1. Introduction
High-resolution mapping using Autonomous Underwater Vehicles (AUVs) at seafloor spreading ridges has ushered in new capabilities for investigating hydrothermal venting at the individual-vent scale. Without meter-scale mapping, hydrothermal vents have typically been visually identified using manned and remotely operated submersibles that investigate areas where water-column temperature or particle anomalies exist [
1,
2,
3]. These surveys focus primarily on active vents and require the submersibles to operate within visual range of the seafloor, at <10 m; this restricts their speed and, thus, the area explored. However, AUV multibeam mapping surveys conducted ~50 m off-bottom produce bathymetry that can be gridded at a ≤1 m resolution [
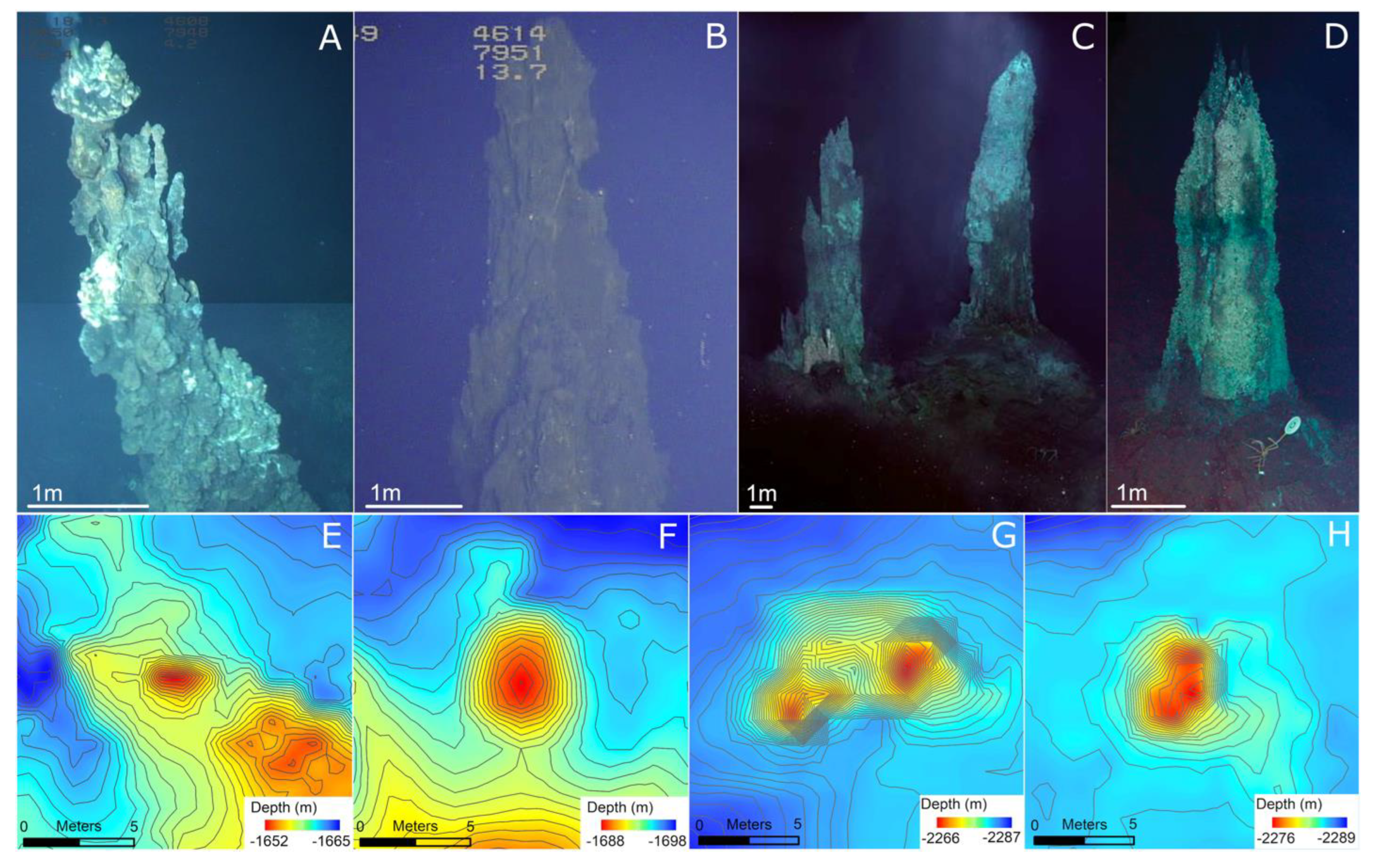
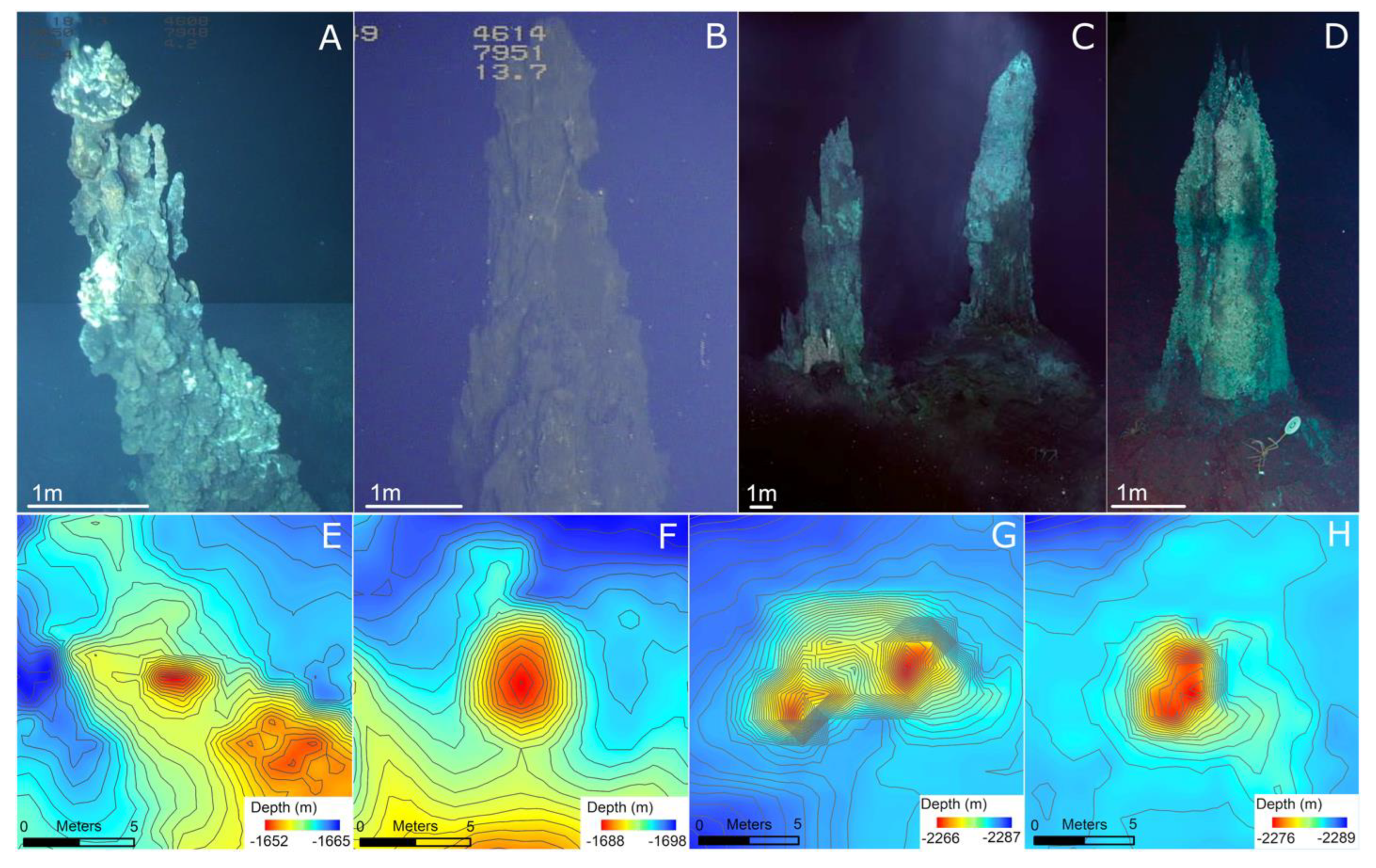
4]. These maps can cover tens to hundreds of square kilometers, while also resolving active and inactive hydrothermal chimneys and mounds that are only a few meters wide and high (
Figure 1) [
4,
5,
6]. Identifying the locations of hydrothermal chimneys across mapped areas of seafloor spreading ridges unlocks the ability to investigate questions about their spatial distributions and correlations to related characteristics of ridge geology, and ultimately, larger questions about the flux of seawater and seawater composition. For example, Jamieson et al. [
5] estimated the volume of hydrothermal sulfide edifices over a 62 km
2 area of the Endeavor segment of the Juan de Fuca ridge by identifying active and inactive chimneys resolved by AUV bathymetry. Clague et al. [
7] observed the clustering of hydrothermal chimneys within segments along the ridge axis of the Endeavor segment, and compared the density of chimneys to the observed distribution from the Alarcón rise identified by Paduan et al. [
6].
High-resolution AUV bathymetry exists at several seafloor spreading ridges and is rapidly becoming much more available. However, classifications of these datasets to identify hydrothermal chimneys from bathymetry have exclusively been performed manually, with individuals looking at visualizations of the bathymetry and selecting features that resemble known chimneys [
5,
6,
7,
8,
9]. In this study, we begin to develop criteria for identifying chimneys from their characteristic spire shape in bathymetry (
Figure 1). Previous manual picking of hydrothermal chimneys developed a general consensus that chimneys manifest in 1 m gridded bathymetry as steep-sided spires, several meters wide, with a round to semi-round base, and have a height range of roughly 3–30 m. Identifying chimneys by manual selection requires substantial time and effort and is not strictly reproducible, as the interpretation is affected by the skill and attention of the individual performing the classification, which varies between people and for an individual over time. An automated computer tool that algorithmically searches high-resolution bathymetry and identifies the hydrothermal chimneys solves both of these issues.
We developed a Chimney Identification Tool (CIT) that utilizes a Convolutional Neural Network (CNN), which works with 1 m gridded bathymetry to identify the locations of hydrothermal vent chimneys. A CNN is a type of Machine-Learning model that classifies raster data by building a network of relative connections between the pixels within the raster [
10,
11]. The nested nature of these connections allows classification based not only on the difference in input pixel values, but also on the incredibly complex relationships between pixels arranged across different parts of the raster that humans visually interpret as shape or texture [
11,
12,
13]. The CNN is uniquely useful in this context of hydrothermal chimney detection where the shapes of features, and not just specific raster values, are a key part of the criteria that have been used in previous manual classifications. One drawback of a CNN is that due to the abstract mathematical structure and complexity, it operates as a black box; it can be successfully trained to classify input, but what it is actually “seeing” in the input is impossible to extract and examine in human terms [
14,
15]. Machine-Learning techniques have been successfully implemented with sonar data to classify seafloor geology in many studies (e.g., [
16,
17,
18,
19,
20]); however, to our knowledge, this is its first application in hydrothermal chimney identification.
