Author Contributions
Conceptualization, D.I.; Methodology, D.I.; Software, F.B.; Validation, F.B. and D.I., Formal Analysis, D.I., F.B., and G.P.; Investigation, D.I. and F.B.; Resources, D.I. and G.P.; Data Curation, F.B.; Writing—Original Draft, F.B. and D.I.; Preparation, D.I. and F.B.; Writing—Review & Editing, D.I. and F.B.; Visualization, F.B.; Supervision, D.I. and G.P.; Project Administration, D.I. and G.P.; Funding Acquisition, D.I. and G.P.
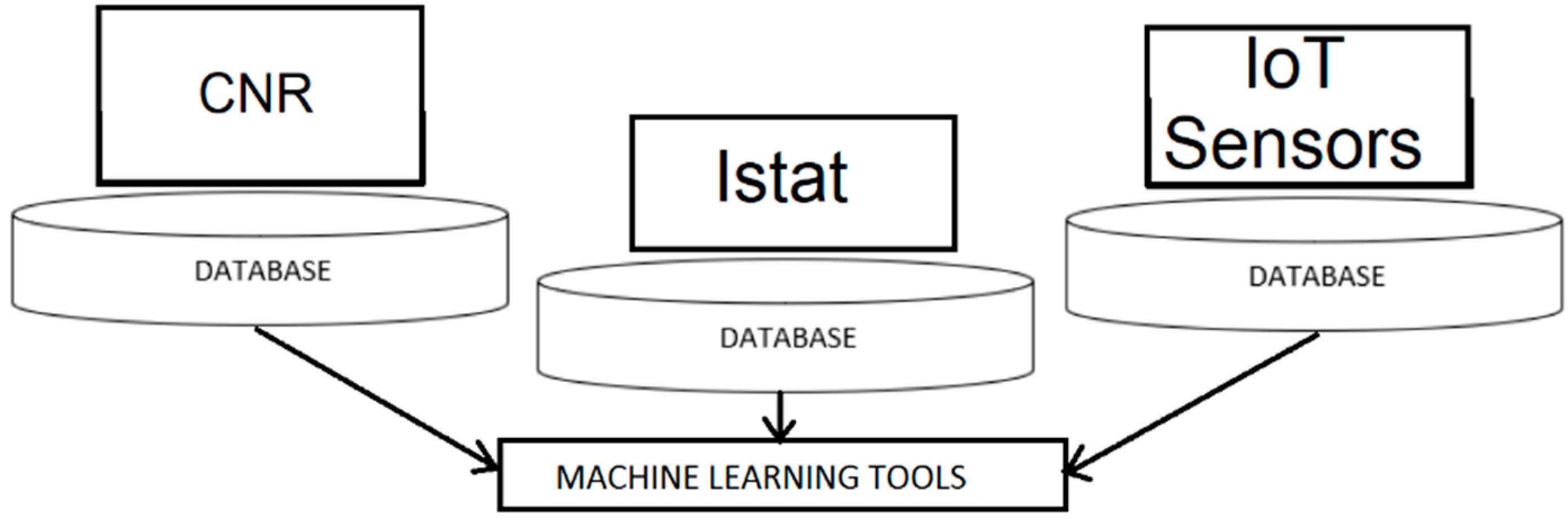
Figure 1.
The datasets used for this study: National Research Council (CNR) scientific dataset, Istat statistical dataset, and the industrial Internet of Things (IoT) Sensors dataset.
Figure 1.
