1. Introduction
The problem of unconstrained minimization of smooth functions in a finite-dimensional Euclidean space has received a lot of attention in the literature [
1,
2]. In unconstrained optimization, in contrast to constrained optimization [
3], the process of optimizing the objective function is carried out in the absence of restrictions on variables. Unconstrained problems arise also as reformulations of constrained optimization problems, in which the constraints are replaced by penalization terms in the objective function that have the effect of discouraging constraint violations [
2].
Well-known methods [
1,
2] that enable us to solve such a problem include the gradient method, which is based on the idea of function local linear approximation, or Newton’s method, which uses its quadratic approximation. The Levenberg–Marquardt method is a modification of Newton’s method, where the direction of descent differs from that specified by Newton’s method. The conjugate gradient method is a two-step method in which the parameters are found from the solution of a two-dimensional optimization problem.
Quasi-Newton minimization methods are effective tools of solving smooth minimization problems when the function level curves have a high degree of elongation [
4,
5,
6,
7]. QNMs are commonly applied in a wide range of areas, such as biology [
8], image processing [
9], technics [
10,
11,
12,
13,
14,
15], and deep learning [
16,
17,
18].
The QNM is based on the idea of using a matrix of second derivatives reconstructed from the gradients of a function. The first QNM was proposed in [
19] and improved in [
20]. The generally accepted notation for the matrix updating formula in this method is DFP. Nowadays, there are a significant number of equations for updating matrices in the QNM [
4,
5,
6,
7,
21,
22,
23,
24,
25,
26,
27,
28], and it is generally accepted [
4,
5] that among a variety of QNMs, the best methods use the BFGS matrix updating equation [
29,
30,
31]. However, it has been experimentally established, but not theoretically explained, why the BFGS generates the best results among the QNMs [
5].
A sampled version of the BFGS method named limited-memory BFGS (L-BFGS) [
32] was presented to handle high-dimensional problems. The algorithm stores only a few vectors that represent the approximation of the Hessian instead of the entire matrix. A version with bound constraints was proposed in [
33].
The penalty method [
2] was developed for solving constrained optimization problems. The unconstrained problems are formed by adding a term, called a penalty function, to the objective function. The penalty is zero for feasible points and non-zero for infeasible points.
The development of QNMs occurred spontaneously through the search for matrix updating equations that satisfy certain properties of data approximation obtained in the problem solving process. In this paper, we consider a method for deriving matrix updating equations in QNMs by forming a quality functional based on learning relations for matrices, followed by obtaining matrix updating equations in the form of a step of the gradient method for minimizing the quality functional. This approach has shown high efficiency in organizing subgradient minimization methods [
34,
35].
In machine learning theory, the system in which the average risk (mathematical expectation of the total loss function) is minimal is considered optimal [
36,
37]. The goal of learning represents the state that has to be reached by the learning system in the process of learning. The selection of such a desired state is actually achieved by a proper choice of a certain functional that has an extremum which corresponds to the desired state [
38]. Thus, in the matrix learning process, it is necessary to formulate a quality functional.
In QNMs, for each of the matrix rows, there is a product of the vector which exists as a learning relation. Consequently, we have a linear model with the coefficients of the matrix row as its parameters. Thus, we may formulate a quadratic learning quality functional for a linear model and obtain a gradient machine learning (ML) algorithm. This paper shows how one can obtain known methods for updating matrices in QNMs based on a gradient learning algorithm. Based on the general properties of convergence of gradient learning algorithms, it seems relevant to study the origins of the effectiveness of metric updating equations in QNMs.
In a gradient learning algorithm, the sequence of steps is represented as a method of minimization along a system of directions. The degree of orthogonality of these directions determines the convergence rate of the algorithm. The use of gradient learning algorithms for deriving matrix updating equations in QNMs enables us to analyze the quality of matrix updating algorithms based on the convergence rate properties of the learning algorithms. This paper shows that the higher degree of orthogonality of learning vectors in the BFGS method determines its advantage compared to the DFP method.
Studies on quadratic functions identify conditions under which the space dimension is reduced during the QNM iterations. The dimension of the minimization space is reduced when the QNM includes iterations with an exact one-dimensional descent or an iteration with additional orthogonalization. It is possible to increase the orthogonality of the learning vectors and thereby increase the convergence rate of the method through special normalization of the initial matrix.
The computational experiment was carried out on functions with a high degree of conditionality. Various ways of increasing the orthogonality of learning vectors were assessed. The theoretically predicted effects of increasing the efficiency of QNMs confirmed their effectiveness in practice. It turned out that with an approximate one-dimensional descent, additional orthogonalization in iterations of the algorithm significantly increased the efficiency of the method. In addition, the efficiency of the method also increased significantly with the correct normalization of the initial matrix.
The rest of this paper is organized as follows. In
Section 2, we provide basic information about matrix learning algorithms in QNMs.
Section 3 contains an analysis of matrix updating formulas in QNMs. A symmetric positive definite metric is considered in
Section 4.
Section 5 gives a qualitative analysis of the BFGS and DFP matrix updating equations. Methods for reducing the minimization space of QNMs on quadratic functions are presented in
Section 6. Methods for increasing the orthogonality of learning vectors in QNMs are considered in
Section 7. In
Section 8, we present a numerical study, and the last section summarizes the work.
2. Matrix Learning Algorithms in Quasi-Newton Methods
Consider the minimization problem
The QNM for this problem is iterated as follows:
Here,
is the gradient of a function,
sk is the search direction, and
βk is chosen to satisfy the Wolfe conditions [
2]. Further,
is a symmetric matrix which is used as an approximation of the Hessian inverse. The operator
specifies a certain equation for updating the initial matrix
H. At the input of the algorithm, the starting point
x0 and the symmetric strictly positive definite matrix
H0 must be specified. Such a matrix will be denoted as
H0 > 0.
Let us consider the relations for obtaining updating equations for
Hk matrices on quadratic functions:
where
x* is the minimum point. Here and below, the expression <·,·> means a scalar product of vectors. Without a loss of generality, we assume
d = 0. The gradient of a quadratic function
f(
x) is ∇
f(
x)
= A(
x −
x*). For Δ
x ∈
Rn, the gradient difference
y = ∇
f(
x + Δ
x) − ∇
f(
x) satisfies the relation:
The equalities in (7) are used to obtain various equations for updating matrices Hk, which are approximations for A−1, or matrices Bk = (Hk)−1, which are approximations for A. An arbitrary equation for updating matrices H or B, the result of which is a matrix satisfying (7), will be denoted by H(H, Δx, y) or B(B, Δx, y), respectively.
Denoting as
Ai and
Ai−1 rows of the corresponding matrices
A and
A−1 with
i-th index, then, according to (7), we obtain equations for the learning relations necessary to formulate algorithms for matrix rows’ learning:
where
yi and Δ
xi are the components of the vectors in (7). The relations in (8) make it possible to use machine learning algorithms of a linear model in the parameters to estimate the rows of the corresponding matrices.
Let us formulate the problem of estimating the parameters of a linear model from observational data.
