
Multi-Output Prediction Model for Basic Oxygen Furnace Steelmaking Based on the Fusion of Deep Convolution and Attention Mechanisms

Abstract
1. Introduction
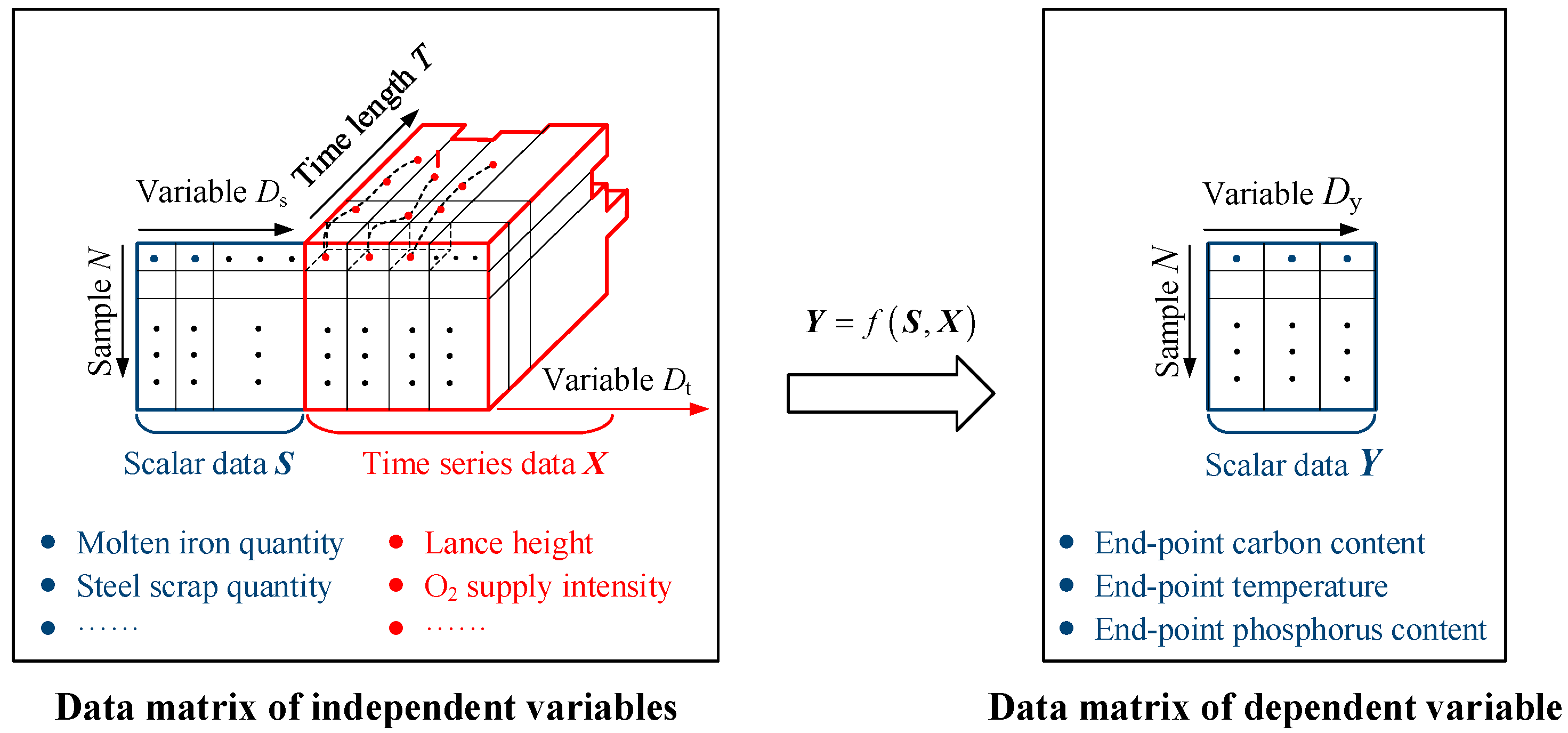
2. Problem Statement
- The BOF steelmaking process includes both scalar data such as raw material properties and time series data such as the process parameters of the blowing process. Traditional prediction models still have certain limitations in capturing the nonlinear and time-varying characteristics of steelmaking data containing mixed data types, especially time series data.
- The final carbon and phosphorous contents and temperature of steel are not only affected by a variety of input variables but also the complex non-linear coupling relationships between these property indicators. For example, the temperature will affect the decarburization rate and dephosphorization rate, which will in turn affect the carbon content and phosphorus content. At different blowing stages, changes in carbon content will have different effects on the dephosphorization rate. Traditional prediction models ignore the mutual coupling relationships between property indicators, and it is necessary to further improve the accuracy of the simultaneous prediction of multiple property indicators.
