1. Introduction
The permutation flow shop scheduling problem (PFSP), as a classical challenge in the domain of combinatorial optimization problems (COPs), has long been a focal point of intense research and enthusiasm within the international academic community. The key to solving this problem lies in designing algorithms that are efficient, fast, and accurate to fulfill the stringent requirements of contemporary manufacturing for both production efficiency and product quality. In the flow line production environment, this scheduling problem is particularly prominent in industries such as automobile assembly, electronic product manufacturing, food processing, steel, textiles, aerospace, and pharmaceutical processing. Therefore, the successful resolution of this problem not only significantly enhances the efficiency of the production process, but also holds promise for opening up new avenues for innovation and development in the entire manufacturing industry.
Currently, the methods for solving the permutation flow shop scheduling problem are mainly divided into two categories: exact algorithms and approximate algorithms. Exact algorithms aim to find the optimal solution by exhaustively enumerating and evaluating all possible scheduling options, such as branch and bound [
1], dynamic programming [
2], and integer programming [
3]. These methods can theoretically guarantee the optimal solution. However, when faced with large-scale practical problems, due to constraints on computational resources and the “combinatorial explosion” phenomenon, exact algorithms often become impractical. Conversely, approximation algorithms aim to quickly find “good enough” solutions rather than theoretically optimal ones. They can provide practical solutions within a reasonable timeframe for addressing large-scale and complex problems, which are further categorized into heuristic and metaheuristic methods. Heuristic methods encompass the Campbell Dudek Smith algorithm (DCS) [
4], the Gupta algorithm [
5], the Nawaz Enscore Ham algorithm (NEH) [
6], and a variety of scheduling rules [
7], with NEH widely regarded as the most effective approach for resolving PFSP [
8,
9,
10,
11]. Nevertheless, these heuristic algorithms often operate under simplified assumptions or rules, which may limit their ability to deliver optimal or satisfactory solutions in the face of complex scheduling challenges. Metaheuristic methods, which simulate natural processes or leverage specific heuristic rules, guide the search process to yield satisfactory scheduling solutions and have achieved a series of results in solving PFSP. For example, Zheng et al. [
12] developed a hybrid bat optimization algorithm that incorporates variable neighborhood structure and two learning strategies to address the PFSP. Chen et al. [
13] proposed a hybrid grey wolf optimization method with a cooperative initialization strategy for solving the PFSP with the objective of minimizing the maximum completion time. Tian et al. [
14] proposed a novel cuckoo search algorithm for solving the PFSP. Khurshid et al. [
15] proposed a hybrid evolutionary algorithm that integrates an improved evolutionary global search strategy and a simulated annealing local search strategy for solving the PFSP. Razali [
16] combined the NEH algorithm with the artificial bee colony algorithm (ABC) to solve the PFSP, which enhances the convergence speed of the ABC. Qin et al. [
17] aimed to minimize the completion time and proposed a hybrid cooperative coevolutionary search algorithm (HSOS) based on the cooperative coevolutionary search algorithm combined with local search strategies to solve the PFSP. Rui et al. [
18] introduced a multi-objective discrete sine optimization method (MDSOA) to address the mixed PFSP, aiming to minimize the makespan and the maximum tardiness. Yan et al. [
19] introduced a novel hybrid crow search algorithm (NHCSA) that enhances the quality of the initial population through an improved version of the NEH method. It employs the smallest-position-value rule for encoding discrete scheduling problems and incorporates a local search mechanism, which is designed to solve the PFSP with the objective of minimizing the maximum completion time. It is evident that metaheuristic algorithms have achieved satisfactory results and performance in the application of PFSP, but their iterative search process is often time-consuming, and they do not fully utilize historical information to optimize and adjust the search strategy. Therefore, there is still significant potential for optimization in solving large-scale problems. For existing specific scheduling problems, delving into the essence of the problem and designing optimization strategies accordingly is crucial. Additionally, rationally utilizing historical information to adjust the search patterns of the algorithms is another key approach to achieve efficient solutions.
In recent years, the rapid advancements in artificial intelligence and machine learning technologies have yielded remarkable achievements across various domains, including speech recognition [
20], energy management [
21], image processing [
22], pattern recognition [
23], healthcare [
24], and traffic management [
25], opening new avenues for solving complex COPs. Consequently, the academic community has started to investigate the application of machine learning techniques to COPs, quickly becoming a research focal point and yielding abundant results. For example, Vinyals et al. [
26] introduced Pointer Networks (PN) as an innovative strategy for tackling sequence-to-sequence modeling issues. Ling et al. [
27] developed a fully convolutional neural network that learns the optimal solution from the feasible domain to solve the traveling salesman problem (TSP). However, the neural networks employed in the aforementioned approaches are all trained and refined on labeled data, where the quality of the labels directly impacts their performance, a category that is known as supervised learning. Additionally, collecting high-quality data for combinatorial optimization problems (COPs) is a time-consuming and expensive process that requires substantial computational resources and expertise to solve complex problems and generate accurate labels. Therefore, exploring neural network models that can effectively solve COPs is an important topic that urgently needs to be addressed in current research.
