
Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s


Abstract
:1. Introduction
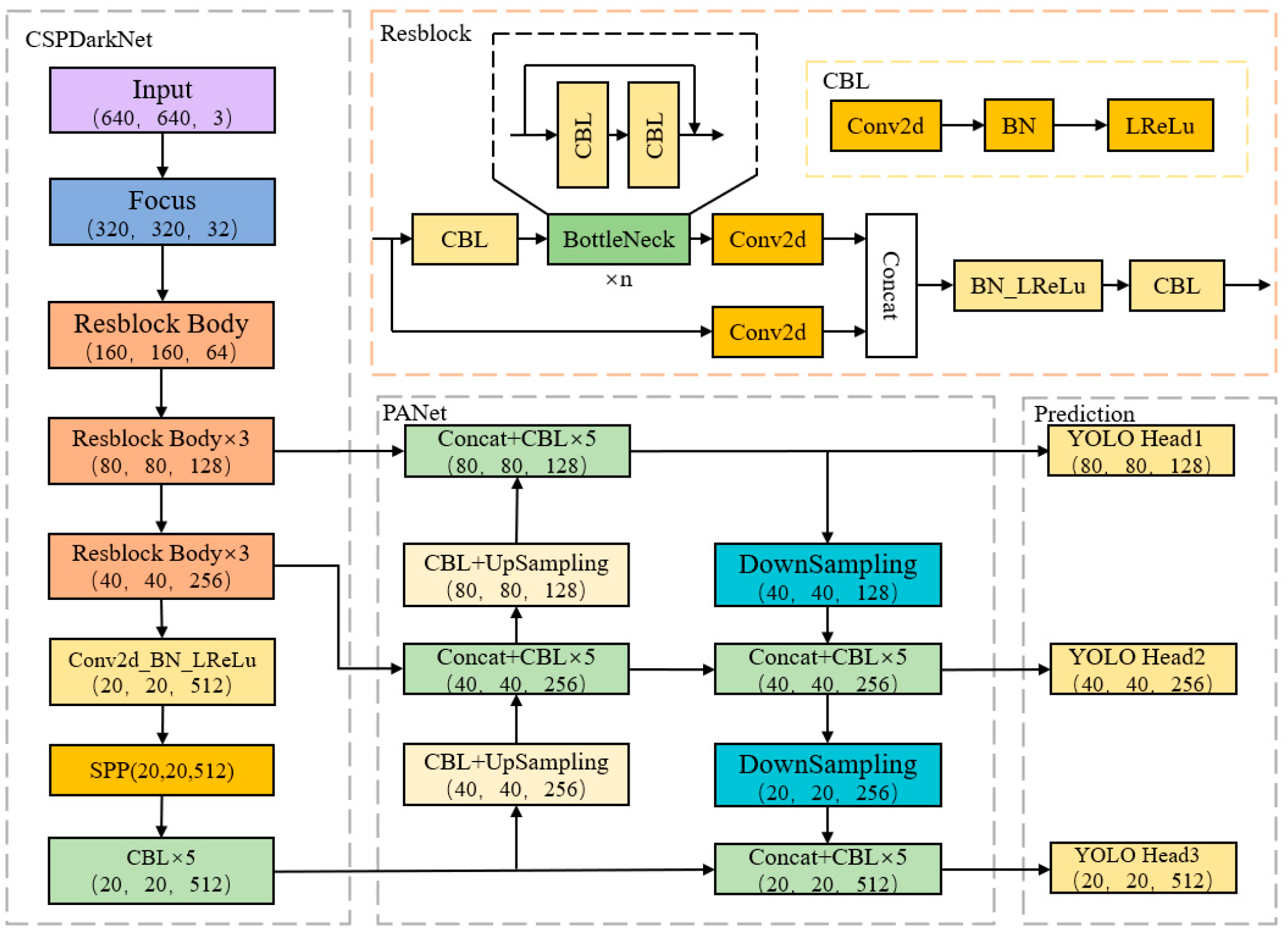
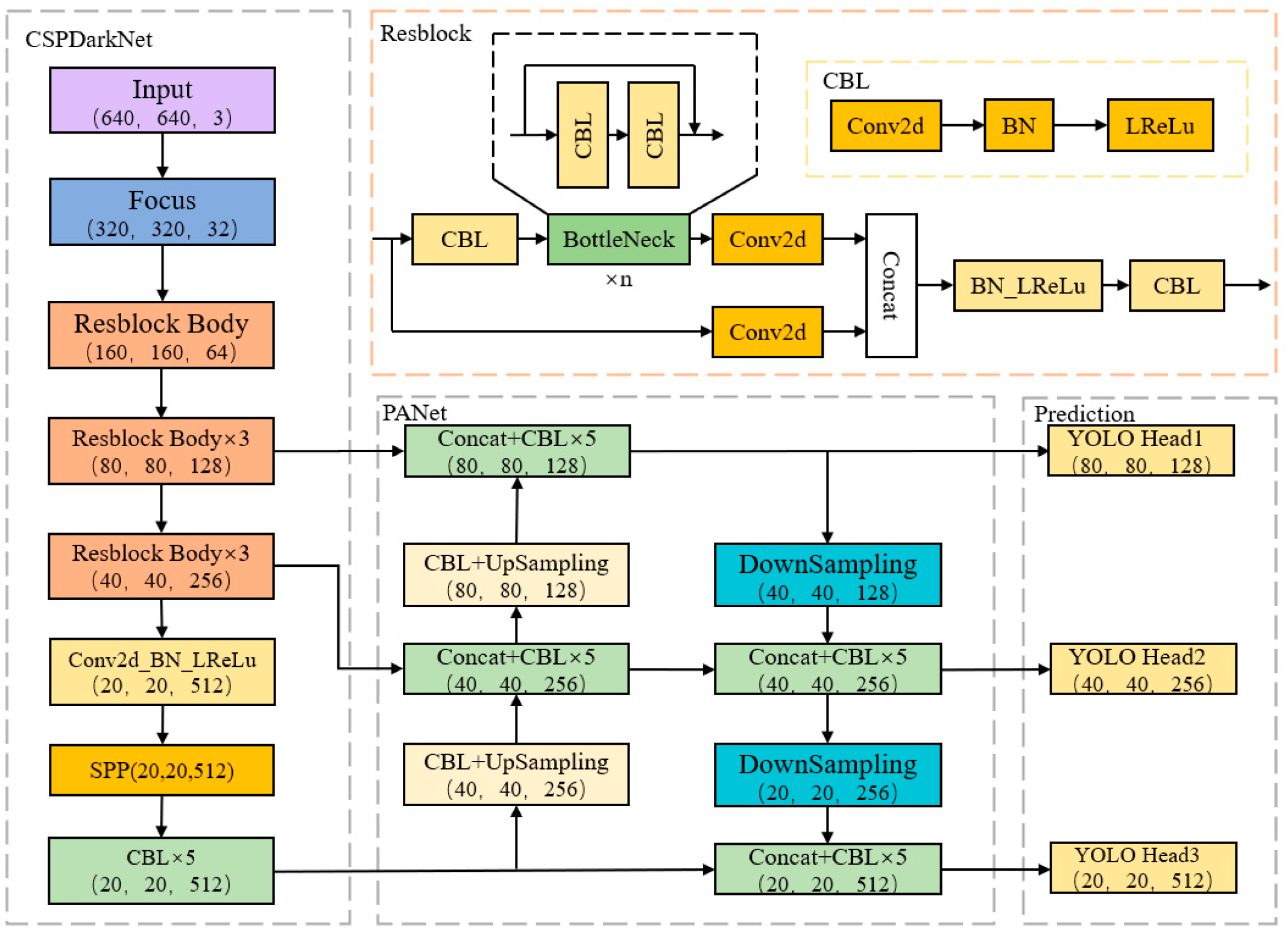
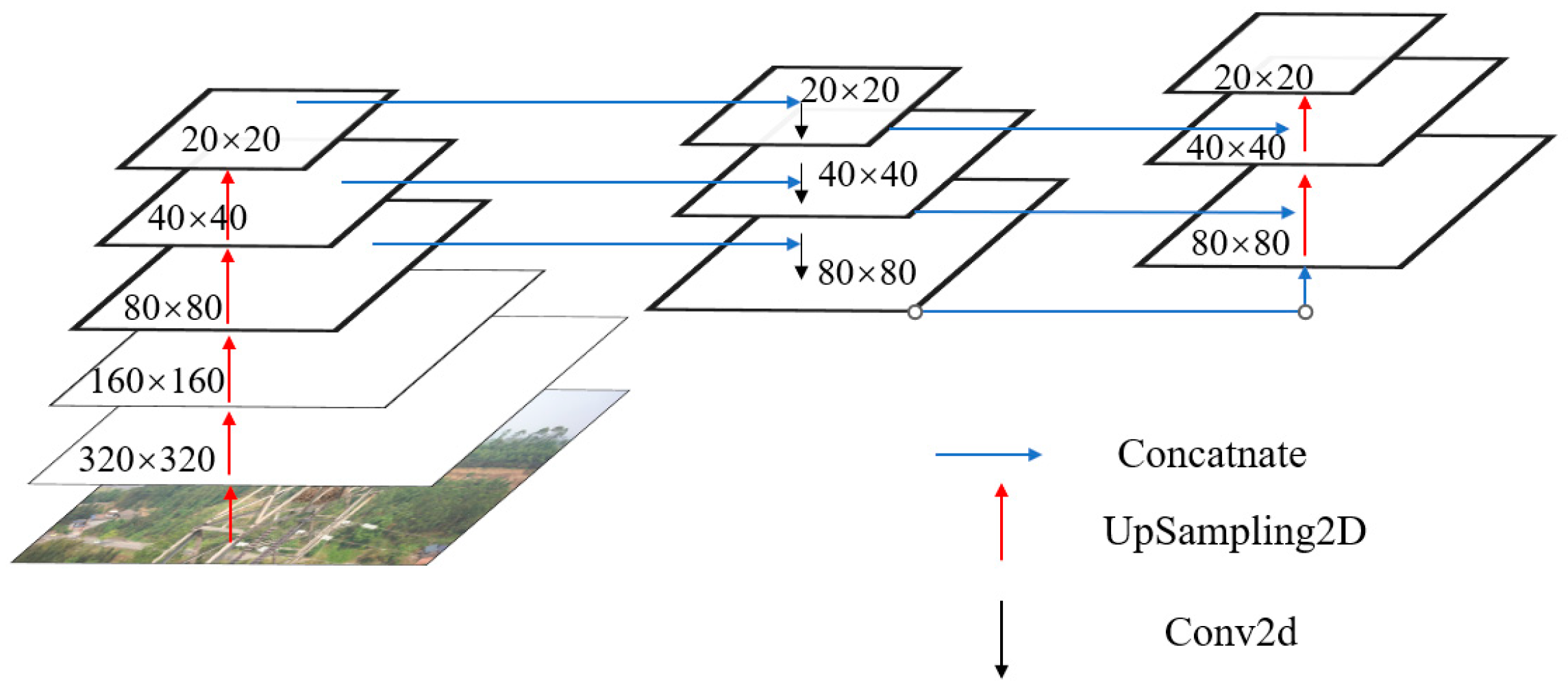
2. Structure and Features of the YOLOv5 Model
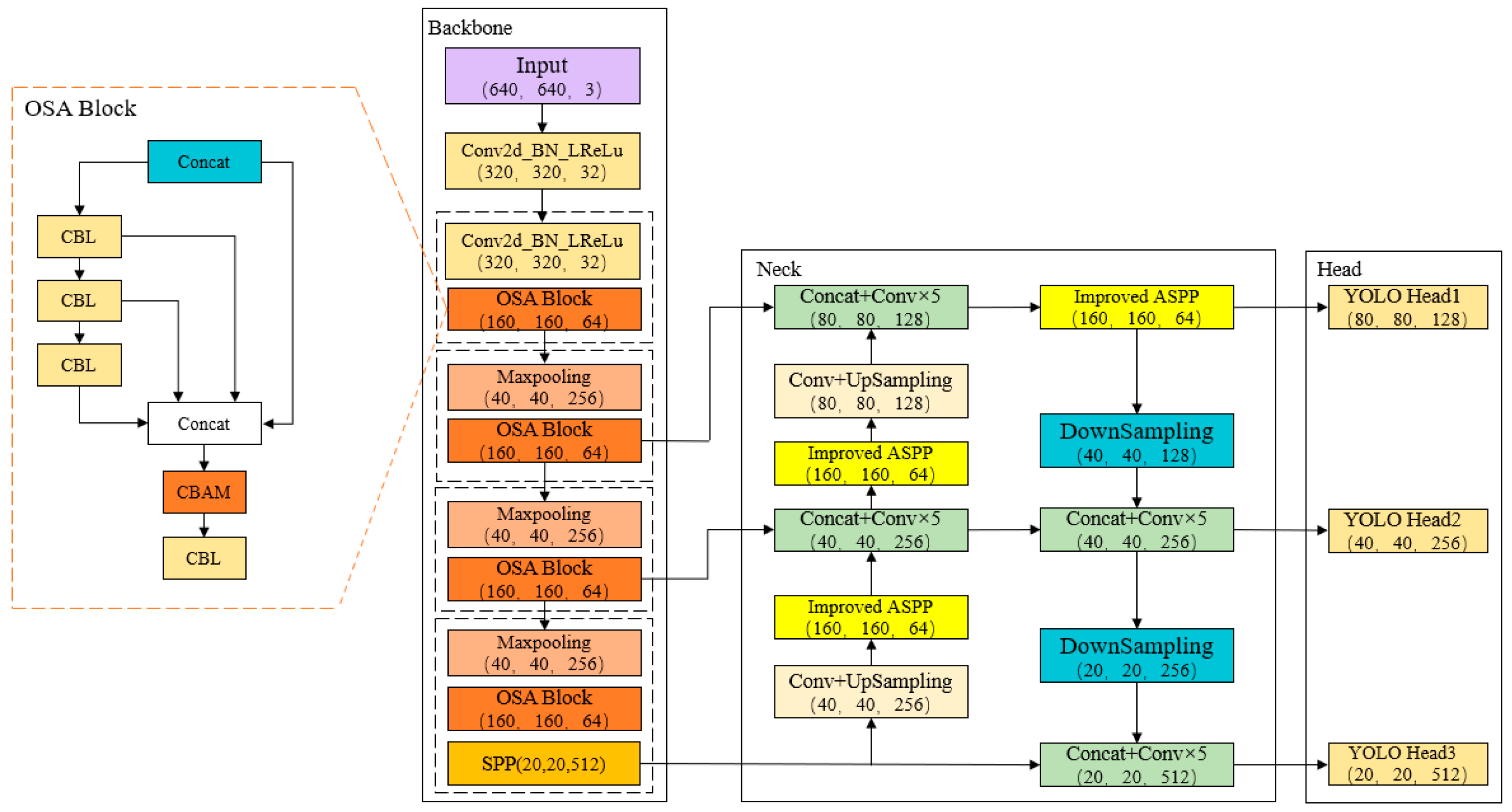
3. Recognition of Bird Nests on Transmission Towers Based on Improved YOLOv5s
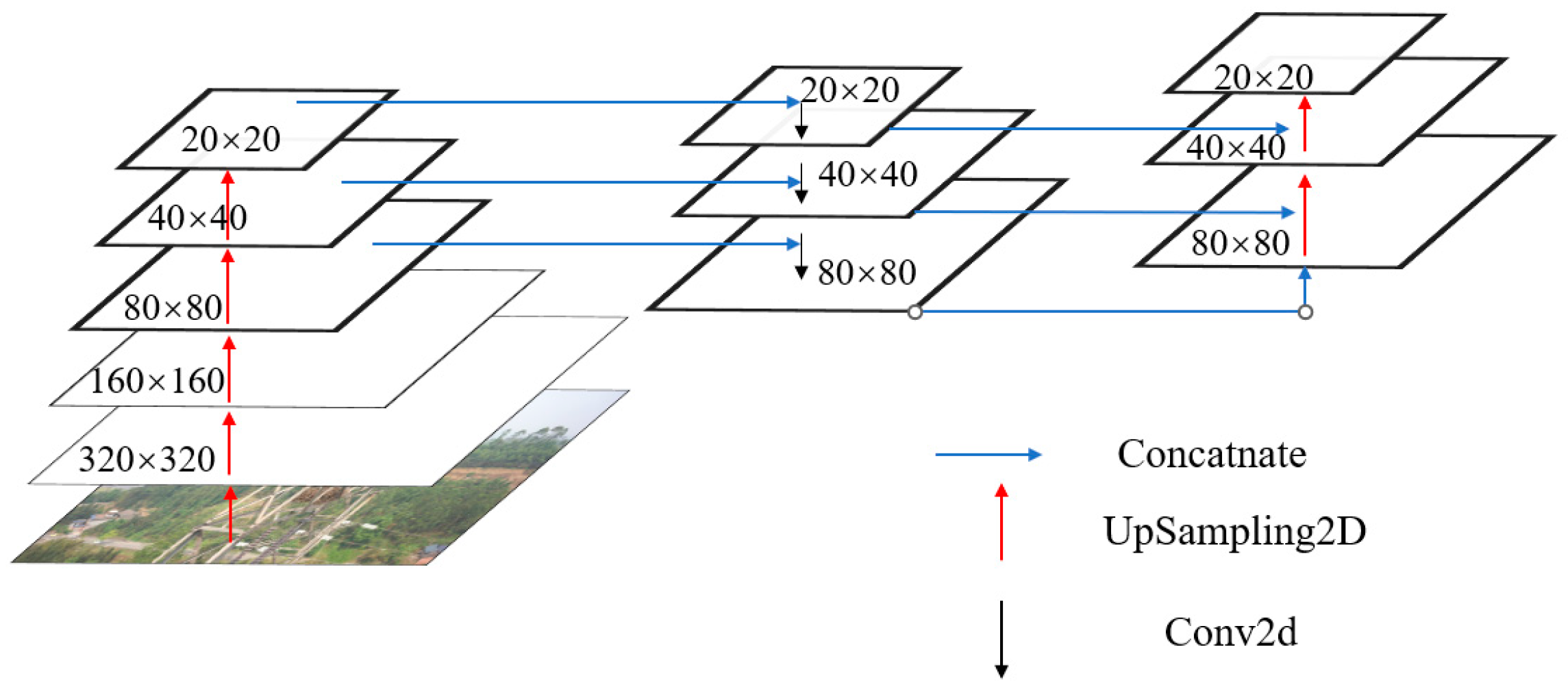
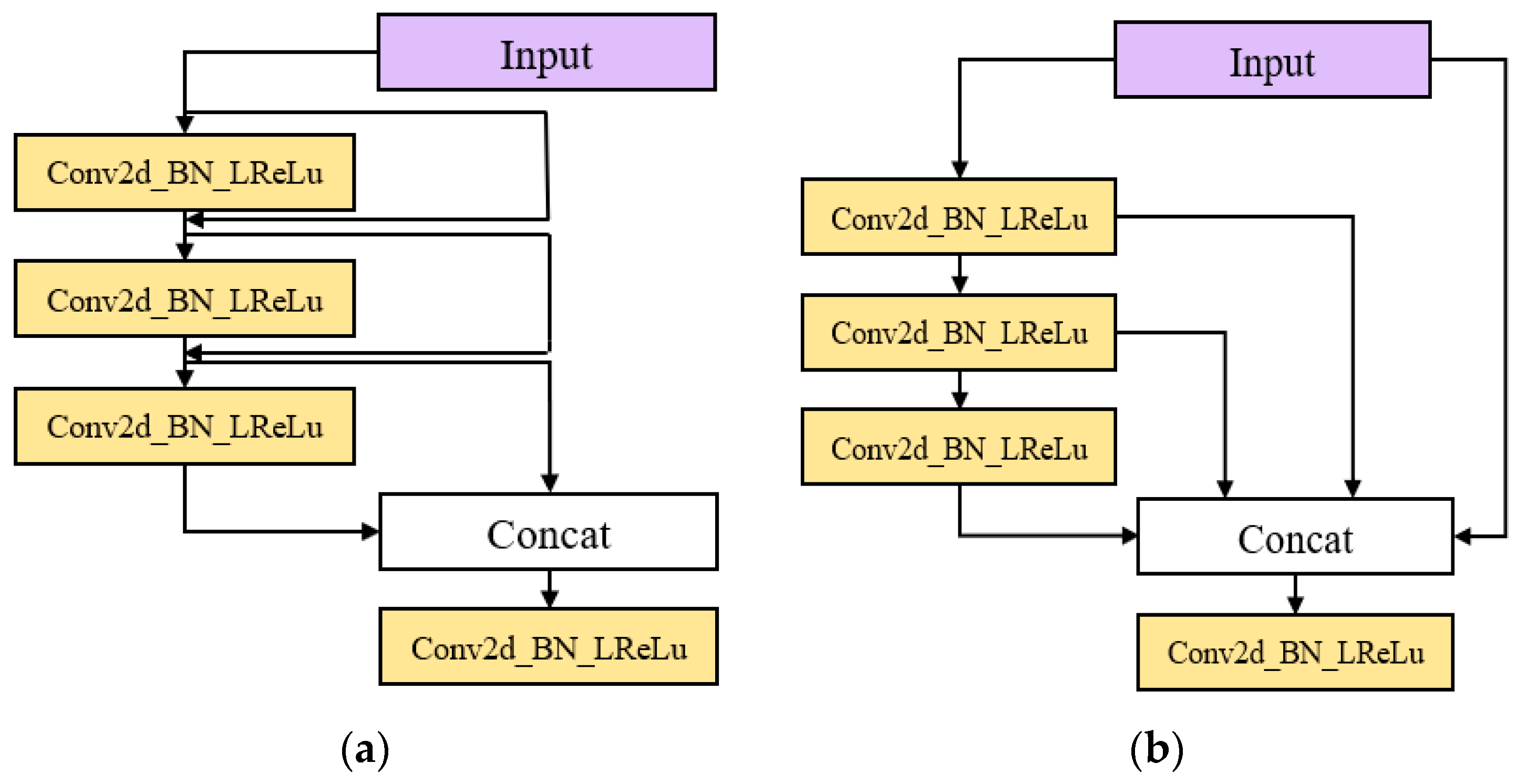
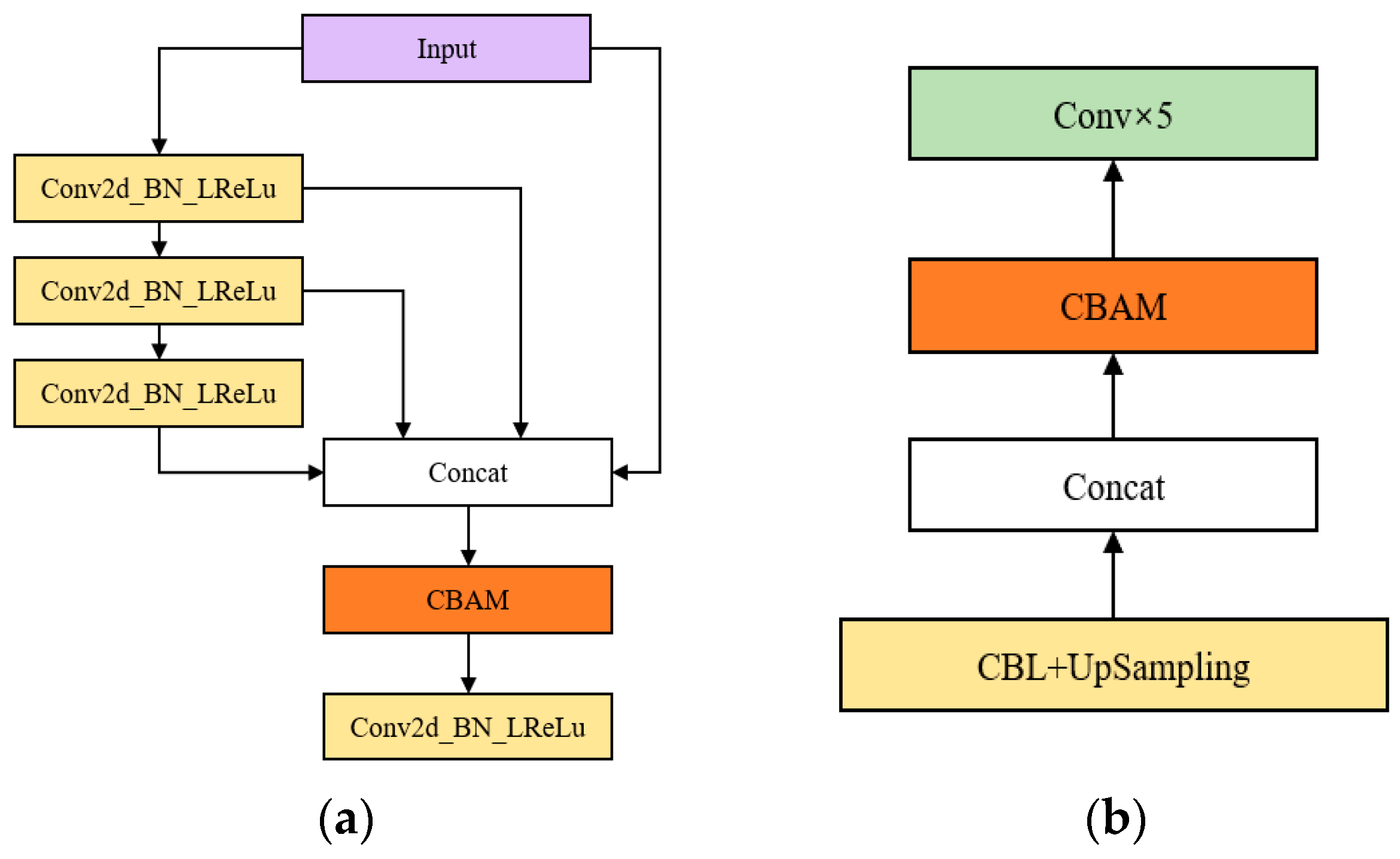
