1. Introduction
The increasing digitalization in mechanical engineering leads to a demand for new, integrated sensor solutions. Martin et al. [
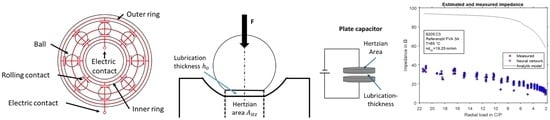
1] have presented a sensor concept, shown in
Figure 1, in which the electrical impedance of rolling bearings is measured to estimate the bearing load. With the use of the sensing bearing concept it is possible to implement predictive maintenance and process monitoring more easily in new and existing machines based on load data. The technology is based on the relationship that elasto-hydrodynamic lubricated contacts have a capacitive behavior, which leads to a measurable electrical impedance in an alternating current circuit [
2]. The voltage levels of the sensor concept are below harmful values as mentioned in [
3]. The literature gives analytical models to describe this effect, but they have an accuracy that is not sufficient to use the models as sensors. For this reason, the models available in the literature were extended in Schirra et al. [
3] so that a much more accurate analytical calculation of the bearing impedance is possible. Despite the improvements in the models achieved, there is still a discrepancy between calculated and measured values.
The aim in the application is therefore to determine bearing forces on the basis of the rotational speed, the temperature and the electrical impedance of the rolling bearing. However, in the experiment, the electrical impedance of the rolling bearing cannot be controlled directly, so the bearing load, rotational speed and temperature are the input parameters of the experiment and the data drive methods where the electrical impedance is evaluated. In addition, this makes it easier to compare the results with the literature, which also evaluates the electrical properties. It is also an obvious step to choose the frequency spectrum of the electrical impedance as input parameter, where Martin et al. [
1] measured a correlation to the bearing frequencies to replace the input parameter rotational speed. Although the procedure in the experiment is such that the electrical impedance is determined from the bearing load, temperature and rotational speed, the model is used in reverse in the application. The frequency spectrum is thus available in the application and offers the possibility to replace the input parameter rotational speed by the dependencies to the bearing frequencies.
The aim of this paper is to implement the determination of the bearing impedance using machine learning algorithms. It is expected that this method can further reduce the deviation between model and measurement, which are described in the current literature [
3].
In the following sections first an overview of the electrical properties of rolling bearings will be given. Thereupon, machine learning methods which are suitable for the regression of the bearing impedance will be presented.
1.1. Electrical Properties of Rolling Bearing Contacts
The electric behavior of rolling bearings was so far mainly analyzed in connection with inverter induced damage phenomena caused by electric discharge (Gemeinder et al. [
2], Furtmann et al. [
4]), being motivated by the analysis of the contact zone of the loaded rolling elements, current research was often motivated by the increased usage of electric drive systems in individual transport. Recently the model has been expanded for the hydrodynamic regime [
3,
4,
5] by including the remaining unloaded rolling elements in the analysis. In the boundary friction regime the rolling element behaves like an ohmic resistor whereas the model of a capacitor is appropriate for the hydrodynamic regime, see
Figure 2. The rolling element with the highest load or the smallest operational lubrication film thickness, respectively, determines the overall behavior of the rolling bearing.
The loaded contact is described using the notion of a plate capacitor with the Hertzian contact area
and the operational lubricant film thickness
as shown in
Figure 3. According to common literature the lubricant is assumed to be an isolator with the specific permittivity
. The nominal capacity
is calculated by:
Usually, a correction factor
is introduced to account for the effects of the inlet and outlet flow zone as well as for the boundary of the Hertzian contact zone shown in
Figure 3 left. Hence, the operational capacity
of the rolling contact in hydrodynamic lubrication conditions is:
The dimensioning of the correction parameter
varies between
(Gemeinder et al. [
4]) and
(Furtmann et al. [
2]). The cage of the rolling bearing can be considered as an insulator or conductor since the influence on the total bearing impedance is within the range of 2%, according to Furtmann. Hence, the overall electric behavior of a rolling bearing in hydrodynamic lubrication can be represented as a network of capacitors as shown in
Figure 3, right.
