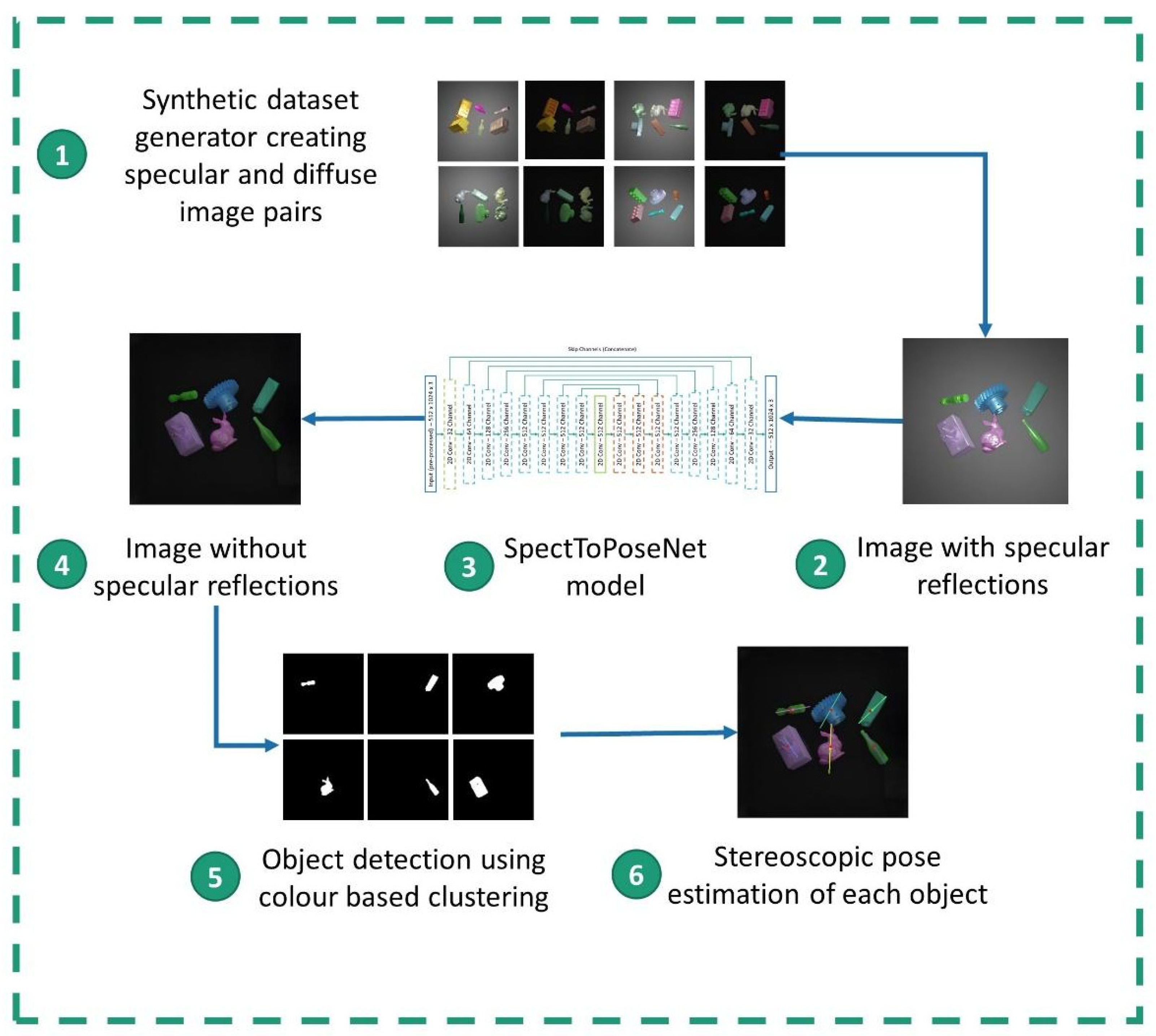
The first step of this research was to either gather or create a sufficiently large dataset that met the target use case of the project. Next, it was essential to implement a suitable testing pipeline to continuously test the results of each development iteration of the specular reflection remover. This pipeline consists of an object detector to separately identify each object in the scene and a stereo-vision-based pose estimator that can deduce the object’s location relative to the camera. Hence, the proposed SpecToPose system consists of three main components, namely, the dataset generator, specular reflection remover, and the combined object detector and pose estimator.
