
Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems



Abstract
:1. Introduction
- To address trajectory tracking in NTVSs, a discrete-time model incorporating system uncertainties and disturbances is formulated. This serves as the foundation for the proposed ILC [30] strategy, which integrates an AKF to enhance state estimation in dynamic environments;
- An ILC algorithm integrated with an AKF is proposed for trajectory tracking in NTVSs, where the AKF estimates system parameters [31] in real time to enhance robustness to variations and disturbances;
- Theoretical analysis confirms the robust convergence and stability of the proposed algorithm under uncertainty, thereby demonstrating its effectiveness in handling varying model parameters and external disturbances;
- Experimental validation on a precision machining platform confirms superior tracking accuracy, faster convergence, and improved disturbance rejection over conventional methods, demonstrating the effectiveness of the proposed approach in engineering applications.
2. Problem Formulation
2.1. Notation
2.2. System Dynamics
3. The Proposed Method
3.1. Knowledge for Estimation Mechanism
3.2. Algorithm Implementation
4. Iterative Learning Algorithm
4.1. ILC Problem for NTVSs
4.2. Implementation of Proposed Framework
- Tracking error term : this term penalizes the difference between the system output and the reference trajectory, ensuring that the system follows the desired reference trajectory;
- Control effort term this term regularizes the control input updates, preventing excessive changes in control efforts and improving system smoothness;
- State estimation error term : this term ensures that the estimated state from the AKF remains close to the true system state, improving robustness against modeling uncertainties.
4.3. Algorithm Description
| Algorithm 1 ILC coupled with adaptive Kalman filter strategy for NTVSs | |
| Input: Initial input , reference trajectory , sample time , total samples , maximum iteration , initial parameter estimate , weighting matrices | |
| Output: Error sequence and output sequence | |
| 1: | Initialization: Set = 0. |
| 2: | Run to (1), and then record the output and tracking error . |
| 3: | Compute based on ILC update law (20). |
| 4: | for = 1, 2, ⋯, do |
