


Deep Q-Learning Based Adaptive MAC Protocol with Collision Avoidance and Efficient Power Control for UWSNs


 ,
,
Abstract
1. Introduction
- The protocol minimizes energy consumption by dynamically adjusting wake-up schedules and integrating adaptive power control mechanisms, thereby significantly extending network lifespan.
- Enhanced synchronization between transmitter and receiver nodes and courier nodes as transmitter and as receiver improves communication reliability, reduces delays, and mitigates packet collisions, ensuring efficient operation under diverse conditions.
- A novel collision-avoidance mechanism combined with priority-based communication optimizes resource utilization, guarantees timely delivery of critical data, and significantly improves system throughput.
- The adaptable and versatile design caters to different traffic priorities and network configurations, allowing the protocol to be customized for a diverse set of underwater applications, all while preserving excellent performance.
2. Literature Review
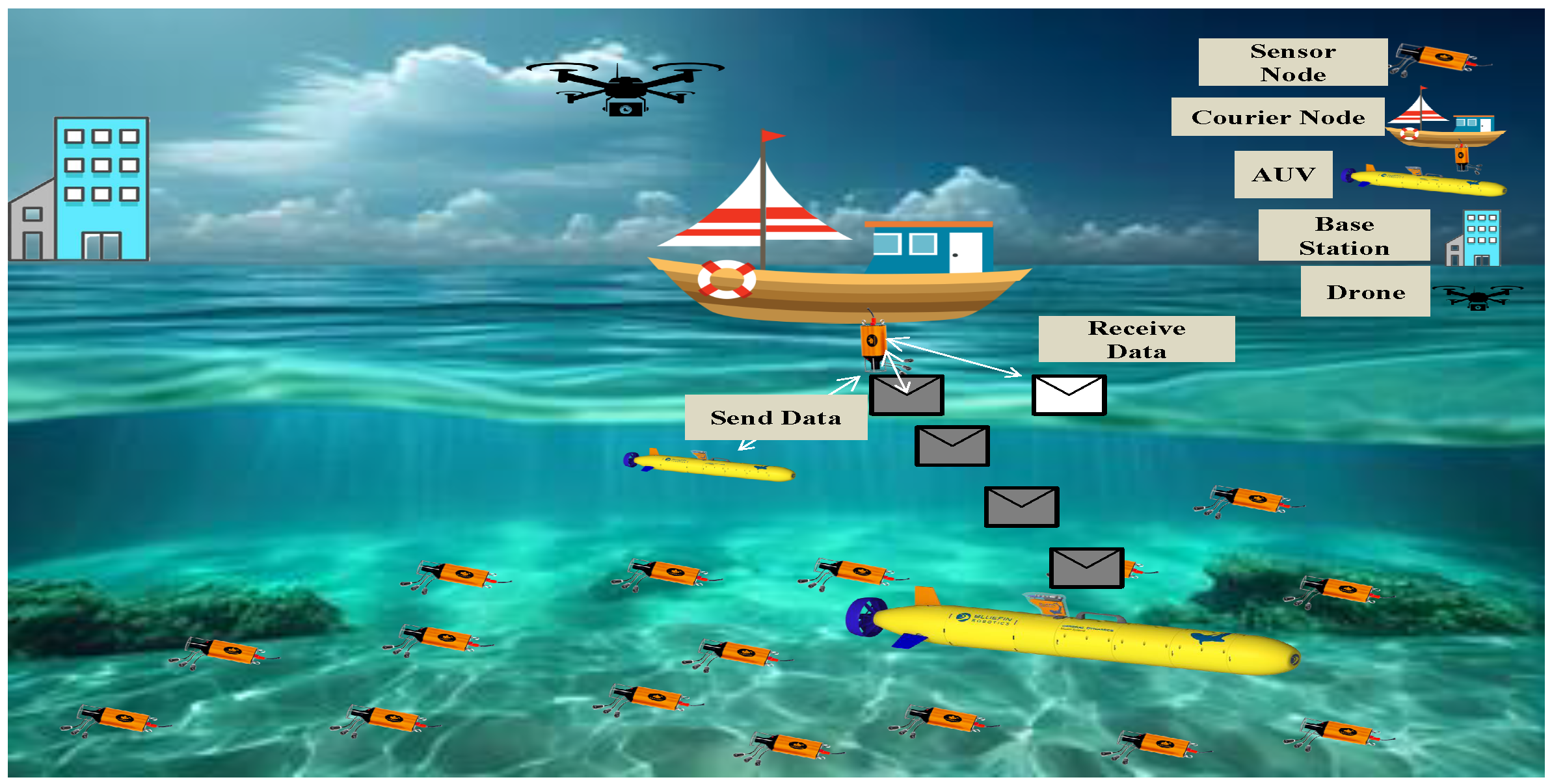
3. Proposed System Model
3.1. Reinforcement Learning Technique for Proposed DAWPC-MAC Protocol
3.2. DAWPC-MAC Model Overview
3.3. Integration of DQN-Base Approach
3.3.1. State Definition S
- Energy Status: (such as the residual energy of receiver and transmitter nodes).
- Traffic Load: Number of pending packets or arrival rate .
- Node Position: Distance between the receiver (Rx) and transmitter (Tx), denoted as .
- Packet Type: Critical () or routine ().
- Channel Conditions: Signal-to-noise ratio (SNR) or interference level.
