
Using a Deep Learning Model to Address Interobserver Variability in the Evaluation of Ulcerative Colitis (UC) Severity
 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Patients and Images
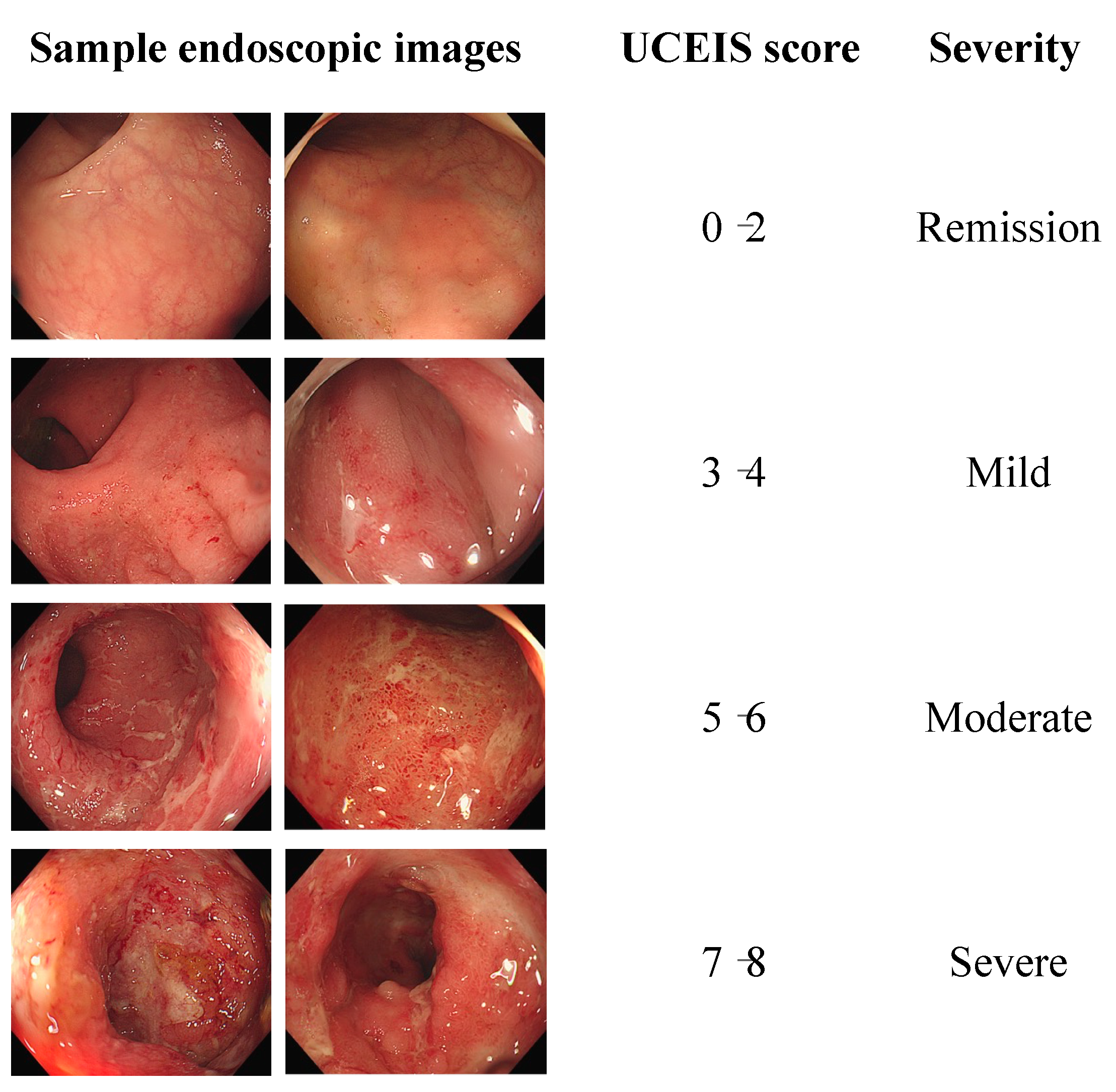
2.2. Scoring System
2.3. Deep Learning Network
2.4. Data Preprocessing
2.5. Interobserver Variation
3. Results
3.1. UCEIS Score Estimation
3.2. Statistical Analysis of Interobserver Variance
3.3. Outcome of the Deep Learning Network Model
3.4. Differences in Accuracy for Each Model
4. Discussion

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study (Year) | Data Set | Outcome | UC Severity Estimation |
|---|---|---|---|
| Ozawa et al. (2019) [6] | 26,304 images/444 patients | MES (Mayo 0, Mayo 1, and Mayo 2–3) | Accuracy: 0.704 |
| Stidham et al. (2019) [29] | 14,862 images/2778 patiens | MES | Kappa: 0.840 Accuracy: 0.778 |
| Maeda et al. (2019) [30] | 12,900 images/87 patients | Histologic inflammation estimation (active vs. healing) MES 0 vs. MES 1 | Accuracy: 0.910 Sensitivity: 0.650 Specificity: 0.980 |
| Bhambhvani et al. (2020) [31] | 90% of 777 images/777 patients | MES estimation (Mayo 1, Mayo 2, and Mayo 3) | Accuracy: 0.772 Sensitivity: 0.724 Specificity: 0.857 |
| Gottlieb et al. (2021) [10] | 80% of 795 videos/249 patients | MES UCEIS | QWK: 0.844 Accuracy: 0.702 Sensitivity: 0.716 Specificity: 0.901 |
| Yao et al. (2021) [9] | 16,000 images/3000 patiens | MES | QWK (A): 0.840 Accuracy (A): 0.780 QWK (B): 0.590 F1 (B): 0.571 |
| Schwab et al. (2022) [32] | 80% 1881 videos/726 patiets | MES | QWK: 0.680 (video level) QWK: 0.660 (frame level) |
| Luo et al. (2022) [33] | (A): 80% of 9928 images, (B): 80% of 4378 images /1317 patients | MES | Accuracy (A): 0.906 F1 (A): 0.868 Accuracy (B): 0.916 F1 (B): 0.858 |
| Polat et al. (2023) [34] | 9590 images/462 patients | MES | QWK: 0.854 F1: 0.697 Accuracy: 0.772 Sensitivity: 0.693 Specificity: 0.911 |
| Kim et al. (Our study) | (A): 254 images/115 patients (B): 262 images | UCEIS | Accuracy: 0.792 F1: 0.760 |
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Magro, F.; Gionchetti, P.; Eliakim, R.; Ardizzone, S.; Armuzzi, A.; Barreiro-de Acosta, M.; Burisch, J.; Gecse, K.B.; Hart, A.L.; Hindryckx, P.; et al. Third European Evidence-Based Consensus on Diagnosis and Management of Ulcerative Colitis. Part 1: Definitions, Diagnosis, Extra-Intestinal Manifestations, Pregnancy, Cancer Surveillance, Surgery, and Ileo-Anal Pouch Disorders. J. Crohns Colitis 2017, 11, 649–670. [Google Scholar] [CrossRef]