2. Study Areas
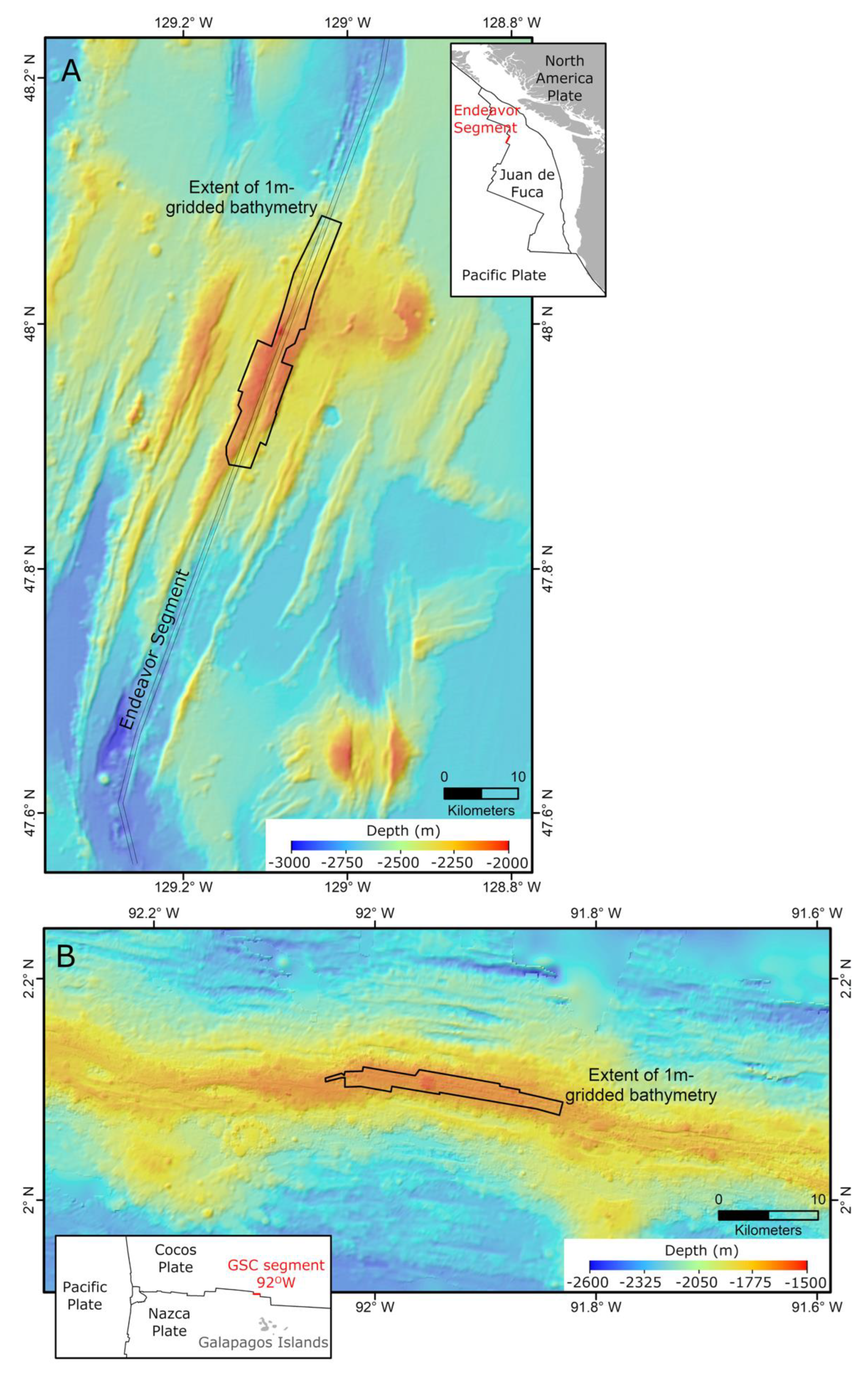
The CIT was developed using data from two study areas: the Endeavor segment of the Juan de Fuca Ridge and the 92° W segment of the Galapagos Spreading Center (GSC) (
Figure 2). These were chosen not only because processed AUV multibeam bathymetry is available at meter-scale resolution [
7,
18], but also because previous manual classifications to identify hydrothermal chimneys have been conducted on both bathymetry datasets [
7,
8] (
Figure 3 and
Figure 4). These inventories of chimney locations provide a ground-reference dataset that is necessary for training a supervised automated classifier, and also provide pre-existing testing data from completely independent manual classification.
The 92° W segment of the GSC and the Endeavor Segment have similar average spreading rates of 54 and 52 mm/year, respectively [
21], and provide a valuable comparison because they have very different geology and bathymetry. The GSC 92° W segment has high levels of magma supply due to its proximity to the Galapagos hotspot; this results in a shallow axial high (1600 m), much less faulting than at the Endeavor Segment, and the presence of unfaulted volcanic cones and mounds (
Figure 2 and
Figure 4) [
22,
23]. The Endeavor Segment has a large axial graben 0.8–1.7 km wide and 100–200 m deep, and a much smaller area covered by unfractured lava flows (
Figure 2 and
Figure 3) [
24,
25]. These geologic environments directly relate to the process of developing the CIT to work in a range of geologic environments; this is because Endeavor has many more steep-sided features and more fractured terrain than GSC, and contains numerous large chimneys due to the combination of increased permeability from the fracturing and the lack of volcanic resurfacing [
7]. Developing a CIT to effectively identify chimneys in both of these settings, with characteristics of both low and high magma-supply environments, suggests that it has the capability to be deployed in a wide range of seafloor spreading ridge environments.
Figure 2.
Regional bathymetry for the 2 study areas: (
A) the Endeavor Segment of the Juan de Fuca Ridge; (
