
Water Temperature Prediction Using Improved Deep Learning Methods through Reptile Search Algorithm and Weighted Mean of Vectors Optimizer

 ,
,  ,
, 
 and
and
Abstract
1. Introduction
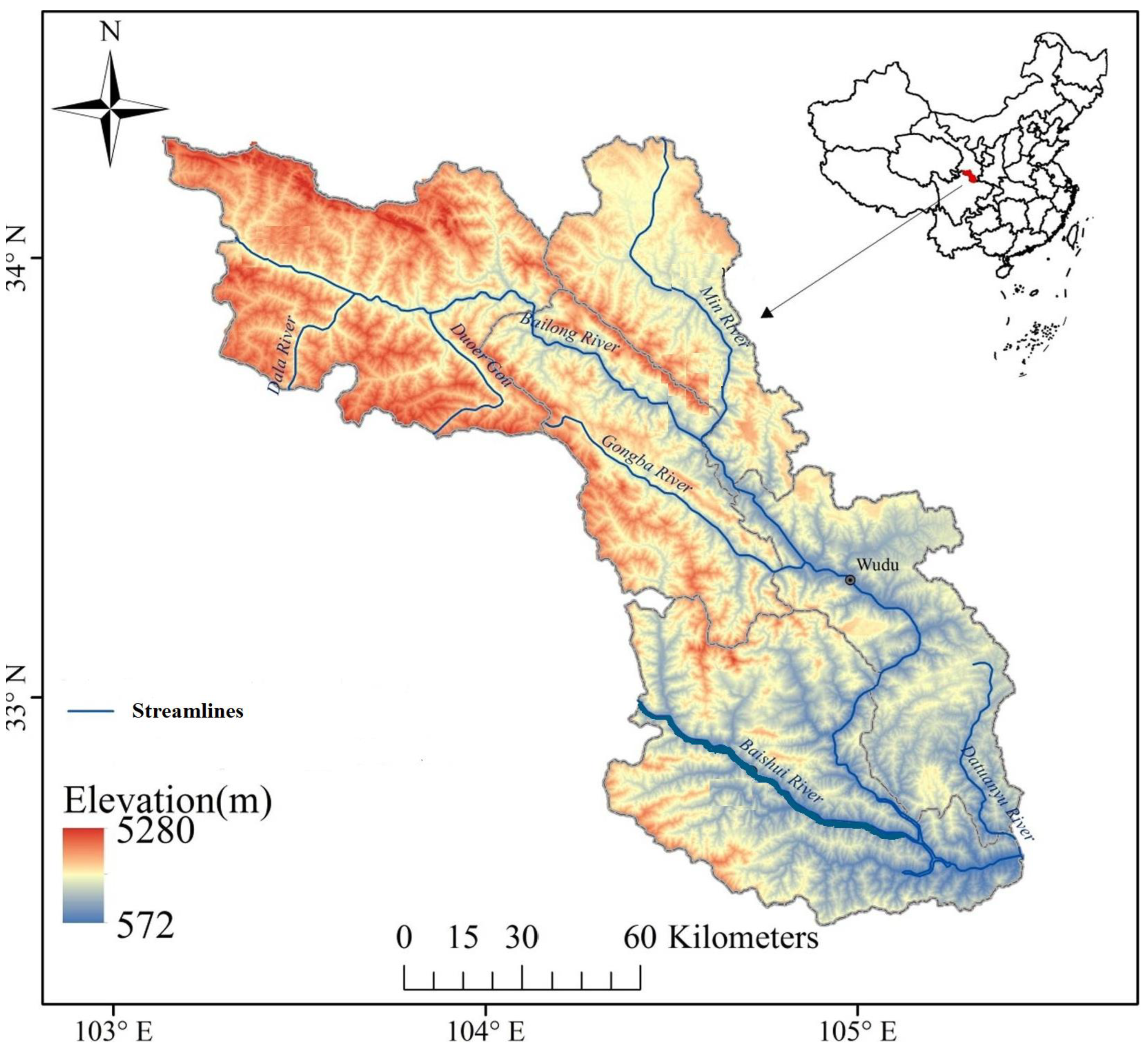
2. Case Study
3. Methods
3.1. Deep Learning Based Models
3.1.1. Convolution Neural Network (CNN)
3.1.2. Long Short Term Memory (LSTM)
3.2. Optimization Algorithms
3.2.1. Weighted Mean of Vectors (INFO) Optimizer
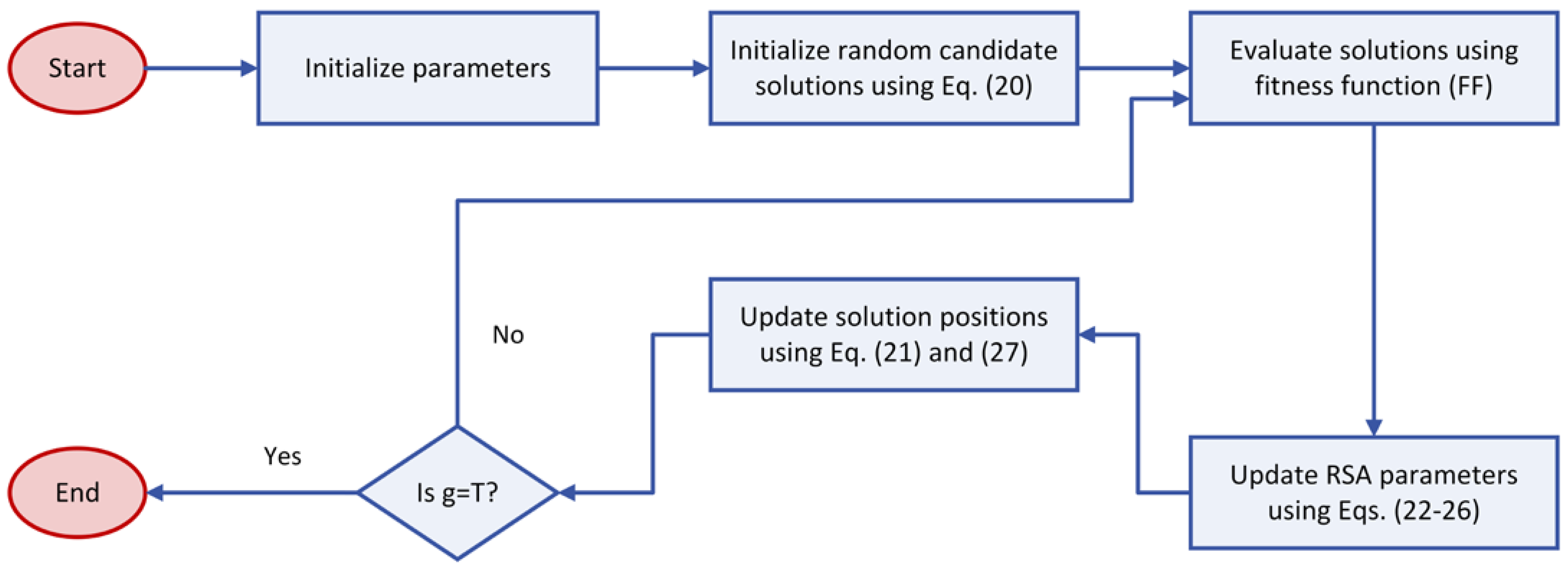
3.2.2. Reptile Search Algorithm (RSA)
3.3. Improved Deep Learning Models
3.3.1. Improved CNN Model
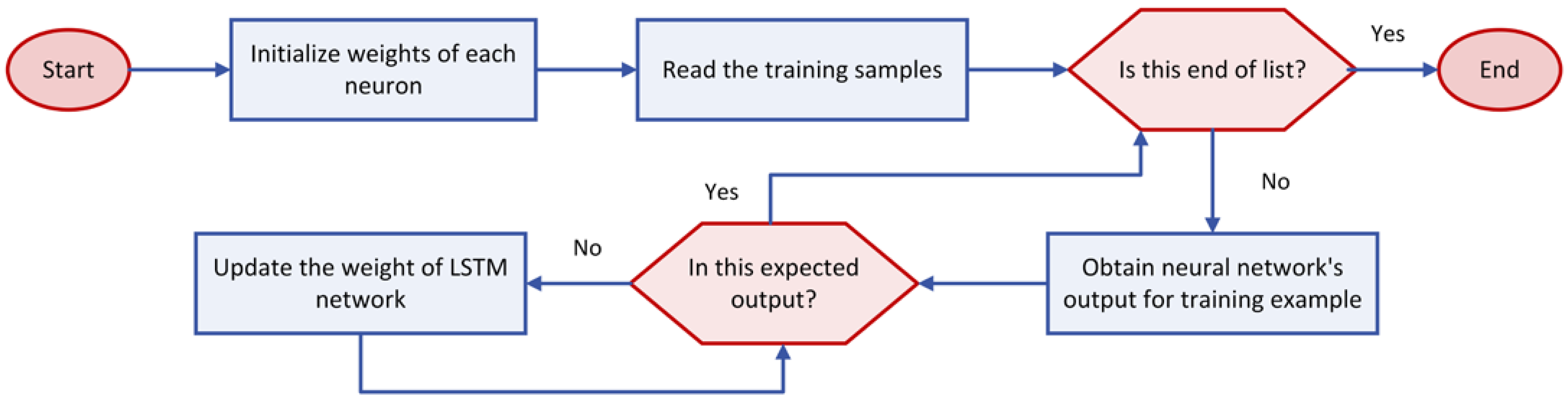
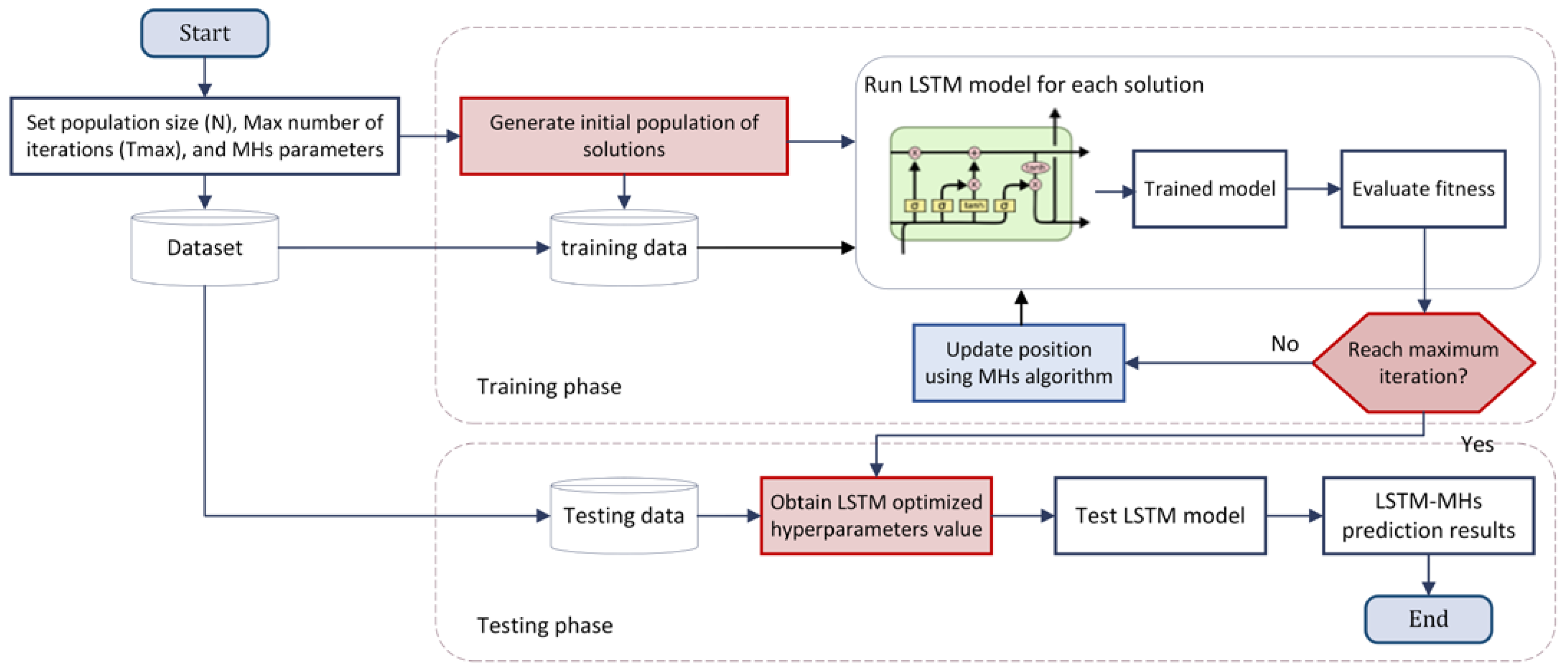
3.3.2. Improved LSTM Model
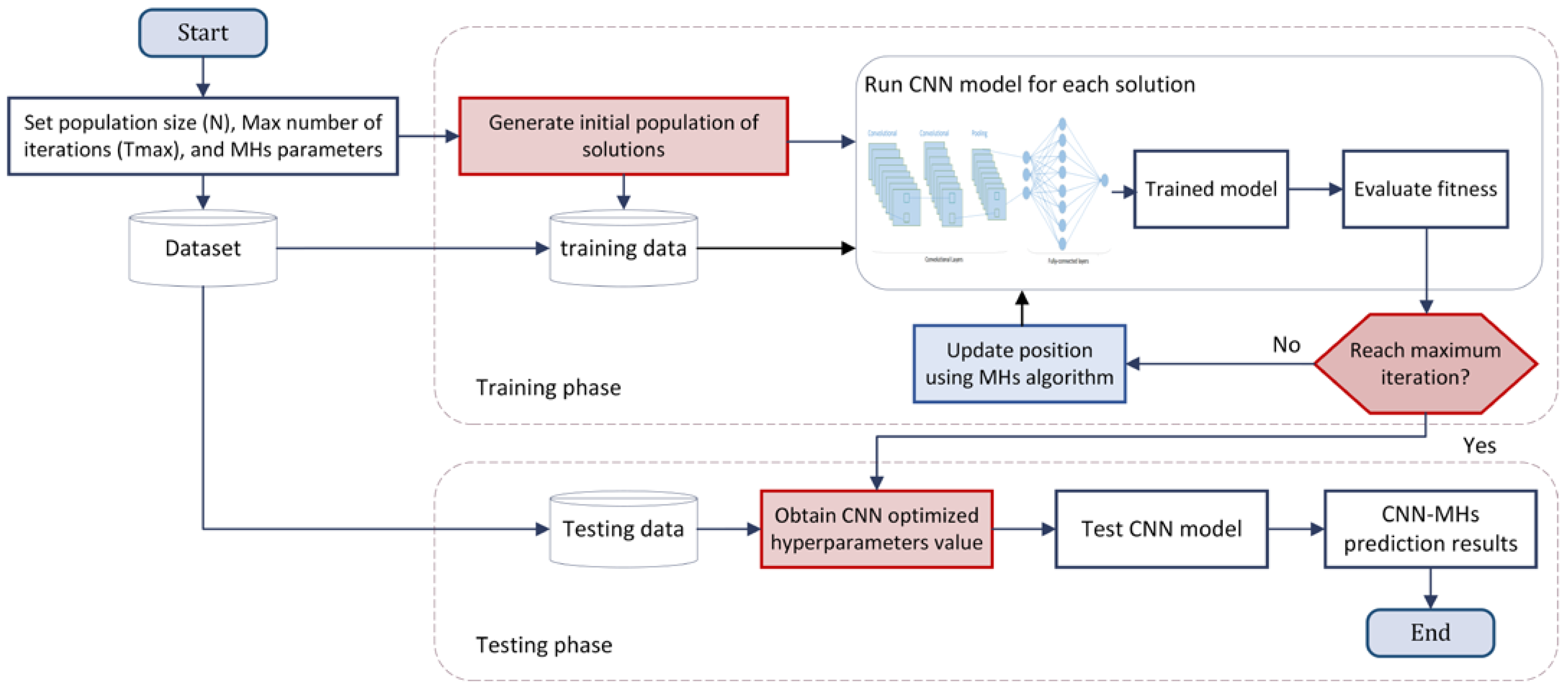
- Step 1:
- Split the input data into two groups to train and test the method.
- Step 2:
- Initialize the relevant parameters: population size (N), the maximum number of iterations (tmax), the upper and lower bounds of the search space ub and lb, respectively, and the range of LSTM parameters (h, α).
- Step 3:
- Generate the initial population of the solution.
- Step 4:
- Calculate the fitness value of each solution using LSTM training.
- Step 5:
- Use the MHs algorithm to optimize the hyperparameters of LSTM by exploring the search domain.
- Step 6:
- Use LSTM objective function to evaluate each candidate parameter.
- Step 7:
- The process is iterated until the maximum number of iterations is reached.
- Step 8:
- The final optimized set of hyperparameters is then passed to ELM to evaluate prediction ability.
4. Model Parameters and Accuracy Assessment
5. Results and Discussion
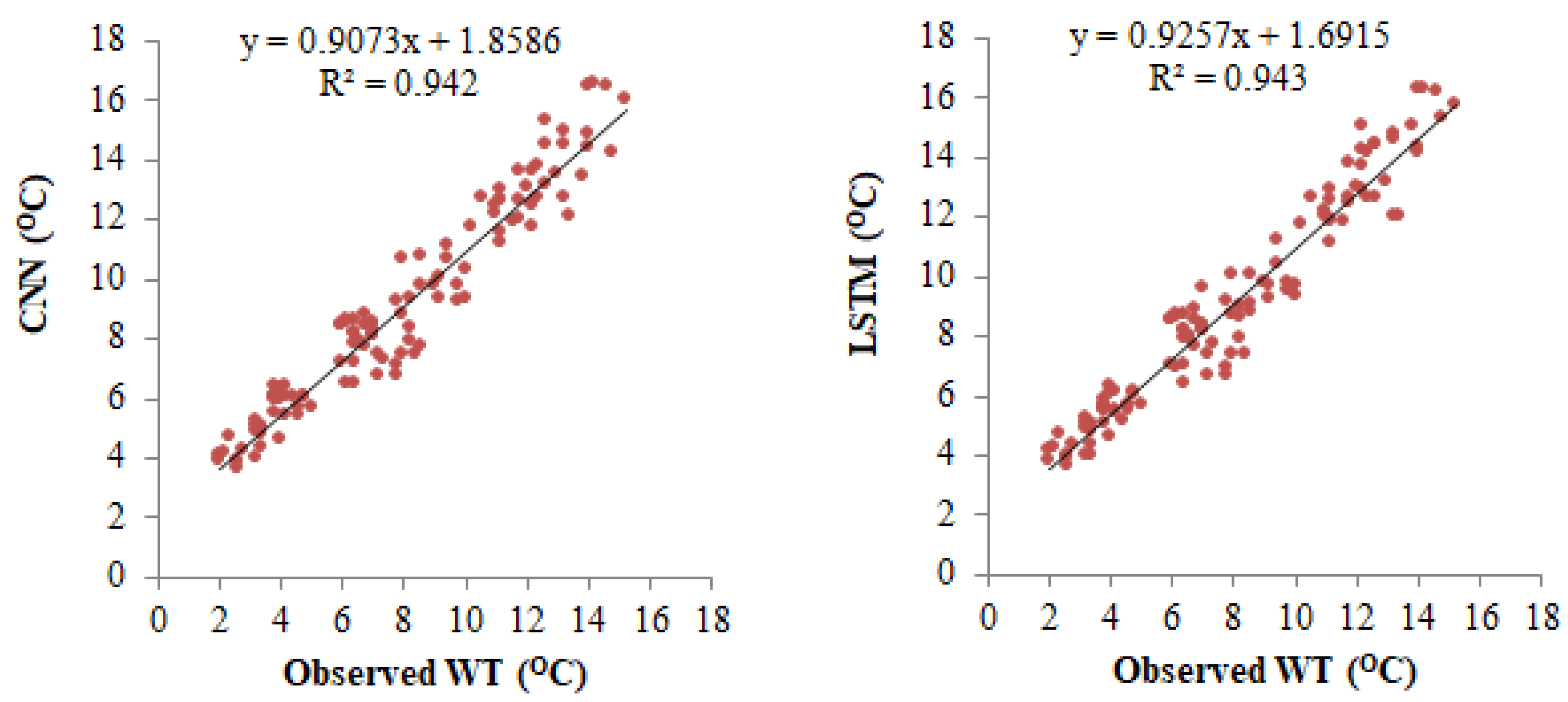
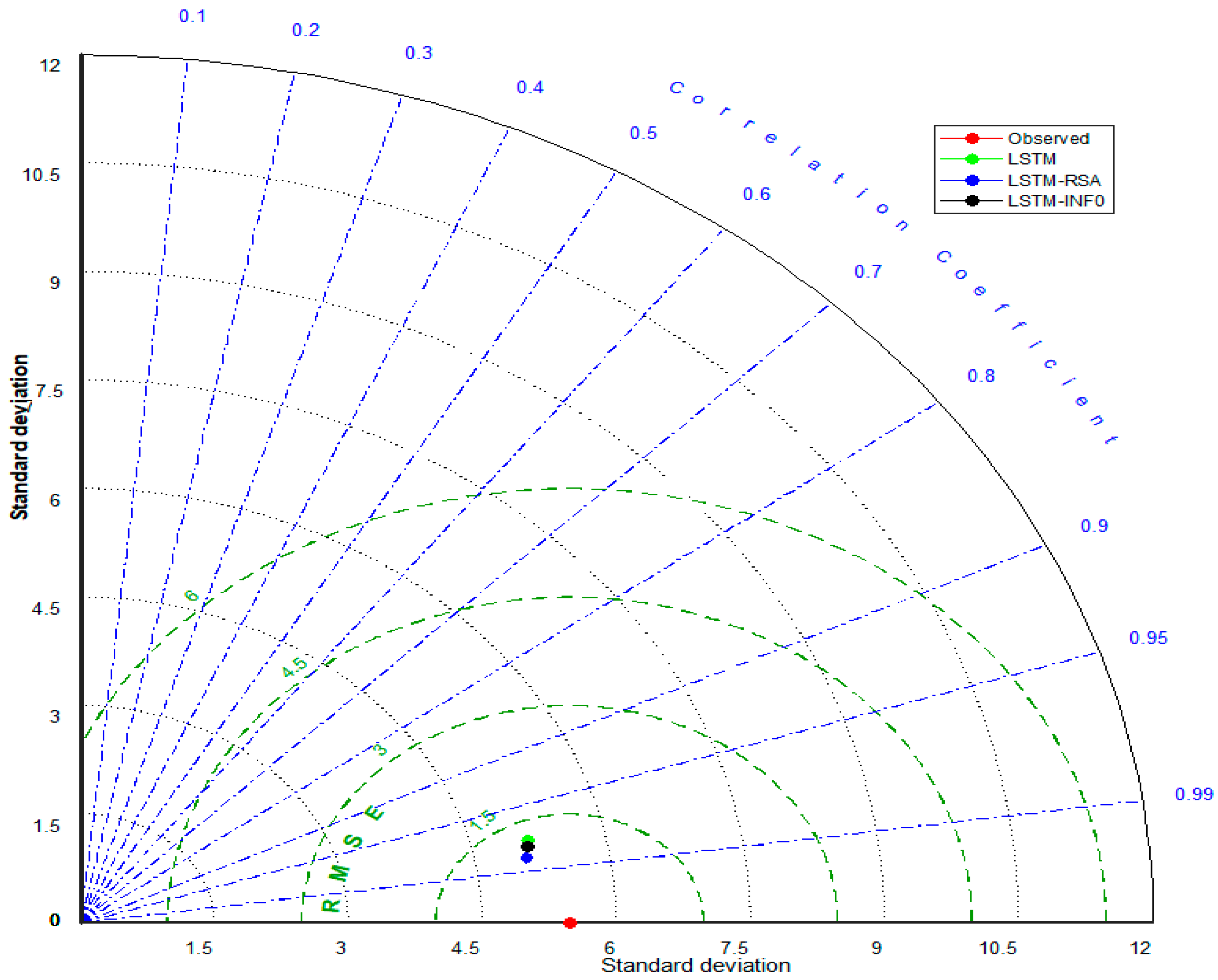
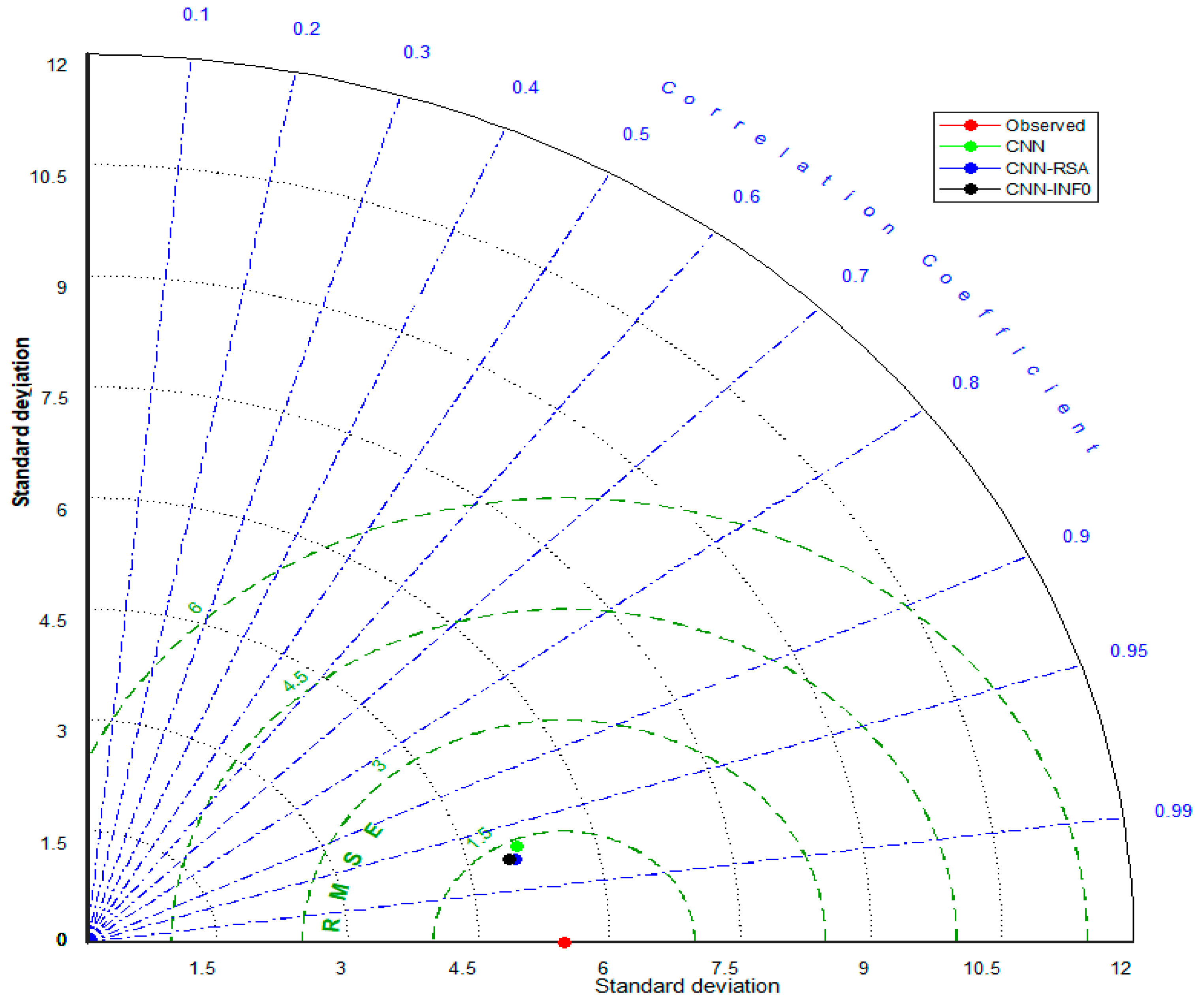
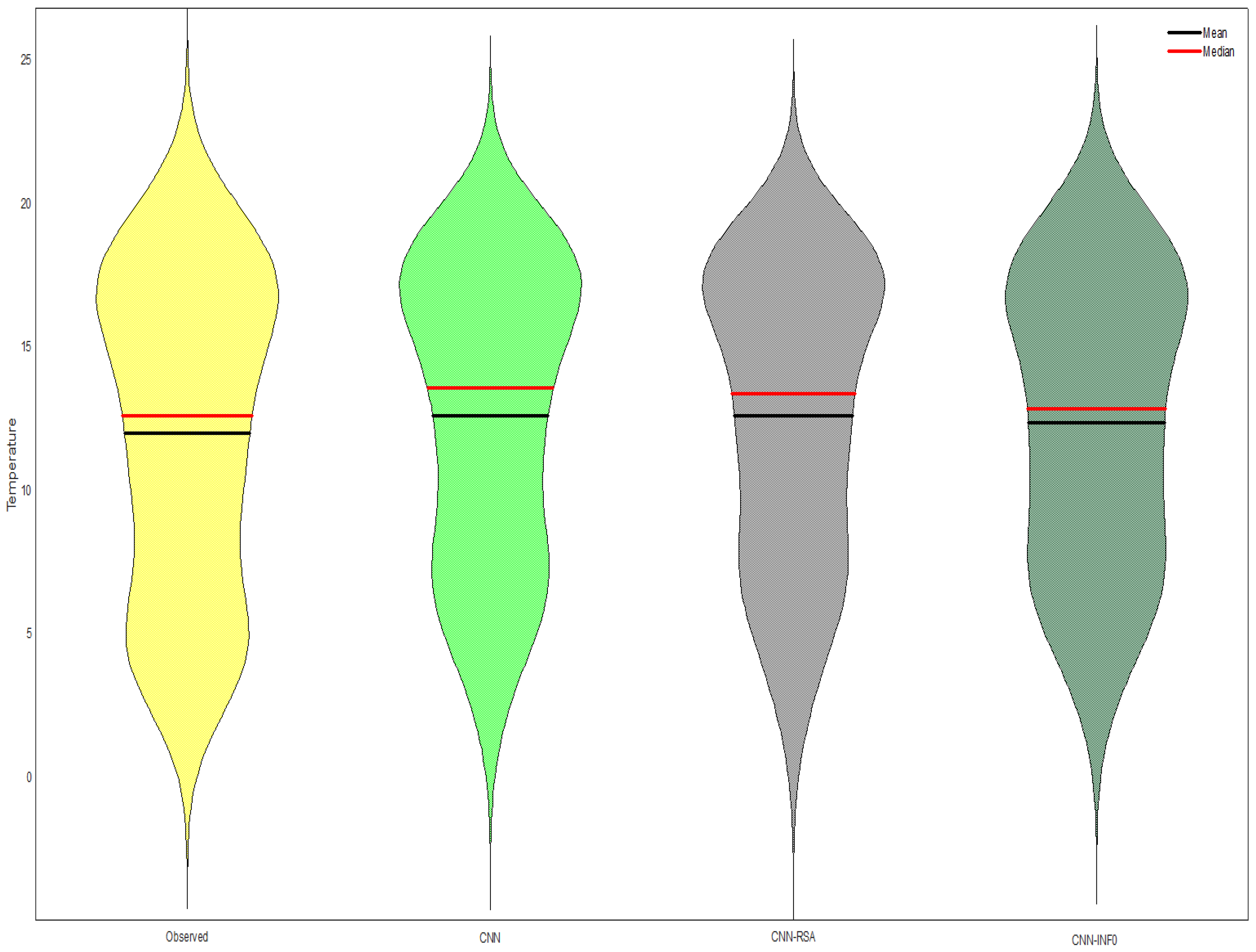
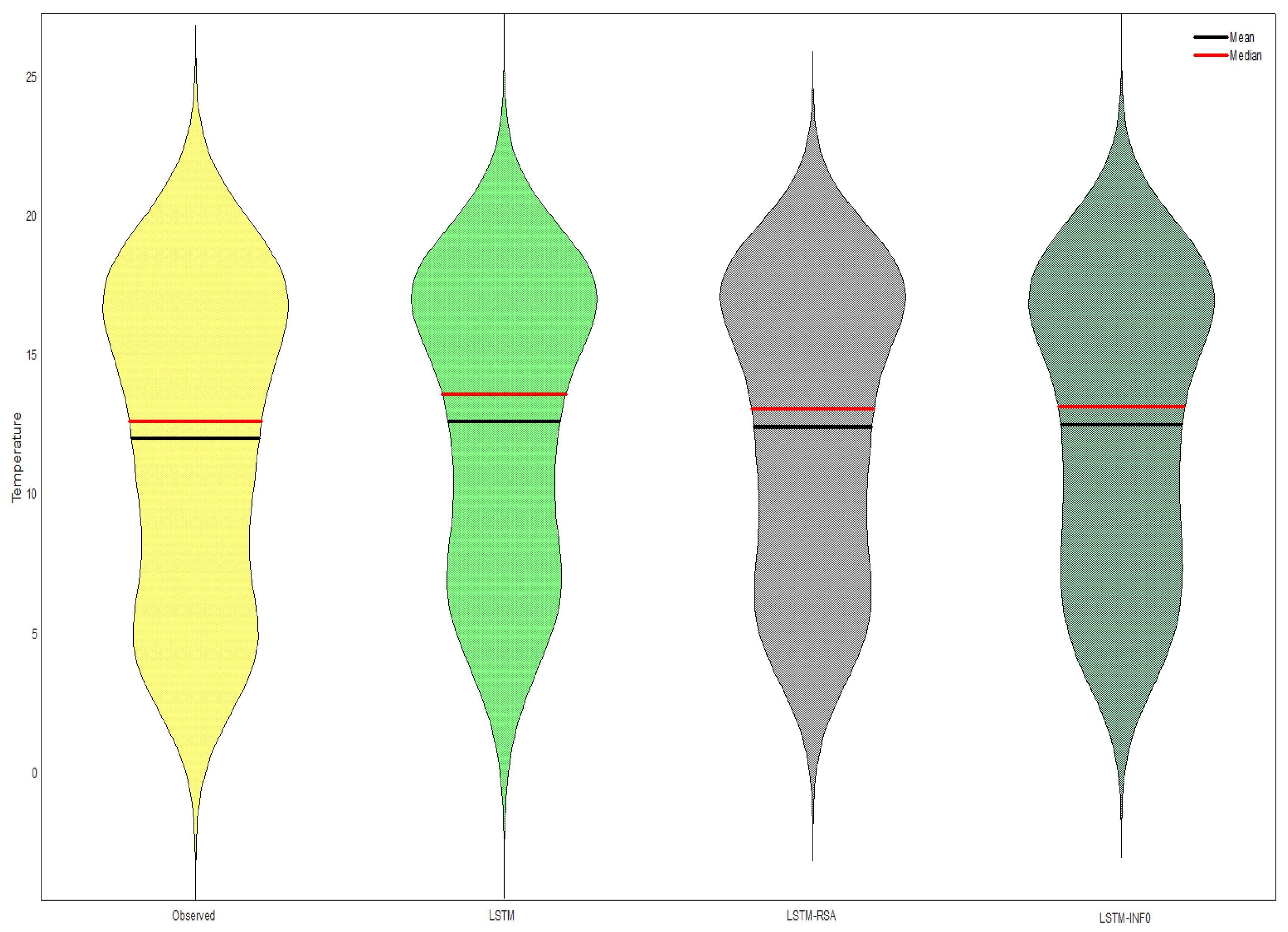
5.1. Results
5.2. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Caissie, D. The thermal regime of rivers: A review. Freshw. Biol. 2006, 51, 1389–1406. [Google Scholar] [CrossRef]
- Sahoo, G.; Schladow, S.; Reuter, J. Forecasting stream water temperature using regression analysis, artificial neural network, and chaotic non-linear dynamic models. J. Hydrol. 2009, 378, 325–342. [Google Scholar] [CrossRef]
- Bernhardt, E.S.; Heffernan, J.B.; Grimm, N.B.; Stanley, E.H.; Harvey, J.W.; Arroita, M.; Appling, A.; Cohen, M.J.; McDowell, W.H.; Hall, R.O.; et al. The metabolic regimes of flowing waters. Limnol. Oceanogr. 2017, 63, S99–S118. [Google Scholar] [CrossRef]
- Wanders, N.; Wada, Y. Human and climate impacts on the 21st century hydrological drought. J. Hydrol. 2015, 526, 208–220. [Google Scholar] [CrossRef]
- Wanders, N.; Van Vliet, M.T.H.; Wada, Y.; Bierkens, M.F.P.; Van Beek, L.P.H. High-Resolution Global Water Temperature Modeling. Water Resour. Res. 2019, 55, 2760–2778. [Google Scholar] [CrossRef]
- Liu, S.; Xu, L.; Li, D. Multi-scale prediction of water temperature using empirical mode decomposition with back-propagation neural networks. Comput. Electr. Eng. 2016, 49, 1–8. [Google Scholar] [CrossRef]
- Cai, H.; Piccolroaz, S.; Huang, J.; Liu, Z.; Liu, F.; Toffolon, M. Quantifying the impact of the Three Gorges Dam on the thermal dynamics of the Yangtze River. Environ. Res. Lett. 2018, 13, 054016. [Google Scholar] [CrossRef]
- Du, X.; Shrestha, N.K.; Wang, J. Assessing climate change impacts on stream temperature in the Athabasca River Basin using SWAT equilibrium temperature model and its potential impacts on stream ecosystem. Sci. Total. Environ. 2019, 650, 1872–1881. [Google Scholar] [CrossRef]
- Sartori, E. A Mathematical Model for Predicting Heat and Mass Transfer from a Free Water Surface. In Advances in Solar Energy Technology; Pergamon: Oxford, UK, 1988; pp. 3160–3164. [Google Scholar] [CrossRef]
- Caissie, D.; El-Jabi, N.; St-Hilaire, A. Stochastic modelling of water temperatures in a small stream using air to water relations. Can. J. Civ. Eng. 1998, 25, 250–260. [Google Scholar] [CrossRef]
