Abstract
A UUV can perform tasks such as underwater surveillance, reconnaissance, surveillance, and tracking by being equipped with sensors and different task modules. Due to the complex underwater environment, the UUV must have good collision avoidance planning algorithms to avoid various underwater obstacles when performing tasks. The existing path planning algorithms take a long time to plan and have poor adaptability to the environment. Some collision-avoidance planning algorithms do not take into account the kinematic limitations of the UUV, thus placing high demands on the performance and control algorithms of UUV. This article proposes a PPO−DWA collision avoidance planning algorithm for the UUV under static unknown obstacles, which is based on the proximal policy optimization (PPO) algorithm and the dynamic window approach (DWA). This algorithm acquires the obstacle information from forward-looking sonar as input and outputs the corresponding continuous actions. The PPO−DWA collision avoidance planning algorithm consists of the PPO algorithm and the modified DWA. The PPO collision avoidance planning algorithm is only responsible for outputting the continuous angular velocity, aiming to reduce the difficulty of training neural networks. The modified DWA acquires obstacle information and the optimal angular velocity from the PPO algorithm as input, and outputs of the linear velocity. The collision avoidance actions output by this algorithm meet the kinematic constraints of UUV, and the algorithm execution time is relatively short. The experimental data demonstrates that the PPO−DWA algorithm can effectively plan smooth collision-free paths in complex obstacle environments, and the execution time of the algorithm is acceptable.
1. Introduction
A UUV is composed of a body structure, power system, navigation system, perception system, control system, and communication system, which plays an important role in underwater search and rescue, terrain exploration, and other fields. Whether the UUV can quickly and safely reach the target point determines the effectiveness of task completion. Collision avoidance planning is a significant research topic in the field of UUV navigation. It enables robots to plan a collision-free trajectory from an initial pose to a target pose, even in uncertain environments [1]. The technologies in the field of global path planning based on known maps have developed tremendously over the past few decades. However, in the face of complex and unknown environments, the use of traditional collision avoidance planning algorithms is limited. The artificial potential field (APF) method does not take into account the kinematic limitations of a UUV, lacks adaptability to the environment, and may fail in complex obstacle environments. The rapidly exploring random tree (RRT) algorithm takes too long to calculate and requires high computational power [2]. Collision avoidance planning algorithms based on intelligent search algorithms are prone to falling into local optima and have a longer planning time.
In recent years, with the progress of science and technology, deep reinforcement learning algorithms have made major breakthroughs in various fields. The deep reinforcement learning algorithms have good decision-making ability, which can explore and learn independently. It is feasible to use deep reinforcement learning algorithms to solve the problem of collision avoidance planning [3]. On the one hand, the self-learning mechanism of reinforcement learning (RL) can improve adaptability to the environment. Conversely, the end-to-end DRL strategy that accomplishes the collision avoidance planning task can take less time to make decisions. Deep reinforcement learning can address high-dimension problems when the states and actions are continuous variables in the environment [4].
In order to improve the adaptability of collision avoidance algorithms to the environment, enhance the algorithms’ real-time planning ability, and meet the kinematic limitations of the UUV, this paper proposes a PPO−DWA collision avoidance planning algorithm for the UUV. The structure of this paper is as follows. Section 2 reviews the main collision avoidance planning algorithms. Section 3 completes the kinematic modeling of the UUV and introduces the collision avoidance algorithm DWA and deep reinforcement learning algorithm PPO. This is followed by a description of the problem definition and the PPO−DWA algorithm. Section 5 verifies the feasibility of the PPO−DWA method through experiments. Section 6 summarizes the entire article and discusses future research directions of this paper.
2. Related Work
The research of collision avoidance planning aims to design an optimal collision-free trajectory based on surrounding obstacle information. In this section, collision avoidance planning algorithms are divided into two categories: traditional algorithms and intelligence algorithms. The traditional collision avoidance planning algorithms mainly include a rapidly exploring random tree (RRT) [5], a dynamic window approach [6], an artificial potential field method [7], a bug algorithm [8], and intelligent collision avoidance algorithms, mainly include ant colony optimization algorithms [9], genetic algorithms (GA), and reinforcement learning algorithms [10]. The advantages and disadvantages of commonly used path planning algorithms are shown in Table 1.

Table 1.
Summary of representative algorithms for path planning.
2.1. Traditional Algorithms
Traditional obstacle avoidance algorithms are limited in uncertain environments. They are characterized by having long planning times, easily falling into local optima, and unstable obstacle avoidance effects. The RRT algorithm is a randomized algorithm that can be directly applied to the planning of nonholonomic constraint systems. This method is suitable for high-dimensional systems because of its low complexity. However, the path planned by the RRT algorithm is not optimal, and the convergence speed of the RRT is slow. Informed RRT* was proposed to improve the convergence rate and final solution quality [11]. Wei Zhang et al. proposed a modified RRT collision avoidance planning algorithm, which could overcome the problems of non-optimal paths and low planning success rates in complex environments [12]. Yutong Lin et al. proposed and applied the improved RRT algorithm to solve the path planning problem of unmanned ships. Experimental results showed that the path length of the improved RRT algorithm was shorter and smoother than that of the traditional RRT algorithm. However, the obstacle environment in the experiment was too simple, and the planned path would have been too close to the obstacle [13]. One of the most commonly used methods for dynamic path planning is the DWA, which can meet the kinematic constraints of the mobile robot. However, the collision avoidance effect of DWA heavily depends on the setting of parameters. Matej- Dobrevski et al. proposed a novel deep convolutional neural network, which can dynamically predict DWA parameters based on environmental changes [14]. APF can be implemented in real-time, but the biggest disadvantage of APF is that the attractive field and the repulsive potential field can easily cancel each other, resulting in the robot falling into local optimization. Riky Dwi Puriyanto et al. proposed a modified APF algorithm using the Gompertz function and the cone-shaped potential field [15]. Another drawback of the APF method is that the planned path is not the shortest. Guanghui Li et al. redefined potential functions and proposed a simultaneous forward search method to shorten the distance of the planned path. The simulation results confirmed that the modified APF can calculate a shorter and safer path to the target point [16]. Subir Kumar proposed the ModifiedCriticalPointBug(MCPB) algorithm based on the Bug algorithm, which could avoid run-time obstacles [17]. Yuanyuan Zhang et al. proposed an improved APF (FV-APF) algorithm to address the local minimal and goal unattainability problems of the classic APF method in the corridor environment by considering the angle constraint and improving the potential field function while combining simple fuzzy ideas. However, the path planned by this method has large corners, which is not conducive to controlling actual robots [18].
2.2. Artificial Intelligence Algorithms
Intelligent algorithms can plan safe paths in complex obstacle environments with minimal planning time. As an intelligent bionics algorithm, the genetic algorithm shows good robustness in solving complex nonlinear optimization problems, such as the path planning problem of mobile robots. Therefore, it has been widely used in mobile robot collision avoidance planning [19]. Won-Seok Kang et al. proposed a stable collision avoidance planning algorithm for avoiding dynamic obstacles based on a genetic algorithm, which focuses on finding optimal movements for stability rather than finding the shortest paths or smallest movements [20]. A grid-based GA path planning algorithm is developed to seek a safe path requiring the least effort. The modified cost function can help the AUV to perform a long-range mission with maximum endurance [21]. The ant colony optimization algorithm (ACO) has the advantage of parallel computing’s strong robustness, so it is used to solve the problem of avoiding obstacles. However, traditional ACO has shortcomings, such as slow convergence speed and easily falling into the local optimal value. To overcome the above problems, a novel variant of ACO is proposed, which introduces a new heuristic mechanism with orientation information, a modified heuristic function, and a modified state transition probability rule [22]. Rajat Agrawal et al. have proposed the multi-object adaptive ant colony optimization for path planning in a static environment [23]. The objective function is formulated as a multiple objective problem by incorporating path length, safety factor, and energy consumption. To help mitigate the slow convergence of the original algorithm, this avoidance obstacle algorithm introduces the A* algorithm to modify the heuristic information function in the conventional ant colony optimization. Chaowei Liu et al. propose a path planning method for the UUV based on the QPSO algorithm. This algorithm is simple to model and easy to implement, and it also has fewer control parameters and rapid convergence. However, this method did not take into account the kinematic limitations of the UUV, and the planned path had too many corners [24].
