
A Novel Swin-Transformer with Multi-Source Information Fusion for Online Cross-Domain Bearing RUL Prediction


Abstract
1. Introduction
- (1)
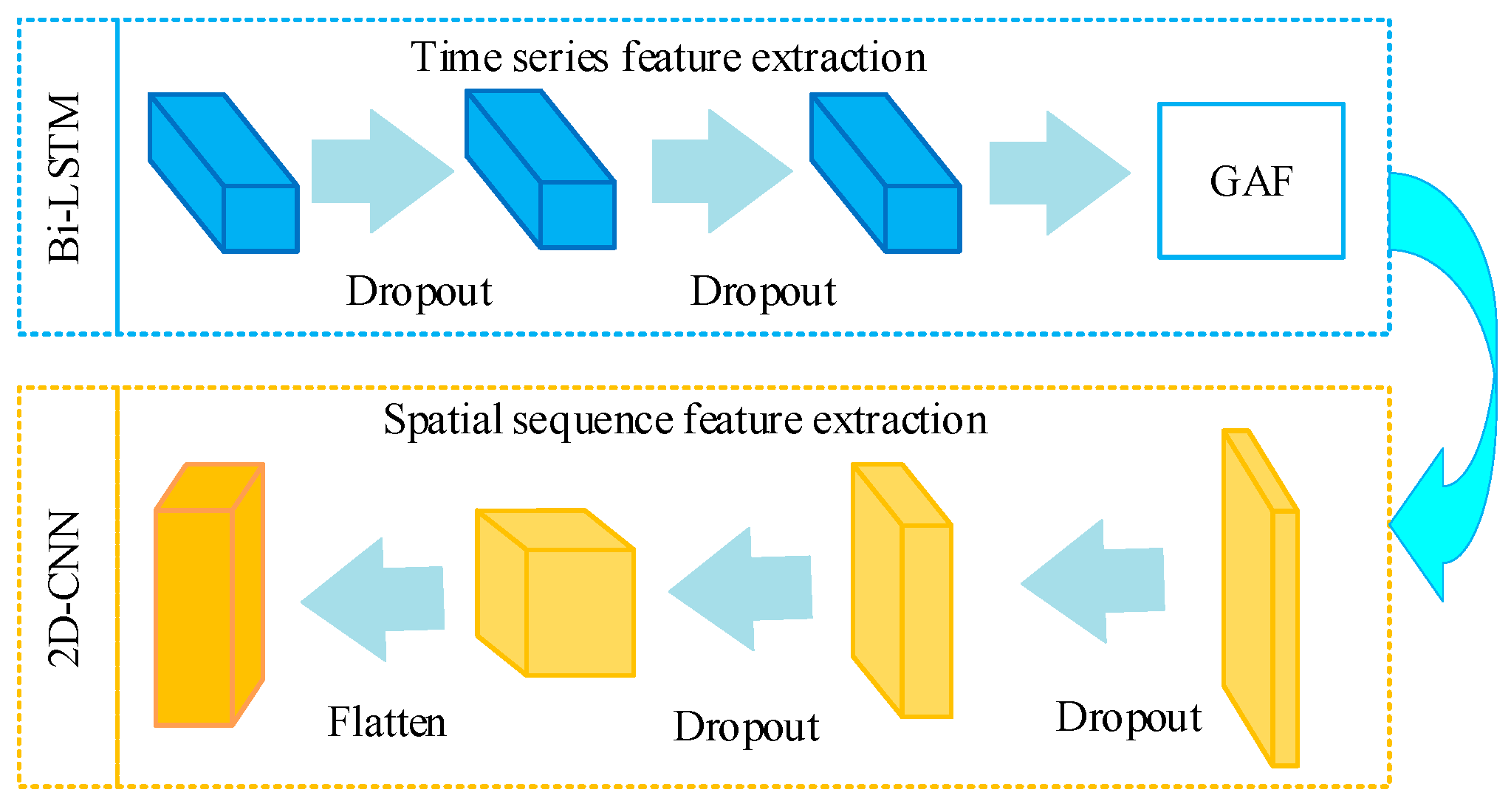
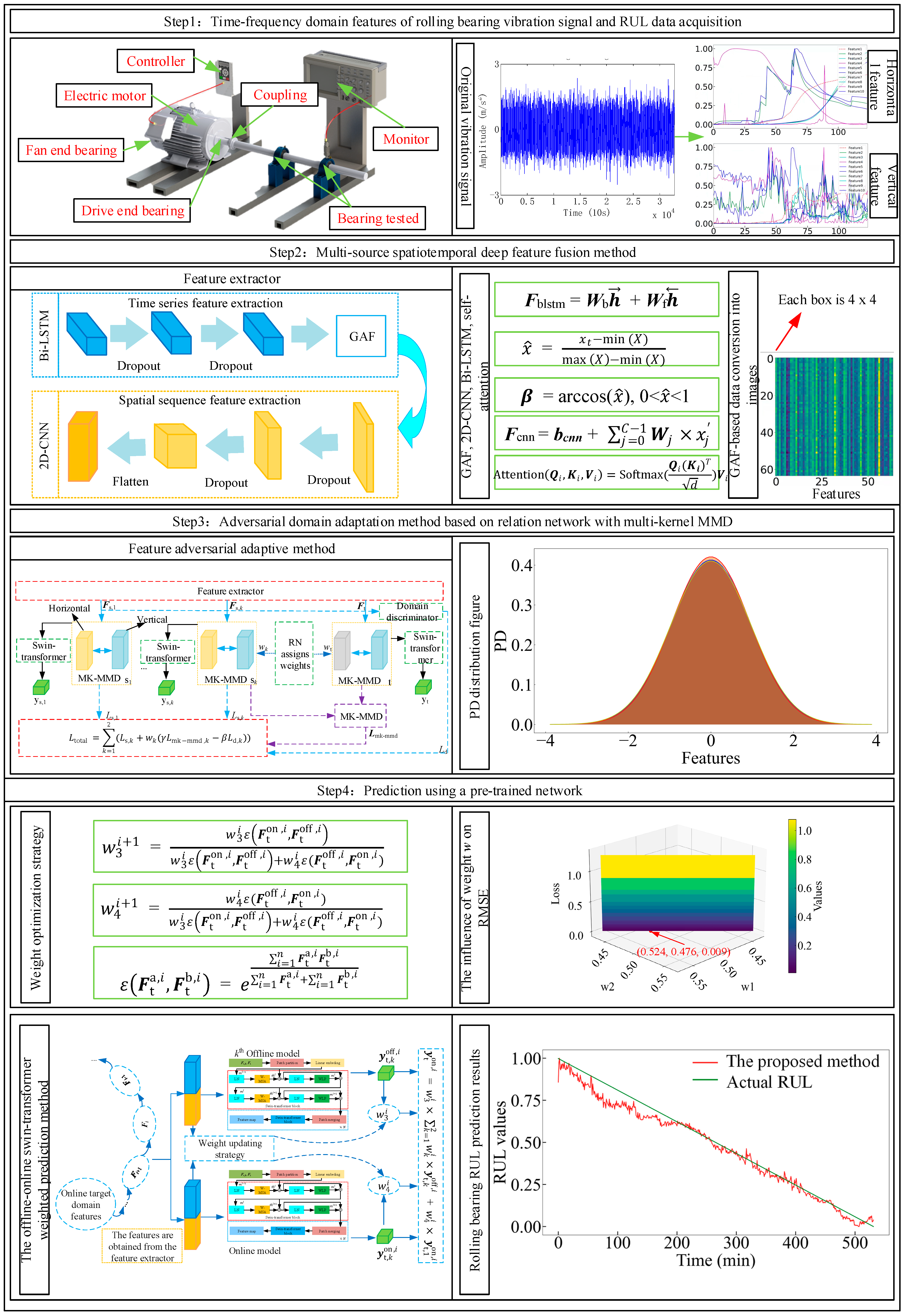
- This paper utilizes Bi-LSTM networks to effectively extract emphasize historical features from bearing multi-source time series data. Additionally, a 2D-CNN based on the Gramian Angular Fields (GAF) is employed to capture intricate deep spatial series features. A self-attention mechanism fuses multi-source spatiotemporal feature information to obtain multi-source fusion features. Multi-source spatiotemporal features are extracted jointly for the first time, and a self-attention mechanism is introduced to integrate multi-source spatiotemporal features dynamically to solve the problem of multi-source data redundancy and conflict. The extracted bearing features provide deep multi-source spatiotemporal series features for the model to improve the model’s performance.