- Nakase, H.; Uchino, M.; Shinzaki, S.; Matsuura, M.; Matsuoka, K.; Kobayashi, T.; Saruta, M.; Hirai, F.; Hata, K.; Hiraoka, S.; et al. Evidence-Based Clinical Practice Guidelines for Inflammatory Bowel Disease 2020. J. Gastroenterol. 2021, 56, 489–526. [Google Scholar] [CrossRef]
- Ikeya, K.; Hanai, H.; Sugimoto, K.; Osawa, S.; Kawasaki, S.; Iida, T.; Maruyama, Y.; Watanabe, F. The Ulcerative Colitis Endoscopic Index of Severity More Accurately Reflects Clinical Outcomes and Long-Term Prognosis than the Mayo Endoscopic Score. J. Crohns Colitis 2016, 10, 286–295. [Google Scholar] [CrossRef]
- Travis, S.P.L.; Schnell, D.; Krzeski, P.; Abreu, M.T.; Altman, D.G.; Colombel, J.-F.; Feagan, B.G.; Hanauer, S.B.; Lémann, M.; Lichtenstein, G.R.; et al. Developing an Instrument to Assess the Endoscopic Severity of Ulcerative Colitis: The Ulcerative Colitis Endoscopic Index of Severity (UCEIS). Gut 2012, 61, 535–542. [Google Scholar] [CrossRef] [PubMed]
- Sasaki, Y.; Hada, R.; Munakata, A. Computer-Aided Grading System for Endoscopic Severity in Patients with Ulcerative Colitis. Dig. Endosc. 2003, 15, 206–209. [Google Scholar] [CrossRef]
- Ozawa, T.; Ishihara, S.; Fujishiro, M.; Saito, H.; Kumagai, Y.; Shichijo, S.; Aoyama, K.; Tada, T. Novel Computer-Assisted Diagnosis System for Endoscopic Disease Activity in Patients with Ulcerative Colitis. Gastrointest. Endosc. 2019, 89, 416–421.e1. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.T.; Zaïane, O.R.; Goebel, R.; Baumgart, D.C. Artificial Intelligence Enabled Automated Diagnosis and Grading of Ulcerative Colitis Endoscopy Images. Sci. Rep. 2022, 12, 2748. [Google Scholar] [CrossRef]
- Takenaka, K.; Ohtsuka, K.; Fujii, T.; Negi, M.; Suzuki, K.; Shimizu, H.; Oshima, S.; Akiyama, S.; Motobayashi, M.; Nagahori, M.; et al. Development and Validation of a Deep Neural Network for Accurate Evaluation of Endoscopic Images From Patients With Ulcerative Colitis. Gastroenterology 2020, 158, 2150–2157. [Google Scholar] [CrossRef] [PubMed]
- Yao, H.; Najarian, K.; Gryak, J.; Bishu, S.; Rice, M.D.; Waljee, A.K.; Wilkins, H.J.; Stidham, R.W. Fully Automated Endoscopic Disease Activity Assessment in Ulcerative Colitis. Gastrointest. Endosc. 2021, 93, 728–736.e1. [Google Scholar] [CrossRef]
- Gottlieb, K.; Requa, J.; Karnes, W.; Chandra Gudivada, R.; Shen, J.; Rael, E.; Arora, V.; Dao, T.; Ninh, A.; McGill, J. Central Reading of Ulcerative Colitis Clinical Trial Videos Using Neural Networks. Gastroenterology 2021, 160, 710–719.e2. [Google Scholar] [CrossRef]
