


Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
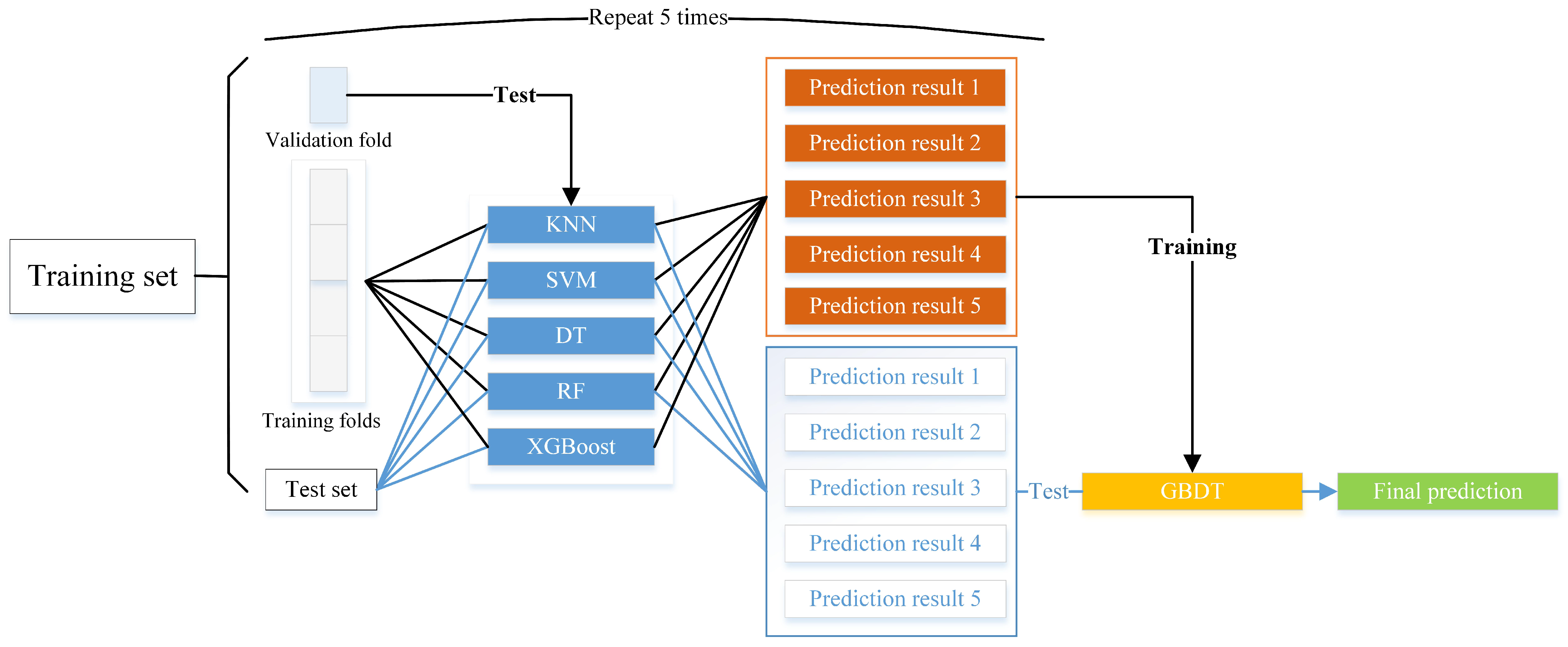
2.1. Stacking Ensemble Learning
- The dataset is divided into a training set and a test set . In these sets, represents the i-th sample in the dataset, and corresponds to the class of the i-th sample. For the training set, represents the -th sample, and is the class associated with the -th sample. In the test set, represents the -th sample, and is the class associated with the -th sample.
- k base classifiers are selected, and the training set is divided into k equal size subsets . Define as a test set; then, . All k base models are trained using the training set , and prediction probabilities are obtained using the test set. A new training set is obtained by combining the predicted probabilities of each base model on the test set during cross-validation. At the same time, the predicted probabilities of each base model on the total test set are averaged, and a new test set is obtained after concatenation.
- The second level meta-model is trained with the newly generated training set. By training the meta-model, the prediction deviation of the base model can be corrected and the prediction accuracy can be improved.
2.2. Base Classifiers
2.2.1. Support Vector Machine
2.2.2. k-Nearest Neighbors
2.2.3. Decision Tree
2.2.4. Logistic Regression

2.2.5. Random Forest
- Data Sampling (Bootstrap): For a given training dataset, a random forest performs random sampling with replacement, generating multiple different subsets. This is referred to as bootstrap sampling. This means that certain samples may appear multiple times in one subset, while others may not appear at all.
- Feature Random Selection: At each node of every decision tree, a random forest does not consider all features for splitting; instead, it randomly selects a subset of features from the feature set. This helps increase the diversity of the model and prevents overfitting.
