
A Novel Acoustic Sediment Classification Method Based on the K-Mdoids Algorithm Using Multibeam Echosounder Backscatter Intensity



Abstract
:1. Introduction
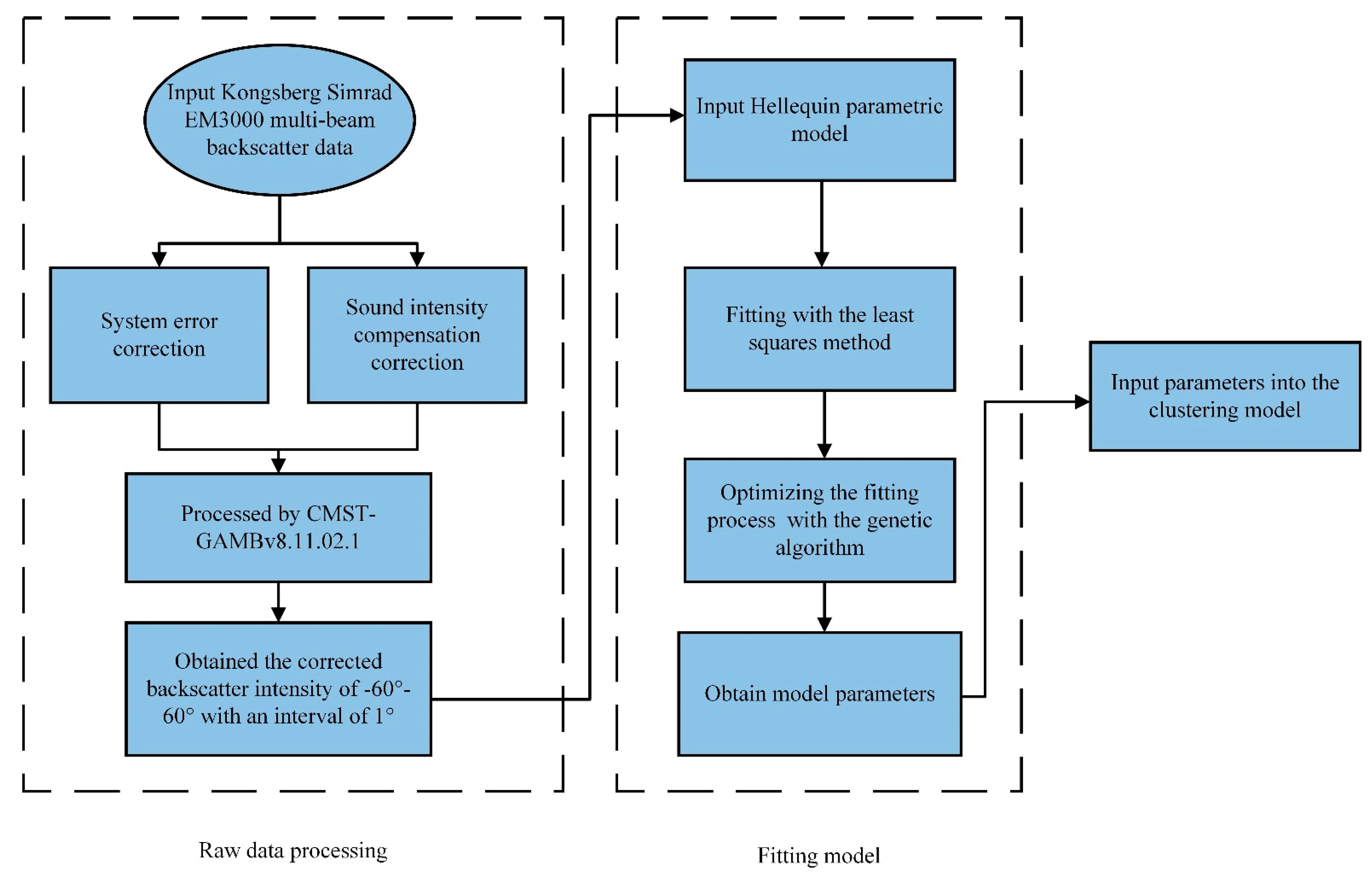
2. Materials and Methods
2.1. Data
2.1.1. MBES Data
2.1.2. The Field Sampling Data
2.2. Lurton Parametric Model
2.3. Least Squares Fitting
2.4. Genetic Algorithm
2.5. K-Medoids
2.6. Self-Organizing Feature Map
2.6.1. Competition
2.6.2. Cooperation
2.6.3. Update
3. Experiments
3.1. Fitting Process
3.2. Fitting Parameters
3.3. Clustering
3.3.1. Training Step Determination
3.3.2. Clustering Experiments
4. Results and Discussion
5. Conclusions and Prospects for Future Research
- (1).