- Bossuyt, P.; Nakase, H.; Vermeire, S.; de Hertogh, G.; Eelbode, T.; Ferrante, M.; Hasegawa, T.; Willekens, H.; Ikemoto, Y.; Makino, T.; et al. Automatic, Computer-Aided Determination of Endoscopic and Histological Inflammation in Patients with Mild to Moderate Ulcerative Colitis Based on Red Density. Gut 2020, 69, 1778–1786. [Google Scholar] [CrossRef]
- Odze, R.D.; Goldblum, J.; Noffsinger, A.; Alsaigh, N.; Rybicki, L.A.; Fogt, F. Interobserver Variability in the Diagnosis of Ulcerative Colitis-Associated Dysplasia by Telepathology. Mod. Pathol. 2002, 15, 379–386. [Google Scholar] [CrossRef]
- de Lange, T.; Larsen, S.; Aabakken, L. Inter-Observer Agreement in the Assessment of Endoscopic Findings in Ulcerative Colitis. BMC Gastroenterol. 2004, 4, 9. [Google Scholar] [CrossRef]
- Thia, K.T.; Loftus, E.V., Jr.; Pardi, D.S.; Kane, S.V.; Faubion, W.A.; Tremaine, W.J.; Schroeder, K.W.; Harmsen, S.W.; Zinsmeister, A.R.; Sandborn, W.J. Measurement of Disease Activity in Ulcerative Colitis:Interobserver Agreement and Predictors of Severity. Inflamm. Bowel Dis. 2011, 17, 1257–1264. [Google Scholar] [CrossRef] [PubMed]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning. In Proceedings of the 12th USENIX conference on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [PubMed]
- Borgli, H.; Thambawita, V.; Smedsrud, P.H.; Hicks, S.; Jha, D.; Eskeland, S.L.; Randel, K.R.; Pogorelov, K.; Lux, M.; Nguyen, D.T.D.; et al. HyperKvasir, a Comprehensive Multi-Class Image and Video Dataset for Gastrointestinal Endoscopy. Sci. Data 2020, 7, 283. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.; Xu, X.; Mu, N. Saliency Detection Based on the Combination of High-Level Knowledge and Low-Level Cues in Foggy Images. Entropy 2019, 21, 374. [Google Scholar] [CrossRef] [PubMed]
- Lee, K.; Jeong, J. Multi-Color Space Network for Salient Object Detection. Sensors 2022, 22, 3588. [Google Scholar] [CrossRef]
- Telea, A. An Image Inpainting Technique Based on the Fast Marching Method. J. Graph. Tools 2004, 9, 23–34. [Google Scholar] [CrossRef]
- Han, X. On Statistical Measures for Data Quality Evaluation. J. Geogr. Inf. Syst. 2020, 12, 178–187. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T.M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep Learning Applications and Challenges in Big Data Analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Ding, J.; Li, X.; Kang, X.; Gudivada, V.N. A Case Study of the Augmentation and Evaluation of Training Data for Deep Learning. J. Data Inf. Qual. 2019, 11, 1–22. [Google Scholar] [CrossRef]