| 5: | for k = 1, 2, …, do |
| 6: | Update process noise covariance and measurement noise covariance using (16) |
| 7: | Compute the predicted state estimate and error covariance using (13) |
| 8: | Obtain system state and observation values using (15). |
| 9: | end for |
| 10: | Compute based on the tracking error and the ILC update law (20), then apply to system (1), and record and . |
| 11: | end for |
| 12: | return . |
4.4. Robust Convergence Analysis
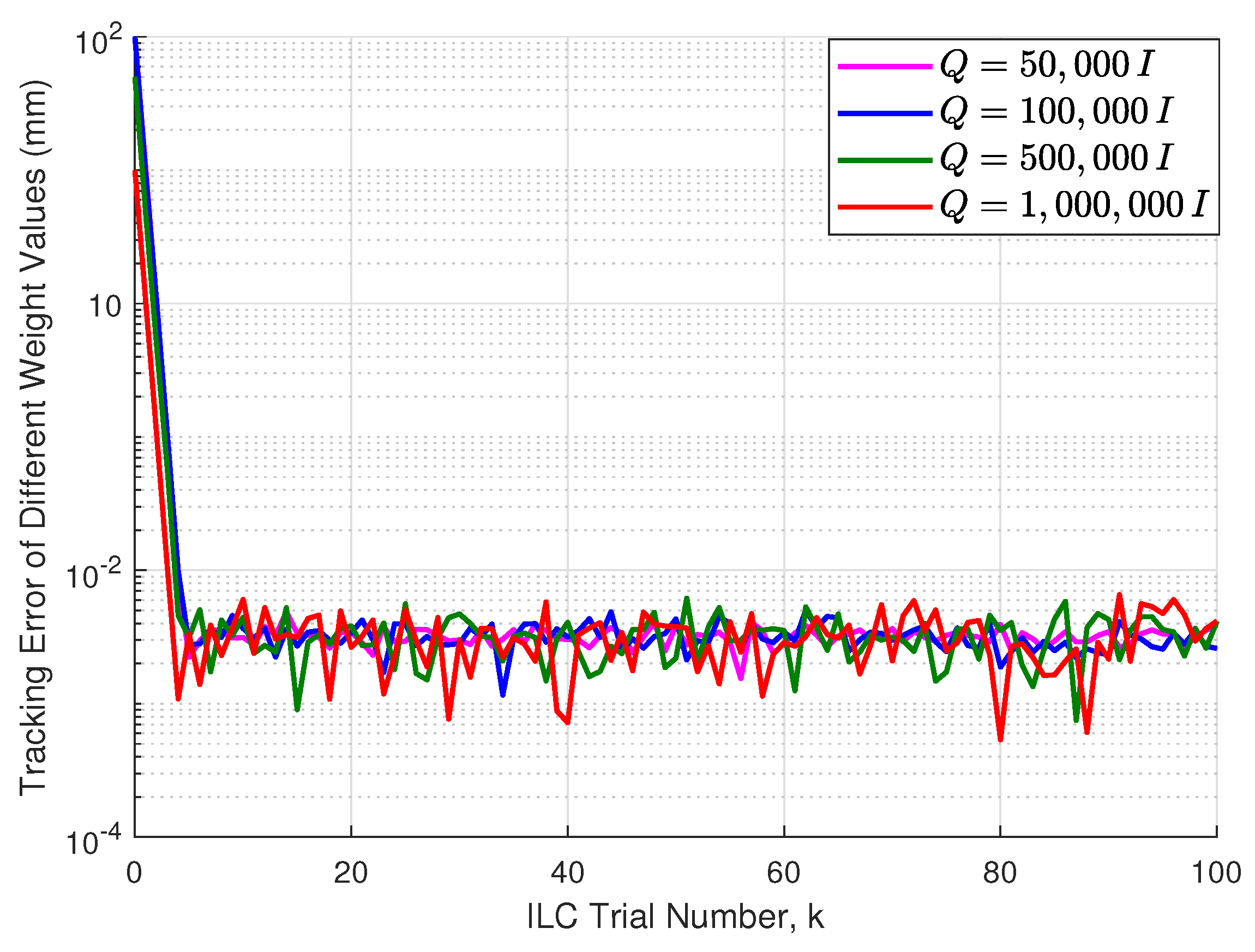
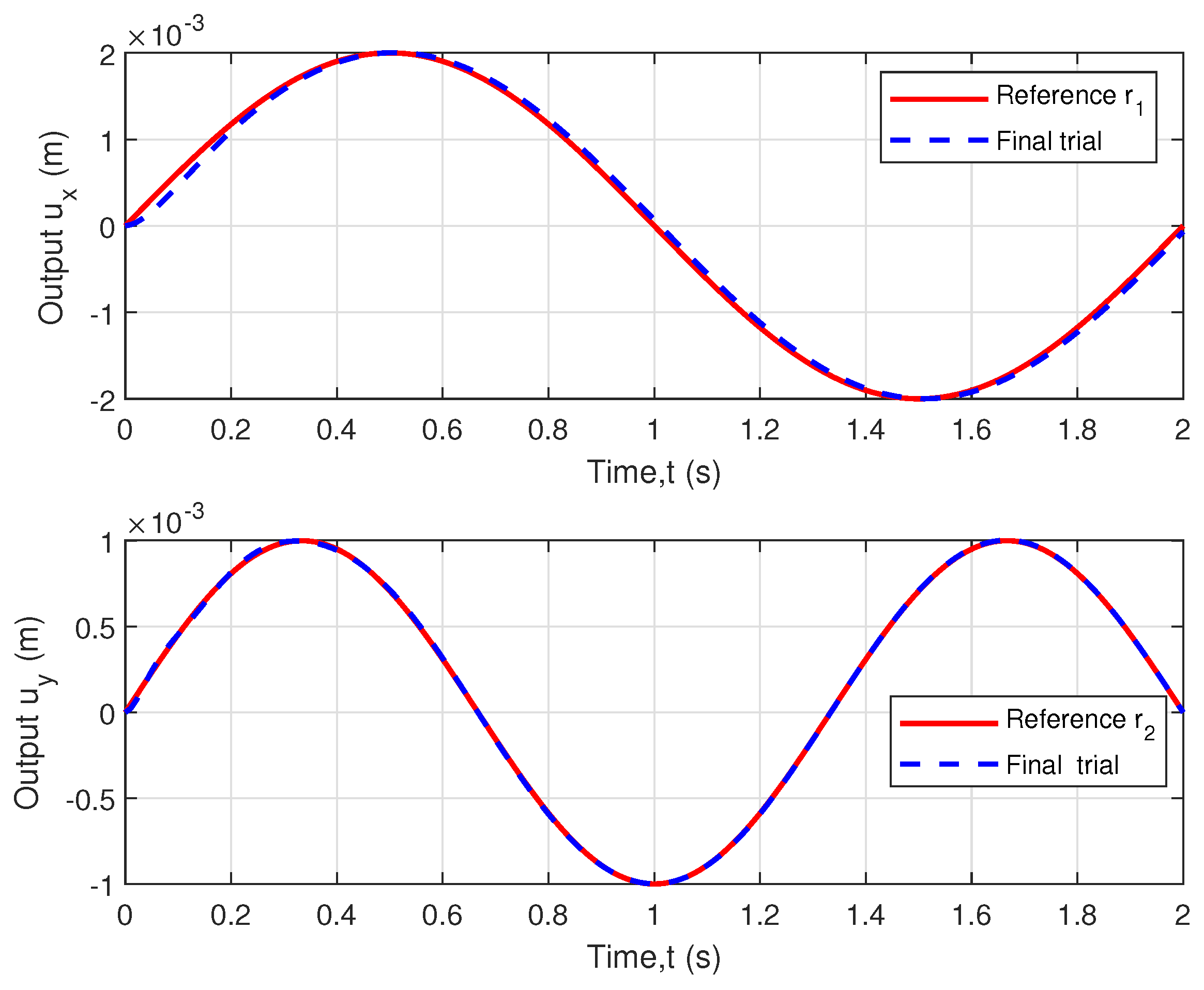
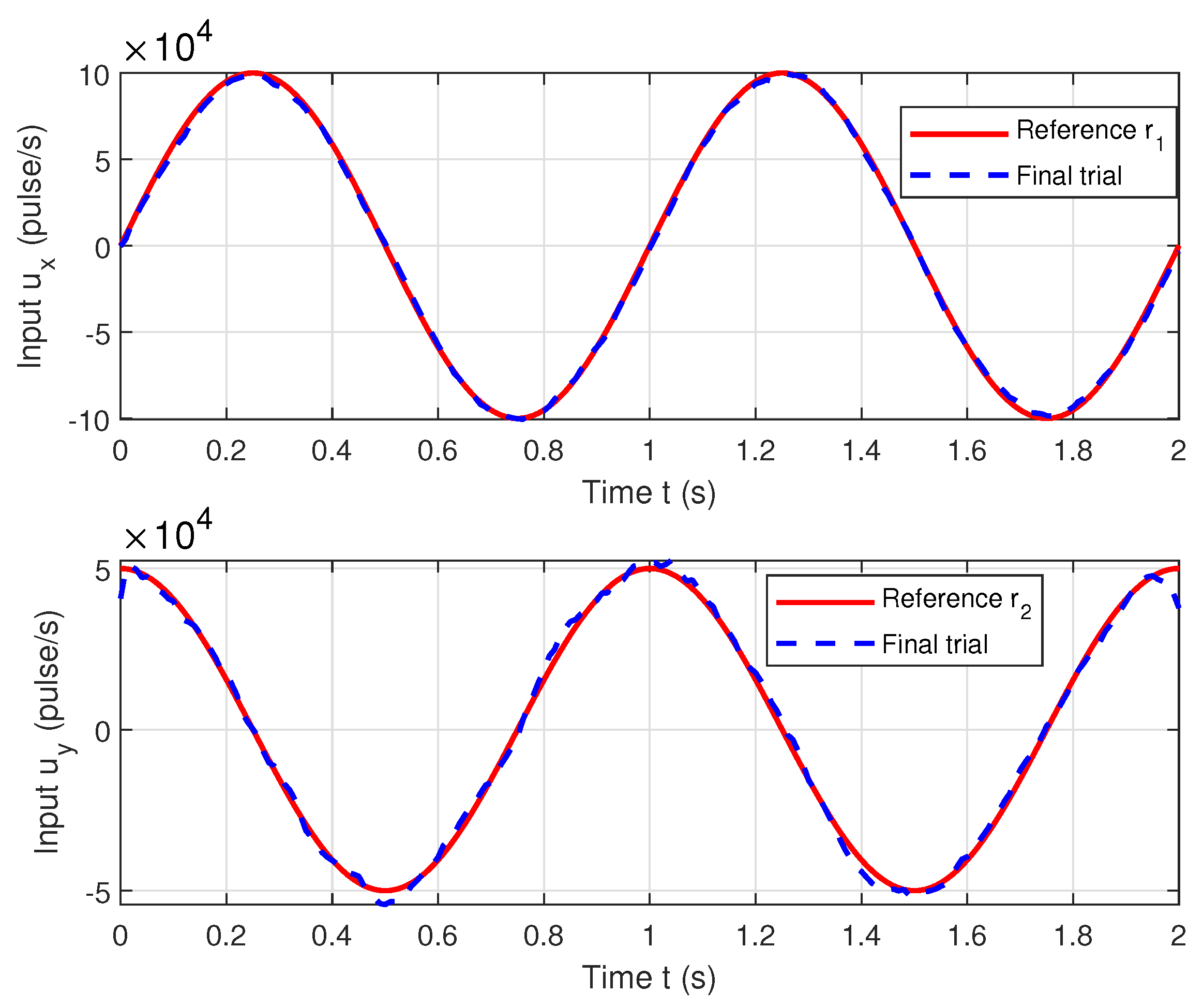
5. Experimental Validation
5.1. Tracking Task Description
5.2. Experimental Analysis
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ILC | iterative learning control |
| AKF | adaptive Kalman filter |
| NTVSs | non-repetitive time-varying system |
| ZOH | zero-order hold |
References
- Zhang, G.; Zhao, X.; Wang, Q.; Ding, D.; Li, B.; Wang, G.; Xu, D. PR internal mode extended state observer-based iterative learning control for thrust ripple suppression of PMLSM drives. IEEE Trans. Power Electron. 2024, 39, 10095–10105. [Google Scholar] [CrossRef]
- Chen, Y.; Chu, B.; Freeman, C.T. A coordinate descent approach to optimal tracking time allocation in point-to-point ILC. Mechatronics 2019, 59, 25–34. [Google Scholar] [CrossRef]
- Chen, Y.; Freeman, C.T. Iterative learning control for piecewise arc path tracking with validation on a gantry robot manufacturing platform. ISA Trans. 2023, 139, 650–659. [Google Scholar] [CrossRef] [PubMed]
- Ye, X.; Wen, B.; Zhang, H.; Xue, F. Leader-following consensus control of multiple nonholomomic mobile robots: An iterative learning adaptive control scheme. J. Frankl. Inst. 2022, 359, 1018–1040. [Google Scholar] [CrossRef]
- Liu, J.; Dong, X.; Huang, D.; Yu, M. Composite Energy Function-Based Spatial Iterative Learning Control in Motion Systems. IEEE Trans. Control Syst. Technol. 2017, 26, 1834–1841. [Google Scholar] [CrossRef]
- Hou, Z. Modified Iterative-Learning-Control-Based Ramp Metering Strategies for Freeway Traffic Control With Iteration-Dependent Factors. IEEE Trans. Intell. Transp. Syst. 2012, 13, 606–618. [Google Scholar] [CrossRef]
