
An Unsupervised Approach to Structuring and Analyzing Repetitive Semantic Structures in Free Text of Electronic Medical Records



Abstract
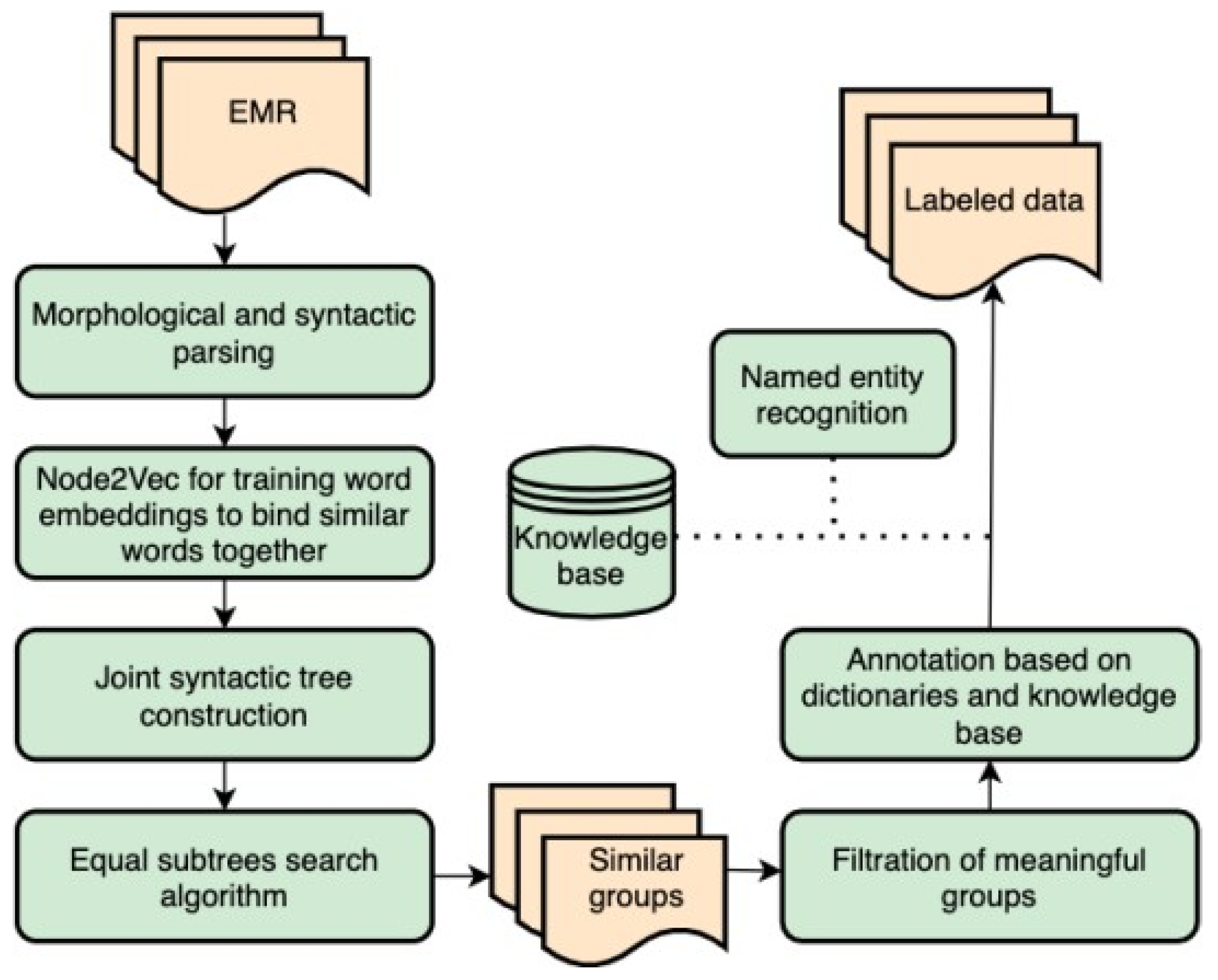
:1. Introduction
2. Methods
2.1. Morphological and Syntactic Parsing
2.2. Node2Vec on Syntactic Trees
2.3. Algorithm for Search of Similar Subtrees in a Tree
| Algorithm 1: Main idea of the base algorithm of an equal subtree search in pseudocode. The base algorithm of an equal subtree search | |
| 1: | |
| 2: | |
| 3: | |
| 4: | // compute heights and map all strings to numbers |
| 6: | |
| 7: | |
| 8: | |
| 9: | // compute string representations of subtrees for each node |
| 10: | |
| 11: | |
| // group equal subtrees together and add to result set | |
| 12: | |
| Algorithm 2: Main idea of a similar subtree search algorithm. The subtree search algorithm | |
| 1: | |
| 2: | |
| 3: | |
| 4: | // create new nodes in T for synonymous words |
| 5: | // compute heights and map all strings to numbers |
| 6: | |
| 7: | |
| 8: | |
| 9: | // compute string representations of subtrees for each node |
| 10: | |
| 11: | |
| // generate possible subtree combinations number of children, | |
| 12: | |
| // group equal subtrees together and add to result set | |
| 13: | |
| 14: | // traverse tree T to restore initial word sequences |
2.4. Labeling Process
2.4.1. Usage of Wikidata for Labeling
2.4.2. Usage of Domain Vocabularies for Labeling
2.4.3. Labels Assignment
2.5. Entity Linking in a New Knowledge Base
3. Results
3.1. Data
3.2. Method’s Implementation Details
3.3. The Resulting Medical Database
3.4. Embeddings Trained with Node2Vec
3.5. Extracted Groups
3.6. Labeling Groups
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, J.; Zhang, Z.; Org, N.R. Deep EHR: Chronic Disease Prediction Using Medical Notes. In Proceedings of the 3rd Machine Learning for Healthcare Conference, Palo Alto, CA, USA, 17–18 August 2018. [Google Scholar]
- Bodenreider, O. The Unified Medical Language System (UMLS): Integrating biomedical terminology. Nucleic Acids Res. 2004, 32, D267–D270. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Savova, G.K.; Masanz, J.J.; Ogren, P.V.; Zheng, J.; Sohn, S.; Kipper-Schuler, K.C.; Chute, C.G. Mayo clinical Text Analysis and Knowledge Extraction System (cTAKES): Architecture, component evaluation and applications. J. Am. Med. Inform. Assoc. 2010, 17, 507–513. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Aronson, A.R. Effective mapping of biomedical text to the UMLS Metathesaurus: The MetaMap program. In Proceedings of the AMIA Annual Symposium, Washington, DC, USA, 3–7 November 2001; pp. 17–21. [Google Scholar]
- Oronoz, M.; Casillas, A.; Gojenola, K.; Perez, A. Automatic annotation of medical records in spanish with disease, drug and substance names. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Tokyo, Japan, 29–31 October 2013; Volume 8259 LNCS. [Google Scholar]
- Shelmanov, A.O.; Smirnov, I.V.; Vishneva, E.A. Information extraction from clinical texts in Russian. Komp’juternaja Lingvist. i Intell. Tehnol. 2015, 1, 560–572. [Google Scholar]