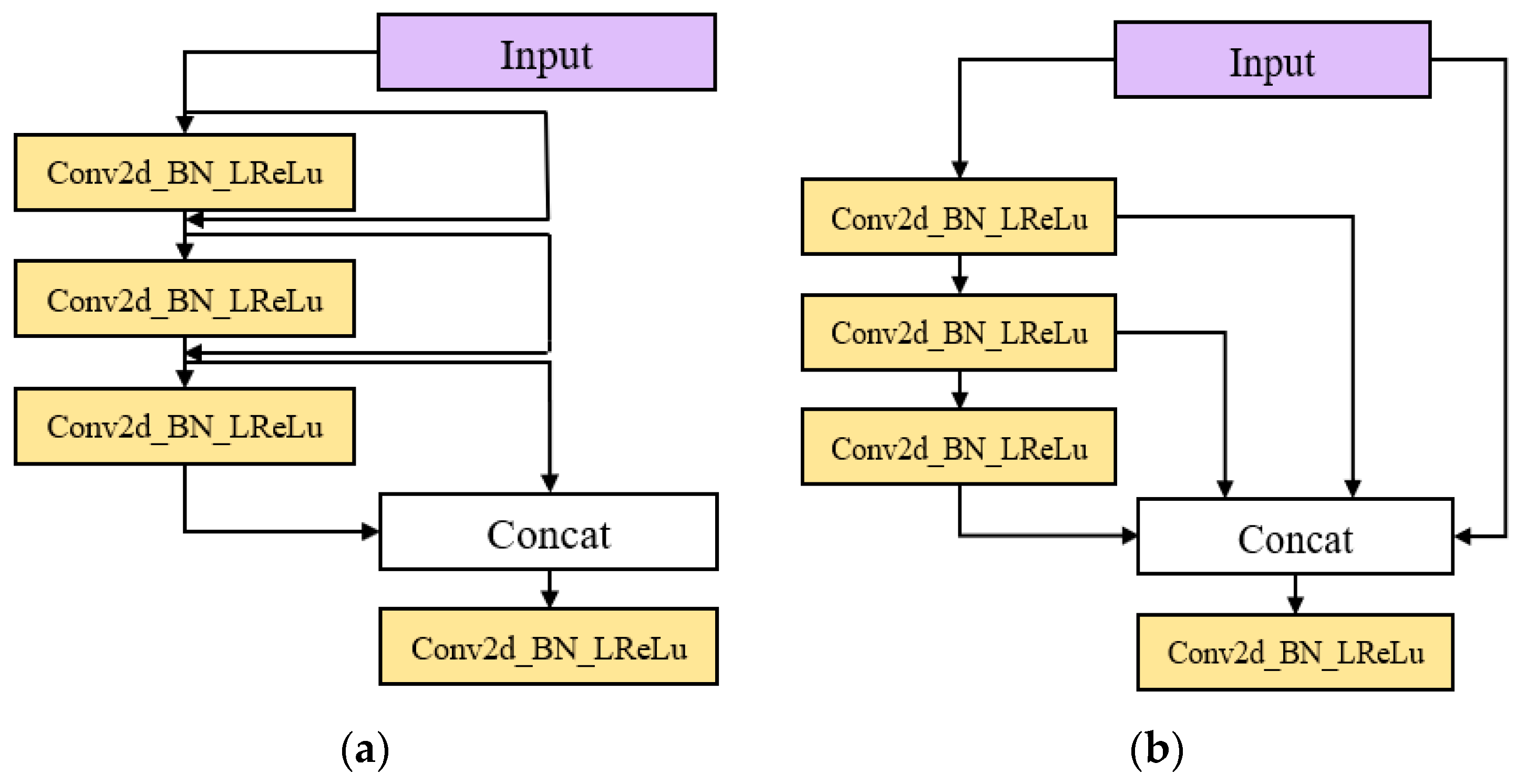
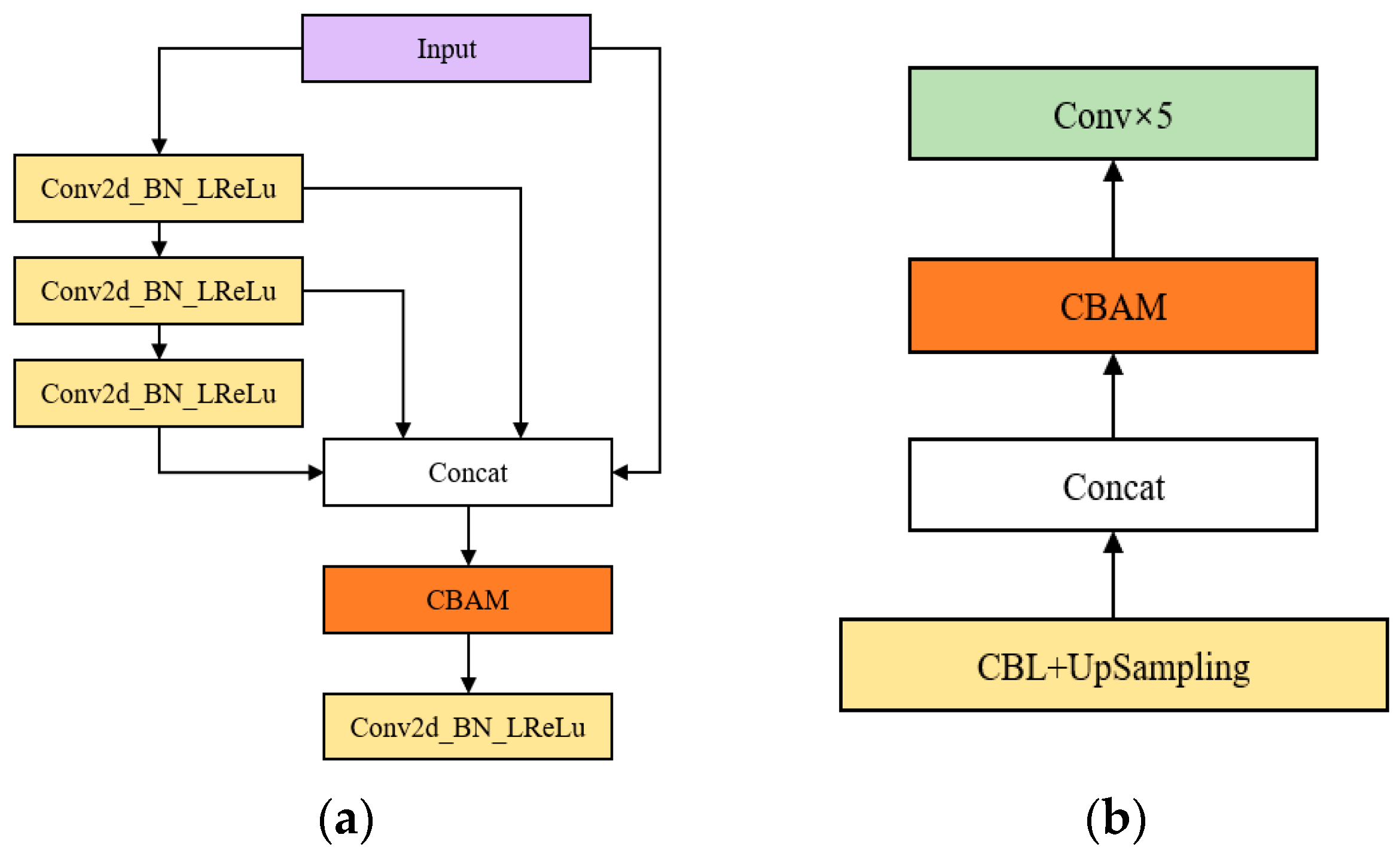
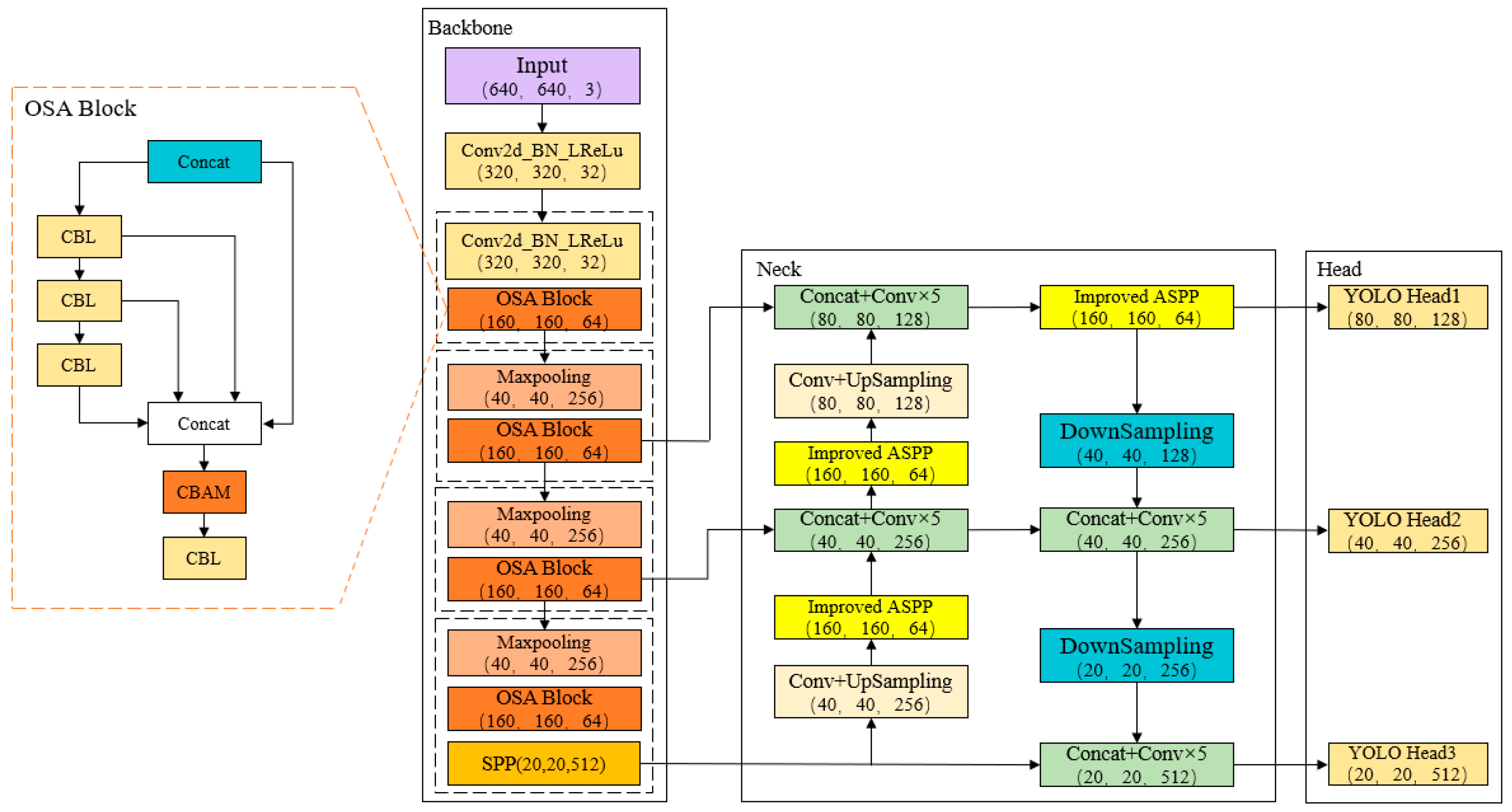
3.1. Feature Extraction Network Based on OSA Module
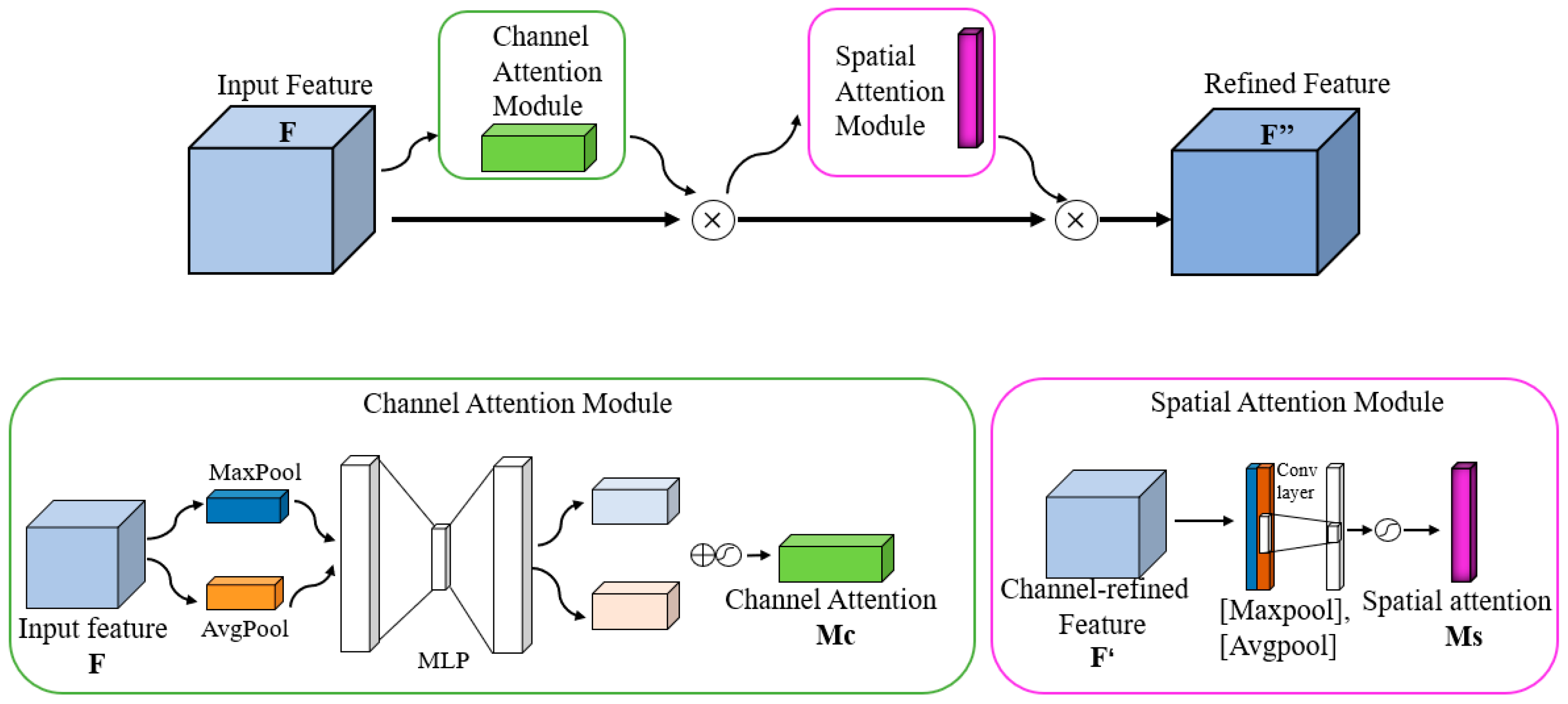
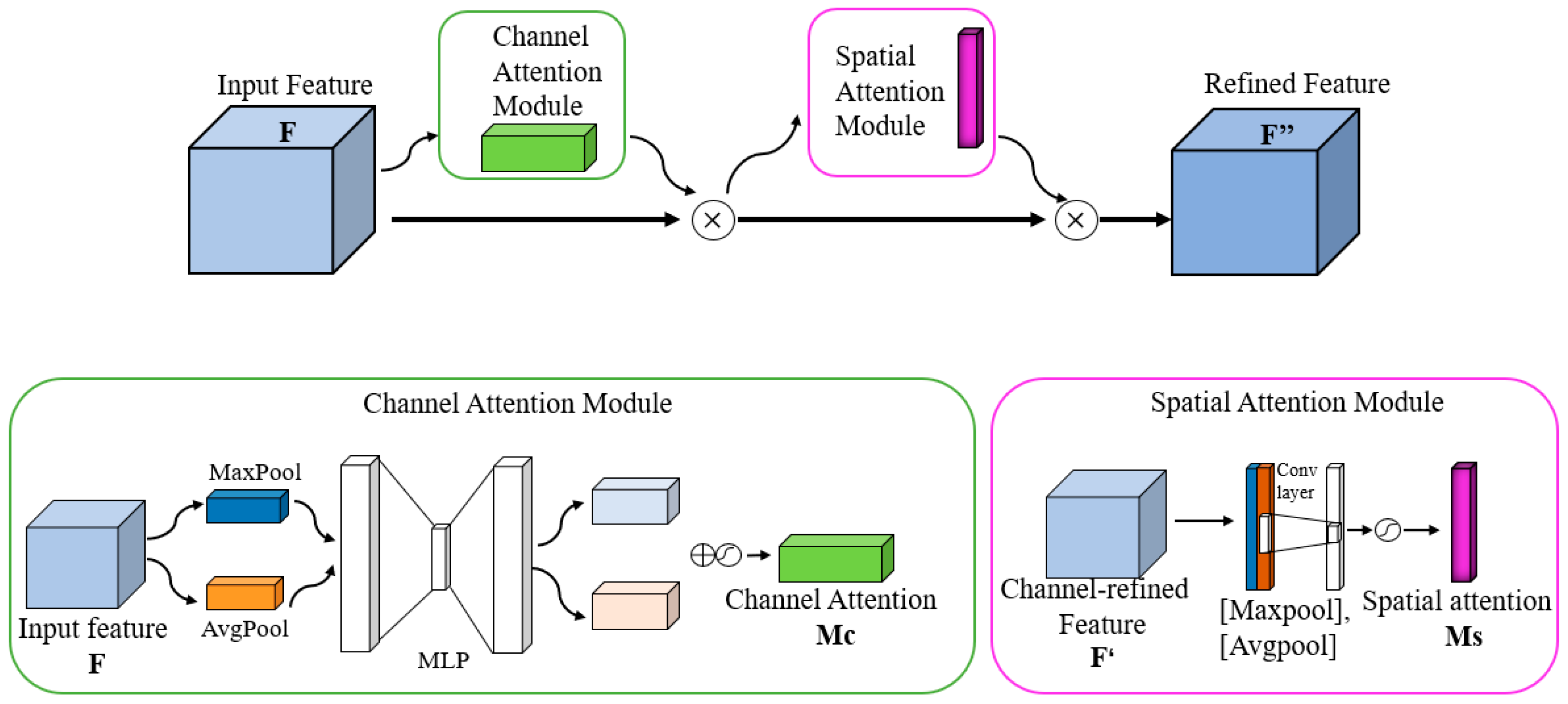
3.2. The Impact of Attentional Mechanism Fusion Studies on the Effectiveness of Small Target Detection
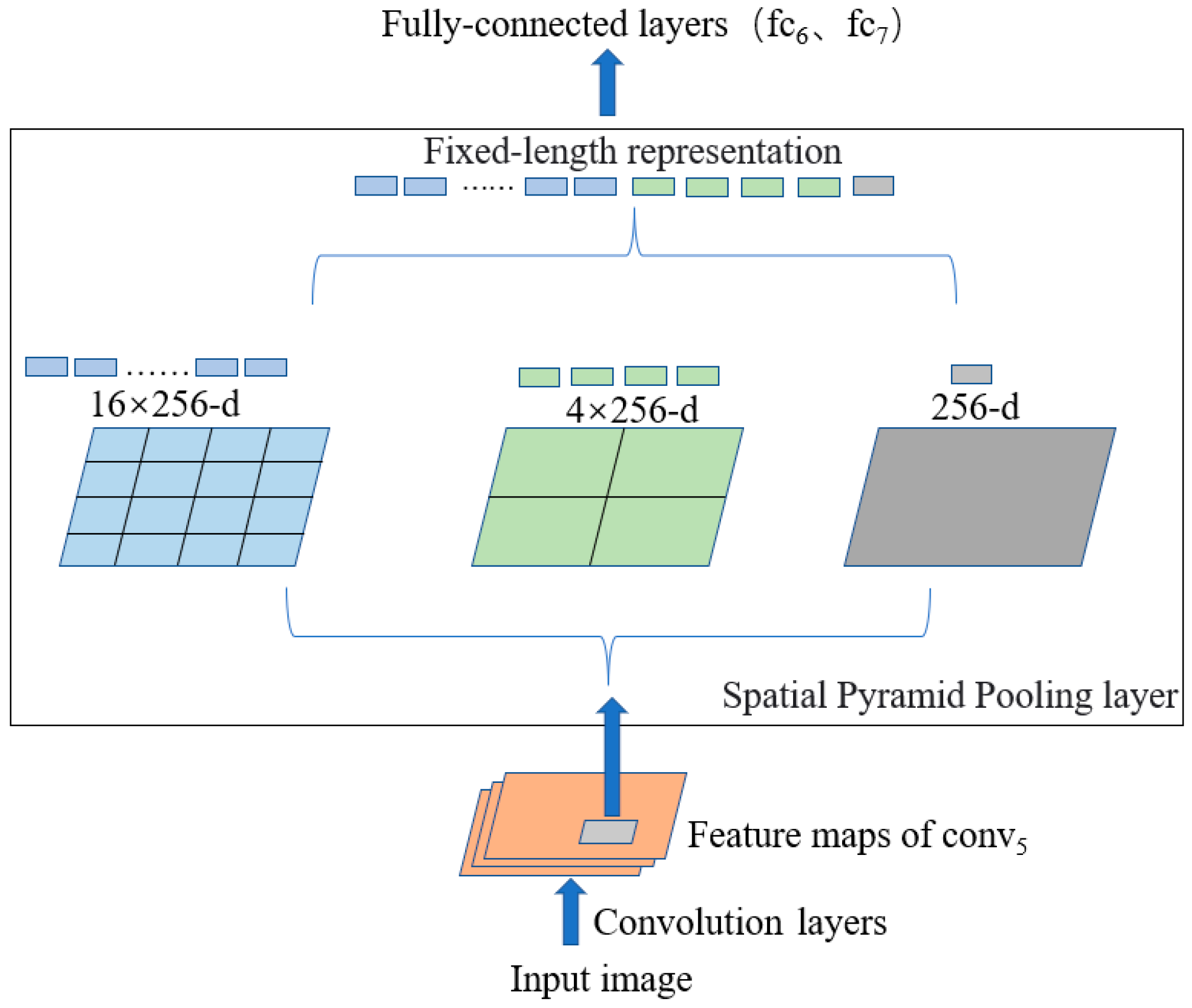
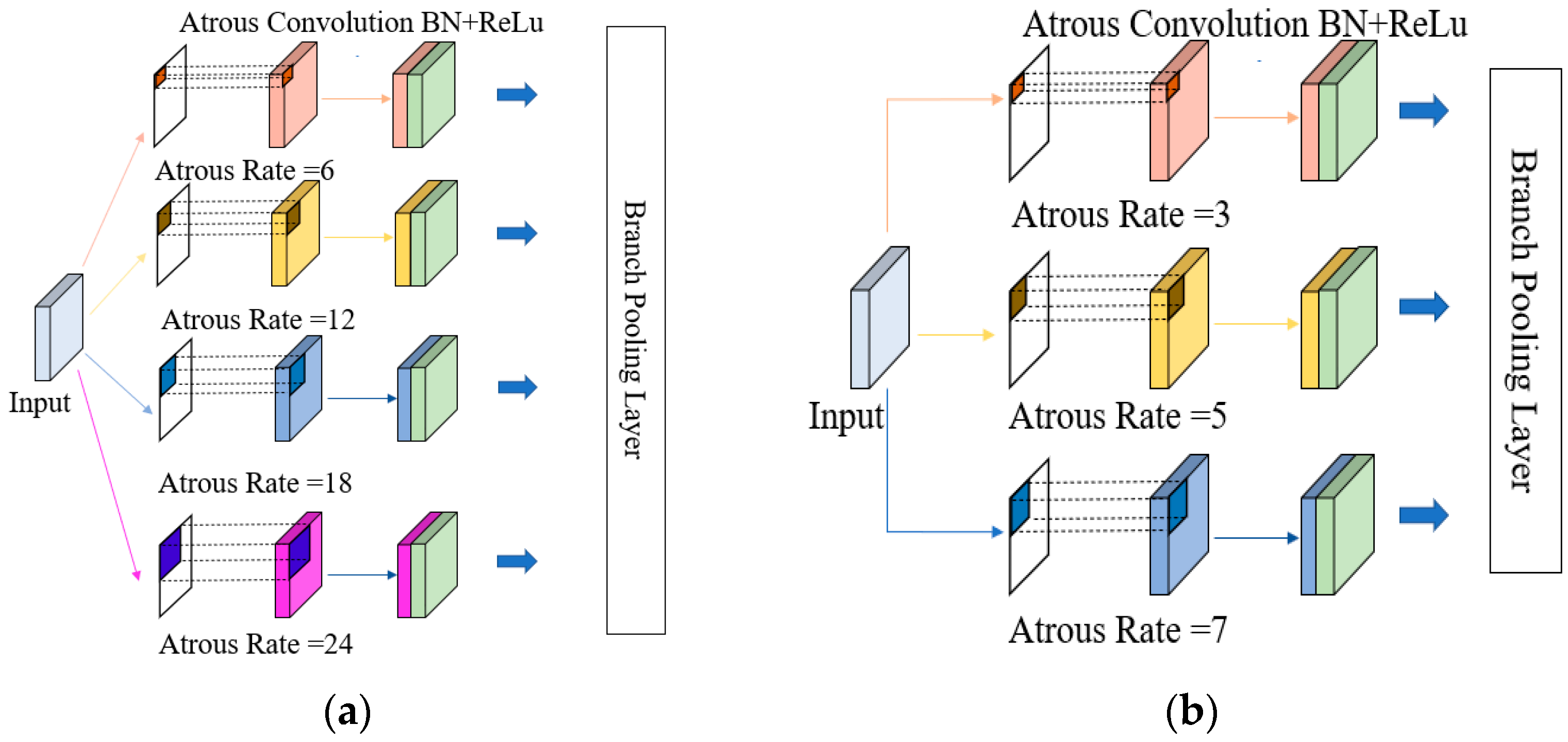
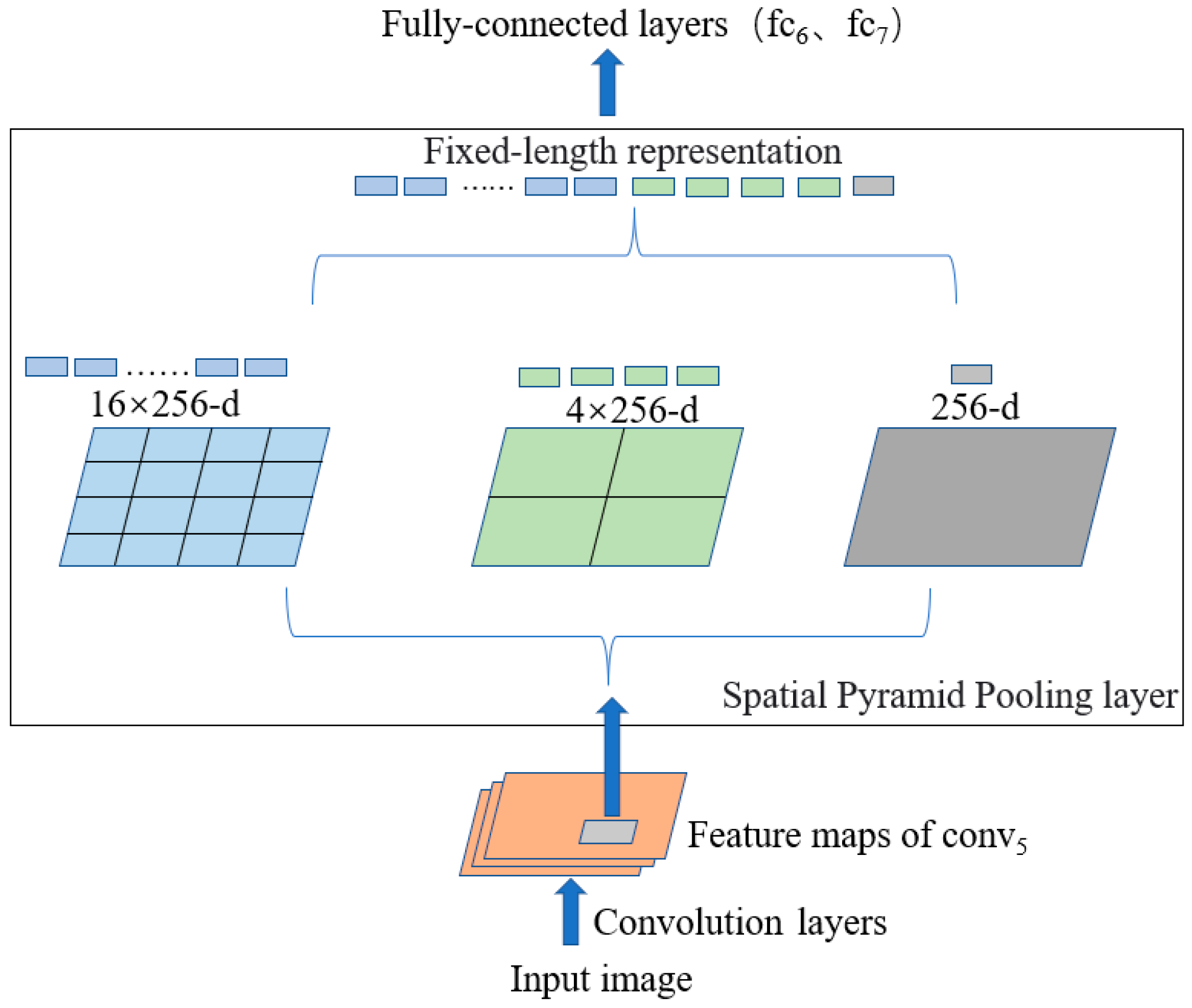