Reinforcement learning (RL), unlike supervised learning methods, is a machine learning approach based on a reward mechanism, where an agent learns the optimal strategy through interactions with the environment. In RL, the agent does not rely on a pre-labeled dataset but instead explores the environment, performs actions, and receives feedback. Through this process, the agent gradually adjusts its behavioral strategies, thereby finding the best solution in a dynamically changing environment. This offers an efficient and adaptable method for solving COPs, yielding substantial advancements and real-world applications in challenging domains, including the TSP, vehicle routing problem (VRP), and workshop scheduling problem. To solve the TSP, Zhang et al. [
28] proposed a manager–worker deep reinforcement learning (DRL) network architecture based on a graph isomorphism network (GIN) for solving the multiple-vehicle TSP with time windows and rejections. Luo et al. [
29] proposed a DRL approach that incorporates a graph convolutional encoder and a multi-head attention mechanism decoder, aimed at addressing the limitations of existing machine learning methods in solving the TSP, which typically does not fully utilize hierarchical features and can only generate single permutations. Bogyrbayeva et al. [
30] proposed a hybrid model that combines an attention-based encoder with a long short-term memory (LSTM) network decoder to address the inefficiency of attention-based encoder and decoder models in solving the TSP involving drones. Gao et al. [
31] developed a multi-agent RL approach based on gated transformer feature representation to improve the solution quality of multiple TSPs. To solve the VRP, Wang et al. [
32] proposed a method that combines generative adversarial networks with DRL to solve the VRP. Pan et al. [
33] presented a method that can monitor and adapt to changes in customer demand in real time, addressing the issue of uncertain customer needs in VRP. Wang et al. [
34] proposed a two-stage multi-agent RL method based on Monte Carlo tree search, aiming for efficient and accurate solutions to the VRP. Xu et al. [
35] developed an RL model with a multi-attention aggregation module that dynamically perceives and encodes context information, addressing the issue of existing RL methods not fully considering the dynamic network structure between nodes when solving VRPs. Zhao et al. [
36] proposed a DRL approach for large-scale VRPs that consists of an attention-based actor, an adaptive critic, and a routing simulator. To solve workshop scheduling problems, Si et al. [
37] designed an environment state based on a multi-agent architecture using DRL to solve the job shop scheduling problem (JSSP). Chen et al. [
38] proposed a deep reinforcement learning method that integrates attention mechanisms and disjunctive graph embedding to solve the JSSP. Shao et al. [
39] redesigned the state space, action space, and reward function of RL to solve the flexible job shop scheduling problem (FJSSP) with the objective of minimizing completion time. Han et al. [
40] proposed an end-to-end DRL method based on an encoder and a decoder to solve the FJSSP. Yuan et al. [
41] constructed a DRL framework based on a multilayer perceptron for extracting environmental state information to solve the FJSSP, which enhances the computational efficiency and decision-making capabilities of the algorithm. Wan et al. [
42] developed a DRL approach based on the actor–critic framework to address the FJSSP with the objective of minimizing the makespan. Peng et al. [
43] presented a multi-agent RL method with double Q-value mixing for addressing the extended FJSSP characterized by technological and path flexibility, a variable transportation time, and an uncertain environment. Wu et al. [
44] proposed a DRL approach for the dynamic job shop scheduling problem (DJSSP) with an uncertain job processing time that incorporates proximal policy optimization (PPO) enhanced by hybrid prioritized experience replay. Liu et al. [
45] introduced a multi-agent DRL framework that can autonomously learn the relationship between production information and scheduling objectives for solving the DJSSP. Gebreyesus et al. [
46] presented an end-to-end scheduling model based on DRL for the DJSSP, which utilizes an attention-based Transformer network encoder and a gate mechanism to optimize the quality of solutions. Wu et al. [
47] introduced a DRL scheduling model combined with a spatial pyramid pooling network (SPP-Net) to address the DJSSP. The model employs novel state representation and reward function design and is trained using PPO. Experiments in both static and dynamic scheduling scenarios demonstrated that this method outperforms existing DRL methods and paired priority. Su et al. [
48] developed a DRL method based on the graph neural network (GNN) for the DJSSP with machine failures and stochastic processing time, which utilizes GNN to extract state features and employs evolutionary strategies (ES) to find the optimal policies. Liu et al. [
49] developed a DRL framework that employs GNN to convert disjunctive graph states into node embeddings and is trained using the PPO algorithm for solving the DJSSP with random job arrivals and random machine failures. Zhu et al. [
50] proposed a method based on deep reinforcement learning to solve the DJSSP. Tiacci et al. [
51] successfully integrated the DRL agent with a discrete event simulation system to tackle a dynamic flexible job shop scheduling problem (DFJSSP) with new job arrivals and machine failures. Zhang et al. [
52] proposed a DRL method integrated with a GNN to address the DFJSSP with uncertain machine processing time, training the agents using the PPO algorithm, and demonstrating through experiments that this method outperforms traditional algorithms and scheduling rules in both static and dynamic environments. Chang et al. [
53] put forward a hierarchical deep reinforcement learning method composed of a double deep Q-network (DDQN) and a dueling DDQN to solve the multi-objective DFJSSP. Zhou et al. [
54] proposed a DRL method that uses a disjunctive graph to represent the state of the environment for solving the PFSP. Pan et al. [
55] designed an end-to-end DRL framework to solve the PFSP with the objective of minimizing the completion time. Wang et al. [
56] introduced a DRL method based on a long short-term memory (LSTM) network to address the non-PFSP.
Table 1 summarizes the common methods for solving PFSP, as well as the application of RL in dealing with various shop scheduling problems.
In summary, RL can learn how to make optimal decisions through interaction with the environment, offering effective solutions for combinatorial optimization problems such as the TSP, VRP, and workshop scheduling problem. However, there are several shortcomings in the existing research on using RL to solve the workshop scheduling problem:
Firstly, most researchers have focused their studies primarily on the static JSSP [
37,
38], static FJSSP [
39,
43], DJSSP [
44,
45,
46,
47,
48,
49,
50], and DFJSSP [
51,
52,
53], with relatively less research on PFSP [
54,
55,
56].