The datasets used for this study: National Research Council (CNR) scientific dataset, Istat statistical dataset, and the industrial Internet of Things (IoT) Sensors dataset.
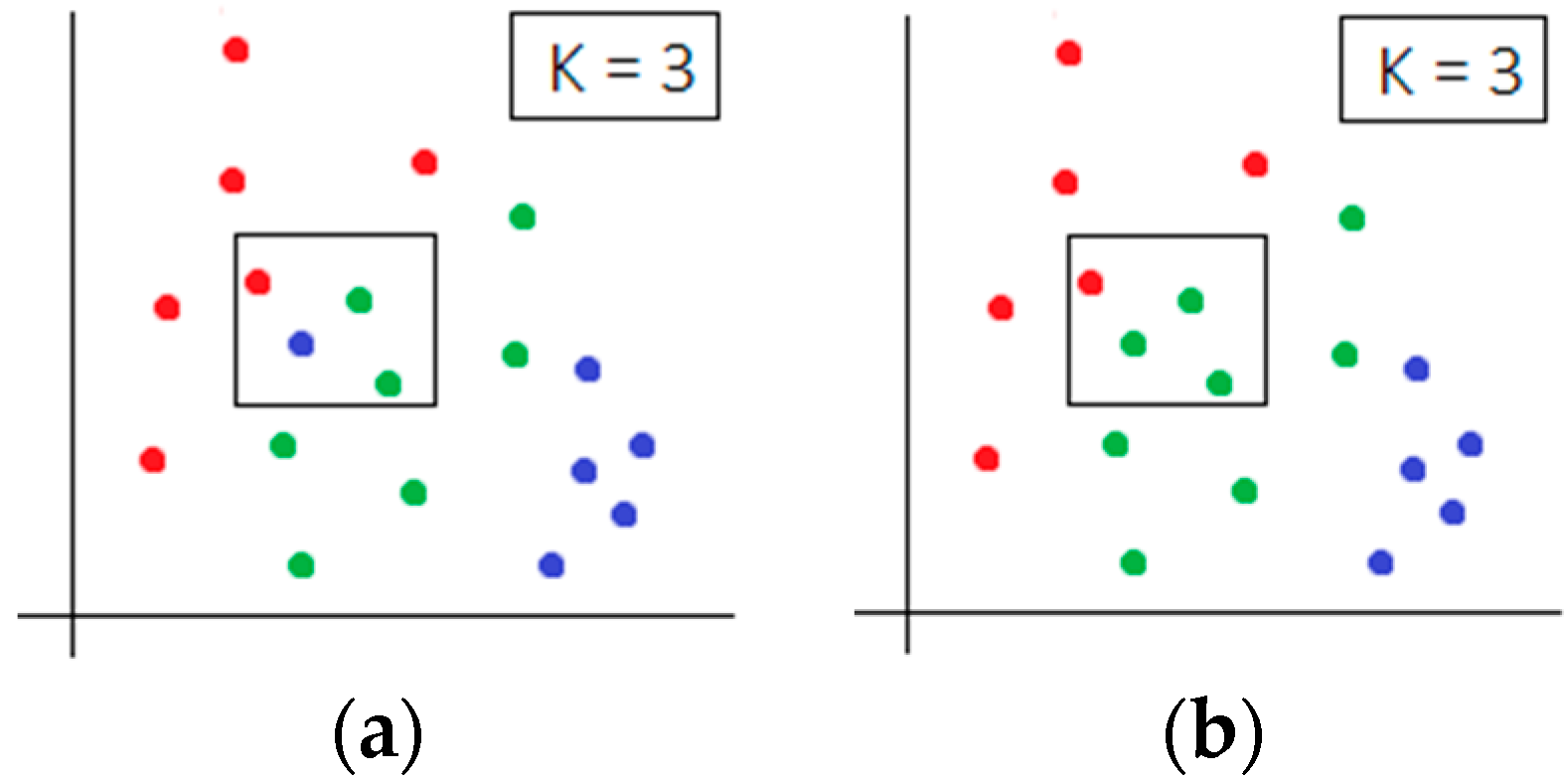
Figure 2.
Two consecutive steps of the K-nearest neighbors (KNN) algorithm (K = 3) in a bi-dimensional feature space; (a): a blue item has ambiguous clustering, (b) the green cluster is assigned to it according to its number and proximity.
Figure 2.
Two consecutive steps of the K-nearest neighbors (KNN) algorithm (K = 3) in a bi-dimensional feature space; (a): a blue item has ambiguous clustering, (b) the green cluster is assigned to it according to its number and proximity.
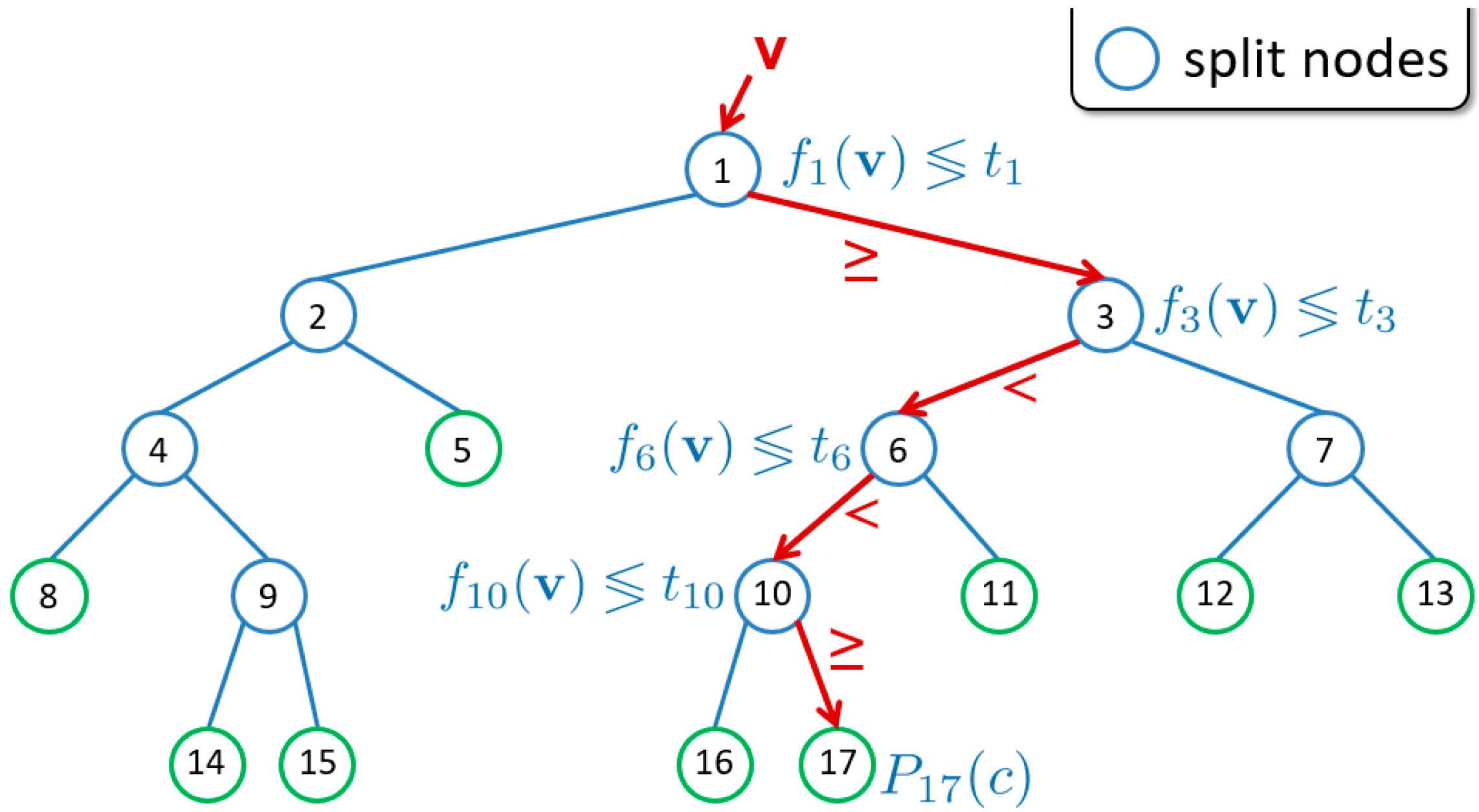
Figure 3.
