Abstract
Surrogate models, also referenced as metamodels, have emerged as attractive data-driven, predictive models for storm surge estimation. They are calibrated based on an existing database of synthetic storm simulations and can provide fast-to-compute approximations of the expected storm surge, replacing the numerical model that was used to establish this database. This paper discusses specifically the development of a kriging metamodel for the prediction of peak storm surges. For nearshore nodes that have remained dry in some of the synthetic storm simulations, a necessary first step, before the metamodel calibration, is the imputation of the database to address the missing data corresponding to such dry instances to estimate the so-called pseudo-surge. This imputation is typically performed using a geospatial interpolation technique, with the k nearest-neighbor (kNN) interpolation being the one chosen for this purpose in this paper. The pseudo-surge estimates obtained from such an imputation may lead to an erroneous classification for some instances, with nodes classified as inundated (pseudo-surge greater than the node elevation), even though they were actually dry. The integration of a secondary node classification surrogate model was recently proposed to address the challenges associated with such erroneous information. This contribution further examines the above integration and offers several advances. The benefits of implementing the secondary surrogate model are carefully examined across nodes with different characteristics, revealing important trends for the necessity of integrating the classifier in the surge predictions. Additionally, the combination of the two surrogate models using a probabilistic characterization of the node classification, instead of a deterministic one, is considered. The synthetic storm database used to illustrate the surrogate model advances corresponds to 645 synthetic tropical cyclones (TCs) developed for a flood study in the Louisiana region. The fact that various flood protective measures are present in the region creates interesting scenarios with respect to the groups of nodes that remain dry for some storms behind these protected zones. Advances in the kNN interpolation methodology, used for the geospatial imputation, are also presented to address these unique features, considering the connectivity of nodes within the hydrodynamic simulation model.
1. Introduction
The use of surrogate models (also referenced as emulators or metamodels) and machine learning techniques has gained increasing popularity for coastal hazard assessment applications [1,2,3,4,5,6,7,8,9,10]. These approaches represent data-driven predictive tools that are calibrated using a database of synthetic storm simulations, with the ultimate goal to establish fast-to-compute emulators that approximate (emulate) the expected storm surge with high accuracy. The output of the emulator is the storm surge (peak values or time-history evolution), and the input is the parametric features that can be used to uniquely describe each storm within the available database, for example, the parameters of the storm wind-field model. The emulator ultimately establishes an approximation of the input/output relationship and, when properly calibrated, can replace the high-fidelity numerical model utilized to develop the original synthetic storm database, offering predictions with similar accuracy and vastly improved computational efficiency. This circumvents any computational challenges associated with using the aforementioned high fidelity numerical models for real-time forecasting and storm surge risk assessment, ultimately allowing the development of efficient and versatile hazard prediction tools for emergency response management and regional planning [11,12]. Gaussian process emulators (kriging) have been proven in several studies [2,3,4,13,14,15] to offer great versatility as a surrogate modeling technique in this context, providing highly accurate storm surge predictions over large coastal regions with thousands of nodes and for databases of various sizes (number of storms) and characteristics (underlying features of the synthetic storms).
Given a database of synthetic storms, two essential steps are needed before the emulator calibration. These steps correspond, respectively, to the establishment of the input and output (observations) training data. First, a parameterization of the database is needed to define a vector of storm features that will serve as the emulator input. These features typically pertain to track, size, and intensity characteristics for each storm, and in order to account for the time evolution of these characteristics, different approaches can be established leading to a definition based on: (i) a specific reference instance (landfall or reference landfall for bypassing storm) [3], (ii) averaged values over some time-window around such a reference instance [16], or (iii) a description that considers the entire functional dependence over time [9,17]. Second, for nearshore or onshore nodes that have remained dry in some of the synthetic storm simulations, the imputation of the database to address the missing data corresponding to such dry instances is warranted. This imputation process provides the pseudo-surge [18], which then replaces the missing data in the original database. Though both steps are important, the emphasis of this paper is on the second step, the database imputation.
Geospatial interpolation techniques, such as kriging [14] or k nearest-neighbor (kNN) interpolation [16] have been proven as appropriate for performing this imputation, leveraging the spatial correlation between nodes in order to infer missing data based on the surge values of other inundated nodes in close proximity. The selection of the exact type of geospatial interpolation depends on the number of nodes for which surge data is available, whether they correspond to the original numerical grid, which may include hundreds of thousands of nodes, or to some selected, few (up to a couple of thousand) save points. In the former case, a weighted kNN interpolation [16] has been shown to provide good accuracy and computational efficiency, whereas for the latter case, advanced geospatial interpolation techniques, such as kriging, can be explored [14] since the smaller size of the database (smaller number of nodes) does not pose insurmountable computational challenges for such techniques. Independently of the approach adopted to perform the imputation, the established pseudo-surge estimates may provide an erroneous classification for some storms, with the node classified as inundated based on the pseudo-surge (pseudo-surge value larger than node elevation), even though it is known, based on the original database, that the node is actually dry. Some adjustment of the imputed pseudo-surge is required for such instances, since the direct use of the erroneous pseudo-surge training data will ultimately lead to a poor emulator performance, over-predicting surge values for such cases. On the other hand, the type of this adjustment is also important since it can generate gaps in the input/output data, as demonstrated later, impacting the emulator calibration process and its predictive capabilities.
This paper examines this specific problem of appropriately adjusting the imputed pseudo-surge values for the accurate, emulator-based prediction of peak storm surge. The integration of a secondary node classification surrogate model was recently proposed [16] to address the challenges associated with the erroneous pseudo-surge values generated at the imputation stage. The proposed secondary surrogate model couples logistic principal component analysis (LPCA) [19] with a kriging emulator on the resultant natural parameters of the logistic process to establish an efficient classifier, even for applications with a large number of nodes. For any node that has been misclassified at least once during the database imputation, termed as a problematic node, the final surge predictions are established by combining the predictions of the secondary classification surrogate model and the primary storm surge surrogate model, which is established using the imputed database. It was recommended in [16] to adopt the predictions of the secondary classification surrogate when the primary surrogate provides the condition of the problematic node to be as inundated (surge estimate larger than the node elevation), in order to counteract the propensity of the latter to overestimate the surge. This contribution considers a number of critical advances for integrating such a node classification setting in storm surge surrogate modeling. The accuracy established from this integration is examined for groups of nodes with different characteristics, instead of averaging over the entire geographical domain, providing an in-depth analysis of the benefits that such an integration can offer and of the cases for which such benefits are critical for coastal hazard assessment. A detailed comparison to an alternative implementation, considering the direct adjustment of any erroneous pseudo-surge imputations, is also considered. Furthermore, potential advantages of combining the two different surrogates (node classification and surge prediction) are discussed across all nodes, without constraining only to the problematic ones. Finally, the probabilistic characterization of the node classification (condition), instead of a deterministic one, is examined for the surrogate model combination. This probabilistic characterization for the secondary surrogate model is facilitated directly using the underlying logistic regression, while for the primary surrogate model, it is developed utilizing the uncertainty quantification offered by the corresponding Gaussian process emulator. All these advances are illustrated using a 645 synthetic tropical cyclones (TCs) database developed for a flood study in the Louisiana region. Various flood protective measures are present in the region, creating interesting scenarios with respect to the group of nodes that remain dry behind them for many of the database storms. Some adjustments in the kNN interpolation used for the geospatial imputation are also discussed, considering the node grid connectivity within the hydrodynamic surge simulation model when deciding on the selection of the neighboring grid point locations, rather than basing any decisions solely on the closest distance. The development of different surge surrogate models for parts of the database with different surge behavior is also incentivized and investigated through some of the examined comparisons.
The remaining of the paper is organized as follows: Section 2 establishes the notation formalism used in this manuscript, with Section 3 presenting an overview of the database used in this study. Section 4 reviews the kNN imputation process and motivates the need to consider the node classification surrogate model. Section 5 reviews the fundamentals of the primary and secondary surrogate model developments, while Section 6 discusses details of the combination of the two surrogate models, distinguishing between different approaches based on the node characteristics at the database imputation stage. Finally, Section 7 considers a detailed presentation of results from the application of the combined surrogate model implementation to the Louisiana case-study database.
2. Notation Formalism
A database of n synthetic storms is available that provides surge predictions for a total of nodes within the computational domain. For the surrogate model development, each of the synthetic storms is parameterized through the -dimensional vector , which will serve as the emulator input, with denoting the ith input component. Further details on the selection of x for the case study database will be provided in Section 3. The input vector for the hth storm will be denoted as . Let denote the peak surge for the ith node and the hth storm. Notation will also be used for the surge of the ith node when the explicit dependence on the storm input vector needs to be highlighted. Let denote the -dimensional surge vector, with its components corresponding to the surge values for all individual nodes of interest. All notations, including the subscript, superscript, and input dependencies, extend to the vector notation z as well. For example, corresponds to the vector of peak surge for all nodes for the hth storm, which is described through the input vector . The classification of the ith node condition for the hth storm is denoted by or when the dependence on the storm input needs to be explicitly noted, with the convention that corresponds to the node being inundated (wet) and to the node being dry. The dry instances correspond to missing data in the original database, with no predictions for the corresponding storm surge . The nodes for which is equal to 1 across all storms correspond to nodes that have been inundated across the entire database and will be referenced as “always wet” nodes, whereas the inland nodes for which is equal to 0 for at least one storm will be referenced as “once dry” nodes. The latter node group has at least one missing value (the surge is not provided for at least one storm) across the suite of storms. The number of at least once dry nodes will be denoted as . Additionally, let the elevation of the ith node be , and for each node define the surge gap as:
where denotes the minimum of the quantity inside the parentheses across all the storms in the database. The surge gap will be used later on to distinguish the dry nodes into different groups.
Finally, assembling the data across all storms, let X, Z, and denote the matrices for the storm input, surge, and node classification, respectively, whose rows correspond to the characteristics for individual storms. Across the manuscript, lower case variables denote characteristics for specific storms, and upper case variables refer to characteristics across the entire database. Matrix X has dimension , with rows corresponding to ; Z has dimension , with rows corresponding to ; and has dimension , with the element (hth row and ith column) corresponding to . The instances/elements in matrix that correspond to value 0 represent the missing data in the original Z matrix. The database for the peak storm surge ultimately provides the parametric input matrix X and the peak surge matrix Z. The classification matrix is derived based on Z, with 0 representing instances of missing surge values (node is dry) and 1 the rest (node is inundated, so surge prediction is available).
3. Louisiana Database Overview
The database used in this study is part of the U.S. Army Corps of Engineers’ (USACE) Coastal Hazards System (CHS; https://chs.erdc.dren.mil (accessed on 15 April 2022)) [12]. The CHS Louisiana Coastal Study (CHS-LA) was conducted for quantifying storm hazards and coastal compound flooding in Louisiana, including areas in the vicinity of the Greater New Orleans Hurricane Storm Damage Risk Reduction System (HSDRRS). The storm suite developed for CHS-LA consists of n = 645 synthetic tropical cyclones (TCs), separated into eight main tracks, referenced herein as master tracks (MTs), as shown in Figure 1 and Figure 2. The grouping of the different tracks is based on the storm heading direction at the final approach before landfall. Figure 1 shows all unique storm tracks, separated into the MTs based on color, whereas Figure 2 presents separately the tracks within each MT, additionally establishing a magnification closer to landfall. All storms are characterized by unique combinations of the following parameters: landfall location, defined by the latitude, , and longitude of the storm track, ; heading direction during final approach to landfall, β; central pressure deficit, ; translational speed, ; and radius of maximum wind speed, . The heading direction (β) dictates the MT (as shown in each of the subplots in Figure 2), and the combination of latitude and longitude the specific track within each MT. The remaining parameters dictate the strength , size , and speed characteristics of each synthetic storm, further distinguishing storms that might correspond to the same track. These characteristics have been held relatively constant prior to landfall, as shown in Figure 3, illustrating the variation of these storm parameters for a typical storm of the database. Table 1 summarizes the range of the TC parameters that constitute the database. The reported values for each parameter correspond to the ones of peak storm intensity in each case.
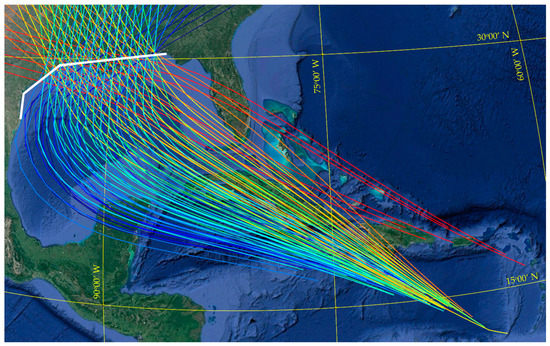
Figure 1.
All the master tracks for the considered database, along with the linearized coastal boundary (white line) for the reference landfall definition.
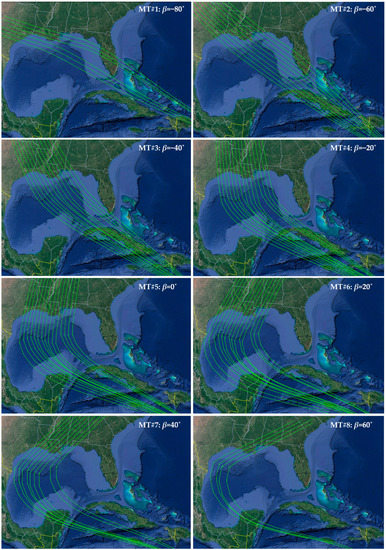
Figure 2.
Storm tracks per master track (MT). Heading direction (β) per MT group also shown.
Figure 3.
The variation of the storm—size, translational speed, and strength—parameters along the track for a specific storm within the database.

Table 1.
Characteristics of the database per master track (MT).
The simulation of the 645 synthetic TCs in the CHS-LA database was performed using high-resolution, high-fidelity atmospheric and hydrodynamic numerical models. The parameters of the synthetic TC suite were first used as input to drive a Planetary Boundary Layer (PBL) model on a nested grid to generate the wind and pressure fields used as forcing in the hydrodynamic modeling. The hydrodynamic simulations were performed by coupling the ADCIRC (Advanced Circulation) model [20] and the SWAN (Simulating Waves Nearshore) wave model [21]. The ADCIRC mesh grid, corresponding to the v14a grid including the 2023 update of the coastal protection systems for the greater Louisiana region, consists of close to 1.6 million nodes and 3.1 million triangular elements. A subset of the entire domain will be considered for the metamodel development, focusing on areas around New Orleans, constrained by latitude (28.5°, 40°) N and longitude (86°, 93.5°) W. This corresponds to a total of 1,179,179 nodes, with 488,216 being dry in at least one storm. Figure 4 presents the dry/wet information for nodes and storms using histograms of (a) the percentage of storms that each node is inundated for, and of (b) the percentage of nodes that are inundated for each storm. Both histograms are presented as relative frequency plots, with the total number of elements per bin divided by the total number of elements, which is nz for part (a) and n for part (b). Note that for part (a) of Figure 4, percentage equal to 1 corresponds to the always wet set.