Secondly, the optimization goal of most research is to minimize completion time, with little consideration given to other objectives such as energy consumption, machine utilization, and delivery time. However, as an essential aspect of manufacturing, energy consumption has become increasingly significant due to its dual impact on production costs and the environment. Therefore, implementing an effective energy-saving strategy in production scheduling not only helps to reduce production costs and enhance the competitiveness of enterprises, but also reduces carbon emissions. It aligns with the global green environmental trend and promotes the achievement of sustainable development goals.
Furthermore, in existing research, the state of the environment for RL algorithms is typically constructed as a set of performance indicators, with each indicator usually mapped to a specific feature. However, the intricate correlations among these performance indicators lead to a complex internal structure of the environmental state, which may contain a large amount of redundant information. This complexity not only increases the difficulty of convergence for neural networks, but may also negatively impact the decision-making process of the agent, reducing the accuracy and efficiency of its decisions.
Finally, in existing research, the action space of the agent is often limited to a series of heuristic rules based on experience. While these rules are easy to understand and implement, they may restrict the exploration of the agent, preventing it from fully uncovering and executing more complex and efficient scheduling strategies.
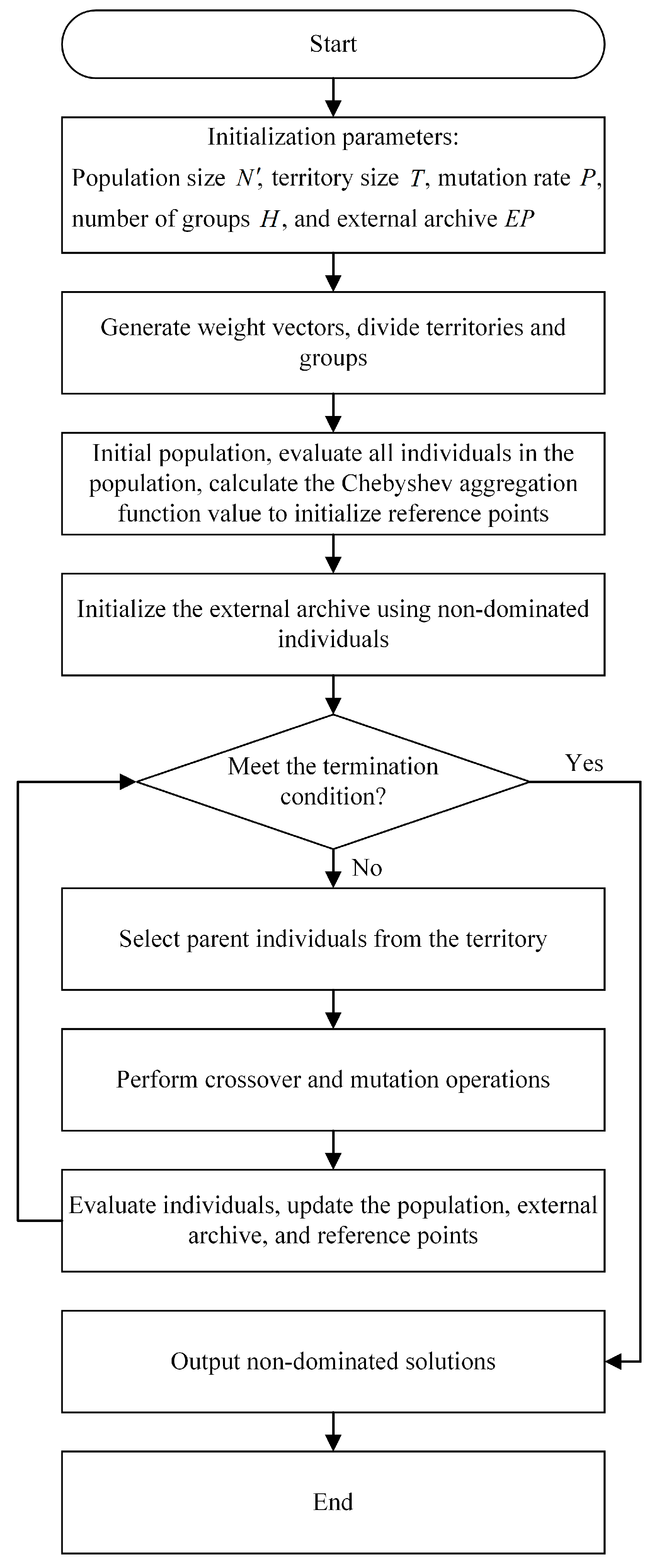
The multi-objective evolutionary algorithm based on decomposition (MOEA/D), as a classic and effective multi-objective optimization method, is favored by many scholars for its intuitive understandability, high robustness, simple parameter setting, and adaptability to a variety of complex problems. These characteristics make the algorithm particularly prominent in solving job shop scheduling problems and have become a commonly adopted approach by scholars in dealing with such challenges. In recent years, MOEA/D has been applied to solve multi-objective permutation flow shop scheduling problems by breaking down complex multi-objective problems into multiple sub-problems for independent optimization and using Chebyshev aggregation functions to guide the convergence process of the population [
57,
58]. However, it is worth noting that MOEA/D is highly dependent on the initial solutions, and the quality of the initial solutions will directly affect the overall performance of the algorithm. This feature requires special attention to the generation strategy of initial solutions when using MOEA/D to ensure that the algorithm can achieve the best results.
