
A Wind Power Combination Forecasting Method Based on GASF Image Representation and UniFormer

Abstract
1. Introduction
1.1. Literature Survey
1.2. Main Contributions
- (1)
- Introducing the BIGU framework, which combines ICEEMDAN, optimized by the BWO algorithm, for signal decomposition and GASF for transforming time-series data into 2D images to capture intricate temporal patterns and spatial relationships, thereby enhancing the feature set for UniFormer models used in accurate wind power prediction.
- (2)
- Employing permutation entropy to reconstruct the IMF into high-frequency, low-frequency, and trend components, followed by Spearman correlation analysis for feature selection to intelligently integrate meteorological variables. This process ensures that the most relevant features are incorporated into the GASF image, enriching the input data for predictive modeling.
- (3)
- The efficacy of the BIGU method is substantiated through diverse case studies, emphasizing its practical advantages and potential applications.
1.3. Organization of the Paper
2. Research Methods
2.1. BWO-ICEEMDAN
2.1.1. ICEEMDAN Decomposition Principle
- (1)
- Incorporate sets of modal components of white noise into the original signal sequence, , to generate the noise-added signal sequence, , as follows:The th signal-to-noise ratio is denoted as , the white noise signal is represented by , and refers to the th modal component of the EMD decomposition.
- (2)
- Use EMD to perform repeated decompositions on the additive noise signal, subtract it from the noisy signal, and calculate the average value to obtain the first residual signal, , and its corresponding intrinsic mode function, , as follows:where ⟨ ⟩ denotes the process of averaging.
- (3)
- Incorporate multiple white noise components into , followed by calculating the mean to obtain . Then, perform a subtraction operation with to derive the second modal component, , as follows:
- (4)
- Repeat step (3) iteratively until the residual signal can no longer be decomposed and the decomposition termination condition is met, thereby obtaining all modal components.
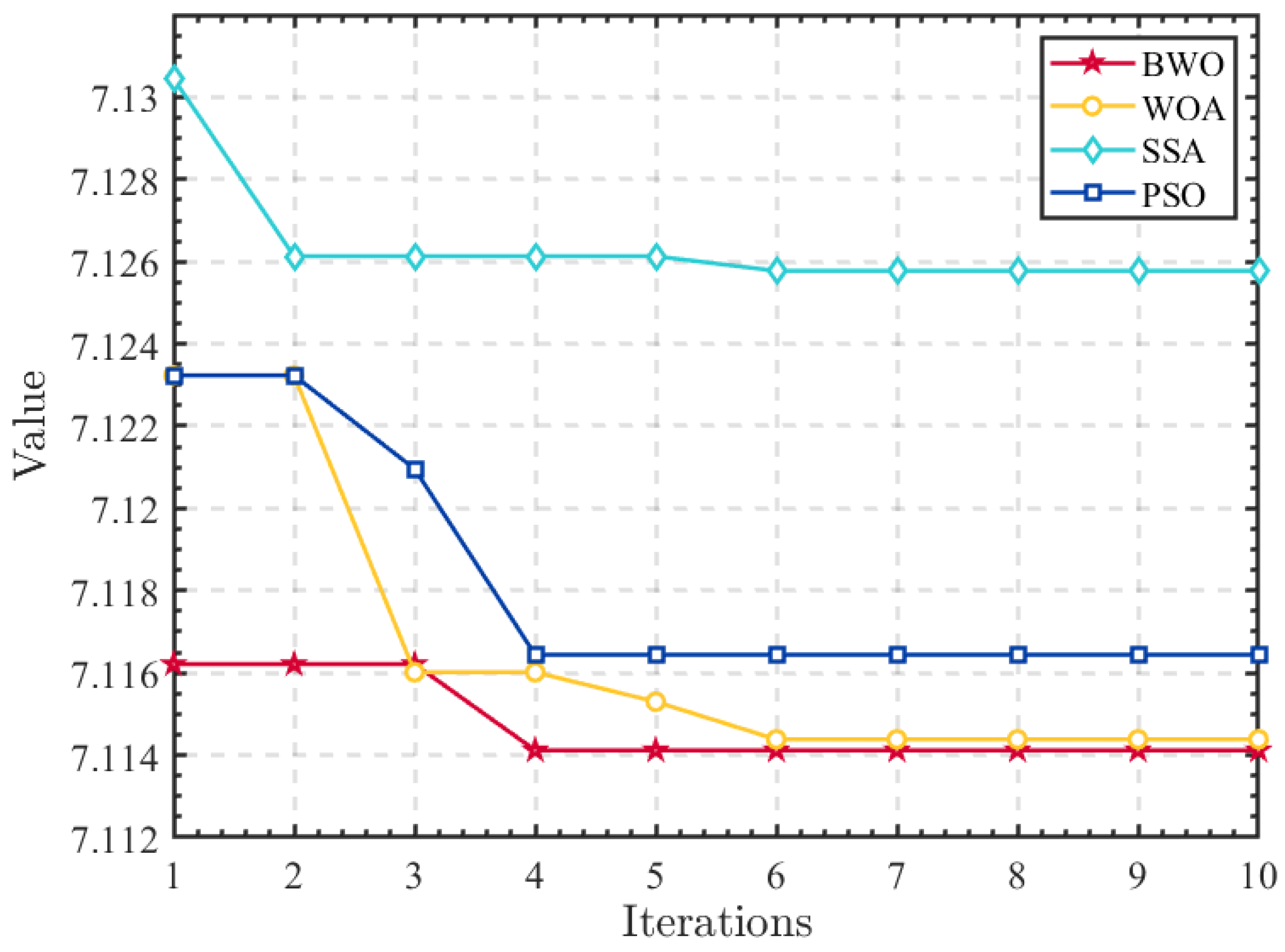
2.1.2. BWO Algorithm
2.1.3. Parameter Optimization Process
- (1)
- Initialize the population of the BWO algorithm; set the total number of iterations, , and the population size, ; and define the range of decision variables. Each individual consists of the following two decision variables: and . The initial solutions for individuals are generated randomly.
- (2)
- Apply ICEEMDAN to decompose the wind power signal into its IMF components. Calculate the envelope entropy for each component and select the minimum value as the fitness function.
- (3)
- Determine whether the optimization has reached the termination condition of the algorithm. If it has, proceed to the next step; if not, update the population’s position based on the formula and parameters of the BWO algorithm and return to step (2).
- (4)
- Employ a greedy selection strategy based on fitness values to save the optimal combinations of ICEEMDAN parameters. Substitute these parameter values into the ICEEMDAN algorithm by replacing and with those from the best solution.
- (5)
- Use the optimized parameter combination to perform ICEEMDAN decomposition on the corresponding wind power sequence and obtain the optimal IMF components.
