
Identification of Therapeutic Targets for the Selective Killing of HBV-Positive Hepatocytes

Abstract
:1. Introduction
2. Materials and Methods
2.1. Overview of the Method
2.2. Datasets and Sample Characteristics
2.3. Data Preprocessing
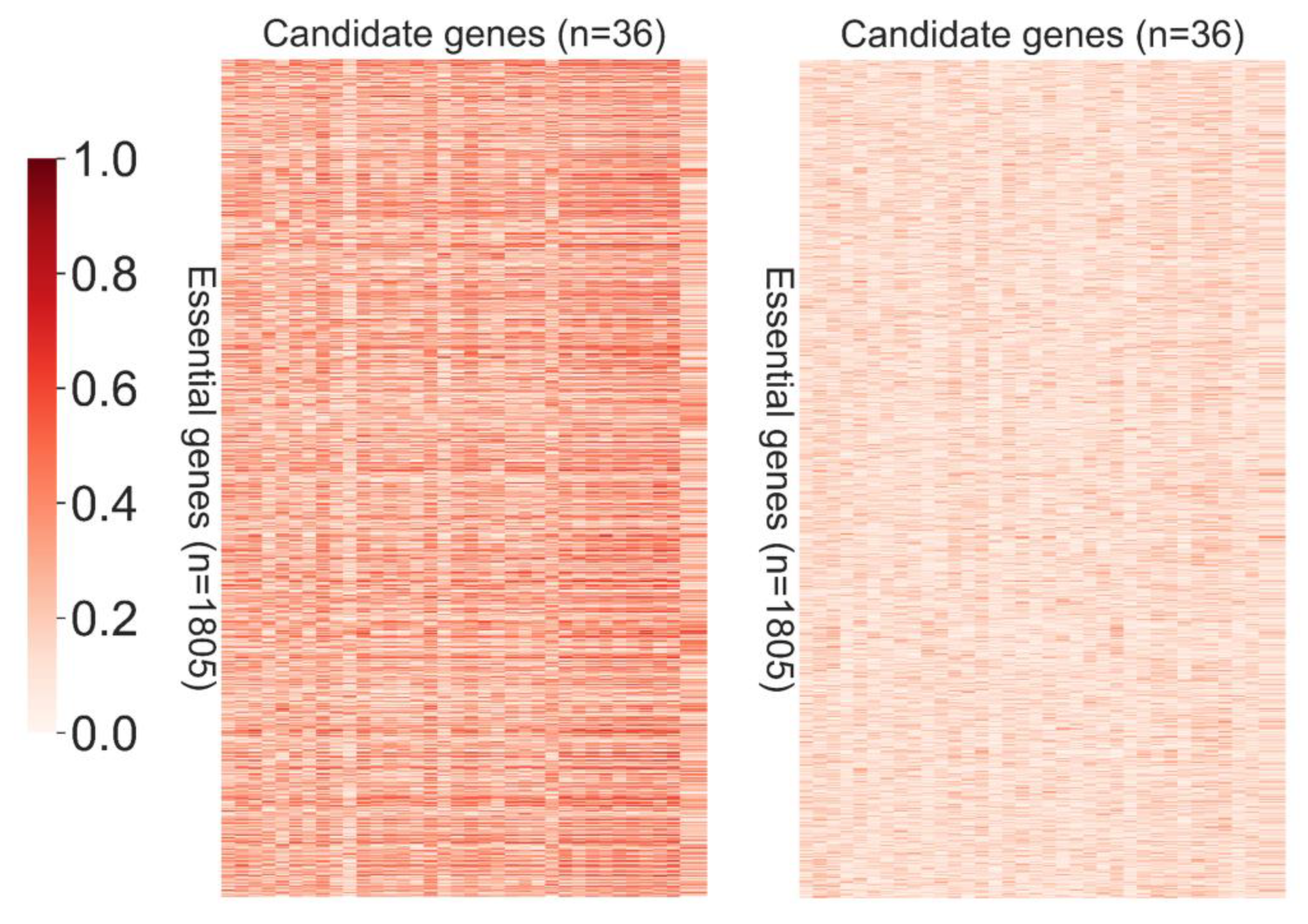
2.4. Selection of the Known Essential Genes
2.5. RWR Algorithm
2.6. SVM Approach
2.7. Gene Set Enrichment Preranked Analysis (GSEAPreranked)
3. Results
3.1. Data Preparation
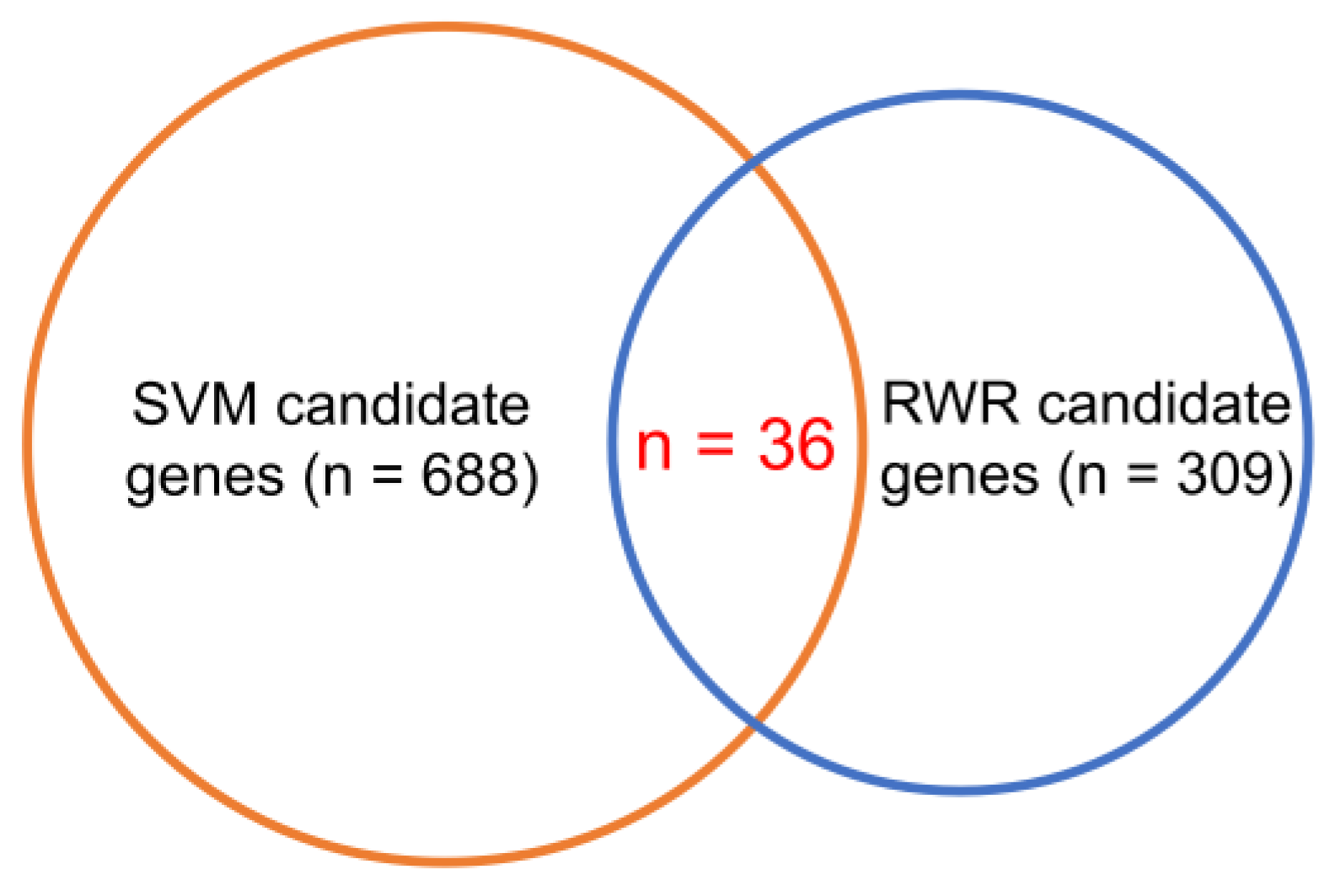
3.2. Using RWR to Identify the CEGs
3.3. Using SVM to Identify the CEGs
3.4. GSEAPreranked for the Average Ranking Gene List
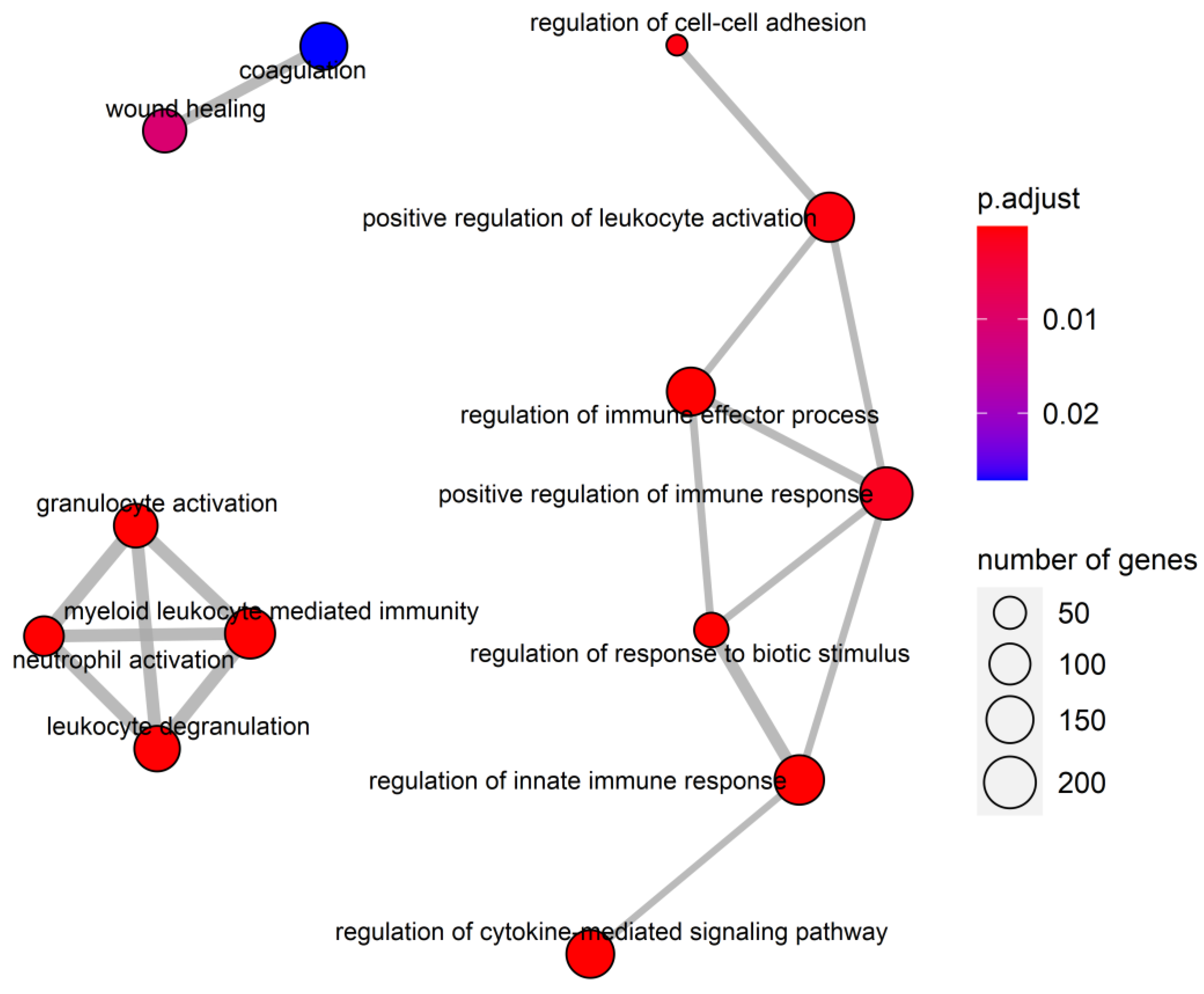
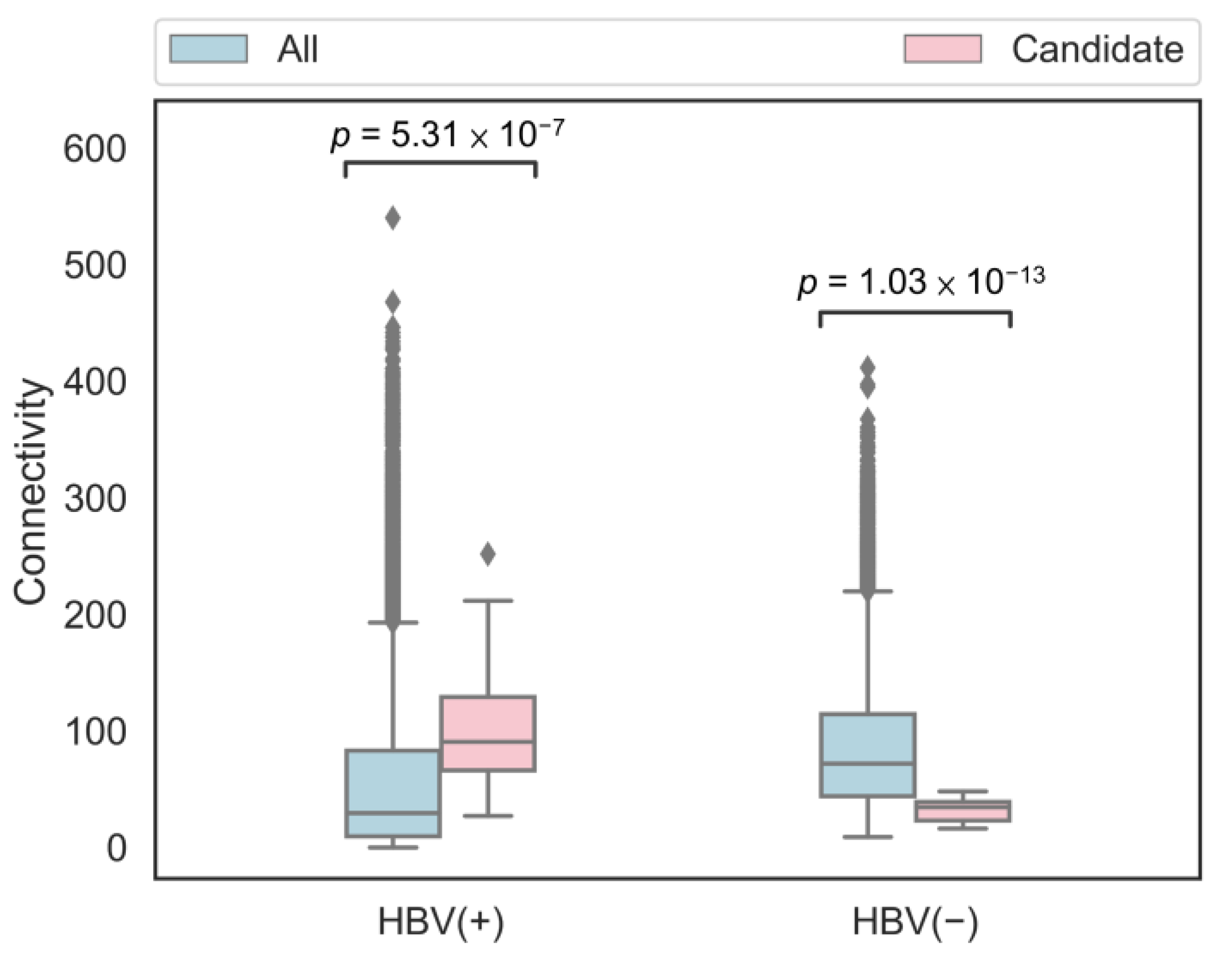
3.5. Candidate Genes Analysis
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- World Health Organization. Global Hepatitis Report; WHO: Geneva, Switzerland, 2017. [Google Scholar]
- Stasi, C.; Silvestri, C.; Voller, F. Emerging Trends in Epidemiology of Hepatitis B Virus Infection. J. Clin. Transl. Hepatol. 2017, 5, 272–276. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-Y.; Hsu, H.-Y.; Liu, C.-C.; Chang, M.-H.; Ni, Y.-H. Stable seroepidemiology of hepatitis B after universal immunization in Taiwan: A 3-year study of national surveillance of primary school students. Vaccine 2010, 28, 5605–5608. [Google Scholar] [CrossRef]
- Alonso, S.; Guerra, A.-R.; Carreira, L.; Ferrer, J.-Á.; Gutiérrez, M.-L.; Fernandez-Rodriguez, C.M. Upcoming pharmacological developments in chronic hepatitis B: Can we glimpse a cure on the horizon? BMC Gastroenterol. 2017, 17, 168. [Google Scholar] [CrossRef] [Green Version]
- Zoulim, F.; Locarnini, S. Optimal management of chronic hepatitis B patients with treatment failure and antiviral drug resistance. Liver Int. 2013, 33, 116–124. [Google Scholar] [CrossRef]
- Lok, A.S.; Zoulim, F.; Dusheiko, G.; Ghany, M.G. Hepatitis B cure: From discovery to regulatory approval. Hepatology 2017, 66, 1296–1313. [Google Scholar] [CrossRef]
- Shafritz, D.A.; Shouval, D.; Sherman, H.I.; Hadziyannis, S.J.; Kew, M.C. Integration of Hepatitis B Virus DNA into the Genome of Liver Cells in Chronic Liver Disease and Hepatocellular Carcinoma. N. Engl. J. Med. 1981, 305, 1067–1073. [Google Scholar] [CrossRef]
