
Lightweight GPU-Accelerated Parallel Processing of the SCHISM Model Using CUDA Fortran

 , , ,
, , , 
Abstract
1. Introduction
2. Data and Methods
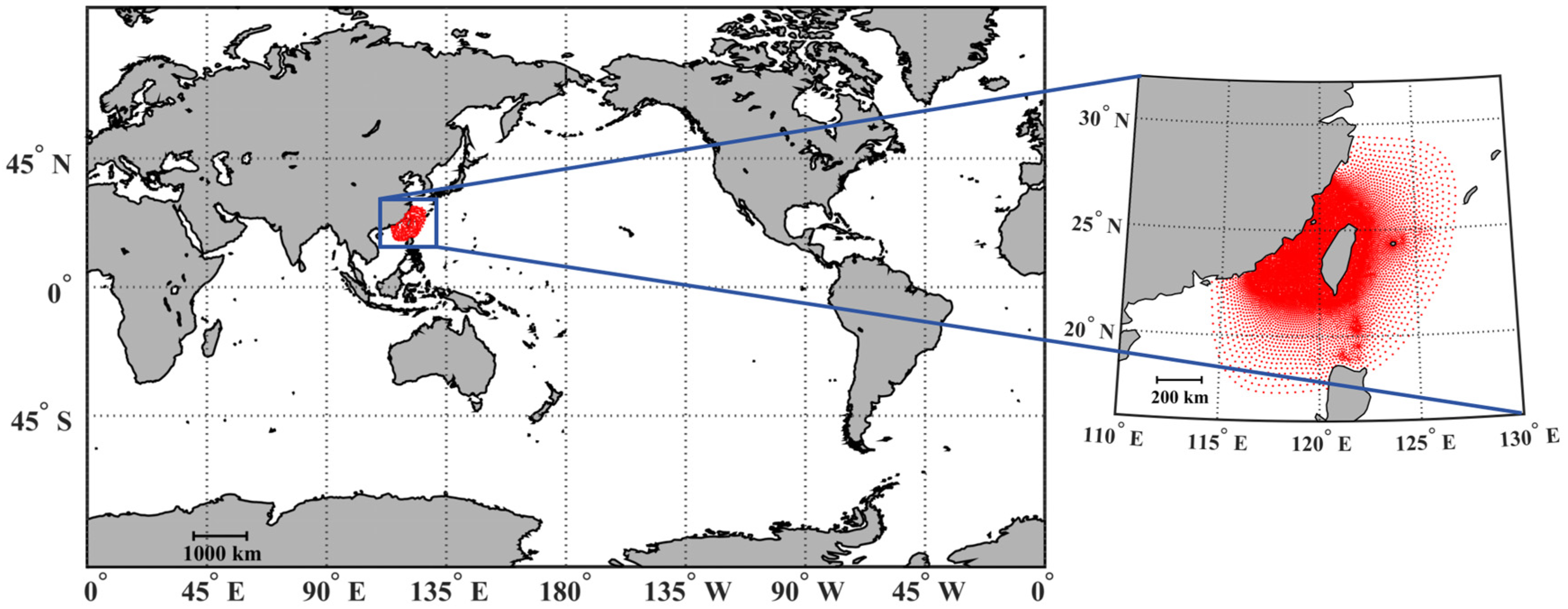
2.1. Data
2.2. Lightweight Methods
3. Results
3.1. Software and Hardware Platform
3.2. Experimental Design
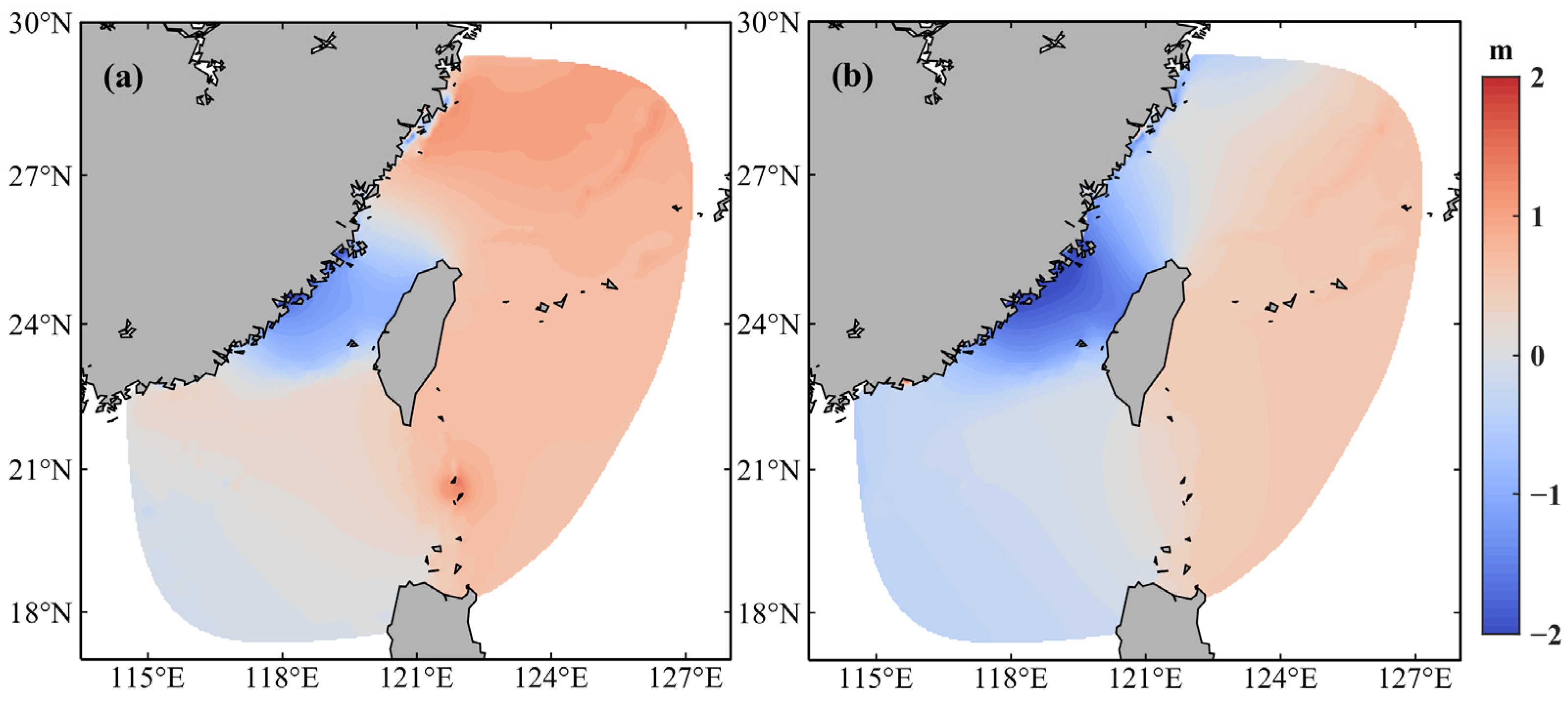
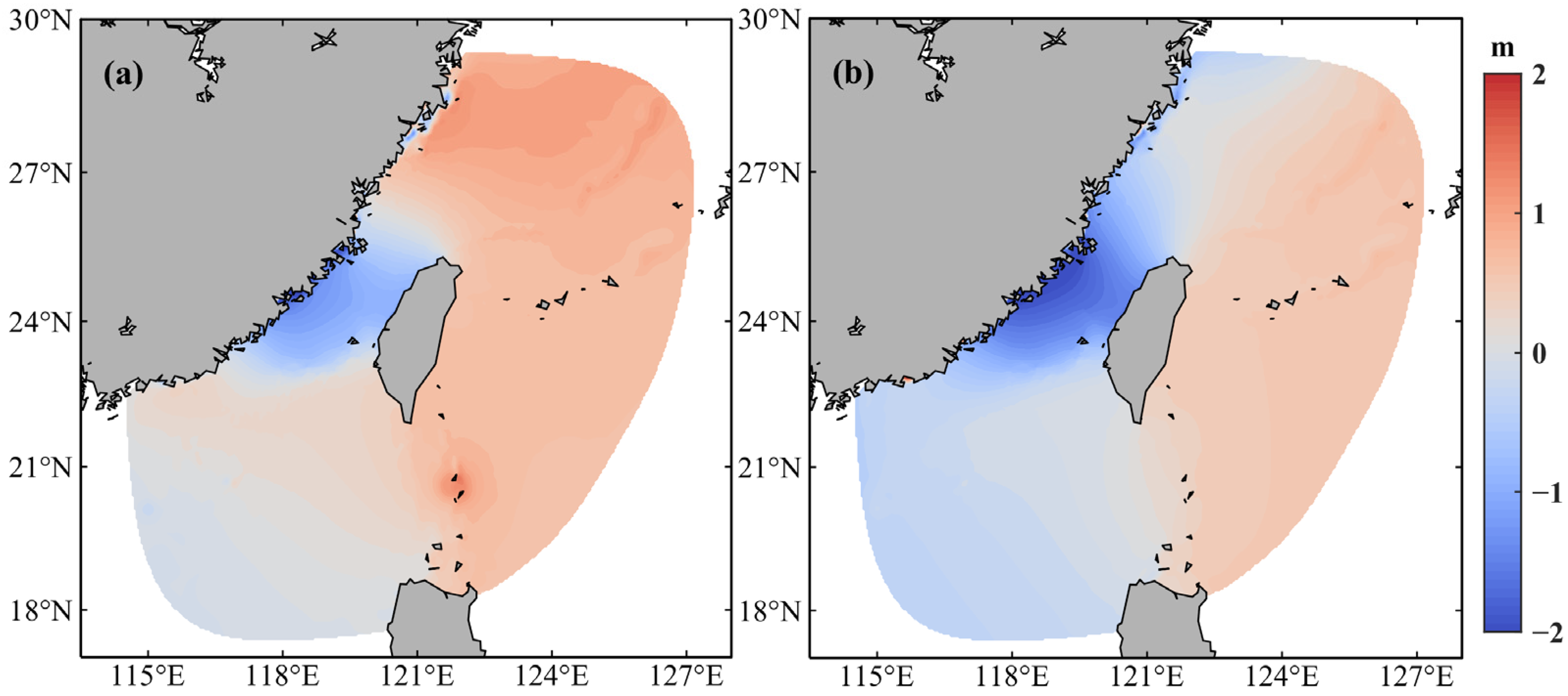
3.3. Accuracy Validation
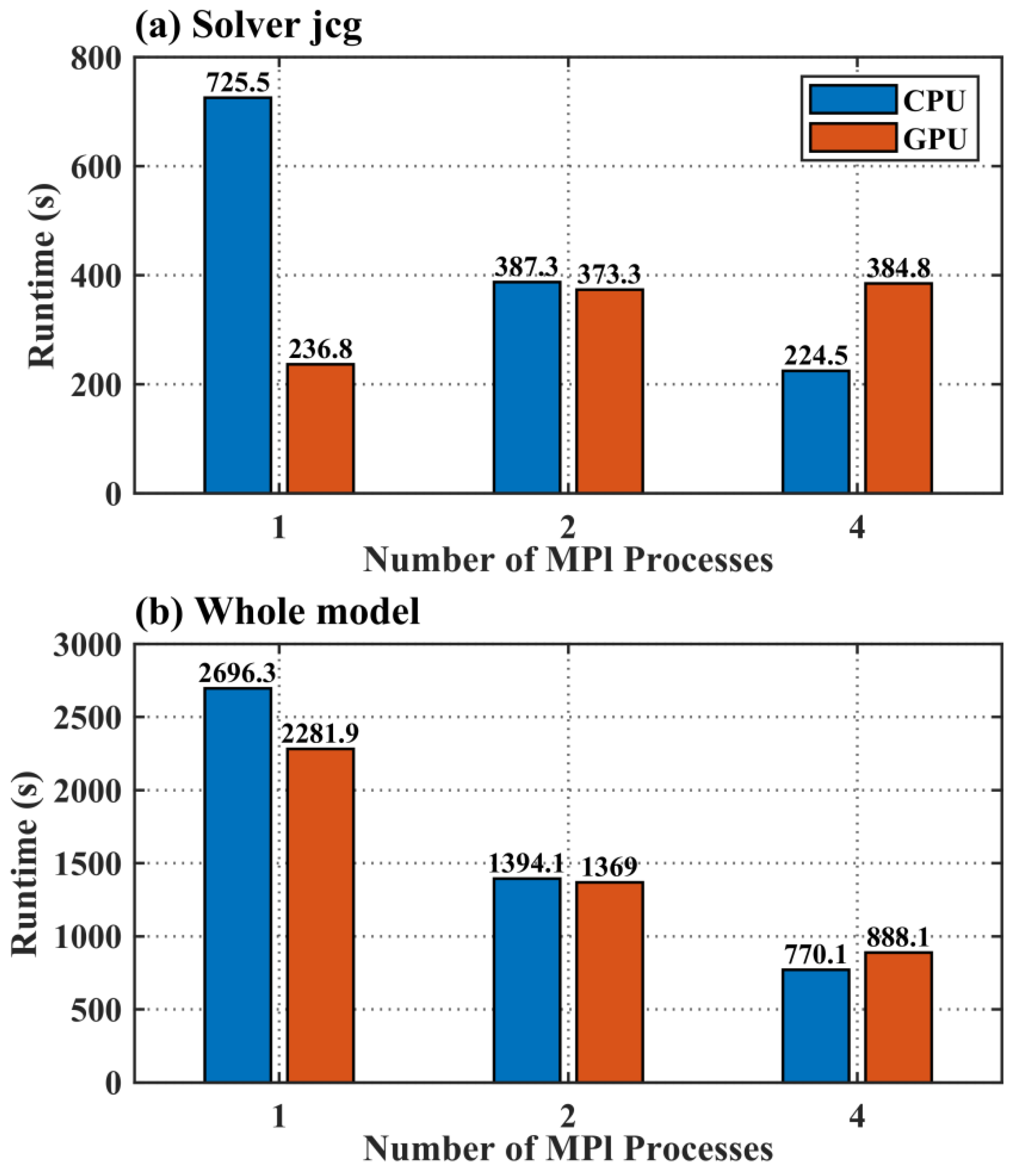
3.4. Lightweight Acceleration Performance
4. Conclusions and Discussion
- The GPU–SCHISM model is able to maintain the accuracy as the simulation results by utilizing only CPU. The error in the water level simulation between the accelerated GPU version and the original CPU version is less than 10−6 m.
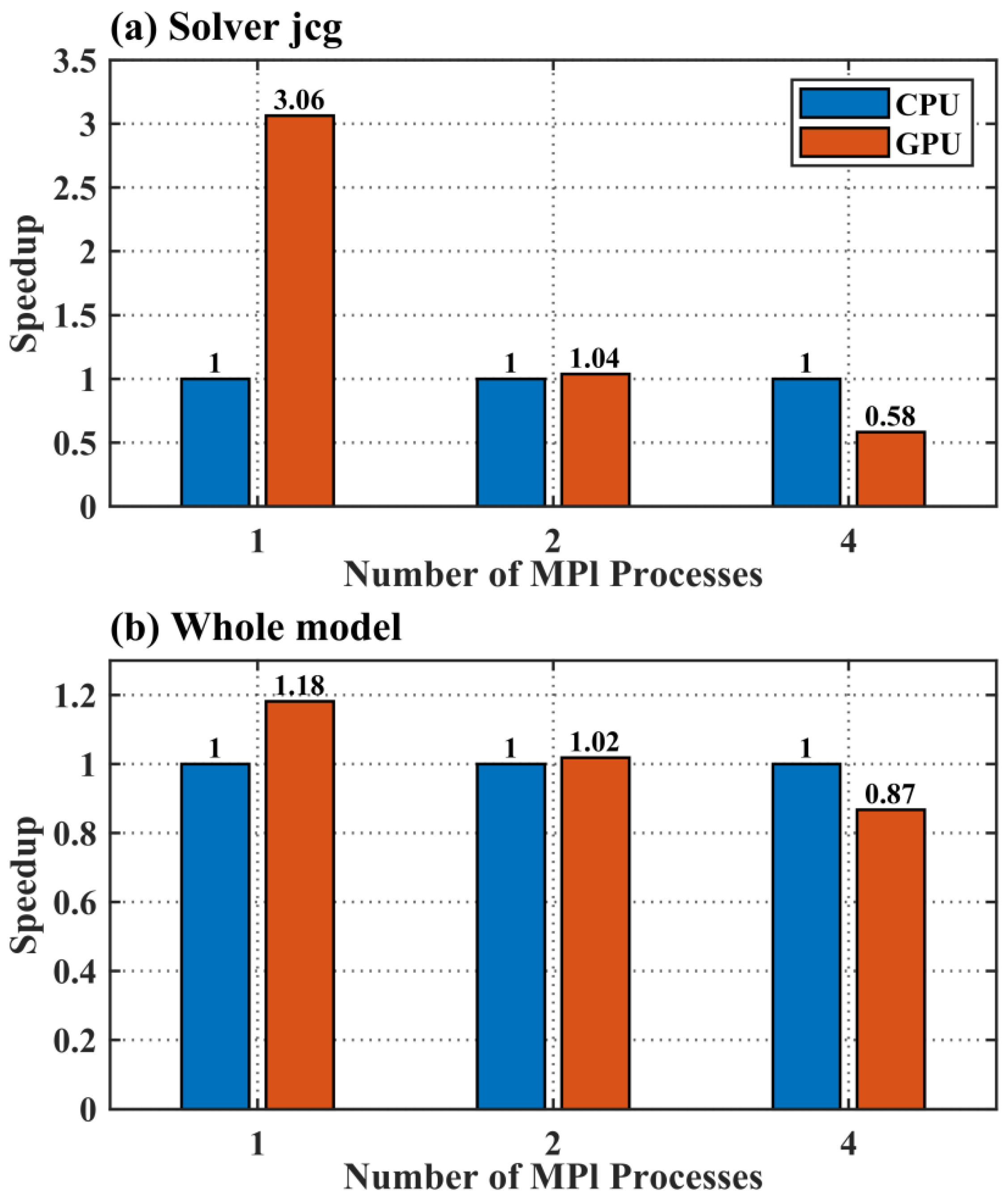
- The model using single GPU exhibits significant acceleration effects. The Jacobian iterative solver module, when accelerated with one GPU, completes a five-day water level forecast in 236.8 s, achieving a speedup ratio of 3.06, differing from that of a single-core CPU. The entire GPU–SCHISM model completes the five-day forecast in 2281.9 s, with an overall speedup ratio of 1.18.
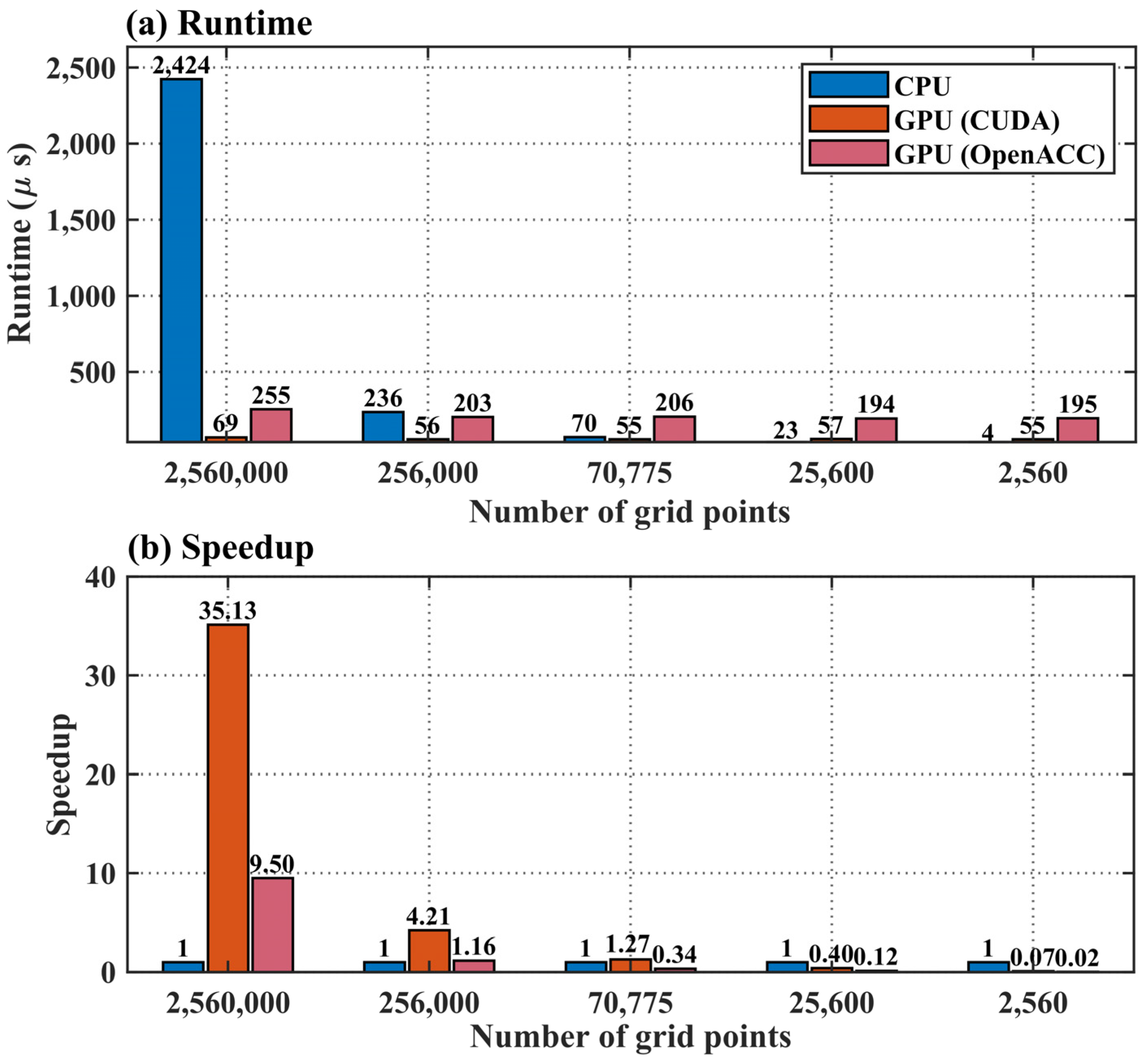