- (2)
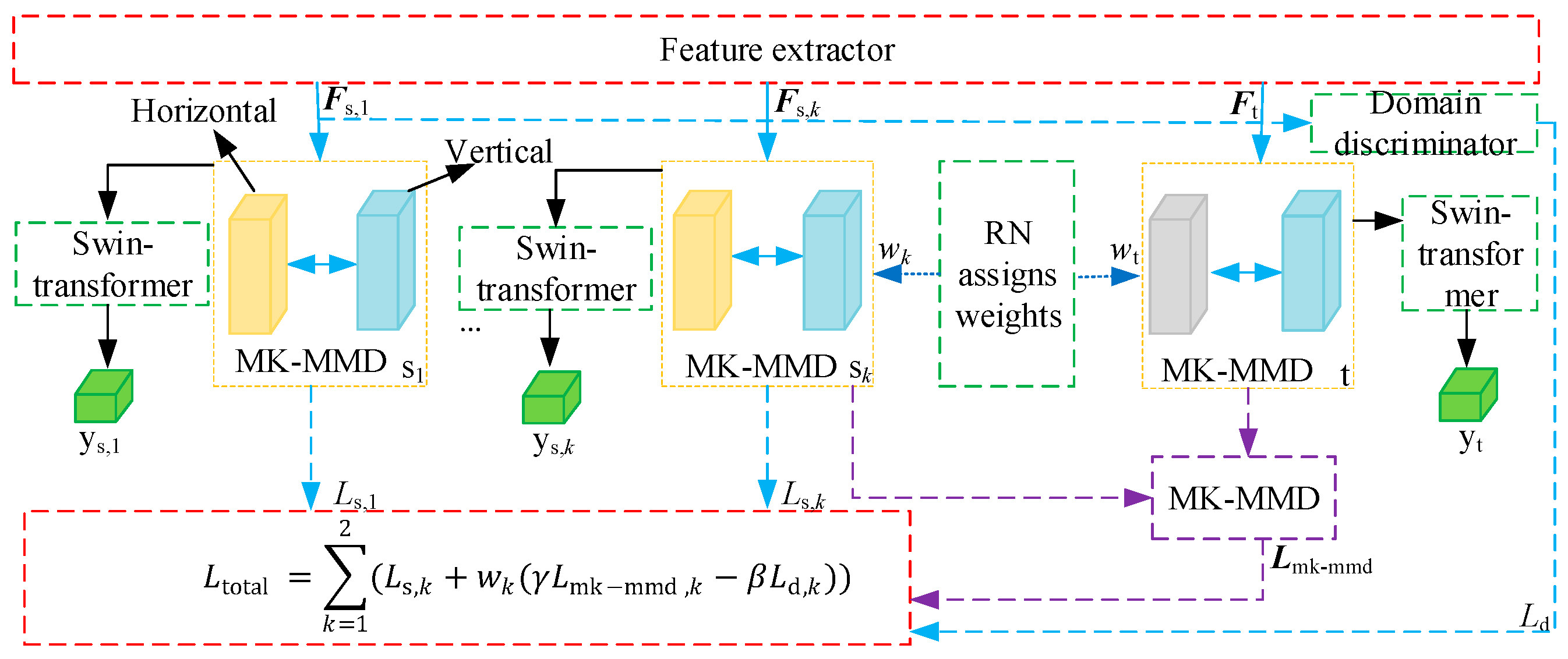
- The existing cross-domain methods, such as MMD, only focus on the inter-domain differences and ignore the multi-source feature distribution inconsistency within the domain. A Relational Network Integrated with Maximum Kernel Mean Discrepancy (RN-MK-MMD) is implemented to minimize discrepancies in multi-source feature distributions both inter-domain and intra-domain. This method assigns consistent weights to multi-source features from the multi-source domain and target domain. The adversarial network is introduced to extract cross-domain invariant features to fully learn important bearing degradation features. It is to balance multi-source feature information and improve the model cross-domain bearing important feature extraction.