B) the 92° W segment of the Galapagos Spreading Center (GSC). The extents of the 1 m gridded bathymetry rasters are outlined. Insets show the plate boundaries and plate names wherein red lines indicate the specific segment of the plate boundary in which the study areas are located. Basemap bathymetry is from GMRT [
26].
Figure 2.
Regional bathymetry for the 2 study areas: (
A) the Endeavor Segment of the Juan de Fuca Ridge; (
B) the 92° W segment of the Galapagos Spreading Center (GSC). The extents of the 1 m gridded bathymetry rasters are outlined. Insets show the plate boundaries and plate names wherein red lines indicate the specific segment of the plate boundary in which the study areas are located. Basemap bathymetry is from GMRT [
26].
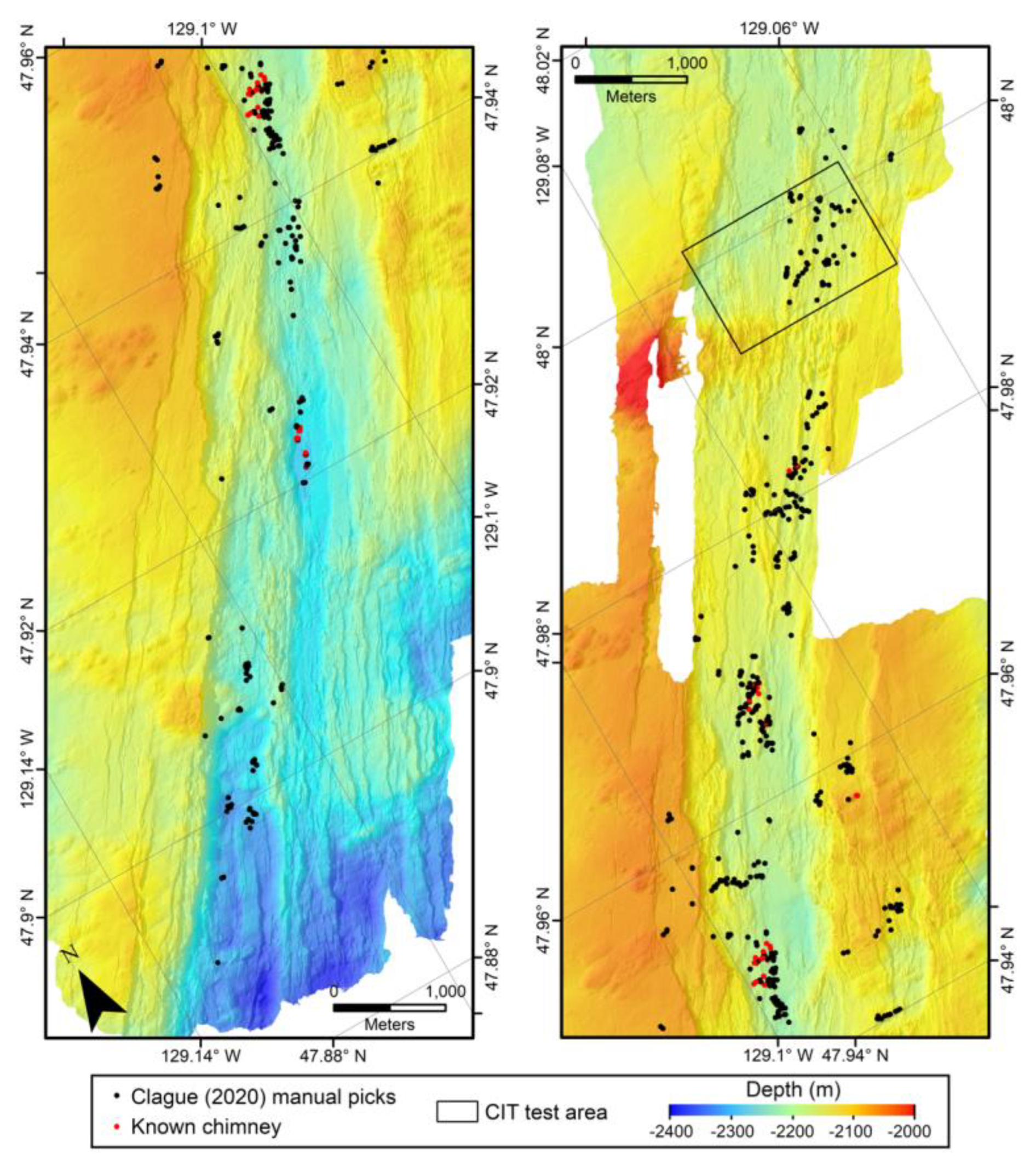
Before developing the CIT, we compiled the bathymetry data from each area into two rasters, each gridded at a 1m-resolution. The Clague et al. [
7] dataset of manual picks from Endeavor contains 406 locations of hydrothermal chimneys (
Figure 3), and the White and Lee [
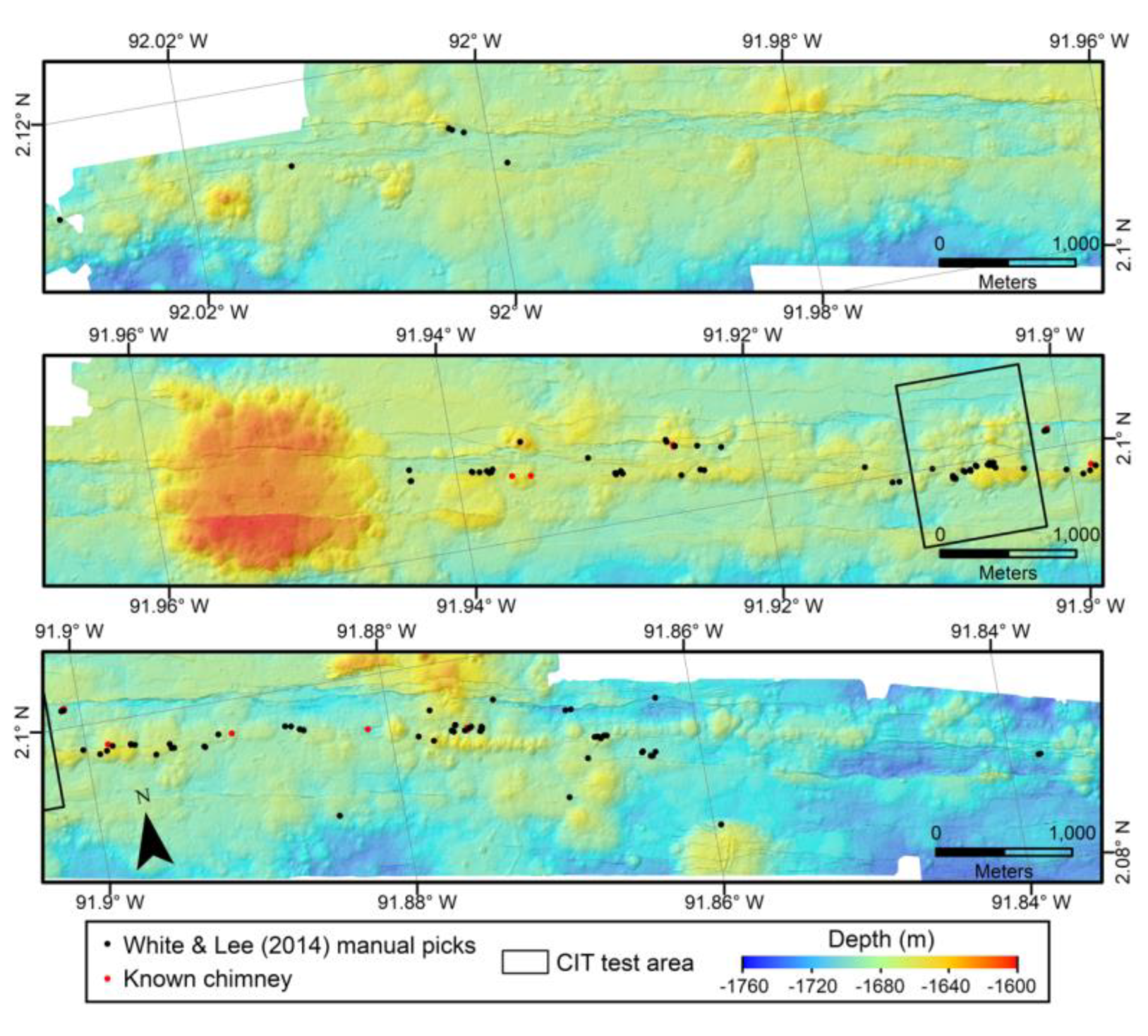
8] dataset from the GSC contains 122 (
Figure 4). There is a subset of each set of manual pick locations that are known vents and are confirmed by direct observation with a submersible. In the Clague et al. [
7] Endeavor dataset, these examples were identified as those with individual chimney names, and in the White and Lee [
8] GSC dataset, these confirmed chimneys are un-named. There are 34 confirmed chimneys in the Endeavor dataset and 14 for the GSC.
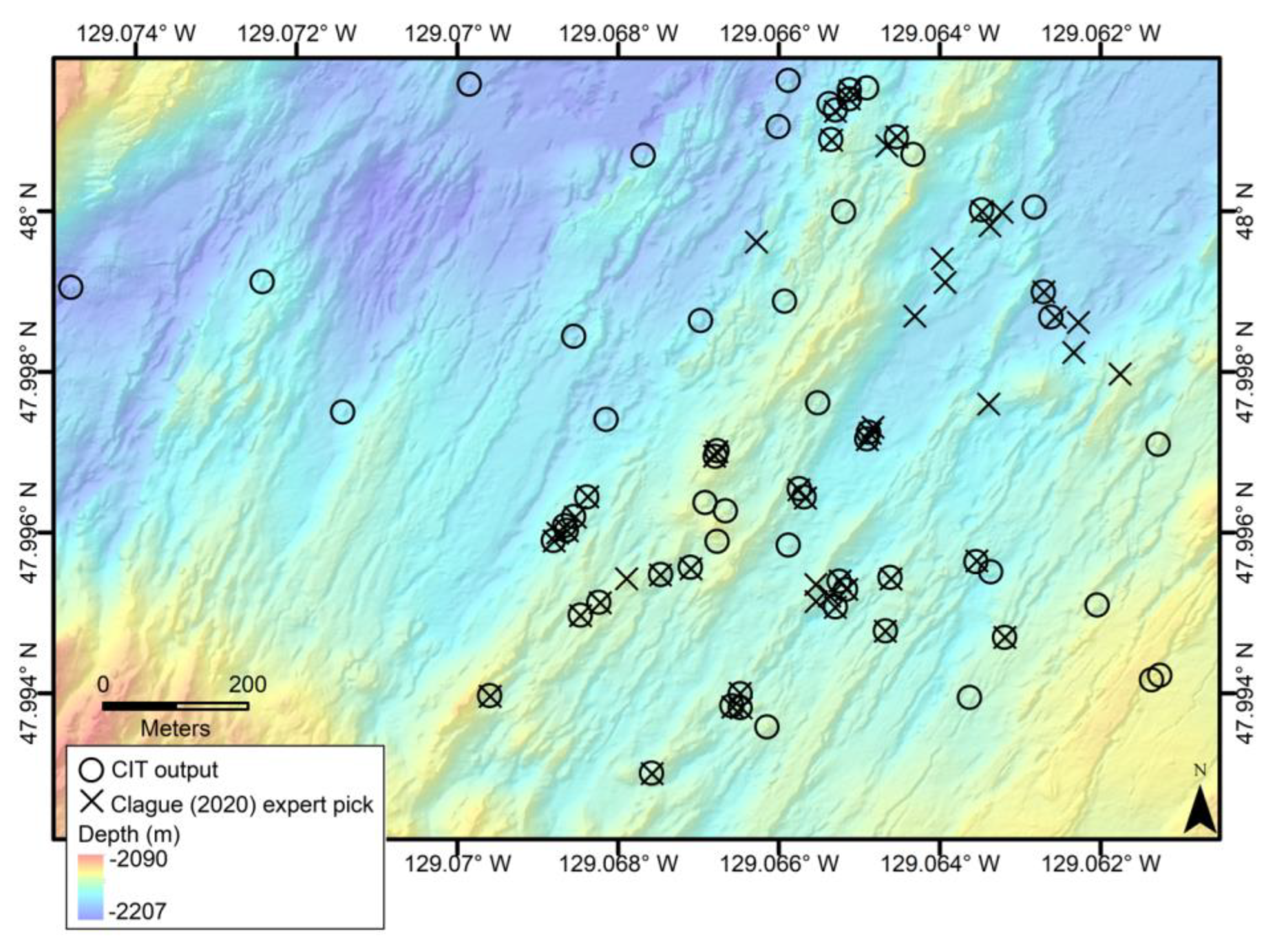
Figure 3.
Shaded relief bathymetry map of the Clague et al. [
7] manually selected chimney locations (black dots) for the Endeavor study area’s 1 m gridded AUV bathymetry. The black box outlines the test area that was used to evaluate the CIT in this study. Note the clustering of chimney locations, the pronounced axial graben, and pervasive faulting, expressed as NE-SW trending lineaments, in the bathymetry.
Figure 3.
Shaded relief bathymetry map of the Clague et al. [
7] manually selected chimney locations (black dots) for the Endeavor study area’s 1 m gridded AUV bathymetry. The black box outlines the test area that was used to evaluate the CIT in this study. Note the clustering of chimney locations, the pronounced axial graben, and pervasive faulting, expressed as NE-SW trending lineaments, in the bathymetry.
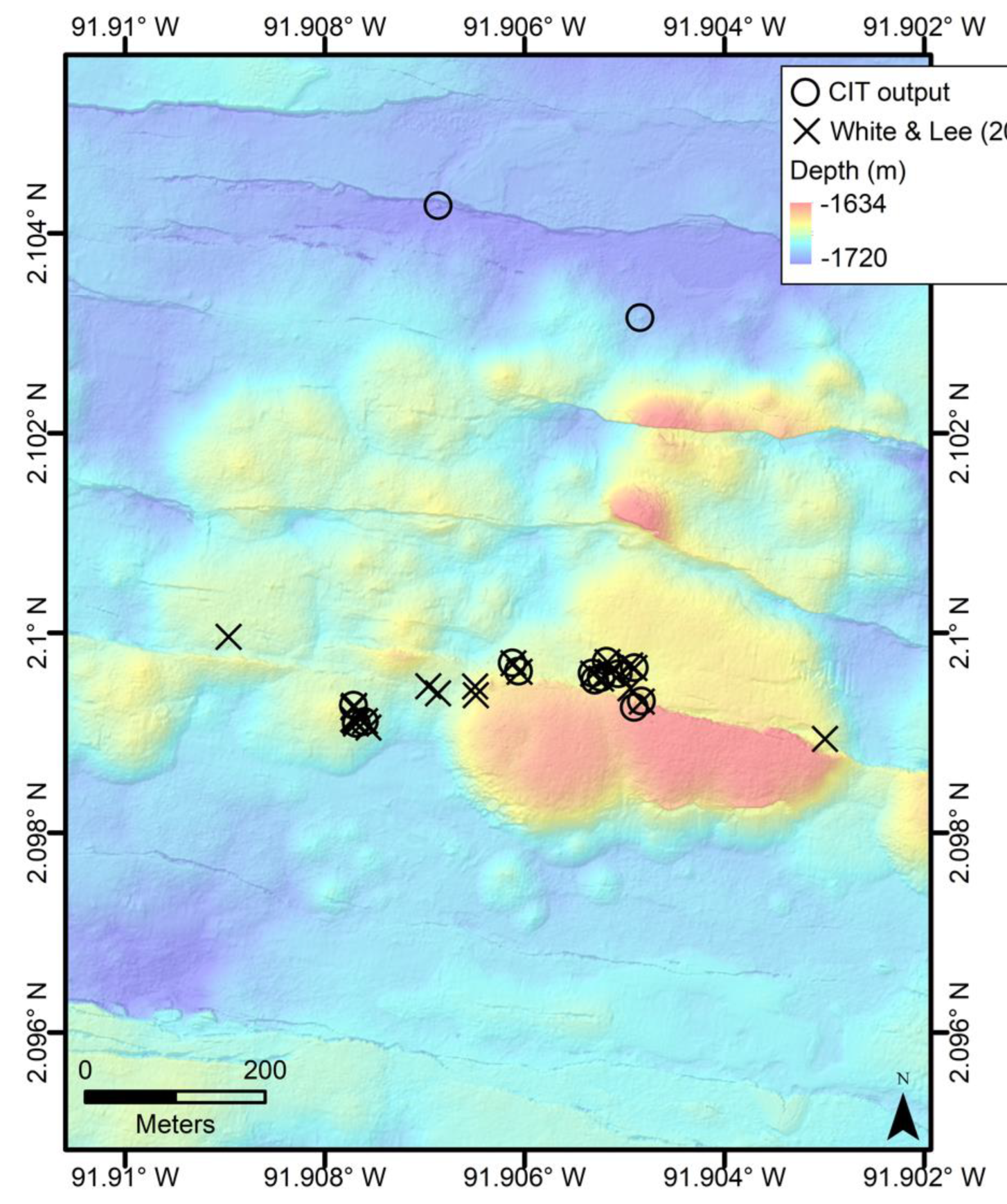
Figure 4.
