1. Introduction
Diesel engines are widely used in industrial environments and are thus expected to be robust. Accordingly, these engines are usually under an effective maintenance program to avoid unplanned shutdowns due to defects [
1]. A few important attributes influence the choice of a diesel engine for a given application, such as cost, performance, and useful life [
2]. The major application of this engine in several sectors is related to the reclamation of the portion of crude petroleum that was once considered to be the refuse of the gasoline refining process. Over time, diesel engine manufacturing technology has evolved, allowing more robust high-torque and energy-efficient equipment, which can be applied in environments that require high power, to be fabricated [
3].
Diesel engines used in the offshore industry, such as in support vessels and oil production units, are subjected to an inhospitable environment, making them more susceptible to failure. Unfortunately, this kind of machine is prone to performance degradation and mechanical breakdowns [
4]. In addition, this equipment is usually the primary power plant on ships. For instance, marine diesel engines are prone to damage due to harsh working conditions, which include, but are not limited to, the presence of water, salt corrosion, and abrupt vibrations. The failures of such equipment are responsible for approximately
of the marine accidents caused by mechanical faults [
5]. Therefore, effective fault diagnosis is essential to improving machinery reliability [
6,
7,
8,
9,
10,
11]. Furthermore, the maintenance cost of diesel engines can vary from
to
of the total value of a vessel [
12,
13]. It is fundamental to have a system capable of preemptively identifying potential motor faults in order to avoid damage to the production, the workers, and the ship itself [
4,
14].
Recently, many methods have been proposed to detect diesel engine faults, which include oil analysis [
15], thermodynamic parameters [
16], and vibration analysis [
17,
18], among others. Furthermore, advances in the development of automation and instrumentation technology have led to the development of efficient monitoring devices [
19], contributing to predictive maintenance techniques. These methods typically use input data in the form of signals. Once the signal has been appropriately diagnosed, it can be used to determine the best course of action to take.
Intelligent fault diagnosis methods to estimate machine conditions have been widely applied [
7,
20,
21,
22]. In order to predict combustion failures in the cylinders of engines, the torsional vibration of high-power internal combustion engines was analyzed in [
23] using the instantaneous angular velocity wave signal. Note that the crankshaft speed is unstable in these types of engines due to the cylinder firing order. In these tests, a magnetic pickup sensor was installed on the flywheel of the motor, and the fast Fourier transform, alongside time series analysis, was used to predict failures. Both techniques attained good results when applied to identifying combustion failures in the engine cylinders.
The work described in [
24] acquired a vibration signal to observe failures in a four-stroke spark-ignition engine. Tests were performed for (i) normal operating conditions, (ii) a separation between the candle electrodes, (iii) open intake valves, and (iv) closed intake valves. The vibration signals were obtained using an accelerometer that had been placed on the cylinder head. In addition, a tachometer was employed to obtain the number of revolutions. A temporal analysis of the vibration signal was used, taking into account the angle of the crankshaft, using as reference the signals recorded when the motor was operating without defects. Their results showed that a non-intrusive methodology could be efficiently utilized to assess the diagnosis of both medium and large engines.
Reference [
4] focused on a four-cylinder commercial diesel engine. In order to measure the vibration signal, four piezoelectric accelerometers were mounted on each cylinder head. Five types of faults were investigated: piston pin fault, piston ring fault, inlet valve fault, outlet valve fault, and connection rod fault. The rotating speed of the engine was 1500 rpm, and each fault scenario was tested ten times. A method based on kernel independent component analysis and the Stockwell transform was used for preprocessing. Twelve features extracted from this initial procedure were used as input for an artificial neural network that performed automatic failure classification. The advanced classifier obtained the accuracy of
in the failure scenarios.
The work described in [
22] developed a methodology for managing the energy efficiency of a vessel, taking into account simulation data and system monitoring. Several critical situations in the main engine were analyzed and implemented as simulations with an engine room simulator for a certain navigation route of a very large crude carrier vessel. Based on the results obtained in this paper, it was verified that fuel consumption and the emission of gases into the atmosphere considerably increased when the vessel presented defective or inefficient operating conditions.