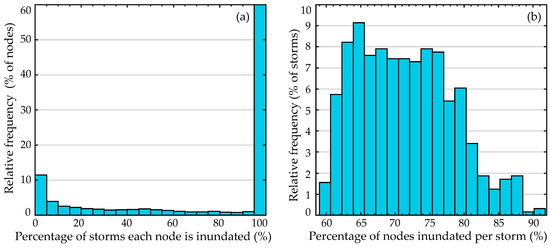
Figure 4.
Information about wet/dry conditions for nodes and storms, expressed as histograms of (a) the percentage of storms that each node is inundated for, and of (b) the percentage of nodes that are inundated for each storm. Both histograms are presented as relative frequency plots (making the y-axis also a percentage of the corresponding characteristic, nodes or storms, respectively).
The geographic domain includes various flood protection systems around the Greater New Orleans area. Within the ADCIRC numerical model, some of these systems were modeled using disconnected grids (no elements connecting nodes) with appropriate constraints across nodes to couple the water elevation.
Related to the storm parameterization, the characteristics at landfall are chosen to define x, taking into account the aforementioned small variability of the size, intensity, and speed along the synthetic storm track (demonstrated in detail in Figure 3). This leads to an input vector that includes the latitude, , and longitude, , for reference landfall; the heading direction for the storm MT, β; the central pressure deficit, ; the radius of maximum winds, ; and the translational speed, : .
A simplified, piece-wise linear coastal boundary is utilized for defining the reference landfall, also shown in Figure 1 (white solid line). The boundary simplification is chosen based on the recommendations in [14] to avoid any ambiguous definition of landfall due to the existence of bays. The input parameters and are defined when the synthetic storm track crosses this boundary.
4. Dry node Imputation and Identification of the Challenges Associated with the Pseudo-Surge Estimates
This section describes the database imputation process, in order to estimate the pseudo-surge values, and discusses the challenges associated with erroneous classification based on such estimates.
4.1. Imputation Using Weighted kNN with ADCIRC Connectivity
A weighted kNN interpolation is adopted for the surge imputation, utilizing the same formulation as in [16]. The proximity of the nodes in the ADCIRC grid, also shown in subplot (a) of Figure 5, promotes high accuracy for the kNN interpolation in this setting, since neighboring nodes are short distances from one another, accommodating reliable predictions based on information from only the closest neighbors. Let denote the geo-distance between nodes i and j and the set of k closest nodes to the ith node for the hth storm, based on the calculated . Only nodes with known surge values are included in set ; these may correspond to inundated nodes for the hth storm (nodes for which ), or to nodes with already imputed values within the iterative formulation discussed next. The ADCIRC connectivity can be incorporated using instead of the closest nodes based purely on , the closest connected nodes, where the latter is defined by the number of ADCIRC element edges between nodes i and j in the graph representing the ADCIRC numerical grid. Figure 5b illustrates this concept; for a specific node of interest (red dot), the one (magenta), two (yellow), and three (cyan) edge connectivity neighbors are shown. Evidently, nodes with a higher edge connectivity cannot be included in set before all other neighbors with lower edge connectivity (irrespective of their distance) are included. This way, nodes that might appear close based on but belong to different or disconnected sections of the ADCIRC grid, for example, due to the presence of bays and/or riverine systems (complex geomorphology) or due to flood protection systems, are not utilized in the kNN implementation.
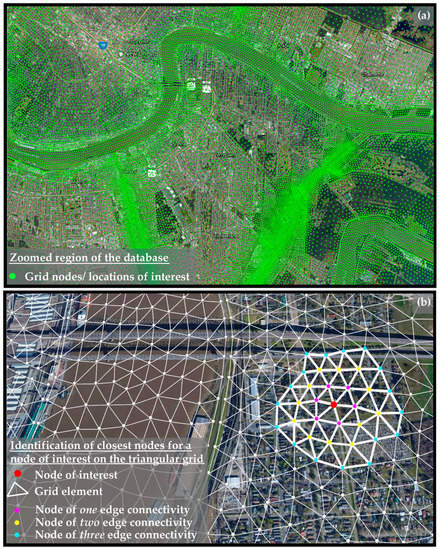
Figure 5.
(a) Part of the grid of nodes that are included as output locations in the database focused on the New Orleans area, and (b) the process of identifying the closest nodes to an arbitrary node of interest using the node connectivity established by the ADCIRC triangular grid elements.
Based on the information in set , the pseudo-surge estimate, , for the ith node and the hth storm based on the weighted kNN interpolation is given by:
where is a distance-dependent weight taken as a power exponential expression with parameters d, q, and p [16]. A cut-off distance d is introduced in the definition of weights to avoid faraway nodes influencing the kNN interpolation in any irregular parts of the grid. The set of parameters of Equation (2) corresponds to the hyper-parameters for the weighted kNN interpolation that need to be calibrated. This calibration can be performed using information for the wet nodes [16], a process briefly reviewed in Appendix A.
As suggested in [16], an iterative imputation can be adopted for each storm to better accommodate hydraulic connectivity. This iterative kNN implementation examines the imputation separately for each storm. At each iteration, the imputation is done only on dry nodes that have at least k wet (imputed and genuine) neighbors in a larger set of nodes. If fewer than k wet neighbors are available, no value is imputed in the current iteration. The value of is chosen equal to twice the value of k in this study, adopting the same recommendation as in [16]. This implementation facilitates a gradual, spatial imputation propagating surge values gradually from offshore to onshore nodes, mimicking the physical wetting process. The use of the ADCIRC connectivity in the nearest neighbor selection, discussed earlier, incorporates additional considerations of the hydraulic connectivity close to any zones with protection systems (i.e., disconnected parts of the grid).
4.2. Issues Related to Misclassification Based on the Pseudo-Surge
The kNN-based imputation is not guaranteed to lead to pseudo-surge values, , that are smaller than the node elevation, , since no such constraint is explicitly enforced into the formulation. Nodes for which the imputed surge is projected to be higher than the node elevation are falsely classified as wet based on the pseudo-surge values. For addressing such erroneous information, two solutions can be considered [16]: (a) artificially modify the estimated pseudo-surge so that it is smaller than the node elevation (e.g., 5 cm below the node elevation, ), guaranteeing that the node is correctly classified even based on the pseudo-surge values; or (b) maintain the pseudo-surge values obtained directly through the geospatial imputation, but consider a classification surrogate model to provide predictions for the node condition based on the original database (condition classification matrix ) to address the erroneous information in the pseudo-surge database. The set of nodes that have been misclassified at least once during the imputation process will be denoted as and will be referenced herein as problematic nodes. The number of those nodes will be denoted as . The database corresponding to the imputed pseudo-surge with no modification (case (b)) will be referenced herein as “pseudo-surge database”, and the database with adjustments to guarantee that the pseudo-surge value is smaller than the node elevation will be referenced herein as “corrected pseudo-surge database”. Before moving forward, is it important to stress that, as discussed in the introduction, the pseudo-surge is introduced merely as a mean to support the surge metamodel development (imputation of missing values in the original database), and there is no correct value for it from a theoretical perspective [16]. Both the pseudo-surge database and corrected pseudo-surge database should be deemed as possible alternatives for supporting the surge metamodel formulation, and the most appropriate one can be only evaluated based on the accuracy of that metamodel. It is important to view the subsequent discussions from this perspective.
Illustration of the challenges associated with some of the problematic nodes is facilitated through Figure 6, depicting the surge and pseudo-surge values for such a node across all the storms within the database. Note that a similar figure and relevant discussion were also included in [16] for this purpose. Here, this discussion is repeated for illustration clarity and in order to further motivate the need to address the falsely classified nodes, while establishing an additional connection to the surge gap defnition introduced in this paper. Specifically, this figure presents the pseudo-surge values obtained through the kNN-imputation in ascending order across the storms, and the node elevation with a horizontal line. Note that a portion of the entire database is shown, corresponding to pseudo-surge values close to the node elevation. The depicted blue circles correspond to surge predictions for the original database (node is inundated), while the green squares and the red × correspond to the kNN-based imputed pseudo-surge for the storms for which the node was originally dry. Green squares correspond to the correctly classified nodes with imputed surge below the node elevation, therefore still classifying the node as dry, while the red × to an erroneous classification, with the node classified as wet based on the imputed surge value. For the corrected pseudo-surge database approach, the erroneously classified values corresponding to the red × would have been mapped below the node elevation, as shown in Figure 6 with the black ×. This creates a discontinuity (“jump”) in the corrected pseudo-surge database for this specific node, which will create challenges for the subsequent surrogate model development. This jump corresponds to the surge gap, , defined earlier in Equation (1). The larger the value of this gap, the greater the reduction of the prediction accuracy for any emulator, as such discontinuities in an otherwise smooth behavior (note the smooth characteristics across the remaining surge and pseudo-surge estimates in this figure) create significant challenges at the emulator calibration stage [22]. This is the motivation for using the pseudo-surge database; it is expected to accommodate the calibration of a higher accuracy surge surrogate model, provided that the secondary classification surrogate model can ultimately address the erroneous information (red × points) in the database.

Figure 6.
Ordered surge and pseudo-surge values for a specific node, with the node elevation also shown as a dashed grey line. Note that a portion of the total storm database is shown, corresponding to pseudo-surge values close to the node elevation. The correctly and incorrectly classified instances are distinguished for the pseudo-surge estimates. Note the jump created if an adjustment for the pseudo-surge is utilized in order to establish a correct classification. The maximum surge misinformation is also highlighted in the plot.
For the case-study database, with = 488,216 nodes that required imputation for some of the storms, the misclassification statistics for the kNN-based imputation are the following: (i) when ADCIRC connectivity information is not utilized, then misclassification is 22.1%, whereas the set of problematic nodes consists of = 322,753 nodes, and (ii) when ADCIRC connectivity is incorporated, then misclassification is 20.2%, whereas the set of problematic nodes consists of np = 311,826 nodes. Minor differences are observed across the two examined variants.
Looking into more detail the characteristics of the problematic nodes for the case study, Figure 7 presents a histogram of the surge gap over their population. The number of nodes having surge gaps larger than 0.25, 0.5, 1, and 2 m are respectively 35,947, 16,504, 4290, and 267. Results indicate that a considerable number of nodes has larger values for the surge gap. Such values can be attributed to the existence of complex geomorphologies or flood protection systems, and are expected to reduce the predictive accuracy if the corrected pseudo-surge database is utilized, as indicated by the illustrative example in Figure 6.
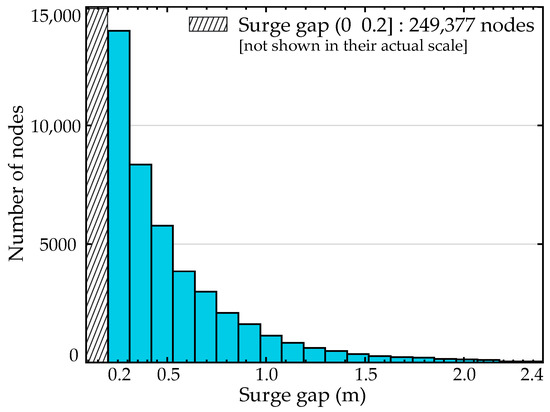
Figure 7.
Histogram of the surge gap for the population of problematic nodes.
Something that needs to be further considered in better assessing the challenges associated with the problematic nodes is the quality of information associated with these. Two different measures are introduced to quantify this. The first measure, denoted , is the maximum surge misinformation, defined as the difference between the largest pseudo-surge value among the instances the node was originally dry and the node elevation, given by:
Note that the multiplication by is leveraged in the above equation to restrict the operation within the brackets (search for maximum in this case) to only the originally dry instances, corresponding to . The maximum surge misinformation represents the largest magnitude of misclassification error. It is indicated in Figure 6 with a dashed line. The second measure, denoted as , is the percentage of misinformation, defined as the ratio of the number of instances (storms) a node has been misclassified at the kNN imputation stage over the total number of storms:
where denotes the indicator function, corresponding to one if the expression inside the brackets is true and to zero otherwise. The percentage of misinformation represents the amount of erroneous information for a problematic node. In Figure 6, this percentage is equivalent to the number of black crosses over the total number of storms. Small values for and indicate that even though a node has been misclassified at least once, both the magnitude and frequency of that misclassification are minimal. This is demonstrated clearly in Figure 8, where for both measures, a large number of nodes has very small and values. Consideration of such nodes, with both and values being very small, as problematic might not be an appropriate approach. This concept will be further investigated when the integration of the different surrogate models is examined later on in Section 6.
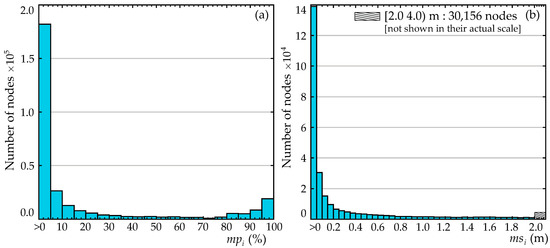
Figure 8.
Histograms of the problematic nodes for (a) the percentage of misinformation and (b) the maximum surge misinformation.
5. Review of the Surrogate Model Development
This section offers an overview of the two surrogate models: the primary one for predicting the storm surge , denoted as herein, and the secondary one for classifying the node condition , denoted as herein. Kriging is adopted for both as the metamodeling technique. However, the foundational ideas for combining the two models, as detailed in Section 6, can be applied to any type of surrogate model. Appendix B reviews the essential characteristics of the metamodel development. To accommodate the large dimensionality of the output vector (nodes of interest for estimating surge), some form of principal component analysis will be used for both types of surrogate models (classification and surge predictions).
5.1. Surrogate Model for Surge Predictions
The surrogate model for the surge prediction, , uses the imputed database as observations for the metamodel calibration. Notation z (for individual storms) and Z (for the entire database across all storms) will be utilized to describe the observations, with the understanding that for any instance for which surge values are missing in the original database (node is dry), the missing is replaced by the pseudo-surge for defining the observation matrix Z.
To improve the metamodel accuracy, some physics-motivated [8] or functional [16] transformation can be applied. The transformed surge for the ith node and the hth storm will be denoted as , with the transformed surge vector across all nodes denoted as , and the corresponding transformed observation database as . The mathematical relationship between and will be denoted as and is assumed to be invertible, with inverse . Without loss of generality, we will assume that is strictly positive. This assumption is only relevant for the implementation of the probabilistic classification based on the surrogate. For the case study, the square root is employed as functional transformation, shown to be beneficial in past applications [16], leading to:
where is chosen equal to the minimum of over the storm database, but not greater than 0, and is utilized to make the argument under the square root positive across all storms.
