1. Introduction
As a clean renewable energy source, wind energy does not produce pollutants [
1], and WT is an important contributor toward energy production free of CO
2 [
2]. According to the most recent report of the WWEA, the global wind power capacity reached 840 Gigawatt in 2021 [
3]. Wind farms are generally located in remote areas such as plateaus or coastal areas, with inconvenient transportation, a poor working environment, and susceptibility to extreme weather conditions, which bring many difficulties to the operation and maintenance of wind turbines [
4]. With the increase in operation time, various types of failures may occur in the electrical system, transmission system, and control system of WT, leading to the WT’s abnormal operation, and high operation and maintenance costs [
5].
Fault diagnosis technology plays an important role in the running safety of WT, and maintenance staff use this technology to detect abnormality in time, handle it accordingly, and to extend the lifetime of WT [
6]. An analysis of the series data obtained by a SCADA system is usually used to diagnose a WT’s condition [
7]. A large number of variables related to WT operating characteristics, such as wind speed, output power, temperature, current, and voltage are collected in the SCADA system, which can provide a rich source of data for WT diagnosis [
8].
Artificial intelligence (AI) methods such as machine learning (ML), artificial neural network (ANN), and deep learning (DL) are commonly used in the WT fault diagnosis, because of their robustness and self-adaptive capabilities. ML is to improve computer intelligence by independently learning the patterns that exist in large amounts of data and gaining new experience and knowledge to have a human-like decision-making ability. The ML algorithms that are most widely used in fault diagnosis are mainly K-nearest neighbor (KNN) [
9], SVM [
10], random forest (RF) [
11], and extreme learning machine (ELM) [
12]. ANN is a complex network that simulates the structure of the biological nervous system, with a large number of simple interconnected neurons. It performs the parallel processing of information and non-linear transformation by imitating the way a human brain neural processes information [
13]. In the past decades, it has been developed rapidly and widely used in fault diagnosis of WT, for example, ANN methods have been used to diagnose faults in gearboxes [
14,
15,
16,
17] bearings [
18,
19], and generators [
20,
21].
Although ANN and ML have been broadly applied for fault diagnosis in recent decades, their diagnostic performance largely relies on feature extraction and selection. Instead, the DL algorithm has gradually become the main method for WT fault diagnosis due to its powerful feature extraction ability. At present, DL methods such as convolutional neural networks (CNN) [
22,
23], stacked automatic encoders (SAE), recurrent neural networks (RNN) [
24], and deep belief networks (DBN) [
25] are used in the fault diagnosis of rotating machinery.
Due to the complex deep structure of DL, which involves a large number of hyperparameters, the DL network is trained slowly and easily falls into a locally optimal solution. To overcome these problems, Chen et al. [
26] proposed the BLS, which not only has a simple structure, fast training speed, and high accuracy rate but also has the advantage of enhanced learning. After BLS was proposed, researchers have successively proposed many improvements of BLS [
27,
28] and applied them to image classification [
29], pattern recognition [
30], numerical regression [
31], automatic control [
32], and other fields.
As a novel learning method, BLS solves the problem that the traditional neural network training methods are not applicable to multi-layer network training, effectively prevents the network from falling into local optimum, and improves the effectiveness of network convergence. In order to build a BLS model that satisfies the requirements, it is necessary to adapt the relevant parameters, and researchers often set the parameters according to their practical experience and a priori knowledge. For different problems, it may be necessary to repeatedly manually tune the relevant parameters.
To solve such problems, the parameters of BLS are optimized using the IPOA algorithm, hence, constructing the IPOA-BLS classification model. The experimental results indicate that the proposed model can better classify the faults of WT. The main contributions are highlighted as follows:
- (1)
The experimental SCAD data were preprocessed and fault-related features were selected based on the principal component analysis (PCA) method [
33,
34];
- (2)
The original POA algorithm was improved and was tested with benchmark functions;
- (3)
The parameters of the BLS such as the number of feature nodes , number of enhancement nodes , and number of mapped feature layers were optimized by the IPOA algorithm;
- (4)
The processed WT fault data were used as the experimental sample with the SVM, DBN, BLS, PSO-BLS, POA-BLS, and IPOA-BLS models to classify and compare performance.
The rest of this paper is organized as follows: BLS, POA, and IPOA algorithms are introduced in
Section 2.
Section 3 describes SCADA data preprocessing, the IPOA-BLS classification model, and relevant parameter settings. Some graphical results with an analysis are given in
Section 4. Finally,
Section 5 concludes this paper.