A four-stroke high-speed marine diesel engine failure simulator based on an adjusted dimensional thermodynamic model was used in [
25]. The method was validated on a dataset of real engines. The developed model was able to generate, with great reliability, a large number of typical thermodynamic diesel engine faults and the standard operating behavior. The work [
26] presents a predictive maintenance system based on the fault diagnosis of diesel engines using the vibration response of the crankshaft and the variation in pressure curves inside the cylinders. The work developed a simulation model based on a zero-dimensional thermodynamic model. A total of 701 scenarios divided into four operations configurations were observed. Two machine learning algorithms were applied: random forest (RF) and multilayer perceptron (MLP) neural networks. The accuracy obtained by the algorithms was about 99.3%. The authors concluded that the signal–noise ratio must be small to guarantee good performance.
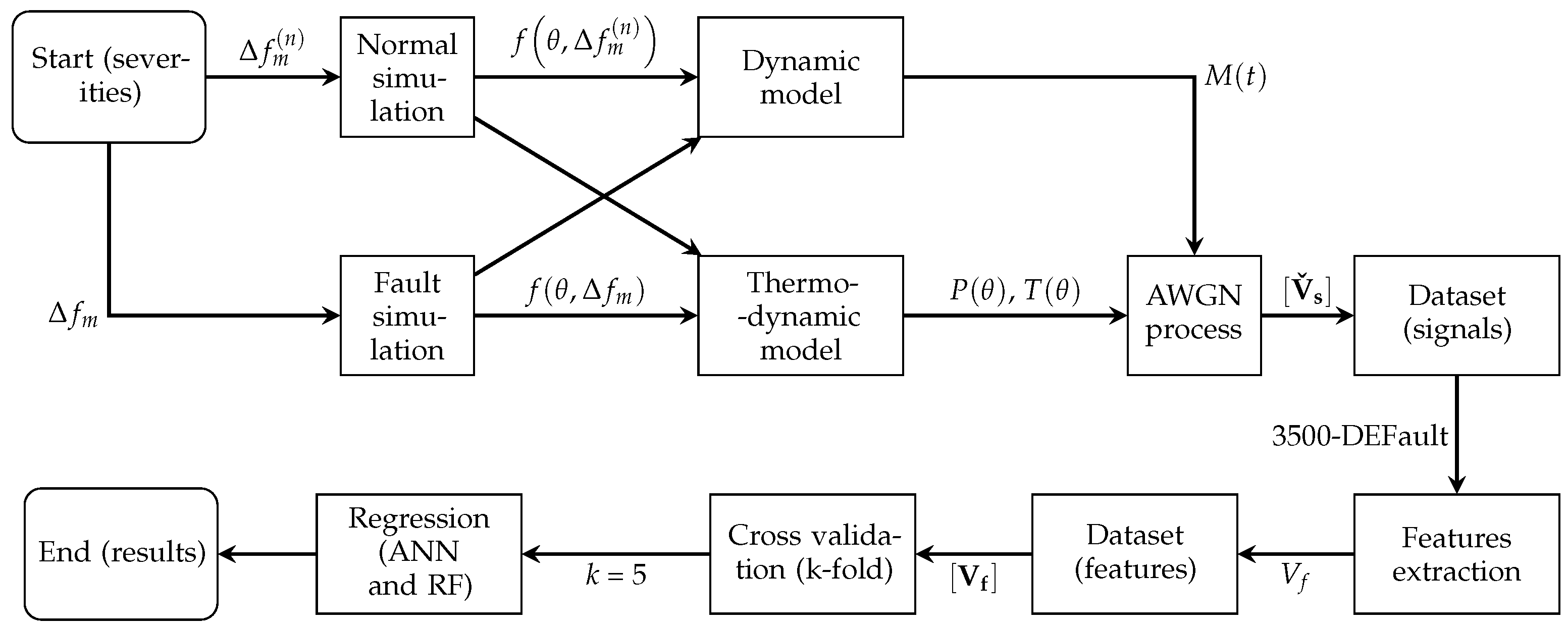
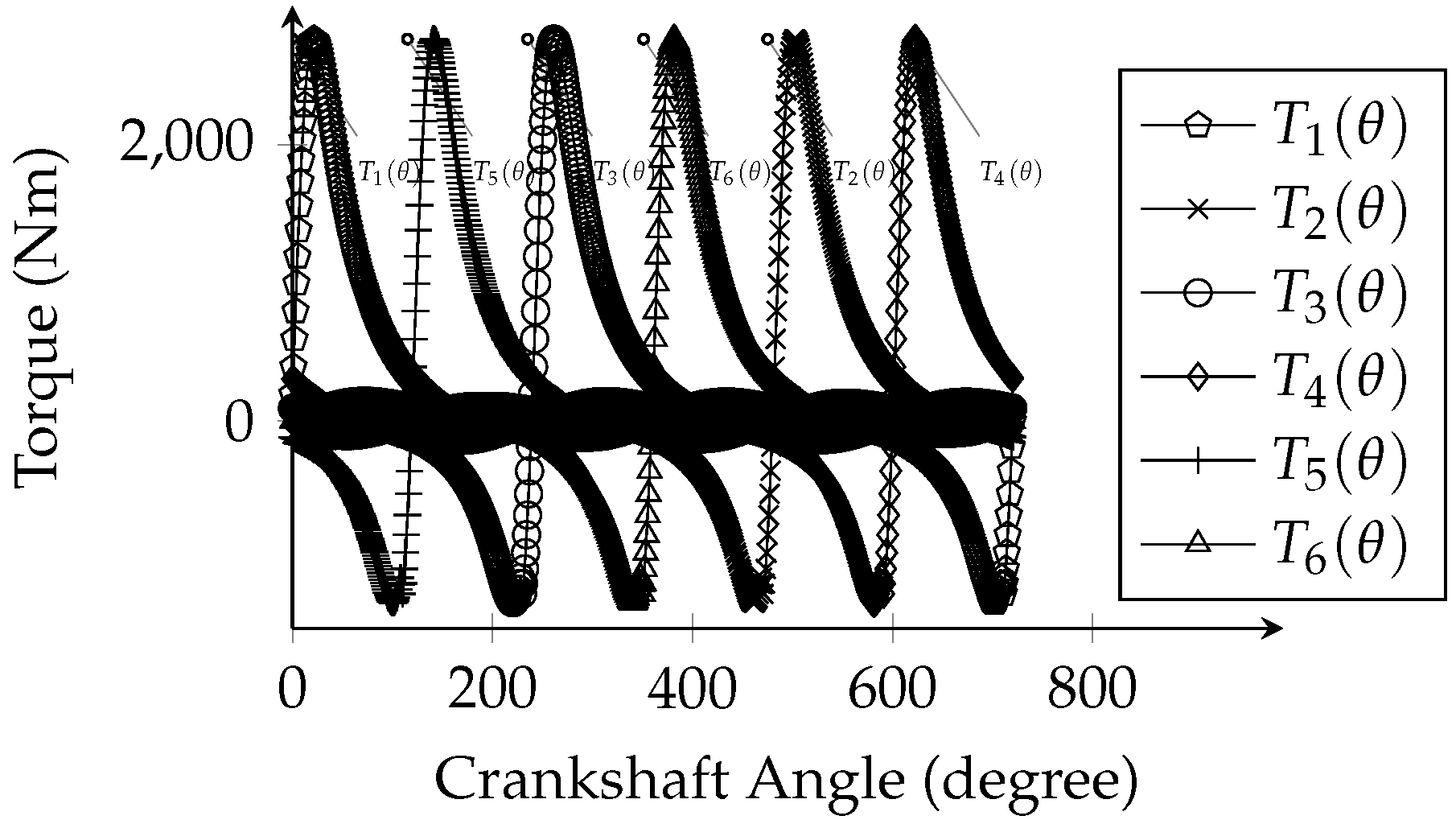
The proposed system possesses a modular architecture (equivalent to the ones described in [
27,
28]) for a condition-based maintenance system comprising twelve blocks. As shown in
Figure 1, the system is composed of the start block (severity input); diesel engine performance simulation, which, in dynamic and thermodynamic model blocks, consists in solving the equations of the model based on the severity applied (start block) and on the returned fault signals (signals from a fault condition); the dataset generation block (split into the creation of fault and normal signals, which result from the normal and fault simulation blocks), which deals with the generation of the normal instances and their relationship with the fault examples; the additive white Gaussian noise (AWGN) process block (which adds noise to the signals); the dataset signal block (file in the form of a dataset according to the applied noise levels); the feature extraction block, which generates attributes from the dataset that are employed in the regression stage; the feature dataset block; the cross-validation block, which is responsible for evaluating the generalization abilities of the model; the regression block (composed of artificial neural networks and random forest-based regressors), which performs the machine learning tests; and the last (end) block, which presents the results. In the remainder of this work, the acronym 3500-DEFault (diesel engine fault) represents the dataset of 3500 signals from a diesel engine simulation.
It is also important to emphasize the differences between the main contributions of this work and the ones presented in [
26]. Namely, the latter focused on diagnosing faults in diesel engines using machine learning algorithms that were trained using a dataset consisting of 701 fault events. This contrasts with the dataset employed herein, which employs 3500 instances of fault event signals. These signals were obtained by developing improved versions of the algorithms responsible for generating these signals. Furthermore, the main idea of this work resides not only in identifying the existence of a fault but also in its corresponding severity (in the form of a numerical value), which is usually the main object of interest in real-world applications. In the context of this work, severity assessment refers to the process of evaluating the gravity of an identified fault or malfunction in a diesel engine. It involves determining the extent to which the fault affects the engine’s performance, safety, and reliability. Severity assessment is not performed in the literature, with one of the main reasons being the lack of a suitable database of signals. Our approach is capable of predicting low-severity fault events up to
variance in parameter input, effectively anticipating fault occurrence and thus enabling our prognosis system.
This work is organized as follows:
Section 2 presents the main concepts of the diesel engine model that was used to generate the fault signals. This section also describes (i) the mathematical foundation of the dynamic torsional model of the crankshaft, (ii) the model verification, and (iii) the failure simulation model. The dataset and the feature extraction process are described, respectively, in
Section 3 and
Section 4. The results and discussions are detailed in
Section 5. Finally, concluding remarks and future work ideas are presented in
Section 6.
3. Dataset
The dataset used to train and test regression models must emulate all operating scenarios under study. In our case, the dataset has to include signals containing enough knowledge to distinguish different diesel engine defects as well as the corresponding severity levels. The dataset employed in this work covers four operational conditions that will be described in
Section 3.1.1,
Section 3.1.2,
Section 3.1.3 and
Section 3.1.4.
