





Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia





Abstract
:1. Introduction
- The selection of water quality parameters was based on assessing the impact of rainfall-runoff on water quality. Five water quality parameters, namely pH, Turbidity, Phosphate (PO4), Ammonia Nitrogen (NH3-N) and Total Dissolved Solids (TDS) were selected to compute the WQI.
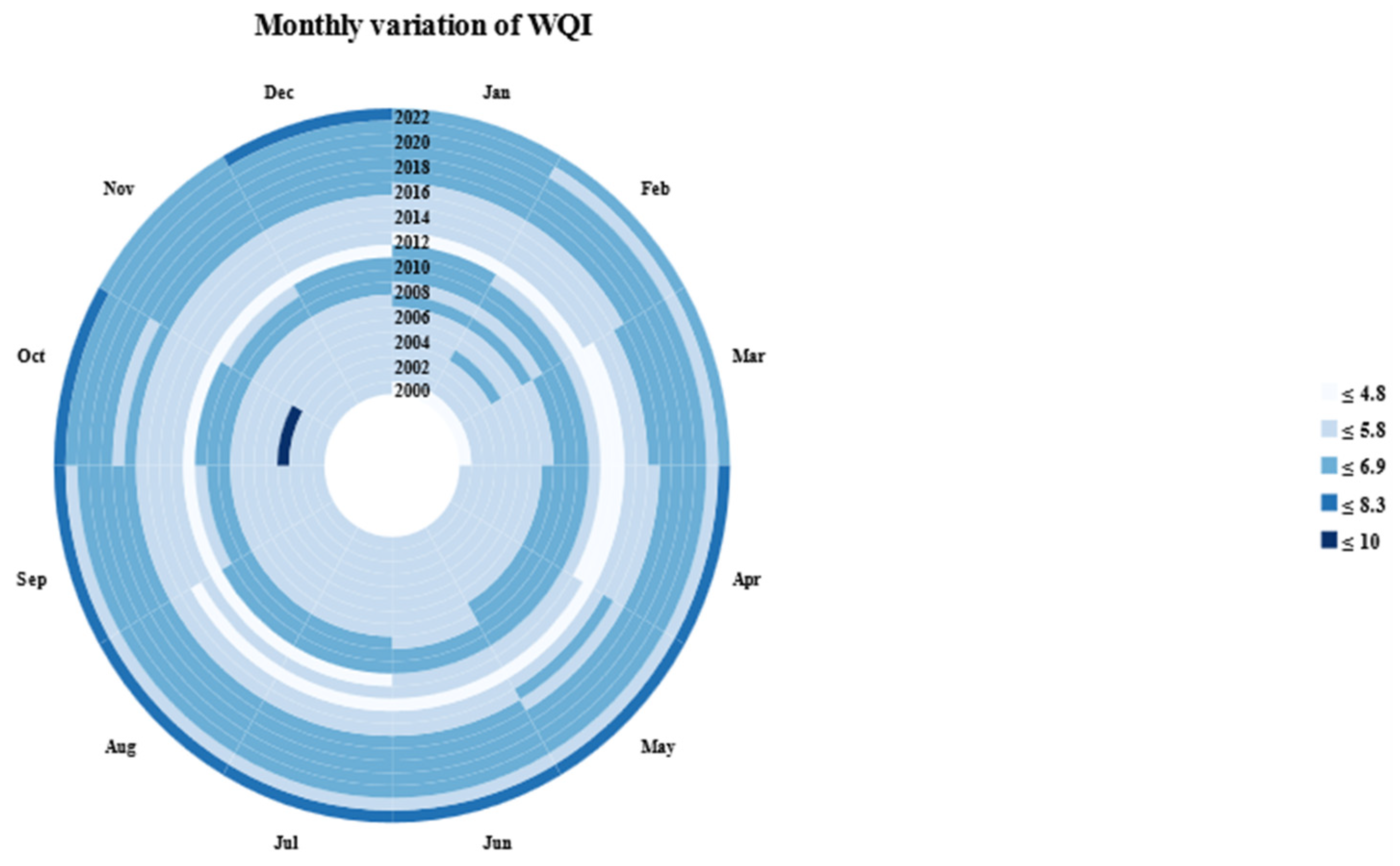
- The monthly and seasonal variation charts demonstrated the applicability of ESRI ArcGIS Pro in water research, highlighting its applicability in the field.
