


A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification

Abstract
:1. Introduction
2. System Overview
2.1. The Design of the Proposed Model
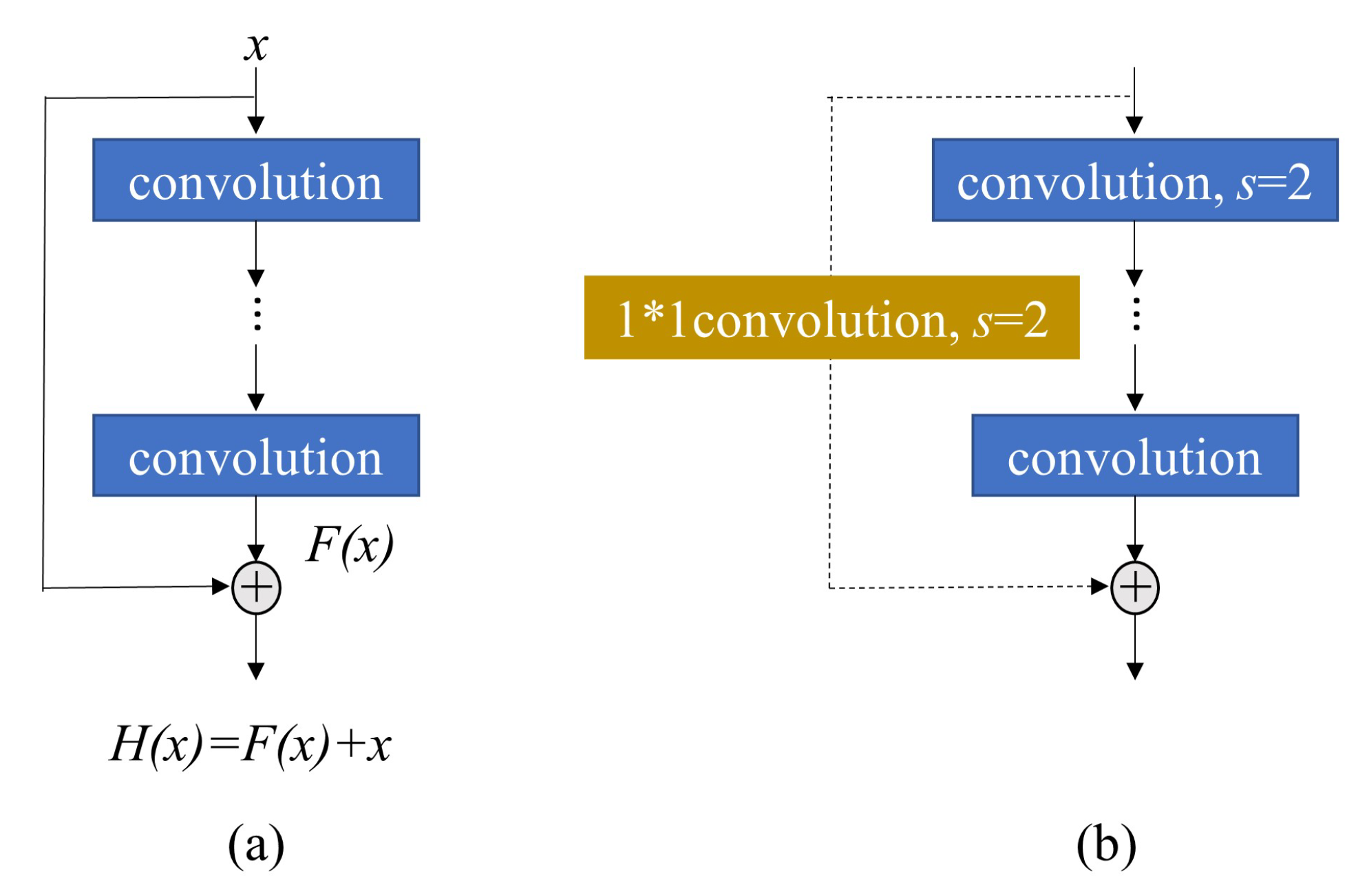
2.1.1. Residual Network (ResNet)
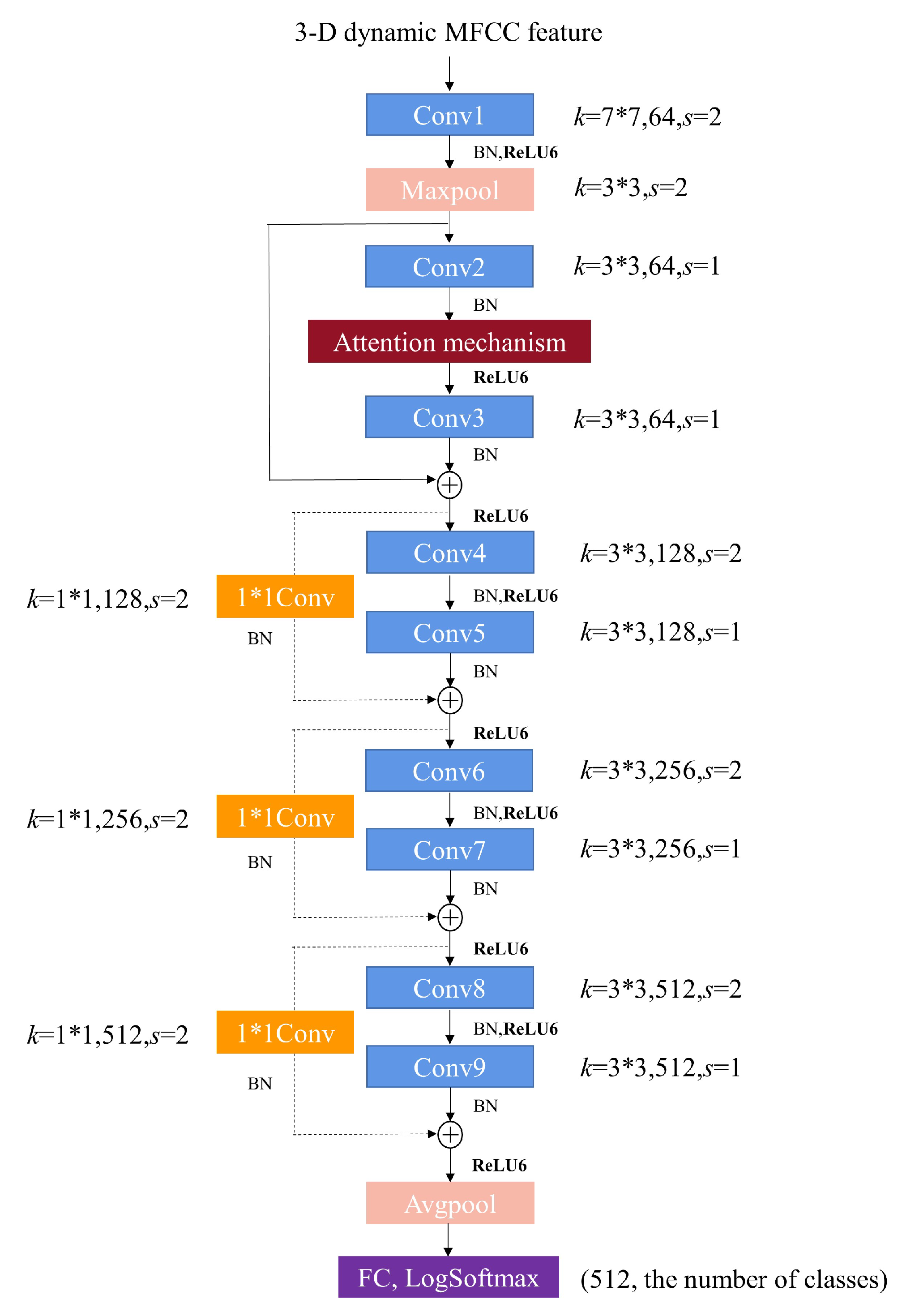
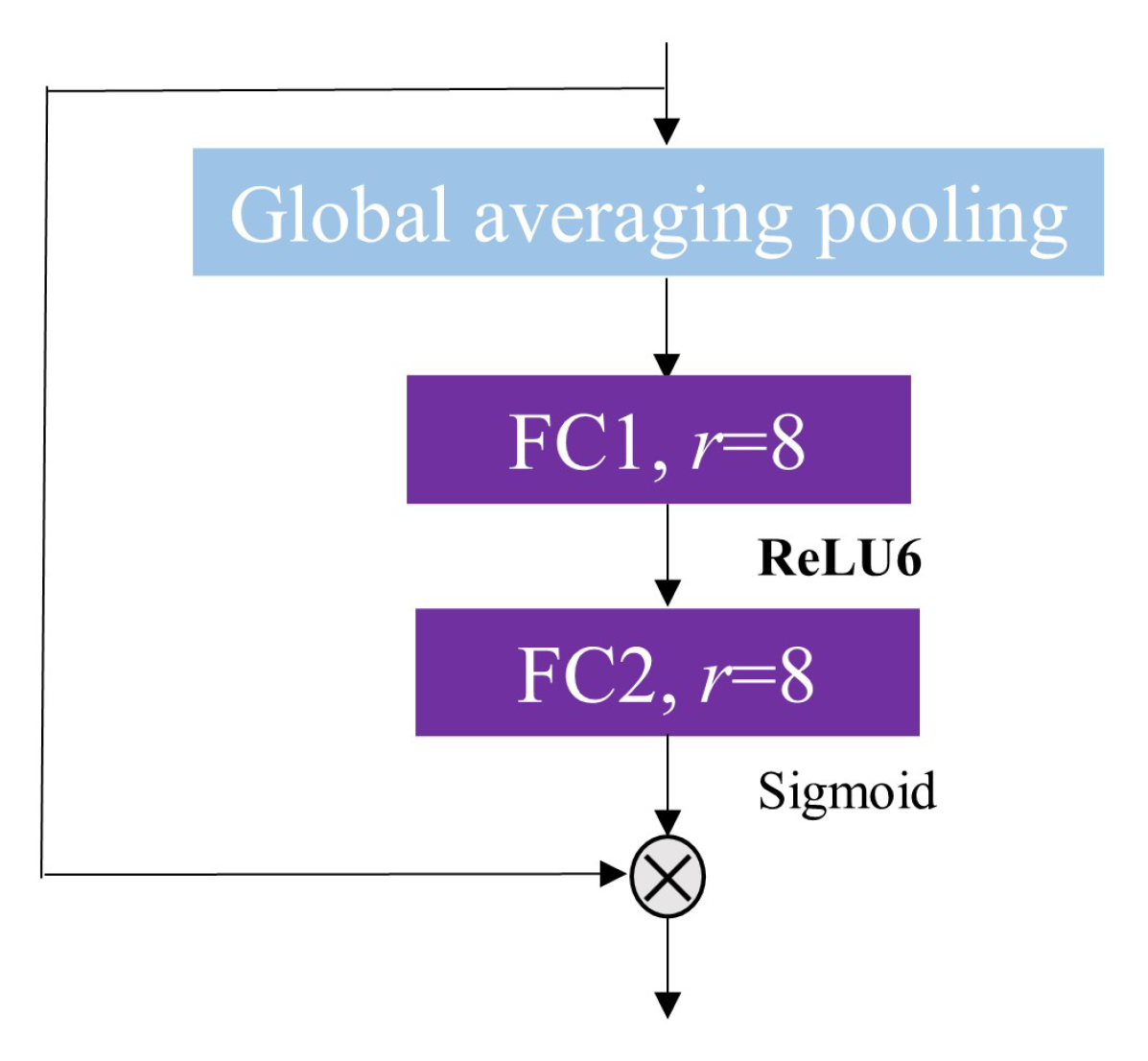
2.1.2. The Proposed Lightweight Squeeze and Excitation Residual Network 10 (LW-SEResNet10)
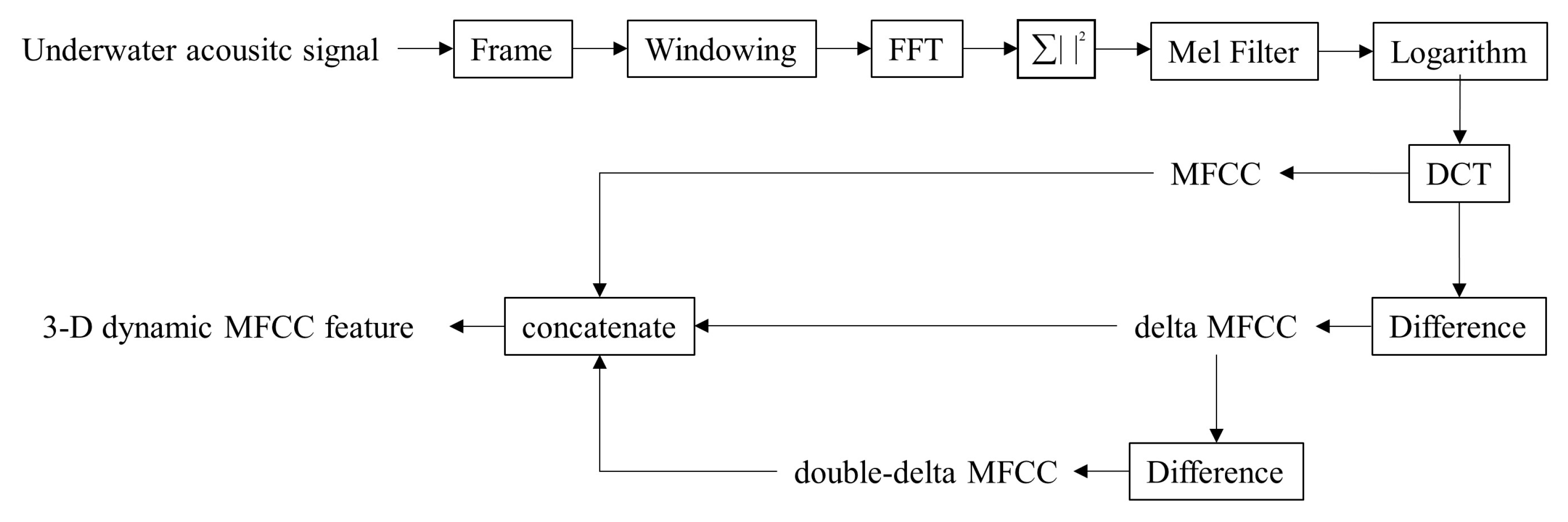
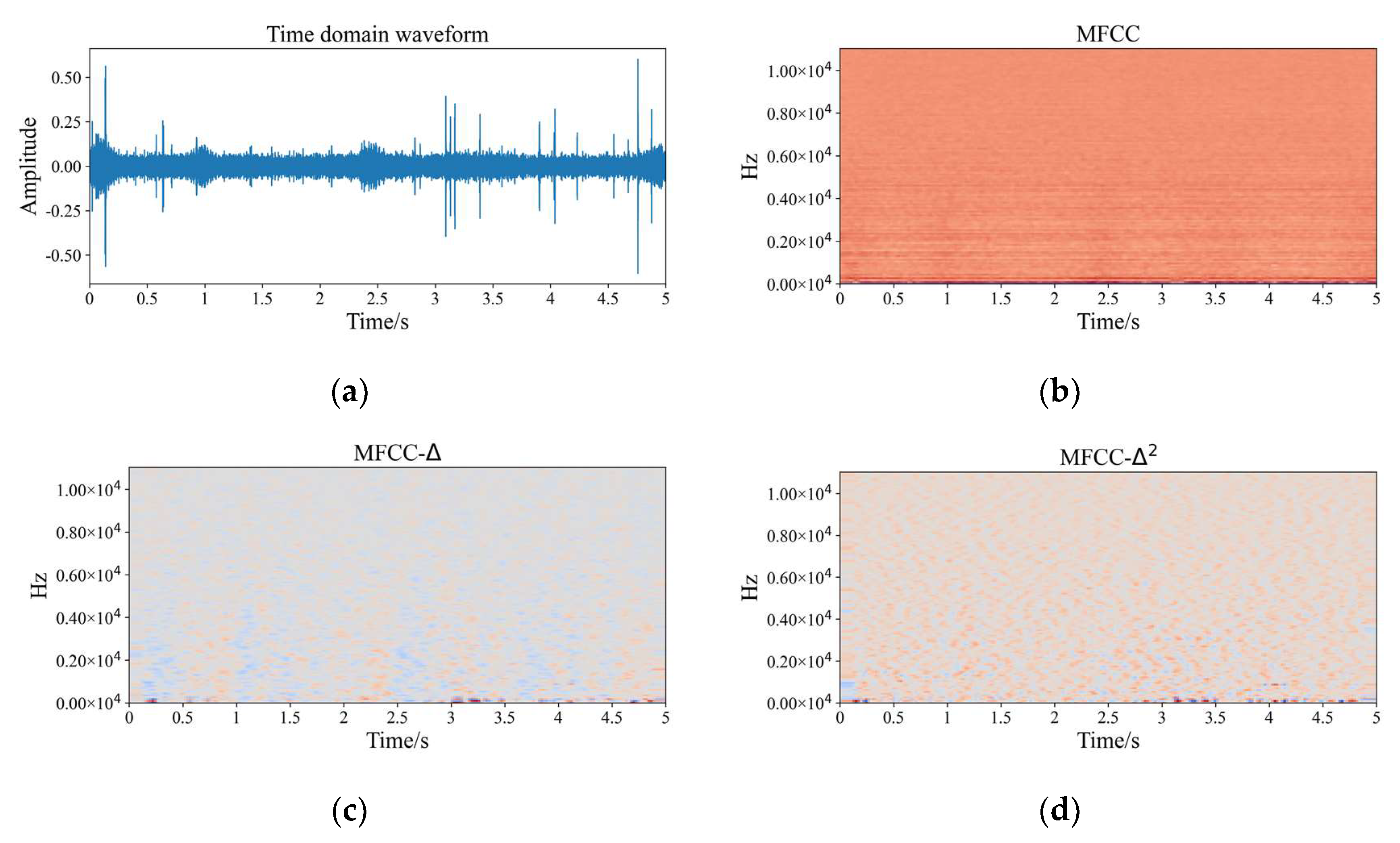
2.2. Feature Extraction
3. Results
3.1. Experimental Data
3.2. Hyperparameter and Cost Function Setup
3.3. Evaluation Metric
3.4. Experimental Results
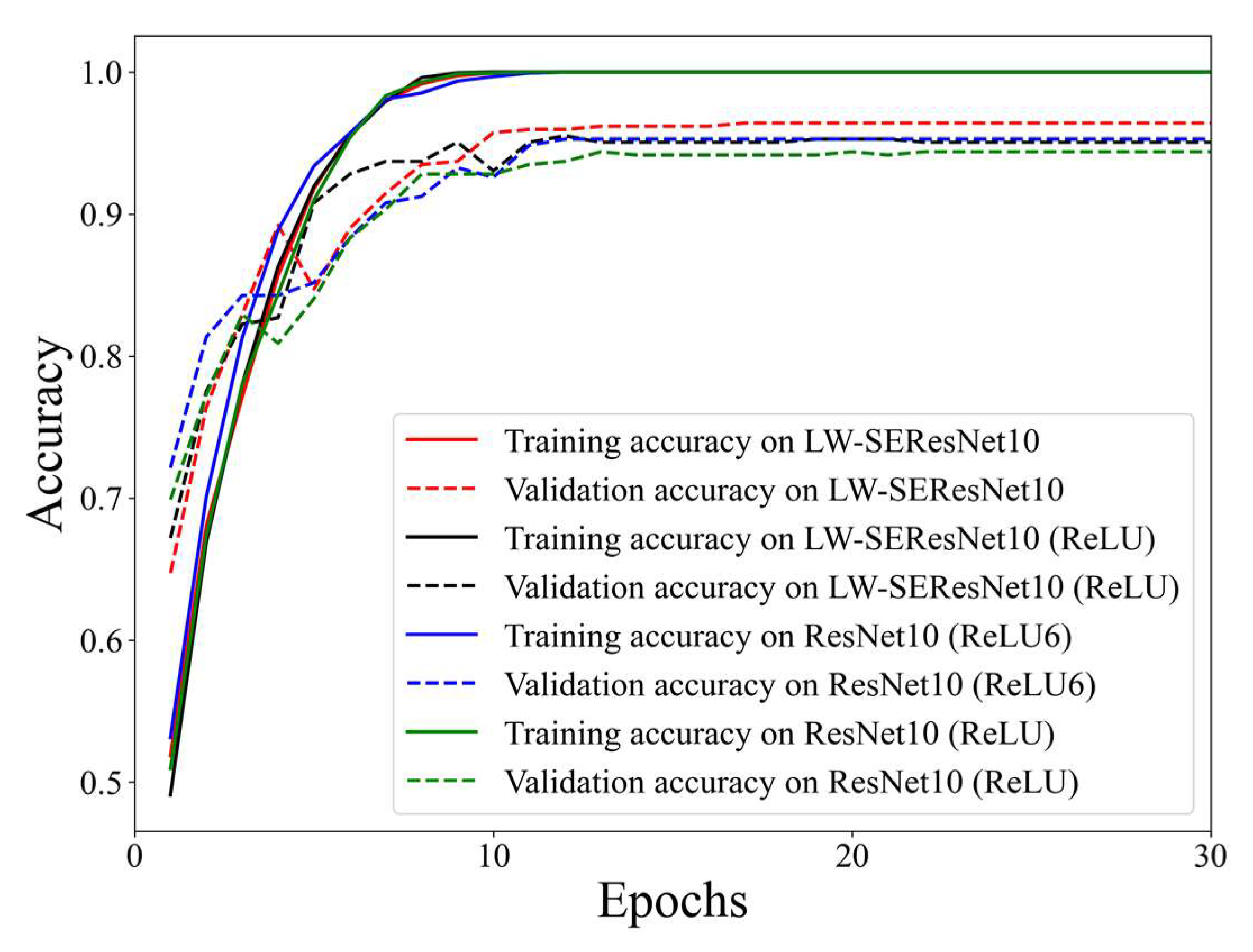
3.4.1. Ablation Experiments
- Model ablation experiments:
- Feature ablation experiments:
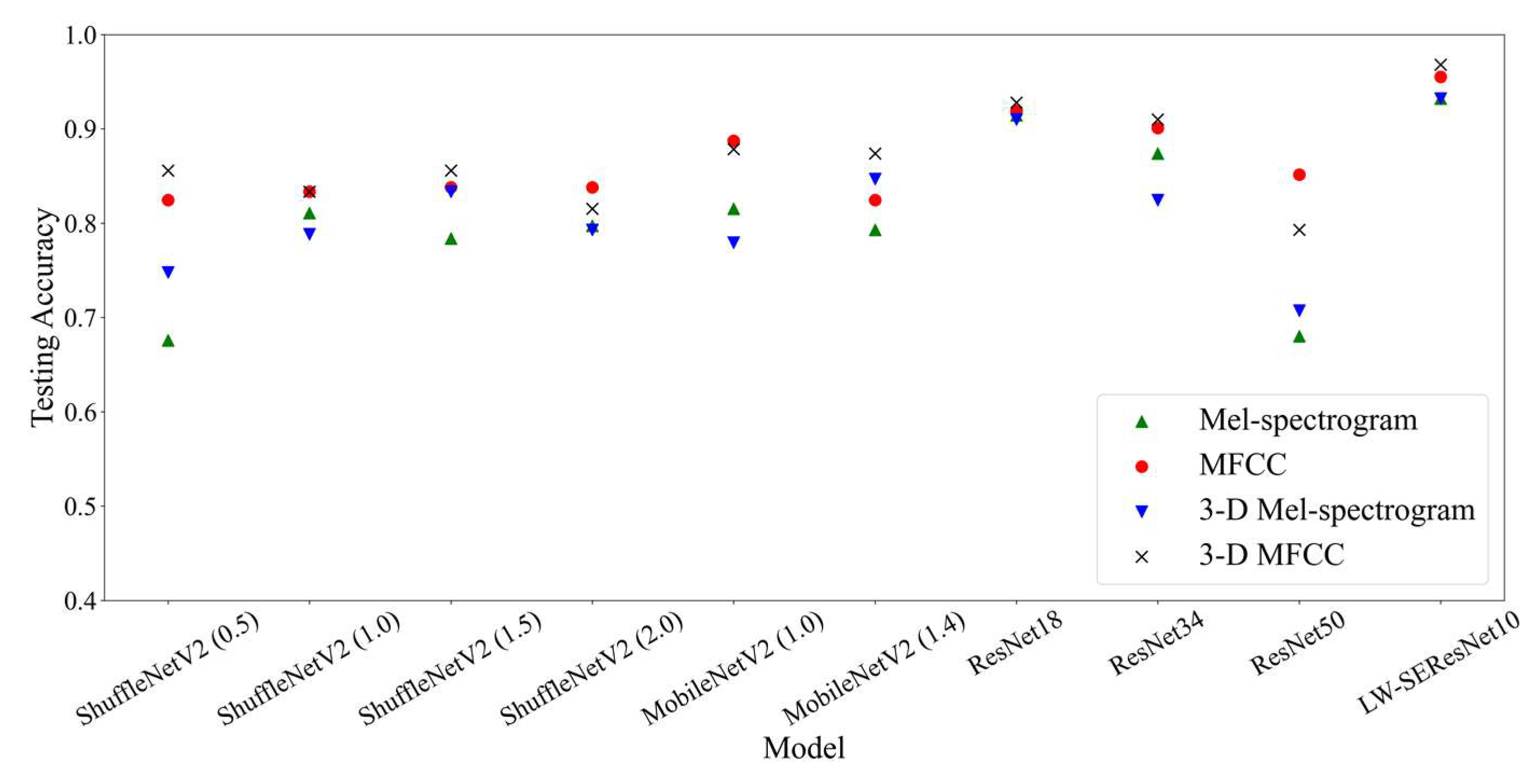
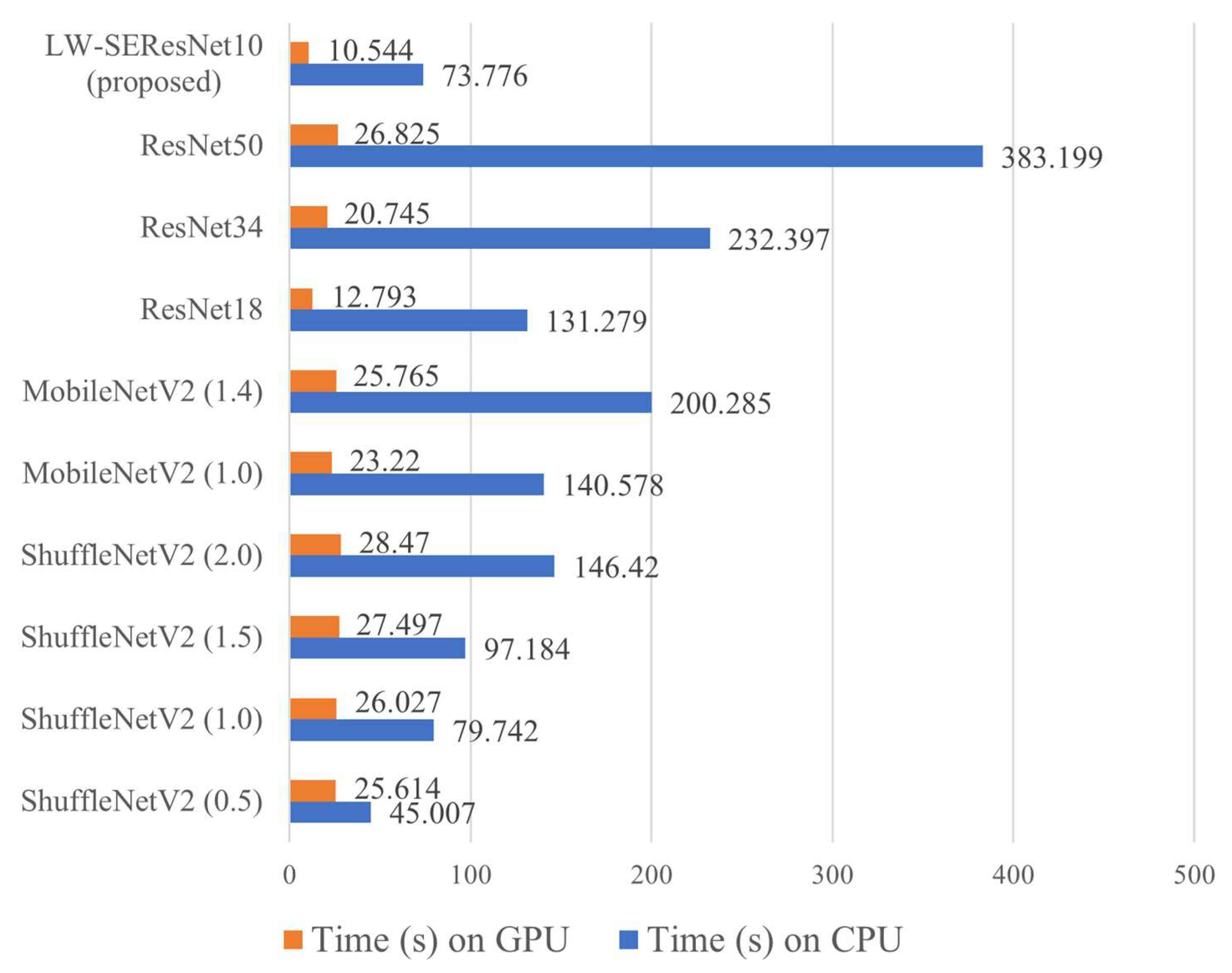
3.4.2. Comparison Experiments
- The comparison between parameters and accuracy:
- The comparison between different features:
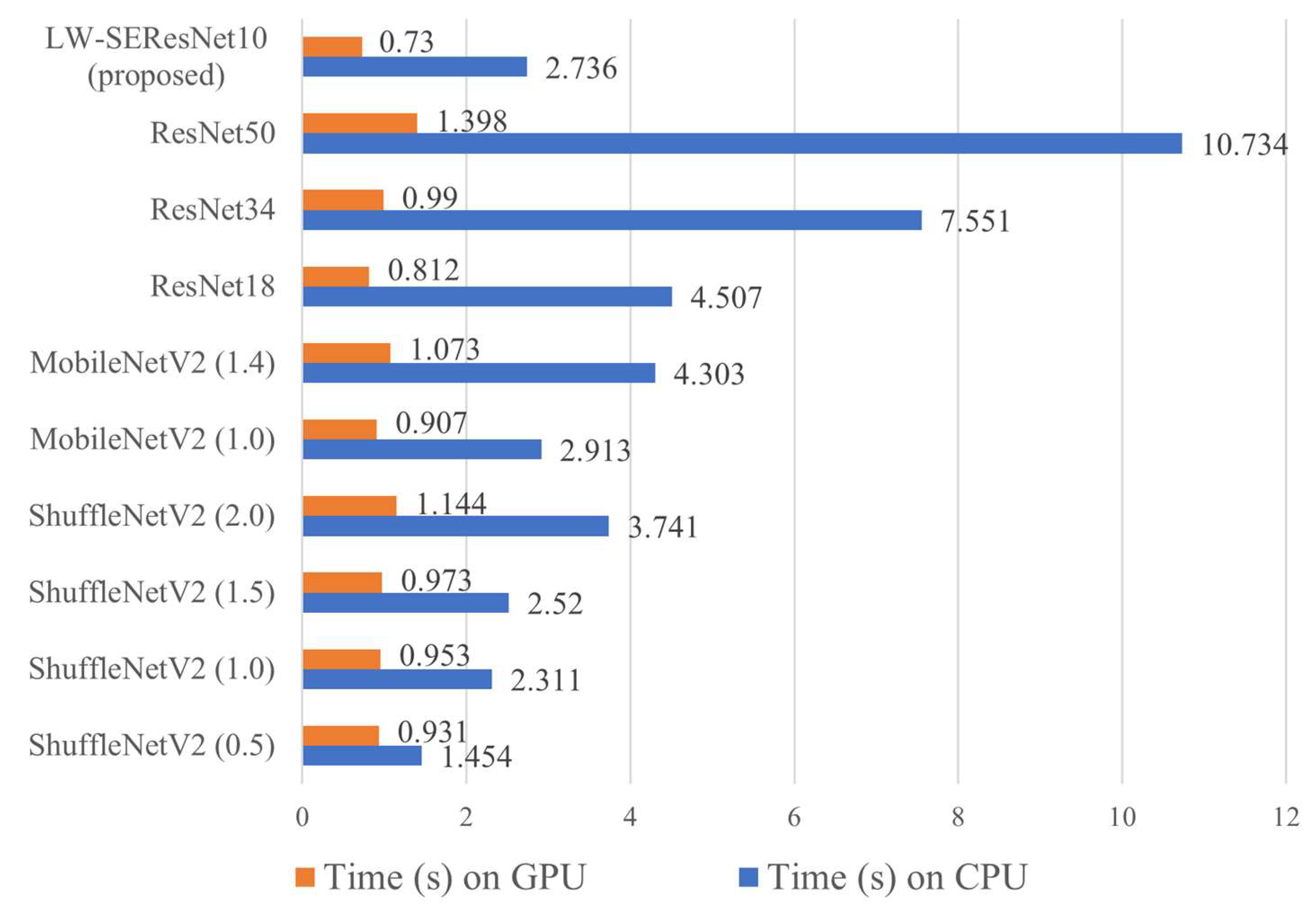
- The comparison between time consumptions:
- Optimization and comparing the performance of various models:
3.4.3. Noise Mismatch Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bernardini, M.; Fredianelli, L.; Fidecaro, F.; Gagliardi, P.; Nastasi, M.; Licitra, G. Noise Assessment of Small Vessels for Action Planning in Canal Cities. Environments 2019, 6, 31. [Google Scholar] [CrossRef] [Green Version]
- Fredianelli, L.; Nastasi, M.; Bernardini, M.; Fidecaro, F.; Licitra, G. Pass-by characterization of noise emitted by different categories of seagoing ships in ports. Sustainability 2020, 12, 1740. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Yang, H. The underwater acoustic target timbre perception and recognition based on the auditory inspired deep convolutional neural network. Appl. Acoust. 2021, 182, 108210. [Google Scholar] [CrossRef]
