
Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey


Abstract
:1. Introduction
- (1)
- The visual sensor on a vessel monitors a wide area. The target vessel is usually far away from the monitor and thus accounts for only a small proportion of the entire image. It is considered to be a dim and small target at sea. On a relative scale, the product of target width and height is less than one-tenth of the entire image; on an absolute scale, the target size is less than 32 × 32 pixels [4].
- (2)
- Poor light, undulating waves, interference due to sea surface refraction, and wake caused by ship motion, among other factors, cause large changes in the image background.
- (3)
- Given the irregular jitter as well as the sway and the heave of the hull, the onboard surveillance video inevitably shows high frequency jitter and low frequency field-of-view (FoV) shifts.
- (4)
- Image definition and contrast in poor visibility due to events such as sea-surface moisture and dense fog are inadequate for effective target detection and feature extraction.
2. Research Progress of Vision-Based Situational Awareness
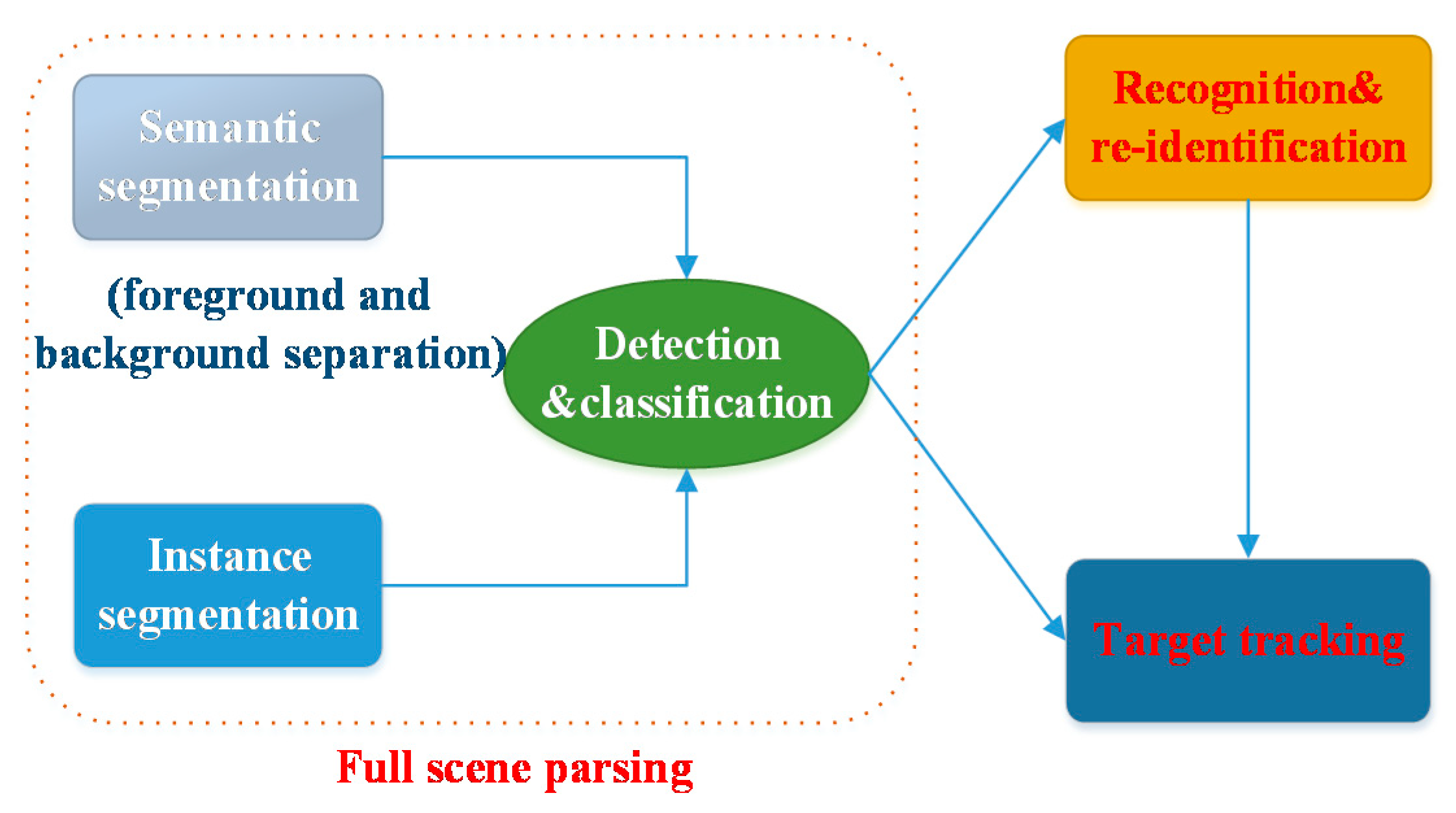
2.1. Ship Target Detection
2.1.1. Target Detection
2.1.2. Image Segmentation
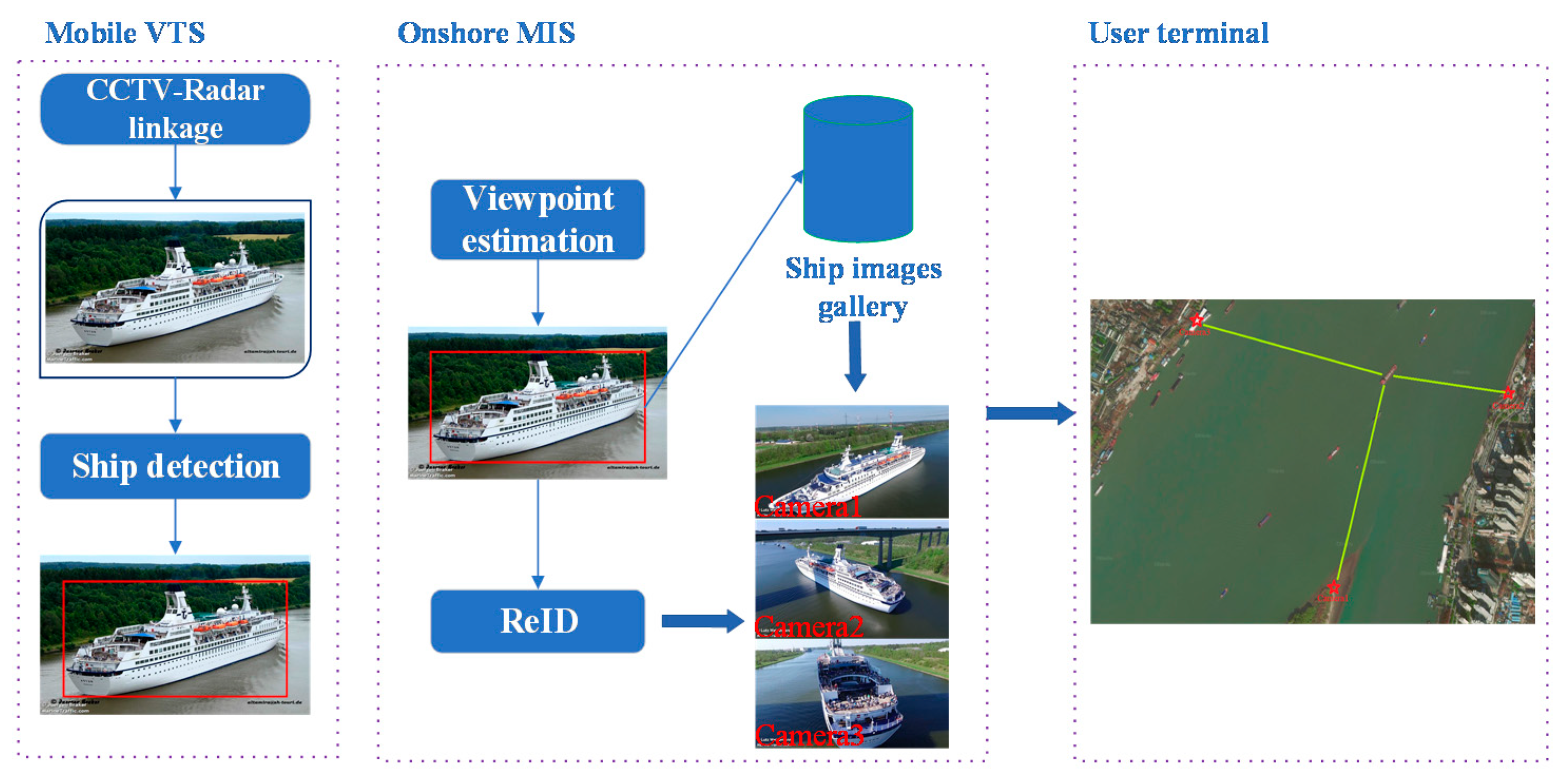
2.2. Ship Recognition and Re-Identification
2.3. Ship Target Tracking
3. Multimodal Awareness with the Participation of Visual Sensors
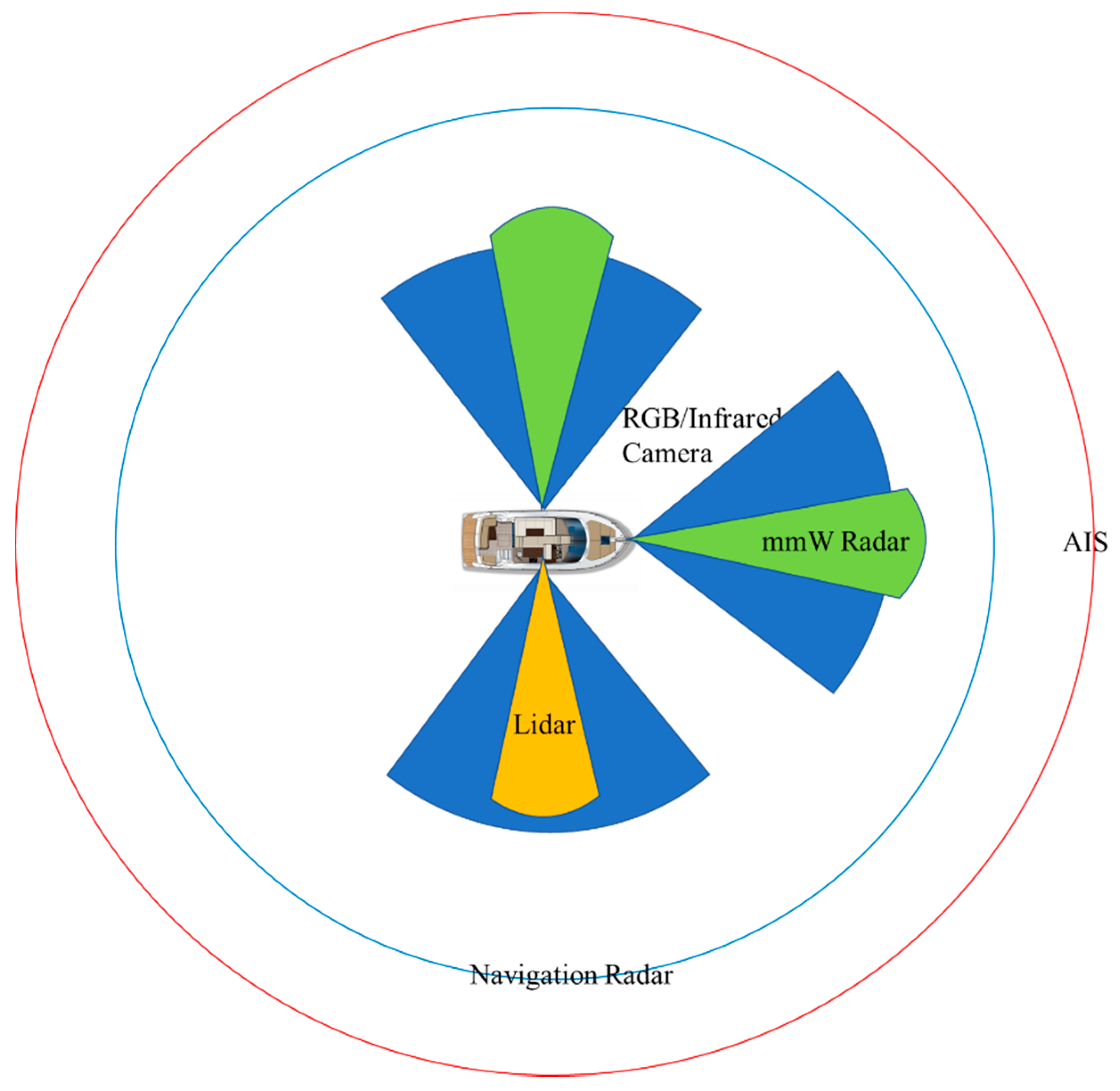
3.1. Multimodal Sensors in the Marine Environment
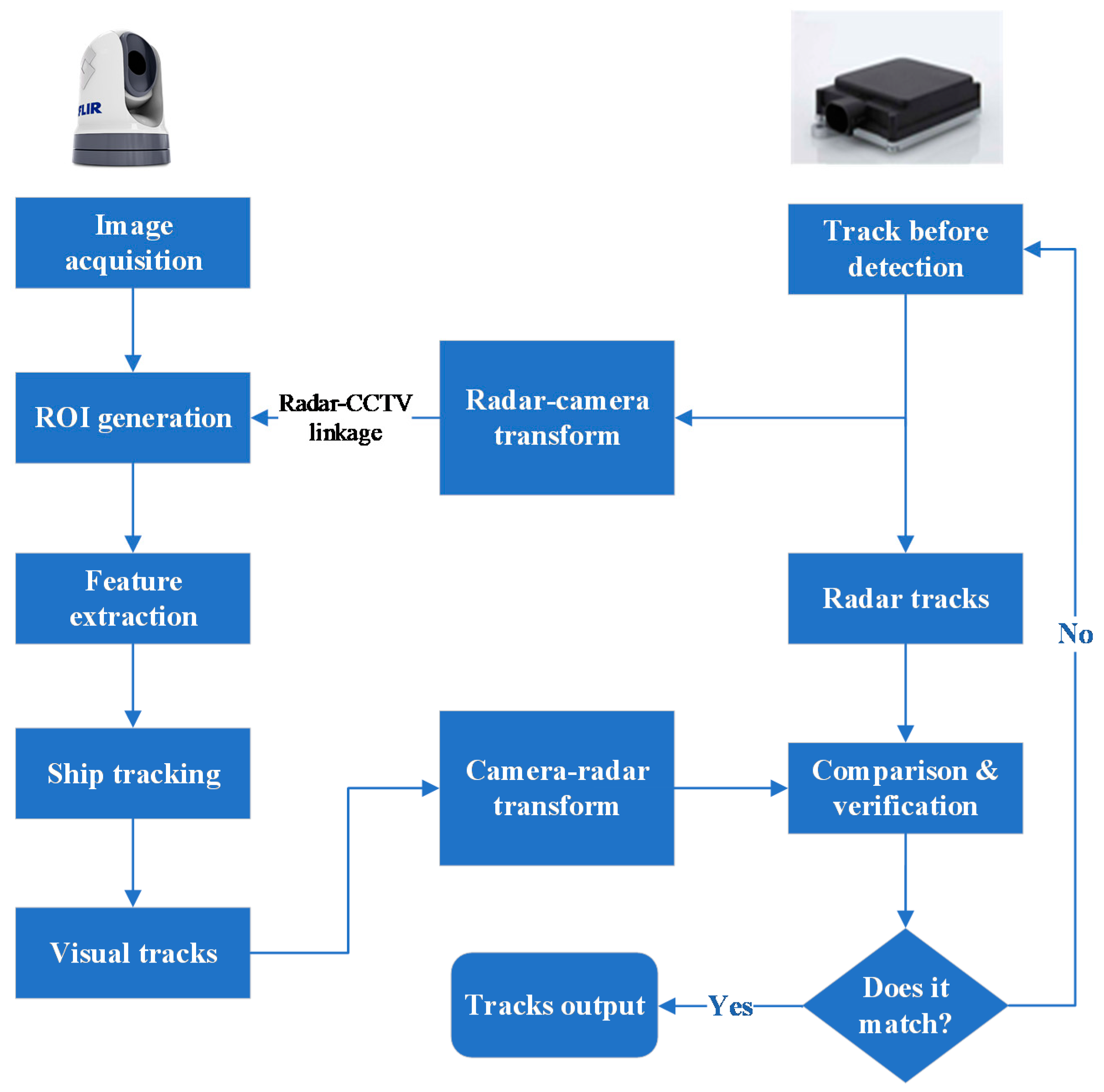
3.2. Multimodal Information Fusion
4. Visual Perception Dataset on Water Surface
4.1. Visual Dataset on the Sea
4.2. Visual Datasets for Inland Rivers
5. Conclusions and Future Work
- (1)
- Multi-task fusion. Semantic segmentation and instance segmentation must be combined architecturally and at the task level. Prediction of the semantic label and instance ID of each pixel in an image is required for full coverage of all objects in a marine scene to correctly divide the scene into uncountable stuff (sea surface, sky, island) and countable things (target vessels, buoys, other obstacles).The combination of object segmentation in fine-grained video with object tracking requires the introduction of semantic mask information into the tracking process. This will require detailed investigation of scene segmentation, combining target detection and tracking using existing tracking-by-detection and joint detection and tracking paradigms, but that is necessary to improve perception of target motion at a fine-grained level.