- The K-medoids algorithms can be combined with multibeam backscattering intensity for use in seabed sediment classification. The overall classification accuracy in our experiments reached 89.7%, the classification of bedrock, sandy clay, and silty sand were all above 90%, and the gravel and clay were nearly 80%.
- (2).
- Compared with the SOM clustering algorithm, the K-medoids algorithm has a greater advantage in seabed sediment classification. As the number of categories increases, the classification accuracy continues to improve. When the SOM algorithm can no longer distinguish the obvious sediment boundary, K-medoids is still able to achieve acceptable accuracy.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lanier, A.; Romsos, C.; Goldfinger, C. Seafloor habitat mapping on the Oregon continental margin: A spatially nested GIS approach to mapping scale, mapping methods, and accuracy quantification. Mar. Geod. 2007, 30, 51–76. [Google Scholar] [CrossRef]
- Menandro, P.S.; Bastos, A.C. Seabed Mapping: A Brief History from Meaningful Words. Geosciences 2020, 10, 273. [Google Scholar] [CrossRef]
- Pearman, T.R.R.; Robert, K.; Callaway, A.; Hall, R.; Lo Iacono, C.; Huvenne, V.A.I. Improving the predictive capability of benthic species distribution models by incorporating oceanographic data—Towards holistic ecological modelling of a submarine canyon. Prog. Oceanogr. 2020, 184. [Google Scholar] [CrossRef]
- Schirmer, F. Experimental Determination of Properties of the Scholte Wave in the Bottom of the North Sea. In Proceedings of the Bottom-Interacting Ocean Acoustics: NATO Conference Series 4, La Spezia, Italy, 9–13 June 1980; Kuperman, W.A., Jensen, B., Eds.; pp. 285–298. [Google Scholar]
- Ellingsen, K.E. Soft-sediment benthic biodiversity on the continental shelf in relation to environmental variability. Mar. Ecol. Prog. 2002, 232, 15–27. [Google Scholar] [CrossRef]
- Anderson, J.T.; Van Holliday, D.; Kloser, R.; Reid, D.G.; Simard, Y. Acoustic seabed classification: Current practice and future directions. ICES J. Mar. Sci. 2008, 65, 1004–1011. [Google Scholar] [CrossRef]
- Lincoln, F.; PratsonMargo, H.; Edwards. Introduction to advances in seafloor mapping using sidescan sonar and multibeam bathymetry data. Mar. Geophys. Res. 1996, 18, 601–605. [Google Scholar]
- De, C.; Chakraborty, B. Model-Based Acoustic Remote Sensing of Seafloor Characteristics. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3868–3877. [Google Scholar] [CrossRef]
- Brown, C.J.; Smith, S.J.; Lawton, P.; Anderson, J.T. Benthic habitat mapping: A review of progress towards improved understanding of the spatial ecology of the seafloor using acoustic techniques. Estuar. Coast. Shelf Sci. 2011, 92, 502–520. [Google Scholar] [CrossRef]
- Nafe, J.E.; Drake, C.L. Physical properties of marine sediments. In The Sea; Wiley-Interscience: New York, NY, USA, 1963; pp. 794–814. [Google Scholar]
- Parrott, D.R.; Dodds, D.J.; King, L.H.; Simpkin, P.G. Measurement and evaluation of the acoustic reflectivity of the sea floor. Can. J. Earth Sci. 1980, 17, 722–737. [Google Scholar] [CrossRef]
