3.1. Analysis of the Vanishing Gradient
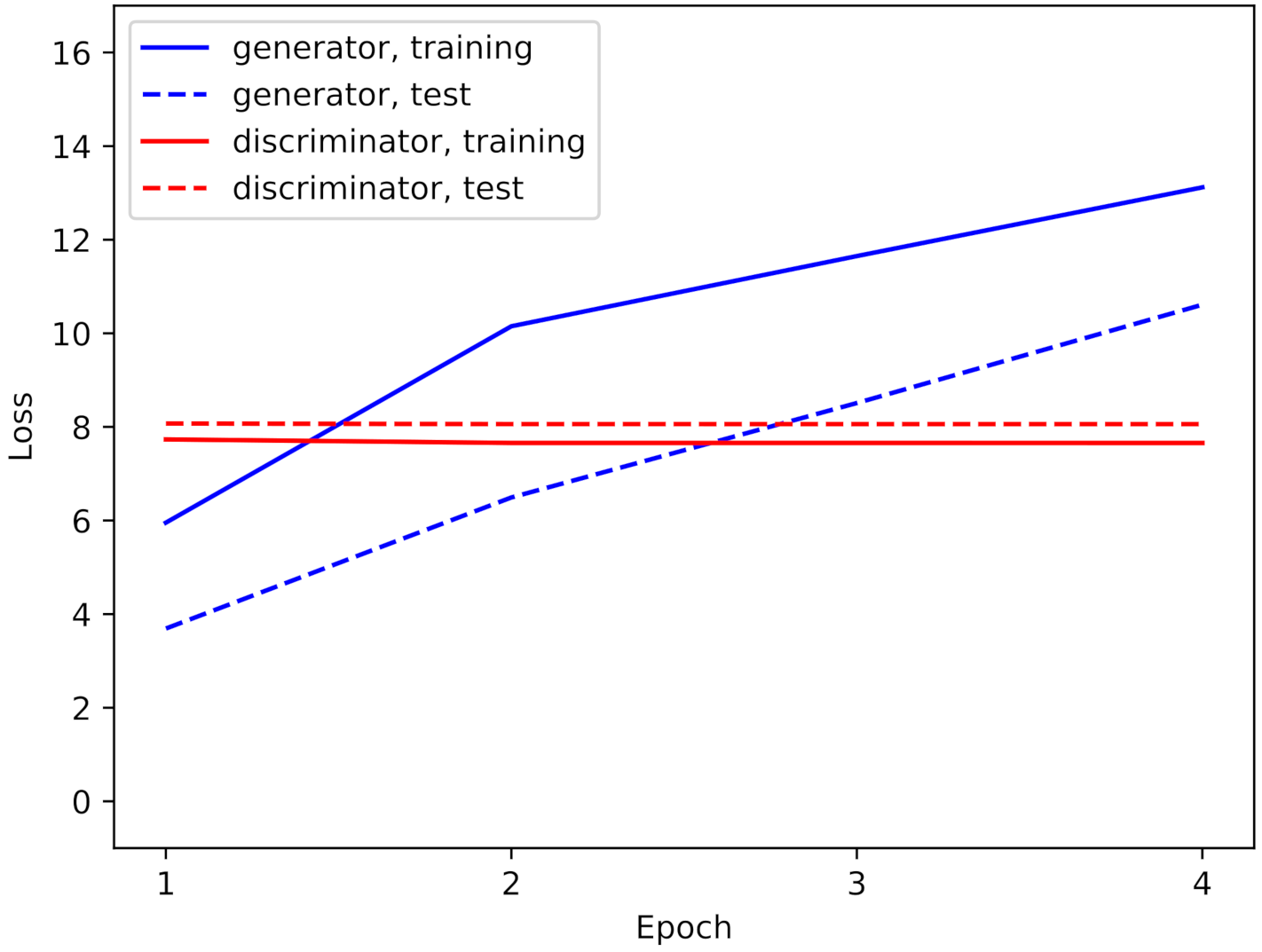
During the fine-tuning step of the TransfGAN, the loss behaves as shown in
Figure 7. The loss of the discriminator remains constant while the loss of the generator increases.
Looking at the training process of a neural network, the weights are updated using the gradient of a loss function with respect to the individual weights. In the very basic stochastic gradient descent, the update follows the rule
where
are the weights from the
i-th iteration,
is the learning rate,
l is the loss function and all calculations are taken element-wise. Using the Adam optimizer [
22] the update rule modifies to
where
and
where
are hyperparameters. Here, the gradient
of the loss function with respect to the weights is used again. The exponential moving averages of the gradient
m and the squared gradient
v are initialized with a value of zero. Consequently, if this gradient is zero, no update to the weights is made.