- Levrero, M. Future therapies for HBV Cure. In Proceedings of the 9th Paris Hepatitis Conference, Paris, France, 11–12 January 2016. [Google Scholar]
- Chen, W.-H.; Lu, G.; Chen, X.; Zhao, X.-M.; Bork, P. OGEE v2: An update of the online gene essentiality database with special focus on differentially essential genes in human cancer cell lines. Nucleic Acids Res. 2016, 45, D940–D944. [Google Scholar] [CrossRef]
- Hart, T.; Chandrashekhar, M.; Aregger, M.; Steinhart, Z.; Brown, K.R.; MacLeod, G.; Mis, M.; Zimmermann, M.; Fradet-Turcotte, A.; Sun, S.; et al. High-Resolution CRISPR Screens Reveal Fitness Genes and Genotype-Specific Cancer Liabilities. Cell 2015, 163, 1515–1526. [Google Scholar] [CrossRef] [Green Version]
- Wang, T.; Birsoy, K.; Hughes, N.W.; Krupczak, K.M.; Post, Y.; Wei, J.J.; Lander, E.S.; Sabatini, D.M. Identification and characterization of essential genes in the human genome. Science 2015, 350, 1096. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.-H.; Minguez, P.; Lercher, M.J.; Bork, P. OGEE: An online gene essentiality database. Nucleic Acids Res. 2011, 40, D901–D906. [Google Scholar] [CrossRef] [Green Version]
- Rancati, G.; Moffat, J.; Typas, A.; Pavelka, N. Emerging and evolving concepts in gene essentiality. Nat. Rev. Genet. 2017, 19, 34. [Google Scholar] [CrossRef]
- Farmer, H.; McCabe, N.; Lord, C.J.; Tutt, A.N.J.; Johnson, D.A.; Richardson, T.B.; Santarosa, M.; Dillon, K.J.; Hickson, I.; Knights, C.; et al. Targeting the DNA repair defect in BRCA mutant cells as a therapeutic strategy. Nature 2005, 434, 917–921. [Google Scholar] [CrossRef]
- Zhou, W.; Ma, Y.; Zhang, J.; Hu, J.; Zhang, M.; Wang, Y.; Li, Y.; Wu, L.; Pan, Y.; Zhang, Y.; et al. Predictive model for inflammation grades of chronic hepatitis B: Large-scale analysis of clinical parameters and gene expressions. Liver Int. 2017, 37, 1632–1641. [Google Scholar] [CrossRef]
- Wurmbach, E.; Chen, Y.-B.; Khitrov, G.; Zhang, W.; Roayaie, S.; Schwartz, M.; Fiel, I.; Thung, S.; Mazzaferro, V.; Bruix, J.; et al. Genome-wide molecular profiles of HCV-induced dysplasia and hepatocellular carcinoma. Hepatology 2007, 45, 938–947. [Google Scholar] [CrossRef]