The surrogate model is ultimately established, for the transformed surge , with observation matrix . The detailed implementation is presented in [2,16]. Here only the basic steps are reviewed:
Step 1 (dimensionality reduction): Perform principal component analysis (PCA) as a dimensionality reduction technique to identify a smaller number of latent outputs (principal components) through a linear projection. Individual components are distinguished through subscript j herein, with uj denoting the jth element of vector u. The PCA is performed for the observation matrix and provides the mean vector , whose ith component corresponds to the mean of (mean surge over the storm database for each node), the projection matrix , and for each latent component, , the output vector of responses over the storm database .
Step 2 (metamodel calibration): Develop separate surrogate models based on the procedure described in Appendix B for each of the principal components, setting and . Note that instead of developing individual surrogate models for each component, a grouping of the components may be considered as an alternative implementation to facilitate higher computational efficiency. Details for this formulation are included in [16].
Step 3 (metamodel predictions for the transformed surge): The surrogate model approximation for the transformed surge is obtained by combining the predictions for each of the latent outputs, given by Equation (A3) for the predictive mean and Equation (A4) for the predictive variance. Note that, as discussed in Appendix B, a functional dependence on the database X is utilized in our notation to accommodate the easier description of the cross-validation predictions used later in the manuscript. Using notation to denote the element of a matrix (ith row and jth column), the kriging predictions (mean) for the ith node are:
whereas the predictive variance is:
Ultimately kriging establishes the following probabilistic model prediction: [2,23], where N(a,b) stands for a Gaussian distribution with mean a and variance b. Though typically only the mean of this distribution is utilized, taken to represent the metamodel predictions, for certain aspects of the integration of the classification estimates that will be investigated in this manuscript, the use of the complete probabilistic description will be explored.
Step 4 (metamodel predictions for surge): Finally, the kriging predictions for the surge can be obtained by the transformation :
where the last equality in Equation (8) holds for the transformation utilized in the case study that follows. The classification of the node condition (wet or dry) based on the surrogate model is obtained by comparing the surge estimate to the node elevation. Denoting as that classification for the ith node and for the storm with input x, we have:
where, as defined earlier, denotes the indicator function, corresponding to one if the expression inside the brackets is true and to zero otherwise.
As discussed in the introduction, for the combination of the predictions based on the two different surrogate models (discussed later in Section 6), the probabilistic characteristics of the classification will be examined. For the surrogate, these characteristics are accommodated by considering the Gaussian nature of the emulator. Let P[.] denote probability, and define as the probability that the ith node is wet (inundated). Then based on the Gaussian distribution for , and assuming that is well-defined, it is straightforward to show that:
where denotes the standard Gaussian cumulative distribution function and for the second equality the fact that is strictly positive function was used. If is not well-defined, for example if for the transformation of Equation (5), then the surge surrogate model will always lead in estimating (surge will never be predicted smaller than the node elevation). This probabilistic classification will be used (in Section 6) for nodes that have remained dry for some of the storms in the database, for which is expected to be positive, leading to a well-defined for transformations like the one discussed in Equation (5). Alternatively, if the importance of establishing a probabilistic classification is greater than any benefits coming from utilizing the transformation , the use of the transformation itself can be omitted if it is deemed as problematic.
Finally, related to the selection of for the PCA, the following comments can be made. Typically, the first few principal components can be predicted well by the corresponding surrogate model, but the accuracy of higher components drastically reduces, leading to a saturation of the surrogate model accuracy as the number of principal components increases [2]. To establish a balance between accuracy and computational efficiency, especially with respect to memory requirements which are critical for real-time applications [11], a parametric analysis can be employed to investigate such benefits [14]. An alternative formulation was proposed in [16], considering only a small number of principal components and complementing the predictions with a surrogate model for the residuals. Such an implementation can also address any concerns related to overfitting stemming from the PCA application. In the case study considered in [16] it was shown that this approach could not offer any accuracy improvements, and since it increases the computational complexity of the overall implementation, it was suggested to be avoided. To provide an additional validation for this manuscript that treats a different database, this implementation that involves the residual surrogate will be briefly revisited later on.
5.2. Surrogate Model for Node Classification
The surrogate model for the node wet/dry classification, , uses as observations the binary output for near-shore nodes that have remained dry for some of the storms. Nodes that are inundated for all the storms are ignored in this classification problem, since they will always be predicted as inundated by a binary classifier. Additionally, the nodes considered for can be further reduced to correspond only to the problematic set . Let denote the set of nodes for which the classification surrogate model is considered (either nodes that were at least once dry or the problematic nodes). The observation matrix for the surrogate is denoted as and corresponds to the columns of matrix that belong in set .
For the surrogate model, logistic principal component analysis (LPCA) [19] is used as the dimensionality reduction technique. LPCA also accommodates the transformation of the original categorical (binary) observations to continuous observations to facilitate the subsequent approximation through the kriging metamodel. The implementation is based on a multivariate generalization of the Bernoulli distribution, using the natural parameters (log-odds) θ and the canonical link function (logistic function). If is the natural parameter for the ith node and the hth storm, then the probability of a node being wet is given by the logistic function:
The dimensionality reduction is integrated into the process by considering a compact representation of the log-odds matrix . This compact representation is expressed as , where T is the matrix of coefficients, V is the matrix of projection vectors, and Δ is a matrix with each row corresponding to the same bias vector ( vector). This representation directly provides the latent space of logistic principal components t with observations T, as well as the projection matrix V and the bias vector Δθ to be used for the transformation from t tο θ, which takes the form:
The vector t ultimately provides the transformation to a continuous output with a significantly reduced dimension compared to the original categorical observations of dimension .
LPCA is the integral first step in the formulation. Details for this formulation are presented in [16]. Here only the basic steps are reviewed:
Step 1 (dimensionality reduction and transformation of the predicted output): Using the observations , perform LPCA for a chosen number of principal components . This is established by maximizing the likelihood of observations given the compact representation of for the natural parameters of the Bernoulli distribution [19], and ultimately provides the bias vector , the projection matrix V and the latent observation matrix T whose hth row corresponds to the latent output for the hth storm .
Step 2 (metamodel calibration): Develop separate surrogate models based on the procedure described in Appendix B for each of the principal components, setting y = tj and , where is the jth column of T. Similar to , instead of developing individual surrogate models for each component, a grouping of the components may be considered to facilitate higher computational efficiency.
Step 3 (metamodel predictions for the natural parameters): The surrogate model approximation for the natural parameters is calculated by combining the predictions for each of the latent outputs, obtained according to Equation (A3). Maintaining, as for , the notation for the functional dependence on the database X, the predictions are:
Step 4 (classification predictions): The probability of the ith node being wet for a specific storm input x according to the model, is given by the logistic function:
The deterministic classification prediction for node i according to surrogate model can then be established by comparing value to the 0.5 threshold. Denoting that prediction as , we have:
LPCA is known to be very prone to overfitting [24,25], a tendency that is exacerbated in the application examined here, since any additional overfitting originating from the metamodel calibration needs to be considered. For this reason, it was suggested in [16] to select in the first step of the formulation through a parametric sensitivity analysis, examining the metamodel accuracy through a cross-validation setting. Similarly to the surrogate model development, using a smaller and coupling it with a surrogate model on the residual predictions can be considered. Details for such an implementation are discussed in [16].
5.3. Metamodel Validation
Validation is important for obtaining a confidence metric for the surrogate model prediction accuracy, as well as for selecting the number of retained components for the PCA and LPCA implementations. Cross-validation (CV) is adopted as the validation approach here, implemented through the following steps: the storm database is partitioned into different groups; each group is sequentially removed from the database, and the remaining storms are used as observations to calibrate a surrogate model; this model is then used to make predictions for the surge of the removed storms; accuracy statistics are estimated comparing these predictions to the actual storm output. Details for the CV implementation and the utilized validation metrics are reviewed in the next two subsections.
5.3.1. Cross-Validation Implementation
The simplest CV approach is the leave-one-out cross-validation (LOOCV), established by removing sequentially a single storm at a time from the original database X. LOOCV is typically implemented without repeating the PCA/LPCA or the hyper-parameter calibration for each reduced database, since the opposite choice would substantially increase the computational complexity, requiring a total of n repetitions of the entire surrogate model calibration. This also allows the use of closed-form solutions [26] to obtain the leave-one-out (LOO) predictions without the need to explicitly remove each of the storms from the database. Computational details for the use of the closed-form solutions are included in [16]. As also discussed in [16], LOOCV cannot explore in depth any challenges associated with overfitting, since it does not repeat the PCA or LPCA implementations and the hyper-parameter calibration after the removal of each storm. This is especially important for examining the proper selection of the value for the LPCA implementation, since for other overfitting challenges (i.e., for the selection of for PCA or for the hyper-parameter calibration) minor impact has been shown in past studies. k-fold CV circumvents this problem by repeating both the PCA or LPCA and the hyper-parameter calibration, since in this case, depending on the number of groups that will be pre-defined, the re-calibration is not as expensive as in a LOOCV setting.
If is the subset containing the hth storm and the remaining database, excluding set , then repeating the surrogate model formulation starting with the observations corresponding to the set , provides, for the hth storm the predictions from the surrogate model and from the surrogate model. Using these predictions, the node classification can also be obtained: according to utilizing Equation (9) [using ] and according to utilizing Equation (15) [using ]. Note that for the LOOCV implementation, only Step 3 of the formulation needs to be repeated, and in this case, closed-form solutions can be used for all predictions.
5.3.2. Validation Metrics
For the node condition classification, the adopted validation metric corresponds to the node misclassification percentage. If are the CV-based metamodel predictions for the ith node condition and the hth storm, corresponding to for the surrogate or to for the surrogate, or to the for the combined formulation discussed in Section 6, then the total misclassification for this specific node and storm is given by:
We can further distinguish between the false positive, i.e., node predicted wet when dry, and false negative, i.e., node predicted dry when wet, indicators, given respectively by:
where max(a,b) is the function that provides the maximum of the two arguments a or b. Average statistics per node or across the entire database can then be obtained. For the total misclassification, these statistics are denoted as and , respectively, and are given by:
Similar expressions as the two presented in Equation (18) hold for the false positive or the false negative misclassification definitions, with the only adjustment being that instead of averaging by , the number of nodes that were dry (for the false positive misclassification) or wet (for the false negative misclassification) is utilized for each storm. Furthermore, statistics can be examined for specific groups instead of the entire node set, simply by considering the averaging in Equation (18) only for the specific nodes belonging to the group of interest (for indexes i corresponding to that group only).
For the surge predictions, both normalized and unnormalized statistics should be utilized. Unnormalized statistics reflect the absolute error, while normalized ones express the relative error, incorporating the response magnitude when assessing the size of the error. For normalized statistics, the correlation coefficient (cc) is adopted here. The correlation coefficient is unitless (as a normalized error metric), with values close to 1 indicating a better performance. For the ith node it is expressed by:
Similar to the misclassification metric presented above, the overall metamodel accuracy is quantified by the averaged error statistics across all output locations, given by:
Common candidates for unnormalized statistics include measures like the absolute mean error or the mean squared error. An alternative option, and the one chosen here, is the surge score [15,18], which for the ith node and the hth storm is described as:
This surge score shares the units of surge (unnormalized) and provides a penalty function for the discrepancy between the predicted and actual surge, further incorporating the node classification: (i) if a node is predicted wet and it is actually wet, then the absolute value of the predicted surge discrepancy is used as a penalty function; (ii) if a node is predicted wet, but it is dry, then the difference between predicted surge and node elevation is used as a penalty; (iii) if a node is predicted dry, but it is wet, then the difference between the actual surge and the node elevation is used as a penalty; (iv) if a node is predicted dry and it is dry, then penalty is zero. The averaged statistics per node or across the entire database can be then obtained, respectively, as:
Similar to the misclassification case, statistics for both the surge score and the normalized root mean squared error can be examined for specific groups instead of the entire node set.
Related to the various surge validation statistics, it is important to note that the correlation coefficient pertains to the predictions of the pseudo-surge, assessing how well the metamodel predicts the imputed database. In contrast, the surge score ultimately evaluates the accuracy with respect to the original surge predictions since the node elevation, and not the pseudo-surge, is utilized in the relevant equations for the dry nodes. In this context, the surge score represents a more appropriate validation metric to quantify the metamodel accuracy, as it measures the accuracy with respect to the actual surge predictions, and not the values established through the database imputation.
6. Combination of Surrogate Models for Storm Surge and Node Classification
This section considers the formal integration of the two surrogate models, and , presented individually in Section 5. This integration focuses on applications that adopt the pseudo-surge database as observations for the surrogate and intends to correct the erroneous information retained in this database for the node condition across the set of problematic nodes. Though components of the integration may also be considered for applications that use the corrected pseudo-surge database as observations for the surrogate, the intention of providing a priori adjustments for the imputed surge is to strictly rely on the surrogate, since no erroneous information has been retained in the database.
Considering the integrated metamodel formulation, predictions for the storm surge are established by the surrogate model through a combination of Equations (6) and (8). The classification of the node condition can be established by combining the deterministic ( of Equation (9) for and of Equation (15) for ) or the probabilistic ( of Equation (10) for and of Equation (14) for ) predictions from the and surrogate models. The combination, which will be examined in this section, ultimately provides the node classification of the integrated metamodel formulation, denoted herein as . This finally adjusts the surge predictions: if =1 then the predicted surge equal to , else the node is predicted as dry.
For the combination of the two surrogates, the following classes of nodes can be distinguished:
- Nodes, denoted as class, that were inundated for the entire database (always wet). As discussed earlier, for these nodes, only predictions from the surrogate are available, so the node condition classification is based entirely on that metamodel.
- The problematic nodes , denoted as class, that were misclassified for at least one storm during the database imputation.
- Remaining nodes, denoted as class, that were dry for at least one storm in the database and the database imputation did not contribute to any misclassifications.
A further adjustment can be established in the definition of groups and based on the values of and . Any nodes that correspond to small values for both and , for which the quality of the available information should be considered as high (even though some erroneous information, expressed through misclassifications, still exists), can be moved from group to . In the case study that will be discussed later, the thresholds used for and are 5 cm and 2.0%, respectively. It should be noted that group is expected to include nodes in areas of complex geomorphology, for example behind or close to protective structures, for which the database imputation is expected to face challenges, as discussed in Section 3. The distinction of the nodes among the different groups is, though, purely based on the misclassification statistics from the database imputation, without the need to incorporate any additional considerations about the location of the nodes. This is motivated by the fact—as was also stressed earlier—that the objective of the database imputation and the classifier integration is the improvement of the data-driven surge predictions.
For establishing rules regarding the combination of the surrogate model predictions, the following two characteristics should be considered. First, binary classification problems, like the one addressed by surrogate model , are in general more challenging metamodeling applications [22]. For this reason, the predictive accuracy of surrogate model is expected to be higher, at least when the database that is used for its calibration does not include any erroneous information. Second, for class , predictions from will tend to be misclassified as false positives (nodes that are dry will be characterized as wet), since, as discussed in Section 4.2 and also clearly illustrated in Figure 3, the pseudo-surge database is biased that way. If predicts nodes as dry, then predictions could be trusted, since such predictions are opposite to the potential metamodel bias. If, on the other hand, a node is predicted as wet, then due to the propensity of for false positive misclassifications, little credibility should be given to those predictions.