3.3.2. Action Space A
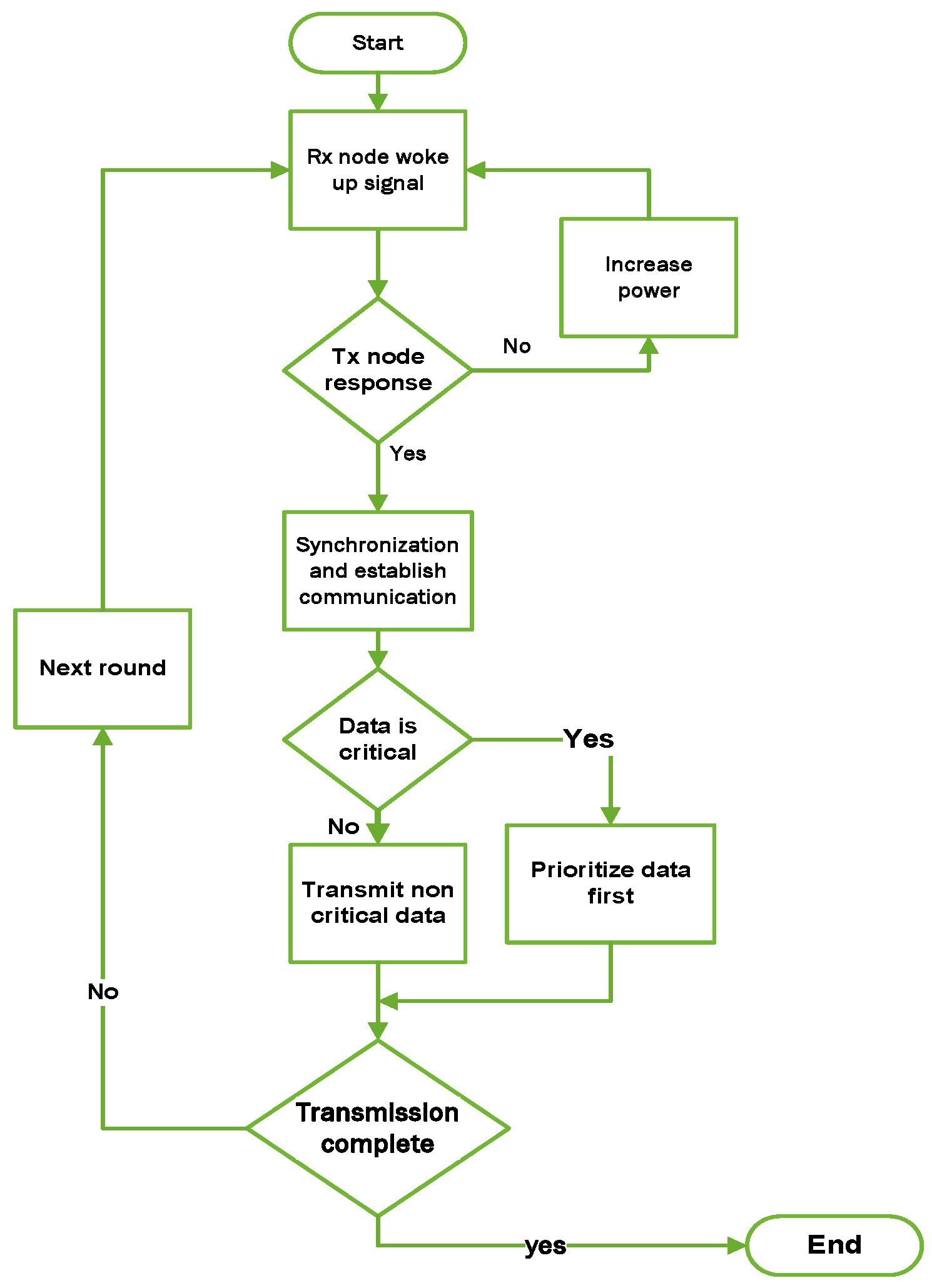
- Wake-Up signal Power Adjustment (): The courier node as the receiver node optimizes energy usage by transmitting a low-power wake-up signal, gradually increasing the power only when necessary to reach distant nodes. This wake-up power, measured in milliwatts (mW), is categorized into discrete levels such as low, medium, and high, each corresponding to specific power values. The decision-making process involves evaluating the state of the current environment to ensure energy-efficient and reliable communication. This state encompasses factors such as distance from neighboring nodes, 3D position, residual energy levels, traffic load, packet type, and required communication reliability. Using Bellman update function, the system calculates Q-values for each potential power adjustment level, balancing energy efficiency with communication performance. The agent selects the power level with the maximum Q-value, indicating the optimal trade-off between minimizing energy consumption while maintaining robust connectivity.
- Data Transmission Power Adjustment (): Transmission power is adjusted based on the node’s distance and environmental conditions (e.g., SNR). Lower power is used for close-range, clear communications, while higher power is employed for distant or interference-prone connections.
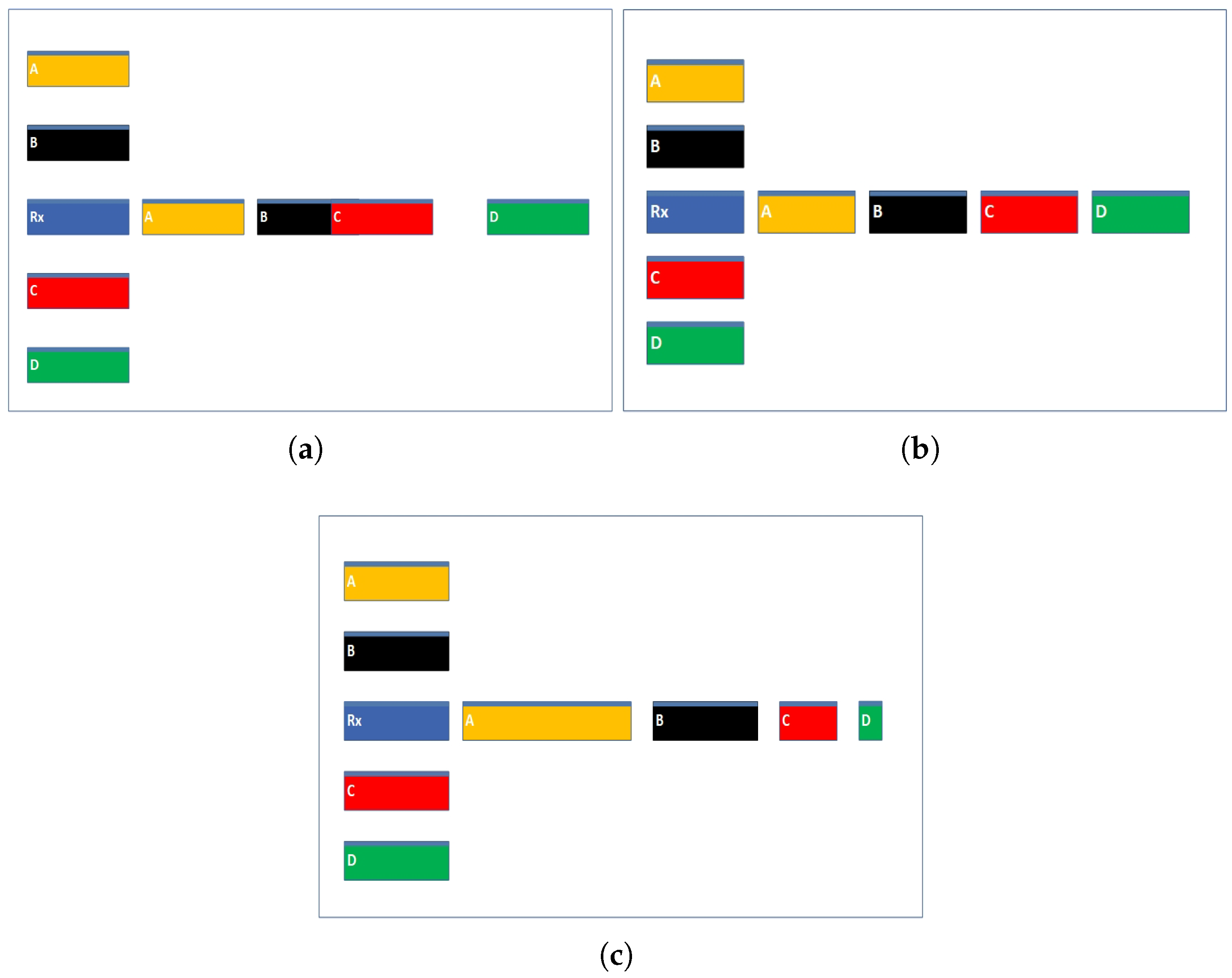
- Dynamic Slot Allocation (): We considered round-based data collection in which the receiver dynamically allocates TDMA slots, prioritizing nodes with higher traffic loads, critical data packets, or higher residual energy. Transmitter nodes send data during their allocated time slots determined by their receiver and then return to an idle state until the next frame. This ensures prompt communication and prevents congestion.