- Farci, P.; Diaz, G.; Chen, Z.; Govindarajan, S.; Tice, A.; Agulto, L.; Pittaluga, S.; Boon, D.; Yu, C.; Engle, R.E.; et al. B cell gene signature with massive intrahepatic production of antibodies to hepatitis B core antigen in hepatitis B virus–associated acute liver failure. Proc. Natl. Acad. Sci. USA 2010, 107, 8766. [Google Scholar] [CrossRef] [Green Version]
- Nissim, O.; Melis, M.; Diaz, G.; Kleiner, D.E.; Tice, A.; Fantola, G.; Zamboni, F.; Mishra, L.; Farci, P. Liver Regeneration Signature in Hepatitis B Virus (HBV)-Associated Acute Liver Failure Identified by Gene Expression Profiling. PLoS ONE 2012, 7, e49611. [Google Scholar] [CrossRef] [Green Version]
- Misu, H.; Takamura, T.; Takayama, H.; Hayashi, H.; Matsuzawa-Nagata, N.; Kurita, S.; Ishikura, K.; Ando, H.; Takeshita, Y.; Ota, T.; et al. A Liver-Derived Secretory Protein, Selenoprotein P, Causes Insulin Resistance. Cell Metab. 2010, 12, 483–495. [Google Scholar] [CrossRef] [Green Version]
- Affò, S.; Dominguez, M.; Lozano, J.J.; Sancho-Bru, P.; Rodrigo-Torres, D.; Morales-Ibanez, O.; Moreno, M.; Millán, C.; Loaeza-del-Castillo, A.; Altamirano, J.; et al. Transcriptome analysis identifies TNF superfamily receptors as potential therapeutic targets in alcoholic hepatitis. Gut 2013, 62, 452. [Google Scholar] [CrossRef] [PubMed]
- Diaz, G.; Zamboni, F.; Tice, A.; Farci, P. Integrated ordination of miRNA and mRNA expression profiles. BMC Genom. 2015, 16, 767. [Google Scholar] [CrossRef] [Green Version]
- Hobbs, B.; Collin, F.; Antonellis, K.J.; Irizarry, R.A.; Speed, T.P.; Scherf, U.; Beazer-Barclay, Y.D. Exploration, normalization, and summaries of high density oligonucleotide array probe level data. Biostatistics 2003, 4, 249–264. [Google Scholar] [CrossRef] [Green Version]
- Ritchie, M.E.; Phipson, B.; Wu, D.; Hu, Y.; Law, C.W.; Shi, W.; Smyth, G.K. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. 2015, 43, e47. [Google Scholar] [CrossRef] [PubMed]
- Langfelder, P.; Horvath, S. WGCNA: An R package for weighted correlation network analysis. BMC Bioinform. 2008, 9, 559. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Horvath, S. A General Framework for Weighted Gene Co-Expression Network Analysis. Stat. Appl. Genet. Mol. Biol. 2005, 4, 17. [Google Scholar] [CrossRef]