Considering these two characteristics, the following recommendations were given in [16] for establishing based on the expectation that will benefit from higher surrogate model accuracy, rely primarily on this metamodel, and utilize only as a safeguard against the false-positive misclassification propensity in class . This means that for class , predictions are established utilizing only, while for , predictions of the are preferred only when predicts the node as inundated. This leads to the following :
For all instances that , the surge estimates are provided directly by the predictions. The definition of Equation (23) guarantees that for all such instances where , the surge estimate indeed corresponds to the node being inundated. For instances that the node is classified as dry.
This integrated implementation described by Equation (23) uses the secondary node classification surrogate only for the problematic nodes (class ). Here we revisit the above integration to examine the potential benefits on the predicted surge across all nodes. This requires that we relax the higher trustworthiness given to the metamodel predictions and treat the predictions from both surrogates and as having a similar degree of credibility. Additionally, it requires one to use the probabilistic predictions associated with each surrogate model instead of the deterministic ones. If the binary classifications and are to be combined, then the requirement to provide a binary classification for leads to prioritizing one node condition, for example predict if either or , which creates a bias towards this condition. Instead, the probabilistic predictions are utilized to establish the probability of the ith node being wet by the combined model, denoted by herein, and the final classification is established based on this value. A weighted average approach is adopted to establish the predictions using and , leading to:
where is defined as the weight given to the surge surrogate model, and the weight given to the classification metamodel. For both classes and , the classification is established using this information, leading to:
Of course, since the weights are node-dependent, the representation of Equation (25) is very versatile.
The selection of these weights, , is made to reflect the degree of confidence for each model. For example, for the case examined in Equation (23), where ( is given substantially higher confidence) apart from nodes in class for which where ( is given no confidence due to the known propensity to overestimate the surge for this class). This combination will be denoted as “ prioritization”. Another extreme case would be to always trust the predictions, leading to always assigning . This combination will be denoted as “ prioritization”. On the other hand, a balanced implementation would weigh both the and predictions for all instances that these predictions could be deemed as reliable, for example, using equal weights . Since, as discussed earlier, for the nodes in class for which the predictions cannot be regarded as reliable, should be adopted for such instances. Though some arguments can be made that for values of close to 0.5 (so the node is classified as wet with a small margin) some degree of trustworthiness exists even for the predictions, defining appropriate thresholds to quantify what close to 0.5 means in this instance is tricky. On the other hand, if , then both models can be combined to provide , even for class . This implementation will be denoted as “balanced combination” and leads to:
It should be noted that for the surrogate, we have that .
For the prioritization and the balanced combination, some further adjustment is needed for providing the final surge prediction. Even though, as discussed earlier, in the prioritization for all instances corresponding to the surge estimates can be provided directly by the metamodel (since it is guaranteed that ), the same does not hold across the other two variants. Certain instances with might be associated with predictions , i.e., the probability given by the surge surrogate is , but finally through the contribution of in Equation (24). This means that a node is classified as wet by the higher confidence of the classification surrogate, but the surge surrogate, which is supposed to offer the value of that surge, has an estimate that is below the elevation, indicating on its part that the node is dry. Thus for those points, although their condition has been determined probabilistically as wet, their respective surge estimate provided by the metamodel is below the node elevation. For this reason, the following modification is established. For instances corresponding to , the surge estimate is taken equal to the predictions, , if , else it is set equal to some margin (taken as 2.0 cm in this study) over the node elevation . This adjustment guarantees that the node is classified indeed as inundated based on the assigned surge predictions for all instances .
One can further extend these concepts to utilize a strictly probabilistic classification, in other words, use as the final predictions instead of converting them to the binary classification , but such implementation falls out of the scope of this study. The intention is to provide surge predictions for new storms, which in turn requires a deterministic classification for each storm.
The validation of the combined surrogate model implementation directly follows the guidelines provided in Section 5.3, with the only requirement being to replace in all instances with . This validation is examined next within the case study to assess the appropriateness of the different techniques introduced here to facilitate the database imputation and the storm surge predictions.
7. Case Study Implementation
This section presents results for the case study with emphasis on the impact of the integration of the and surrogate models. This is accomplished by comparing the implementations of the pseudo-surge database and the corrected pseudo-surge database, examining both formulations for defining (as discussed in Section 6), and presenting results for different groups of nodes, separately for classes , , and , as well as for nodes with different surge gaps. Two different settings are considered for the classes and ; the first one uses all the problematic nodes, and the second one moves nodes corresponding to < 2% and < 5 cm, from group to . These alternative class definitions are denoted as and . The number of such nodes is 109,701. Table 2 presents the number of nodes corresponding to the different group definitions along with the respective percentages of instances these nodes are inundated within the original database. It is evident from this table that nodes that correspond to larger surge gaps (even as large as 0.25 m) are predominantly dry within the original database.
Table 2.
Properties of nodes across groups with different characteristics.
Unless specified otherwise, all results (including the numbers presented in Table 2) refer to the kNN implementation that incorporates the ADCIRC connectivity. Across all implementations, the weights for the balanced combination (Equation (26)) are chosen as .
Initially, some results are presented separately for each of the two surrogate models (surge and classification) across all the nodes, briefly examining the selection of the number of principal components and the impact of overfitting before the emphasis is shifted to the integration of the two surrogate models.
Two different validation implementations are considered: (i) LOOCV without repeating the PCA (for ) or LPCA (for ) and the hyper-parameter calibration, and (ii) k-fold cross-validation (Section 5.3). These will be denoted as LOOCV and k-fold CV, respectively. Ten (10) different folds were used for the k-fold validation implementation. It should be stressed that, as discussed in Section 5.3, k-fold corresponds to the proper cross-validation implementation, with the PCA (or LPCA) and the hyper-parameter calibration repeated after the removal of each set of storms. As such, it will be considered as the reference in all comparisons. Since k-fold has, though, a substantial computational burden, LOOCV is explored as a more efficient alternative.
7.1. Selection of Principal Components and Examining Overfitting Challenges
A parametric investigation is initially performed to examine the impact of the (for ) and (for ) values on the metamodel accuracy. For both metamodels, the formulation incorporating the residual discussed in Section 5.1 and 5.2 is presented, denoted as “Residual” in the plots. Additionally, both LOOCV and k-fold CV results are presented to establish thorough comparisons between them. Figure 9 shows results for the metamodel looking at the average misclassification for an increasing number of latent components. Figure 10 presents the results for the metamodel for the use of the pseudo-surge database, presenting both the average correlation coefficient, , and the surge score, , for an increasing number of latent components.
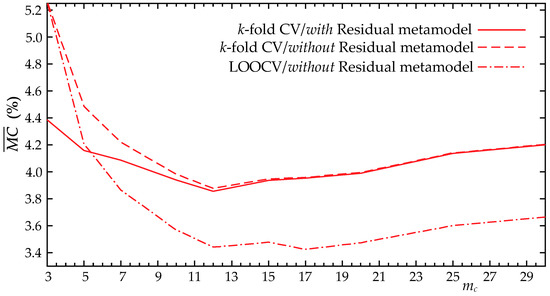
Figure 9.
Averaged misclassification for the surrogate model for different number of components without considering the node grid connectivity. Different metamodel variants (use of additional metamodel on the residuals) and different validation approaches are shown.
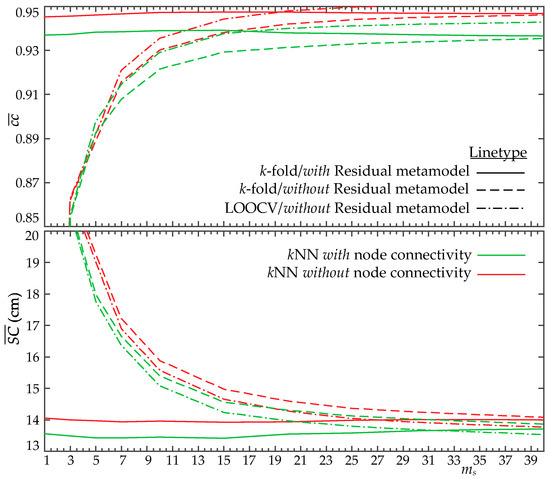
Figure 10.
Averaged correlation coefficient (top row) and surge score (bottom row) validation metrics for the surrogate model utilizing the pseudo-surge database for different number of components . Different metamodel variants (use of additional metamodel on the residuals), the use of the node grid connectivity or not, and two different validation approaches are shown.
Results indicate that as the number of latent components (for ) and (for ) increase, the accuracy of both metamodels improves, as expected. The incorporation of the residuals improves the accuracy when a small number of principal components is used, but for a sufficiently large number, it offers no benefits. As explained in detail in [22], the incorporation of this residual substantially increases the computational complexity, especially the memory requirements for accommodating the metamodel predictions. Trends, therefore, indicate that the use of a larger number of principal components without the incorporation of the residual in the metamodel formulation is the preferred implementation. For the metamodel, a number of principal components close to = 12−15 offers the greater accuracy, while for the metamodel, a constant improvement is observed till an accuracy plateau is reached. This behavior is similar to the one reported in study [22]. For reference, if the implementation of [25] was used to address strictly the LPCA overfitting, the optimal number of principal components, , would have been 35. As stressed earlier, needs to be adjusted appropriately while considering the coupling with the surrogate model error through the proposed parametric investigation, which in this case yields a significantly lower number of components in the order of 12–15.
Considering the difference between the LOOCV and k-fold CV, and although LOOCV seems to over predict, offering higher estimates for the metamodel accuracy (more on this later), the decisions related to the optimal number of principal components would be practically identical using either of the two approaches. This means that overfitting effects related to the cross-validation implementation are substantially smaller than those observed in [22], in which LOOCV implementation contributed to some erroneous decisions. These trends indicate that the larger database size greatly helps mitigate any adverse overfitting effects. Note that the reduced accuracy estimated by the k-fold CV is an expected trend, associated with the fact that for some of the folds, many of the storms that are removed will belong to the parametric boundaries of the database X, forcing extrapolations for the metamodeling validation increasing this way the prediction errors, and should not be necessarily attributed as an accuracy over prediction by the LOOCV.
Finally, the comparison for the metamodel between the cases with and without the node grid connectivity in the kNN imputation indicates different trends with respect to the two compared metrics. Using the node connectivity provides better accuracy for , but a lower accuracy for . This should be attributed to the differences mentioned in Section 5.3.2 between these metrics; assesses accuracy with respect to the imputed surge database, and with respect to the original database. Using the grid connectivity at the imputation stage evidently provides pseudo-surge estimates with smaller smoothness, contributing to lower values, but accommodates also smaller misclassifications, as reported in Section 4.2, leading to smaller values. Since, as discussed in Section 5.3.2, is a more appropriate measure to assess metamodel accuracy, the results in Figure 10 indicate that for the pseudo-surge database, the use of node connectivity in the kNN implementation accommodates, ultimately, a higher metamodel accuracy.
7.2. Integration of the Two Surrogate Models
For the remaining results, the number of principal components utilized are for and for , while all validation statistics presented correspond to the k-fold CV implementation. Results are presented for the different groups of nodes identified earlier in Table 2, and for different metamodel variants. The following variants are examined:
- (a)
- Using the pseudo-surge database and relying strictly on the surge metamodel predictions. This is denoted as implementation in the results.
- (b)
- Using the pseudo-surge database, but considering the combination of the classification and surge metamodels, either using prioritization (abbreviated as SP implementation in the results), prioritization (abbreviated as CP implementation in the results), or the balanced combination (abbreviated as CB implementation in the results), using the original definition for classes and . For the CB, an implementation without the surge transformation (function g(.)) will also be considered, denoted as CBNoTr implementation in the results.
- (c)
- Using the pseudo-surge database and considering the balanced combination of the classification and surge metamodels for the alternative definition for classes and . This will be denoted as .
- (d)
- Using the corrected pseudo-surge database. In this case, the surge metamodel is strictly used, since it is developed based on a correct node condition database.
All variants are presented looking at both the incorporation or not of the grid connectivity for the kNN imputation. Table 3 presents the averaged (across different groups of nodes) surge score values, while Table 4 the averaged misclassification values. Table 5 and Table 6 present, respectively, the averaged false positive and negative misclassification values for the different node classes. Note that in all these tables, class corresponds to the always wet nodes, whereas the once dry group corresponds to the complement of , also representing the union of classes and (or and ). Figure 11, finally, presents the surge score and the misclassification for the once dry nodes as a function of the surge gap for some of the variant implementations of interest. It is important to note that when comparing across the different groups of nodes, the differences in surge score/misclassification percentages and all the associated trends are small when examining results for the always wet nodes or groups that involve a large portion of nodes that are predominantly inundated in the original database. For this reason, emphasis in all the comparisons will be placed on groups/classes of nodes with characteristics that create challenges in the metamodel development (problematic nodes or nodes with large gaps). Note also that for certain comparisons, for example, when examining the different variants for the same pseudo-surge database, the results are identical for some of the groups. This is true for the group of always wet nodes ().
Table 3.
Surge score (cm) averaged across different groups of nodes for different surrogate model variants.
Table 4.
Misclassification (%) averaged across different groups of nodes for different surrogate model variants.
Table 5.
False-positive misclassification percentage for different variants and different groups of nodes.
Table 6.
False-negative misclassification percentage for different variants and different groups of nodes.
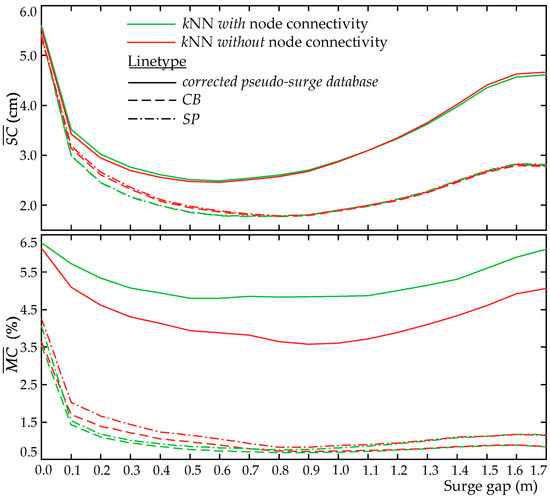
Figure 11.
Averaged surge score (top row) and misclassification (bottom row) validation metrics for different metamodel variants (integrations of the surge and the classification surrogates) for an increasing surge gap. The use of the node grid connectivity or not, as well as the use of the corrected pseudo-surge database or not, are also examined.