- (2)
- Multi-modal fusion. Data provided by the monocular vision technology summarized in this paper can be fused with other modal data, such as the point cloud data provided by a binocular camera or a lidar sensor, to provide more comprehensive data for the detection and the tracking of vessels and objects in three-dimensional space. This will significantly increase the perception capability of ASV navigational systems. The pre-fusion of multimodal data in full-scene marine parsing, vessel re-identification, and tracking (i.e., fusing data before other activities occur) will allow us to make full use of the richer original data from each sensor, such as edge and texture features of images from monocular vision sensors or echo amplitude, angular direction, target size, and shape of X-band navigation radar. We will thus be able to incorporate data from radar sensors into image features and then fuse them with visual data at the lowest level to increase the accuracy of MSA.
- (3)
- The fusion of DL-based awareness algorithms and traditional ones. Traditional awareness algorithms have the advantages of strong interpretability and high reliability. Combining them with the deep learning paradigm summarized in this paper, a unified perception framework with the advantages of both paradigms will be obtained, which can further enhance the ability of marine situation awareness.
- (4)
- Domain adaptation learning. Draw lessons from the development experience of unmanned vehicles and UAVs to build a ship–shore collaborative situational awareness system. In particular, it is necessary to start with the improvement of self-learning ability and introduce reinforcement learning to design a model that can acquire new knowledge from sea scenes.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fields, C. Safety and Shipping 1912–2012: From Titanic to Costa Concordia; Allianz Global Corporate and Speciality AG: Munich, Germany, 2012; Available online: http://www.agcs.allianz.com/content/dam/onemarketing/agcs/agcs/reports/AGCS-Safety-Shipping-Review-2012.pdf (accessed on 20 March 2021).
- Brcko, T.; Androjna, A.; Srše, J.; Boć, R. Vessel multi-parametric collision avoidance decision model: Fuzzy approach. J. Mar. Sci. Eng. 2021, 9, 49. [Google Scholar] [CrossRef]
- Prasad, D.K.; Prasath, C.K.; Rajan, D.; Rachmawati, L.; Rajabaly, E.; Quek, C. Challenges in video based object detection in maritime scenario using computer vision. arXiv 2016, arXiv:1608.01079. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for small object detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Trichler, D.G. Are you missing the boat in training aids. Film AV Comm. 1967, 1, 14–16. [Google Scholar]
- Soloviev, V.; Farahnakian, F.; Zelioli, L.; Iancu, B.; Lilius, J.; Heikkonen, J. Comparing CNN-Based Object Detectors on Two Novel Maritime Datasets. In Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Marques, T.P.; Albu, A.B.; O’Hara, P.D.; Sogas, N.S.; Ben, M.; Mcwhinnie, L.H.; Canessa, R. Size-invariant Detection of Marine Vessels From Visual Time Series. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 5–9 January 2021; pp. 443–453. [Google Scholar]
- Moosbauer, S.; Konig, D.; Jakel, J.; Teutsch, M. A benchmark for deep learning based object detection in maritime environments. In Proceedings of the IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit. Work (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 916–925. [Google Scholar]
- Shao, Z.; Wu, W.; Wang, Z.; Du, W.; Li, C. SeaShips: A Large-Scale Precisely Annotated Dataset for Ship Detection. IEEE Trans. Multimed. 2018, 20, 2593–2604. [Google Scholar] [CrossRef]
- Betti, A.; Michelozzi, B.; Bracci, A.; Masini, A. Real-Time target detection in maritime scenarios based on YOLOv3 model. arXiv 2020, arXiv:2003.00800. [Google Scholar]
- Nalamati, M.; Sharma, N.; Saqib, M.; Blumenstein, M. Automated Monitoring in Maritime Video Surveillance System. In Proceedings of the 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020; pp. 1–6. [Google Scholar]
- Spraul, R.; Sommer, L.; Arne, S. A comprehensive analysis of modern object detection methods for maritime vessel detection.Artificial Intelligence and Machine Learning in Defense Applications II. Int. Soc. Opt. Photonics 2020, 1154305. [Google Scholar] [CrossRef]
- Bosquet, B.; Mucientes, M.; Brea, V.M. STDnet: Exploiting high resolution feature maps for small object detection. Eng. Appl. Artif. Intell. 2020, 91, 1–16. [Google Scholar] [CrossRef]
- Shao, Z.; Wang, L.; Wang, Z.; Du, W.; Wu, W. Saliency-Aware Convolution Neural Network for Ship Detection in Surveillance Video. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 781–794. [Google Scholar] [CrossRef]
- Kim, Y.M.; Lee, J.; Yoon, I.; Han, T.; Kim, C. CCTV Object Detection with Background Subtraction and Convolutional Neural Network. KIISE Trans. Comput. Pract. 2018, 24, 151–156. [Google Scholar] [CrossRef]