3. Methodology
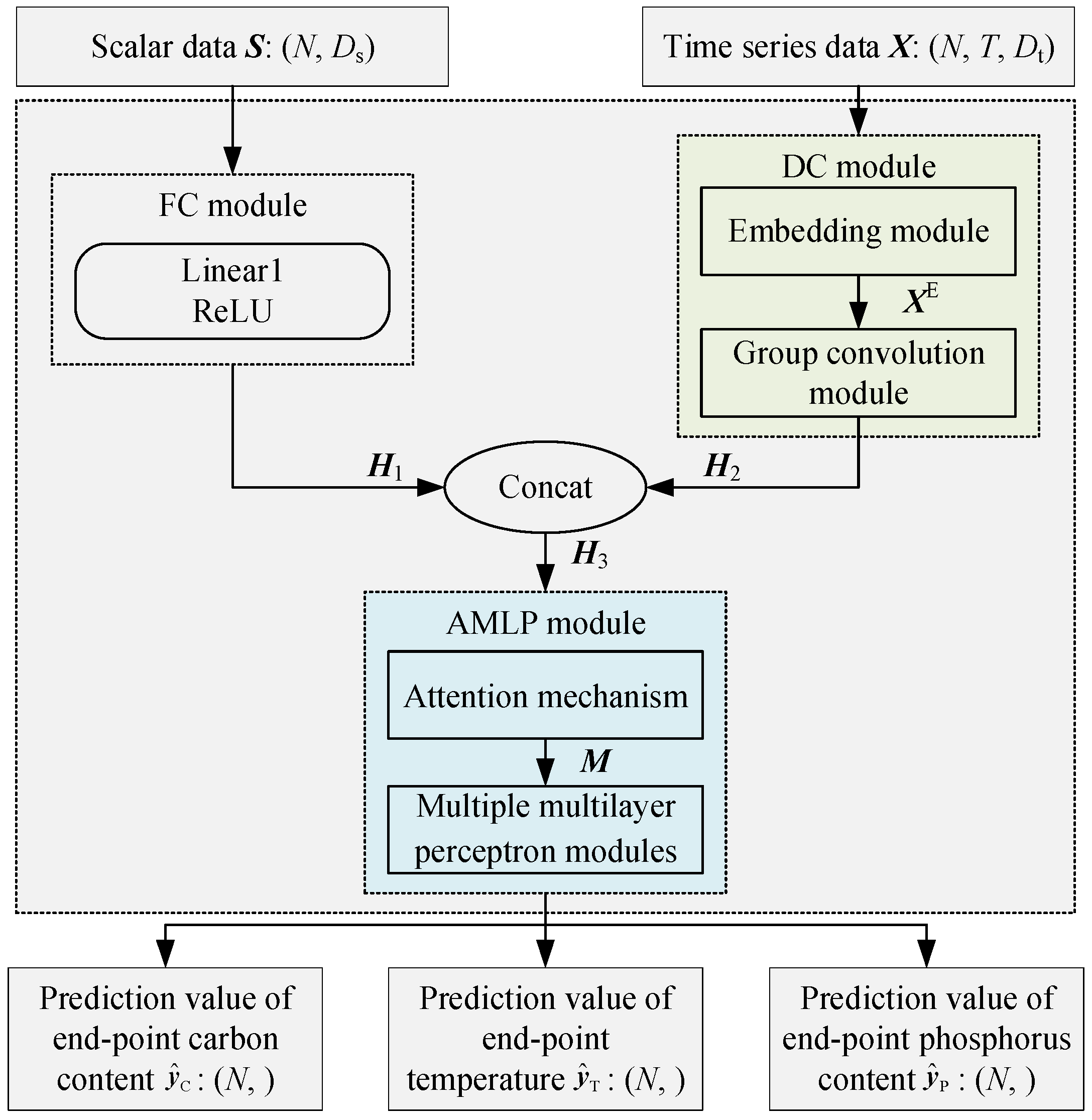
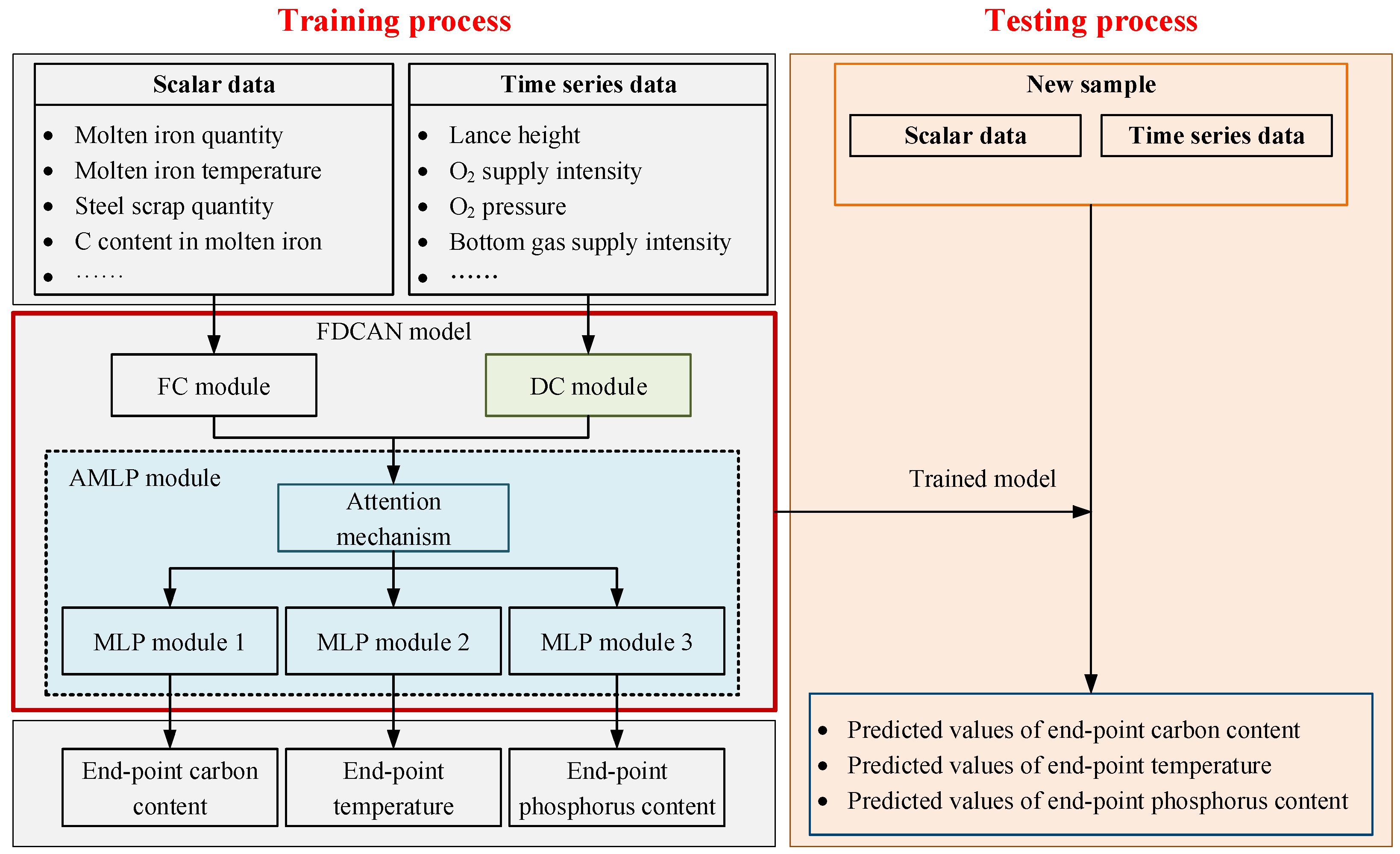
3.1. Network Structure
3.2. Deep Convolution Module
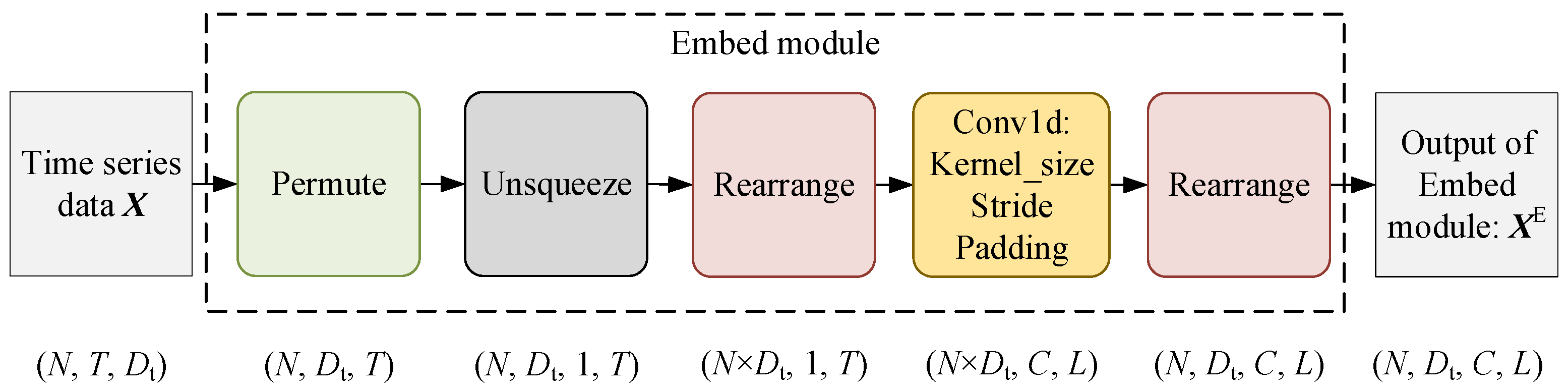
3.2.1. Embedding Module
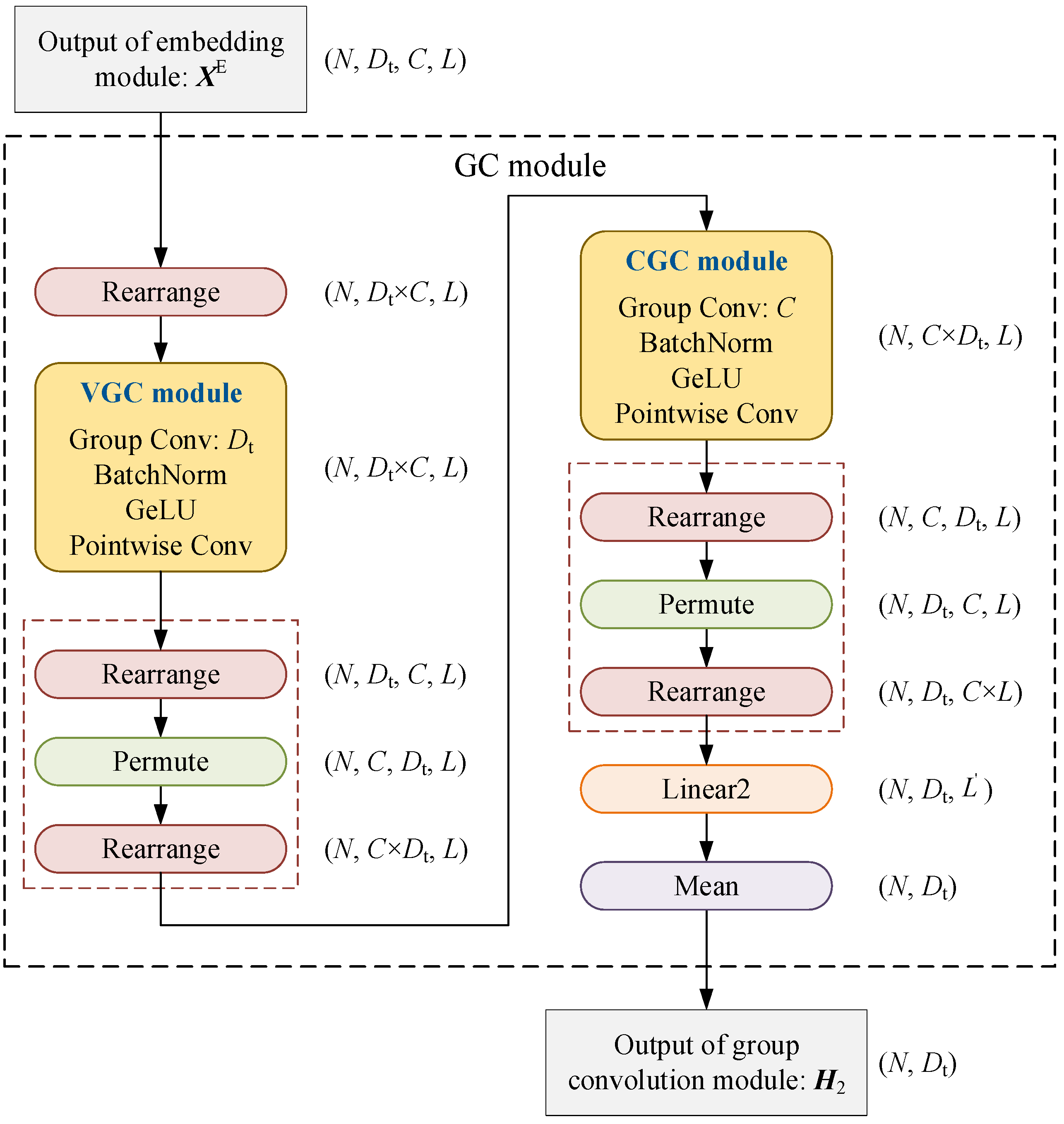
3.2.2. Group Convolution Module
3.3. Attention-Augmented Multi-Layer Perceptron Module
3.4. Flow of FDCAN
- Normalize the training set sample to eliminate the influence of dimension.
- Initialize the global parameters of the FDCAN model, including the maximum number of iteration epochs, the sample batch size, the learning rate lr, and the weight decay wd.
- Use the fully connected module to extract features of scalar data and obtain hidden features ;
- Use the embedding module and deep convolution module to extract the characteristics of time series data in the time dimension, variable dimension, and channel dimension to obtain hidden features ;
- Hidden features and are concatenated to obtain , which is input into the attention mechanism of the attention-augmented multi-layer perceptron module to obtain hidden features . Multiple multi-layer perceptron modules are used to predict multiple output variables.
- Employ the MSE loss to measure the difference between the predicted and real values. The Adam optimizer is applied to update the FDCAN model.
- Train the FDCAN model and obtain the prediction results of the training set.
- The maximum and minimum values of each variable in the training dataset are used to normalize the testing dataset.
- The trained FDCAN model is employed to obtain the predicted values of final carbon content, temperature, and phosphorus content of new samples in the testing dataset.
