
Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models

 ,
,
Abstract
:1. Introduction
Research Hypothesis
2. Materials and Methods
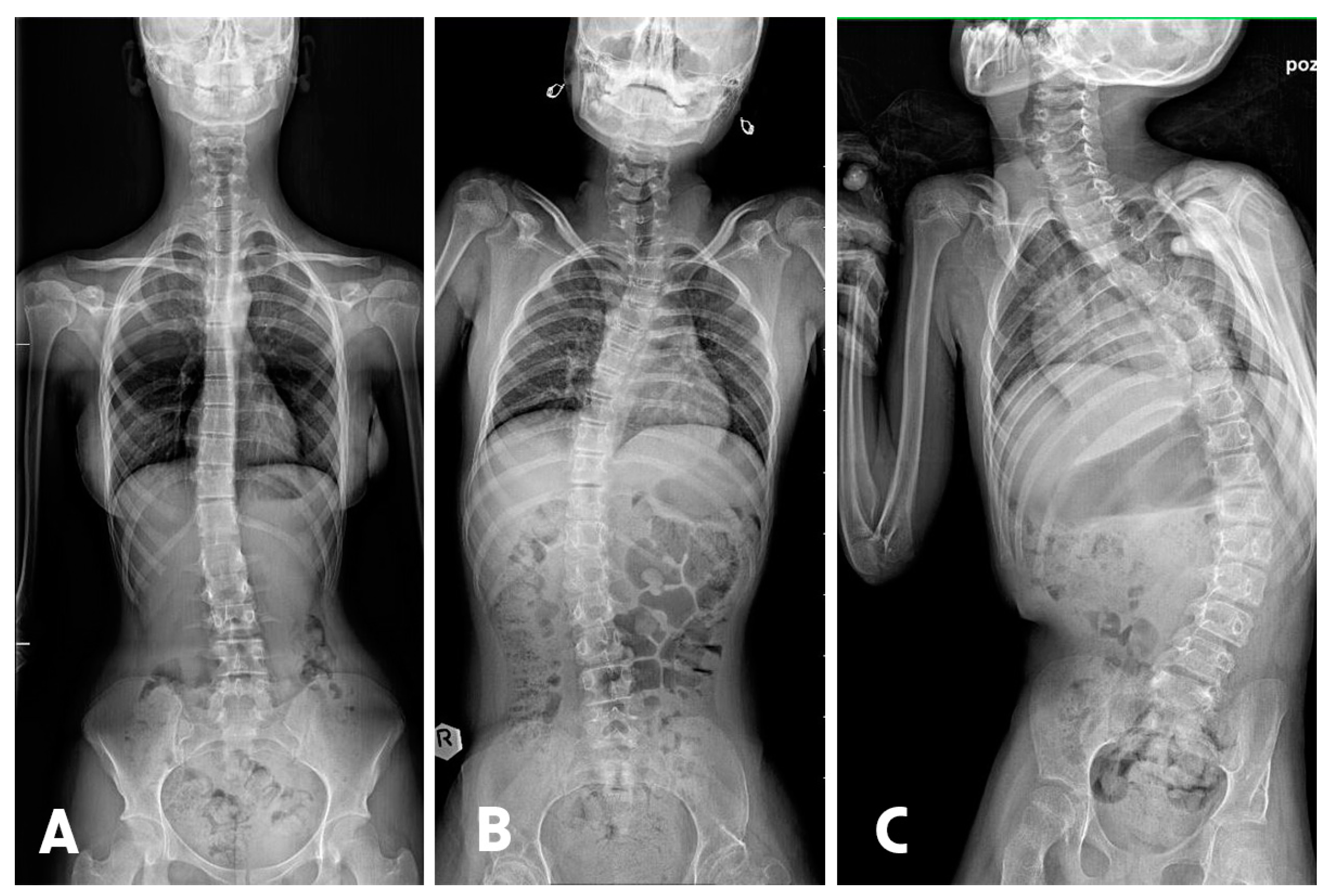
2.1. Manual Measurement
2.2. AI Systems Evaluation Methodology
2.3. Data Analysis
2.4. Statistical Environment
3. Results
3.1. Characteristics of the Sample
Comparison of Actual and AI-Predicted Scoliosis Classifications: An Analysis of Performance Evaluation Metrics
3.2. Fleiss Kappa
3.3. Sensitivity
3.4. Specificity
3.5. Positive Predictive Value
3.6. Negative Predictive Value
3.7. Accuracy with CI 95%
3.8. Balanced Accuracy
Comparison of Actual and AI-Predicted Scoliosis Classifications: An Analysis of MAE
4. Discussion
4.1. Analysis of ChatGPT 4 and Scholar AI Premium Models
4.2. Analysis of Scholar AI Free and Microsoft Bing Models
4.3. Incorrect Classification of Scoliosis by AI Models
4.4. Lack of References to Scientific Data in AI Models
- Accessibility of Knowledge: AI models might be programmed to utilize publicly available and widely recognized information, often accepted as standard or clinical practice. If the classification is based on broadly accepted practices, the model may not need to refer to specific studies if this information is encoded in its knowledge base as generally accepted. However, a study on AI hallucination in scientific writing through ChatGPT references found that a significant number of references listed by ChatGPT did not have a Digital Object Identifier (DOI) or were not found in Google searches, suggesting limitations in ChatGPT’s ability to generate reliable references [40].
- Data Processing: AI models might use advanced natural language processing techniques, enabling them to understand and apply knowledge from various sources. Although they have access to vast databases, their ability to cite specific sources in real-time may be limited by their programming or algorithms, prioritizing easily accessible information and response speed over the depth and detail of scientific references. This is exemplified in the phenomenon of hallucination in large language models, where they occasionally produce outputs that deviate from user input or factual knowledge [41].
- Interface and Usage Limitations: Some platforms using AI may restrict the length or complexity of responses, consequently limiting the model’s ability to present detailed arguments based on specific scientific research. This limitation can contribute to the issue of hallucination, where AI models generate content that diverges from the real facts, resulting in unfaithful outputs [42].
- Interpretation and Flexibility: Medical knowledge is often interpreted and modeled by AI algorithms in a flexible manner to fit many different contexts. This could result in a preference for more general statements instead of specific references to studies, especially when there are multiple studies with varying outcomes or interpretations. The challenge is further compounded by the nuanced categorization of hallucination in AI models, which can manifest in various forms and degrees of severity, affecting the reliability and specificity of the information provided [42].