2.1. Dataset Generator
To develop and test the SpecToPose, a dataset is required that consists of images that conform to the specific target use case of this research. The images must contain a scene with multiple glossy or metallic objects of varying shapes and colors. The objects must be placed on a dark, flat surface, such as a bin. A strong enough light must also be directed at these objects to make them give out a significant amount of specular reflections. As this solution aims to improve stereo-vision-based pose estimation, images should also come in stereo pairs taken from two calibrated cameras. For the case of using a supervised deep learning approach, additional image pairs with no specular reflections are required for each image set described above to use as a target image for a network. The maximum variability of parameters such as object shapes, colors, light angles, and camera angles in the dataset is also preferred in order to build a highly generalized solution.
Finding a freely available image dataset that conforms to all of the above requirements is nearly impossible. Especially in the case of using DL-based methods, a significantly large dataset is essential to ensure satisfactory results that are not over-fitted. Due to this reason, a synthetic dataset generator was implemented in the SpecToPose system that can 3D render a sufficiently large dataset that meets all the requirements.
The open-source 3D graphics toolkit Blender was used to generate the required dataset [
23]. Manually designing each and every scene in data points is not possible in the case of generating a large dataset. Therefore, the entire dataset generation process was automated using Python scripting that Blender supports. The generation script takes in a set of 3D models in Polygon File Format (PLY) files. There is an abundance of freely available 3D models of complex objects for this purpose, enabling the building of a dataset with various shapes and sizes.
Each randomly generated Blender scene would contain multiple objects (5 to 7), created by randomly selecting from the 3D model set, scattered across a dark plane. Overlapping of these objects is constrained as it is challenging to automate realistic overlapping of solid objects using Blender. The objects would be placed in randomized rotations and sizes (constrained to a limited range to ensure objects are not too large or small). Two light sources (point lights) are also placed above the objects in randomized locations around a circular perimeter so that the direction and placement of specular reflections can vary from scene to scene. The first camera is focused on the objects. The second camera is placed to only have a slight horizontal offset from the first camera (with no relative rotation, vertical or depth offset) so that the images are coplanar. This ensures that each pixel in two images has a horizontal epipolar line (no vertical variation), which ensures that no calibration or rectification has to be carried out when estimating the pose.
After rendering the stereo pairs of the scene with specular reflections, the exact same images without specular reflections are also required. To achieve this, the material of each object is changed into a matte finish (with low reflective properties). The light sources are also removed and replaced with a low-intensity area light (instead of a point light) to reduce the point reflective nature. A single data point in the generated dataset contains stereo pairs of images with and without specular reflections (four images in total) as shown in
Figure 3, along with the location coordinates of each object in the scene relative to the first camera.
Additionally, the intrinsic properties of the cameras are saved as a calibration matrix
(Equation (1)), where
and
are the products of the focal length and the pixel width and height, respectively;
and
are the coordinates of the principles point of the image; and
is the skew coefficient (set to 0). The extrinsic parameters for each camera in respective to the Blender world coordinates are also saved in the form of a
matrix, as shown in Equation (2), where
refers to its rotation matrix and
refers to its translation matrix. Using this setup, a dataset of 1500 data points was created, which is sufficient enough to be used in a deep learning application.
2.2. Object Detection
The ultimate objective of the
SpecToPose system should be to use it on images with any object without limiting it to a particular predefined object. However, a completely general object detection algorithm that can be used in such a situation has not surfaced so far. There are some popular algorithms such as R-CNN [
24], Fast R-CNN [
25], Faster R-CNN [
26], and YOLO [
27], and pre-trained convolutional neural networks that are widely used for object detection applications such as AlexNet [
28], VGGNet [
29], and ResNet [
30]. These networks will only work on generic objects but will not work for specific objects. Even when tested on a dataset generated using 3D models of generic objects, such as cars, spoons, or bottles, the accuracy levels were very low. Hence, through the combination of some existing technologies, a simple approach was implemented for object detection and segmentation with certain constraints.