- Hong, F.; Liu, C.; Guo, L. Underwater Acoustic Target Recognition with ResNet18 on ShipsEar Dataset. In Proceedings of the 2021 IEEE 4th International Conference on Electronics Technology (ICET), Chengdu, China, 7–10 May 2021; pp. 1240–1244. [Google Scholar] [CrossRef]
- Jin, A.; Zeng, X. A Novel Deep Learning Method for Underwater Target Recognition Based on Res-Dense Convolutional Neural Network with Attention Mechanism. J. Mar. Sci. Eng. 2023, 11, 69. [Google Scholar] [CrossRef]
- Hu, G.; Wang, K.; Liu, L. Underwater acoustic target recognition based on depthwise separable convolution neural networks. Sensors 2021, 21, 1429. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Q.; Da, L.; Zhang, Y. Integrated neural networks based on feature fusion for underwater target recognition. Appl. Acoust. 2021, 182, 108261. [Google Scholar] [CrossRef]
- Li, P.; Wu, J.; Wang, Y.; Lan, Q.; Xiao, W. STM: Spectrogram Transformer Model for Underwater Acoustic Target Recognition. J. Mar. Sci. Eng. 2022, 10, 1428. [Google Scholar] [CrossRef]
- Cheng, Y.; Li, Z.; Qiu, J.; Ji, S. Underwater Acoustic Target Recognition; Science Press: Beijing, China, 2018. [Google Scholar]
- Sutskever, I.; Hinton, G.E. Deep, Narrow Sigmoid Belief Networks Are Universal Approximators. Neural Comput. 2008, 20, 2629–2636. [Google Scholar] [CrossRef] [Green Version]
- Le, N.; Bengio, Y. Deep belief networks are compact universal approximators. Neural Comput. 2010, 22, 2192–2207. [Google Scholar] [CrossRef]
- Yang, H.; Shen, S.; Yao, X. Competitive deep-belief networks for underwater acoustic target recognition. Sensors 2018, 18, 952. [Google Scholar] [CrossRef] [Green Version]
- Irfan, M.; Zheng, J.; Ali, S.; Iqbal, M.; Hamid, U. Deepship: An underwater acoustic benchmark dataset and a separable convolution based autoencoder for classification. Expert Syst. Appl. 2021, 183, 115270. [Google Scholar] [CrossRef]
