
A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement


Abstract
:1. Introduction
- We proposed a two-stage network, composed of a Soft Reconstruction Network (SRN) and a Hard Enhancement Network (HEN). SRN performs reconstruction via the Jaffe–McGramery model, in which the parameters are estimated through our proposed joint parameter estimation method (JPE). HEN further enhances the images by estimating the global residual.
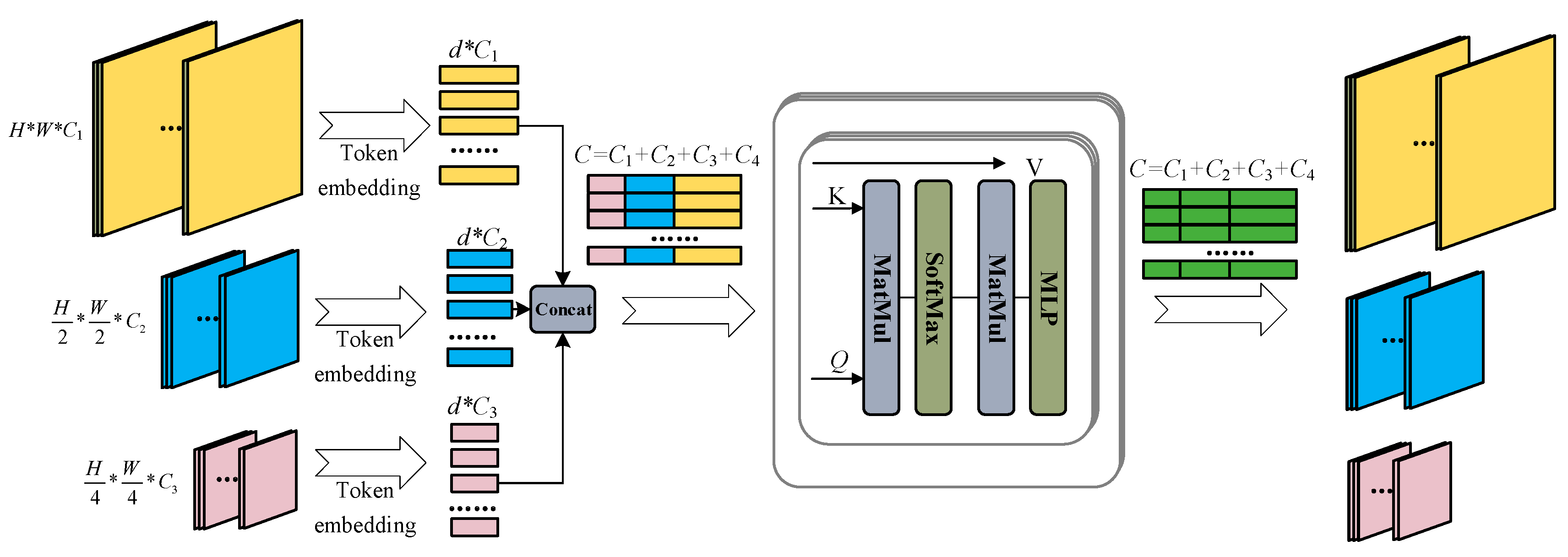
- We utilized the Transformer structure to leverage its potential for capturing long-range dependencies. Moreover, to better leverage local information and channel-wise information in underwater images, we propose two novel modules: Locally Intended Multiple layer Perception (LIMP) and the Channel-Wise Self-Attention module (CSA).
- We introduced a task-oriented loss function for our model, which combines the L2 loss and SSIM loss. By jointly optimizing the L2 and SSIM losses, our model can better capture both the structural and texture details.