- (3)
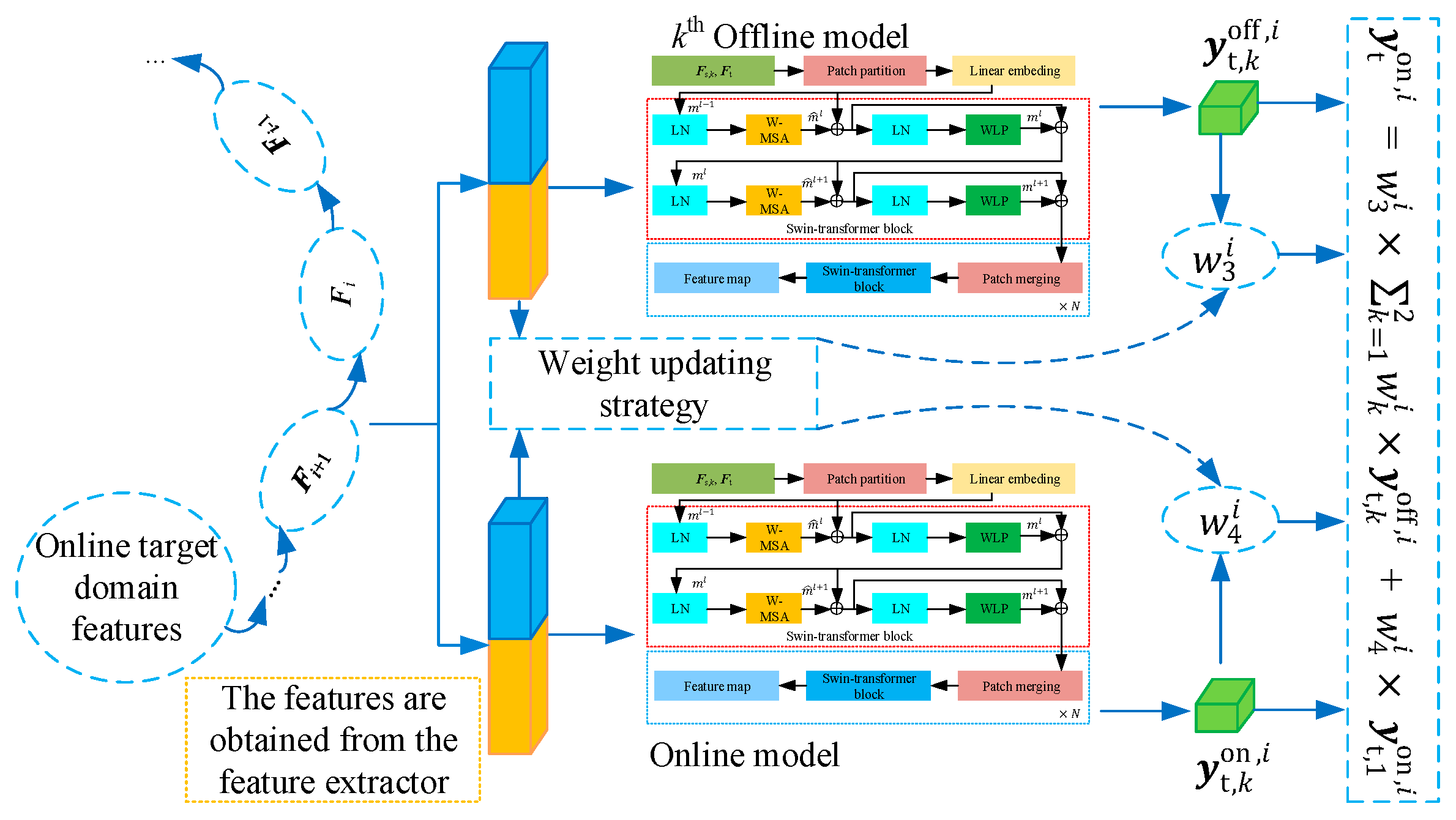
- A weight updating strategy is introduced to assign appropriate weights to both offline and online prediction methods based on the swin-transformer. This approach enhances the prediction performance and robustness of the model, ensuring that the model remains adaptable and accurate under varying operational conditions by effectively leveraging real-time and reliable online data.
- (4)
- The existing work usually deals with multi-source fusion, cross-domain adaptation, or online prediction in isolation, but this framework integrates the three for the first time to realize end-to-end online cross-domain RUL prediction. A novel swin-transformer with multi-source information fusion for an online cross-domain bearing RUL prediction framework is proposed.
2. Multi-Source Information Fusion with Adversarial Domain Adaptive Method
2.1. Multi-Source Spatiotemporal Deep Feature Fusion Method
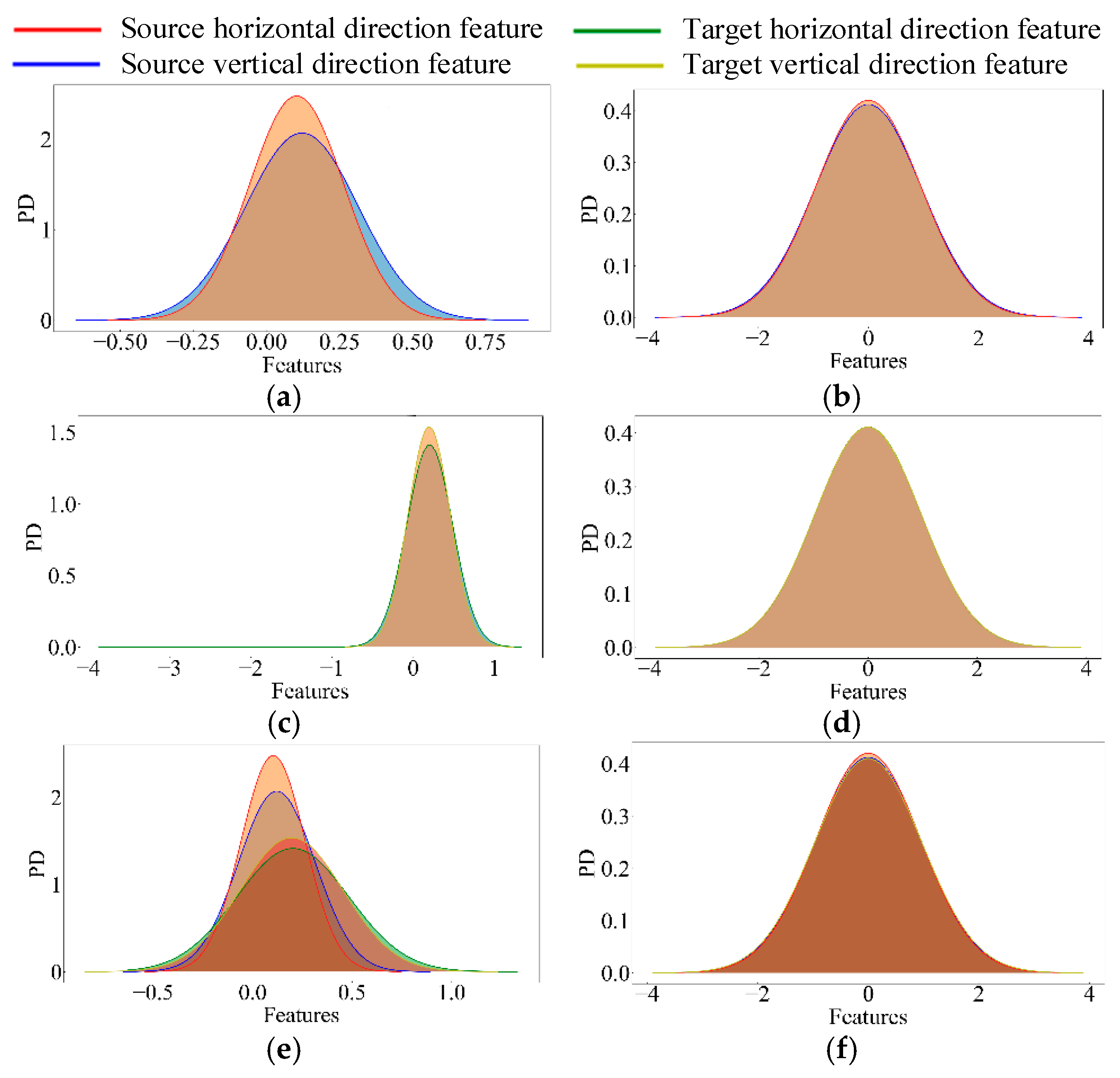
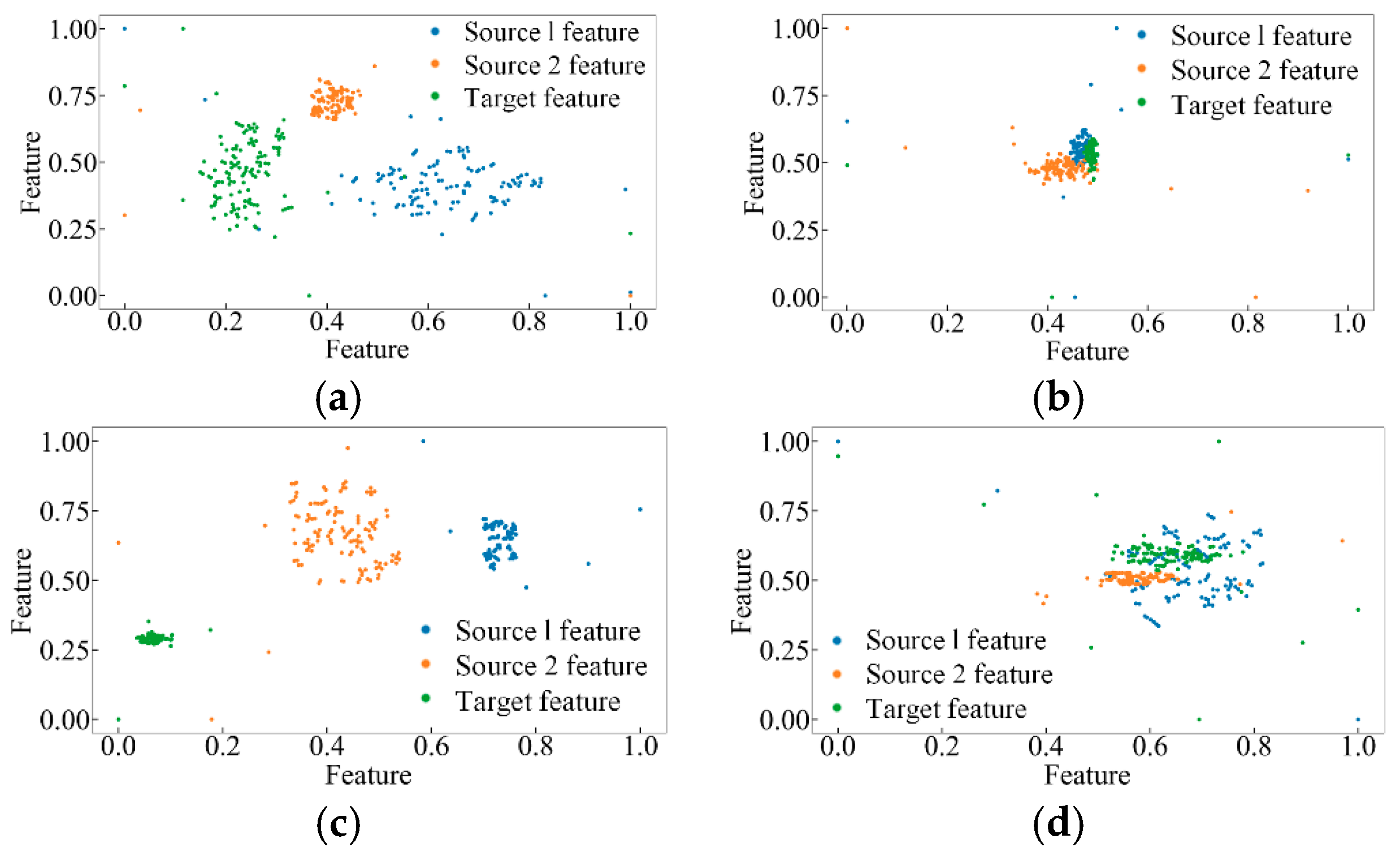
2.2. Adversarial Domain Adaptation Method Based on Relation Network with Multi-Kernel MMD
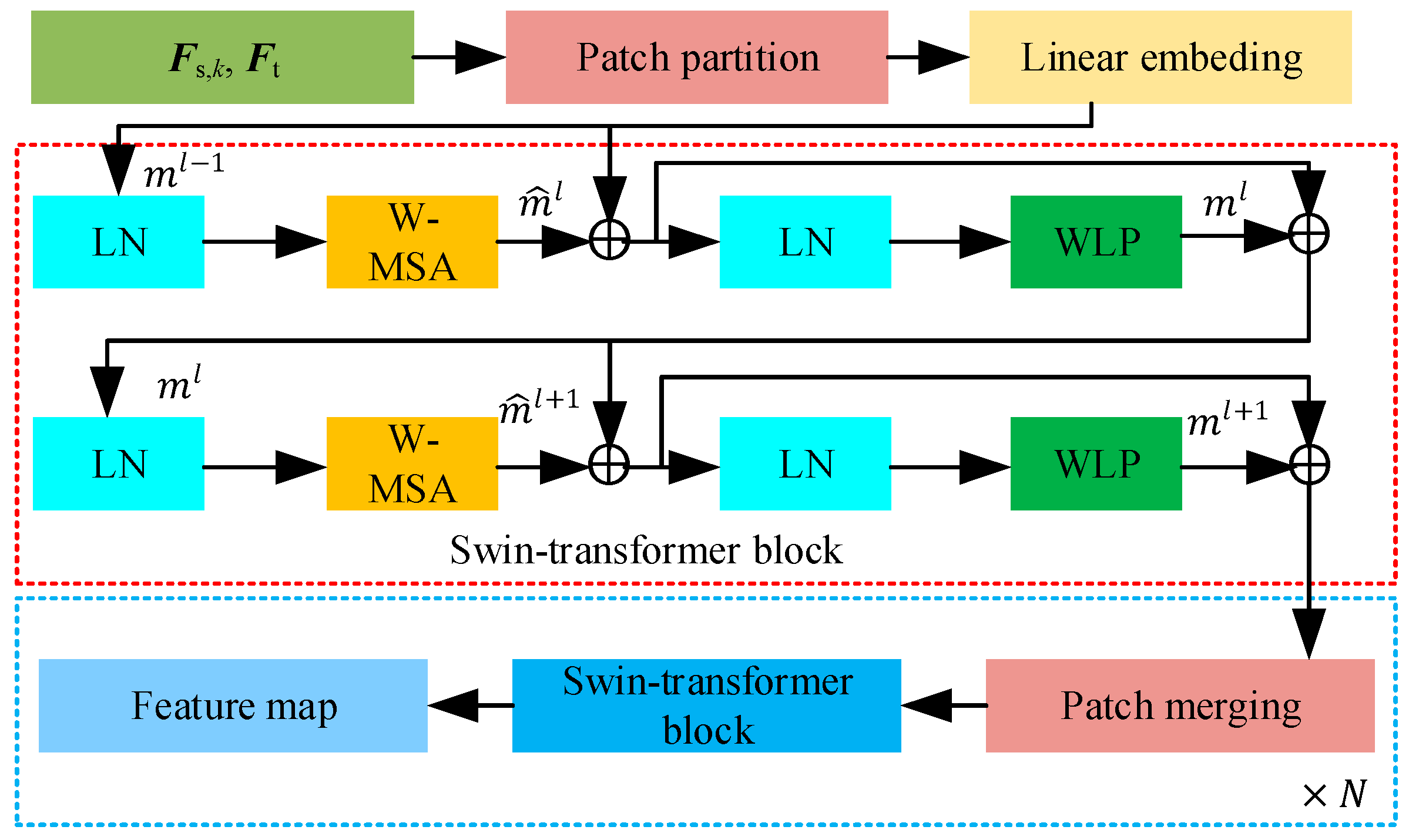
3. The Offline-Online Swin-Transformer Prediction Method
4. The Proposed Method
5. Experimental Verification
5.1. Case1: XJTU-SY Dataset
5.2. Case2: PHM2012 Dataset
6. Comparative Analysis
6.1. Model Parameter Description and Experimental Setup
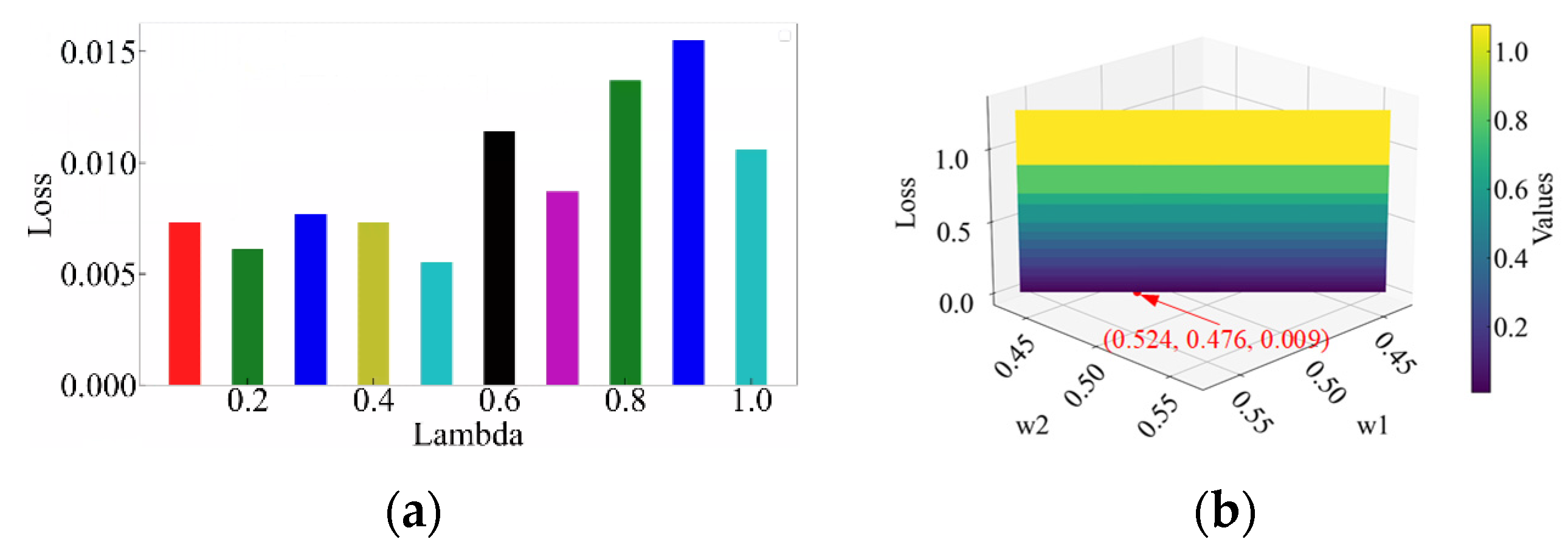
6.2. Comparison of Different Adaptive Methods
6.3. Comparison of Prediction Methods
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Wang, H.; Chen, J.; Qu, J.; Ni, G. A new approach for safety life prediction of industrial rolling bearing based on state recognition and similarity analysis. Saf. Sci. 2020, 122, 104530. [Google Scholar] [CrossRef]
- Siahpour, S.; Li, X.; Lee, J. A novel transfer learning approach in remaining useful life prediction for incomplete dataset. IEEE Trans. Instrum. Meas. 2022, 71, 3509411. [Google Scholar] [CrossRef]
- Zou, Y.; Li, Z.; Liu, Y.; Zhao, S.; Liu, Y.; Ding, G. A method for predicting the remaining useful life of rolling bearings under different working conditions based on multi-domain adversarial networks. Measurement 2022, 188, 110393. [Google Scholar] [CrossRef]
- Pan, T.; Chen, J.; Ye, Z.; Li, A. A multi-head attention network with adaptive meta-transfer learning for RUL prediction of rocket engines. Reliab. Eng. Syst. Saf. 2022, 225, 108610. [Google Scholar] [CrossRef]
- Ren, L.; Sun, Y.; Cui, J.; Zhang, L. Bearing remaining useful life prediction based on deep autoencoder and deep neural networks. J. Manuf. Syst. 2018, 48, 71–77. [Google Scholar] [CrossRef]
- Huang, C.G.; Zhu, J.; Han, Y.; Peng, W. A novel bayesian deep dual network with unsupervised domain adaptation for transfer fault prognosis across different machines. IEEE Sens. J. 2022, 22, 7855–7867. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, K.; Liu, Y.; Zou, Y.; Ding, G. A novel remaining useful life transfer prediction method of rolling bearings based on working conditions common benchmark. IEEE Trans. Instrum. Meas. 2022, 71, 3524909. [Google Scholar] [CrossRef]