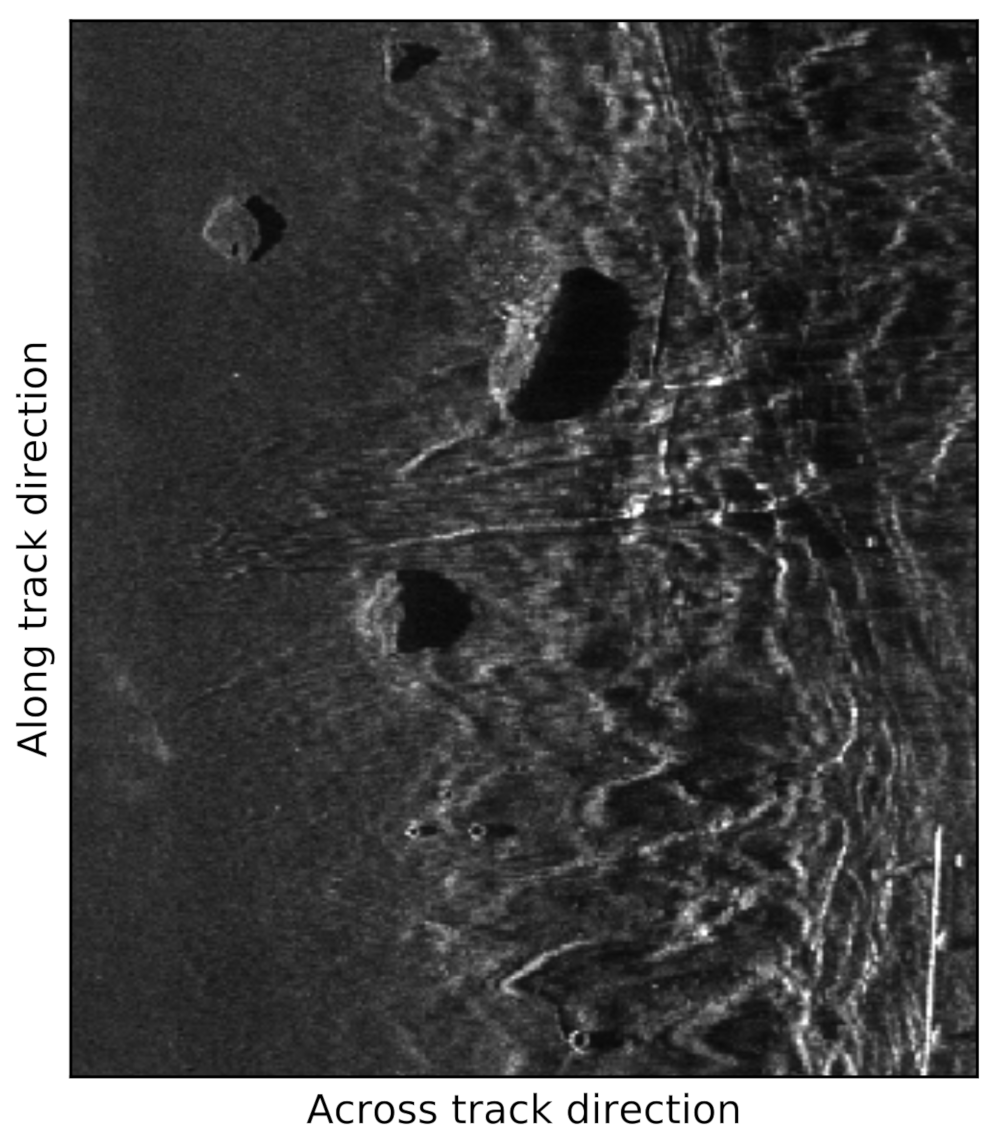
Figure 8 shows the gradients of the discriminator over the first four epochs for the real sidescan snippet (red) and the fake images generated by the TransfGAN’s generator (blue). It becomes clear that the gradient of the TransfGAN’s discriminator vanishes when it is trained with the real sidescan snippets. Due to the chain rule of calculus used in the back-propagation algorithm for training a neural network, a vanishing gradient in the last layer of the network leads to a gradient of zero in the remaining ones. Furthermore, the GAN is not able to recover from this vanishing gradient problem and will stay in this stage in all consecutive epochs.
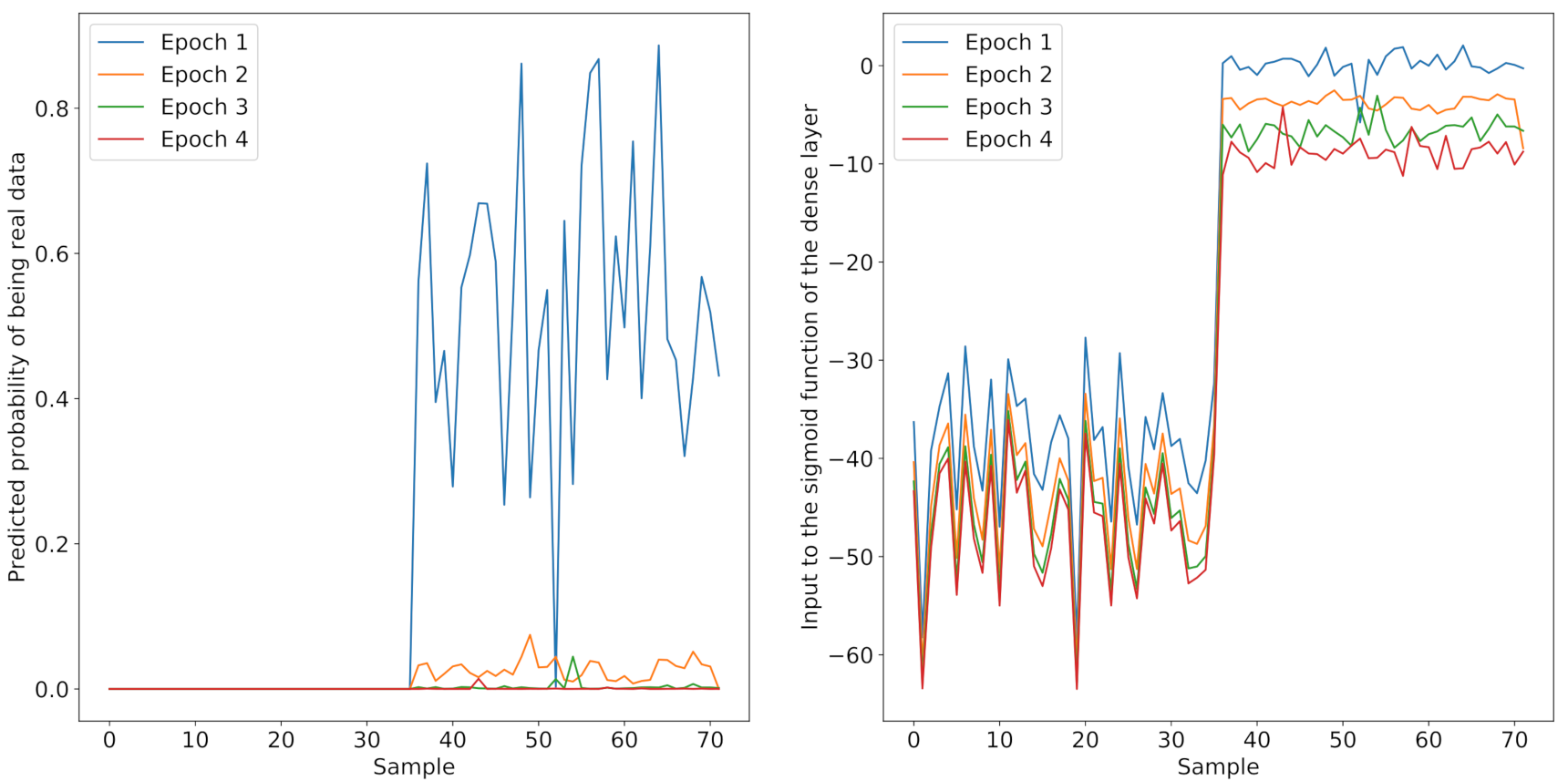
In order to explain the occurrence of the vanishing gradient in the discriminator,
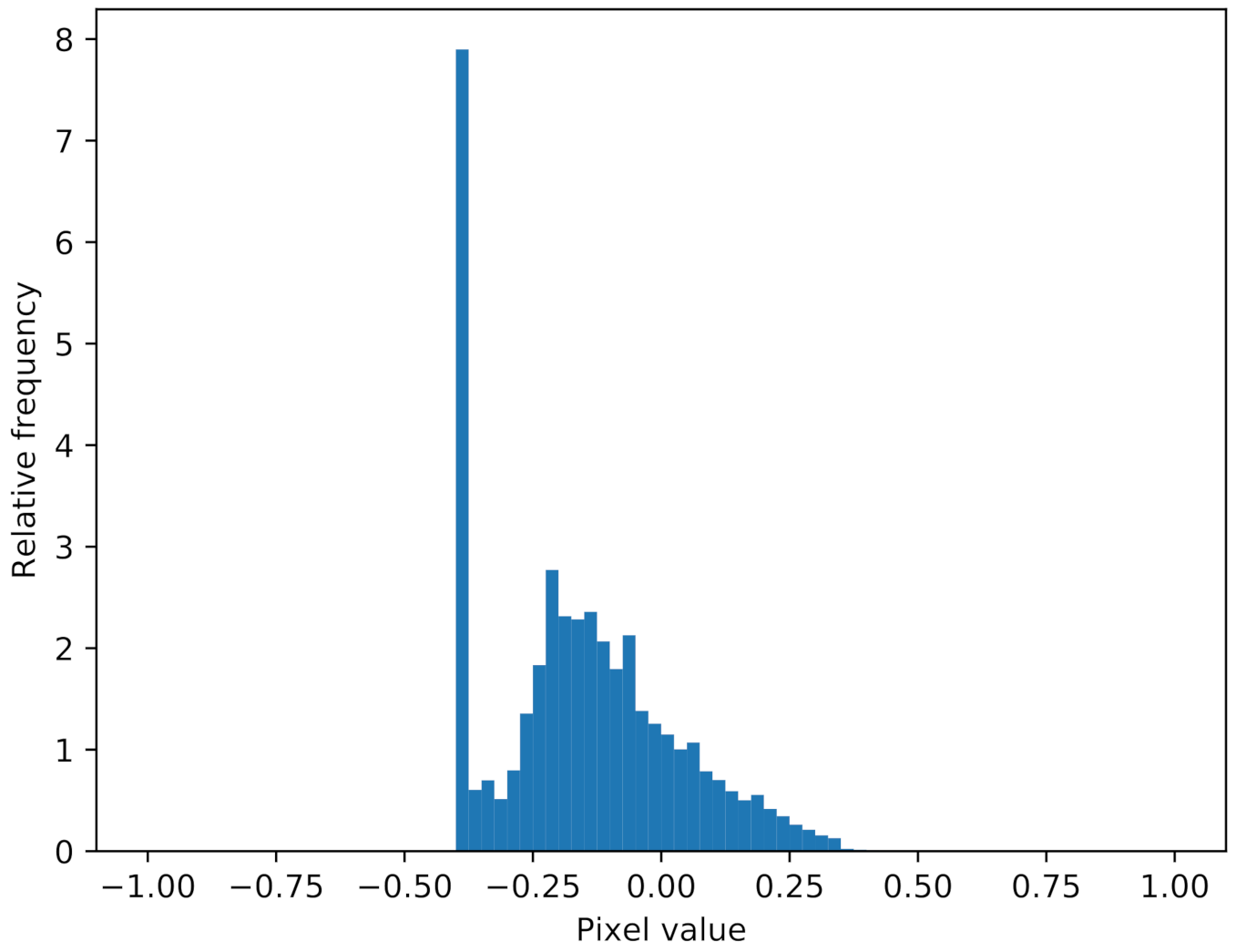
Figure 9 displays the predictions of the discriminator before updating the weights for the first four epochs. For the real sidescan snippets (sample 0–35), the discriminator classifies all images as fake. The right sub-figure in
Figure 9 shows the output of the dense layer prior to processing by the sigmoid function. For the real samples, the sigmoid function saturates. Note that a sigmoid(−40) is already
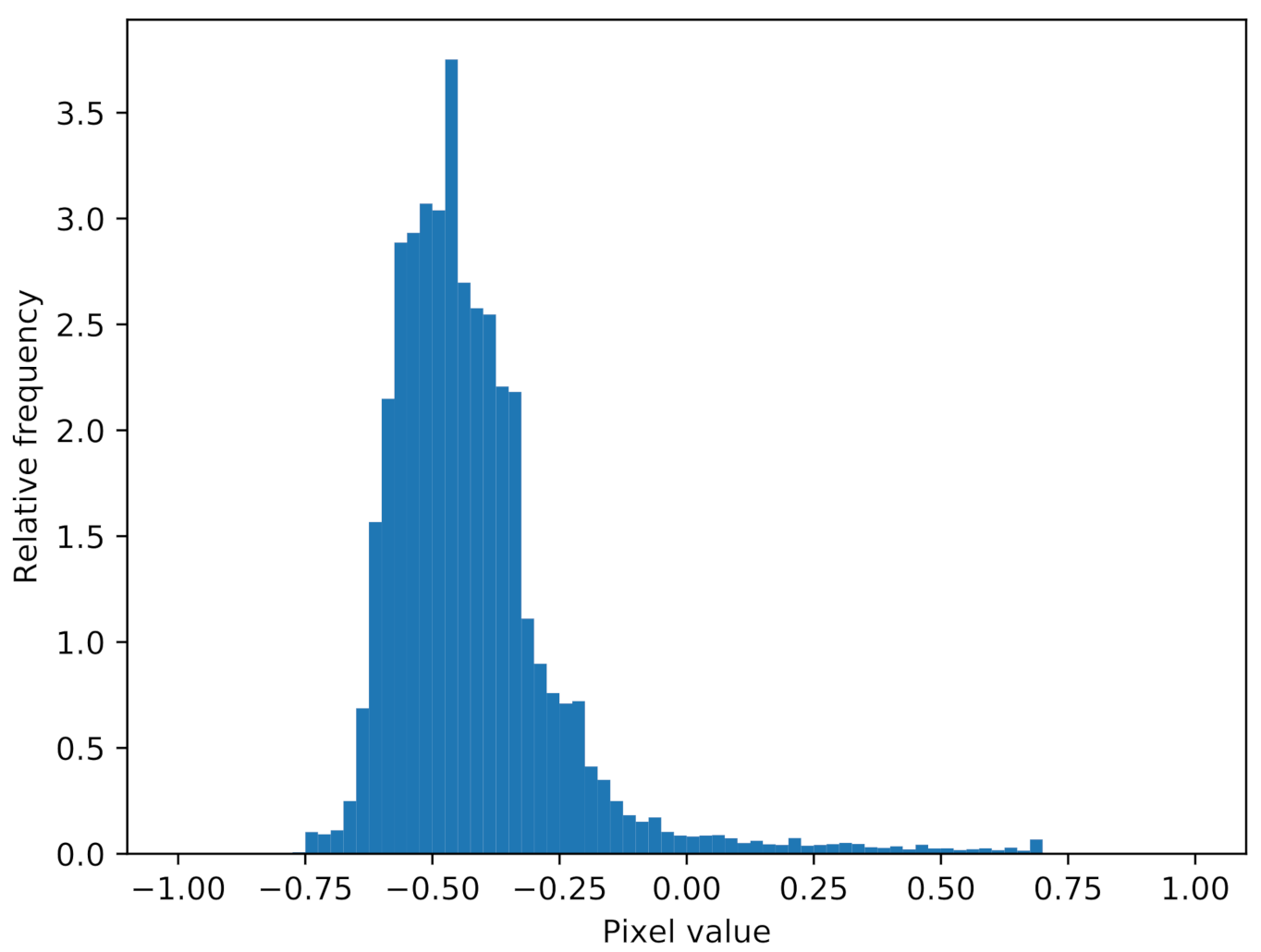
. This reveals a fundamental problem in the transfer-learning of the GAN. During the pre-training, the discriminator sees ray-traced images as real images. These ray-traced images often consist of only a few pixel values, as shown in the histogram in