- Four machine learning algorithms (Random Forest Regressor, Support Vector Regressor, AdaBoost Regressor and XGBoost Regressor) and two deep learning algorithms (BiLSTM and GRU) were used for the prediction of the WQI. The performance evaluation of these models was conducted using seven accuracy metrices such as R2, RMSE, MAE, MAPE, CE, d and MSRE.
2. Materials and Methods
2.1. Study Area
2.2. Data Collection
2.3. Determination of Water Quality Index (WQI)
2.3.1. Parameter Selection
2.3.2. Computation of WQI
2.3.3. Parameter Weighting
2.3.4. Evaluation of WQI
2.4. WQI Temporal Data Analysis Using ESRI ArcGIS Pro
2.4.1. Bar Chart
2.4.2. Data Clock
2.5. Machine Learning and Deep Learning Models
2.5.1. Missing Value Replacement
2.5.2. Outlier Detection and Removal
2.5.3. Normalisation of Data
2.5.4. Data Splittingx
2.5.5. Machine Learning Models
- (i)
- Random Forest Regression (RFR)
- (ii)
- Support Vector Regression (SVR)
- (iii)
- AdaBoost Regression:
- (iv)
- Extreme Gradient Boosting (XGBoost) Regression:
2.5.6. Deep Learning Models
- (i)
- Bidirectional LSTM (BiLSTM)
- (ii)
- Gated Recurrent Unit (GRU)
2.5.7. Accuracy Metrices
3. Results
3.1. Descriptive Statistics of Variables
3.2. Seasonal Variation of WQI:
3.3. Monthly Variation of WQI
3.4. Performance Comparison of Machine Learning and Deep Learning Models
3.5. Comparison of Results by Radar Graph
- For the Cooby Reservoir charts (Figure 9), the R2 values prominently reach 0.99, demonstrating the robust predictive capabilities of the models. Remarkably, this high accuracy is maintained consistently except for the BiLSTM model, signifying its comparative deviation. The RMSE and MAE values align well with the R2 results, remaining relatively low, further underscoring the models’ proficiency. There is some deviation in the MAPE value in the case of the SVR and AdaBoost models.
- In the context of the Cressbrook Reservoir (Figure 10), the radar charts accentuate a trend that closely mirrors the Cooby Reservoir results. Once again, the models yield impressive R2 values near 0.99, underscoring their accuracy in predicting water quality.
- The radar charts for Perseverance Reservoir (Figure 11) offer insights parallel to those of the Cooby and Cressbrook Reservoirs.
- The Coefficient of Efficiency (CE) and Willmott Index (d) continue to shine as indicators of an impressive match between observed and simulated data, substantiating the models’ reliability for all three reservoirs.
4. Discussion
5. Conclusion and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wu, D.; Wang, H.; Seidu, R. Smart data driven quality prediction for urban water source management. Future Gener. Comput. Syst. 2020, 107, 418–432. [Google Scholar] [CrossRef]
- Ritchie, H.; Roser, M. Urbanisation. In Our World in Data. 2018. Available online: https://ourworldindata.org/urbanization (accessed on 9 June 2023).
- Bakkes, J.A.; Bosch, P.R.; Bouwman, A.F.; Eerens, H.C.; Den Elzen, M.G.J.; Isaac, M.; Janssen, P.H.M.; Goldewijk, K.K.; Kram, T.; De Leeuw, F.A.A.M.; et al. Background Report to the OECD Environmental Outlook to 2030: Overviews, Details, and Methodology of Model-Based Analysis; Netherlands Environmental Assessment Agency (MNP): Bilthoven, The Netherlands; OECD: Paris, France, 2008. [Google Scholar]
- Nouraki, A.; Alavi, M.; Golabi, M.; Albaji, M. Prediction of water quality parameters using machine learning models: A case study of the Karun River, Iran. Environ. Sci. Pollut. Res. 2021, 28, 57060–57072. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Gao, X.; Yang, Z.; Xu, T. Trend and attribution analysis of runoff changes in the Weihe River basin in the last 50 years. Water 2021, 14, 47. [Google Scholar] [CrossRef]