- Miao, M.; Yu, J.; Zhao, Z. A sparse domain adaption network for remaining useful life prediction of rolling bearings under different working conditions. Reliab. Eng. Syst. Saf. 2022, 219, 108259. [Google Scholar] [CrossRef]
- Zhuang, J.; Jia, M.; Zhao, X. An adversarial transfer network with supervised metric for remaining useful life prediction of rolling bearing under multiple working conditions. Reliab. Eng. Syst. Saf. 2022, 225, 108599. [Google Scholar] [CrossRef]
- Berghout, T.; Mouss, L.H.; Bentrcia, T.; Benbouzid, M. A semi-supervised deep transfer learning approach for rolling-element bearing remaining useful life prediction. IEEE Trans. Energy Conver. 2022, 37, 1200–1210. [Google Scholar] [CrossRef]
- Mao, W.; Liu, J.; Chen, J.; Liang, X. An interpretable deep transfer learning-based remaining useful life prediction approach for bearings with selective degradation knowledge fusion. IEEE Trans. Instrum. Meas. 2022, 71, 3508616. [Google Scholar] [CrossRef]
- Hu, T.; Guo, Y.; Gu, L.; Zhou, Y.; Zhang, Z.; Zhou, Z. Remaining useful life estimation of bearings under different working conditions via Wasserstein distance-based weighted domain adaptation. Reliab. Eng. Syst. Saf. 2022, 224, 108526. [Google Scholar] [CrossRef]
- Hu, T.; Guo, Y.; Gu, L.; Zhou, Y.; Zhang, Z.; Zhou, Z. Remaining useful life prediction of bearings under different working conditions using a deep feature disentanglement based transfer learning method. Reliab. Eng. Syst. Saf. 2022, 219, 108265. [Google Scholar] [CrossRef]
- Ye, Z.; Yu, J. A selective adversarial adaptation network for remaining useful life prediction of machines under different working conditions. IEEE Syst. J. 2023, 17, 62–71. [Google Scholar] [CrossRef]
- Rathore, M.S.; Harsha, S.P. Rolling bearing prognostic analysis for domain adaptation under different operating conditions. Eng. Fail. Anal. 2022, 139, 106414. [Google Scholar] [CrossRef]
- Ding, Y.; Ding, P.; Zhao, X.; Cao, Y.; Jia, M. Transfer learning for remaining useful life prediction across operating conditions based on multisource domain adaptation. IEEE-ASME Trans. Mechatron. 2022, 27, 4143–4152. [Google Scholar] [CrossRef]
- Zhu, R.; Peng, W.; Wang, D.; Huang, C.G. Bayesian transfer learning with active querying for intelligent cross-machine fault prognosis under limited data. Mech. Syst. Signal Process. 2023, 183, 109628. [Google Scholar] [CrossRef]
- Huang, C.G.; Huang, H.Z.; Li, Y.F.; Peng, W. A novel deep convolutional neural network-bootstrap integrated method for RUL prediction of rolling bearing. J. Manuf. Syst. 2021, 61, 757–772. [Google Scholar] [CrossRef]
- Mao, W.; Liu, K.; Zhang, Y.; Liang, X.; Wang, Z. Self-supervised deep tensor domain-adversarial regression adaptation for online remaining useful life prediction across machines. IEEE Trans. Instrum. Meas. 2023, 72, 2509916. [Google Scholar] [CrossRef]