2.2. Permutation Entropy
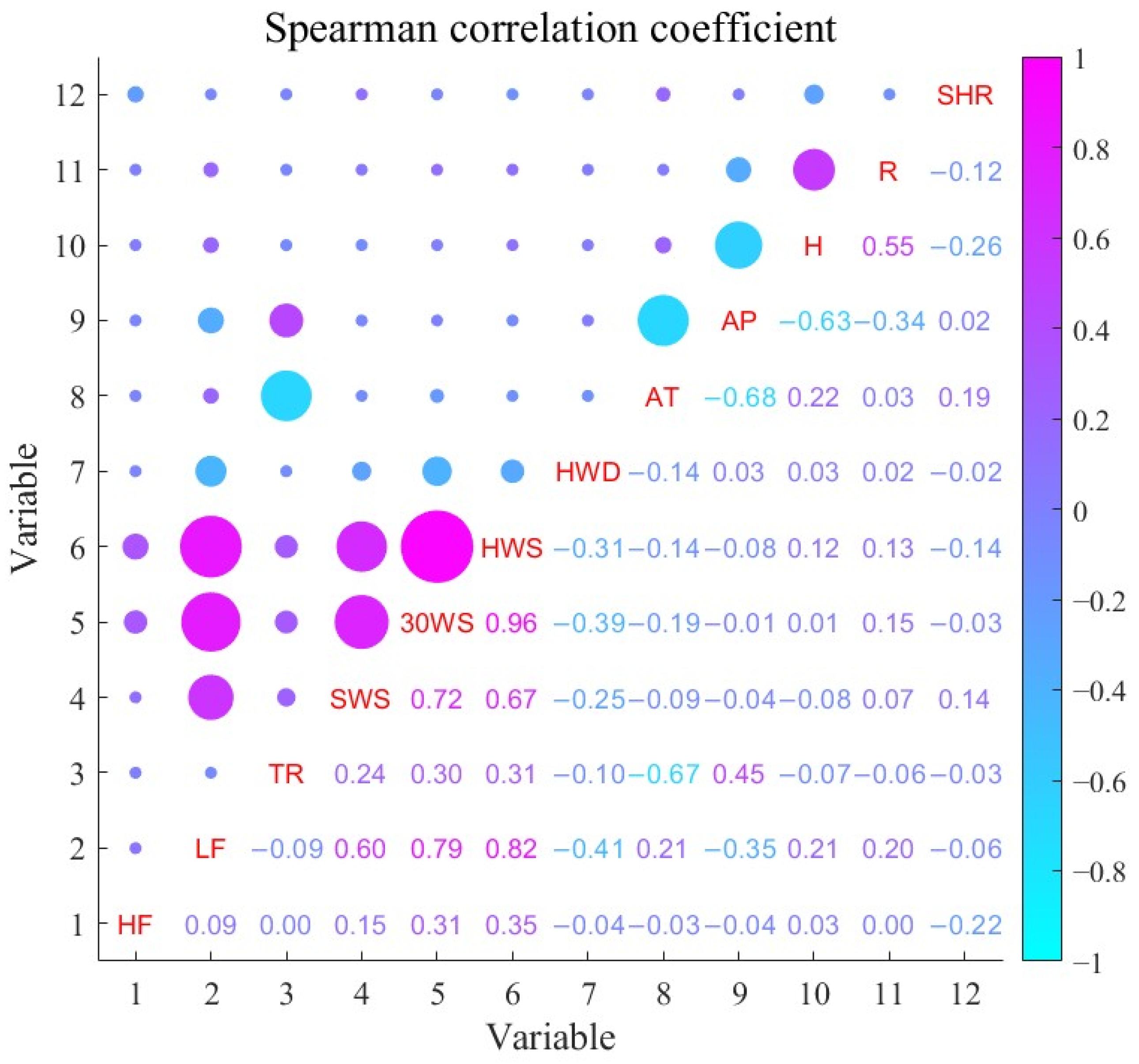
2.3. Spearman Feature Selection
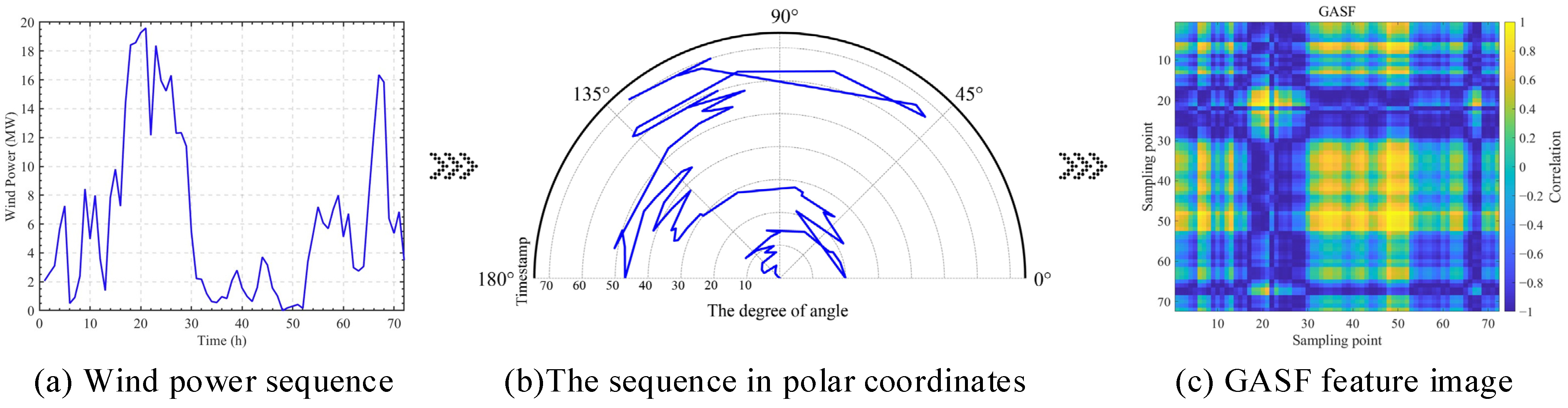
2.4. GASF
- (1)
- Firstly, the time series X values are normalized to the interval [−1, 1] using Equation (16), as follows:where is the th sampled signal, and is the normalized value of .
- (2)
- The normalized time series values are transformed in polar coordinates by Equation (17), as follows:where is the angular cosine of the polar coordinates; is the radius; is the timestamp; and is a constant factor of the span of the regularized polar coordinate system.