Therefore, in response to the aforementioned issues, this paper proposes an innovative algorithmic framework that integrates DRL with the MOEA/D algorithm (GDR-MOEA/D) to address the green permutation flow shop scheduling problem, aiming to minimize the objectives of maximum completion time and total energy consumption. The main contributions of this paper are as follows:
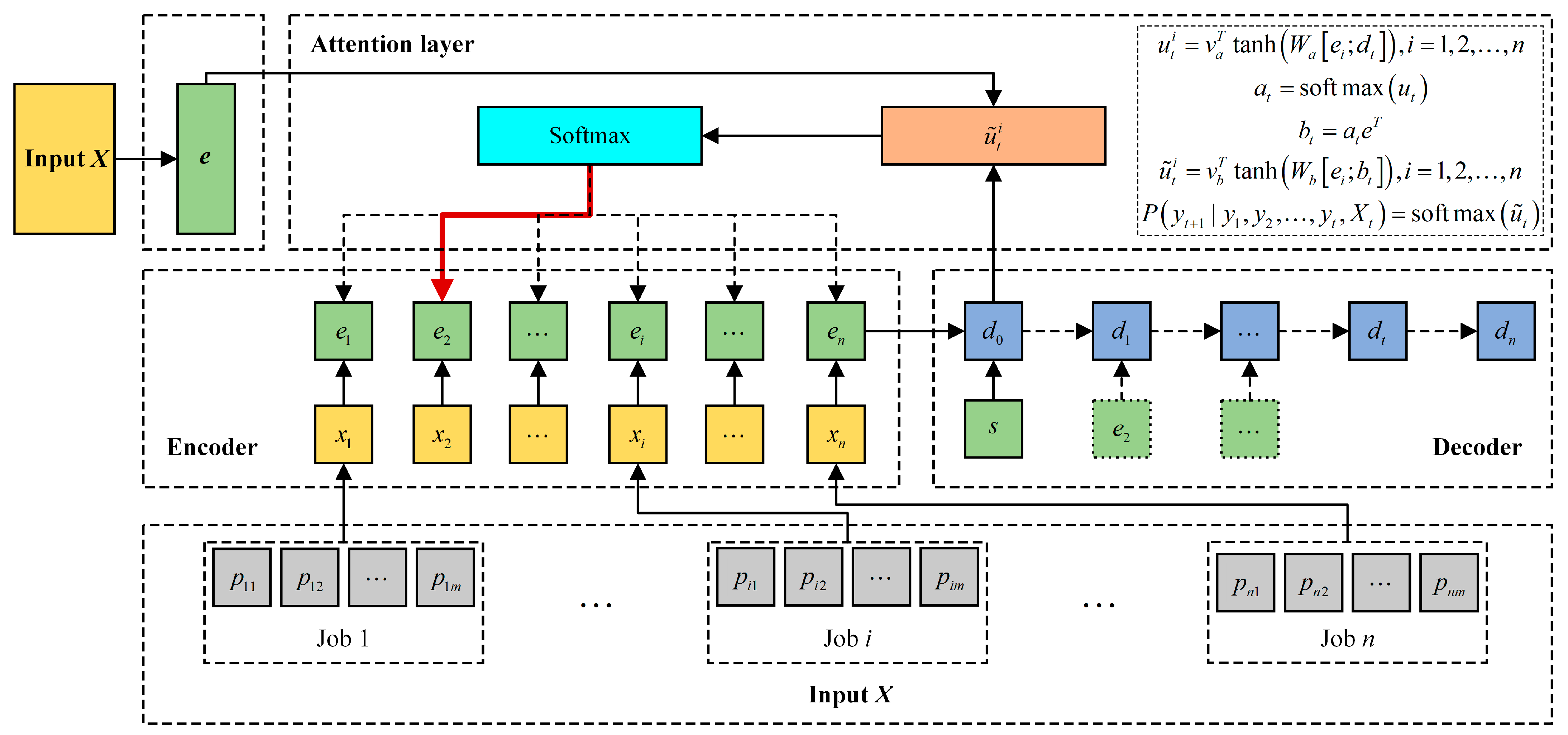
Firstly, for the existing end-to-end deep reinforcement learning network, which is difficult to apply to different scales of the green permutation flow shop scheduling problem (GPFSP) considering energy consumption, we designed a network model based on DRL (DRL-PFSP) to solve PFSP. This network model does not require any high-quality labeled data and can flexibly handle PFSPs of various sizes, directly outputting the corresponding scheduling solutions, which greatly enhances the practicality and usability of the algorithm.
Secondly, the DRL-PFSP model is trained using the actor–critic RL method. After the model is trained, it can directly generate scheduling solutions for PFSPs of various sizes in a very short time.
Furthermore, in order to significantly enhance the quality of solutions produced by the MOEA/D algorithm, this study innovatively employs solutions generated by the DRL-PFSP model as the initial population for MOEA/D. This approach not only provides MOEA/D with a high-quality starting point, but also accelerates the convergence of the algorithm and improves the performance of the final solutions. Additionally, to further optimize the energy consumption target, a strategy of job postponement for energy saving is proposed. This strategy reduces the machine’s idle time without increasing the completion time, thereby achieving further optimization of energy consumption.
