2.2. Correlative Microscopy
In order to guarantee a reliable application of modern DL approaches in the field of material science, high-quality data are essential. To establish an objective and well-founded ground truth, it is often not sufficient to limit oneself to a single methodology used for such complex steels, as demonstrated in
Figure 2 and
Figure 3. Therefore, all samples were characterized using LOM, SEM, as well as EBSD. In correlative microscopy, these methods were combined to benefit from the advantages of the different approaches and to eliminate their respective disadvantages and thereby overcome their limits. In this way, the complementary information necessary for a holistic characterization can be collected on different length scales and from different contrasting mechanisms. However, the goal behind the correlative microscopy approach is to apply the detailed information obtained from more advanced methods to the simplest methodology possible.
All specimens were first ground with 80–1200 grit SiC abrasive paper and then subjected to diamond polishing using 6, 3, and 1 µm suspension. Subsequently, the sample preparation was completed by a colloidal OPS polish to achieve the best possible surface quality for the subsequent EBSD measurement. The respective region of interest (ROI) with a size of 400 × 400 µm, at which the correlative microscopy is being conducted, are marked using hardness indentations.
After each EBSD measurement, which was made on a Zeiss Merlin (Zeiss, Oberkochen, Germany) with an EDAX detector (EDAX, Pleasanton, CA, USA) under an accelerating voltage of 25 kV and a beam current of 10 nA at a working distance of 15 mm with a step size of 0.35 µm, the sample was briefly polished again using OP-S to remove the contamination layer before further optical examination.
The EBSD data were post-processed with the help of the EDAX OIM software (Version 7, TSL Solutions, Nishihashimoto, Japan). For this purpose, a standard routine with a filter operation for poorly indexed measurement points was applied.
Subsequently, the samples were contrasted for 25 s using a 2.5% alcoholic Nital solution, and the micrographs of the respective ROIs were captured in LOM and SEM. As LOM, an Olympus LEXT OLS 4100 laser scanning microscope (Olympus, Shinjuku, Japan) was used, and the images were taken at a 1000× magnification, resulting in a pixel size of 126.6 nm. The SEM images were acquired using a ZEISS Supra SEM (Zeiss, Oberkochen, Germany) using a secondary electron contrast, using an acceleration voltage of 5 kV and a working distance of 5 mm, at a magnification of 850× with a respective image size of 2048 × 1536 px corresponding to a pixel size of 47.5 nm. The brightness and contrast settings were adjusted so that the gray-level histogram was approximately normally distributed. In order to capture an entire ROI, several single images need to be taken with a respective overlap and, subsequently, stitched together. Therefore, Microsoft Image Composite Editor was used.
In order to superimpose the different image data congruently, image registration is necessary due to the different contrast generation mechanisms as well as unequal perspectives on the respective sample location. For the registration operation, the ImageJ [
18] Plugin bUnwarpJ [
19], as proposed in [
16,
20], was used. In contrast to their presented procedure, however, the individual features within the different images had to be selected manually. No corresponding features could be found using common automated feature extraction algorithms such as SIFT (Scale-Invariant Feature Transform), due to the high complexity, as well as the fine visual features of the microstructural images of the investigated steels. First, the high-resolution SEM image was registered on the corresponding image quality (IQ) map of the EBSD measurement. Afterward, the LOM micrograph was registered on the already registered SEM image.
Another obstacle here is the different resolutions of the individual methods: either the lower-resolution method must be scaled up and thus interpolated, or important details of the higher-resolution methods may be lost when scaling down. Since the microscopy images are later used in DL algorithms, it is reasonable to adjust, for the sake of simplicity, the image dimensions to powers of 2. Here, it is recommended to deviate as little as possible from the native resolutions of the microscopes.
Hence, the final DL approaches take LOM as well as SEM images as input; the EBSD mappings will be resized to the native resolution of LOM/SEM in order to properly create the ground truth annotations using all complementary information. This results in image dimensions of 4096 × 4096 px for LOM and 8192 × 8192 px for SEM for respective imaging of the mentioned sample sections of 400 × 400 µm. The EBSD mappings with a native resolution of 1320 × 1320 px, measured in a hexagonal grid using the mentioned step size of 0.35 µm, were resized accordingly.
Thus, the correlative datasets of the respective samples were aligned and congruent to be used directly as complementary information for the later annotations being used in the deep learning methodology.