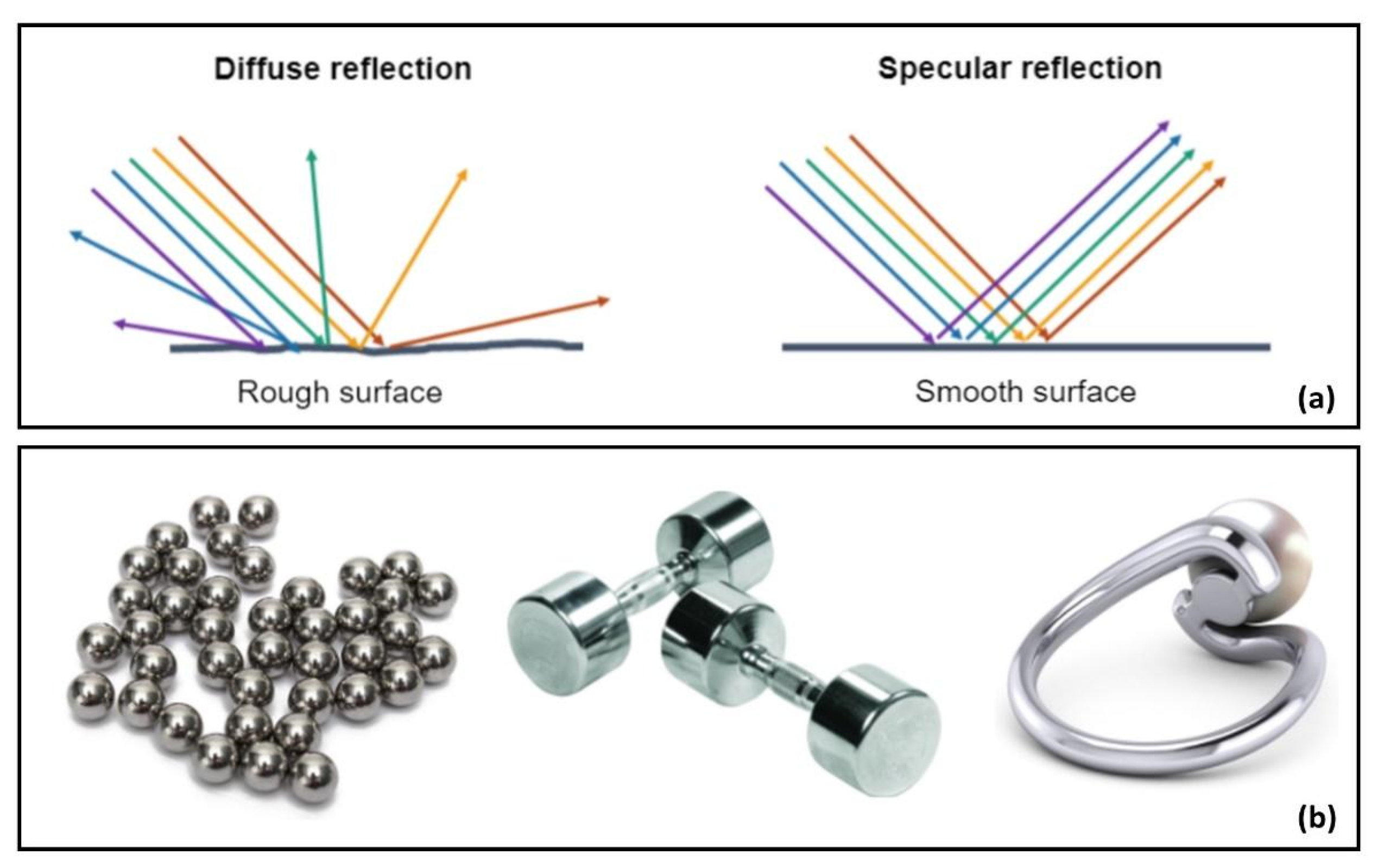
The algorithm explained below requires single-color objects in the image and works best if the objects in the scene are spread out with little overlapping. If the overlapping is between objects of different colors, the algorithm can distinguish them. However, if the color is the same, it may detect them as one single object. The first step of this approach was to convert the images from the BGR color space to the hue, saturation, and value (HSV) color space. In the BGR space, the components are correlated with the image luminance and with each other, making discrimination of colors difficult [
31]. By converting into the HSV space, image luminance is separated from the color information, making the objects pop out better from the background and each other, as shown in
Figure 4.
The next step is to segment the image using the color information [
32], and K-means clustering was chosen for this purpose. First, the HSV image is clustered with a relatively high number of clusters to separately identify segments of the image based on the color. The HSV image is then converted back to the BGR space and clustered again using the same K-means algorithms but with a lower cluster number (
Figure 4c–e). The reason for the second clustering is to ensure that the single object is not detected as two separate objects, which can be clearly seen in
Figure 5a.