- Le, D.H.; Verbeke, L.; Son, L.H.; Chu, D.T.; Pham, V.H. Random walks on mutual microRNA-target gene interaction network improve the prediction of disease-associated microRNAs. BMC Bioinform. 2017, 18, 479. [Google Scholar] [CrossRef] [Green Version]
- Li, L.; Wang, Y.; An, L.; Kong, X.; Huang, T. A network-based method using a random walk with restart algorithm and screening tests to identify novel genes associated with Menière’s disease. PLoS ONE 2017, 12, e0182592. [Google Scholar] [CrossRef] [Green Version]
- Köhler, S.; Bauer, S.; Horn, D.; Robinson, P.N. Walking the Interactome for Prioritization of Candidate Disease Genes. Am. J. Hum. Genet. 2008, 82, 949–958. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Huang, G.; Hu, Q.; Zou, Q. A network-based method for the identification of putative genes related to infertility. Biochim. Biophys. Acta Gen. Subj. 2016, 1860, 2716–2724. [Google Scholar] [CrossRef]
- Yuan, F.; Zhang, Y.-H.; Wan, S.; Wang, S.; Kong, X.-Y. Mining for Candidate Genes Related to Pancreatic Cancer Using Protein-Protein Interactions and a Shortest Path Approach. Biomed. Res. Int. 2015, 2015, 623121. [Google Scholar] [CrossRef]
- Wang, B.; Yuan, F.; Kong, X.; Hu, L.-D.; Cai, Y.-D. Identifying Novel Candidate Genes Related to Apoptosis from a Protein-Protein Interaction Network. Comput. Math. Methods Med. 2015, 2015, 715639. [Google Scholar] [CrossRef] [Green Version]
- Yang, L.; Wang, J.; Wang, H.; Lv, Y.; Zuo, Y.; Li, X.; Jiang, W. Analysis and identification of essential genes in humans using topological properties and biological information. Gene 2014, 551, 138–151. [Google Scholar] [CrossRef]
- Tian, D.; Wenlock, S.; Kabir, M.; Tzotzos, G.; Doig, A.J.; Hentges, K.E. Identifying mouse developmental essential genes using machine learning. Dis. Models Mech. 2018, 11, dmm034546. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hwang, Y.-C.; Lin, C.-C.; Chang, J.-Y.; Mori, H.; Juan, H.-F.; Huang, H.-C. Predicting essential genes based on network and sequence analysis. Mol. Biosyst. 2009, 5, 1672–1678. [Google Scholar] [CrossRef] [PubMed]
- Hagberg, A.; Swart, P.; Chult, D.S. Exploring Network Structure, Dynamics, and Function Using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008. [Google Scholar]