Shaded relief map of the 1 m gridded AUV bathymetry of the GSC study areas [
18], with the White and Lee [
8] manually picked chimney locations plotted as black dots. The black box outlines the test area that was used to evaluate the CIT. Note the pronounced volcanic cone and numerous volcanic mounds, along with much lower expression of faulting compared to the Endeavor Ridge segment in
Figure 3.
Figure 4.
Shaded relief map of the 1 m gridded AUV bathymetry of the GSC study areas [
18], with the White and Lee [
8] manually picked chimney locations plotted as black dots. The black box outlines the test area that was used to evaluate the CIT. Note the pronounced volcanic cone and numerous volcanic mounds, along with much lower expression of faulting compared to the Endeavor Ridge segment in
Figure 3.
3. Methods
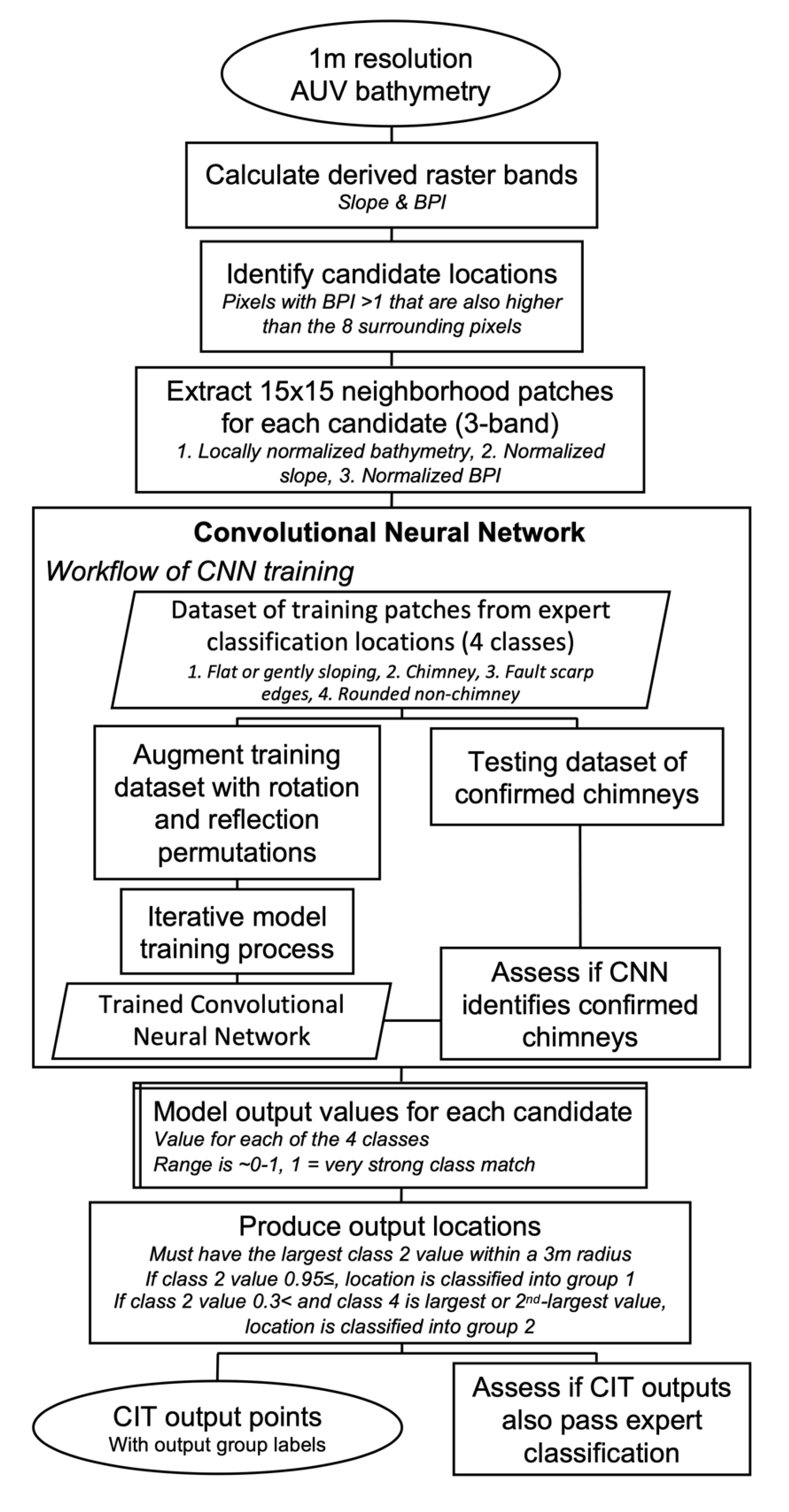
The initial construction of the CIT came from implementing techniques from the field of image classification. The idea of using a selective search to classify subsets of a larger raster using a Neural Network is known in the field of computer vision as Object Detection [
27]. We drew direct guidance on how to apply this technique—originally developed for analyzing digital photographs—to bathymetric rasters from Bycroft et al. [
28], who adapted it for high-resolution surveying with unmanned aerial vehicles, and Valentine et al. [
20], who classified seafloor bathymetry to identify seamounts. Bycroft et al. [
28] found a CNN successful at identifying round crab burrows which have a footprint of typically <15 pixels in diameter; this is a similar pixel footprint to hydrothermal chimneys in 1 m gridded bathymetry. Valentine et al. [
20] used a selective search to extract subset patches of the larger bathymetric raster and identified discrete output locations by identifying extrema in a model output raster, inspiring the use of similar techniques in the CIT. The overall structure of the CIT workflow was derived and modified from these previous applications (
Figure 5).
We refined the CIT workflow to tailor it specifically to the task of hydrothermal chimney detection through iterative testing; we achieved this by utilizing two criteria for evaluation, each focused on a different type of classification error, omission, or commission. Omission was measured by running each known (visually observed) hydrothermal chimney from both the Endeavor and GSC datasets (34 and 14, respectively) through the CIT and confirming whether they were correctly identified. The number of these known chimneys that were correctly identified gave a measure of how effectively the CIT met the target goal of identifying all the chimneys. Commission was evaluated by generating a CIT output for a test area raster from each study area (areas outlined in
Figure 3 and
Figure 4). We manually classified each of the generated locations, plotting the bathymetry and 0.5m contours in ArcGIS, and positively labeling round features with ≥5 closed 0.5 m contours that resembled the size and shape of known chimneys. We studied both the bathymetry associated with the known hydrothermal chimneys and the methods by which previous manual classifications were conducted, to gain an understanding of how hydrothermal chimneys look in bathymetry: steep-sided spires several meters wide, with a rounded footprint and a height range of roughly 3 to 30 m tall. The number of CIT output locations that also passed our manual classification gave a measure of how effectively the CIT included only chimneys in the output. Throughout the development process, we were often faced with a choice between optimizing for lower omission or lower commission. In these cases, we chose to optimize for lower omission, wanting to ensure that the CIT had the lowest chance possible of missing hydrothermal vent chimneys if they were present in the input data.
The CIT was built using Python 3.7 and PyTorch 1.6 [
29]. A GitHub repository containing the Python scripts created for this project is linked in the data availability statement. The initial stage of raster filtering was not automated within the CIT, and was performed manually using a combination of ArcGIS Desktop 10.7, R 4.0.3, and Python 3.7.