- The parallel expansion acceleration of GPU depends on the scale of calculation. In high-resolution, large-scale calculations, GPU has a significant advantage, with a GPU speedup ratio of 35.13 with 2,560,000 grid points; in small-scale calculations, the GPU calculation efficiency is lower than that of CPU.
- A comparison between the two Fortran-based GPU acceleration approaches, CUDA and OpenACC, reveals that the CUDA method employed in this study provides superior acceleration performance.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feng, X.; Li, M.; Li, Y.; Yu, F.; Yang, D.; Gao, G.; Xu, L.; Yin, B. Typhoon storm surge in the southeast Chinese mainland modulated by ENSO. Sci. Rep. 2021, 11, 10137. [Google Scholar] [CrossRef]
- Wang, K.; Yang, Y.; Reniers, G.; Huang, Q. A study into the spatiotemporal distribution of typhoon storm surge disasters in China. Nat. Hazards 2021, 108, 1237–1256. [Google Scholar]
- Glahn, B.; Taylor, A.; Kurkowski, N.; Shaffer, W.A. The role of the SLOSH model in National Weather Service storm surge forecasting. Natl. Weather. Dig. 2009, 33, 3–14. [Google Scholar]
- Kohno, N.; Dube, S.K.; Entel, M.; Fakhruddin, S.H.M.; Greenslade, D.; Leroux, M.; Rhome, J.; Thuy, N.B. Recent progress in storm surge forecasting. Trop. Cyclone Res. Rev. 2018, 7, 55–66. [Google Scholar] [CrossRef]