- Bouziane, A.; Bouchiha, D.; Doumi, N. Annotating Arabic Texts with Linked Data. In Proceedings of the ISIA 2020—Proceedings, 4th International Symposium on Informatics and its Applications, M’sila, Algeria, 15–16 December 2020. [Google Scholar]
- Zhang, J.; Cao, Y.; Hou, L.; Li, J.; Zheng, H.T. Xlink: An unsupervised bilingual entity linking system. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Thessaloniki, Greece, 22–24 November 2017; Volume 10565 LNAI. [Google Scholar]
- Sysoev, A.A.; Andrianov, I.A. Named entity recognition in Russian: The power of Wiki-based approach. In Proceedings of the International Conference “Dialogue 2016”, Moscow, Russia, 1–4 June 2016. [Google Scholar]
- Raiman, J.; Raiman, O. DeepType: Multilingual entity linking by neural type system evolution. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Funkner, A.A.; Kovalchuk, S.V. Time Expressions Identification without Human-Labeled Corpus for Clinical Text Mining in Russian; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; ISBN 9783030504236. [Google Scholar]
- Yan, C.; Zhang, Y.; Liu, K.; Zhao, J.; Shi, Y.; Liu, S. Enhancing unsupervised medical entity linking with multi-instance learning. BMC Med. Inform. Decis. Mak. 2021, 21, 317. [Google Scholar] [CrossRef] [PubMed]
- Grover, A.; Leskovec, J. Node2vec: Scalable feature learning for networks. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Kim, M.; Baek, S.H.; Song, M. Relation extraction for biological pathway construction using node2vec. BMC Bioinform. 2018, 19, 75–84. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shen, F.; Liu, S.; Wang, Y.; Wang, L.; Wen, A.; Limper, A.H.; Liu, H. Constructing Node Embeddings for Human Phenotype Ontology to Assist Phenotypic Similarity Measurement. In Proceedings of the 2018 IEEE International Conference on Healthcare Informatics Workshops, ICHI-W 2018, New York, NY, USA, 4–7 June 2018. [Google Scholar]
- Bhardwaj, S. Syntree2Vec-An Algorithm to Augment Syntactic Hierarchy into Word Embeddings. arXiv 2018, arXiv:1808.05907. [Google Scholar]
- Zhang, M.; Su, J.; Wang, D.; Zhou, G.; Tan, C.L. Discovering relations between named entities from a large raw corpus using tree similarity-based clustering. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Tallinn, Estonia, 12–15 September 2005; Volume 3651 LNAI. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, ICLR 2013-Workshop Track Proceedings, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Heigold, G.; Neumann, G.; Van Genabith, J. An Extensive Empirical Evaluation of Character-Based Morphological Tagging for 14 Languages. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2017-Proceedings of Conference, Valencia, Spain, 3–7 April 2017; Volume 1. [Google Scholar]
- Dozat, T.; Manning, C.D. Deep biaffine attention for neural dependency parsing. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017-Conference Track Proceedings, Toulon, France, 24–26 April 2017. [Google Scholar]