- Decision Tree Training: For each bootstrap-sampled subset and feature subset, a decision tree is trained. The commonly used decision tree algorithm is CART (Classification and Regression Trees).
- Voting or Averaging: For classification problems, a random forest employs a majority voting approach, where each decision tree votes for a class, and the final prediction is the class with the most votes.
2.2.6. Gradient Boosting Decision Tree
2.2.7. Extreme Gradient Boosting Decision Tree
2.3. SMOTE
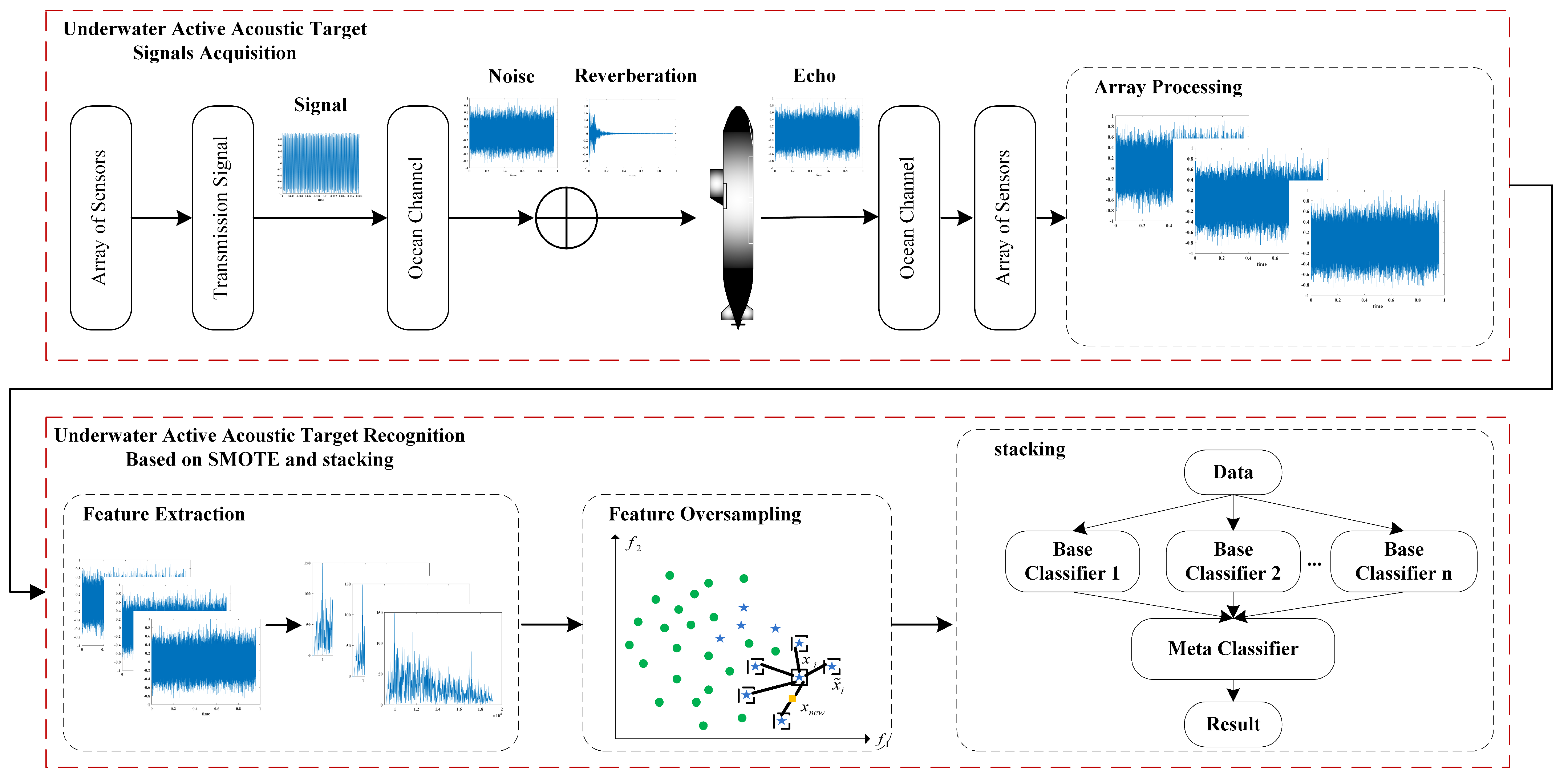
3. Modeling of UAHW Target Recognition Algorithm Based on SMOTE-Stacking
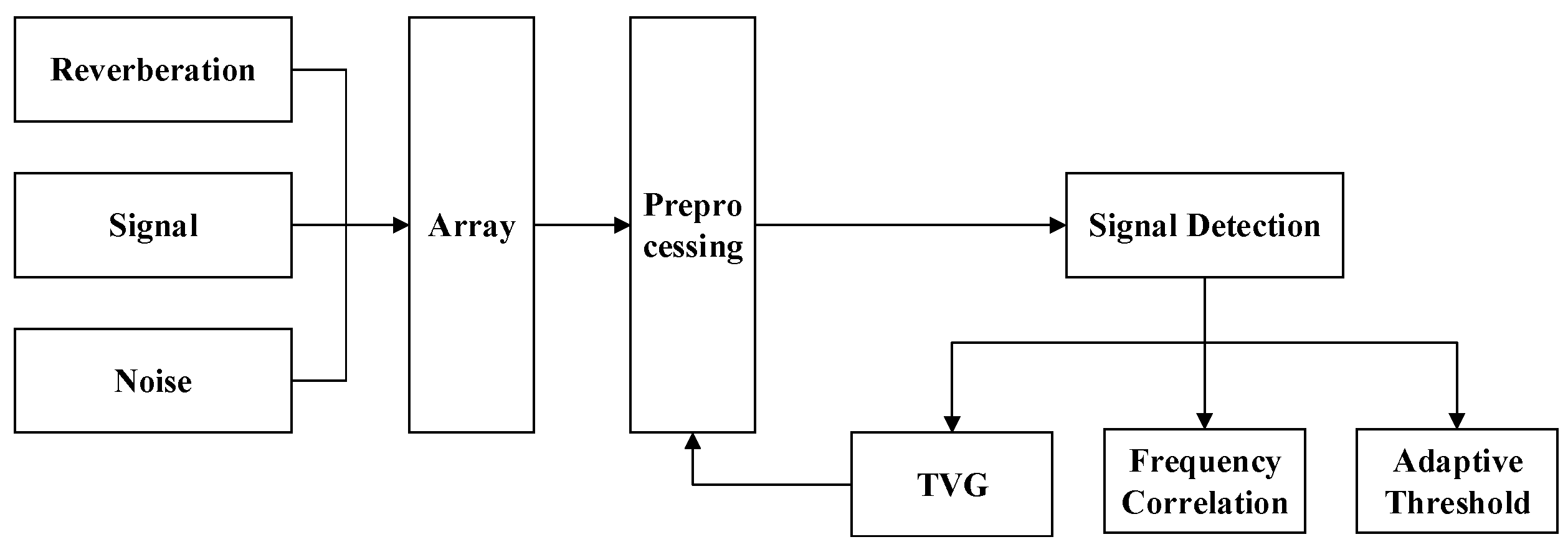
3.1. Active Acoustic Signal Detection System of UAHW
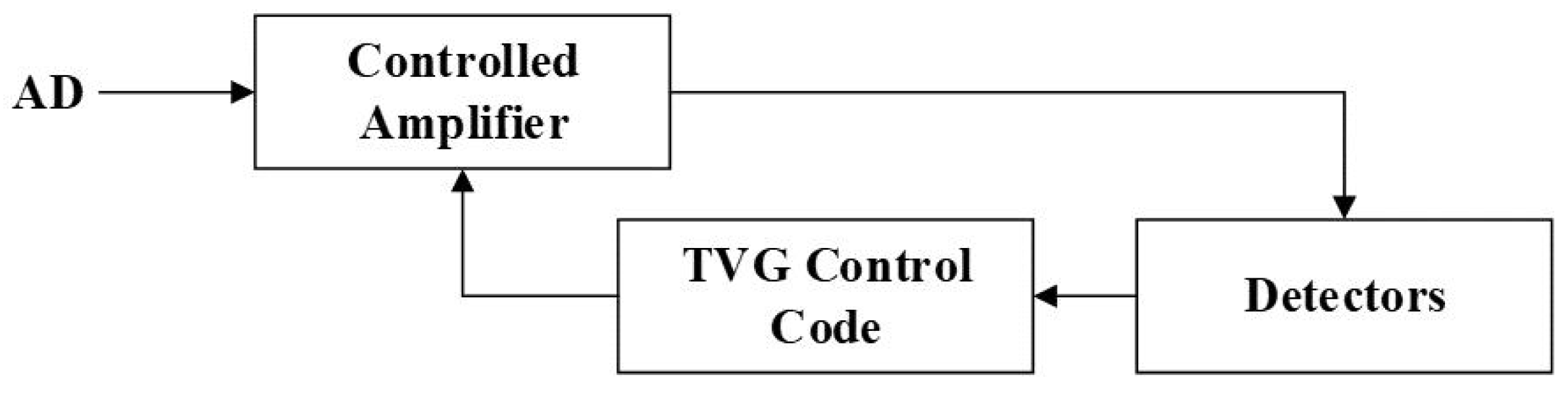
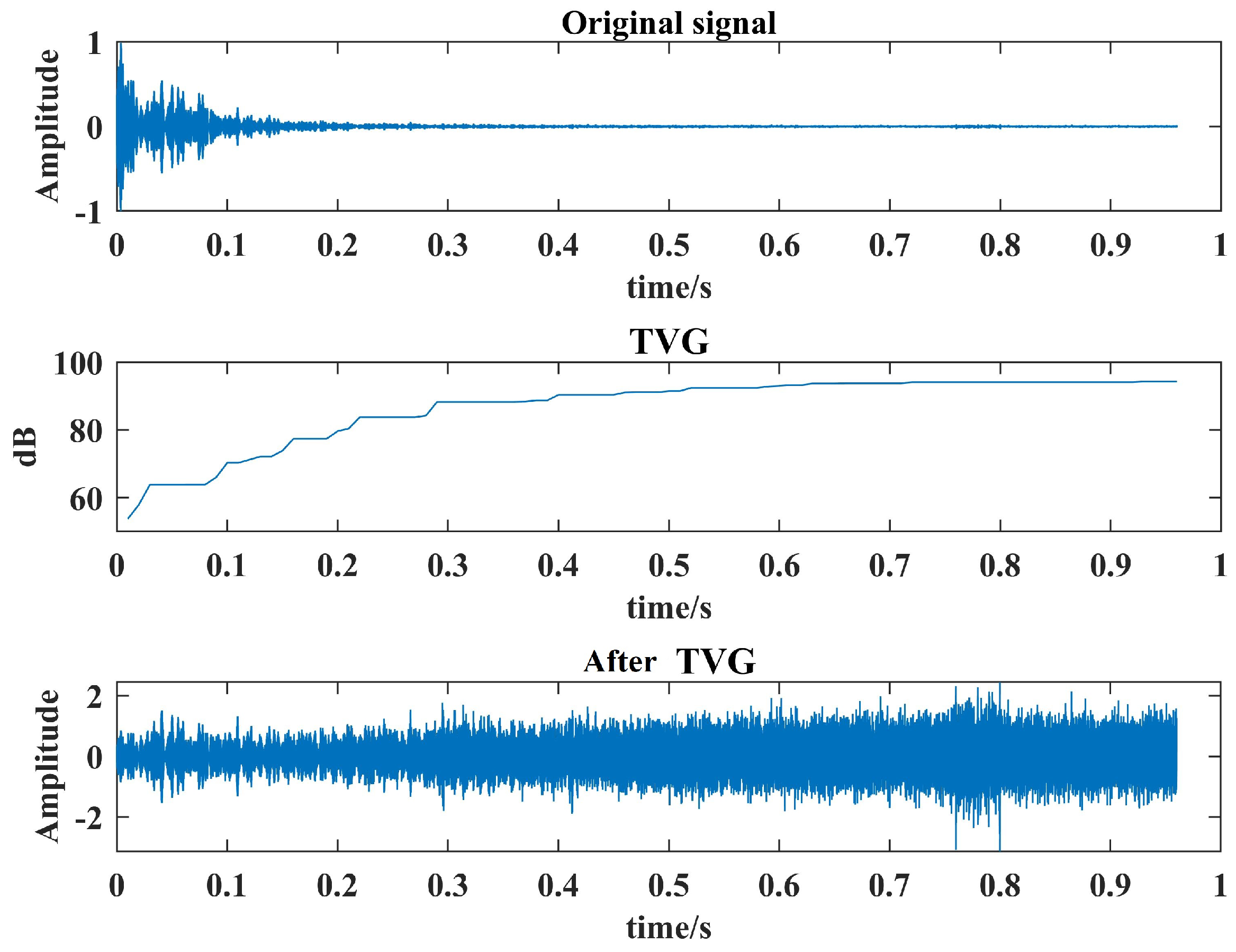
3.1.1. Time-Varying Gain Control (TVG)
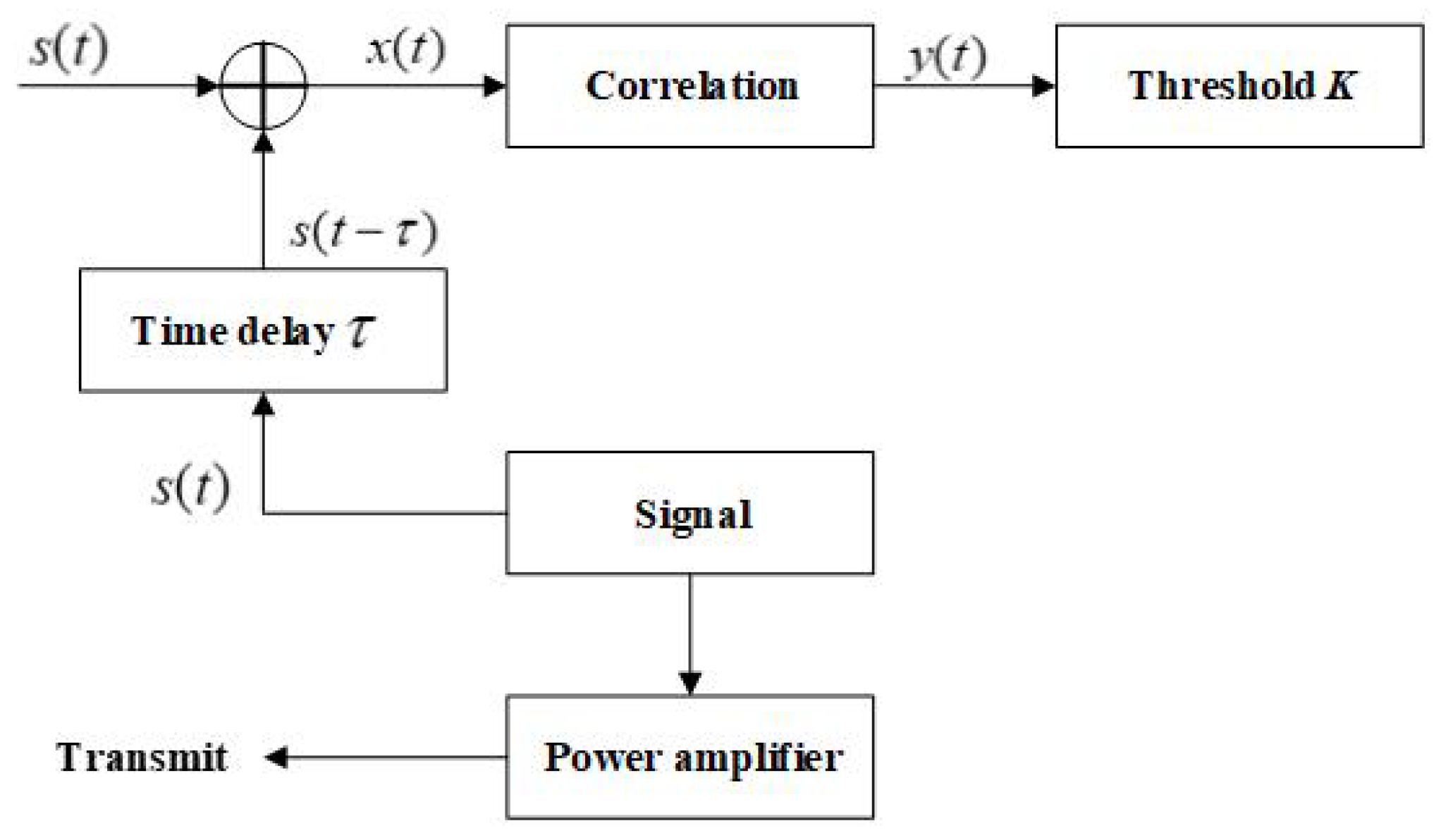
3.1.2. Adaptive Threshold
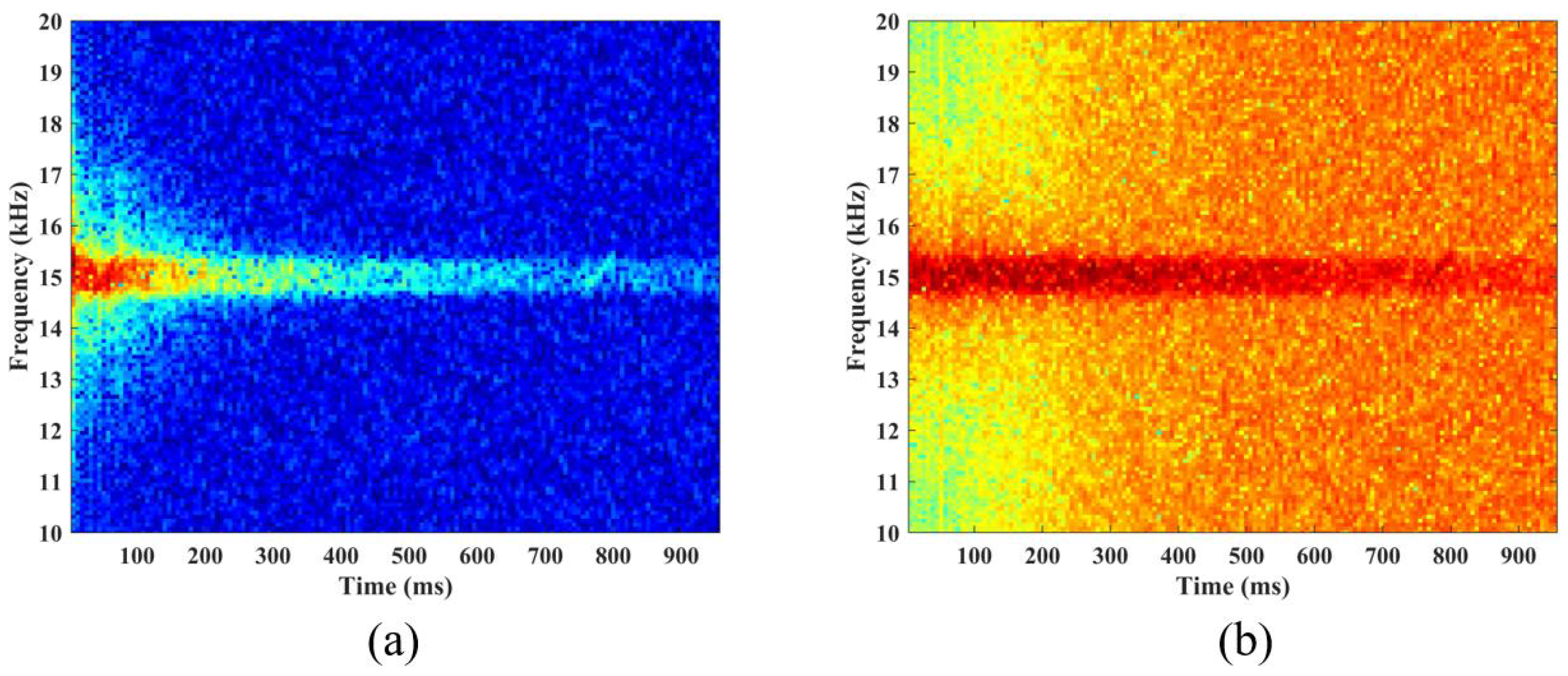
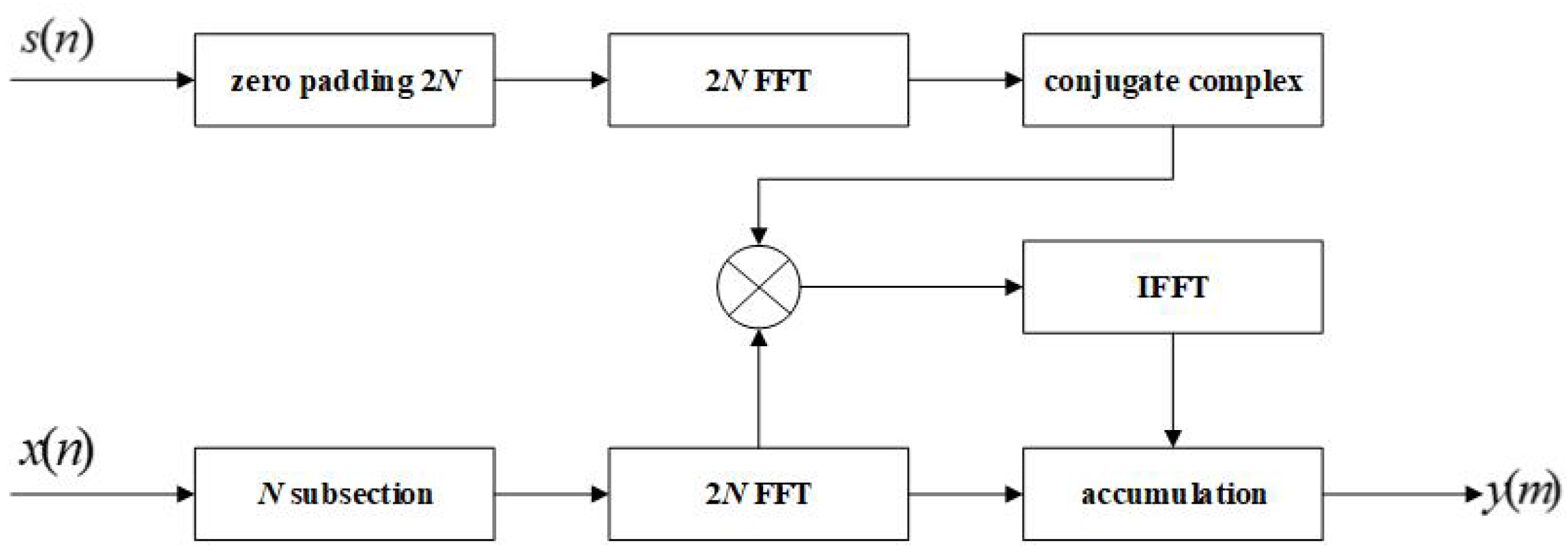
3.1.3. Frequency Correlation
3.2. Feature Extraction
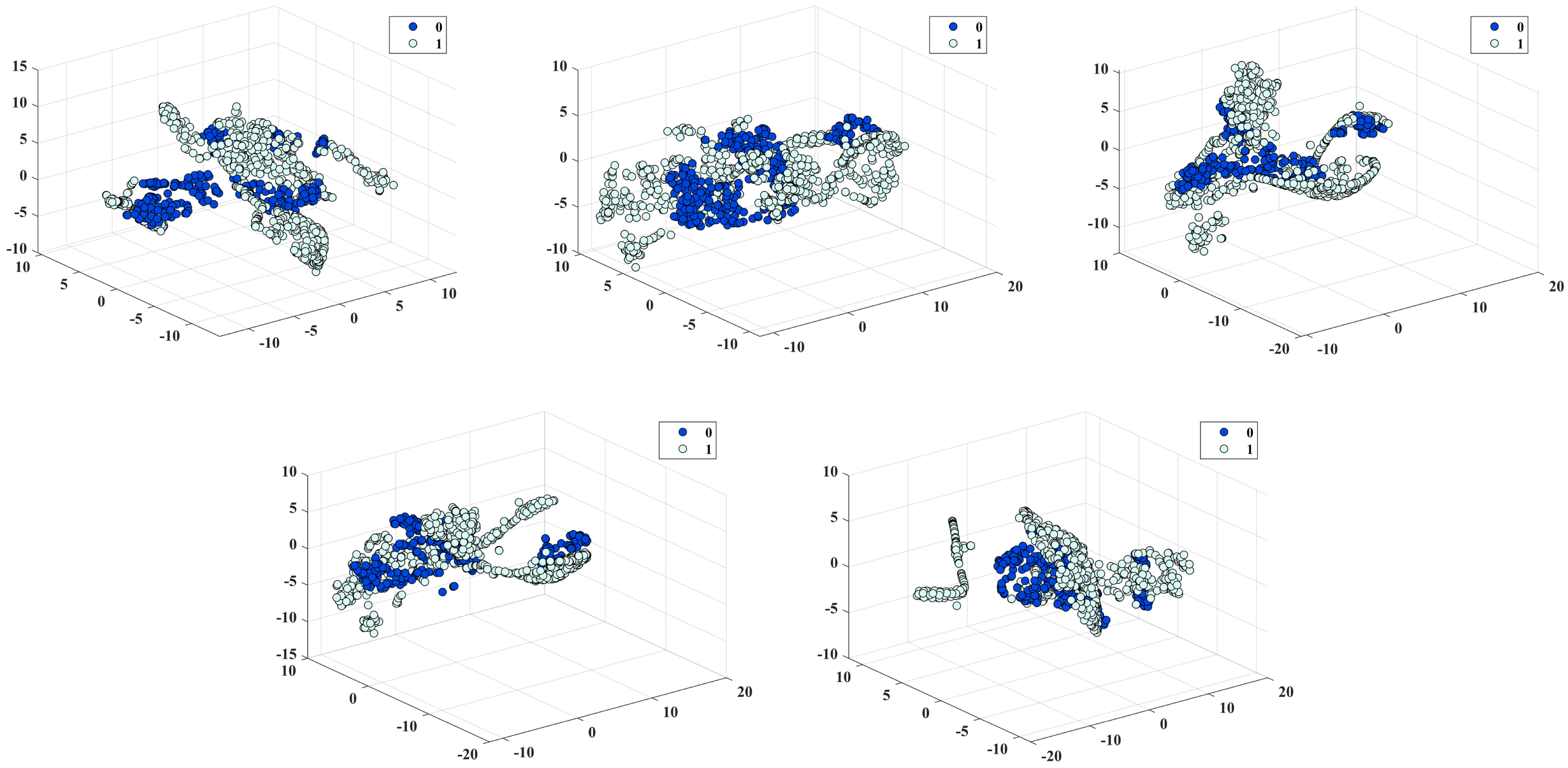
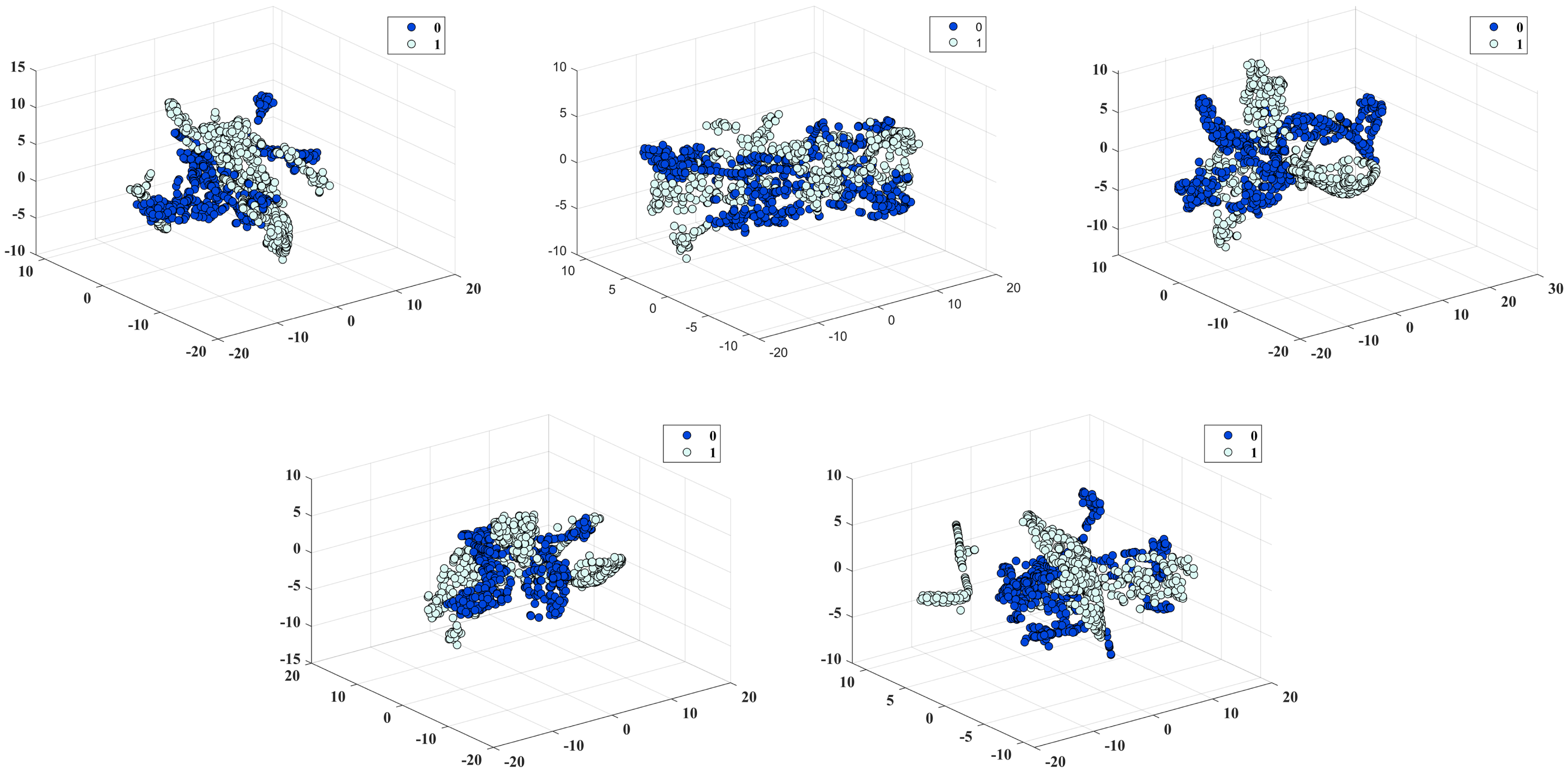
3.3. Feature Oversampling Based on SMOTE
3.4. Model Establishment

4. Results and Analysis
4.1. Evaluation Metrics
4.2. Hyperparameter Selection of Classifiers
- For the SVM classifier, the main hyperparameters are the kernel function type (we selected the radial basis function, i.e., RBF), penalty coefficient C, and RBF kernel function coefficient g. The penalty coefficient C reflects the tolerance of the SVM for errors. The larger the value of C, the higher the training accuracy, but the generalization ability of SVM is weakened. The smaller the value of C, the higher the tolerance of the SVM for errors, and the stronger the generalization ability of the SVM. The kernel function coefficient g determines the mapped feature space. The larger the value of g, the higher the dimensionality of the kernel function mapping; the smaller the value of g, the lower the mapping dimension.
