1. Introduction
In recent decades, as the shipping industry of China has grown by leaps and bounds, water transportation has been confronted with issues, such as an increase in ship traffic density, the frequency of water traffic accidents, and the increasing difficulty of maritime safety supervision, all of which pose obstacles to the sustainable growth of the shipping industry [
1,
2]. AIS data, whose primary information is spatiotemporal data consisting of ship location and time, provides ship trajectory data that can be used to analyze ship navigation behavior in real time, as well as provide critical supplementary information in the process of collision avoidance [
3,
4]. The target ship trajectory can be predicted based on known historical location information using full analysis and deep mining of AIS ship behavior data, which can provide a strong reference for the supervision of vessel traffic services (VTS), allowing for the timely detection and resolution of abnormal and non-standard ship navigation problems [
5,
6]. Therefore, real-time and accurate ship trajectory prediction can contribute significantly to ensuring water traffic safety and enhancing the efficacy of water traffic guarantee. Methods for ship trajectory prediction can be broadly categorized into two types: kinematic modeling-based approaches and neural network modeling-based approaches, respectively [
7].
Methods based on kinematic modeling are widely used in the ship trajectory prediction industry, with the most common being the Gaussian process regression models (GP) and the Kalman filter (KF). With time as the independent variable, Anderson measured the trajectory as a one-dimensional Gaussian process. This method determines the posterior distribution of the projected value by extracting the joint prior density and covariance matrix of the observed value and the anticipated value, as well as models smooth trajectory estimation with the aid of dynamical systems [
8]. Rong et al. regarded the shipping local as a Gaussian distribution and used GP modeling to forecast the route of a ship [
9]. Jiang proposed constructing a polynomial Kalman filter to suit the nonlinear system based on the classic Kalman filter theory, compensating for the lack of track location data information and sluggish update, and predicting the ship’s trajectory based on the longitude and latitude data [
10]. These aforementioned methods function effectively when the ship’s navigation behavior state is somewhat steady. However, ship dynamics are typically sensitive to distinct environmental excitations in different areas, which may result in a non-stationary condition and render the prediction result less accurate in reality.
The widespread usage of neural networks has ushered in a new stage in ship trajectory prediction. Giulia et al. developed a radial basis neural network for the construction of a short-term vessel prediction [
11]. Zhou et al. built a track prediction model based on a three-layer back-propagation (BP) neural network, the training and prediction results of which match the standards of the VTS for accuracy, real time, and universality. However, due to the fact that the hidden units of this model are fewer in number, its expressive capacity is constrained [
12]. Liu et al. suggested a trace estimation method with support vector regression and used an enhanced differential evolution approach to optimize the parameters of this model [
13]. However, these solutions cannot effectively overcome the problem of long-term sequence dependency.
Due to AIS data being typically time series data, it is required to evaluate not only the present time step’s ship trajectory but also the previously observed trajectory data in order to anticipate future ship trajectory. A recurrent neural network (RNN) can be regarded as a representative neural network capable of predicting future data using time series information, despite gradient-vanishing and gradient-explosion problems [
14,
15]. To work out these gradient errors of RNN, long short-term memory (LSTM) introduces the memory unit and gate mechanism to replace the hidden layer unit in RNN [
16]. Additionally, then, Ger et al. optimized the LSTM by introducing a forget gate, which enables the LSTM to learn to reset itself [
17]. The gated recurrent unit (GRU) is an excellent variation on LSTM, in that it only requires an update and reset gate to regulate the information flow [
18]. Thus, due to their effectiveness in time series prediction, RNN and its variant models have been applied to the field of ship trajectory prediction in recent years. Ferrandis et al. established the LSTM method to predict the ship trajectory and solve the problem of the gradient vanishing and gradient explosion of RNN owing to rising data length [
19]. Agarap utilized the GRU method for time series prediction and proved this method has a good performance and is suitable for time series forecasting [
20]. The bidirectional recurrent neural network structure enables the output layer to receive complete past and future information for each point in the input sequence [
21]. Gao et al. and Siami-Namini et al. created a bidirectional structure to improve contextual relevance based on the RNN method, which improves the accuracy of the ship trajectory prediction compared to RNN alone [
22,
23]. It is worth mentioning that Stateczny et al. proposed the optimum dataset method, which contributes to comparative navigation and provides a model for big data set processing [
24]. After the application of attention mechanism (AM) in the field of image recognition, Vaswani et al. used this mechanism to replace the recurrent neural network modeling, provided a model for machine translation, and then, it became prevalent in regression problems [
25]. Cheng et al. implemented AM in the area of ship trajectory prediction, with the attention modes enhancing the AIS data characteristics extracted by each block and the attention module classifying these characteristics [
26].
However, although these deep-learning approaches based on AIS data performed reasonably well at predicting ship trajectory, there are still a few issues with insufficient accuracy and real-time enforcement. The primary reason for these issues is that the majority of existing approaches for mining AIS data are relatively isolated and overlook elements such as AIS data characteristics and ship track sequence information. Thus, a high-precision ship track prediction model based on a combination of multi-head attention mechanism and bidirectional gate recurrent unit (MHA-BiGRU) is developed to solve the issues mentioned above. The contribution of this model is briefly summarized below: Firstly, this model retains long-term ship track sequence information, filters and modifies ship track historical data for enhanced time series prediction, and models the potential association between historical and future ship trajectory status information with the current state, thereby increasing forecast accuracy. Secondly, an MHA mechanism based on BiGRU is introduced, which not only calculates the correlation between the characteristics of AIS information but also actively learns cross-time synchronization between the hidden layers of the output and input ship track sequences and assigns different weights to the result based on the input criterion, thereby improving the accuracy and robustness of the overall model. Finally, the comparative experimental results in this paper verify that MHA-BiGRU, which fully exploits the advantages of bidirectional RNN, multi-head attention mechanisms, and GRU, outperforms the other seven ship track prediction models, demonstrating that the MHA-BiGRU possesses the characteristics of ease of implementation, high precision, and high reliability.