The pixels in the image are then split into separate images based on their cluster. For an example, if the image contains two clusters only, the image is split into two images, each containing only the pixels related to that cluster. The next step is to take each of these images and find the connected components to separately identify the objects, as seen in
Figure 6. A connected component algorithm such as Tarjan’s algorithm [
33] with 8-connectivity can be used for this with few filters to remove too large or too small regions. These connected components are then used to create a set of masks, which can later be used to separate the object from the rest of the image.
2.3. Pose Estimation
The final element of
SpecToPose is to estimate the pose of the objects detected in the previous step. Two rectified images can be used to find the horizontal and vertical location of a point with respect to camera coordinates by backwards projection using the projection matrix. To calculate the depth, the disparity-to-depth-map matrix
in Equation (3) is calculated, where
and
are the principal point in the left camera,
is the horizontal coordinate of the principal point of the right camera,
refers to the focal length of the cameras, and
is the horizontal translation between the two cameras. These parameters can be derived using the calibration matrix
and extrinsic matrix
of the cameras.
Next, the disparity map is generated for the stereo image pair areas as shown in
Figure 7 using a modified version of the semi-global matching (SGM) algorithm [
34]. Then, the pixels in the image are filtered out, where the disparity cannot be calculated correctly using some threshold values. Furthermore, the segmentation masks obtained through object detection are used to filter out unwanted pixels. Using the
matrix and the disparity map, the location coordinate of every pixel is obtained with Equations (4) and (5). The values
and
refer to coordinates of the pixel on the left image and
is the disparity at that point. Finally,
,
, and
, corresponding to horizontal, vertical and depth coordinate of the point, are calculated with respect to the left camera in world coordinates.
In order to estimate the translation of the objects from the camera, the centroid in world coordinates is calculated and taken as the coordinates of the center of the object. For arbitrary objects, there is no way to correctly define the rotation of the object as the orientation in the
position is unknown. As an approximation, this pose estimator will iterate through the real-world location of all points corresponding to the object and find the point that is the furthest from the above-calculated center, and take the line joining them as a rotating axis of the object, as shown in
Figure 8a. The red dots of
Figure 8b correspond to the actual center point of the object (saved during the dataset generation) and the colored dot is the estimated center.
2.4. Preprocessing for Deep Learning
When exploring deep learning approaches, the large synthetic dataset generated comes in handy. In each data point, the image with the specular reflections can be called the specular input to the network. The diffuse counterpart of it can be called the target diffuse, meaning the ideally perfect output to expect from the network. The network output can be compared with the target diffuse to form an error function to train the network, such that the output can become more and more similar to the target.
It is always better to reduce the glare effects as much as possible from the input using image processing techniques before feeding them to a neural network. The contrast limited adaptive histogram equalization (CLAHE) is an excellent method to bring down high contrast areas of the image (glares) [
35]. This algorithm works better in the HSV color space; therefore, both the specular input and diffuse target are converted to it. The CLAHE algorithm can be directly applied to the value channel of the specular input image and clipped using a constant value (set through trial and error). Inpainting is another technique that can be used to further reduce the glares in the image by coloring the glare points based on the neighboring pixels. First, a copy of the image is taken and converted to a gray scale, and a Gaussian blur is applied. Then, it is thresholded with a high value to find the points of the image that contain the specular highlights and they are used as a mask when applying the Telea inpainting algorithm [
36].
Figure 9a shows an example input, while
Figure 9b and c depict the results of histogram equalization and the inpainting, respectively.
The pixel values of an image are in the range of [0, 255], making it unsuitable for use in a neural network. The neural network needs inputs and targets within a fixed range of data that can be ensured through some activation. All the values in the image are normalized to the range of [−1, 1], so that the output layer of the network can apply a activation to ensure an output in the same value range. During inference, the network output values have to be brought back to the original [0, 255] range to construct a meaningful image.
2.5. Initial Neural Network Architectures
A convolutional neural network (CNN)-based approach is the best approach to tackle problems of visual imagery. The network should take an image as an input and provide another image as the output after transforming it. The basic starting point to develop such a network is, to begin with, a simple convolutional auto encoder (CAE) [
37]. The CAE contains two main parts, namely, the encoder and the decoder. The encoder would take the image as an input, and through convolutional layers, the spatial dimensions would be reduced, while increasing the number of channels. The final layer is then flattened and further reduced to create a middle layer called the embedded layer. The decoder’s job is to take the embedded layer and increase the dimensions through convolutions to produce an output with the same shape as the input. The network is trained by comparing the mean squared error between the output and target.