- Debaque, B.; Florea, M.C.; Duclos-Hindie, N.; Boury-Brisset, A.C. Evidential Reasoning for Ship Classification: Fusion of Deep Learning Classifiers. In Proceedings of the 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–8. [Google Scholar]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A Deep Fully Convolutional Network for Pixel-Level Sea-Land Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Fefilatyev, S.; Goldgof, D.; Shreve, M.; Lembke, C. Detection and tracking of ships in open sea with rapidly moving buoy-mounted camera system. Ocean Eng. 2012, 54, 1–12. [Google Scholar] [CrossRef]
- Jeong, C.Y.; Yang, H.S.; Moon, K.D. Fast horizon detection in maritime images using region-of-interest. Int. J. Distrib. Sens. Netw. 2018, 14, 14. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Sun, Y.; Fu, L. Coarse-fine-stitched: A robust maritime horizon line detection method for unmanned surface vehicle applications. Sensors 2018, 18, 2825. [Google Scholar] [CrossRef] [Green Version]
- Steccanella, L.; Bloisi, D.D.; Castellini, A.; Farinelli, A. Waterline and obstacle detection in images from low-cost autonomous boats for environmental monitoring. Rob. Auton. Syst. 2020, 124, 103346. [Google Scholar] [CrossRef]
- Shan, Y.; Zhou, X.; Liu, S.; Zhang, Y.; Huang, K. SiamFPN: A Deep Learning Method for Accurate and Real-Time Maritime Ship Tracking. IEEE Trans. Circuits Syst. Video Technol. 2020, 31, 315–325. [Google Scholar] [CrossRef]
- Su, L.; Sun, Y.-X.; Liu, Z.-L.; Meng, H. Research on Panoramic Sea-sky line Extraction Algorithm. DEStech Trans. Eng. Technol. Res. 2020, 104–109. [Google Scholar] [CrossRef]
- Gladstone, R.; Moshe, Y.; Barel, A.; Shenhav, E. Distance estimation for marine vehicles using a monocular video camera. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 2405–2409. [Google Scholar]
- Bovcon, B.; Perš, J.; Kristan, M. Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation. Rob. Auton. Syst. 2018, 104, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Bovcon, B.; Muhovic, J.; Pers, J.; Kristan, M. The MaSTr1325 dataset for training deep USV obstacle detection models. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019; pp. 3431–3438. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition (CVPR), Honolulu, Hawaii, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Bovcon, B.; Kristan, M. A water-obstacle separation and refinement network for unmanned surface vehicles. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–30 June 2020; pp. 9470–9476. [Google Scholar]
- Cane, T.; Ferryman, J. Evaluating deep semantic segmentation networks for object detection in maritime surveillance. In Proceedings of the AVSS 2018—15th IEEE International Conference Advanced Video Signal-Based Surveillance, Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing From Electro-Optical Sensors for Object Detection and Tracking in a Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef] [Green Version]
- Patino, L.; Nawaz, T.; Cane, T.; Ferryman, J. Pets 2016: Dataset and Challenge. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Las Vegas, NV, USA, 1–26 June 2016; pp. 1–8. [Google Scholar]
- Ribeiro, R.; Cruz, G.; Matos, J.; Bernardino, A. A Data Set for Airborne Maritime Surveillance Environments. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2720–2732. [Google Scholar] [CrossRef]
- Zhang, W.; He, X.; Li, W.; Zhang, Z.; Luo, Y.; Su, L.; Wang, P. An integrated ship segmentation method based on discriminator and extractor. Image Vis. Comput. 2020, 93, 103824. [Google Scholar] [CrossRef]
- Jeong, C.Y.; Yang, H.S.; Moon, K.D. Horizon detection in maritime images using scene parsing network. Electron. Lett. 2018, 54, 760–762. [Google Scholar] [CrossRef]
- Qiu, Y.; Yang, Y.; Lin, Z.; Chen, P.; Luo, Y.; Huang, W. Improved denoising autoencoder for maritime image denoising and semantic segmentation of USV. China Commun. 2020, 17, 46–57. [Google Scholar] [CrossRef]
- Kim, H.; Koo, J.; Kim, D.; Park, B.; Jo, Y.; Myung, H.; Lee, D. Vision-Based Real-Time Obstacle Segmentation Algorithm for Autonomous Surface Vehicle. IEEE Access 2019, 7, 179420–179428. [Google Scholar] [CrossRef]
- Liu, Z.; Waqas, M.; Jie, Y.; Rashid, A.; Han, Z. A Multi-task CNN for Maritime Target Detection. IEEE Signal Process. Lett. 2021, 28, 434–438. [Google Scholar] [CrossRef]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 9404–9413. [Google Scholar]
- Huang, Z.; Sun, S.; Li, R. Fast Single-shot Ship Instance Segmentation Based on Polar Template Mask in Remote Sensing Images. arXiv 2020, arXiv:2008.12447. [Google Scholar]
- Nie, X.; Duan, M.; Ding, H.; Hu, B.; Wong, E.K. Attention Mask R-CNN for ship detection and segmentation from remote sensing images. IEEE Access 2020, 8, 9325–9334. [Google Scholar] [CrossRef]
- van Ramshorst, A. Automatic Segmentation of Ships in Digital Images: A Deep Learning Approach. 2018. Available online: https://repository.tudelft.nl/islandora/object/uuid:55de4322-8552-4a2c-84d0-427b2891015b (accessed on 20 March 2021).