- For the KNN classifier, the main hyperparameter is the number of neighbors (k) and the weight of neighbors at different distances. The larger the value of k, the higher the accuracy of KNN, but oversized k will lead to overfitting. The smaller the value of k, the lower the accuracy of KNN, but too small a value will lead to underfitting. The weight selection for neighbors with different distances is distance, which means that the weight of neighbors is inversely proportional to the size of the distance.
- For the DT classifier, the main hyperparameters are min sample split, min sample leaf, and criterion. Min sample split represents the minimum number of samples required to split internal nodes, min sample leaf represents the minimum number of samples required for an effective terminal node, and criterion represents the selection criteria of features.
- For the LR classifier, the main hyperparameters are the penalty parameter C and the optimization type solver. The penalty parameter C reflects the reciprocal of the regularization strength. The smaller the value of C, the stronger the regularization. The solver represents the optimization type of the algorithm.
- For the GBDT classifier, the main hyperparameters are learning rate, n estimators, max depth, max features, min sample split, and min sample leaf. Among them, the learning rate is the weight reduction coefficient for each tree, n estimators is the number of trees, max depth is the maximum depth of the tree, max features is the number of features selected by the tree, and min sample split and min sample leaf are similar to the definition in DT.
- For the RF classifier, the main hyperparameters are n estimators, max depth, max features, min sample split, and min sample leaf. These hyperparameters are similar to the definitions in GBDT.
- For the XGBoost classifier, the main hyperparameters are learning rate, n estimators, max depth, max features, min sample split, and min sample leaf. These hyperparameters are similar to the definition in GBDT.