2. Description of BLS, POA, and IPOA
2.1. BLS
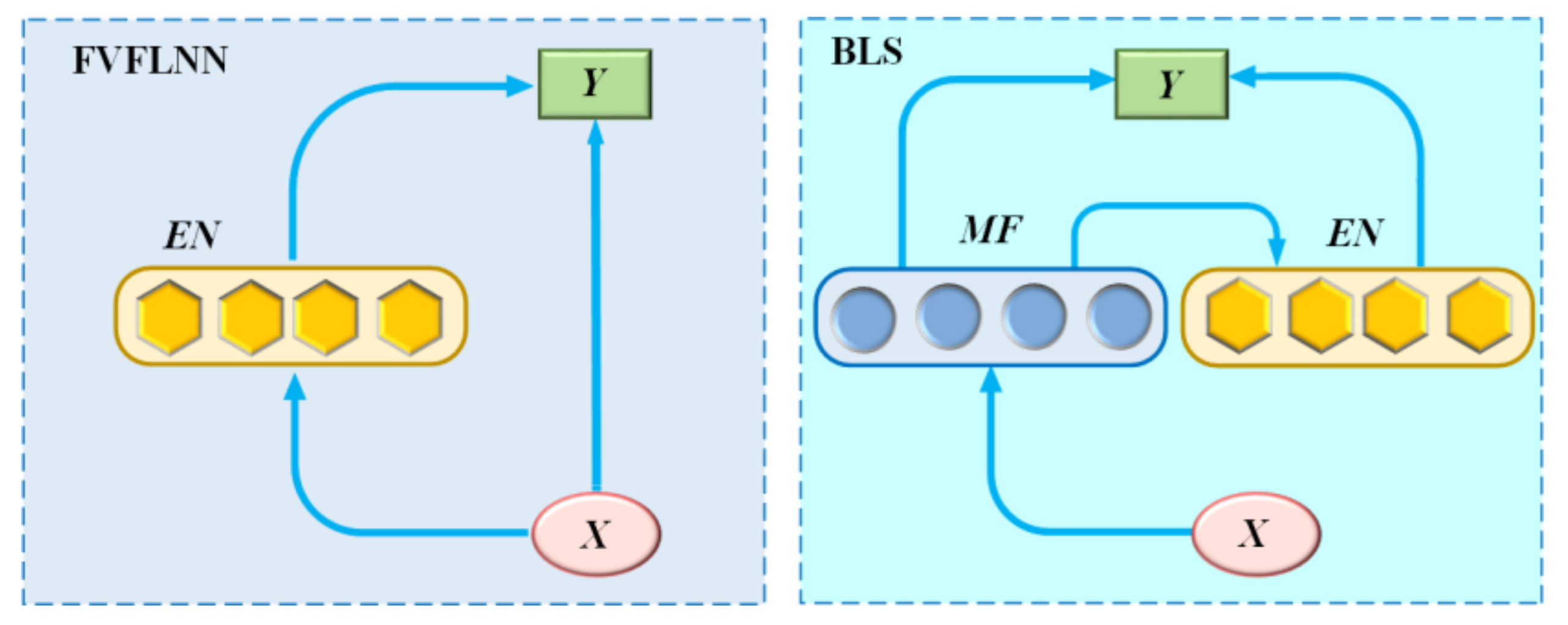
BLS is a novel learning method proposed on the basis of a random vector functional-link neural network (RVFLNN) [
35,
36]. It does not require a time-consuming training process and has a strong function approximation capability. The structure diagram of RVFLNN and BLS is shown in
Figure 1.
As can be seen from
Figure 1, RVFLNN consists of three parts, namely the input layer, the enhancement node, and the output layer, and the output layer connects both the input layer and the enhancement nodes (EN). In contrast to RVFLNN, the BLS maps to the mapped feature (MF) first before the input layer data is mapped to EN, and the output layer connects both MF and EN.
In terms of network structure, the network of BLS is horizontally expanded and vertically fixed, which is very different from deep neural networks, and the number of layers is greatly reduced, and its structure is shown in
Figure 2. A feature node
, maps the original data to obtain the following formula:
where
is the input layer data;
and
denote the weight and bias of the input layer
to
, respectively, which is generally fine-tuned by a sparse autoencoder to produce the optimal value;
is a linear or nonlinear activation function;
is the
i-th group of feature nodes containing
neurons.
All feature nodes can be represented as
, after obtaining the feature node
, it can be used to calculate the enhancement node
.
where
is the
j-th group of enhancement nodes containing
neurons;
is the nonlinear activation function;
and
represent weights and biases, respectively. The model of the BLS can be obtained by further calculations:
where
represents the weight between the output layer and the hidden layer formed by the feature nodes and enhancement nodes. In the BLS, parameters such as
,
,
,
are randomly generated and fine-tuned by a sparse autoencoder, and remain constant during the training process; the metrics learned in the network are only
. The objective function of the BLS is:
where
is used to control the minimization of training error;
is used to prevent overfitting of the model;
is the regularization factor;
is the output;
is the transpose matrix of
;
is the unit matrix.