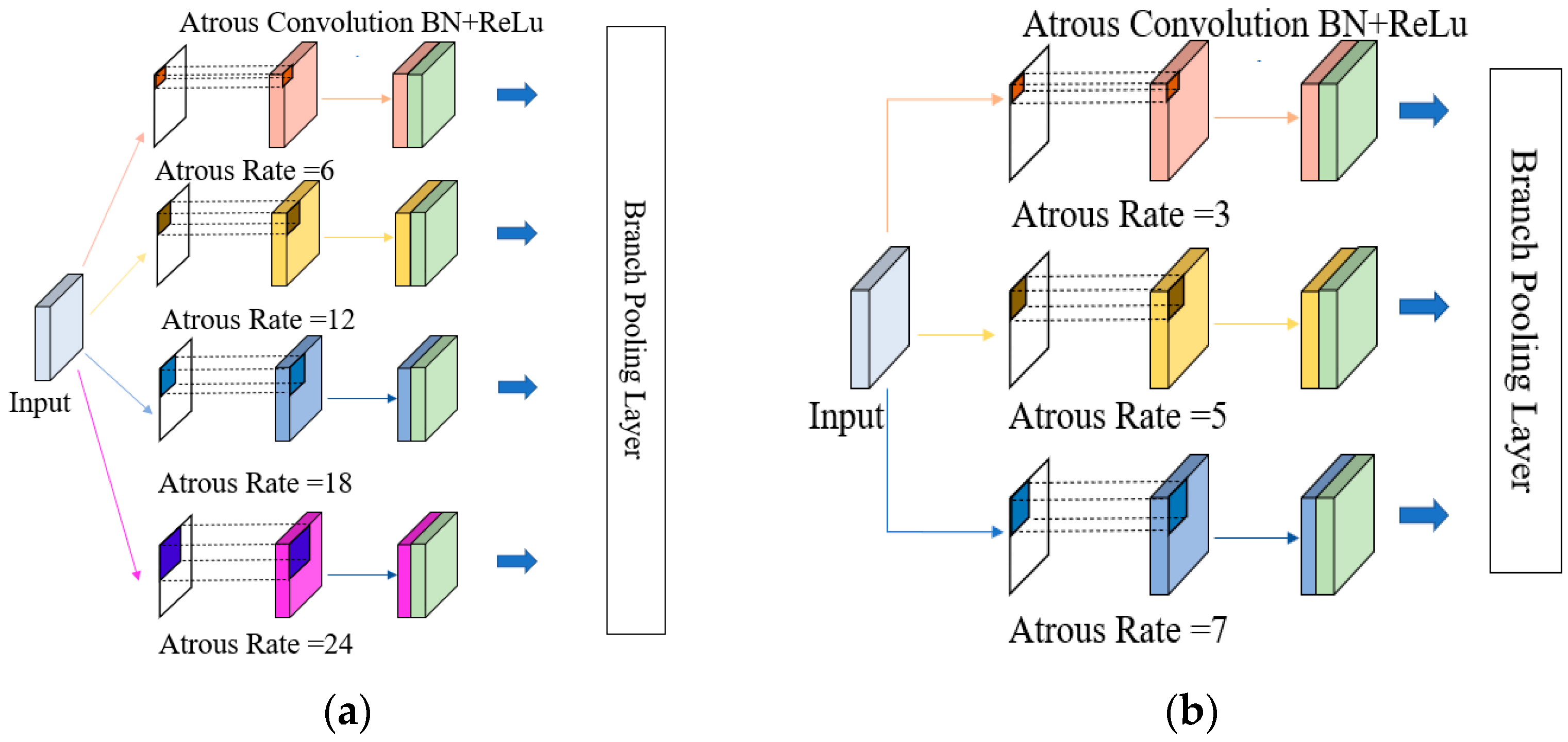
3.3. Modified ASPP to Enhance Targets Detection in Complex Background
3.4. The Improved YOLOv5 Algorithm Structure
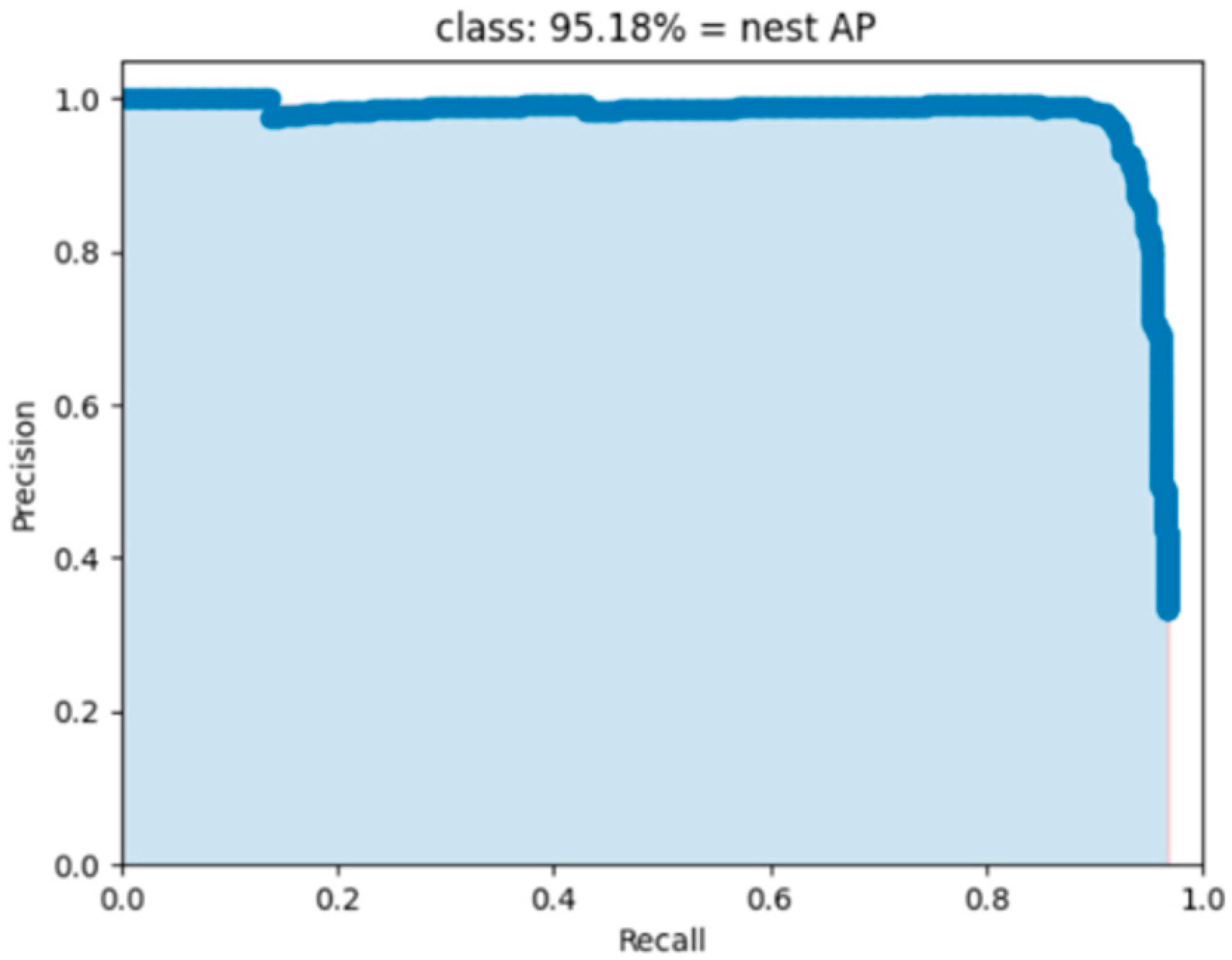
4. Experimental Results and Analysis
4.1. Data Structure and Processing
4.2. Experimental Environment
4.3. Training Process
4.4. Evaluation Indexes
4.5. Comparison of Experimental Results
4.5.1. Cross-Direction Comparison of Experimental Results