Figure 4. This makes it likely that the discriminator will reject all samples which differ from this pixel-value distribution. In the fine-tuning step, the sidescan sonar snippets become the real images, but due to the pre-training, the discriminator will reject them. This problem remains if, in the pre-training step, a small portion of noise is added to the ray-traced images in order to disturb the pixel value distribution. However, the effect of adjusting the pixel distribution in the highlight, shadow and background regions of the ray-traced snippets according to a more realistic distribution still needs to be investigated. In the following section, experiments are conducted to investigate possible solutions to this vanishing gradient problem.
3.2. Experimental Study
Since the vanishing gradient in the discriminator only becomes visible in the fine-tuning step, this would make it necessary to re-initialize the GAN and to repeat the pre-training. A more convenient way of doing this would be to make the fine-tuning step more robust, so that it can deal with the vanishing gradient. Two slightly different approaches are analyzed in this study. In Experiment “All”, the weights of all layers in the discriminator are re-initialized prior to the fine-tuning step. Only the generator keeps the information from the pre-training step, while the discriminator is trained from scratch. This, however, would delete already learned features of the discriminator, which may still be useful for classifying the sidescan snippet into real or fake, e.g., basic geometric features. Therefore, in the Experiment “Last”, the re-initialization of only the last layer of the discriminator, i.e., the fully connected layer, will be analyzed. Here, the features learned by the convolutional layers in the discriminator (see
Table 4) are used in the fine-tuning step.
For both experiments, a grid-search over the learning rate is carried out to determine its optimum value. The learning rate for the generator and for the discriminator is allowed to differ since the (partial) re-initialization of the discriminator may give the generator a head start in the fine-tuning phase. For the same reason, training only the discriminator for a few epochs before fine-tuning the whole GAN is analyzed as well. During the grid search, the learning rates are set to . In all experiments, the TransfGAN is fine-tuned for 200 epochs. This number of epochs is sufficient to see if the applied method is able to train the TransfGAN without vanishing gradient. All experiments are conducted three times to account for the randomness in the re-initialization, resulting in a total of 300 experiment runs. While reporting the results of all these runs is beyond the scope of this article, the main findings are presented.