Results present some interesting and quite complex trends. To better identify these trends, we initially restrict the comparisons to the same type of imputation process, looking separately into the different variants that adopt databases with or without node connectivity in the kNN implementation (left or right columns in each table, or same color lines in Figure 11). Comparing first the variants that rely strictly on the surge metamodel, i.e., the implementation for the pseudo-surge database or the implementation using the corrected pseudo-surge database, it is evident that use of the pseudo-surge database leads to substantial worse accuracy across all node groups, with larger surge scores (Table 3) and larger misclassification percentages (Table 4). The lower performance stems from over predicting the surge values, as evident by the false-positive rates shown in Table 5. In contrast, this performance deteriorates for dry nodes that are problematic (classes or ) or for the nodes that correspond to larger surge gaps, as evident from the results in all tables. These trends are anticipated since, as discussed earlier, the pseudo-surge database includes erroneous information for these specific groups of nodes, something that substantially impacts the quality of the metamodel that is calibrated based on this information. The use of the corrected pseudo-surge database improves all these vulnerabilities.
A more remarkable improvement is established, though, when the integration of the classification and the surge metamodels is considered. All variants using the pseudo-surge database that additionally adopt the metamodel combination improve upon the variant utilizing the corrected pseudo-surge database across both the surge score (Table 3) and the misclassification (Table 4), with the greatest improvements stemming from the reduction of the false positive misclassifications (Table 5). The improvement is more significant for the problematic nodes (class or ), especially the ones corresponding to large surge gaps, as evident in both Table 3 and Table 4 as well as in Figure 11. These observations showcase that the benefits from the integration of the classifier in the overall metamodel implementation will be larger for nodes with problematic behavior that are predominantly dry in the original surge simulations (check the information provided in Table 2) and belong in regions with complex geomorphologies, as indicated by the large surge gap values. As the prediction of coastal hazard for such nodes could be of greater practical interest, these trends clearly demonstrate the substantial benefits that the use of the classifier can provide, stressing the importance of considering its integration for providing the surge predictions. Comparing across the two different validation metrics, greater differences are observed for the misclassification percentage compared to the surge score. This trend actually holds for most of the comparisons that will be examined in this section, and it is influenced by the fact that the surge score also considers contributions from instances that the node is correctly classified as inundated (predicted surge compared to actual surge), with these contributions being substantial in many instances, though surge score is the most important validation metric, demonstrating how well the actual surge is explained. However, the misclassification is also of high importance, as it relates to the ability of the metamodel to identify the dry/wet boundary. As such, the larger discrepancies that exist in some of the comparisons for the misclassification accuracy should be considered as important trends.
Comparing across the different variants that consider the metamodel combination, it is evident that from the alternative implementations introduced in this paper, the prioritization or the balanced combination outperform the original prioritization introduced in study [22]. These trends indicate that the classification surrogate model provides high-quality estimates, with prioritization outperforming prioritization, illustrating that the concerns about the reliability of the metamodel might not always hold (they will be database and application dependent). It is important to note that the misclassification percentages in Table 4, Table 5 and Table 6 for the prioritization and prioritization implementations for class facilitate a direct comparison between these two variants, as the corresponding classification predictions have been established using only this variant. These comparisons clearly illustrate the fact that for this specific case study, the prioritization outperforms the prioritization. Overall, the best variant is actually the balanced combination adopting the alternative definition regarding the problematic nodes (using classes and ). This demonstrates that the greatest robustness in the classification predictions is obtained by the probabilistic combination of the two metamodels and the careful definition of the problematic nodes for which the metamodel predictions are assumed to over predict the surge. It should be noted that the differences between the variants that consider the metamodel combination are even smaller for the surge score predictions. Beyond the reasons identified in the previous paragraph, the smaller differences stem from the fact that the prioritization and balanced combination variants rely on the artificial adjustment of metamodel surge predictions for some instances, as discussed in Section 6, with the choice to set the predictions to 2 cm above the node elevation might not being the optimal one. Finally, the consideration of the surge transformation g(.) provides substantial benefits across most comparisons, with the exception of surge score for nodes with large surge gaps (Table 3). Even for those exceptions, the performance of the different variants is practically identical, demonstrating a clear preference for utilizing the surge transformation. Additionally, no challenges are associated with the use of the transformation for estimating the classification probabilities according to Equation (10), as indicated by the better classification performance in Table 4, Table 5 and Table 6.
Moving now to the comparison of the two different imputation strategies, the consideration of the node connectivity leads to better misclassification performance (Table 4, Table 5 and Table 6 and bottom row of Figure 11), but not necessarily to a better surge score (Table 3 and top row of Figure 11). Even though for the metamodel using the pseudo-surge database considering the node connectivity at the imputation stage always provides better surge score performance, when the classifier is integrated into the formulation, or for the corrected pseudo-surge database, the consideration of the node connectivity reduces the surge score accuracy for the always wet nodes or the nodes that correspond to smaller surge gaps. For nodes that correspond to larger surge gaps, clear advantages are identified from using the node connectivity. Specifically, the discrepancies for the always wet nodes should be attributed to some overall smoothness reduction across the imputed database when the node connectivity is incorporated, ultimately impacting the quality of the predictions across all nodes (since the metamodel formulation is established simultaneously across the entire database). This agrees with the trends of the correlation coefficient identified earlier in Figure 10. This discussion indicates that perhaps it is better to consider the development of separate metamodels across the different classes of nodes. Though one can envision different separation of the database for this purpose, the one investigated here is the distinction to the following two groups: the problematic ones and the rest.
7.3. Considering Separate Surge Metamodels for Different Classes of Nodes
The developments of two separate metamodels to obtain the predictions is examined in this section, distinguishing the nodes based on the quality of information available for them: the class of problematic nodes, , and the remaining nodes, composed of classes and , referenced herein as “trustworthy nodes”. For the problematic nodes, , the previous established predictions are utilized, while a separate metamodel is developed for the trustworthy nodes. For this portion of the database (trustworthy nodes), the pseudo-surge values are expected to have a higher degree of smoothness independent of the approach taken at the kNN imputation stage (regarding the use or not of the connectivity information), which should establish higher accuracy surge predictions. This is the motivation for considering a separate surrogate model for them, developed without including the problematic nodes. It should be stressed that the latter nodes are expected to belong to domains with complex geomorphologies with little correlation to the remaining nodes, as clearly indicated by the large values of the maximum surge misinformation. Therefore, combining their information in the development of a single metamodel, , for the surge predictions across all nodes has the potential to lower the overall accuracy, since this metamodel is forced to fit portions of the database with highly dissimilar behavior.
To accommodate the development of the two independent surge metamodel predictions (one for the problematic nodes and one for the trustworthy nodes), the formulation of the surge surrogate model (Section 5.1) is repeated twice, for each of the respective databases, and the overall predictions for the storm surge metamodel, , are ultimately obtained by combining them. All other steps regarding the combination of with the metamodel and the validation remain the same. Table 7, Table 8, Table 9 and Table 10 present the validation results in identical format to Table 3, Table 4, Table 5 and Table 6. The difference is that in these tables, the predictions are established by using different surge metamodels for the different classes of nodes.
Table 7.
Surge score (cm) averaged across different groups of nodes for different surrogate model variants for the implementation that considers different surge metamodels for different classes of nodes.
Table 8.
Misclassification (%) averaged across different groups of nodes for different surrogate model variants for the implementation that considers different surge metamodels for different classes of nodes.
Table 9.
False-positive misclassification percentage for different variants and different groups of nodes for different surrogate model variants for the implementation that considers different surge metamodels for different classes of nodes.
Table 10.
False-negative misclassification percentage for different variants and different groups of nodes for different surrogate model variants for the implementation that considers different surge metamodels for different classes of nodes.
Results indicate that the consideration of a separate surge metamodel for the trustworthy nodes improves overall the quality of the predictions for them with respect to both the surge score (compare Table 3 to Table 7) and the misclassification percentage (compare Table 4, Table 5 and Table 6 to Table 8, Table 9 and Table 10) validation metrics. This is especially evident in the comparisons for nodes belonging in classes and or . Note that for class , results remain the same, since the surge metamodel for these nodes is the one that was used previously. For this reason, the results for the groups of nodes corresponding to large surge gap values also remain unchanged, since a significant portion of these nodes in those groups belongs to class . The remaining trends, already identified in Section 7.2 with respect to the benefits of the integration of the surge classifier and the superiority of the combination approach, are the same, experiencing simply an overall improvement in the accuracy due to the higher quality of surge predictions for the trustworthy nodes. The overall predictions for the imputed database established without the node connectivity are still better than the predictions for the imputed database with the node connectivity, though the differences in this case are smaller, and the improvement for the trustworthy nodes is greater when separate surge metamodels are considered. The better overall performance for the imputed database without the node connectivity stems primarily from the nodes in class .
The above discussions show the advantages of separating the portions of the database with different surge behavior (in this case between problematic and trustworthy nodes) and considering separate surge surrogate models for each of them. Though this objective could perhaps be accomplished through the identification of principal components within PCA, the linear character of PCA evidently prohibits it from establishing a complete separation of the portions of the database with substantially dissimilar behavior, since some (linear) correlation between these portions evidently exists. Only if these portions were completely uncorrelated would PCA be able to accommodate the desired separation. Unless a different dimensionality reduction technique is adopted, the formal separation of the database into two different groups is the only mean for achieving the desired objective.
8. Conclusions
The development of surrogate models for predicting peak storm surges requires an imputation of the original simulation data for nearshore nodes that have remained dry in some of the synthetic storm simulations, resulting in the estimation of the so-called pseudo-surge. This imputation is typically performed using a geospatial interpolation technique, which may lead to erroneous information for some instances, with nodes classified as inundated (pseudo-surge greater than the node elevation), even though they were actually dry. This paper examined the appropriate adjustment of the imputed pseudo-surge values in this setting in order to support accurate, emulator-based predictions of peak storm surges. The integration of a secondary node classification surrogate model was examined in detail for this purpose.
To investigate the benefits from the implementation of the secondary surrogate model across nodes with different characteristics, and to reveal important trends for the necessity of this classifier integration in the surge predictions, a variable termed surge gap was introduced. Surge gap is defined as the difference between the lowest recorded surge in the database and the node elevation. Additionally, the combination of the two surrogate models using the probabilistic characterization of the node classification, instead of a deterministic one, was examined in detail. To support this combination, the nodes that were dry at least once in the original database were grouped into two different classes: one class of problematic nodes for which the imputed pseudo-surge was at least once larger than the node elevation (providing an erroneous classification), and another class with the remaining well-behaved nodes for which no specific challenges were identified at the database imputation stage. The degree of problematic behavior was further evaluated through the quantification of the magnitude and the frequency of that misclassification at the imputation stage, and a suggestion was made to move some nodes that have small values for both of these quantities from the problematic group to the well-behaved group. Different schemes that combine the surge and classification metamodel predictions across the two classes of nodes were discussed.
As a case study, the development of a surrogate model for the Louisiana region was considered using 645 synthetic tropical cyclones (TCs) from the CHS-LA study. The fact that various flood protection measures are present in the region creates interesting scenarios with respect to the groups of nodes that remain dry for some storms behind these protected zones. Advances in the k- nearest neighbor (kNN) geospatial interpolation methodology, used for the database imputation, were also introduced to address these unique features, incorporating the connectivity of nodes within the hydrodynamic simulation model to identify those nearest neighbors. The main results for the case study were the following:
- For both the surge and the classification surrogate models, challenges associated with overfitting at the calibration stage are reduced compared to previous studies that had a significantly reduced number of synthetic storms. If the classification surrogate model is based on principal component analysis, the selection of the number of principal components needs to be established through a parametric investigation that considers the combined effect of that dimensionality reduction and surrogate modeling.
- The development of a surrogate model without any adjustment of the imputed database (maintaining the erroneous information) leads to significant over predictions of the storm surge. This can be remedied if the erroneous pseudo-surge is adjusted to always be below the node elevation.
- Even greater benefits can be accommodated if the pseudo-surge is not adjusted, but the surge predictions are complemented by a classification metamodel. It was shown that the benefits from the integration of the classifier in the overall metamodel implementation are substantially larger for nodes with problematic behavior that are predominantly dry in the original database and belong in regions with complex geomorphologies, having larger surge gap values.
- Across the different variants that couple the surge and classification metamodels, the best one was shown to be the one that relies on the combination of probabilistic information that utilizes the alternative definition of the problematic and well-behaved node classes, moving nodes with a low degree of problematic behavior from the former to the latter class of nodes. Overall, better reliability of the classification metamodel was demonstrated compared to past studies.
- Incorporating the node connectivity at the imputation stage does not necessarily provide better results when the development of a single surge metamodel across the entire database is considered. Even though this connectivity contributes to a better metamodel-aided classification, it reduces the accuracy of the surge predictions. Results and associated trends indicate some overall smoothness reduction across the imputed database when the node connectivity is incorporated, ultimately impacting the quality of the predictions across all nodes.
- This challenge is partially remedied by considering the development of separate metamodels for the surge predictions for two different groups of nodes: the problematic nodes and the remaining nodes (trustworthy nodes). Results show clear advantages when considering separate surge surrogate models for the portions of the database with different surge behavior, with the quality of surge predictions for the trustworthy nodes significantly improving when a surge surrogate model is developed explicitly for them. It is important to note that even with this modification, incorporating the node connectivity at the imputation stage does not necessarily provide better results, although the differences are smaller for the instances that the implementation without the node connectivity emerges as the better one.
Author Contributions
Conceptualization, A.P.K., A.A.T. and N.C.N.-C.; Data curation, N.C.N.-C., M.C.Y. and L.A.A.; Funding acquisition, A.A.T.; Methodology, A.P.K. and A.A.T.; Project administration, A.A.T.; Software, A.P.K. and A.A.T.; Validation, A.P.K. and A.A.T.; Writing—original draft, A.P.K. and A.A.T.; Writing—review and editing, A.P.K., A.A.T., N.C.N.-C., M.C.Y. and L.A.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was done under contract with the U.S. Army Corps of Engineers (USACE), Engineer Research and Development Center, Coastal and Hydraulics Laboratory (ERDC-CHL), under grant number W912HZ19P0164.
Data Availability Statement
The database of synthetic storms used in this study is part of the U.S. Army Corps of Engineers (USACE) Coastal Hazards System (CHS) program (https://chs.erdc.dren.mil) (accessed on 15 April 2022).
Acknowledgments
This work was done under contract with the U.S. Army Corps of Engineers (USACE), Engineer Research and Development Center, Coastal and Hydraulics Laboratory (ERDC-CHL). The support of the USACE’s Flood and Coastal Systems R&D Program is also gratefully acknowledged.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. A Weighted k Nearest Neighbor (kNN) Calibration
The calibration of the weighted kNN interpolation is performed using the cross-validation accuracy as recommended in [16]. Let denote the set of always wet nodes within the database, and a subset of that set, with nodes, that the calibration is based upon. may be chosen identical to , though it should be further restricted to nodes corresponding to smaller depths, so that the calibration is based on predictions for near-shore nodes only. The surge for the ith node in is predicted using Equation (2) by considering its neighbors that belong in set , excluding the ith node. This ultimately corresponds to a leave-one-out kNN prediction of the surge. The calibration is finally expressed through the optimization of the hyper-parameters as introduced in Equation (2), with the selected objective function corresponding to the average mean absolute error across all wet nodes and storms, leading to the expression:
with appropriate box-bounded constraints for minimum (subscript min) and maximum (subscript max) value of each of the hyper-parameters. Numerical details for efficiently performing this calibration, and the necessity for the aforementioned box-bounded constraints, are discussed in [16].