- Data Prioritization (): Critical packets (e.g., emergency data) are prioritized over routine data, ensuring that urgent transmissions are delivered first, even when the network is under heavy load.
- Wake-Up Time intervals Adjustment (): The receiver adjusts the wake-up intervals to optimize the communication cycle. If the network is underutilized, the wake-up period can be extended to save energy. However, in times of high activity or critical data transmissions, the wake-up interval may be shortened to reduce latency and ensure faster responses.
3.3.3. Reward Function R
- : Total energy consumed by the courier node as the receiver node. Minimizing this leads to energy-efficient behavior.
- : Number of transmission collisions. Minimizing this improves channel utilization and reduces congestion.
- : Quality of delivery, specifically for critical data packets (e.g., emergency data). Maximizing this ensures reliable communication for time-sensitive data.
- : Transmission delay. Minimizing this ensures low latency, particularly for critical data.
- : Energy load (a measure of how much energy each node has left). It helps balance load across the network, preventing overuse of high-energy nodes.
- : A factor representing the importance of critical data. Higher values should prioritize these packets over non-critical data.
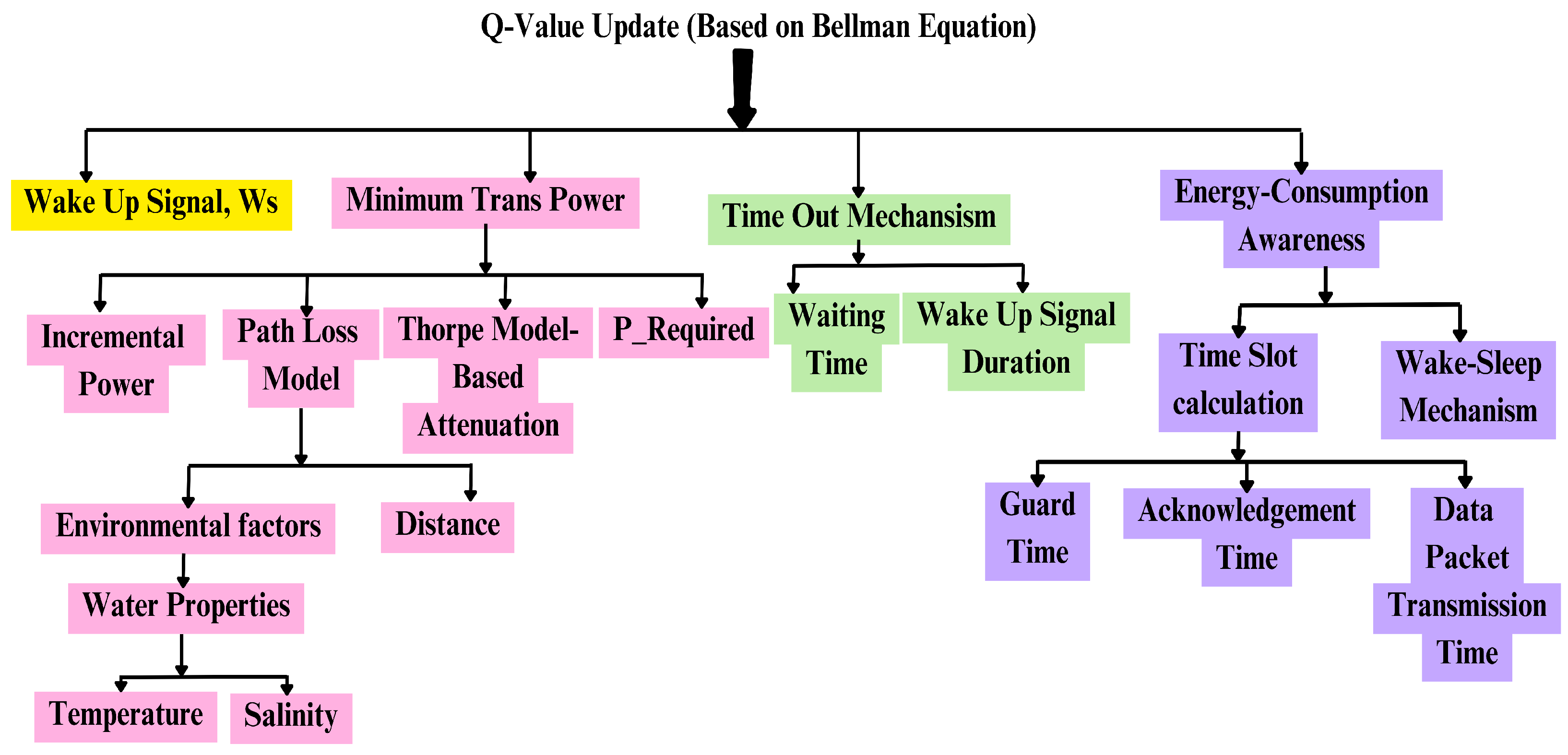
3.4. Proposed Methodology and Q-Value Updates
- is the Q-value for the state-action pair .
- R is the immediate reward received after taking action A in state S.
- is the discount factor that determines the weight given to future rewards. It ranges from 0 to 1.
- is the learning rate, which controls the learning speed and ranges from 0 to 1.
- represents the maximum expected future reward for the next state , over all possible actions .
- is the action selected by the agent at time t,
- is the Q-value of action a in state ,
- is the probability of choosing a random action (exploration),
- is the probability of selecting the action that maximizes the Q-value (exploitation).
- is the reward received after taking action in state ,
- is the discount factor, determining the importance of future rewards,
- is the maximum Q-value predicted by the target network for the next state .
- represents the parameters of the current Q-network,
- represents the parameters of the target Q-network, which is updated less frequently to stabilize the training process.
3.4.1. Q-Value Update
- is the target Q-value (derived from the Bellman equation),
- is the predicted Q-value for the state-action pair given the current Q-network with parameters ,
- are the parameters of the current Q-network.
3.4.2. Gradient Descent
3.4.3. Target Network Update
3.5. Neural Network Architecture in DQN
3.5.1. Input Layer
3.5.2. Hidden Layers and Activation Functions
3.5.3. Output Layer and Q-Value Estimation
3.5.4. Training Process and Loss Function
3.5.5. Performance Enhancements via Neural Networks
- Function Approximation: This contrasts with naive tabular Q-learning which faces the curse of dimensionality, because DQNs effectively generalize across state spaces, and learn efficiently even in high-dimensional environments.
- Improved Convergence Stability: This allows to stabilize training and reduces oscillation due to high weight updates.
- Efficient Representation Learning: The hidden layers extract hierarchical representations of states, enabling the model to capture complex patterns in the environment.
- Non-Linear Decision Boundaries: The ReLU activation function allows the network to model highly non-linear Q-functions, improving decision-making capabilities in dynamic scenarios.