2.2. POA
The POA is a new meta-heuristic optimization algorithm [
37] inspired by pelican hunting behaviors. It has the advantages of few adjustment parameters, fast convergence speed, and simple calculation. Pelicans are found in the warm waters of the world and live mainly in lakes, rivers, coasts, and swamps [
38]. Pelicans generally live in flocks; they are not only good at flying but also good at swimming [
39]. They have sharp eyesight in flight, as well as excellent observation skills, and they mainly feed on fish. After determining the location of the prey, the pelicans rush towards the prey from a height of 10–20 m and dive straight into the water to hunt [
40]. If pelicans find schools of fish, they will arrange themselves in a line or U-shape to swoop down from the sky towards the fish in the water and use their wings to flap the water, forcing fishes to move upwards, and then collect the fishes in their throat pouch. Depending on the above explanation, the mathematical model of the POA algorithm was built.
- (1)
Initialization: Assuming that there are
pelicans in an
dimensional space, the position of the
i-th pelican in the
dimensional space is
, the position
of the
pelicans is expressed as follows:
where
denotes the position of the
i-th pelican in the
m-th dimension. At the initialization stage, pelicans are randomly distributed within a certain range, and the position update of the pelican is described as
where
,
is the search range of the pelican;
is a random number between (0, 1).
- (2)
Moving towards prey: In this phase, the pelican identifies the prey’s location and then rushes to the prey from a high altitude as shown in
Figure 3. The random distribution of the prey in the search space increases the exploration ability of the pelican, and the update of the pelican’s location during each iteration is described as
where is a current iteration number; denotes the position of the i-th pelican in the m-th dimension; is the position of the prey in the m-th dimension; is randomly equal to 1 or 2; is the objective function value; denotes the value of the fitness function of i-th pelican in the m-th dimension.
- (3)
Winging on the water surface: After the pelicans reach the surface of the water, they spread their wings on the surface of the water to move the fish upwards, then collect the prey in their throat pouch. This behavior of pelicans during hunting is mathematically simulated
where is a current number of iterations; is a maximum iteration number; is the neighborhood radius of , and it represents the radius of the neighborhood of the population members to search locally near each member to converge to a better solution; is a random number between (0, 1).
2.3. IPOA
After improving the original POA algorithm, the optimization efficiency could be further improved. The specific improvement strategy is as follows.
- (1)
Initialization strategy: The Tent chaotic map [
41] is used to replace the randomly generated method in the original POA to initialize the pelicans after the Tent chaotic mapping is introduced, and the Equation (6) can be rewritten as follows:
where is a current number of iterations; is a maximum iteration number; where , , .
At this stage, the position of the pelicans is initialized using the Tent chaotic map, which helps to improve the global search performance of the POA algorithm.
- (2)
Moving towards prey: At this stage, the dynamic weight factor [
42]
helps the pelican to constantly update its position. At the beginning of the iteration,
has a large value, when the pelican is able to perform a better global search, and at the end of the iteration
decreases adaptively, and this time the pelican is able to perform a better local search while increasing the convergence speed. the Equation (7) can be rewritten as follows:
To prove the correctness and validity of the IPOA algorithm, ten benchmark functions were tested using PSO, GWO, WOA, POA, and IPOA. The value of each algorithm parameter is shown in
Table 1.
Descriptions of the benchmark functions are shown in
Table 2. In this table,
f 1–f 4 are the unimodal test functions,
f 5–f 7 are the multimodal test functions, and
f 8–f 10 are the composite benchmark functions.
Table 3,
Table 4 and
Table 5 report the relevant statistical experiment results from running each algorithm 30 times in the benchmark function independently. In these tables, “Best”, “Worst”, “Average”, and “Std.” represent the best value, the worst value, the average value, and the standard deviation of the algorithm, respectively.
The convergence curve of the
f 1–
f 10 functions is shown in
Figure 4: the red line denotes the IPOA algorithm, and the blue line represents the POA algorithm. It implies that the fitness value of the IPOA algorithm is lower and the convergence speed faster than other algorithms.
4. Experimental Results and Analysis
In order to state the advantages of the IPOA-BLS model in fault diagnosis, the classification results were compared with SVM, DBN, BLS, PSO-BLS, and POA-BLS diagnostic models. The classification results of each model are shown in
Figure 6. In
Figure 6, the blue circle (○) and red star (✲) mean the actual and predicted classification of the testing set samples, respectively. The blue circles and red stars overlap each other when the actual and predicted values of the classification are equal. If they are different, the blue circle and the red star do not overlap. The more overlapping means the fault resolution of the model is higher. In
Figure 6a, the blue circle and red star overlap less, and the classification effect of the SVM model plays worse. In
Figure 6f, the red star and the blue circle overlap each other the most times, which indicates that the IPOA-BLS model has the best classification effect.