4.3. Prediction Results
4.3.1. Prediction Results Based on Imbalanced Training Dataset
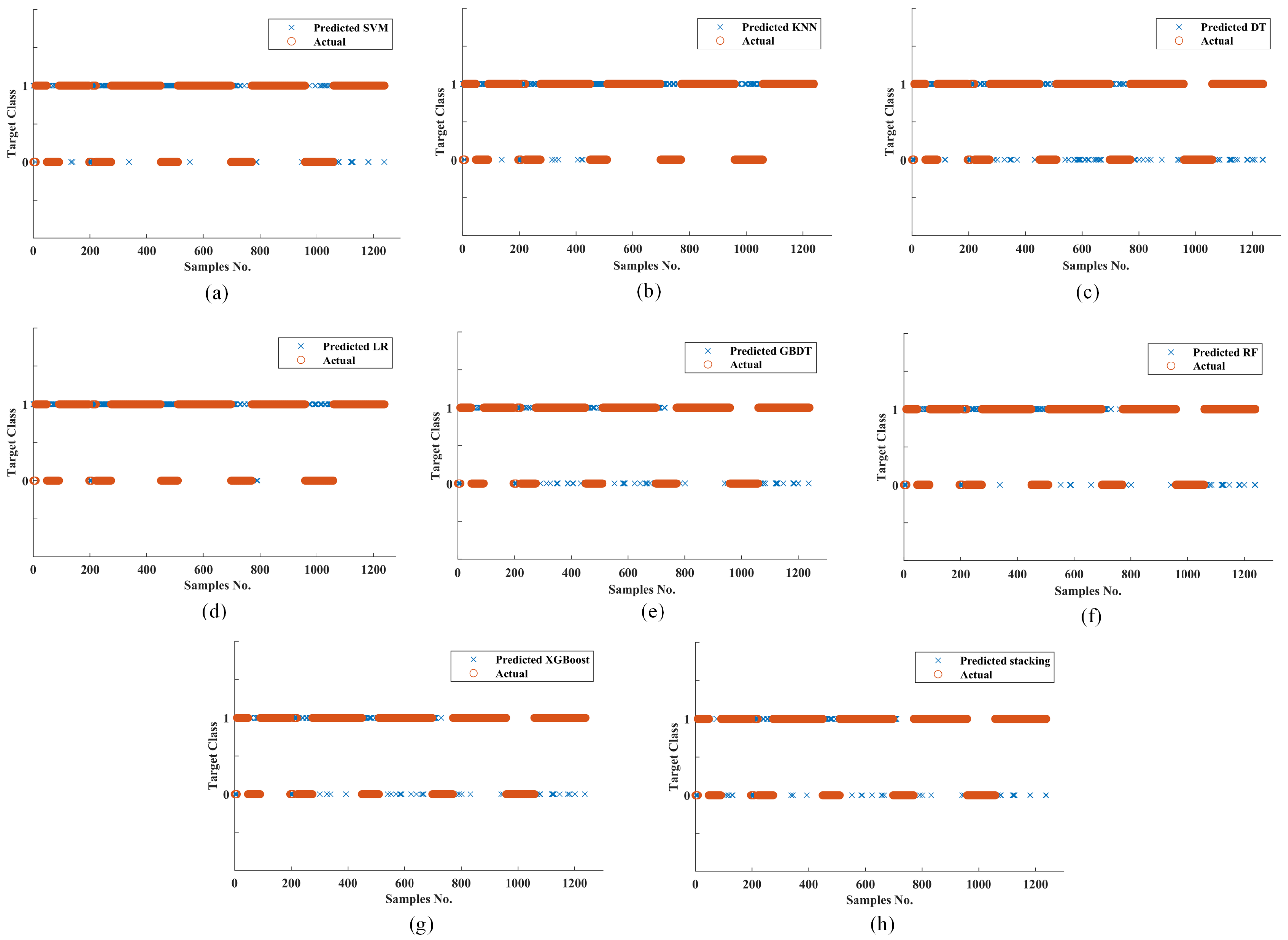
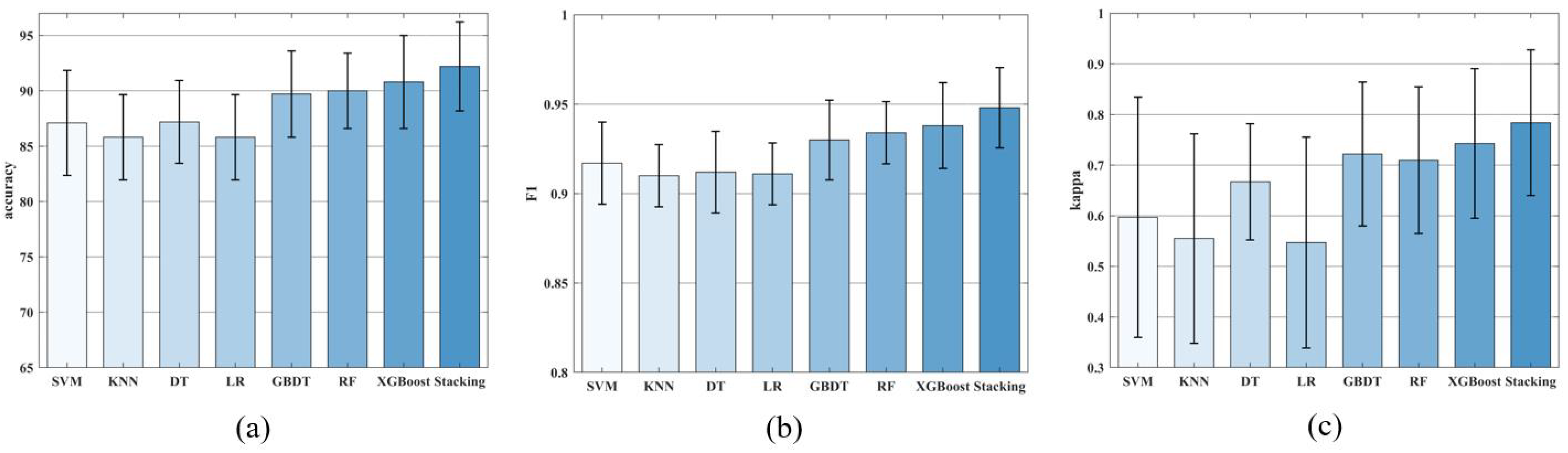
- Compared with other classifiers, the stacking ensemble classifier has the best performance. For , the stacking ensemble classifier reaches 0.922 ± 0.0402, which is higher than all other eight individual classifiers. For , the stacking ensemble classifier reaches 0.958 ± 0.0735, which is higher than all other eight individual classifiers. For , the stacking ensemble classifier reaches 0.948 ± 0.0225, which is higher than all other eight individual classifiers. For , the stacking ensemble classification algorithm reaches 0.941 ± 0.0559, which is higher than all other eight individual classifiers. For , the stacking ensemble classifier reaches 0.957 ± 0.0257, which is lower than the LR classifier (0.997 ± 0.0072) and RF classifier (0.967 ± 0.0479). It is worth noting that although the LR classifier has a higher REC, the PRE is not high. This phenomenon is due to the imbalanced dataset.
- Tree-based classifiers, such as XGBoost, GBDT, and RF classifiers, have relatively good performance. These classifiers are also ensemble models based on decision trees. This indicates that ensemble classifiers have advantages in classification problems. We use these ensemble models as the base classifiers for the stacking ensemble classifier in this study. For these tree-based classifiers, XGBoost shows the best performance. The , , , , and of XGBoost reach 0.908 ± 0.0420 (the best of three ensemble classifiers), 0.950 ± 0.0550 (second only to the RF classifier at 0.956 ± 0.0483), 0.938 ± 0.0240 (the best of the three ensemble models), 0.922 ± 0.0522 (the best of the three ensemble models, equal to the mean of the GBDT classifier, with a standard deviation less than the GBDT classifier), and 0.957 ± 0.0383 (second only to the RF classifier at 0.967 ± 0.0479), respectively.