4. Experiment on BOF Steelmaking
4.1. Data Description
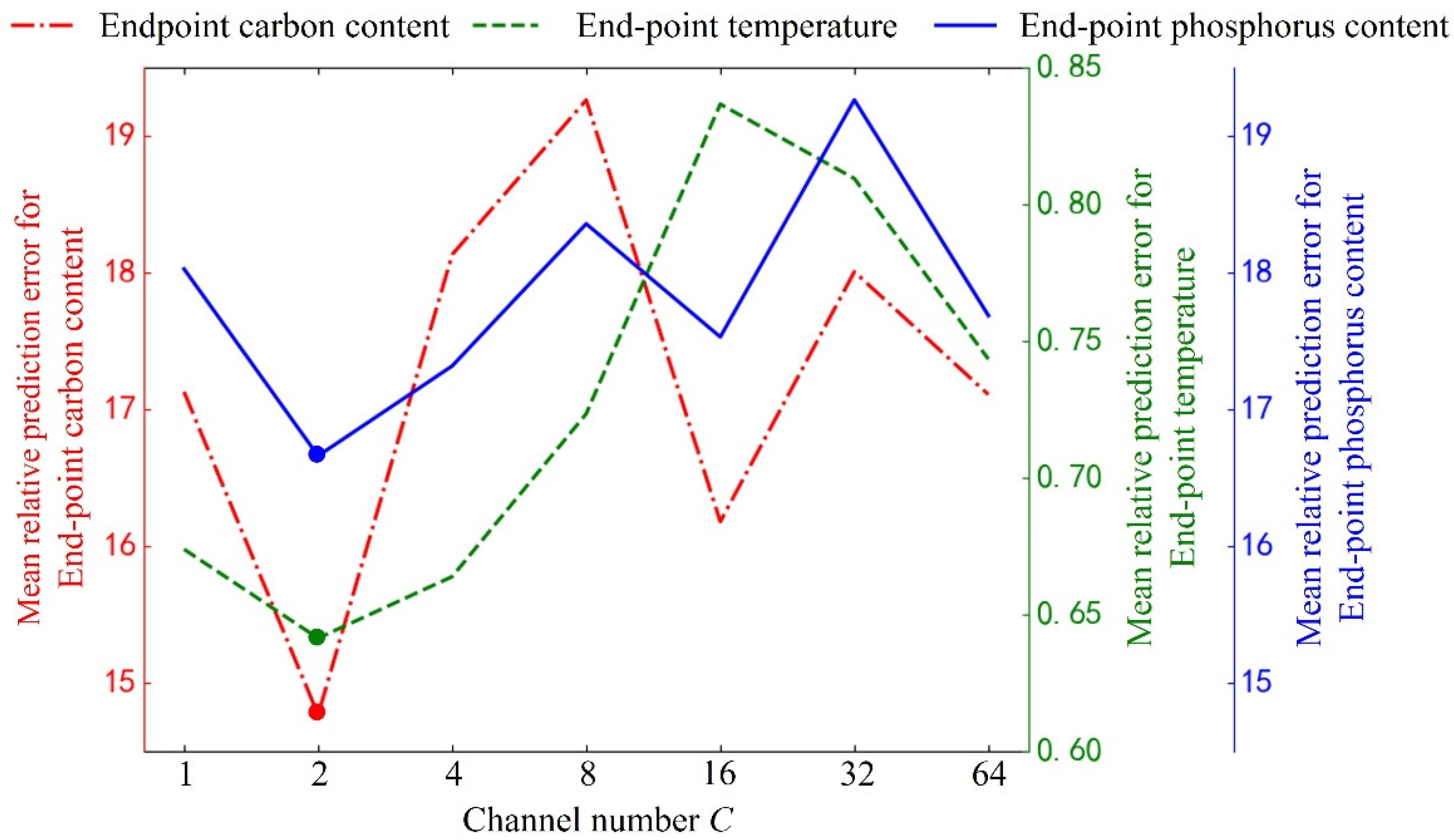
4.2. Parameter Settings
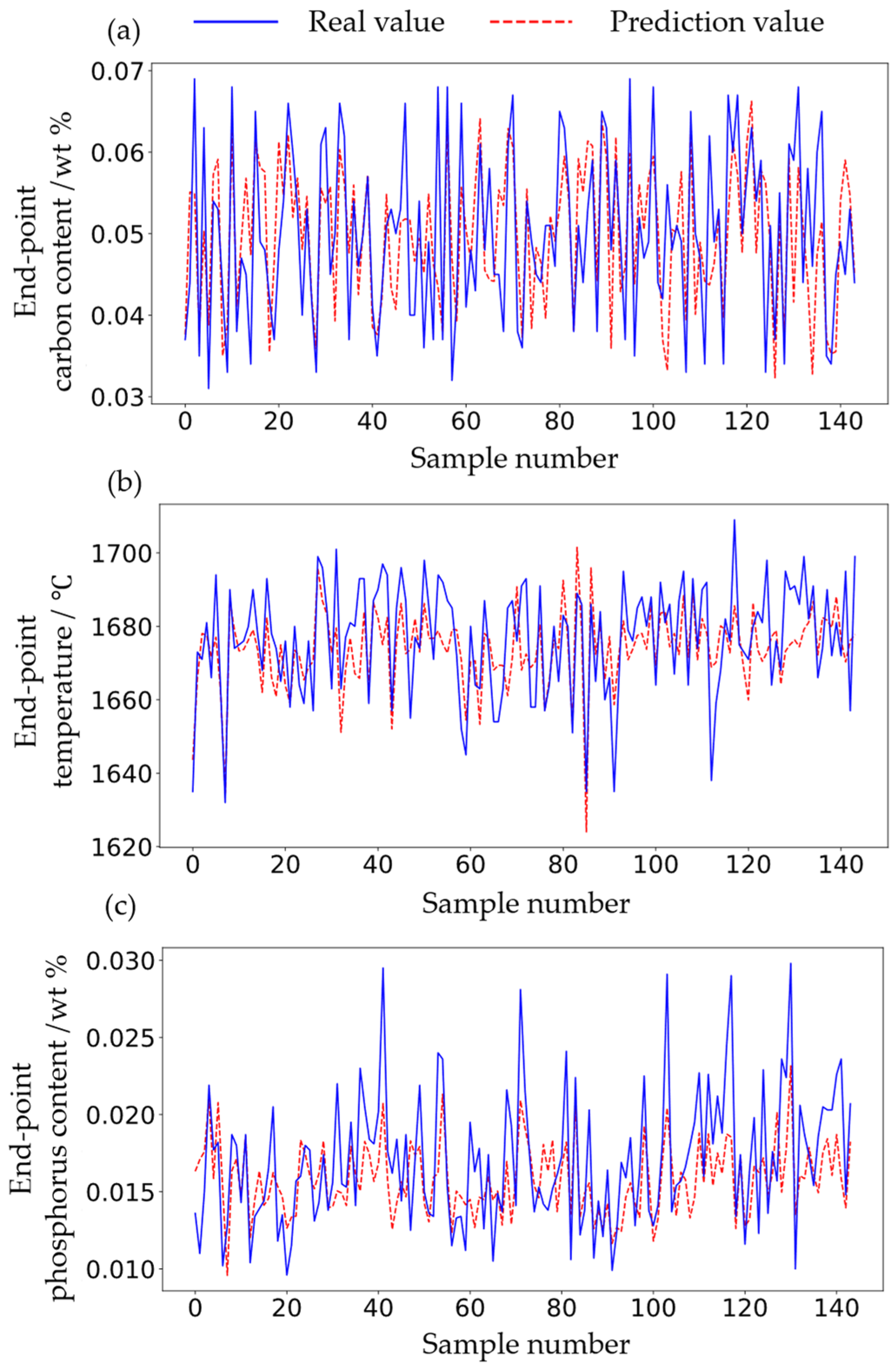
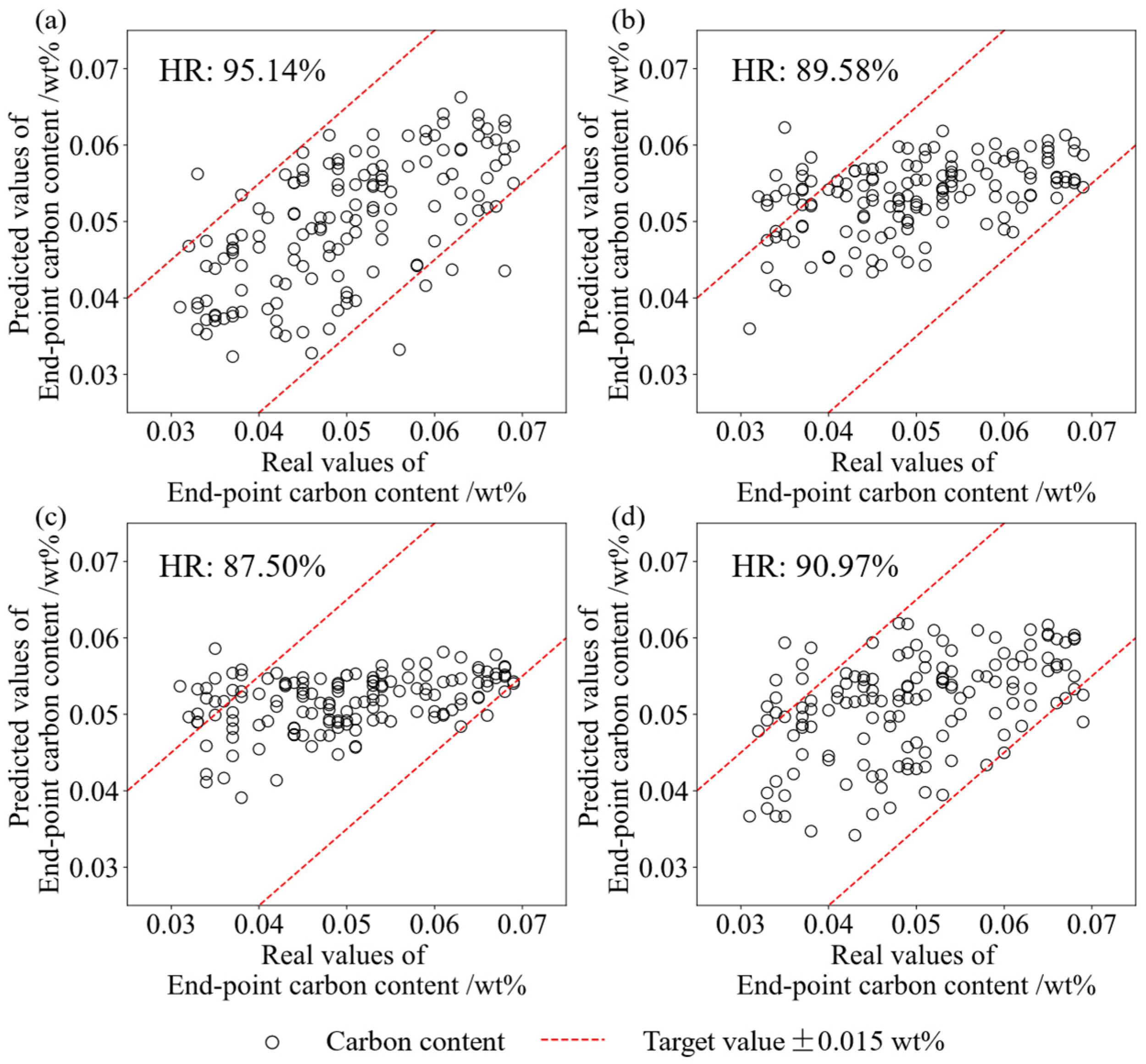
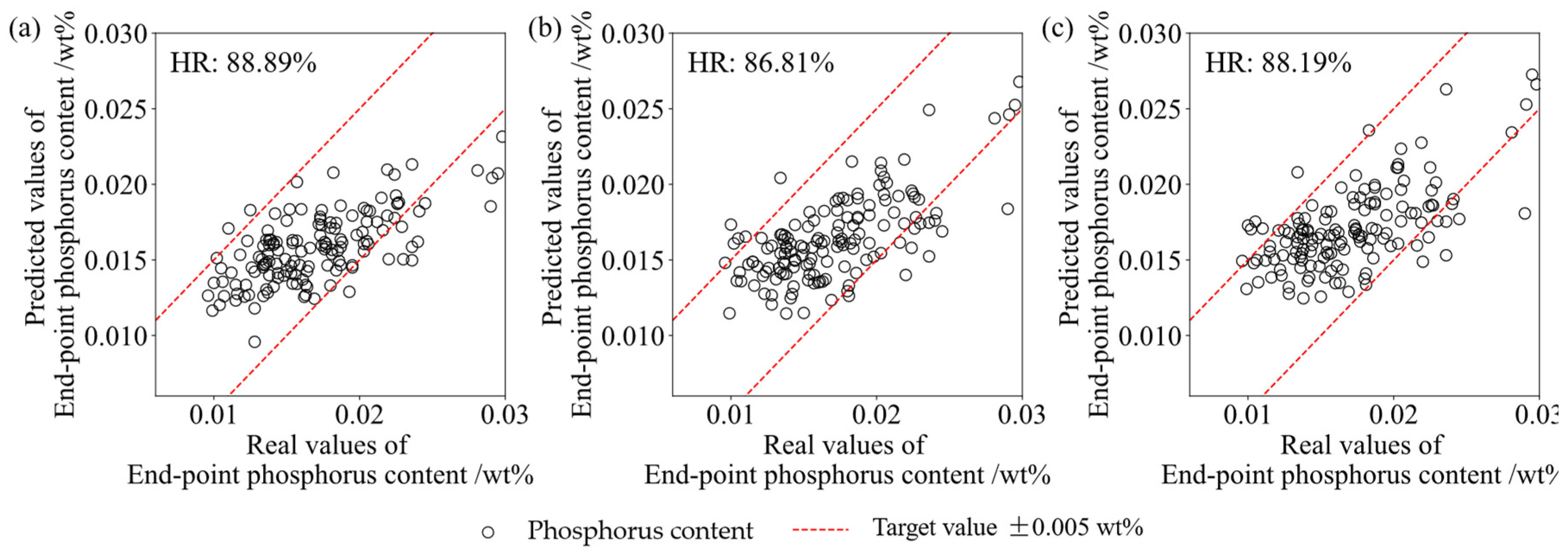
4.3. Prediction Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qian, Q.; Dong, Q.; Xu, J.; Zhao, W.; Li, M. A metallurgical dynamics-based method for production state characterization and end-point time prediction of basic oxygen furnace steelmaking. Metals 2022, 13, 2. [Google Scholar] [CrossRef]
- Wang, R.; Mohanty, I.; Srivastava, A.; Roy, T.K.; Gupta, P.; Chattopadhyay, K. Hybrid method for endpoint prediction in a basic oxygen furnace. Metals 2022, 12, 801. [Google Scholar] [CrossRef]
- Wang, Z.; Liu, Q.; Liu, H.; Wei, S. A review of end-point carbon prediction for BOF steelmaking process. High Temp. Mater. Process. 2020, 39, 653–662. [Google Scholar] [CrossRef]
- Guo, J.-W.; Zhan, D.-P.; Xu, G.-C.; Yang, N.-H.; Wang, B.; Wang, M.-X.; You, G.-W. An online BOF terminal temperature control model based on big data learning. J. Iron Steel Res. Int. 2023, 30, 875–886. [Google Scholar] [CrossRef]
- Barui, S.; Mukherjee, S.; Srivastava, A.; Chattopadhyay, K. Understanding dephosphorization in basic oxygen furnaces (BOFs) using data driven modeling techniques. Metals 2019, 9, 955. [Google Scholar] [CrossRef]
- Qing, X.; Niu, Y. Hourly day-ahead solar irradiance prediction using weather forecasts by LSTM. Energy 2018, 148, 461–468. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, B.; Gorban, A.N. Multivariate Gaussian and Student-t process regression for multi-output prediction. Neural Comput. Appl. 2020, 32, 3005–3028. [Google Scholar] [CrossRef]
- Li, H.; Barui, S.; Mukherjee, S.; Chattopadhyay, K. Least squares twin support vector machines to classify end-point phosphorus content in BOF steelmaking. Metals 2022, 12, 268. [Google Scholar] [CrossRef]
- Phull, J.; Egas, J.; Barui, S.; Mukherjee, S.; Chattopadhyay, K. An application of decision tree-based twin support vector machines to classify dephosphorization in bof steelmaking. Metals 2019, 10, 25. [Google Scholar] [CrossRef]
- Wang, Z.; Xie, F.; Wang, B.; Liu, Q.; Lu, X.; Hu, L.; Cai, F. The Control and Prediction of End-Point Phosphorus Content during BOF Steelmaking Process. Steel Res. Int. 2014, 85, 599–606. [Google Scholar] [CrossRef]
- Cai, X.-Y.; Duan, H.-J.; Li, D.-H.; Xu, A.-J.; Zhang, L.-F. Water modeling on fluid flow and mixing phenomena in a BOF steelmaking converter. J. Iron Steel Res. Int. 2024, 31, 595–607. [Google Scholar] [CrossRef]
- Schlautmann, M.; Kleimt, B.; Khadhraoui, S.; Hack, K.; Monheim, P.; Glaser, B.; Antonic, R.; Adderley, M.; Schrama, F. Dynamic on-line monitoring and end point control of dephosphorisation in the BOF converter. In Proceedings of the 3rd European Steel Technology and Application Days (ESTAD), Vienna, Austria, 26–29 June 2017. [Google Scholar]