One outcome from the previous analysis of the vanishing gradient is that the loss of the discriminator stays constant if its gradient vanishes. Thus, a decaying loss indicates a success in countering the vanishing gradient. However, this criterion alone does not allow for direct statements about the quality of the generated images. A qualitative analysis of the images generated by the TransfGAN after fine-tuning will be carried out to rate the success of the two approaches “All” and “Last”. The criteria for sufficient quality of the generated images are:
Physically meaningful highlight and shadow;
Shadow connected to the right side of the object;
Realistic pixel value distribution in highlight, shadow and background regions;
No mode collapse.
As expected in most cases, both re-initialization approaches solve the problem of the vanishing gradient. Only for a discriminator learning rate of does the problem remain. Since a gradient of zero means no update in the discriminator, the extra training also does not help in these learning rate configurations. The learning rate is too high for the discriminator to converge to a minimum.
For all configurations of the experiments, the quality of the generated images is rated according to the criteria defined above. If all criteria are satisfied, a value of one is manually assigned to this configuration and a zero otherwise.
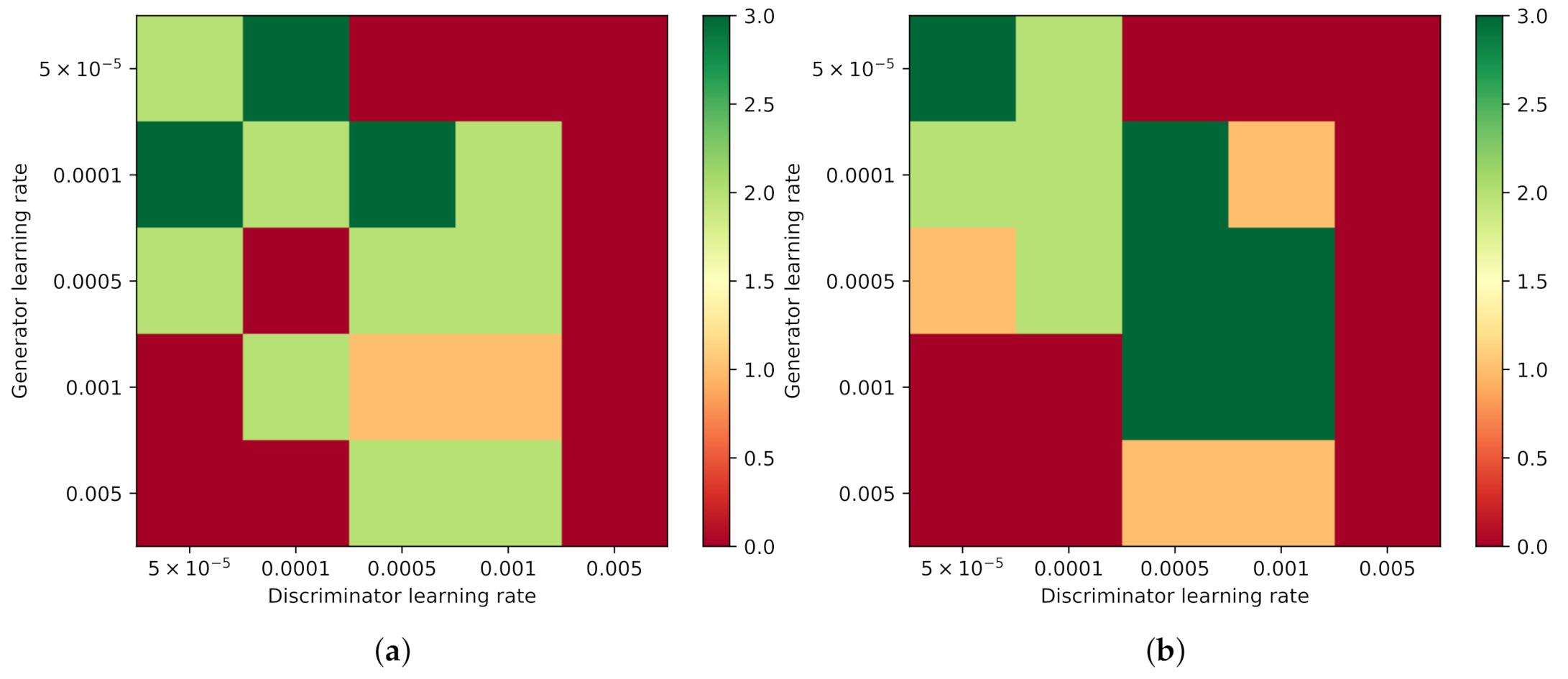
Figure 10 shows the rating quality of the images for the grid search configurations when re-initializing the last layer (Experiment “Last”). Because the training is done three times per experiment, the quality rating can be averaged over these three runs. A dark green value indicates that, in all three runs, the quality was good according to the criteria, and the light green indicates that only two of the three trained TransfGANs produce good images. The orange field encodes one TransfGAN which produces good images, and the red one indicates that all images lack one or all quality characteristics.
In Experiment “Last”, the images for
lack quality because they are not showing a realistic pixel distribution due to the remaining presence of the vanishing gradient. For low generator learning rates (
) and higher discriminator learning rates, the generator is not able to generate good images and a noisy pattern is visible. Examples of bad-quality images are given in
Figure 11. This pattern remains visible if the TransfGAN is trained for an additional 300 epochs.
If the generator learning rate is large (
), it can move into some regions in the loss-space where no highlight and shadow are generated. An example for this failure is shown in
Figure 12. This type of error occurs with and without the extra training of the discriminator and for all discriminator learning rates.
