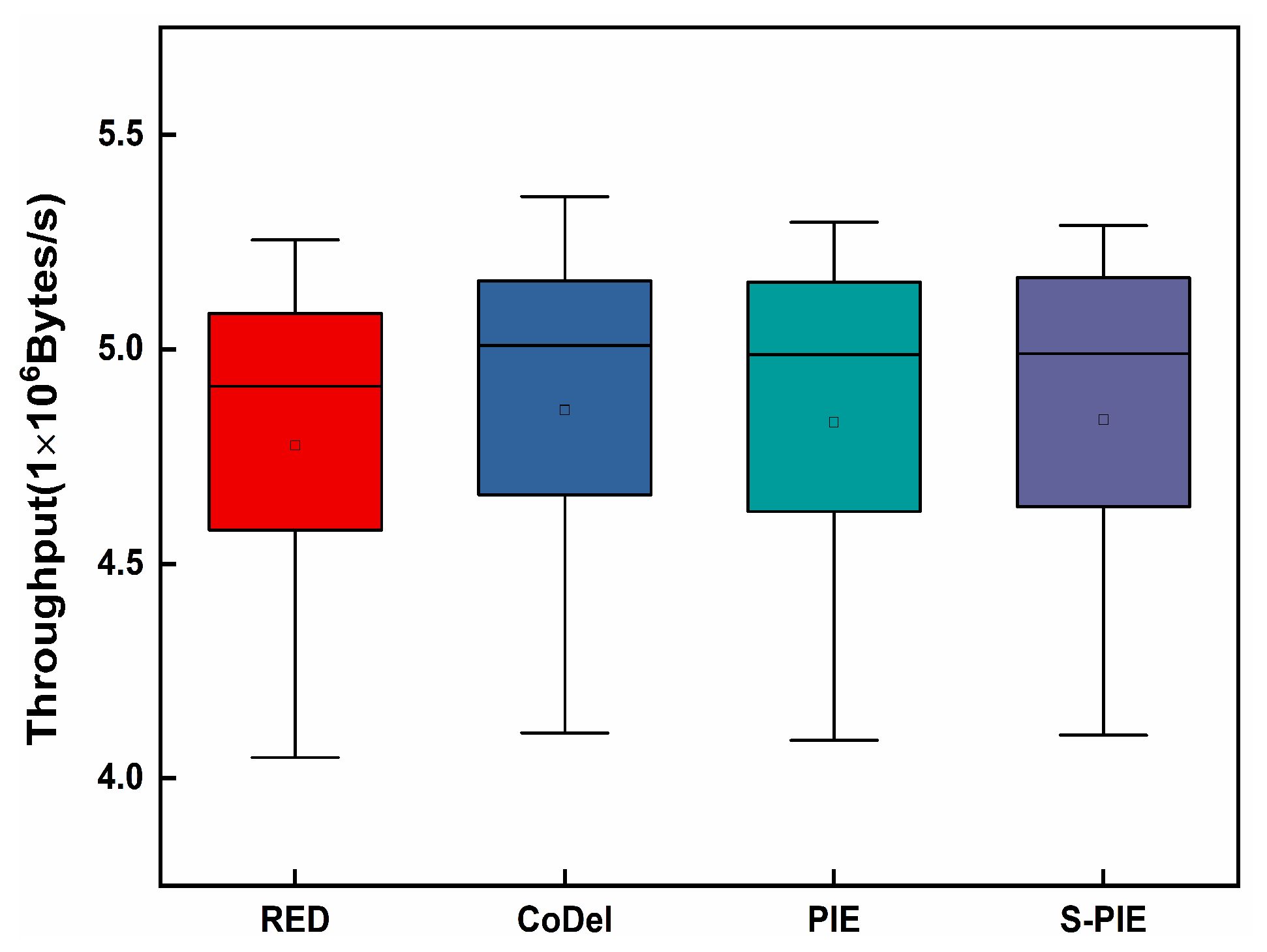
- ThroughputThroughput refers to the number of packets received at the receiving end per unit time, and a higher throughput represents the actual transmission capability of the link. In the throughput comparison experiment, we first considered Scenario 1, where there is a significant difference in traffic distribution, and whether the link can allocate reasonable resources for small traffic. Then, by comparing the performance of the average queue length, we found that S-PIE can maintain a shorter average queue length, so we want to test whether S-PIE will cause excessive throughput performance drop in this case.
- (3)
- FairnessFairness refers to the fairness of the different flows in a network. The AQM algorithm should guarantee fairness between different flows to avoid some flows taking up too many network resources and affecting other flows.