- The performance of SVM, KNN, LR, and DT classifiers are relatively poorer than that of the stacking ensemble classifier and tree-based classifiers XGBoost, RF, and GBDT. For , DT has the highest accuracy at 0.872 ± 0.0374, followed by SVM at 0.871 ± 0.0474, and KNN and LR have the worst accuracy at 0.858 ± 0.0384 and 0.858 ± 0.0385, respectively. For , SVM has the highest value of 0.945 ± 0.0417; LR takes second place, with a value of 0.932 ± 0.0774; the next is DT, which is 0.890 ± 0.0958; and KNN is the worst, with a value of 0.897 ± 0.0916. For , all four individual classifiers are greater than 0.9 and relatively close. The scores of SVM, KNN, LRm and DT are 0.917 ± 0.0230, 0.910 ± 0.0174, 0.912 ± 0.0228, and 0.911 ± 0.0173, respectively. For , only DT is greater than 0.9, at 0.922 ± 0.0509. Furthermore, the PRE values of the other three classifiers are all below 0.9, and the PRE values of SVM, KNN, and LR are 0.868 ± 0.0512, 0.842 ± 0.0314, and 0.839 ± 0.0324, respectively. For , all four individual classifiers are greater than 0.9. The values for SVM, KNN, DT, and LR are 0.975 ± 0.0273, 0.991 ± 0.0149, 0.901 ± 0.0605, and 0.997 ± 0.0072, respectively. This phenomenon is also due to the imbalanced dataset and will be discussed in Section 4.3.2.
- For the coefficient, the stacking ensemble classifier is the highest, at 0.784 ± 0.1437. The three tree class ensemble classifiers XGBoost, RF, and GBDT take second place, with 0.743 ± 0.1479, 0.722 ± 0.1420, and 0.710 ± 0.1450, respectively. The four individual classifiers, SVM, KNN, LR, and DT have relatively low mean values below 0.7, which are 0.597 ± 0.2372, 0.555 ± 0.2070, 0.667 ± 0.1148, and 0.547 ± 0.2085, respectively. This phenomenon reflects the advantage of ensemble classifiers in the processing imbalanced dataset. In conclusion, it can be seen that the stacking ensemble classifier has the best performance. The , , , , and values of the stacking ensemble