- (3)
- In the polar coordinate system ϕ, the cosine and angle values are calculated for each polar coordinate, and the encoded results are input into a matrix using Equation (18), as follows:
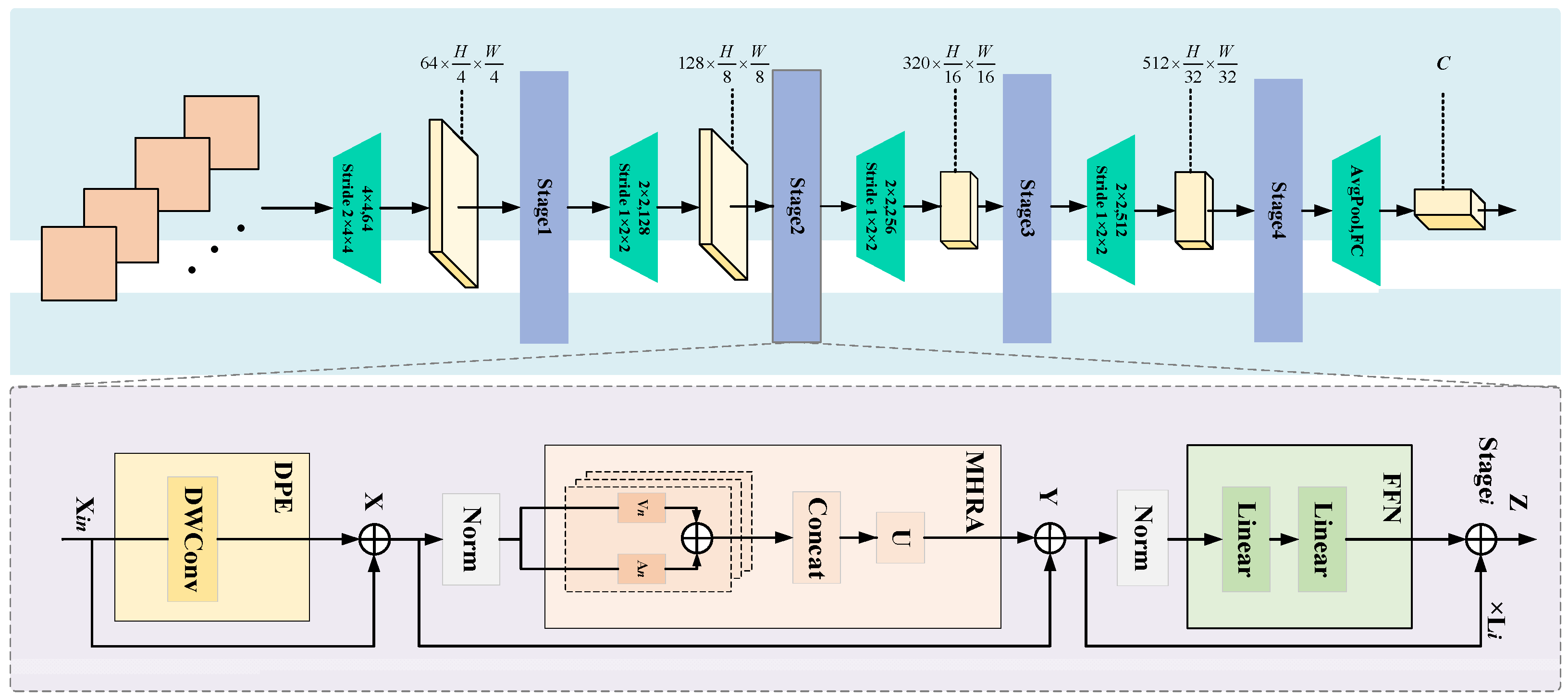
2.5. UniFormer
3. Model Structure and Evaluation Metrics
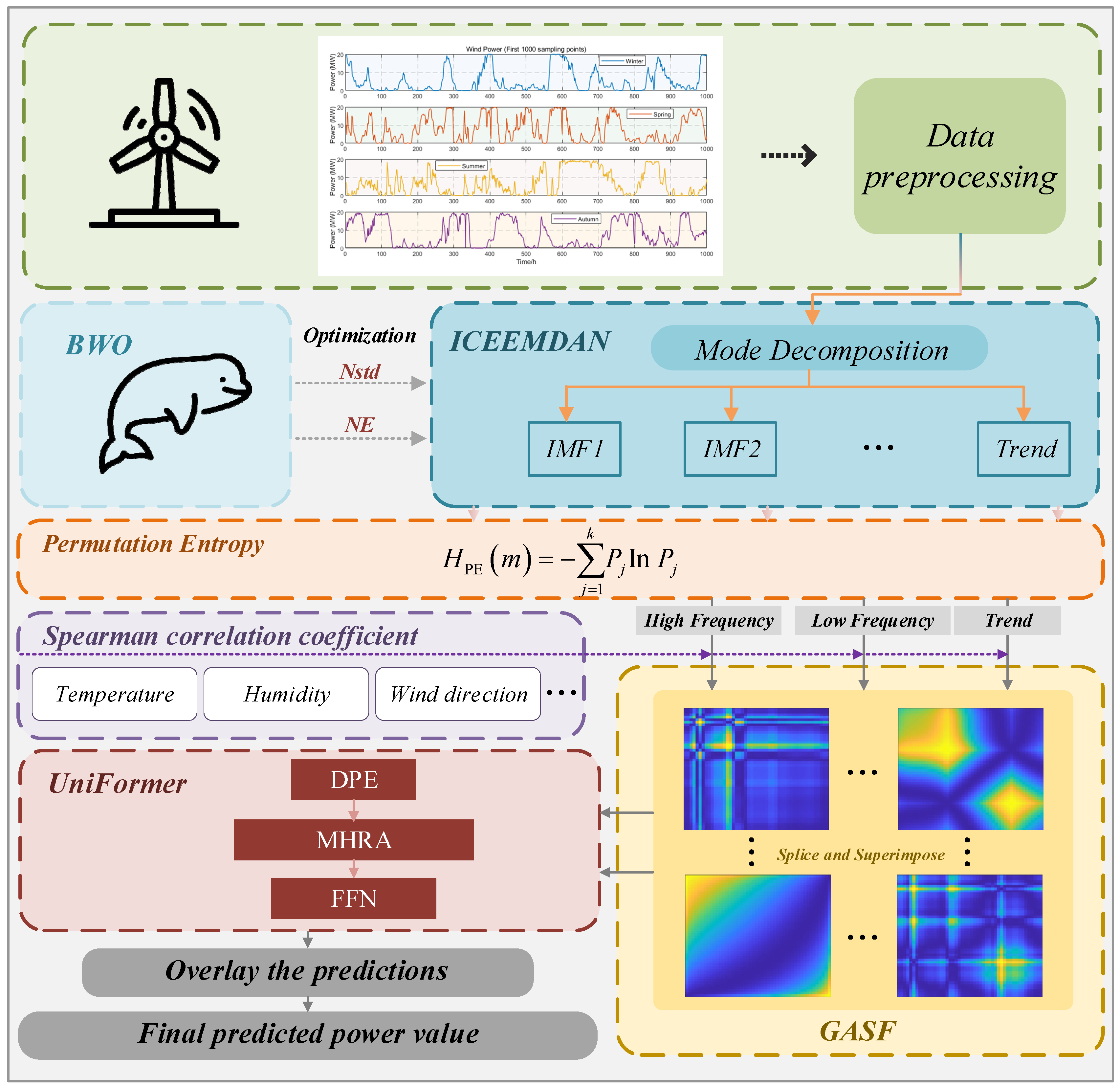
3.1. Model Structure
- (1)
- Initially, the BWO algorithm is employed to optimize the and parameters of the ICEEMDAN decomposition algorithm, with the minimal value of the envelope entropy of wind power sequences in different seasons serving as the fitness function. Subsequently, wind power data undergo ICEEMDAN decomposition for each season to obtain multiple submodal IMF components.