- (4)
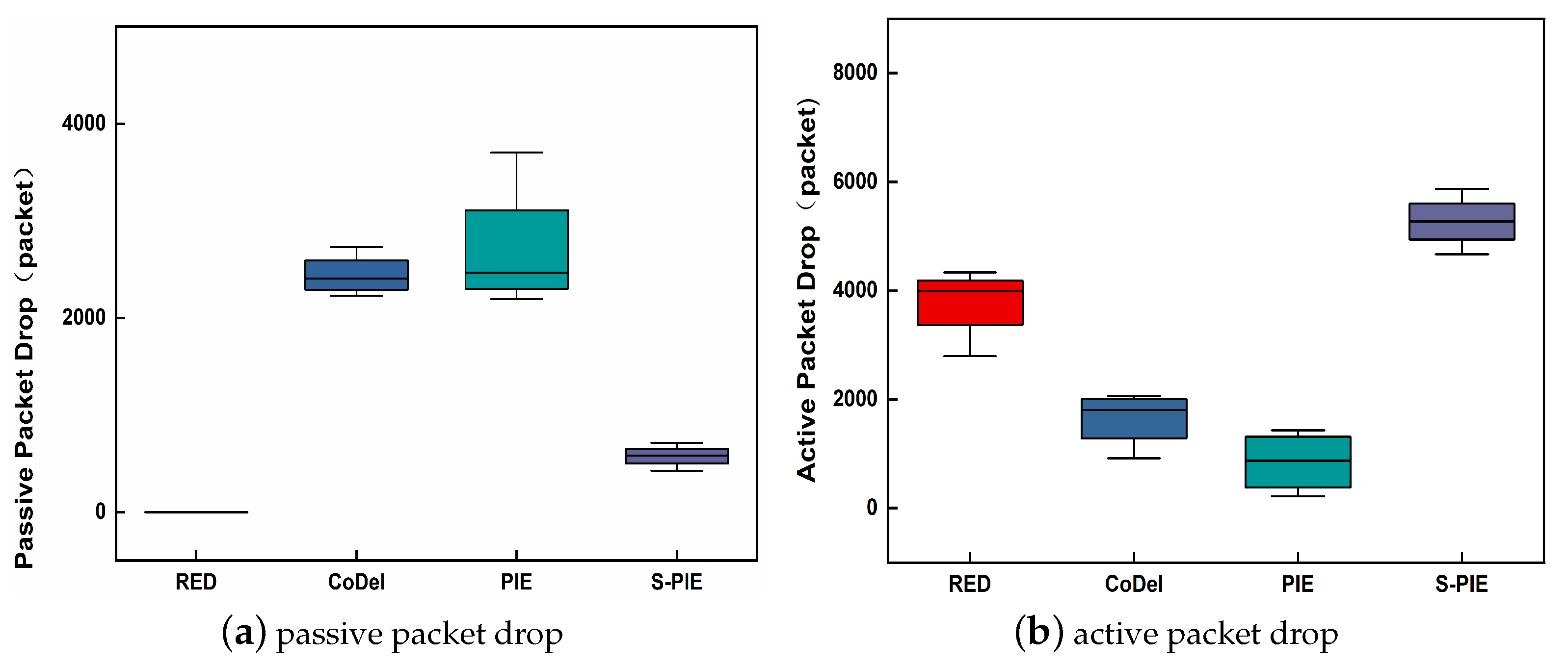
- Packet dropFigure 10a,b show the passive and active packet drops for each of the four active queuing algorithms, respectively. A proactive packet drop means that when the number of packets in the network exceeds the processing capacity of the network and, thus, causes network congestion, packets are dropped proactively to relieve congestion. On the other hand, passive packet drop is a reactive strategy. When a passive packet drop occurs, the buffer of the network node is full, and the network is in a state of extreme congestion. Excessive passive packet drops can lead to unstable data transmission and degradation of the network performance; therefore, it is important to reduce passive packet drops.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Xie, C.; Hu, H.; Liu, Y. Shared Bottleneck Detection for Multipath Transmission in High Latency Satellite Network. In Proceedings of the IEEE 7th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 19–20 October 2019; pp. 38–42. [Google Scholar] [CrossRef]
- Cerf, V.G. Bufferbloat and other Internet challenges. IEEE Internet Comput. 2014, 18, 80. [Google Scholar] [CrossRef]
- Floyd, S.; Jacobson, V. Random early detection gateways for congestion avoidance. IEEE ACM Trans. Netw. 1993, 1, 397–413. [Google Scholar] [CrossRef]
- Feng, W.C.; Shin, K.G.; Kandlur, D.D.; Saha, D. The BLUE active queue management algorithms. IEEE ACM Trans. Netw. 2002, 10, 513–528. [Google Scholar] [CrossRef]
- Nichols, K.; Jacobson, V.; McGregor, A.; Iyengar, J. Controlled Delay Active Queue Management. Available online: https://www.rfc-editor.org/rfc/rfc8289.html (accessed on 3 July 2023).