classifier are the highest among all classifiers. At the same time, the and values of the stacking ensemble classifier are relatively balanced, which indicates that the stacking ensemble classifier has strong adaptability to imbalanced datasets. For XGBoost, RF, and GBDT, the results are second only to the stacking ensemble classifier, and their and values are both greater than 0.9, indicating that the ensemble classifiers have strong adaptability to imbalanced datasets. For SVM, KNN, LR, and DT, their performances are relatively poor. With the exception of DT, there is a significant gap between the PRE and REC values of the other three individual classifiers. Although cost-sensitive methods were used for the three individual classifiers, the results were still poor.
4.3.2. Prediction Results Based on Relatively Balanced Training Dataset
- For , all classifiers improved differently on the relatively balanced dataset. The mean accuracy of SVM, KNN, DT, LR, GBDT, RF, XGBoost, and the stacking ensemble classifier increased by , 2.6%, 1.8%, 2.3%, 0.9%, 0.8%, 0.6%, and 1.1%, respectively. It is worth noting that the accuracy increase in the ensemble classifiers represented by the stacking ensemble classifier is lower than that of the individual classifiers, which also indicates that the ensemble classifiers have advantages in processing imbalanced datasets. In addition, the accuracy increase in the stacking ensemble classifier is greater than that of the GBDT, RF, and XGBoost ensemble classifiers. This phenomenon can be attributed to the accuracy increase in the base classifiers. The use of SMOTE has led to a relatively balanced training dataset, resulting in improved performance for individual classifiers. The moderately balanced dataset reduces the risk of classifier overfitting and ultimately enhances the evaluation metrics for the classifier. Due to the improved performance of base classifiers, the final stacking ensemble model also shows improvement.