- (2)
- The permutation entropy value of each decomposed IMF component is calculated and used to reconstruct them into a high-frequency term, low-frequency term, and trend term (i.e., residual term).
- (3)
- Spearman’s feature selection algorithm is utilized to correlate the reconstructed IMF components with corresponding weather features, selecting high-scoring meteorological feature vectors which are then transformed into 2D GASF images after splicing and superimposing them with their respective modal components.
- (4)
- The GASF feature image is inputted into the UniFormer prediction model for predicting high-frequency terms, low-frequency terms, and trend terms separately before combining all prediction results.
3.2. Evaluation Metrics
4. Case Study I
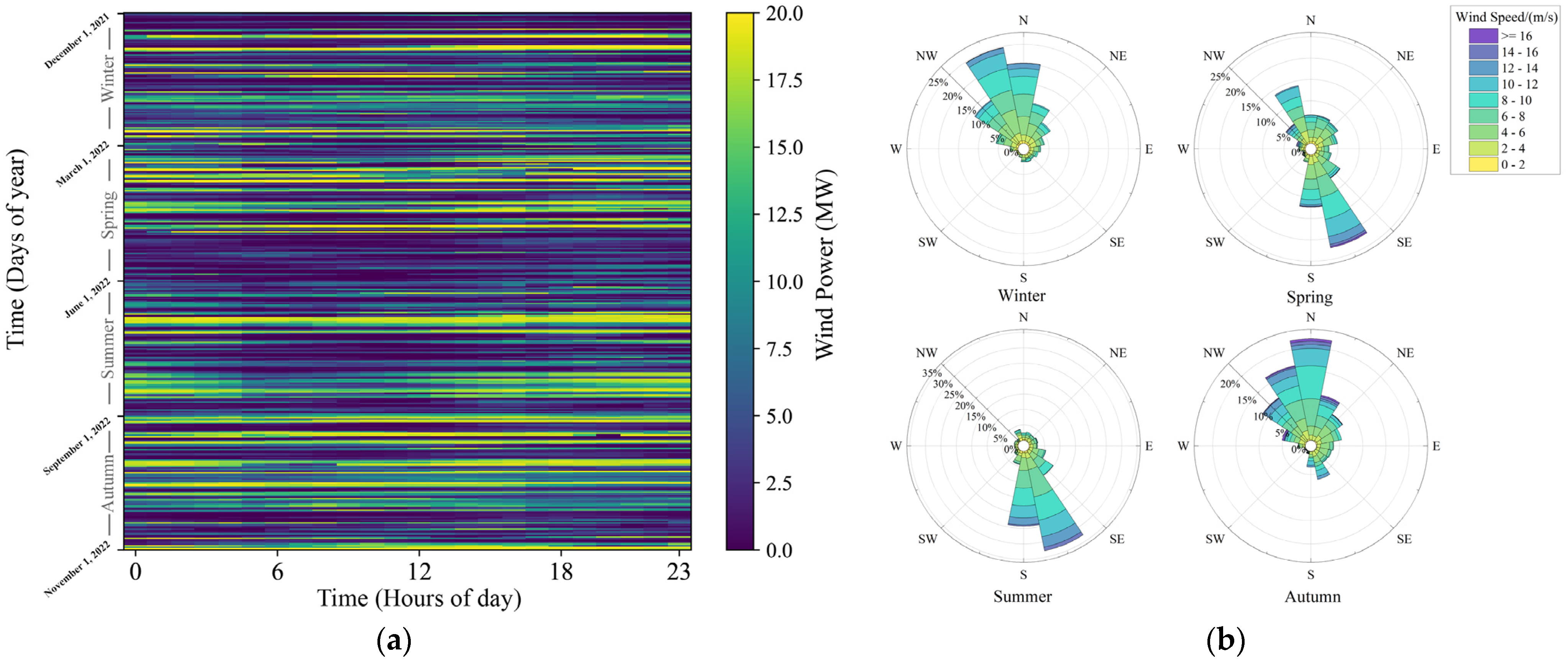
4.1. Data Description
4.2. Model Parameter Settings
4.3. Prediction Process
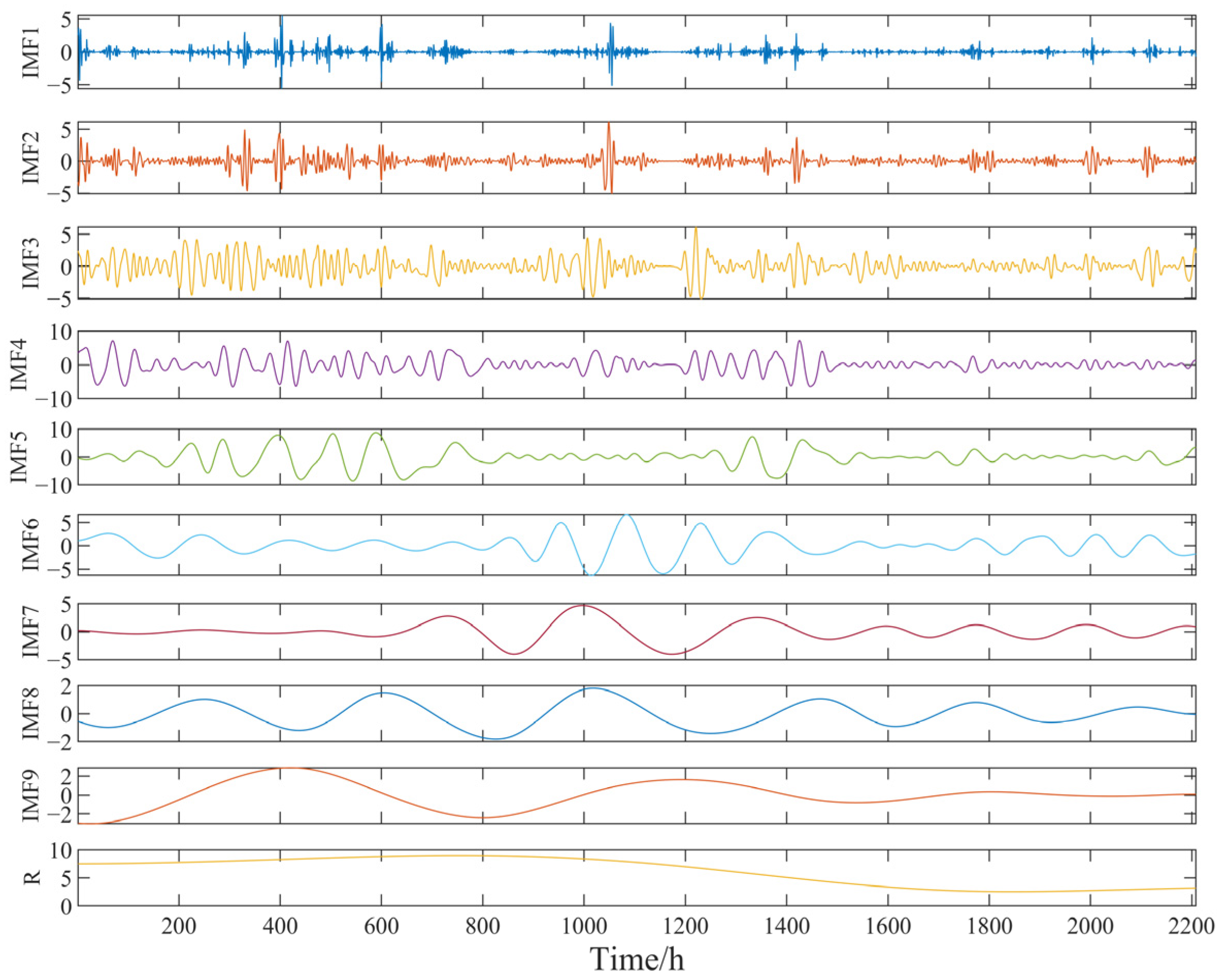
4.3.1. Modal Decomposition
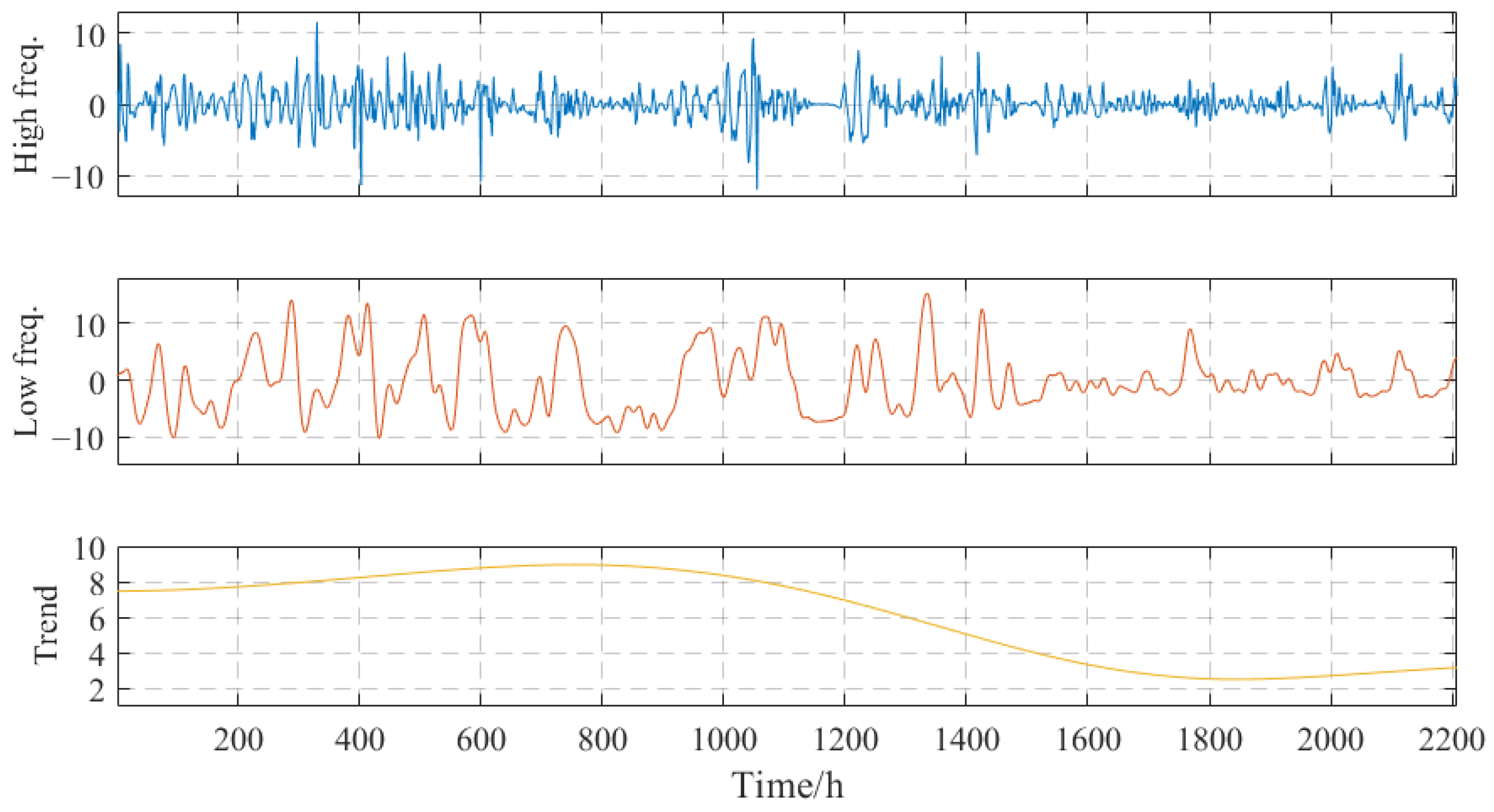
4.3.2. Modal Reconstruction
4.3.3. Feature Selection
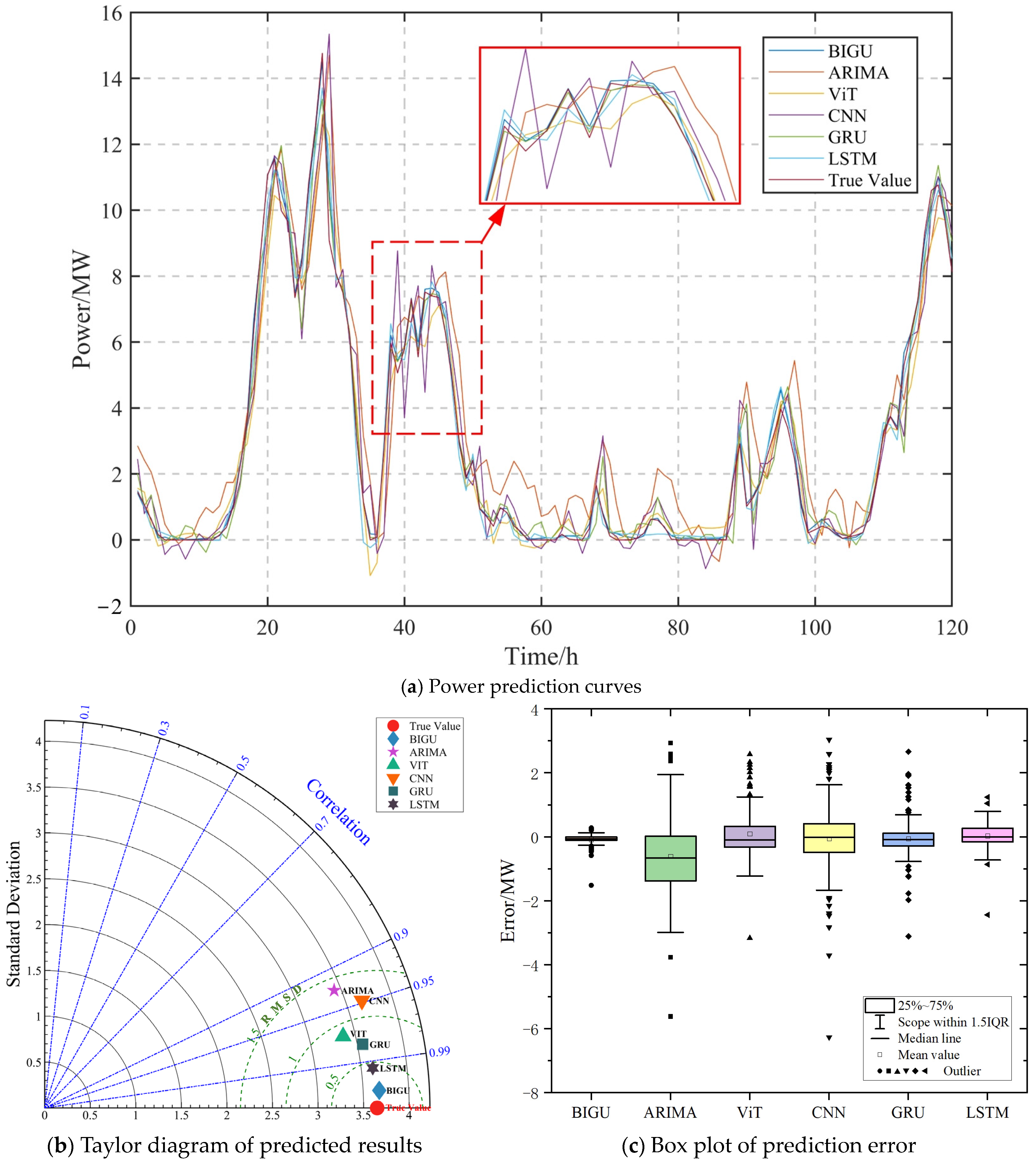
4.3.4. Predicted Results
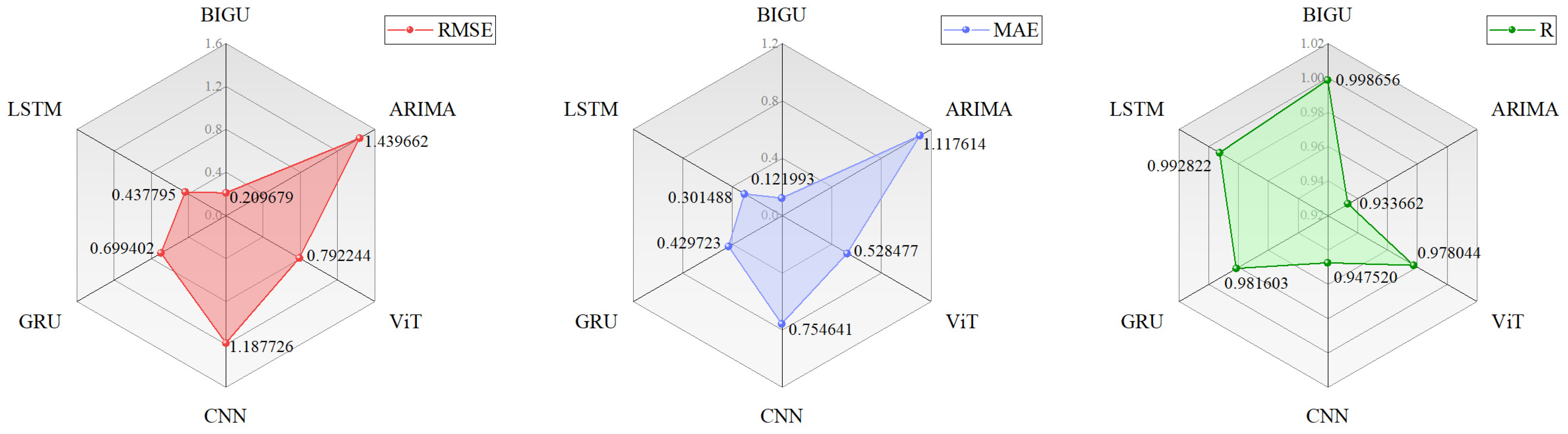
4.4. Comprehensive Assessment
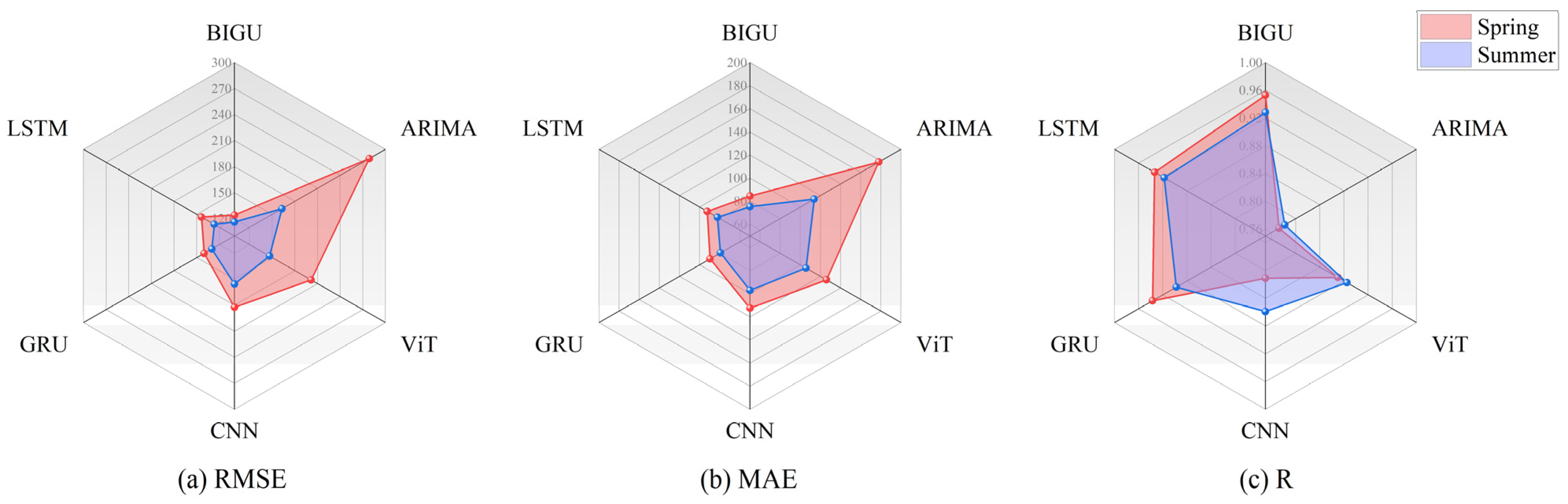
4.4.1. Summer, Autumn, and Winter Comparison
4.4.2. Ablation Experiments
5. Case Study II
5.1. Data Description
5.2. Predicted Results
6. Conclusions and Suggestions
6.1. Conclusions
6.2. Limitations and Future Suggestions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yin, L.; Zhao, M. Inception-embedded attention memory fully-connected network for short-term wind power prediction. Appl. Soft Comput. 2023, 141, 110279. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, J.; Wei, D.; Luo, T.; Xia, Y. A novel ensemble system for short-term wind speed forecasting based on Two-stage Attention-Based Recurrent Neural Network. Renew. Energy 2023, 204, 11–23. [Google Scholar] [CrossRef]
- Wang, H.; Wang, G. The prediction model for haze pollution based on stacking framework and feature extraction of time series images. Sci. Total Environ. 2022, 839, 156003. [Google Scholar] [CrossRef] [PubMed]
- Niu, Y.; Wang, J.; Zhang, Z.; Yu, Y.; Liu, J. A combined interval prediction system based on fuzzy strategy and neural network for wind speed. Appl. Soft Comput. 2024, 155, 111408. [Google Scholar] [CrossRef]
- Zhang, Y.-M.; Wang, H. Multi-head attention-based probabilistic CNN-BiLSTM for day-ahead wind speed forecasting. Energy 2023, 278, 127865. [Google Scholar] [CrossRef]
- Sheng, Y.; Wang, H.; Yan, J.; Liu, Y.; Han, S. Short-term wind power prediction method based on deep clustering-improved Temporal Convolutional Network. Energy Rep. 2023, 9, 2118–2129. [Google Scholar] [CrossRef]