- Yang, L.; Li, Y.; Huang, D.; Xia, J.; Zhou, X. Spatial iterative learning control for robotic path learning. IEEE Trans. Cybern. 2022, 52, 5789–5798. [Google Scholar] [CrossRef]
- Liu, G.; Hou, Z. Adaptive Iterative Learning Control for Subway Trains Using Multiple-Point-Mass Dynamic Model Under Speed Constraint. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1388–1400. [Google Scholar] [CrossRef]
- Luo, D.; Wang, J.; Shen, D.; Fečkan, M. Iterative learning control for fractional-order multi-agent systems. J. Frankl. Inst. 2019, 356, 6328–6351. [Google Scholar] [CrossRef]
- Duan, J.B.; Zhang, Z.Y. Aeroelastic Stability Analysis of Aircraft Wings with High Aspect Ratios by Transfer Function Method. Int. J. Struct. Stab. Dyn. 2018, 18, 1850150. [Google Scholar] [CrossRef]
- Foroutan, K.; Shaterzadeh, A.; Ahmadi, H. Nonlinear static and dynamic hygrothermal buckling analysis of imperfect functionally graded porous cylindrical shells. Appl. Math. Model. 2020, 77, 539–553. [Google Scholar] [CrossRef]
- Chen, F.; Cao, Y.; Ren, W. Distributed Average Tracking of Multiple Time-Varying Reference Signals with Bounded Derivatives. IEEE Trans. Autom. Control 2012, 57, 3169–3174. [Google Scholar] [CrossRef]
- Huang, K.; Yuen, K.V. Online decentralized parameter estimation of structural systems using asynchronous data. Mech. Syst. Signal Process. 2020, 145, 106933. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Du, Y. A novel robust adaptive Kalman filter with application to urban vehicle integrated navigation systems. Measurement 2024, 236, 114844. [Google Scholar] [CrossRef]
- Chi, R.; Zhang, H.; Huang, B.; Hou, Z. Quantitative Data-Driven Adaptive Iterative Learning Control: From Trajectory Tracking to Point-to-Point Tracking. IEEE Trans. Cybern. 2020, 52, 4859–4873. [Google Scholar] [CrossRef]
- Owens, D.H.; Freeman, C.T.; Van Dinh, T. Norm-Optimal Iterative Learning Control with Intermediate Point Weighting: Theory, Algorithms, and Experimental Evaluation. IEEE Trans. Control Syst. Technol. 2013, 21, 999–1007. [Google Scholar] [CrossRef]
- Wang, L.; Huangfu, Z.; Li, R.; Wen, X.; Sun, Y.; Chen, Y. Iterative learning control with parameter estimation for non-repetitive time-varying systems. J. Frankl. Inst. 2024, 361, 1455–1466. [Google Scholar] [CrossRef]