Figure 4 shows a section of a correlative data set consisting of LOM, SEM, and EBSD data containing all phases to be distinguished. There, the corresponding added value of the complementary information for the identification of the occurring phases becomes clear. With the help of the high resolution of the SEM, fine carbide precipitates can be clearly identified, and thus LB and MST can be reliably detected. In addition, a distinction between LB and UB is possible based on the localization and orientation of the fine carbides, which would not always be the case based purely on light microscopy images. Furthermore, contrasting artifacts, as well as ambiguous morphologies, can be considered with the help of crystallographic EBSD information. Though, the most helpful information from EBSD data for identifying the different microstructural constituents is provided by the misorientation.
2.3. Used Quantification Approach: Patchwise Classification as Alternative to Semantic Segmentation
Semantic segmentation is the common DL approach for segmenting more complex problems that cannot be solved using conventional approaches, such as threshold segmentation. It is a pixelwise classification: each pixel of the image is assigned a class, and thereby, the entire image is segmented [
21]. Additionally, it is possible to carry out segmentation with more than two classes in the same segmentation step, which offers great added value. In order to train a model for semantic segmentation, masks must be created in which every pixel can clearly be assigned to a specific class.
In contrast to most segmentation problems, for the microstructures of Q/QT steels, it is not straightforward to create unambiguous masks to train a DL segmentation approach. In the case of dual-phase and complex-phase steels, the complementary information of the correlative images is sufficient to clearly identify the respective microstructural constituents. There, the respective phases can be clearly separated from each other by grain/phase boundaries [
3,
6]. Morphology and corresponding misorientation information allow us to confidently differentiate one phase from another. Due to the complex formation mechanisms in Q/QT steels and the resulting interwoven structure of the microstructural constituents, it is not possible to reproducibly define the boundaries of the different phase regions. In addition, various areas of the microstructure often cannot be clearly assigned to a corresponding class. Even crystallographic EBSD information, as well as corresponding high-resolution imaging techniques, often do not allow annotation with required confidence according to the common classification schemes, which is illustrated in
Figure 5.
A reasonable approach would be to annotate only unambiguous regions and then assign the ambiguous regions to a common mixed class. An obvious disadvantage of this would be the great diversity of the resulting mixed class. This would accordingly mix up the characteristic visual features of the individual classes. Accordingly, it can be assumed that the significance of the decisive features for determining the clearly defined classes would decrease. Therefore, an alternative approach to segment the different microstructural constituents in Q/QT steels as reliably and unambiguously as possible was chosen in this work.
In contrast to the pixel-by-pixel approach used in semantic segmentation, this approach reduces the microstructural images to individual patches. These patches are classified individually, and the result is considered representative of the particular microstructure section, as illustrated in
Figure 6. In order to be able to characterize an entire microstructure, the individual microstructural images are scanned and segmented by a CNN patch by patch using a sliding window approach [
22]. Thereby, the complex problem of segmentation is reduced to a simple classification. This saves a decent amount of time during annotation or makes annotation possible in the first place in complex cases.
The respective patch size is predefined by the CNN architecture’s input size. However, in order to achieve a higher “segmentation resolution” and to better map the fine transitions between the areas of the individual microstructural components, the step size can be adjusted in the scanning process. The smaller the step size, the higher the resolution of the resulting classification map. As a result, the possible resolution of the result depends on the original resolution of the entire recording, as well as the step size with the corresponding input size, and is, thus, dependent on the total amount of input images, limited by computing resources.
In this approach, a classification model is trained with patches of reference states that are representative of the structural constituents that are present. With respect to the patches to be selected for training the models, only relatively unambiguous reference states are selected. Inconclusive patches are left out. The idea behind this is to classify these objectively and reproducibly by the ML model. Due to the versatility of the individual phases occurring in Q/QT steels, the training data must cover the widest possible spectrum of microstructural features and represent their high variance as accurately as possible. There is a trade-off between the amount of data and the confidence with which the data is labeled. Hence, 22 correlative data sets from the above-mentioned samples were elaborately created in the course of this work and used to extract sufficient high-quality data to build a final training dataset.
The probabilistic character of the CNN classification approach makes it possible to take the uncertainty of the ambiguous regions into account when evaluating entire microstructural images. Usually, classification CNNs give the corresponding probabilities of the available classes as output, from which a final prediction can be derived. A confidence component can be built into this approach by using appropriate thresholds with respect to the class probabilities. Thus, individual patches can be declared as uncertain with no clear class affiliation, which is an analogy to the microstructural regions that are ambiguous for experts during the characterization of the respective microstructure. This means that even ambiguous structure sections containing a combination of different phases can be identified and considered in the evaluation routine by summarizing the uncertain predictions in a separate class.