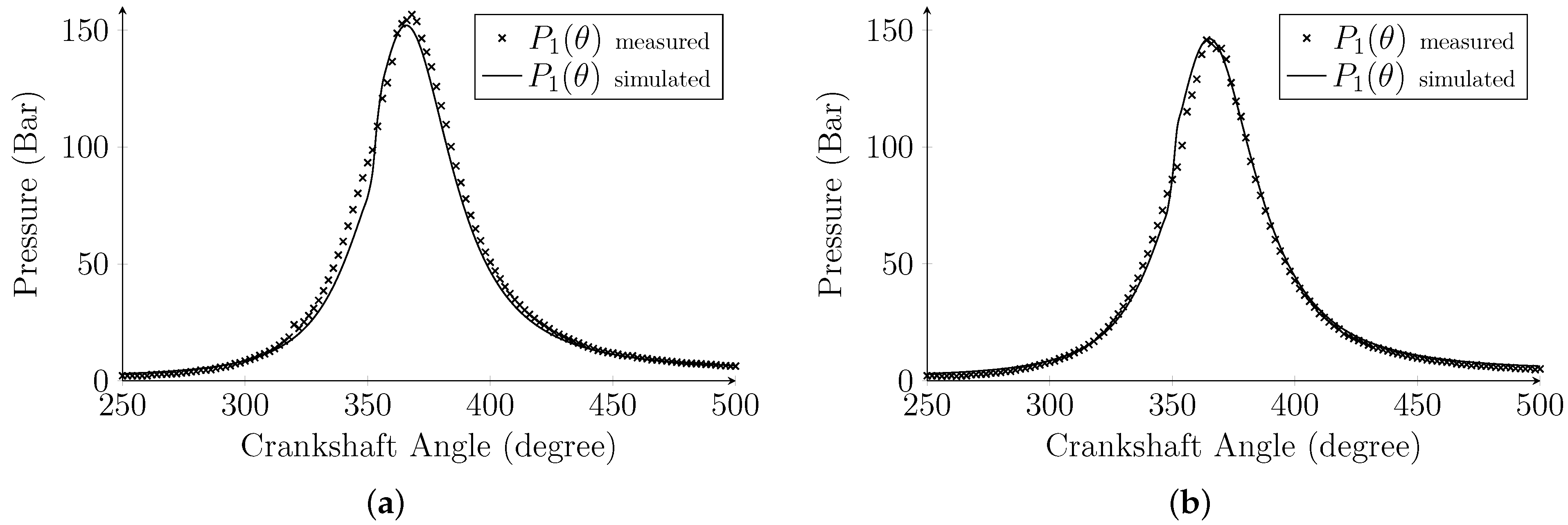
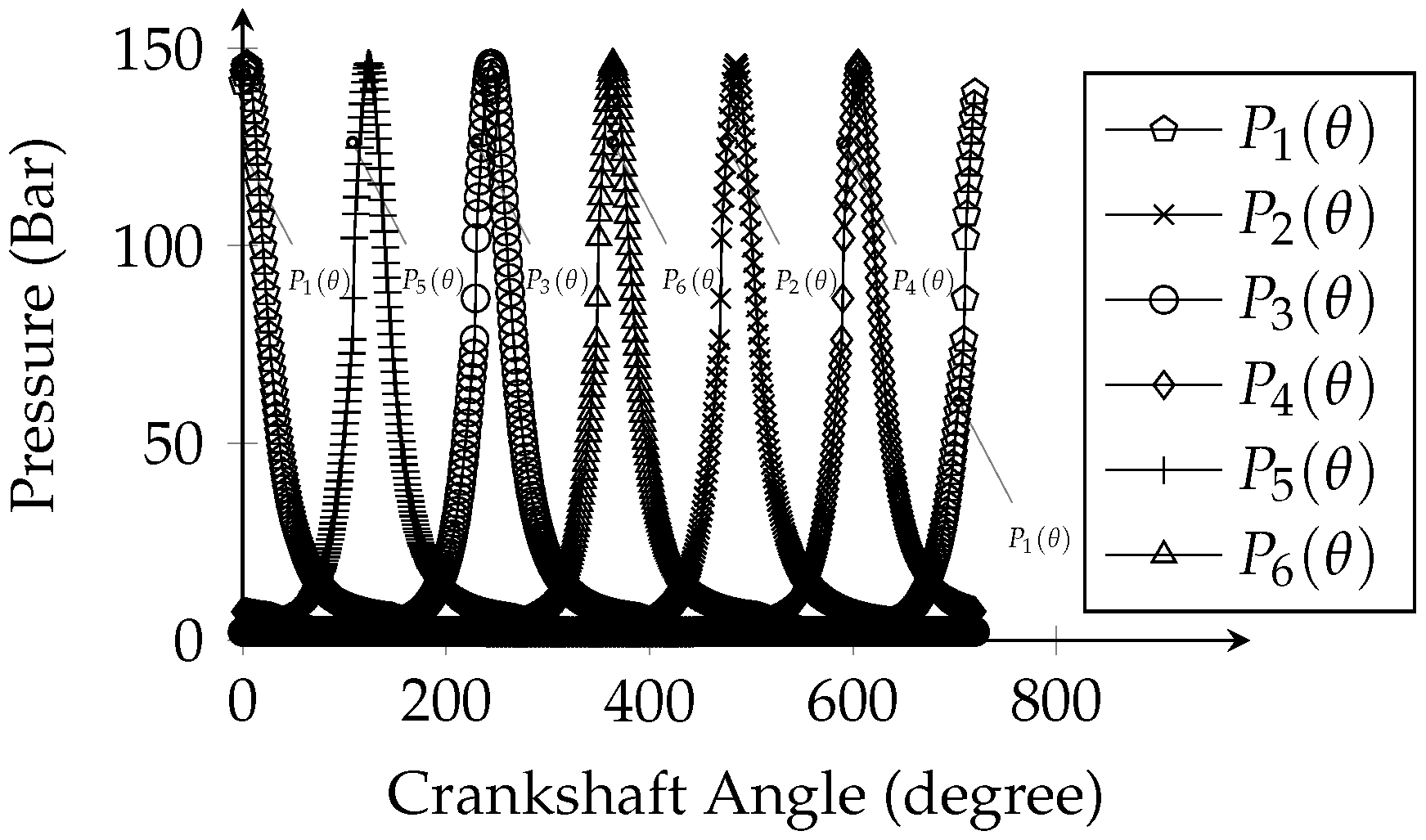
Engine rotation at 2500 RPM was applied in all scenarios because it presented the lowest joint error value (between the simulated and experimental instances) in estimating the maximum and mean pressures of the burning cycle. The joint error was obtained in the validation step of the dynamic/thermodynamic models by taking into consideration the deviation that exists between the values produced by the models and the ones provided by the manufacturer of the equipment.
The dataset contains 3500 distinct fault signals, which were constructed using the model detailed in
Section 2, for four distinct operational conditions: the normal condition, “pressure reduction in the intake manifold”, “compression ratio reduction in the cylinders”, and “reduction of the fuel quantity injected inside the cylinders”. The 3500 fault scenarios consist of 250 instances from the normal class, 250 instances from the “pressure reduction in the intake manifold” class, 1500 instances from the “compression ratio reduction in the cylinders” class, and 1500 instances from the “reduction of the amount of fuel injected into the cylinders” class. This dataset is named Diesel Engine Faults Features Dataset (3500-DEFault) and is publicly available among the Mendeley datasets [
35].
3.1. Fault Classes
This section presents the scenarios analyzed in this research work. Four different types of scenarios were evaluated, namely:
Normal operation;
Pressure reduction in the intake manifold;
Compression ratio reduction in the cylinders;
Reduction in the amount of fuel injected into the cylinders.
3.1.1. Normal
This case represents engine operation without faults. A total of 250 different signals were generated by simulating using the variable. This stage covers a span between 0 and 0.1% of maximum severity (with uniform probability distribution) in the 27 input severity parameters chosen from the thermodynamic/dynamic models , , , , , , and . This stage aspires to emulate the real engine condition without faults, where the machine variables vary in a slight range near optimal functioning.
3.1.2. Pressure Reduction in the Intake Manifold
Severity values of in increments were considered, i.e., (in %), enabling 250 instances of this class to be constructed.
3.1.3. Compression Ratio Reduction in the Cylinders
To generate this type of fault, the use of all cylinders is required. Many instances with (in %) severity values corresponding to the cylinders were evaluated. This strategy allowed 250 distinct examples per cylinder to be constructed, thus producing a total of 1500 instances of this class.
3.1.4. Reduction in the Amount of Fuel Injected into the Cylinders
The scenarios of this condition also require all cylinders. Several scenarios with severity values of (in %) with respect to the cylinders were considered. A total of 250 different scenarios were addressed for each cylinder, generating a total of 1500 instances of this class.