- Alam, M.J.; Dutta, D. Predicting climate change impact on nutrient pollution in waterways: A case study in the upper catchment of the Latrobe River, Australia. Ecohydrology 2013, 6, 73–82. [Google Scholar] [CrossRef]
- Delpla, I.; Jung, A.-V.; Baures, E.; Clement, M.; Thomas, O. Impacts of climate change on surface water quality in relation to drinking water production. Environ. Int. 2009, 35, 1225–1233. [Google Scholar] [CrossRef]
- Van Vliet, M.; Zwolsman, J. Impact of summer droughts on the water quality of the Meuse river. J. Hydrol. 2008, 353, 1–17. [Google Scholar] [CrossRef]
- Prathumratana, L.; Sthiannopkao, S.; Kim, K.W. The relationship of climatic and hydrological parameters to surface water quality in the lower Mekong River. Environ. Int. 2008, 34, 860–866. [Google Scholar] [CrossRef]
- Evans, C.; Monteith, D.; Cooper, D. Long-term increases in surface water dissolved organic carbon: Observations, possible causes and environmental impacts. Environ. Pollut. 2005, 137, 55–71. [Google Scholar] [CrossRef]
- Zhu, Z.; Arp, P.A.; Mazumder, A.; Meng, F.; Bourque, C.P.-A.; Foster, N.W. Modeling stream water nutrient concentrations and loadings in response to weather condition and forest harvesting. Ecol. Model. 2005, 185, 231–243. [Google Scholar] [CrossRef]
- Zhou, Z.-Z.; Huang, T.-L.; Ma, W.-X.; Li, Y.; Zeng, K. Impacts of water quality variation and rainfall runoff on Jinpen Reservoir, in Northwest China. Water Sci. Eng. 2015, 8, 301–308. [Google Scholar] [CrossRef]
- Witek, Z.; Jarosiewicz, A. Long-Term Changes in Nutrient Status of River Water. Pol. J. Environ. Stud. 2009, 18, 1177–1184. [Google Scholar]
- Tiri, A.; Belkhiri, L.; Mouni, L. Evaluation of surface water quality for drinking purposes using fuzzy inference system. Groundw. Sustain. Dev. 2018, 6, 235–244. [Google Scholar] [CrossRef]
- Horton, R.K. An index number system for rating water quality. J. Water Pollut. Control Fed. 1965, 37, 300–306. [Google Scholar]
- Brown, R.M.; McClelland, N.I.; Deininger, R.A.; Tozer, R.G. A water quality index-do we dare. Water Sew. Work. 1970, 117, 339–343. [Google Scholar]
- Pesce, S.F.; Wunderlin, D.A. Use of water quality indices to verify the impact of Córdoba City (Argentina) on Suquía River. Water Res. 2000, 34, 2915–2926. [Google Scholar] [CrossRef]
- Khan, F.; Husain, T.; Lumb, A. Water quality evaluation and trend analysis in selected watersheds of the Atlantic region of Canada. Environ. Monit. Assess. 2003, 88, 221–248. [Google Scholar] [CrossRef]
- Štambuk-Giljanović, N. Water quality evaluation by index in Dalmatia. Water Res. 1999, 33, 3423–3440. [Google Scholar] [CrossRef]
- Abdul Hameed M Jawad, A.; Haider, S.A.; Bahram, K.M. Application of water quality index for assessment of Dokan lake ecosystem, Kurdistan region, Iraq. J. Water Resour. Prot. 2010, 2, 2715. [Google Scholar]
- El Osta, M.; Masoud, M.; Alqarawy, A.; Elsayed, S.; Gad, M. Groundwater suitability for drinking and irrigation using water quality indices and multivariate modeling in makkah Al-Mukarramah province, Saudi Arabia. Water 2022, 14, 483. [Google Scholar] [CrossRef]
- Abbasi, T.; Abbasi, S.A. Water Quality Indices; Elsevier: Amsterdam, The Netherlands, 2012. [Google Scholar]
- Chidiac, S.; El Najjar, P.; Ouaini, N.; El Rayess, Y.; El Azzi, D. A comprehensive review of water quality indices (WQIs): History, models, attempts and perspectives. Rev. Environ. Sci. Bio/Technol. 2023, 22, 349–395. [Google Scholar] [CrossRef]
- Uddin, M.G.; Nash, S.; Olbert, A.I. A review of water quality index models and their use for assessing surface water quality. Ecol. Indic. 2021, 122, 107218. [Google Scholar] [CrossRef]