- Yu, G.; Wang, L.-G.; Han, Y.; He, Q.-Y. clusterProfiler: An R Package for Comparing Biological Themes Among Gene Clusters. OMICS J. Integr. Biol. 2012, 16, 284–287. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, Z.; Jiang, S.; Li, R.; Li, W.; Zhao, C.; Hong, H.; Huang, X.; Li, H.; Bo, X. New insights on human essential genes based on integrated analysis and the construction of the HEGIAP web-based platform. Brief Bioinform. 2020, 21, 1397–1410. [Google Scholar] [CrossRef] [Green Version]
- Shang, D.; Li, C.; Yao, Q.; Yang, H.; Xu, Y.; Han, J.; Li, J.; Su, F.; Zhang, Y.; Zhang, C.; et al. Prioritizing candidate disease metabolites based on global functional relationships between metabolites in the context of metabolic pathways. PLoS ONE 2014, 9, e104934. [Google Scholar] [CrossRef]
- Li, Y.; Li, J. Disease gene identification by random walk on multigraphs merging heterogeneous genomic and phenotype data. BMC Genom. 2012, 13, S27. [Google Scholar] [CrossRef] [Green Version]
- Gao, Y.; Zhang, T.-Y.; Yuan, Q.; Xia, N.-S. Antibody-mediated immunotherapy against chronic hepatitis B virus infection. Hum. Vaccin. Immunother. 2017, 13, 1768–1773. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, D.; He, W.; Liu, X.; Zheng, S.; Qi, Y.; Li, H.; Mao, F.; Liu, J.; Sun, Y.; Pan, L.; et al. A potent human neutralizing antibody Fc-dependently reduces established HBV infections. eLife 2017, 6, e26738. [Google Scholar] [CrossRef]
- Rösler, C.; Köck, J.; Kann, M.; Malim, M.H.; Blum, H.E.; Baumert, T.F.; von Weizsäcker, F. APOBEC-mediated interference with hepadnavirus production. Hepatology 2005, 42, 301–309. [Google Scholar] [CrossRef]
- Nguyen, D.H.; Gummuluru, S.; Hu, J. Deamination-Independent Inhibition of Hepatitis B Virus Reverse Transcription by APOBEC3G. J. Virol. 2007, 81, 4465. [Google Scholar] [CrossRef] [Green Version]
- Yan, Y.; Huang, P.; Mao, K.; He, C.; Xu, Q.; Zhang, M.; Liu, H.; Zhou, Z.; Zhou, Q. Anti-oncogene PTPN13 inactivation by hepatitis B virus X protein counteracts IGF2BP1 to promote hepatocellular carcinoma progression. Oncogene 2021, 40, 28–45. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Zhang, Y.; Wong, K.C.; Liu, K.; Yang, Y.; Wu, B.; Tong, J.H.M.; Chan, A.W.H.; Chan, H.L.Y.; Yu, J. Increased expression of GATA zinc finger domain containing 1 through gene amplification promotes liver cancer by directly inducing phosphatase of regenerating liver 3. Hepatology 2018, 67, 2302–2319. [Google Scholar] [CrossRef] [PubMed]
