
Research on Performance Prediction Method of Refractory High-Entropy Alloy Based on Ensemble Learning



Abstract

1. Introduction
2. Material and Methods
2.1. Data Acquisition and Preprocessing
2.1.1. Data Preprocessing
- (1)
- Outlier Sample Elimination
- (2)
- High Missing-Value Feature Processing
- (3)
- Redundant feature processing
- (4)
- Stress type standardization
- (5)
- Data filling
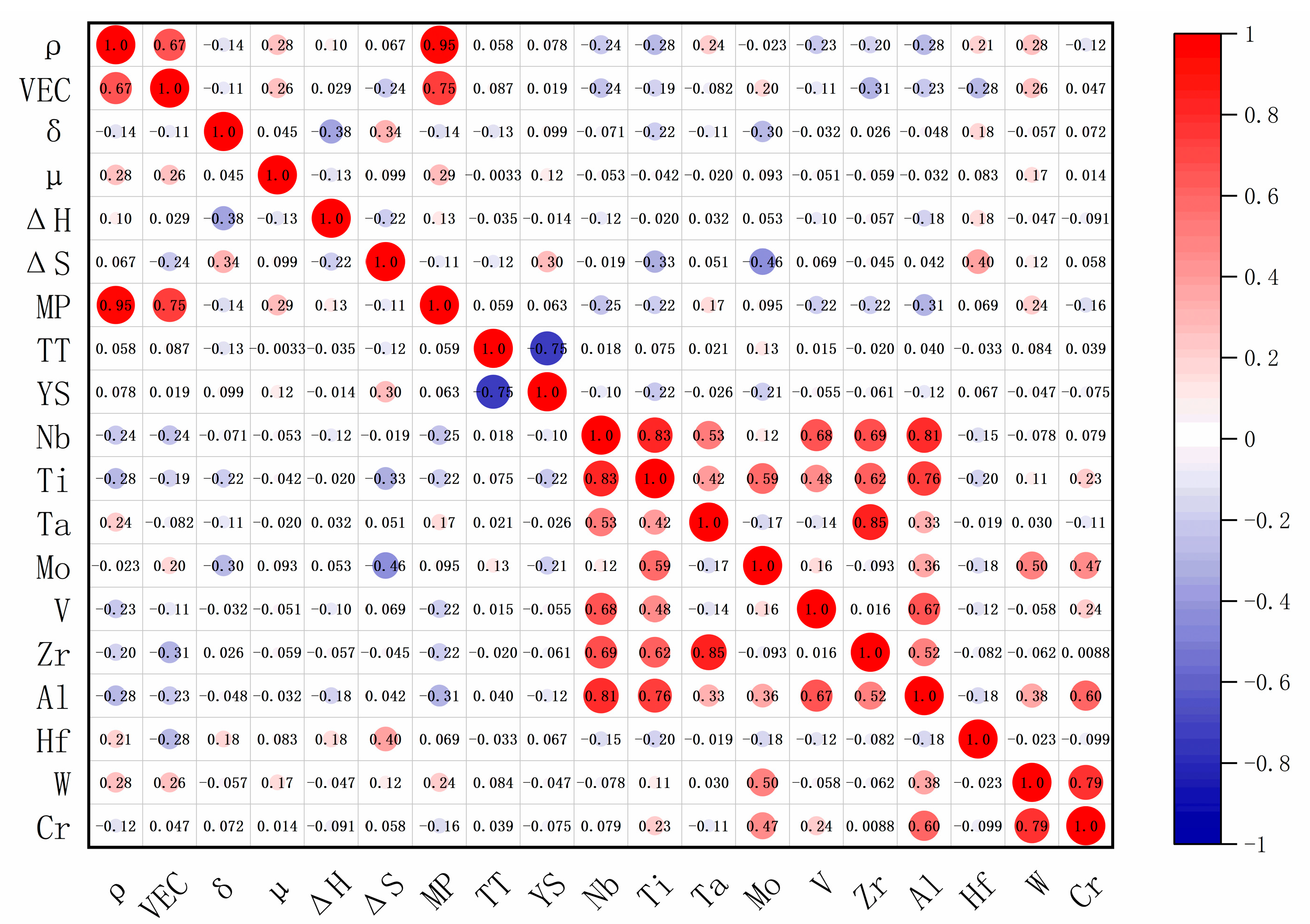
2.1.2. Feature Screening
2.2. Model Building and Optimization
2.2.1. Model Introduction
- (1)
- AdaB: This model is an ensemble learning method, and its core principle is to assign different weights to each weak learner by combining multiple weak learners. During the training process, AdaB gradually adjusts the model, focusing the learning on those samples that are difficult to predict. Through continuous iteration, multiple weak learners are eventually combined into one strong learner. This method can effectively improve the prediction ability of the model, especially for dealing with complex datasets.