- Huang, Y.; Tao, H.; Chen, Y.; Rogers, E.; Paszke, W. Point-to-point iterative learning control with quantised input signal and actuator faults. Int. J. Control 2024, 97, 1361–1376. [Google Scholar] [CrossRef]
- Guan, S.; Zhuang, Z.; Tao, H.; Chen, Y.; Stojanovic, V.; Paszke, W. Feedback-aided PD-type iterative learning control for time-varying systems with non-uniform trial lengths. Trans. Inst. Meas. Control 2023, 45, 2015–2026. [Google Scholar] [CrossRef]
- Tao, Y.; Tao, H.; Zhuang, Z.; Stojanovic, V.; Paszke, W. Quantized iterative learning control of communication-constrained systems with encoding and decoding mechanism. Trans. Inst. Meas. Control 2024, 46, 1943–1954. [Google Scholar] [CrossRef]
- Kim, H.; Lee, J.; Kim, J. Electromyography-signal-based muscle fatigue assessment for knee rehabilitation monitoring systems. Biomed. Eng. Lett. 2018, 8, 345–353. [Google Scholar] [CrossRef] [PubMed]
- Jha, S.; Singh, B.; Mishra, S. Control of ILC in an autonomous AC–DC hybrid microgrid with unbalanced nonlinear AC loads. IEEE Trans. Ind. Electron. 2022, 70, 544–554. [Google Scholar] [CrossRef]
- Chen, Y.; Chu, B.; Freeman, C.T. Iterative learning control for path-following tasks with performance optimization. IEEE Trans. Control Syst. Technol. 2021, 30, 234–246. [Google Scholar] [CrossRef]
- Tang, Y.; Jiang, J.; Liu, J.; Yan, P.; Tao, Y.; Liu, J. A GRU and AKF-based hybrid algorithm for improving INS/GNSS navigation accuracy during GNSS outage. Remote Sens. 2022, 14, 752. [Google Scholar] [CrossRef]
- Huangfu, Z.; Li, W.; Chen, Y.; Wang, L. ILC Coupled with Unscented Kalman Filter Strategy for Trajectory Tracking. In Proceedings of the 2024 7th International Conference on Robotics, Control and Automation Engineering (RCAE), Wuhu, China, 25–27 October 2024; pp. 598–602. [Google Scholar]
- Cai, J.; Liu, G.; Jia, H.; Zhang, B.; Wu, R.; Fu, Y.; Xiang, W.; Mao, W.; Wang, X.; Zhang, R. A new algorithm for landslide dynamic monitoring with high temporal resolution by Kalman filter integration of multiplatform time-series InSAR processing. Int. J. Appl. Earth Obs. Geoinf. 2022, 110, 102812. [Google Scholar] [CrossRef]
- Casey, J.A.; Kioumourtzoglou, M.A.; Padula, A.; González, D.J.; Elser, H.; Aguilera, R.; Northrop, A.J.; Tartof, S.Y.; Mayeda, E.R.; Braun, D.; et al. Measuring long-term exposure to wildfire PM2.5 in California: Time-varying inequities in environmental burden. Proc. Natl. Acad. Sci. USA 2024, 121, e2306729121. [Google Scholar] [CrossRef]