Appendix B. Review of Surrogate Model Formulation
This appendix reviews the kriging surrogate model formulation. This formulation is common for the two surrogate model implementations examined in Section 5. Both utilize the storm input x [input matrix X], but each predicts a different output and therefore utilizes a different set of observations. To unify the presentation here, the output will be represented through a scalar quantity, , and may correspond to any of the individual PCA components, or LPCA natural parameters. The respective observation vector for the metamodel calibration will be denoted as . Any extension to cases where the output corresponds to a vector quantity representing, for example, groups of PCA components or LPCA natural parameters are straightforward and are examined in detail in [16].
The fundamental building blocks for kriging are the -dimensional basis vector f(x) and the correlation function , with s denoting the hyper-parameter vector that needs to be calibrated. In the case study considered in this paper, with input vector , a linear basis is adopted for , while for the correlation function, an adjusted power exponential function is considered:
using different parameters for the exponents of the three main input groups: the landfall location, the heading at landfall, and the remaining (strength/intensity/translational speed) inputs. Let denote the basis matrix over database X, the n-dimensional correlation vector between x and each of the elements of X, and the correlation matrix over the database X with the lmth element defined as . To improve the surrogate model’s numerical stability or even its accuracy when fitting noisy data [23,27,28], a nugget is included in the formulation of the correlation function , with δ denoting the nugget value and an identity matrix of dimension n.
Utilizing the available observations kriging approximates the output y as a Gaussian Process (GP) with mean and variance . The GP predictive mean, representing the kriging predictions, is given by [23]:
where . Note that the dependence on the database X is explicitly denoted in all expressions in order to facilitate the cross-validation discussions within the manuscript. For quantities that are a function of x, for example and , this dependence is expressed through the conditioning on X, denoted as “|X”. The GP predictive variance, quantifying the uncertainty in the kriging predictions, is given by [23]:
where and the process variance is given by:
The calibration of kriging pertains to the selection of the hyper-parameters, namely, and can be performed using maximum likelihood estimation (MLE) [23,29] or cross-validation techniques [30]. The MLE implementation, which is the approach used in the case study that is presented in this paper, leads to the following optimization for the selection of the hyper-parameters:
where det(.) stands for the determinant of a matrix. The optimization of Equation (A6) is well known to have multiple local minima [29] and non-smooth characteristics for small values of δ [27]. To address these challenges, all numerical optimizations that are performed in this study use a pattern-search optimization algorithm [31].
References
- Irish, J.L.; Resio, D.T.; Cialone, M.A. A surge response function approach to coastal hazard assessment. Part 2: Quantification of spatial attributes of response functions. Nat. Hazards 2009, 51, 183–205. [Google Scholar] [CrossRef]