- Feng, K.; Xu, A.; He, D.; Wang, H. An improved CBR model based on mechanistic model similarity for predicting end phosphorus content in dephosphorization converter. Steel Res. Int. 2018, 89, 1800063. [Google Scholar] [CrossRef]
- Li, G.-H.; Wang, B.; Liu, Q.; Tian, X.-Z.; Zhu, R.; Hu, L.-N.; Cheng, G.-G. A process model for BOF process based on bath mixing degree. Int. J. Miner. Metall. Mater. 2010, 17, 715–722. [Google Scholar] [CrossRef]
- Zhang, C.-J.; Zhang, Y.-C.; Han, Y. Industrial cyber-physical system driven intelligent prediction model for converter end carbon content in steelmaking plants. J. Ind. Inf. Integr. 2022, 28, 100356. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, J. State of the art in applications of machine learning in steelmaking process modeling. Int. J. Miner. Metall. Mater. 2023, 30, 2055–2075. [Google Scholar] [CrossRef]
- Gao, C.; Shen, M.; Liu, X.; Wang, L.; Chen, M. End-point prediction of BOF steelmaking based on KNNWTSVR and LWOA. Trans. Indian Inst. Met. 2019, 72, 257–270. [Google Scholar] [CrossRef]
- Liu, L.; Li, P.; Chu, M.; Gao, C. End-point prediction of 260 tons basic oxygen furnace (BOF) steelmaking based on WNPSVR and WOA. J. Intell. Fuzzy Syst. 2021, 41, 2923–2937. [Google Scholar] [CrossRef]
- Xin, Z.; Zhang, J.; Jin, Y.; Zheng, J.; Liu, Q. Predicting the alloying element yield in a ladle furnace using principal component analysis and deep neural network. Int. J. Miner. Metall. Mater. 2023, 30, 335–344. [Google Scholar] [CrossRef]
- Qi, L.; Liu, H.; Xiong, Q.; Chen, Z. Just-in-time-learning based prediction model of BOF endpoint carbon content and temperature via vMF mixture model and weighted extreme learning machine. Comput. Chem. Eng. 2021, 154, 107488. [Google Scholar] [CrossRef]
- Han, M.; Cao, Z. An improved case-based reasoning method and its application in endpoint prediction of basic oxygen furnace. Neurocomputing 2015, 149, 1245–1252. [Google Scholar] [CrossRef]
- Gao, C.; Shen, M.; Liu, X.; Zhao, N.; Chu, M. End-point dynamic control of basic oxygen furnace steelmaking based on improved unconstrained twin support vector regression. J. Iron Steel Res. Int. 2020, 27, 42–54. [Google Scholar] [CrossRef]
- Zhang, R.; Yang, J.; Wu, S.; Sun, H.; Yang, W. Comparison of the Prediction of BOF End-Point Phosphorus Content Among Machine Learning Models and Metallurgical Mechanism Model. Steel Res. Int. 2023, 94, 2200682. [Google Scholar] [CrossRef]
- Qian, Q.; Li, M.; Xu, J. Dynamic prediction of multivariate functional data based on functional kernel partial least squares. J. Process Control 2022, 116, 273–285. [Google Scholar] [CrossRef]
- Qian, Q.; Chang, F.; Dong, Q.; Li, M.; Xu, J. Dynamic Prediction with Statistical Uncertainty Evaluation of Phosphorus Content Based on Functional Relevance Vector Machine. Steel Res. Int. 2024, 95, 2300351. [Google Scholar] [CrossRef]