- Wei, X.; Gang-Hu, L.I.; Wang, Z.Q. Underwater Target Recognition Based on Wavelet Packet and Principal Component Analysis. Comput. Simul. 2011, 28, 8–290. [Google Scholar] [CrossRef] [Green Version]
- Azimi-Sadjadi, M.R.; Yao, D.; Huang, Q. Underwater target classification using wavelet packets and neural networks. IEEE Trans. Neural Netw. 2000, 11, 784–794. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, Y.; Xu, X. The research of underwater target recognition method based on deep learning. In Proceedings of the 2017 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), Xiamen, China, 22–25 October 2017. [Google Scholar] [CrossRef]
- Liu, F.; Shen, T.; Luo, Z. Underwater target recognition using convolutional recurrent neural networks with 3-D Mel-spectrogram and data augmentation. Appl. Acoust. 2021, 178, 107989. [Google Scholar] [CrossRef]
- Zhang, L.; Wu, D.; Han, X. Feature Extraction of Underwater Target Signal Using Mel Frequency Cepstrum Coefficients Based on Acoustic Vector Sensor. J. Sens. 2016, 2016, 92–102. [Google Scholar] [CrossRef] [Green Version]
- Santos-Domínguez, D.; Torres-Guijarro, S.; Cardenal-López, A. ShipsEar: An underwater vessel noise database. Appl. Acoust. 2016, 113, 64–69. [Google Scholar] [CrossRef]
- Jin, G.; Liu, F.; Wu, H. Deep learning-based framework for expansion, recognition and classification of underwater acoustic signal. J. Exp. Theor. Artif. Intell. 2020, 32, 205–218. [Google Scholar] [CrossRef]
- Gao, Y.; Chen, Y.; Wang, F. Recognition Method for Underwater Acoustic Target Based on DCGAN and DenseNet. In Proceedings of the 2020 IEEE 5th International Conference on Image, Vision and Computing (ICIVC), Beijing, China, 10–12 July 2020; pp. 215–221. [Google Scholar] [CrossRef]
- Jiang, Z.; Zhao, C.; Wang, H. Classification of Underwater Target Based on S-ResNet and Modified DCGAN Models. Sensors 2022, 22, 2293. [Google Scholar] [CrossRef]