The reinforcement learning algorithms can avoid the robot’s dependence on environmental maps and prior knowledge and show good self-learning capability and adaptability in practical applications. The avoidance obstacle algorithm based on is proposed [25]. The method expands the concave obstacle area, which can avoid repeated invalid actions and accelerate the convergence speed of the algorithm. In order to meet the kinematic constraints of the mobile robots, the path planning method based on deep reinforcement learning is proposed [26]. The method can find the optimal strategy in the continuous action space. In order to achieve safe obstacle avoidance in agricultural scenarios, the Residual-like Soft actor–critic algorithm is proposed [27]. The method proposes an online expert experience pre-training model, which can alleviate the time-consuming problem of the exploration process of RL. Aiming to solve the Q-Learning algorithm that suffers from slow convergence speed and needs large storage space, K. Cai et al. proposed the distributed path planning algorithm [28]. The distributed path planning algorithm uses multiple mobile robots to explore local space and share information with other mobile robots. Changjian Lin et al. proposed an improved recurrent neural network for unmanned underwater vehicles’ online obstacle avoidance [29]. This algorithm obtains shorter paths, uses less energy through its actuators, and is resistant to noise. However, the collision avoidance strategy learned by this algorithm is based on expert data and lacks adaptability to the environment. Jian Xu proposed a novel event-triggered soft actor–critic algorithm for AUV collision avoidance [30]. This method can enable a UUV to avoid both unknown static obstacles and unknown dynamic obstacles under the condition of a limited detection range. In this method, the SAC algorithm is responsible for outputting three consecutive actions, increasing the network’s training difficulty. Had Behnaz proposed a DRL-based motion planning approach for an AUV, focusing on producing a short, safe, and feasible path [31]. However, this method does not change the longitudinal velocity of the UUV, and the obstacle environments are too simple. Prashant Bhopale proposed a modified Q-learning algorithm obstacle avoidance algorithm for a UUV [32]. This method reduces the chances of collision with obstacles, but the action space of this method is discrete, which may result in the resulting path not being optimal.
3. Materials
This section mainly introduces the kinematic modeling of the UUV and the basic principles of DWA and PPO to facilitate the proposal of a PPO−DWA collision avoidance planning algorithm.
3.1. UUV Model
This article takes the UUV as the research object, with a total length of 4.5 m, a total width of 1.1 m, and a height of 0.6 m. According to research needs, only the two-dimensional motion in the horizontal direction of the UUV is considered. Therefore, the following assumptions are made:
- (1)
- Neglecting the influence of third-order and higher-order hydrodynamic coefficients on UUV;
- (2)
- Neglecting the influence of roll, pitch, and heave movements of UUV on horizontal motion.
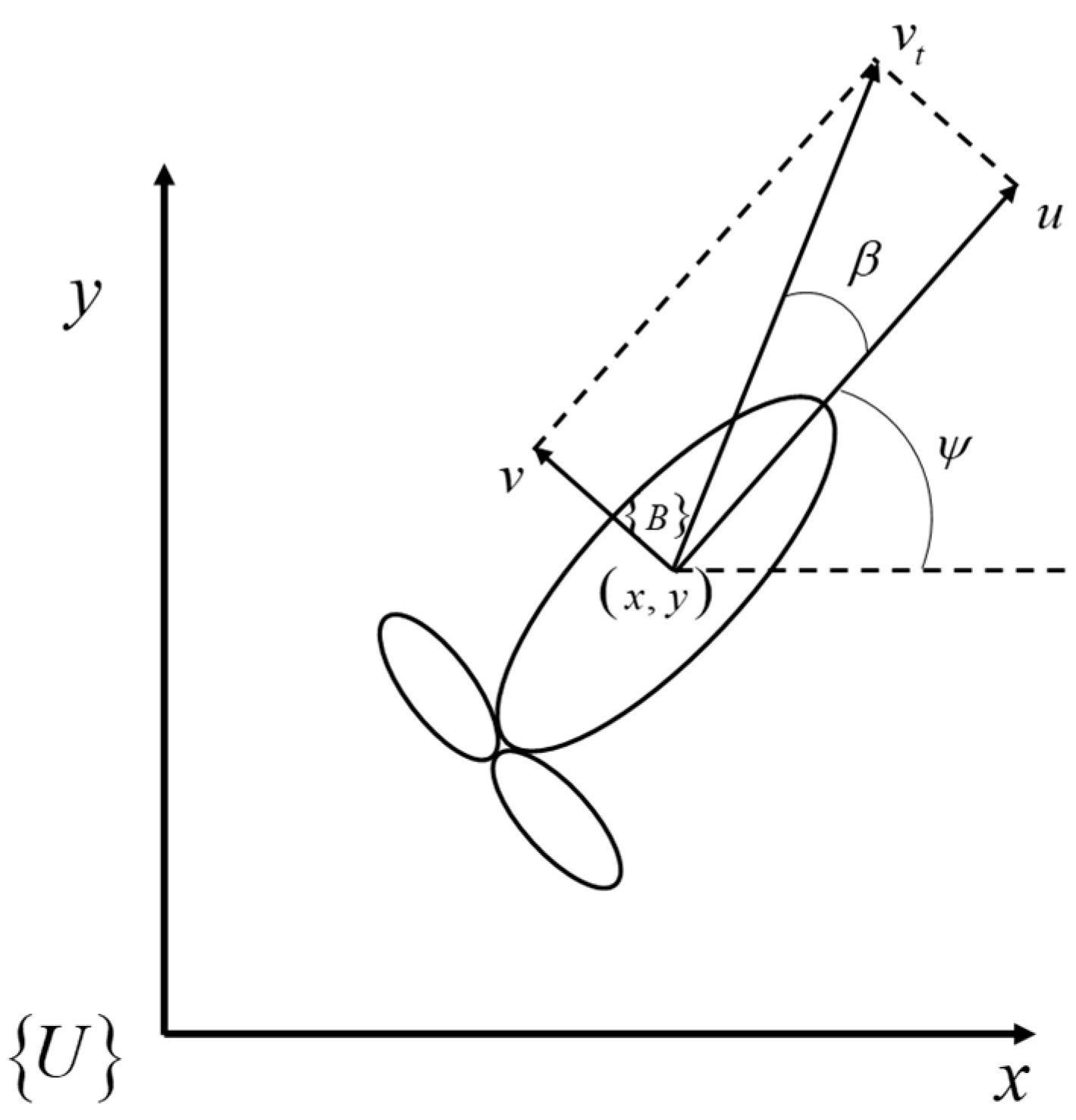
The UUV coordinate system is shown in Figure 1. The movement of UUV is mainly carried out in three degrees of freedom: longitudinal, transverse, and bow. This article defines the vector to represent the generalized position information of UUV in a fixed coordinate system. The vector represents the generalized velocity of UUV, where is the longitudinal velocity of UUV, is the lateral velocity of UUV, and is the heading angular velocity. The schematic diagram of the horizontal movement of UUV is shown in the following figure, where is the UUV synthesis speed and is the drift angle.
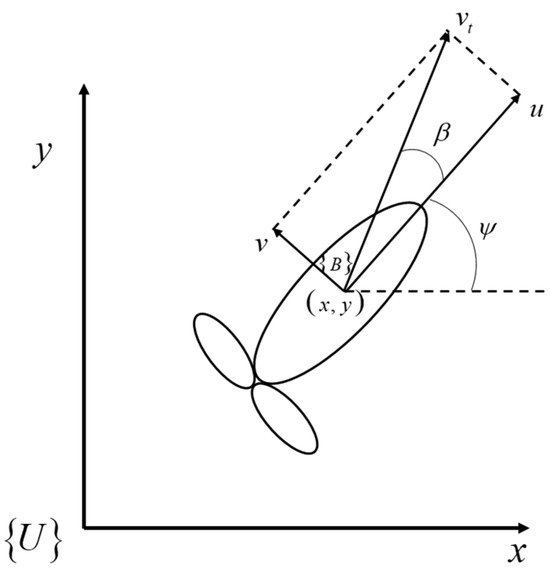
Figure 1.