- Liu, Y.; Li, L.; Liu, J. Short-term wind power output prediction using hybrid-enhanced seagull optimization algorithm and support vector machine: A high-precision method. Int. J. Green Energy 2024, 1–14. [Google Scholar] [CrossRef]
- Al-qaness, M.A.A.; Ewees, A.A.; Fan, H.; Abualigah, L.; Elsheikh, A.H.; Abd Elaziz, M. Wind power prediction using random vector functional link network with capuchin search algorithm. Ain Shams Eng. J. 2023, 14, 102095. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, Y.; Fu, Y.; Qiao, X.; Nazir, S.; Peng, T. A novel DWTimesNet-based short-term multi-step wind power forecasting model using feature selection and auto-tuning methods. Energy Convers. Manag. 2024, 301, 118045. [Google Scholar] [CrossRef]
- Liu, Z.; Ware, T. Capturing Spatial Influence in Wind Prediction with a Graph Convolutional Neural Network. Front. Environ. Sci. 2022, 10, 836050. [Google Scholar] [CrossRef]
- Wang, C.; He, Y.; Zhang, H.-L.; Ma, P. Wind power forecasting based on manifold learning and a double-layer SWLSTM model. Energy 2024, 290, 130076. [Google Scholar] [CrossRef]
- Wei, C.-C.; Chiang, C.-S. Assessment of Offshore Wind Power Potential and Wind Energy Prediction Using Recurrent Neural Networks. J. Mar. Sci. Eng. 2024, 12, 283. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, J. Short-term wind power forecasting based on multivariate/multi-step LSTM with temporal feature attention mechanism. Appl. Soft Comput. 2024, 150, 111050. [Google Scholar] [CrossRef]
- Meng, A.; Chen, S.; Ou, Z.; Xiao, J.; Zhang, J.; Chen, S.; Zhang, Z.; Liang, R.; Zhang, Z.; Xian, Z.; et al. A novel few-shot learning approach for wind power prediction applying secondary evolutionary generative adversarial network. Energy 2022, 261, 125276. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, Y.; Kong, C.; Chen, B. A new prediction method based on VMD-PRBF-ARMA-E model considering wind speed characteristic. Energy Convers. Manag. 2020, 203, 112254. [Google Scholar] [CrossRef]
- Lei, P.; Ma, F.; Zhu, C.; Li, T. LSTM Short-Term Wind Power Prediction Method Based on Data Preprocessing and Variational Modal Decomposition for Soft Sensors. Sensors 2024, 24, 2521. [Google Scholar] [CrossRef]
- Jiang, T.; Liu, Y. A short-term wind power prediction approach based on ensemble empirical mode decomposition and improved long short-term memory. Comput. Electr. Eng. 2023, 110, 108830. [Google Scholar] [CrossRef]
- Ai, C.; He, S.; Hu, H.; Fan, X.; Wang, W. Chaotic time series wind power interval prediction based on quadratic decomposition and intelligent optimization algorithm. Chaos Solitons Fractals 2023, 177, 114222. [Google Scholar] [CrossRef]