- Jin, L.; Liang, H. Deep learning for underwater image recognition in small sample size situations. In Proceedings of the OCEANS 2017-Aberdeen, Aberdeen, UK, 19–22 June 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Fei-Fei, L. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the Las Vegas: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Gao, H.; Yu, S.; Zhuang, L. Deep Networks with Stochastic Depth. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; Volume 9908. [Google Scholar] [CrossRef] [Green Version]
- Tian, S.; Chen, D.; Wang, H.; Liu, J. Deep convolution stack for waveform in underwater acoustic target recognition. Sci. Rep. 2021, 11, 9614. [Google Scholar] [CrossRef]
- Xue, L.; Zeng, X.; Jin, A. A Novel Deep-Learning Method with Channel Attention Mechanism for Underwater Target Recognition. Sensors 2022, 22, 5492. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge distillation: A survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Ma, N.; Zhang, X.; Zheng, H.T. ShuffleNet V2: Practical guidelines for efficient CNN architecture design. In Proceedings of the European Conference on Computer Vision, 2018, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar] [CrossRef] [Green Version]
- Yu, X.; Liu, T.; Wang, X.; Tao, D. On compressing deep models by low rank and sparse decomposition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Park, S.; Kwak, N. Feature-level Ensemble Knowledge Distillation for Aggregating Knowledge from Multiple Networks. In ECAI 2020; IOS Press: Amsterdam, The Netherlands, 2020; pp. 1411–1418. [Google Scholar]
- Lei, Z.; Lei, X.; Wang, N. Present status and challenges of underwater acoustic target recognition technology: A review. Front. Phys. 2022, 10, 1018. [Google Scholar]
