Abstract
For multiple unmanned underwater vehicles (UUVs) systems, obstacle avoidance during cooperative operation in complex marine environments remains a challenging issue. Recent studies demonstrate the effectiveness of deep reinforcement learning (DRL) for obstacle avoidance in unknown marine environments. However, existing methods struggle in marine environments with complex non-convex obstacles, especially during multi-UUV cooperative operation, as they typically simplify environmental obstacles to convex shapes with sparse distributions and ignore the dynamic coupling between cooperative operation and collision avoidance. To address these limitations, we propose a centralized training with decentralized execution framework with a novel multi-agent dynamic encoder based on an efficient self-attention mechanism. The framework, to our knowledge, is the first to dynamically process observations from an arbitrary number of neighbors that effectively addresses multi-UUV collision avoidance in marine environments with complex non-convex obstacles while satisfying additional constraints derived from cooperative operation. Experimental results show that the proposed method effectively avoids obstacles and satisfies cooperative constraints in both simulated and real-world scenarios with complex non-convex obstacles. Our method outperforms typical collision avoidance baselines and enables policy transfer from simulation to real-world scenarios without additional training, demonstrating practical application potential.
1. Introduction
The multiple unmanned underwater vehicles (UUVs) system demonstrates significant application potential in marine exploration [1] and high-risk military missions [2] due to its autonomous cooperative capabilities and enhanced environmental perception. However, collision avoidance for multi-UUV systems poses a critical challenge in unknown marine environments [3], particularly in environments with complex non-convex obstacles. During cooperative operation, the dynamic coupling within the system introduces additional cooperative constraints to collision avoidance, including a limitation on communication distance and the need to avoid collisions within the multi-UUV system. Moreover, the underactuated characteristics of UUVs result in large turning radii and lack of hovering capability, severely restricting their mobility. These factors complicate collision avoidance in multi-UUV systems, demanding research attention.
Current multi-UUV collision avoidance methods can be classified into two categories: traditional methods [4,5] and intelligent methods [6]. Traditional methods, typically regarded as reaction-based, face unique challenges in underwater environments due to the underactuated nature of UUVs, which motivates the development of enhanced collision avoidance strategies. These methods often struggle with real-time responsiveness and the complexities of dynamic underwater environments, as UUVs are inherently limited in their control capabilities. For instance, Fan et al. proposed a UUV path planning method using an Improved Artificial Potential Field (IAPF) incorporating a distance correction factor to address both static and dynamic obstacle avoidance [7]. This method, while effective in many scenarios, faces challenges in highly dynamic and high-speed environments, where the potential field approach may not adapt quickly enough. Similarly, Taheri et al. developed a Closed-Loop Rapidly Exploring Random Tree (CL-RRT) method using a six-degree-of-freedom UUV model to generate feasible paths that consider kinematic and dynamic constraints [8]. While the CL-RRT method offers more flexibility, it still requires improvements in terms of real-time adaptability and computational efficiency in complex, uncertain underwater environments. On the other hand, the Optimal Reciprocal Collision Avoidance (ORCA) method, which employs the velocity obstacle concept, selects a velocity that ensures collision-free movement for a predefined duration, making it particularly effective for multi-UUV scenarios [9]. However, despite its effectiveness, ORCA still requires fine-tuning for non-ideal underwater conditions, where uncertainties and variations in environmental factors can impact its performance. Despite the merits of these traditional methods, they often fail to fully exploit the potential of UUVs in highly dynamic and unpredictable underwater settings, underscoring the need for more advanced, intelligent collision avoidance techniques.
While intelligent methods are mainly based on reinforcement learning and deep learning, deep reinforcement learning has demonstrated significant progress in addressing the UUV collision avoidance problem in recent years. Carlucho et al. proposed an end-to-end reinforcement learning method using the Deep Deterministic Policy Gradient (DDPG) algorithm for UUV navigation [10]. Yang et al. developed an N-step Priority Double DQN (NPDDQN) algorithm for path planning, enhancing underwater robot autonomy and stability by addressing obstacle avoidance in dynamic 3D marine environments with an experience screening mechanism [11]. However, these studies primarily focused on single-UUV scenarios with simplified environmental assumptions. Research on multi-UUV collision avoidance in complex environments is still scarce.
However, collision avoidance based on DRL for multi-agent systems has gained increasing attention [12,13,14,15]. For example, Long et al. proposed a decentralized sensor-level collision avoidance policy, which, through a multi-scenario and multi-stage training framework, effectively avoids collisions and generalizes to new scenarios [16]. However, these methods neglected inter-agent interactions. To address this, Du et al. and Everett et al. employed long short-term memory (LSTM) networks to process inputs from an arbitrary number of neighbors [15,17]. However, LSTMs may fail to capture critical interaction information over long time steps, limiting their applicability in complex scenarios. In contrast, Chen et al. and Wu et al. employed attention mechanisms to process an arbitrary number of neighboring agents’ information, but their works suffered from exponentially growing computational costs with increasing neighbor counts [18,19].