- Jackson, D.R.; Richardson, M. High-Frequency Seafloor Acoustics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Huvenne, V.A.I.; Blondel, P.; Henriet, J.P. Textural analyses of sidescan sonar imagery from two mound provinces in the Porcupine Seabight. Mar. Geol. 2002, 189, 323–341. [Google Scholar] [CrossRef] [Green Version]
- Tan, Y.; Tan, J.K.; Kim, H.; Ishikawa, S. Automatic Classification of Seabed Sediments Based on HLAC. In Proceedings of the IEEE/SICE International Symposium on System Integration, Kobe, Japan, 15–17 December 2013; pp. 653–658. [Google Scholar]
- Lucieer, V.L. Object-oriented classification of sidescan sonar data for mapping benthic marine habitats. Int. J. Remote Sens. 2008, 29, 905–921. [Google Scholar] [CrossRef]
- Wang, C.-K.; Philpot, W.D. Using airborne bathymetric lidar to detect bottom type variation in shallow waters. Remote Sens. Environ. 2007, 106, 123–135. [Google Scholar] [CrossRef]
- Stevenson, I.R.; McCann, C.; Runciman, P.B. An attenuation-based sediment classification technique using Chirp sub-bottom profiler data and laboratory acoustic analysis. Mar. Geophys. Res. 2002, 23, 277–298. [Google Scholar] [CrossRef]
- Hughes Clarke, J.; Mayer, L.; Wells, D.E. Shallow-water imaging multibeam sonars: A new tool for investigating seafloor processes in the coastal zone and on the continental shelf. Mar. Geophys. Res. 1996, 18, 607–629. [Google Scholar] [CrossRef]
- Kenny, A.J.; Cato, I.; Desprez, M.; Fader, G.; Schuettenhelm, R.T.E.; Side, J. An overview of seabed-mapping technologies in the context of marine habitat classification. ICES J. Mar. Sci. 2003, 60, 411–418. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Siwabessy, J.; Nichol, S.; Anderson, T.; Brooke, B. Predictive mapping of seabed cover types using angular response curves of multibeam backscatter data: Testing different feature analysis approaches. Cont. Shelf Res. 2013, 61–62, 12–22. [Google Scholar] [CrossRef]
- Brown, C.J.; Blondel, P. The application of underwater acoustics to seabed habitat mapping. Appl. Acoust. 2009, 70, 1241. [Google Scholar] [CrossRef]
- Chakraborty, B.; Schenke, H.W.; Kodagali, V.; Hagen, R. Seabottom characterization using multibeam echosounder angular backscatter: An application of the composite roughness theory. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2419–2422. [Google Scholar] [CrossRef]
- De Falco, G.; Tonielli, R.; Di Martino, G.; Innangi, S.; Simeone, S.; Parnum, I.M. Relationships between multibeam backscatter, sediment grain size and Posidonia oceanica seagrass distribution. Cont. Shelf Res. 2010, 30, 1941–1950. [Google Scholar] [CrossRef]
- Sutherland, T.F.; Galloway, J.; Loschiavo, R.; Levings, C.D.; Hare, R. Calibration techniques and sampling resolution requirements for groundtruthing multibeam acoustic backscatter (EM3000) and QTC VIEW (TM) classification technology. Estuar. Coast. Shelf Sci. 2007, 75, 447–458. [Google Scholar] [CrossRef]
- Fawcett, J.A.; Fox, W.L.J.; Maguer, A. Modeling of scattering by objects on the seabed. J. Acoust. Soc. Am. 1998, 104, 3296–3304. [Google Scholar] [CrossRef]