- Burtsev, M.; Seliverstov, A.; Airapetyan, R.; Arkhipov, M.; Baymurzina, D.; Bushkov, N.; Gureenkova, O.; Khakhulin, T.; Kuratov, Y.; Kuznetsov, D.; et al. DeepPavlov: Open-Source library for dialogue systems. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics-System Demonstrations, Melbourne, Australia, 15–20 July 2018; pp. 122–127. [Google Scholar] [CrossRef]
- Kara, E.; Zeen, T.; Gabryszak, A.; Budde, K.; Schmidto, D.; Roller, R. A domain-adapted dependency parser for German clinical text. In Proceedings of the KONVENS 2018—Conference on Natural Language Processing/Die Konferenz zur Verarbeitung Naturlicher Sprache, Vienna, Austria, 19–21 September 2018. [Google Scholar]
- Fan, J.w.; Yang, E.W.; Jiang, M.; Prasad, R.; Loomis, R.M.; Zisook, D.S.; Denny, J.C.; Xu, H.; Huang, Y. Syntactic parsing of clinical text: Guideline and corpus development with handling ill-formed sentences. J. Am. Med. Inform. Assoc. 2013, 20, 1168–1177. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Christou, M.; Crochemore, M.; Flouri, T.; Iliopoulos, C.S.; Janoušek, J.; Melichar, B.; Pissis, S.P. Computing all subtree repeats in ordered ranked trees. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Virtual Event, 3–5 December 2011; Volume 7024. [Google Scholar]
- Christou, M.; Crochemore, M.; Flouri, T.; Iliopoulos, C.S.; Janoušek, J.; Melichar, B.; Pissis, S.P. Computing all subtree repeats in ordered trees. Inf. Process. Lett. 2012, 112, 958–962. [Google Scholar] [CrossRef]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia—A crystallization point for the Web of Data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- Thorne, C.; Faralli, S.; Stuckenschmidt, H. Cross-evaluation of entity linking and disambiguation systems for clinical text annotation. In Proceedings of the ACM International Conference Proceeding Series, Indianapolis, IN, USA, 24–28 October 2016. [Google Scholar]
- Turki, H.; Shafee, T.; Hadj Taieb, M.A.; Ben Aouicha, M.; Vrandečić, D.; Das, D.; Hamdi, H. Wikidata: A large-scale collaborative ontological medical database. J. Biomed. Inform. 2019, 99, 103292. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Parravicini, A.; Patra, R.; Bartolini, D.B.; Santambrogio, M.D. Fast and accurate entity linking via graph embedding. In Proceedings of the ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, Amsterdam, The Netherlands, 30 June–5 July 2019. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online learning of social representations. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining; New York, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Rehurek, R.; Sojka, P. Gensim—Python Framework for Vector Space Modelling; NLP Centre, NLP Centre, Faculty of Informatics, Masaryk University: Brno, Czech Republic, 2011; p. 3. [Google Scholar]
- CSIRO’s Data61. StellarGraph Machine Learning Library. GitHub Repository. Available online: https://github.com/stellargraph/stellargraph (accessed on 30 December 2021).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Russian Word | English Word | Russian Synonyms Node2Vec | English Synonyms Node2Vec | Russian Synonyms Word2Vec | English Synonyms Word2Vec |
|---|---|---|---|---|---|
| бeдpeнный | лaтepaльный | lateral | диcтaльный | distal | |