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Quazi, S. Artificial intelligence and machine learning in precision and genomic medicine. Med. Oncol. 2022, 39, 120. [Google Scholar] [CrossRef]
- Takada, K. Artificial intelligence expert systems with neural network machine learning may assist decision-making for extractions in orthodontic treatment planning. J. Evid. Based Dent. Pract. 2016, 16, 190–192. [Google Scholar] [CrossRef]
- Ahmed, Z.; Mohamed, K.; Zeeshan, S.; Dong, X. Artificial intelligence with multi-functional machine learning platform development for better healthcare and precision medicine. Database 2020, 2020, baaa010. [Google Scholar] [CrossRef]
- Meier, J.M.; Tschoellitsch, T. Artificial Intelligence and Machine Learning in Patient Blood Management: A Scoping Review. Anesth. Analg. 2022, 135, 524–531. [Google Scholar] [CrossRef]
- Daeschler, S.C.; Bourget, M.-H.; Derakhshan, D.; Sharma, V.; Asenov, S.I.; Gordon, T.; Cohen-Adad, J.; Borschel, G.H. Rapid, automated nerve histomorphometry through open-source artificial intelligence. Sci. Rep. 2022, 12, 5975. [Google Scholar] [CrossRef]
- Hentschel, S.; Kobs, K.; Hotho, A. CLIP knows image aesthetics. Front. Artif. Intell. 2022, 5, 976235. [Google Scholar] [CrossRef]
- Gómez Cano, C.A.; Sánchez Castillo, V.; Clavijo Gallego, T.A. Unveiling the Thematic Landscape of Generative Pre-trained Transformer (GPT) Through Bibliometric Analysis. Metaverse Basic Appl. Res. 2023, 2, 33. [Google Scholar] [CrossRef]
- Milani Fitria, K. Information Retrieval Performance in Text Generation using Knowledge from Generative Pre-trained Transformer (GPT-3). Jambura J. Math. 2023, 5, 327–338. [Google Scholar] [CrossRef]
- Atallah, S.B.; Banda, N.R.; Banda, A.; Roeck, N.A. How large language models including generative pre-trained transformer (GPT) 3 and 4 will impact medicine and surgery. Tech. Coloproctol. 2023, 27, 609–614. [Google Scholar] [CrossRef]
- Swan, M.; Kido, T.; Roland, E.; dos Santos, R.P. Math Agents: Computational Infrastructure, Mathematical Embedding, and Genomics. arXiv 2023, arXiv:2307.02502. [Google Scholar] [CrossRef]
- Kadam, A.D.; Joshi, S.D.; Shinde, S.V.; Medhane, S.P. Notice of Removal: Question Answering Search engine short review and road-map to future QA Search Engine. In Proceedings of the 2015 International Conference on Electrical, Electronics, Signals, Communication and Optimization (EESCO), Visakhapatnam, India, 24–25 January 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Scholar AI. Available online: https://scholar-ai.net/ (accessed on 29 October 2023).