3.2. Additive White Gaussian Noise Process
In 3500-DEFault, different noise levels were applied with a signal-to-noise ratio (in dB) of
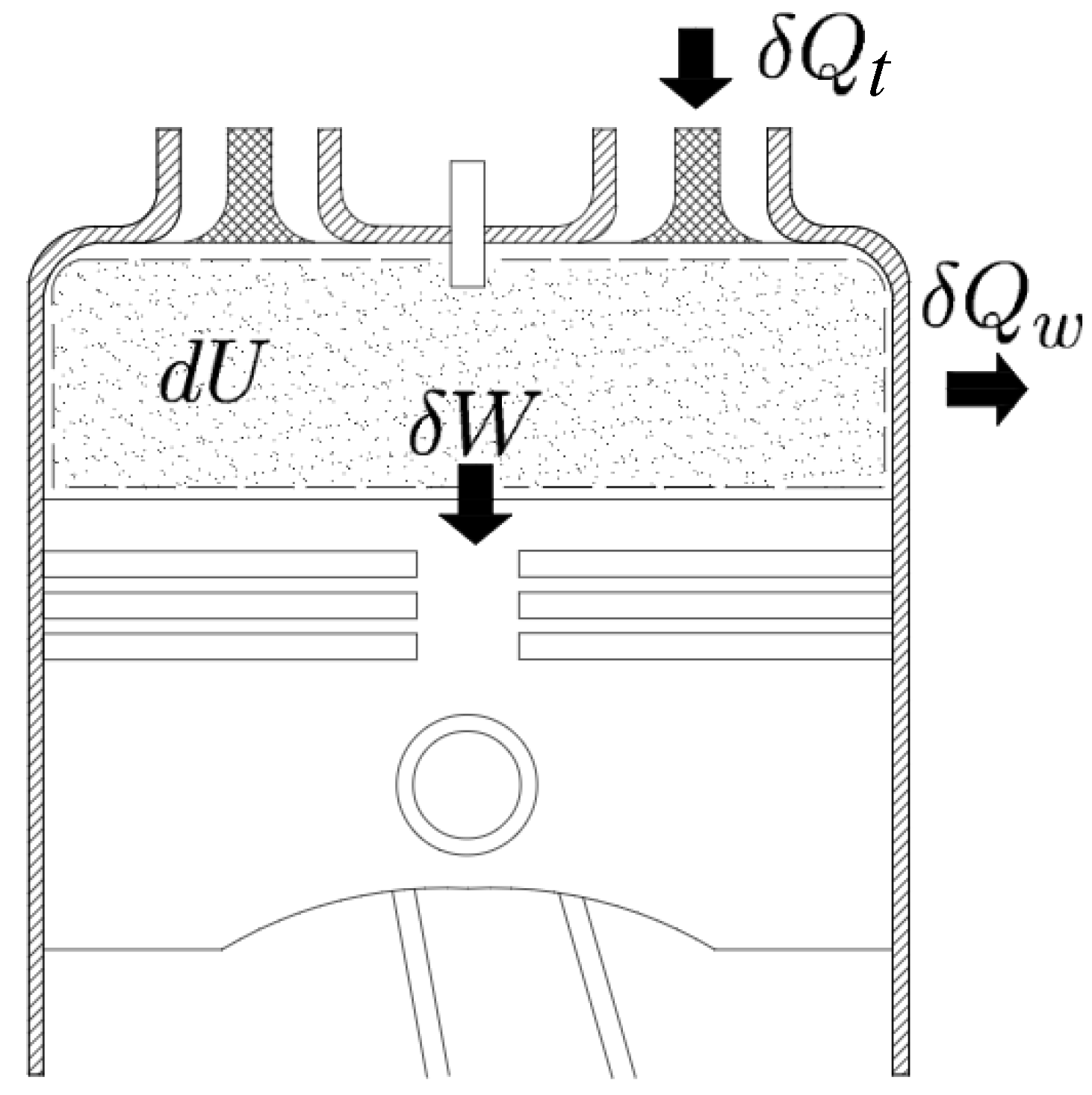
, which was obtained using additive Gaussian white noise (AWGN). Noise addition was implemented to investigate its influence on the regression performance and to emulate a measured signal. The clean vector of engine signals
is defined in Equation (
9).
where the variables
,
, and
represent torque and pressure for a single slide–crank system, and external torque, without noise addition (Equations (
1)–(
3), respectively).
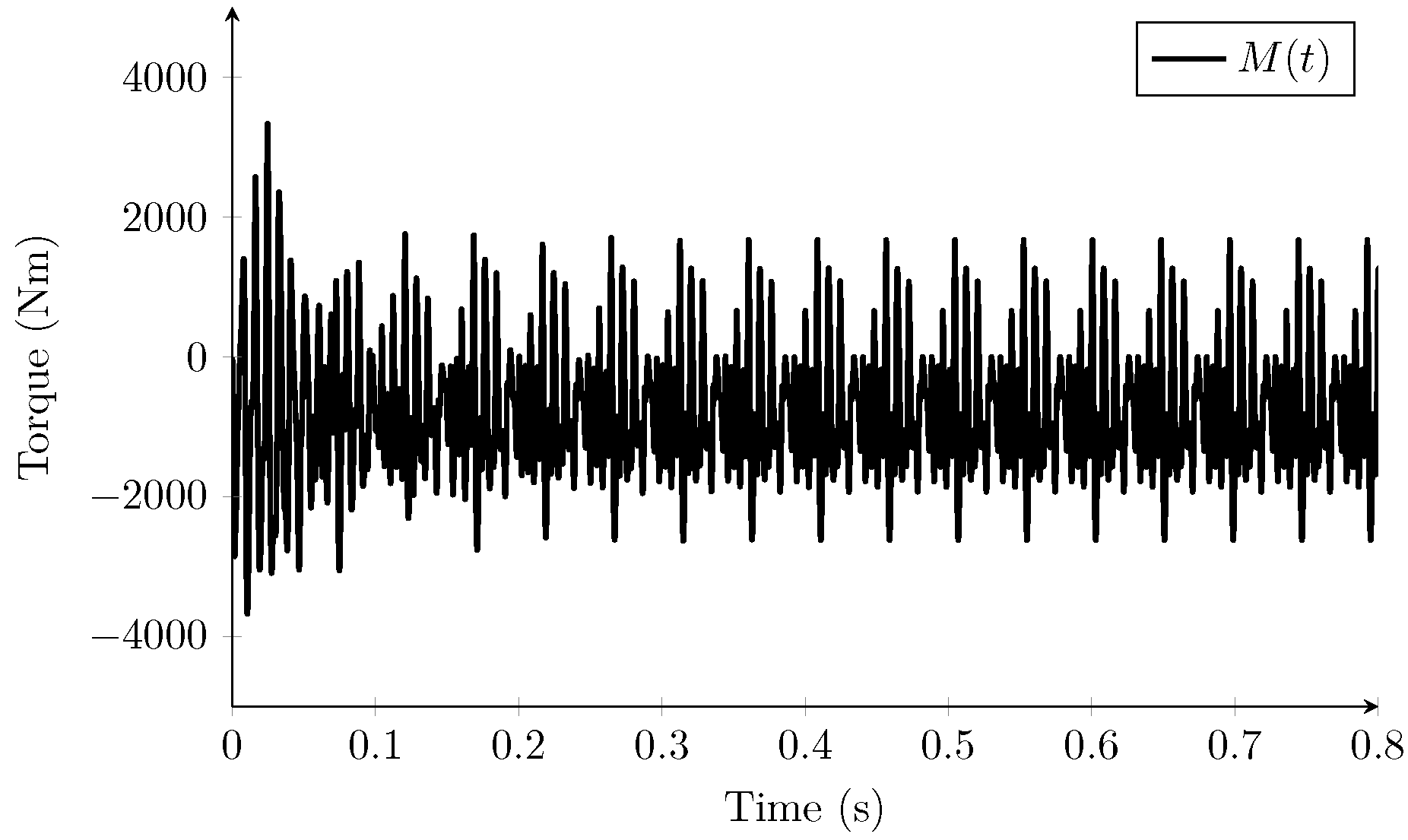
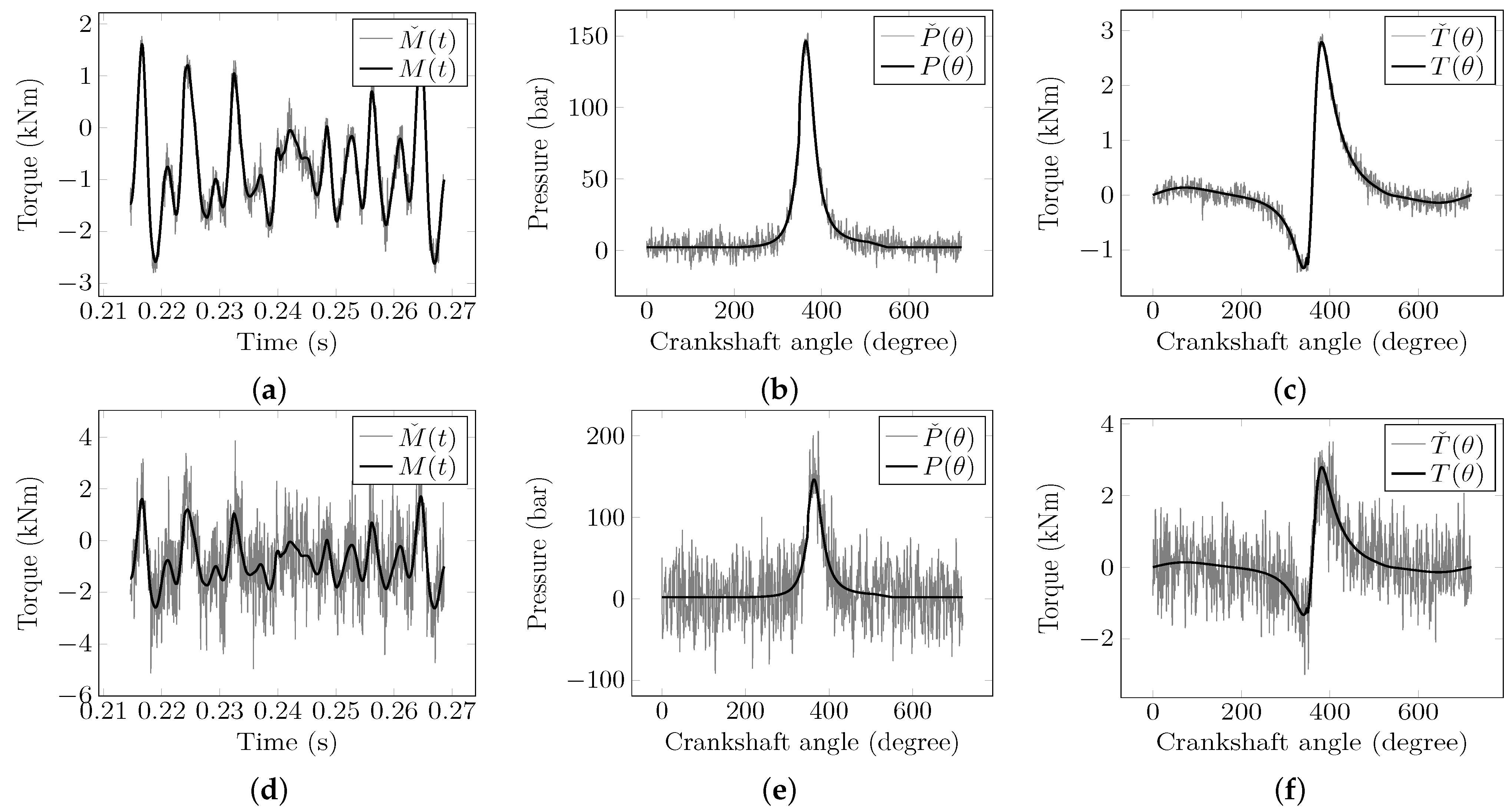
Figure 7 shows the variables
,
, and
with different levels
L of AWGN, labeled as
. Note that
is a vector with the original corrupted signals. The addition of white noise for each element
of
can be expressed as is described in Equation (
10).