- Yang, J.; Wang, X. Meta-learning with deep flow kernel network for few shot cross-domain remaining useful life prediction. Reliab. Eng. Syst. Saf. 2024, 244, 109928. [Google Scholar] [CrossRef]
- Xiang, S.; Li, P.; Luo, J.; Qin, Y. Micro transfer learning mechanism for cross-domain equipment rul prediction. IEEE Trans. Autom. Sci. Eng. 2024, 22, 1460–1470. [Google Scholar] [CrossRef]
- Dong, S.; Xiao, J.; Hu, X.; Fang, N.; Liu, L.; Yao, J. Deep transfer learning based on Bi-LSTM and attention for remaining useful life prediction of rolling bearing. Reliab. Eng. Syst. Saf. 2023, 230, 108914. [Google Scholar] [CrossRef]
- Lv, S.; Liu, S.; Li, H.; Wang, Y.; Liu, G.; Dai, W. A hybrid method combining Levy process and neural network for predicting remaining useful life of rotating machinery. Adv. Eng. Inform. 2024, 61, 102490. [Google Scholar] [CrossRef]
- Zhang, H.B.; Cheng, D.J.; Zhou, K.L.; Zhang, S.W. Deep transfer learning-based hierarchical adaptive remaining useful life prediction of bearings considering the correlation of multistage degradation. Knowl. Based Syst. 2023, 266, 110391. [Google Scholar] [CrossRef]
- Li, Y.; Li, J.; Wang, H.; Liu, C.; Tan, J. Knowledge enhanced ensemble method for remaining useful life prediction under variable working conditions. Reliab. Eng. Syst. Saf. 2024, 242, 109748. [Google Scholar] [CrossRef]
- Ding, N.; Li, H.; Xin, Q.; Wu, B.; Jiang, D. Multi-source domain generalization for degradation monitoring of journal bearings under unseen conditions. Reliab. Eng. Syst. Saf. 2023, 230, 108966. [Google Scholar] [CrossRef]
- Ren, L.; Wang, H.; Huang, G. DLformer: A dynamic length transformer-based network for efficient feature representation in remaining useful life prediction. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 5942–5952. [Google Scholar] [CrossRef]
- Wang, J.L.; Zhang, F.D.; Ng, H.K.T.; Shi, Y.M. Remaining useful life prediction via information enhanced domain adversarial generalization. IEEE Trans. Reliab. 2024; early access. [Google Scholar] [CrossRef]
- Hu, T.; Mo, Z.; Zhang, Z. A life-stage domain aware network for bearing health prognosis under unseen temporal distribution shift. IEEE Trans. Instrum. Meas. 2024, 73, 3511112. [Google Scholar] [CrossRef]
- Tong, S.; Han, Y.; Zhang, X.; Tian, H.; Li, X.; Huang, Q. Uncertainty-weighted domain generalization for remaining useful life prediction of rolling bearings under unseen conditions. IEEE Sens. J. 2024, 24, 10933–10943. [Google Scholar] [CrossRef]
- Zhang, T.; Wang, H. Quantile regression network-based cross-domain prediction model for rolling bearing remaining useful life. Appl. Soft Comput. 2024, 159, 111649. [Google Scholar] [CrossRef]
- Cui, J.; Ji, J.C.; Zhang, T.; Cao, L.; Chen, Z.; Ni, Q. A novel dual-branch transformer with gated cross attention for remaining useful life prediction of bearings. IEEE Sens. J. 2024, 24, 41410–41423. [Google Scholar] [CrossRef]
- Cao, W.; Meng, Z.; Li, J.; Wu, J.; Fan, F. A remaining useful life prediction method for rolling bearing based on TCN-transformer. IEEE Trans. Instrum. 2025, 74, 1–9. [Google Scholar] [CrossRef]
