1. Introduction
In the condition monitoring of rolling element bearings, the vibration data of rolling element bearings is usually collected by using sensors. Then, fault diagnosis is carried out in time domain, frequency domain or time-frequency domain based on these data [
1,
2]. Because the monitoring environment is often accompanied by strong vibration, sometimes there may be uncertain impacts on the normal operation of sensors. For example, in the actual vibration signal acquisition process, the vibration data in some time periods may be lost due to sensor failure, signal transmission or poor line contact [
3,
4]. In addition, a large number of outliers, missing values and inconsistent data are mixed in the monitoring of big data, resulting in decreased data quality [
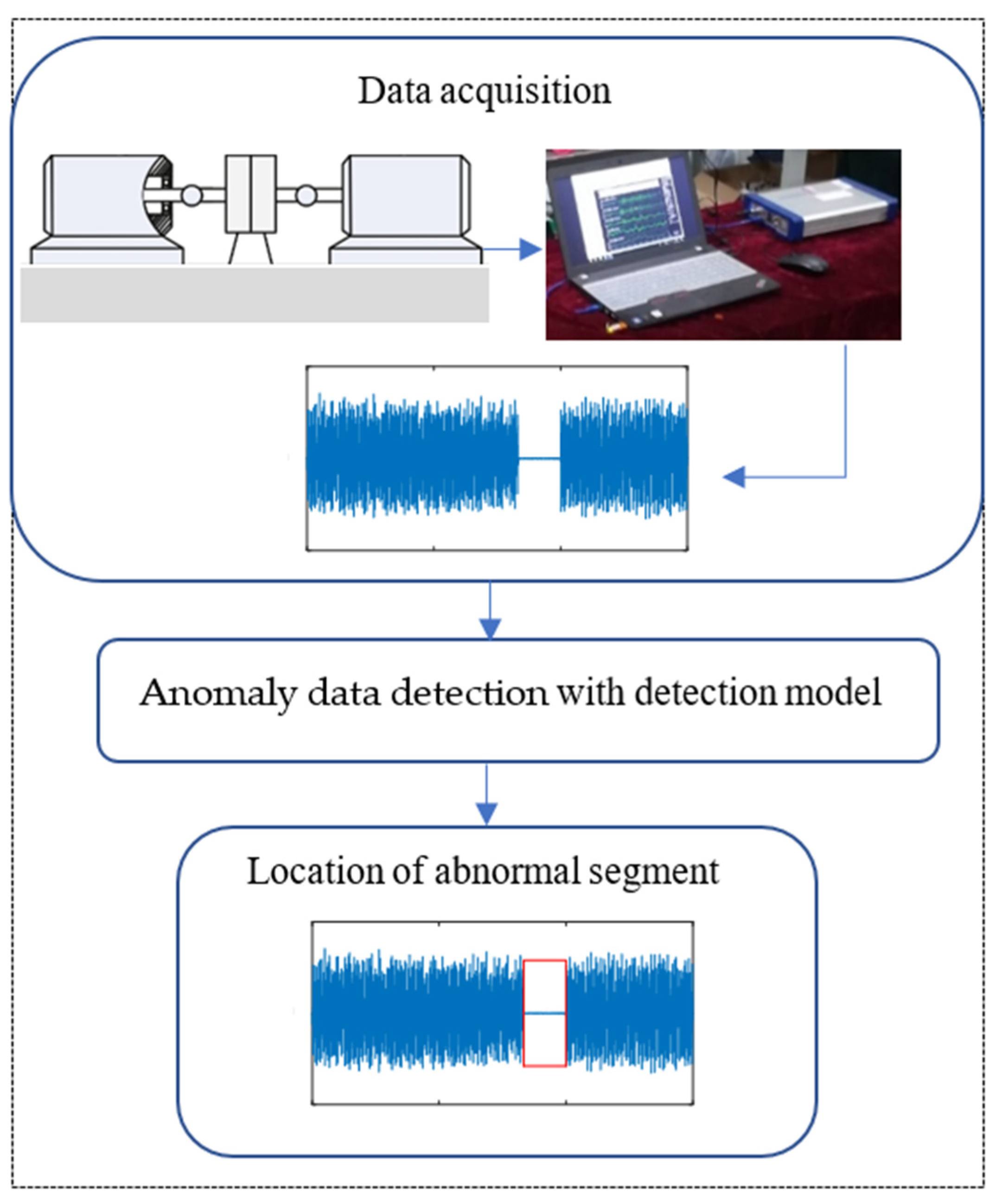
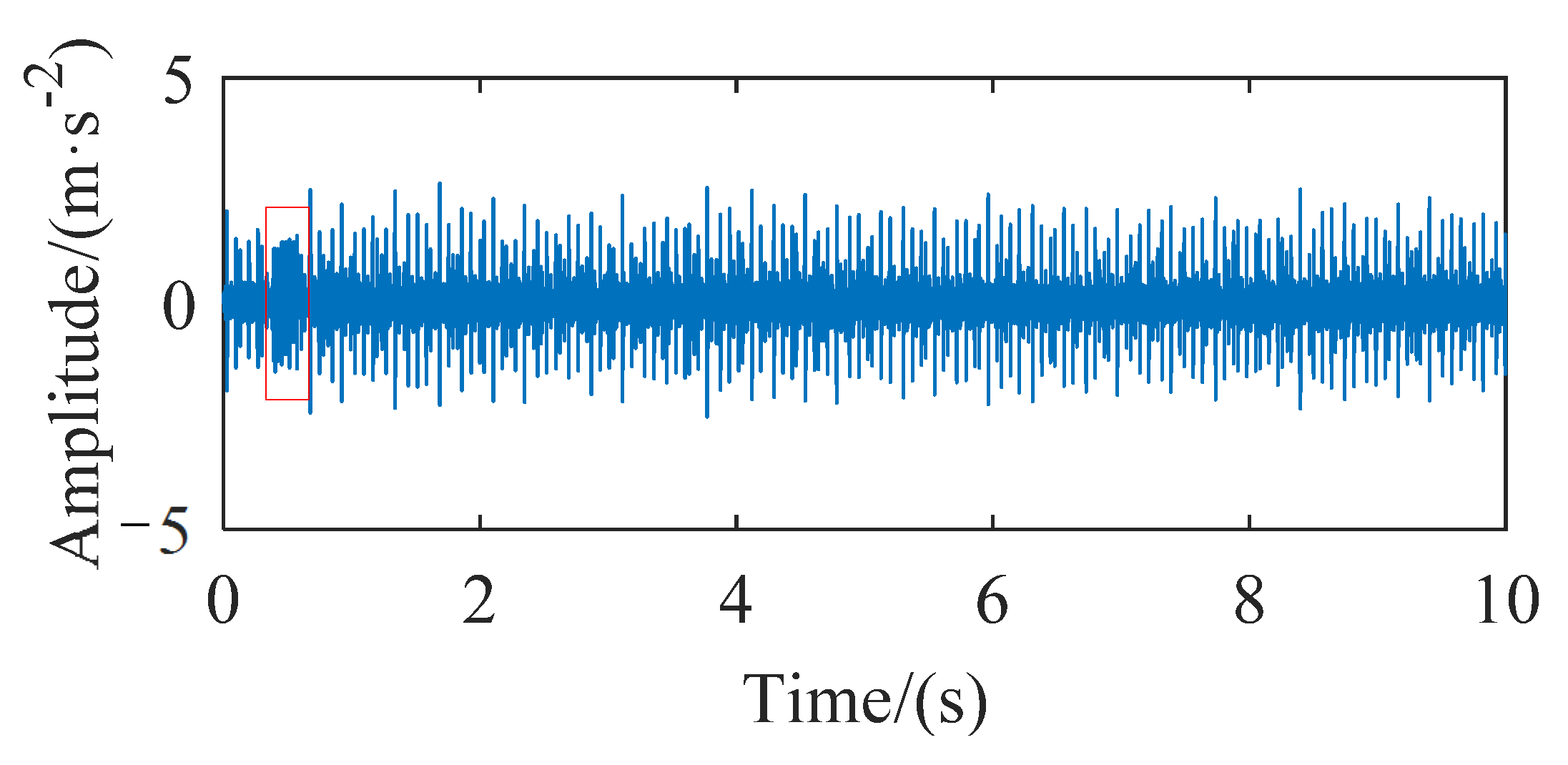
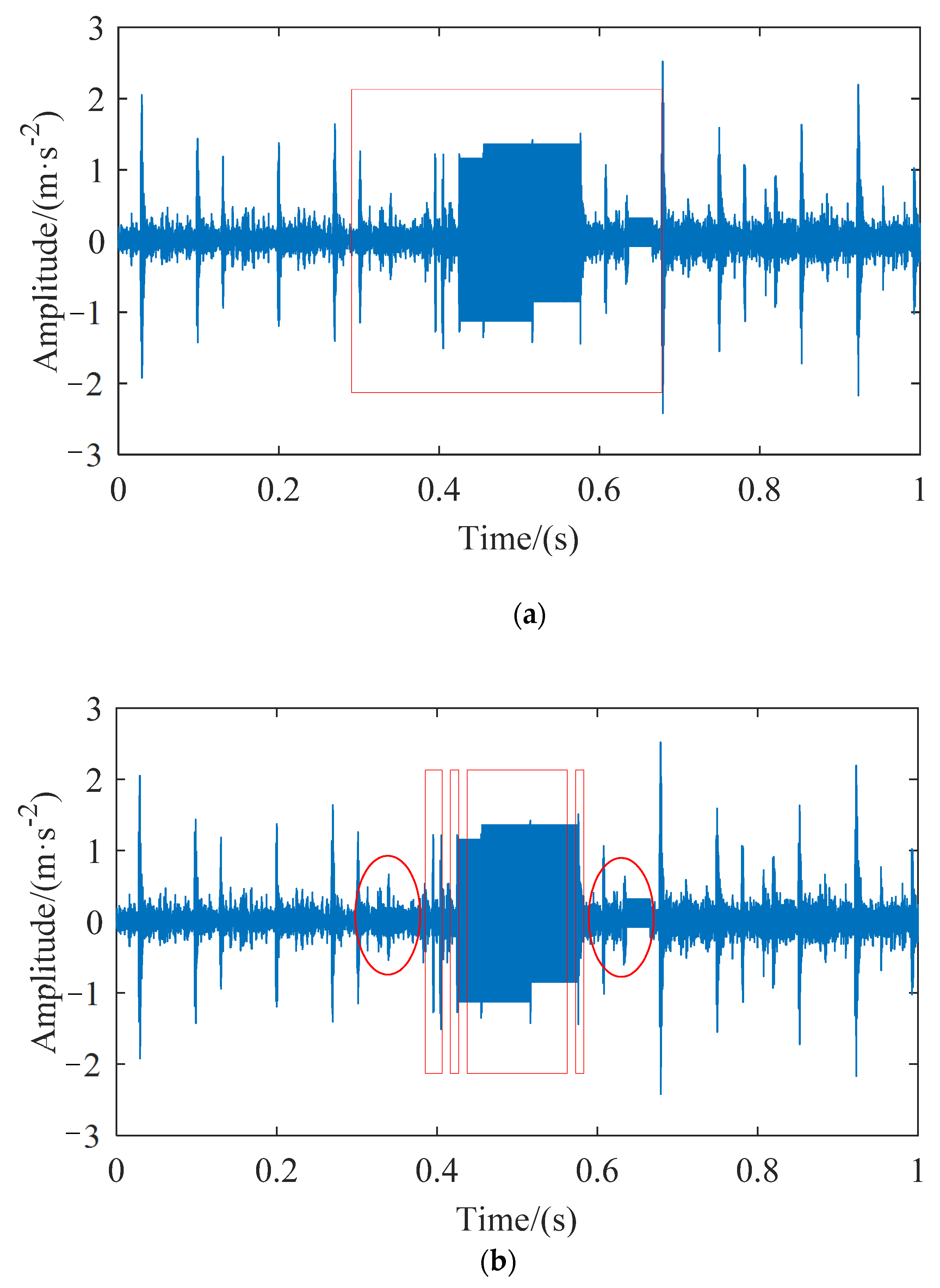
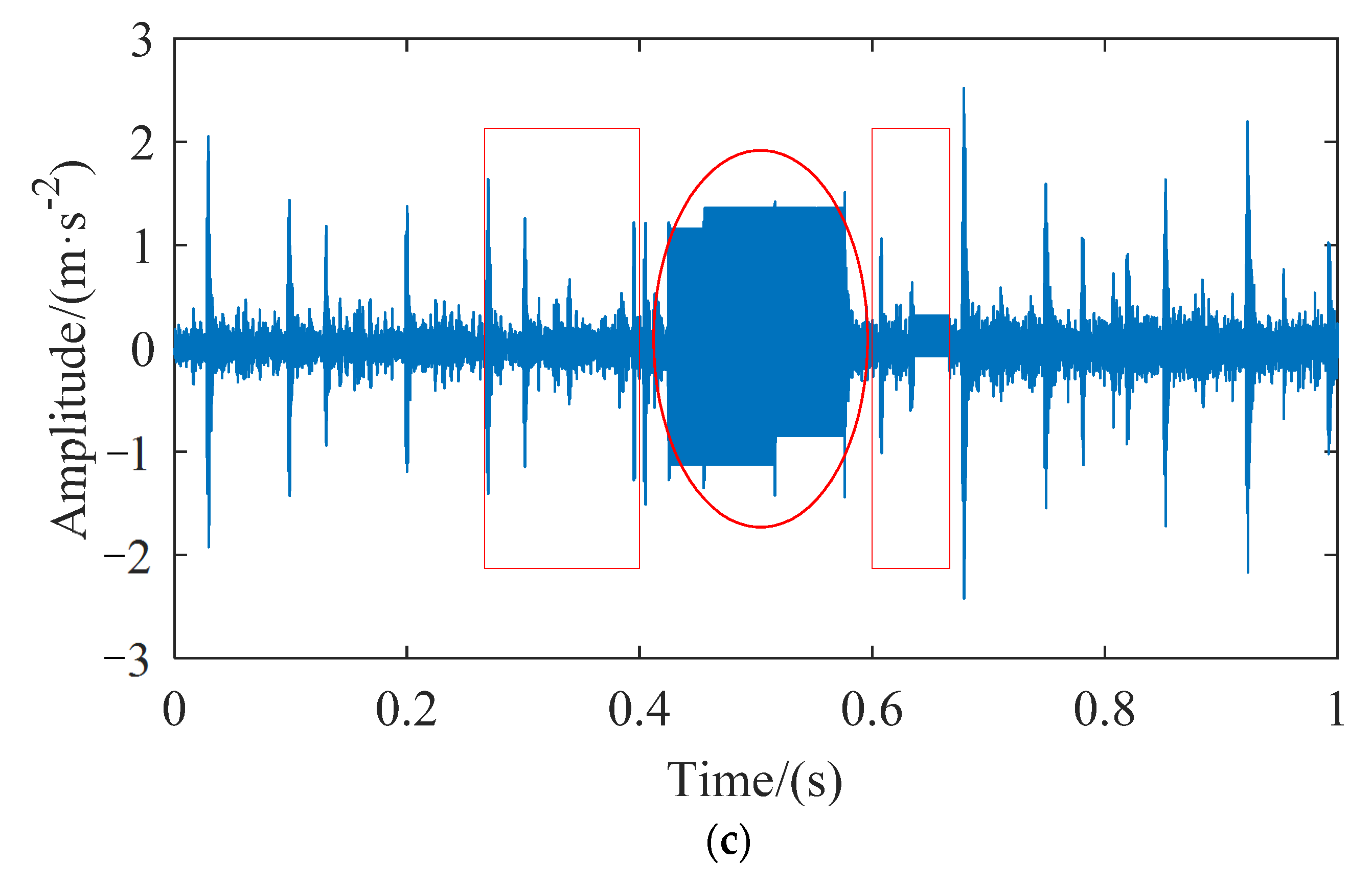
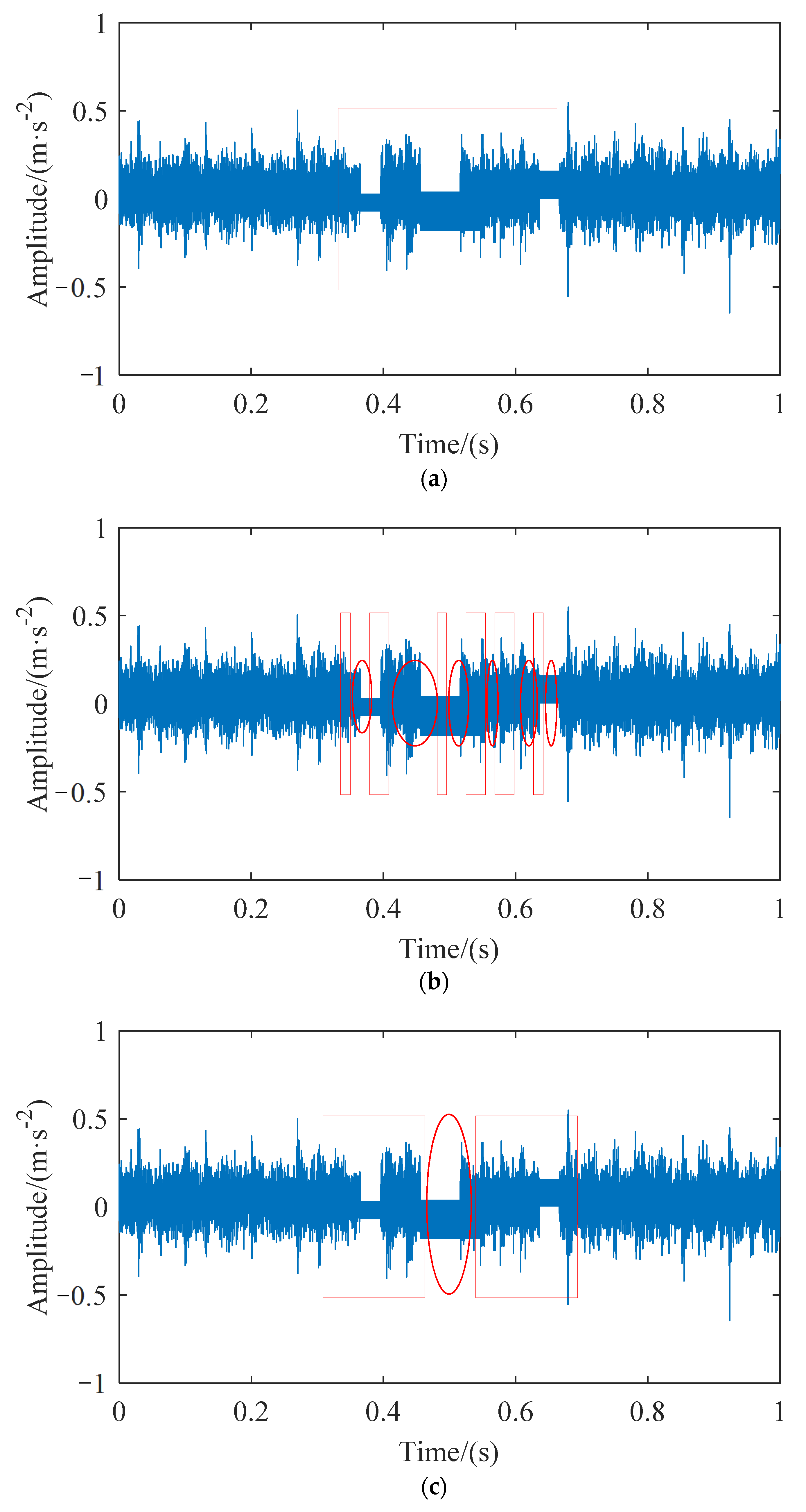
5]. The direct use of these dirty data will affect the accuracy of fault detection or diagnosis and increase the difficulty of rolling bearings health monitoring. The abnormal data positioning and detection process of rolling bearings is shown in
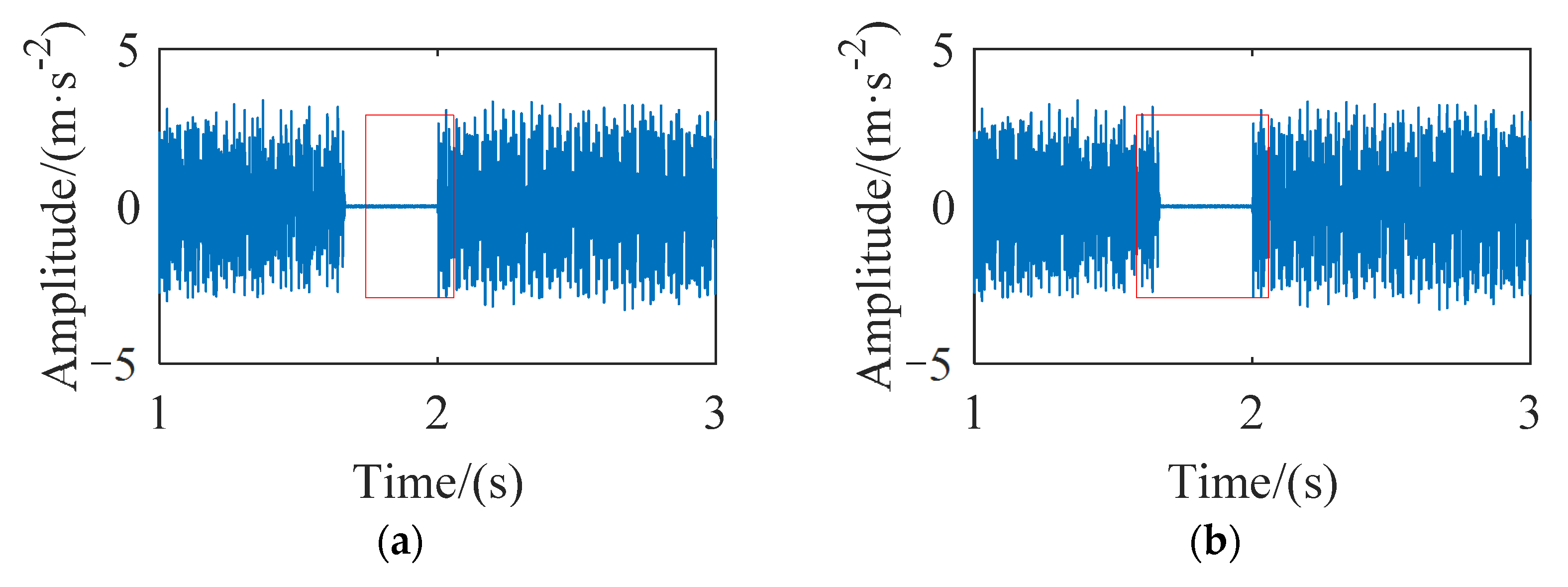
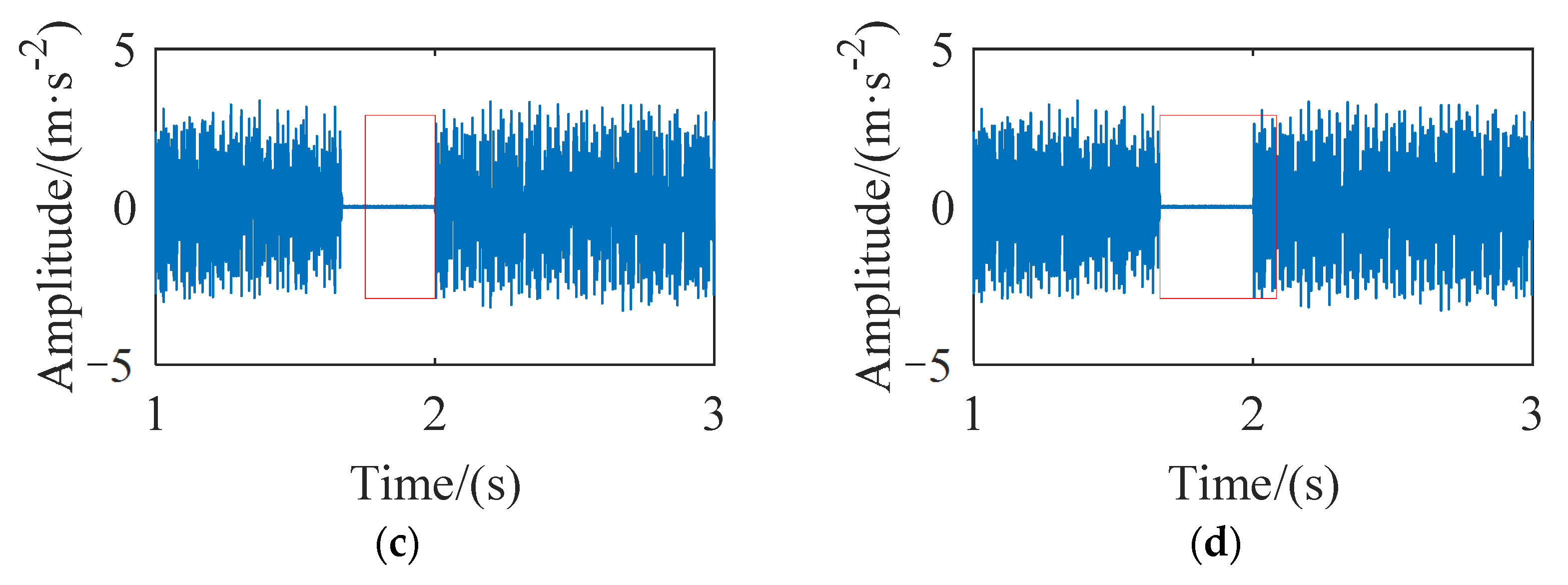
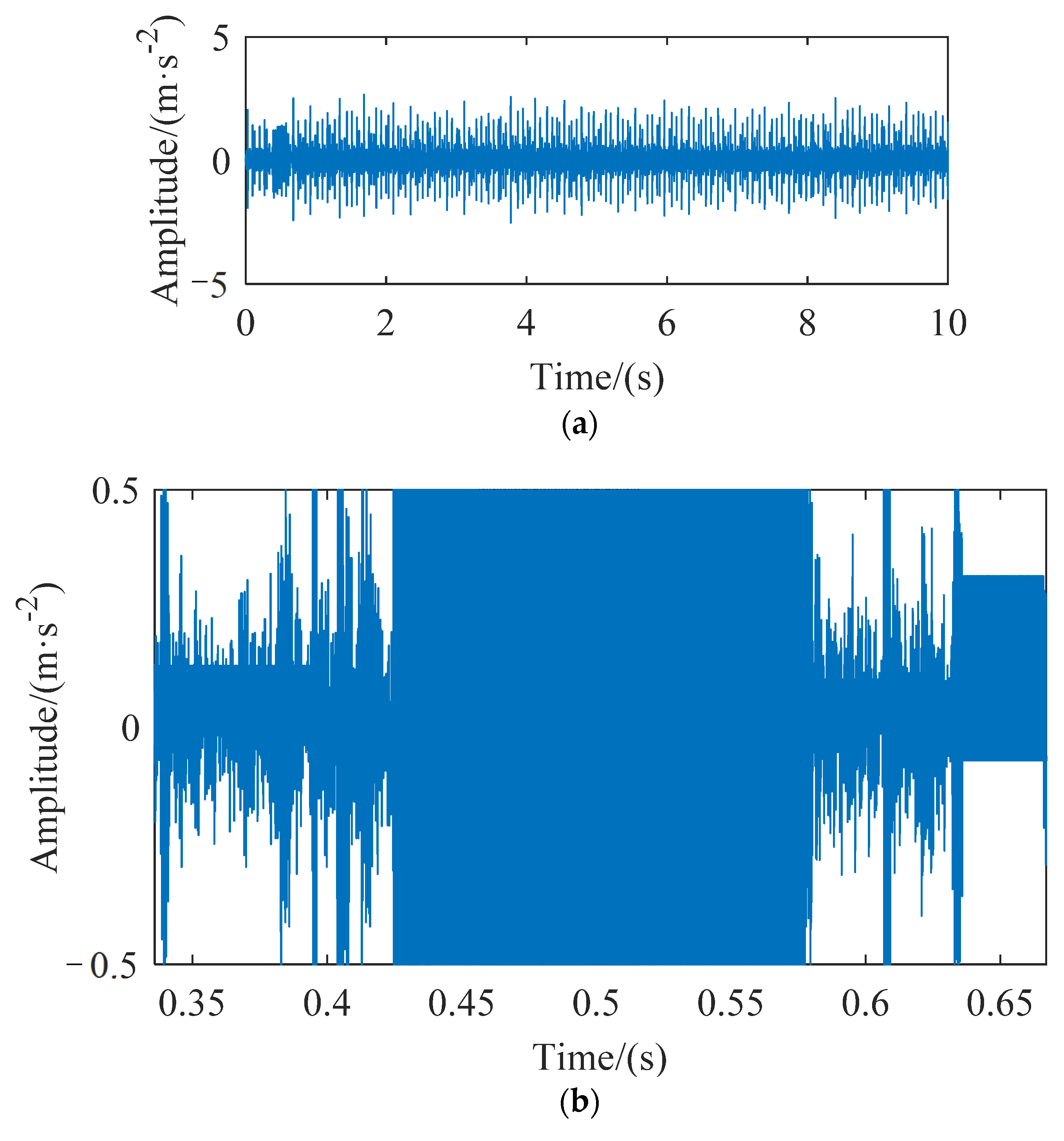