- Grbić, R.; Kurtagić, D.; Slišković, D. Stream water temperature prediction based on Gaussian process re-gression. Expert Syst. Appl. 2013, 40, 7407–7414. [Google Scholar] [CrossRef]
- Parmar, K.S.; Bhardwaj, R. Water quality management using statistical analysis and time-series predic-tion model. Appl. Water Sci. 2014, 4, 425–434. [Google Scholar] [CrossRef]
- Tiyasha, T.; Tung, T.M.; Bhagat, S.K.; Tan, M.L.; Jawad, A.H.; Mohtar WH, M.W.; Yaseen, Z.M. Func-tionalization of remote sensing and on-site data for simulating surface water dissolved oxygen: Development of hy-brid tree-based artificial intelligence models. Mar. Pollut. Bull. 2021, 170, 112639. [Google Scholar] [CrossRef] [PubMed]
- Quan, Q.; Hao, Z.; Xifeng, H.; Jingchun, L. Research on water temperature prediction based on improved sup-port vector regression. Neural Comput. Appl. 2022, 34, 8501–8510. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Adnan, R.M.; Kuriqi, A. Modelling reference evapotranspiration by combining neuro-fuzzy and evolutionary strategies. Acta Geophys. 2020, 68, 1113–1126. [Google Scholar] [CrossRef]
- Yuan, X.; Chen, C.; Lei, X.; Yuan, Y.; Muhammad Adnan, R. Monthly runoff forecasting based on LSTM–ALO model. Stoch. Environ. Res. Risk Assess. 2018, 32, 2199–2212. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Dai, H.-L.; Ewees, A.A.; Shiri, J.; Kisi, O.; Zounemat-Kermani, M. Application of improved version of multi verse optimizer algorithm for modeling solar radiation. Energy Rep. 2022, 8, 12063–12080. [Google Scholar] [CrossRef]
- Adnan, R.M.; Kisi, O.; Mostafa, R.R.; Ahmed, A.N.; El-Shafie, A. The potential of a novel support vector machine trained with modified mayfly optimization algorithm for streamflow prediction. Hydrol. Sci. J. 2022, 67, 161–174. [Google Scholar] [CrossRef]
- Zhu, S.; Nyarko, E.K.; Hadzima-Nyarko, M. Modelling daily water temperature from air temperature for the Missouri River. Peerj 2018, 6, e4894. [Google Scholar] [CrossRef]
- Zhu, S.; Nyarko, E.K.; Hadzima-Nyarko, M.; Heddam, S.; Wu, S. Assessing the performance of a suite of machine learning models for daily river water temperature prediction. Peerj 2019, 7, e7065. [Google Scholar] [CrossRef]
- Zhu, S.; Heddam, S.; Nyarko, E.K.; Hadzima-Nyarko, M.; Piccolroaz, S.; Wu, S. Modeling daily water temperature for rivers: Comparison between adaptive neuro-fuzzy inference systems and artificial neural networks models. Environ. Sci. Pollut. Res. 2018, 26, 402–420. [Google Scholar] [CrossRef]
- Han, M.; Feng, Y.; Zhao, X.; Sun, C.; Hong, F.; Liu, C. A Convolutional Neural Network Using Surface Data to Predict Subsurface Temperatures in the Pacific Ocean. IEEE Access 2019, 7, 172816–172829. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Mostafa, R.R.; Chen, Z.; Islam, A.R.M.T.; Kisi, O.; Kuriqi, A.; Zounemat-Kermani, M. Advanced Hybrid Metaheuristic Machine Learning Models Application for Reference Crop Evapotranspiration Prediction. Agronomy 2023, 13, 98. [Google Scholar] [CrossRef]
- Zounemat-Kermani, M.; Keshtegar, B.; Kisi, O.; Scholz, M. Towards a comprehensive assessment of statis-tical versus soft computing models in hydrology: Application to monthly pan evaporation prediction. Water 2021, 13, 2451. [Google Scholar] [CrossRef]
- Mahdavi-Meymand, A.; Sulisz, W.; Zounemat-Kermani, M. A comprehensive study on the application of firefly algorithm in prediction of energy dissipation on block ramps. Eksploat. I Niezawodn. 2022, 24, 200–210. [Google Scholar] [CrossRef]
- Qiu, R.; Wang, Y.; Wang, D.; Qiu, W.; Wu, J.; Tao, Y. Water temperature forecasting based on modified artificial neural network methods: Two cases of the Yangtze River. Sci. Total. Environ. 2020, 737, 139729. [Google Scholar] [CrossRef]
- Stajkowski, S.; Kumar, D.; Samui, P.; Bonakdari, H.; Gharabaghi, B. Genetic-Algorithm-Optimized Sequential Model for Water Temperature Prediction. Sustainability 2020, 12, 5374. [Google Scholar] [CrossRef]
- Abualigah, L.; Abd Elaziz, M.; Sumari, P.; Geem, Z.W.; Gandomi, A.H. Reptile Search Algorithm (RSA): A nature-inspired meta-heuristic optimizer. Expert Syst. Appl. 2022, 191, 116158. [Google Scholar] [CrossRef]