Existing multi-UUV collision avoidance methods exhibit three critical limitations. First, obstacle representations are often oversimplified as convex shapes (e.g., cylinders) [20,21,22,23], which demonstrate effectiveness in sparse environments but become inadequate for complex scenarios such as harbor structures or shipwrecks. Second, existing methods focus on individual robot collision avoidance [24], neglecting collision constraints stemming from multi-UUV cooperation. Finally, existing methods limited by fixed input [25], cannot dynamically adapt to changes in the number of UUVs within the system during practical missions.
To address the aforementioned limitations, this work proposes COO-CADRL, a centralized training, decentralized execution framework for multi-UUV systems collision avoidance during cooperative operation, based on proximal policy optimization algorithms [26]. The framework incorporates a novel multi-agent dynamic encoder based on an efficient self-attention mechanism, reducing computational complexity and enabling multi-UUV systems to efficiently avoid obstacles in marine environments with complex non-convex obstacles while satisfying cooperative constraints. The proposed method supports an arbitrary number of UUVs and various types of obstacles. It is validated through a simulation scenario of the Port of Long Beach, USA (33.755689° N, 118.216498° W), where comparative experiments with two baseline methods are conducted. Additionally, the performance of the proposed method in satisfying cooperative constraints is further analyzed. Finally, lake experiments are conducted to further validate the method’s generalization, robustness, and real world applicability, as shown in Figure 1.
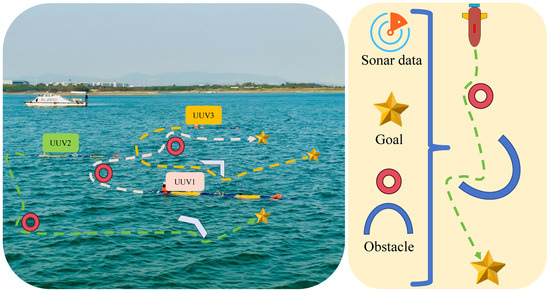
Figure 1.
Multi-UUV collision avoidance experiments are conducted in a lake environment at a depth of 15 m. For presentation purposes, the UUVs in the image are shown on the surface, but the experiments are actually carried out underwater at 15 m. Each UUV uses onboard sensors to perceive environmental obstacles and acquire neighbors’ states, employing the proposed collision avoidance method for online distributed inference to navigate safely through dense obstacle areas.
Our main contributions are summarized as follows:
- To the best of our knowledge, this is the first study to propose a multi-agent deep reinforcement learning framework for multi-UUV systems that develops collision avoidance policies in marine environments with complex non-convex obstacles through onboard sensor information while satisfying cooperative constraints.
- A novel multi-agent dynamic encoder is proposed, based on an efficient self-attention mechanism, to effectively handle observations from an arbitrary number of neighboring agents without requiring additional training. It also significantly reduces computational complexity compared to traditional attention mechanisms.
- The policy trained in simulation successfully transfers to the real-world environment without requiring additional training. Experimental results demonstrate that our method significantly outperforms typical collision avoidance methods, exhibiting strong generalizability and robustness.
2. Problem Formulation
The multi-UUV system collision avoidance problem is formulated as a partially observable sequential decision-making process [16,27]. The UUV adopts a continuous process of observation and action. At each timestep t, the i-th UUV () obtains its local observation . The objective is to output a collision-free action that drives each
to approach the goal from its current position . The observation contains the UUV’s partially perceived environmental data and receives state information from neighboring UUVs. Since the i-th UUV has no explicit knowledge of the environment or other UUVs, our partial-observation-based method improves generalization capability and robustness in physical deployments. Based on the local observation , each UUV independently determines its action sampled from a stochastic policy shared by all UUVs as defined in the following:
Therefore, the set of trajectories , which consists of each UUV trajectory from its start position to its desired goal , can be defined as
where denotes the trajectory length of . represents the action of the i-th UUV at time t, which is sampled from the policy based on the current observation , i.e., . represents the observation of the i-th UUV at time t, including environmental information, the positions of other UUVs, and obstacle locations. denotes the position of the i-th UUV at time t, which is updated as . is the time step. represents the velocity of the i-th UUV at time t, which is determined by the action . and are the minimum and maximum velocity limits of the i-th UUV, respectively. denotes the obstacle set, and is the safety distance for all UUVs. N is the total number of UUVs, and M is the total number of obstacles.
The policy shared by all UUVs is developed with the objective of minimizing the expected trajectory length to goal, which is defined as
where A denotes the total number of agents. is the global trajectory length of agent i. is the policy.
3. Multi-Agent Dynamic Encoder
Multi-UUV systems performing cooperative tasks in complex obstacle scenarios must address the coupled problem of collision avoidance and cooperative operation. This collision avoidance issue introduces additional constraints arising from cooperative operation, referred to as cooperative constraints, which mainly include the following two aspects:
(a) Effective collision avoidance within multi-UUV systems is critical because cooperative operation requires keeping identical depth and tight spacing, which significantly increases the risk of collision between UUVs.
(b) Avoiding exceeding communication distance during collision avoidance is critical because acoustic communication, which serves as the foundation of cooperative operation, is inherently constrained by propagation loss and limited effective distance.