2. Materials and Methods
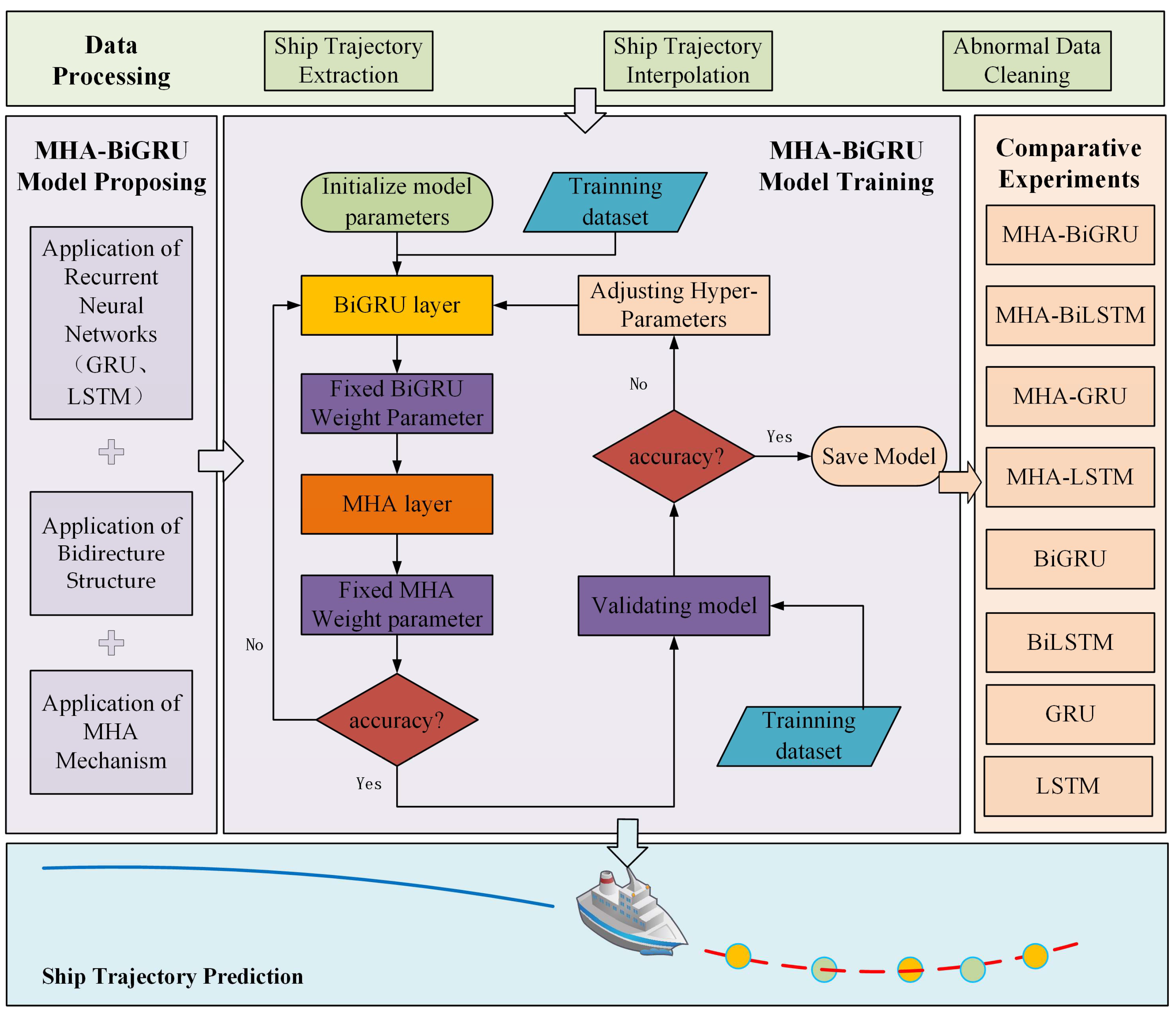
Figure 1 depicts the framework of the proposed method, which consists of four components: data processing, MHA-BiGRU model proposal, MHA-BiGRU model training, and comparison experiments. Specifically, data processing, which includes ship trajectory extraction, missing value recognition and completion, and data cleansing, is a crucial step in deep learning, as the processed data enable an improved model performance. An easy-to-implement method that is suitable for quick and concise analysis is proposed by combining the advantages of bidirectional RNN, multi-head attention mechanism, and GRU, which enables the improvement of prediction efficiency and accuracy of the ship trajectory. Additionally, then, the structure, application principle, training method, and contribution of the MHA-BiGRU are presented in a step-by-step manner. Finally, in order to demonstrate the effectiveness of the proposed method, some other prediction methods are compared in this paper.
2.1. AIS Data Processing
The AIS is a critical component of modern ship navigation systems, which is installed and widely available for ships to reinforce the capacity to mark the location and identify targets. There are two major issues with trajectory prediction using AIS data: time interval inconsistency and measurement error. The former issue is caused by a variety of circumstances, including variability in the broadcast frequency and packet losses. The latter issue occurs when the received AIS data value does not match the true value of the sensor at the moment of measurement, and the deviation can be rather considerable [
7,
27]. These two issues may result in data loss, sparsity, and offset. Thus, processing data, such as ship trajectory extraction, missing value recognition and completion, and data cleaning, are vital stages in deep learning, as processed data enable model performance to be improved.