3.6. Energy-Efficient Communication Flow
4. Performance Evaluation
4.1. Simulation Metrics
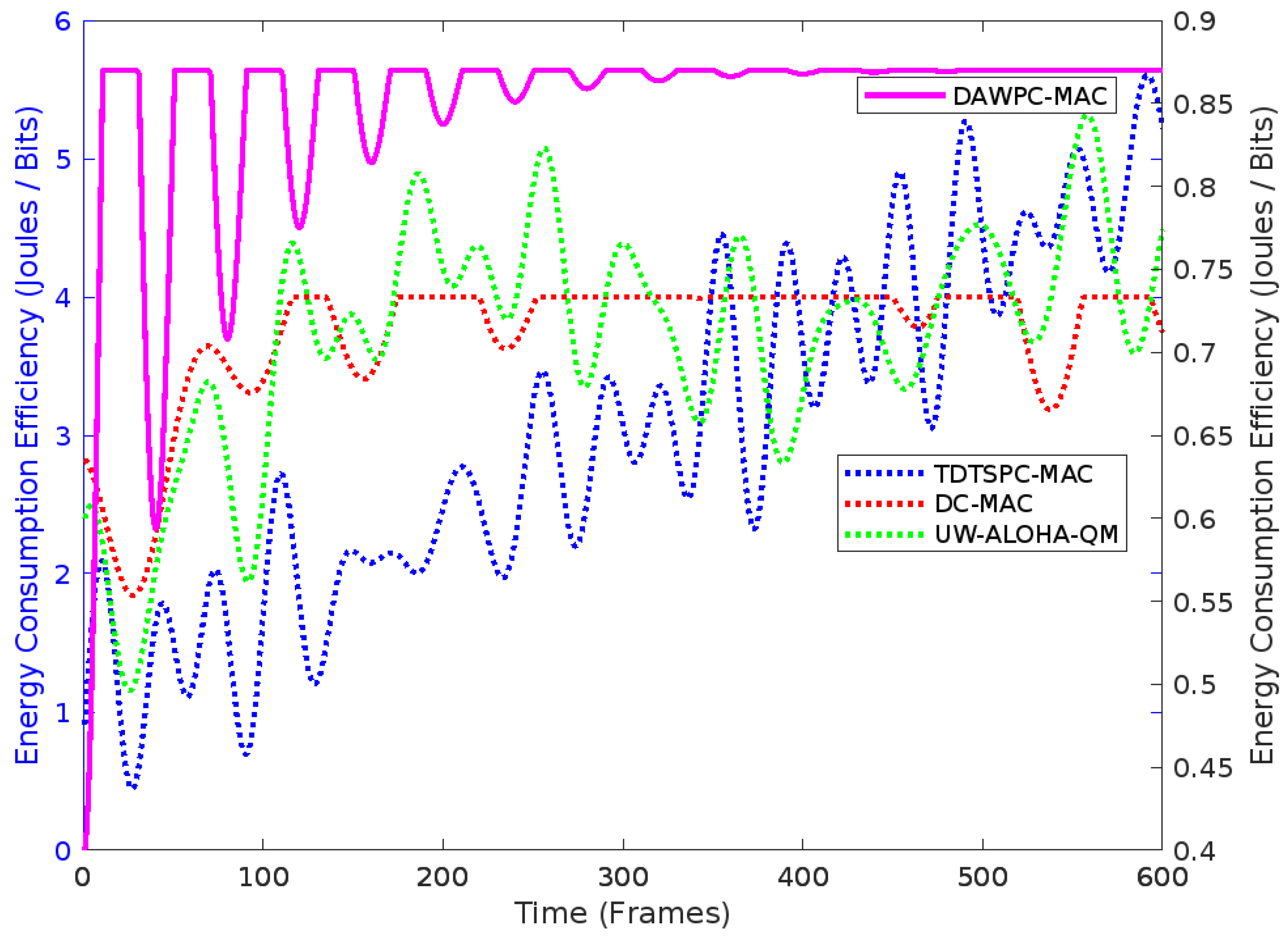
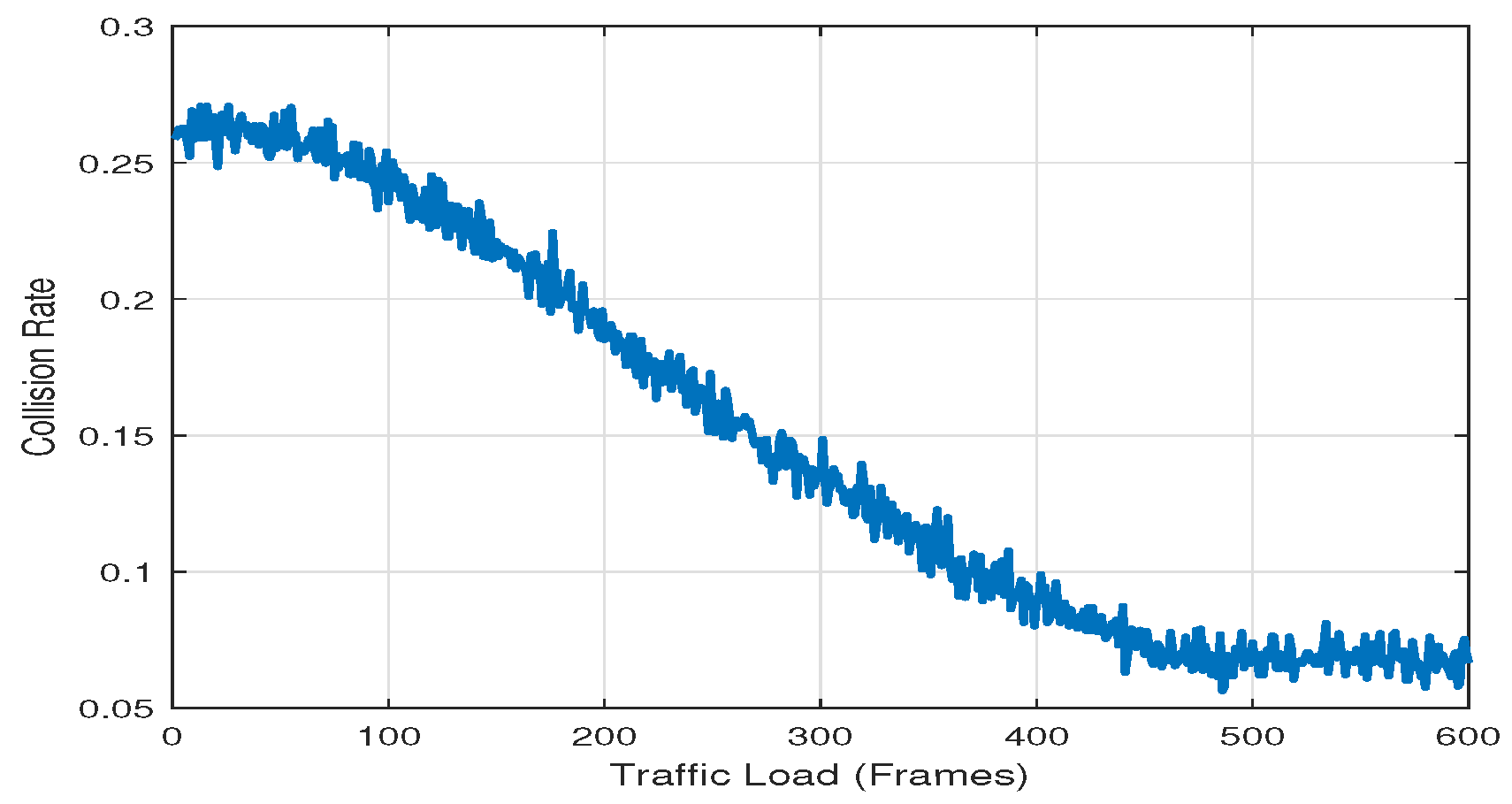
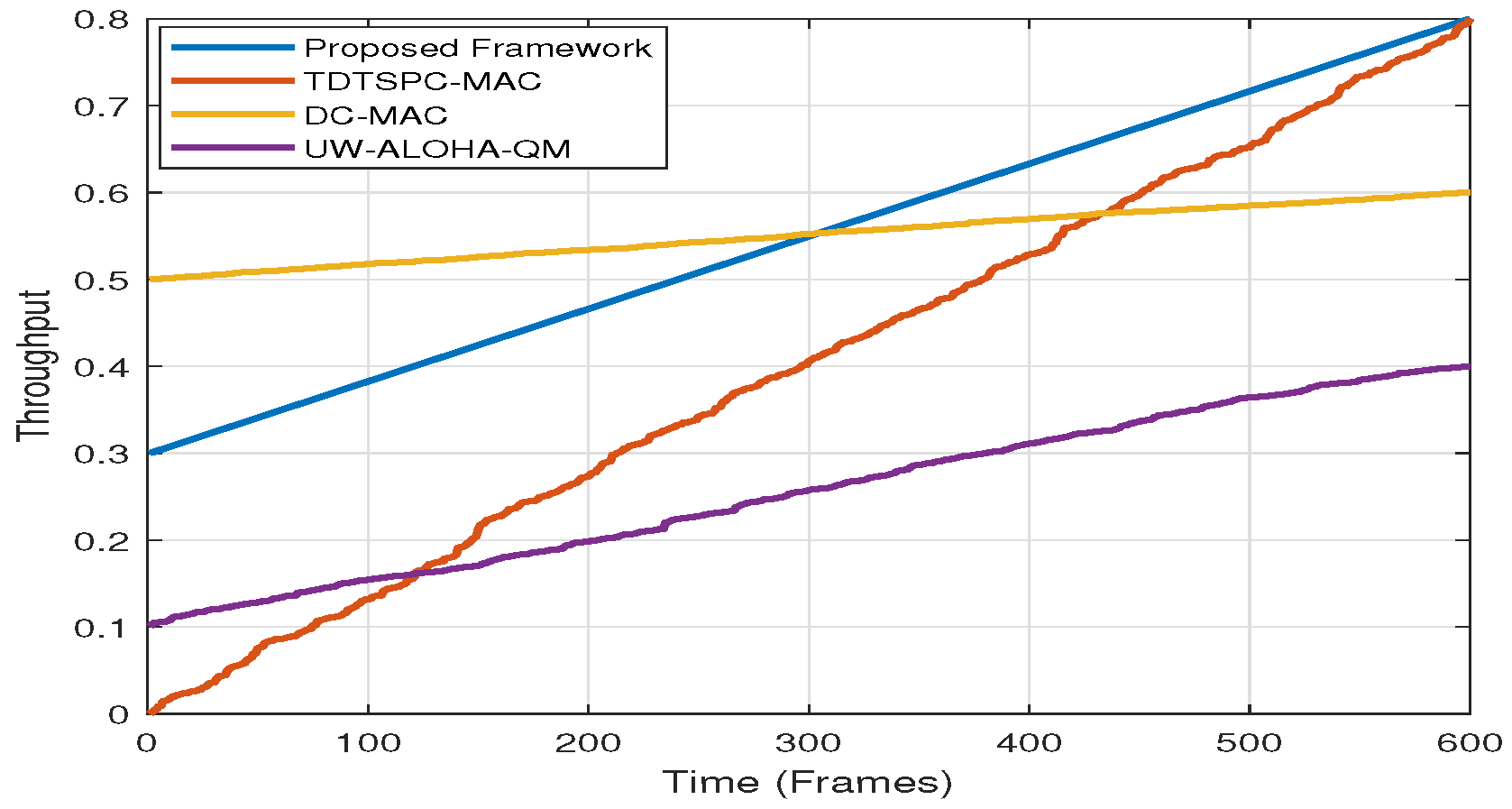
4.2. Simulation Results and Discussion
4.3. Convergence Metrics and Sensitivity Analysis
- Number of Iterations for Convergence: The Q-values stabilize within 5000 to 7000 iterations, significantly reducing computational overhead compared to conventional approaches that often require 10,000+ iterations.
- Convergence Threshold (): The convergence is considered achieved when the absolute change in Q-values satisfies .
- Adaptive Q-value Updates: The Q-value updates are performed every 10 to 20 actions, minimizing redundant computations while maintaining learning efficiency.