To address the coupling between constraint satisfaction and collision avoidance, our method prioritizes obstacle avoidance while satisfying cooperative constraints. When conflicts occur between avoidance decisions and cooperative constraints, the system comprehensively considers environmental information and UUV interaction states to determine optimal decisions. This requires efficient processing of neighboring information and adaptation to dynamic changes in the number of neighbors. Therefore, we adopted a self-attention mechanism to fully capture the key features of neighbors. However, traditional self-attention suffers from high computational complexity due to matrix multiplication. We addressed this issue by employing the efficient additive self-attention from [28], which replaces quadratic matrix multiplication with linear element-wise multiplication, reducing complexity without sacrificing accuracy. The additive attention output follows Equation (4). This mechanism dynamically adjusts the weights of different neighbors, allowing each UUV to flexibly focus on relevant neighboring information based on current task requirements and environmental conditions.
where denotes the normalized query matrix, denotes the linear transformation, denotes the key matrix, and denotes the global query matrix.
Furthermore, inspired by [18], we introduced a pooling operation that encodes information from neighbors of variable numbers into a fixed length feature vector to facilitate subsequent network processing. As shown in Figure 2, a multi-agent dynamic encoder is designed in which neighbor state information is processed through an efficient self-attention mechanism and a fully connected layer to compute attention scores and feature encoding. The encoded features are weighted and aggregated through a pooling layer based on attention scores, capturing essential state information while encoding multiple neighbors into a fixed-length vector. To aggregate features from neighbor nodes, first, Query () and Key () representations are derived from the input neighbor features . The Query is computed as , while the Key is obtained via . Next, attention weights are calculated by projecting the Query into a scalar space and applying normalization as follows: , where is a learnable vector that maps the Query into a scalar representation, and s is a scalar scaling factor used to adjust the range of the attention weights. These attention weights are then used to compute a global feature representation , which aggregates information across all neighbors. The global features are repeated N times to match the neighbor dimension and are combined with the Key features via element-wise multiplication as follows: . Finally, softmax weights are computed from , and these weights are used to perform a weighted aggregation of neighbor features , producing the final output .
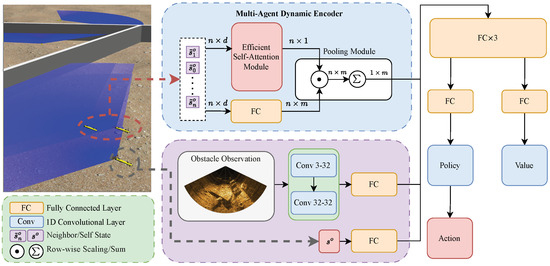
Figure 2.
COO-CADRL network architecture. Environmental observations are processed through sequential 1D convolutional layers, while the UUV self-state is processed by a fully connected layer (purple box). The states of neighboring UUVs are encoded by the multi-agent dynamic encoder (blue box). Combined features pass through subsequent fully connected layers to output actions and values.
4. Reinforcement Learning for Collision Avoidance in Multi-UUV Systems
4.1. State Representation
The proposed policy directly derives all state information from sensor data. Obstacle avoidance in multi-UUV systems requires both navigation through complex environments and satisfying cooperative constraints. The optimal policy also depends on each UUV’s state. Therefore, efficient encoding and transmission of this information is essential. They are described as follows.
Agent-level representations: The agent-level representations include both the UUV’s own state and the states of its neighbors. Self-state includes goal, desired speed, current speed, and heading. Although the UUV primarily avoids obstacles at fixed depths, vertical plane variations in pitch angle and depth still affect horizontal motion planning. Therefore, we also need to encode the state of the vertical plane. The self-state is defined in Equation (5), with all state variables normalized.
where denote the goal in polar coordinates (distance and angle) relative to the UUV’s current position, denotes the desired surge speed, v denotes the current surge speed, denotes the heading angle, denotes the pitch angle, and z denotes the depth of the UUV.
The neighboring UUV’s state, obtained through underwater acoustic communication between UUVs, is designed in Equation (6).
where denote the relative position of the neighbor, denotes the relative heading, denotes the relative surge speed, and denotes the distance from the neighbor to the goal, enabling collision avoidance decision making at a global scale.
Obstacle representations: The UUV perceives obstacles using a forward-facing multibeam sonar with 130° horizontal aperture, 20° vertical aperture, 512 beams, and a 30 m detection range. Obstacle detection is achieved by projecting returns with vertical deviations within 1.5 m from its navigation plane onto the horizontal coordinate system, which generates an angular map (AM), as shown in Equation (7). We constructed the obstacle-related state by encoding three consecutive AM frames, followed by state normalization.
where , with L denoting the maximum detection range, denoting the closest distance to the obstacle in the angular slice i, and with .
4.2. Reward Design
Our goal is to minimize the average trajectory length for all UUVs while ensuring stabilized arrival at their goal with the preset speed, considering collision avoidance and cooperative constraints. The reward function comprises several key components.
Reward associated with goal: Due to the UUV’s long travel distances, the reward for reaching the goal becomes sparse. Therefore, inspired by [16], we introduced an intermediate reward to guide each UUV towards the goal. The reward associated with the goal was designed as shown in Equation (8), and the episode ends once the goal is reached.
where is considered to have reached the goal when the distance between and its goal is less than the UUV’s length L, and a large reward is assigned. If the goal has not been reached, the UUV is guided towards the goal by the difference in distance between the UUV and the goal at times and t. denotes the reward coefficient.