- Microsoft Bing. Available online: https://www.bing.com/search?showconv=1&q=bing%20AI&sf=codex3p&form=MA13FV (accessed on 29 October 2023).
- Mofatteh, M. Neurosurgery and artificial intelligence. AIMS Neurosci. 2021, 8, 477–495. [Google Scholar] [CrossRef]
- Maharathi, S.; Iyengar, R.; Chandrasekhar, P. Biomechanically designed Curve Specific Corrective Exercise for Adolescent Idiopathic Scoliosis gives significant outcomes in an Adult: A case report. Front. Rehabil. Sci. 2023, 4, 1127222. [Google Scholar] [CrossRef]
- Horng, M.H.; Kuok, C.P.; Fu, M.J.; Lin, C.J.; Sun, Y.N. Cobb Angle Measurement of Spine from X-ray Images Using Convolutional Neural Network. Comput. Math. Methods Med. 2019, 2019, 6357171. [Google Scholar] [CrossRef]
- Hey, H.W.; Ramos, M.R.; Lau, E.T.; Tan, J.H.; Tay, H.W.; Liu, G.; Wong, H.K. Risk Factors Predicting C- Versus S-shaped Sagittal Spine Profiles in Natural, Relaxed Sitting: An Important Aspect in Spinal Realignment Surgery. Spine 2020, 45, 1704–1712. [Google Scholar] [CrossRef]
- Meng, N.; Cheung, J.P.; Wong, K.K.; Dokos, S.; Li, S.; Choy, R.W.; To, S.; Li, R.J.; Zhang, T. An artificial intelligence powered platform for auto-analyses of spine alignment irrespective of image quality with prospective validation. EClinicalMedicine 2022, 43, 101252. [Google Scholar] [CrossRef]
- Islam, M.R.; Urmi, T.J.; Mosharrafa, R.A.; Rahman, M.S.; Kadir, M.F. Role of ChatGPT in health science and research: A correspondence addressing potential application. Health Sci. Rep. 2023, 6, e1625. [Google Scholar] [CrossRef]
- Eigenmann, P.; Akenroye, A.; Markovic, M.A.; Candotti, F.; Ebisawa, M.; Genuneit, J.; Kalayci, Ö.; Kollmann, D.; Leung, A.S.Y.; Peters, R.L.; et al. Pediatric Allergy and Immunology (PAI) is for polishing with artificial intelligence, but careful use. Pediatr. Allergy Immunol. 2023, 34, e14023. [Google Scholar] [CrossRef]
- Fabijan, A.; Fabijan, R.; Zawadzka-Fabijan, A.; Nowosławska, E.; Zakrzewski, K.; Polis, B. Evaluating Scoliosis Severity Based on Posturographic X-ray Images Using a Contrastive Language–Image Pretraining Model. Diagnostics 2023, 13, 2142. [Google Scholar] [CrossRef]
- Altman, D.G.; Bland, J.M. Diagnostic tests. 1: Sensitivity and specificity. BMJ 1994, 308, 1552. [Google Scholar] [CrossRef]
- Altman, D.G.; Bland, J.M. Diagnostic tests 2: Predictive values. BMJ 1994, 309, 102. [Google Scholar] [CrossRef]
- Velez, D.R.; White, B.C.; Motsinger, A.A.; Bush, W.S.; Ritchie, M.D.; Williams, S.M.; Moore, J.H. A balanced accuracy function for epistasis modeling in imbalanced datasets using multifactor dimensionality reduction. Genet. Epidemiol. 2007, 31, 306–315. [Google Scholar] [CrossRef]
- Fleiss, J.L. Measuring nominal scale agreement among many raters. Psychol. Bull. 1971, 76, 378–382. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2023; Available online: https://www.R-project.org/ (accessed on 10 November 2023).