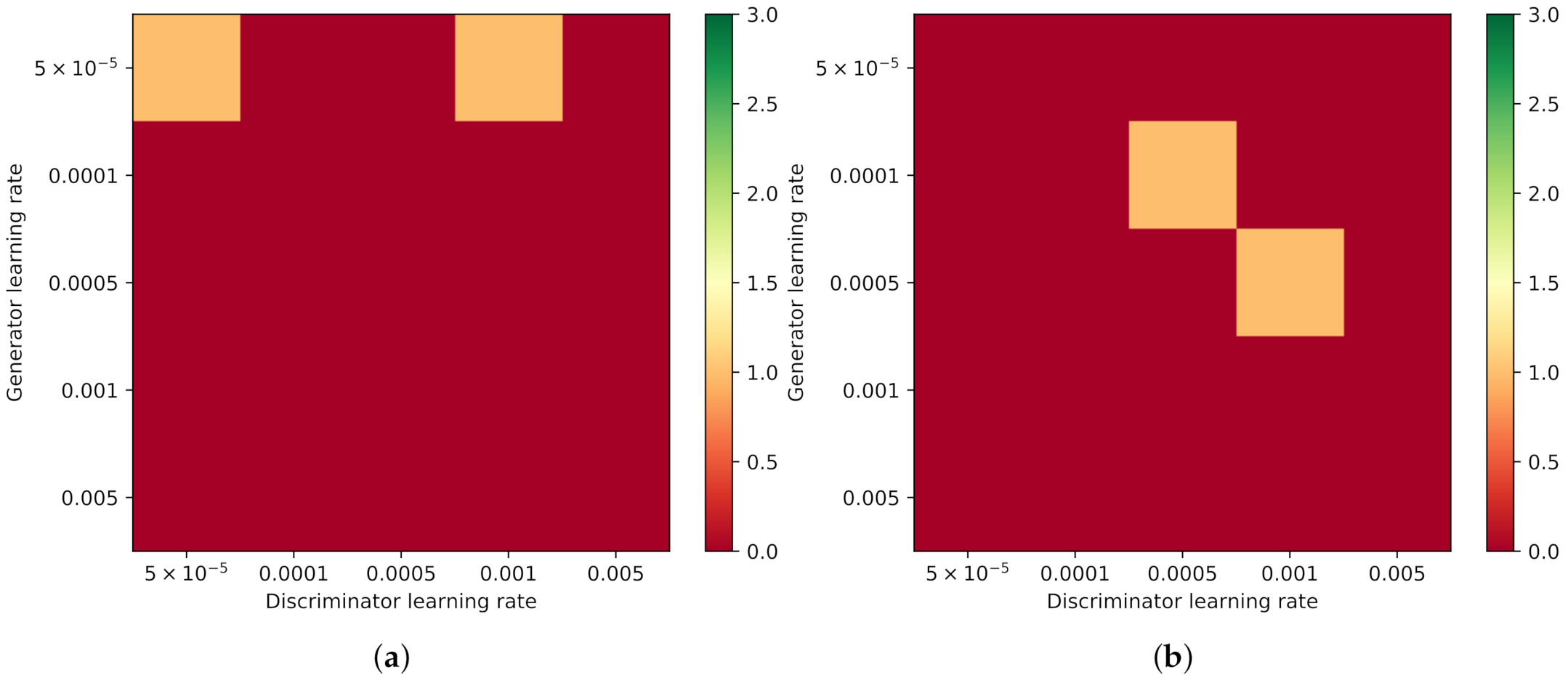
When all layers of the discriminator are re-initialized (Experiment “All”), the TransfGAN is not able to learn to generate realistic sidescan snippets, as can be seen in
Figure 13. Since, in this experiment, only the generator is able to benefit from the pre-training, the results indicate that the number of training samples is not enough to train the whole discriminator from scratch.
Besides the noisy pattern or cases in which no object at all is generated, another error arising using this approach is that the images look blurry.
Figure 14 shows some examples of this type of error, which occurs mostly for larger
in combination with smaller
. In addition, the presence of mode collapse can be observed in these examples, since all images look the same but were generated by a different noise vector. Mode collapse happened in multiple runs in different learning rate combinations in Experiment “All”, but not in Experiment “Last”, where only the last layer of the discriminator was re-initialized. This again indicates that it is essential to keep information from the pre-training in the discriminator during fine-tuning when the number of training samples is limited.
3.3. Generated Image Analysis
In order to analyze the quality of the generated images from the TransfGAN, of which only the last layer was re-initialized, three additional experiments are carried out. First, besides the qualitative analysis from the previous section, the ability of the generated images to serve as an augmentation dataset for a deep learning classifier is analyzed. In addition, the diversity in the generated samples is investigated. Finally, an analysis of the frequency domain of the images is carried out.
For the first experiment, a CNN is used to classify sidescan sonar snippets into the classes Tire, Rock and Background. The number of samples in each class is given in
Table 5, where an imbalance between the number of samples of class Tire and Rock or Background can be seen. The structure of the CNN is taken from [
12] and shown in
Table 6.