Reward associated with collision: To ensure safe obstacle avoidance, a minimum safety distance is introduced. When the distance between the UUV and any obstacle is less than , a large penalty is given, and the episode ends, as shown in Equation (9).
Reward associated with cooperative constraints: On one hand, to prevent collisions between UUVs, we designed a collision penalty as shown in Equation (10). When the distance between any two UUVs is less than the safety distance , a large collision penalty is applied, and the episode ends.
On the other hand, to satisfy the communication distance constraint, a penalty is applied when the distance between any two UUVs exceeds the threshold based on acoustic device characteristics, as shown in Equation (11).
Reward associated with smooth motion: To reduce the heading fluctuations during UUV navigation, a small penalty is applied for heading changes between consecutive time steps, as shown in Equation (12).
To encourage UUVs to maintain their preferred speed, a small penalty is applied for deviations between the actual surge speeds and the preferred surge speeds , as shown in Equation (13).
4.3. Action Design
Given the underactuated characteristics of the UUV, it is capable of generating only surge thrust and yaw moment in the horizontal plane. Due to inherent positive buoyancy, UUVs exhibit depth control instability in low-speed conditions, which necessitates a minimum speed requirement. Thus, the action output is defined as increments in the surge speed and heading , with the surge speed defined as .
4.4. Curriculum Learning
To achieve progressive policy optimization and accelerate training convergence, we developed a multi-stage training framework based on curriculum learning principles. The framework consists of three sequential stages. First, the UUV learns basic static obstacle avoidance while navigating towards goals in simplified environments. Once reliable navigation capability is established, the training advances to environments with complex non-convex obstacles. The final stage focuses on training the UUV to satisfy cooperative constraints. During this stage, the robots are divided into two groups for parallel training. The majority of the robots focus on learning the new skill of satisfying cooperative constraints, while a smaller portion continues training in scenarios involving complex non-convex obstacles. This approach ensures that the robots can acquire new skills in a phased manner without forgetting the knowledge gained in previous stages. This three-stage framework progressively enhances the UUV’s autonomy and task execution capabilities.
5. Results
This section first details the training configuration and computational complexity and then compares the proposed method with baseline methods through quantitative evaluations in simulated marine scenarios. To further validate the generalization capability and robustness, real-world experiments were conducted in lake environments. The results demonstrate the effectiveness of our method in both challenging simulated and real-world environments. Each UUV independently makes collision avoidance decisions using its own sensors and neighbor information acquired through underwater acoustic communication. This distributed execution approach enhances the system’s robustness.
5.1. Training Configuration and Computational Complexity
Our method was implemented in Pytorch with a sensor-level simulation framework developed using the UUV Simulator [29]. The multi-UUV collision avoidance policy was trained on a computer equipped with an Intel Core i7-7700 CPU and Nvidia RTX 3060 GPU, with the training environment simulated at a depth of 15 m underwater. The training process took 24 h (approximately 1500 iterations) to converge to robust performance. In both simulation and real-world experiments, our policy performed inference every 1 s. Due to the small number of parameters in the policy network, the inference was completed within milliseconds, resulting in almost no control delay. The training hyperparameters are provided in Table 1.

Table 1.
Training hyperparameters.
5.2. Performance Metrics
To compare our method’s performance with baseline methods across multiple test cases, the following metrics were evaluated with 100 repetitions per test case for each method.
- Success Rate: The ratio of the number of times the UUV successfully reaches the goal without collisions within the given time steps to the total number of test cases.
- Collision Rate: The ratio of the number of collisions during testing to the total number of test cases.
- Timeout Rate: The ratio of the number of times the UUV fails to reach the goal without collision within the specified time limit.
- Extra Distance: The difference between the UUV’s average travel trajectory length and the lower bound of the UUV’s travel distance (i.e., the average traveled distance for the UUV following the shortest path towards the goal).
5.3. Simulation Experiments
5.3.1. Multi-UUV Collision Avoidance Experiment in Unknown Complex Obstacle Environments
To assess the collision avoidance performance of the proposed method during cooperative operation in unknown environments relying solely on local sensor observations without global obstacle information, a real-world environment (Port of Long Beach, USA) was selected, and its underwater structure was reconstructed in simulation through proportional scaling of key features, as shown in Figure 3. We randomly selected four sets of start and goal positions to compare our method with the Improved Artificial Potential Field (IAPF) method described in [30] and the Variable Responsibility Optimal Reciprocal Collision Avoidance (VR-ORCA) method described in [31].
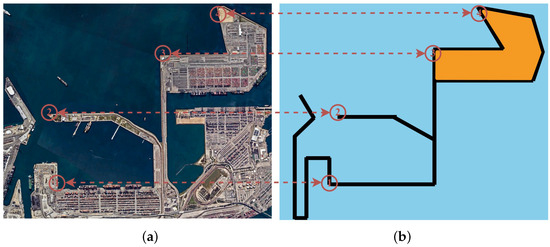
Figure 3.
Experimental validation scenario: (a) Long Beach Port satellite imagery (Source: Google Maps), (b) simulation scenario reconstructed from (a).