- (2)
- LR: This model assumes a linear relationship between the dependent and independent variables and fits the data by minimizing the squared error between the predicted and actual values. It is a simple and intuitive regression model that has the advantage of being easy to understand and interpret. When the data show an obvious linear trend, the linear regression model can often achieve better results.
- (3)
- DT: The decision tree regression model divides the feature space into different regions recursively and assigns a predicted value to each region, so as to build a model with a tree structure. The advantage of decision trees is that they can deal with nonlinear relations and can intuitively show the relationship between features. However, it is also prone to overfitting problems, especially when the depth of the tree is large.
- (4)
- RF: The random forest regression model is an integrated learning method based on decision trees, which constructs multiple decision trees and introduces randomness into the training process. In the prediction, random forest will integrate the prediction results of each decision tree by means of average or voting, so as to improve the stability and generalization ability of the model. Random forest can effectively deal with high-dimensional data and complex nonlinear relationships and has strong robustness to outliers.
- (5)
- KR: Nuclear ridge regression combines the advantages of nuclear technique and ridge regression. It solves the nonlinear regression problem by mapping the data to the high-dimensional space and transforming the nonlinear problem into a linear problem for processing. At the same time, the regularization term is introduced in a kernel ridge regression, which can effectively prevent overfitting and improve the generalization ability of the model.
- (6)
- SVR: Support vector regression is based on the idea of support vector machines by finding a function that fits the data as best as possible while maintaining a balance between model complexity and prediction error. SVR can deal with nonlinear relations and has a good performance when dealing with high-dimensional data.
- (7)
- XGB: XGB is an efficient gradient lifting framework and integrated learning method based on a decision tree. It works by iteratively training a series of decision trees, each optimized on the basis of the previous tree to minimize the loss function. On the basis of the traditional gradient lifting algorithm, XGB performs a number of optimizations, including adding regularization terms to the objective function to prevent overfitting and adopting parallelization and hardware optimization techniques in the calculation process to improve the training efficiency and model performance. Its characteristics include high efficiency, high accuracy, and strong flexibility. It can process various types of data, including sparse data and distributed data and support custom loss functions and evaluation indicators, and is suitable for a variety of tasks such as classification, regression, etc., but parameter tuning is more complex and requires certain experience and skills.
- (8)
- GBM: GBM is an iterative decision tree integration algorithm that corrects the prediction error of the previous tree by gradually adding new decision trees, thereby minimizing the loss function. Each step builds a new decision tree based on the gradient direction of the current model to gradually approximate the optimal model. Its features include being able to deal with complex nonlinear relationships, having certain robustness to outliers in data, and strong generalization ability, but the training time is long, the parameter selection is more sensitive, and the parameter optimization is difficult.
- (9)
- LGBM: LGBM is a decision tree algorithm based on gradient lifting, employing a method called “gradient basis learning”. Different from traditional GBM, LGBM uses a histogram algorithm and feature parallelism to construct a decision tree, which makes training faster and memory consumption lower. By discretizing the continuous eigenvalues into bins of the histogram, the computation is reduced, and the sampling method based on feature importance is adopted in feature selection, which improves the efficiency and performance of the model. Its features include a fast training speed, low memory consumption, efficient processing of large-scale data, support for distributed training, good adaptability to high-dimensional data and large-scale datasets, parameter tuning that still requires a certain amount of experience, high data quality requirements, and the need for appropriate preprocessing.