- Huang, C.; Dai, Z.; Sun, Y.; Wang, Z.; Liu, W.; Yang, S.; Li, J. Recognition of Converter Steelmaking State Based on Convolutional Recurrent Neural Networks. Metall. Mater. Trans. B 2024, 55, 1856–1868. [Google Scholar] [CrossRef]
- Yang, L.; Li, B.; Guo, Y.; Wang, S.; Xue, B.; Hu, S. Influence factor analysis and prediction model of end-point carbon content based on artificial neural network in electric arc furnace steelmaking process. Coatings 2022, 12, 1508. [Google Scholar] [CrossRef]
- Song, G.W.; Tama, B.A.; Park, J.; Hwang, J.Y.; Bang, J.; Park, S.J.; Lee, S. Temperature control optimization in a steel-making continuous casting process using a multimodal deep learning approach. Steel Res. Int. 2019, 90, 1900321. [Google Scholar] [CrossRef]
- Lu, Z.; Liu, H.; Chen, F.; Li, H.; Xue, X. BOF steelmaking endpoint carbon content and temperature soft sensor based on supervised dual-branch DBN. Meas. Sci. Technol. 2023, 35, 035119. [Google Scholar] [CrossRef]
- He, F.; Zhang, L. Prediction model of end-point phosphorus content in BOF steelmaking process based on PCA and BP neural network. J. Process Control 2018, 66, 51–58. [Google Scholar] [CrossRef]
- Liu, Z.; Cheng, S.; Liu, P. Prediction model of BOF end-point temperature and carbon content based on PCA-GA-BP neural network. Metall. Res. Technol. 2022, 119, 605. [Google Scholar] [CrossRef]
- Zhou, K.-X.; Lin, W.-H.; Sun, J.-K.; Zhang, J.-S.; Zhang, D.-Z.; Feng, X.-M.; Liu, Q. Prediction model of end-point phosphorus content for BOF based on monotone-constrained BP neural network. J. Iron Steel Res. Int. 2022, 29, 751–760. [Google Scholar] [CrossRef]
- Gu, M.; Xu, A.; Wang, H.; Wang, Z. Real-time dynamic carbon content prediction model for second blowing stage in BOF based on CBR and LSTM. Processes 2021, 9, 1987. [Google Scholar] [CrossRef]
- Wang, X.; Kan, M.; Shan, S.; Chen, X. Fully learnable group convolution for acceleration of deep neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Xie, T.-Y.; Zhang, C.-D.; Zhou, Q.-L.; Tian, Z.-Q.; Liu, S.; Guo, H.-J. TSC prediction and dynamic control of BOF steelmaking with state-of-the-art machine learning and deep learning methods. J. Iron Steel Res. Int. 2024, 31, 174–194. [Google Scholar] [CrossRef]
- Niu, T.; Wang, J.; Lu, H.; Yang, W.; Du, P. Developing a deep learning framework with two-stage feature selection for multivariate financial time series forecasting. Expert Syst. Appl. 2020, 148, 113237. [Google Scholar] [CrossRef]
- Triwiyanto, T.; Pawana, I.P.A.; Purnomo, M.H. An improved performance of deep learning based on convolution neural network to classify the hand motion by evaluating hyper parameter. IEEE Trans. Neural Syst. Rehabil. Eng. 2020, 28, 1678–1688. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Fang, Z.; Xiao, Y.; Hou, J.; Fu, Z. An intelligent fault diagnosis method for lithium battery systems based on grid search support vector machine. Energy 2021, 214, 118866. [Google Scholar] [CrossRef]