- Almotairi, K.H.; Abualigah, L. Improved reptile search algorithm with novel mean transition mechanism for constrained industrial engineering problems. Neural Comput. Appl. 2022, 34, 17257–17277. [Google Scholar] [CrossRef]
- Al-Shourbaji, I.; Helian, N.; Sun, Y.; Alshathri, S.; Abd Elaziz, M. Boosting Ant Colony Optimization with Rep-tile Search Algorithm for Churn Prediction. Mathematics 2022, 10, 1031. [Google Scholar] [CrossRef]
- Khan, R.A.; Sabir, B.; Sarwar, A.; Liu, H.D.; Lin, C.H. Reptile Search Algorithm (RSA)-Based Selective Har-monic Elimination Technique in Packed E-Cell (PEC-9) Inverter. Processes 2022, 10, 1615. [Google Scholar] [CrossRef]
- Ahmadianfar, I.; Heidari, A.A.; Noshadian, S.; Chen, H.; Gandomi, A.H. INFO: An efficient optimization al-gorithm based on weighted mean of vectors. Expert Syst. Appl. 2022, 195, 116516. [Google Scholar] [CrossRef]
- Hassan, A.Y.; Ismaeel, A.A.K.; Said, M.; Ghoniem, R.M.; Deb, S.; Elsayed, A.G. Evaluation of Weighted Mean of Vectors Algorithm for Identification of Solar Cell Parameters. Processes 2022, 10, 1072. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive fields of single neurons in cat’s striate cortex. J. Physiol. 1959, 148, 1959. [Google Scholar] [CrossRef] [PubMed]
- Hubel, D.H.; Wiesel, T.N. Receptive fields and functional architecture of monkey striate cortex. J. Physiol. 1968, 195, 215–243. [Google Scholar] [CrossRef]
- Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 1980, 36, 193–202. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML’10), Haifa, Israel, 21–24 June 2010; Omnipress: Haifa, Israel, 2010; pp. 807–814. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Sundermeyer, M.; Schlüter, R.; Ney, H. From feedforward to recurrent. LSTM neural networks for language modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Gensler, A.; Henze, J.; Sick, B.; Raabe, N. Deep Learning for solar power forecasting—An approach using AutoEncoder and LSTM Neural Networks. In Proceedings of the 2016 IEEE International Conference, Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9 October 2016. [Google Scholar] [CrossRef]
- Nelson, D.M.Q.; Pereira, A.C.M.; de Oliveira, R.A. Stock market’s price movement prediction with LSTM neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 June 2017; pp. 1419–1426. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Heddam, S.; Zounemat-Kermani, M.; Kisi, O.; Li, B. Least square support vector machine and multivariate adaptive regression splines for streamflow prediction in mountainous basin using hydro-meteorological data as inputs. J. Hydrol. 2020, 586, 124371. [Google Scholar] [CrossRef]
- Elgamal, Z.; Sabri, A.Q.M.; Tubishat, M.; Tbaishat, D.; Makhadmeh, S.N.; Alomari, O.A. Improved Reptile Search Optimization Algorithm Using Chaotic Map and Simulated Annealing for Feature Selection in Medical Field. IEEE Access 2022, 10, 51428–51446. [Google Scholar] [CrossRef]
- Al-Shourbaji, I.; Kachare, P.H.; Alshathri, S.; Duraibi, S.; Elnaim, B.; Elaziz, M.A. An Efficient Parallel Reptile Search Algorithm and Snake Optimizer Approach for Feature Selection. Mathematics 2022, 10, 2351. [Google Scholar] [CrossRef]
- Shi, J.; Guo, J.; Zheng, S. Evaluation of hybrid forecasting approaches for wind speed and power generation time series. Renew. Sustain. Energy Rev. 2012, 16, 3471–3480. [Google Scholar] [CrossRef]
- Zhang, D.; Peng, X.; Pan, K.; Liu, Y. A novel wind speed forecasting based on hybrid decomposition and online sequential outlier robust extreme learning machine. Energy Convers. Manag. 2018, 180, 338–357. [Google Scholar] [CrossRef]
- Webb, B.W.; Clack, P.D.; Walling, D.E. Water-air temperature relationships in a Devon river system and the role of flow. Hydrol. Process. 2003, 17, 3069–3084. [Google Scholar] [CrossRef]