- Pan, R.; Natarajan, P.; Piglione, C.; Prabhu, M.S.; Subramanian, V.; Baker, F.; VerSteeg, B. PIE: A lightweight control scheme to address the bufferbloat problem. In Proceedings of the IEEE 14th International Conference on High Performance Switching and Routing (HPSR), Taipei, Taiwan, 8–11 July 2013; pp. 148–155. [Google Scholar] [CrossRef]
- Chawla, J.; Kumari, S. Performance Evaluation of DropTail and Random Early Detection. IRJET 2016, 3, 721–727. [Google Scholar]
- Zhang, L.; Shenker, S.; Clark, D.D. Observations on the dynamics of a congestion control algorithm: The effects of two-way traffic. In Proceedings of the conference on Communications architecture & protocols, Zürich, Switzerland, 3–6 September 1991; pp. 133–147. [Google Scholar] [CrossRef]
- Hoeiland-Joergensen, T.; McKenney, P.; Taht, D.; Gettys, J.; Dumazet, E. The fLow Queue Codel Packet Scheduler and Active Queue Management Algorithm. Available online: https://www.rfc-editor.org/rfc/rfc8290.html (accessed on 3 July 2023).
- Palmei, J.; Gupta, S.; Imputato, P.; Morton, J.; Tahiliani, M.P.; Avallone, S.; Täht, D. Design and evaluation of COBALT queue discipline. In Proceedings of the 2019 IEEE International Symposium on Local and Metropolitan Area Networks (LANMAN), Paris, France, 1–3 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Hollot, C.V.; Chait, Y. Nonlinear stability analysis for a class of TCP/AQM networks. In Proceedings of the 40th IEEE Conference on Decision and Control (Cat. No. 01CH37228), Orlando, FL, USA, 4–7 December 2001; pp. 2309–2314. [Google Scholar] [CrossRef]
- Ünal, H.U.; Melchor-Aguilar, D.; Üstebay, D.; Niculescu, S.I.; Özbay, H. Comparison of PI controllers designed for the delay model of TCP/AQM networks. Comput. Commun. 2013, 36, 1225–1234. [Google Scholar] [CrossRef]
- Jiang, W.; Li, H.; Peng, L.; Wu, J.; Ruan, C.; Wang, J. Analysis and improvement of the latency-based congestion control algorithm DX. FCGS 2021, 123, 206–218. [Google Scholar] [CrossRef]
- Pan, C.; Zhang, S.; Zhao, C.; Shi, H.; Kong, Z.; Cui, X. A novel active queue management algorithm based on average queue length change rate. IEEE Access 2022, 10, 75558–75570. [Google Scholar] [CrossRef]
- Kar, S.; Alt, B.; Koeppl, H.; Rizk, A. PAQMAN: A principled approach to active queue management. arXiv 2022, arXiv:2202.10352. [Google Scholar] [CrossRef]
- Hu, S.; Sun, J. An Active Queue Management Mechanism for Minimizing Queueing Delay. In Proceedings of the 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 612–617. [Google Scholar] [CrossRef]
- Patel, S.; Gupta, A.; Singh, M.; Nikhil, N.; Sharma, V. A new active queue management algorithm: Altdrop. In Proceedings of the 2018 International Conference on Advances in Computing, Communication Control and Networking (ICACCCN), Greater Noida, India, 12–13 October 2018; pp. 124–127. [Google Scholar] [CrossRef]
- Li, Y.; Miao, R.; Liu, H.H.; Zhuang, Y.; Feng, F.; Tang, L.; Yu, M. HPCC: High precision congestion control. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 44–58. [Google Scholar] [CrossRef]
- Szyguła, J.; Domański, A.; Domańska, J.; Marek, D.; Filus, K.; Mendla, S. Supervised learning of neural networks for active queue management in the internet. Sensors 2021, 21, 4979. [Google Scholar] [CrossRef] [PubMed]
- Gumus, F.; Yiltas-Kaplan, D. Congestion Prediction System with Artificial Neural Networks. Int. J. Interdiscip. Telecommun. Netw. 2020, 12, 28–43. [Google Scholar] [CrossRef]
- Wang, K.; Liu, Y.; Liu, X.; Jing, Y.; Dimirovski, G.M. Study on TCP/AQM network congestion with adaptive neural network and barrier Lyapunov function. Neurocomputing 2019, 363, 27–34. [Google Scholar] [CrossRef]