At low speeds or very high loads, respectively, the electric behavior of the rolling bearing tribological system in mixed lubrication conditions changes towards an ohmic resistor, the behavior is of similar type as in (1) and the dependency reads as:
When summarizing the electric behavior of the contact in the loaded tribological system by including both the hydrodynamic state represented by Equation (2) as well as the boundary friction state represented by Equation (3) for an alternating current loading condition with frequency
one arrives at the complex impedance of the rolling contact:
The imaginary unit is indicated by the symbol . When measuring with an alternating current of frequency the transition from mixed, resistive dominated friction to hydrodynamic, capacitive friction should be detectable by a change of the phase angle according to Equation (4) and of the magnitude. When applying a direct current in the measuring circuit the change to occur is from ohmic behavior to an insulating behavior indicated by a change of the impedance of several orders of magnitude.
Given the different load conditions (Hamrock & Dowson [
7]) the rolling elements are exposed to while traveling through the load zone
, the lubrication film governing the overall electric behavior of the rolling bearing is located at the inner race underneath the applied load, as it is shown in
Figure 4. This tribological contact is the last one to change its state of operation from mixed to hydrodynamic lubrication since the high load leads to the smallest lubrication film thickness over all contacts, which is why it has a strong impact on the total impedance. Hence, this change from resistive to capacitive behavior needs to be monitored.
So far, the discussion in this section assumes loaded rolling contacts. In rolling bearings, especially when loaded by radial loads only, the unloaded rolling elements outside the load zone
sketched in
Figure 4 contribute to the overall bearing impedance. Therefore, additional aspects were recently added by Schirra et al. in [
3] to the analyses performed by Jablonka et al. in [
5] who analyzed a single rolling contact. The additional contributions to the total bearing impedance have significantly helped to reduce the differences between measured and calculated impedance. Remarkably is that, even though no fitting parameter can be used to tune the enhanced model, the difference between model and measurement assumes a more or less constant value which indicates a possible systematic measurement peculiarity which can be easily identified by methods of artificial intelligence.
1.2. Machine Learning Methods
With the increasing amount of available data in all scientific disciplines, the interest in methods that extract information from these data is also growing. This can be observed in the scientific environment as well as in the free market [
9]. Hence there is a hypothesis that machine learning can outperform the not sufficient accurate analytical equations in the field of bearing impedance. This machine learning approach has not been studied so far in the scientific environment.
The potential of machine learning methods is enabled by larger data streams made possible by technological advances in hardware, computing power, data storage and data transfer. Likewise, the technologies mentioned are becoming more and more economical. In addition, algorithms are becoming more and more powerful and software less expensive. This is based on the current open source trend since investments primarily come from data-driven industries [
9].
Machine learning methods are increasingly used to solve such data-driven problems due to the newly emerging possibilities. Supervised learning methods are particularly suitable for solving data-driven problems. These are presented below regarding their application in engineering sciences. The investigated methods are linear methods, tree-based methods, and neural networks, where each method maps the input matrix X on the target variable Y. Where in this context the input is temperature, velocity and force. The output is the bearing impedance.
1.2.1. Linear Regression Methods
The linear regression linearly maps correlations between input parameters and output parameters. Mathematically, the relationship for
input parameters is formulated as follows [
9]:
The parameters
for
describe the linear dependence between the different input parameters
and the output parameter
. These must be optimized based on the available data set. Due to the linear character of Equation (5) an optimum is guaranteed [
10].
For regression problems with many input parameters, advanced linear methods like lasso regression can be used. These ensure that only input parameters that are vastly correlated with the output are included in the regression. This is done with a regularization parameter 𝜆. The optimization problem is according to [
11]:
The first summand represents the root-squared-mean-error [
9] and the second one the regularized regression parameters.
Since physical phenomena are often nonlinear, correlations with polynomial regression can also be regressed in higher dimensions [
9]. This is a special form of linear regression. In the one-dimensional case, a d-order polynomial is adapted to existing data with the following equation:
The optimization of the parameters is still a convex optimization problem and is performed like the linear regression with iterative methods for example the gradient descent method [
11].