Schematic diagram of horizontal movement of UUV.
In the absence of interference, the kinematic model of UUV in the horizontal plane is as follows:
In the actual process of underwater navigation, ocean currents cannot be eliminated and are the biggest interference factor affecting UUV. Therefore, in actual simulation research, it is necessary to consider the impact of ocean currents on UUV. However, in reality, ocean currents vary with time and space, but in the process of simulation research, this article simplifies them. Assuming that the ocean current is a constant current, the velocity in a fixed coordinate system is , and the direction angle is . The mathematical model for a constant horizontal current is as follows:
Among them, and are the longitudinal and transverse components in the motion coordinate system, respectively.
If and are defined as the longitudinal and transverse velocities of UUV in a fixed coordinate system, and are the longitudinal and transverse components of UUV relative to the velocity measured by the surrounding ocean current. Thus, the kinematic equation of UUV under current interference is obtained as follows:
3.2. DWA
DWA is a local collision avoidance planning algorithm studied by FOX and Thrun in 1997 [33]. This method samples the linear velocity and angular velocity in the constrained sampling space, generates a virtual path according to the sampling values of the two speeds, and then uses certain evaluation criteria to evaluate the generated virtual path. The biggest advantage of this method is that it can ensure the feasibility of the robot’s motion speed command. This method can also meet various constraints on the robot’s speed and can provide speed control commands based on the surrounding obstacles to achieve obstacle avoidance effect.
The DWA collision avoidance planning algorithm is mainly divided into two parts: (1) Generating a feasible velocity value space for the next moment based on the motor limits and safety constraints—the velocity window. The velocities within this range are the velocities that the mobile robot can reach, and these velocities form a dynamic window centered on the current velocity in the velocity space. (2) The speed in the dynamic window is sampled to obtain a series of discrete speed values. According to the sampled speed values, the future movement trajectory of the mobile robot is predicted, and then the predicted trajectory is scored to select the optimal speed combination at the next time.
3.3. PPO
Collision avoidance planning can be considered as a process of interaction between the robot and the obstacle environment. At every moment, the mobile robot needs to make decisions according to the observation information of the environment, and select the best action at the next moment until the mobile robot reaches the expected target point. Reinforcement learning is a common intelligent decision-making algorithm, so it is reasonable to use RL to solve collision avoidance planning problems.
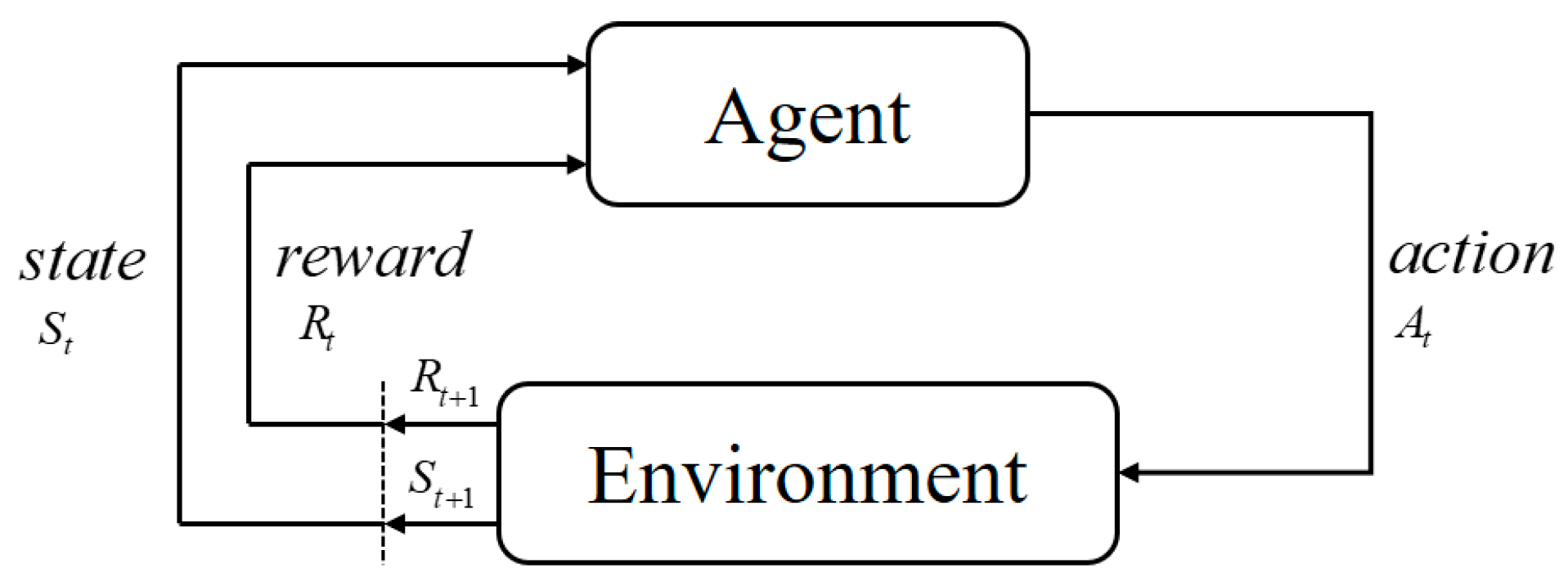
In the framework of reinforcement learning, the agent will constantly make “mistakes” in the learning process, and it will absorb these experiences and constantly adjust its strategy to be closer to human thinking habits [34]. When a reinforcement learning algorithm is used to solve the task of collision avoidance planning, it is necessary to build the corresponding simulation environment for the task. The agent is constantly interacting with the environment, and sometimes the agent will adopt a very poor strategy, resulting in a collision between the mobile robot and obstacles. However, it can adjust its behavior through the reward information provided by the environment to obtain the maximum average cumulative reward [35]. The framework of RL is shown in Figure 2. The agent first generates the next action based on the current environment state, and the action will interact with the environment. The agent’s own state will change under the influence of the action, and the environment will also give feedback on the quality of the action.
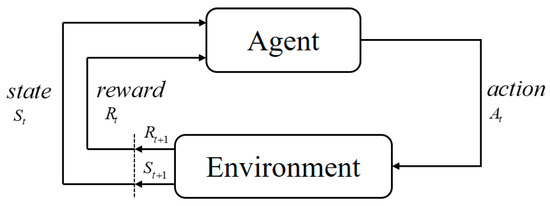
Figure 2.
A schematic diagram of reinforcement learning.
Reinforcement learning has good decision-making ability, but this algorithm can only solve the situation where the state and action space are discrete, while the obstacle information returned by the sensor is the continuous value, and in order to exert accurate control over the robot, the action space is sometimes required to be a continuous value, so the use of traditional reinforcement learning algorithms in these scenarios is limited. Deep reinforcement learning combined with deep learning breaks through the limitations of the number of states and the number of actions, which has a higher intelligence level and the ability to solve complex problems. As a reinforcement learning algorithm of actor–critic structure, the PPO algorithm has the advantage of good robustness and simple parameter adjustment [36].
The PPO algorithm process is shown in Algorithm 1.
