1. Introduction
Data mining traditionally represents the identification of information, not known a priori, through targeted extrapolation using single or multiple databases. Techniques and strategies applied to data mining operations are largely automated and frequently based on machine learning (ML) algorithms.
To date, prediction methods, such as neural networks, decision trees, clustering, regression and the analysis of associations, are commonly used in material engineering. With the capacity to recognize existing patterns undetected by other means of investigation, they can provide unforeseen information in a way that permits a better understanding of material properties and behaviors. This is exactly what it is presented here, with an investigation focused on a nodular cast iron (GJS).
Also known as spheroidal graphite cast iron (SGI), this is a standardized [
1] type of cast iron in which graphite is solidified as spheroids (instead of flakes or lamellae), with the effect of providing the material with better mechanical properties (e.g., ultimate/yield strength, hardness, etc.). They also provide properties that are rarely associated with cast irons, such as the ductility, which explains the further denomination of ductile iron [
2].
The nodules of graphite exert a preventative action against the development of cracks, unlike lamellar graphite, which offers a preferential path for their propagation. In addition, their spheroidal shape reduces the stress concentration, reducing the damage in the matrix structure [
3].
The intense influence exercised by the graphite shape on the matrix structure produces significant correlations between the mechanical properties. It is very common, e.g., to have tensile strength (
UTS) correlated with elongation at break (
ε) in the case of SGI, by means of an equation such as:
where Q is a constant. High values of Q indicate a high strength and/or elongation, denoting a cast iron with advanced properties [
4].
The proper nucleation of the graphite spheroids AIn be achieved by combining two phases: firstly, by reducing the sulfur (
S) content below 0.018% through a desulfurization treatment, and then, by increasing the magnesium (
Mg) content up to 0.3% from its 0.04–0.05% initial content through the addition of
Fe-Si-Mg alloys to the liquid metal ([
5]). This a delicate part of the process.
There are equations (e.g., those proposed by CTIF and ESF, France) that can relate the weight of Mg-based additives with the expected Mg content. However, these relationships can be inaccurate. For instance, the desulfurization pre-treatment is essential for preventing the Mg from reacting, to a large extent, with the sulfur, hindering the complete spheroidization of the graphite. However, the local sulfur content can be influenced by the casting geometry and characteristic dimensions in a way that causes the microstructures to be unpredictable.
From a research perspective, this unpredictability is a perfect way of assessing data mining tools and their benefits, provided that we have adequate data for their analyses.
The distribution and morphology of graphite nodules can be detected using qualitative methods based on metallography. For instance, their shape can be evaluated according to ASTM A247, which defines seven basic morphologies and also provides parameters for their classification [
6], before other standards are used to define specific tests methods.
The
nodularity, which refers to the % of graphite present as
type-I or -
II nodules, can be evaluated by counting the graphite particles of each type [
7]. A nodularity greater than 90% is generally recommended in the case of nodular iron, although a nodularity greater than 80% is acceptable.
The mechanical properties can be evaluated using a consolidated list of standards merging experimental procedures for testing metallic materials (e.g., ASTM E8M-16 for tensile tests [
8]) with other procedures that were explicitly developed for testing cast iron (e.g., ASTM A327 for impact tests of cast iron [
9]).
There are numerous experimental works characterizing spheroidal cast irons in the literature, including some studies regarding specimens produced in the same foundry using similar processes and chemical compositions [
10,
11,
12]. These papers describe SGIs with a good carbon content (3.50–3.70%), correct fractions of magnesium (0.055%) and minimal residues of sulfur (0.004%), as one should expect. Moreover, their spheroids appear to be correctly formed and distributed, while mechanical tests highlight the typical mechanical properties of SGI (i.e., tensile strength (
UTS) ~500–670 MPa, yield strength (
YS) ~320–380 MPa, Poisson’s ratio~0.24, and elongation at break (
ε) ~9–14%).
Starting from the experimental data, models have been proposed in the past by researchers who were attempting to correlate the microstructural and mechanical information. They are usually based on the deployment of empirical relations correlating measurements, followed by remarkable attempts to interpret these relationships on a physical basis (e.g., [
13,
14,
15]).
However, recent promising studies have introduced the concept of data mining as a new method for investigating the complexity behind the experimental data for cast irons.