- Ahmadi-Nedushan, B.; St-Hilaire, A.; Ouarda, T.B.M.J.; Bilodeau, L.; Robichaud, E.; Thiemonge, N.; Bobee, B. Predicting river water temperatures using stochastic models: Case study of the Moisie River (Qu’ebec, Cana-da). Hydrol. Process. 2007, 21, 21–34. [Google Scholar] [CrossRef]
- Sohrabi, M.M.; Benjankar, R.; Tonina, D.; Wenger, S.J.; Isaak, D.J. Estimation of daily stream water temperatures with a Bayesian regression approach. Hydrol. Process. 2017, 31, 1719–1733. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean | Min. | Max | Skewness | Std. Dev. | |
|---|---|---|---|---|---|
| Air Temperature | |||||
| M1 | 15.41 | −4 | 28.9 | −0.282 | 8.165 |
| M2 | 15.41 | −2.3 | 31.9 | −0.145 | 7.942 |
| M3 | 14.82 | −2.1 | 30.2 | −0.179 | 8.314 |
| Sediment Flow | |||||
| M1 | 207.8 | 0.001 | 4330 | 5.117 | 484.3 |
| M2 | 128.4 | 1.88 | 8710 | 10.55 | 487.4 |
| M3 | 231.0 | 1.9 | 8640 | 6.770 | 687.3 |
| Streamflow | |||||
| M1 | 108.3 | 38.3 | 327 | 1.047 | 56.29 |
| M2 | 102.4 | 33.8 | 413 | 1.217 | 59.3 |
| M3 | 128.4 | 36 | 653 | 1.642 | 92.17 |
| Precipitation | |||||
| M1 | 1.257 | 0 | 31.3 | 4.413 | 3.548 |
| M2 | 1.10 | 0 | 42 | 5.360 | 3.503 |
| M3 | 1.270 | 0 | 34 | 4.799 | 3.907 |
| Water Temperature | |||||
| M1 | 11.98 | 1.2 | 21 | −0.265 | 5.477 |
| M2 | 12.33 | 1.8 | 22.8 | −0.142 | 5.300 |
| M3 | 12.35 | 2.2 | 28.8 | −0.245 | 5.079 |
| Number of filters | [1–300] |
| Kernel size | [1–20] |
| Number of epochs | [1–200] |
| Batch size | [10–100] |
| Pooling size | [1–15] |
| Algorithm | Parameter | |
|---|---|---|
| RSA | 0.1 | |
| 0.1 | ||
| INFO | 2 | |
| 4 | ||
| Common Settings | Population | 30 |
| Number of iterations | 100 | |
| Number of runs for each algorithm | 30 | |
| Inputs Combinations | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.554 | 1.211 | 0.914 | 0.914 | 1.652 | 1.289 | 0.918 | 0.894 |
| (ii) Ta, P | 1.453 | 1.120 | 0.925 | 0.924 | 1.689 | 1.302 | 0.917 | 0.889 |
| (iii) Ta, Q | 1.538 | 1.194 | 0.915 | 0.915 | 1.654 | 1.294 | 0.918 | 0.894 |
| (iv) Ta, S | 1.494 | 1.154 | 0.920 | 0.920 | 1.645 | 1.294 | 0.921 | 0.895 |
| (v) Ta, P, Q | 1.497 | 1.162 | 0.920 | 0.920 | 1.636 | 1.281 | 0.920 | 0.896 |
| (vi) Ta, Q, S | 1.477 | 1.140 | 0.922 | 0.922 | 1.675 | 1.310 | 0.917 | 0.891 |
| (vii) Ta, P, Q, S | 1.489 | 1.149 | 0.921 | 0.921 | 1.644 | 1.287 | 0.922 | 0.895 |
| (viii) Ta, DOY | 1.414 | 1.089 | 0.928 | 0.928 | 1.623 | 1.256 | 0.921 | 0.898 |
| (ix) Ta, P, Q, S, DOY | 1.376 | 1.067 | 0.934 | 0.934 | 1.567 | 1.223 | 0.928 | 0.905 |
| Mean | 1.475 | 1.141 | 0.922 | 0.922 | 1.643 | 1.282 | 0.920 | 0.895 |
| M2 | ||||||||
| (i) Ta | 1.434 | 1.119 | 0.924 | 0.924 | 1.559 | 1.248 | 0.927 | 0.926 |
| (ii) Ta, P | 1.384 | 1.075 | 0.929 | 0.929 | 1.512 | 1.191 | 0.937 | 0.936 |
| (iii) Ta, Q | 1.444 | 1.119 | 0.923 | 0.923 | 1.528 | 1.221 | 0.929 | 0.928 |
| (iv) Ta, S | 1.464 | 1.140 | 0.921 | 0.920 | 1.552 | 1.237 | 0.929 | 0.925 |
| (v) Ta, P, Q | 1.379 | 1.068 | 0.929 | 0.929 | 1.491 | 1.199 | 0.932 | 0.929 |
| (vi) Ta, Q, S | 1.434 | 1.112 | 0.924 | 0.924 | 1.585 | 1.240 | 0.931 | 0.928 |
| (vii) Ta, P, Q, S | 1.468 | 1.061 | 0.920 | 0.920 | 1.480 | 1.178 | 0.929 | 0.926 |
| (viii) Ta, DOY | 1.360 | 1.046 | 0.930 | 0.930 | 1.441 | 1.165 | 0.937 | 0.933 |
| (ix) Ta, P, Q, S, DOY | 1.417 | 1.100 | 0.926 | 0.925 | 1.514 | 1.179 | 0.925 | 0.924 |
| Mean | 1.422 | 1.096 | 0.925 | 0.925 | 1.527 | 1.204 | 0.931 | 0.928 |
| M3 | ||||||||
| (i) Ta | 1.433 | 1.113 | 0.930 | 0.929 | 1.446 | 1.136 | 0.933 | 0.929 |
| (ii) Ta, P | 1.479 | 1.138 | 0.925 | 0.925 | 1.345 | 1.067 | 0.939 | 0.937 |
| (iii) Ta, Q | 1.393 | 1.076 | 0.933 | 0.933 | 1.426 | 1.119 | 0.936 | 0.932 |
| (iv) Ta, S | 1.407 | 1.091 | 0.932 | 0.932 | 1.449 | 1.122 | 0.934 | 0.930 |
| (v) Ta, P, Q | 1.374 | 1.063 | 0.935 | 0.935 | 1.457 | 1.145 | 0.938 | 0.924 |
| (vi) Ta, Q, S | 1.403 | 1.083 | 0.932 | 0.932 | 1.423 | 1.109 | 0.931 | 0.916 |
| (vii) Ta, P, Q, S | 1.334 | 1.031 | 0.937 | 0.937 | 1.420 | 1.105 | 0.934 | 0.921 |
| (viii) Ta, DOY | 1.420 | 1.112 | 0.931 | 0.931 | 1.409 | 1.113 | 0.936 | 0.926 |
| (ix) Ta, P, Q, S, DOY | 1.331 | 1.020 | 0.939 | 0.939 | 1.395 | 1.096 | 0.942 | 0.935 |