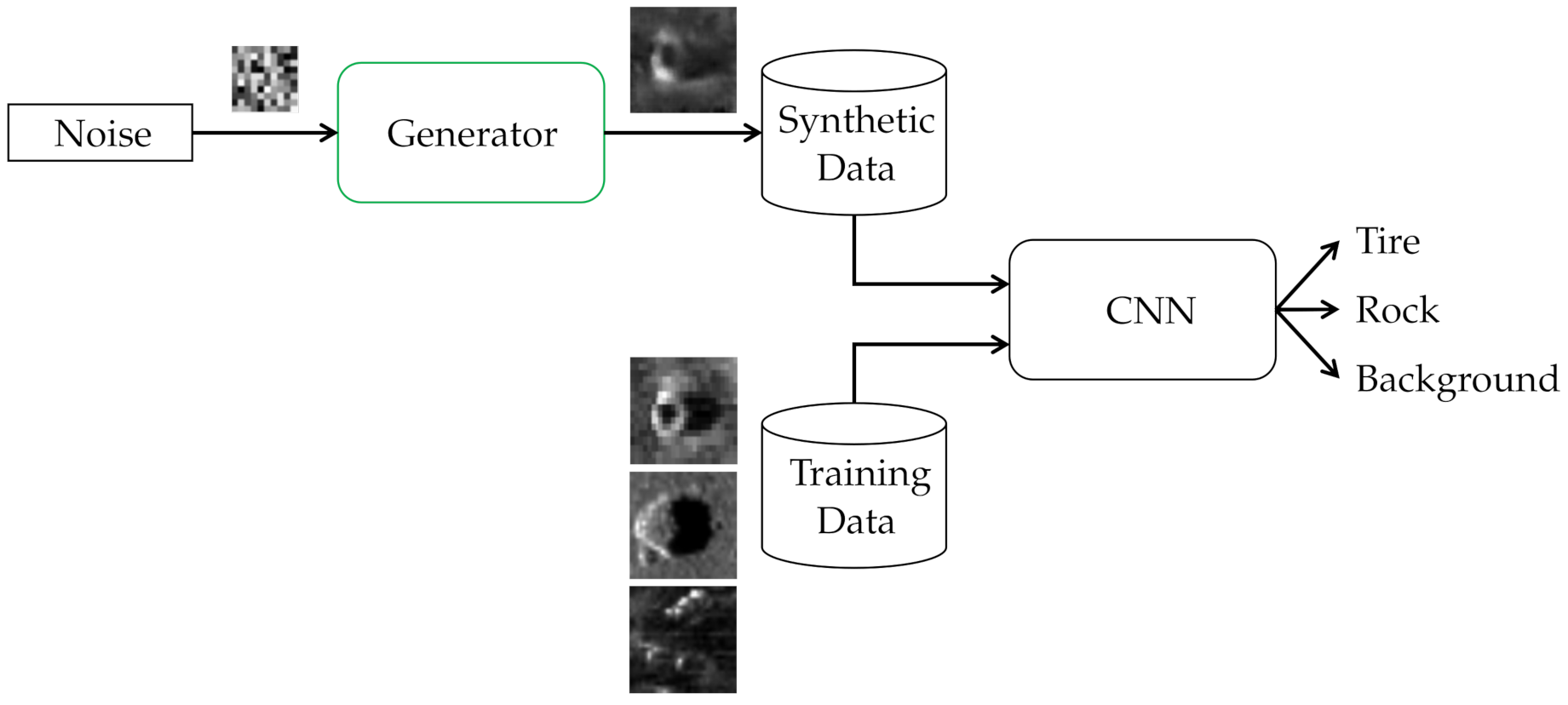
This CNN is trained once with the training set specified in
Table 5, and once with an additional 18 tire samples generated by a TransfGAN.
Figure 15 illustrates this augmentation scheme.
Following the results from the previous experiment, re-initialization of the last layer of the discriminator was applied to the TransfGAN. Three different configurations of the TransfGAN, which have been shown to generate good images, are compared:
, , no extra training of the discriminator prior to the fine-tuning
, , no extra training of the discriminator prior to the fine-tuning
, , with extra training of the discriminator prior to the fine-tuning
The balanced accuracy
and the macro F1 score
with
are used as performance measures. The classification experiments were carried out ten times to account for the random initialization of the CNN.
Table 7 reports the mean and standard deviation of the two metrics over these ten runs.
The results show a slight improvement in balanced accuracy and in the macro F1 score of 1% when the training dataset is augmented with generated snippets. Only a negligible difference is seen between the performance achieved from using different TransfGANs. Compared to the results from [
12], the performance of the baseline CNN without synthetic augmentation is worse, which can be explained by differences in the sonar data themselves. The increase in classification performance due to the synthetic augmentation is not as large either. Since the variability of the data used for augmentation is a critical factor for potential performance increase, the ability of the TransfGANs used in the classification experiment to generate different images is further investigated.
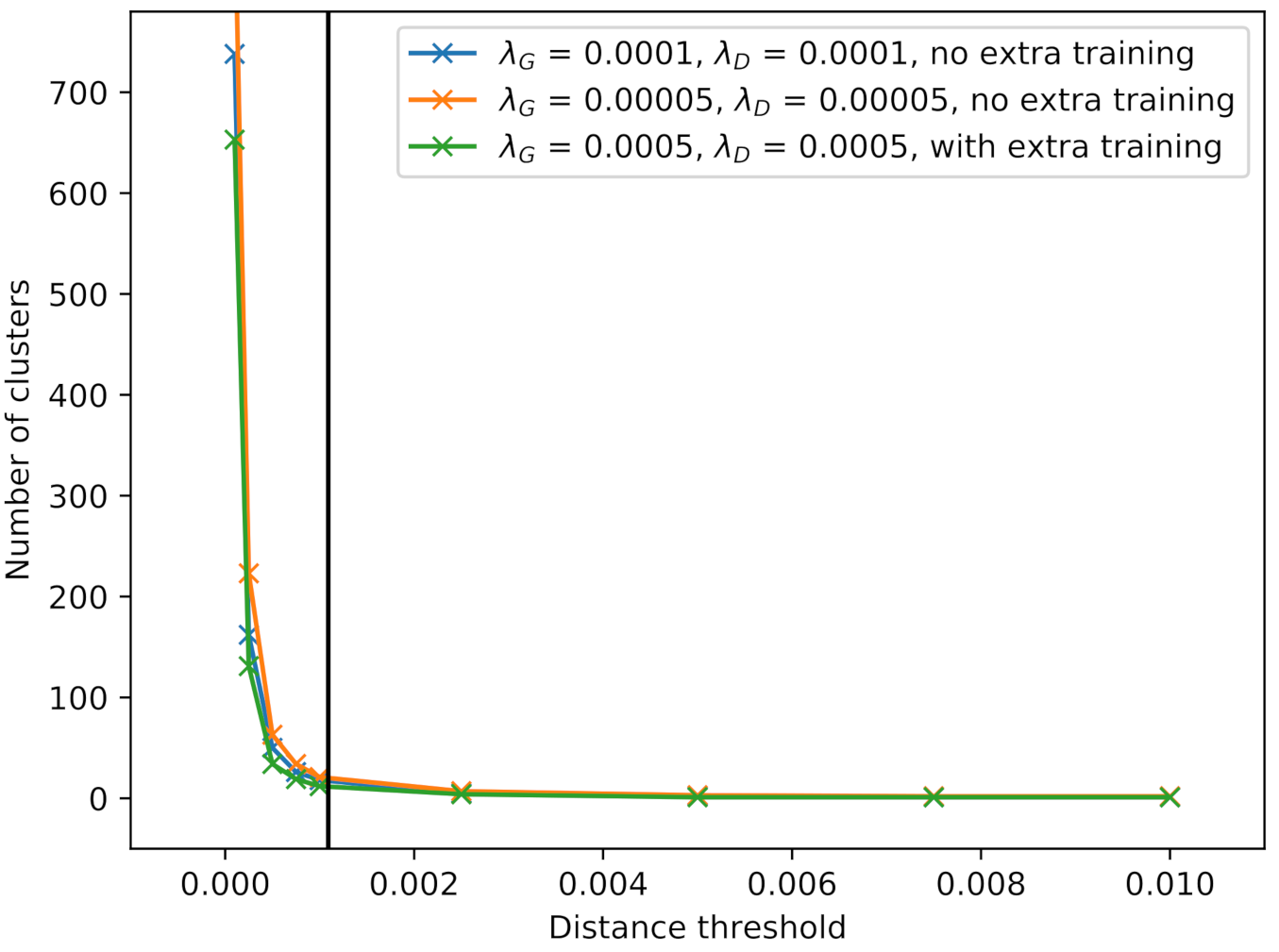
To measure the variability in the generated images, 1000 snippets are generated and clustered by use of the pixel-wise Euclidean distance
between two
images
and
, where, for the generated snippets,
. This distance measure is sensitive to translation, i.e., if the same tire was generated by the TransfGAN but placed at different locations inside the snippet, the distance would be large. Since translation can be seen as a type of additional augmentation, it should not harm the variability measure. The pixel-wise Euclidean distance is calculated between all pairs of the 1000 images. Starting with the first image, all other images with a distance smaller than a certain threshold form a cluster to this image. The next not-already-clustered image is then taken as the starting point for the next cluster. Finally, the number of clusters can be seen as the number of different images generated by the TransfGAN, or, in other words, as a measure for image variability. All three TransfGANs from the classification experiment are analyzed in this way.