- Ma, Y.F.; Jia, X.; Hu, Q.; Bai, H.; Guo, C.; Wang, S. A new state recognition and prognosis method based on a sparse representation feature and the hidden semi-markov model. IEEE Access 2020, 8, 119405–119420. [Google Scholar] [CrossRef]
- Sun, J.; Zhang, X.; Wang, J. Lightweight bidirectional long short-term memory based on automated model pruning with application to bearing remaining useful life prediction. Eng. Appl. Artif. Intell. 2023, 118, 105662. [Google Scholar] [CrossRef]
- Jiang, F.; Ding, K.; He, G.; Lin, H.; Chen, Z.; Li, W. Dual-attention-based multiscale convolutional neural network with stage division for remaining useful life prediction of rolling bearings. IEEE Trans. Instrum. Meas. 2022, 71, 3525410. [Google Scholar] [CrossRef]
- Xia, P.; Huang, Y.; Li, P.; Liu, C.; Shi, L. Fault knowledge transfer assisted ensemble method for remaining useful life prediction. IEEE Trans. Industr. Inform. 2022, 18, 1758–1769. [Google Scholar] [CrossRef]
- Gu, Y.; Chen, R.; Huang, P.; Chen, J.; Qiu, G. A lightweight bearing compound fault diagnosis method with gram angle field and ghost-resnet model. IEEE Trans. Reliab. 2023, 73, 1768–1781. [Google Scholar] [CrossRef]
- Chao, Z.; Han, T. A novel convolutional neural network with multiscale cascade midpoint residual for fault diagnosis of rolling bearings. Neurocomputing 2022, 506, 213–227. [Google Scholar] [CrossRef]
- Tang, B.; Yao, D.C.; Yang, J.W.; Zhang, F. Remaining Useful Life Prognosis Method of Rolling Bearings Considering Degradation Distribution Shift. IEEE Trans. Instrum. Meas. 2024, 73, 3523013. [Google Scholar] [CrossRef]
- Li, J.; Ye, Z.; Gao, J.; Meng, Z.; Tong, K.; Yu, S. Fault transfer diagnosis of rolling bearings across different devices via multi-domain information fusion and multi-kernel maximum mean discrepancy. Appl. Soft Comput. 2024, 159, 111620. [Google Scholar] [CrossRef]
- Shen, F.; Yan, R. A new intermediate-domain SVM-Based transfer model for rolling bearing rul prediction. IEEE-ASME Trans. Mechatron. 2022, 27, 1357–1369. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Zhuang, J.; Ding, P. Deep imbalanced regression using cost-sensitive learning and deep feature transfer for bearing remaining useful life estimation. Appl. Soft Comput. 2022, 127, 109271. [Google Scholar] [CrossRef]






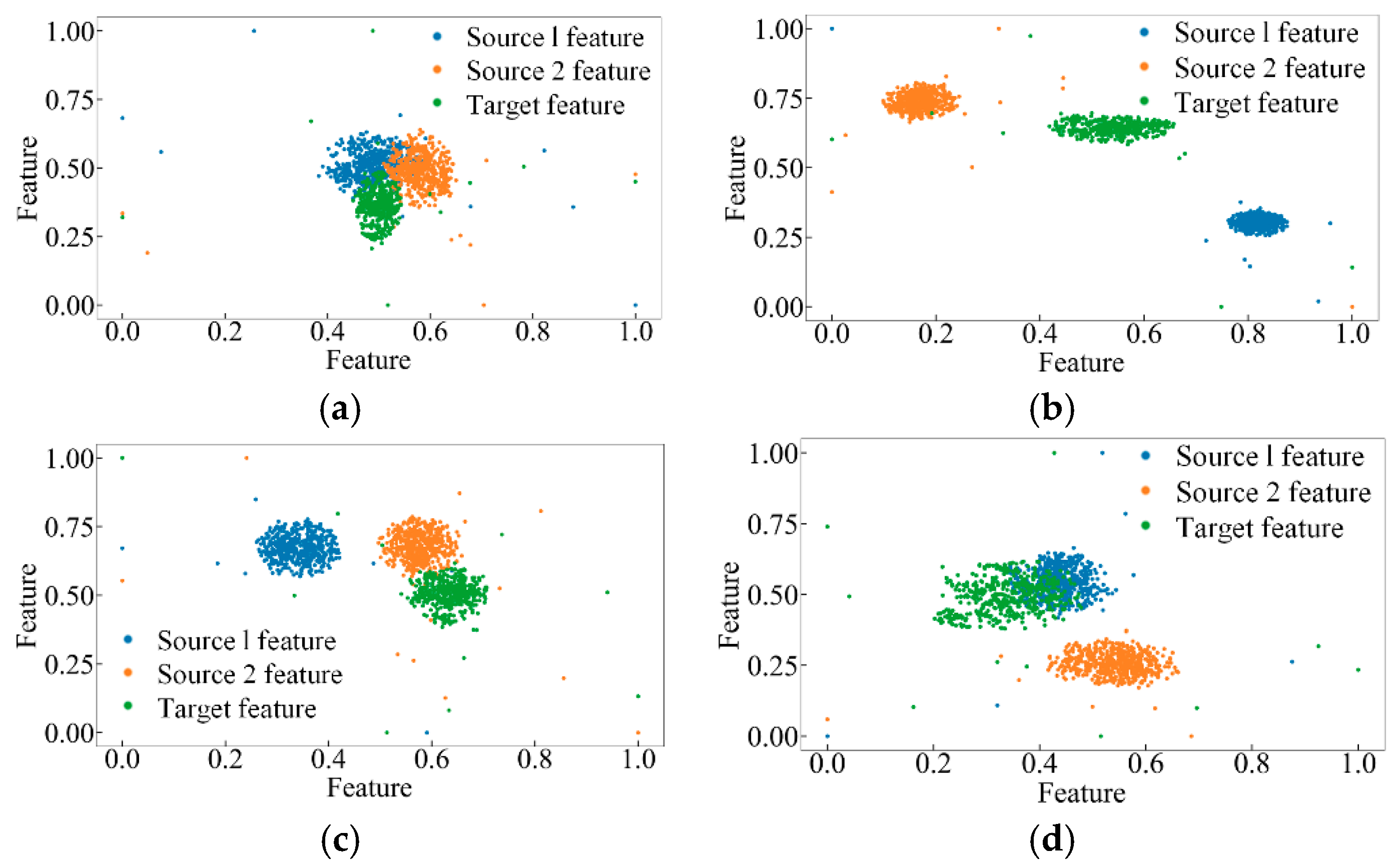


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Task | Transfer Scenario | Offline Dataset in Source Domain | Number of Data | Online Dataset in Target Domain | Number of Data | Testing Dataset in Target Domain | Number of Data |
|---|---|---|---|---|---|---|---|
| XT1 | I, II III | S1:XB11, S2:XB21 | 123, 491 | XB31 | 2538 | XB33 | 371 |
| XT2 | I, III II | S1:XB11, S2:XB31 | 123, 2538 | XB21 | 491 | XB23 | 533 |
| XT3 | II, III I | S1:XB21, S2:XB31 | 161, 2496 | XB11 | 123 | XB13 | 158 |
| Task | Transfer Scenario | Offline Dataset in Source Domain | Number of Data | Online Dataset in Target Domain | Number of Data | Testing Dataset in Target Domain | Number of Data |