- Tian, S.; Chen, D.; Yan, F.; Zhou, J. Joint learning model for underwater acoustic target recognition. Knowl. -Based Syst. 2023, 260, 110119. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Albanie, S. Squeeze-and-Excitation Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2011–2023. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Woo, S.; Park, J.; Lee, J.Y. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Bu, Z.; Zhou, B.; Cheng, P. Encrypted Network Traffic Classification Using Deep and Parallel Network-in-Network Models. IEEE Access 2020, 8, 132950–132959. [Google Scholar] [CrossRef]
- Dian Handy Permana, S.; Bayu Yogha Bintoro, K. Implementation of Constant-Q Transform (CQT) and Mel Spectrogram to converting Bird’s Sound. In Proceedings of the 2021 IEEE International Conference on Communication, Networks and Satellite (COMNETSAT), Purwokerto, Indonesia, 17–18 July 2021; pp. 52–56. [Google Scholar] [CrossRef]
- Liu, G.; Sun, C.; Yang, Y. Target feature extraction for passive sonar based on two cepstrums. In Proceedings of the 2008 2nd International Conference on Bioinformatics and Biomedical Engineering, Shanghai, China, 16–18 May 2008; pp. 539–542. [Google Scholar] [CrossRef]
- Kumar, K.; Kim, C.; Stern, R.M. Delta-spectral cepstral coefficients for robust speech recognition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4784–4787. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic gradient descent with restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]
- He, T.; Zhang, Z.; Zhang, H. Bag of tricks for image classification with convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 558–567. [Google Scholar] [CrossRef] [Green Version]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; 800p, ISBN 0262035618. [Google Scholar] [CrossRef] [Green Version]
- Brown, J.C. Calculation of a constant Q spectral transform. J. Acoust. Soc. Am. 1991, 89, 425–434. [Google Scholar] [CrossRef] [Green Version]