- Hu, W.; Mao, Z. Forecasting for Chaotic Time Series Based on GRP-lstm GAN Model: Application to Temperature Series of Rotary Kiln. Entropy 2022, 25, 52. [Google Scholar] [CrossRef]
- Tian, W.; Wu, J.; Cui, H.; Hu, T. Drought Prediction Based on Feature-Based Transfer Learning and Time Series Imaging. IEEE Access 2021, 9, 101454–101468. [Google Scholar] [CrossRef]
- Liu, B.; Cen, W.; Zheng, C.; Li, D.; Wang, L. A combined optimization prediction model for earth-rock dam seepage pressure using multi-machine learning fusion with decomposition data-driven. Expert Syst. Appl. 2024, 242, 122798. [Google Scholar] [CrossRef]
- Zhong, C.; Li, G.; Meng, Z. Beluga whale optimization: A novel nature-inspired metaheuristic algorithm. Knowl.-Based Syst. 2022, 251, 109215. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation entropy: A natural complexity measure for time series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Zhao, P.; Sun, S. A new secondary decomposition-reconstruction-ensemble approach for crude oil price forecasting. Resour. Policy 2022, 77, 102762. [Google Scholar] [CrossRef]
- Peng, Y.; Song, D.; Qiu, L.; Wang, H.; He, X.; Liu, Q. Combined Prediction Model of Gas Concentration Based on Indicators Dynamic Optimization and Bi-LSTMs. Sensors 2023, 23, 2883. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Lin, H.; Hu, H.; Yang, M.; Ma, L. A hybrid model with combined feature selection based on optimized VMD and improved multi-objective coati optimization algorithm for short-term wind power prediction. Energy 2024, 293, 30684. [Google Scholar] [CrossRef]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. UniFormer: Unifying Convolution and Self-Attention for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef]
- Chaudhari, K.; Thakkar, A. Neural network systems with an integrated coefficient of variation-based feature selection for stock price and trend prediction. Expert Syst. Appl. 2023, 219, 119527. [Google Scholar] [CrossRef]
- Xu, M.; Mao, Y.; Yan, Z.; Zhang, M.; Xiao, D. Coal and Gangue Classification Based on Laser-Induced Breakdown Spectroscopy and Deep Learning. ACS Omega 2023, 8, 47646–47657. [Google Scholar] [CrossRef]
- Zhang, Z.; Li, J.; Cai, C.; Ren, J.; Xue, Y. Bearing Fault Diagnosis Based on Image Information Fusion and Vision Transformer Transfer Learning Model. Appl. Sci. 2024, 14, 2706. [Google Scholar] [CrossRef]
- Yu, E.; Xu, G.; Han, Y.; Li, Y. An efficient short-term wind speed prediction model based on cross-channel data integration and attention mechanisms. Energy 2022, 256, 124569. [Google Scholar] [CrossRef]