- Batch Size for Training: A batch size of 16 to 32 samples is used, optimizing memory usage and computational load.
- Neural Network Complexity: The Q-network is designed with one hidden layer containing 32–64 neurons, ensuring lightweight processing while achieving effective policy learning.
- 18% improvement in energy efficiency over baseline MAC protocols.
- 12% higher packet delivery ratio (PDR) compared to conventional MAC schemes.
- 25% reduction in packet collisions compared to static time-slot scheduling methods.
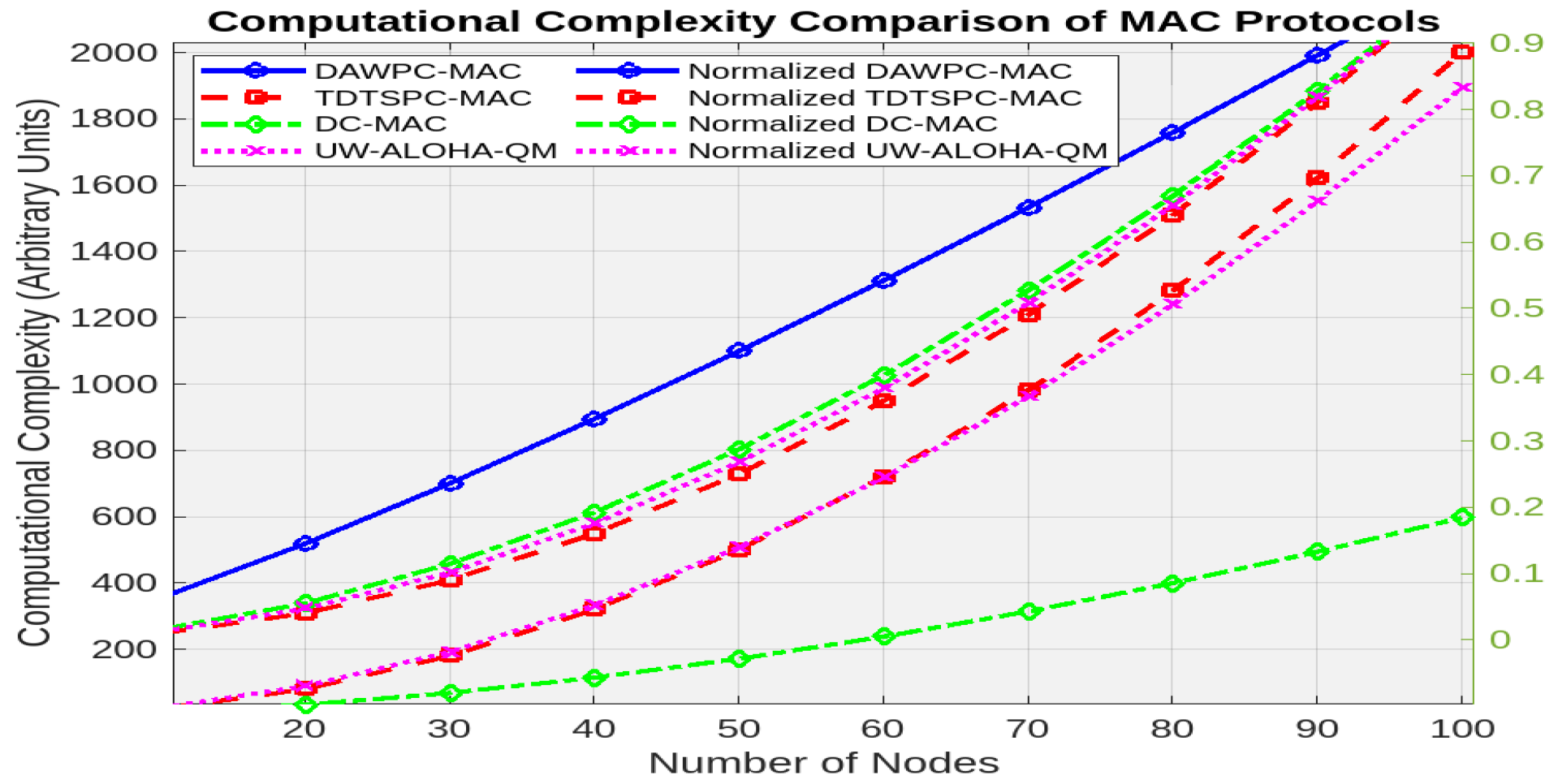
5. Analysis of Computational Complexity
5.1. Key Observations
- DAWPC-MAC exhibits the lowest computational complexity, growing as .