- Domingos, L.C.; Santos, P.E.; Skelton, P.S. An investigation of preprocessing filters and deep learning methods for vessel type classification with underwater acoustic data. IEEE Access 2022, 10, 117582–117596. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.A.; Glass, J.R. AST: Audio Spectrogram Transformer. In Proceedings of the Interspeech 2021, 22nd Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2021; pp. 571–575. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Hong, F.; Liu, C.; Guo, L.; Chen, F.; Feng, H. Underwater Acoustic Target Recognition with a Residual Network and the Optimized Feature Extraction Method. Appl. Sci. 2021, 11, 1442. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Target | The Number of Samples |
|---|---|---|
| Class A | Background noise recordings. | 224 |
| Class B | Dredgers/Fishing boats/Mussel boats/Trawlers/Tugboats | 52/101/144/32/40 |
| Class C | Motorboats/Pilot boats/Sailboats | 196/26/79 |
| Class D | Passenger ferries. | 843 |
| Class E | Ocean liners/Ro-ro vessels. | 186/300 |
| Model | Validation Accuracy | Testing Accuracy | Parameters |
|---|---|---|---|
| LW-SEResNet10 (1) | 0.948 | 0.964 | 4.682M |
| LW-SEResNet10 (2) | 0.964 | 0.968 | 4.682M |
| LW-SEResNet10 (3) | 0.948 | 0.968 | 4.682M |
| LW-SEResNet10 (4) | 0.960 | 0.964 | 4.685M |
| LW-SEResNet10 (5) | 0.962 | 0.964 | 4.685M |
| LW-SEResNet10 (6) | 0.960 | 0.968 | 4.697M |
| LW-SEResNet10 (7) | 0.960 | 0.968 | 4.697M |
| LW-SEResNet10 (8) | 0.960 | 0.964 | 4.744M |
| LW-SEResNet10(9) | 0.964 | 0.964 | 4.744M |
| LW-SEResNet10 (2,4,6,8) | 0.955 | 0.968 | 4.765M |
| LW-SEResNet10 (3,5,7,9) | 0.960 | 0.964 | 4.765M |
| Model | Activation Function | Validation Accuracy | Testing Accuracy | Parameters |
|---|---|---|---|---|
| LW-SEResNet10 | ReLU6 | 0.964 | 0.968 | 4.682M |
| LW-SEResNet10 | ReLU | 0.955 | 0.950 | 4.682M |
| ResNet10 | ReLU6 | 0.953 | 0.955 | 4.681M |