|---|---|---|---|---|---|---|---|
| PT1 | I, II III | S1:PB11, S2:PB21 | 2803, 911 | PB31 | 515 | PB32 | 1637 |
| PT2 | I, III II | S1:PB11, S2:PB31 | 2803, 515 | PB21 | 911 | PB22 | 797 |
| PT3 | II, III I | S1:PB21, S2:PB31 | 911, 515 | PB11 | 2803 | PB12 | 871 |
| Module | Layer(s) | Kernl /Hidden Size | Stride | Padding | Activation | Input | Output |
|---|---|---|---|---|---|---|---|
| Feature extractor | Bi-LSTM | 128 | / | / | ReLu | N × 10 | N × 128 |
| GAF | / | / | / | / | N × 128 | N × 8 × 4 × 4 | |
| Convolution | 3 | 1 | 1 | ReLu | N × 8 × 4 × 4 | N × 16 × 4 × 4 | |
| Max Pooling | 3 | 2 | 0 | / | N × 16 × 4 × 4 | N × 16 × 1 × 1 | |
| Concatenate | horizontal and vertical features | / | N × 16 × 1 × 1, N × 16 × 1 × 1 | N × 32 × 1 × 1 | |||
| Self-attention | / | / | / | / | N × 32 × 1 × 1 | N × 32 × 1 × 1 | |
| RUL regression | Swin-transformer | / | / | / | / | N × 32 × 1 × 1 | N × 512 × (1/4) × (1/4) |
| / | / | / | / | N × 512 × (1/4) × (1/4) | N × 1024 × (1/8) × (1/8) | ||
| 128 | / | / | / | N × 1024 × (1/8) × (1/8) | N × 128 | ||
| Concatenate | Total feature | / | N × 128, N × 128 | N × 256 | |||
| Dense | 32 | / | / | ReLU | N × 256 | N × 32 | |
| Dense | 1 | / | / | ReLU | N × 256 | N × 1 | |
| Domain classification | Dense | 32 | / | / | ReLU | N × 256 | N × 32 |
| Output | 2 | / | / | Softmax | N × 32 | N × 2 | |
| Hyperparameters | Values |
|---|---|
| Learning rate | 0.001 |
| Batch size | 64 |
| Max epoch | 100 |
| Weight optimization | mini-batch SGD |
| Transfer coefficient | 0.5 |
| window_size | 5 |
| Comparison Method | Description |
|---|---|
| Baseline [28] | The prediction model without TL; verifies the transferring performance of other TL-based methods. |
| Deep subdomain adaptation time-quantile regression network (DSATQRN) [31] | These methods are the domain adaptation methods; it can be used to evaluate the performance of the proposed method. |
| Dual-branch transformer with gated cross attention (DTGCA) [32] | These methods are the different domains’ integrated features methods; it can be used to evaluate the effectiveness of bearing multi-source feature information fusion method. |
| TCN-transformer [33] | These methods have good predictive performance; it can be used to evaluate the computational complexity, reliability, and effectiveness of the model. |
| Scheme 1 | The Bi-LSTM module is removed. |
| Scheme 2 | The GAF-2D-CNN module is removed. |
| Scheme 3 | The RN-MK-MMD module is removed. |
| Scheme 4 | Replace dynamic update weights with fixed weights. |
| Scheme 5 | Replace swin-transformer with transformer. |
| Metrics | Proposed Methos | TCN-Transformer | Baseline | DSATQRN | DTGCA |
|---|---|---|---|---|---|
| FLOPs | 685.3K | 9652.4 K | 2894.7 K | 2055.6 K | 1725.9 K |
| Params | 42.4 K | 182.5 K | 106.1 K | 82.68 K | 65.3 K |
| GPU | 1.76 s | 3.56 s | 1.92 s | 1.87 s | 1.98 s |
| CPU | 6.89 s | 40.58 s | 15.68 s | 15.23 s | 10.02 s |
| Metrics | Model | XT1 | XT2 | XT3 | Average |