- Liland, K.H.; Skogholt, J.; Indahl, U.G. A new formula for faster computation of the k-fold cross-validation and good regularisation parameter values in Ridge Regression. IEEE Access 2024, 12, 17349–17368. [Google Scholar] [CrossRef]
- Shi, C.; Guo, S.; Wang, B.; Ma, Z.; Wu, C.L.; Sun, P. Prediction model of BOF end-point phosphorus content and sulfur content based on LWOA-TSVR. Ironmak. Steelmak. 2023, 50, 857–866. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbols | Data Type | Variable Name | Sampling Frequency/Hz | Min | Max | Mean |
|---|---|---|---|---|---|---|
| v1 | Scalar | Steel scrap quantity/t | / | 24.48 | 64.94 | 44.41 |
| v2 | Molten iron quantity/t | / | 213.77 | 269.11 | 242.58 | |
| v3 | Molten iron temperature/°C | / | 1232 | 1407 | 1327.28 | |
| v4 | C content in molten iron/wt% | / | 3.9 | 4.82 | 4.48 | |
| v5 | Si content in molten iron/wt% | / | 0.08 | 0.65 | 0.35 | |
| v6 | Mn content in molten iron/wt% | / | 0.08 | 0.20 | 0.13 | |
| v7 | P content in molten iron/wt% | / | 0.06 | 0.15 | 0.10 | |
| v8 | S content in molten iron/wt% | / | 0.001 | 0.015 | 0.004 | |
| v9 | TSC C content/wt% | / | 0.07 | 0.855 | 0.42 | |
| v10 | TSC temperature/°C | / | 1541 | 1673 | 1609.22 | |
| v11 | Target tapping temperature/°C | / | 1620 | 1705 | 1675.92 | |
| v12 | Time series | Lance height/cm | 0.5 | 167 | 393 | / |
| v13 | O2 supply intensity/(m3 · t−1·min−1) | 0.5 | 2.00 | 4.66 | / | |
| v14 | O2 pressure/MPa | 0.5 | 1.04 | 1.50 | / | |
| v15 | Bottom gas supply intensity/(m3 · t−1·min−1) | 0.5 | 0.002 | 0.104 | / | |
| v16 | Amount of slagging agent/kg | 0.5 | 0 | 20,530 | / | |
| v17 | Amount of coolant/kg | 0.5 | 0 | 8430 | / | |
| yC | Scalar | TSO C content/wt% | / | 0.02 | 0.07 | 0.05 |
| yT | TSO temperature/°C | / | 1626 | 1714 | 1675.09 | |
| yP | TSO P content/wt% | / | 0.006 | 0.030 | 0.016 |
| Network | Name | Shape of Input Data | Number of Output Features | Shape of Output Data | Parameters |
|---|---|---|---|---|---|
| FC module | Linear1 | (64,12) | 64 | (64,64) | / |
| Embed module | Conv1d | (64×6,1,605) | 2 | (64×6,2,151) | kernel_size = 8 stride = 4 padding = (0,4) |
| GC module | Group Conv1d1 | (64,6×2,151) | 12 | (64,6×2,151) | kernel_size = 1, stride = 1, groups = 6 |
| Pointwise Conv1d1 | (64,6×2,151) | 12 | (64,6×2,151) | kernel_size = 1, stride = 1 | |
| Group Conv1d2 | (64,2×6,151) | 12 | (64,2×6,151) | kernel_size = 1, stride = 1, groups = 2 | |
| Pointwise Conv1d2 | (64,2×6,151) | 12 | (64,2×6,151) | kernel_size = 1, stride = 1 | |
| Linear2 | (64,6,302) | 20 | (64,6,20) | / | |
| AMLP module | Linear3 | (64,70) | 70 | (64,70) | / |
| Linear4 | (64,70) | 32 | (64,32) | / | |