A (binary) decision tree used to classify and predict values with numerical features.
Figure 3.
A (binary) decision tree used to classify and predict values with numerical features.
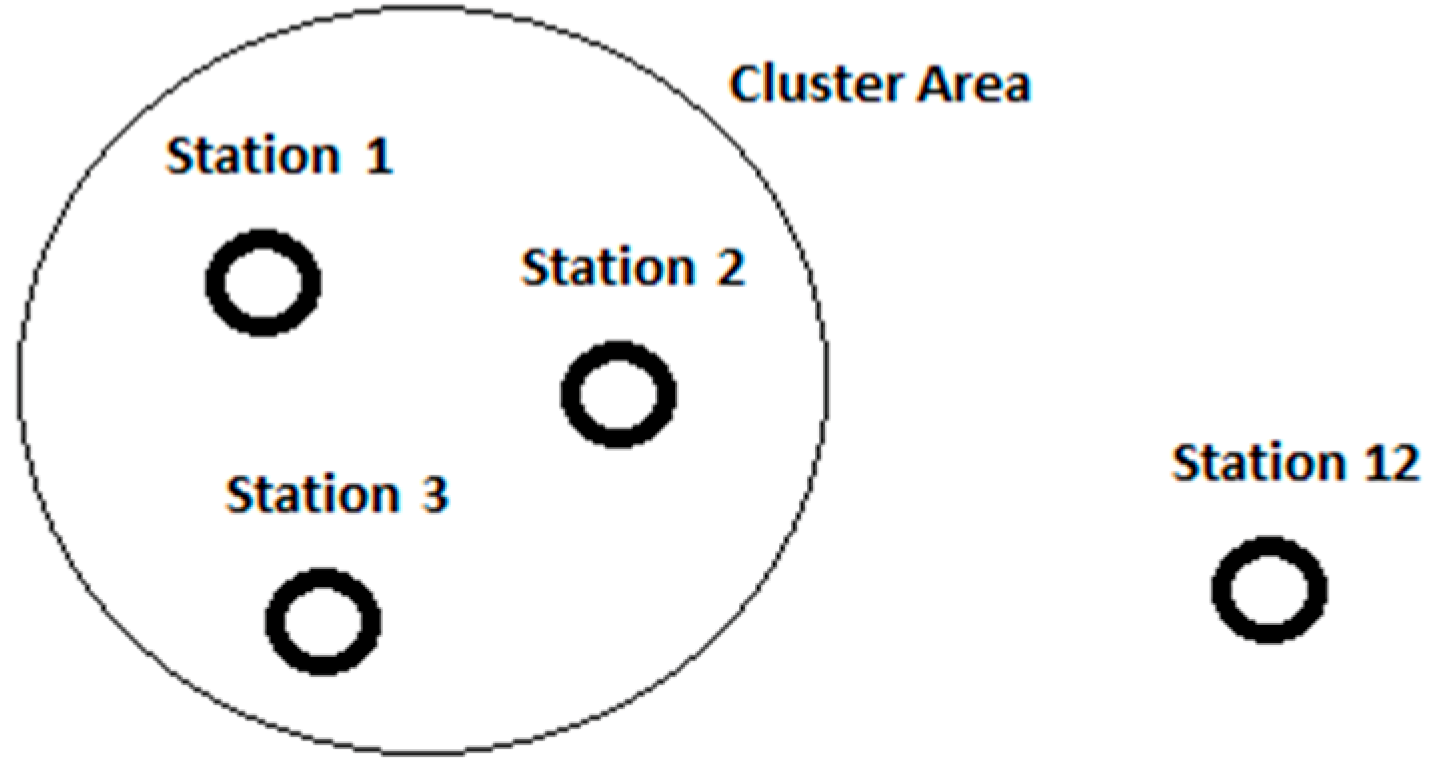
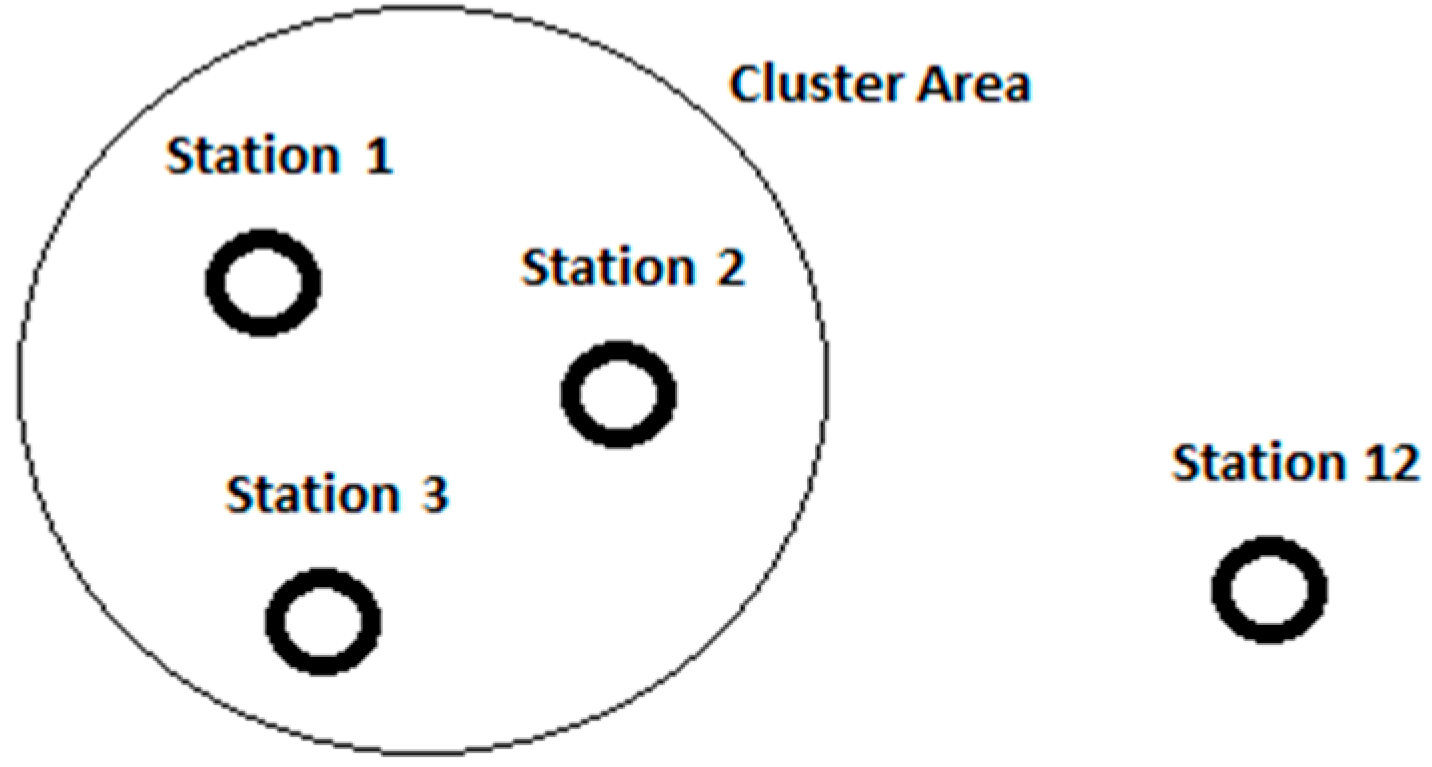
Figure 4.
Task 4: the monitoring station clustering brings together geographically close sensors that are expected to record very similar data values.
Figure 4.
Task 4: the monitoring station clustering brings together geographically close sensors that are expected to record very similar data values.
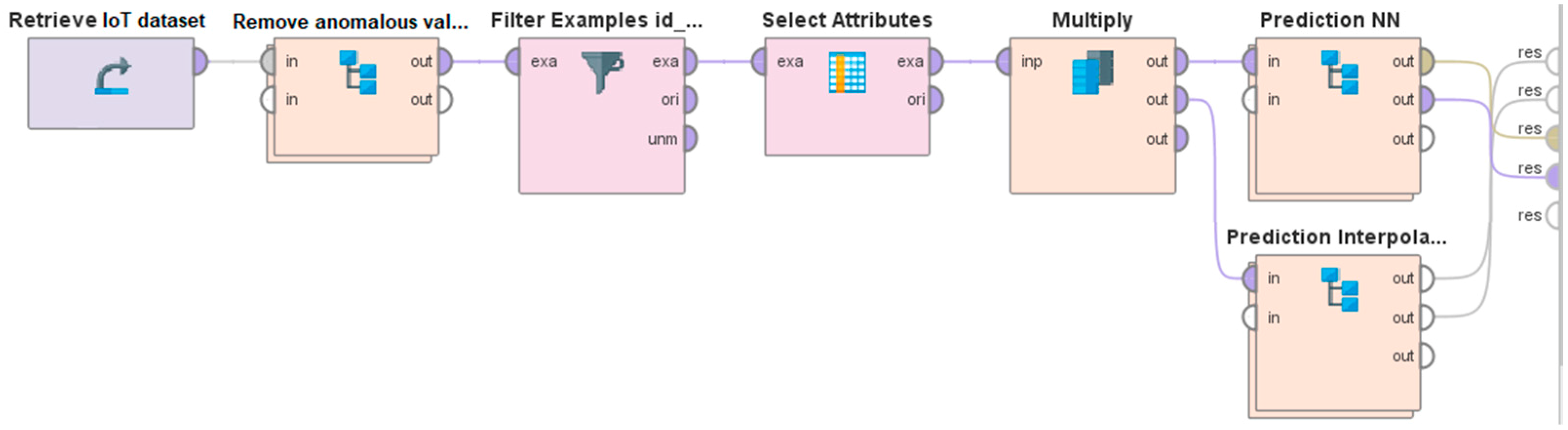
Figure 5.
The workflow blocks on the IoT dataset featuring the two predictive models for the Task 3: the IoT sensors dataset is loaded, invalid and missing values are removed, there are filters to find the monitoring stations and the combination of their attributes, and finally the two machines learning sub-process blocks for the execution of the models.
Figure 5.
The workflow blocks on the IoT dataset featuring the two predictive models for the Task 3: the IoT sensors dataset is loaded, invalid and missing values are removed, there are filters to find the monitoring stations and the combination of their attributes, and finally the two machines learning sub-process blocks for the execution of the models.