In [
16], e.g., data mining was used to classify the microstructures (i.e., martensite, pearlite and bainite) in the case of two-phases steels. This work offers valuable considerations regarding methods for producing a pertinent dataset for a machine learning (ML) approach, starting with the morphological parameters (such as the nodule shape, areas and diameters) detected using micrographs (i.e., light-optical and SEM images). The analysis also provides evidence with respect to the high accuracy of classification that can be achieved (i.e., 88.3%) when aspects such as data preprocessing, feature selection and the data split technique are properly handled. In this case, a support vector machine (SVM) tool trained using 80% of the available data was used as the classifier, and the other 20% of the data were retained for the validation.
The present investigation is similar in terms of the methods used and precision achieved, but significant there are differences in terms of the materials (i.e., cast iron vs. steel), training dataset consistency, morphological features, the application of learners, validation approach, etc.
In [
17], the same SVM learner was applied to classify the material phases for SGI, as in the present work. However, the analysis was not based on the determination of the morphology of spheroids (as was the case, e.g., in [
18]). Rather, the authors preferred to omit a grayscale (8-bit) transformation and evaluation, opening up the concept of
image embeddings [
19].
Clustering and classification algorithms rarely work when using images directly. To perform the image analysis, it is necessary to transform (‘encode’) them into vectors of numbers. The image embedding is a vector representation of an image, whereby images with similar patterns have similar vector profiles.
Today, many powerful image embedders are easily accessible (e.g.,
InceptionV3 by Google) and applied in several research fields (including materials engineering [
20]). They are based on deep learning models that are able to calculate a
feature vector for the image and return the image descriptors. These descriptors, which are altogether capable of precisely characterizing each image, lose every evident connection with the original image content. For researchers, they offer nothing more than thousands of values (many of which are useless and will ultimately be eliminated by a
PCA), which are devoid of any obvious physical meaning.
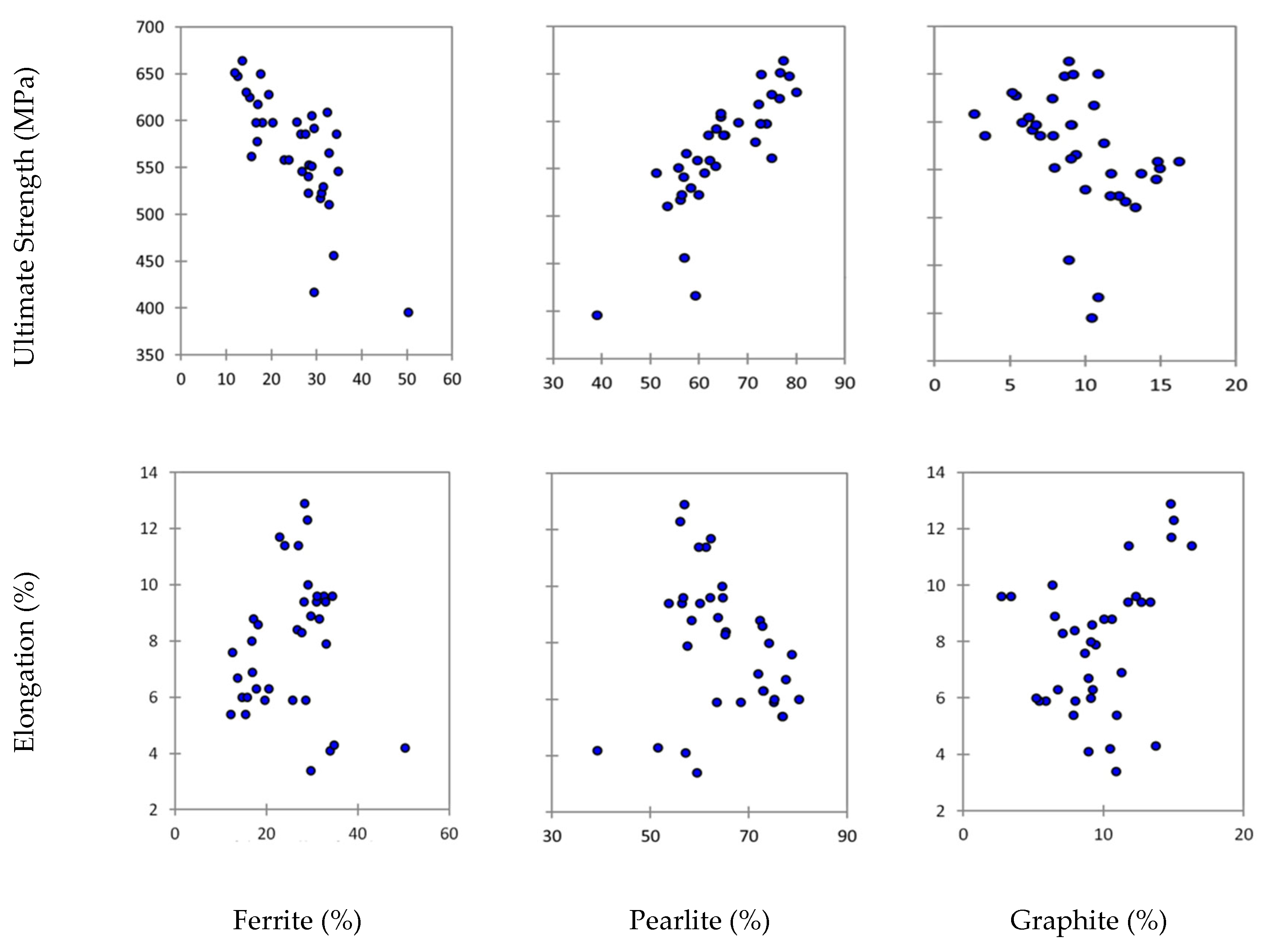
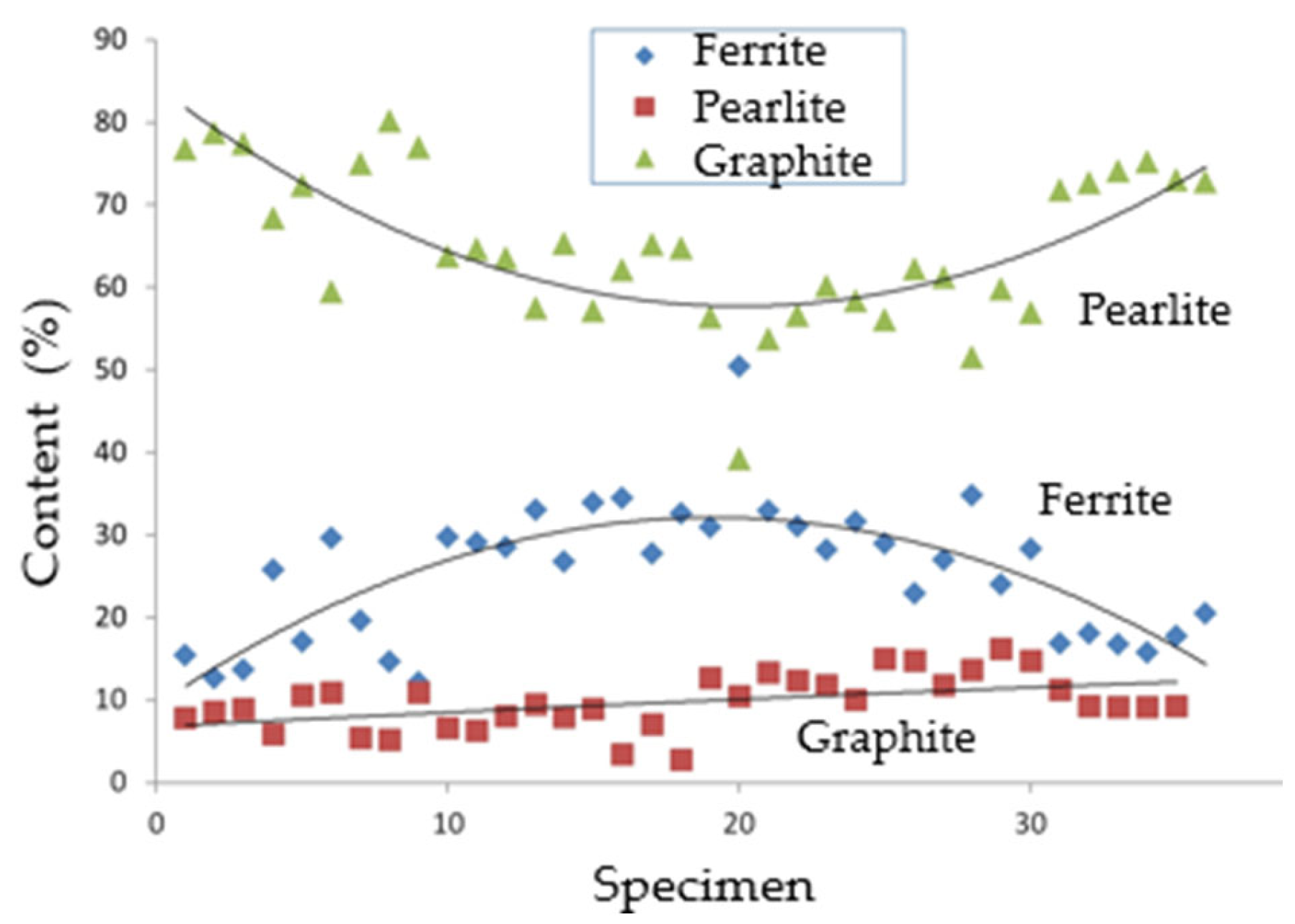
The present work prefers to focus its analysis on standardized factors, such as the contents of graphite (GR), ferrite (FE) and pearlite (PE), or the grade of nodularity (NO), considering their immediate correspondence with the physical meanings. For instance, we can observe that:
Graphite nodules in a completely ferritic matrix provide the cast iron with a good ductility, impact resistance, tensile strength (UTS) and yield strength (YS), making the cast iron almost equivalent to a non-alloy steel.