The experimental results are shown in Figure 4 and Table 2. In complex obstacle environments, UUVs must avoid both static obstacles and collisions with other UUVs. Our method demonstrated superior performance compared to the two baseline methods. The IAPF method employs virtual attractive and repulsive forces for path planning. However, in our experiment, the attractive force decreased as the UUV approached the goal, while the repulsive force intensified in dense obstacle fields, resulting in frequent local optima, where UUVs stagnated near the goal or drifted away from the goal. In contrast, our method achieved reliable goal convergence and identified paths that exhibited near-optimal performance in such environments. Our method demonstrated superior performance in balancing long-term rewards and avoiding local optima under complex obstacle conditions. The VR-ORCA method could precisely reach the goal but suffered from elevated collision rates when the goal lay behind the UUV during obstacle avoidance. In contrast, our method maintained a higher success rate under such conditions and sustained high stability and accuracy in complex obstacle environments. The experimental results indicate that our method, compared with the typical methods, considers long-term rewards, resulting in superior performance across all examples in terms of the success rate, collision rate, timeout rate, and extra distance, outperforming the other two methods in most cases.
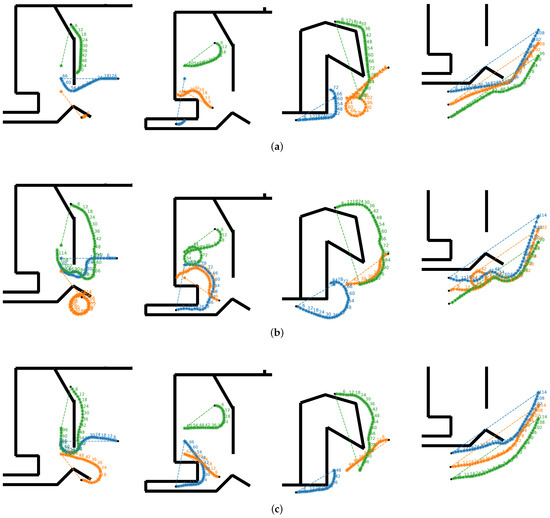
Figure 4.
Simulation results of three multi-UUV collision avoidance methods in an underwater port scenario are presented. Cases 0–3 (from left to right) show four randomly selected start and goal positions. Each case involves three UUVs with different IDs: blue for ID 0, orange for ID 1, and green for ID 2. Black dots denote UUV starting positions, pentagrams denote goals, numerical labels denote time steps, and arrow-headed circles denote heading directions. (a) VR-ORCA; (b) IAPF; (c) Our method.
Table 2.
Simulation experiments in port scenarios compare VR-ORCA, IAPF, and our method across four test cases 0–3, each involving three UUVs, in terms of success rate, crash rate, timeout rate, and extra distance. Best results are highlighted in bold.
5.3.2. Collision Avoidance Within Multi-UUV Systems
As shown in Figure 5 and Table 3, a circular scenario with a 30 m radius was designed, where 2–5 UUVs were deployed at randomized initial positions and guided to the goal on the opposite side. This setup evaluated both collision avoidance performance and adaptability to variable numbers of neighbors. Notably, the policy was trained exclusively on groups of 3–4 UUVs, yet it generalizes to scenarios with an arbitrary number of neighbors. The experimental results demonstrate that processing neighbor states through our multi-agent dynamic encoder enabled the method to achieve an over 89% success rates across all collision scenarios with varying number of neighbors. Moreover, it achieved effective collision avoidance with a minimal increase in path length, validating the method’s effectiveness and generalization capability.
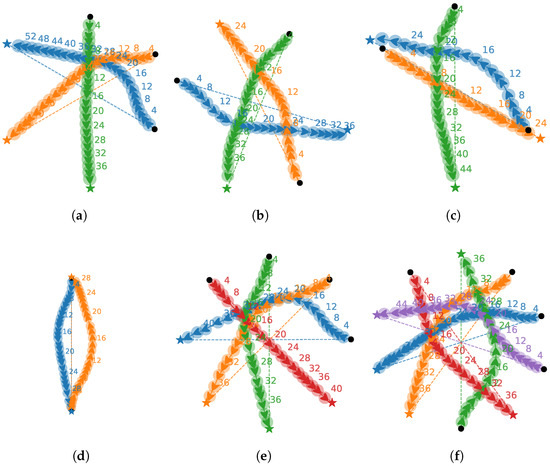
Figure 5.
Collision avoidance trajectories within the multi-UUV system. Trajectories demonstrating collision avoidance are shown in (a–c) for 3 UUVs at random positions, with cases for 2, 4, and 5 UUVs presented in (d–f), respectively. Each color represents the trajectory of a different UUV, arrows denote the UUVs’ headings, and labels denote time.
Table 3.
Simulation experimental results of collision avoidance within the multi-UUV system. Cases a–f correspond to the six scenarios in Figure 5. Each case was evaluated on the same 100 samples.
To verify the effectiveness of our proposed efficient self-attention module, we conducted an ablation experiment. In this experiment, we removed the efficient self-attention module from the model and instead used a simple average aggregation method to process neighbor features. Specifically, multiple neighbor features were aggregated by averaging to obtain fixed-dimensional features as input to the subsequent network. This approach allowed us to clearly evaluate the role of the attention mechanism in feature processing and task performance.