3.1. Filtering Bathymetry to Produce Multiple Derived Rasters
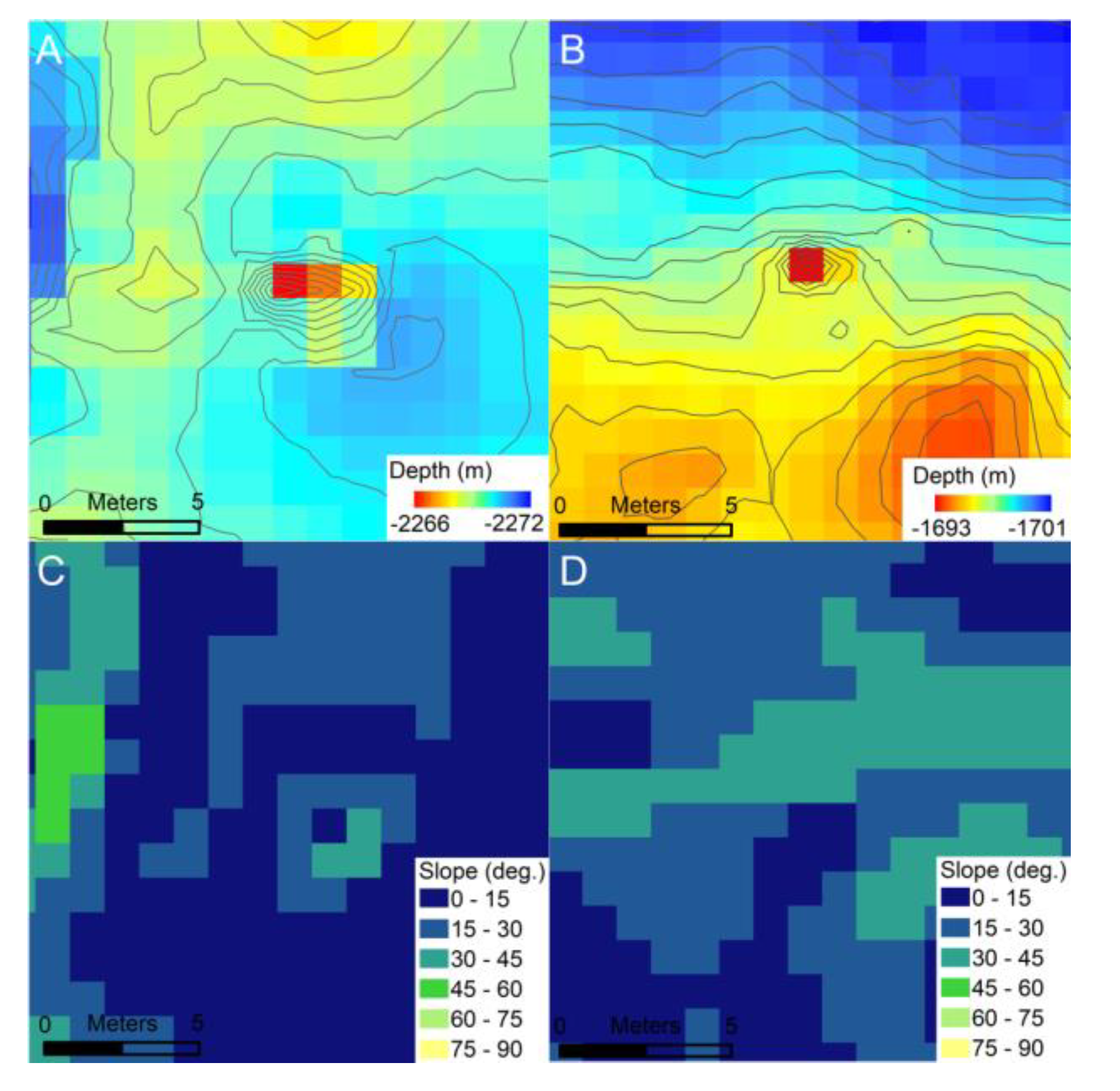
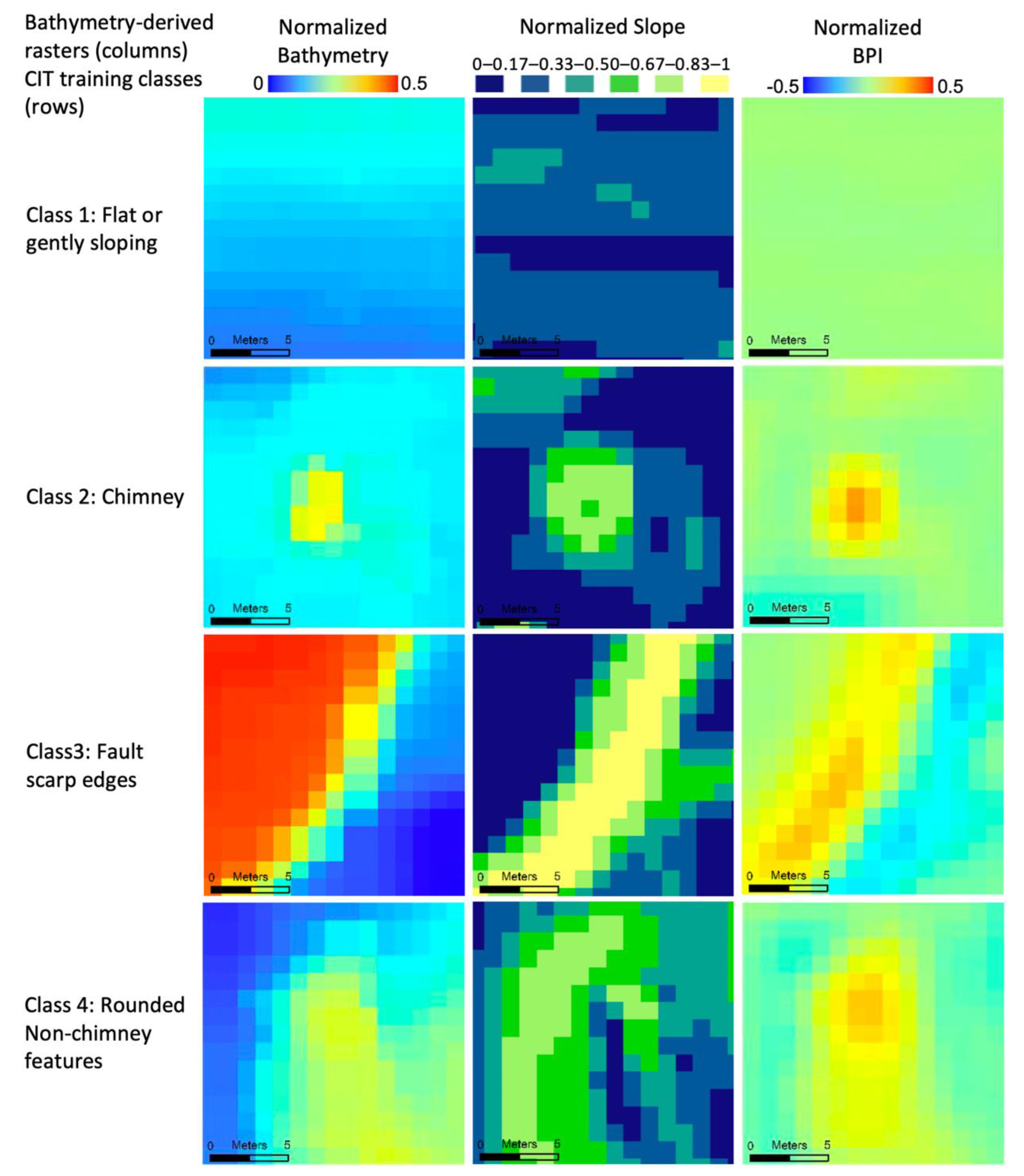
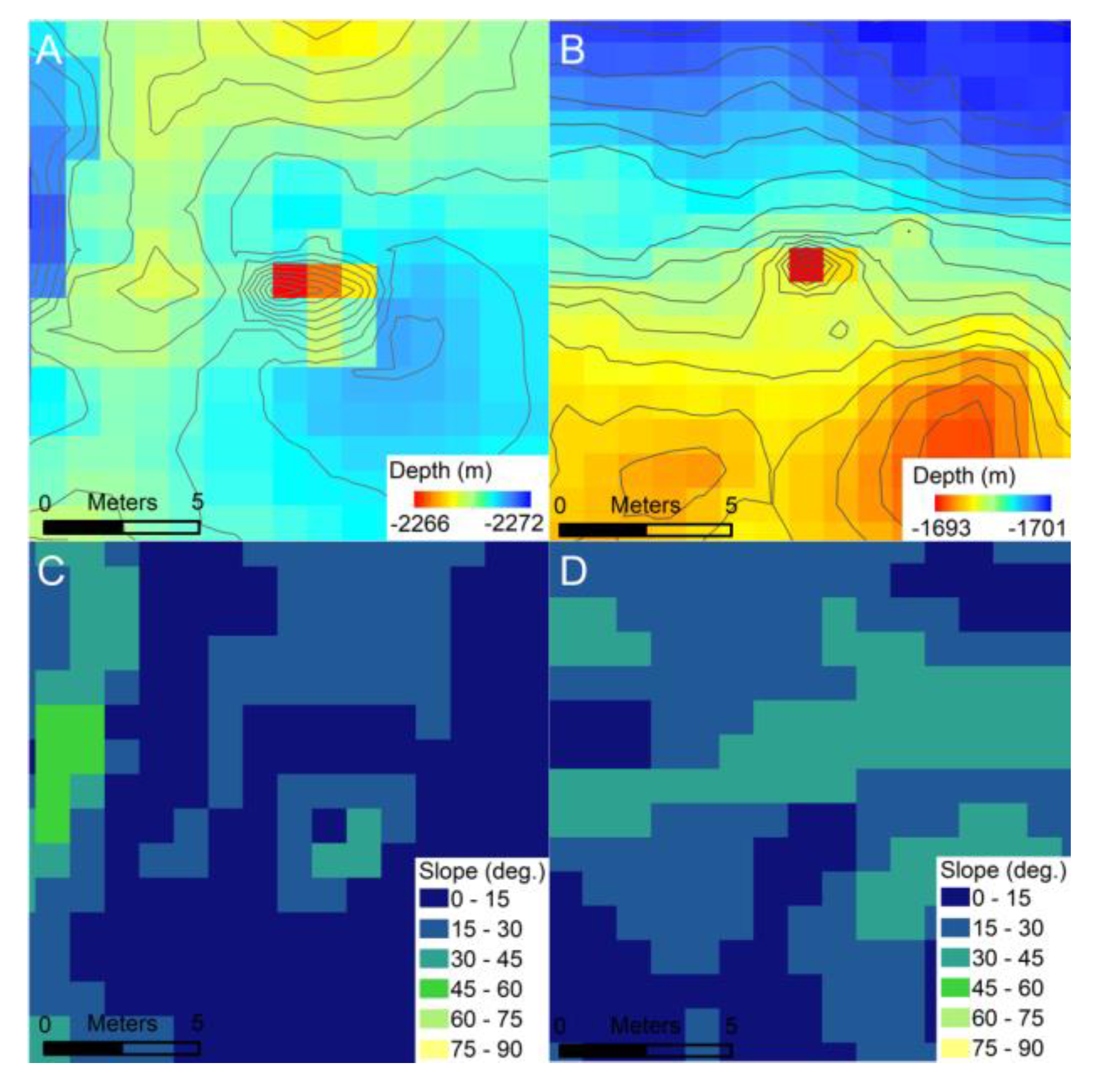
The CIT was developed to take 3 raster layers as inputs—(1) normalized bathymetry, (2) normalized local slope, and (3) normalized Bathymetric Position Index (BPI)—derived from an initial bathymetric raster (
Figure 6). During the development process, we found that utilizing this combination of 3 layers resulted in consistent improvements in omission and commission errors compared to using a single layer. Pixel values in the derived rasters are the outputs of a function applied to a square moving-window neighborhood of pixels. Each raster layer is normalized so that all pixel values are within the range of −1 to 1. This is a standard step when using a CNN as it brings the input values to a similar magnitude as the function coefficients contained in each node of the network.