An almost completely pearlitic matrix, with small amounts of ferrite around the graphite nodules, gives the cast iron a high tensile strength, good wear resistance and moderate ductility, with a higher machinability than steel.
A mixed matrix consisting of ferrite and pearlite, the most frequent form of SGI as it appears in a foundry, gives the cast iron intermediate properties between the ferritic and pearlitic ones, with a good machinability and low production costs.
Returning to data mining applications for SGI, in [
21], the k-nearest neighbors (kNN) learner, another supervised classifier, was used to predict defects in a foundry by relating historical process data (about the mold sand, pouring process, chemical composition, etc.) to the percentage of defective castings. This is a valid example regarding the use of ML for monitoring the quality of the casting process in the case of SGI, but it required a large amount of data in order to define the time series from which one can recognize the time-depending patterns. Thus, the present work is very different in terms of its data consistency and scope.
In [
22], machine learning and pattern recognition were used to investigate an important aspect of the casting process: the cooling and solidification of the metal. In general, this aspect is also relevant in the present case, but the two investigations are based on different databases (i.e., mechanical properties vs. thermal analysis cooling curves).
Nevertheless, the use of artificial intelligence
(AI) and data mining to investigate the materials’ behavior is a topic of great interest in current research. This is why a great number of articles deals with this theme. Limiting the discussion to the most recent contributions, in [
23,
24], ML methods were used to relate material defects (such as porosity), which emerged after solidification, with mechanical properties (such as fatigue strength). In other research papers, the use of ML tools was implemented in the earlier stages of the production process, with the aim of predicting impurities [
25] or tracing the evolution of other chemical elements [
26] inside the blast furnace hot metal. The general aim was to improve the level of control over the whole metal melting production process [
27], which is characterized by a strong intrinsic variability. There are also interesting cases where an ML approach permitted the improvement of specifical material characteristics (such as the required impact strength in the case of [
28]) or even the development of a substantially new and different cast alloy ([
29]).
All these works, together with many similar studies (such as [
30,
31]), are mainly based on the validated assumption that ML can be conveniently applied for the recognition of the metal alloy microstructures, constituents, and morphological characteristics.
Nevertheless, even more relevant studies are those related to the prediction of mechanical properties in the case of cast irons, starting with their metallurgy characteristics. Firstly, it is interesting to mention [
32], where ML algorithms properly classified nodular cast irons, while this ability was used to predict (by regression) the stress–strain [
33], Poisson’s ratio [
34] and hardness [
35], even when comparing different ductile cast alloys [
36].
However, unlike other studies, here an additional target is involved in the assessment of the proposed methods and tools with respect to a real industrial production environment.