- Ge, Q.; Hu, X.; Li, Y.; He, H.; Song, Z. A novel adaptive Kalman filter based on credibility measure. IEEE/CAA J. Autom. Sin. 2023, 10, 103–120. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Al-Sumaiti, A.S.; Vu, V.P.; Al-Durra, A.; Do, T.D. Optimal power tracking of PMSG based wind energy conversion systems by constrained direct control with fast convergence rates. Int. J. Electr. Power Energy Syst. 2020, 118, 105807. [Google Scholar] [CrossRef]
- Chen, Y.; Chu, B.; Freeman, C.T. Iterative learning control for robotic path following with trial-varying motion profiles. IEEE/ASME Trans. Mechatron. 2022, 27, 4697–4706. [Google Scholar] [CrossRef]
- Zhai, M.; Yang, T.; Wu, Q.; Guo, S.; Pang, R.; Sun, N. Extended Kalman Filtering-Based Nonlinear Model Predictive Control for Underactuated Systems With Multiple Constraints and Obstacle Avoidance. IEEE Trans. Cybern. 2024, 55, 369–382. [Google Scholar] [CrossRef]
- Hoelzle, D.J.; Barton, K.L. On Spatial Iterative Learning Control via 2-D Convolution: Stability Analysis and Computational Efficiency. IEEE Trans. Control Syst. Technol. 2016, 24, 1504–1512. [Google Scholar] [CrossRef]
- Shen, D.; Wang, Y. Survey on stochastic iterative learning control. J. Process Control 2014, 24, 64–77. [Google Scholar] [CrossRef]
- Liang, M.; Li, J. Data-Driven Iterative Learning Security Consensus for Nonlinear Multi-Agent Systems with Fading Channels and Deception Attacks. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Li, S.; Li, X. Finite-time extended state observer-based iterative learning control for nonrepeatable nonlinear systems. Nonlinear Dyn. 2025, 1–13. [Google Scholar] [CrossRef]
- Khodarahmi, M.; Maihami, V. A review on Kalman filter models. Arch. Comput. Methods Eng. 2023, 30, 727–747. [Google Scholar] [CrossRef]
- Ni, X.; Revach, G.; Shlezinger, N. Adaptive KalmanNet: Data-driven Kalman filter with fast adaptation. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 5970–5974. [Google Scholar]