- Luettich, R.A.; Westerink, J.J. Formulation and Numerical Implementation of the 2D/3D ADCIRC Finite Element Model Version 44; University of North Carolina: Chapel Hill, NC, USA, 2004. [Google Scholar]
- Chen, C.; Beardsley, R.C.; Cowles, G. An Unstructured Grid, Finite-Volume Coastal Ocean Model (FVCOM) System. Oceanography 2006, 19, 78–89. [Google Scholar] [CrossRef]
- Zhang, Y.; Baptista, A.M. SELFE: A semi-implicit Eulerian–Lagrangian finite-element model for cross-scale ocean circulation. Ocean Model. 2008, 21, 71–96. [Google Scholar] [CrossRef]
- Yin, B.-S.; Hou, Y.-J.; Cheng, M.-H.; Su, J.-Z.; Lin, M.-X.; Li, M.-K.; El-Sabh, M.I. Numerical study of the influence of waves and tide-surge interaction on tide-surges in the Bohai Sea. Chin. J. Oceanol. Limnol. 2001, 19, 97–102. [Google Scholar]
- Dietrich, J.C.; Zijlema, M.; Westerink, J.J.; Holthuijsen, L.H.; Dawson, C.; Luettich, R.A.; Jensen, R.E.; Smith, J.M.; Stelling, G.S.; Stone, G.W. Modeling hurricane waves and storm surge using integrally-coupled, scalable computations. Coast. Eng. 2011, 58, 45–65. [Google Scholar]
- Feng, X.; Sun, J.; Yang, D.; Yin, B.; Gao, G.; Wan, W. Effect of Drag Coefficient Parameterizations on Air–Sea Coupled Simulations: A Case Study for Typhoons Haima and Nida in 2016. J. Atmos. Ocean. Technol. 2021, 38, 977–993. [Google Scholar] [CrossRef]