- Lumb, A.; Sharma, T.; Bibeault, J.-F. A review of genesis and evolution of water quality index (WQI) and some future directions. Water Qual. Expo. Health 2011, 3, 11–24. [Google Scholar] [CrossRef]
- Dadolahi-Sohrab, A.; Arjomand, F.; Fadaei-Nasab, M. Water quality index as a simple indicator of watersheds pollution in southwestern part of I ran. Water Environ. J. 2012, 26, 445–454. [Google Scholar] [CrossRef]
- Kannel, P.R.; Lee, S.; Lee, Y.-S.; Kanel, S.R.; Khan, S.P. Application of water quality indices and dissolved oxygen as indicators for river water classification and urban impact assessment. Environ. Monit. Assess. 2007, 132, 93–110. [Google Scholar] [CrossRef] [PubMed]
- Sutadian, A.D.; Muttil, N.; Yilmaz, A.G.; Perera, B. Development of river water quality indices—A review. Environ. Monit. Assess. 2016, 188, 1–29. [Google Scholar] [CrossRef]
- Ma, Z.; Li, H.; Ye, Z.; Wen, J.; Hu, Y.; Liu, Y. Application of modified water quality index (WQI) in the assessment of coastal water quality in main aquaculture areas of Dalian, China. Mar. Pollut. Bull. 2020, 157, 111285. [Google Scholar] [CrossRef]
- Chen, K.; Chen, H.; Zhou, C.; Huang, Y.; Qi, X.; Shen, R.; Liu, F.; Zuo, M.; Zou, X.; Wang, J.; et al. Comparative analysis of surface water quality prediction performance and identification of key water parameters using different machine learning models based on big data. Water Res. 2020, 171, 115454. [Google Scholar] [CrossRef]
- Chen, H.; Yang, J.; Fu, X.; Zheng, Q.; Song, X.; Fu, Z.; Wang, J.; Liang, Y.; Yin, H.; Liu, Z.; et al. Water Quality Prediction Based on LSTM and Attention Mechanism: A Case Study of the Burnett River, Australia. Sustainability 2022, 14, 13231. [Google Scholar] [CrossRef]
- Malek, N.H.A.; Yaacob, W.F.W.; Nasir, S.A.M.; Shaadan, N. Prediction of Water Quality Classification of the Kelantan River Basin, Malaysia, Using Machine Learning Techniques. Water 2022, 14, 1067. [Google Scholar] [CrossRef]
- Ahmed, U.; Mumtaz, R.; Anwar, H.; Shah, A.A.; Irfan, R.; García-Nieto, J. Efficient water quality prediction using supervised machine learning. Water 2019, 11, 2210. [Google Scholar] [CrossRef]
- Tung, T.M.; Yaseen, Z.M. A survey on river water quality modelling using artificial intelligence models: 2000–2020. J. Hydrol. 2020, 585, 124670. [Google Scholar]
- Deka, P.C. Support vector machine applications in the field of hydrology: A review. Appl. Soft Comput. 2014, 19, 372–386. [Google Scholar]
- Sengorur, B.; Koklu, R.; Ates, A. Water quality assessment using artificial intelligence techniques: SOM and ANN—A case study of Melen River Turkey. Water Qual. Expo. Health 2015, 7, 469–490. [Google Scholar] [CrossRef]
- Xu, T.; Coco, G.; Neale, M. A predictive model of recreational water quality based on adaptive synthetic sampling algorithms and machine learning. Water Res. 2020, 177, 115788. [Google Scholar] [CrossRef] [PubMed]
- Lutins, E. Ensemble Methods in Machine Learning: What Are They and Why Use Them? Available online: https://towardsdatascience.com/ensemble-methods-in-machine-learning-what-are-they-and-why-use-them (accessed on 8 June 2023).
- Lu, H.; Ma, X. Hybrid decision tree-based machine learning models for short-term water quality prediction. Chemosphere 2020, 249, 126169. [Google Scholar] [CrossRef]
- Chen, L. Basic Ensemble Learning (Random Forest, AdaBoost, Gradient Boosting)-Step by Step Explained. Available online: https://towardsdatascience.com/basic-ensemble-learning-random-forest-adaboost-gradient-boosting-step-by-step-explained (accessed on 8 June 2023).
- Masui, T. All You Need to Know about Gradient Boosting Algorithm. Available online: https://towardsdatascience.com/all-you-need-to-know-about-gradient-boosting-algorithm (accessed on 8 June 2023).