ML problem: find unknown parameters
c* ∈
Rn of the linear model
from observational data
where
yk = <
c*,
zk>. We will use an indicator of training quality,
which is an estimate of the quality functional required to find
c*.
Function (11) is a loss function. Due to the large dimension of the problem of estimating the elements of metric matrices, the use of the classical least squares method becomes difficult. We use the adaptive least squares method (recurrent least squares formulas).
The gradient learning algorithm based on (11) has the following form:
Due to the orthogonality of the training vectors, the stochastic gradient method in the form “receiving of an observation-training-forgetting the observation information” in quasi-Newton methods enables us to obtain good approximations of the inverse matrices of second derivatives while maintaining their symmetry and positive definiteness.
In this paper, the value of such consideration is that we are able to identify the advantages of the BFGS method and obtain a method with orthogonalization of learning vectors and prove these provisions through testing.
The Kaczmarz algorithm [
39] is a special case of (12) with the form
Let us list some of the properties of process (13), which we use to justify the properties of matrix updating in QNMs.
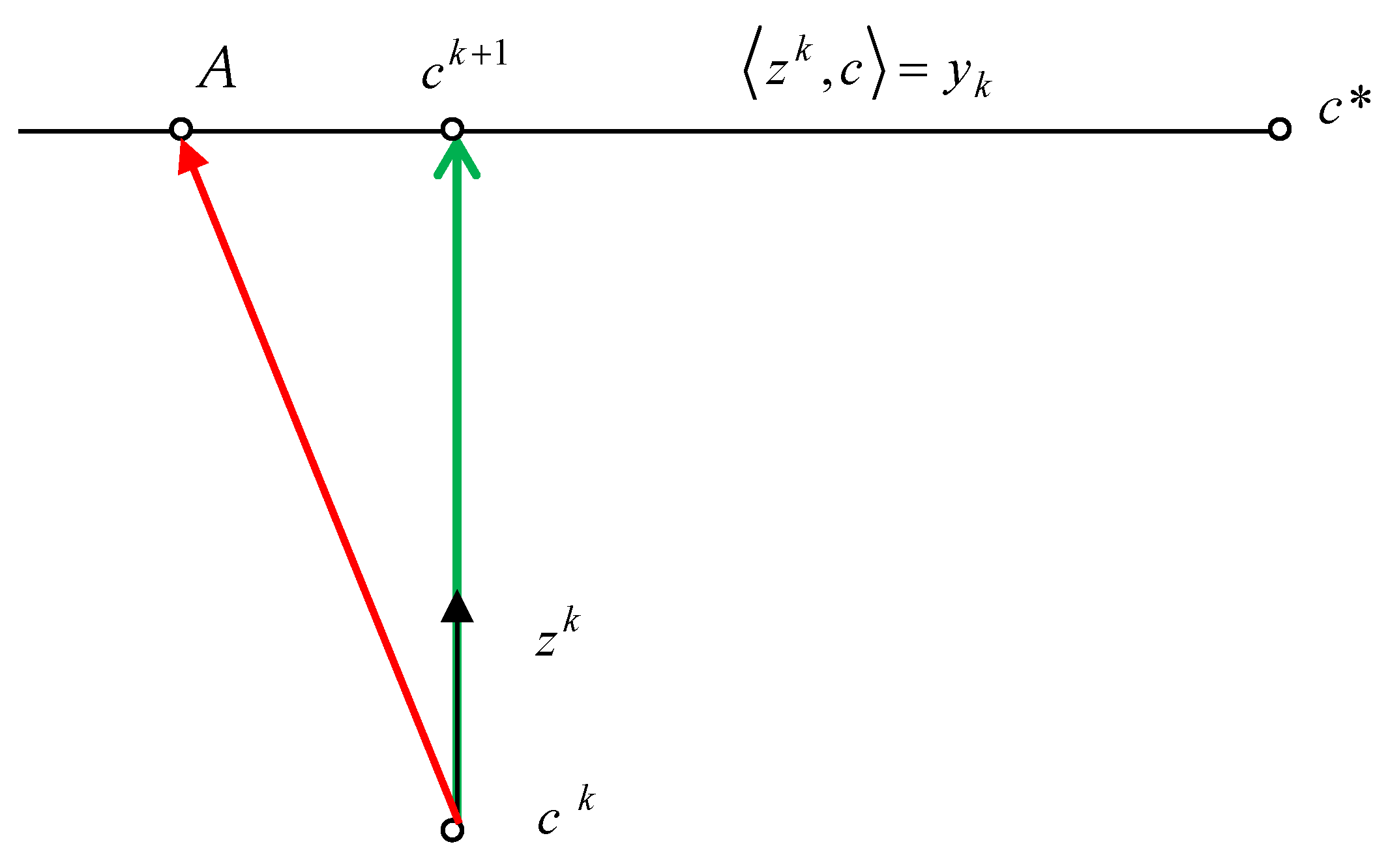
Property 1. Process (13) ensures the equalityand the solution is achieved under the condition of minimum changes in the parameters’ values . Property 2. If yk = <c*, zk> then the iteration of process (13) is equivalent to the step of minimizing the quadratic functionfrom the point ck along the direction zk. Proof. Property 2 is justified by the direct implementation of the function in (15) which is the minimizing step along the direction
zk, which is presented in
Figure 1. Property 1 follows from the fact that movement to the point
ck+1 is carried out along the normal to the hyperplane <
zk,
c> =
yk, that is, along the shortest path (
Figure 1). Movement to other points on the hyperplane, for example to point
A, satisfy only the condition in (14). □
Let us denote the residual as
rk = ck −
c*. By subtracting
c* from both sides of (13) and making transformations, we obtain the following learning algorithm in the form of residuals:
where
I is the identity matrix. The sequence of minimization steps can be represented in the form of the residual transformation, where
m is the number of iterations:
The convergence rate of process (13) is significantly affected by the degree of orthogonality of the learning vectors z. The following property reflects the well-known fact of the minimization algorithm termination along orthogonal directions of the quadratic form of (15) with equal Hessian eigenvalues.
Property 3. Let vectors zk, k = l, l + 1,…, l + n − 1 for a sequence of n iterations (13) be mutually orthogonal. Then, the solution c* minimizing the function (15) is obtained in no more than n steps of the process (13) for an arbitrary initial , wherein The following results are useful to estimate the convergence rate of the process in (13) as a method for minimizing the function in (15) without orthogonality of the descent vectors.
Consider a cycle of iterations for minimizing a function
θ(
x),
x ∈
Rn, along the column vectors
zk, ‖
zk‖ = 1,
k = 1,…,
n, of matrix
Z ∈
Rn×n:
Here and below, we will use the Euclidean vector norm ‖
x‖ = <
x,
x>
1/2. Let us present the result of the iterations in (19) in the form of the operator
xn+1 =
XP(
x1,
Z). Consider the process
where matrices
Zq and the initial approximation
u0 are given. To estimate the convergence rate of the QNM and the convergence rate of the metric matrix approximation, we need the following assumption about the properties of the function.
Assumption 1. Let the function be strongly convex, with a constant ρ > 0, and differentiable, and its gradient satisfy the Lipschitz condition with a constant L > 0.