- Nita, C.; Vandewal, M. CNN-based object detection and segmentation for maritime domain awareness[C]//Artificial Intelligence and Machine Learning in Defense Applications II. Int. Soc. Opt. Photonics 2020, 11543, 1154306. [Google Scholar]
- Ghahremani, A.; Kong, Y.; Bondarev, E.; de With, P.H.N. Towards parameter-optimized vessel re-identification based on IORnet. In Proceedings of the International Conference on Computational Science, Faro, Portugal, 12–14 June 2019; pp. 125–136. [Google Scholar]
- Ghahremani, A.; Kong, Y.; Bondarev, E.; De With, P.H.N. Re-identification of vessels with convolutional neural networks. In Proceedings of the 2019 5th International Conference on Computer and Technology Applications (ICCTA), Turkey, Istanbul, 16–17 April 2019; pp. 93–97. [Google Scholar]
- Qiao, D.; Liu, G.; Dong, F.; Jiang, S.X.; Dai, L. Marine Vessel Re-Identification: A Large-Scale Dataset and Global-and-Local Fusion-Based Discriminative Feature Learning. IEEE Access 2020, 8, 27744–27756. [Google Scholar] [CrossRef]
- Qiao, D.; Liu, G.; Zhang, J.; Zhang, Q.; Wu, G.; Dong, F. M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV. Electronics 2019, 8, 723. [Google Scholar] [CrossRef] [Green Version]
- Wang, N.; Wang, Y.; Er, M.J. Review on deep learning techniques for marine object recognition: Architectures and algorithms. Control Eng. Pract. 2020, 104458. [Google Scholar] [CrossRef]
- Cao, X.; Gao, S.; Chen, L.; Wang, Y. Ship recognition method combined with image segmentation and deep learning feature extraction in video surveillance. Multimed. Tools Appl. 2020, 79, 9177–9192. [Google Scholar] [CrossRef]
- Ren, Y.; Yang, J.; Zhang, Q.; Guo, Z. Ship recognition based on Hu invariant moments and convolutional neural network for video surveillance. Multimed. Tools Appl. 2021, 80, 1343–1373. [Google Scholar] [CrossRef]
- Spagnolo, P.; Filieri, F.; Distante, C.; Mazzeo, P.L.; D’Ambrosio, P. A new annotated dataset for boat detection and re-identification. In Proceedings of the 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Taipei, Taiwan, 18–21 September 2019; pp. 1–7. [Google Scholar]
- Heyse, D.; Warren, N.; Tesic, J. Identifying maritime vessels at multiple levels of descriptions using deep features. Proc. SPIE 11006 Artif. Intell. Mach. Learn. Multi-Domain Oper. Appl. 2019, 1100616. [Google Scholar] [CrossRef]
- Groot, H.G.J.; Zwemer, M.H.; Wijnhoven, R.G.J.; Bondarev, Y.; de With, P.H.N. Vessel-speed enforcement system by multi-camera detection and re-identification. In Proceedings of the 15th International Conference on Computer Vision Theory and Applications (VISAPP), Valletta, Malta, 30 November–4 December 2020; pp. 268–277. [Google Scholar]
- Kaido, N.; Yamamoto, S.; Hashimoto, T. Examination of automatic detection and tracking of ships on camera image in marine environment. In Proceedings of the 2016 Techno-Ocean (Techno-Ocean), Kobe, Japan, 6–8 October 2016; pp. 58–63. [Google Scholar]
- Zhang, Z.; Wong, K.H. A computer vision based sea search method using Kalman filter and CAMSHIFT. In Proceedings of the 2013 Int. Conf. Technol. Adv. Electr. Electron. Comput. Eng (TAEECE), Konya, Turkey, 9–11 May 2013; pp. 188–193. [Google Scholar]
- Chen, Z.; Li, B.; Tian, L.F.; Chao, D. Automatic detection and tracking of ship based on mean shift in corrected video sequence. In Proceedings of the 2nd International Conference on Image, Vision and Computing (ICIVC), Chengdu, China, 2–4 June 2017; pp. 449–453. [Google Scholar]
- Zhang, Y.; Li, S.; Li, D.; Zhou, W.; Yang, Y.; Lin, X.; Jiang, S. Parallel three-branch correlation filters for complex marine environmental object tracking based on a confidence mechanism. Sensors 2020, 20, 5210. [Google Scholar] [CrossRef]
- Zhang, S.Y.; Shu, S.J.; Hu, S.L.; Zhou, S.Q.; Du, S.Z. A ship target tracking algorithm based on deep learning and multiple features. Twelfth International Conference on Machine Vision (ICMV 2019). Int. Soc. Opt. Photonics 2020, 11433, 1143304. [Google Scholar]
- Yang, J.; Li, Y.; Zhang, Q.; Ren, Y. Surface Vehicle Detection and Tracking with Deep Learning and Appearance Feature. In Proceedings of the 5th International Conference on Control, Automation and Robotics (ICCAR), Beijing, China, 19–22 April 2019; pp. 276–280. [Google Scholar]
- Leclerc, M.; Tharmarasa, R.; Florea, M.C.; Boury-Brisset, A.C.; Kirubarajan, T.; Duclos-Hindié, N. Ship Classification Using Deep Learning Techniques for Maritime Target Tracking. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 737–744. [Google Scholar]
- Schöller, F.E.T.; Blanke, M.; Plenge-Feidenhans’l, M.K.; Nalpantidis, L. Vision-based Object Tracking in Marine Environments using Features from Neural Network Detections, IFAC-PapersOnLine. 2021. Available online: https://backend.orbit.dtu.dk/ws/portalfiles/portal/219717632/IFAC20_home_papercept_ifac.papercept.net_www_conferences_conferences_IFAC20_submissions_3234_FI.pdf (accessed on 20 March 2021).