| femoral | мaлoбepцoвый | peroneal | виcoчный | temporal | |
| cycтaвный | articular | пaxoвый | inguinal | ||
| пpeднизoлoн | prednisone | вepoшпиpoн | verospiron | в/в | intravenously |
| нoвoкaинaмид | novokainamide | мг/cyт | mg/day | ||
| φypoceмид | furosemide | φypoceмид | furosemide | ||
| нии | nii (national research institute) | кб oкб | ch (clinical hospital) lch (local clinical hospital) | кб | ch |
| oкб | lch | ||||
| пpиëмный | emergency | ||||
| xлcнpc | surgical treatment of complex cardiac arrhythmias | ||||
| φeльдшep | paramedic | вpaч | physician | вpaч | physician |
| мeдcaнчacть | medical unit | ||||
| нaгнoeниe | suppuration | ceпcиc | sepsis | aбcцecc | abscess |
| вocпaлeниe | inflammation | oпyxoль | tumor | ||
| гнoй | pus | инφeкция | infection | ||
| pyбцeвaниe | scarring | гeмaтoмa | hematoma | ||
| инφeкция | infection | кpoвoтeчeниe | bleeding |
| Russian Word | English Word | Russian Synonyms Node2Vec | English Synonyms Node2Vec |
|---|---|---|---|
| цpб | cch (central clinical hospital) | cтaциoнap | hospital |
| диcпaнcep | dispensary | ||
| мpт | mri | гacтpocкoпия | gastroscopy |
| oэкт | spect | ||
| экг | ecg | ||
| peнтгeнoгpaφия | radiography | ||
| гкмп | hcm (hypertrophic cardiomyopathy) | пpoлaпc | prolapse |
| пoликиcтoз | polycystic | ||
| кapдиoмиoпaтия | cardiomyopathy | ||
| иcкycтвeнный | atificial | иcкyccтвeнный | artificial |
| oтcyтcвиe | absense | oтcyтcтвиe | absence |
| тoшнoтa | nausea | гoлoвoкpyжeниe | dizziness |
| жжeниe | burning | ||
| pвoтa | vomit |
| Group Russian | Group English | Label Russian | Label English |
|---|---|---|---|
| выявили в 2009 гoдy | identified in 2009 | вpeмeннaя мeткa, coбытиe | timestamp, event |
| зapeгиcтpиpoвaн в 1995 г | registered in 1995 | ||
| oбнapyжeнa в 2004 гoдy | discovered in 2004 | ||
| зaφикcиpoвaны в 2009 г | recorded in 2009 | ||
| yxyдшeниe cocтoяния | deterioration | xapaктepиcтикa зaбoлeвaния | disease characteristic |
| пepeлoмы кocтeй | bone fractures | тип клacca aнaтoмичecкoй cтpyктypы, пoвpeждeниe opгaнизмa, бoлeзнь | anatomical structure class type, body injury, disease |
| пpиcтyпы тaxикapдии пapoкcизм тaxикapдии | bouts of tachycardia paroxysm of tachycardia | мeдицинcкoe зaключeниe, бoлeзнь, oбocтpeниe | medical report, disease, exacerbation |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koshman, V.; Funkner, A.; Kovalchuk, S. An Unsupervised Approach to Structuring and Analyzing Repetitive Semantic Structures in Free Text of Electronic Medical Records. J. Pers. Med. 2022, 12, 25. https://doi.org/10.3390/jpm12010025
Koshman V, Funkner A, Kovalchuk S. An Unsupervised Approach to Structuring and Analyzing Repetitive Semantic Structures in Free Text of Electronic Medical Records. Journal of Personalized Medicine. 2022; 12(1):25. https://doi.org/10.3390/jpm12010025
Chicago/Turabian StyleKoshman, Varvara, Anastasia Funkner, and Sergey Kovalchuk. 2022. "An Unsupervised Approach to Structuring and Analyzing Repetitive Semantic Structures in Free Text of Electronic Medical Records" Journal of Personalized Medicine 12, no. 1: 25. https://doi.org/10.3390/jpm12010025