We assume that the function
f(
x),
x ∈
Rn, is differentiable and strongly convex in
Rn, i.e., there exists
ρ > 0 such that for all
x,y ∈
Rn and α ∈ [0, 1], the inequality holds,
and its gradient ∇
f(
x) satisfies the Lipschitz condition:
Let us denote the minimum point of the function
θ(
x) by
x*. The following theorem [
40] establishes the convergence rate of the iteration cycle (20).
Theorem 1. Let the function θ(x), x ∈ Rn, satisfy Assumption 1; let matrices Zq of the process in (20) be such that minimum eigenvalues μ q of matrices (Zq)T Zq satisfy the constraint μ q ≥ μ0 > 0. Then, the following inequality estimates the convergence rate of the process in (20): Estimate (22) enables us to formulate the following property of the process in (13).
Property 4. Let vectors zk, k = 1,…,n−1, be given in (13), the columns of the matrices Z be composed of vectors zk/‖zk‖, and the minimum eigenvalue μ of the matrix ZT Z satisfy the constraint μ ≥ μ0 > 0. Then, the following inequality estimates the convergence rate: Proof. Let us apply the results of Theorem 1 to the process in (13). The strong convexity and Lipschitz constants for the gradient of the quadratic function in (15) are the same: ρ = L = 1. Using Property 2 and the estimate in (22) for m = 1, we obtain (23). □
The property of operators
, when the conditions of Property 4 are met, is determined by the estimate in (23), which can be represented in the following form:
Thus, the Kaczmarz algorithm provides a solution to the equality in (14) for the last observation, while it implements a local learning strategy, i.e., a strategy for iteratively improving the approximation quality from a functional (15) point of view. If the learning vectors are orthogonal, the solution is found in no more than n iterations. When n learning vectors are linearly independent, the convergence rate (23) is determined by the degree of the learning vectors’ orthogonality. The degree of the vectors’ orthogonality will indicate the boundedness of the minimum eigenvalue μ ≥ μ0 > 0 of the matrix ZTZ defined in Property 4.
Using the learning relations in (8), we obtain machine learning algorithms for estimating the rows of the corresponding matrices in the form of the process in (13). Consequently, the question of analyzing the quality of algorithms for updating matrices in QNMs will consist of analyzing learning relations like (8) and the degree of orthogonality of the vectors involved in training.
3. Gradient Learning Algorithms for Deriving and Analyzing Matrix Updating Equations in Quasi-Newton Methods
Well-known equations for matrix updating in QNMs were found as equations that eliminate mismatch on a new portion of training information. In machine learning theory, a quality measure is formulated. A gradient minimization algorithm is used to minimize this measure. Our goal is to give an account of QNMs from the standpoint of machine learning theory, i.e., to formulate quality measures of training and construct their minimization algorithms. This approach enables us to obtain a unified method for deriving matrix updating equations and extend the known facts and algorithms of learning theory to solve analysis of and achieve improvement in QNMs.
Let us obtain formulas for updating matrices in QNMs using the quadratic model of the minimized function in (6) and learning relations in (7). For one of the learning relations in (7), we present a complete study of Properties 1–4.
Let the current approximation
H of the matrix
H* = A−1 be known. It is required to construct a new approximation using the learning relations in (7) for the rows of the matrix in (8):
To evaluate each row of the matrix
H* based on (25), we apply Algorithm (13). As a result, we obtain the following matrix updating equation:
which is known as the 2nd Broyden method for estimating matrices when solving systems of non-linear equations [
5,
6].
Equation (26) determines the step of minimizing a type of functional of (15) for each of the rows
Hi of matrix
H along the direction
y:
The matrix residual is
R = H −
H*. Because of the iteration of (26), the residual is transformed according to the rule
Let us denote the scalar product for matrices
A,
B ∈
as
We use the Frobenius norm of matrices:
Let us define the function,
and reformulate Properties 1–4 for the matrix updating process in (26).
Theorem 2. Iteration (26) is equivalent to the minimization step Φ(H) from a point H along the direction ΔH:wherefor arbitrary matrices satisfying the condition in (31). Proof of Theorem 2. Let us show that the condition for the minimum of the function in (27) along the direction Δ
H (30) is satisfied at the point
:
□
Next, we prove (32) by showing that Δ
H is the normal of the hyperplane of matrices satisfying the condition in (31). To do this, we prove orthogonality of the vector in (30) to an arbitrary vector of the hyperplane, formed as the difference of matrices belonging to the hyperplane
V = H1 −
H2:
Let us prove an analogue of Property 3 for (26).
Theorem 3. Let the vectors yk, k = l, l + 1, …, l + n − 1, for the sequence of n iterations in (26) be mutually orthogonal, then the solution H* to the minimization problem in (29) will be obtained in no more than n steps of the process in (26),for an arbitrary matrix Hl, Proof of Theorem 3. From (28), the orthogonality of vectors yk and (18) follows (35). □
Theorem 4. Let vectors yk, k = 0, 1, …, n − 1, in (13) be given, vectors yk/‖yk‖ be columns of matrix P, and the minimum eigenvalue μ of a matrix PTP satisfy the constraint μ ≥ μ0 > 0. Then, to estimate the convergence rate of the process in (34), the following inequality holds: Proof of Theorem 4. According to Property 4 and conditions of the theorem, the rows of matrices will have the following estimates (23):
A similar inequality will be true for the sums of the left and right sides. Considering the connection between the norms
, we obtain the estimate in (36). □
In the case when the matrix
H is symmetric, two products of the matrix
H* and the vector
y are known:
Applying the process in (28) twice for (37), we obtain a new process for updating the matrix residual:
Expanding (38), we obtain the updating formula
of J. Grinstadt [
5,
6], where
Let us reformulate Properties 1–4 of the matrix updating process (26) for (39).
Theorem 5. The iteration of (39) is equivalent to the minimization step Φ(H) from a point H along the direction:At the same time,for arbitrary matrices satisfying the condition in (41). Proof of Theorem 5. Let us show that at the point
, the condition for the minimum of the function in (27) along the direction Δ
H is satisfied:
In (43), let us consider the scalar product for each term of (40) separately. The third term of Expression (40) coincides with (30). The equality to zero of the scalar product for it was obtained in (33). For the first term, the calculations are similar to (33):
Let us carry out calculations for the second term using the symmetry of matrices:
Proof (43) is complete. Next, we prove that Δ
H is the normal of the hyperplane of matrices satisfying the condition in (42). To do this, we prove that the vector Δ
H is orthogonal to an arbitrary vector of the hyperplane, formed as the difference of matrices belonging to the hyperplane
, that is, <Δ
H,
> = 0. Since the matrices
and
satisfy the condition in (42), the proof is identical to the justification of the equality in (43). □
The following theorem establishes the convergence rate for a series of successive updates (39).