AIS data are multidimensional and multiparametric in nature and are used to characterize ship behavior, such as the direction, position, and speed of the ship, as they change over time [
28]. Each ship was classified based on its Maritime Mobile Service Identification (MMSI). After that, the ships were sorted according to their timestamps. To handle deficiency, deviation, and sparse AIS data from the original dataset, this section employs the following data processing techniques: ship trajectory extraction, deficiency value recognition, linear interpolation, and data cleaning.
The method for extracting the ship trajectory is based on time intervals and navigation speed. When the time interval between the ship trajectory points reaches 6 h, or the ship navigation speed reaches 0, the ship trajectory points are identified as tangent points to the trajectory sequence. Each track point contains information about the longitude and latitude positions, as well as its navigation speed and direction of ships.
Let the original data be
and the time interval between
and
be
. When
exceeds 10 min, the linear interpolation method is used to complete the missing value, with one deficiency value being completed every 5 min. If
is the deficiency data and
and
are the two data points closest to the deficiency data, then the completed data can be shown as follows [
29]:
Additionally, to address the ship trajectory deviation and sparse data, set as the current track point. If the distance between the current track point pi and its adjacent track point , is greater than the threshold, the adjacent track point , should be used as the observation point for linear fitting. When the track is too sparse and a significant amount of data are missing, the sparse ship trajectory is removed and no longer used.
2.2. Comparasion of GRU and LSTM
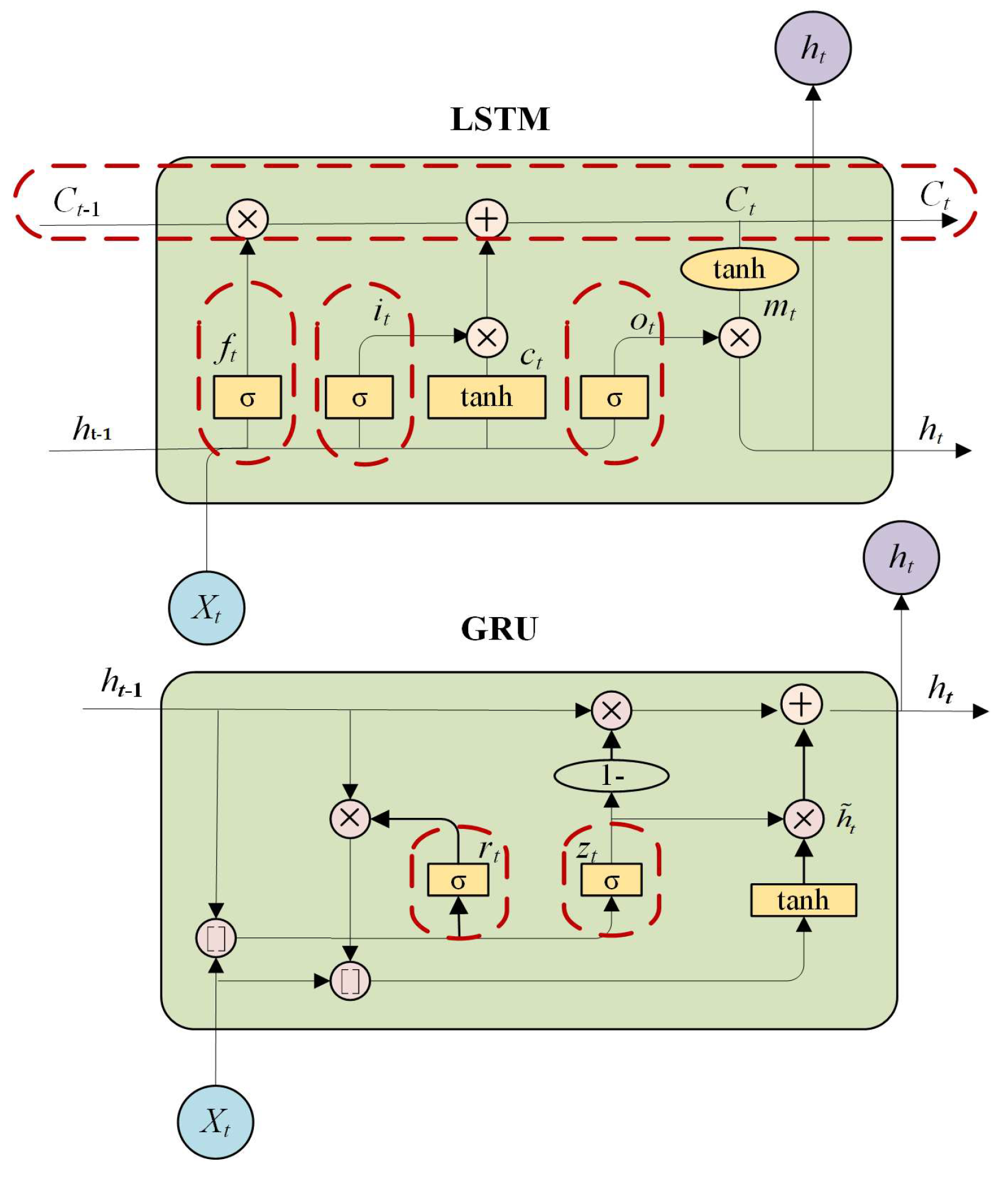
To work out the gradient-vanishing and gradient-explosion problems of RNN, LSTM introduces a memory unit and a gate mechanism to replace the hidden layer unit in RNN [
15,
16]. The LSTM modifies the current state of the memory cell and determines the output content via the forget gate, input gate, and output gate, which correspond to the writing and reading of the ship track reading characteristic data sequence and the reset operation of the previous state, respectively, in this paper. GRU is a great variation of LSTM, in that it requires only an update and reset gate to govern the flow of information. As a result of its smaller parameters compared to LSTM, it is extremely easy to train and enables it to respond more effectively to the implications of this information on current time inputs [
18,
29]. The comparison of the LSTM and GRU neural network structures can be seen in
Figure 2 [
17,
18], and then, the following describes the concrete calculation process for these two models:
The following section details the precise calculation procedure employed by LSTM.