Figure 1. The quality of complete data is reduced due to the existence of missing data. If abnormal polluted data can be detected and subsequent cleaning work can be carried out, the accuracy of state analysis of rolling bearings will be improved.
Outlier detection [
6] methods have been widely studied in wind power generation [
7], aerospace [
8] and other fields. Witayangkurn et al. [
9] proposed the use of a Hidden Markov Model (HMM) to detect anomalies in large-scale GPS data. Nonetheless, this approach does not consider the time self-dependence of the observation sequence and requires that the model complexity be predefined, which may bias the unsupervised approach to the analysis [
10]. According to the hypothesis of HMM, the HMM model is memoryless and cannot use the information of context. Since it is only related to its previous state, a high-order HMM model has to be established to obtain more information.
There are generally two ideas for PCA [
11] in anomaly detection, and both pay special attention to the feature vector corresponding to the smaller eigenvalue. The purpose of the PCA principle is mainly to eliminate the correlation between variables, and assuming that this correlation is linear, it may not obtain good results for nonlinear dependence. The anomaly detection method based on automatic encoder (AE) is a typical reconstruction method that detects anomalies through the error of reconstruction sequence [
12,
13], while its training data require a large amount of normal data for abnormal recognition scenarios. The statistic-based method assumes a distribution or probability model for data and then the points in the regions of low probability are determined as outliers [
14]. In order to recognize the dirty data included in the machinery monitoring data, a new auto regression-generalized, autoregressive conditional heteroskedasticity (AR-GARCH) method is proposed by Lei [
15], which can detection local pulse in time series, but it is not validated by other types of abnormal data.
As for distance-based methods, there is the Mahalanobis distance [
16], in which each object is calculated and those objects far away from most objects are regarded as outliers. This method may fail to detect outliers in areas with different densities. The local outlier factor (LOF) [
17] method is proposed through comparing the density around the data points with the density of their local neighbors. However, in practical application, due to its limitation of only establishing local anomaly models and high complexity, the effect of LOF may not be as good as that of the distance-based method. In the LGBD [
18] method, each data point is regarded as an object of the mass and local resultant force (LRF) generated by its neighbors. The main advantage of LGBD is that the detection performance is improved. However, its algorithm complexity is still close to LOF.
Amer et al. [
19] proposed an anomaly detection method based on the one-class SVM. Its training set should not be doped with outliers, because the model may match these outliers in the test set. A clustering-based method [
20], such as K-means [
21], supports vector domain description (SVDD) [
22] and density-based spatial clustering of applications with noise (DBSCAN) [
23]. They detect outliers which are against clusters, and since the main objective of a clustering method is to find clusters, the cluster-based method may also fail to detect outliers.