2.4. Annotations and Final Data Set
Based on the microscopy images, a comparison of the respective structural components can be made using the morphological information after appropriate contrast. In the case of LOM, further information is obtained by looking at the coloration. The major advantage of SEM methodology is the ability to resolve substructures, such as carbides and finer lath boundaries, which delivers essential information about class affiliation. Considering the related step size of 0.35 µm, the resolution of the EBSD is behind those of LOM and SEM. Nevertheless, the crystallographic and misorientation information provides crucial added value in contributing to an objective labeling process.
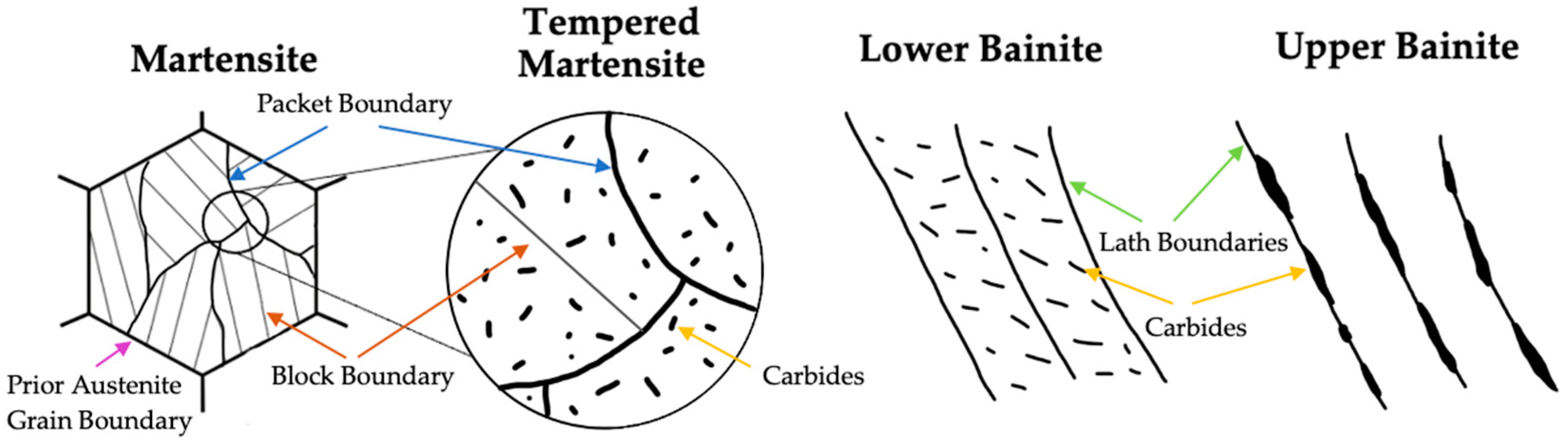
Thus, upper and lower bainite can be distinguished on the basis of the quantity and type of misorientations or boundaries that occur [
14]. Upper bainite contains a higher fraction of low misorientations (<20°), as well as a low proportion of misorientations (>40°). In the case of the lower bainite, this situation is reversed. Bainitic objects also exhibit more global misorientations that create intra-structural gradients visible in the inverse pole figure (IPF). Furthermore, the packet size can provide information about the distinction between martensite and the different bainite types [
23]. In addition, the IQ can be used to compare local dislocation densities qualitatively. Thus, this information can provide further evidence for an assignment to the ground truth [
24,
25]. Due to the displacive forming mechanism, martensite exhibits the highest misorientations, as well as the highest density of dislocations. The individual martensite plates are very well visible and separable from each other in the IPF as well as in the IQ map [
26]. Their lath boundaries are strongly contrasted and characterized by high misorientations (>50°). It was observed that the contrast of the lath boundaries is weaker in tempered martensite within the IQ map. In general, the contours become more blurred. The amount of high misorientations decreases slightly, whereas the amount of smaller misorientations increases during the tempering process. This is shown in
Figure 7b by the number of green interfaces. This is the same material as in
Figure 7a, except that it has been subjected to a subsequent annealing process. These phenomena can be attributed to carbon diffusion during the tempering process.