- Chen, J.; Hu, Q.; Zhao, R.; Guojun, P.; Yang, C. Tracking a vessel by combining video and AIS reports. In Proceedings of the 2008 2nd International Conference Future Genereration Communication Networking (FGCN), Hainan Island, China, 13–15 December 2008; pp. 374–378. [Google Scholar]
- Thompson, D. Maritime Object Detection, Tracking, and Classification Using Lidar and Vision-Based Sensor Fusion. Master’s Thesis, Embry-Riddle Aeronautical University, Daytona Beach, FL, USA, 2017. Available online: https://commons.erau.edu/edt/377 (accessed on 20 March 2021).
- Helgesen, Ø.K.; Brekke, E.F.; Helgesen, H.H.; Engelhardtsen, O. Sensor Combinations in Heterogeneous Multi-sensor Fusion for Maritime Target Tracking. In Proceedings of the 2019 22th International Conference on Information Fusion (FUSION), Ottawa, ON, Canada, 2–5 July 2019; pp. 1–9. [Google Scholar]
- Haghbayan, M.H.; Farahnakian, F.; Poikonen, J.; Laurinen, M.; Nevalainen, P.; Plosila, J.; Heikkonen, J. An Efficient Multi-sensor Fusion Approach for Object Detection in Maritime Environments. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2163–2170. [Google Scholar]
- Farahnakian, F.; Movahedi, P.; Poikonen, J.; Lehtonen, E.; Makris, D.; Heikkonen, J. Comparative analysis of image fusion methods in marine environment. In Proceedings of the IEEE International Symposium on Robotic and Sensors Environments (ROSE), Ottawa, ON, Canada, 17–18 June 2019; pp. 535–541. [Google Scholar]
- Stanislas, L.; Dunbabin, M. Multimodal Sensor Fusion for Robust Obstacle Detection and Classification in the Maritime RobotX Challenge. IEEE J. Ocean. Eng. 2018, 44, 343–351. [Google Scholar] [CrossRef] [Green Version]
- Farahnakian, F.; Heikkonen, J. Deep learning based multi-modal fusion architectures for maritime vessel detection. Remote Sens. 2020, 12, 2509. [Google Scholar] [CrossRef]
- Farahnakian, F.; Haghbayan, M.H.; Poikonen, J.; Laurinen, M.; Nevalainen, P.; Heikkonen, J. Object Detection Based on Multi-sensor Proposal Fusion in Maritime Environment. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 971–976. [Google Scholar]
- Cho, H.J.; Jeong, S.K.; Ji, D.H.; Tran, N.H.; Vu, M.T.; Choi, H.S. Study on control system of integrated unmanned surface vehicle and underwater vehicle. Sensors 2020, 20, 2633. [Google Scholar] [CrossRef] [PubMed]
- Stateczny, A.; Błaszczak-Bak, W.; Sobieraj-Złobińska, A.; Motyl, W.; Wisniewska, M. Methodology for processing of 3D multibeam sonar big data for comparative navigation. Remote Sens. 2019, 11, 2245. [Google Scholar] [CrossRef] [Green Version]
- Remmas, W.; Chemori, A.; Kruusmaa, M. Diver tracking in open waters: A low-cost approach based on visual and acoustic sensor fusion. J. F. Robot. 2020. [Google Scholar] [CrossRef]
- Bloisi, D.D.; Previtali, F.; Pennisi, A.; Nardi, D.; Fiorini, M.; Member, S. Enhancing automatic maritime surveillance systems with visual information. IEEE Trans. Intell. Transp. Syst. 2016, 18, 824–833. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-Road Vehicle Detection and Tracking Using MMW Radar and Monovision Fusion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2075–2084. [Google Scholar] [CrossRef]
- Gundogdu, E.; Solmaz, B.; Yücesoy, V.; Koc, A. Marvel: A large-scale image dataset for maritime vessels. In Proceedings of the Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016; pp. 165–180. [Google Scholar]
- Bloisi, D.D.; Iocchi, L.; Pennisi, A.; Tombolini, L. ARGOS-Venice boat classification. In Proceedings of the 2015 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Zhang, M.M.; Choi, J.; Daniilidis, K.; Wolf, M.T.; Kanan, C. VAIS: A dataset for recognizing maritime imagery in the visible and infrared spectrums. In Proceedings of the IEEE Computer Society Conference Computer Vision Pattern Recognition Work (CVPRW), Boston, MA, USA, 7–12 June 2015; pp. 10–16. [Google Scholar]
- Teng, F.; Liu, Q. Visual Tracking Algorithm for Inland Waterway Ships; Wuhan University of Technology Press: Wuhan, China, 2017; pp. 18–24. [Google Scholar]
- Liu, Q.; Mei, L.Q.; Lu, P.P. Visual Detection Algorithm for Inland Waterway Ships; Wuhan University of Technology Press: Wuhan, China, 2019; pp. 98–102. [Google Scholar]
- Shin, H.C.; Lee, K.I.L.; Lee, C.E. Data augmentation method of object detection for deep learning in maritime image. In Proceedings of the 2020 IEEE International Conference Big Data Smart Computers (BigComp), Pusan, Korea, 19–22 February 2020; pp. 463–466. [Google Scholar]