The first raster layer is a locally normalized bathymetry. The textures and shapes observed in this layer capture the seafloor surface just as the raw bathymetry does, but it can be directly compared between different areas that vary in absolute water depth. Each pixel value is scaled by subtracting the minimum value within a 30 m wide neighborhood window, and then dividing it by a scaling factor of 50 m. This 50 m scaling factor was chosen to be greater than the largest range of bathymetry, which was observed to be within a 30 m neighborhood from the GSC and Endeavor datasets. In future applications of the CIT, using this constant scaling factor could potentially lead to pixels from an area with larger variation than was observed in these 2 study areas, having pixel values greater than 1. This would not directly lead to the CIT being ineffective, as a CNN can take input values outside of the −1 to 1 range; however, if these input values were several times larger than 1, it could negatively affect performance. CIT is developed to handle inputs from different bathymetry datasets and areas. If each input was normalized using the minimum and maximum values of its containing raster, features of the same size and shape from different areas would not translate in the same way when normalized. Choosing this constant scaling factor is necessary to ensure that examples from different rasters are normalized consistently.
The second layer is the local slope of median-filtered bathymetry using a 3 × 3 pixel (or 3 m square) neighborhood. This layer represents the rate of change of the bathymetry and is calculated by taking the maximum change in depth between each pixel and its 8 neighbors. This slope can be calculated as an angle relative to a flat surface of constant bathymetry. With calculating slope as an angle, the resulting layer can be normalized by simply dividing by 90°, as that is the largest possible value.
The third layer is the normalized Bathymetric Position Index (BPI), with an inner neighborhood of 3 m and an outer neighborhood 11m in diameter [
30]. BPI calculates the difference in the mean bathymetry between the inner and outer neighborhoods. At the meter scale, features such as chimneys and the upper edges of fault scarps show up as more positive values, and features such as pits, fissures, and the lower edges of fault scarps show up as more negative values (
Figure 6). Flat areas, including those that slope uniformly over 10 m or larger spatial scales, have BPI values close to zero (
Figure 6). This layer was normalized similarly to the locally normalized bathymetry by using a scaling value of 20, resulting in the same considerations for future applications that might have BPI values larger than 20. This value was chosen to be greater than largest absolute value observed in any of the input training areas (18.0). The mean for BPI was ~0, with positive and negative values indicating local highs and lows, respectively; therefore, dividing by this constant value rescaled all of the input values to within the desired range of −1 to 1, while preserving the sign. Layers 1 and 2 do not contain negative values, because there is no change in sign associated with the un-normalized raster layers as there is with BPI. This difference in the range of values between layers is not a problem for the CNN, as this normalization step is needed to adjust the absolute values of inputs to be a similar magnitude to the internal coefficients.
3.2. Selective Search to Extract Candidate Patches
In order to improve the runtime of the CIT, a simple logical filter is used to identify potential chimney candidate locations from the entire study area, and then local 15 × 15-pixel patches are extracted for input to the CNN, only from those areas that passed this preliminary set of criteria. The goal of this filter is to rapidly restrict the search by eliminating any areas that contain no chimney-like features. Pixels are selected by this preliminary search if they are local maxima in the bathymetry compared to the 8 adjacent pixels and have a BPI value ≥1. The BPI values used were from the 3 m/11 m BPI raster used as input into the CNN, but before the normalization was applied. This threshold value of 1 for the filter value was selected to be extremely conservative based on our empirical observation of the training data. The spire of a hydrothermal chimney will always be a local maximum in 1 m gridded bathymetry, and no hydrothermal chimneys in the two training datasets have an observed BPI value below 1. For each candidate pixel that passed the selective search, a 15 × 15 raster patch centered on that pixel is extracted. The 3-band normalized raster for each patch is sent into a CNN for classification. This logical filter does successfully execute the role of restricting the local patches needed for the search, as less than 1% of the pixels from the input raster are usually passed.
3.3. Evaluating Each Candidate with a CNN
The CNN produces output values for 4 different classes that it was constructed to classify between: (1) flat or gently sloping areas, (2) chimneys, (3) fault scarp edges, and (4) rounded non-chimney features (
Figure 7). Each of these output values ranges roughly from 0 to 1, with 1 being a strong class match. Additionally, the sum of all 4 for a given output is roughly equal to 1, so equal confusion in the CNN between 2 classes would result in each of those classes having an output value of ~0.5.
Before implementation in the CIT, the CNN was trained with reference examples from the 4 classes. These examples were 15 × 15 raster patches of the 3 normalized raster layers extracted for each point in a set of training locations. Training examples for classes 1, 3, and 4 were originally produced for this project by manually identifying locations in the two study areas. We generated 300 of each class from the Endeavor dataset and 140 of class 1 and 3 from the GSC dataset. We only generated 85 examples for class 4 from the GSC dataset, as the frequency of these rounded non-chimney features was much lower than at Endeavor. The chimney (class 2) examples were adapted from the existing manual classification picks of Clague et al. [
7] and White and Lee [
8]. We adjusted these locations, by no more than 5 m, so that the center pixel of each training patch would be the exact peak of the chimney. Ensuring that each chimney training example has the peak in the center minimizes unnecessary variation that could confuse the CNN and leads to a model that is trained to identify patches that not only contain a chimney, but are specifically centered on one. This ties directly into the end goal of the CIT, which is to identify a distinct point location for each chimney.
One of the common difficulties with training Machine-Learning models is the limited number of training examples. Between the two study areas, there were only ~500 chimney examples available for training the model. We were only able to reach the model performance of this version of the CIT after generating artificial training examples by transforming the original ones [
31]. Before model training, new permutations of each 15 × 15 m example patch from the 4 classes are generated using all 8 unique combinations of 90° rotations and mirror flips. Chimneys are theoretically radially symmetric features and, therefore, can be viewed as transformation invariant for rotations and flips. Creating these new examples from modifications of the existing ones has the effect of multiplying the training dataset 7×. After augmentation of the training dataset, the original training examples for the 48 known chimneys, as well as those located in both test areas, were removed from the training dataset, as these examples are used to evaluate the CIT performance.
The CNN model is trained by iteratively providing single 15 × 15 example patches of a known class, running the CNN model, evaluating the output against that known class, then updating the values of the nodes within the network in a way that would improve the classification of that example. Because this is a very basic overview, an in-depth explanation of the mathematical theory behind the structure of a Convolutional Neural Network and the iterative training process is beyond the scope of this paper; however, it is extensively covered in other literature [
10,
11,
12,
13,
31]. The order in which these examples are shown to the network is randomized, and the set of training examples is sampled so that the CNN sees the same total number of examples from each class by the end of the training process. The CIT uses a mean-square-error loss for evaluating the accuracy of each training iteration, and a stochastic gradient descent method for determining how the nodes should be updated [
32,
33]. The amount of change applied to the CNN on a single iteration is controlled by a learning-rate parameter. The CNN in the CIT is trained using epochs. An epoch is a full cycle of training whereby the set of training examples is sent through the model. Between each Epoch, the order of the training examples is rerandomized and the learning rate incrementally decreases. The model training ends after the model performance converges using the criteria, which state that the average mean-square-error loss for the epoch is <0.005 and that the value has changed by less than 5% from the previous epoch.
3.4. Deriving Distinct Chimney Locations from the Output Values of the CNN
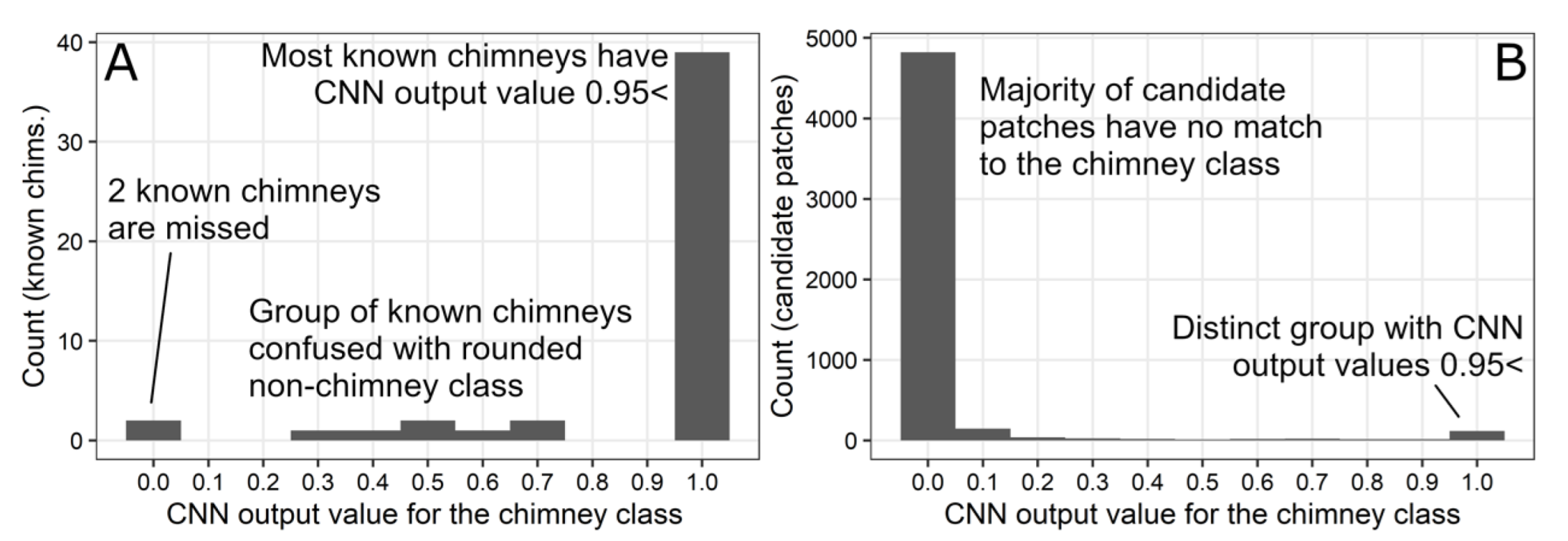
The CIT generates chimney locations from the candidate pixel locations by evaluating the output values produced by the CNN. In order to be classified as a chimney, the CNN output value for the chimney class (class 2) must be higher than any other chimney (class 2) value within a 3 m radius. Any two candidate pixels that are within this distance are assumed to be from the same feature. From these, two sets of classified chimney locations are generated. First, pixels are assigned to a ‘most likely chimney’ set if the class 2 value is above 0.95, as there is a distinct peak of examples with values near 1 and above a threshold near 0.95 (
Figure 8).
To provide the ability for the CIT to be as inclusive of hydrothermal chimneys as possible, the CIT generated a second ‘probable chimney’ set of points with a combination of intermediate class 2 and class 4 values. When we evaluated how the CNN classified the examples of known chimneys, we observed a smaller but distinct group with class 2 values of 0.3–0.75 (
Figure 8). Each of these examples had a corresponding class 4 value for which the sum of both was equal to ~1. We interpreted this group of examples to be chimneys (class 2) that the model was unable to fully discern from the features of class 4, which loosely resembled chimneys. To allow for the inclusion of chimneys that might be confused with class 4, the CIT generated this second group of ‘probable chimney’ outputs, with class 2 CNN output values in the range of 0.30–0.95, and for which the sum of class 2 and class 4 values was ≥0.95.