2.2.2. Model Training Details
- (1)
- Dataset splitting
- (2)
- Normalization
- (3)
- Development Environment Configuration
2.2.3. Hyperparameter Optimization
3. Test Results and Analysis
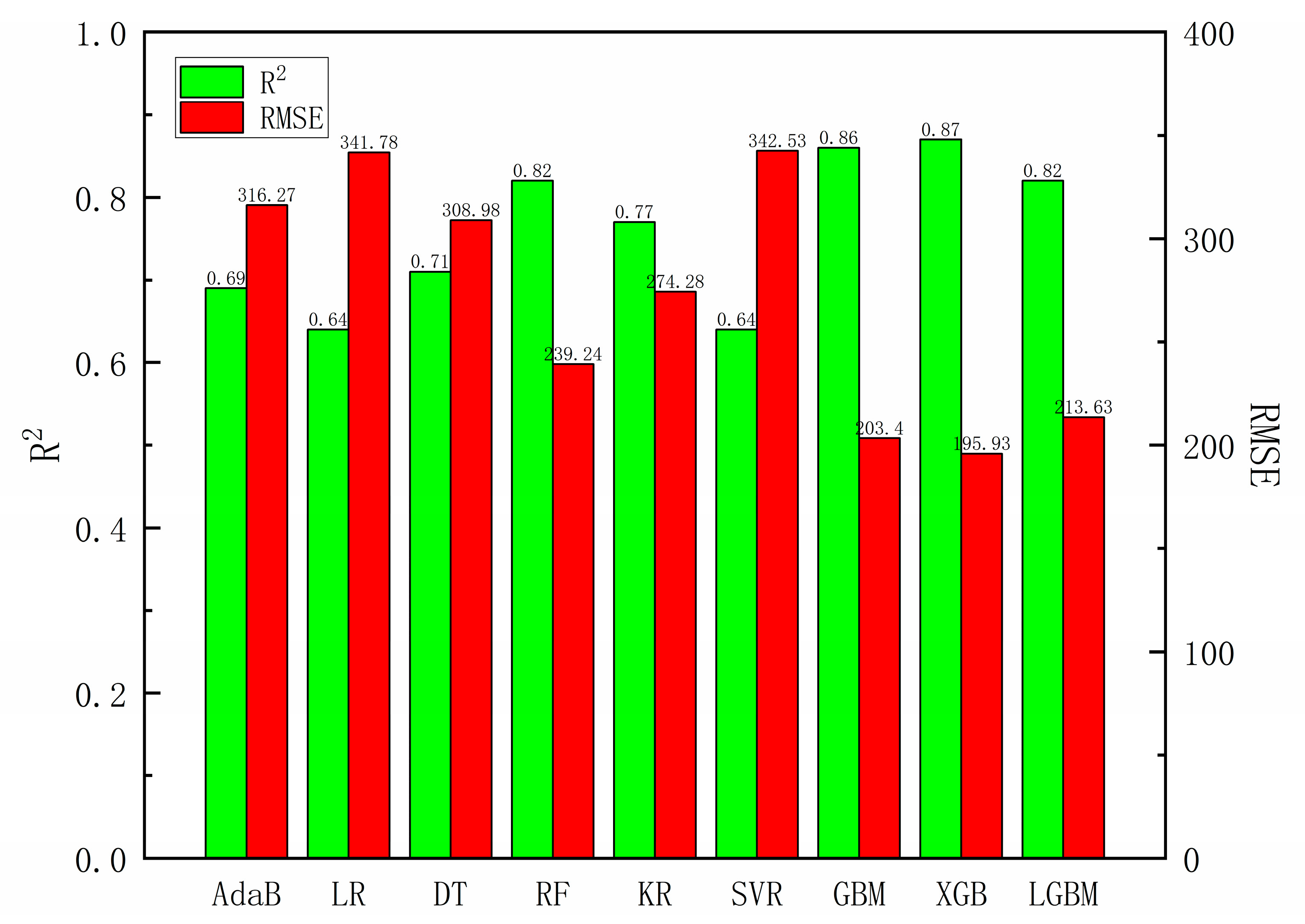
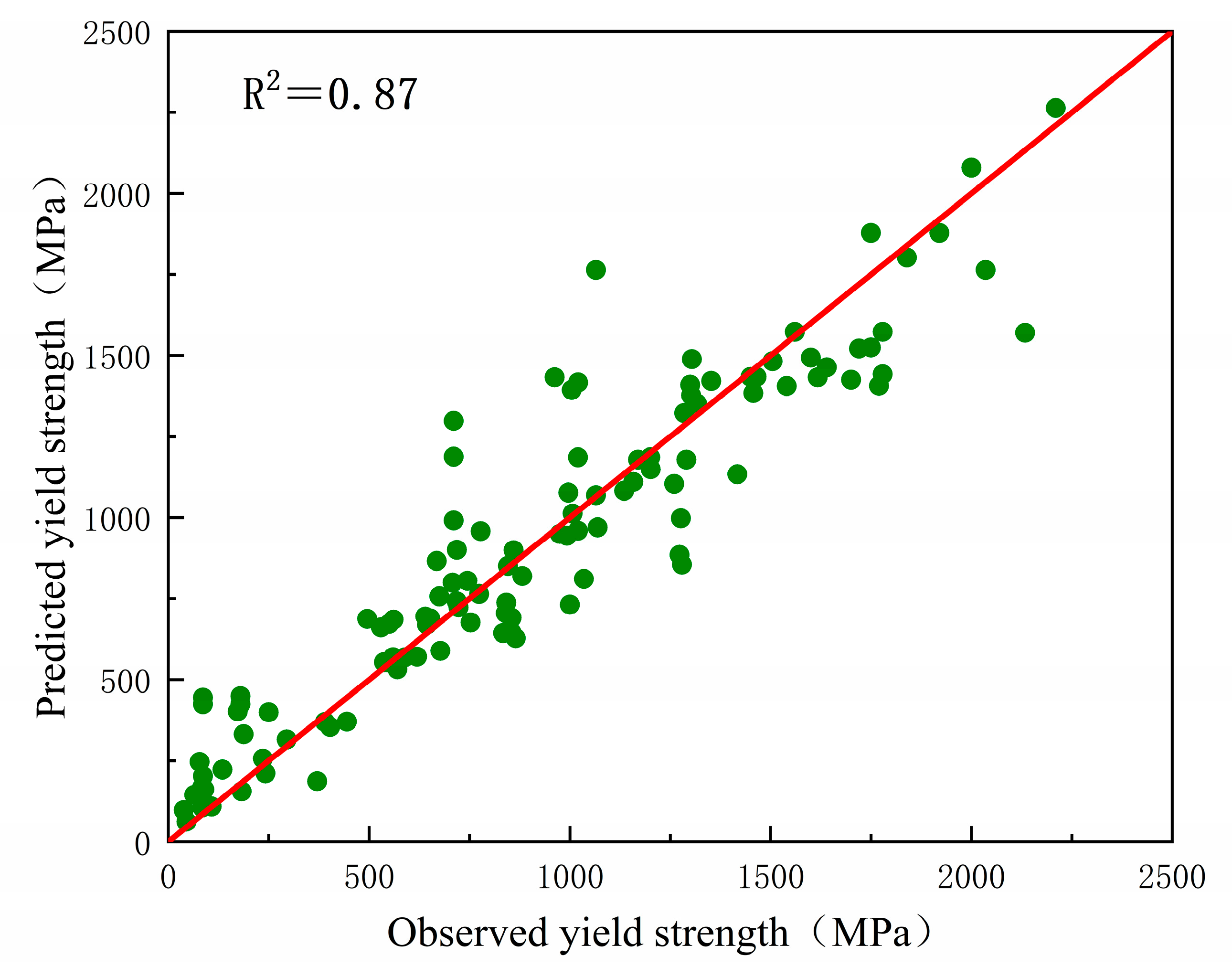
3.1. Model Evaluation
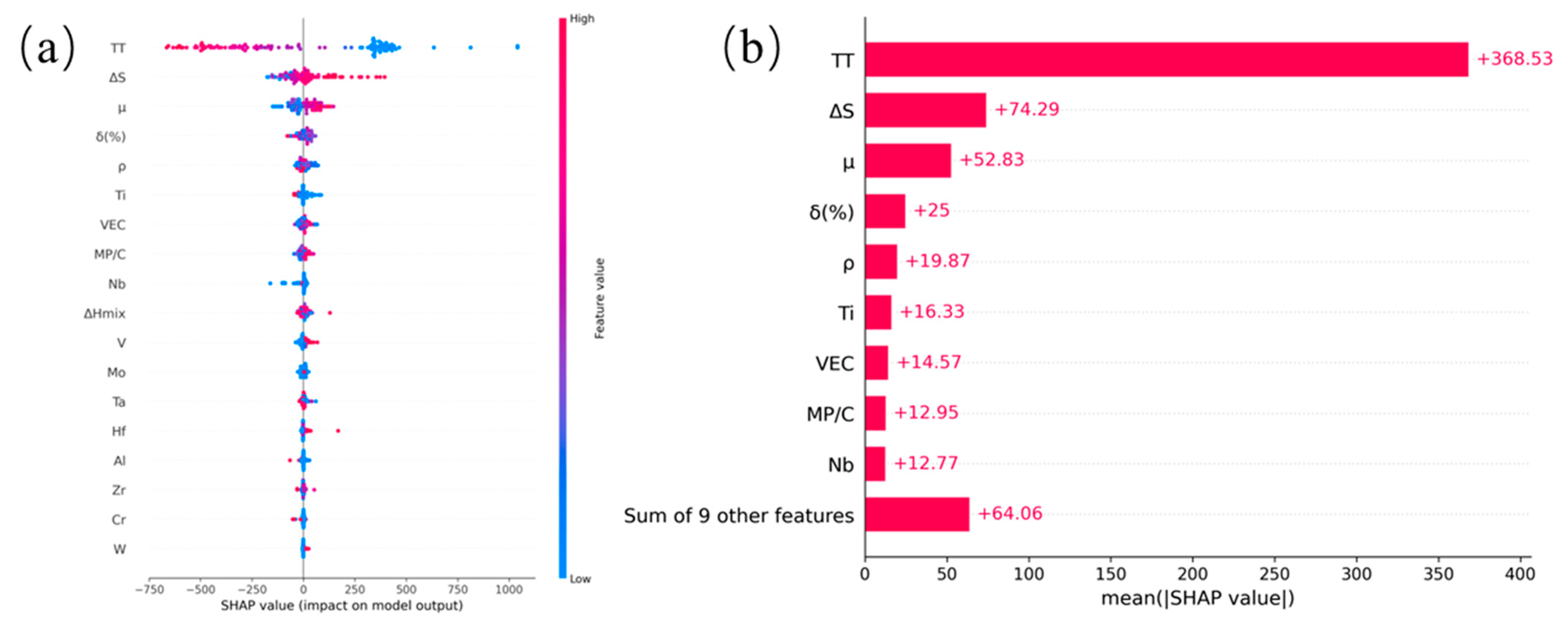
3.2. SHAP Analysis
3.3. Model Application
4. Conclusions
- (1)
- A total of 652 sets of high-entropy alloy data were collected and processed, and the composition, property, and performance dataset of refractory high-entropy alloy was established. The key parameters that affect the mechanical properties of the refractory high-entropy alloy, including atomic size difference (δ), test temperature (TT), mixing entropy (ΔS), titanium (Ti) and molybdenum (Mo), were determined by correlation analysis of the dataset.
- (2)
- Based on the literature data, nine kinds of machine learning models were established, and the optimal hyperparameters were found by the combination of grid search and Bayesian optimization. The XGB model was selected as the prediction model for the mechanical properties of the high-entropy alloy, and the R2 and RMSE of the model reached 0.87 and 195.67 Mpa, respectively. The average prediction error of the XGB model was 12.62% through internal evaluation of randomly selected test set samples. By vacuum arc melting preparation, Ti27.5Zr26.5Nb25.5Ta8.5Al12 refractory high-entropy alloys were prepared for external data validation. The yield strength was 1365 MPa, the alloy experiment models predicted a yield strength of 1304.71 MPa, and the prediction model’s error was 3.8%. The results show that the model has a strong ability to predict the yield strength of the unknown high-entropy alloy.