In the experiment, we kept all other settings of the model consistent with the original configuration, including the training setup with 3–4 UUVs per group and the evaluation methods. The experimental results showed that after removing the attention module, the model’s performance dropped significantly: In the trained setting with 3–4 UUVs per group, the success rate decreased by approximately 40%. In the untrained setting with two and five UUVs per group, the model performed even worse, with a success rate of only about 10%. These results clearly demonstrate the importance of the efficient attention module in processing neighbor features.
From a theoretical perspective, while the average aggregation method can simply integrate neighbor features, it lacks the ability to model the differences and importance among neighbor features. Specifically, average aggregation assigns equal weights to all neighbor features, ignoring the fact that different neighbors may vary significantly in their importance to the task at hand. For example, in practical scenarios, certain neighbors may provide crucial information, while others may contribute noise or redundant details. The core advantage of the attention mechanism lies in its ability to dynamically adjust weights based on the contextual relationships of neighbor features, thereby highlighting critical neighbor features while suppressing irrelevant or distracting ones. This dynamic weight allocation capability is precisely what average aggregation methods fail to achieve.
Moreover, the experimental results indicate that the efficient attention module not only improves the model’s performance on training data but also significantly enhances its generalization ability on unseen data. In the untrained setting (e.g., groups with two and five UUVs), the success rate of the average aggregation method was only around 10%, whereas the attention mechanism could effectively capture the complex relationships among neighbor features through dynamic weight allocation, reducing information loss and improving the model’s robustness and generalization ability. This further demonstrates that the attention mechanism helps the model adapt to different data distributions and task scenarios.
5.3.3. Communication Distance Constraint Experiments
To assess the communication distance constraint effectiveness, we selected an effective communication distance of 100 m based on the specifications of underwater acoustic communication systems. Three parallel routes were allocated to the three UUVs, with a 95 m distance between the routes of the UUVs on both sides. During movement, each UUV must avoid a cylindrical obstacle with a radius of 5 m whose center coincides with its predefined path. If both UUVs avoid obstacles by moving away from neighbors, they will exceed the effective communication distance. To assess the effectiveness of the communication distance constraint and analyze its impact on collision avoidance, we conducted a comparative evaluation between policies with and without this constraint in the aforementioned scenario. The experimental results are shown in Figure 6. The policy with the communication distance constraint directed UUVs to prefer avoiding obstacles on the side closer to their neighbors, ensuring that the communication distance remained within the limit. In contrast, when operating without the communication constraint, the policy allowed UUVs to make avoidance decisions based solely on individual behaviors without considering the influence of neighbors, resulting in distances exceeding the communication constraint. We repeated 100 experiments and calculated the success rate of maintaining the communication distance, defined as the proportion of times the communication distance is not exceeded during collision avoidance. The results show that with the communication distance constraint, the policy’s success rate reached 100%, while without the constraint, it was only 1%. This demonstrates the effectiveness of our method in maintaining the communication distance within the limit.
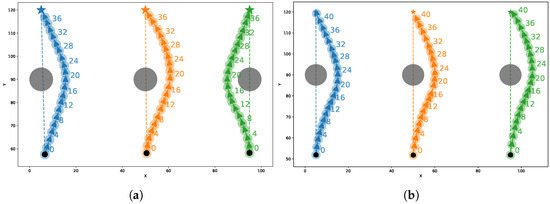
Figure 6.
Communication distance constraint experiment trajectories. (a) shows the UUV trajectories considering the communication distance constraint, while (b) shows the trajectories without the constraint. The UUVs on both sides moved along parallel lines with a 95 m spacing, and the centers of the cylindrical obstacles lay on these lines. Different colors represent the trajectories of different UUVs.
5.4. Lake Experiments
To assess the generalization and robustness of our method under real-world conditions, we conducted lake experiments at Zhanghe Reservoir (Jingmen, Hubei Province, China) using a conventional cylindrical UUV (4 m in length, 324 mm in diameter) featuring a stern thruster and x-rudder configuration, representing a typical underactuated system. We randomly assigned start and goal positions and generated obstacles with radii ranging from 5 to 15 m. The experimental results, as shown in Figure 7, demonstrate that our method successfully avoided obstacles and precisely reached the goal in all experimental trials. Despite the UUV’s large turning radius and limited maneuverability in real-world deployment, our method maintained effective obstacle avoidance while satisfying motion constraints, demonstrating successful sim-to-real transfer. The policy retained consistent generalization capability even when the real-world UUV configuration diverged from the simulated model.
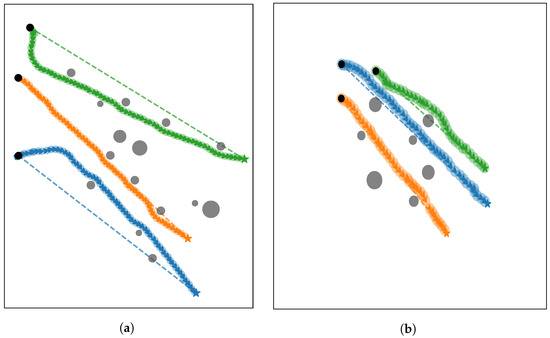
Figure 7.