Figure 16 displays the number of clusters for different thresholds. The black line indicates the mean distance between all images as a reference. If the distance threshold for calculating the clusters is set too high, it can be observed that the resulting images, which serve as the center of each cluster, still look very similar. From this observation, the threshold can be set to 0.001 in order to give a reasonable number of different images. For this threshold, the number of clusters is 12, 18 and 21, respectively. When generating the 18 snippets for the augmentation dataset, the probability of generating a very similar image multiple times is high, which may explain the only slight increase in classification performance.
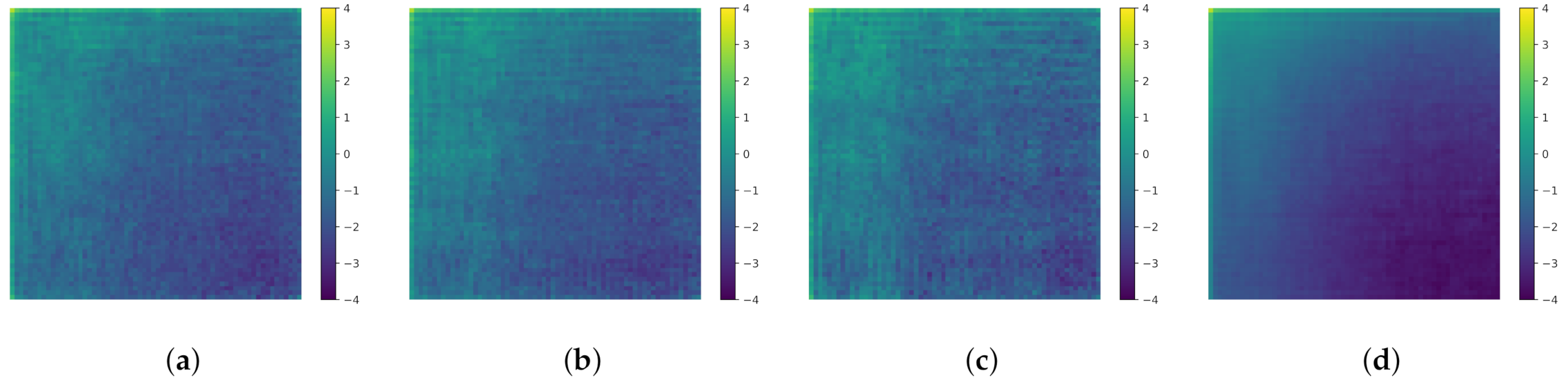
Finally, the generated images are analyzed in the frequency domain. The work of [
23] has shown that images generated by a GAN often contain artifacts in the frequency domain which make these images easy to detect as fake when they are processed in the frequency domain. The images from the previous experiment are transformed using the 2D discrete cosine transformation, as is done in [
23]. The mean spectra over the 1000 images for the three TransfGANs are displayed in
Figure 17 together with the mean spectrum for the real tire images. The upper left corner of the images indicates the low-frequency components and the lower right corner the high-frequency components, respectively. The spectra are displayed in a logarithmic scaling.
All three spectra of the generated images look more noisy compared to the one of the real sidescan snippets, but do not show the artifacts described in [
23]. The authors of [
23] argue that the artifacts arise due to the upsampling methods used in the generator of the GANs which they have studied. They focus on GANs which were trained on the celebA and LSUN bedrooms datasets, containing images with more details compared to sidescan snippets. Moreover, the resolution of the images is
larger than the one of the sidescan snippets with
, which results in one fewer upsampling operation. Consequently, the effect from the upsampling on the spectra is smaller.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