Theorem 6. Let vectors yk, k = l, l + 1, …, l + n − 1, for the sequence of n iterations of (39) be mutually orthogonal. Then, the solution to the minimization problem in (29) can be obtained in no more than n steps of the process in (39),for an arbitrary symmetric matrix : Proof of Theorem 6. The update in (45) can be represented as two successive multiplications by , first from the left and then from the right. For each of the updates, the estimate in (35) is valid. □
Theorem 7. Let vectors yk, k = 0, 1, …, n − 1, be given, vectors yk/‖yk‖ be columns of matrix P, and the minimum eigenvalue μ of a matrix PTP satisfy the constraint μ ≥ μ0 > 0. Then, to estimate the convergence rate of the process in (44), the following inequality holds: Proof of Theorem 7. The matrix residual is updated according to the rule
which can be represented as two successive multiplications by
, first from the left and then from the right. The estimate in (36) is valid for each of the updates, which proves (46). □
4. Symmetric Positive Definite Metric and Its Analysis
Let Function (6) be quadratic. We use the coordinate transformation
Let the matrix
V satisfy the relation
In the new coordinate system, the minimized function takes the following form:
Quadratic Function (6), considering (49), (47), and (48), takes the following form:
Here,
is the minimum point of the function. According to (38) and (50), the matrix of second derivatives is the identity matrix
. Let us denote
. The gradient is
For the characteristics of functions
and
f(
x), the following relationships are valid:
where notation
is used.
From (53), (54), and the properties of matrices
V (48), the following equality holds:
For the symmetric matrix
, two products of the matrix
and the vector
y are known:
Applying the process in (28) twice to (56), we obtain a new process for updating the matrix residual
:
Taking into account (55), the update in (39) takes the form
Let us consider the methods in (1)–(4) in relation to the function
in the new coordinate system.
Parameter
in (59) characterizes the accuracy of a one-dimensional descent. If the matrices are correlated by
and the initial conditions are
then these processes generate identical sequences
and characteristics connected by the relations in (47) and (52)–(54). In this case, the equality
holds.
Considering the equality
from (55), Equation (58) can be transformed. As a result, we obtain the BFGS equation:
Equation (65) satisfies the requirement of (63) and has the same form in various coordinate systems. Similar properties have the matrix transformation equation
HDFP, which can be represented as a transformed formula
HBFGS [
29,
30,
31]:
Taking into account (55) and (58), we obtain the following expression in the new coordinate system:
The form of the matrices in (65) and (66) does not change depending on the coordinate system. Consequently, the form of the processes in (1)–(4) and (59)–(62) is completely identical in different coordinate systems when using Formulas (65) and (67). Thus, for further studies of the properties of QNMs on quadratic functions, we can use Equations (58) and (67) in the coordinate system specified by the transformation in (47).
Within the iteration of the processes in (59)–(62) for a quadratic function with an identity matrix of second derivatives, the residual can be represented in the form of components
where
is a component along the vector
zk (or, which is the same, along
), and
is a component orthogonal to
zk. With an inexact one-dimensional descent in (59), the component
decreases but does not disappear completely. For the convenience of theoretical studies, the residual transformation in Equation (68) in this case can be represented by introducing parameter
γk ∈ (0, 2) instead of
, characterizing the degree of descent accuracy:
Here, at arbitrary γk ∈ (0, 2), the objective function decreases. With an inexact one-dimensional descent, a certain value γk ∈ (0, 2) will be attained, at which the new value of the function becomes smaller.
The restriction on the one-dimensional search in (59), imposed on
γk in (69), ensures a reduction in the objective function
As a result of the iterations in (59)–(62) with (65) and according to (57), the matrix residual
is transformed according to the rule
Therefore, one system of vectors zk is used in the new coordinate system of the QNM iteration with the aim of minimizing the function and residual functional for matrices (29). With the orthogonality of vectors zk and an exact one-dimensional search, the solution will be obtained in no more than n iterations. By virtue of the equality , the orthogonality of vectors zk in the chosen coordinate system is equivalent to the conjugacy of vectors Δxk.
Due to the type of identity which defines the QNM iteration in different coordinate systems, we further denote the iteration of processes (59)–(62) and (1)–(4), considering the accuracy of one-dimensional descent (introduced in (69) by the parameter
) by the operator
To simplify the notation in further studies of quasi-Newton methods on quadratic functions, without a loss of generality, we use an iteration of the method in (71) adjusted to minimize the function
which allows us, without transforming the coordinate system (47), to use all associated relations for the processes in (59)–(62) with the function in (50) for studying the process in (71), omitting the hats above the variables in the notation.
Let us note some of the properties of the QNM.
Theorem 8. Let > 0 and the iteration of (71) be carried out with matrix transformation equations and (67). Then, the vector zk is an eigenvector of the matrices , , , and : Proof of Theorem 8. The first of the equalities in (72) follows from (70). The second of the equalities in (72) follows from this fact and the definition of the matrix residual.
By direct verification, based on (67), we establish that the vectors zk and vk are orthogonal. Therefore, the additional term v vT in Equation (67) does not affect the multiplication of vector zk by a matrix, which together with (72) proves (73). □
As consequence of Theorem 8, the dimension of the space being minimized is reduced by one in the case of an exact one-dimensional descent, which will be shown below.
Section 5 justifies the advantages of the BFGS equation (65) over the DFP equation (66) for matrix transformation.
5. Qualitative Analysis of the Advantages of the BFGS Equation over the DFP Equation
The effectiveness of the learning algorithm is determined by the degree of orthogonality of the learning vectors in the operator factors
. In the new coordinate system, the transformation in (70) is determined by the factors
in the residual expressions. Therefore, to analyze the orthogonality degree of the system of vectors
z, it is necessary to involve the method of their formation. Let us show that the vectors
zk in (69) and (70) generated by the BFGS equation have a higher degree of orthogonality compared to those generated by DFP. To get rid of a large number of indices, consider the iteration of the QNM (71) in the form
Theorem 9. Let and the iteration of (74) be carried out with the matrix updating equations (58) and (67), andThen, the following statements are valid. 1. The descent directions for the next iteration are of the formwhere 2. With respect to the cosine of the angle between adjacent directions of the descent, we have the following estimate: 3. In the subspace of vectors orthogonal to z, the trace of the matrix does not change,and the trace of the matrix decreases,
Proof of Theorem 9. We represent the residual, similarly to (69), in the following form:
After performing the iteration of (74), the residual takes the form
According to (83), in , the component does not depend on the accuracy of the one-dimensional search. Therefore, initially, we find new descent directions in (76) and (77) under the condition of an exact one-dimensional search, that is, with .
Considering the gradient expression in (51), the direction of minimization in the iteration of (74) is
. Based on that result, considering (55) and the equality
following from the condition of exact one-dimensional minimization (60), we obtain
From (84), taking into account the orthogonality of the vectors
,
z, we obtain the equality
Let us find the expression
necessary to form the descent direction
in the next iteration. Considering the orthogonality of the vectors
and
z, using the BFGS matrix transformation formula (58), we obtain
Transformation of the equality in (86) based on (87) leads to
Making the replacement (89) in the last expression from (88), we find
According to (90), the new descent vector can be represented using the expression for
from (67)
Since the component in (83) does not depend on the accuracy of the one-dimensional search, Expression (91) determines its contribution to the direction of descent in (76). Finally, the property of (72) together with the residual representation in (82) proves (76).