The operations carried out in Equation (
10) and
Figure 7 can be summarized as presented in Equation (
11).
where the white noise
can be characterized as a random process of zero mean and variance defined by the chosen SNR level
L. The SNR is defined as shown in Equation (
12).
where
is the expected value and the variable
is the maximum value for each element
of vector
.
3.3. Data Normalization
In statistical studies, normalization or feature scaling is widely used to standardize data and thus optimize data processing. In machine learning, normalization plays a significant role when attributes can hinder data processing, such as features with dynamic ranges of different orders of magnitude, measured on different scales, that do not equally contribute to model fitting. Normalization is a way to standardize and minimize the problems arising from these dispersions. In addition, by not analyzing data considered inconsistent, data processing is also more efficient [
36]. This work employs minimum–maximum normalization, which uses the minimum and maximum values of each feature to define a common range yield, as is illustrated in Equation (
13).
where
is the normalized
array,
is the lowest value of the vector
, and
is the highest value of the
array. Minimum–maximum normalization sets all dynamic data ranges to a scale from zero to one and decreases the overall standard deviation. However, this normalization may exclude outliers, which can bring important information to the analysis of the dataset [
37].
3.4. Partitioning the Dataset
The dataset was divided into two parts, namely, training and test sets. The training samples were used to teach the regressor about the data pattern, whereas the test samples were used to evaluate the chosen regressor model. The training set can be subdivided into training and validation subsets, with the latter being used to fine-tune the algorithm model.
When the dataset used is sufficiently large, the hold-out technique [
38] is used to separate 70% of the instances for training, 10% for validation, and 20% for testing. This technique might generate overfitting in the classifier, especially when the dataset is not large enough to properly train the classifier. In these cases, cross-validation techniques, such as
K-fold, can be applied.
K-fold makes the classification algorithms more robust to overfitting, producing classification models with greater generalization capacity [
39,
40,
41].
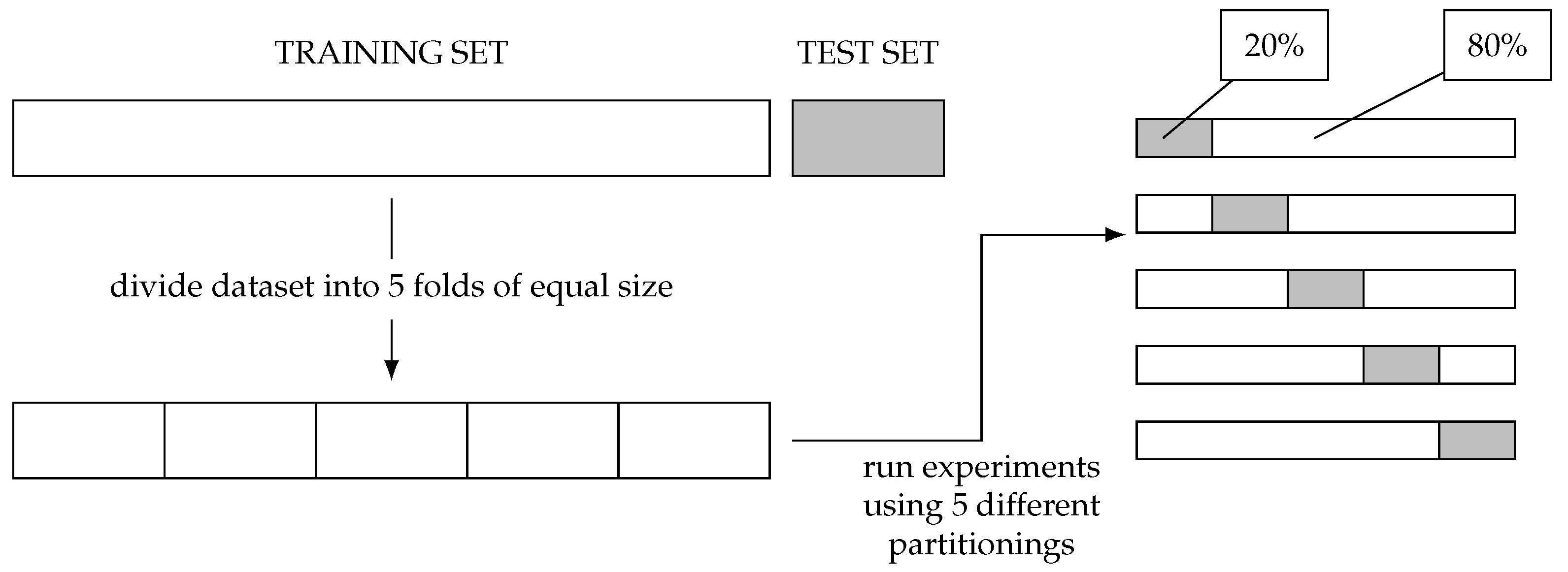
The
K-fold procedure randomly divides the dataset into
K blocks of approximately equal size. Subsequently, it uses
samples to perform the training of the model and a sample to perform the test. This process is then iteratively performed for each block that can be used as test data. The performance of this method is given by the mean accuracy associated with the standard deviation. The values of
K usually chosen are
or
[
41]. In this work, five
K-fold blocks were used, as is depicted in
Figure 8, where the gray blocks correspond to the test sets, and the white blocks are the training sets.
3.5. Dataset Regression
Regression is a statistical method for finding the relationship among variables [
42]. Regression algorithms are employed to predict the outcome based on the relationship among variables obtained from the dataset [
43]. The regression algorithm output is a real number that depends on a hypothesis function defined according to the problem [
44]. The hypothesis function is defined with hidden parameters [
45]. These hidden parameters are optimized for the training set input in the training phase [
46].
3.5.1. Artificial Neural Networks
Artificial neural networks (ANNs) are computational structures with interconnected nodes that mathematically model, in a simplified way, the basic principle of cognitive processing of neurons in the human brain [
47,
48,
49]. Using algorithms and mathematical models, ANNs can recognize hidden patterns and estimate non-linear relationships among elements in a database. Classification and estimation are examples of tasks that a neural network can perform after a training phase. Neural network accuracy can be continually improved by training and feeding it with new data [
47].