Figure 10 depicts the basic architecture of the CAE. It has fewer layers than the actual implementation for simplicity. The output of the target is compared with the target diffuse to train and the results of an example can be seen in
Figure 11. It is clear that a simple CAE network is not suitable for images containing complex details. A large amount of details are lost in the output, and there is some unnecessary noise in the output. Hence, the next step is to modify the network to keep some of the features of the input image intact during the transformation process. A flattened embedded layer in the middle can also contribute to this issue, as a significant amount of spatial data can be lost by it; hence, avoiding it altogether is another option. There is also the possibility of a vanishing gradient through the network in the latter stages of training, requiring a small learning rate.
The U-net architecture [
38] has come into popularity recently for image to image translation, and it addresses the problems faced in the above network. It has an encoder–decoder-style architecture with contracting and expansion layers at its core. The two sides are symmetrical, which gives it the signature U shape. This architecture removes the fully connected layers altogether. One special feature of this architecture is the inclusion of skip connections from the encoder layers to the decoder layers with the same dimensions, which concatenate them together. These skip connections serve two purposes; first, they pass features from the encoder layers to the decoder layer so that they can recover some spatial information lost during the contraction; second, they provide an uninterrupted gradient flow, tackling the vanishing gradient problem.
As shown in
Figure 12, a slightly modified version of the original architecture was implemented, which contains sets of convolutional layers with an increasing number of filters, along with ReLU activation across them. Max pooling is used to contract the spatial dimensions of the layers in the first half of the network. In the latter half, the spatial dimensions are recovered through up-sampling, and the corresponding layer output with the exact dimensions in the first half is concatenated to it. Following this approach yielded better results compared to the previous iterations.
As this system works in stereo pairs of images, going through the network twice is required during generation time. This can double the inference time, making the entire operation much slower. Instead of inputting a single camera view image at a time, combining the left and right image together to make a single input and feeding it to the network to obtain the left and right image output together is a feasible approach. One option is to concatenate the images channel-wise, and the other is to concatenate them spatially. Shihao Wu et al. [
22] found that concatenating the pairs horizontally led to the best results. This approach is much simpler to perform and allows more straightforward error calculation and output extraction. As the stereo pairs are rectified, this approach also establishes a connection between pixels on the same horizontal lines and helps to maintain matching points during the translation.
2.6. SpecToPoseNet Architecture
So far, the convolutional neural networks that were implemented rely solely on the mean squared error between the output and the target. Even though this error is reduced while training, it does not guarantee the authenticity of the output. Hence, the output still does not look realistic enough compared with the input and output. GAN [
18] is a popular development in the world of neural networks that boasts of providing extremely realistic and authentic-looking outputs. It is commonly used for generative or translation work, perfectly matching our use case. GAN is also used in works such as Shihao Wu et al. [
22] and John Lin et al. [
21] to minimize reflective effects. Over-fitting is common in very large networks and standard encoder–decoder-style networks. GAN incorporates randomness in the middle of traditional generators in GAN by sampling from a latent space instead of directly taking the layer output. The other portion of the GAN architecture is the discriminator network. The input for this network is a concatenation of the specular input and the diffuse target or the specular input with the generator network’s output. The input can be named the ideal input for the former, while the latter can be called the translated input. The discriminator network is trained to properly distinguish these two inputs and provide a label to them. Therefore, when the ideal input is given, the network should output a label of all ones, and when a translated input is given, it should give a label of all zeros in a perfect scenario. Similar to the encoder portion of the generator network, the concatenated input’s spatial dimensions are reduced through convolutions while increasing the channel size, as seen in
Figure 13. The layers similarly use Leaky ReLU activations along with batch normalization (except in the first layer). The final layer is subjected to a convolution with a single filter, resulting in a single channel output. A sigmoid activation is applied here such that the output values are in the [0, 1] range expected from the discriminator label. As with the generator network, this was also implemented so that it is auto-scaled to fit the input image’s dimensions. The proposed deep learning model is named the
SpecToPoseNet, and it is developed based on the Pix2pix [
39] GAN architecture, which specializes in the image to image translation using conditional adversarial networks.