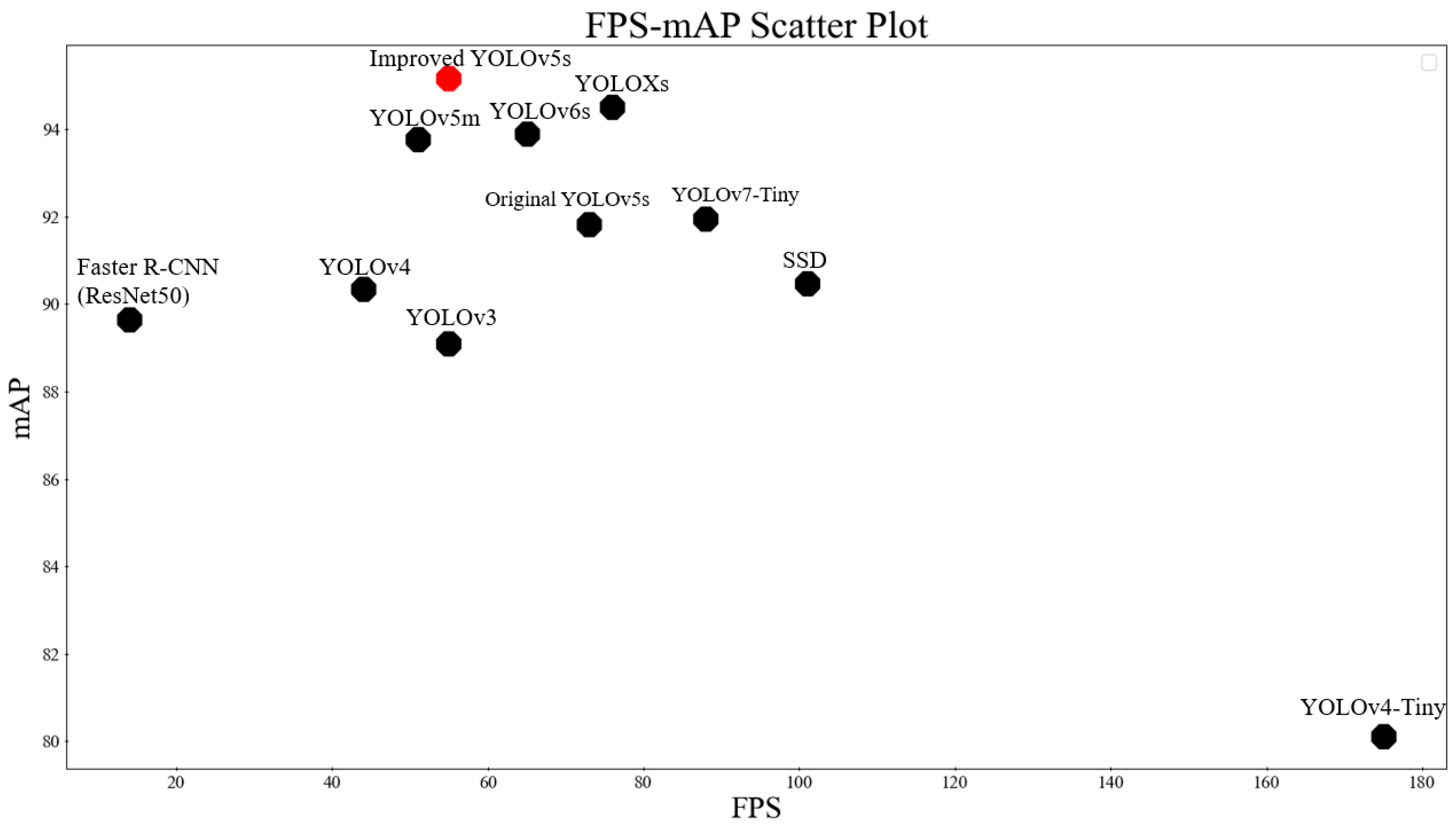
- Among the five mainstream algorithms of Faster R-CNN, SSD, YOLOv3, YOLOv4, and YOLOv4-Tiny, since Faster R-CNN is a two-stage algorithm, it has the highest mAP at 90.48% but the slowest speed is only 10.1FPS, less than 14% of YOLOv5s speed. YOLOv4-Tiny, with only two prediction heads, has the fastest model detection speed at 175 FPS but the lowest mAP at 80.12, which sacrifices detection accuracy for increased detection speed;
- The base model chosen in this paper, YOLOv5s, has higher accuracy than all the previous five algorithms and is second only to YOLOv4-Tiny in terms of detection speed and model size, which is why it is chosen as the base algorithm in this paper;
- The fusion improvement algorithm in this paper improves by 3.34% over the original YOLOv5s, with only a 27.6% increase in model size. Compared to YOLOv5m, which improves network depth and width in YOLOv5, the mAP is improved by 1.41%, the model size is only 46.4% of YOLOv5m, and the detection speed is 4 FPS higher than YOLOv5m, which is eligible for deployment in embedded devices;
- As Figure 11 shows, the improved fusion algorithm in this paper outperforms the mAP of the latest YOLO series of algorithms such as YOLOXs, YOLOv6s, and YOLOv7-Tiny. Moreover, there is a little difference in terms of speed. This shows that the improved algorithm in this paper is still competitive even when compared to the latest algorithms.