|---|---|---|---|---|---|
| MAE | Proposed methods | 0.044 | 0.036 | 0.040 | 0.040 |
| Baseline | 0.098 | 0.077 | 0.099 | 0.091 | |
| DSATQRN | 0.104 | 0.046 | 0.074 | 0.075 | |
| DTGCA | 0.079 | 0.071 | 0.092 | 0.081 | |
| TCN-transformer | 0.069 | 0.062 | 0.073 | 0.068 | |
| Scheme 1 | 0.052 | 0.045 | 0.048 | 0.048 | |
| Scheme 2 | 0.050 | 0.042 | 0.046 | 0.046 | |
| Scheme 3 | 0.048 | 0.040 | 0.044 | 0.044 | |
| Scheme 4 | 0.047 | 0.039 | 0.043 | 0.043 | |
| Scheme 5 | 0.049 | 0.041 | 0.045 | 0.045 | |
| RMSE | Proposed methods | 0.063 | 0.049 | 0.054 | 0.055 |
| Baseline | 0.112 | 0.086 | 0.120 | 0.106 | |
| DSATQRN | 0.121 | 0.054 | 0.087 | 0.087 | |
| DTGCA | 0.095 | 0.079 | 0.114 | 0.096 | |
| TCN-transformer | 0.086 | 0.080 | 0.092 | 0.086 | |
| Scheme 1 | 0.075 | 0.060 | 0.065 | 0.067 | |
| Scheme 2 | 0.070 | 0.055 | 0.060 | 0.062 | |
| Scheme 3 | 0.068 | 0.053 | 0.058 | 0.060 | |
| Scheme 4 | 0.066 | 0.052 | 0.052 | 0.058 | |
| Scheme 5 | 0.069 | 0.054 | 0.059 | 0.061 |
| Metrics | Model | PT1 | PT2 | PT3 | Average |
|---|---|---|---|---|---|
| MAE | Proposed methods | 0.023 | 0.042 | 0.051 | 0.039 |
| Baseline | 0.098 | 0.133 | 0.138 | 0.123 | |
| DSATQRN | 0.035 | 0.085 | 0.133 | 0.084 | |
| DTGCA | 0.066 | 0.068 | 0.128 | 0.087 | |
| TCN-transformer | 0.045 | 0.072 | 0.118 | 0.078 | |
| Scheme 1 | 0.028 | 0.050 | 0.060 | 0.046 | |
| Scheme 2 | 0.026 | 0.048 | 0.057 | 0.044 | |
| Scheme 3 | 0.025 | 0.046 | 0.055 | 0.042 | |
| Scheme 4 | 0.024 | 0.045 | 0.054 | 0.041 | |
| Scheme 5 | 0.027 | 0.049 | 0.058 | 0.045 | |
| RMSE | Proposed methods | 0.031 | 0.059 | 0.066 | 0.052 |
| Baseline | 0.116 | 0.144 | 0.172 | 0.144 | |
| DSATQRN | 0.046 | 0.102 | 0.154 | 0.101 | |
| DTGCA | 0.071 | 0.082 | 0.147 | 0.100 | |
| TCN-transformer | 0.062 | 0.080 | 0.140 | 0.094 | |
| Scheme 1 | 0.037 | 0.068 | 0.075 | 0.060 | |
| Scheme 2 | 0.035 | 0.065 | 0.072 | 0.057 | |
| Scheme 3 | 0.034 | 0.063 | 0.070 | 0.056 | |
| Scheme 4 | 0.033 | 0.062 | 0.069 | 0.055 | |
| Scheme 5 | 0.036 | 0.066 | 0.073 | 0.058 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xie, Z.; Mo, C.; Jia, B. A Novel Swin-Transformer with Multi-Source Information Fusion for Online Cross-Domain Bearing RUL Prediction. J. Mar. Sci. Eng. 2025, 13, 842. https://doi.org/10.3390/jmse13050842
Xie Z, Mo C, Jia B. A Novel Swin-Transformer with Multi-Source Information Fusion for Online Cross-Domain Bearing RUL Prediction. Journal of Marine Science and Engineering. 2025; 13(5):842. https://doi.org/10.3390/jmse13050842
Chicago/Turabian StyleXie, Zaimi, Chunmei Mo, and Baozhu Jia. 2025. "A Novel Swin-Transformer with Multi-Source Information Fusion for Online Cross-Domain Bearing RUL Prediction" Journal of Marine Science and Engineering 13, no. 5: 842. https://doi.org/10.3390/jmse13050842
APA StyleXie, Z., Mo, C., & Jia, B. (2025). A Novel Swin-Transformer with Multi-Source Information Fusion for Online Cross-Domain Bearing RUL Prediction. Journal of Marine Science and Engineering, 13(5), 842. https://doi.org/10.3390/jmse13050842