Figure 6.
A workflow for a correlation matrix to visualize the attributes magnitude for Task 5, where the input dataset is the result of the monitoring stations clustering.
Figure 6.
A workflow for a correlation matrix to visualize the attributes magnitude for Task 5, where the input dataset is the result of the monitoring stations clustering.
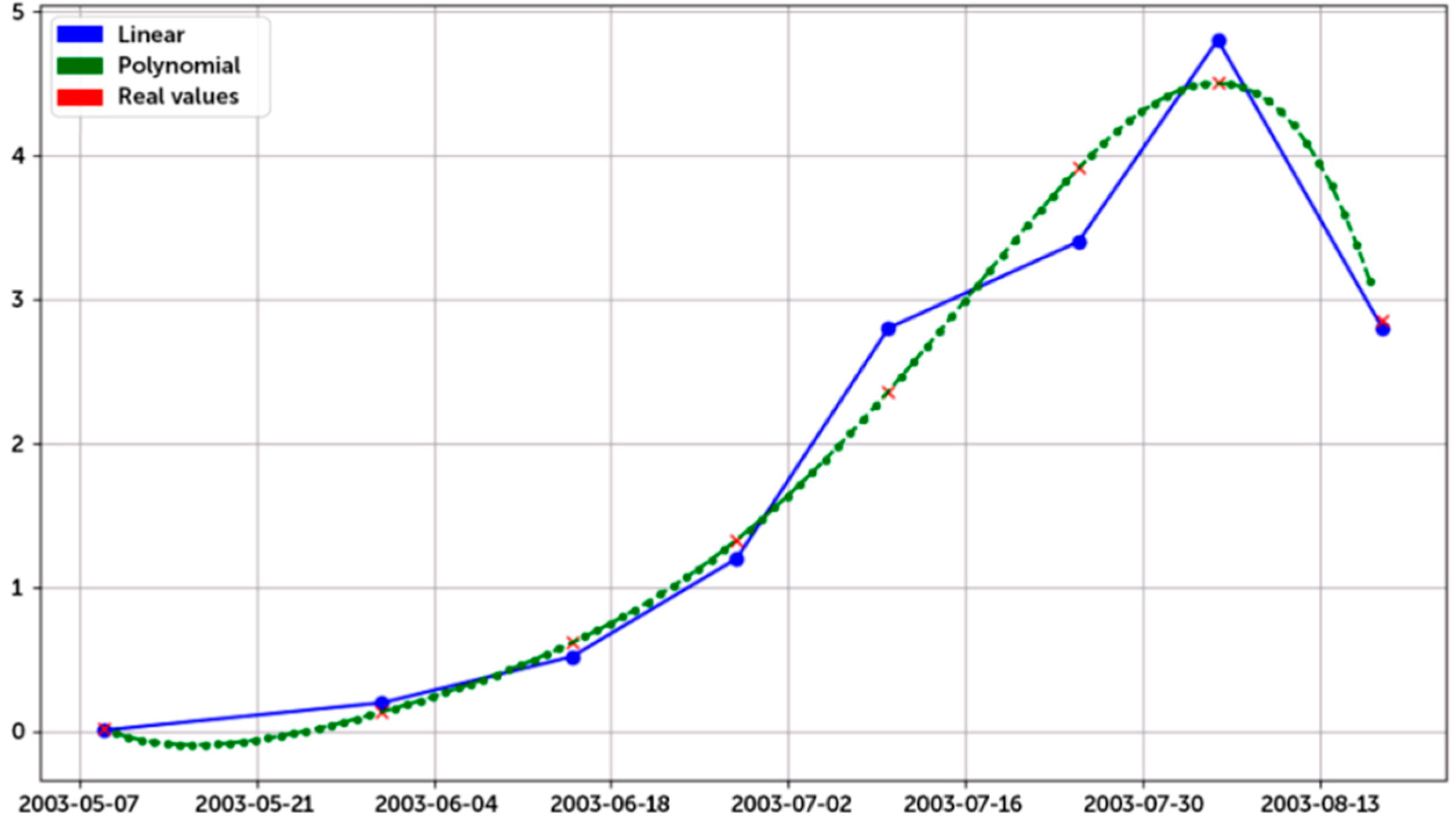
Figure 7.
Task 2: plot comparison between real-values (red dots), the linear (blue), and polynomial (green) predictive model on the CNR scientific agrarian dataset.
Figure 7.
Task 2: plot comparison between real-values (red dots), the linear (blue), and polynomial (green) predictive model on the CNR scientific agrarian dataset.