| Mean | 1.397 | 1.081 | 0.933 | 0.933 | 1.418 | 1.112 | 0.936 | 0.934 |
| Inputs Combinations | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.470 | 1.149 | 0.923 | 0.923 | 1.611 | 1.252 | 0.919 | 0.899 |
| (ii) Ta, P | 1.421 | 1.091 | 0.928 | 0.928 | 1.574 | 1.217 | 0.924 | 0.904 |
| (iii) Ta, Q | 1.451 | 1.112 | 0.925 | 0.925 | 1.594 | 1.229 | 0.920 | 0.902 |
| (iv) Ta, S | 1.477 | 1.143 | 0.922 | 0.922 | 1.620 | 1.260 | 0.919 | 0.898 |
| (v) Ta, P, Q | 1.399 | 1.077 | 0.930 | 0.930 | 1.600 | 1.258 | 0.925 | 0.901 |
| (vi) Ta, Q, S | 1.450 | 1.133 | 0.926 | 0.925 | 1.649 | 1.292 | 0.920 | 0.895 |
| (vii) Ta, P, Q, S | 1.401 | 1.080 | 0.930 | 0.930 | 1.584 | 1.254 | 0.929 | 0.903 |
| (viii) Ta, DOY | 1.388 | 1.080 | 0.933 | 0.931 | 1.557 | 1.212 | 0.928 | 0.906 |
| (ix) Ta, P, Q, S, DOY | 1.336 | 1.034 | 0.936 | 0.933 | 1.507 | 1.54 | 0.930 | 0.912 |
| Mean | 1.421 | 1.100 | 0.928 | 0.927 | 1.588 | 1.236 | 0.924 | 0.902 |
| M2 | ||||||||
| (i) Ta | 1.420 | 1.104 | 0.925 | 0.925 | 1.535 | 1.227 | 0.931 | 0.921 |
| (ii) Ta, P | 1.358 | 1.053 | 0.932 | 0.932 | 1.478 | 1.173 | 0.941 | 0.927 |
| (iii) Ta, Q | 1.419 | 1.098 | 0.925 | 0.925 | 1.526 | 1.216 | 0.931 | 0.922 |
| (iv) Ta, S | 1.436 | 1.114 | 0.924 | 0.923 | 1.548 | 1.232 | 0.934 | 0.920 |
| (v) Ta, P, Q | 1.376 | 1.053 | 0.930 | 0.930 | 1.471 | 1.163 | 0.938 | 0.928 |
| (vi) Ta, Q, S | 1.430 | 1.110 | 0.924 | 0.924 | 1.540 | 1.254 | 0.933 | 0.921 |
| (vii) Ta, P, Q, S | 1.413 | 1.096 | 0.926 | 0.926 | 1.474 | 1.146 | 0.937 | 0.928 |
| (viii) Ta, DOY | 1.352 | 1.047 | 0.932 | 0.932 | 1.452 | 1.173 | 0.937 | 0.930 |
| (ix) Ta, P, Q, S, DOY | 1.330 | 1.019 | 0.938 | 0.936 | 1.445 | 1.146 | 0.943 | 0.933 |
| Mean | 1.393 | 1.077 | 0.930 | 0.929 | 1.496 | 1.192 | 0.936 | 0.925 |
| M3 | ||||||||
| (i) Ta | 1.413 | 1.100 | 0.931 | 0.931 | 1.416 | 1.118 | 0.933 | 0.929 |
| (ii) Ta, P | 1.354 | 1.056 | 0.937 | 0.937 | 1.316 | 1.043 | 0.940 | 0.938 |
| (iii) Ta, Q | 1.370 | 1.064 | 0.936 | 0.935 | 1.419 | 1.116 | 0.934 | 0.928 |
| (iv) Ta, S | 1.389 | 1.077 | 0.934 | 0.934 | 1.399 | 1.093 | 0.933 | 0.930 |
| (v) Ta, P, Q | 1.317 | 1.009 | 0.941 | 0.940 | 1.330 | 1.032 | 0.941 | 0.937 |
| (vi) Ta, Q, S | 1.379 | 1.072 | 0.935 | 0.935 | 1.397 | 1.098 | 0.936 | 0.930 |
| (vii) Ta, P, Q, S | 1.324 | 1.020 | 0.940 | 0.940 | 1.365 | 1.069 | 0.940 | 0.934 |
| (viii) Ta, DOY | 1.279 | 1.002 | 0.945 | 0.944 | 1.266 | 0.978 | 0.947 | 0.943 |
| (ix) Ta, P, Q, S, DOY | 1.316 | 1.019 | 0.940 | 0.940 | 1.351 | 1.066 | 0.943 | 0.935 |
| Mean | 1.349 | 1.046 | 0.938 | 0.937 | 1.362 | 1.068 | 0.939 | 0.934 |
| Inputs Combinations | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.450 | 1.131 | 0.925 | 0.925 | 1.606 | 1.243 | 0.922 | 0.900 |
| (ii) Ta, P | 1.413 | 1.089 | 0.929 | 0.929 | 1.573 | 1.218 | 0.925 | 0.904 |
| (iii) Ta, Q | 1.348 | 1.043 | 0.935 | 0.935 | 1.546 | 1.182 | 0.928 | 0.907 |
| (iv) Ta, S | 1.442 | 1.124 | 0.926 | 0.926 | 1.620 | 1.276 | 0.921 | 0.898 |
| (v) Ta, P, Q | 1.330 | 1.020 | 0.937 | 0.937 | 1.505 | 1.186 | 0.933 | 0.912 |
| (vi) Ta, Q, S | 1.358 | 1.054 | 0.935 | 0.934 | 1.561 | 1.222 | 0.927 | 0.905 |
| (vii) Ta, P, Q, S | 1.333 | 1.035 | 0.937 | 0.936 | 1.507 | 1.176 | 0.933 | 0.912 |
| (viii) Ta, DOY | 1.318 | 1.013 | 0.940 | 0.938 | 1.360 | 1.081 | 0.945 | 0.928 |
| (ix) Ta, P, Q, S, DOY | 1.369 | 1.051 | 0.933 | 0.933 | 1.538 | 1.188 | 0.928 | 0.908 |
| Mean | 1.373 | 1.062 | 0.933 | 0.932 | 1.535 | 1.197 | 0.929 | 0.908 |
| M2 | ||||||||
| (i) Ta | 1.425 | 1.108 | 0.925 | 0.925 | 1.515 | 1.225 | 0.931 | 0.923 |
| (ii) Ta, P | 1.334 | 1.030 | 0.934 | 0.934 | 1.451 | 1.148 | 0.942 | 0.930 |
| (iii) Ta, Q | 1.388 | 1.073 | 0.930 | 0.928 | 1.435 | 1.151 | 0.931 | 0.931 |
| (iv) Ta, S | 1.440 | 1.119 | 0.923 | 0.923 | 1.531 | 1.213 | 0.933 | 0.922 |
| (v) Ta, P, Q | 1.288 | 1.000 | 0.939 | 0.938 | 1.421 | 1.113 | 0.938 | 0.933 |
| (vi) Ta, Q, S | 1.326 | 1.044 | 0.936 | 0.935 | 1.525 | 1.214 | 0.934 | 0.922 |