The key to this approach of quantitative structural evaluation via patch-wise classification lies in the creation of representative and well-founded data sets. A crucial parameter for the creation of the datasets is the choice of the patch size. To use the native resolutions of the microscopes to avoid resizing and thus falsification of the morphological features by interpolation, the size scales of the microstructural constituents within the specimens examined were used as a guide. As a result, it was decided to create two separate datasets, each optimized with respect to the different microscope types, LOM and SEM. To achieve the highest possible classification resolution in the evaluation routine described above, it makes sense to keep the size of the squared patches to be classified as small as possible. The size of the characteristic morphological features of the different structural components is another limiting factor. A patch should therefore be as small as possible, but it must contain enough information to be able to assign a well-founded and objective label for the ground truth. As a result, a patch size of 128 px was chosen for the SEM-optimized dataset, which corresponds to a size of 6.25 µm. Due to the lower resolution of the LOM, a patch size of 128 px was selected, which in this case corresponds to an actual length of 12.5 µm. In the labeling process of each dataset, the corresponding microscopy images of SEM and LOM, respectively, were first inspected. Each section, which could be a candidate to be added to the training dataset, was validated with the help of the corresponding complementary information from correlative microscopy.
The different representations were overlaid in an image processing program to extract the patches. For this purpose, LOM, SEM images, as well as the EBSD information in the form of IPF, IQ, and kernel average misorientation (KAM) maps and, mostly, the representation of the different misorientations in the form of boundaries with the threshold values 2, 5, and 15 degrees, were used. To mark the labeled sections, a square brush tool was used to create masks of the respective four classes, respectively, for the LOM and the SEM optimized dataset. These binary masks were then used to automatically extract the corresponding labeled patches from LOM and SEM images, respectively.
When creating the SEM data set, superimposed representations of the misorientations combined with the SEM images were used in order to be able to reproducible assign more of the unclear areas to one of the classes, which may have appeared ambiguous due to possible contrasting artifacts. The crucial information, e.g., regarding the orientation of the precipitated carbides, which is to be regarded as a decisive distinguishing criterion, is most evident in the SEM images themselves, as it is the highest-resolution method. Therefore, although it proved to be very time-consuming to create a well-founded data set from SEM patches due to the volume of information as well as the criteria to be considered, it can be evaluated with great confidence as objective and representative.
Figure 8 shows a selection of characteristic features of the individual classes within the different complementary information sources. Thus, LB, shown in (a) and (b), is characterized by moderate misorientations, as well as the orientation and size of the carbides within the laths. The IPF overlay shows similar orientations of the adjacent laths. UB, as shown in (c) and (d), is characterized by elongated carbide precipitation between the laths, which have a homogeneous orientation by comparison, sometimes with pronounced gradients within the laths and the least misorientation. For the remaining structural components M, shown in (e) and (f), and MST, shown in (g) and (h), the disordered orientation of the individual laths can be confirmed by looking at the IPF. Here, MST can be identified by the fine and disordered carbide precipitates visible in the high-resolution SEM image.
The creation of the LOM data set proved to be much more complex. In order to be able to train a model that is able to assign the patches to a class, the input image must have sufficient characteristic visual features. For some patches that can be clearly assigned to a class based on the SEM image, a clear classification based on the LOM images was not possible. The resolution of the LOM was simply not sufficient to represent the fine microstructural features appropriately. For this reason, the corresponding input size of the LOM dataset was adjusted upward, as mentioned above, to capture more context and more global characteristics in the dataset accordingly. When selecting the LOM patches, care had to be taken to ensure that the decisive features could be identified solely based on the LOM image. The corresponding correlative information from SEM and EBSD should therefore only be consulted as additional information. Due to the increased input size, the number of possible representative areas was reduced. The reason for this is that the consideration of larger sample areas, accompanied by larger patch size, results in fewer homogeneous areas that can be predominantly assigned to one microstructural constituent. This results, on the one hand, in a smaller amount of training data, which is not insignificant for DL applications, and, on the other hand, in patches that also include more visual features of further microstructural components in comparison to the SEM patches.
Figure 9 shows a selection of labeled patches based on the LOM dataset. Using the same characteristics outlined in the case of
Figure 8, the potential reference ranges were validated using the complementary information from the correlative datasets.
However, the explained compromise regarding the adjusted patch size of the LOM dataset leads to the fact that many, especially bainitic areas, are too small to fill an entire patch (
Figure 8d)). As a result, features of the adjacent phases are also visible on these patches, which is unavoidable considering the amount of data required to capture the variety of the phases occurring in real Q/QT steels. Thereby, care was taken to ensure that the characteristic areas occupy most of the patch area and are located in the center. However, this could prove to be advantageous for the evaluation routine explained since the patches often contain more than one phase when the sliding window approach is used.