- Berkelaar, M.; and others. lpSolve: Interface to ‘Lpsolve’ v. 5.5 to Solve Linear/Integer Programs, R package version 5.6.19, lpSolve; 2023. CRAN.R-project.org. Comprehensive R Archive Network, University of Vienna, Austria. Available online: https://CRAN.R-project.org/package=lpSolve (accessed on 10 November 2023).
- Gamer, M.; Lemon, J.; Singh, P. irr: Various Coefficients of Interrater Reliability and Agreement, R package version 0.84.1, irr. 2019. Available online: https://CRAN.R-project.org/package=irr (accessed on 10 November 2023).
- Kuhn, M. Building Predictive Models in R Using the caret Package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Makowski, D.; Lüdecke, D.; Patil, I.; Thériault, R.; Ben-Shachar, M.; Wiernik, B. Automated Results Reporting as a Practical Tool to Improve Reproducibility and Methodological Best Practices Adoption. CRAN 2023. Available online: https://easystats.github.io/report/ (accessed on 10 November 2023).
- Wickham, H. ggplot2: Elegant Graphics for Data Analysis; Springer-Verlag: New York, NY, USA, 2016; ISBN 978-3-319-24277-4. Available online: https://ggplot2.tidyverse.org (accessed on 10 November 2023).
- Revelle, W. psych: Procedures for Psychological, Psychometric, and Personality Research, R package version 2.3.9, psych; Northwestern University: Evanston, IL, USA, 2023; Available online: https://CRAN.R-project.org/package=psych (accessed on 10 November 2023).
- Ray, P.P. ChatGPT: A comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. IoT CPS 2023, 3, 121–154. [Google Scholar] [CrossRef]
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Dave, T.; Athaluri, S.A.; Singh, S. ChatGPT in medicine: An overview of its applications, advantages, limitations, future prospects, and ethical considerations. Front. Artif. Intell. 2023, 6, 1169595. [Google Scholar] [CrossRef]
- Egli, A. ChatGPT, GPT-4, and Other Large Language Models: The Next Revolution for Clinical Microbiology? Clin. Infect. Dis. 2023, 77, 1322–1328. [Google Scholar] [CrossRef]
- How Does ChatGPT Work? Available online: https://moosend.com/blog/how-does-chatgpt-work/ (accessed on 1 December 2023).