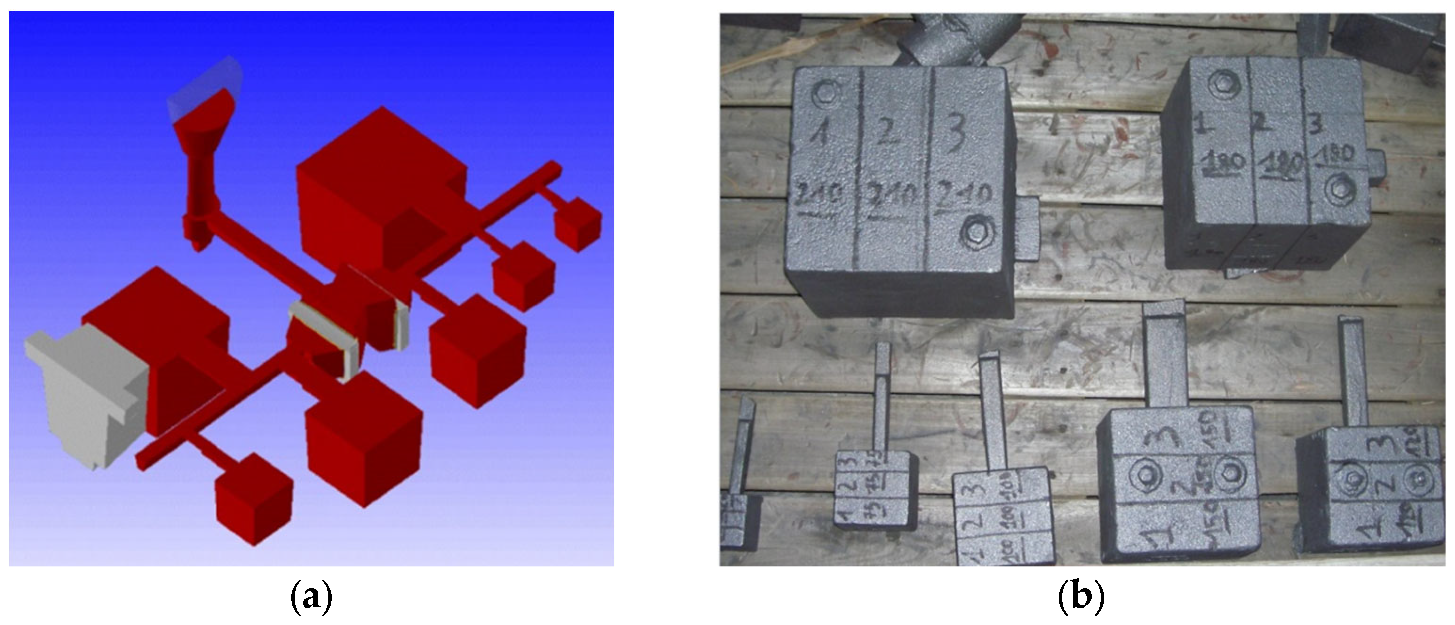
With such a scope, this research was designed to be implemented within a traditional sand cast iron foundry during its daily operation and without significant alterations to the process scheduling. Precise limits emerged from this work in terms of:
Production (e.g., alloys, geometries, process factors and specimen numbers);
Experiments (e.g., mechanical and microstructural tests);
Data mining (e.g., platforms, algorithms and data representation).
Finally, the research was intentionally based on methods that have already been applied in past, which, here, are largely reconsidered with the aim of providing additional outcomes.
Specifically, the abovementioned [
10,
11,
12] offer similar experimental characterizations (tensile, flexural and fracture properties, respectively) of different cast irons, including SGI, produced using relatively analogous process conditions (i.e., open-cast conditions in green sand). Their measurements are very useful and, here, are used for the purposes of comparison and discussion.
At the same time, these past investigations differ in the (smaller) number of specimens used and the means by which these specimens were produced. Here, for the first time, specimens were extracted from castings with the detection of their geometry, dimensions and processes, which are fully in line with those representing the daily production. These differences are important. For instance, while the characteristic dimension was defined as 26 mm in all the previous works, here, it varies from 75 to 220 mm, permitting a better investigation of the cooling phenomena.
Regarding methods, [
35,
37] offer a valid overview of the data mining techniques, which have been validated in the past and are used again here. Nevertheless, here, several important methodological improvements were combined so as to provide a fruitful analysis, including the following:
The dataset was enlarged by two additional features, including hardness and resilience.
The SVM was included in the ML procedure in light of the consistent results that other researchers achieved using this learner for their predictions.
Learners were optimized through changes to their constitutive parameters (vs. the default values used in the past), in accordance with their specific meanings.
The validation was performed on a different basis, improving the accuracy.