To further visually reflect the fault identification capabilities of the model, the confusion matrix was used to visualize the fault recognition ability of SVM, DBN, BLS, PSO-BLS, POA-BLS, and IPOA-BLS models. The confusion matrix of each diagnostic model was calculated and plotted separately, and the results are shown in
Figure 7. The diagonal elements of the confusion matrix indicate the number of samples that can be accurately classified, and the greater the number of diagonal elements, the better the classification performance of the model. The off-diagonal elements of the confusion matrix represent the number of samples that can be wrongly classified, and the smaller number of off-diagonal elements, the better the classification efficiency of the model.
In
Figure 7a, the SVM model can only accurately classify fault-F3. In total, 14 samples originally belonging to fault-F1 were misclassified as fault-F2. Two samples originally belonged to fault-F2; however, one of them was misclassified as fault-F1, and another one was misclassified as fault-F4, respectively. Altogether, 45 samples originally belonged to fault-F4; however, 1 of them was misclassified as fault-F5, 12 of them were misclassified as fault-F1, and 32 of them were misclassified as fault-F1, respectively. In total, 37 samples originally belonged to fault-F5, but 1 of them was misclassified as fault-F4, and 36 of them were misclassified as fault-F2, respectively. In
Figure 7f, the IPOA-BLS model almost accurately classified fault-F1, fault-F2, fault-F3, and fault-F5. Only nine samples originally belonging to fault-F4 were misclassified as fault-F1.
It can be seen from
Figure 7 that among the 800 test samples, the SVM model accurately classified 702 samples with an accuracy of 87.75%. The DBN model accurately classified 730 samples, and its accuracy was 91.25%. The BLS model exactly categorized 734 samples with an accuracy of 91.75%. The PSO-BLS model accurately classified 759 samples with an accuracy of 94.875%. The POA-BLS model rightly classified 774 samples, and its accuracy was 96.75%. The IPOA-BLS model exactly classified 790 samples with an accuracy of 98.75%. An observation can be made that the IPOA-BLS model was the most accurate compared with other models.
In order to better assess the performance of the proposed classification model, accuracy, precision, recall, and F1-score were used in the present study. The specific expressions are, respectively, as follows.
- (1)
The accuracy represents the number of correctly predicted samples as a percentage of the total number of samples.
- (2)
The precision reflects the proportion of samples with a positive prediction that are really positive.
- (3)
The recall is the proportion of the number of correctly classified positive samples to the number of true positive samples.
- (4)
The
F1-score is the weighted harmonic mean of precision and recall.
In the above equations, TP represents true positives; FP is false positives; and FN is false negatives.
In each fault, the classification performance metrics are shown in
Table 9. It can be seen from
Table 9 that the proposed model had the higher evaluation indicators no matter which evaluation standard was used.
The IPOA-BLS model has many advantages. Compared with the other models, there was a significant improvement in the classification accuracy in terms of WT fault diagnosis. The PCA method played an important role in dimension reduction and feature extraction, and it was used to reduce the number of features of the experimental SCADA data from 52 to 35, which helped to decrease the calculation time of the model. The IPOA algorithm was evaluated through some different benchmark functions and was applied to the parameter’s estimation of BLS. As can be seen from
Figure 6 and
Figure 7, compared with the standard pelican optimization algorithm, the improved pelican optimization algorithm had a positive effect on BLS’s parameters optimization. After optimizing the related parameters of BLS with the improved pelican optimization algorithm, the number of rightly classified samples increased by about 16, and the accuracy improved by 2%.
5. Conclusions
In this paper, in addition to the chaotic map strategy, the dynamic weight factor strategy was also used to improve the location of the standard pelican optimization algorithm in the initialization and moving towards prey stage; this helps to enhance the exploration of the improved pelican optimization algorithm technique. To improve the classification accuracy of the broad learning system model, the experimental data were normalized and the improved pelican optimization algorithm was used to optimize hyperparameters such as the number of feature nodes , number of enhancement nodes , and number of mapped feature layers . Performance indexes, classification accuracy, a classification results diagram, and confusion matrices fully demonstrate the excellent performance of the proposed classification model and verify the classification effect. The proposed model is very suitable for wind turbine fault classification in future practical applications.
The classification accuracy rate of the proposed model reaches a high level for typical wind turbine faults. Consequently, this model possesses great potential in wind turbine fault detection. In future studies, the development of the algorithms for fault feature extraction purposes will be investigated, and classification models based on deep learning will be analyzed.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}