The condition in (75) according to (91) prevents the completion of the minimization process. If
, then as a result of exact one-dimensional minimization, we obtain
, which, taking into account
, means
. As before, using (67), we find a new descent direction for the DFP method, assuming that the one-dimensional search is exact:
The last term in (92), taking into account (91) and the orthogonality of the vectors
, can be represented in the form
Let us transform the scalar value as follows:
Based on (92), together with (93) and (94), we obtain the expression
And finally, the last expression, using the property of (73) together with the representation of the residual, considering the accuracy of the one-dimensional descent (82), proves (77).
Since
, the left inequality in (78) will hold. We prove the right inequality by contradiction. Let us denote by
a matrix with eigenvectors of the matrix
H and eigenvalues in the form of powers of the corresponding eigenvalues of the matrix
H, given by
. Let
. Then,
Consequently, the equality holds if q = 1. Therefore, u is an eigenvector of the matrix H, and therefore, all matrices also have such an eigenvector. Due to this fact and the equality , the vector is also an eigenvector, and , where ρ is the eigenvalue of the matrix . In this case, considering the representation in (85) of vector z, vector , according to its representation in (67), is zero, which cannot be true according to the condition in (75). Therefore, the right inequality in (78) also holds.
Due to the orthogonality of vectors and z and according to (76) and (77), the numerators in (79) are the same, and for the denominators, taking into account (78), the inequality holds, which proves (79). In an exact one-dimensional search, the equality is satisfied in (79) since the numerators in (79) are zero.
Let us justify point 3 of the theorem. In accordance with the notation of equations
(58) and
(67), we introduce an orthogonal coordinate system in which the first two orthonormal vectors are determined by the following equations:
where vectors
p and
z are orthogonal and
. In such a coordinate system, these vectors are defined by
Let us consider the form of matrix
in the selected coordinate system. Let us determine the type of vector
p based on its representation in (95). Taking into account
, components of vector
p have the form
Hence,
. Comparing the last expression with the expression in (96), we conclude that in the chosen coordinate system, the first column
of matrix
has the following form:
From (97) and (96), it follows that
and the original matrix will have the form
When correcting matrices with formulas BFGS (58) and DFP (67), changes will occur only in the space of the first two variables, determined by the unit vectors in (95). As a result of the BFGS transformation in (58), we obtain the following two-dimensional matrix:
Based on the relationship of matrices expressed in (67), using (98), we obtain the result of the transformation according to the DFP equation in (67):
Thus, the resulting two-dimensional matrices have the following form:
The corresponding complete matrices are presented below:
Due to the condition in (75) from Expression (98) for , it follows that . Consequently, the trace of matrix , according to (102) and (104), will decrease by . The last expression can be transformed considering the definition of the coordinate system in (96). As a result, we obtain (81). From (103), we obtain (80). □
Regarding the results of Theorem 9, we can draw the following conclusions.
With an inexact one-dimensional descent in the DFP method, the successive descent directions are less orthogonal than in the BFGS method (79).
The trace of matrix in the DFP method in the unexplored space decreases (81). This makes it difficult to enter a new subspace during subsequent minimization. Moreover, in the case of an exact one-dimensional descent, in the next step, this decrease is restored; however, a new one appears.
Theorem 9 also shows that in the case of an exact one-dimensional search, the minimization space on quadratic functions is reduced by one.
Due to the limited computational accuracy on ill-conditioned problems (i.e., problems with a high condition number), the noted effects can significantly worsen the convergence of the DFP method.
In conjugate gradient methods [
39], if the accuracy of the one-dimensional descent is violated, the sequence of vectors ceases to be conjugated. In QNMs, due to the reduction in the minimization subspace by one during exact one-dimensional descent, the effect of reducing the minimization space accumulates. In
Section 6, we look at methods for replenishing the space excluded from the minimization process.
6. Methods for Reducing the Minimization Space of Quasi-Newton Methods on Quadratic Functions
We will assume that the quadratic function has the form expressed in (71a):
For matrices
and
obtained using the iteration of (71),
, the relations in (72) and (73) hold:
Vector zk is an eigenvector for matrices and with one and zero eigenvalues, respectively. Let us consider ways to increase the dimension of the quasi-Newton relations’ execution subspace.
Let us denote by H ∈ Im a matrix H > 0 that has m eigenvectors with unit eigenvalues, and the corresponding matrix R = H − I with the corresponding eigenvectors and zero eigenvalues we will denote by R ∈ Om. Let us denote by Qm a subspace of dimension m spanned by a system of eigenvectors with unit eigenvalues of the matrix H ∈ Im, and its complement by .
An arbitrary orthonormal system of
m vectors
e1, …,
em, of subspace
Qm is a system of eigenvectors of matrices
H ∈
Im and
R ∈
Om:It follows that an arbitrary vector, which is a linear combination of vectors ei, will satisfy the quasi-Newton relations.
Lemma 1. Consider the matrix H ∈ Im and the vectorsThen, Proof of Lemma 1. The system of m eigenvectors of matrix H ∈ Im is contained in the set Qm. Due to the orthogonality of the eigenvectors, the remaining part of the matrix H ∈ Im is contained in the set Dm. Therefore, the operation of multiplying the vectors in (107) by the matrix in (108) does not take them beyond their subspace. In this case, for the vector rQ, the equality HrQ = rQ ∈ Qm holds, which follows from the definition of the subspace Qm. □
Lemma 2. Let Hk > 0, Hk ∈ Im, m < n, , and iteration be completed. Then, Proof of Lemma 2. The descent direction, taking into account (51), has the form . Based on Lemma 1, it follows that . As follows from Theorem 8, a new eigenvector expressed in (72) and (73) with a unit eigenvalue appears in the subspace Dm, regardless of the accuracy of the one-dimensional descent, which proves (109), taking into account the accuracy of the one-dimensional search. With an inexact descent, part of the residual remains along the vector zk, which proves (110). □
Lemma 3. Let Hk > 0, Hk ∈ Im, m ≤ n, , , and iteration be completed. Then, it follows that Proof of Lemma 3. Since , we take a system, where one of the eigenvectors is the vector , as an orthogonal system of eigenvectors in Qm. From the remaining eigenvectors, we form a subspace Qm−1 in which there is no residual. Applying to Qm−1 the results of Lemma 2 under the condition Hk ∈ Im−1, we obtain (111) and (112). □
By alternating operations with an exact and inexact one-dimensional descent, it is possible to obtain finite convergence on quadratic functions of QNMs.
Theorem 10. Let Hk > 0, Hk ∈ Im, , m < n − 1, and the iterations be completed as follows:Then, Proof of Theorem 10. For the iteration of (113), we apply the result of Lemma 3 (111), and for the iteration of (114), we apply the result of Lemma 2 (110). As a result, we obtain (115). □
Theorem 10 says that individual iterations with an exact one-dimensional descent make it possible to increase by one the dimension of the space where the quasi-Newton relation is satisfied. This means that after a finite number of such iterations, the matrix Hk = I will be obtained.