- Holliday, D.V. Theory of sound scattering from the seabed. ICES Coop. Res. Rep. 2007, 286, 7–28. [Google Scholar]
- Collier, J.S.; Brown, C.J. Correlation of sidescan backscatter with grain size distribution of surficial seabed sediments. Mar. Geol. 2005, 214, 431–449. [Google Scholar] [CrossRef]
- Preston, J. Automated acoustic seabed classification of multibeam images of Stanton Banks. Appl. Acoust. 2009, 70, 1277–1287. [Google Scholar] [CrossRef]
- McGonigle, C.; Brown, C.; Quinn, R.; Grabowski, J. Evaluation of image-based multibeam sonar backscatter classification for benthic habitat discrimination and mapping at Stanton Banks, UK. Estuar. Coast. Shelf Sci. 2009, 81, 423–437. [Google Scholar] [CrossRef]
- Rzhanov, Y.; Fonseca, L.; Mayer, L. Construction of seafloor thematic maps from multibeam acoustic backscatter angular response data. Comput. Geosci. 2012, 41, 181–187. [Google Scholar] [CrossRef]
- Lamarche, G.; Lurton, X. Recommendations for improved and coherent acquisition and processing of backscatter data from seafloor-mapping sonars. Mar. Geophys. Res. 2018, 39, 5–22. [Google Scholar] [CrossRef] [Green Version]
- Biot, M.A. Theory of propagation of elastic waves in a fluid-saturated porous solid. I. Low frequency range. II. Higher frequency range. J. Acoust. Soc. Am. 1955, 28, 168–191. [Google Scholar] [CrossRef]
- Biot, M.A. Theory of propagation of elastic waves in a fluid-saturated porous solid: II. Higher frequency range. J. Acoust. Soc. Am. 1956, 28. [Google Scholar] [CrossRef]
- Stoll, R.D. Acoustic Waves in Saturated Sediments; Springer: New York, NY, USA, 1974; pp. 19–39. [Google Scholar]
- Jackson, D.R.; Baird, A.M.; Crisp, J.J.; Thomson, P.A.G. High-frequency bottom backscatter measurements in shallow water. Acoust. Soc. Am. 1986, 80, 1188–1199. [Google Scholar] [CrossRef]
- Hughes Clarke, J. Toward remote seafloor classification using the angular response of acoustic backscattering: A case study from multiple overlapping GLORIA data. IEEE J. Ocean. Eng. 1994, 19, 112–127. [Google Scholar] [CrossRef]
- Landmark, K.; Solberg, A.H.S.; Austeng, A.; Hansen, R.E. Bayesian Seabed Classification Using Angle-Dependent Backscatter Data from Multibeam Echo Sounders. IEEE J. Ocean. Eng. 2014, 39, 724–739. [Google Scholar] [CrossRef]
- Santos, R.; Rodrigues, A.; Quartau, R. Acoustic remote characterization of seabed sediments using the Angular Range Analysis technique: The inlet channel of Tagus River estuary (Portugal). Mar. Geol. 2018, 400, 60–75. [Google Scholar] [CrossRef]
- Alevizos, E.; Greinert, J. The Hyper-Angular Cube Concept for Improving the Spatial and Acoustic Resolution of MBES Backscatter Angular Response Analysis. Geosciences 2018, 8, 446. [Google Scholar] [CrossRef] [Green Version]
- Hellequin, L.; Boucher, J.M.; Lurton, X. Processing of high-frequency multibeam echo sounder data for seafloor characterization. IEEE J. Ocean. Eng. 2003, 28, 78–89. [Google Scholar] [CrossRef] [Green Version]