2. Related Works
2.1. UIE Methods
2.2. Summary
3. Proposed Method
3.1. Network Architecture
3.1.1. Soft Reconstruction Network
3.1.2. Hard Enhancement Network
3.1.3. WaterFormer Block
3.1.4. Channel-Wise Self-Attention Module
3.2. Loss Function
4. Experiment and Results Analysis
4.1. Experimental Environment Configuration and Datasets Preparation
4.2. Experimental Results and Analysis
4.2.1. Qualitative Evaluation
4.2.2. Quantification Evaluation
4.3. Ablation Experiments
4.3.1. Two-Stage Structure
4.3.2. Channel-Wise Self-Attention Module
4.3.3. SSIM Loss
4.3.4. SWSA
5. Application
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jaffe, J.S. Underwater Optical Imaging: The Past, the Present, and the Prospects. IEEE J. Ocean. Eng. 2015, 40, 683–700. [Google Scholar] [CrossRef]
- Peng, L.; Zhu, C.; Bian, L. U-shape Transformer for Underwater Image Enhancement. In Computer Vision—ECCV 2022 Workshops; Springer: Cham, Switzerland, 2023; pp. 290–307. [Google Scholar]
- Liu, R.; Fan, X.; Zhu, M.; Hou, M.; Luo, Z. Real-World Underwater Enhancement: Challenges, Benchmarks, and Solutions Under Natural Light. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 4861–4875. [Google Scholar] [CrossRef]
- Li, C.; Chunle, G.; Ren, W.; Cong, R.; Hou, J.; Kwong, S.; Tao, D. An Underwater Image Enhancement Benchmark Dataset and Beyond. IEEE Trans. Image Process. 2019, 29, 4376–4389. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hitam, M.; Yussof, W.; Awalludin, E.; Bachok, Z. Mixture contrast limited adaptive histogram equalization for underwater image enhancement. In Proceedings of the 2013 International conference on computer applications technology (ICCAT), Sousse, Tunisia, 20–22 January 2013; pp. 1–5. [Google Scholar]
- Ancuti, C.; Codruta, A.; Haber, T.; Bekaert, P. Enhancing Underwater Images and Videos by Fusion. In Proceedings of the 2012 IEEE conference on computer vision and pattern recognition, Providence, RI, USA, 16–21 June 2012; pp. 81–88. [Google Scholar]
- Fu, X.; Zhuang, P.; Huang, Y.; Liao, Y.; Zhang, X.P.; Ding, X. A retinex-based enhancing approach for single underwater image. In Proceedings of the 2014 IEEE International Conference on Image Processing, ICIP 2014, Paris, France, 27–30 October 2014; pp. 4572–4576. [Google Scholar] [CrossRef]
- Chen, Y.; Li, W.; Xia, M.; Li, Q.; Yang, K. Super-resolution reconstruction for underwater imaging. Opt. Appl. 2011, 41, 841–853. [Google Scholar]
- Quevedo Gutiérrez, E.; Delory, E.; Marrero Callico, G.; Tobajas, F.; Sarmiento, R. Underwater video enhancement using multi-camera super-resolution. Opt. Commun. 2017, 404, 94–102. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.-C. Underwater Image Enhancement by Wavelength Compensation and Dehazing. IEEE Trans. Image Process. 2012, 21, 1756–1769. [Google Scholar] [CrossRef] [PubMed]
- Drews, P., Jr.; Nascimento, E.; Botelho, S.; Campos, M. Underwater Depth Estimation and Image Restoration Based on Single Images. IEEE Comput. Graph. Appl. 2016, 36, 24–35. [Google Scholar] [CrossRef] [PubMed]
- Carlevaris-Bianco, N.; Mohan, A.; Eustice, R. Initial Results in Underwater Single Image Dehazing. In Proceedings of the Oceans 2010 Mts/IEEE Seattle, Seattle, WA, USA, 20–23 September 2010; pp. 1–8. [Google Scholar]
- Li, C.; Anwar, S. Underwater Scene Prior Inspired Deep Underwater Image and Video Enhancement. Pattern Recognit. 2019, 98, 107038. [Google Scholar] [CrossRef]