4. Results
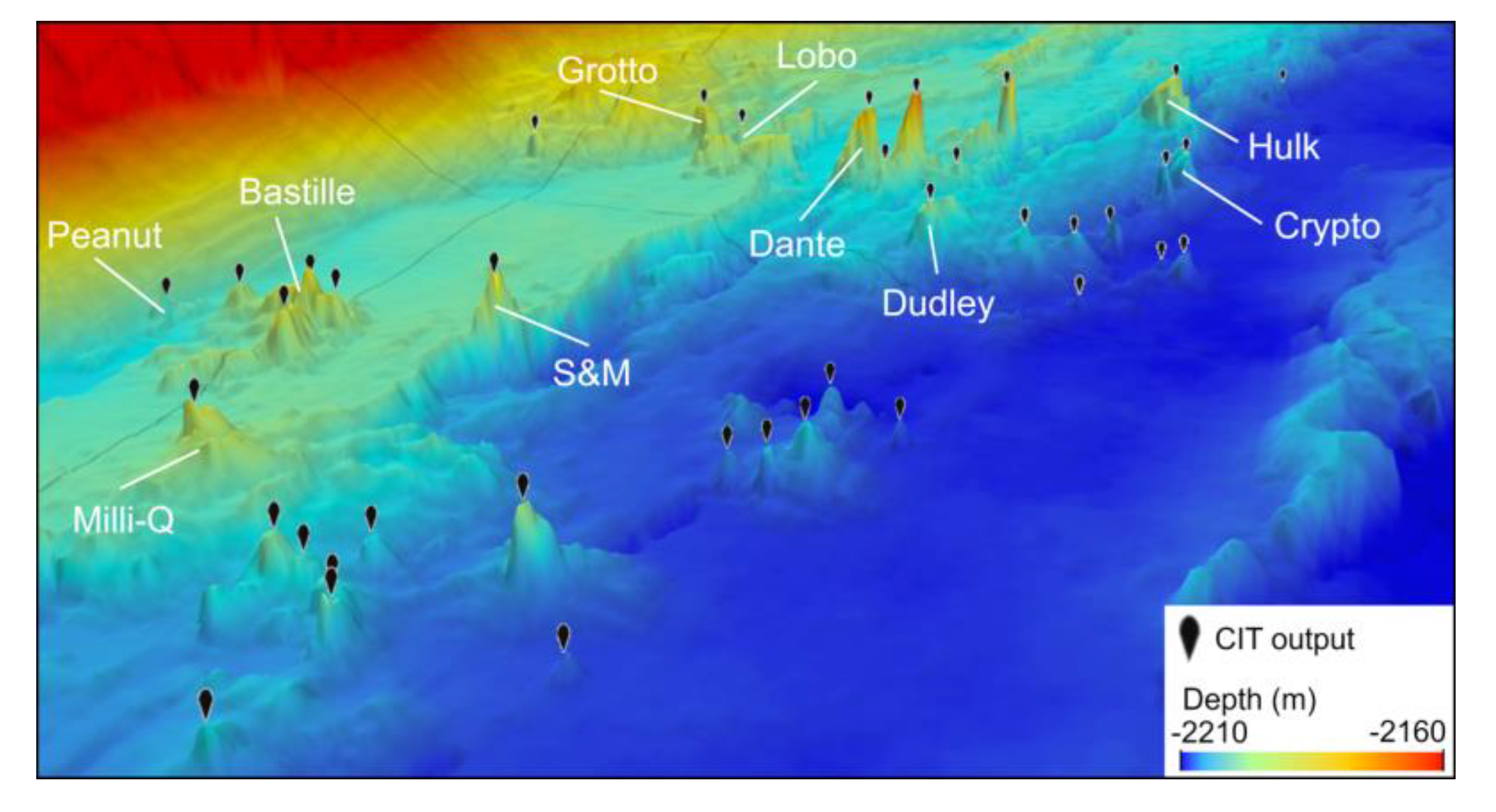
Looking qualitatively at the CIT output for the Main Endeavor Field suggests that the CIT consistently identifies local peaks that resemble chimneys and identifies all of the known (named) chimneys (
Figure 9). The CIT output is very similar to the chimney picks from Clague et al. [
7]. All of the identified features are rounded, spiky features, and no outputs are erroneously placed on features such as fault scarp edges that obviously are not chimney-like.
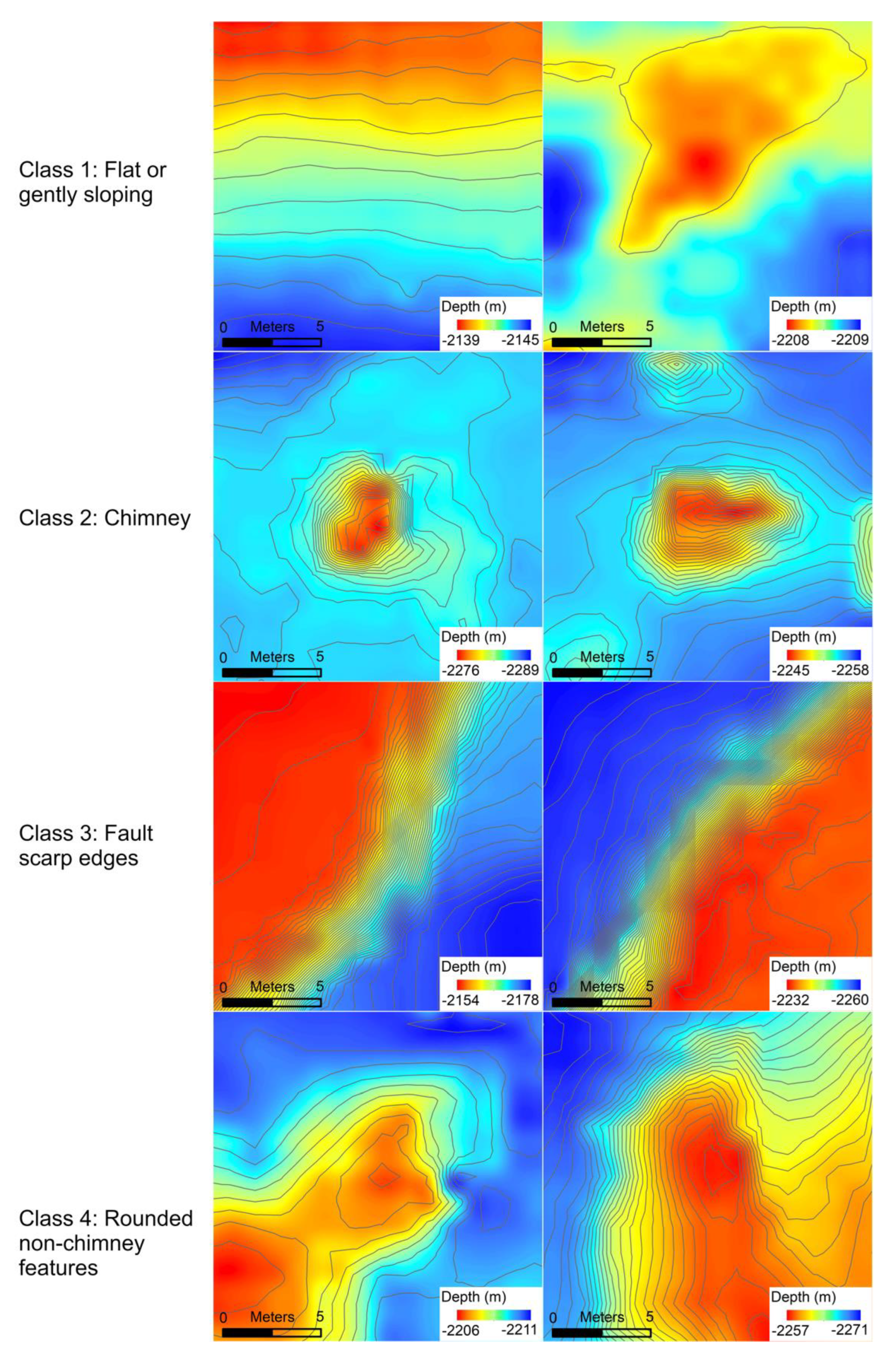
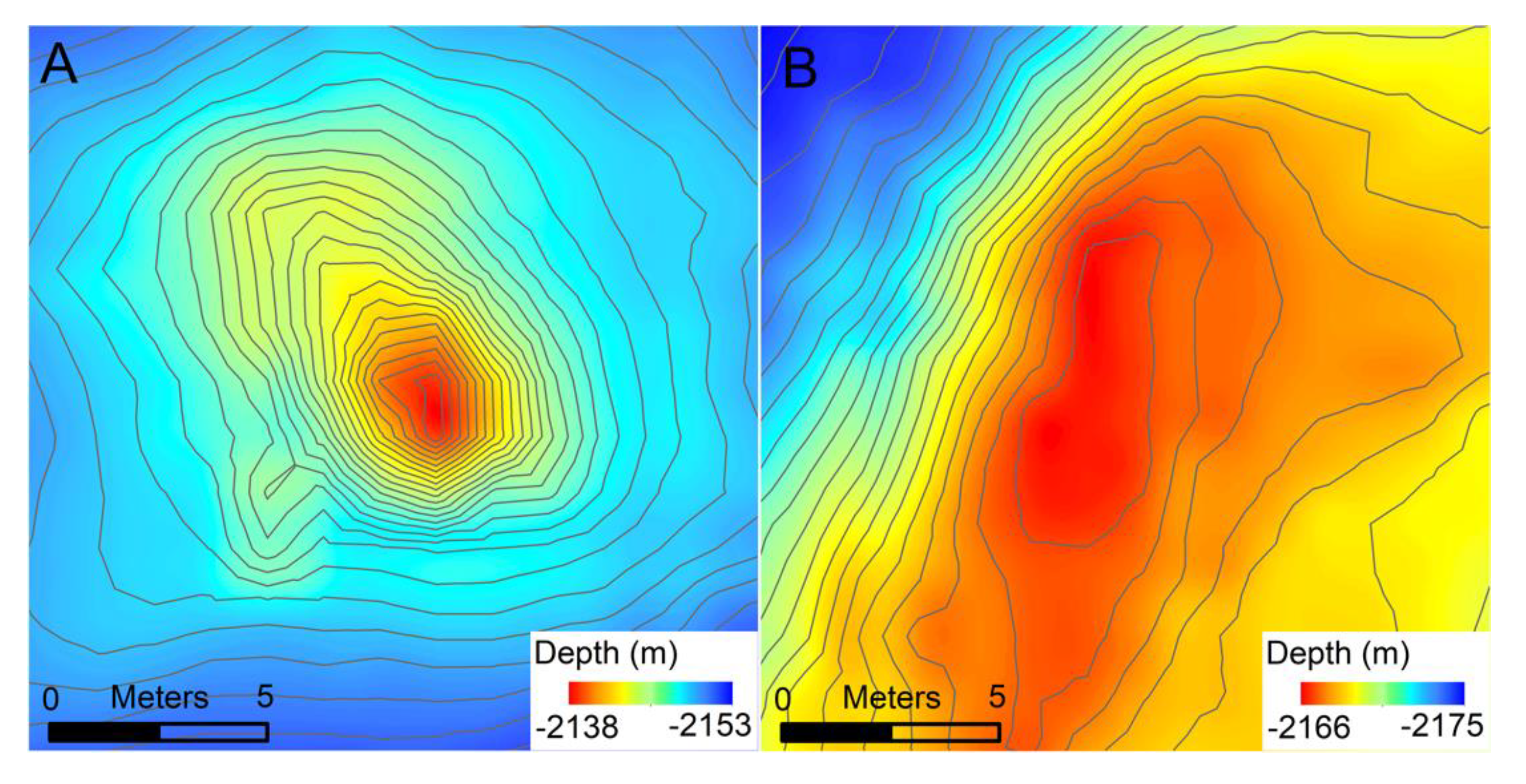
The CIT correctly classified as ‘most likely chimneys’ 29/34 known chimneys from Endeavor and 10/14 from the GSC, for a combined accuracy of 81.3% (
Table 1). The CIT classified 95.8% of known chimneys when the more inclusive set of ‘probable chimneys’ was also included. We note that the two known chimneys that were missed by the CIT are very small, each only consisting of one bathymetry pixel that rises significantly above the surrounding area (
Figure 10).