- Yan, Y.; Wang, X.; Ren, F.; Shao, Z.; Tian, C. Wind speed prediction using a hybrid model of EEMD and LSTM considering seasonal features. Energy Rep. 2022, 8, 8965–8980. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, Y.; Liu, J.; Zhang, X.; Liu, S. A Short-Term Wind Power Forecasting Model Based on 3D Convolutional Neural Network–Gated Recurrent Unit. Sustainability 2023, 15, 14171. [Google Scholar] [CrossRef]
- Li, Y. Data for: Short-term wind power forecasting approach based on clustering algorithm and Seq2Seq model using NWP data. Mendeley Data 2021, 1. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Meteorological Variable | Unit | Abbreviation |
|---|---|---|
| Surface horizontal wind speed | m/s | SWS |
| Horizontal wind speed at a height of 30 m | m/s | 30 WS |
| Wind turbine hub wind speed | m/s | HWS |
| Wind turbine hub wind direction | ° | HWD |
| Air temperature | °C | AT |
| Air pressure | hPa | AP |
| Humidity | % | H |
| Rainfall | mm/h | R |
| Surface horizontal radiation | W/m2 | SHR |
| Fluctuation Indicator | Winter | Spring | Summer | Autumn |
|---|---|---|---|---|
| 7.030020 | 6.545597 | 6.922030 | 7.416649 | |
| 2.970527 | 3.159641 | 3.206690 | 3.388796 | |
| 0.422549 | 0.482712 | 0.463259 | 0.456917 |
| Structure | Parameters |
|---|---|
| BWO | Population size: 8 Maximum number of iterations: 10 optimization range: 0.15–0.6 optimization range: 50–600 |
| GASF | Sampling interval: 48 |
| UniFormer | Depth = [3, 4, 8, 3] Embedding dimension = [64, 128, 320, 512] Head dimension = 64 Mlp ratio = 4 |
| Loss function | MSE |
| Optimizer | Adam |
| Learning rate | 0.0001 |
| Time window | 48 |
| Batch size | 32 |
| Model | Description |
|---|---|
| CNN | CNN is a deep learning model for processing grid-like topology data with powerful feature extraction capabilities, especially good at processing image data. |
| ViT | ViT splits the image into fixed-size patches and uses a self-attention mechanism to capture the relationships between the patches, which is very effective in capturing long-distance dependencies. |
| ARIMA | ARIMA is suitable for modeling and forecasting stationary time-series data through differential and autoregressive methods. |
| LSTM | LSTM is an improved recurrent neural network (RNN), which controls information flow by introducing memory cells and gates to retain dependent information for a long time. |
| GRU | GRU includes an update gate and reset gate, which simplifies the gating mechanism of LSTM and makes the computation more efficient. |
| Modal | PE Value | Modal | PE Value |
|---|---|---|---|
| IMF1 | 0.9980 | IMF6 | 0.4369 |
| IMF2 | 0.8440 | IMF7 | 0.4162 |
| IMF3 | 0.6638 | IMF8 | 0.4074 |
| IMF4 | 0.5457 | IMF9 | 0.3985 |
| IMF5 | 0.4796 | R | 0.3909 |
| Modal Component | Selection of Features |