- Aldhyani, T.H.; Al-Yaari, M.; Alkahtani, H.; Maashi, M. Water quality prediction using artificial intelligence algorithms. Appl. Bionics Biomech. 2020, 2020, 6659314. [Google Scholar] [CrossRef]
- Chen, Z.; Xu, H.; Jiang, P.; Yu, S.; Lin, G.; Bychkov, I.; Hmelnov, A.; Ruzhnikov, G.; Zhu, N.; Liu, Z. A transfer Learning-Based LSTM strategy for imputing Large-Scale consecutive missing data and its application in a water quality prediction system. J. Hydrol. 2021, 602, 126573. [Google Scholar] [CrossRef]
- Sugandhi, A. What Is Long Short Term Memory (LSTM)—Complete Guide. Knowledge Hut. Available online: https://www.knowledgehut.com/blog/web-development/long-short-term-memory (accessed on 8 June 2023).
- Zhou, J.; Chu, F.; Li, X.; Ma, H.; Xiao, F.; Sun, L. Water quality prediction approach based on t-SNE and SA-BiLSTM. In Proceedings of the 2020 IEEE 22nd International Conference on High Performance Computing and Communications; IEEE 18th International Conference on Smart City; IEEE 6th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Yanuca Island, Fiji, 14–16 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 708–714. [Google Scholar]
- Kostadinov, S. Understanding GRU Networks. Towards Data Science. Available online: https://towardsdatascience.com/understanding-gru-networks (accessed on 9 June 2023).
- Xu, J.; Wang, K.; Lin, C.; Xiao, L.; Huang, X.; Zhang, Y. FM-GRU: A Time Series Prediction Method for Water Quality Based on seq2seq Framework. Water 2021, 13, 1031. Available online: https://www.mdpi.com/2073-4441/13/8/1031 (accessed on 9 June 2023). [CrossRef]
- Miles, K.; Byrnes, J.; Bannon, K. Review of Regional Water Quality and Security, Review and Reform Strategy; Infrastucture Australia; AECOM Australia Pty Ltd.: Sydney, Australia, 2010; Volume 1. [Google Scholar]
- Wyrwoll, P.R.; Manero, A.; Taylor, K.S.; Rose, E.; Quentin Grafton, R. Measuring the gaps in drinking water quality and policy across regional and remote Australia. NPJ Clean Water 2022, 5, 32. [Google Scholar] [CrossRef]
- T. R. Council. Where Our Water Comes from. TRC. Available online: https://www.tr.qld.gov.au/environment-water-waste/water-supply-dams/dams-bores/13244-where-our-water-comes-from (accessed on 9 June 2023).
- Climate Data Org. Toowoomba Climate, (Australia). Available online: https://en.climate-data.org/oceania/australia/queensland/toowoomba-66/ (accessed on 9 June 2023).
- Amos, M.; Baxter, G.; Finch, N.; Lisle, A.; Murray, P. I just want to count them! Considerations when choosing a deer population monitoring method. Wildl. Biol. 2014, 20, 362–370. [Google Scholar] [CrossRef]
- Department of Environment and Heritage Protection. Queensland Water Quality Guidelines (2009), Version 3; Queensland Government: Brisbane, Australia, 2009; ISBN 978-0-9806986-0-2.
- EOS Project Science Office. NASA Earth Observationory, (N.E.O)-Chlorophyll. NASA. Available online: https://earthobservatory.nasa.gov/global-maps/MY1DMM_CHLORA (accessed on 12 June 2023).
- Calvert Marine Museum, Using your Secchi Disk. Available online: https://www.calvertmarinemuseum.com/293/Using-Your-Secchi-Disc (accessed on 12 June 2023).
- Rusydi, A.F. Correlation between conductivity and total dissolved solid in various type of water: A review. In IOP Conference Series: Earth and Environmental Science; IOP Publishing: Bristol, UK, 2018; Volume 118, p. 012019. [Google Scholar]
- Singh, A.K.; Sathya, M.; Verma, S.; Jayakumar, S. Spatiotemporal variation of water quality index in Kanwar wetland, Begusarai, India. Sustain. Water Resour. Manag. 2020, 6, 1–8. [Google Scholar] [CrossRef]
- Cotruvo, J.A. WHO guidelines for drinking water quality: First addendum to the fourth edition. J.-Am. Water Work. Assoc. 2017, 109, 44–51. [Google Scholar] [CrossRef]
- Esri. Chart. Available online: https://pro.arcgis.com/en/pro-app/3.0/help/analysis/geoprocessing/charts (accessed on 7 June 2023).
- Bureau of Meteorology. Climate Glossary. BOM. Available online: http://www.bom.gov.au/climate/glossary/seasons.shtml (accessed on 13 June 2023).