- Feng, X.; Yin, B.; Yang, D. Development of an unstructured-grid wave-current coupled model and its application. Ocean Model. 2016, 104, 213–225. [Google Scholar] [CrossRef]
- Li, S. On the consistent parametric description of the wave age dependence of the sea surface roughness. J. Phys. Oceanogr. 2023, 53, 2281–2290. [Google Scholar] [CrossRef]
- Häfner, D.; Nuterman, R.; Jochum, M. Fast, cheap, and turbulent-global ocean modeling with GPU acceleration in Python. J. Adv. Model. Earth Syst. 2021, 13, e2021MS002717. [Google Scholar]
- Yuan, Y.; Yang, H.; Yu, F.; Gao, Y.; Li, B.; Xing, C. A wave-resolving modeling study of rip current variability, rip hazard, and swimmer escape strategies on an embayed beach. Nat. Hazards Earth Syst. Sci. 2023, 23, 3487–3507. [Google Scholar]
- Ikuyajolu, O.J.; Van Roekel, L.; Brus, S.R.; Thomas, E.E.; Deng, Y.; Sreepathi, S. Porting the WAVEWATCH III (v6.07) wave action source terms to GPU. Geosci. Model Dev. Discuss. 2023, 16, 1445–1458. [Google Scholar]
- Xu, S.; Huang, X.; Oey, L.-Y.; Xu, F.; Fu, H.; Zhang, Y.; Yang, G. POM.gpu-v1.0: A GPU-based princeton ocean model. Geosci. Model Dev. 2015, 8, 2815–2827. [Google Scholar] [CrossRef]