- Luca, A.R.; Ursuleanu, T.F.; Gheorghe, L.; Grigorovici, R.; Iancu, S.; Hlusneac, M.; Grigorovici, A. Impact of Quality, Type and Volume of Data Used by Deep Learning Models in the Analysis of Medical Images. Inform. Med. Unlocked 2022, 29, 100911. [Google Scholar] [CrossRef]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Hestness, J.; Narang, S.; Ardalani, N.; Diamos, G.; Jun, H.; Kianinejad, H.; Patwary, M.M.A.; Yang, Y.; Zhou, Y. Deep Learning Scaling Is Predictable, Empirically. arXiv 2017, arXiv:1712.00409. [Google Scholar]
- DeRoche, T.C.; Xiao, S.-Y.; Liu, X. Histological Evaluation in Ulcerative Colitis. Gastroenterol. Rep. 2014, 2, 178–192. [Google Scholar] [CrossRef]
- Geboes, K. A Reproducible Grading Scale for Histological Assessment of Inflammation in Ulcerative Colitis. Gut 2000, 47, 404–409. [Google Scholar] [CrossRef]
- Stidham, R.W.; Liu, W.; Bishu, S.; Rice, M.D.; Higgins, P.D.R.; Zhu, J.; Nallamothu, B.K.; Waljee, A.K. Performance of a Deep Learning Model vs Human Reviewers in Grading Endoscopic Disease Severity of Patients With Ulcerative Colitis. JAMA Netw. Open. 2019, 2, e193963. [Google Scholar] [CrossRef]
- Maeda, Y.; Kudo, S.-E.; Mori, Y.; Misawa, M.; Ogata, N.; Sasanuma, S.; Wakamura, K.; Oda, M.; Mori, K.; Ohtsuka, K. Fully Automated Diagnostic System with Artificial Intelligence Using Endocytoscopy to Identify the Presence of Histologic Inflammation Associated with Ulcerative Colitis (with Video). Gastrointest. Endosc. 2019, 89, 408–415. [Google Scholar] [CrossRef]
- Bhambhvani, H.P.; Zamora, A. Deep Learning Enabled Classification of Mayo Endoscopic Subscore in Patients with Ulcerative Colitis. Eur. J. Gastroenterol. Hepatol. 2021, 33, 645–649. [Google Scholar] [CrossRef]
- Schwab, E.; Cula, G.O.; Standish, K.; Yip, S.S.F.; Stojmirovic, A.; Ghanem, L.; Chehoud, C. Automatic Estimation of Ulcerative Colitis Severity from Endoscopy Videos Using Ordinal Multi-Instance Learning. Comput. Methods Biomech. Biomed. Eng. Imaging Vis. 2021, 10, 425–433. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, J.; Li, Z.; Yang, R. Diagnosis of Ulcerative Colitis from Endoscopic Images Based on Deep Learning. Biomed. Signal Process. Control. 2022, 73, 103443. [Google Scholar] [CrossRef]
- Polat, G.; Kani, H.T.; Ergenc, I.; Ozen Alahdab, Y.; Temizel, A.; Atug, O. Improving the Computer-Aided Estimation of Ulcerative Colitis Severity According to Mayo Endoscopic Score by Using Regression-Based Deep Learning. Inflamm. Bowel Dis. 2023, 29, 1431–1439. [Google Scholar] [CrossRef] [PubMed]







| Index | Data | |
|---|---|---|
| Sex, n | Male | 57 |
| Female | 58 | |
| Age, years | Mean (range) | 46 (19–78) |
| Median | 44 | |