| Algorithm 1 Proximal policy optimization |
| 1: Input: initial policy parameters , initial value function parameters . 2: for do 3: Run policy for timesteps, collecting 4: Estimate advantages 5: 6: for do 7: 8: Update by a gradient method w.r.t. 9: end for 10: for do 11: 12: Update by a gradient method w.r.t. 13: end for 14: if then 15: 16: else if then 17: 18: end if 19: end for |
4. The Proposed Algorithm
4.1. Framework of PPO−DWA Collision Avoidance Planning Algorithm
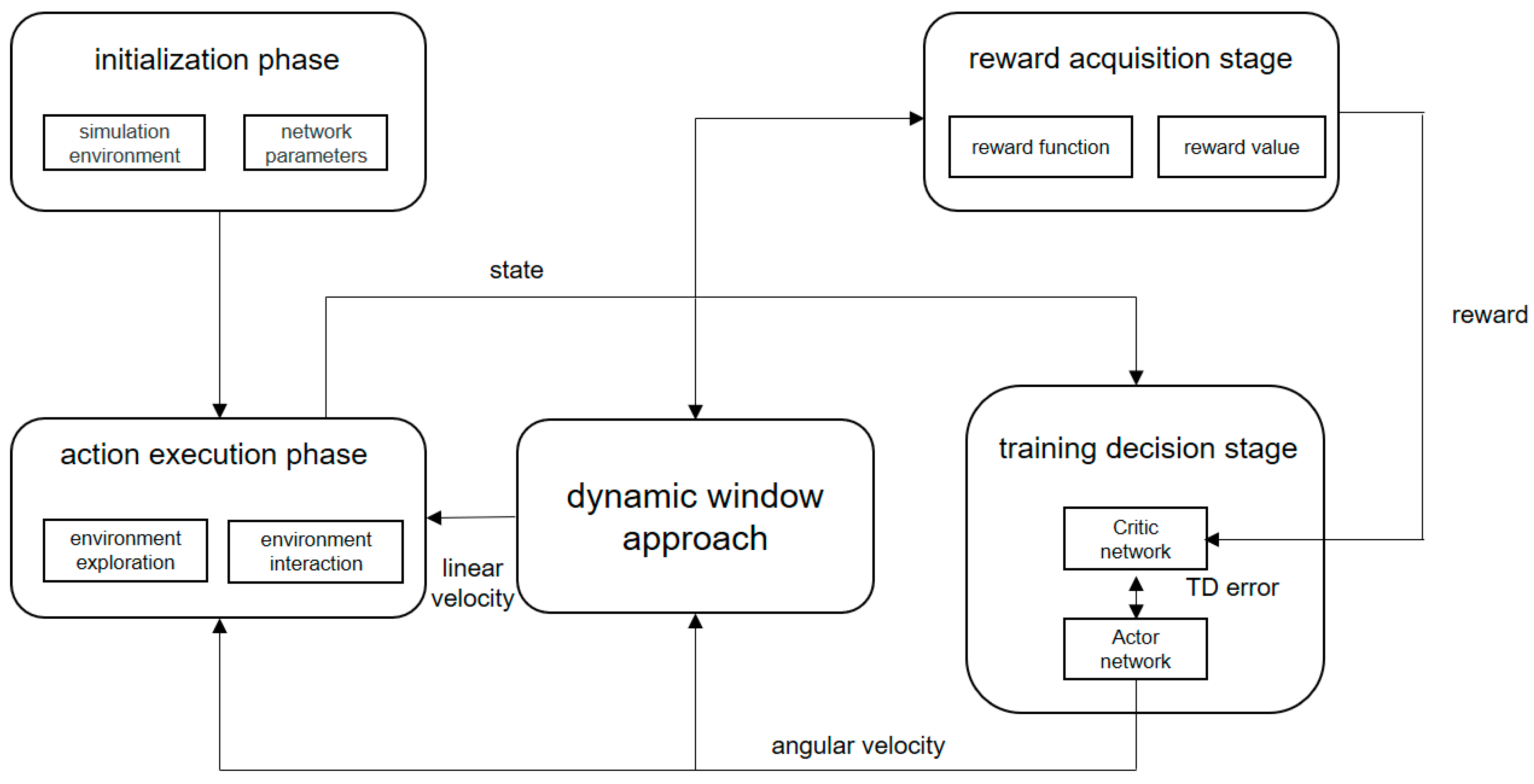
The framework of the PPO−DWA collision avoidance planning algorithm is shown in the Figure 3. The PPO−DWA collision avoidance planning algorithm consists of two parts, namely the PPO collision avoidance planning method and the modified dynamic window method. These two parts are explained in Section 4.2 and Section 4.3, respectively.
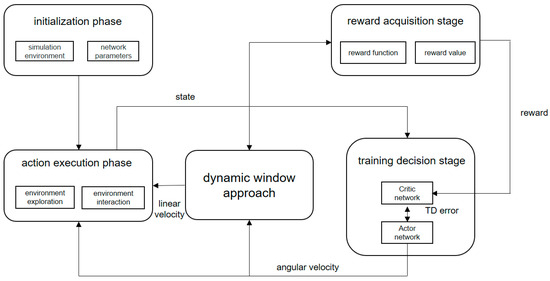
Figure 3.
The framework of PPO–DWA collision avoidance planning algorithm.
The algorithm process is as follows:
- (1)
- Load obstacle environment information and trained network parameters;
- (2)
- Enter the execution stage, according to the mobile robot’s own sensors to detect the surrounding obstacle information;
- (3)
- The detected obstacle information is transmitted to the training decision stage, and the angular velocity of the next moment is outputted;
- (4)
- The modified DWA module accepts the obstacle information detected by the sensor and the angular velocity in the training decision-making stage to produce the next better linear velocity;
- (5)
- The execution action module accepts the optimal linear velocity output by the dynamic window method and the optimal angular velocity output in the training decision-making stage, and the robot can drive to a new position through the environmental interaction part;
- (6)
- Determine whether the distance between the robot and the target is less than the threshold set in advance; if it is less than the threshold, the robot reaches the target point, and the algorithm ends. Otherwise, it enters step (2).
The PPO−DWA collision avoidance planning algorithm takes into account the yaw limitation of the UUV when designing collision avoidance rules, which can reduce the performance requirements for the UUV. At the same time, the turning motion of the algorithm is trained in the environment, so it has good adaptability to the environment.
4.2. PPO Collision Avoidance Planning Algorithm
This section designs the PPO collision avoidance planning method for the mobile robot. The method is a local path planner that can perform online real-time planning. The framework of the PPO collision avoidance planning method is shown in the Figure 4.
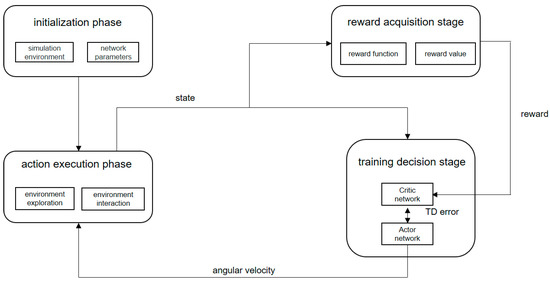
Figure 4.
The framework of PPO collision avoidance planning algorithm.
4.2.1. State Space
The state space includes the observation information from the forward-looking sonar and the target point information. Due to the unique nature of underwater environments, acoustic equipment is often used as a sensing instrument for UUVs to perceive the environment. This article carries the SeaBat 8125-H forward-looking sonar model from the RESON company, which can detect a horizontal 120° fan-shaped area with a vertical opening angle of 17°. In normal mode, it contains a total of 240 beams, divided into three layers, each layer containing 80 beams, with a beam angle of 0.5° and a maximum range of 120 m. Because the data returned by the forward-looking sonar is too large, and the high-dimension obstacle data is not required in the collision avoidance planning task, the obstacle data can be cut by zones to simplify the calculation. This paper divides 120° sensor data into 10 sector regions and uses the minimum distance in each sector region to represent the obstacle distance value in that region. In the collision avoidance process of the mobile robots, the relative angle of the obstacle closest to the mobile robot is directly related to whether the mobile robot can avoid the obstacle, so this is also considered as a part of the state space.