| (vii) Ta, P, Q, S | 1.358 | 1.047 | 0.932 | 0.932 | 1.467 | 1.157 | 0.937 | 0.928 |
| (viii) Ta, DOY | 1.132 | 0.874 | 0.953 | 0.952 | 1.383 | 1.099 | 0.946 | 0.936 |
| (ix) Ta, P, Q, S, DOY | 1.303 | 1.016 | 0.937 | 0.937 | 1.403 | 1.109 | 0.938 | 0.934 |
| Mean | 1.333 | 1.034 | 0.934 | 0.934 | 1.459 | 1.159 | 0.937 | 0.929 |
| M3 | ||||||||
| (i) Ta | 1.404 | 1.090 | 0.932 | 0.932 | 1.414 | 1.112 | 0.936 | 0.929 |
| (ii) Ta, P | 1.337 | 1.036 | 0.939 | 0.939 | 1.275 | 0.993 | 0.943 | 0.942 |
| (iii) Ta, Q | 1.359 | 1.057 | 0.937 | 0.937 | 1.395 | 1.078 | 0.941 | 0.931 |
| (iv) Ta, S | 1.357 | 1.052 | 0.937 | 0.937 | 1.401 | 1.100 | 0.934 | 0.930 |
| (v) Ta, P, Q | 1.256 | 0.962 | 0.946 | 0.946 | 1.335 | 1.051 | 0.944 | 0.937 |
| (vi) Ta, Q, S | 1.378 | 1.066 | 0.935 | 0.935 | 1.382 | 1.086 | 0.935 | 0.932 |
| (vii) Ta, P, Q, S | 1.290 | 0.990 | 0.943 | 0.943 | 1.364 | 1.069 | 0.941 | 0.934 |
| (viii) Ta, DOY | 1.219 | 0.947 | 0.950 | 0.949 | 1.241 | 0.962 | 0.949 | 0.945 |
| (ix) Ta, P, Q, S, DOY | 1.276 | 0.996 | 0.944 | 0.944 | 1.351 | 1.067 | 0.944 | 0.935 |
| Mean | 1.320 | 1.022 | 0.940 | 0.940 | 1.351 | 1.058 | 0.941 | 0.935 |
| Inputs Combinations | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.529 | 1.186 | 0.916 | 0.916 | 1.631 | 1.259 | 0.919 | 0.897 |
| (ii) Ta, P | 1.438 | 1.108 | 0.926 | 0.926 | 1.612 | 1.251 | 0.925 | 0.899 |
| (iii) Ta, Q | 1.438 | 1.118 | 0.926 | 0.926 | 1.580 | 1.233 | 0.926 | 0.903 |
| (iv) Ta, S | 1.500 | 1.160 | 0.919 | 0.919 | 1.639 | 1.281 | 0.919 | 0.896 |
| (v) Ta, P, Q | 1.400 | 1.079 | 0.930 | 0.930 | 1.592 | 1.243 | 0.925 | 0.902 |
| (vi) Ta, Q, S | 1.452 | 1.118 | 0.925 | 0.925 | 1.654 | 1.295 | 0.918 | 0.894 |
| (vii) Ta, P, Q, S | 1.414 | 1.089 | 0.928 | 0.928 | 1.595 | 1.251 | 0.925 | 0.901 |
| (viii) Ta, DOY | 1.499 | 1.162 | 0.920 | 0.920 | 1.614 | 1.261 | 0.934 | 0.899 |
| (ix) Ta, P, Q, S, DOY | 1.386 | 1.068 | 0.932 | 0.932 | 1.566 | 1.221 | 0.929 | 0.905 |
| Mean | 1.451 | 1.121 | 0.925 | 0.925 | 1.609 | 1.255 | 0.924 | 0.900 |
| M2 | ||||||||
| (i) Ta | 1.428 | 1.111 | 0.924 | 0.924 | 1.535 | 1.242 | 0.930 | 0.921 |
| (ii) Ta, P | 1.384 | 1.069 | 0.929 | 0.929 | 1.466 | 1.151 | 0.937 | 0.928 |
| (iii) Ta, Q | 1.444 | 1.119 | 0.923 | 0.923 | 1.525 | 1.216 | 0.932 | 0.922 |
| (iv) Ta, S | 1.429 | 1.115 | 0.924 | 0.924 | 1.587 | 1.272 | 0.933 | 0.916 |
| (v) Ta, P, Q | 1.383 | 1.071 | 0.929 | 0.929 | 1.537 | 1.218 | 0.935 | 0.921 |
| (vi) Ta, Q, S | 1.434 | 1.113 | 0.924 | 0.924 | 1.572 | 1.271 | 0.932 | 0.918 |
| (vii) Ta, P, Q, S | 1.379 | 1.070 | 0.929 | 0.929 | 1.523 | 1.202 | 0.936 | 0.923 |
| (viii) Ta, DOY | 1.440 | 1.118 | 0.923 | 0.923 | 1.558 | 1.258 | 0.932 | 0.919 |
| (ix) Ta, P, Q, S, DOY | 1.358 | 1.052 | 0.932 | 0.932 | 1.456 | 1.168 | 0.937 | 0.929 |
| Mean | 1.409 | 1.093 | 0.927 | 0.927 | 1.529 | 1.222 | 0.934 | 0.922 |
| M3 | ||||||||
| (i) Ta | 1.417 | 1.092 | 0.931 | 0.931 | 1.424 | 1.117 | 0.934 | 0.928 |
| (ii) Ta, P | 1.361 | 1.050 | 0.936 | 0.936 | 1.341 | 1.050 | 0.939 | 0.936 |
| (iii) Ta, Q | 1.380 | 1.067 | 0.935 | 0.935 | 1.422 | 1.107 | 0.935 | 0.928 |
| (iv) Ta, S | 1.402 | 1.088 | 0.932 | 0.932 | 1.428 | 1.110 | 0.928 | 0.927 |
| (v) Ta, P, Q | 1.328 | 1.056 | 0.936 | 0.935 | 1.363 | 1.088 | 0.934 | 0.934 |
| (vi) Ta, Q, S | 1.383 | 1.068 | 0.934 | 0.934 | 1.411 | 1.091 | 0.940 | 0.929 |
| (vii) Ta, P, Q, S | 1.328 | 1.024 | 0.939 | 0.939 | 1.365 | 1.068 | 0.935 | 0.934 |
| (viii) Ta, DOY | 1.393 | 1.081 | 0.933 | 0.933 | 1.405 | 1.110 | 0.931 | 0.930 |
| (ix) Ta, P, Q, S, DOY | 1.319 | 1.021 | 0.940 | 0.940 | 1.354 | 1.055 | 0.943 | 0.935 |
| Mean | 1.367 | 1.056 | 0.936 | 0.936 | 1.390 | 1.088 | 0.936 | 0.931 |
| Inputs Combinations | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.486 | 1.155 | 0.921 | 0.921 | 1.608 | 1.252 | 0.923 | 0.900 |
| (ii) Ta, P | 1.399 | 1.084 | 0.931 | 0.930 | 1.555 | 1.197 | 0.927 | 0.906 |
| (iii) Ta, Q | 1.400 | 1.089 | 0.930 | 0.930 | 1.549 | 1.165 | 0.921 | 0.907 |
| (iv) Ta, S | 1.368 | 1.078 | 0.933 | 0.933 | 1.623 | 1.286 | 0.925 | 0.898 |