- Qin, X.; LeVeque, R.J.; Motley, M.R. Accelerating an adaptive mesh refinement code for depth-averaged flows using graphics processing units (GPUs). J. Adv. Model. Earth Syst. 2019, 11, 2606–2628. [Google Scholar]
- Jiang, J.; Lin, P.; Wang, J.; Liu, H.; Chi, X.; Hao, H.; Wang, Y.; Wang, W.; Zhang, L. Porting LASG/IAP Climate System Ocean Model to Gpus Using OpenAcc. IEEE Access 2019, 7, 154490–154501. [Google Scholar] [CrossRef]
- Brodtkorb, A.R.; Holm, H.H. Coastal ocean forecasting on the GPU using a two-dimensional finite-volume scheme. Tellus A Dyn. Meteorol. Oceanogr. 2021, 73, 1–22. [Google Scholar]
- Yuan, Y.; Yu, F.; Chen, Z.; Li, X.; Hou, F.; Gao, Y.; Gao, Z.; Pang, R. Towards a real-time modeling of global ocean waves by the fully GPU-accelerated spectral wave model WAM6-GPU v1.0. Geosci. Model Dev. 2024, 17, 6123–6136. [Google Scholar]
- Jablin, T.B.; Prabhu, P.; Jablin, J.A.; Johnson, N.P.; Beard, S.R.; August, D.I. Automatic CPU-GPU communication management and optimization. In Proceedings of the 32nd ACM SIGPLAN Conference on Programming Language Design and Implementation, San Jose, CA, USA, 4–8 June 2011; pp. 142–151. [Google Scholar]
- Mittal, S.; Vaishay, S. A survey of techniques for optimizing deep learning on GPUs. J. Syst. Arch. 2019, 99, 101635. [Google Scholar]