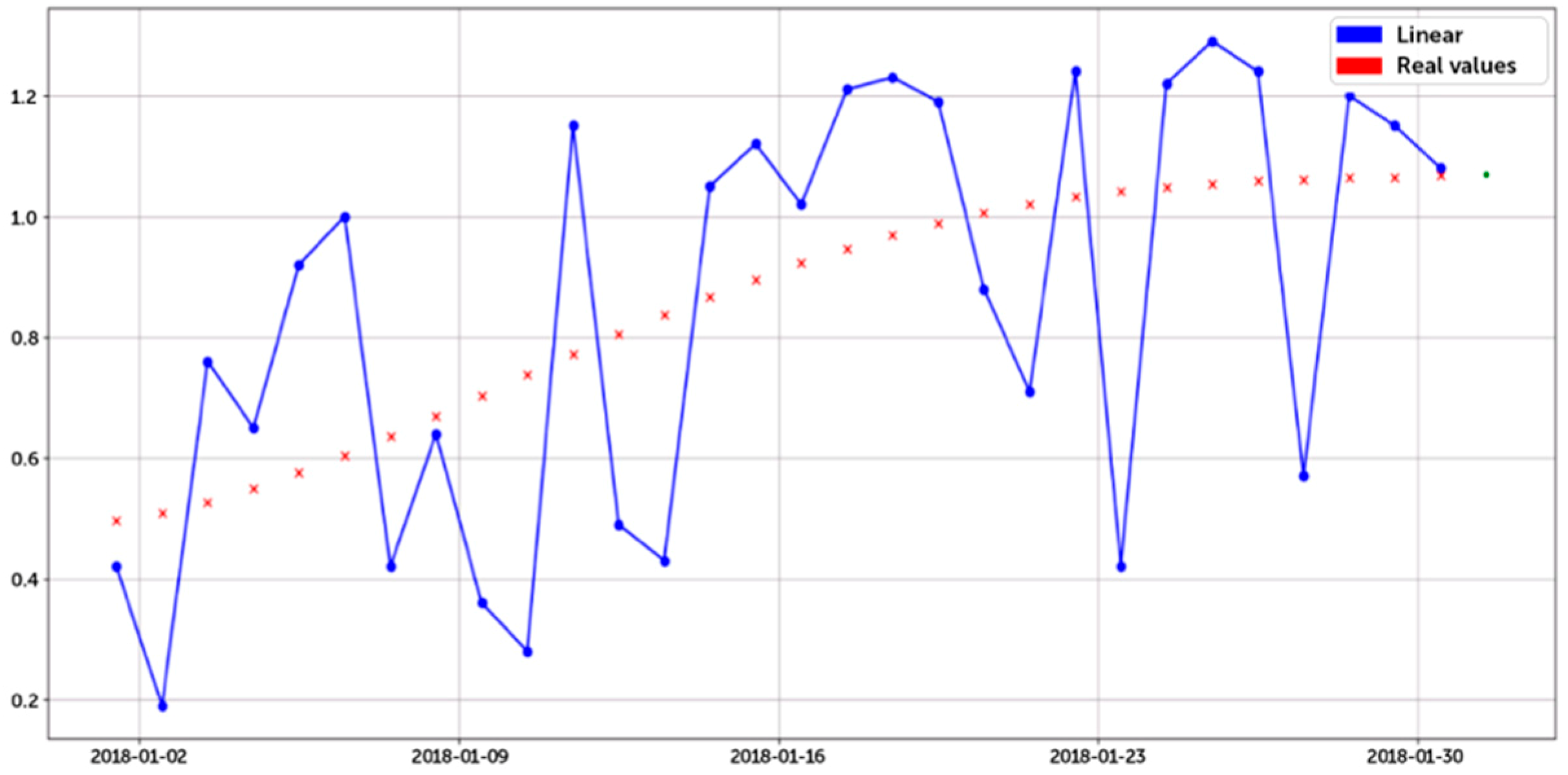
Figure 8.
Task 3: sensor real-values (red dots) and their still insufficient linear predictive model (blue lines-at-step) employing a training time series of thirty days.
Figure 8.
Task 3: sensor real-values (red dots) and their still insufficient linear predictive model (blue lines-at-step) employing a training time series of thirty days.
Table 1.
Details about culture time-series in the Istat dataset.
Table 1.
Details about culture time-series in the Istat dataset.
| Crop type | Year | Province | Altitude | Tot. Area | Cult. Area | Tot. Prod. | Tot. Harvest | Temp. (Avg) |
|---|
| Apple | 2006 | Torino | 239 | 928 | 866 | 264,240 | 264,240 | 7.6 |
| Apple | 2006 | Vercelli | 130 | 26 | 26 | 4686 | 4686 | 10 |
| Temp. (Max) | Temp. (Min) | Tot. Rain. | Phosph. Minerals | Potash Minerals | Organic Fert. | Organic Comp. | | |
| 12.6 | 2.5 | 623 | 22,312 | 130,651 | 11,731 | 491,498 | | |
| 14.7 | 5.3 | 644 | 1404 | 47,612 | 96,244 | 280,932 | | |
Table 2.
Details of the National Research Council (CNR) scientific agrarian dataset. LAI—leaf area index; ETc—evapotranspiration; ETo—evapotranspiration reference value; PM—Penman-Monteith.
Table 2.
Details of the National Research Council (CNR) scientific agrarian dataset. LAI—leaf area index; ETc—evapotranspiration; ETo—evapotranspiration reference value; PM—Penman-Monteith.
| Beamplant-2003 Crop | | | | |
|---|
| Date | Etc (mm/d) | ETo PM (mm/d) | ETc/ETo | LAI |
|---|
| 9 May 2003 | 1.19 | 4.8 | 0.25 | 0.01 |
| 11 May 2003 | 1.29 | 4.5 | 0.29 | 0.2 |
Table 3.
Details of the Internet of Things (IoT) sensors dataset.
Table 3.
Details of the Internet of Things (IoT) sensors dataset.
| Id_Station | Poi | Latitude | Longitude | Altitude | Date_Time | | | | | |
|---|
| 46 | Cellino San Marco | 40.475614 | 17.939421 | 61.14 | 8 March 2015 12:50 | | | | | |
| 46 | Cellino San Marco | 40.475614 | 17.939421 | 61.14 | 8 March 2015 13:04 | | | | | |
| r_inc | Rain | Tmin | Tmax | Tmed | RH_min | RH_max | RH_med | WS | Wdir | Pmed |
| \N | 0.00 | 22.70 | 22.70 | 22.70 | \N | \N | 25.60 | \N | \N | \N |
| \N | 0.00 | 23.30 | 23.30 | 23.30 | \N | \N | 23.10 | \N | \N | \N |
Table 4.