This paper used the sigmoidal activation function, which describes a non-linear output for each neuron. Consequently, there is non-linearity between the two layers, which is ideal for recognizing non-linear failure patterns. The sigmoidal activation function was selected because it presented good results in related research, as described in [
50,
51]. Additionally, this paper uses the multi-layer feedforward network called multilayer perceptron (MLP) [
52]. MLP was chosen due to its hidden layer, which can be used to recognize and classify problems that are not linearly separable. A linear activation function is used in the output layer, and the sigmoidal activation function is used in the hidden layer.
The trained network is tested by obtaining a prediction for each test point [
47]. We compute the error with respect to the test dataset using quadratic loss as in the training phase.
3.5.2. Random Forest
Random forest (RF) is an ensemble supervised machine learning algorithm that can be used for classification and regression tasks [
53]. This algorithm is formed by decision trees, which are simple predictor elements. An ensemble classifier is often more powerful than the individual predictors that form it [
54]. The choice of random forest was due to its excellent predictive ability not only in diesel engine-related research, as can be seen in [
55,
56], but also in fault detection [
26,
57]. This paper used this algorithm in the regression task.
Each model of the set is used to create a prediction for a new sample. The average results of each tree characterize the regressor accuracy. Since the classifier randomly chooses the predictors in each division, the tree correlation decreases. This selection gives strong and complex predictors presenting low-bias yield in an RF algorithm with low variance. This selection causes a decrease in error rates. Each predictor is independently chosen. Because of this independence, the RF has an effective noise response. RF is computationally more efficient than bagging, since in constructing the algorithm, it only needs to analyze a part of the original predictors in each division. However, RF needs to use many trees to form the regressor set. In addition, RF also presents a high level of parallelization, which allows high computational efficiency to be achieved [
53].
Training and test errors tend to level off after some trees have been fitted. The difference between the bagging algorithm and the RF algorithm is that the latter uses a modified tree learning algorithm that selects, at each candidate split within the learning process, a random subset of the features [
58].
3.5.3. Regression Metrics
Let
P be a discrete variable. The point-to-point correspondence between the numerical solution and the observational measures of the same variable provides a quantitative test to measure the ability of the model (or dexterity) to reproduce or estimate observed data [
59]. Let
and
be the severity of the simulated failure and that of the failure observed in the same point at time
i in a numerical domain with
N samples, respectively. The fundamental quantity for the study of errors is the difference
between the predicted or simulated values of input variable
x and output variable
y in point
i (
) at time
t, where (
), and the measured or observed values of the same variables in the same points
x and
y at time (
), which is simply expressed in Equation (
14).
Essentially,
indicates an exact simulation for that point
i, while
or
characterizes non-exact simulations. The further away from zero the value of
is, the more inaccurate the simulation is. That is,
is equivalent to the
error of a given analysis [
60]. Although
provides an idea of the quality of the simulation for a given variable, it does not explain the particular sources or characteristics of the magnitudes of the errors. Note that from the basic quantity
, it is possible to derive errors that reflect different components of the total error [
60].
The metric adopted in this work is the root mean square error (RMSE), which is derived from
and points to the trend or bias. The bias measures the tendency of the model to overestimate or underestimate the severity of the failure of what was observed. This trend can be approximated as is described in Equation (
15).
RMSE is used to express the accuracy of the numerical results, with the advantage that it also presents error values in the same dimension of the analyzed variable [
59]. Let
be a hypothesis–candidate to approximate the unknown function
, and let
denote the labeled sample. In principle, considering
, the quadratic error average RMSE is presented in Equation (
16).
Since hypothesis
h can be seen as a certain regressor configuration, motivated by training with a specific portion of the dataset, where
is the adjustment of the regression variable, for each of the
K successive
K-fold implementations of the cross-validation step, the average value of RMSE (
) after
K implementations is described by Equation (
17), and the associated standard deviation of the RMSE (
) is detailed in Equation (
18).
where
j represents the implementations of the cross-validation set.
was adopted as the metric for evaluating the regressors to quantify the performance of adjusting the regression curves of the severity variable, using first- and second-order statistics.
3.5.4. Pearson Correlation Coefficient
In order to quantify the performance of the regression curves, the Pearson correlation coefficient was used. This metric measures the degree of linear correlation between two quantitative variables. It is a dimensionless index with values between −1 and 1 inclusive that reflects the intensity of a linear relationship between two sets of data. describes a perfect positive correlation between the two variables. characterizes a perfect negative correlation between the two variables, i.e., if one increases, the other one always decreases. signifies that the two variables do not linearly depend on each other. However, there may be another dependency that is “non-linear”. Thus, the result must be investigated with other means.
Let
be the values of a set of points for a regression, with
, and let
be a set of points representing a perfect regression. The Pearson correlation coefficient is defined as shown in Equation (
19).
5. Results and Discussions
In the fault regression experiment, a procedure similar to the one presented in Pestana [
26,
61] was adopted. In this procedure, the ability of a system to identify fault severity is evaluated by adding the maximum and average pressure, and spectral measures for each possible fault. In this work, ANN and RF regressors were trained to identify fault severity. For both regressors, the feature vector was used as an input. The outputs of the regressors were the fault severity variables, one for each fault severity. The number of trees of the RF regressor was obtained empirically as in [
26]. The algorithm used to implement the ANN was MLP. The ANN input layer had the same dimension as the feature input vector. The ANN had one hidden layer, whose number of neurons was empirically obtained with the tuning of the hyperparameters, as discussed in
Section 5.1. Finally, the ANN output layer had a number of neurons equal to the number of severity variables to be estimated.
For the RF regressor, the 3500-DEFault dataset was divided into two disjoint sets, and approximately 80% of the signals were used for training, while 20% were employed for testing. For the ANN regressor, on the other hand, the 3500-DEFault dataset was divided into three disjoint sets, and approximately 70%, 10%, and 20% of the signals were utilized for training, validation, and testing, respectively. Each set must represent the fault severity intensity data with maximum variability. The RF learning (training) process was performed by applying the bootstrap aggregating (bagging) algorithm. The ANN learning process was performed by applying the scaled conjugate gradient backpropagation algorithm to improve the training time. The validation set was employed to avoid overtraining, which results in generalization capability loss [
27].
In order to avoid biased data performance in regression, the K-fold cross-validation technique was applied in all regression tests. In order to do so, the 3500-DEFault dataset was divided in K = 5 folds to circularly change the test subset. Each subset maintained the proportions of 80% and 20% for training and testing.
The tables and plots in this section are related to the fault regression experiment that presents the regression RMSE performance on the test data from the 3500-DEFault dataset. In such tables and plots, represents the test set observed elements, and is the vector of test set predicted elements. The total RMSE accuracy regression performance is represented by , where W is the total accuracy and is its standard deviation during K-fold validation.
Empirical tests were performed to determine whether for
, the execution time of each test was reduced [
62]. By using
instead of the usual
, the total execution time (ToE) of each regression, depending on each method and the evolved noise levels, was significantly reduced. The ToE was reduced due to the size of the dataset and the parameters that were optimized in each regressor. In the simplest optimization regression (i.e., ANN), when
, 13,000 rounds (5 folds × 13 operating variables × 4 noise levels × 50 neuron configurations in the hidden layer) were performed. The computational ToE was measured in seconds, while the regression was performed with a personal computer with CPU core i5-2500 and 8 GB RAM and without GPU, using the two physical cores for parallel processing.