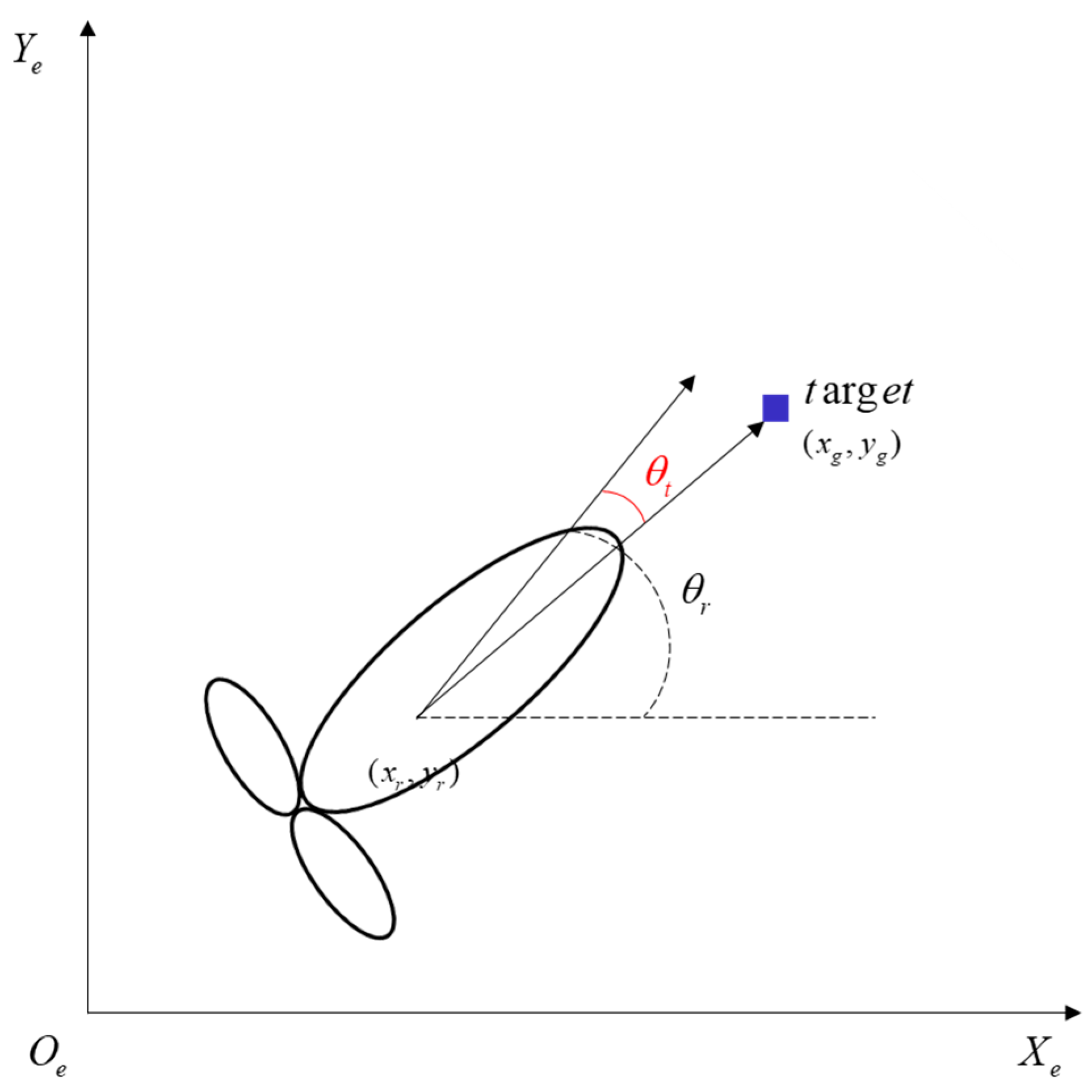
In local collision avoidance planning, the target point information is given as a polar coordinate system, as shown in Figure 5. Using to express the distance information between the target point and the UUV at time , is the angle of the UUV heading away from the target at time . The distance and angle are as follows:
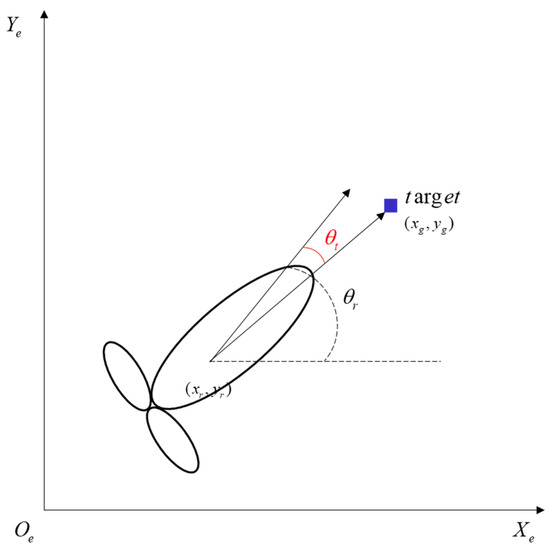
Figure 5.
Representation diagram of target point information.
The expression for and is as follows:
is the coordinate of the robot in the local tangent plane coordinates, is the heading angle of the robot, and is the coordinate of the target point in the local tangent plane coordinates.
4.2.2. Action Space
The actions in most of the literature are designed to discretize the linear speed and angular velocity or simply discretize the angular velocity. Blind discretization may not take into account the impact of motor performance, which will cause the mobile robot to adjust its heading and linear speed significantly, and it will take a long time for the mobile robot to reach the target action [37]. In order to apply more precise control to the UUV, this paper adopts the continuous action space. However, if the linear velocity and angular velocity are both continuous, the reward function of reinforcement learning is difficult to converge. Therefore, the PPO collision avoidance planning algorithm keeps the linear velocity unchanged and only changes the heading of the UUV; that is, the action space only includes the angular velocity item. Considering the actual situation, the angular velocity of the UUV is limited between and .
4.2.3. Reward Function
In the framework of the PPO collision avoidance planning algorithm, the design of the reward function is a key point. When training the mobile robot for collision avoidance planning through deep reinforcement learning, if rewards are given only when the UUV reaches the target point, the training process will face the problem of spare reward. Therefore, the corresponding reward value will be given to the agent when the agent makes decisions. Aiming to enable the mobile robot to avoid obstacles and drive towards the target point, the reward function is set as follows:
represents the reward received by the agent when it reaches the final target point. If the UUV reaches the target point, then , otherwise ; represents the reward received by the agent when colliding with obstacles in the environment. If the UUV collides with an obstacle, then , otherwise ; , and represents the distance reward between the robot and the target point, represents the distance between the robot and the target, and is the corresponding coefficient term. This article sets as an auxiliary reward, with ; represents the heading angle reward, and its specific expression is as follows:
represents the minimum distance between the mobile robot and the obstacle, represents the angle of the robot heading deviation from the target point, represents the angle of the robot heading deviation from the obstacle which is closet with the robot. and are corresponding coefficients, both of which are set to 5.
4.3. The Modified DWA Method
Although the PPO collision avoidance planning algorithm can guide the UUV to safely reach the target point, the linear velocity of the UUV is fixed, which can lead to poor collision avoidance performance. When obstacles are too dense, the UUV may not have enough time to make turns. The ideal collision avoidance effect is to reduce the linear velocity of the UUV when the distance between the surrounding obstacles and the UUV is small and to drive toward the target at a faster speed when the robot is far from the obstacle. Therefore, this section proposes the PPO−DWA collision avoidance planning algorithm, which can adjust the linear velocity of the mobile robot by combining the modified DWA algorithm.
The improved DWA algorithm has the same linear velocity sampling space and trajectory estimation method as the traditional DWA algorithm. However, there is no angular velocity sampling in the velocity sampling space; only linear velocity is sampled. This is because the PPO collision avoidance planning algorithm can output the optimal angular velocity in the current state, so only linear velocity sampling is required.
The velocity vector sampling space consists of the following parts:
(1) Constraint on maximum and minimum speeds:
and are the minimum and maximum linear velocities of the robot along the direction of the vehicle body, respectively.
(2) Limitation on motor performance:
is the time step; represents the linear velocity of the robot at the current moment; and are the maximum linear deceleration and maximum linear acceleration, respectively.
(3) Limitation on safety during mobile robot driving:
represents the minimum distance between surrounding obstacles and the predicted trajectory corresponding to the sampling speed .
The trajectory prediction model of the mobile robot is as follows [38]:
The objective function of the modified DWA is only to dynamically adjust the linear velocity of the robot based on the distance between the obstacle and the robot. The objective function expression for the modified DWA algorithm is as follows:
where is the angular velocity output by the PPO collision avoidance planning algorithm, and are the proportions of the and the in the total objective function, respectively.
The original DWA algorithm needs to sample the linear velocity and angular velocity at the same time, and its time complexity is . When predicting the trajectory of each group of sampling speeds, it needs to increase the complexity of the algorithm, which will waste more computing resources and take longer to execute the algorithm. The PPO collision avoidance planning algorithm only changes the angular velocity without changing the linear velocity. The PPO−DWA collision avoidance planning algorithm combines the characteristics of two algorithms, which can change the linear speed while ensuring real-time planning.