The amount of memory cell information used at the previous moment is controlled by the forget gate (
).
The input gate (
) enables the control of the amount of information updated by the memory unit.
is a candidate vector produced by the tanh layer and will be added to the cell state. Additionally, then, it integrates the
with the
to update the cell units.
The output gate (
) controls the amount of information output to the next hidden state. The output value is passed to the status value (
) of the next unit to complete the training procedure.
The description of the concrete calculation process of GRU is as follows.
The reset gate (
) enables the determination of how to combine the new input information with the previous memory. Additionally, when it is turned off, GRU cells can effectively forget the previous calculation and return to the state in which they are reading the first input sequence, so as to achieve the purpose of the reset.
The update gate (
) determines the activation status of GRU cells and the degree of update content.
The reset gate is applied to the
vector, and the obtained result is multiplied by
to form a splicing vector with
. The obtained result is transformed into a vector with elements between −1 and 1 through the tanh function, and the candidate hidden state value is obtained. Through the above steps, the final hidden layer output information can be obtained.
where [ ] represents the multiplication of two vectors,
means matrix multiplication,
shows that each element in the matrix is multiplied accordingly,
W and
b are the weight item of corresponding gates and bias items, respectively,
is the sigmoid activation function.
Overall, as shown in
Figure 2, GRU integrates
and
of the LSTM unit into
, and it also integrates the hidden state and unit state of the LSTM with the
, which can be used to control the extent of ignoring the states information of the previous time, so as to master the flow of vessel trajectory information. Based on this, GRU preserves the most critical data in order to avoid information loss during long-term propagation. Because the structure of GRU is simpler than that of LSTM, fewer parameters must be taught, and it also offers the benefit of quick training speed throughout the training process.
2.3. Application of Bidirectional RNN Structure
The bidirectional recurrent neural network structure enables the output layer to receive complete past and future information for each point in the input sequence. To be more precise, the forward RNN learns from previous data, while the reverse RNN learns from future data, so that each time step makes optimal use of upper- and lower-related data. Additionally, then, these two outputs are spliced together as the final output of the whole bidirectional RNN [
21,
30].
From this, BiGRU is a bidirectional RNN neural network that employs the GRU for each hidden node [
31]. BiGRU divides GRU neurons into forward and backward layers that correspond to positive and negative time directions, respectively.
As shown in
Figure 3 [
21,
29], the current statement of the hidden layer of BiGRU is determined by current input
, the hidden layer statement output of the forward layer
and the backward layer
. Since BiGRU can be regarded as two single GRU, the hidden layer state of BiGRU at time t can be obtained by the weighted sum of
and
, which can be shown as follows:
In conclusion, BiGRU enables the modeling of the potential association between historical and future ship trajectory status information with the current state, hence increasing forecast accuracy.
2.4. Application of MHA Mechanism
The attention-based model originated in the field of image recognition and can now be used in place of RNN in the area of machine translation. By assigning a different weight to each factor in the input sequence, the attention-based model highlights the most significant influencing factors, thereby increasing the model’s accuracy. It is expressed as follows [
26]:
Where represents the input sequence, It is mapped in the (0, 1) interval through the normalized exponential function, which is “weight”. Additionally, dot product attention is the weighted combination of .
With the attention-based model mechanism being widely used in image and natural language processing tasks, the multi-head attention (MHA) mechanism emerges as the situation requires [
32]. An MHA is a combination of multiple self-attention structures. Using the query and kex’Iy, the MHA mechanism calculates the weight coefficient of the relevant value and then performs weighted summation. MHA works by performing a linear transformation on the query, key, and value and then inserting them into the zoom point to garner attention; this process is repeated a number of times. Additionally, each iteration’s linear transformation parameters
W for
Q,
K, and
V are unique; they are not shared. Rather than using simple maximum or average pooling, MHA is used to process the data from the BiGRU output layer, as demonstrated by the following formula:
Thus, the multi-head attention mechanism, which is a combination of multiple attention-based models, can be regarded as a weighting scheme for information, which can assign weights to the hidden layer of BiGRU, so that they can make more rational use of information sources when making predictions.