1.2.2. Decision Trees
Decision trees are simple methods for the solution of classification and regression problems. They consist of root nodes and nodes that can be interpreted as decision points and leaves that can be described as decision results [
12]. The data set is divided binary at points where a division has the highest information content. This can be described using the Gini coefficient
, where
stands for the proportion of the
k-th class in the
m-th region [
11]:
Decision trees can adapt very well to the training data, but when applied to the test data, this can lead to rather inaccurate results. This behavior is called overfitting and can be interpreted as memorization [
11]. Possibilities to increase the generalization of the results are the modification of the algorithm to a random forest or the boosting of decision trees [
12]. The random forest is based on many uncorrelated partial decision trees and is called an ensemble method. The same applies to boosting, which determines the result by weighted weak learners [
11].
1.2.3. Neural Networks
The neural network is a nonlinear optimization problem. Due to its ability to learn complex facts it is used with increasing frequency for complex tasks. The basic algorithm was published several decades ago [
13]. It consists of units arranged in layers. The units represent the calculation rule
:
The input
is optimized with the help of the weights
where
is a bias parameter. The output
is finally activated and passed on with activation functions [
13]. Currently the rectified linear unit (ReLU) function is state of the art and used as the activation function [
13]. If the output of a unit is positive, it is activated linearly and if it is less than or equal to zero, it is deactivated. Mathematically formulated, the nonlinear ReLU function is according to [
14]:
The weights
are minimized to train the neural network using nonlinear optimization algorithms. Classical methods are the stochastic gradient descent [
10] and Newton methods like the limited-memory Broyden-Flechter-Goldfarb-Shanno (L-BFGS) algorithm [
15,
16].
The aim of the experiments was the comparison of measurement results with the analytical models from the literature to identify promising approaches for the further development of these models [
3]. To limit the complexity of the analytical models in the first step, only bearings under purely radial load were tested. The difference between the extended analytical model and the measurement led to the choice of a data-based approach. In the following work, combined axial and radial loads as well as the size influence of different bearing types will be investigated [
8].
3. Results and Discussion
Based on the different model approaches, the regression results are compared. Different aspects such as accuracy and generalizability of the algorithms are discussed. For each case one single bearing and all eight measured bearings are considered in one model and the errors are compared.
Table 3 shows the accuracy of the impedance prediction depending on the parameters and the regression method used. In
Figure 10 the value of the prediction error is reported. F stands for radial force, V for velocity, T for temperature and A for impedance spectrum of the impedance Z. The abbreviations of the input parameters are FVT 1 or FVT 8. The input parameters are load (F) velocity (V) temperature (T). The designation FVT 1 considers data measured with only one bearing (160 measuring points). FVT 8 considers the whole data measured with the eight bearings examined in the test (1280 measuring points). The comparison of the accuracies will show whether bearing tolerances caused by manufacturing or the assembly process have a major influence on the measurement result.
Linear regression performs least well in the FVT investigation. All other algorithms used deliver very high accuracies in the range between 97 % and 99 % for both one and eight bearings. A significant trend cannot be identified when comparing one and eight bearings in use.
Table 4 shows the accuracy of the impedance prediction depending on the parameters and the regression method used. With the abbreviations FAT 1 and FAT 8 the input parameter velocity is replaced by the amplitude spectrum (A) of the bearing impedance. The reason is the possible use case for the technology, Schirra et al. [
3] mentioned. Thereby, bearing impedance is measured to predict bearing loads for predictive maintenance applications. The question is if an additional sensor for the velocity is needed or the amplitude spectrum of the impedance contains this information.
From the accuracy results shown in
Table 3 and
Table 4 it can be concluded that a second-order polynomial yield more accurate results than linear regression. Thus, it can be concluded that the physical relations for at least one input parameter are nonlinear, otherwise the match would be perfect to the interpolation chosen. For complex models with many input parameters, as in the case of the amplitude peak, the lasso extension must be used for the linear regression, because not every amplitude correlates significantly with the impedance and therefore gives bad results for a non-weighted approach. The random forest and gradient boost algorithms can be used for both FVT and FAT as they are decision tree- based ensemble methods that automatically identify relevant parameters [
11].