- Meng, F.; Liu, J.; Lu, T.; Zang, L.; Wang, J.; He, Q.; Zhou, A. SNHG1 knockdown upregulates miR-376a and downregulates FOXK1/Snail axis to prevent tumor growth and metastasis in HCC. Mol. Ther. Oncolytics 2021, 21, 264–277. [Google Scholar] [CrossRef]
- Tian, L.; Chan, L.K.; Ho, D.W.H.; Zhao, L.; Ng, I.O.L. Abstract 2589: Dysregulation of RalGAPA2 in hepatocellular carcinoma. Cancer Res. 2020, 80, 2589. [Google Scholar] [CrossRef]
- Peng, Y.; Li, Y.; Tian, Y.; Ao, G. PDE4a predicts poor prognosis and promotes metastasis by inducing epithelial-mesenchymal transition in hepatocellular carcinoma. J. Cancer 2018, 9, 2389–2396. [Google Scholar] [CrossRef]
- Zhao, W.; Dai, Y.; Dai, T.; Xie, T.; Su, X.; Li, J.; Zhou, X.; Meng, K.; Zhao, X. TRIP6 promotes cell proliferation in hepatocellular carcinoma via suppression of FOXO3a. Biochem. Biophys. Res. Commun. 2017, 494, 594–601. [Google Scholar] [CrossRef]
- Chiu, A.P.; Tschida, B.R.; Lo, L.H.; Moriarity, B.S.; Rowlands, D.K.; Largaespada, D.A.; Keng, V.W. Transposon mouse models to elucidate the genetic mechanisms of hepatitis B viral induced hepatocellular carcinoma. World J. Gastroenterol. 2015, 21, 12157–12170. [Google Scholar] [CrossRef]
- Li, W.; Cui, X.; Huo, Q.; Qi, Y.; Sun, Y.; Tan, M.; Kong, Q. Profile of HBV Integration in the Plasma DNA of Hepatocellular Carcinoma Patients. Curr. Genomics 2019, 20, 61–68. [Google Scholar] [CrossRef]
- Sun, S.; Nakashima, K.; Ito, M.; Li, Y.; Chida, T.; Takahashi, H.; Watashi, K.; Sawasaki, T.; Wakita, T.; Suzuki, T. Involvement of PUF60 in Transcriptional and Post-transcriptional Regulation of Hepatitis B Virus Pregenomic RNA Expression. Sci. Rep. 2017, 7, 12874. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.; Chen, S.; Wang, H.; Gao, B.; Kallakury, B.; Bhuvaneshwar, K.; Cahn, K.; Gusev, Y.; Wang, X.; Wu, Y.; et al. SPTBN1 inhibits inflammatory responses and hepatocarcinogenesis via the stabilization of SOCS1 and downregulation of p65 in hepatocellular carcinoma. Theranostics 2021, 11, 4232–4250. [Google Scholar] [CrossRef]