- Li, J.; Skinner, K.; Eustice, R.; Johnson-Roberson, M. WaterGAN: Unsupervised Generative Network to Enable Real-time Color Correction of Monocular Underwater Images. IEEE Robot. Autom. Lett. 2017, 3, 387–394. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Li, H.; Zhuang, P. Underwater Image Enhancement Using a Multiscale Dense Generative Adversarial Network. IEEE J. Ocean. Eng. 2019, 45, 862–870. [Google Scholar] [CrossRef]
- Sun, B.; Mei, Y.; Yan, N.; Chen, Y. UMGAN: Underwater Image Enhancement Network for Unpaired Image-to-Image Translation. J. Mar. Sci. Eng. 2023, 11, 447. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 9992–10002. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Horé, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Chen, Q.; Zhang, Z.; Li, G. Underwater Image Enhancement Based on Color Balance and Multi-Scale Fusion. IEEE Photonics J. 2022, 14, 1–10. [Google Scholar] [CrossRef]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Yang, M.; Sowmya, A. An Underwater Color Image Quality Evaluation Metric. IEEE Trans. Image Process. A Publ. IEEE Signal Process. Soc. 2015, 24, 6062–6071. [Google Scholar] [CrossRef] [PubMed]
- Fulton, M.; Hong, J.; Islam, M.; Sattar, J. Robotic Detection of Marine Litter Using Deep Visual Detection Models. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Layer Names | Input Size | Output Size |
|---|---|---|---|
| 1 | Conv | (512, 512, 3) | (512, 512, 24) |
| 2 | WaterFormer Block × L1 | (512, 512, 24) | (256, 256, 48) |
| 3 | WaterFormer Block × L2 | (256, 256, 48) | (128, 128, 96) |
| 4 | WaterFormer Block × L3 | (128, 128, 96) | (256, 256, 48) |
| 5 | WaterFormer Block × L4 | (256, 256, 48) | (512, 512, 24) |
| 6 | Conv | (512, 512, 24) | (512, 512, 3) |
| Hyperparameter | Parameter Setting |
|---|---|
| The sample size was trained | 256 × 256 × 3 |
| learning rate | 0.0001 |
| Batch size | 16 |
| Optimizer/momentum | Adam W/0.5 |
| Method | PSNR | SSIM | UCIQE | Time Cost (s) |
|---|---|---|---|---|
| CLAHE | 16.67 | 0.66 | 0.567 | 0.0139 |
| IBLA | 16.88 | 0.63 | 0.611 | 28.12 |
| Fusion | 16.75 | 0.73 | 0.654 | 0.152 |
| UWCNN | 16.22 | 0.80 | 0.464 | 1.21 |
| WaterNet | 18.14 | 0.77 | 0.570 | 1.03 |
| UWGAN | 19.05 | 0.74 | 0.502 | 1.58 |
| WaterGAN | 16.85 | 0.62 | 0.603 | 1.67 |
| CycleGAN | 15.75 | 0.51 | 0.511 | 1.96 |
| Ours | 23.82 | 0.91 | 0.632 | 1.57 |
| SRN | HEN | PSNR | UCIQE |
|---|---|---|---|
| √ | - | 18.89 | 0.596 |
| - | √ | 21.96 | 0.611 |
| √ | √ | 23.82 | 0.623 |
| CSA | Simple Skip Connection | PSNR | UCIQE |
|---|---|---|---|
| - | √ | 22.91 | 0.601 |
| √ | - | 23.82 | 0.623 |
| SSIM Loss | L2 Loss | PSNR | UCIQE |
|---|---|---|---|
| - | √ | 21.31 | 0.612 |
| √ | √ | 23.82 | 0.623 |
| MSA | SWSA | Time Cost (s) |
|---|---|---|
| √ | - | 6.25 |
| - | √ | 1.57 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Chen, D.; Zhang, Y.; Shen, M.; Zhao, W. A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement. J. Mar. Sci. Eng. 2023, 11, 787. https://doi.org/10.3390/jmse11040787
Zhang Y, Chen D, Zhang Y, Shen M, Zhao W. A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement. Journal of Marine Science and Engineering. 2023; 11(4):787. https://doi.org/10.3390/jmse11040787
Chicago/Turabian StyleZhang, Yuhao, Dujing Chen, Yanyan Zhang, Meiling Shen, and Weiyu Zhao. 2023. "A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement" Journal of Marine Science and Engineering 11, no. 4: 787. https://doi.org/10.3390/jmse11040787
APA StyleZhang, Y., Chen, D., Zhang, Y., Shen, M., & Zhao, W. (2023). A Two-Stage Network Based on Transformer and Physical Model for Single Underwater Image Enhancement. Journal of Marine Science and Engineering, 11(4), 787. https://doi.org/10.3390/jmse11040787