- Sharkawi, S.S.; Chochia, G.A. Communication protocol optimization for enhanced GPU performance. IBM J. Res. Dev. 2020, 64, 9:1–9:9. [Google Scholar]
- Hopkins, M.; Mikaitis, M.; Lester, D.R.; Furber, S. Stochastic rounding and reduced-precision fixed-point arithmetic for solving neural ordinary differential equations. Philos. Trans. R. Soc. Lond. Ser. A 2020, 378, 20190052. [Google Scholar]
- Gupta, R.R.; Ranga, V. Comparative study of different reduced precision techniques in deep neural network. In Proceedings of the International Conference on Big Data, Machine Learning and their Applications, Prayagraj, India, 29–31 May 2020; Tiwari, S., Suryani, E., Ng, A.K., Mishra, K.K., Singh, N., Eds.; Springer: Singapore, 2021; pp. 123–136. [Google Scholar]
- Rehm, F.; Vallecorsa, S.; Saletore, V.; Pabst, H.; Chaibi, A.; Codreanu, V.; Borras, K.; Krücker, D. Reduced precision strategies for deep learning: A high energy physics generative adversarial network use case. arXiv 2021, arXiv:2103.10142. [Google Scholar]
- Noune, B.; Jones, P.; Justus, D.; Masters, D.; Luschi, C. 8-bit numerical formats for deep neural networks. arXiv 2022, arXiv:2206.02915. [Google Scholar]