- Mayinuer, A.; Yasen, M.; Mogushi, K.; Obulhasim, G.; Xieraili, M.; Aihara, A.; Tanaka, S.; Mizushima, H.; Tanaka, H.; Arii, S. Upregulation of Protein Tyrosine Phosphatase Type IVA Member 3 (PTP4A3/PRL-3) is Associated with Tumor Differentiation and a Poor Prognosis in Human Hepatocellular Carcinoma. Ann. Surg. Oncol. 2013, 20, 305–317. [Google Scholar] [CrossRef] [Green Version]
- Kong, F.; You, H.; Kong, D.; Zheng, K.; Tang, R. The interaction of hepatitis B virus with the ubiquitin proteasome system in viral replication and associated pathogenesis. Virol. J. 2019, 16, 73. [Google Scholar] [CrossRef] [Green Version]
- Dong, Z.-R.; Zhou, W.; Sun, D.; Yan, Y.-C.; Yang, C.-C.; Yang, Y.-F.; Li, H.-C.; Zhi, X.-T.; Li, T. Role of the E3 Ubiquitin Ligase TRIM4 in Predicting the Prognosis of Hepatocellular Carcinoma. J. Cancer 2020, 11, 4007–4014. [Google Scholar] [CrossRef] [Green Version]
- Ding, D.; Lou, X.; Hua, D.; Yu, W.; Li, L.; Wang, J.; Gao, F.; Zhao, N.; Ren, G.; Li, L.; et al. Recurrent Targeted Genes of Hepatitis B Virus in the Liver Cancer Genomes Identified by a Next-Generation Sequencing–Based Approach. PLoS Genet. 2012, 8, e1003065. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dou, C.-Y.; Fan, Y.-C.; Cao, C.-J.; Yang, Y.; Wang, K. Sera DNA Methylation of CDH1, DNMT3b and ESR1 Promoters as Biomarker for the Early Diagnosis of Hepatitis B Virus-Related Hepatocellular Carcinoma. Dig. Dis. Sci. 2016, 61, 1130–1138. [Google Scholar] [CrossRef] [PubMed]
- Lei, Y.; Xu, X.; Liu, H.; Chen, L.; Zhou, H.; Jiang, J.; Yang, Y.; Wu, B. HBx induces hepatocellular carcinogenesis through ARRB1-mediated autophagy to drive the G1/S cycle. Autophagy 2021, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Sun, S.; Xu, M.Z.; Poon, R.T.; Day, P.J.; Luk, J.M. Circulating Lamin B1 (LMNB1) Biomarker Detects Early Stages of Liver Cancer in Patients. J. Proteome Res. 2010, 9, 70–78. [Google Scholar] [CrossRef] [PubMed]
- Barabási, A.-L.; Gulbahce, N.; Loscalzo, J. Network medicine: A network-based approach to human disease. Nat. Rev. Genet. 2010, 12, 56. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | GEO ID | Sample Number | Country | Year |
|---|---|---|---|---|