The U-Net model that was implemented in the previous iteration can be modified and taken as the generator network shown in
Figure 14. The encoder of the network consists of 2D convolution layers with a stride of two, such that the spatial dimensions are halved in each layer. The input image has three channels, which are increased to 32 by the first convolutional layer and subsequently increased until the middle layer is reached. The decoder layers then use 2D transposed convolutional layers to contract the channels by 2 in each layer until reaching 32 and finally giving a three-channel image output. The spatial dimensions work the opposite way, with encoders reducing them by 2 in each layer; a vertical dimension of 1 is reached and again increased to the original image’s dimensions. Due to the usage of strides of 2 throughout the network, the input image’s horizontal
and vertical
dimensions must be of a power of 2, and the condition
must be satisfied.
Batch normalization is also used in almost all the layers in the generator, which can help stabilize and accelerate the learning process [
39]. As seen in
Figure 14, the first layer does not use batch normalization as by doing so, the colors of the input image can become normalized based on the batch and be ignored. Since the color should be preserved intact, especially for the implemented object detection algorithm, batch normalization is omitted in the first layer. ReLU activation is used in all layers to avoid the vanishing gradient problem that other activation types suffer. Simple ReLU activations, which provide a better sparsity in the layer outputs (act more closely to real neurons), are used in the decoder layers, while Leaky ReLU activations that avoid the dying ReLU problem are implemented in the deeper encoder layers. Only in the final layer, a
activation is used to bring the output to the desired range.
SpecToPoseNet requires to be highly generalized, especially as the solution at hand is expected to work in any case if trained correctly. Avoiding over-fitting of the network is highly important for this purpose. Instead of using real data, a synthetic dataset was generated, nevertheless the network is also expected to work on real data. When training with the dataset, it can easily be overfitted to the synthetic data, providing inferior results in real-world scenarios. For this generator, as proposed in the Pix2pix architecture, dropout layers are incorporated into the network’s decoder potion to add a source of randomness to it. These layers are responsible for randomly dropping nodes during training and generation, which helps to avoid the over-fitting problem [
40].
2.7. Training the Networks
When training the
SpecToPoseNet, multiple types of losses are calculated and combined. The loss relating to the discriminator network is the adversarial loss. The discriminator network is a classification network responsible for assigning class 0 across the output for a translated input and class 1 for an ideal input. Binary cross-entry entropy loss is a trendy way to evaluate such networks, and it can be calculated using Equation (6), where
is the points in the output,
is the label, and
is the probability output of the node.
In the case of the generator, multiple loss components are calculated, weighed, and used during back-propagation. One of the significant losses is the same adversarial loss explained above, applied to the generator training as well by sending the generator output through the discriminator network. However, in this case, the difference is that the loss is calculated by comparing the output with a label of all 1s (real label) to see how well the generator was able to fool the discriminator. The loss with the most significant weight for the generator is the Mean Squared Error (MSE) between the network output and the diffuse target image, which is calculated using Equation (7). For each pixel
in the network output, the deviation is calculated from the corresponding pixel
in the target diffuse image and squared to obtain a positive error. The mean is calculated by dividing by the total number of pixels, which is the product of the width
, height
and the number of channels
.
The third component of the generator’s loss is the feature consistency loss. Calculating this error may reduce the training speed of the network by a small amount due to the high computational power needed. First, the target diffuse image pairs are taken, and the Oriented FAST and Rotated BRIEF (ORB) feature detector [
41] is used to extract features in the pair. These ORB features are compared, and matching points between the pairs are found using a Flann-based matching [
42]. A single matching feature point pair is randomly sampled from these points. The next step is to extract a small patch (32 × 32) centered around these points from each pair. We also extract the same patches from the corresponding generator output images as well. In summary, the above process looks at the target image pair, finds key feature points in both images, and extracts a patch from those points from the target and generated images.
Another popular image classification and object detection neural network, VGG [
28] is used, along with its publicly available pre-trained weights, to calculate the error. This network uses convolutions, and we are only interested in the outputs at each convolution layer, not the network’s final output. From the input image, each convolutional layer is tasked with finding a particular pattern or feature in the image. Starting from more prominent features and patterns, more minuscule details are found as it is subjected to more and more convolutions. The network is already heavily trained with an extensive dataset, and each convolutional layer in the network is now good at identifying various visual features and patterns in any input image. Hence, the patches that were extracted earlier are fed in to calculate the error. At each convolutional layer output, the difference between the patch from the target and generated output are calculated, the average value is found, and the sum is taken. The calculation is summarized in Equation (8), where
is the total layers in the VGG network,
is the number of nodes in the output of layer
,
refers to a patch from the diffuse target,
corresponds to a patch from the generator output,
refers to the left image, and
refers to the right image. For example, going by the above definitions,
refers to the output of node
of layer
when a patch from the left image from the generator output is fed to the VGG network, and similarly, the remaining
values are also referred as such.