|---|---|
| HF | 30 WS, HWS |
| LF | SWS, 30 WS, HWS, HWD, AP |
| TR | HWS, AT, AP |
| Seasons | Models | RMSE | MAE | R |
|---|---|---|---|---|
| Summer | BIGU | 0.375476 | 0.264877 | 0.998891 |
| ARIMA | 1.054093 | 0.784270 | 0.947841 | |
| ViT | 0.675443 | 0.480176 | 0.989460 | |
| CNN | 0.890668 | 0.631627 | 0.959301 | |
| GRU | 0.466659 | 0.311891 | 0.988728 | |
| LSTM | 0.445184 | 0.309603 | 0.996183 | |
| Autumn | BIGU | 0.397771 | 0.312885 | 0.998520 |
| ARIMA | 1.751570 | 1.097257 | 0.974751 | |
| ViT | 1.487874 | 1.081197 | 0.983571 | |
| CNN | 1.657794 | 1.126866 | 0.976416 | |
| GRU | 1.520318 | 1.104290 | 0.981943 | |
| LSTM | 0.727626 | 0.500639 | 0.995559 | |
| Winter | BIGU | 0.336125 | 0.214817 | 0.998922 |
| ARIMA | 1.261596 | 0.89405 | 0.980482 | |
| ViT | 0.939161 | 0.632682 | 0.988128 | |
| CNN | 0.966694 | 0.669616 | 0.98682 | |
| GRU | 0.549251 | 0.383941 | 0.996163 | |
| LSTM | 0.571366 | 0.399887 | 0.996554 |
| Spring | BWO Optimum Fitness Value: 7.3190 | |
| : 0.31, : 163 | ||
| High-frequency terms | Reconstruction mode: IMF1–IMF3 | |
| Meteorological variables selection: HWS | ||
| Low-frequency terms | Reconstruction mode: IMF4–IMF9 | |
| Meteorological variables selection: HWS, SWS | ||
| Trend term | Meteorological variable selection: AT | |
| Summer | BWO Optimum fitness value: 7.2384 | |
| : 0.49, : 353 | ||
| High-frequency terms | Reconstruction mode: IMF1–IMF3 | |
| Meteorological variable selection: HWS | ||
| Low-frequency terms | Reconstruction mode: IMF4–IMF10 | |
| Meteorological variables selection: HWS, SWS | ||
| Trend term | Meteorological variable selection: AT | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, W.; Xu, L.; Zhao, D.; Zhou, D.; Wang, T.; Tang, X. A Wind Power Combination Forecasting Method Based on GASF Image Representation and UniFormer. J. Mar. Sci. Eng. 2024, 12, 1173. https://doi.org/10.3390/jmse12071173
Guo W, Xu L, Zhao D, Zhou D, Wang T, Tang X. A Wind Power Combination Forecasting Method Based on GASF Image Representation and UniFormer. Journal of Marine Science and Engineering. 2024; 12(7):1173. https://doi.org/10.3390/jmse12071173
Chicago/Turabian StyleGuo, Wei, Li Xu, Danyang Zhao, Dianqiang Zhou, Tian Wang, and Xujing Tang. 2024. "A Wind Power Combination Forecasting Method Based on GASF Image Representation and UniFormer" Journal of Marine Science and Engineering 12, no. 7: 1173. https://doi.org/10.3390/jmse12071173
APA StyleGuo, W., Xu, L., Zhao, D., Zhou, D., Wang, T., & Tang, X. (2024). A Wind Power Combination Forecasting Method Based on GASF Image Representation and UniFormer. Journal of Marine Science and Engineering, 12(7), 1173. https://doi.org/10.3390/jmse12071173