| ResNet10 | ReLU | 0.944 | 0.932 | 4.681M |
| ResNet18 | ReLU | 0.946 | 0.928 | 10.661M |
| Feature | Validation Accuracy | Testing Accuracy |
|---|---|---|
| MFCC | 0.960 | 0.955 |
| 3-D dynamic MFCC | 0.964 | 0.968 |
| Mel-spectrogram | 0.935 | 0.932 |
| 3-D dynamic Mel-spectrogram | 0.921 | 0.932 |
| Feature | Dimension | Logarithmic Scale | Validation Accuracy | Testing Accuracy |
|---|---|---|---|---|
| CQT | 64 × 216 × 1 | 0.813 | 0.820 | |
| 64 × 216 × 1 | 0.948 | 0.941 | ||
| 84 × 216 × 1 | 0.831 | 0.811 | ||
| 84 × 216 × 1 | 0.955 | 0.950 | ||
| 120 × 216 × 1 | 0.834 | 0.829 | ||
| 120 × 216 × 1 | 0.939 | 0.941 |
| Model | MFCC | 3D Dynamic MFCC | Mel-Spectrogram | 3D Dynamic Mel-Spectrogram |
|---|---|---|---|---|
| ShuffleNetV2 (0.5) | 0.824 | 0.856 | 0.676 | 0.748 |
| ShuffleNetV2 (1.0) | 0.833 | 0.833 | 0.811 | 0.788 |
| ShuffleNetV2(1.5) | 0.838 | 0.856 | 0.784 | 0.833 |
| ShuffleNetV2 (2.0) | 0.838 | 0.815 | 0.797 | 0.793 |
| MobileNetV2 (1.0) | 0.887 | 0.878 | 0.815 | 0.779 |
| MobileNetV2 (1.4) | 0.824 | 0.874 | 0.793 | 0.847 |
| ResNet18 | 0.919 | 0.928 | 0.914 | 0.910 |
| ResNet34 | 0.901 | 0.910 | 0.874 | 0.824 |
| ResNet50 | 0.851 | 0.793 | 0.680 | 0.707 |
| LW-SEResNet10 (proposed) | 0.955 | 0.968 | 0.932 | 0.932 |
| STM [8] | 0.868 | 0.857 |
| Model | Parameters(M) |
|---|---|
| ShuffleNetV2 (0.5) | 0.339 |
| ShuffleNetV2 (1.0) | 1.200 |
| ShuffleNetV2(1.5) | 2.369 |
| ShuffleNetV2 (2.0) | 5.107 |
| MobileNetV2 (1.0) | 2.127 |
| MobileNetV2 (1.4) | 4.124 |
| ResNet18 | 10.661 |
| ResNet34 | 20.301 |
| ResNet50 | 22.429 |
| LW-SEResNet10 (proposed) | 4.682 |
| STM (AST) [49] | 86 |
| Model | Accuracy | Parameters(M) |
|---|---|---|
| Baseline [19] | 0.754 | |
| ResNet + 3D [51] | 0.943 | |
| CRNN-9 [17] | 0.946 | |
| STM + AudioSet [8] | 0.977 | 86 (AST [49]) |
| LW-SEResNet10 + SGD | 0.968 | 4.682 |
| LW-SEResNet10 + Adam | 0.977 | 4.682 |