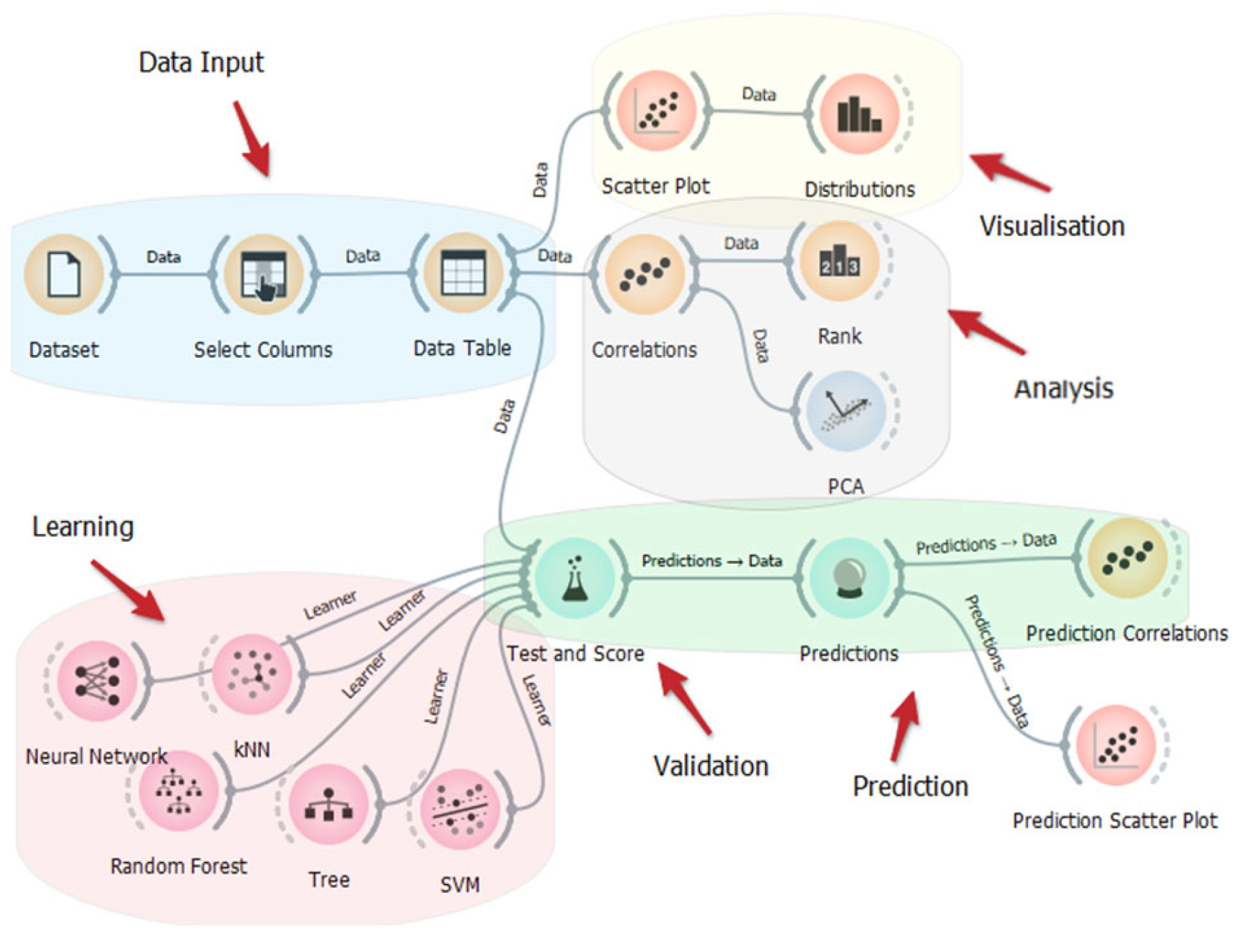
4. Data Mining Perspective
4.5. Machine Learning
The ML methods discussed here are based on training and use supervised learners. Specifically, the following learners were preferred for this study (in alphabetical order):
For the theory behind these mathematical tools, the reader should refer to specialized texts. For their validation and practical use in similar cases, the reader can refer to [
43].
Specifically, according to common practice for the use and validation of ML algorithms, the dataset was fractionized into two parts, one for training and the other for testing the learners’ ability to make predictions. Random sampling randomly splits the data into the training and testing sets in the given proportions. Then, the whole procedure is repeated a specified number of times. Here, different settings were considered, with the most balanced results achieved using 90% of the data for the training and 10% for the testing. In practice, respectively, 32 and 4 of the 36 available items were used, with 10–20 repetitions so as to statistically consolidate the results. Then, the learners’ degrees of effectiveness were compared and ranked.