5. Experiments and Results
The experiments are conducted to verify the PPO−DWA algorithm. The programming language used in the experiment is Python, and the compiler version is Python 3.6. The open-source libraries include Pygame 2.4.0, Tensorflow 1.10.0, and Numpy 1.16.0. In the obstacle map, the yellow block represents the starting point and the blue block represents the ending point. The velocity in the ocean current interference model is set to 0.1 m/s, and the direction angle is set to rad.
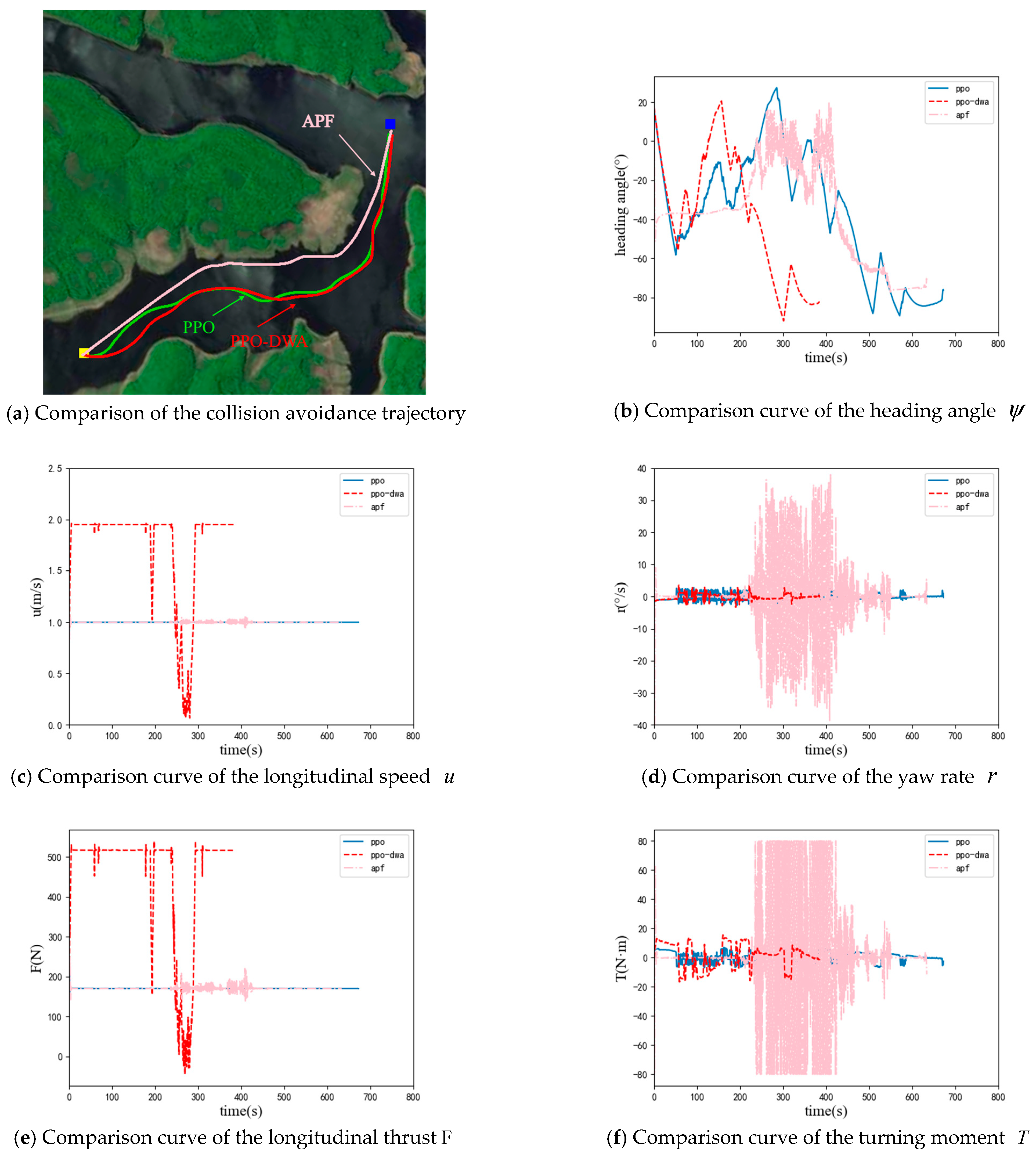
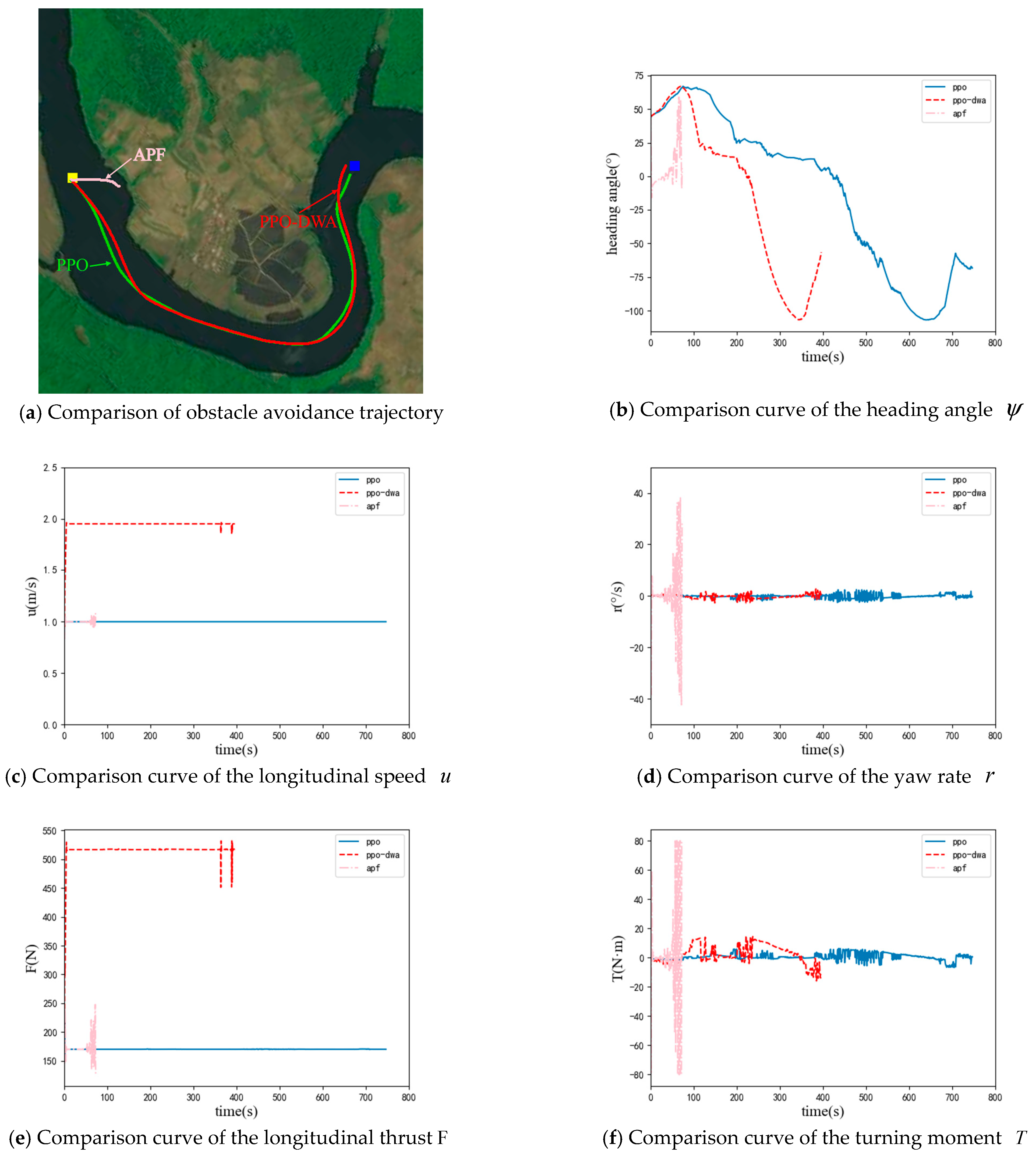
This experiment takes the UUV model in Section 3 as the research object and selects an area near Songhua Lake in Jilin Province as the obstacle environment. In order to demonstrate the advantages of the algorithm in this article, this section uses the PPO collision avoidance planning method designed in 4.2 and the APF algorithm as the comparison. The performance of algorithms is evaluated from the aspects of path length, the number of steps to reach the target point, and the average solution time of the algorithm. The experimental results are shown in Figure 6 and Figure 7.