- For , it can be found that, with the exception of the RF (a decrease of 0.005) and XGBoost (a decrease of 0.006) classifiers, the AUC values of all other classifiers increased. Among them, the SVM classifier has the highest improvement of 0.012, and DT showed the lowest improvement of 0.003.
- It can be found that all classifiers have varying degrees of increases in . Among them, KNN and DT have the largest increase, at 0.011, and the stacking ensemble classifier shows the smallest increase of 0.003. Obviously, the improvement values of the ensemble classifiers are smaller than that of the individual classifier, which also reflects the advantage of the ensemble classifiers in processing imbalanced datasets.
- The coefficients of all classifiers increased, with the LR classifier showing an improvement value of 0.121 and XGBoost showing an improvement value of 0.023, which is the smallest. This phenomenon not only reflects the enhanced separability of the dataset after SMOTE oversampling but also the effectiveness of oversampling from another perspective.
4.4. Model Deployment on Embedded Systems
5. Discussion
6. Conclusions
- Multiple features based on highlights were extracted from real sea trial data.
- SMOTE oversampling technology was utilized to expand minority scale acoustic decoy data in the feature domain to solve the problem of data imbalance.
- A stacking ensemble classification model was established to improve classification ability and robustness compared to single classification models.
- A semi-physical simulation experiment was conducted on an embedded system, a digital computer was used to calculate features, input them into the embedded system, and provide inference results, proving that the model has real-time performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- He, X.Y.; He, G.; Jin, C.; Chen, S.Z. Current Situation and Prospect on Torpedo’s True/False Target Identification Technologies. Torpedo Technol. 2016, 24, 23–27. [Google Scholar]
- Wang, M.Z.; Hao, C.Y.; Huang, X.W. Underwater Target Dimension Recognition Based on Bearings Analysis of Signal Correlation Feature. J. Northwestern Polytech. Univ. 2003, 21, 317–320. [Google Scholar]
- Liu, Z.H.; Fu, Z.P.; Wang, M.Z. Underwater Target Identification Based on the Methods of Bearing and Cross-spectrum. Acta Armamentarii 2006, 27, 932–935. [Google Scholar]
- Fan, S.-H.; Wang, Y.M.; Yue, L.; Kang, W.Y. Underwater Target Simulation System Based on Towed Long Line Array. J. Syst. Simul. 2012, 24, 1083–1087. [Google Scholar]
- Zhao, Z.; Cai, Z. Simulation and analysis of acoustic linear array decoy for counterworking the torpedo with target scale recognition capability. Tech. Acoust. 2011, 30, 493–495. [Google Scholar]
- Xu, J.; Huang, Z.; Li, C. Advances in Underwater Target Passive Recognition Using Deep Learning. J. Signal Process. 2019, 35, 1460–1475. [Google Scholar]
- Luo, X.; Chen, L.; Zhou, H.; Cao, H. A Survey of Underwater Acoustic Target Recognition Methods Based on Machine Learning. J. Mar. Sci. Eng. 2023, 11, 384. [Google Scholar] [CrossRef]
- Meng, Q.; Yang, S.; Piao, S. The classification of underwater acoustic target signals based on wave structure and support vector machine. J. Acoust. Soc. Am. 2014, 136, 2265. [Google Scholar] [CrossRef]
- De Moura, N.N.; de Seixas, J.M. Novelty detection in passive SONAR systems using support vector machines. In Proceedings of the 2015 Latin America Congress on Computational Intelligence (LA-CCI), Curitiba, Brazil, 13–16 October 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Mallat, S.; Zhang, Z. Matching pursuits with time-frequency dictionaries. IEEE Trans. Signal Process. 1993, 41, 3397–3415. [Google Scholar] [CrossRef]
- Lee, S.; Seo, I.; Seok, J.; Kim, Y.; Han, D.S. Active Sonar Target Classification with Power-Normalized Cepstral Coefficients and Convolutional Neural Network. Appl. Sci. 2020, 10, 8450. [Google Scholar] [CrossRef]
- Sabara, R.; Jesus, S. Underwater acoustic target recognition using graph convolutional neural networks. J. Acoust. Soc. Am. 2018, 144, 1744. [Google Scholar] [CrossRef]
- Nguyen, H.T.; Lee, E.H.; Lee, S. Study on the Classification Performance of Underwater Sonar Image Classification Based on Convolutional Neural Networks for Detecting a Submerged Human Body. Sensors 2019, 20, 94. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.P. Underwater target classification in synthetic aperture sonar imagery using deep convolutional neural networks. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 2497–2502. [Google Scholar] [CrossRef]
- Wang, Y.; Zhang, H.; Xu, L.; Cao, C.; Gulliver, T.A. Adoption of hybrid time series neural network in the underwater acoustic signal modulation identification. J. Frankl. Inst. 2020, 357, 13906–13922. [Google Scholar] [CrossRef]
- Kamal, S.; Chandran, C.S.; Supriya, M.H. Passive sonar automated target classifier for shallow waters using end-to-end learnable deep convolutional LSTMs. Eng. Sci. Technol. Int. J. 2021, 24, 860–871. [Google Scholar] [CrossRef]
- Feng, S.; Zhu, X. A Transformer-Based Deep Learning Network for Underwater Acoustic Target Recognition. IEEE Geosci. Remote. Sens. Lett. 2022, 19, 1505805. [Google Scholar] [CrossRef]
- Gu, J.; Liu, S.; Zhou, Z.; Chalov, S.R.; Zhuang, Q. A Stacking Ensemble Learning Model for Monthly Rainfall Prediction in the Taihu Basin, China. Water 2022, 14, 492. [Google Scholar] [CrossRef]
- Zhan, Y.; Zhang, H.; Li, J.; Li, G. Prediction Method for Ocean Wave Height Based on Stacking Ensemble Learning Model. J. Mar. Sci. Eng. 2022, 10, 1150. [Google Scholar] [CrossRef]
- Hou, S.; Liu, Y.; Yang, Q. Real-time prediction of rock mass classification based on TBM operation big data and stacking technique of ensemble learning. J. Rock Mech. Geotech. Eng. 2022, 14, 123–143. [Google Scholar] [CrossRef]
- Ding, W.; Li, X.; Yang, H.; An, J.; Zhang, Z. A Novel Method for Damage Prediction of Stuffed Protective Structure under Hypervelocity Impact by Stacking Multiple Models. IEEE Access 2020, 8, 130136–130158. [Google Scholar] [CrossRef]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- Raghavendra, N.S.; Deka, P.C. Support vector machine application in the field of hydrology: A review. Appl. Soft Comput. 2014, 19, 371–386. [Google Scholar] [CrossRef]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1953, 13, 21–27. [Google Scholar] [CrossRef]
- Nowozin, S.; Rother, C.; Bagon, S.; Sharp, T.; Yao, B.; Kohli, P. Decision Tree Fields. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Barros, A.J.; Hirakata, V.N. Alternatives for logistic regression in cross-sectional studies: An empirical comparison of models that directly estimate the prevalence ratio. BMC Med. Res. Methodol. 2003, 3, 21. [Google Scholar] [CrossRef] [PubMed]