| Images | Sampling date | 06/2019–02/2021 |
| Number of images (remission/mild, moderate, severe) | 254 (204, 42, 8) | |
| Severity | |||
|---|---|---|---|
| Remission/Mild | Moderate | Severe | |
| Training set | 218 | 154 | 48 |
| Testing set | 51 | 38 | 12 |
| Total | 269 | 192 | 60 |
| ICC | Level of Agreement |
|---|---|
| 0.9–1.0 | Excellent |
| 0.75–0.9 | Good |
| 0.5–0.75 | Moderate |
| <0.5 | Poor |
| Kappa | Level of Agreement |
|---|---|
| 1.00 | Perfect |
| 0.81–0.99 | Near perfect |
| 0.61–0.80 | Substantial |
| 0.41–0.60 | Moderate |
| 0.21–0.40 | Fair |
| 0.10–0.20 | Slight |
| 0 | Equivalent to chance |
| Model | Accuracy | F1 Score | Recall | Precision |
|---|---|---|---|---|
| EfficientNetB0 | 0.7920 | 0.8125 | 0.7647 | 0.8666 |
| MobileNetV3Large | 0.7473 | 0.7415 | 0.7473 | 0.7686 |
| ResNet50 | 0.7473 | 0.7302 | 0.7473 | 0.7704 |
| VGG16 | 0.7363 | 0.7328 | 0.7363 | 0.7422 |
| EfficientNetB7 | 0.7033 | 0.6981 | 0.7033 | 0.7308 |
| DenseNet121 | 0.6923 | 0.6671 | 0.6923 | 0.7621 |
| InceptionV3 | 0.6813 | 0.6788 | 0.6813 | 0.6846 |
| VGG19 | 0.6813 | 0.6517 | 0.6813 | 0.6502 |
| DenseNet201 | 0.6374 | 0.5898 | 0.6374 | 0.5736 |
| Xception | 0.6044 | 0.5765 | 0.6044 | 0.7029 |
| MobileNetV2 | 0.5934 | 0.5864 | 0.5934 | 0.5808 |
| ResNet152V2 | 0 5495 | 0.5041 | 0.5495 | 0.5335 |
| ResNet50V2 | 0.5385 | 0.5415 | 0.5385 | 0.6988 |
| Consensus Model | Expert Models | |||||
|---|---|---|---|---|---|---|
| A | B | C | D | E | ||
| Pass | 46 | 40 | 39 | 44 | 28 | 32 |
| Fail | 4 | 10 | 11 | 16 | 22 | 18 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-H.; Choe, A.R.; Park, Y.; Song, E.-M.; Byun, J.-R.; Cho, M.-S.; Yoo, Y.; Lee, R.; Kim, J.-S.; Ahn, S.-H.; et al. Using a Deep Learning Model to Address Interobserver Variability in the Evaluation of Ulcerative Colitis (UC) Severity. J. Pers. Med. 2023, 13, 1584. https://doi.org/10.3390/jpm13111584
Kim J-H, Choe AR, Park Y, Song E-M, Byun J-R, Cho M-S, Yoo Y, Lee R, Kim J-S, Ahn S-H, et al. Using a Deep Learning Model to Address Interobserver Variability in the Evaluation of Ulcerative Colitis (UC) Severity. Journal of Personalized Medicine. 2023; 13(11):1584. https://doi.org/10.3390/jpm13111584
Chicago/Turabian StyleKim, Jeong-Heon, A Reum Choe, Yehyun Park, Eun-Mi Song, Ju-Ran Byun, Min-Sun Cho, Youngeun Yoo, Rena Lee, Jin-Sung Kim, So-Hyun Ahn, and et al. 2023. "Using a Deep Learning Model to Address Interobserver Variability in the Evaluation of Ulcerative Colitis (UC) Severity" Journal of Personalized Medicine 13, no. 11: 1584. https://doi.org/10.3390/jpm13111584