- TDTSPC-MAC has the highest complexity, growing as .
- DC-MAC and UW-ALOHA-QM show intermediate complexity, growing as and , respectively.
- At 100 nodes, DAWPC-MAC’s complexity is 79 (arbitrary units), while TDTSPC-MAC, DC-MAC, and UW-ALOHA-QM have complexities of 2000, 950, and 1900, respectively.
- Normalized complexity at 100 nodes is 1 for DAWPC-MAC, compared to 25 for TDTSPC-MAC, 12 for DC-MAC, and 24 for UW-ALOHA-QM.
5.2. Reasons for DAWPC-MAC’s Superiority
- Deep Q-Learning (DQN): Enables adaptive scheduling and power control, reducing computational overhead.
- Collision Avoidance: Minimizes retransmissions and interference, lowering complexity.
- Energy Efficiency: Reduces computational burden on nodes, enhancing scalability.
5.3. Comparison with Benchmark Protocols
5.4. Implications for Underwater Networks
- Energy Efficiency: DAWPC-MAC’s low complexity reduces energy consumption, critical for battery-operated nodes.
- Scalability: DAWPC-MAC’s complexity ensures efficient performance in large-scale networks.
- Latency and Reliability: DAWPC-MAC’s adaptive mechanisms reduce latency and improve reliability, making it suitable for time-sensitive applications.
6. Conclusions and Future Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Luo, J.; Chen, Y.; Wu, M.; Yang, Y. A survey of routing protocols for underwater wireless sensor networks. IEEE Commun. Surv. Tutor. 2021, 23, 137–160. [Google Scholar] [CrossRef]
- Nkenyereye, L.; Nkenyereye, L.; Ndibanje, B. Internet of Underwater Things: A Survey on Simulation Tools and 5G-Based Underwater Networks. Electronics 2024, 13, 474. [Google Scholar] [CrossRef]
- Liu, S.; Khan, M.A.; Bilal, M.; Zuberi, H.H. Low Probability Detection Constrained Underwater Acoustic Communication: A Comprehensive Review. IEEE Commun. Mag. 2025, 63, 21–30. [Google Scholar] [CrossRef]
- Zuberi, H.H.; Liu, S.; Bilal, M.; Alharbi, A.; Jaffar, A.; Mohsan, S.A.H.; Miyajan, A.; Khan, M.A. Deep-neural-network-based receiver design for downlink non-orthogonal multiple-access underwater acoustic communication. J. Mar. Sci. Eng. 2023, 11, 2184. [Google Scholar] [CrossRef]
- Tian, X.; Du, X.; Wang, L.; Li, C.; Han, D. MAC protocol of underwater acoustic network based on state coloring. Chin. J. Sens. Technol. 2023, 36, 124–134. [Google Scholar]
- Xue, L.; Lei, H.; Zhu, R. A Collision Avoidance MAC Protocol with Power Control for Adaptive Clustering Underwater Sensor Networks. J. Mar. Sci. Eng. 2025, 13, 76. [Google Scholar] [CrossRef]
- Gang, Q.; Rahman, W.U.; Zhou, F.; Bilal, M.; Ali, W.; Khan, S.U.; Khattak, M.I. A Q-Learning-Based Approach to Design an Energy-Efficient MAC Protocol for UWSNs Through Collision Avoidance. Electronics 2024, 13, 4388. [Google Scholar] [CrossRef]
- Zhang, T.; Gou, Y.; Liu, J.; Cui, J.-H. Traffic Load-Aware Resource Management Strategy for Underwater Wireless Sensor Networks. IEEE Trans. Mob. Comput. 2024, 24, 243–260. [Google Scholar] [CrossRef]
- Kulla, E.; Matsuo, K.; Barolli, L. MAC Layer Protocols for Underwater Acoustic Sensor Networks: A Survey. In International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing; Springer International Publishing: Cham, Switzerland, 2022. [Google Scholar]
- Lin, W.; Cheng, E.; Yuan, F. A MACA-based MAC protocol for Underwater Acoustic Sensor Networks. J. Commun. 2011, 6, 179–184. [Google Scholar] [CrossRef]
- Wang, J.; Shen, J.; Shi, W.; Qiao, G.; Wu, S.; Wang, X. A novel energy-efficient contention-based MAC protocol used for OA-UWSN. Sensors 2019, 19, 183. [Google Scholar] [CrossRef]
- Park, S.H.; Mitchell, P.D.; Grace, D. Performance of the ALOHA-Q MAC protocol for underwater acoustic networks. In Proceedings of the 2018 International Conference on Computing, Electronics & Communications Engineering (iCCECE), Southend, UK, 16–17 August 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Ye, X.; Fu, L. Deep reinforcement learning based MAC protocol for underwater acoustic networks. In Proceedings of the 14th International Conference on Underwater Networks & Systems, Atlanta, GA, USA, 23–25 October 2019. [Google Scholar]
- Chirdchoo, N.; Soh, W.-S.; Chua, K.C. RIPT: A receiver-initiated reservationbased protocol for underwater acoustic networks. IEEE J. Sel. Areas Commun. 2008, 26, 1744–1753. [Google Scholar]
- Sendra, S.; Lloret, J.; Jimenez, J.M.; Parra, L. Underwater acoustic modems. IEEE Sens. J. 2015, 16, 4063–4071. [Google Scholar] [CrossRef]
- Hsu, C.C.; Kuo, M.S.; Chou, C.F.; Lin, K.C.J. The Elimination of Spatial-Temporal Uncertainty in Underwater Sensor Networks. IEEE/ACM Trans. Netw. 2013, 21, 1229–1242. [Google Scholar]
- Rahman, W.U.; Gang, Q.; Feng, Z.; Khan, Z.U.; Aman, M.; Ullah, I. A Q Learning-Based Multi-Hop Energy-Efficient and Low Collision MAC Protocol for Underwater Acoustic Wireless Sensor Networks. In Proceedings of the IEEE IBCAST, Bhurban, Murree, Pakistan, 22–25 August 2023. [Google Scholar] [CrossRef]
- Du, H.; Wang, X.; Sun, W.; Zhang, J. An Adaptive MAC Protocol for Underwater Acoustic Networks Based on Deep Reinforcement Learning. In Proceedings of the IEEE CISCE, Guangzhou, China, 10–12 May 2024. [Google Scholar] [CrossRef]
- Sun, W.; Sun, X.; Wang, B.; Wang, J.; Du, H.; Zhang, J. MR-SFAMA-Q: A MAC Protocol Based on Q-Learning for Underwater Acoustic Sensor Networks. Diannao Xuekan 2024, 35, 51–63. [Google Scholar]