Task 1: apples and pears crop prediction error exploiting the neural network and the polynomial linear predictive model on the Istat dataset.
Table 4.
Task 1: apples and pears crop prediction error exploiting the neural network and the polynomial linear predictive model on the Istat dataset.
| Italian Province | Prediction Error—Apple | Prediction Error—Pears |
|---|
| NN | LR | NN | LR |
|---|
| Udine | 6.10% | 25.50% | 3.53% | 14.19% |
| Gorizia | 12.72% | 45.56% | 6.64% | 16.33% |
| Trieste | 21.80% | 21.25% | 9.83% | 21.25% |
| Pordenone | 12.04% | 38.47% | 154.79% | 153.12% |
| L’Aquila | 0.05% | 0.06% | 0.04% | 0.08% |
| Teramo | 2.52% | 2.53% | 1.52% | 13.03% |
| Pescara | 3.74% | 5.45% | 10.52% | 19.17% |
| Chieti | 3.65% | 10.54% | 2.26% | 2.73% |
| Cosenza | 22.68% | 63.79% | 16.57% | 20.62% |
| Catanzaro | 8.23% | 21.12% | 2.97% | 55.93% |
| Reggio Calabria | 11.38% | 42.60% | 6.14% | 13.08% |
| Crotone | 7.00% | 95.57% | 7.46% | 133.60% |
| Vibo Valentia | 7.50% | 27.55% | 29.40% | 45.31% |
| Mean | 9.19% | 30.77% | 19.36% | 39.11% |
Table 5.
Task 1: a comparison example between the real values and their neural network model prediction for the apple and pear total crops for the Italian province of L’Aquila on the Istat dataset.
Table 5.
Task 1: a comparison example between the real values and their neural network model prediction for the apple and pear total crops for the Italian province of L’Aquila on the Istat dataset.
| Method: NN | Apple | Pears |
|---|
| Italian Province | Real Value | Predicted Value | Real Value | Predicted Value |
|---|
| L’Aquila | 45,900 | 45,000 | 3925 | 3750 |
Table 6.
Task 2: comparison on the prediction error for the cultures leaf area index (LAI) value exploiting machine learning methods on the CNR scientific agrarian dataset.
Table 6.
Task 2: comparison on the prediction error for the cultures leaf area index (LAI) value exploiting machine learning methods on the CNR scientific agrarian dataset.
| Culture | Prediction Error |
|---|
| NN | LR | Polynomial |
|---|
| Artichokes | 139.00% | 101.63% | 25.70% |
| Pear | 1779.38% | 81.80% | 10.00% |
| Pacciamata Eggplant | 933.10% | 564.89% | 6.26% |
Table 7.
Task 3: prediction error of the sensor attribute r_inc coming from monitoring station 173 using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
Table 7.
Task 3: prediction error of the sensor attribute r_inc coming from monitoring station 173 using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
| Station: 173 | Prediction Error (Training: 1 January–30 January 2018) |
|---|
| Factors | NN | LR | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 53.71 | 57.77 | 469.78 |
| BASE + Temp | 83.70 | 42.55 | 469.78 |
| BASE + RH + Temp | 28.91 | 28.80 | 469.78 |
| BASE + RH | 31.40 | 25.54 | 469.78 |
| BASE + RH + Temp + Rain | 28.82 | 28.80 | 469.78 |
Table 8.
Task 3: prediction error of the sensor attribute r_inc coming from monitoring station 186 using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
Table 8.
Task 3: prediction error of the sensor attribute r_inc coming from monitoring station 186 using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
| Station: 186 | Prediction Error (Training: 1 January–30 January 2018) |
|---|
| Factors | NN | LR | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 105.37 | 110.31 | 526.33 |
| BASE + Temp | 108.41 | 73.77 | 526.33 |
| BASE + RH + Temp | 104.84 | 50.10 | 526.33 |
| BASE + RH | 82.15 | 60.17 | 526.33 |
| BASE + RH + Temp + Rain | 82.42 | 50.10 | 526.33 |
Table 9.
Task 3: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
Table 9.
Task 3: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using neural network, and linear and polynomial regression machine learning models on the IoT Sensors dataset.
| Station: 173 + 186 | Prediction Error (Training: 1 January–30 January 2018) |
|---|
| Factors | NN | LR | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 104.52 | 85.21 | 248.28 |
| BASE + Temp | 78.76 | 65.66 | 248.28 |
| BASE + RH + Temp | 76.16 | 43.48 | 248.28 |
| BASE + RH | 51.73 | 51.04 | 248.28 |
| BASE + RH + Temp + Rain | 85.08 | 43.48 | 248.28 |
Table 10.
Task 3: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using neural network, and linear and polynomial regression machine learning models trained with different time-series interval for the training on the IoT Sensors dataset.
Table 10.
Task 3: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using neural network, and linear and polynomial regression machine learning models trained with different time-series interval for the training on the IoT Sensors dataset.
| Station: 173 + 186 | Prediction Error |
|---|
| Training Interval | Prediction Test | NN | LR | Polynomial |
|---|
| 1 January–30 January 2018 | 31 January 2018 | 7.38% | 17.36% | 25.22% |
| 26 January–30 January 2018 | 31 January 2018 | 5.96% | 17.07% | 66.81% |
1 January–4 January 2018;
6 January–9 January 2018 | 5 January 2018 | 22.18% | 13.83% | 9.37% |
Table 11.