- TensorFlow Accelerating AI Performance on 3rd Gen Intel Xeon Scalable Processors with TensorFlow and Bfloat16, 2020. Available online: https://blog.tensorflow.org/2020/06/accelerating-ai-performance-on-3rd-gen-processors-with-tensorflow-bfloat16.html (accessed on 18 June 2021).
- Tintó Prims, O.; Acosta, M.C.; Moore, A.M.; Castrillo, M.; Serradell, K.; Cortés, A.; Doblas-Reyes, F.J. How to use mixed precision in ocean models: Exploring a potential reduction of numerical precision in NEMO 4.0 and ROMS 3.6. Geosci. Model Dev. 2019, 12, 3135–3148. [Google Scholar]
- Zhang, Y.J.; Ye, F.; Stanev, E.V.; Grashorn, S. Seamless cross-scale modeling with SCHISM. Ocean Model. 2016, 102, 64–81. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Average Water Level from CPU-Based SCHISM (m) | Average Water Level Simulated by GPU–SCHISM (m) | RMSE Between CPU-Based SCHISM and GPU–SCHISM (m) |
|---|---|---|---|
| Day 3, 24:00 | 0.3714 | 0.3714 | 4.08 × 10−4 |
| Day 5, 24:00 | 0.0294 | 0.0294 | 4.57 × 10−6 |
| Model Name | Model Description | Porting Modules to GPU | Speedup |
|---|---|---|---|
| WRF | Weather Research and Forecasting | WSM5 microphysics | 8 |
| WRF-Chem | WRF Chemical | Chemical kinetics kernel | 8.5 |
| POP | Parallel Ocean Program | Loop structures | 2.2 |