- Tian, R.; Chen, F.; Dong, S. Compound Fault Diagnosis of Stator Interturn Short Circuit and Air Gap Eccentricity Based on Random Forest and XGBoost. Math. Probl. Eng. 2021, 2021, 2149048. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2000, 29, 1189–1232. [Google Scholar] [CrossRef]
- He, J.; Hao, Y.; Wang, X. An Interpretable Aid Decision-Making Model for Flag State Control Ship Detention Based on SMOTE and XGBoost. J. Mar. Sci. Eng. 2021, 9, 156. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. AI Access Found. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Wang, M.; Huang, X.; Hao, C. Model of an Underwater Target Based on Target Echo Highlight Structure. J. Syst. Simul. 2003, 15, 5. [Google Scholar]
- Cheng, J.; Liu, H.; Wang, F.; Li, H.; Zhu, C. Silhouette analysis for human action recognition based on supervised temporal t-SNE and incremental learning. IEEE Trans. Image Process. 2015, 24, 3203–3217. [Google Scholar] [CrossRef]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar] [CrossRef]
- Zhang, J.; Jiang, X.-Z.; Chen, X. Way of Identifying Target Based on Covariance of Bearing Fluctuation. J. Nav. Univ. Eng. 2005, 17, 91–96. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Target Type | Sea Trial Number | Data Number |
|---|---|---|
| Acoustic decoy | 10 | 349 |
| Submarine | 50 | 889 |
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual positives | TPs (true positives) | FNs (false negatives) |
| Actual negatives | FPs (false positives) | TNs (true negatives) |
| Classifiers | Hyperparameters |
|---|---|
| SVM | Kernel = ‘’, , |
| KNN | , weights = distance |
| DT | Min sample split = 4, min sample leaf = 3, criterion = ‘’ |
| LR | , penalty = ‘’, solver = ‘’ |
| GBDT | Learning rate = 0.1, n estimators = 100, max depth = 4, |
| max features = 5, min sample split = 4, min sample leaf = 4 | |
| RF | n estimators = 100, max depth = 6, max features = 5, |
| min samples split = 6, min sample leaf = 6 | |
| XGBoost | Learning rate = 0.1, n estimators = 100, max depth = 5, |
| max features = 5, min sample split = 5, min sample leaf = 5 |
| Classifier | |||
|---|---|---|---|
| SVM | 0.945 ± 0.0417 | 0.868 ± 0.0512 | 0.975 ± 0.0273 |
| KNN | 0.897 ± 0.0916 | 0.842 ± 0.0314 | 0.991 ± 0.0149 |
| DT | 0.890 ± 0.0958 | 0.922 ± 0.0509 | 0.901 ± 0.0605 |
| LR | 0.932 ± 0.0774 | 0.839 ± 0.0324 | 0.997 ± 0.0072 |
| GBDT | 0.934 ± 0.0778 | 0.922 ± 0.0538 | 0.943 ± 0.0515 |
| RF | 0.956 ± 0.0483 | 0.907 ± 0.0589 | 0.967 ± 0.0479 |
| XGBoost | 0.950 ± 0.0550 | 0.922 ± 0.0522 | 0.957 ± 0.0383 |
| Stacking | 0.958 ± 0.0735 | 0.941 ± 0.0559 | 0.957 ± 0.0257 |
| Classifiers | Hyperparameters |
|---|---|
| SVM | Kernel = ‘’, , |
| KNN | , weights = distance |
| DT | Min sample split = 5, min sample leaf = 4, criterion = ‘’ |
| LR | , penalty = ‘’, solver = ‘’ |
| GBDT | Learning rate = 0.1, n estimators = 110, max depth = 4, |
| max features = 5, min sample split = 4, min sample leaf = 4 | |
| RF | n estimators = 110, max depth = 6, max features = 5, |
| min sample split = 6, min sample leaf = 6 | |
| XGBoost | Learning rate = 0.1, n estimators = 110, max depth = 5, |
| max features = 5, min sample split = 5, min sample leaf = 5 |
| Classifier | ||
|---|---|---|
| SVM | 0.913 ± 0.0809 | 0.943 ± 0.0530 |
| KNN | 0.930 ± 0.0865 | 0.921 ± 0.0583 |
| DT | 0.947 ± 0.0484 | 0.901 ± 0.0285 |
| LR | 0.934 ± 0.0827 | 0.909 ± 0.0527 |
| GBDT | 0.938 ± 0.0557 | 0.937 ± 0.0364 |
| RF | 0.931 ± 0.0531 | 0.943 ± 0.0317 |
| XGBoost | 0.945 ± 0.0612 | 0.943 ± 0.0250 |
| Stacking | 0.955 ± 0.0399 | 0.955 ± 0.0326 |
| Classifier | Imbalanced | Relatively Balanced | Mean Variation (%) |
|---|---|---|---|
| SVM | 0.871 ± 0.0474 | 0.886 ± 0.0478 | 1.5 |
| KNN | 0.858 ± 0.0384 | 0.884 ± 0.0476 | 2.6 |
| DT | 0.872 ± 0.0374 | 0.890 ± 0.0375 | 1.8 |
| LR | 0.858 ± 0.0385 | 0.881 ± 0.0404 | 2.3 |
| GBDT | 0.897 ± 0.0390 | 0.906 ± 0.0416 | 0.9 |
| RF | 0.900 ± 0.0340 | 0.908 ± 0.0393 | 0.8 |
| XGBoost | 0.908 ± 0.0420 | 0.914 ± 0.0445 | 0.6 |
| Stacking | 0.922 ± 0.0402 | 0.933 ± 0.0472 | 1.1 |
| Classifier | Imbalanced | Relatively Balanced | Mean Variation |
|---|---|---|---|
| SVM | 0.945 ± 0.0417 | 0.957 ± 0.0463 | 0.012 |
| KNN | 0.897 ± 0.0916 | 0.904 ± 0.1039 | 0.007 |
| DT | 0.890 ± 0.0958 | 0.893 ± 0.0854 | 0.003 |
| LR | 0.932 ± 0.0774 | 0.938 ± 0.0728 | 0.006 |
| GBDT | 0.934 ± 0.0778 | 0.945 ± 0.0669 | 0.011 |
| RF | 0.956 ± 0.0483 | 0.951 ± 0.0511 | −0.005 |
| XGBoost | 0.950 ± 0.0550 | 0.944 ± 0.0747 | −0.006 |
| Stacking | 0.958 ± 0.0735 | 0.962 ± 0.0606 | 0.004 |
| Classifier | Imbalanced | Relatively Balanced | Mean Variation |
|---|---|---|---|
| SVM | 0.917 ± 0.0230 | 0.924 ± 0.0225 | 0.007 |
| KNN | 0.910 ± 0.0174 | 0.921 ± 0.0218 | 0.011 |
| DT | 0.912 ± 0.0228 | 0.923 ± 0.0209 | 0.011 |
| LR | 0.911 ± 0.0173 | 0.918 ± 0.0175 | 0.007 |
| GBDT | 0.930 ± 0.0223 | 0.936 ± 0.0241 | 0.006 |
| RF | 0.934 ± 0.0174 | 0.938 ± 0.0221 | 0.004 |
| XGBoost | 0.938 ± 0.0240 | 0.942 ± 0.0250 | 0.004 |
| Stacking | 0.948 ± 0.0225 | 0.951 ± 0.0278 | 0.003 |
| Classifier | Imbalanced | Relatively Balanced | Mean Variation |
|---|---|---|---|
| SVM | 0.597 ± 0.2372 | 0.668 ± 0.2258 | 0.071 |
| KNN | 0.555 ± 0.2070 | 0.661 ± 0.2371 | 0.106 |
| DT | 0.667 ± 0.1148 | 0.720 ± 0.1227 | 0.053 |
| LR | 0.547 ± 0.2085 | 0.668 ± 0.1910 | 0.121 |
| GBDT | 0.722 ± 0.1420 | 0.748 ± 0.1468 | 0.026 |
| RF | 0.710 ± 0.1450 | 0.747 ± 0.1435 | 0.037 |
| XGBoost | 0.743 ± 0.1479 | 0.766 ± 0.1580 | 0.023 |
| Stacking | 0.784 ± 0.1437 | 0.821 ± 0.1341 | 0.037 |
| Method | Point Source Decoy Recognition Capability | Scale Decoy Recognition Capability | Real-Time Capability |
|---|---|---|---|
| Ours | Scalable | Possesses | Possesses |
| The literature [2] | Possesses | Does not possess | Possesses |
| The literature [3] | Possesses | Does not possess | Possesses |
| The literature [34] | Possesses | Does not possess | Possesses |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, J.; Yang, X.; Liu, L.; Shi, L.; Li, Y.; Yang, Y. Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning. J. Mar. Sci. Eng. 2023, 11, 2305. https://doi.org/10.3390/jmse11122305
Deng J, Yang X, Liu L, Shi L, Li Y, Yang Y. Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning. Journal of Marine Science and Engineering. 2023; 11(12):2305. https://doi.org/10.3390/jmse11122305
Chicago/Turabian StyleDeng, Jianjing, Xiangfeng Yang, Liwen Liu, Lei Shi, Yongsheng Li, and Yunchuan Yang. 2023. "Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning" Journal of Marine Science and Engineering 11, no. 12: 2305. https://doi.org/10.3390/jmse11122305
APA StyleDeng, J., Yang, X., Liu, L., Shi, L., Li, Y., & Yang, Y. (2023). Real-Time Underwater Acoustic Homing Weapon Target Recognition Based on a Stacking Technique of Ensemble Learning. Journal of Marine Science and Engineering, 11(12), 2305. https://doi.org/10.3390/jmse11122305