2.5. MHA-BiGRU Model
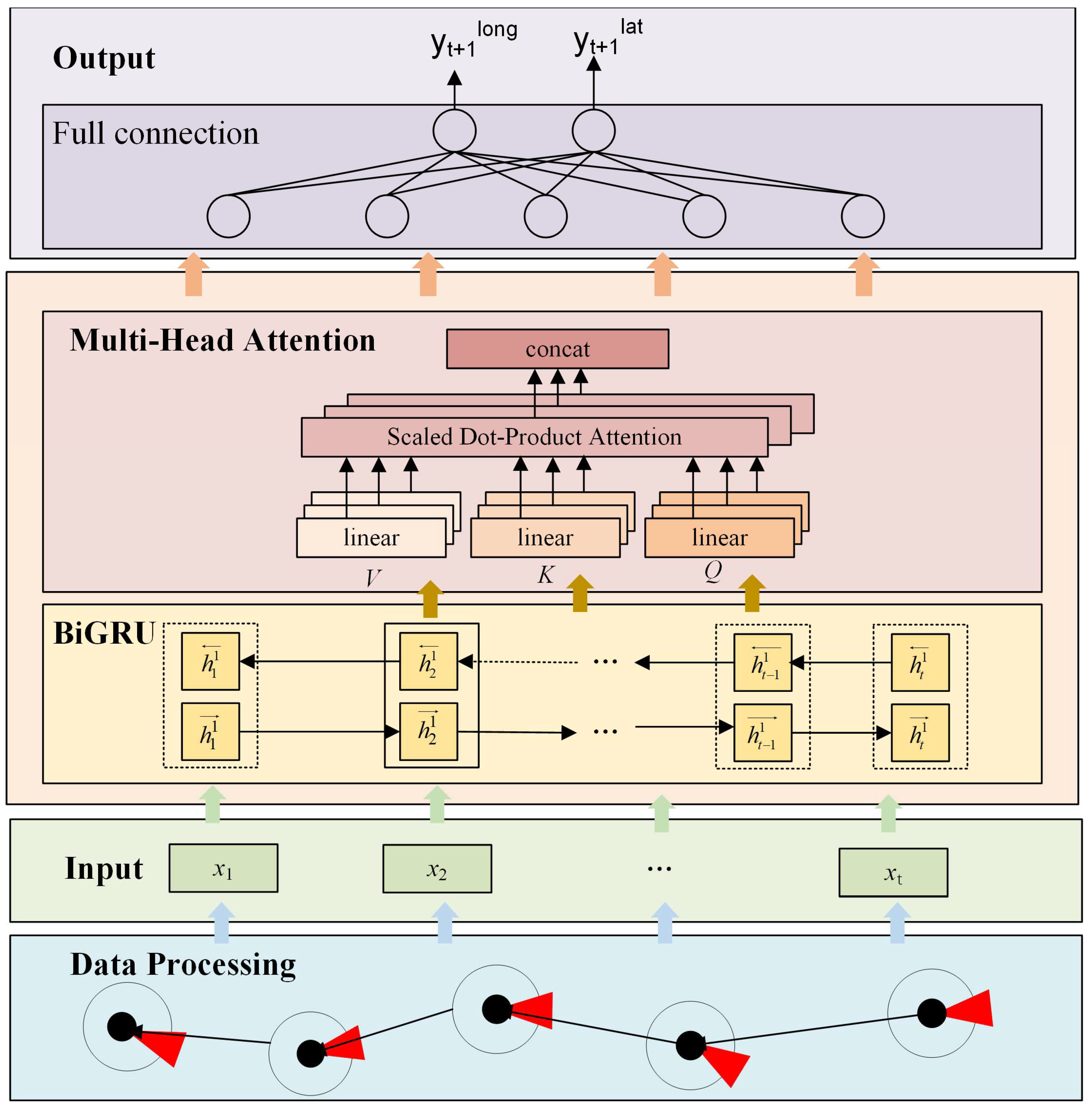
By combining the advantages of bidirectional RNN, multi-head attention mechanism, and GRU, the MHA-BiGRU model is proposed as an easy-to-implement method suitable for quickly and succinctly analyzing ship trajectory. This model improves the prediction efficiency and accuracy of ship trajectory. This section introduces the MHA-BiGRU model in a hierarchical fashion and demonstrates the benefits of this method.
Figure 4 vividly illustrates the structure of the proposed model.
The MHA-BiGRU model retains long-term ship track sequence information, filters and modifies ship track historical data for enhanced time series prediction via GRU, and models the potential association between historical and future ship trajectory status information with the current state via the BiGRU structure, thereby increasing forecast accuracy.
Additionally, then, in order to resolve the common problems associated with RNN, which include AIS data being relatively isolated and overlooking elements such as AIS data characteristics and ship track sequence information, it is essential to implement an MHA mechanism based on the BiGRU structure. Firstly, this method allows for the calculation of the correlation between AIS information characteristics, such as time, latitude, longitude, speed, course, and heading, and the critical of the global impact. That is, a weighted representation is obtained by using attention sort and then put into a feedforward neural network to obtain a new representation that takes into account the correlation between various parameters.
Secondly, because the vector length is difficult to summarize with the complete track sequence information, and the information input after BiGRU will dilute the information of the previous vector to a certain extent, the accuracy of the fixed context vector response track data will gradually decrease. In addition, because the ship operation in the application scenario changes dynamically with time, to address the aforementioned issue, the MHA mechanism can actively learn the degree of cross-time synchronization between the hidden layers of the output and input sequences and assign different weights to the result based on the input criterion, thereby improving the accuracy and robustness of the overall model.