4.5.2. Longitudinal Comparison of Experimental Results
- The YOLOv5s-V algorithm only reconstructs the backbone network with the OSA Block in VOVNet. The mAP is increased from 91.84% to 93.08%; FNR is reduced by 0.38%; and the model size is increased by only 2.4MB;
- The YOLOv5s-V-att1 algorithm is based on YOLOv5s-V, after adding the CBAM attention mechanism to the Concat layer in the feature fusion network. YOLOv5s-V-att1 has a 0.29% increase in mAP compared to YOLOv5s-V without the attention mechanism module, which is not a significant increase. This is because, for feature fusion networks, where the CBAM attention mechanism is added after the feature fusion Concat layer after ResBlock, the feature extraction network loses some of the semantic information;
- The YOLOv5s-V-att2 algorithm is based on YOLOv5s-V, after adding the CBAM attention mechanism to the Concat layer in the OSA module of the feature extraction network. YOLOv5s-V-att2 has a 1.33% improvement in mAP compared to the original YOLOv5s-V. For the feature extraction network, CBAM performs spatial and channel attention on the fused Concat layer of features in the OSA module, which is good for information retention and weight assignment. Therefore, this paper chose to use the YOLOv5s-V-att2 algorithm, which adds an attention mechanism to the feature extraction network;
- Compared to the original YOLOv5s, the improved backbone YOLOv5s-V and the YOLOv5s-V-att2 with the attention mechanism have both improved on the aspects of FNR. YOLOv5s-V-att2 improved by 1.08% compared to the original model, which indicates that the improved model has a good improvement in small target detection.
4.5.3. Experimental Comparison of the Improved ASPP Module
- From Experiments I, II, and IV, we find that the number of atrous convolutions affects the model parameters but has little effect on mAP; the atrous rate has a greater effect on mAP;
- From experiments II, IV, V, and VI, we find that the ASPP module with the atrous rate of (3, 5, 7) has the best result, with the mAP 0.06% higher than the original ASPP module with the atrous convolution number of 4 and the model size reduction of 3.76 MB;
- From experiments V and VII, we find that the mAP is increased by 0.27%, and the model size is increased by 3.76 MB by increasing the number of atrous convolutions by one proportional to the atrous rate along (3, 5, 7). Combining mAP and model size, the ASPP module with many atrous convolutions of 3 and the atrous rate of (3, 5, 7) is chosen in this paper.
4.5.4. Comparison of Results of Ablation Experiments
- Improvements to the backbone network resulted in a 1.24% improvement in mAP and an increase in the model size of only 2.4 MB. Adding either the attention mechanism or the Improved ASPP module alone, the attention mechanism works better than the Improved ASPP module because the attention mechanism can better assign weights to detection targets. The reason for the relatively small increase in the mAP of the improved ASPP module is that it duplicates the role of the SPP structure in the backbone network. Therefore, we chose to remove the SPP structure for experimental comparison. It can be seen that after removing the SPP module, YOLOv5s-V-att2 (No SPP) decreased by 0.55% compared to the previous mAP. YOLOv5s-V-Improved ASPP (No SPP) decreased by 0.32% compared to the previous mAP. This suggests that the improved ASPP module does duplicate the role of the SPP structure in the backbone. However, the combined comparison is still the improvement of the attention mechanism that improves the model accuracy more;
- Both the YOLOv5s-V-improved ASPP and the YOLOv5s-V-att2-improved ASPP have improved on FDR. This represents an improvement in the effectiveness of the improved algorithm in this paper for target detection in complex backgrounds;
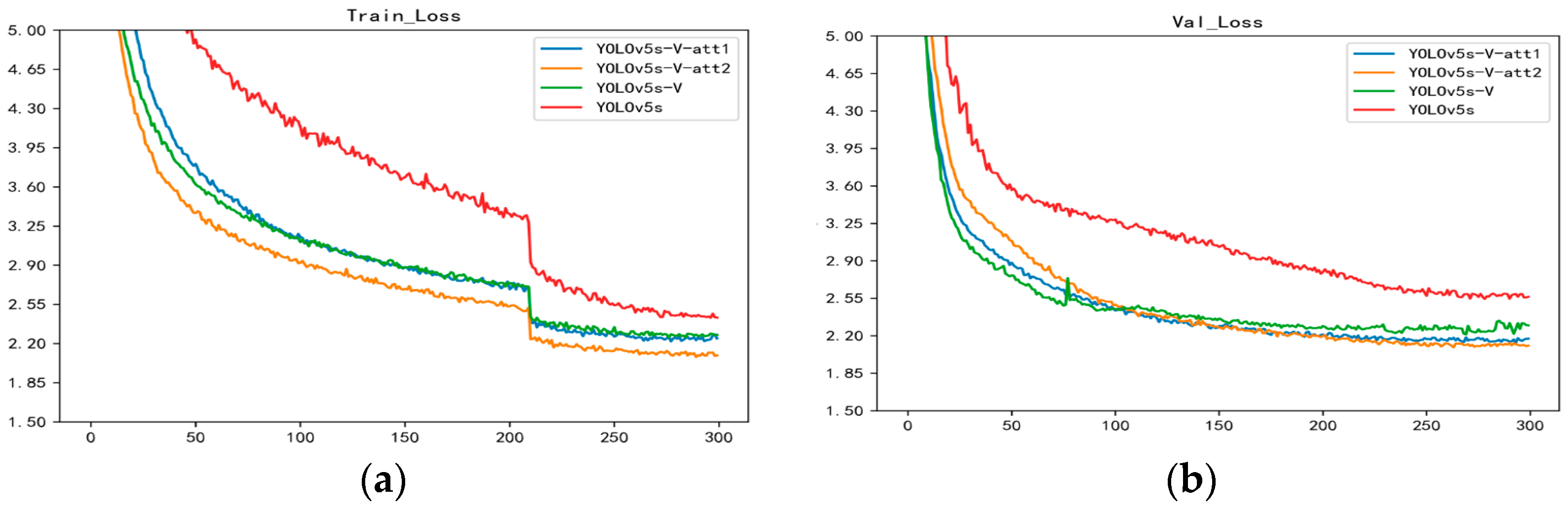
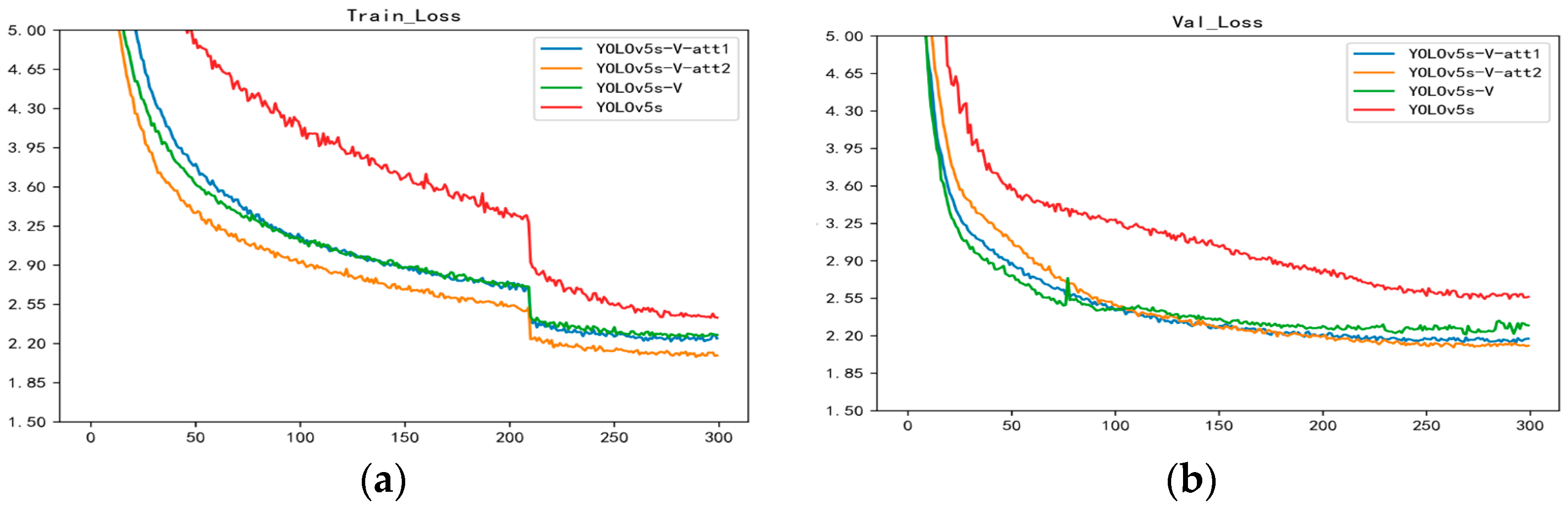
- As Figure 13 shows, the improved model converges faster and has a lower loss value compared to the original model;
- The three improved ablation experiments resulted in a 3.34% improvement over the original results, with an increase in the model size of only 11.5 M and a reduction in detection speed of 18FPS.
5. Embedded Device Deployment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yi, H.; Xiong, Y.; Zhou, G. Overhead transmission line bird damage fault analysis and countermeasures. Power Syst. Technol. 2008, 32, 95–100. [Google Scholar]
- Shi, L.; Chen, Y.; Fang, G. Comprehensive identification method of bird’s nest on transmission line. Energy Rep. 2022, 8, 742–753. [Google Scholar] [CrossRef]
- Zhang, F.; Wang, W.; Zhao, Y. Automatic diagnosis system of transmission line abnormalities and defects based on UAV. In Proceedings of the 4th International Conference on Applied Robotics for the Power Industry (CARPI), Jinan, China, 11–13 October 2016; pp. 1–5. [Google Scholar]
- Wu, X.; Yuan, P.; Peng, Q. Detection of bird nests in overhead catenary system images high-speed rail. Pattern Recognit. 2016, 51, 242–254. [Google Scholar] [CrossRef]
- Chao, Y.; Xu, Z.; Yue, Y. Analysis of fault characteristics and preventive measures for bird damage on transmission lines in Hunan. High Volt. Eng. 2016, 42, 3853–3860. [Google Scholar]
- Liu, X.; Miao, X.; Jiang, H.; Chen, J. Box-point detector: A diagnosis method for insulator faults in power lines using aerial images and convolutional neural networks. IEEE Trans. Power Deliv. 2021, 36, 3765–3773. [Google Scholar] [CrossRef]
- Qiu, Z.; Shi, D.; Kuang, Y. Image Recognition of Harmful Bird Species Related to Transmission Line Outages Based on Deep Transfer Learning. High Volt. Eng. 2021, 47, 3785–3794. [Google Scholar]
- Zhou, H.; Yu, G. Research on pedestrian detection technology based on SVM classifier trained by HOG and LTP features. Future Gener. Comput. Syst. 2021, 125, 604–615. [Google Scholar] [CrossRef]
- Duan, W.; Tang, P.; Jin, W. Bird’s nest detection on railway contact networks based on HOG features in critical areas. China Railw. 2015, 8, 73–77. [Google Scholar]
- Wang, Y.; Shen, Z.; Zhao, H. Fault Diagnosis Method of Photovoltaic Modules Infrared Image Based on Improved CNN-SVM. J. North China Electr. Power Univ. 2022, 1–8. [Google Scholar]
- Fang, Q.; Hou, J.; Weng, Y. Risk early warning system for long distance high voltage transmission lines based on GA-BP algorithms. J. Xian Polytech. Univ. 2019, 33, 531–537. [Google Scholar]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Ren, S.; He, K. Faster R-CNN: Towards Real-Time Object Detection with Regin Proposal Networks. arXiv 2017, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Luo, H.; Yu, P. Bird’s nest detection in multi-scale of high-voltage tower based on Faster R-CNN. J. Beijing Jiaotong Univ. 2019, 43, 37–43. [Google Scholar]
- Liu, W.; Anguelov, D.; Rhan, D. SSD: Single Shot MultiBox Detector; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farrhadi, A. YOLO9000: Better, Faster, stronger. In Proceedings of the IEEE Conference on Computer Vision & Patt-ern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farrhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 21 May 2022).