- Jia, G.; Taflanidis, A.A. Kriging metamodeling for approximation of high-dimensional wave and surge responses in real-time storm/hurricane risk assessment. CMAME 2013, 261, 24–38. [Google Scholar] [CrossRef]
- Jia, G.; Taflanidis, A.A.; Nadal-Caraballo, N.C.; Melby, J.; Kennedy, A.; Smith, J. Surrogate modeling for peak and time dependent storm surge prediction over an extended coastal region using an existing database of synthetic storms. Nat. Hazards 2016, 81, 909–938. [Google Scholar] [CrossRef]
- Rohmer, J.; Lecacheux, S.; Pedreros, R.; Quetelard, H.; Bonnardot, F.; Idier, D. Dynamic parameter sensitivity in numerical modelling of cyclone-induced waves: A multi-look approach using advanced meta-modelling techniques. Nat. Hazards 2016, 84, 1765–1792. [Google Scholar] [CrossRef]
- Contento, A.; Xu, H.; Gardoni, P. Probabilistic formulation for storm surge predictions. Struct. Infrastruct. Eng. 2020, 16, 547–566. [Google Scholar] [CrossRef]
- Kim, S.-W.; Melby, J.A.; Nadal-Caraballo, N.C.; Ratcliff, J. A time-dependent surrogate model for storm surge prediction based on an artificial neural network using high-fidelity synthetic hurricane modeling. Nat. Hazards 2015, 76, 565–585. [Google Scholar] [CrossRef]
- Hsu, C.-H.; Olivera, F.; Irish, J.L. A hurricane surge risk assessment framework using the joint probability method and surge response functions. Nat. Hazards 2018, 91, 7–28. [Google Scholar] [CrossRef]
- Al Kajbaf, A.; Bensi, M. Application of surrogate models in estimation of storm surge: A comparative assessment. Appl. Soft Comput. 2020, 91, 106184. [Google Scholar] [CrossRef]
- Lee, J.-W.; Irish, J.L.; Bensi, M.T.; Marcy, D.C. Rapid prediction of peak storm surge from tropical cyclone track time series using machine learning. Coast. Eng. 2021, 170, 104024. [Google Scholar] [CrossRef]
- Kyprioti, A.P.; Taflanidis, A.A.; Nadal-Caraballo, N.C.; Campbell, M.O. Incorporation of sea level rise in storm surge surrogate modeling. Nat. Hazards 2020, 105, 531–563. [Google Scholar] [CrossRef]
- Kijewski-Correa, T.; Taflanidis, A.; Vardeman, C.; Sweet, J.; Zhang, J.; Snaiki, R.; Wu, T.; Silver, Z.; Kennedy, A. Geospatial environments for hurricane risk assessment: Applications to situational awareness and resilience planning in New Jersey. Front. Built Environ. 2020, 6, 162. [Google Scholar] [CrossRef]
- Nadal-Caraballo, N.C.; Campbell, M.O.; Gonzalez, V.M.; Torres, M.J.; Melby, J.A.; Taflanidis, A.A. Coastal Hazards System: A Probabilistic Coastal Hazard Analysis Framework. J. Coast. Res. 2020, 95, 1211–1216. [Google Scholar] [CrossRef]
- Zhang, J.; Taflanidis, A.A.; Nadal-Caraballo, N.C.; Melby, J.A.; Diop, F. Advances in surrogate modeling for storm surge prediction: Storm selection and addressing characteristics related to climate change. Nat. Hazards 2018, 94, 1225–1253. [Google Scholar] [CrossRef]
- Kyprioti, A.P.; Taflanidis, A.A.; Nadal-Caraballo, N.C.; Campbell, M. Storm hazard analysis over extended geospatial grids utilizing surrogate models. Coast. Eng. 2021, 168, 103855. [Google Scholar] [CrossRef]
- Plumlee, M.; Asher, T.G.; Chang, W.; Bilskie, M.V. High-fidelity hurricane surge forecasting using emulation and sequential experiments. Ann. Appl. Stat. 2021, 15, 460–480. [Google Scholar] [CrossRef]