An intensive review of the correlative data sets in a cross-scale and holistic approach revealed fundamental problems in assigning well-founded ground truth when no complementary information was available and only the LOM images were used for the labeling processes. In the process, not only are the present micrographs accepted as such, but they are critically scrutinized throughout the entire process of data acquisition. Thus, additional information, such as differences in chemical composition and the manufacturing processes of the samples, as well as contrasting and methodological influences, are also considered. Here, correlative microscopy enhances the interpretation of this information.
Figure 10 illustrates patches of the LOM-optimized dataset with a size of 12.5 µm, for which the exclusive use of LOM images for the labeling process could be quite misleading. Here, based on the visual characteristics, it can quickly lead to false labels regarding the assignment of ground truth.
Thus,
Figure 10a appears to be lower bainite based on the LOM patch. This is indicated by the visible preferred orientation of the bainite plates, as well as the brownish coloration, which is caused by the finely precipitated carbides. However, if we now look at the high-resolution SEM image, it becomes apparent that the majority of the carbides have not precipitated within the laths but that they have formed between the very fine bainitic laths. Thus, this is extremely fine upper bainite according to the common classification schemes.
Looking at the LOM micrograph of the patch
Figure 10b, one would possibly choose martensite for classification as an experienced expert. This is supported by the disordered, lathlike morphology and the distinct coloration of the features. However, with the aid of the corresponding SEM image, the extremely fine, disordered precipitation of the cementite particles becomes clear, which in combination with the previously named morphology, is a characteristic of tempered martensite.
Based on the pronounced dark brown coloration, as well as misinterpreting lath boundaries, the LOM patch shown in
Figure 10c indicates a martensitic affiliation. Like
Figure 10a, however, the coloration can be attributed to the fineness of the cementite lamellae, which is even more pronounced in this case. Again, it can be assumed that according to the characteristics, it deals with very fine upper bainite.
Due to the dark spots in combination with a light brown coloration, both corresponding to a fine dispersion of small cementite precipitations, one expects an assignment to lower bainite or tempered martensite for
Figure 10d. With the help of the SEM, the distinct topography becomes visible, which provides higher confidence in an assignment to the latter.
The holistic approach via correlative microscopy, which also takes into account the significant influence of contrasting as part of specimen preparation with regard to imaging, can identify further misleading factors.
Figure 11 again illustrates the problematic reproducibility of electrochemical etching processes. After contrasting under apparently identical conditions
Figure 11b,c, the correlative LOM images reveal an obvious difference. In
Figure 11c, especially the precipitated carbides within the microstructure, which was identified as tempered martensite, are clearly more pronounced, which simplifies an assessment as such. Based on
Figure 11b, one could also assume that it is martensite. Once again, only the high-resolution SEM image provides clarity regarding an unambiguous assignment.
An orientation dependence of the Nital etching was observed across all specimens. Crystal orientations of <100> show a significantly reduced etching effect, as shown in
Figure 12 [
17]. As a result, the areas in the LOM appear bright, similar to areas associated with upper bainite. Though, the high-resolution SEM micrograph reveals the presence of martensitic topography, which due to the reduced etchability, is not as pronounced as those regions with different crystal orientations. Therefore, it is not visible in the LOM image. Additionally, selective contrasting of the lath boundaries of the martensite reinforces the false impression so that confusion with upper bainite can quickly arise (red marking).
Considering the problems demonstrated in this section, it can be concluded again that the most challenging problem behind the application of modern ML approaches in the field of materials science is finding an absolute ground truth. Considering the available complementary information, as well as the occurring misleading factors, two final datasets were created based on the 22 correlative datasets optimized for SEM and LOM images, respectively. Unfortunately, these can only be compared indirectly due to different patch sizes and different underlying slices. In conclusion, it can be stated that despite the reduction to the most homogeneous patches possible, it is not possible to guarantee the correctness of all labels. Nevertheless, a lot of time and consideration of all complementary information was used to work out the underlying ground truth. This represents, at the current state of research, the best approach to a classification in terms of the structural constituents that occur in combination with the samples investigated and taking into account the widely recognized identification criteria of the common phases occurring in modern steels. In order to train the model to a certain degree of variance and to make it as robust as possible, more critical patches were also included in the data set. These partially deviate from the reference states of the respective microstructural constituents to be able to characterize real Q/QT steels as successfully as possible. Ultimately, an SEM-optimized training data set of 6680 individual patches (14% LB—41% M—25% MST—20% UB), as well as a LOM-optimized training data set of 2246 individual patches (17% LB—40% M—27% MST—15% UB), has successfully been created to train respective DL Classification models as good as possible.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}