- Liu, S.; Deng, D.; Wang, S.; Luo, W.; Takyi-Aninakwa, P.; Qiao, J.; Li, S.; Jin, S.; Hu, C. Dynamic adaptive square-root unscented Kalman filter and rectangular window recursive least square method for the accurate state of charge estimation of lithium-ion batteries. J. Energy Storage 2023, 67, 107603. [Google Scholar] [CrossRef]
- Takyi-Aninakwa, P.; Wang, S.; Zhang, H.; Xiao, Y.; Fernandez, C. A NARX network optimized with an adaptive weighted square-root cubature Kalman filter for the dynamic state of charge estimation of lithium-ion batteries. J. Energy Storage 2023, 68, 107728. [Google Scholar] [CrossRef]
- Lavretsky, E.; Wise, K.A. Robust adaptive control. In Robust and Adaptive Control: With Aerospace Applications; Springer: London, UK, 2024; pp. 469–506. [Google Scholar]
- Bristow, D.A.; Tharayil, M.; Alleyne, A.G. A survey of iterative learning control. IEEE Control Syst. Mag. 2006, 26, 96–114. [Google Scholar]
- Hashemizadeh, A.; Ju, Y.; Abadi, F.Z.B. Policy design for renewable energy development based on government support: A system dynamics model. Appl. Energy 2024, 376, 124331. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Content | Parameter | |
|---|---|---|
| 1 | Space of n-dimensional real vectors | |
| 2 | Space of real matrices | |
| 3 | The inner product in Hilbert space | |
| 4 | The induced norm in Hilbert space | |
| 5 | Process noise covariance matrix | |
| 6 | Measurement noise covariance matrix | |
| 7 | State estimation error covariance matrix | |
| 8 | Adaptive weights for covariance matrix update |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Zhu, S.; Wei, M.; Wang, X.; Huangfu, Z.; Chen, Y. Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems. Axioms 2025, 14, 324. https://doi.org/10.3390/axioms14050324
Wang L, Zhu S, Wei M, Wang X, Huangfu Z, Chen Y. Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems. Axioms. 2025; 14(5):324. https://doi.org/10.3390/axioms14050324
Chicago/Turabian StyleWang, Lei, Shunjie Zhu, Menghan Wei, Xiaoxiao Wang, Ziwei Huangfu, and Yiyang Chen. 2025. "Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems" Axioms 14, no. 5: 324. https://doi.org/10.3390/axioms14050324
APA StyleWang, L., Zhu, S., Wei, M., Wang, X., Huangfu, Z., & Chen, Y. (2025). Iterative Learning Control with Adaptive Kalman Filtering for Trajectory Tracking in Non-Repetitive Time-Varying Systems. Axioms, 14(5), 324. https://doi.org/10.3390/axioms14050324