- Gnauck, A. Interpolation and approximation of water quality time series and process identification. Anal. Bioanal. Chem. 2004, 380, 484–492. [Google Scholar] [CrossRef] [PubMed]
- Swetha, P.; Rasheed, A.H.K.; Harigovindan, V. Random Forest Regression based Water Quality Prediction for Smart Aquaculture. In Proceedings of the 2023 4th International Conference on Computing and Communication Systems (I3CS), Shillong, India, 16–18 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Peddisetty, T. Support Vector Regression in Python. Towards Data Science. Available online: https://towardsdatascience.com/baby-steps-towards-data-science-support-vector-regression-in-python (accessed on 14 June 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011. Available online: https://scikit-learn.org/stable/modules/ensemble.html#adaboost (accessed on 15 June 2023). [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Kang, H.; Yang, S.; Huang, J.; Oh, J. Time series prediction of wastewater flow rate by bidirectional LSTM deep learning. Int. J. Control Autom. Syst. 2020, 18, 3023–3030. [Google Scholar] [CrossRef]
- Zhang, Y.-g.; Tang, J.; He, Z.-y.; Tan, J.; Li, C. A novel displacement prediction method using gated recurrent unit model with time series analysis in the Erdaohe landslide. Nat. Hazards 2021, 105, 783–813. [Google Scholar] [CrossRef]
- Nagelkerke, N.J. A note on a general definition of the coefficient of determination. Biometrika 1991, 78, 691–692. [Google Scholar] [CrossRef]
- Singh, A.; Singh, R.; Kumar, A.S.; Kumar, A.; Hanwat, S.; Tripathi, V. Evaluation of soft computing and regression-based techniques for the estimation of evaporation. J. Water Clim. Chang. 2021, 12, 32–43. [Google Scholar] [CrossRef]
- Heddam, S. Use of optimally pruned extreme learning machine (OP-ELM) in forecasting dissolved oxygen concentration (DO) several hours in advance: A case study from the Klamath River, Oregon, USA. Environ. Process. 2016, 3, 909–937. [Google Scholar] [CrossRef]
- Willmott, C.J.; Ackleson, S.G.; Davis, R.E.; Feddema, J.J.; Klink, K.M.; Legates, D.R.; O’donnell, J.; Rowe, C.M. Statistics for the evaluation and comparison of models. J. Geophys. Res. Ocean. 1985, 90, 8995–9005. [Google Scholar] [CrossRef]
- Rowe, W. Mean Square Error & R2 Score Clearly Explained. BMC. Available online: https://www.bmc.com/blogs/mean-squared-error-r2-and-variance-in-regression-analysis (accessed on 15 June 2023).
- Tang, T.; Wang, S.; Wang, Z.; Chen, Y.; Wen, Y. Data-Driven Comprehensive Evaluation Model Based on the Radar Chart for the Operating State of XLPE Cables. In Proceedings of the 2022 4th Asia Energy and Electrical Engineering Symposium (AEEES), Chengdu, China, 25–28 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 644–649. [Google Scholar]
- Saary, M.J. Radar plots: A useful way for presenting multivariate health care data. J. Clin. Epidemiol. 2008, 61, 311–317. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Standard Limits | Weighting Value | Relative Weight |
|---|---|---|---|
| pH | 6.5–8.5 | 4 | 0.19 |
| TDS | 500 mg/L | 4 | 0.19 |
| Turbidity | 5 NTU | 3 | 0.14 |
| Ammonia Nitrogen | 0.5 | 5 | 0.24 |
| Phosphate | 0.005 to 0.05 mg/L Generally, less than 0.03 mg/L | 5 | 0.24 |
| Sum = 1 |
| WQI | Class | Water Quality | Treatment and Application |
|---|---|---|---|
| 90–100 | I | Excellent | Water treatment not required. Can be utilised for protection of ecosystem. |