| Linear5 | (64,32) | 1 | (64,1) | / | |
| Linear6 | (64,70) | 32 | (64,32) | / | |
| Linear7 | (64,32) | 1 | (64,1) | / | |
| Linear8 | (64,70) | 32 | (64,32) | / | |
| Linear9 | (64,32) | 1 | (64,1) | / |
| No. | Model | * | * | * | Remarks |
|---|---|---|---|---|---|
| 1 | FDCAN | 13.99 | 0.57 | 15.78 | Simultaneous prediction model of final carbon content, temperature, and phosphorus content |
| 2 | ANN | 18.24 | / | / | Carbon content prediction model |
| 3 | DCNN | / | 0.51 | / | Temperature prediction model |
| 4 | SD-DBN | 17.56 | 0.58 | / | Simultaneous prediction model of final carbon content and temperature |
| 5 | PCA-BP | / | / | 15.82 | Phosphorus content prediction model |
| 6 | MC-BP | / | / | 16.74 | Phosphorus content prediction model |
| 7 | LSTM | 17.44 | / | / | Carbon content prediction model |
| No. | Model | Hit Rate of [C]/% | Hit Rate of [T]/% | Hit Rate of [P]/% | Number of Parameters | Computation Efficiency | |
|---|---|---|---|---|---|---|---|
| Training/s | Testing/ms | ||||||
| 1 | FDCAN | 95.14 | 84.72 | 88.89 | 19,643 | 63.525 | 0.692 |
| 2 | ANN | 89.58 | / | / | 24,897 | 127.402 | 0.894 |
| 3 | DCNN | / | 85.42 | / | 54,081 | 455.379 | 1.850 |
| 4 | SD-DBN | 87.50 | 81.94 | / | 32,450 | 349.968 | 1.493 |
| 5 | PCA-BP | / | / | 86.81 | 25,025 | 66.059 | 0.751 |
| 6 | MC-BP | / | / | 88.19 | 30,465 | 79.163 | 0.743 |
| 7 | LSTM | 90.97 | / | / | 28,135 | 56.303 | 0.634 |
| No. | Structural Description | Hit Rate of [C]/% | Hit Rate of [T]/% | Hit Rate of [P]/% |
|---|---|---|---|---|
| 1 | FDCAN model | 95.14 | 84.72 | 88.89 |
| 2 | Remove the Embed module | 70.83 | 75.69 | 80.56 |
| 3 | Remove the GC module | 85.42 | 57.64 | 81.25 |
| 4 | Remove the attention mechanism | 81.94 | 75.69 | 85.42 |
| 5 | Remove the MLP module | 80.56 | 70.14 | 75.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Q.; Li, M.; Hu, S.; Yu, Y.; Gu, M. Multi-Output Prediction Model for Basic Oxygen Furnace Steelmaking Based on the Fusion of Deep Convolution and Attention Mechanisms. Metals 2024, 14, 773. https://doi.org/10.3390/met14070773
Dong Q, Li M, Hu S, Yu Y, Gu M. Multi-Output Prediction Model for Basic Oxygen Furnace Steelmaking Based on the Fusion of Deep Convolution and Attention Mechanisms. Metals. 2024; 14(7):773. https://doi.org/10.3390/met14070773
Chicago/Turabian StyleDong, Qianqian, Min Li, Shuaijie Hu, Yan Yu, and Maoqiang Gu. 2024. "Multi-Output Prediction Model for Basic Oxygen Furnace Steelmaking Based on the Fusion of Deep Convolution and Attention Mechanisms" Metals 14, no. 7: 773. https://doi.org/10.3390/met14070773
APA StyleDong, Q., Li, M., Hu, S., Yu, Y., & Gu, M. (2024). Multi-Output Prediction Model for Basic Oxygen Furnace Steelmaking Based on the Fusion of Deep Convolution and Attention Mechanisms. Metals, 14(7), 773. https://doi.org/10.3390/met14070773