| (v) Ta, P, Q | 1.332 | 1.035 | 0.940 | 0.936 | 1.556 | 1.220 | 0.930 | 0.906 |
| (vi) Ta, Q, S | 1.446 | 1.116 | 0.925 | 0.925 | 1.645 | 1.289 | 0.920 | 0.895 |
| (vii) Ta, P, Q, S | 1.400 | 1.082 | 0.930 | 0.930 | 1.586 | 1.242 | 0.925 | 0.902 |
| (viii) Ta, DOY | 1.180 | 0.914 | 0.950 | 0.950 | 1.520 | 1.175 | 0.939 | 0.910 |
| (ix) Ta, P, Q, S, DOY | 1.351 | 1.048 | 0.932 | 0.932 | 1.553 | 1.205 | 0.926 | 0.907 |
| Mean | 1.372 | 1.066 | 0.932 | 0.932 | 1.577 | 1.226 | 0.926 | 0.904 |
| M2 | ||||||||
| (i) Ta | 1.418 | 1.101 | 0.925 | 0.925 | 1.530 | 1.228 | 0.929 | 0.922 |
| (ii) Ta, P | 1.372 | 1.062 | 0.930 | 0.930 | 1.419 | 1.130 | 0.941 | 0.933 |
| (iii) Ta, Q | 1.314 | 1.015 | 0.936 | 0.936 | 1.437 | 1.147 | 0.933 | 0.931 |
| (iv) Ta, S | 1.384 | 1.077 | 0.929 | 0.929 | 1.501 | 1.214 | 0.936 | 0.925 |
| (v) Ta, P, Q | 1.327 | 1.028 | 0.935 | 0.935 | 1.426 | 1.122 | 0.939 | 0.932 |
| (vi) Ta, Q, S | 1.378 | 1.058 | 0.930 | 0.930 | 1.512 | 1.202 | 0.932 | 0.924 |
| (vii) Ta, P, Q, S | 1.378 | 1.073 | 0.930 | 0.930 | 1.463 | 1.152 | 0.940 | 0.929 |
| (viii) Ta, DOY | 1.027 | 0.799 | 0.961 | 0.961 | 1.176 | 0.921 | 0.945 | 0.939 |
| (ix) Ta, P, Q, S, DOY | 1.342 | 1.037 | 0.936 | 0.936 | 1.449 | 1.158 | 0.938 | 0.930 |
| Mean | 1.328 | 1.029 | 0.935 | 0.935 | 1.428 | 1.135 | 0.938 | 0.932 |
| M3 | ||||||||
| (i) Ta | 1.393 | 1.075 | 0.933 | 0.933 | 1.421 | 1.113 | 0.935 | 0.928 |
| (ii) Ta, P | 1.305 | 1.006 | 0.942 | 0.941 | 1.317 | 1.040 | 0.944 | 0.938 |
| (iii) Ta, Q | 1.354 | 1.056 | 0.937 | 0.937 | 1.392 | 1.082 | 0.942 | 0.931 |
| (iv) Ta, S | 1.394 | 1.089 | 0.934 | 0.933 | 1.375 | 1.064 | 0.942 | 0.933 |
| (v) Ta, P, Q | 1.314 | 1.013 | 0.941 | 0.941 | 1.328 | 1.015 | 0.944 | 0.937 |
| (vi) Ta, Q, S | 1.343 | 1.049 | 0.938 | 0.938 | 1.404 | 1.096 | 0.935 | 0.930 |
| (vii) Ta, P, Q, S | 1.325 | 1.021 | 0.940 | 0.940 | 1.314 | 1.031 | 0.941 | 0.939 |
| (viii) Ta, DOY | 1.138 | 0.861 | 0.956 | 0.955 | 1.112 | 0.866 | 0.949 | 0.942 |
| (ix) Ta, P, Q, S, DOY | 1.191 | 0.921 | 0.954 | 0.951 | 1.354 | 1.067 | 0.944 | 0.935 |
| Mean | 1.306 | 1.010 | 0.942 | 0.941 | 1.342 | 1.048 | 0.944 | 0.936 |
| Model Inputs | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| (i) Ta | 1.405 | 1.087 | 0.927 | 0.927 | 1.606 | 1.245 | 0.920 | 0.900 |
| (ii) Ta, P | 1.311 | 1.000 | 0.936 | 0.936 | 1.561 | 1.229 | 0.929 | 0.905 |
| (iii) Ta, Q | 1.270 | 0.963 | 0.940 | 0.940 | 1.445 | 1.105 | 0.931 | 0.919 |
| (iv) Ta, S | 1.371 | 1.076 | 0.930 | 0.930 | 1.574 | 1.246 | 0.927 | 0.904 |
| (v) Ta, P, Q | 1.248 | 0.967 | 0.942 | 0.942 | 1.457 | 1.142 | 0.936 | 0.918 |
| (vi) Ta, Q, S | 1.287 | 1.020 | 0.939 | 0.939 | 1.512 | 1.183 | 0.932 | 0.911 |
| (vii) Ta, P, Q, S | 1.338 | 1.059 | 0.934 | 0.934 | 1.476 | 1.145 | 0.936 | 0.916 |
| (viii) Ta, DOY | 1.161 | 0.889 | 0.950 | 0.950 | 1.256 | 1.010 | 0.955 | 0.939 |
| (ix) Ta, P, Q, S, DOY | 1.263 | 0.982 | 0.942 | 0.941 | 1.416 | 1.108 | 0.941 | 0.922 |
| Mean | 1.295 | 1.005 | 0.938 | 0.938 | 1.478 | 1.157 | 0.934 | 0.915 |
| M2 | ||||||||
| (i) Ta | 1.460 | 1.139 | 0.924 | 0.924 | 1.511 | 1.213 | 0.930 | 0.924 |
| (ii) Ta, P | 1.356 | 1.042 | 0.934 | 0.934 | 1.420 | 1.124 | 0.942 | 0.933 |
| (iii) Ta, Q | 1.285 | 0.976 | 0.941 | 0.941 | 1.484 | 1.208 | 0.931 | 0.927 |
| (iv) Ta, S | 1.453 | 1.137 | 0.925 | 0.924 | 1.487 | 1.198 | 0.935 | 0.926 |
| (v) Ta, P, Q | 1.261 | 0.971 | 0.943 | 0.943 | 1.402 | 1.116 | 0.940 | 0.935 |
| (vi) Ta, Q, S | 1.301 | 1.018 | 0.939 | 0.939 | 1.524 | 1.213 | 0.935 | 0.923 |
| (vii) Ta, P, Q, S | 1.256 | 0.982 | 0.944 | 0.944 | 1.459 | 1.149 | 0.938 | 0.929 |
| (viii) Ta, DOY | 1.076 | 0.798 | 0.959 | 0.959 | 1.290 | 1.008 | 0.960 | 0.945 |
| (ix) Ta, P, Q, S, DOY | 1.052 | 0.823 | 0.960 | 0.960 | 1.198 | 0.946 | 0.950 | 0.952 |
| Mean | 1.278 | 0.987 | 0.941 | 0.941 | 1.419 | 1.131 | 0.940 | 0.932 |
| M3 | ||||||||
| (i) Ta | 1.378 | 1.060 | 0.935 | 0.935 | 1.412 | 1.104 | 0.935 | 0.929 |
| (ii) Ta, P | 1.254 | 0.963 | 0.946 | 0.946 | 1.292 | 1.006 | 0.945 | 0.941 |