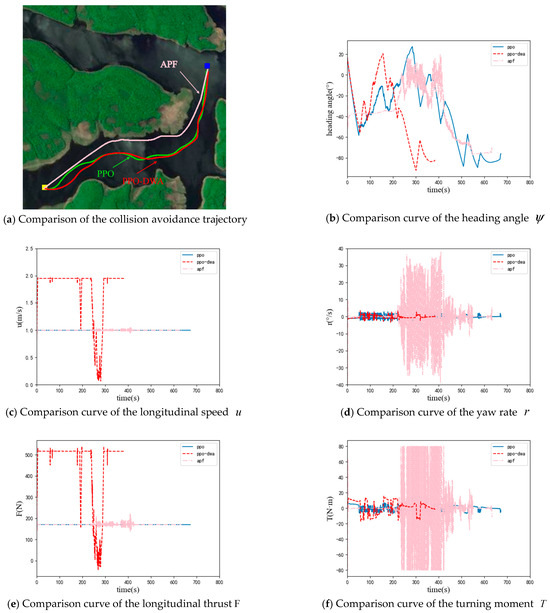
Figure 6.
Experiment results in the obstacle environment 1.
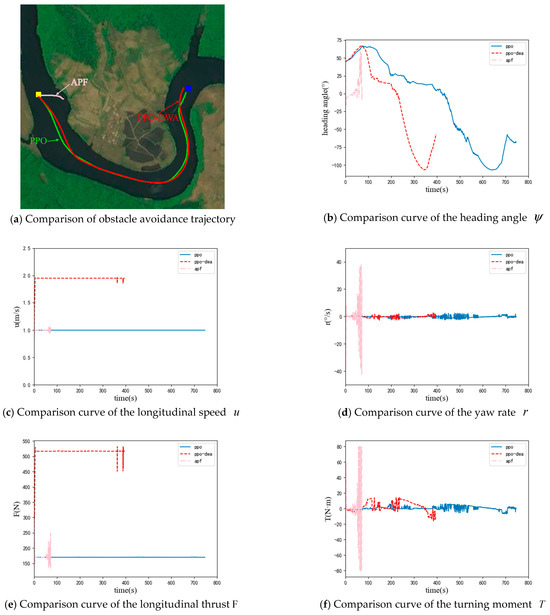
Figure 7.
Simulation results in the obstacle environment 2.
Figure 6 shows the experiment results of the PPO algorithm, the APF algorithm and the PPO−DWA algorithm in the obstacle environment 1. From the results of Figure 6a, it can be seen that three collision avoidance planning algorithms can plan a smooth and safe path. Figure 6b−d, respectively, show the comparison curves of the heading angle , longitudinal speed , and yaw rate r for the two algorithms, and Figure 6e,f respectively, show the comparison curves of longitudinal thrust and turning moment. Table 2 shows the performance of the two collision avoidance planning algorithms.
Table 2.
Performance comparison in the obstacle environment 1.
From the above experimental results, it can be seen that the path lengths of the three collision avoidance planning algorithms in obstacle environment 1 are similar, with the artificial potential field method having the shortest path length. However, from the heading angle and yaw rate curves, it can be seen that the artificial potential field method can cause frequent and significant changes in the heading of UUV, which puts high requirements on the performance and control algorithm of the UUV. At the same time, the path planned by the artificial potential field method may be too close to obstacles. When encountering interference from waves and currents, the UUV may collide with obstacles. In obstacle environment 2, from Figure 7 and Table 3, it can be seen that the artificial potential field method cannot reach the target point. The PPO collision avoidance planning algorithm and PPO−DWA collision avoidance planning algorithm can successfully reach the target point in both obstacle environments, and the path lengths planned by the two algorithms are similar. But, the PPO−DWA collision avoidance planning algorithm can dynamically adjust the linear velocity, so the number of steps to reach the target point is less; that is, the time to reach the target point is shorter. Due to the addition of the DWA module, the average solution time of the PPO−DWA algorithm is much greater than that of the PPO algorithm. However, it is still at the millisecond level, and real-time performance can still be guaranteed. The PPO−DWA collision avoidance planning algorithm can dynamically adjust the linear velocity, which can enable the UUV to reach the target point as soon as possible with guaranteed performance.
Table 3.
Performance comparison in the obstacle environment 2.
6. Conclusions
In this work, the PPO−DWA collision avoidance planning algorithm can output continuous angular velocity and linear velocity values, which can take less time to plan a smooth, safe, and reasonable path according to the surrounding obstacle information. The PPO−DWA collision avoidance planning algorithm consists of the PPO algorithm and modified DWA. Firstly, the PPO collision avoidance planning algorithm is proposed. Aiming at the task of collision avoidance planning, the simulation environment is built, and the action space, state space, and reward function are designed. Secondly, combined with the modified DWA, the PPO−DWA collision avoidance planning algorithm is proposed. In order to control the linear velocity, the evaluation function and velocity sampling space of the DWA method are modified according to the requirement. Then, the modified DWA can output the best linear velocity the next time according to the obstacle information and the angular velocity information from the PPO algorithm. Finally, it is demonstrated through experiments that the PPO−DWA collision avoidance planning algorithm can plan smooth and feasible paths in irregular real obstacle environments. The PPO−DWA can change the linear and angular velocities of the UUV according to the environment without increasing the training difficulty of the network. At the same time, the action space output by this algorithm can meet the kinematic limitations of the UUV, and there will be no situation where the UUV adjusts its heading significantly in a short period of time.
This article only considers the problem of collision avoidance planning in static obstacle environments. However, in real scenarios, dynamic obstacles inevitably exist in the environment, which limits the use of the algorithm proposed in this article. Subsequently, deep reinforcement learning will be applied to the study of collision avoidance planning for dynamic obstacles, with a focus on processing detection data and predicting the trajectory of dynamic obstacles.
Author Contributions
W.G., methodology, investigation, software, and writing—original and draft; M.H., conceptualization, writing—reviewing and editing; Z.W., writing—original and draft, software; L.D., formal analysis and data curation; H.W., supervision, funding, and acquisition. J.R., methodology, investigation. All authors have read and agreed to the published version of the manuscript.
Funding
This research work is supported by the National Science and Technology Innovation Special Zone Project (21-163-05-ZT-002-005-03), the National Key Laboratory of Underwater Robot Technology Fund (No. JCKYS2022SXJQR-09), and a special program to guide high-level scientific research (No. 3072022QBZ0403).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Acknowledgments
The authors would like to thank the anonymous reviewers and the handling editors for their constructive comments that greatly improved this article from its original form.
Conflicts of Interest
Author Mengxue Han was employed by the AVIC China Aero-Polytechnology Establishment. Author Lihui Deng was employed by the Tianjin Navigation and Instrument Institute. The all authors declare no conflict of interest.