| 70–90 | II | Good | Pre-treatment is necessary. After the treatment, suitable for human use and ecosystem conservation. |
| 50–70 | III | Medium | Can be applied for agricultural purposes. Not suitable for human use. |
| 25–50 | IV | Poor | Substantial treatment is required before any use. Not fit for human use. |
| 0–25 | V | Very Poor | Not suitable for any kind of consumption. Only usage is for navigation or transportation on water. |
| Name | Purpose | Value |
|---|---|---|
| Coefficient of Determination (R2) | Measure of variance of regression model. Measures the ability to predict the dependent variable from independent variable [68]. | More than 0.90 indicates good fit of data. |
| Root Mean Squared Error (RMSE) | Measures the deviation between actual and predicted values [69]. | Zero value indicates perfect fit. The lower the value, the closer to perfect the estimation. |
| Mean Absolute Error (MAE) | Estimates the mean absolute error between the actual and predicted values [70]. | A lower value close to zero indicates higher accuracy. |
| Mean Absolute Percentage Error (MAPE) | Indicates how far the predictions are from average. It measures the average magnitude of error in a model [70]. | A value closer to zero indicates better predictions. |
| Coefficient of Efficiency (CE) | Compares the relative performance of residual variance with initial variance [69]. | CE > 0.90—complete appropriate simulation. 0.90 > CE > 0.60—appropriate simulation. CE < 0.60—inappropriate simulation |
| Index of Agreement, Willmott Index (d) | Measures how the model estimates the simulated actual data [71]. | Zero indicates no match; one indicates ideal match. |
| Mean Squared Relative Error (MSRE) | Mean of square of errors [72]. | Closer it is to 0, the closer to perfect the prediction. |
| Reservoir | Variable | Phosphate | Turbidity | pH | N_NH3_FIA | TDS | WQI |
|---|---|---|---|---|---|---|---|
| Cooby | Mean | 0.005960 | 4.263257 | 8.312166 | 0.004962 | 621.36277 | 23.670963 |
| Std | 0.023644 | 30.103567 | 0.433122 | 0.015783 | 269.16741 | 10.253997 | |
| Min | 0.000000 | 0.000000 | 2.400000 | 0.000000 | 29.00000 | 1.104762 | |
| Max | 0.580000 | 1025.000000 | 9.400000 | 0.200000 | 1247.00000 | 47.504762 | |
| Cressbrook | Mean | 0.011060 | 2.715590 | 7.863962 | 0.008916 | 212.052381 | 8.078186 |
| Std | 0.037834 | 14.225074 | 0.411165 | 0.017249 | 36.742244 | 1.399705 | |
| Min | 0.000000 | 0.470000 | 6.000000 | 0.000000 | 106.000000 | 4.038095 | |
| Max | 0.950000 | 461.000000 | 8.900000 | 0.075000 | 325.000000 | 12.380952 | |
| Perseverance | Mean | 0.006308 | 3.918630 | 7.658132 | 0.006209 | 139.206337 | 5.303099 |
| Std | 0.033561 | 6.634551 | 0.391520 | 0.018787 | 16.958400 | 0.646034 | |
| Min | 0.000000 | 0.270000 | 6.380000 | 0.000000 | 91.000000 | 3.466667 | |
| Max | 1.000000 | 106.000000 | 8.700000 | 0.300000 | 185.000000 | 7.047619 |
| Algorithm | Phase | R2 | RMSE | MAE | MAPE | CE | d | MSRE |
|---|---|---|---|---|---|---|---|---|
| RFR | Training | 0.99 | 0.0799 | 0.0217 | 0.4518 | 0.99 | 0.99 | 0.00174 |
| Testing | 0.99 | 0.048 | 0.0192 | 0.266 | 0.99 | 0.99 | 0.000048 | |
| SVR | Training | 0.98 | 1.22 | 0.2696 | 6.895 | 0.98 | 0.98 | 0.0466 |
| Testing | 0.99 | 0.2127 | 0.0643 | 1.48 | 0.98 | 0.98 | 0.0020 | |
| AdaBoost | Training | 0.993 | 0.871 | 0.706 | 3.535 | 0.99 | 0.99 | 0.018 |
| Testing | 0.993 | 0.55 | 0.308 | 3.58 | 0.99 | 0.99 | 0.0022 | |
| XGBoost | Training | 0.9999 | 0.1752 | 0.0119 | 0.0657 | 0.99 | 0.99 | 0.0000005 |