- von Schacky, C.E. Artificial Intelligence (AI) for Radiological Diagnostics of Bone Tumors: Potential Approaches, Possibilities, and Limitations. Osteologie 2021, 30, 261–263. [Google Scholar] [CrossRef]
- Ye, Z. Editorial for “A Deep Learning Approach to Diagnostic Classification of Prostate Cancer Using Pathology-Radiology Fusion”. J. Magn. Reson. Imaging 2021, 54, 472–473. [Google Scholar] [CrossRef]
- Athaluri, S.A.; Manthena, S.V.; Kesapragada, V.S.R.K.M.; Yarlagadda, V.; Dave, T.; Duddumpudi, R.T.S. Exploring the Boundaries of Reality: Investigating the Phenomenon of Artificial Intelligence Hallucination in Scientific Writing Through ChatGPT References. Cureus 2023, 15, e37432. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv 2023, arXiv:2309.01219. [Google Scholar] [CrossRef]
- Rawte, V.; Chakraborty, S.; Pathak, A.; Sarkar, A.; Tonmoy, S.M.; Chadha, A.; Sheth, A.P.; Das, A. The Troubling Emergence of Hallucination in Large Language Models—An Extensive Definition, Quantification, and Prescriptive Remediations. arXiv 2023, arXiv:2310.04988. [Google Scholar] [CrossRef]
- Kumari, A.; Singh, A.; Singh, S.K.; Juhi, A.; Dhanvijay, A.K.D.; Pinjar, M.J.; Mondal, H.; Dhanvijay, A.K. Large Language Models in Hematology Case Solving: A Comparative Study of ChatGPT-3.5, Google Bard, and Microsoft Bing. Cureus 2023, 15, e43861. [Google Scholar] [CrossRef]
- Rad, A.A.; Nia, P.S.; Athanasiou, T. ChatGPT: Revolutionizing cardiothoracic surgery research through artificial intelligence. Interdiscip. Cardiovasc. Thorac. Surg. 2023, 36, ivad090. [Google Scholar] [CrossRef]
- Fawzi, S. A Review of the Role of ChatGPT for Clinical Decision Support Systems. In Proceedings of the 2023 5th Novel Intelligent and Leading Emerging Sciences Conference (NILES), Giza, Egypt, 21–23 October 2023; pp. 439–442. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Parameter | Class | n | AI Model | |||
|---|---|---|---|---|---|---|
| ChatGPT 4 | Microsoft Bing | Scholar AI Free | Scholar AI Premium | |||
| Fleiss’ Kappa * | mild | 22 | 1.00 | 0.93 | 0.82 | 1.00 |
| moderate | 10 | 1.00 | 0.66 | 0.62 | 1.00 | |
| severe | 24 | 1.00 | 0.85 | 1.00 | 1.00 | |
| Overall | 56 | 1.00 | 0.83 | 0.85 | 1.00 | |
| Sensitivity | mild | 22 | 1.00 | 0.92 | 0.81 | 1.00 |
| moderate | 10 | 1.00 | 0.67 | 1.00 | 1.00 | |
| severe | 24 | 1.00 | 1.00 | 1.00 | 1.00 | |
| Specificity | mild | 22 | 1.00 | 1.00 | 1.00 | 1.00 |
| moderate | 10 | 1.00 | 0.95 | 0.90 | 1.00 | |
| severe | 24 | 1.00 | 0.89 | 1.00 | 1.00 | |
| Positive predictive value | mild | 22 | 1.00 | 1.00 | 1.00 | 1.00 |
| moderate | 10 | 1.00 | 0.80 | 0.50 | 1.00 | |
| severe | 24 | 1.00 | 0.83 | 1.00 | 1.00 | |
| Negative predictive value | mild | 22 | 1.00 | 0.94 | 0.85 | 1.00 |
| moderate | 10 | 1.00 | 0.91 | 1.00 | 1.00 | |
| severe | 24 | 1.00 | 1.00 | 1.00 | 1.00 | |
| Accuracy with CI 95% | Overall | 56 | 1.00 [0.94, 1.00] | 0.89 [0.78, 0.96] | 0.91 [0.80, 0.97] | 1.00 [0.94, 1.00] |
| Balanced accuracy | mild | 22 | 1.00 | 0.96 | 0.91 | 1.00 |
| moderate | 10 | 1.00 | 0.81 | 0.95 | 1.00 | |
| severe | 24 | 1.00 | 0.94 | 1.00 | 1.00 | |
| Class | N | AI Model | |
|---|---|---|---|
| Microsoft Bing | Scholar AI Free | ||
| Mild | 22 | 0 | 0 |
| Moderate | 10 | 0.90 | 1.50 |
| Severe | 24 | 1.13 | 0 |
| Overall | 56 | 0.64 | 0.27 |
| AI Model | Actual Class | Predicted Class | ||
|---|---|---|---|---|