- ur Rahman, W.; Gang, Q.; Feng, Z.; Khan, Z.U.; Aman, M.; Bilal, M. A MACA-Based Energy-Efficient MAC Protocol Using Q-Learning Technique for Underwater Acoustic Sensor Network. In Proceedings of the IEEE ICCSNT, Dalian, China, 21–22 October 2023. [Google Scholar] [CrossRef]
- Tomovic, S.; Radusinovic, I. DR-ALOHA-Q: A Q-learning-based adaptive MAC protocol for underwater acoustic sensor networks. Sensors 2023, 23, 4474. [Google Scholar] [CrossRef] [PubMed]
- Hong, L.; Hong, F.; Guo, Z.W.; Yang, X. A TDMA-based MAC protocol in underwater sensor networks. In Proceedings of the IEEE WCNC, Dalian, China, 12–14 October 2008; pp. 1–4. [Google Scholar]
- Yang, S.; Liu, X.; Su, Y. A Traffic-Aware Fair MAC Protocol for Layered Data Collection Oriented Underwater Acoustic Sensor Networks. Remote Sens. 2023, 15, 1501. [Google Scholar] [CrossRef]
- Gazi, F.; Ahmed, N.; Misra, S.; Wei, W. Reinforcement learning-based MAC protocol for underwater multimedia sensor networks. ACM Trans. Sens. Netw. 2022, 18, 1–25. [Google Scholar] [CrossRef]
- Chen, Y.D.; Lien, C.Y.; Chuang, S.W.; Shih, K.P. DSSS: A TDMA-based MAC protocol with dynamic slot scheduling strategy for underwater acoustic sensor networks. In Proceedings of the IEEE Oceans-Spain, Santander, Spain, 6–9 June 2011; pp. 1–6. [Google Scholar]
- Cho, H.J.; Namgung, J.I.; Yun, N.Y.; Park, S.H.; Kim, C.H.; Ryuh, Y.S. Contention-free MAC protocol based on priority in underwater acoustic communication. In Proceedings of the IEEE Oceans-Spain, Santander, Spain, 6–9 June 2011; pp. 1–7. [Google Scholar]
- Zheng, M.; Ge, W.; Han, X.; Yin, J. A spatially fair and low conflict medium access control protocol for underwater acoustic networks. J. Mar. Sci. Eng. 2023, 11, 802. [Google Scholar] [CrossRef]
- Alablani, I.A.; Arafah, M.A. EE-UWSNs: A joint energy-efficient MAC and routing protocol for underwater sensor networks. J. Mar. Sci. Eng. 2022, 10, 488. [Google Scholar] [CrossRef]
- Alfouzan, F.A. Energy-efficient collision avoidance MAC protocols for underwater sensor networks: Survey and challenges. J. Mar. Sci. Eng. 2021, 9, 741. [Google Scholar] [CrossRef]
- Xu, F.; Yang, F.; Zhao, C.; Wu, S. Deep reinforcement learning based joint edge resource management in maritime network. China Commun. 2020, 17, 211–222. [Google Scholar]
- Giannopoulos, A.E.; Spantideas, S.T.; Zetas, M.; Nomikos, N.; Trakadas, P. FedShip: Federated Over-the-Air Learning for Communication-Efficient and Privacy-Aware Smart Shipping in 6G Communications. IEEE Trans. Intell. Transp. Syst. 2024, 25, 19873–19888. [Google Scholar]
- Wang, C.; Zhang, X.; Gao, H.; Bashir, M.; Li, H.; Yang, Z. Optimizing anti-collision strategy for MASS: A safe reinforcement learning approach to improve maritime traffic safety. Ocean. Coast. Manag. 2024, 253, 107161. [Google Scholar]
- He, J.; Liu, Z.; Zhang, Y.; Jin, Z.; Zhang, Q. Power Allocation Based on Federated Multi-Agent Deep Reinforcement Learning for NOMA Maritime Networks. IEEE Internet Things J. 2024; early access. [Google Scholar]
- Rodoshi, R.T.; Song, Y.; Choi, W. Reinforcement learning-based routing protocol for underwater wireless sensor networks: A comparative survey. IEEE Access 2021, 9, 154578–154599. [Google Scholar]
- Xylouris, G.; Nomikos, N.; Kalafatelis, A.; Giannopoulos, A.; Spantideas, S.; Trakadas, P. Sailing into the future: Technologies, challenges, and opportunities for maritime communication networks in the 6G era. Front. Commun. Netw. 2024, 5, 1439529. [Google Scholar]
- Wang, C.; Shen, X.; Wang, H.; Zhang, H.; Mei, H. Reinforcement learning-based opportunistic routing protocol using depth information for energy-efficient underwater wireless sensor networks. IEEE Sens. J. 2023, 23, 17771–17783. [Google Scholar]
- Park, S.H.; Mitchell, P.D.; Grace, D. Reinforcement learning based MAC protocol (UW-ALOHA-QM) for mobile underwater acoustic sensor networks. IEEE Access 2020, 9, 5906–5919. [Google Scholar]
- AlamAlam, M.I.I.; Hossain, M.F.; Munasinghe, K.; Jamalipour, A. MAC protocol for underwater sensor networks using EM wave with TDMA based control channel. IEEE Access 2020, 8, 168439–168455. [Google Scholar]
- Rodoplu, V.; Park, M.K. An energy-efficient MAC protocol for underwater wireless acoustic networks. In Proceedings of the OCEANS 2005 MTS/IEEE, Washington, DC, USA, 17–23 September 2005; IEEE: Piscataway, NJ, USA, 2005. [Google Scholar]
- Qian, L.; Zhang, S.; Liu, M.; Zhang, Q. A MACA-based power control MAC protocol for underwater wireless sensor networks. In Proceedings of the 2016 IEEE/OES China Ocean Acoustics (COA), Harbin, China, 9–11 January 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–8. [Google Scholar]
- Alfouzan, F.A.; Shahrabi, A.; Ghoreyshi, S.M.; Boutaleb, T. A Collision-Free Graph Coloring MAC Protocol for Underwater Sensor Networks. IEEE Access 2019, 7, 39862–39878. [Google Scholar] [CrossRef]
- Zhu, R.; Liu, L.; Li, P.; Chen, N.; Feng, L.; Yang, Q. DC-MAC: A delay-aware and collision-free MAC protocol based on game theory for underwater wireless sensor networks. IEEE Sens. J. 2024, 24, 6930–6941. [Google Scholar]
- Lokam, A. ADRP-DQL: An adaptive distributed routing protocol for underwater acoustic sensor networks using deep Q-learning. Ad Hoc Netw. 2025, 167, 103692. [Google Scholar]
- Zhang, Z.; Shi, W.; Niu, Q.; Guo, Y.; Wang, J.; Luo, H. A load-based hybrid MAC protocol for underwater wireless sensor networks. IEEE Access 2019, 7, 104542–104552. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Approach | Pros | Cons |
|---|---|---|---|