| Model/SNR(dB) | −20 | −15 | −10 | −5 | 0 | 5 | 10 | 15 | 20 |
|---|---|---|---|---|---|---|---|---|---|
| ShuffleNetV2 (0.5) | 0.056 | 0.127 | 0.139 | 0.215 | 0.298 | 0.372 | 0.478 | 0.619 | 0.703 |
| ShuffleNetV2 (1.0) | 0.050 | 0.130 | 0.155 | 0.169 | 0.275 | 0.374 | 0.453 | 0.532 | 0.584 |
| ShuffleNetV2(1.5) | 0.060 | 0.050 | 0.118 | 0.199 | 0.275 | 0.421 | 0.532 | 0.614 | 0.702 |
| ShuffleNetV2 (2.0) | 0.042 | 0.036 | 0.090 | 0.147 | 0.244 | 0.386 | 0.486 | 0.635 | 0.756 |
| MobileNetV2 (1.0) | 0.036 | 0.047 | 0.076 | 0.173 | 0.338 | 0.461 | 0.598 | 0.685 | 0.744 |
| MobileNetV2 (1.4) | 0.036 | 0.036 | 0.057 | 0.091 | 0.244 | 0.417 | 0.540 | 0.650 | 0.715 |
| ResNet18 | 0.216 | 0.237 | 0.380 | 0.525 | 0.654 | 0.708 | 0.762 | 0.838 | 0.864 |
| ResNet34 | 0.230 | 0.313 | 0.432 | 0.508 | 0.564 | 0.622 | 0.715 | 0.781 | 0.803 |
| ResNet50 | 0.216 | 0.186 | 0.194 | 0.263 | 0.391 | 0.521 | 0.612 | 0.708 | 0.751 |
| LW-SEResNet10 (proposed) | 0.183 | 0.172 | 0.238 | 0.309 | 0.438 | 0.546 | 0.690 | 0.816 | 0.848 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Xue, L.; Hong, X.; Zeng, X. A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification. J. Mar. Sci. Eng. 2023, 11, 432. https://doi.org/10.3390/jmse11020432
Yang S, Xue L, Hong X, Zeng X. A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification. Journal of Marine Science and Engineering. 2023; 11(2):432. https://doi.org/10.3390/jmse11020432
Chicago/Turabian StyleYang, Shuang, Lingzhi Xue, Xi Hong, and Xiangyang Zeng. 2023. "A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification" Journal of Marine Science and Engineering 11, no. 2: 432. https://doi.org/10.3390/jmse11020432
APA StyleYang, S., Xue, L., Hong, X., & Zeng, X. (2023). A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification. Journal of Marine Science and Engineering, 11(2), 432. https://doi.org/10.3390/jmse11020432