Let us consider another way of increasing the dimension of the quasi-Newton relation. It consists of using, after iterations of QNMs, an additional iteration of descent along the orthogonal vector
vk defined in (67), and according to (91), with an exact one-dimensional descent coinciding, up to a scalar factor, with the descent direction
of the BFGS method:
Let us denote the iterations in (116)–(119) by
Lemma 4. Let Hk > 0, Hk ∈ Im, , , m ≤ n − 1, and the iteration of (120) be completed. Then, Proof of Lemma 4. For the iteration of (116), as in the proof of Lemma 3, since , we take this as an orthogonal system of eigenvectors in Qm, where one of the eigenvectors is the vector . From the remaining eigenvectors, we form a subspace Qm−1 in which there is no residual, and for this subspace, Hk ∈ Im−1 holds. As a result of (116), according to the results of Theorem 8, an eigenvector zk ∉ Qm−1 is formed. It is a derivative of vector , which, due to multiplication by a matrix Hk ∈ Im−1 with residual , according to the results of Lemma 1, does not belong to the subspace Qm−1. For this reason, the vector vk ∉ Qm−1 obtained by Formula (118), orthogonal to zk, because of (117)–(119), becomes an eigenvector of the matrix Hk+1. Thus, the subspace Qm−1 is replenished with two eigenvectors of the matrix Hk+1, resulting in (121). □
Theorem 11. To obtain Hk ∈ In, it is necessary to perform the iteration of (120) (n − 1) times.
Proof of Theorem 11. In the first iteration of (120), we obtain Hk+1 ∈ I2. In the next (n − 2) iterations of (120), according to the results of Lemma 4, we obtain Hk+n−1 ∈ In. □
The results of Theorem 11 and Lemma 5 indicate the possibility of using techniques for increasing the dimension of the subspace of quasi-Newton relations’ execution at arbitrary moments, which enables us, as will be shown below, to develop QNMs that are resistant to the inaccuracies of a one-dimensional search.
In summary, the following conclusions can be drawn about properties of QNMs on quadratic functions without the condition of an exact one-dimensional descent.
The dimension of the minimization subspace decreases as the dimension of the subspace of fulfillment of the quasi-Newton relation increases (Lemma 2).
The dimension of the subspace of fulfillment of the quasi-Newton relation does not decrease during the execution of the QNM (Lemmas 2–5).
Individual iterations with an exact one-dimensional descent increase the dimension of the subspace of the quasi-Newton relation (Lemma 4).
Separate inclusions of iterations with the transformation of matrices for pairs of conjugate vectors increase the dimension of the subspace of the quasi-Newton relation (Lemma 5).
It is sufficient to perform at most the (n − 1) inclusion of an exact one-dimensional descent (113) in arbitrary iterations to solve the problem of minimizing a quadratic function in a finite number of steps in the QNM (Lemma 4 and Theorem 10).
To solve the problem of minimizing a quadratic function in a finite number of steps in the QNM, it is sufficient to perform in arbitrary iterations no more than (n − 1) inclusions of matrix transformations for pairs of descent vectors obtained as a result of the transformations in (118) and (119) (Lemma 5 and Theorem 11).
7. Methods for Increasing the Orthogonality of Learning Vectors in Quasi-Newton Methods
The term “degree of orthogonality” refers to the type of function (71a). For the type of function (6), this term means the degree of conjugacy of the vectors. Several conclusions can be drawn from our considerations.
Firstly, it is preferable to use the BFGS method. With imprecise one-dimensional descent in the DFP method, successive descent directions are less orthogonal than in the BFGS method (79).
Secondly, it makes sense to increase the degree of accuracy of the one-dimensional search, since individual iterations with an exact one-dimensional descent increase the dimension of the subspace of the quasi-Newton relation (Theorem 10), which reduces the dimension of the minimum search region.
Thirdly, separate inclusions of iterations with matrix transformation for pairs of conjugate vectors increase the dimension of the subspace of the quasi-Newton relation (Lemma 4). This requires applying a sequence of descent iterations for pairs of conjugate vectors (120).
On the other hand, it is important to correctly select the scaling factor
ω of the initial matrix
H0 =
ωI from (1) in the QNM. Let us consider an example of a function of the form expressed in (6):
The eigenvalues of the matrix of second derivatives
A and its inverse
are
respectively. The gradient of the quadratic function in (122) is
In the first stages of the search for
in the gradients
and gradient differences, components of eigenvectors with large eigenvalues of matrix
A and, accordingly, small eigenvalues of the matrix
A−1 =
H prevail. Let us calculate an approximation of the eigenvalues for scaling the initial matrix using data from (3) of the first iteration of the methods in (1)–(4):
where
are the minimum and maximum eigenvalues of the matrix
A−1 =
H, respectively. To scale the initial matrix
H0, consider the following:
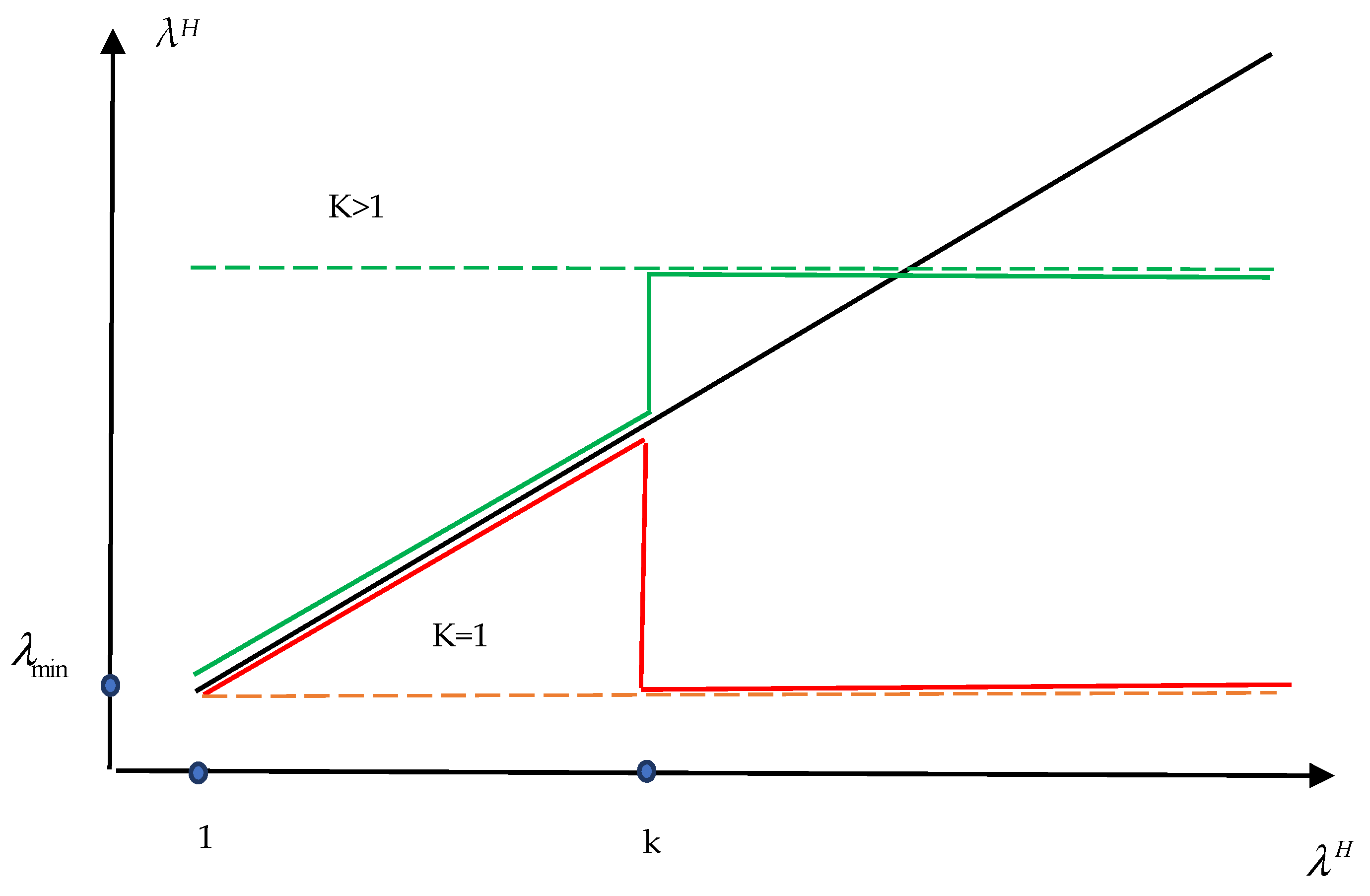
Let us qualitatively investigate the operation of the quasi-Newton BFGS method (71). Taking into account the predominance of eigenvectors with large eigenvalues of the matrix
A and, accordingly, small eigenvalues of the matrix
A−1 =
H, it is possible to qualitatively display the picture of the reconstruction of the matrix
A−1 eigenvectors for different values of
K, making a rough assumption that small eigenvalues are sequentially restored. A rough diagram of the process of reconstructing the spectrum of matrix eigenvalues is shown in
Figure 2.