- Kyprioti, A.P.; Taflanidis, A.A.; Plumlee, M.; Asher, T.G.; Spiller, E.; Luettich, R.A.; Blanton, B.; Kijewski-Correa, T.L.; Kennedy, A.; Schmied, L. Improvements in storm surge surrogate modeling for synthetic storm parameterization, node condition classification and implementation to small size databases. Nat. Hazards 2021, 109, 1349–1386. [Google Scholar] [CrossRef]
- Betancourt, J.; Bachoc, F.; Klein, T.; Idier, D.; Pedreros, R.; Rohmer, J. Gaussian process metamodeling of functional-input code for coastal flood hazard assessment. Reliab. Eng. Syst. Saf. 2020, 198, 106870. [Google Scholar] [CrossRef] [Green Version]
- Shisler, M.P.; Johnson, D.R. Comparison of Methods for Imputing Non-Wetting Storm Surge to Improve Hazard Characterization. Water 2020, 12, 1420. [Google Scholar] [CrossRef]
- Schein, A.I.; Saul, L.K.; Ungar, L.H. A generalized linear model for principal component analysis of binary data. In Proceedings of the International Workshop on Artificial Intelligence and Statistics, Key West, FL, USA, 3–6 January 2003; p. 10. [Google Scholar]
- Luettich, R.A., Jr.; Westerink, J.J.; Scheffner, N.W. ADCIRC: An Advanced Three-Dimensional Circulation Model for Shelves, Coasts, and Estuaries. Report 1. Theory and Methodology of ADCIRC-2DDI and ADCIRC-3DL; Coastal Engineering Research Center Vicksburg MS: Vicksburg, MS, USA, 1992. [Google Scholar]
- Booij, N.; Holthuijsen, L.H.; Ris, R.C. The SWAN wave model for shallow water. In Proceedings of the 25th International Conference on Coastal Engineering, Orlando, FL, USA, 2–6 September 1996; pp. 668–676. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: New York, NY, USA, 2006. [Google Scholar]
- Sacks, J.; Welch, W.J.; Mitchell, T.J.; Wynn, H.P. Design and analysis of computer experiments. Stat. Sci. 1989, 4, 409–435. [Google Scholar] [CrossRef]
- Lee, S.; Huang, J.Z.; Hu, J. Sparse logistic principal components analysis for binary data. Ann. Appl. Stat. 2010, 4, 1579. [Google Scholar] [CrossRef] [Green Version]
- Song, Y.; Westerhuis, J.A.; Smilde, A.K. Logistic principal component analysis via non-convex singular value thresholding. Chemom. Intell. Lab. Syst. 2020, 204, 104089. [Google Scholar] [CrossRef]
- Dubrule, O. Cross validation of kriging in a unique neighborhood. J. Int. Assoc. Math. Geol. 1983, 15, 687–699. [Google Scholar] [CrossRef]
- Bostanabad, R.; Kearney, T.; Tao, S.; Apley, D.W.; Chen, W. Leveraging the nugget parameter for efficient Gaussian process modeling. Int. J. Numer. Methods Eng. 2018, 114, 501–516. [Google Scholar] [CrossRef]
- Gramacy, R.B.; Lee, H.K. Cases for the nugget in modeling computer experiments. Stat. Comput. 2012, 22, 713–722. [Google Scholar] [CrossRef]
- Lophaven, S.N.; Nielsen, H.B.; Sondergaard, J. DACE-A MATLAB Kriging Toolbox; Technical University of Denmark: Lyngby, Denmark, 2002. [Google Scholar]
- Sundararajan, S.; Keerthi, S.S. Predictive approaches for choosing hyperparameters in Gaussian processes. Neural Comput. 2001, 13, 1103–1118. [Google Scholar] [CrossRef] [PubMed]
- Audet, C.; Dennis, J.E., Jr. Analysis of generalized pattern searches. SIAM J. Optim. 2002, 13, 889–903. [Google Scholar] [CrossRef] [Green Version]
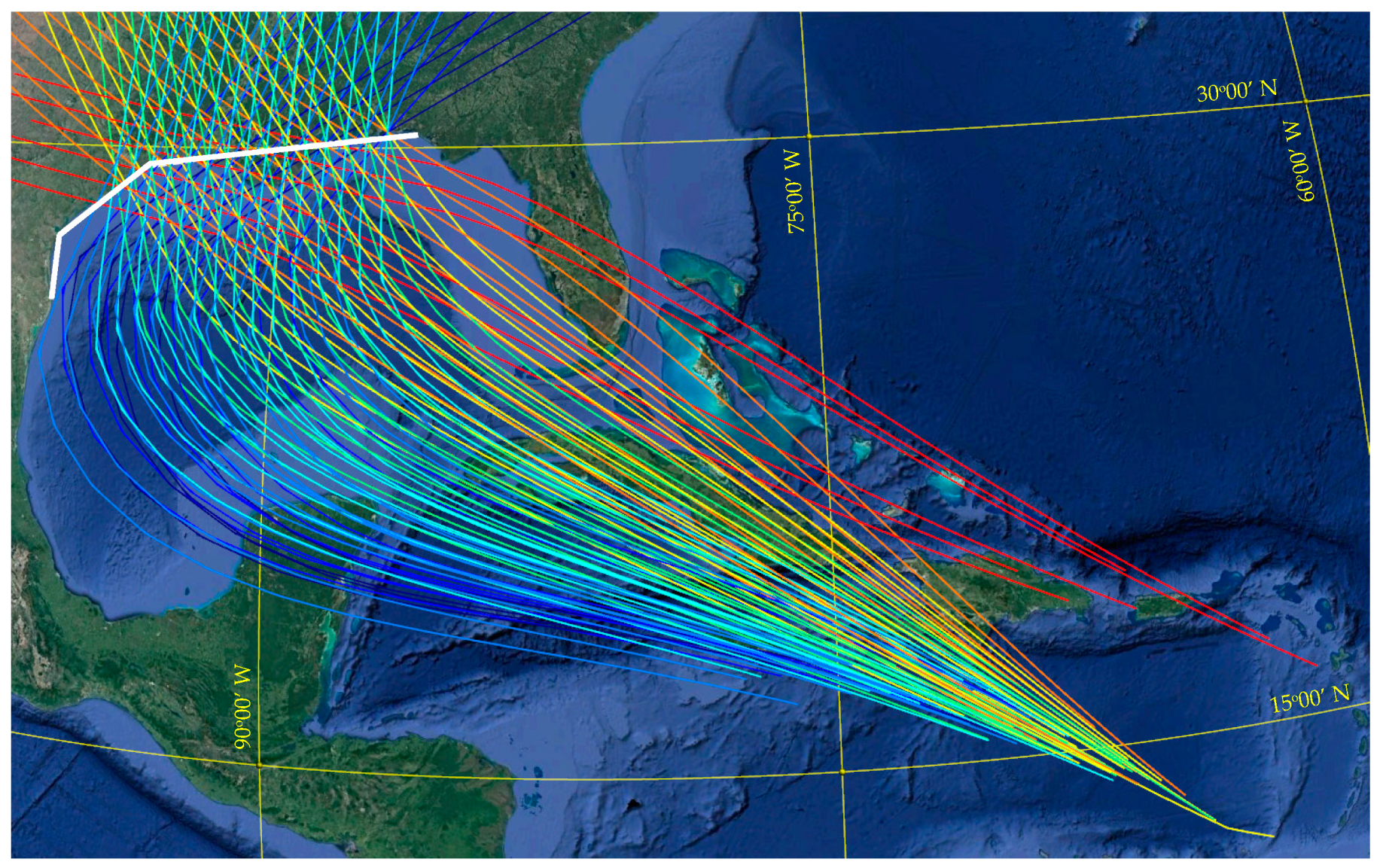
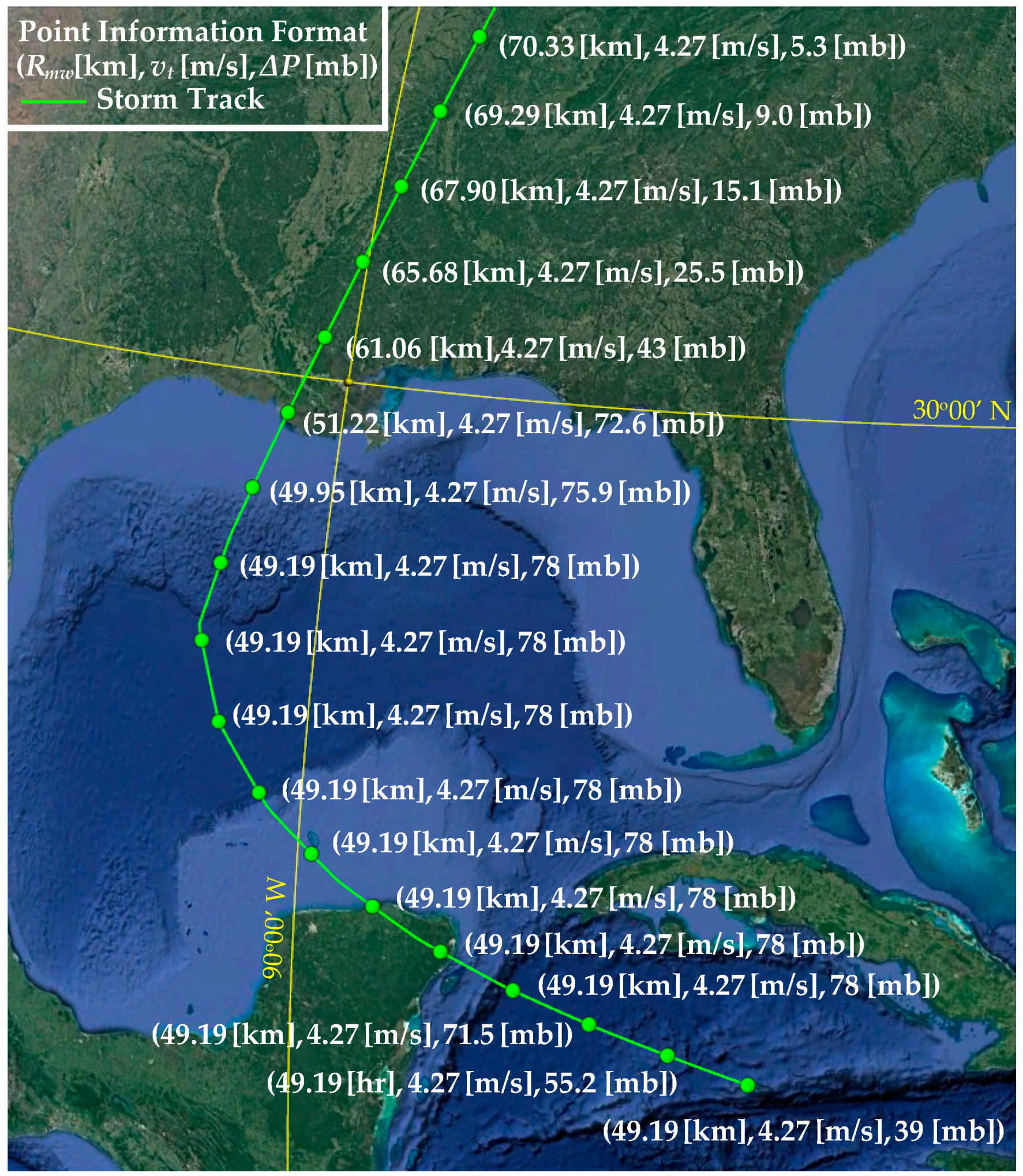
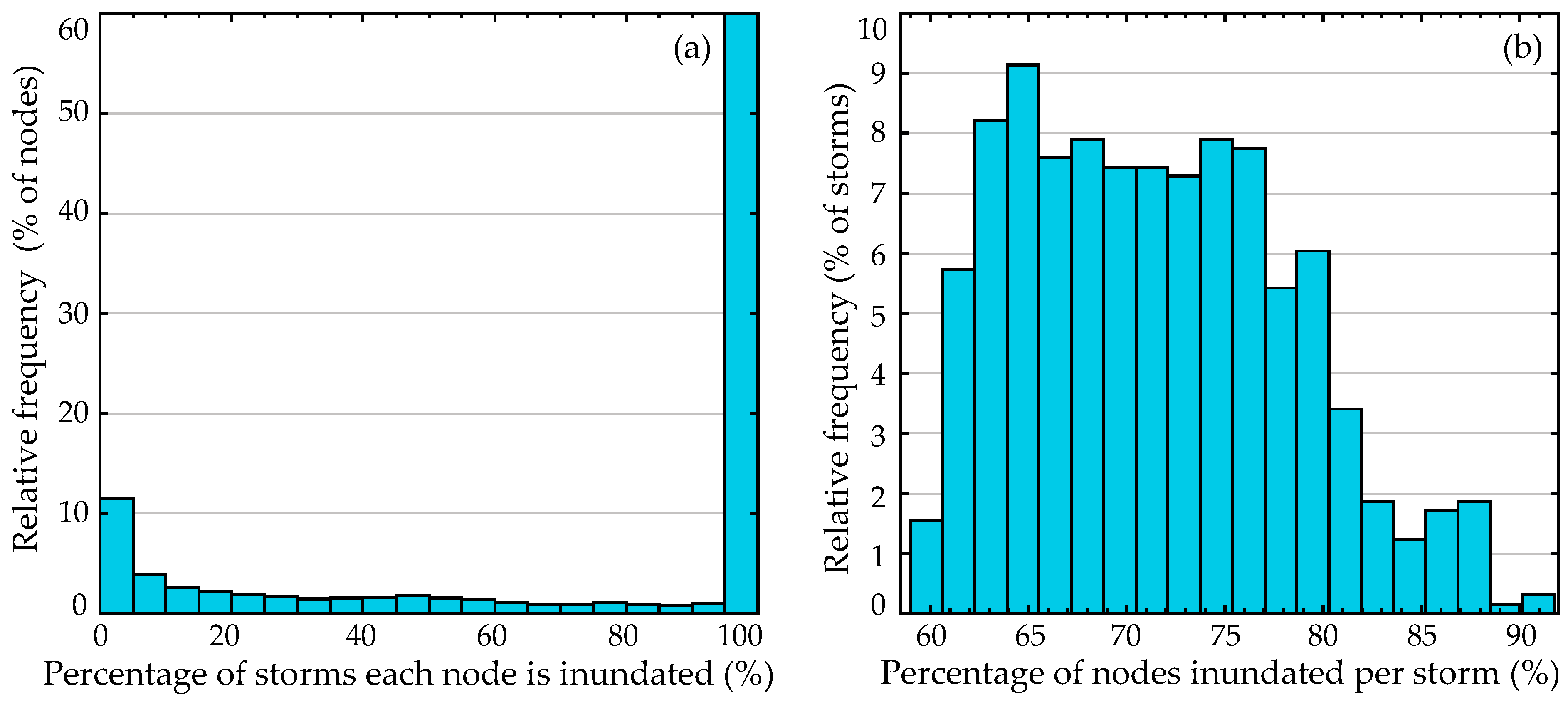
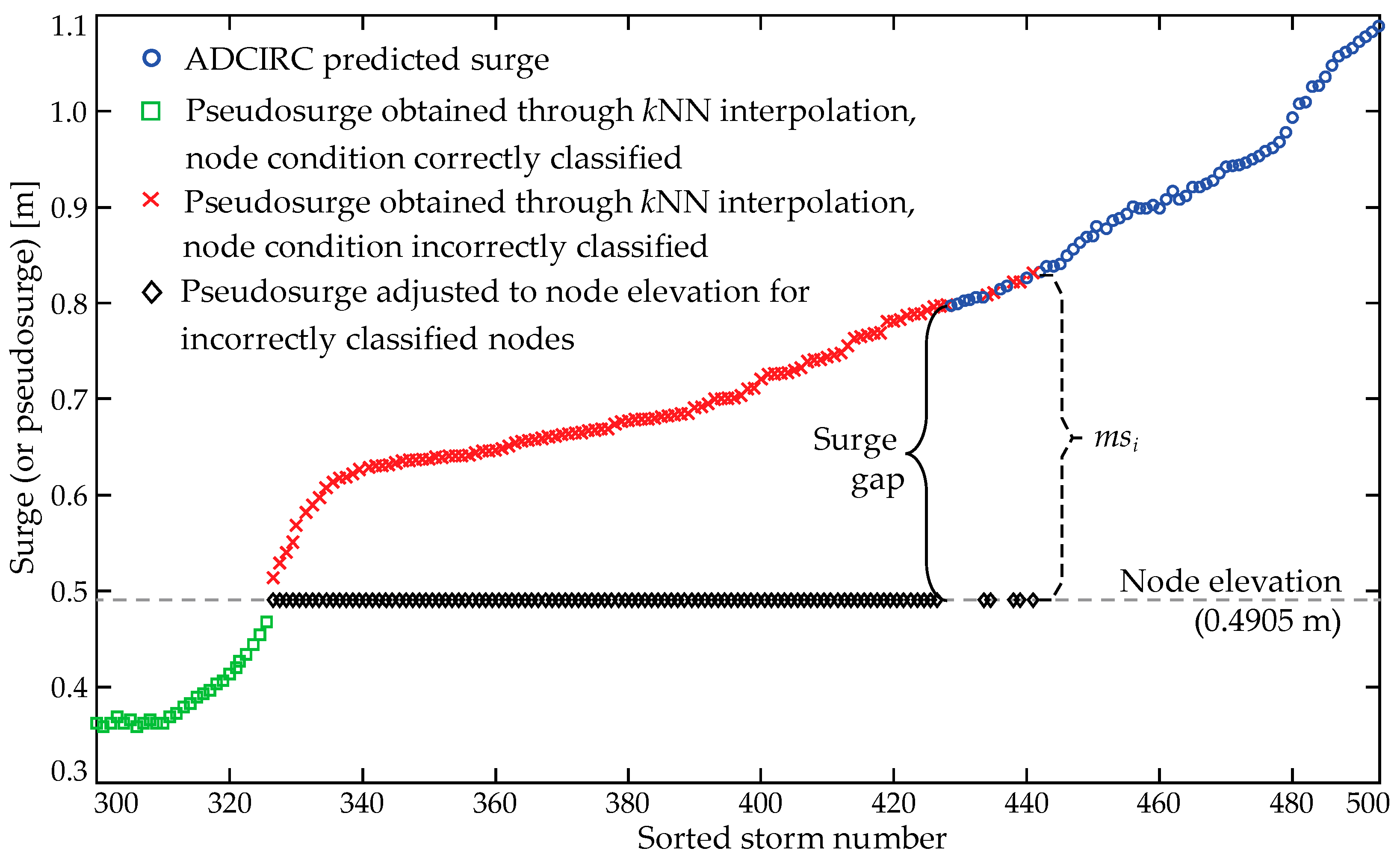
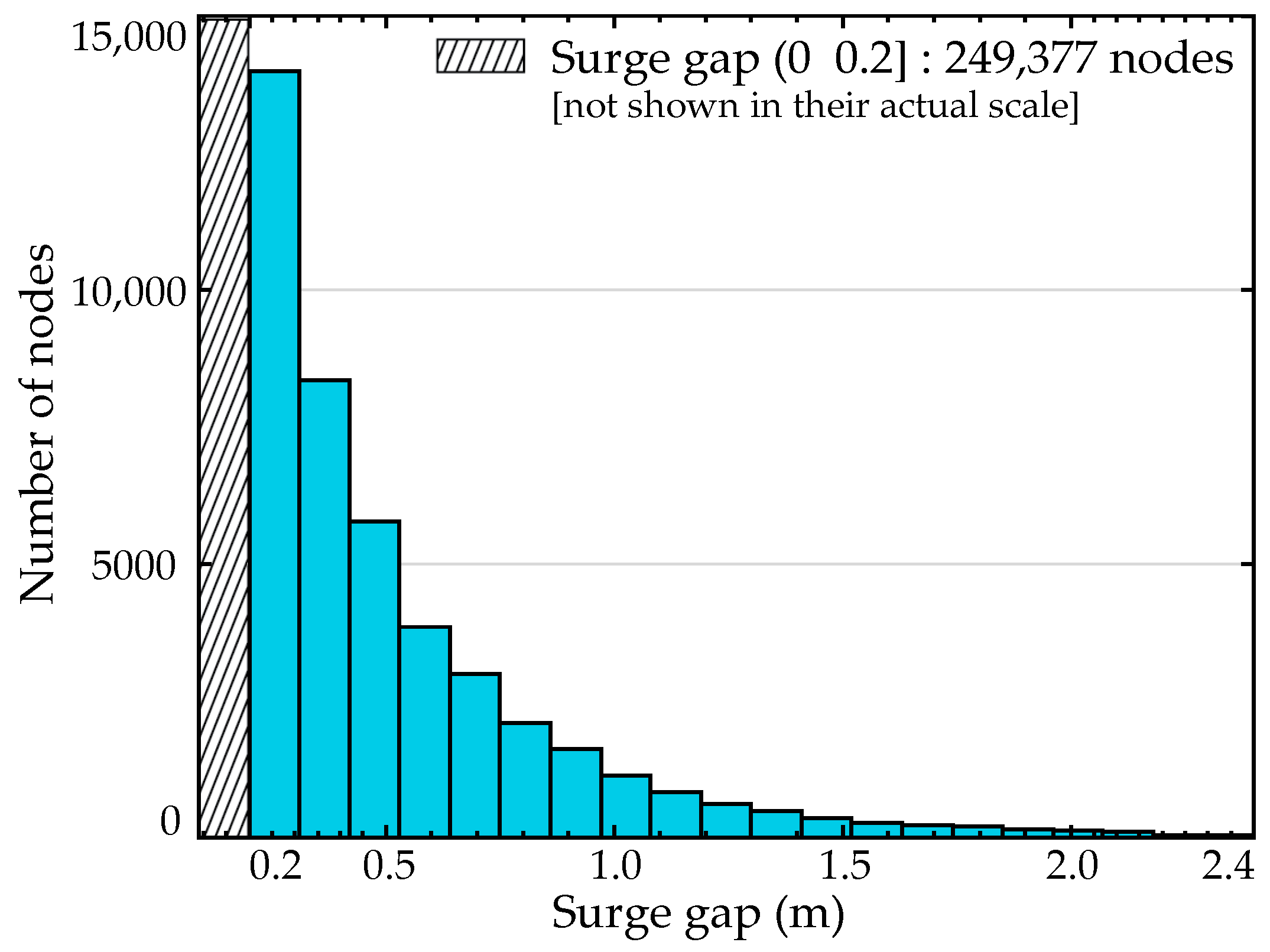
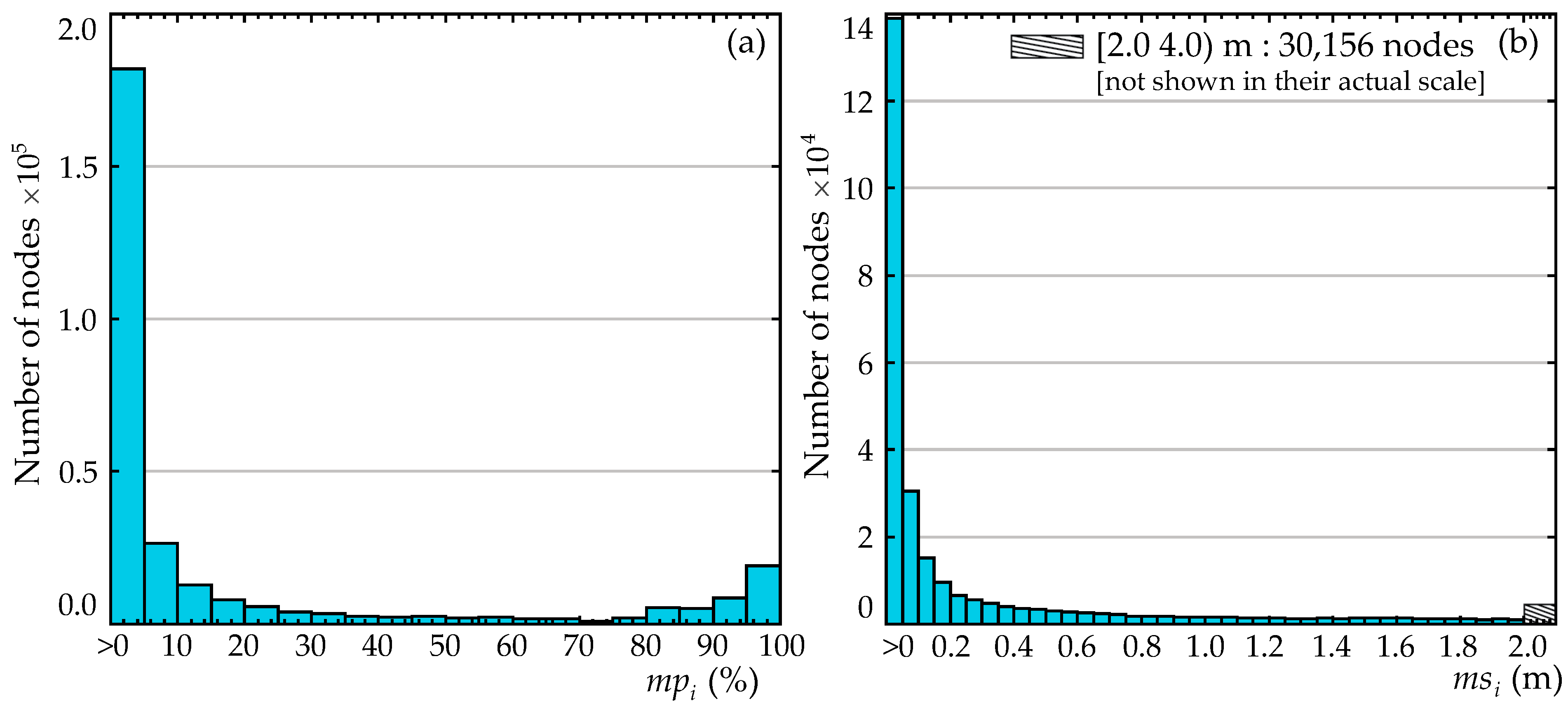
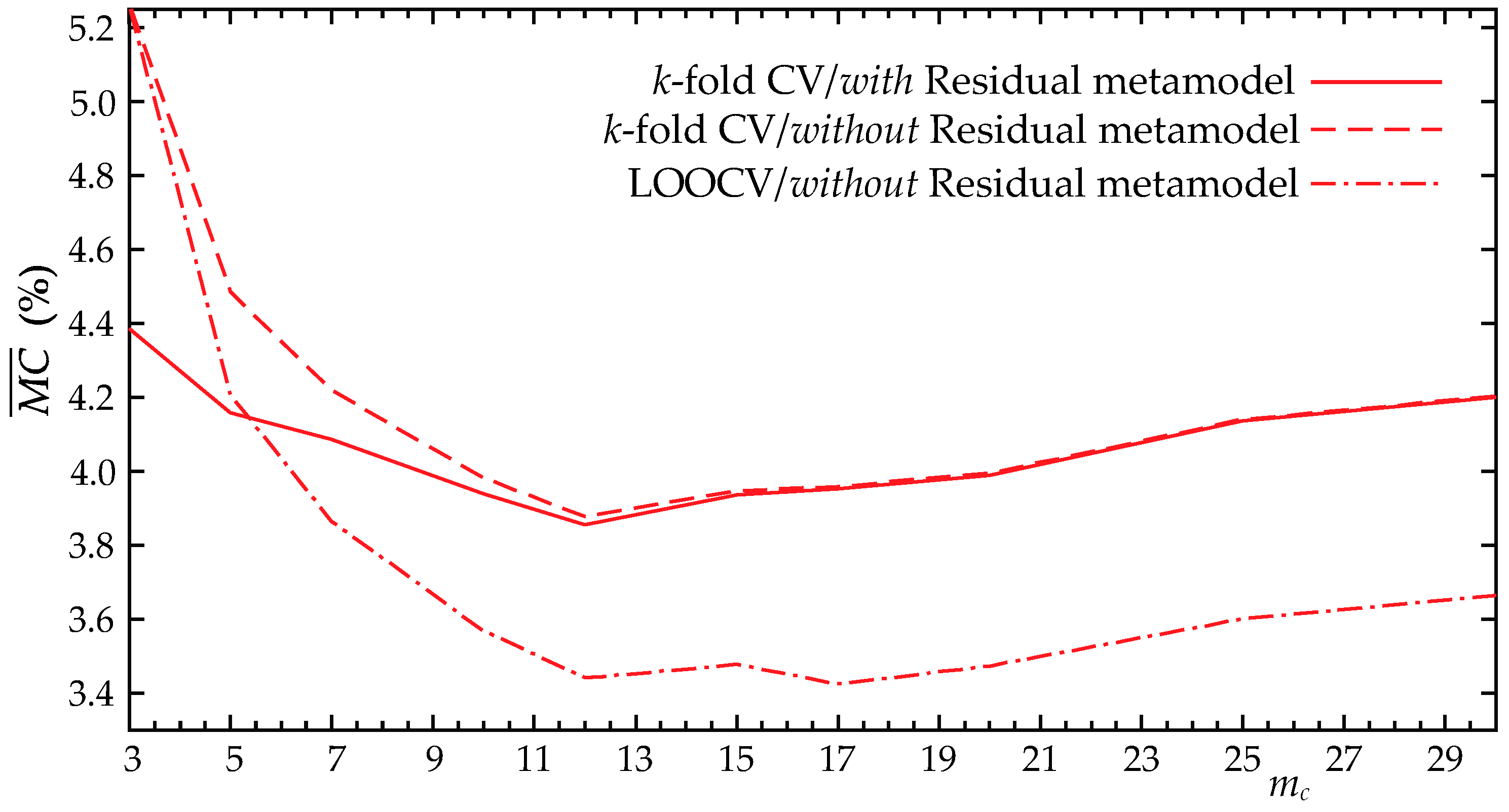
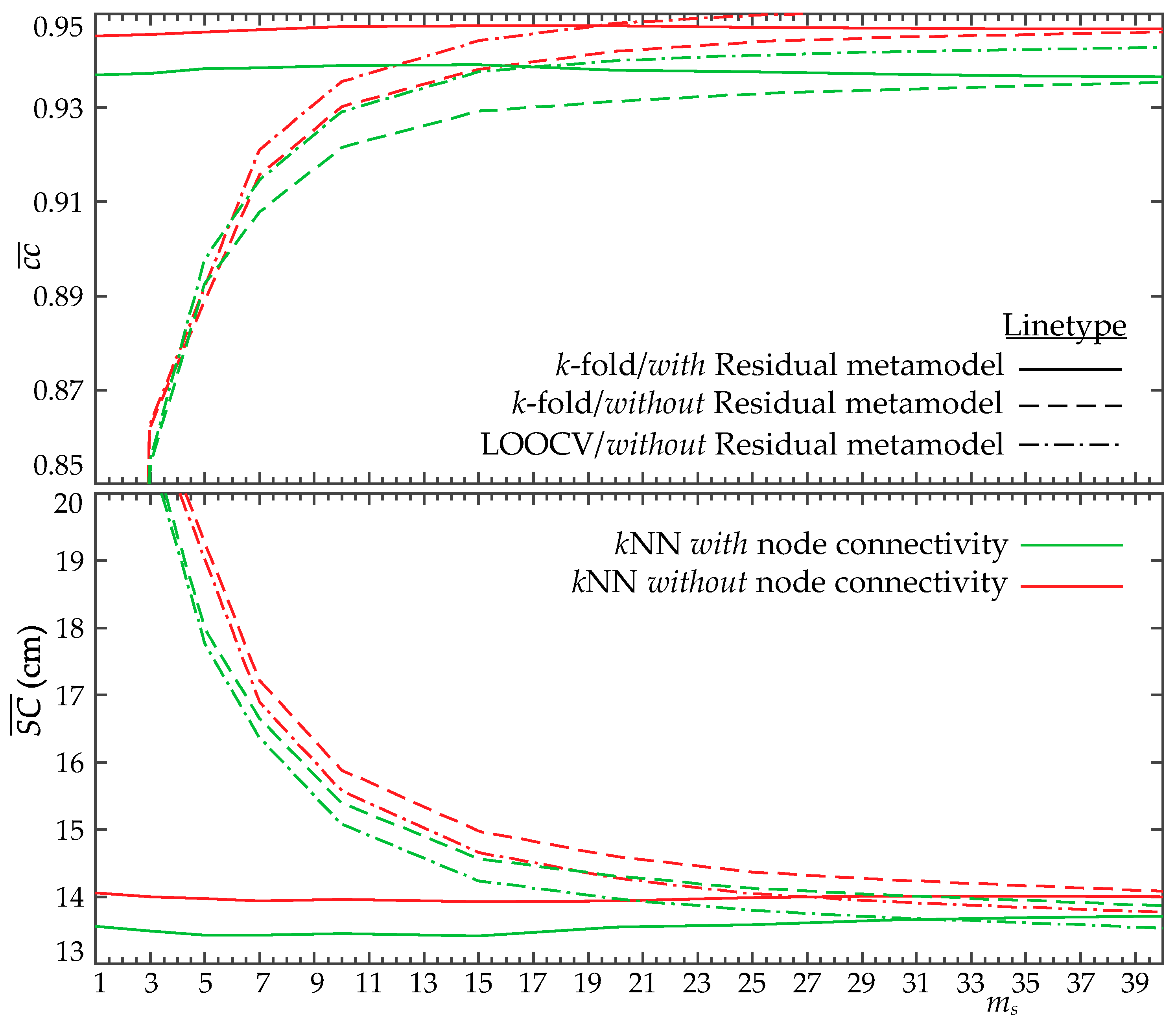
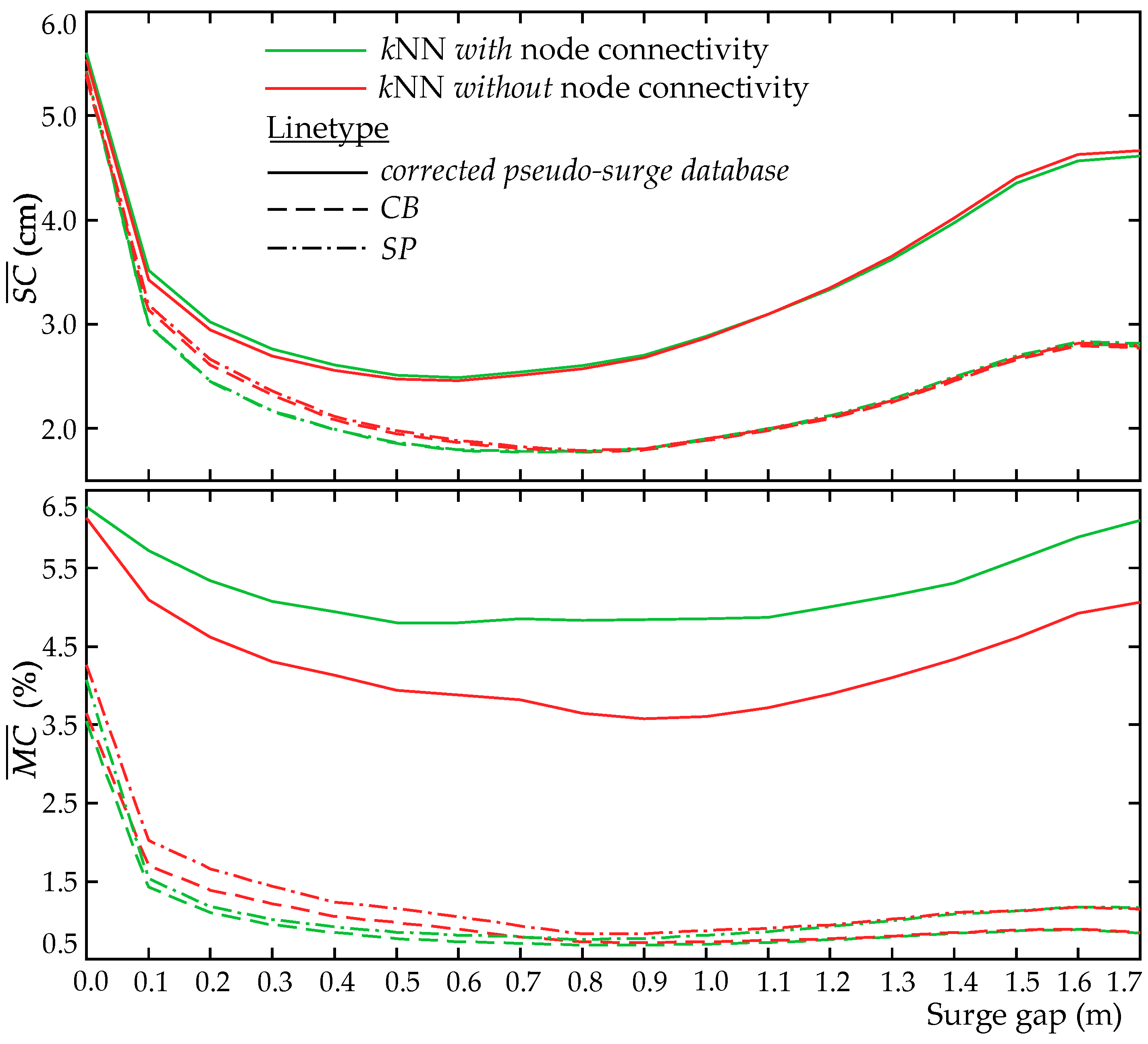
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).