Lake experiment results under two different scenarios are shown in (a,b) at a depth of 15 m. The circles denote cylindrical virtual obstacles of varying sizes, and arrows denote the UUVs’ headings. Different colors represent the trajectories of different UUVs.
6. Conclusions
In this paper, we propose COO-CADRL, an efficient collision avoidance method developed with our proposed centralized training with decentralized execution framework, to address the multi-UUV system collision avoidance problem in complex marine environments. Our method introduces a novel multi-agent dynamic encoder based on an efficient self-attention mechanism, which is incorporated into the network. Compared to previous studies that typically simplify environmental obstacles to convex shapes with sparse distributions and ignore new constraints arising from cooperative operation, COO-CADRL addresses multi-UUV collision avoidance in marine environments with certain types of complex non-convex obstacles while satisfying cooperative constraints and processing an arbitrary number of neighboring observations. Compared to existing baselinses, our method achieved higher success rates and greater efficiency, while its practical applicability was demonstrated through real-world experiments. In future work, we will consider additional marine constraints such as ocean current disturbances and communication latency to further enhance our method.
Author Contributions
Conceptualization, H.X.; methodology, H.X., F.C., J.R. and H.Z.; software, F.C. and Z.L.; validation, H.X., F.C., J.R., Z.L. and H.Z.; formal analysis, H.X. and F.C.; data curation, F.C.; writing—original draft preparation, F.C.; writing—review and editing, Z.L. and H.L.; project administration, H.X.; funding acquisition, H.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Defense Preliminary Research Project under Grant 50911020604, the Young Scientists Fund of the National Natural Science Foundation of China (62303099), the Joint Fund of Science & Technology Department of Liaoning Province (2023-MSBA-071), and the Fundamental Research Funds for the Central Universities of the Ministry of Education of China (N2426004).
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to research restrictions.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wynn, R.B.; Huvenne, V.A.; Le Bas, T.P.; Murton, B.J.; Connelly, D.P.; Bett, B.J.; Ruhl, H.A.; Morris, K.J.; Peakall, J.; Parsons, D.R.; et al. Autonomous Underwater Vehicles (AUVs): Their past, present and future contributions to the advancement of marine geoscience. Mar. Geol. 2014, 352, 451–468. [Google Scholar] [CrossRef]
- Liu, Y.; Li, J.; Guo, W.; Ngo, H.H.; Hu, J.; Gao, M.T. Use of magnetic powder to effectively improve the performance of sequencing batch reactors (SBRs) in municipal wastewater treatment. Bioresour. Technol. 2018, 248, 135–139. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.; Sha, Q.; He, B.; Li, G. Path planning and obstacle avoidance for AUV: A review. Ocean Eng. 2021, 235, 109355. [Google Scholar] [CrossRef]
- Yan, Z.; Zhao, L.; Wang, Y.; Zhang, M.; Yang, H.; Zhang, C. Path Planning of AUV for Obstacle Avoidance with Improved Artificial Potential Field. In Proceedings of the IECON 2023-49th Annual Conference of the IEEE Industrial Electronics Society, Singapore, 16–19 October 2023; pp. 1–5. [Google Scholar]
- Shokouhi, S.; Mu, B.; Thein, M.-W. Optimized Path Planning and Control for Autonomous Surface Vehicles using B-Splines and Nonlinear Model Predictive Control. In Proceedings of the OCEANS 2023—MTS/IEEE U.S. Gulf Coast, Biloxi, MS, USA, 25–28 September 2023; pp. 1–9. [Google Scholar]
- Chen, T.; Zhang, Z.; Fang, Z.; Jiang, D.; Li, G. Imitation learning from imperfect demonstrations for AUV path tracking and obstacle avoidance. Ocean Eng. 2024, 298, 117287. [Google Scholar] [CrossRef]
- Fan, X.; Guo, Y.; Liu, H.; Wei, B.; Lyu, W. Improved artificial potential field method applied for AUV path planning. Math. Probl. Eng. 2020, 2020, 6523158. [Google Scholar] [CrossRef]
- Taheri, E.; Ferdowsi, M.H.; Danesh, M. Closed-loop randomized kinodynamic path planning for an autonomous underwater vehicle. Appl. Ocean Res. 2019, 83, 48–64. [Google Scholar] [CrossRef]
- Alonso-Mora, J.; Breitenmoser, A.; Rufli, M.; Beardsley, P.; Siegwart, R. Optimal reciprocal collision avoidance for multiple non-holonomic robots. In Proceedings of the Distributed Autonomous Robotic Systems: The 10th International Symposium; Springer: Berlin/Heidelberg, Germany, 2013; pp. 203–216. [Google Scholar]
- Carlucho, I.; De Paula, M.; Wang, S.; Menna, B.V.; Petillot, Y.R.; Acosta, G.G. AUV position tracking control using end-to-end deep reinforcement learning. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–8. [Google Scholar]