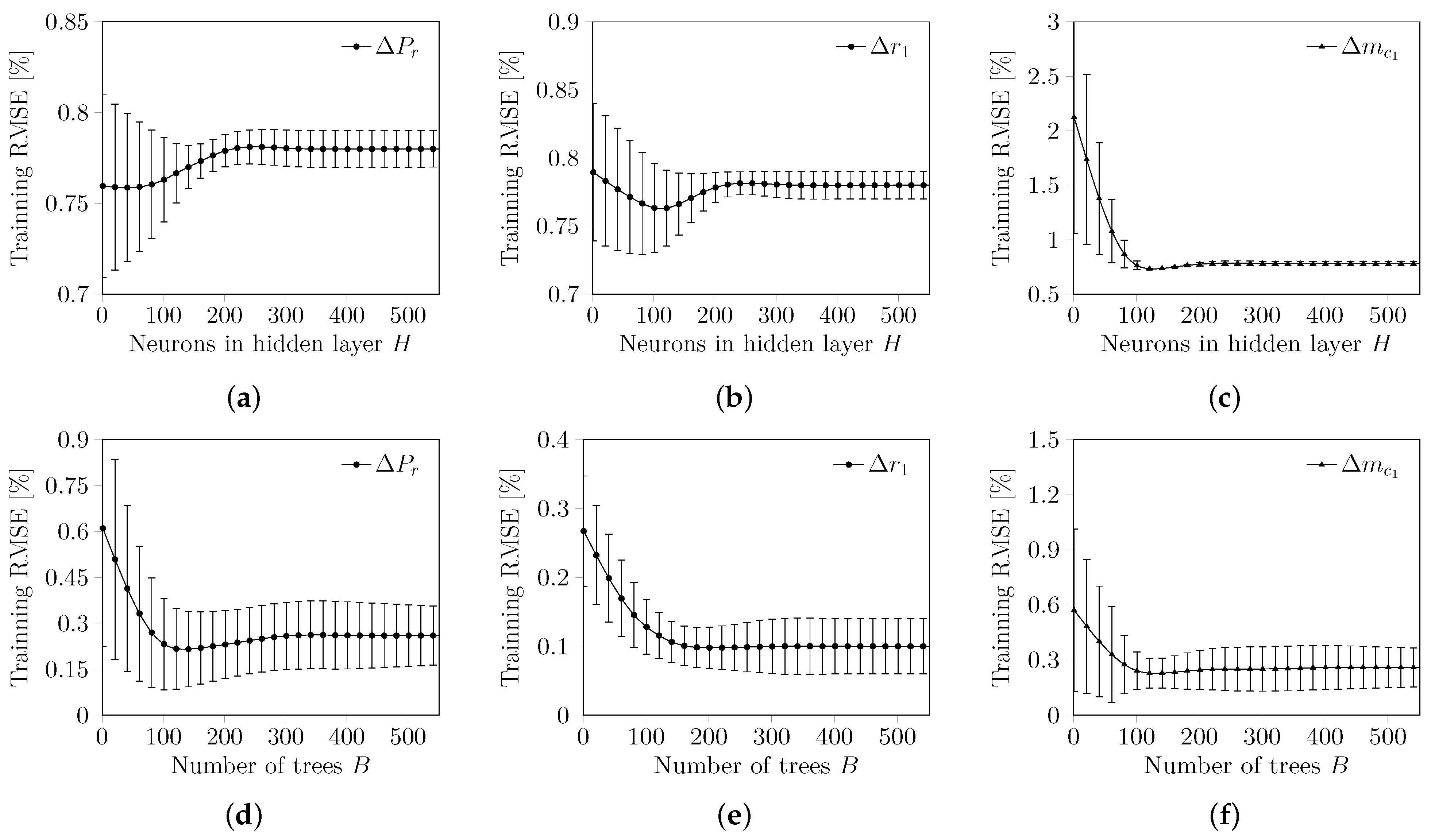
5.1. Regressor Hyperparameter Tuning
Hyperparameter tuning is the step dedicated to adjusting the hyperparameters of the regressor in order to maximize the training results of the regressors and, consequently, the testing performance. In the case of the ANN, the hyperparameter to be tuned is the number of neurons, while in RF, the tuning variable is the number of trees. The optimization of the hyperparameters of a regressor is implemented during training by varying the hyperparameters in a predefined set of values and monitoring the RMSE minimum (i.e., mean and standard deviation). For each hyperparameter simulation, is defined in order for the cross-validation step not to reduce the bias results and to extract the first- and second-order statistics from the obtained results. The tuning curves are evaluated using the average value of the RMSE, , and the variability of the RMSE, , for each simulated hyperparameter during training.
Figure 10 presents the tuning curve plot for each hyperparameter. In these plots,
and
are shown with respect to the number of neurons, in the case of the ANN, or the number of trees, in the case of RF. In
Figure 10, the x-axis shows the range of values assigned to the simulations of the regressor hyperparameters.
For the ANN, the number of neurons of the hidden layer in the hyperparameter simulation was tested over the set
. For RF, the number of simulated trees was tested over the set
. After analyzing each tuning curve in
Figure 10, it was decided that 120 neurons had to be employed in the ANN hidden layer and 100 trees had to compose the RF regressor.
Table 2 summarizes these values.
One can notice in
Figure 10 that the tuning curves tend to be minimum transient or stable. Moreover, there is an intrinsic decrease in the standard deviation of the validation set. The standard deviation decrease emphasizes the importance of using second-order statistics aside from first-order statistics when choosing these parameters, since smaller variability in the training error leads to more stable results.
5.2. Regression Tests
After adjusting the hyperparameters of the regressors in the tuning step (described in
Section 5.1), regression tests were implemented according to studies described in [
20,
21]. The hyperparameters used in all regression tests are the ones shown in
Table 2. With the purpose of evaluating the noise influence on regression performance, different noise levels were applied to the 3500-DEFault dataset original signals.
Table 3 and
Table 4, and
Figure 11 and
Figure 12 show the results when different SNR levels of additive Gaussian white noise (AWGN) 60, 30, 15, and 0 dB, respectively, were applied.
In the tests, all scenarios of the 3500-DEFault dataset were considered; thus, all types of faults were included. Different fault classes with varying levels of severity were used to investigate the performance of the regressor. The regressor output layer must be able to predict different variables. In addition to obtaining the results with the analysis of the degree of severity of each variable (failure), the output variable precision was also considered. The tests were defined by the severity level that had to be predicted by the regressor. The severity levels considered in the tests belonged to
%.
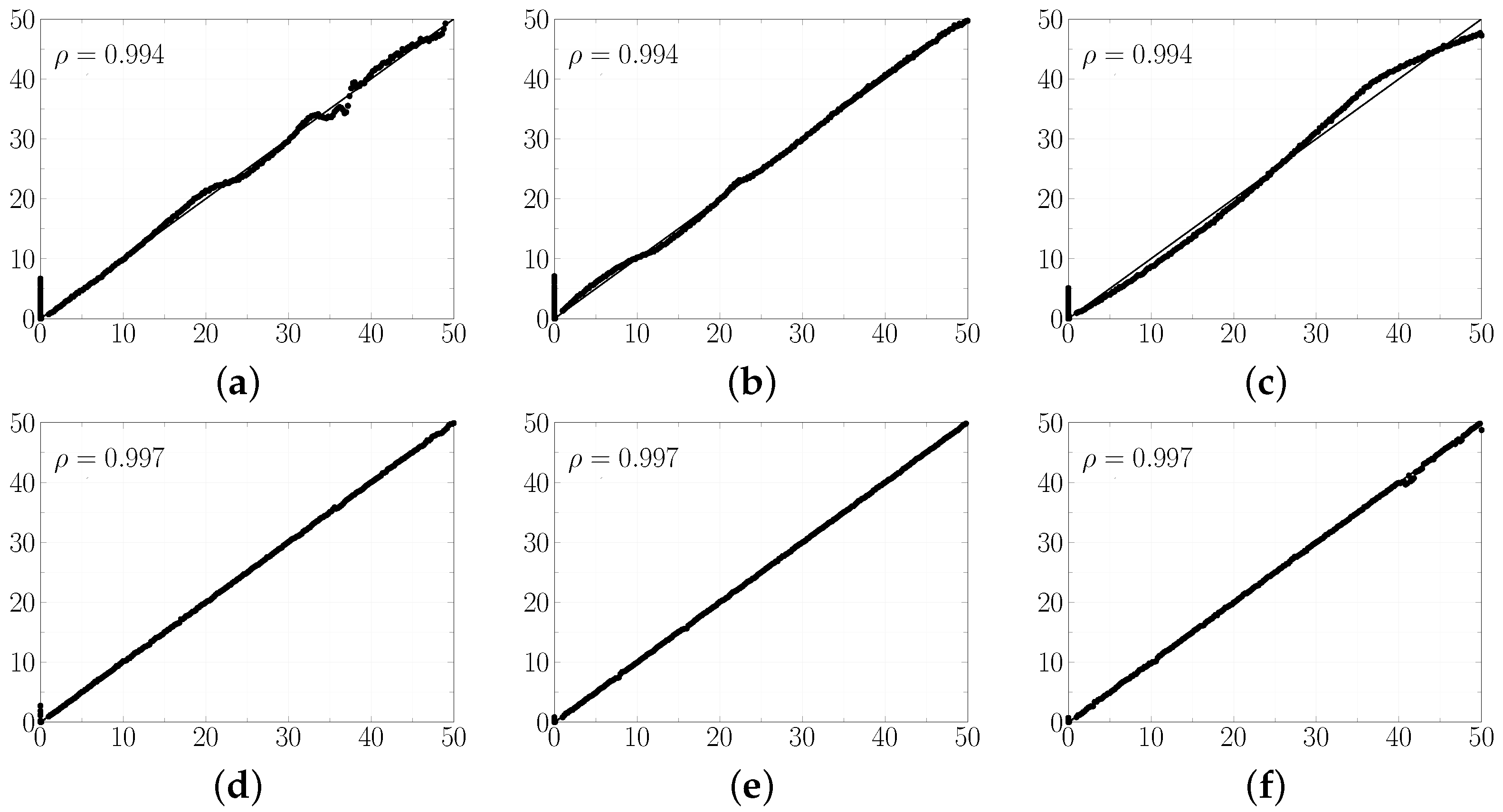
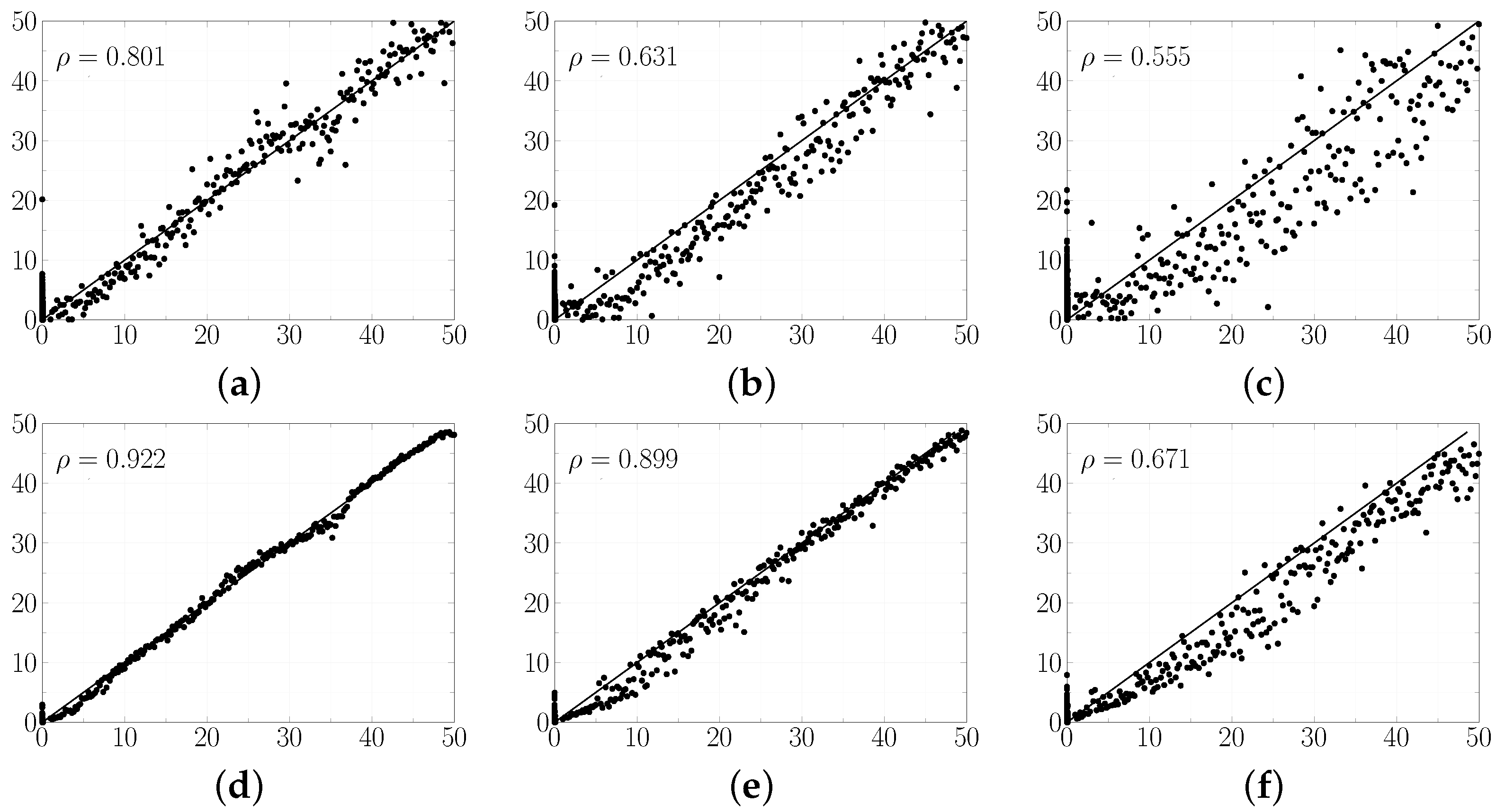
Figure 11 and
Figure 12 show the prediction curves of the tests with SNRs equal to 60 and 0 dB.
Table 3 and
Table 4 present a summary of the RMSE values considering regressor and AWGN level
L.
By analyzing
Figure 11, and
Table 3 and
Table 4, it is possible to see a good performance of the regressors for a high SNR, with RMSE of less than 1%. The low RMSE values are a consequence of the low dispersion of the characteristic vector elements and low noise level present in the signals coming from the machine. In
Figure 12, there is an increase in RMSE value in the presence of a low SNR. One can notice a significant dispersion of the predictions when compared with the ideal prediction curve.
By examining
Table 3 and
Table 4, it is possible to observe that the highest dispersion is for