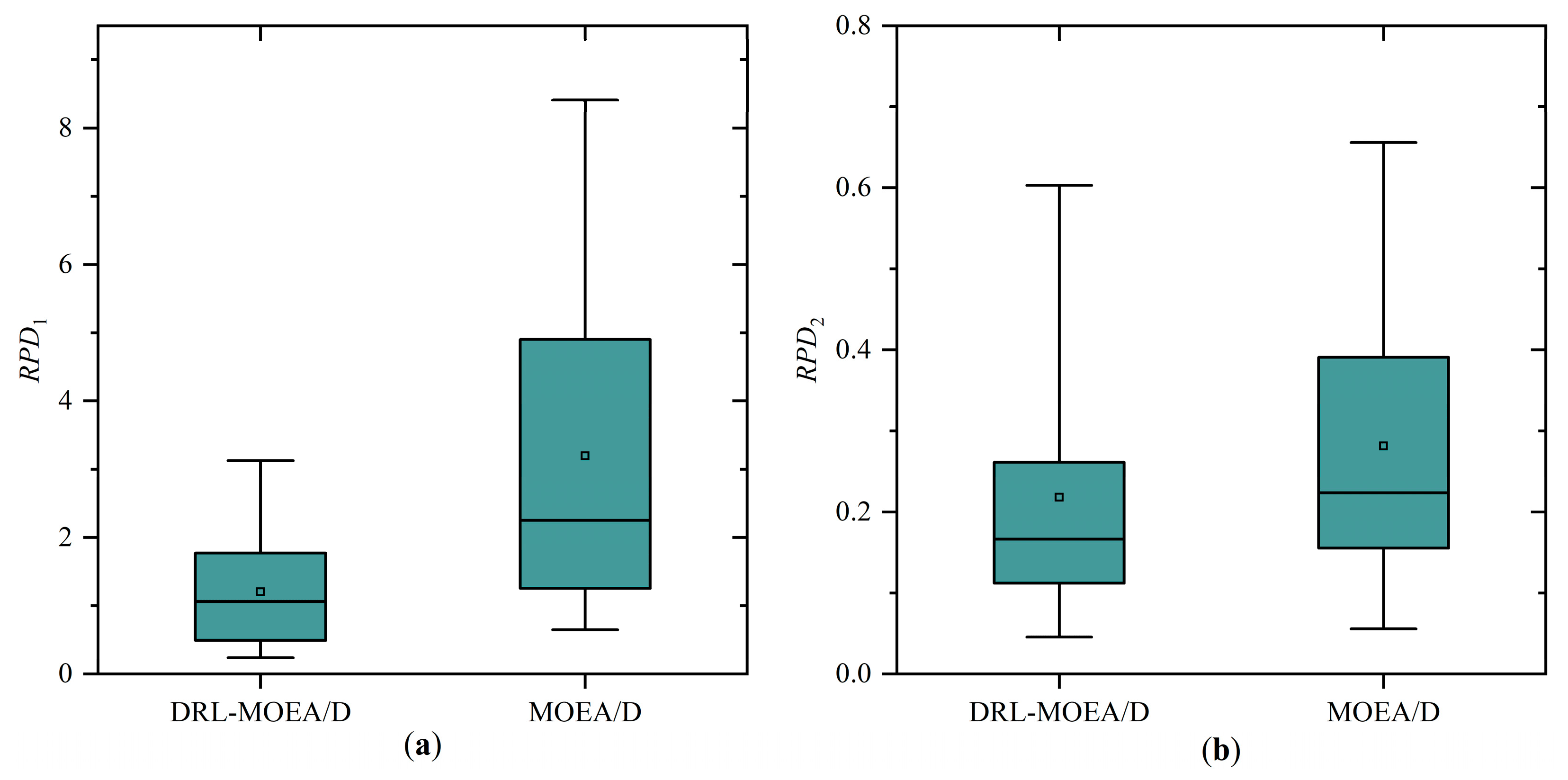
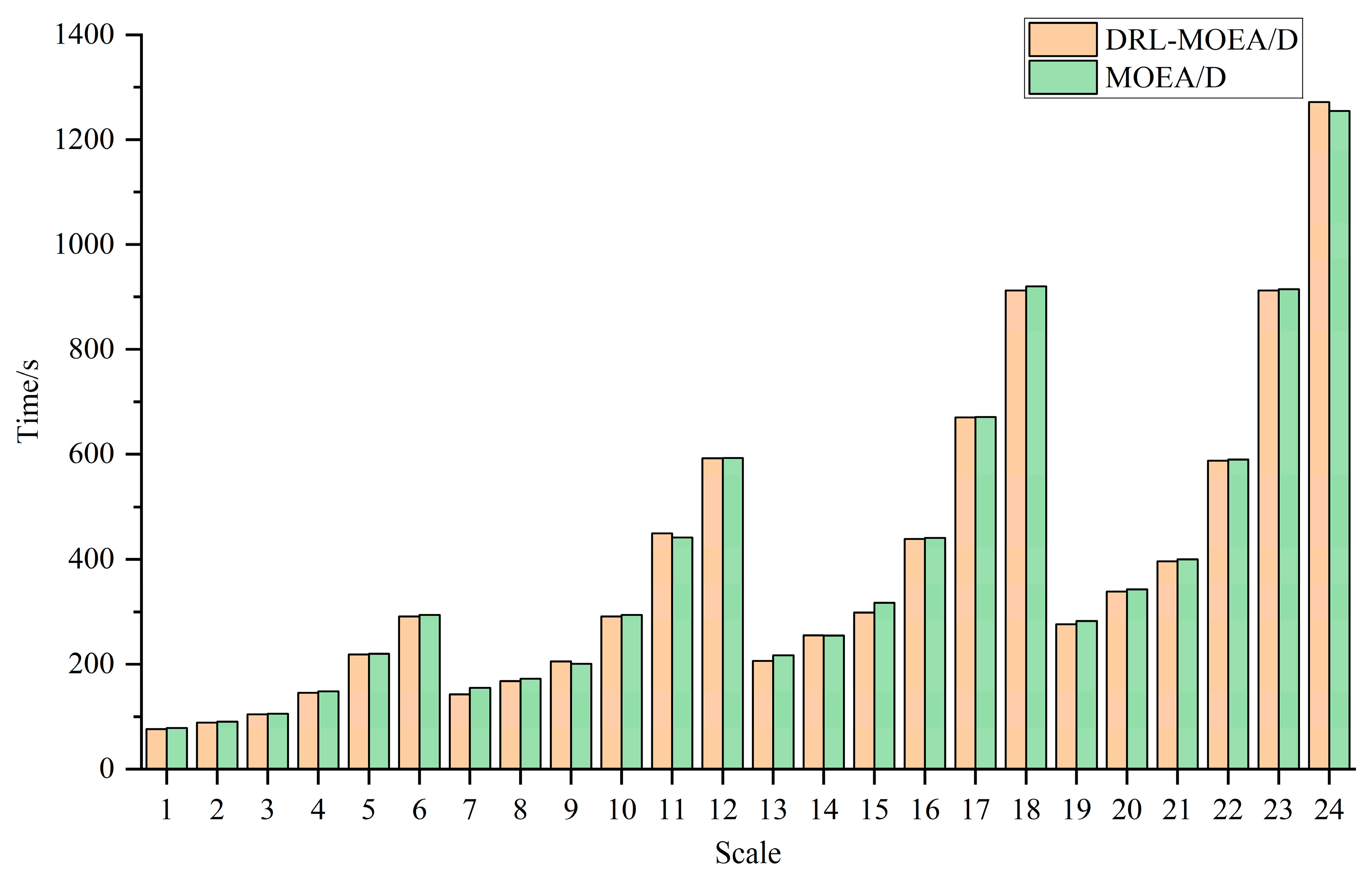
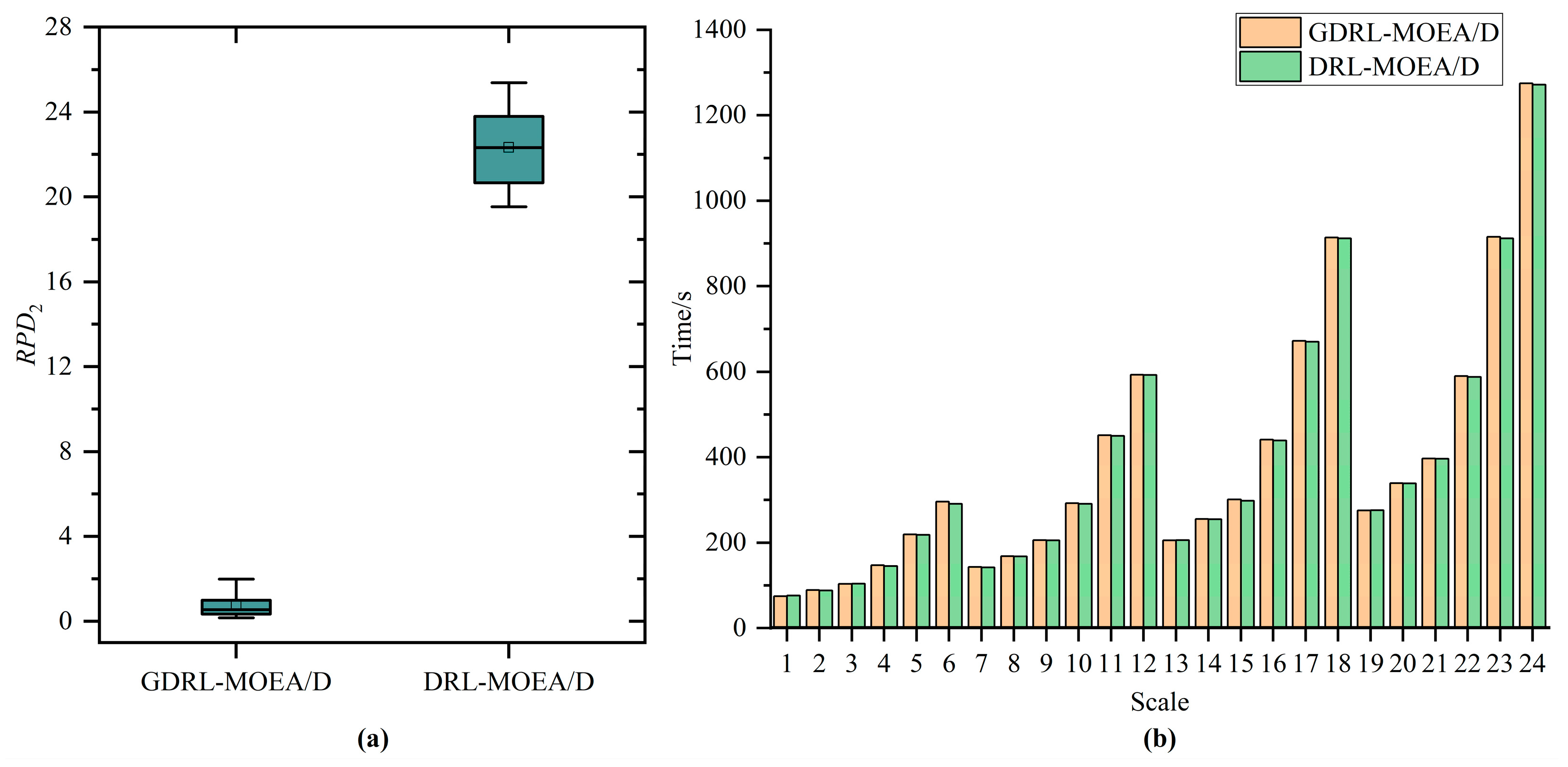
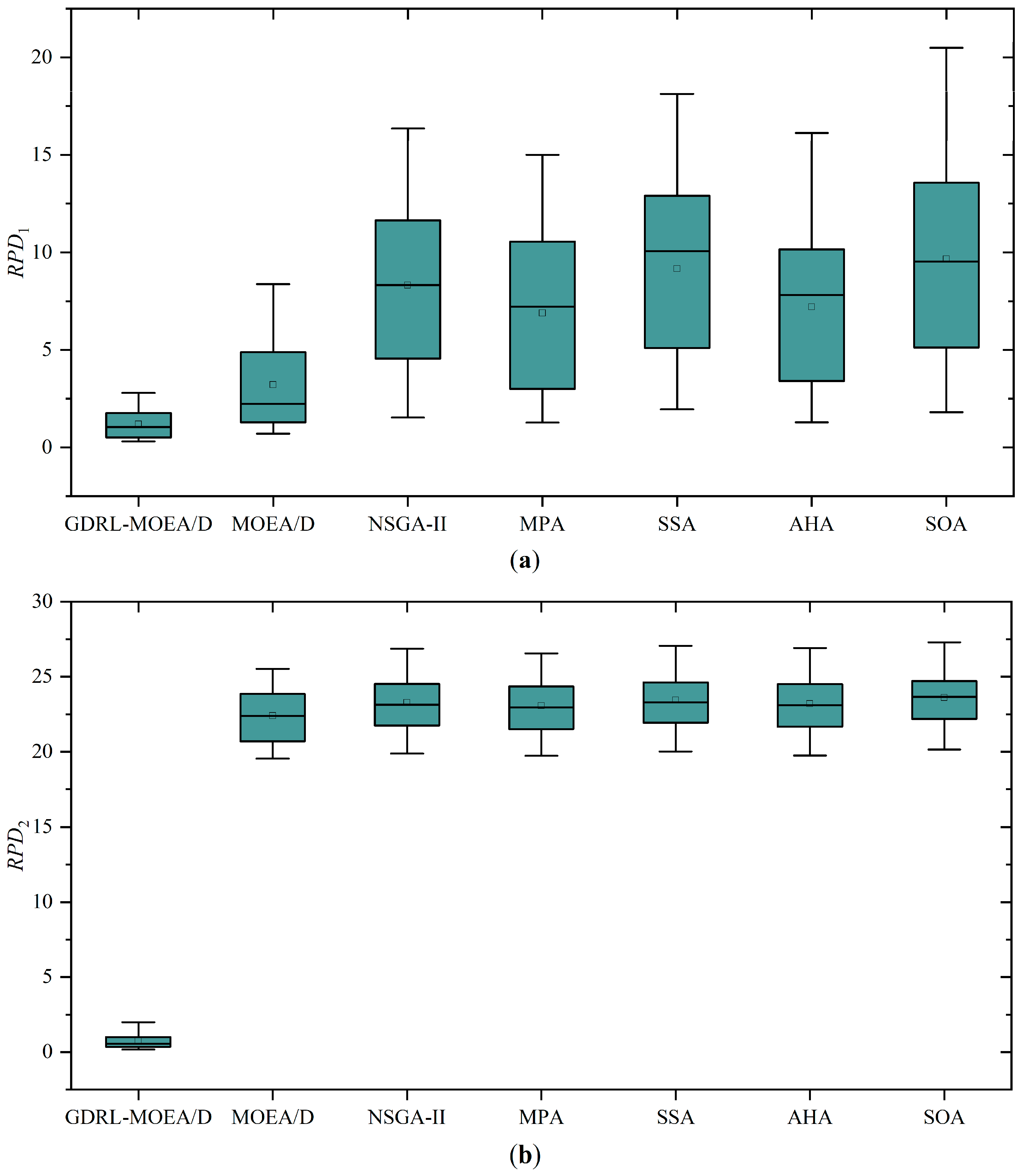
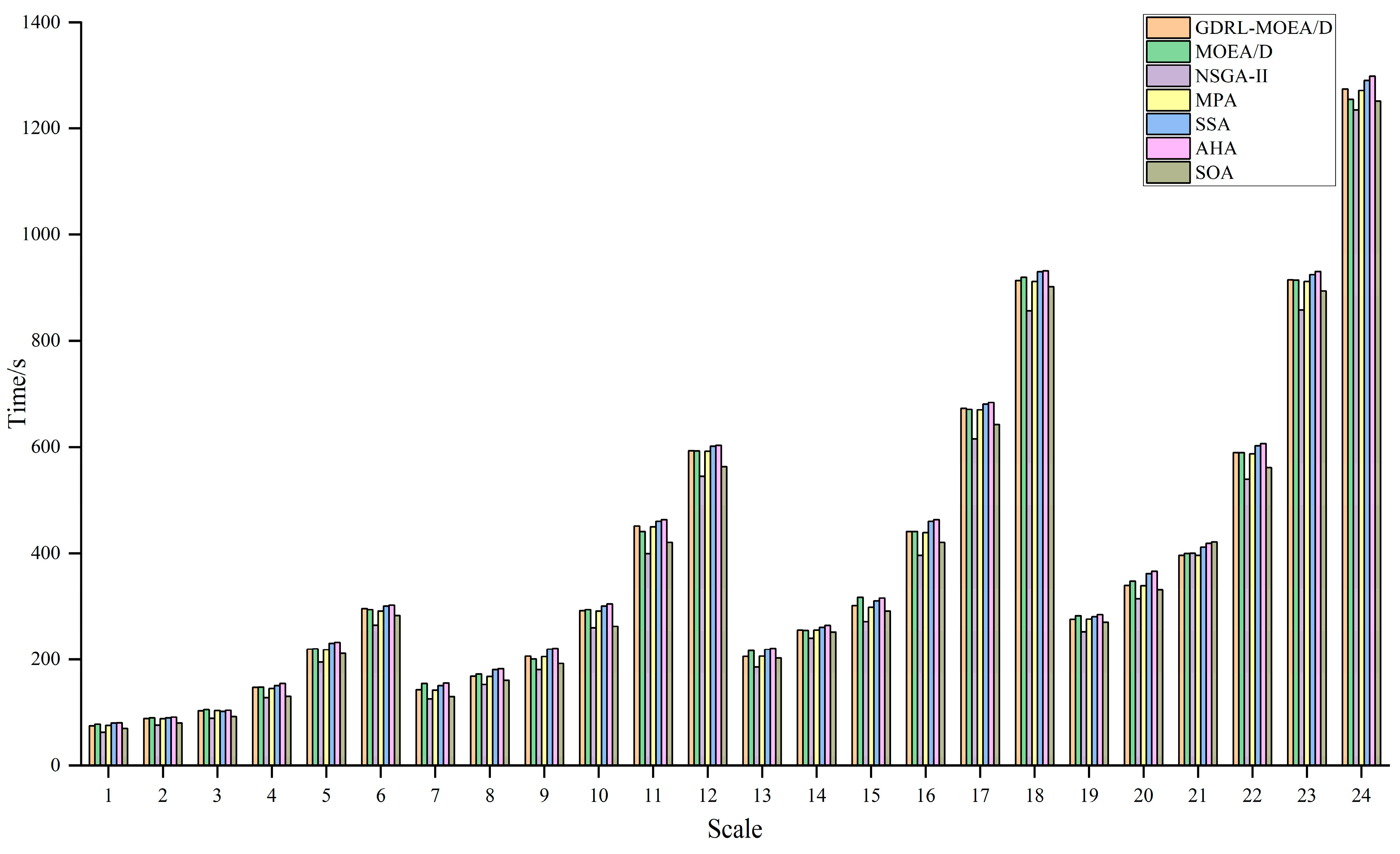
Eventually, through comparative analysis of simulation experiments with the unimproved MOEA/D, NSGA-II, MPA, SSA, AHA, and SOA, the GDRL-MOEA/D model algorithm constructed in this study demonstrated superior performance. The experimental results reveal that the solution quality of GDRL-MOEA/D was superior to the other six algorithms in all 24 test cases. In terms of solution speed, GDRL-MOEA/D was not significantly different from the other algorithms, and the difference was within an acceptable range.
The remainder of this paper is organized as follows. The mathematical model of the GPFSP and the objective functions are presented in
Section 2. In