4. Discussion
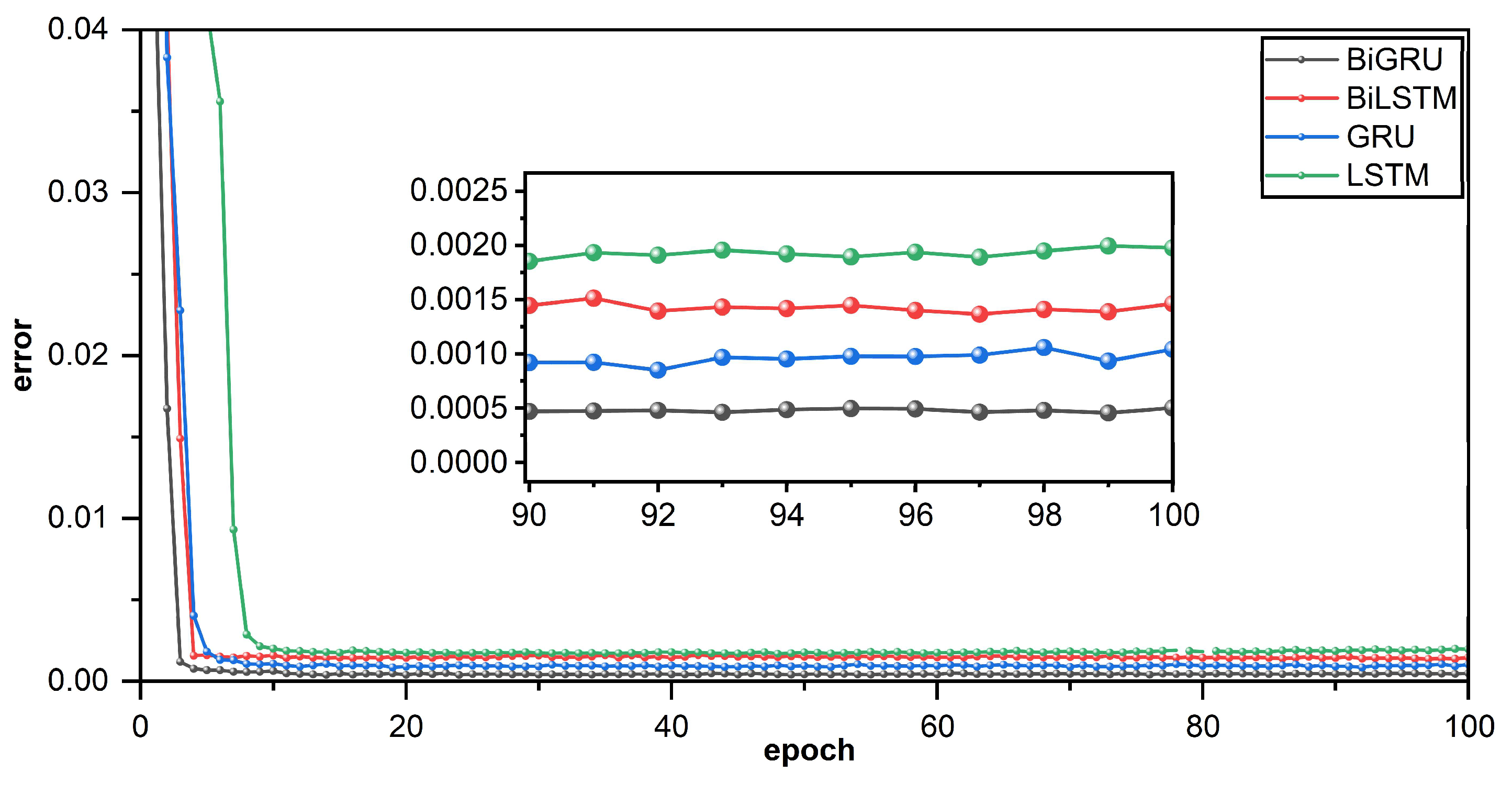
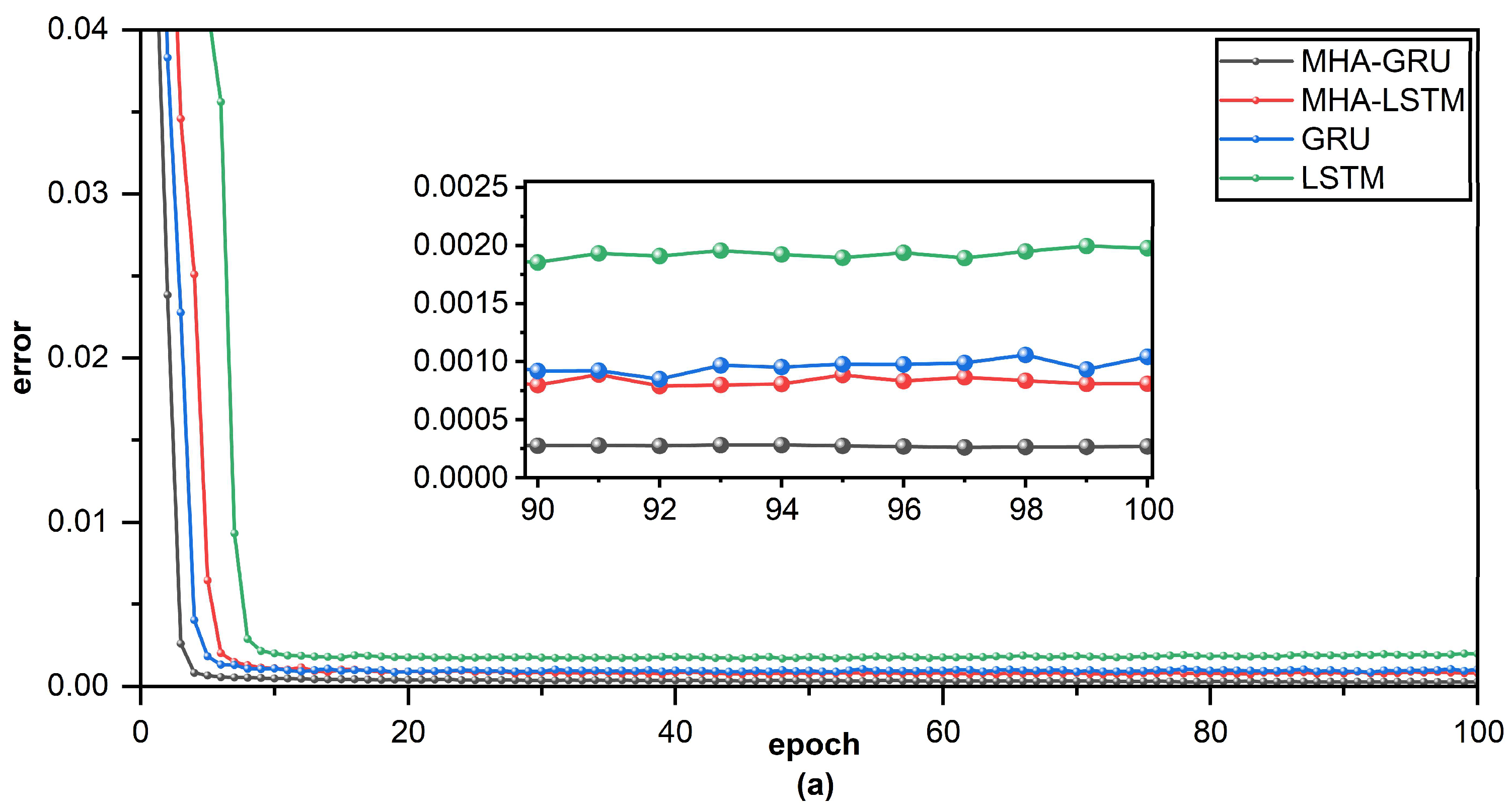
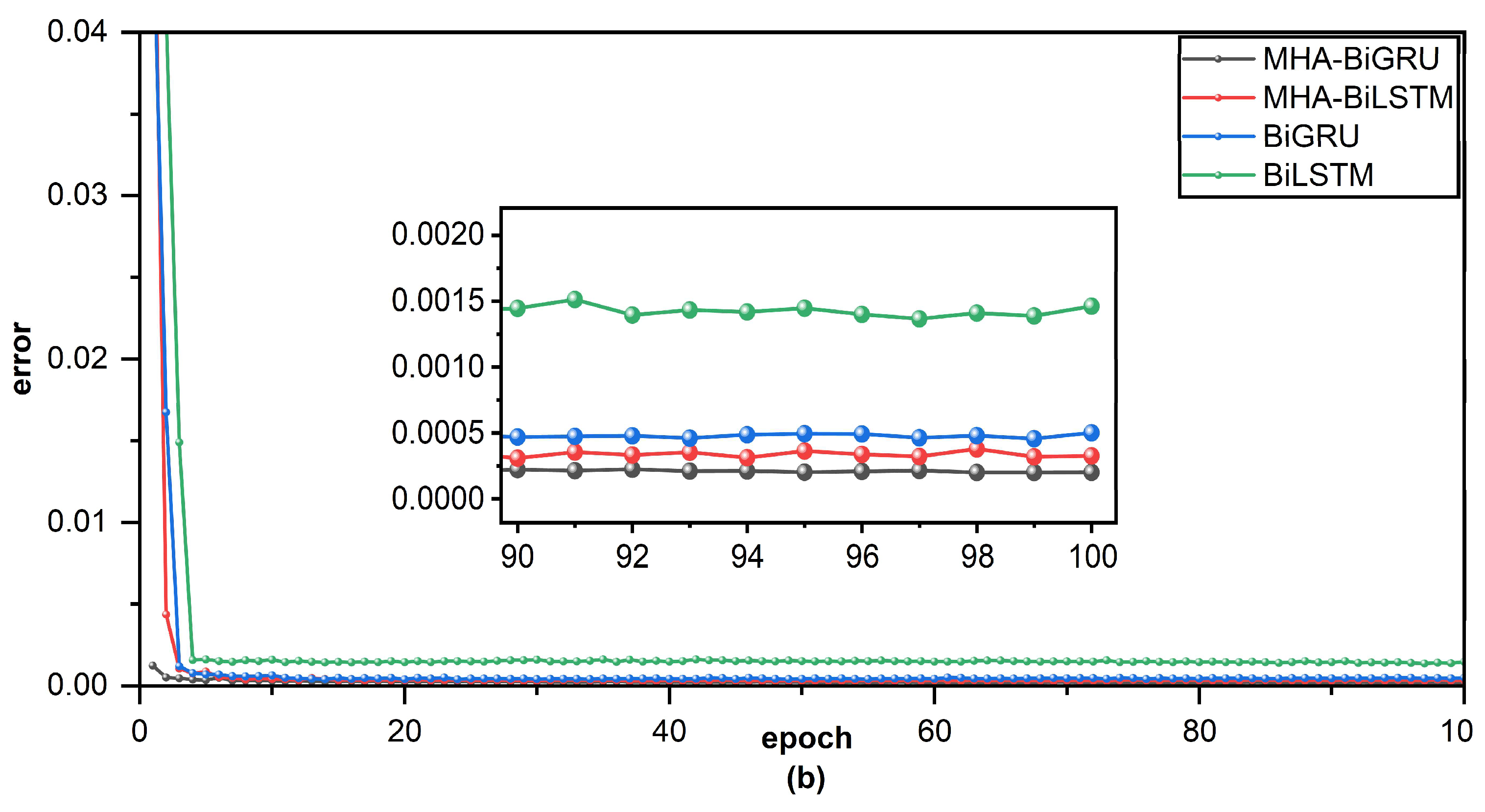
By gradually demonstrating the benefits of bidirectional RNN, multi-head attention mechanism, and GRU, the comparative experiment results demonstrated that MHA-BiGRU outperforms other models in terms of effectiveness and accuracy of ship trajectory prediction.
4.1. The Contribution of the MHA-BiGRU Model
The LSTM and GRU, excellent variants of RNN, have a gate structure that not only preserves long-term sequence information but also filters and modifies ship track historical data for enhanced time series prediction. Additionally, in comparison with LSTM, the prediction task with GRU can be accomplished with fewer model parameters, but it can perform similarly to LSTM [
17,
18,
19]. This experiment finds that GRU can outperform LSTM in this comparison scenario, both in terms of efficiency and accuracy, regardless of whether the model is combined with a two-way structure, the MHA mechanism, or neither. Although GRU outperforms LSTM in this experiment, there is no final conclusion on which is better or worse and which must be chosen based on specific tasks and datasets.
Gao et al. and Siami-Namini et al. proved that the use of a bidirectional structure to improve contextual relevance based on the RNN method improves the accuracy of ship trajectory prediction compared to RNN alone [
23,
24]. Whether combined with LSTM or GRU, this experiment further demonstrated that the bidirectional structure can improve the accuracy of ship trajectory prediction. As a result, this finding thoroughly demonstrates that the bidirectional RNN structure can simulate the prospective relationship between past ship trajectory status information and future ship trajectory status information with current state in order to increase prediction accuracy.