One of the components of increasing the degree of orthogonality of learning vectors in QNMs is the normalization of the initial metric matrix (124). In
Section 8, we will consider the impact of the methods noted in this section on increasing the efficiency of QNMs.
8. Numerical Study of Ways to Increase the Orthogonality of Learning Vectors in Quasi-Newton Methods
We implemented and compared quasi-Newtonian BFGS and DFP methods. A one-dimensional search procedure with cubic interpolation [
41] (exact one-dimensional descent) and a one-dimensional minimization procedure [
34] (inexact one-dimensional descent) were used. We used both the classical QNM with the iterations of (1)–(4) (denoted as BFGS and DFP) and the QNM including iterations with additional orthogonalization (116)–(119) in the form of a sequence of iterations (120) (denoted as BFGS_V and DFP_V). The experiments were carried out by varying the coefficients of the initial normalization of the matrices of the QNM metric.
Since the use of quasi-Newtonian methods is justified primarily based on functions with a high degree of conditionality where conjugate gradient methods do not work efficiently, the test functions were selected based on this principle. Since the QNM is based on a quadratic model of a function, its local convergence rate in a certain neighborhood of the current minimum is largely determined by the efficiency of minimizing the ill-conditioned quadratic functions. The test functions are as follows:
(1)
The optimal value and minimum point are The condition number of the matrix of second derivatives for some n is . When n = 1000, the condition number will be .
(2)
The optimal value and minimum point are The condition number of the matrix of second derivatives for some n is . When n = 1000, the condition number will be .
(3) .
The optimal value and minimum point are
The function
f3 is based on a quadratic function with the condition number of the matrix of second derivatives for some
n . When
n = 1000, the condition number will be
. The topology of the level surfaces of the function
f3 is identical to the topology of the level surfaces of the basic quadratic function. The matrix of second derivatives of a function tends to zero as it approaches the minimum. Consequently, the inverse matrix tends to infinity. The approximation pattern for the matrix of second derivatives in the QNM will correspond to
K = 1 in
Figure 2. This case makes it difficult to enter a new subspace due to the significant predominance of eigenvalues in the metric matrix in the already surveyed part of the subspace compared to the eigenvalues of the metric matrix in the unsurveyed area.
(4) .
The optimal value and minimum point of rescaled multidimensional Rosenbrock function [
42] are
This function has a curved ravine with small values of the second derivative in the direction of the bottom of the ravine and large values of the second derivative in the direction of the normal to the bottom of the ravine. The ratio of second derivatives along such directions is approximately 10
8.
The stopping criterion is
The results of minimizing the presented functions are given in
Table 1 and
Table 2 for
n = 1000. The problem was considered solved if the method, within the allotted number of iterations and calculations of the function and gradient, reached a function value that satisfied the stopping criterion. The cell indicates the number of iterations (one-dimensional searches along a direction), and below is the number of calls to the function procedure, where the function and gradient are calculated simultaneously. The number of iterations in all tests were limited to 40,000. If the costs of the method exceeded the specified number of iterations, the method was stopped. It was believed that no solution had been found by this method. The dash sign indicates options where a solution could not be obtained. In cases where there was no solution, looping of methods occurred due to the smallness of the minimization steps and, as a consequence, large errors in the gradient differences used in the transformation operations of metric matrices.
Let us consider the effects of reducing the convergence rate of the method. For example, for the function
f3, the matrix of second derivatives tends to zero as it approaches the minimum. Consequently, the inverse matrix tends to infinity. The approximation pattern for the matrix of second derivatives in the QNM will correspond to K = 1 in
Figure 2. In the explored part of the subspace, the matrix of the QNM grows. Therefore, the slight presence of residuals in this part of the subspace is greatly amplified. In the unexplored part of the space, the eigenvalues are fixed. This case makes it difficult to enter a new subspace due to the significant predominance of eigenvalues in the metric matrix in the explored part of the subspace compared to the eigenvalues of the metric matrix in the unexplored area. In order to enter the unexplored part of the subspace, it is necessary to eliminate the discrepancy in the explored part of the space. As a consequence, when minimizing functions with a high degree of conditionality, the search steps become smaller, the errors in the gradient differences increase, and the minimization method becomes loopy.
For exact descent, there are practically no differences between the BFGS and BFGS_V methods. In exact descent, successive descent vectors for quadratic functions are conjugated, and matrix learning, considered in a coordinate system with an identity matrix of second derivatives, is carried out using an orthogonal system of vectors. Minor errors lead to the fact that this orthogonality is violated, which affects the DFP method.
For inexact descent, the BFGS_V method significantly outperforms the BFGS method. The DFP and DFP_V methods are practically ineffective on these tests, although the DFP_V method shows better results.
Thus, with one-dimensional search errors, the BFGS_V algorithm is significantly more effective than the BFGS method. The DFP method is practically not applicable when the problem is highly conditioned.
Table 2 shows the experimental data with normalization of the matrix (124) at
K > 1. For the functions
f3(
x) and
f4(
x), the coefficient
K had to be reduced to obtain a more effective result.