- (3)
- SHAP interpretable analysis of the model shows that the absolute values of TT, ΔS, and μ are 368.53, 74.29, and 52.83, respectively, which are significantly higher than other features. These results indicate that TT, ΔS, and μ have a great influence on the yield strength of refractory high-entropy alloys. In the subsequent material design, materials with desired properties can be synthesized by adjusting these three parameters.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Senkov, O.N.; Isheim, D.; Seidman, D.N.; Pilchak, A.L. Development of a Refractory High Entropy Superalloy. Entropy 2016, 18, 102. [Google Scholar] [CrossRef]
- Tan, C.; Weng, F.; Sui, S.; Chew, Y.; Bi, G. Progress and perspectives in laser additive manufacturing of key aeroengine materials. Int. J. Mach. Tools Manuf. 2021, 170, 103804. [Google Scholar] [CrossRef]
- Zhang, X.S.; Chen, Y.J.; Hu, J.L. Recent advances in the development of aerospace materials. Prog. Aerosp. Sci. 2018, 97, 22–34. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, S.; Yang, S.; Luo, Q.; Jin, Y.; Xie, W.; Zhang, L.; Li, Q. Light-weight refractory high-entropy alloys: A comprehensive review. J. Mater. Sci. Technol. 2023, 151, 41–65. [Google Scholar] [CrossRef]
- Senkov, O.N.; Wilks, G.B.; Miracle, D.B.; Chuang, C.P.; Liaw, P.K. Refractory high-entropy alloys. Intermetallics 2010, 18, 1758–1765. [Google Scholar] [CrossRef]
- Maiti, S.; Steurer, W. Structural-disorder and its effect on mechanical properties in single-phase TaNbHfZr high-entropy alloy. Acta Mater. 2016, 106, 87–97. [Google Scholar] [CrossRef]
- Wang, M.L.; Lu, Y.P.; Lan, J.G.; Wang, T.M.; Zhang, C.; Cao, Z.Q.; Li, T.J.; Liaw, P.K. Lightweight, ultrastrong and high thermal-stable eutectic high-entropy alloys for elevated-temperature applications. Acta Mater. 2023, 248, 118806. [Google Scholar] [CrossRef]
- Yao, H.W.; Qiao, J.W.; Hawk, J.A.; Zhou, H.F.; Chen, M.W.; Gao, M.C. Mechanical properties of refractory high-entropy alloys: Experiments and modeling. J. Alloys Compd. 2017, 696, 1139–1150. [Google Scholar] [CrossRef]
- Li, T.; Chen, J.-X.; Liu, T.-W.; Chen, Y.; Luan, J.-H.; Jiao, Z.-B.; Liu, C.-T.; Dai, L.-H. D022 precipitates strengthened W-Ta-Fe-Ni refractory high-entropy alloy. J. Mater. Sci. Technol. 2024, 177, 85–95. [Google Scholar] [CrossRef]
- Xiong, W.; Guo, A.X.Y.; Zhan, S.; Liu, C.T.; Cao, S.C. Refractory high-entropy alloys: A focused review of preparation methods and properties. J. Mater. Sci. Technol. 2023, 142, 196–215. [Google Scholar] [CrossRef]
- Karantzalis, A.E.; Poulia, A.; Georgatis, E.; Petroglou, D. Phase formation criteria assessment on the microstructure of a new refractory high entropy alloy. Scr. Mater. 2017, 131, 51–54. [Google Scholar] [CrossRef]
- Han, Z.D.; Chen, N.; Zhao, S.F.; Fan, L.W.; Yang, G.N.; Shao, Y.; Yao, K.F. Effect of Ti additions on mechanical properties of NbMoTaW and VNbMoTaW refractory high entropy alloys. Intermetallics 2017, 84, 153–157. [Google Scholar] [CrossRef]
- Juan, C.C.; Tsai, M.H.; Tsai, C.W.; Lin, C.M.; Wang, W.R.; Yang, C.C.; Chen, S.K.; Lin, S.J.; Yeh, J.W. Enhanced mechanical properties of HfMoTaTiZr and HfMoNbTaTiZr refractory high-entropy alloys. Intermetallics 2015, 62, 76–83. [Google Scholar] [CrossRef]