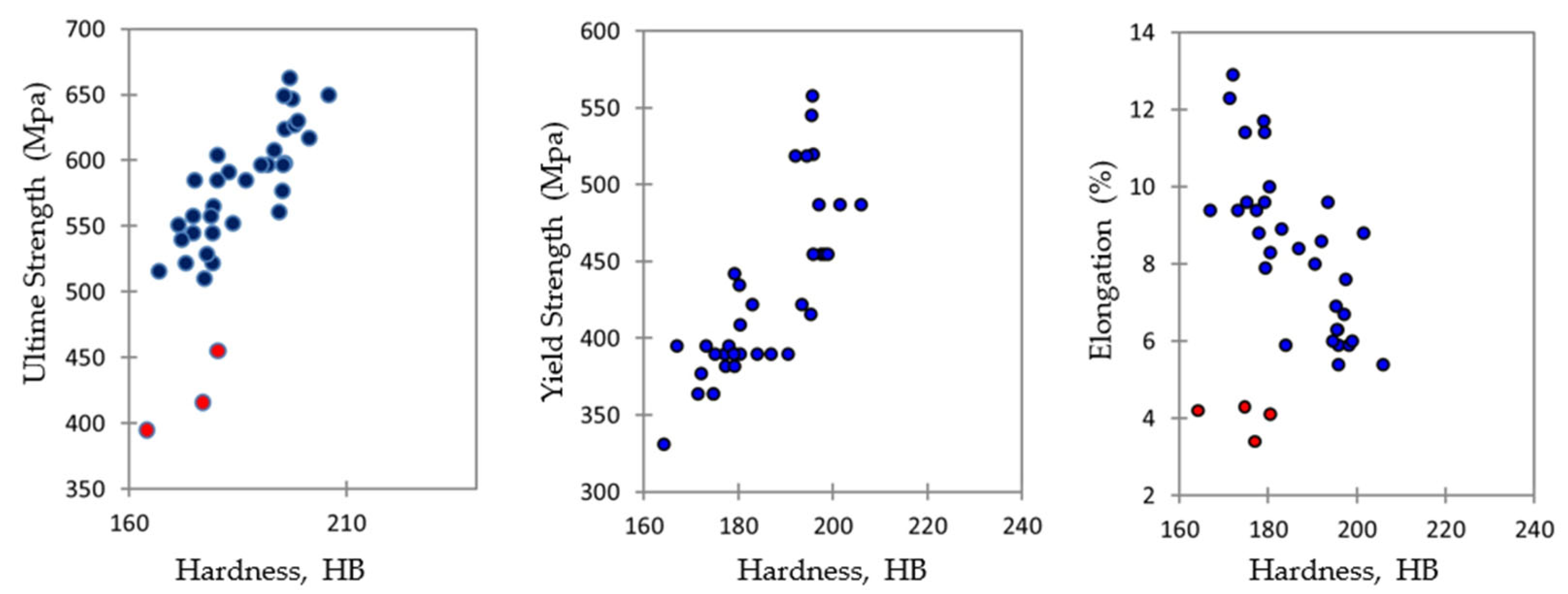
For performance statistics, several standard methods may be used (e.g., mean square error, relative mean square error, mean absolute error, etc.). In the present discussion, the coefficient of determination (R2) was preferred due to its relationship with the Pearson correlation coefficient and its linearity. The R2 is interpreted as the proportion of the variance in the dependent variable that is predicted using the independent variable. In brief, the R2 can be between −∞ and 1. When R2 = 0, this means that the adopted model offers an interpretation of that data that is not better than the average data value and, under 0, the model is even worse than the average value. However, when R2 = 1, this means that the model perfectly explains the data.
The initial tests, which used the default settings for the learners, were not especially encouraging, with the R2 often being negative and never higher than + 0.3/0.4. However, after some changes to the settings, the accuracies were greatly improved, especially for NN and RF, with an R2 over 0.9. This means that these learners are extremely precise in predicting the target values. SVM and tree also offer a reasonable level of accuracy. In the case of SVM, which is frequently used in similar investigations on cast irons, a precision level of 82–85% was also confirmed here.
The following (main) parameters were selected in order to achieve the declared accuracy:
NN: max 500 neurons in hidden layers, logistic activation, L-BFGS-B solver, max 400 iterations, and regularization at 0.0001
RF: max 24 trees, 5 attributes at each split, and 3 as the limit depth of individual trees.
SVM: cost = 200, regression loss epsilon = 1.00, and kernel polynomial.
Tree: max 7 instances in the leaves, 3 as the smaller subset, and 10 as the max tree depth, stopping when the majority reaches 99%.
kNN: five as the number of neighbors, Mahalanobis metrics, and uniform weight.
Table 4 offers an a priori evaluation of the learners using all the available methods.
4.6. Predictions
After the learners’ validation, they were used to predict the target values (
Table A2 in
Appendix A). Specifically, the ‘leave on out’ approach was applied. This means that one specimen was excluded from the dataset, and the others (35) were used to train the learners. Then, they were required to predict the target value in the case of the excluded specimen. The same process was repeated for each specimen, with the aim of predicting every available target value. In other words, the learners were required to offer their best evaluation of the cube side for each specimen, considering all the others. The results are shown in
Figure 13 in terms of the predicted and expected target values. The accuracy is evident.