- Galparsoro, I.; Agrafojo, X.; Roche, M.; Degrendele, K. Comparison of supervised and unsupervised automatic classification methods for sediment types mapping using multibeam echosounder and grab sampling. Ital. J. Geosci. 2015, 134, 41–49. [Google Scholar] [CrossRef] [Green Version]
- Janowski, L.; Madricardo, F.; Fogarin, S.; Kruss, A.; Molinaroli, E.; Kubowicz-Grajewska, A.; Tegowski, J. Spatial and Temporal Changes of Tidal Inlet Using Object-Based Image Analysis of Multibeam Echosounder Measurements: A Case from the Lagoon of Venice, Italy. Remote Sens. 2020, 12, 2117. [Google Scholar] [CrossRef]
- Tegowski, J. Acoustical classification of the bottom sediments in the southern Baltic Sea. Quat. Int. 2005, 130, 153–161. [Google Scholar] [CrossRef]
- Marsh, I.; Brown, C. Neural network classification of multibeam backscatter and bathymetry data from Stanton Bank (Area IV). Appl. Acoust. 2009, 70, 1269–1276. [Google Scholar] [CrossRef]
- Lucieer, V.; Lamarche, G. Unsupervised fuzzy classification and object-based image analysis of multibeam data to map deep water substrates, Cook Strait, New Zealand. Cont. Shelf Res. 2011, 31, 1236–1247. [Google Scholar] [CrossRef]
- Chakraborty, B.; Kaustubha, R.; Hegde, A.; Pereira, A. Acoustic seafloor sediment classification using self-organizing feature maps. IEEE Trans. Geosci. Remote Sens. 2001, 39, 2722–2725. [Google Scholar] [CrossRef]
- Koza, J.R. Genetic Programming: V. 1 On the Programming of Computers by Means of Natural Selection; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Rønhovde, L.A. High-resolution beamforming for multibeam echo sounders using raw EM3000 data. In Proceedings of the Oceans ‘99 MTS/IEEE Riding the Crest into the 21st Century Conference and Exhibition, Seattle, WA, USA, 13–16 September 1999. [Google Scholar]
- Naar, D.F.; Donahue, B.T. High-Resolution Multibeam Survey of ONR Mine Burial and Scour Study Area near Clearwater, Florida. In AGU Fall Meeting Abstracts; American Geophysical Union: Washington, DC, USA, 2002. [Google Scholar]
- Zhi, H.; Siwabessy, J.; Nichol, S.L.; Brooke, B.P. Predictive mapping of seabed substrata using high-resolution multibeam sonar data: A case study from a shelf with complex geomorphology. Mar. Geol. 2014, 357, 37–52. [Google Scholar] [CrossRef]
- Shepard, F.P. Nomenclature Based on Sand-silt-clay Ratios. J. Sediment. Res. 1954, 24, 151–158. [Google Scholar]
- Brekhovskikh, L.M.; Lysanov, Y.P.; Beyer, R.T. Fundamentals of Ocean Acoustics. J. Acoust. Soc. Am. 1998, 90, 566–567. [Google Scholar]
- Macqueen, J.B. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, CA, USA, 21 June–18 July 1965. [Google Scholar]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering—ScienceDirect. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Hebb, D.O. The Organization of Behavior; Wiley-Interscience: New York, NY, USA, 1949. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Settings |
|---|---|
| operating depth | 1–150 m |
| ping rate | 40 Hz |
| beamwidth | 1.5° |
| across-track coverage | four times the depth |
| sonar frequency | 300 kHz |
| seafloor detection mode | phase and amplitude bottom detection algorithm |
| swath width | 130° |