References
- Campbell, S.; O’Mahony, N.; Carvalho, A.; Krpalkova, L.; Riordan, D.; Walsh, J. Path Planning Techniques for Mobile Robots A Review. In Proceedings of the 2020 6th International Conference on Mechatronics and Robotics Engineering (ICMRE), Barcelona, Spain, 12–15 February 2020; pp. 12–16. [Google Scholar]
- Liu, L.; Wang, X.; Yang, X.; Liu, H.; Li, J.; Wang, P. Path planning techniques for mobile robots: Review and prospect. Expert Syst. Appl. 2023, 227, 120254. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Wang, R.; Xu, L. Application of Deep Reinforcement Learning in UAVs: A Review. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022; pp. 4096–4103. [Google Scholar]
- Rodriguez, S.; Tang, X.; Lien, J.M.; Amato, N.M. An Obstacle-based Rapidly exploring Random Tree. In Proceedings of the 2006 IEEE International Conference on Robotics and Automation, Orlando, FL, USA, 15–19 May 2006; IEEE: Piscataway, NJ, USA; pp. 895–900. [Google Scholar]
- Marder-Eppstein, E.; Berger, E.; Foote, T.; Gerkey, B.; Konolige, K. The office marathon: Robust navigation in an indoor office environment. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 300–307. [Google Scholar]
- Igarashi, H.; Kakikura, M. Path and Posture Planning for Walking Robots by Artificial Potential Field Method. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- Lumelsky, V.J.; Stepanov, A.A. Path-planning Strategies for a Point Mobile Automation Moving Amidst Unknown Obstacle of Arbitrary Shape. Algorithmica 1987, 2, 403–430. [Google Scholar] [CrossRef]
- Li, S.; Su, W.; Huang, R.; Zhang, S. Mobile Robot Navigation Algorithm Based on Ant Colony Algorithm with A* Heuristic Method. In Proceedings of the 2020 4th International Conference on Robotics and Automation Sciences, Wuhan, China, 12–14 June 2020; pp. 28–33. [Google Scholar]
- Nguyen, T.T.; Nguyen, N.D.; Nahavandi, S. Deep Reinforcement Learning for Multiagent Systems: A Review of Challenges, Solutions, and Applications. IEEE Trans. Cybern. 2020, 50, 3826–3839. [Google Scholar] [CrossRef] [PubMed]
- Gammell, J.D.; Srinivasa, S.S.; Barfoot, T.D. Informed RRT*: Optimal sampling-based path planning focused via direct sampling of an admissible ellipsoidal heuristic. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; pp. 2997–3004. [Google Scholar]
- Zhang, W.; Yi, C.; Gao, S.; Zhang, Z.; He, X. Improve RRT Algorithm for Path Planning in Complex Environments. In Proceedings of the 2020 39th Chinese Control Conference(CCC), Shenyang, China, 27–29 July 2020; pp. 3728–3777. [Google Scholar]
- Lin, Y.; Zhang, W.; Mu, C.; Wang, J. Application of improved RRT algorithm in unmanned surface vehicle path planning. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022; pp. 4861–4865. [Google Scholar]
- Dobrevski, M.; Skočaj, D. Adaptive Dynamic Window Approach for Local Navigation. In Proceedings of the2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–4 January 2021; pp. 6930–6936. [Google Scholar]
- Puriyanto, R.D.; Wahyunggoro, O.; Cahyadi, A.I. Implementation of Improved Artificial Potential Field Path Planning Algorithm in Differential Drive Mobile Robot. In Proceedings of the 2022 14th International Conference on Information Technology and Electrical Engineering (ICITEE), Yogyakarta, Indonesia, 18–19 October 2022; pp. 18–23. [Google Scholar]
- Li, G.; Tong, S.; Lv, G.; Xiao, R.; Cong, F.; Tong, Z.; Asama, H. An Improved Artificial Potential Field-based Simultaneous Forward Search Method for Robot Path Planning. In Proceedings of the 2015 12th International Conference on Ubiquitous Robots and Ambient Intelligence, Goyangi, Republic of Korea, 28–30 October 2015; pp. 330–335. [Google Scholar]
- Das, S.K.; Roy, K.; Pandey, T.; Kumar, A.; Dutta, A.K.; Debnath, S.K. Modified Critical Point—A Bug Algorithm for Path Planning and Obstacle Avoiding of Mobile Robot. In Proceedings of the 2020 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 28–30 July 2020. [Google Scholar]
- Zhang, Y. Improved Artificial Potential Field Method for Mobile Robots Path Planning in a Corridor Environment. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 185–190. [Google Scholar]
- Hu, Y.; Yang, S.X. A Knowledge Based Genetic Algorithm for Path Planning of a Mobile Robot. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004. [Google Scholar]
- Kang, W.S.; Yun, S.; Kwon, H.O.; Choi, R.H.; Son, C.S.; Lee, D.H. Stable Path Planning Algorithm for Avoidance of Dynamic Obstacles. In Proceedings of the 2015 Annual IEEE Systems Conference (SysCon) Proceedings, Vancouver, BC, Canada, 13–16 April 2015; pp. 578–581. [Google Scholar]
- Tanakitkorn, K.; Wilson, P.A.; Turnock, S.R.; Phillips, A.B. Grid-based GA path planning with improved cost function for an over-actuated hover-capable AUV. In Proceedings of the 2014 IEEE/OES Autonomous Underwater Vehicles (AUV), Oxford, MS, USA, 6–9 October 2014; pp. 1–8. [Google Scholar]
- Wu, L.; Huang, X.; Cui, J.; Liu, C.; Xiao, W. Modified adaptive ant colony optimization algorithm and its application for solving path planning of mobile robot. Expert Syst. Appl. 2023, 215, 119410. [Google Scholar] [CrossRef]
- Agrawal, R.; Singh, B.; Kumar, R.; Vijayvargiya, A. Mobile Robot Path Planning using Multi-Objective Adaptive Ant Colony Optimization. In Proceedings of the 2022 IEEE International Conference on Power Electronics, Drives and Energy Systems (PEDES), Jaipur, India, 14–17 December 2022; pp. 1–6. [Google Scholar]
- Liu, C.; Wang, H.; Yingmin, G.U.; He, J.; Tong, H.; Wang, H. UUV path planning method based on QPSO. In Proceedings of the Global Oceans 2020: Singapore—U.S. Gulf Coast, Biloxi, MS, USA, 5–30 October 2020; pp. 1–5. [Google Scholar]
- Chen, H.; Ji, Y.; Niu, L. Reinforcement Learning Path Planning Algorithm Based on Obstacle Area Expansion Strategy. Intell. Serv. Robot. 2020, 13, 289–297. [Google Scholar] [CrossRef]
- Yan, T.; Zhang, Y.; Wang, B. Path Planning for Mobile Robot’s Continuous Action Space Based on Deep Reinforcement Learning. In Proceedings of the 2018 International Conference on Big Data and Artificial Intelligence (BDAI), Beijing, China, 22–24 June 2018; pp. 42–46. [Google Scholar]
- Yang, J.; Ni, J.; Li, Y. The Intelligent Path Planning System of Agricultural Robot via Reinforcement Learning. Sensors 2022, 22, 4316. [Google Scholar] [CrossRef] [PubMed]
- Cai, K.; Chen, G. A Distributed Path Planning Algorithm via Reinforcement Learning. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 3365–3370. [Google Scholar]
- Lin, C.; Wang, H.; Yuan, J.; Yu, D.; Li, C. An Improved Recurrent Neural Network for Unmanned Underwater Vehicle Online Obstacle Avoidance. Ocean. Eng. 2019, 189, 106327. [Google Scholar] [CrossRef]
- Xu, J.; Huang, F.; Wu, D.; Cui, Y.; Yan, Z.; Du, X. A learning method for AUV collision avoidance through deep reinforcement learning. Ocean. Eng. 2022, 260, 112038. [Google Scholar] [CrossRef]
- Behnaz, H.; Alireza, K.; Pouria, S. Deep reinforcement learning for adaptive path planning and control of an autonomous underwater vehicle. Appl. Ocean. Res. 2022, 129, 103326. [Google Scholar]
- Bhopale, P.; Kazi, F.; Singh, N. Reinforcement Learning Based Obstacle Avoidance for Autonomous Underwater Vehicle. J. Mar. Sci. Appl. 2019, 18, 228–238. [Google Scholar] [CrossRef]
- Fox, D.; Burgard, W.; Thrun, S. The Dynamic Window Approach to Collision Avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D. Human-level Control through Deep Reinforcement Learning. Nature 2019, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Sun, H.; Yu, R.; Zhang, Y. Motion Planning for Mobile Robots―Focusing on Deep Reinforcement Learning: A Systematic Review. IEEE Access 2021, 9, 69061–69081. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Surmann, H.; Jestel, C.; Marchel, R. Deep Reinforcement Learning for Real Autonomous Mobile Robot Navigation in Indoor Environments. In Proceedings of the 2020 IEEE/SICE International Symposium on System Integration, Honolulu, HI, USA, 12–15 January 2020; pp. 1040–1045. [Google Scholar]
- Gao, H.; Ma, Z.; Zhao, Y. A fusion approach for mobile robot path planning based on improved A* algorithm and adaptive dynamic window approach. In Proceedings of the2021IEEE4th International Conference on Electr-onics Technology(ICET), Chengdu, China, 7–10 May 2021. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).