| POM | Princeton Ocean Model | POM.gpu code | 6.8 |
| GPU–SCHISM | GPU-Semi-implicit Cross-scale Hydroscience Integrated System Model | Jacobian iterative solver module | 3.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Cao, Q.; Wu, C.; Xu, G.; Liu, Y.; Feng, X.; Jin, M.; Dong, C. Lightweight GPU-Accelerated Parallel Processing of the SCHISM Model Using CUDA Fortran. J. Mar. Sci. Eng. 2025, 13, 662. https://doi.org/10.3390/jmse13040662
Zhang H, Cao Q, Wu C, Xu G, Liu Y, Feng X, Jin M, Dong C. Lightweight GPU-Accelerated Parallel Processing of the SCHISM Model Using CUDA Fortran. Journal of Marine Science and Engineering. 2025; 13(4):662. https://doi.org/10.3390/jmse13040662
Chicago/Turabian StyleZhang, Hongchun, Qian Cao, Changmao Wu, Guangjun Xu, Yuli Liu, Xingru Feng, Meibing Jin, and Changming Dong. 2025. "Lightweight GPU-Accelerated Parallel Processing of the SCHISM Model Using CUDA Fortran" Journal of Marine Science and Engineering 13, no. 4: 662. https://doi.org/10.3390/jmse13040662
APA StyleZhang, H., Cao, Q., Wu, C., Xu, G., Liu, Y., Feng, X., Jin, M., & Dong, C. (2025). Lightweight GPU-Accelerated Parallel Processing of the SCHISM Model Using CUDA Fortran. Journal of Marine Science and Engineering, 13(4), 662. https://doi.org/10.3390/jmse13040662