- Singh, P.; Vela, B.; Ouyang, G.; Argibay, N.; Cui, J.; Arroyave, R.; Johnson, D.D. A ductility metric for refractory-based multi-principal-element alloys. Acta Mater. 2023, 257, 119104. [Google Scholar] [CrossRef]
- Guo, S.; Ng, C.; Lu, J.; Liu, C.T. Effect of valence electron concentration on stability of fcc or bcc phase in high entropy alloys. J. Appl. Phys. 2011, 109, 103505. [Google Scholar] [CrossRef]
- Catal, A.A.; Bedir, E.; Yilmaz, R.; Swider, M.A.; Lee, C.; El-Atwani, O.; Maier, H.J.; Ozdemir, H.C.; Canadinc, D. Machine learning assisted design of novel refractory high entropy alloys with enhanced mechanical properties. Comput. Mater. Sci. 2024, 231, 112612. [Google Scholar] [CrossRef]
- Yan, Y.G.; Lu, D.; Wang, K. Accelerated discovery of single-phase refractory high entropy alloys assisted by machine learning. Comput. Mater. Sci. 2021, 199, 110723. [Google Scholar] [CrossRef]
- Wen, C.; Zhang, Y.; Wang, C.; Huang, H.; Wu, Y.; Lookman, T.; Su, Y. Machine-Learning-Assisted Compositional Design of Refractory High-Entropy Alloys with Optimal Strength and Ductility. Engineering 2024, 46, 214–223. [Google Scholar] [CrossRef]
- Debnath, A.; Krajewski, A.M.; Sun, H.; Lin, S.; Ahn, M.; Li, W.J.; Priya, S.; Singh, J.; Shang, S.L.; Beese, A.M.; et al. Generative deep learning as a tool for inverse design of high entropy refractory alloys. J. Mater. Inform. 2021, 1, 3. [Google Scholar] [CrossRef]
- Qu, N.; Zhang, Y.; Liu, Y.; Liao, M.Q.; Han, T.Y.; Yang, D.N.; Lai, Z.H.; Zhu, J.C.; Yu, L. Accelerating phase prediction of refractory high entropy alloys via machine learning. Phys. Scr. 2022, 97, 125710. [Google Scholar] [CrossRef]
- Cheng, C.; Zou, Y. Accelerated discovery of nanostructured high-entropy alloys and multicomponent alloys via high-throughput strategies. Prog. Mater. Sci. 2025, 151, 101429. [Google Scholar] [CrossRef]
- Churyumov, A.Y.; Kazakova, A.A. Prediction of True Stress at Hot Deformation of High Manganese Steel by Artificial Neural Network Modeling. Materials 2023, 16, 1083. [Google Scholar] [CrossRef] [PubMed]
- Klimenko, D.; Stepanov, N.; Li, J.; Fang, Q.H.; Zherebtsov, S. Machine Learning-Based Strength Prediction for Refractory High-Entropy Alloys of the Al-Cr-Nb-Ti-V-Zr System. Materials 2021, 14, 7213. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description | Value Range |
|---|---|---|
| ρ | Alloy density | [5 g/cm³, 15 g/cm³] |
| VEC | Valence electron concentration | [4, 6] |
| δ | Atomic size difference | [1%, 13%] |
| μ | Electronegativity difference | [−3, 1] |
| ΔS | Entropy of mixing | [5 J/K, 18 J/K] |
| ΔH | Enthalpy of mixing | [−43 KJ/mol, 5 KJ/mol] |
| TT | Test temperature | [−269 °C, 1600 °C] |
| Ti | Titanium | [0, 40] |
| Nb | niobium | [0, 20] |
| Ta | tantalum | [0, 5] |
| Mo | molybdenum | [0, 27] |
| V | vanadium | [0, 25] |
| Zr | zirconium | [0, 40] |
| Al | aluminum | [0, 20] |
| Hf | hafnium | [0, 1] |
| W | tungsten | [0, 10] |
| Cr | chromium | [0, 21] |
| Model | Application Situation |
|---|---|
| AdaB | 1. Uniform data distribution and less noise; 2. Sufficient data. |