| Mild | Moderate | Severe | ||
| Chat GPT 4, Bing, Scholar free, Scholar premium | Mild | 22 | 0 | 0 |
| Chat GPT 4, Scholar premium | Moderate | 0 | 10 | 0 |
| Bing | 2 | 8 | 0 | |
| Scholar free | 5 | 5 | 0 | |
| Chat GPT 4, Scholar free, Scholar premium | Severe | 0 | 0 | 24 |
| Bing | 0 | 4 | 20 | |
| AI Model | Proposed Classification of Scoliosis |
|---|---|
| ChatGPT 4 | Mild scoliosis: Cobb angle less than 20 degrees. Moderate scoliosis: Cobb angle between 20 and 40 degrees. Severe scoliosis: Cobb angle greater than 40 degrees. |
| Microsoft Bing | Mild scoliosis: Cobb angle less than 20 degrees. Moderate scoliosis: Cobb angle between 20 and 50 degrees. Severe scoliosis: Cobb angle greater than 50 degrees. |
| Scholar AI Free | Mild scoliosis: Cobb angle less than 25 degrees. Moderate scoliosis: Cobb angle between 25 and 40 degrees. Severe scoliosis: Cobb angle greater than 40 degrees. |
| Scholar AI Premium | Mild scoliosis: Cobb angle less than 20 degrees. Moderate scoliosis: Cobb angle between 20 and 40 degrees. Severe scoliosis: Cobb angle greater than 40 degrees. |
| AI Model | Rationale |
|---|---|
| ChatGPT 4 | ‘The classification I used for assessing scoliosis based on the Cobb angle is widely accepted and used in clinical practice.’ |
| Microsoft Bing | ‘The division I presented earlier was somewhat simplified. A more detailed division, which I found, is consistent with information provided on the Spine-health website [https://www.spine-health.com/conditions/scoliosis/cobb-angle-measurement-and-treatment-guidelines (accessed on 29 October 2023)].’ |
| Scholar AI Free | ‘The classification of scoliosis based on Cobb angles that I presented is a generally accepted practice in medicine. However, it is not information that I derived from a specific scientific source.’ |
| Scholar AI Premium | ‘I am sorry, but unfortunately, I could not find a specific scientific study that precisely defines the ranges for mild, moderate, and severe scoliosis based on the Cobb angle. All the articles I found pertain to different aspects of scoliosis and its measurement, but none of them directly answers your question. Nonetheless, the classification I used for assessing scoliosis based on the Cobb angle is widely accepted and used in clinical practice.’ |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fabijan, A.; Polis, B.; Fabijan, R.; Zakrzewski, K.; Nowosławska, E.; Zawadzka-Fabijan, A. Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models. J. Pers. Med. 2023, 13, 1695. https://doi.org/10.3390/jpm13121695
Fabijan A, Polis B, Fabijan R, Zakrzewski K, Nowosławska E, Zawadzka-Fabijan A. Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models. Journal of Personalized Medicine. 2023; 13(12):1695. https://doi.org/10.3390/jpm13121695
Chicago/Turabian StyleFabijan, Artur, Bartosz Polis, Robert Fabijan, Krzysztof Zakrzewski, Emilia Nowosławska, and Agnieszka Zawadzka-Fabijan. 2023. "Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models" Journal of Personalized Medicine 13, no. 12: 1695. https://doi.org/10.3390/jpm13121695
APA StyleFabijan, A., Polis, B., Fabijan, R., Zakrzewski, K., Nowosławska, E., & Zawadzka-Fabijan, A. (2023). Artificial Intelligence in Scoliosis Classification: An Investigation of Language-Based Models. Journal of Personalized Medicine, 13(12), 1695. https://doi.org/10.3390/jpm13121695