| HBV(+) | GSE83148 | 122 | China | 2017 |
| HBV(−) | GSE83148 | 6 | China | 2017 |
| GSE6764 | 10 | USA | 2007 | |
| GSE14668 | 11 | USA | 2010 | |
| GSE38941 | 10 | USA | 2012 | |
| GSE23343 | 7 | Japan | 2010 | |
| GSE28619 | 7 | Spain | 2012 | |
| GSE62029 | 10 | Italy | 2015 | |
| GSE101685 | 8 | Taiwan | 2019 |
| Ranking | Entrez ID | Gene Symbol | Association with HBV/HCC | Ranking | Entrez ID | Gene Symbol | Association with HBV/HCC |
|---|---|---|---|---|---|---|---|
| 1 | 200030 | NBPF11 | 19 | 27350 | APOBEC3C | HBV [42,43] | |
| 2 | 284565 | NBPF15 | 20 | 57798 | GATAD1 | HCC [44,45] | |
| 3 | 221937 | FOXK1 | HCC [46] | 21 | 342979 | PALM3 | |
| 4 | 148266 | ZNF569 | 22 | 4335 | MNT | ||
| 5 | 9883 | POM121 | 23 | 57186 | RALGAPA2 | HCC [47] | |
| 6 | 2077 | ERF | 24 | 9743 | ARHGAP32 | ||
| 7 | 5141 | PDE4A | HBV and HCC [48] | 25 | 7205 | TRIP6 | HCC [49] |
| 8 | 7328 | UBE2H | HBV and HCC [50,51] | 26 | 51479 | ANKFY1 | |
| 9 | 84433 | CARD11 | 27 | 6934 | TCF7L2 | HBV [52] | |
| 10 | 6711 | SPTBN1 | HCC [53] | 28 | 7025 | NR2F1 | |
| 11 | 11156 | PTP4A3 | HCC [54] | 29 | 79719 | AAGAB | |
| 12 | 89122 | TRIM4 | HCC [55,56] | 30 | 23365 | ARHGEF12 | HBV and HCC [57] |
| 13 | 999 | CDH1 | HBV and HCC [58] | 31 | 5269 | SERPINB6 | |
| 14 | 23568 | ARL2BP | 32 | 56935 | SMCO4 | ||
| 15 | 60401 | EDA2R | 33 | 408 | ARRB1 | HBV and HCC [59] | |
| 16 | 7559 | ZNF12 | 34 | 90268 | OTULIN | ||
| 17 | 6310 | ATXN1 | 35 | 81030 | ZBP1 | ||
| 18 | 4001 | LMNB1 | HCC [60] | 36 | 342371 | ATXN1L |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, C.-J.; Wang, L.H.-C.; Wang, Y.-C. Identification of Therapeutic Targets for the Selective Killing of HBV-Positive Hepatocytes. J. Pers. Med. 2021, 11, 649. https://doi.org/10.3390/jpm11070649
Huang C-J, Wang LH-C, Wang Y-C. Identification of Therapeutic Targets for the Selective Killing of HBV-Positive Hepatocytes. Journal of Personalized Medicine. 2021; 11(7):649. https://doi.org/10.3390/jpm11070649
Chicago/Turabian StyleHuang, Chien-Jung, Lily Hui-Ching Wang, and Yu-Chao Wang. 2021. "Identification of Therapeutic Targets for the Selective Killing of HBV-Positive Hepatocytes" Journal of Personalized Medicine 11, no. 7: 649. https://doi.org/10.3390/jpm11070649