| LR | 1. Regression of linear relationship; 2. Low computing resource requirements. |
| DT | 1. Complex nonlinear relationship; 2. Low data preprocessing requirements. |
| RF | 1. High data dimension and noise; 2. Scenarios that require high prediction accuracy and generalization ability and relatively loose training time. |
| KR | 1. Nonlinear relationship, and easy to overfit; 2. The data dimensions are high. |
| SVR | 1. Nonlinear regression problem with small amount of data; 2. High requirement for prediction accuracy. |
| GBM | 1. Strong adaptability to data distribution; 2. Able to process different types of data. |
| LGBM | 1. Good at handling large-scale datasets and high-dimensional sparse data. |
| XGB | 1. Strong adaptability to data distribution and type; 2. Suitable for regression and classification of structured data. |
| Model | Hyperparameter | Optimal Value |
|---|---|---|
| AdaB | learning_rate | 0.938 |
| n_estimators | 50 | |
| LR | fit_intercept | False |
| Positive | False | |
| DT | max_depth | 12 |
| min_samples_leaf | 4 | |
| min_samples_split | 8 | |
| RF | max_depth | 29 |
| min_samples_leaf | 1 | |
| min_samples_split | 3 | |
| n_estimators | 50 | |
| KR | Alpha | 0.1 |
| Kernel | polynomial | |
| SVR | C | 10.0 |
| Gamma | scale | |
| Kernel | poly | |
| XGB | colsample_bytree | 0.509 |
| learning_rate | 0.093 | |
| max_depth | 3 | |
| n_estimators | 200 | |
| Subsample | 0.693 | |
| GBM | learning_rate | 0.0989 |
| max_depth | 3 | |
| min_samples_leaf | 2 | |
| min_samples_split | 2 | |
| n_estimators | 200 | |
| LGBM | learning_rate | 0.766 |
| max_depth | 6 | |
| min_child_samples | 58 | |
| min_data_in_leaf | 72 | |
| n_estimators | 200 | |
| num_leaves | 50 |
| Alloy | True Yield Strength /MPa | Predicted Yield Strength/MPa | Prediction Error/(%) |
|---|---|---|---|
| TiZrHfVNb | 1170.00 | 1178.73 | 0.75 |
| MoNbVTa0.5 | 1505.00 | 1482.13 | 1.52 |
| TiZrHfTaMo | 1600.00 | 1493.50 | 6.66 |
| Hf0.5MoNbTaW | 882.00 | 819.28 | 7.11 |
| NbTaMoW | 996.00 | 1076.99 | 8.13 |
| HfMoNbTaW | 840.00 | 705.4. | 16.02 |
| Ti1.5ZrVNb | 778.00 | 958.28 | 23.17 |
| Ti30Zr40Nb15Ta5Al | 45.50 | 62.62 | 37.62 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, G.; Zhao, P.; Wang, Y.; Zhang, H.; Xing, L.; Cheng, X. Research on Performance Prediction Method of Refractory High-Entropy Alloy Based on Ensemble Learning. Metals 2025, 15, 371. https://doi.org/10.3390/met15040371
Tian G, Zhao P, Wang Y, Zhang H, Xing L, Cheng X. Research on Performance Prediction Method of Refractory High-Entropy Alloy Based on Ensemble Learning. Metals. 2025; 15(4):371. https://doi.org/10.3390/met15040371
Chicago/Turabian StyleTian, Guangxiang, Pingluo Zhao, Yangwei Wang, Hongmei Zhang, Liying Xing, and Xingwang Cheng. 2025. "Research on Performance Prediction Method of Refractory High-Entropy Alloy Based on Ensemble Learning" Metals 15, no. 4: 371. https://doi.org/10.3390/met15040371
APA StyleTian, G., Zhao, P., Wang, Y., Zhang, H., Xing, L., & Cheng, X. (2025). Research on Performance Prediction Method of Refractory High-Entropy Alloy Based on Ensemble Learning. Metals, 15(4), 371. https://doi.org/10.3390/met15040371