Task 4: missing data prediction error of the sensor attribute r_inc from monitoring station 173 using decision trees, KNN, and polynomial machine learning methods on IoT Sensors dataset.
Table 11.
Task 4: missing data prediction error of the sensor attribute r_inc from monitoring station 173 using decision trees, KNN, and polynomial machine learning methods on IoT Sensors dataset.
| Station: 173 | Prediction Error (Training: 1 January–30 January 2018) |
|---|
| Factors | DT | KNN | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 56.22 | 65.02 | 469.78 |
| BASE + Temp | 38.10 | 48.26 | 469.78 |
| BASE + RH + Temp | 24.11 | 42.71 | 469.78 |
| BASE + RH | 27.07 | 42.71 | 469.78 |
| BASE + RH + Temp + Rain | 24.11 | 42.71 | 469.78 |
Table 12.
Task 4: missing data prediction error of the sensor attribute r_inc from monitoring station 186 using decision trees, KNN, and polynomial machine learning methods on IoT Sensors dataset.
Table 12.
Task 4: missing data prediction error of the sensor attribute r_inc from monitoring station 186 using decision trees, KNN, and polynomial machine learning methods on IoT Sensors dataset.
| Station: 186 | Prediction Error (Training: 1 January–30 January 2018) |
|---|
| Factors | DT | KNN | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 117.80 | 107.17 | 526.33 |
| BASE + Temp | 89.16 | 104.14 | 526.33 |
| BASE + RH + Temp | 63.20 | 104.84 | 526.33 |
| BASE + RH | 62.98 | 104.84 | 526.33 |
| BASE + RH + Temp + Rain | 69.82 | 104.84 | 526.33 |
Table 13.
Task 4: missing data prediction error of the sensor attribute r_inc from both monitoring station 173 and 186 using decision trees (DT), KNN, and polynomial machine learning methods on IoT Sensors dataset.
Table 13.
Task 4: missing data prediction error of the sensor attribute r_inc from both monitoring station 173 and 186 using decision trees (DT), KNN, and polynomial machine learning methods on IoT Sensors dataset.
| Station: 173 + 186 | Prediction Error (training: 1 January–30 January 2018) |
|---|
| Factors | DT | KNN | Polynomial |
|---|
| BASE(r_inc + lat + lon + alt) | 68.74 | 71.01 | 248.28 |
| BASE + Temp | 86.04 | 85.17 | 248.28 |
| BASE + RH + Temp | 39.53 | 80.12 | 248.28 |
| BASE + RH | 41.44 | 80.12 | 248.28 |
| BASE + RH + Temp + Rain | 40.12 | 80.12 | 248.28 |
Table 14.
Task 4: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using decision tree, KNN, and polynomial regression machine learning models trained with different time-series interval for the training on the IoT Sensors dataset.
Table 14.
Task 4: prediction error of the sensor attribute r_inc coming from both 173 and 186 monitoring station using decision tree, KNN, and polynomial regression machine learning models trained with different time-series interval for the training on the IoT Sensors dataset.
| Station: 173 + 186 | Prediction Error |
|---|
| Training Interval | Prediction Test | DT | KNN | Polynomial |
|---|
| 1 January–30 January 2018 | 31 January 2018 | 12.10 | 9.66 | 25.22 |
| 26 January–30 January 2018 | 31 January 2018 | 29.37 | 7.65 | 66.81 |
1 January–4 January 2018;
6 January–9 January 2018 | 5 January 2018 | 22.38 | 16.16 | 9.37 |
Table 15.
Task 5: a cluster of three monitoring stations where the high value of the difference_max on the r_inc attribute indicates a hardware sensor issue from June 2017 for the station 396.
Table 15.
Task 5: a cluster of three monitoring stations where the high value of the difference_max on the r_inc attribute indicates a hardware sensor issue from June 2017 for the station 396.
| r_inc (Station 394) | r_inc (Station 396) | r_inc (Station 397) | Date_Time | Diff_Max |
|---|
| 3.740 | 0.570 | 3.430 | 9 June 2017 2:00:00 p.m. | 3.170 |
| 3.610 | 0.470 | 3.320 | 14 June 2017 2:00:00 p.m. | 3.140 |
Table 16.
Task 5: the correlation matrix for the clustering attributes magnitude.
Table 16.
Task 5: the correlation matrix for the clustering attributes magnitude.
| Attributes | r_inc | Tmin | Tmax | Tmed | RH_min | RH_max | RH_med | WS |
|---|
| r_inc | 1 | 0.077 | 0.351 | 0.213 | −0.739 | −0.431 | −0.232 | 0.114 |
| Tmin | 0.077 | 1 | 0.945 | 0.986 | −0.361 | −0.346 | −0.646 | 0.098 |
| Tmax | 0.351 | 0.945 | 1 | 0.985 | −0.638 | −0.463 | −0.667 | 0.097 |
| Tmed | 0.213 | 0.986 | 0.985 | 1 | −0.525 | −0.441 | −0.666 | 0.099 |
| RH_min | −0.739 | −0.361 | 0.638 | −0.525 | 1 | 0.589 | 0.896 | −0.016 |
| RH_max | −0.431 | −0.346 | −0.463 | −0.441 | 0.589 | 1 | 0.777 | −0.055 |
| RH_med | −0.232 | −0.646 | −0.667 | −0.666 | 0.896 | 0.777 | 1 | −0.339 |
| WS | 0.114 | 0.098 | 0.097 | 0.099 | −0.016 | −0.055 | −0.339 | 1 |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}