| RIPT [14] | Receiver-Initiated MAC | Reduces collisions, improves throughput | Synchronization precision issues, increased latency |
| Handshaking-based [15] | Synchronization-based MAC | Better channel utilization | High latency, synchronization challenges |
| Aloha Variants [16] | Random Access MAC | Improved throughput in low-density networks | High collision risk in dense networks |
| Q-learning MAC [17] | Reinforcement Learning MAC | Adaptive and efficient | Scalability issues, high computational overhead |
| DR-D3QN-MA [18] | Time-slot Optimization | Better slot allocation | Lacks real-world validation, energy inefficiency |
| MR-SFAMA-Q [19] | Multi-Receiver Handshake | Increased adaptability | High complexity, energy consumption |
| MACA-Q [20] | Q-learning MACA | Energy-efficient, improved throughput | Multi-hop inefficiency, collision risks |
| Framed Aloha-Q [21] | Q-learning Framed Aloha | Reduces delay | Poor multi-hop efficiency, residual collisions |
| TDMA Scheduling [22] | Time-Division MAC | Low collision rate | Inefficient under dynamic traffic conditions |
| Traffic-Aware MAC [23] | Adaptive Scheduling | Improves fairness | Lacks routing integration |
| RL-Multimedia MAC [24] | RL for Multimedia | Optimized throughput | High computational complexity |
| Dynamic Slot Scheduling [25] | Adaptive Time Slot Allocation | Enhances adaptability | High processing overhead |
| Contention-Free MAC [26] | Priority-based MAC | Ensures critical data transmission | Ignores lower-priority traffic |
| Spatially Fair MAC [27] | Fairness-Based MAC | Improves network stability | Lacks dynamic adaptation |
| EE-UWSNs [28] | Energy-Efficient MAC | Energy-aware routing integration | Limited real-world validation |
| RL-Based MAC [29] | Reinforcement Learning MAC | Enhances scalability | High computational overhead |
| Proposed Work | DQN-based MAC-Routing | Dynamic optimization, energy-efficient, scalable | Requires real-world testing and fine-tuning |
| Network Parameters | Purpose | Value |
|---|---|---|
| N | Number of nodes in the network | 50 nodes |
| Distance | Distance between a generating node and a sink node | 12.9 m |
| Simulation Area | Area for node placement | 600 × 600 m |
| Traffic Rate | Rate of traffic generated by nodes | 0.05 to 0.4 packets/s |
| Transmission Parameters | ||
| Data Packet Size | Size of the data packet | 1044 bits |
| Duration of a data packet transmission | 16.704 ms | |
| ACK Packet Size | Size of the acknowledgment packet | 20 bits |
| Duration of an acknowledgment packet transmission | 0.32 ms | |
| Tx/Rx data rate | 62,500 bps | |
| Transmission Rate | Communication data rate | 13,900 bps |
| Propagation speed in the underwater medium | 1500 m/s | |
| Propagation delay | 8.6 ms | |
| Duration of guard time | 0.576 ms | |
| Slot duration in the TDMA schedule | 34.8 ms | |
| Time-offset step size | 5 ms | |
| Ocean Water Parameters | ||
| Salinity | Concentration of dissolved salts | {35, 37} PSU |
| Temperature | {0, 35} | |
| Learning Parameters (DQN) | ||
| Learning rate for deep Q-learning algorithm | 0.1 | |
| Discount Factor (DQN) | Discount factor for Q-learning update | 0.9 |
| Number of Episodes (DQN) | Total number of episodes for training | 1000 |
| Batch Size (DQN) | Number of samples in each training batch | 32 |
| Epsilon (DQN) | Exploration factor for epsilon-greedy policy | 0.1 |
| Parameter | Symbol | Value | Justification |
|---|---|---|---|
| Learning Rate | 0.05 | Ensures stable learning while avoiding divergence. | |
| Discount Factor | 0.85 | Balances short-term and long-term reward optimization. | |
| Exploration Decay Rate | Gradual decay maintains sufficient exploration. | ||
| Mini-batch Size | - | 16–32 | Optimizes memory efficiency while retaining learning quality. |
| Target Network Update Frequency | - | Every 500 iterations | Reduces computational complexity while maintaining stability. |
| Protocol | Complexity Order | Scalability | Key Strengths |
|---|---|---|---|
| DAWPC-MAC | Excellent | Adaptive, energy-efficient | |
| TDTSPC-MAC | Poor | Time synchronization | |
| DC-MAC | Moderate | Game-theoretic optimization | |
| UW-ALOHA-QM | Moderate | Reinforcement learning |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, W.U.; Gang, Q.; Zhou, F.; Tahir, M.; Ali, W.; Adil, M.; Khattak, M.I. Deep Q-Learning Based Adaptive MAC Protocol with Collision Avoidance and Efficient Power Control for UWSNs. J. Mar. Sci. Eng. 2025, 13, 616. https://doi.org/10.3390/jmse13030616
Rahman WU, Gang Q, Zhou F, Tahir M, Ali W, Adil M, Khattak MI. Deep Q-Learning Based Adaptive MAC Protocol with Collision Avoidance and Efficient Power Control for UWSNs. Journal of Marine Science and Engineering. 2025; 13(3):616. https://doi.org/10.3390/jmse13030616
Chicago/Turabian StyleRahman, Wazir Ur, Qiao Gang, Feng Zhou, Muhammad Tahir, Wasiq Ali, Muhammad Adil, and Muhammad Ilyas Khattak. 2025. "Deep Q-Learning Based Adaptive MAC Protocol with Collision Avoidance and Efficient Power Control for UWSNs" Journal of Marine Science and Engineering 13, no. 3: 616. https://doi.org/10.3390/jmse13030616
APA StyleRahman, W. U., Gang, Q., Zhou, F., Tahir, M., Ali, W., Adil, M., & Khattak, M. I. (2025). Deep Q-Learning Based Adaptive MAC Protocol with Collision Avoidance and Efficient Power Control for UWSNs. Journal of Marine Science and Engineering, 13(3), 616. https://doi.org/10.3390/jmse13030616