The isolation forest (IF) [
24], which is based purely on the concept of isolation to detect anomalies without relying on any distance or density measurement, is an unsupervised method without the process of modeling normal data. Since most of the samples do not need to be trained when using this algorithm, the detection model can be constructed by using a data set with a small sample size. IF has strong advantages in detection accuracy and complexity through constructing an isolation tree (iTree) and limiting the depth of the trees [
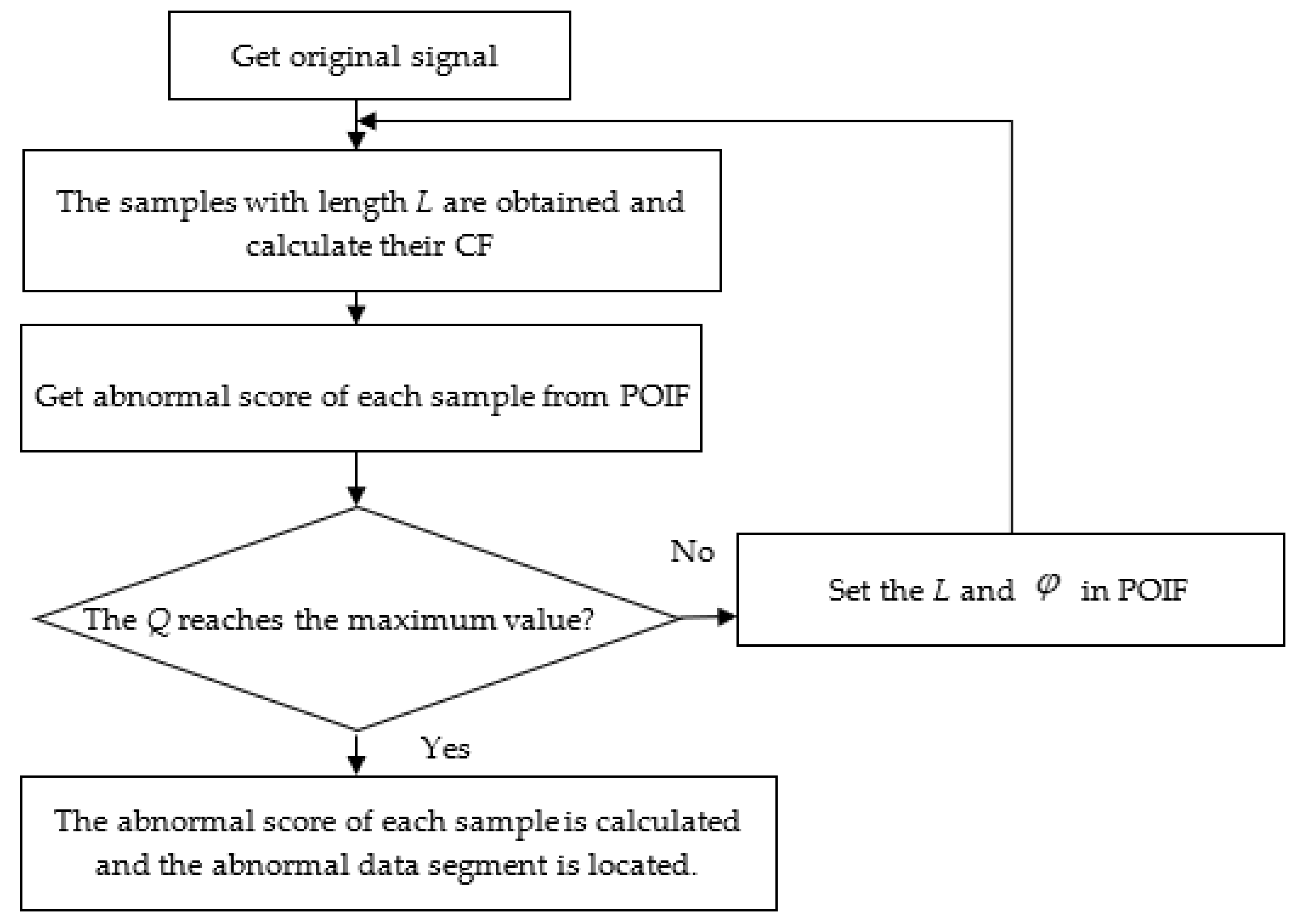
25]. However, the anomaly detection score of the traditional IF is greatly affected by the sample length and capacity. Based on the above analysis, in order to detect and realize the location of abnormal data segments adaptively, a model based on comprehensive features and parameter optimization of the isolation forest, which can identify the abnormal data segment in the vibration signal of rolling element bearings adaptively, is proposed in this paper.
The organizational structure of the rest of this paper is as follows.
Section 2 introduces the basic principle of the parameter optimization isolation forest method and comprehensive features.
Section 3 shows the steps of the parameter optimization isolation forest and comprehensive characteristics.
Section 4 validates and analyzes the proposed method with some data from realistic scenarios. Conclusions are drawn in
Section 5.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}