The various machine learning algorithms offer varying degrees of transparency. Linear and polynomial regression offer good comprehensibility due to their simple structure. Random forest and gradient boost are tree-based methods, which are difficult to interpret due to the large number of trees used for prediction. NNs are the least interpretable in comparison to the other models due to their complex architecture. Furthermore, these properties are related to the algorithms’ generalizability. When using test data that is not within the range of the training data, the algorithms behave in different ways. Linear and polynomial regression extrapolate relatively well based on their simple defined structure. The prediction of the neural network outside of the training range is rather erratic. However, these extrapolation characteristics are not discussed in detail here, since these are known properties of the machine learning algorithms. The test data used for the results shown here originates from the same data set as the training data. Therefore, extrapolation effects do not arise in this case.
It turns out that algorithms based on a single bearing have about the same quality as for a stack of bearings, so that the training can be done individually for a bearing or a pre-trained algorithm can be considered over many bearings. In addition, bearing tolerances and the assembly process do not have a major influence on the measurement result. An overview of the expected error in all investigated models can be found in
Figure 10. In addition to the mean error of the predicted impedance, its standard deviation is shown.
Based on the test data it seems, that random forest, gradient boosting and neural network are superior to both linear and polynomial regression in terms of their prediction results. But looking at the higher variance of the sensors in comparison to the machine learning methods the output even of the best algorithm can vary. Based on the results obtained the following observations are made: Depending on the test case, different algorithms perform particularly well. The standard deviation with only a very limited number of bearing is in generally higher compared to the use of eight or more bearings. This can be caused by the different amount of data available for training. The machine learning algorithms are able to obtain information about the excitation frequency on the amplitude spectrum (
Figure 10c,d), so that a speed measurement of the shaft for impedance determination can be omitted at the cost of about 1% accuracy. Ensemble methods are the most accurate for the problems at hand. However, it should be mentioned that ensemble methods do not learn on-line but can only be used for closed data sets. The neural network always delivers predictions with above-average accuracy and is therefore the most suitable algorithm for the determination of the electrical impedance.
An example of predictions made by a neural network compared to actual measured impedances is shown in
Figure 11. The accuracy is 98.97%. Furthermore, the well calculable correlation between the electrical impedance and the operating conditions shows that the impedance can also be an additional influencing variable for determining the remaining useful life of rolling bearings, as shown in [
22]. The analytical model of Schirra et al. [
3] exhibits an almost constant offset to the measurement results, which is nearly independent of temperature and rotational speed. It is clearly shown in in
Figure 11 that the description with a neural network does not have the observed offset between the measurement and the analytical calculation. In addition, the description with the neural network has the advantage that every single measuring point can be described with its exact temperature. In the experiment, the temperature is set to 65 °C, but the control is only accurate to 1 °C, so deviations by this difference are possible. The analytical model has the temperature of 65 °C as input parameter, while the neural network has the exact, measured temperature as input parameter for each individual point. Thus, the uncertainty that is introduced into the analytical calculation by the control is notably reduced here.
In general the accuracy of the load predictions by either machine learning method is the range of measuring accuracy of the test device. Hence, it can be concluded, that from a practical perspective all methods applied in this paper lead to the same quality of bearing load estimates, which is on the order of the total measurement error of the apparatus. The prediction accuracy for the rotational speed is independent from the accuracy of bearing load prediction since only the governing orders in the measured spectrum are analysed, the absolute value or the phase angle of the impedance is here only of minor importance. As an overall estimate the rotational speed can be calculated with a precision of 95% over the complete operational range of the bearing.
4. Conclusions
Even though the accuracy of analytical calculations of bearing impedance has already been improved in previous publications, there is still a notable deviation from the real measurement data in the analytical calculations, leading to an off-set which is almost constant for the operational range analyzed so far. For this reason, the approach chosen here is to predict the bearing impedance using machine learning algorithms. As shown, these data-based approaches achieve much higher accuracies than the current analytical models and reduce the error to 2% as a rule of thumb. Within the compared machine learning algorithms, the neural network performs particularly well.
In addition to the prediction of the bearing impedance, it is also shown that the rotational speed can be predicted with high accuracy from the frequency spectrum of the bearing impedance. Thus, it is shown that in future investigations the direct measurement of the rotational speed is not mandatory, since it can be calculated from the measured bearing impedance.
Consequently, in the present paper the example of the bearing impedance demonstrates, that the deficits of analytical methods can be compensated with the help of data-driven algorithms. Since the underlying physics are taken into account when selecting the relevant parameters, the models used here can be categorized as so-called grey-box models.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}