When translating the images using the network, some features of the objects (such as corners and edges) may be lost. This can impact the visual quality of the output and also the pose estimation process. For calculating the disparity in pose estimation, finding matching points between the image pair is essential, since losing features and inconsistencies in matching points are not favorable. The network should be encouraged to maintain the consistency of matching features through the translation, and this is achieved through the above-explained feature consistency loss. A point is chosen that should match between the images for each training iteration, and the network is informed that those points should be matched even in the final output. Incorporating this loss successfully increases the overall details on objects in the output image.
The final component of the generator loss is the location loss, which plays a role in ensuring that the output of the networks helps enhance object detection and pose estimation. Calculating this loss can use a large amount of computation power and slow down the training speed by a significant amount. Due to this reason, this loss function is optional for the model, but incorporating it to some extent has shown to provide slightly better results in the accuracy of the final estimated poses. If the machine used to train the networks is not very powerful, the speed trade-off may not be worth it, and this loss can be neglected during training. In the early stages of training the network, this loss also adds very little value, as a clear enough output will not be available to evaluate the pose. The most efficient way to incorporate this loss is to train without it for most of the training sessions and enable this loss for the final few epochs.
To compute this loss, first take the output from the generator and pass it through the object detection and pose estimation pipeline to determine the pose of each object in the image. During the synthetic dataset generation, the object coordinates (actual location)
for each data point are saved in a file for later use. The pose estimation error is estimated by calculating the Euclidean distance between
and the object location
determined by the proposed pose estimation pipeline. Because the correspondences between actual objects and detected objects are unknown, the calculated and actual values are paired by taking the pairs with the shortest Euclidean distance into account. When the output is passed through the testing pipeline, it is possible that some objects are not detected at all or that some non-existent objects are detected. To account for them, the difference between the total number of detected objects
and the actual number of objects
is calculated. The error is defined as the product of the mean pose estimation error and the deviation of the number of objects, as shown in Equation (9).
After calculating all the required losses, the weighted sum of them can be taken as shown in Equation (10) (where
,
,
and
are weights) as the final loss for back-propagation in the generator network. The feature consistency loss and the location loss do not have to be active from the beginning and can be activated after a provided number of epochs are passed. The weights used in the total loss function can be adjusted whenever activated. The weights used during each mode of training for the final network are given in
Table 1.
When training the SpecToPoseNet, every image of the dataset is input one by one using the data pipeline. Each input is a training iteration called a step. An epoch is when the entire dataset is covered. For example, when using a dataset with 1500 data points, one epoch consists of 1500 steps. The following four tasks are carried out in each step with the data point (specular input and diffuse target).
The specular input is fed into the generator, and an output is obtained.
The specular input and the diffuse target are concatenated and fed to the discriminator network (ideal input). (binary cross-entropy) is calculated with a label of all 1s (real labels), and the network weights are adjusted through back-propagation.
The discriminator network is trained again, similar to task 2, but with the specular input concatenated with the generator output obtained in task 1 as the input. is calculated with a label of all 0s (generated labels) in this case.
The specular input is again fed to the generator, and that output is fed to the discriminator again. The generator losses are calculated as shown in
Figure 15, and only the weights of the generator network are adjusted (the discriminator is not trained).
If the step number is a multiple of 100:
Save the generator and discriminator model’s weights and optimizer state on disk.
Update the epoch and step count on the model metadata file on disk.
Test the generator with an input file, and create a comparison image (training summary) between the generated image pairs (on top) and the target diffuse image pairs (on the bottom). Store this image on the disk as well, stamping it with the epoch and step count so that the progress of the training can be observed during training.
A metadata file is also stored on the disk for each model, including the name given to the particular model, input dimensions, and channels, the dataset used to train it, the number of epochs, and the number of training steps. This file helps to identify the model information and input parameters during inference and restart the training without losing the epoch/step count. For inference, only the generator network is needed, which is read from the disk. The input must be subjected to the same preprocessing implemented on the training data, using an interface provided by the data pipeline. The output must also be transformed back into the correct value ranges to obtain the final image.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}