- Kim, M.; Jaseemuddin, M.; Anpalagan, A. Deep reinforcement learning based active queue management for iot networks. J. Netw. Syst. Manag. 2021, 29, 34. [Google Scholar] [CrossRef]
- Szyguła, J.; Domański, A.; Domańska, J.; Czachórski, T.; Marek, D.; Klamka, J. AQM Mechanism with Neuron Tuning Parameters. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Phuket, Thailand, 23–26 March 2020; pp. 299–311. [Google Scholar] [CrossRef]
- Hu, M.; Mukaidani, H. Nonlinear model predictive congestion control based on lstm for active queue management in tcp network. In Proceedings of the 2019 12th Asian Control Conference (ASCC), Kitakyushu-shi, Japan, 9–12 June 2019; pp. 710–715. [Google Scholar]
- Abualhaj, M.M.; Al-Tahrawi, M.M.; Hussein, A.H.; Al-Khatib, S.N. Fuzzy-logic based active queue management using performance metrics mapping into multi-congestion indicators. CIT 2021, 21, 29–44. [Google Scholar] [CrossRef]
- Wang, K.; Liu, Y.; Liu, X.; Jing, Y.; Zhang, S. Adaptive fuzzy funnel congestion control for TCP/AQM network. ISA Trans. 2019, 95, 11–17. [Google Scholar] [CrossRef] [PubMed]
- Singh, P.; Gupta, A.K.; Singh, R. Improved priority-based data aggregation congestion control protocol. Mod. Phys. Lett. B 2020, 34, 2050029. [Google Scholar] [CrossRef]
- Pandey, D.; Kushwaha, V. An exploratory study of congestion control techniques in wireless sensor networks. Comput. Commun. 2020, 157, 257–283. [Google Scholar] [CrossRef]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and issues in data stream systems. In Proceedings of the Twenty-First ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Estan, C.; Varghese, G. New directions in traffic measurement and accounting. In Proceedings of the 2002 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Pittsburgh, PA, USA, 19–23 August 2002; pp. 323–336. [Google Scholar] [CrossRef]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Málaga, Spain, 8–13 July 2002; pp. 693–703. [Google Scholar] [CrossRef]
- Cormode, G. Data sketching. Commun. ACM 2017, 60, 48–55. [Google Scholar] [CrossRef]
- Campanile, L.; Gribaudo, M.; Iacono, M.; Marulli, F.; Mastroianni, M. Computer network simulation with ns-3: A systematic literature review. Electronics 2020, 9, 272. [Google Scholar] [CrossRef]
- Jain, R.K.; Chiu, D.M.W.; Hawe, W.R. A Quantitative Measure of Fairness and Discrimination; Eastern Research Laboratory, Digital Equipment Corporation: Hudson, MA, USA, 1984. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| LeafLink Bandwidth | 100 Mbps |
| BottleneckLink | 50 Mbps |
| LeafLink Delay | 5 ms |
| BottleneckLink Delay | 20 ms |
| Active Sender | 100 |
| Maxsize | 50 p |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, H.; Sun, H.; Jiang, Y.; He, G.; Zhang, L.; Lu, Y. A Sketch-Based Fine-Grained Proportional Integral Queue Management Method. Axioms 2023, 12, 814. https://doi.org/10.3390/axioms12090814
Zhu H, Sun H, Jiang Y, He G, Zhang L, Lu Y. A Sketch-Based Fine-Grained Proportional Integral Queue Management Method. Axioms. 2023; 12(9):814. https://doi.org/10.3390/axioms12090814
Chicago/Turabian StyleZhu, Haiting, Hu Sun, Yixin Jiang, Gaofeng He, Lu Zhang, and Yin Lu. 2023. "A Sketch-Based Fine-Grained Proportional Integral Queue Management Method" Axioms 12, no. 9: 814. https://doi.org/10.3390/axioms12090814
APA StyleZhu, H., Sun, H., Jiang, Y., He, G., Zhang, L., & Lu, Y. (2023). A Sketch-Based Fine-Grained Proportional Integral Queue Management Method. Axioms, 12(9), 814. https://doi.org/10.3390/axioms12090814