The MHA mechanism is frequently employed in image recognition and automatic translation. It was combined with a recurrent neural network in this experiment, from which significant conclusions are drawn. The most important results of the comparative experiments demonstrate the advantage of the MHA mechanism in combination with RNN and BiRNN. Additionally, when compared to bidirectional structures, the MHA mechanism contributes significantly more to the model’s accuracy and robustness. Thus, the MHA mechanism not only calculates the correlation between the characteristics of AIS information but also actively learns cross-time synchronization between the hidden layers of the output and input sequences, and it assigns different weights to the result based on the input criterion, thereby improving the overall model’s accuracy and robustness.
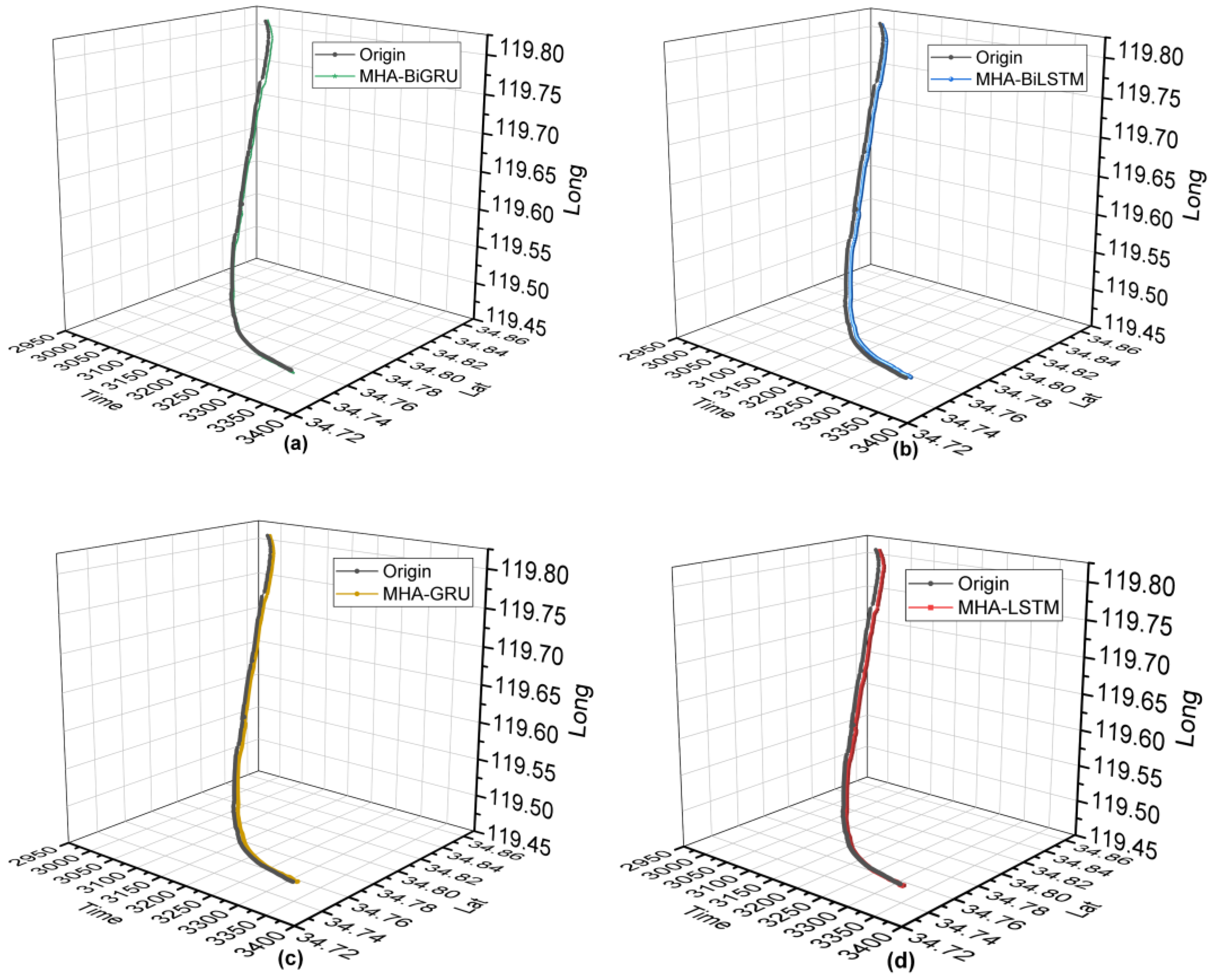
Overall, the most crucial advantage of MHA-BiGRU is that it enables the preservation of long-term sequence information, filters and modifies ship track historical data for improved time series prediction, models the potential relationship between historical and future ship trajectory status information and the current state via a bidirectional structure, and highlights critical ship trajectory prediction information in AIS characteristics and time series dimension via an MHA mechanism.
4.2. The Limitations and Future Development
Experiments indicate that the MHA-BiGRU model has high prediction accuracy under normal navigation conditions, as well as good applicability and track prediction reliability. However, as the navigational status of each ship changes over time, the navigational status of other ships will have varying effects on the future course of the ship in inquiry. Additionally, the bad weather will impact the ship’s navigation, leading to an abnormal ship trajectory. Moreover, in addition to using AIS data for ship trajectory prediction, it can also be supplemented with other system data, such as the radar system, to further increase the model’s accuracy. Thus, in order to further investigate whether the model can correct and avoid ship collisions under abnormal conditions, it is necessary to combine other ship spatial information and bad weather information to verify the model’s performance under abnormal circumstances.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}