| (iii) Ta, Q | 1.279 | 0.978 | 0.944 | 0.944 | 1.394 | 1.087 | 0.942 | 0.931 |
| (iv) Ta, S | 1.330 | 1.034 | 0.939 | 0.939 | 1.390 | 1.078 | 0.942 | 0.931 |
| (v) Ta, P, Q | 1.245 | 0.964 | 0.947 | 0.947 | 1.326 | 1.046 | 0.949 | 0.937 |
| (vi) Ta, Q, S | 1.295 | 1.004 | 0.942 | 0.942 | 1.376 | 1.104 | 0.935 | 0.933 |
| (vii) Ta, P, Q, S | 1.258 | 0.971 | 0.946 | 0.946 | 1.339 | 1.058 | 0.942 | 0.936 |
| (viii) Ta, DOY | 0.957 | 0.721 | 0.968 | 0.968 | 1.079 | 0.839 | 0.956 | 0.959 |
| (ix) Ta, P, Q, S, DOY | 1.067 | 0.816 | 0.961 | 0.961 | 1.187 | 0.880 | 0.965 | 0.950 |
| Mean | 1.229 | 0.946 | 0.947 | 0.947 | 1.310 | 1.022 | 0.946 | 0.938 |
| Model | Training Period | Test Period | ||||||
|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | NSE | RMSE | MAE | R2 | NSE | |
| M1 | ||||||||
| CNN | 1.376 | 1.067 | 0.934 | 0.934 | 1.567 | 1.223 | 0.928 | 0.905 |
| CNN-RSA | 1.336 | 1.034 | 0.936 | 0.933 | 1.507 | 1.54 | 0.930 | 0.912 |
| CNN-INFO | 1.318 | 1.013 | 0.940 | 0.938 | 1.360 | 1.081 | 0.945 | 0.928 |
| Mean | 1.343 | 1.038 | 0.937 | 0.935 | 1.478 | 1.281 | 0.934 | 0.915 |
| LSTM | 1.386 | 1.068 | 0.932 | 0.932 | 1.566 | 1.221 | 0.929 | 0.905 |
| LSTM-RSA | 1.180 | 0.914 | 0.950 | 0.950 | 1.520 | 1.175 | 0.939 | 0.910 |
| LSTM-INFO | 1.161 | 0.889 | 0.950 | 0.950 | 1.256 | 1.010 | 0.955 | 0.939 |
| Mean | 1.242 | 0.957 | 0.944 | 0.944 | 1.447 | 1.135 | 0.941 | 0.918 |
| M2 | ||||||||
| CNN | 1.360 | 1.046 | 0.930 | 0.930 | 1.441 | 1.165 | 0.937 | 0.933 |
| CNN-RSA | 1.330 | 1.019 | 0.938 | 0.936 | 1.445 | 1.146 | 0.943 | 0.930 |
| CNN-INFO | 1.132 | 0.874 | 0.953 | 0.952 | 1.383 | 1.099 | 0.946 | 0.936 |
| Mean | 1.274 | 0.980 | 0.940 | 0.939 | 1.423 | 1.137 | 0.942 | 0.933 |
| LSTM | 1.358 | 1.052 | 0.932 | 0.932 | 1.456 | 1.168 | 0.937 | 0.929 |
| LSTM-RSA | 1.027 | 0.799 | 0.961 | 0.961 | 1.116 | 0.866 | 0.955 | 0.959 |
| LSTM-INFO | 1.052 | 0.823 | 0.960 | 0.960 | 1.198 | 0.946 | 0.950 | 0.952 |
| Mean | 1.146 | 0.891 | 0.951 | 0.951 | 1.257 | 0.993 | 0.947 | 0.947 |
| M3 | ||||||||
| CNN | 1.331 | 1.020 | 0.939 | 0.939 | 1.395 | 1.096 | 0.942 | 0.935 |
| CNN-RSA | 1.279 | 1.002 | 0.945 | 0.944 | 1.266 | 0.978 | 0.947 | 0.943 |
| CNN-INFO | 1.219 | 0.947 | 0.950 | 0.949 | 1.241 | 0.962 | 0.949 | 0.945 |
| Mean | 1.276 | 0.990 | 0.945 | 0.944 | 1.301 | 1.012 | 0.946 | 0.941 |
| LSTM | 1.319 | 1.021 | 0.940 | 0.940 | 1.354 | 1.055 | 0.943 | 0.935 |
| LSTM-RSA | 1.138 | 0.861 | 0.956 | 0.955 | 1.112 | 0.866 | 0.949 | 0.942 |
| LSTM-INFO | 0.957 | 0.721 | 0.968 | 0.968 | 1.079 | 0.839 | 0.956 | 0.959 |
| Mean | 1.138 | 0.868 | 0.955 | 0.954 | 1.202 | 0.938 | 0.952 | 0.948 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ikram, R.M.A.; Mostafa, R.R.; Chen, Z.; Parmar, K.S.; Kisi, O.; Zounemat-Kermani, M. Water Temperature Prediction Using Improved Deep Learning Methods through Reptile Search Algorithm and Weighted Mean of Vectors Optimizer. J. Mar. Sci. Eng. 2023, 11, 259. https://doi.org/10.3390/jmse11020259
Ikram RMA, Mostafa RR, Chen Z, Parmar KS, Kisi O, Zounemat-Kermani M. Water Temperature Prediction Using Improved Deep Learning Methods through Reptile Search Algorithm and Weighted Mean of Vectors Optimizer. Journal of Marine Science and Engineering. 2023; 11(2):259. https://doi.org/10.3390/jmse11020259
Chicago/Turabian StyleIkram, Rana Muhammad Adnan, Reham R. Mostafa, Zhihuan Chen, Kulwinder Singh Parmar, Ozgur Kisi, and Mohammad Zounemat-Kermani. 2023. "Water Temperature Prediction Using Improved Deep Learning Methods through Reptile Search Algorithm and Weighted Mean of Vectors Optimizer" Journal of Marine Science and Engineering 11, no. 2: 259. https://doi.org/10.3390/jmse11020259
APA StyleIkram, R. M. A., Mostafa, R. R., Chen, Z., Parmar, K. S., Kisi, O., & Zounemat-Kermani, M. (2023). Water Temperature Prediction Using Improved Deep Learning Methods through Reptile Search Algorithm and Weighted Mean of Vectors Optimizer. Journal of Marine Science and Engineering, 11(2), 259. https://doi.org/10.3390/jmse11020259