- Chen, Z.; Chen, D.; Zhang, Y.; Cheng, X.; Zhang, M.; Wu, C. Deep learning for autonomous ship-oriented small ship detection. Saf. Sci. 2020, 130, 104812. [Google Scholar] [CrossRef]
- Milicevic, M.; Zubrinic, K.; Obradovic, I.; Sjekavica, T. Data augmentation and transfer learning for limited dataset ship classification. WSEAS Trans. Syst. Control 2018, 13, 460–465. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Anchor-Free or Not | Backbone | Dataset | Performance |
|---|---|---|---|---|
| Mask R-CNN [9] | no | ResNet-101 | SMD | F-score: 0.875 |
| Mask R-CNN [12] | no | ResNet-101 | MarDCT | AP(IoU = 0.5): 0.964 |
| Mask R-CNN [12] | no | ResNet-101 | IPATCH | AP(IoU = 0.5): 0.925 |
| RetinaNet [13] | no | ResNet-50 | MSCOCO + SMD | AP(IoU = 0.3): 0.880 |
| Faster R-CNN [10] | no | ResNet-101 | Seaships | AP(IoU = 0.5): 0.924 |
| SSD 512 [10] | no | VGG16 | Seaships | AP(IoU = 0.5): 0.867 |
| CenterNet [12] | yes | Hourglass | SMD + Seaships | AP(IoU = 0.5): 0.893 |
| EfficientDet [12] | no | EfficientDet-D3 | SMD + Seaships | AP(IoU = 0.5): 0.981 |
| FCOS [13] | yes | ResNeXt-101 | Seaships + private | AP: 0.845 |
| Cascade R-CNN [13] | no | ResNet-101 | Seaships + private | AP: 0.846 |
| YOLOv3 [11] | no | Darknet-53 | private | AP(IoU = 0.5): 0.960 (specific ship) |
| Sensor | Frequency Range | Work Mode | Advantage | Disadvantage |
|---|---|---|---|---|
| RGB camera | visible light (380–780 nm) | passive | low cost rich appearance high spatial resolution | small coverage sensitive to light and weather lack of depth |
| infrared camera | far infrared (9–14 μm) | passive | strong penetrating power not affected by light and weather | low imaging resolution weak contrast |
| navigation radar | X-band (8–12 GHz), S-band (2–4 GHz) | active | independent perception robust for bad weather long distance | low precision low data rate high electromagnetic radiation have blind area |
| millimeter wave radar | millimeter wave (30–300 GHz) | active | wide frequency band high angular resolution high data rate | short detection range have blind area |
| automated identification systems (AIS) | very high frequency (161.975 or 162.025 MHz) | passive | robust for bad weather long distance wide coverage | low data rate only identify ships need to report actively |
| Lidar | Laser (905 nm or 1550 nm) | active | 3D perception high spatial resolution good electromagnetic resistance | sensitive to weather high cost |
| Datasets | Shooting Angle | Usage Scenarios | Resolution (Pixels) | Scale | Open Access |
|---|---|---|---|---|---|
| MARVEL [78] | onshore, onboard | classification | 512 × 512, etc. | >140k images | yes |
| MODD [27] | onboard | detection and segmentation | 640 × 480 | 12 videos, 4454 frames | yes |
| SMD [34] | onshore, onboard | detection and tracking | 1920 × 1080 | 36 videos, >17k frames | yes |
| IPATCH [35] | onboard | detection and tracking | 1920 × 1080 | 113 videos | no |
| SEAGULL [36] | drone-borne | detection, tracking, and pollution detection | 1920 × 1080 | 19 videos, >150k frames | yes |
| MarDCT [79] | onshore, overlook | detection, classification, and tracking | 704 × 576, etc. | 28 videos | yes |
| SeaShips [10] | onshore | detection | 1920 × 1080 | >31k frames | partial |
| MaSTr1325 [28] | onboard | detection and segmentation | 512 × 384, 1278 × 958 | 1325 frames | yes |
| VesselReID [47] | onboard | re-identification | 1920 × 1080 | 4616 frames, 733 ships | no |
| VesselID-539 [49] | onshore, onboard | re-identification | 1920 × 1080 | >149k frames, 539 ships | no |
| Boat ReID [54] | overlook | detection and re-identification | 1920 × 1080 | 5523 frames, 107 ships | yes |
| VAIS [80] | onshore | multimodal fusion | vary in size | 1623 visible light, 1242 infrared images | yes |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, D.; Liu, G.; Lv, T.; Li, W.; Zhang, J. Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey. J. Mar. Sci. Eng. 2021, 9, 397. https://doi.org/10.3390/jmse9040397
Qiao D, Liu G, Lv T, Li W, Zhang J. Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey. Journal of Marine Science and Engineering. 2021; 9(4):397. https://doi.org/10.3390/jmse9040397
Chicago/Turabian StyleQiao, Dalei, Guangzhong Liu, Taizhi Lv, Wei Li, and Juan Zhang. 2021. "Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey" Journal of Marine Science and Engineering 9, no. 4: 397. https://doi.org/10.3390/jmse9040397
APA StyleQiao, D., Liu, G., Lv, T., Li, W., & Zhang, J. (2021). Marine Vision-Based Situational Awareness Using Discriminative Deep Learning: A Survey. Journal of Marine Science and Engineering, 9(4), 397. https://doi.org/10.3390/jmse9040397