Section 3, the proposed GDRL-MOEA/D framework is elaborately concluded.
Section 4 presents simulation experiments that assess the proposed algorithm against traditional methods, validating its efficiency. Finally,
Section 5 offers a comprehensive summary and an outlook on the future of the work.
5. Conclusions and Future Work
This paper focuses on solving the green permutation flow shop scheduling problem with energy consumption consideration (GPFSP), aiming to minimize the maximum completion time and the total energy consumption of machines. A novel solution method combining the end-to-end deep reinforcement learning technique with the MOEA/D algorithm (DRL-MOEA/D) is proposed. Firstly, an end-to-end DRL method is employed to model the PFSP as a sequence-to-sequence model (DRL-PFSP), which is then trained using the actor–critic algorithm. This model does not rely on high-quality labels and can directly output scheduling solutions for PFSP of various scales once it has been trained. Secondly, considering the advantages of the MOEA/D algorithm in solution quality, robustness, and adaptability to complex problems, the solutions output by the DRL-PFSP model are used as the initial solutions for the MOEA/D algorithm, thereby enhancing the quality of the final solutions produced by the MOEA/D algorithm. Moreover, to more effectively optimize the energy consumption target, a job postponement energy-saving strategy is proposed, which reduces machine idle time without increasing the maximum completion time, thus further optimizing energy consumption. Finally, through a series of simulation experiments, the proposed GDRL-MOEA/D algorithm is compared with the unimproved MOEA/D, NSGA-II, MPA, SSA, AHA, and SOA. The experimental results indicate that the GDRL-MOEA/D algorithm outperforms MOEA/D, NSGA-II, MPA, SSA, AHA, and SOA in solution quality. These algorithms exhibit similar solution speeds across different scales, with the speed differences falling within an acceptable range.
However, the GDRL-MOEA/D method proposed in this paper is designed to solve static GPFSP without considering the dynamic factors that GPFSP may encounter in the actual production process, such as machine failures, sudden order arrivals, and random order arrivals. Therefore, in future work, we will design an DRL algorithm that takes into account the dynamic factors of the workshop and extend the algorithm to solve other types of workshop scheduling problems, such as the parallel machine scheduling problem, the flexible flow shop scheduling problem, and the distributed flow shop scheduling problem.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}