- Yang, J.; Ni, J.; Xi, M.; Wen, J.; Li, Y. Intelligent path planning of underwater robot based on reinforcement learning. IEEE Trans. Autom. Sci. Eng. 2022, 20, 1983–1996. [Google Scholar] [CrossRef]
- Saravanan, M.; Kumar, P.S.; Dey, K.; Gaddamidi, S.; Kumar, A.R. Exploring spiking neural networks in single and multi-agent rl methods. In Proceedings of the 2021 International Conference on Rebooting Computing (ICRC), Los Alamitos, CA, USA, 30 November–2 December 2021; pp. 88–98. [Google Scholar]
- Huang, S.; Zhang, H.; Huang, Z. CoDe: A Cooperative and Decentralized Collision Avoidance Algorithm for Small-Scale UAV Swarms Considering Energy Efficiency. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 13152–13159. [Google Scholar]
- Liu, H.; Shen, Y.; Zhou, C.; Zou, Y.; Gao, Z.; Wang, Q. TD3 based collision free motion planning for robot navigation. In Proceedings of the 2024 6th International Conference on Communications, Information System and Computer Engineering (CISCE), Guangzhou, China, 10–12 May 2024; pp. 247–250. [Google Scholar]
- Everett, M.; Chen, Y.F.; How, J.P. Motion planning among dynamic, decision-making agents with deep reinforcement learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3052–3059. [Google Scholar]
- Long, P.; Fan, T.; Liao, X.; Liu, W.; Zhang, H.; Pan, J. Towards optimally decentralized multi-robot collision avoidance via deep reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6252–6259. [Google Scholar]
- Du, Y.; Zhang, J.; Xu, J.; Cheng, X.; Cui, S. Global map assisted multi-agent collision avoidance via deep reinforcement learning around complex obstacles. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 298–305. [Google Scholar]
- Chen, C.; Liu, Y.; Kreiss, S.; Alahi, A. Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 6015–6022. [Google Scholar]
- Wu, J.; Wang, Y.; Asama, H.; An, Q.; Yamashita, A. Risk-Sensitive Mobile Robot Navigation in Crowded Environment via Offline Reinforcement Learning. In Proceedings of the 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 1–5 October 2023; pp. 7456–7462. [Google Scholar]
- Zhang, C.; Cheng, P.; Du, B.; Dong, B.; Zhang, W. AUV path tracking with real-time obstacle avoidance via reinforcement learning under adaptive constraints. Ocean Eng. 2022, 256, 111453. [Google Scholar] [CrossRef]
- Xu, J.; Huang, F.; Wu, D.; Cui, Y.; Yan, Z.; Du, X. A learning method for AUV collision avoidance through deep reinforcement learning. Ocean Eng. 2022, 260, 112038. [Google Scholar] [CrossRef]
- Li, X.; Yu, S. Obstacle avoidance path planning for AUVs in a three-dimensional unknown environment based on the C-APF-TD3 algorithm. Ocean Eng. 2025, 315, 119886. [Google Scholar] [CrossRef]
- Wang, P.; Liu, R.; Tian, X.; Zhang, X.; Qiao, L.; Wang, Y. Obstacle avoidance for environmentally-driven USVs based on deep reinforcement learning in large-scale uncertain environments. Ocean Eng. 2023, 270, 113670. [Google Scholar] [CrossRef]
- Hadi, B.; Khosravi, A.; Sarhadi, P. Adaptive formation motion planning and control of autonomous underwater vehicles using deep reinforcement learning. IEEE J. Ocean. Eng. 2023, 49, 311–328. [Google Scholar] [CrossRef]
- Hadi, B.; Khosravi, A.; Sarhadi, P. Hybrid Motion Planning and Formation Control of Multi-AUV Systems Based on DRL. In Proceedings of the 2024 American Control Conference (ACC), Toronto, ON, Canada, 10–12 July 2024; pp. 2368–2373. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar] [CrossRef]
- Zhang, C.; Yip, K.W.; Yang, B.; Zhang, Z.; Yuan, M.; Yan, R.; Tang, H. CASRL: Collision Avoidance with Spiking Reinforcement Learning Among Dynamic, Decision-Making Agents. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; pp. 8031–8038. [Google Scholar]
- Shaker, A.; Maaz, M.; Rasheed, H.; Khan, S.; Yang, M.H.; Khan, F.S. Swiftformer: Efficient additive attention for transformer-based real-time mobile vision applications. In Proceedings of the IEEE/CVF International Conference on Computer Cision, Paris, France, 1–6 October 2023; pp. 17425–17436. [Google Scholar]
- Manhães, M.M.M.; Scherer, S.A.; Voss, M.; Douat, L.R.; Rauschenbach, T. UUV simulator: A gazebo-based package for underwater intervention and multi-robot simulation. In Proceedings of the Oceans 2016 MTS/IEEE Monterey, Monterey, CA, USA, 19–23 September 2016; pp. 1–8. [Google Scholar]
- Zhang, Y.; Wang, Q.; Shen, Y.; Dai, N.; He, B. Multi-AUV cooperative control and autonomous obstacle avoidance study. Ocean Eng. 2024, 304, 117634. [Google Scholar] [CrossRef]
- Guo, K.; Wang, D.; Fan, T.; Pan, J. VR-ORCA: Variable responsibility optimal reciprocal collision avoidance. IEEE Robot. Autom. Lett. 2021, 6, 4520–4527. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).