The CIT identified 78 ‘most likely chimneys’ within the two test areas, with 63 features from Endeavor and 15 from the GSC (
Table 2). Compared to our manual chimney picks of those that strongly resembled, and were interpreted to be, hydrothermal chimneys, 61/63 and 14/15 matched from the Endeavor and GSC test areas, respectively. This translates to 96% agreement across both areas combined. The less selective ‘probable chimney’ set did introduce more commission error, as anticipated, matching 38/61 and 5/10 manual picks from the Endeavor and GSC test areas, respectively, for a combined accuracy of 61% (
Table 2).
5. Discussion
The CIT was developed in order to support future investigations into hydrothermal venting in seafloor spreading ridge environments, specifically those that benefit from the ability to find individual chimneys or make a more complete inventory of both active and inactive chimneys. Examples of these types of investigations include the recent discovery of off-axis hydrothermal venting at the 9° N segment of the EPR [
34], an investigation the relationship between hydrothermal venting and eruptive fissures [
35,
36], and a study of the role of faults in hydrothermal vent field locations [
3]. Previous investigations, where ≤1 m gridded AUV bathymetry data exist, currently rely on the time-consuming manual picking of hydrothermal vents to achieve these goals and, consequently, are uncommon in the literature (e.g., [
7,
33]). In the context of exploration efforts, AUV surveys are becoming commonplace for hydrothermal vent research, and yet, pinpointing locations for near-bottom work is crucial [
4]. One of the advantages that the CIT provides for future research into hydrothermal systems is that the classification method is consistent and repeatable, meaning that differences in the observations between seafloor environments can be attributed to environmental variables rather than variations in the classification procedure by humans.
The two output sets of classified chimneys from the CIT, ‘most likely chimneys’ and ‘probable chimneys’, can be used in different ways to identify chimneys in areas of exploration. For example, utilizing the ‘most likely chimneys’ output from the CIT provides a way to quickly identify candidates for follow-up investigations (e.g., sampling or visual imaging) from exploratory AUV mapping because of the low commission error. The ‘probable chimneys’ group of the CIT output provides the ability to not only identify areas with hydrothermal chimneys present, but also to confidently identify those areas where there are no chimneys due to the low omission error.
The accurate classification of chimneys by the CNN is the most important aspect of the CIT, and we found that changes to the training dataset had the largest impact on the CNN model. The most drastic improvements to CNN performance were observed with the addition of more training classes, so that the CNN could learn to recognize and exclude features that are similar to but not hydrothermal chimneys. When initially constructed, the CNN was trained using two sets of examples: locations from the manual-pick datasets from each study area, and a set of randomly selected points from each dataset that were not chimneys. Visual inspection of the results of this version of the CIT showed many misclassified points located on the upper edges of fault scarps. In order to directly address this error, we implemented four classes of training data: flat/gently sloping areas, chimneys, the upper edges of fault scarps, and rounded local maxima that were at the edges of larger features (
Figure 7). The flat, fault scarp, and rounded training datasets were produced using manual classification. We were unable to continue this method of adding training classes to improve performance, because there was no longer a consistent group of features with shared characteristics showing up in the output. This area of seafloor geosciences is still developing, and only a limited number of hydrothermal chimneys are available for training at this time. However, with additional training data, future AUV mapping surveys in more areas with past or present hydrothermal activity could benefit the performance of the CNN developed here.
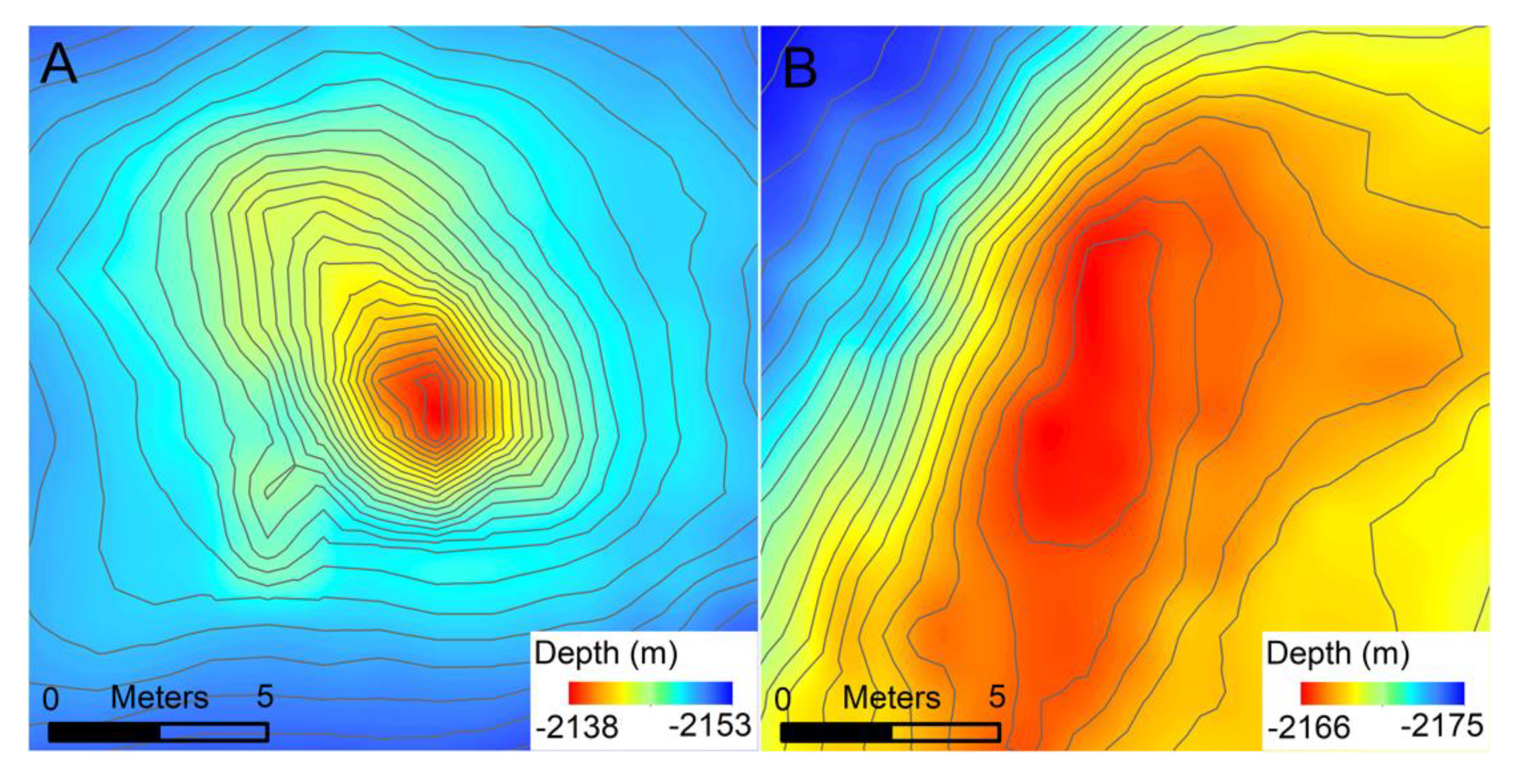
The comparison of the CIT classification with the manual picking of hydrothermal chimneys show some mismatch between these datasets (
Figure 11 and
Figure 12). For the GSC, there are only two chimneys identified by the CIT as ‘most likely chimneys’ that are not in the White and Lee [
8] dataset, and several of the manual picks are also included in the ‘probable chimneys’ group. However, in the Endeavor test area, the CIT output sets and Clague et al.’s [
7] manual picks show several examples of spatial disagreement (
Figure 11) despite only two of the CIT outputs being caught by our manual classification in this study (
Table 2). There are 51 Clague et al. [
7] picks within this test area and 63 ‘most likely’ CIT outputs, and 34 of them are shared. Some features that strongly resemble a chimney are included in the CIT output but not in the Clague et al. [
7] manual picks, and a hydrothermal mound without a spire shape was included in the pre-existing dataset but not the CIT output (
Figure 13). One potential reason for this is that Clague et al. [
7] used other data to supplement the AUV bathymetry where available, such as ROV observations, to improve their hydrothermal chimney catalog. The CIT is designed to identify features that have the characteristics of a hydrothermal chimney from only the AUV bathymetry, which is the data available for most areas of the seafloor. Because the previous manual classifications use other observations and are interpretations made by expert human judgement, an imperfect match is expected. Additionally, we analyzed the CIT outputs by manually evaluating each output ourselves—instead of just comparing the output locations to the pre-existing datasets—as a basis for comparison to human picks from bathymetry alone, without the aid of a priori knowledge.
The comparison of the CIT classifications and previous manual picks highlights the diversity of features, such as chimneys, that appear in meter-scale bathymetry of seafloor spreading ridges. Distinguishing hydrothermal chimneys in bathymetry is a difficult task not only for a Machine-Learning tool, but for humans as well. Clague et al. [
7] discuss how both lava pillars and mounds of pillow lava were included in their preliminary manual picks of chimneys on the Endeavor segment, and although they removed many, they expect that some still remain in their results. This point underscores the need for accuracy assessment inherent in all classifications from remote-sensing data [
37]. The CIT performs well into the 80% accuracy range, but consideration of the potential for misclassification of features is important for future applications of the CIT. Areas of complex bathymetry, faulted grabens, calderas, and collapsed axial summit troughs will pose challenges for hydrothermal chimney detection from bathymetric mapping alone.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}