.
Table 3 and
Table 4 show the prediction performance in each failure class, where three failure classes were studied:
,
, and
.
The fault, which is global in nature and affects the entire engine combustion dynamics, was easier to predict once it had strong coupling with the operating parameters used in this work. The and faults, which are local faults that only affect the dynamics of combustion of one cylinder, had a higher level of prediction difficulty, because they were only coupled with the variables of the cylinder in question. The regression performance in the failures referring to the variables was lower than the others, indicating that this failure class was more difficult to predict. One possibility for improving the prediction performance could consist in adding more discriminating features and performing specific adjustments in the regressor.
The Pearson correlation coefficient, displayed in
Figure 11 and
Figure 12, shows a moderate correlation between the vector of points predicted by the regressor and the perfect prediction curve. For signals with 60 dB AWGN, the prediction was moderate, whilst for signals with 0 dB AWGN, the prediction was not as accurate. The latter was caused by the dispersion of the prediction points due to the high level of noise in the tests. As expected, ANN and RF regressors presented stable results with low ToE due to the noise level and the defined adjustment. The obtained results are consistent with [
21]. Overall, the RF was the most stable regressor among the four addressed noise levels. The RF presented the lowest RMSE amongst the analyses considered. In addition, RF also presented the lowest dispersion among the cross-validation procedures.
6. Conclusions and Future Work
A quantitative framework for severity analysis composed of signal processing and regression techniques based on machine learning is proposed in this work. Compared with traditional classification methods reported in other studies, the proposed framework does not solely aim at identifying patterns of diesel engine failure. Instead, it assesses the diesel engine health conditions in the deterioration process by evaluating the absolute value of the failure severity.
The proposed scheme is crucial, since in practice, the life service of a diesel engine undergoes a deterioration process before its functional failure occurs. This was accomplished by extracting representative statistical parameters from the signals measured inside the cylinders and from the frequency response of the torsional vibration signal of the engine flywheel.
The evaluation of the fault severity level was performed using machine learning techniques that took into account the extracted features. This approach presents important advantages over traditional numerical methods, namely, it is able to predict the severity in a shorter time. This time advantage is a consequence of employing a trained regressor. On the other hand, in traditional numerical methods, there is always a prior need for convergence to estimate the severity level.
The hyperparameters of the regressors had to be fine-tuned for obtaining the best classification performance. Furthermore, the regression analysis with four different levels of white noise was fundamental, as it allowed the robustness assessment of each regressor to be performed, given the intrinsic increase in the noise level of the measurement. Therefore, it was possible to define the best regressor for signals with a low SNR. The RF was the most stable regressor among the four addressed noise levels and presented the lowest RMSE and the lowest dispersion for the cross-validation procedure.
In this work, the only rotation frequency considered was 2500 RPM. Future work will further expand the dataset, covering other rotation frequencies. Furthermore, new features will be incorporated to improve the regression results of fuel failure under loud-noise conditions. Other regressors, based on kernel machines, will also be studied, such as support vector machines for regression (SVM) and the Gaussian regression (GP) process.





 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}