- Satheeswari, D.; Shanmugam, L.; Swaroopan, N. Recognition of Bird’s Nest in High Voltage Power Line using SSD. In Proceedings of the 1st International Conference on Electrical, Electronics, Information and Communication Technologies, ICEEICT, Trichy, India, 16–18 February 2022. [Google Scholar]
- Jiang, H.; Huang, W. Detection of Bird Nests on Power Line Patrol Using Single Shot Detector. In Proceedings of the 2019 Chinese Automation Congress, Hangzhou, China, 22–24 November 2019. [Google Scholar]
- Yang, X.; He, P.; Chen, L.; Li, J. Bird’s Nest Detection on Lightweight YOLOv3 Transmission Line Based on Deep Separable Convolution. Smart Power 2021, 49, 88–95. [Google Scholar]
- Zhang, Z.; He, G. Recognition of Bird Nests on Power Transmission Lines in Aerial Images Based on Improved YOLOv4. Front. Energy Res. 2022, 10, 870253. [Google Scholar] [CrossRef]
- Han, G.; He, M.; Zhao, F. Insulator detection and damage identification based on improved lightweight YOLOv4 network. Energy Rep. 2021, 7, 187–197. [Google Scholar] [CrossRef]
- Ying, Z.; Lin, Z.; Wu, Z.; Liang, K.; Hu, X. A modified-YOLOv5s model for detection of wire braided hose defects. Measurement 2022, 190, 110683. [Google Scholar] [CrossRef]
- Han, G.; He, M.; Gao, M.; Yu, J.; Liu, K.; Qin, L. Insulator Breakage Detection Based on Improved YOLOv5. Sustainability 2022, 14, 6066. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, B.; Lan, Z. FINet: An Insulator Dataset and Detection Benchmark Based on Synthetic Fog and Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 99. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; He, Y. YOLOv5-Fog: A Multiobjective Visual Detection Algorithm for Fog Driving Scenes Based on Improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Deng, F.; Xie, Z.; Mao, W. Research on edge intelligent recognition method oriented to transmission line insulator fault detection. Int. J. Electr. Power Energy Syst. 2022, 139, 108054. [Google Scholar] [CrossRef]
- Gao, H.; Zhuang, L. Densely Connecter Convolution Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar]
- Bai, H.; Tang, B.; Cheng, T.; Liu, H. High impedance fault detection method in distribution network based on improved Emanuel model and DenseNet. Energy Rep. 2022, 8, 982–987. [Google Scholar] [CrossRef]
- Ren, H.; Wang, X. The overview of attentional mechanisms. J. Comput. Appl. 2021, 41, 1–6. [Google Scholar]
- Ye, T.; Zhang, J.; Li, Y.; Zhang, X.; Zhao, Z.; Li, Z. CT-Net: An Efficient Network for Low-Altitude Object Detection Based on Convolution and Transformer. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Wang, L.; Cao, Y.; Wang, S.; Song, X.; Zhang, S.; Zhang, J.; Niu, J. Investigation into Recognition Algorithm of Helmet Violation Based on YOLOv5-CBAM-DCN. IEEE Access 2022, 10, 60622–60632. [Google Scholar] [CrossRef]
- Woo, S.; Park, J. CBAM: Convolution Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Jabir, B.; Falih, N. Deep learning-based decision support system for weeds detection in wheat fields. Int. J. Electr. Comput. Eng. 2022, 12, 816. [Google Scholar] [CrossRef]
- Li, C.; Li, L.; Jiang, H. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Yao, C.; Bochkovskiy, A.; Liao, H. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mAP/% | Speed/FPS | Model Size/MB |
|---|---|---|---|
| Faster R-CNN | 89.65 | 14 | 113 |
| SSD | 90.48 | 101 | 100.27 |
| YOLOv3 | 89.10 | 55 | 236 |
| YOLOv4 | 90.35 | 44 | 245 |
| YOLOv4-Tiny | 80.12 | 175 | 23 |
| Original YOLOv5s | 91.84 | 73 | 27.8 |
| YOLOv5m | 93.77 | 51 | 81.54 |
| YOLOXs | 94.52 | 76 | 35.9 |
| YOLOv6s | 93.9 | 65 | 17.2 |
| YOLOv7-Tiny | 91.96 | 88 | 24.2 |
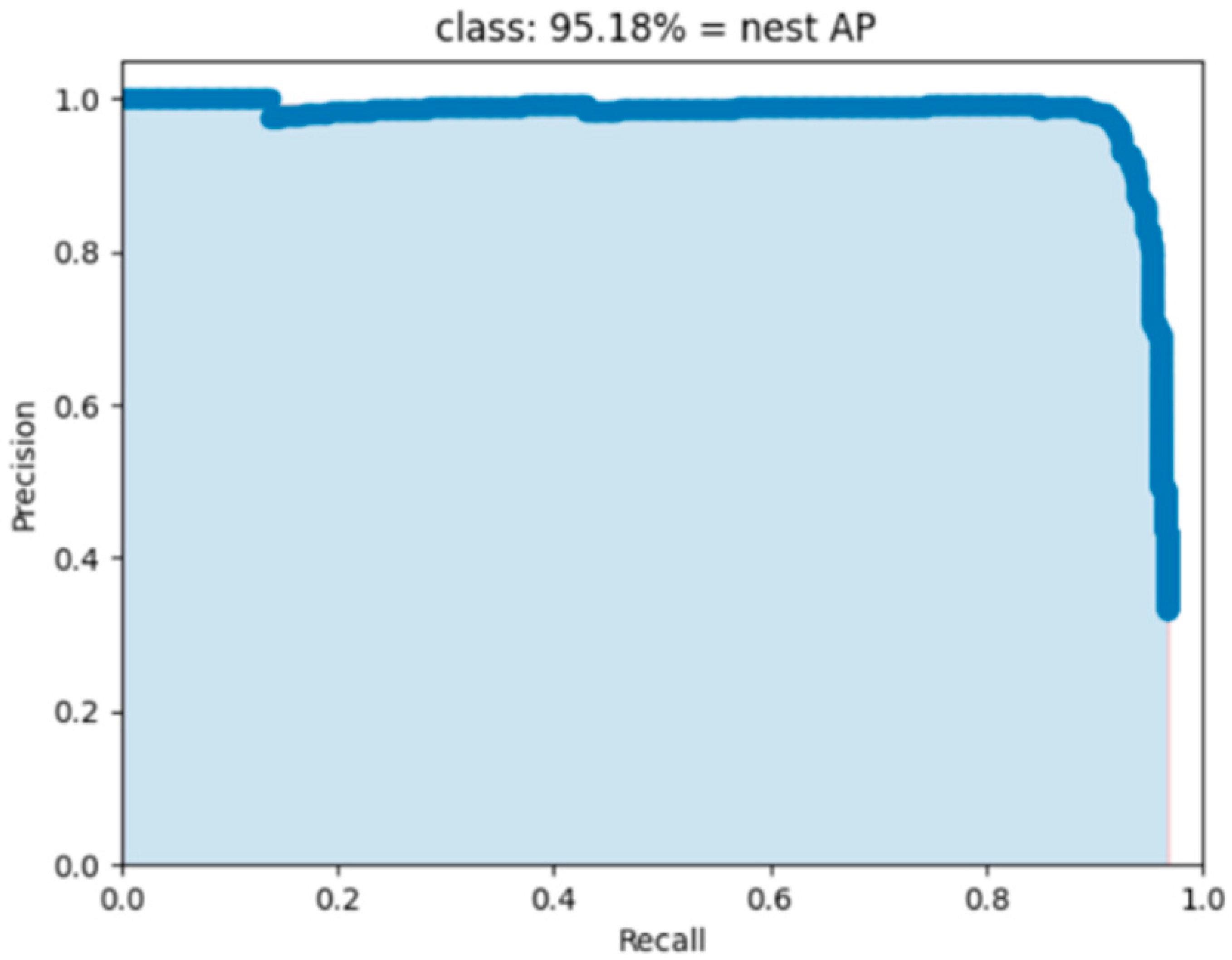
| Improved YOLOv5s | 95.18 | 55 | 37.85 |
| Models | mAP/% | Speed/FPS | FNR/% | Model Size/MB |
|---|---|---|---|---|
| YOLOv5s | 91.84 | 73 | 2.84 | 27.8 |
| YOLOv5s-V | 93.08 | 65 | 2.46 | 30.2 |
| YOLOv5s-V-att1 | 93.37 | 61 | 2.11 | 31.28 |
| YOLOv5s-V-att2 | 94.41 | 61 | 1.76 | 31.58 |
| Experiments | The Number of Atrous Convolutions | Atrous Rates | mAP/% | Model Size/MB |
|---|---|---|---|---|
| I | 4 | (6, 12, 18, 24) | 92.95 | 38.11 |
| II | 3 | (6, 12, 18) | 91.73 | 34.35 |
| III | 5 | (6, 12, 18, 24, 30) | 92.58 | 41.86 |
| IV | 3 | (4, 6, 8) | 92.92 | 34.35 |
| V | 3 | (3, 5, 7) | 93.01 | 34.35 |
| VI | 3 | (2, 4, 6) | 92.65 | 34.35 |
| VII | 4 | (3, 5, 7, 9) | 93.28 | 38.11 |
| Models | mAP/% | Speed/FPS | FDR/% | Model Size/MB |
|---|---|---|---|---|
| YOLOv5s | 91.84 | 73 | 6.56 | 27.8 |
| YOLOv5s-V | 93.08 | 65 | 6.44 | 30.2 |
| YOLOv5s-V-att2 | 94.41 | 61 | 5.9 | 31.58 |
| YOLOv5s-V-att2(No SPP) | 93.86 | 63 | 6.4 | 29.58 |
| YOLOvs5-V-Improved ASPP | 93.97 | 60 | 5.42 | 38.47 |
| YOLOvs5-V-Improved ASPP(No SPP) | 93.65 | 61 | 5.64 | 36.47 |
| YOLOv5s-V-att2-Improved ASPP | 95.18 | 55 | 5.17 | 39.85 |
| Original Algorithm | Improved Algorithm | |
|---|---|---|
| (a) |  |  |
| (b) |  |  |
| (c) |  |  |
| (d) |  |  |
| Original Algorithm | Improved Algorithm | |
|---|---|---|
| (a) |  |  |
| (b) |  |  |
| (c) |  |  |
| (d) |  |  |
| Models | mAP/% | Speed/FPS |
|---|---|---|
| Original YOLOv5s | 91.84 | 10.9 |
| Improved YOLOv5s | 95.18 | 10.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, G.; Wang, R.; Yuan, Q.; Li, S.; Zhao, L.; He, M.; Yang, S.; Qin, L. Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s. Machines 2023, 11, 257. https://doi.org/10.3390/machines11020257
Han G, Wang R, Yuan Q, Li S, Zhao L, He M, Yang S, Qin L. Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s. Machines. 2023; 11(2):257. https://doi.org/10.3390/machines11020257
Chicago/Turabian StyleHan, Gujing, Ruijie Wang, Qiwei Yuan, Saidian Li, Liu Zhao, Min He, Shiqi Yang, and Liang Qin. 2023. "Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s" Machines 11, no. 2: 257. https://doi.org/10.3390/machines11020257
APA StyleHan, G., Wang, R., Yuan, Q., Li, S., Zhao, L., He, M., Yang, S., & Qin, L. (2023). Detection of Bird Nests on Transmission Towers in Aerial Images Based on Improved YOLOv5s. Machines, 11(2), 257. https://doi.org/10.3390/machines11020257