Specifically, the accuracy offered by NN, SVM, RF and k-NN was evaluated by measuring the correlations between the predicted and expected values using Pearson’s coefficient, which equaled, respectively, rpxy = 0.952, 0.914, 0,799 and 0.768. The tree classification is ignored here, since its results were always in line with those of RF (e.g., rpxy = 0.746).
Details regarding the full correlation analysis are available in
Table 5.
With respect to the initial comparison of the learners (performed a priori using a different method, the R2), the high accuracy rate of NN is also confirmed here. As evident in the diagram, the NN learner is able to categorize predictions for the five target values (210, 180, 150, 120, 75). The overlap between categories is quite limited, and no evident outliers exist, as in the case of RF. SVM’s accuracy is also confirmed. Indeed, for this different classification, performed a posteriori, it is better than RF, confirming the validity of other researchers’ decision to use SVM for their own analyses. The difference in precision between NN and SVM is minimal and mainly linked to the data variability with respect to one of the categories (target = 120), which appears to be the most complex class recognized here, possibly due to a stronger variability among the input data. An inadequate precision is instead evident in the graph of k-NN. The learner tends not to categorize values into groups but into indifferent ones within the same range (e.g., 130–180). This creates several problems, such as, e.g., an inability to identify all the targets and loss of the extremes (i.e., 75 and 210).
The learners’ levels of precision can be represented using a diagram of the predicted vs. expected values (as in
Figure 14, in the representative cases of NN and k-NN), where the points closer to the bisector line represent the highest prediction accuracy, and their distance from that line exemplifies the error. It is evident that NN, in comparison with k-NN, exhibits points more clustered points around the bisector line.
6. Conclusions and Future Work
The present experimental investigation was focused on a nodular cast iron, a material that has found an increasing number of applications in industry over the last few decades. This alloy, like many others, has metallurgical and mechanical properties that are closely related to each other. Moreover, even minimal changes in the chemical composition and/or process parameters may significantly affect such properties. It follows that cast iron, including nodular cast iron, has been extensively studied, starting with experimental measurements, to develop predictive models.
Here, data mining and machine learning techniques were used to perform a data analysis in search of information that was not evident, rather than a more traditional method of study.
The experimental data were derived through an experiment designed to ensure adequate consistency with respect to some key aspects of casting (e.g., the characteristic dimensions) but also to the operation of a traditional foundry. The measurements were performed through standard tests: image analysis for the microstructures and strength tests for the mechanics. Firstly, considerations were developed through a preliminary data evaluation. Then, the dataset, consisting of 36 instances × 12 features, was analyzed by principal component analysis (PCA) and correlation analysis (CA), which permitted the identification and weighting of the correlations. Finally, data were used to train several different machine learning (ML) algorithms on the Orange Data Mining platform, including random forest (RF), neural network (NN), k-nearest neighbors (kNN) and the support vector machine (SVM), which are able to predict material properties with remarkable accuracy (i.e., >90% in half of the cases).
The next step in the research is to overcome the limits imposed by the current dataset, whose consistency varies from 432 to 756 values, which, through appropriate pre-processing, could be extended to even more than one thousand data. However, this number is still quite low for expressing the ML potential. At the same time, it must be considered that the prediction accuracy is more closely related to the data quality than the numerosity. Foundry processes are intrinsically variable, and every action aimed at expanding the dataset must take this into account. This means, e.g., that it is not convenient to merge data from other investigations if they are subject to dissimilar (processes and materials) conditions. However, a different approach can be taken, with the aim of extracting more data from the available information. Specifically, it is possible to integrate the current dataset with information from a different image analysis. Here, each microstructure was considered according to specific parameters (such as, e.g., the pearlite, nodularity, nodular area, etc.), as in many other similar studies. Later, this information could be integrated through the output of an image embedder that is capable of transforming the image into hundreds of new parameters (limiting the choice to the most significant ones in the PCA). Beyond this explosion of the data and parameters, however, we must understand whether new and useful information is really embedded in the analysis.
A second way of improving the method is the introduction of a diverse concept of supervised learning. Although some of the learners offered excellent predictions, they also proved to be quite erratic and unpredictable. One of the most recently tested ways of overcoming this (rather common) limitation combines the predictions in what is called ensemble learning. Among its different techniques, the stacking technique is expected to be more valid, which can be used to introduce an additional ‘meta-learner’ (usually a linear regression) that is trained using the predictions of those learners, which, here, were scored as the most effective through the cross-validation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}