| Testing | 0.9999 | 0.0816 | 0.0314 | 0.3186 | 0.99 | 0.99 | 0.000044 | |
| BiLSTM | Training | 0.91 | 0.286 | 0.1969 | 0.838 | 0.99 | 0.99 | 0.00016 |
| Testing | 0.91 | 0.339 | 0.212 | 0.676 | 0.99 | 0.99 | 0.00072 | |
| GRU | Training | 0.9999 | 0.0382 | 0.0343 | 0.1481 | 0.99 | 0.99 | 0.0000018 |
| Testing | 0.9999 | 0.0271 | 0.0155 | 0.2552 | 0.9 | 0.99 | 0.0000045 |
| Algorithm | Phase | R2 | RMSE | MAE | MAPE | CE | d | MSRE |
|---|---|---|---|---|---|---|---|---|
| RFR | Training | 0.9997 | 0.0234 | 0.0042 | 0.0452 | 0.99 | 0.99 | 0.000002 |
| Testing | 0.999 | 0.0367 | 0.0033 | 0.0354 | 0.99 | 0.99 | 0.00002 | |
| SVR | Training | 0.997 | 0.0754 | 0.0562 | 0.7203 | 0.99 | 0.99 | 0.000071 |
| Testing | 0.998 | 0.0967 | 0.0264 | 0.6494 | 0.99 | 0.99 | 0.000575 | |
| AdaBoost | Training | 0.992 | 0.1221 | 0.0933 | 1.2027 | 0.99 | 0.99 | 0.000122 |
| Testing | 0.992 | 0.085 | 0.040 | 1.221 | 0.99 | 0.99 | 0.00033 | |
| XGBoost | Training | 0.9999 | 0.00199 | 0.00138 | 0.01681 | 0.99 | 0.99 | 0.00000003 |
| Testing | 0.9999 | 0.011538 | 0.00380 | 0.11146 | 0.99 | 0.99 | 0.0000047 | |
| BiLSTM | Training | 0.89 | 1.404 | 1.211 | 1.033 | 0.97 | 0.96 | 0.0168 |
| Testing | 0.89 | 1.494 | 1.229 | 1.111 | 0.97 | 0.96 | 0.0376 | |
| GRU | Training | 0.9999 | 0.00128 | 0.00123 | 0.02538 | 0.99 | 0.99 | 0.00000007 |
| Testing | 0.9999 | 0.00397 | 0.000969 | 0.02233 | 0.99 | 0.99 | 0.00000038 |
| Algorithm | Phase | R2 | RMSE | MAE | MAPE | CE | d | MSRE |
|---|---|---|---|---|---|---|---|---|
| RFR | Training | 0.9999 | 0.00335 | 0.000857 | 0.02126 | 0.99 | 0.99 | 0.0000003 |
| Testing | 0.9999 | 0.00554 | 0.00182 | 0.03643 | 0.99 | 0.99 | 0.0000012 | |
| SVR | Training | 0.998 | 0.0403 | 0.0364 | 0.6929 | 0.99 | 0.99 | 0.000025 |
| Testing | 0.998 | 0.0396 | 0.0359 | 0.6705 | 0.99 | 0.99 | 0.000055 | |
| AdaBoost | Training | 0.988 | 0.0704 | 0.0595 | 1.1601 | 0.99 | 0.99 | 0.000083 |
| Testing | 0.988 | 0.0713 | 0.0603 | 1.1543 | 0.99 | 0.99 | 0.000191 | |
| XGBoost | Training | 0.9999 | 0.0011 | 0.00668 | 0.0126 | 0.99 | 0.99 | 0.000000046 |
| Testing | 0.9999 | 0.00825 | 0.00204 | 0.0966 | 0.99 | 0.99 | 0.0000082 | |
| BiLSTM | Training | 0.89 | 0.6404 | 0.5191 | 1.119 | 0.99 | 0.99 | 0.0188 |
| Testing | 0.88 | 0.4199 | 0.222 | 1.232 | 0.98 | 0.99 | 0.0159 | |
| GRU | Training | 0.9999 | 0.0386 | 0.00297 | 0.0405 | 0.99 | 0.99 | 0.00000077 |
| Testing | 0.9999 | 0.00315 | 0.002697 | 0.03311 | 0.99 | 0.99 | 0.00000014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Farzana, S.Z.; Paudyal, D.R.; Chadalavada, S.; Alam, M.J. Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia. Geosciences 2023, 13, 293. https://doi.org/10.3390/geosciences13100293
Farzana SZ, Paudyal DR, Chadalavada S, Alam MJ. Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia. Geosciences. 2023; 13(10):293. https://doi.org/10.3390/geosciences13100293
Chicago/Turabian StyleFarzana, Syeda Zehan, Dev Raj Paudyal, Sreeni Chadalavada, and Md Jahangir Alam. 2023. "Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia" Geosciences 13, no. 10: 293. https://doi.org/10.3390/geosciences13100293
APA StyleFarzana, S. Z., Paudyal, D. R., Chadalavada, S., & Alam, M. J. (2023). Prediction of Water Quality in Reservoirs: A Comparative Assessment of Machine Learning and Deep Learning Approaches in the Case of Toowoomba, Queensland, Australia. Geosciences, 13(10), 293. https://doi.org/10.3390/geosciences13100293