The initial normalization of the metric matrices, as follows from the results of
Table 1 and
Table 2, significantly improves the convergence of QNMs. The situation corresponds to the case in
Figure 2 for K > 1. Large eigenvalues in the unexplored part of the subspace make it easy to find new conjugate directions and efficiently train metric matrices with almost orthogonal training vectors.
For exact descent, there are practically no differences between the BFGS and BFGS_V methods. For inexact descent, the BFGS_V method significantly outperforms the BFGS method. The DFP and DFP_V methods are efficient for functions f1(x) − f3(x), while for inexact descent, the DFP_V method significantly outperforms the DFP method.
Thus, in the case of one-dimensional search errors, the BFGS_V algorithm is significantly more efficient than the BFGS method and correct initial normalization of metric matrices can significantly increase the convergence rate of the method.
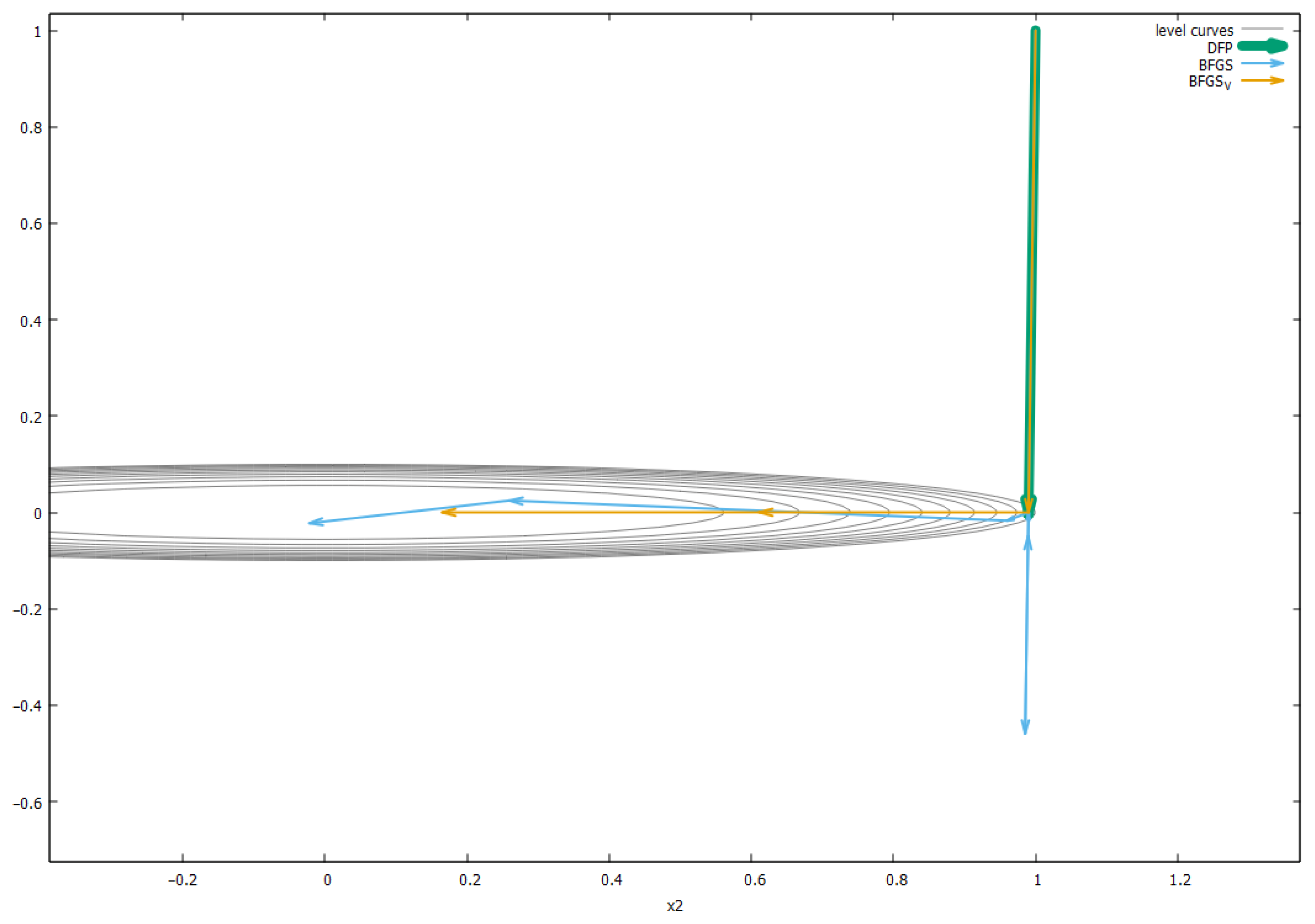
For the purpose of giving a visual demonstration of the method, we minimize a two-dimensional function as follows:
To test the idea of the efficiency of orthogonalization to increase the performance of the quasi-Newton method, to adversely affect the minimization conditions, the initial matrix was normalized at K = 0.000001, which should significantly complicate the solution of the problem and reveal the effect of the advantages of the degree of orthogonality of the learning vectors of the BFGS and BFGS_V methods over the DFP method.
The stopping criterion was
The results are shown in
Table 3. The row with
f5(
x) shows the number of iterations, while the row with
fmin shows the minimal function value achieved.
The path of three considered algorithms is shown in
Figure 3.
Here, theoretical results of the influence of the orthogonality degree of matrix learning vectors on the convergence rate of the method are confirmed. The BFGS_V method performs forced orthogonalization, which improves the result of the BFGS method. The trajectories of the methods are listed in
Table A1,
Table A2 and
Table A3 of
Appendix A (the trajectory of the DFP method is shown partially).
9. Conclusions
This paper presents methods for converting metric matrices in quasi-Newton methods based on gradient learning algorithms. As a result, it is possible to represent the system of learning steps in the form of an algorithm for minimizing a certain objective function along a system of directions and to draw conclusions about the convergence rate of the learning process based on the properties of this system of directions. The main conclusion is that the convergence rate is directly dependent on the degree of orthogonality of the learning vectors.
Based on the study of learning algorithms in the DFP and BFGS methods, it is possible to show that the degree of orthogonality of the learning vectors in the BFGS method is higher than that in the DFP method. This means that entering the unexplored region of the minimization space due to the noise and inaccuracies of one-dimensional descent in the DFP method is more difficult than in the BFGS method, which explains why the BFGS updating formula has the best results.
As a result of studies on quadratic functions, it has been revealed that the dimension of the minimization space is reduced when iterations with an exact one-dimensional descent or iterations with additional orthogonalization are included in the quasi-Newton method. It is shown that it is also possible to increase the orthogonality of the learning vectors and thereby increase the convergence rate of the method through special normalization of the initial metric matrix. The theoretically predicted effects of increasing the efficiency of quasi-Newton methods were confirmed as a result of a computational experiment on complex ill-conditioned minimization problems. In future work, we plan to study minimization methods under the conditions of a linear background that adversely affects the convergence.


 ,
, 


{kind=link}
{kind=link}
{kind=link}