| beams per ping | 127 |
| gain | −3 dB |
| Sediment | Parameter | ||||
|---|---|---|---|---|---|
| Bedrock | maximum | −8.3 | −14.6 | 164 | 1.4 |
| minimum | −27.8 | −21.8 | 4.2 | −2.0 | |
| average | −13.3 | 24.1 | 24.1 | −0.5 | |
| standard deviation | 3.1 | 1.6 | 35.1 | 0.8 | |
| Gravel | maximum | −8.0 | −17.1 | 108.2 | 2.6 |
| minimum | −17.1 | −22.6 | 9.1 | −0.4 | |
| average | −14.0 | −18.5 | 9.8 | 1.4 | |
| standard deviation | 1.9 | 1.2 | 30.6 | 0.7 | |
| Clay | maximum | −6.8 | −20.4 | 234.1 | 2.3 |
| minimum | −14.9 | −17.5 | 47.8 | 0.9 | |
| average | −10.2 | −19.6 | 116.2 | 1.4 | |
| standard deviation | 1.8 | 0.6 | 27.6 | 0.3 | |
| Sandy clay | maximum | −5.8 | −17.2 | 197.6 | 1.6 |
| minimum | −12.8 | −20.1 | 90.1 | 0.7 | |
| average | −9.6 | −18.6 | 143.2 | 1.3 | |
| standard deviation | 1.9 | 0.3 | 24.0 | 0.2 | |
| Silty sand | maximum | −14.7 | −24.3 | 144.9 | 3.1 |
| minimum | −18.1 | −26.8 | 107.3 | 2.2 | |
| average | −16.5 | −25.7 | 114.1 | 2.8 | |
| standard deviation | 0.6 | 0.4 | 10.2 | 0.1 | |
| Sand–silt–clay | maximum | −13.8 | −23.5 | 151.8 | 3.2 |
| minimum | −18.6 | −25.5 | 104.1 | 2.3 | |
| average | −16.5 | −24.6 | 116.4 | 2.9 | |
| standard deviation | 0.7 | 0.5 | 10.9 | 0.1 |
| Sediment Type | Field Sampling | Number of Categories | K-Medoids Result | SOM Result | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bedrock | 206 | 2 | 1(206) | 2(0) | 1(206) | 2(0) | ||||
| 3 | 1(17) | 2(0) | 3(189) | 1(204) | 2(2) | 3(0) | ||||
| 4 | 1(9) | 2(54) | 3(0) | 4(143) | 1(0) | 2(15) | 3(0) | 4(191) | ||
| Gravel | 44 | 2 | 1(44) | 2(0) | 1(25) | 2(19) | ||||
| 3 | 1(36) | 2(8) | 3(0) | 1(21) | 2(0) | 3(23) | ||||
| 4 | 1(19) | 2(4) | 3(6) | 4(5) | 1(10) | 2(18) | 3(12) | 4(0) | ||
| Clay | 294 | 2 | 1(283) | 2(11) | 1(262) | 2(32) | ||||
| 3 | 1(294) | 2(0) | 3(0) | 1(249) | 2(0) | 3(45) | ||||
| 4 | 1(261) | 2(33) | 3(0) | 4(0) | 1(85) | 2(191) | 3(0) | 4(18) | ||
| Sandy clay | 93 | 2 | 1(87) | 2(6) | 1(38) | 2(55) | ||||
| 3 | 1(90) | 2(3) | 3(0) | 1(10) | 2(3) | 3(84) | ||||
| 4 | 1(80) | 2(13 | 3(0) | 4(0) | 1(38) | 2(15) | 3(10) | 4(33) | ||
| Silty sand | 236 | 2 | 1(0) | 2(236) | 1(0) | 2(236) | ||||
| 3 | 1(0) | 2(236) | 3(0) | 1(0) | 2(236) | 3(0) | ||||
| 4 | 1(0) | 2(236) | 3(0) | 4(0) | 1(0) | 2(236) | 3(0) | 4(0) | ||
| Sediment Type | Field Sampling | K-Medoids | SOM | K-Medoids Accuracy | SOM Accuracy | ||
|---|---|---|---|---|---|---|---|
| Bedrock | 206 | Bedrock | 188 | Bedrock | 160 | 91.3% | 77.7% |
| Gravel | 18 | Gravel | 18 | ||||
| Sandy clay | 25 | ||||||
| Clay | 3 | ||||||
| Gravel | 44 | Bedrock | 2 | Sandy clay | 12 | 75.0% | 47.7% |
| Clay | 9 | Clay | 11 | ||||
| Gravel | 33 | Gravel | 21 | ||||
| Clay | 294 | Sandy clay | 25 | Sandy clay | 143 | 81.6% | 10.9% |
| Gravel | 29 | Gravel | 110 | ||||
| Clay | 240 | Silty sand | 9 | ||||
| Clay | 32 | ||||||
| Sandy clay | 93 | Sandy clay | 90 | Sandy clay | 64 | 96.8% | 68.8% |
| Clay | 3 | Clay | 15 | ||||
| Silty sand | 4 | ||||||
| Gravel | 10 | ||||||
| Silty sand | 236 | Sandy clay | 4 | Sandy clay | 5 | 98.3% | 97.8% |
| Silty sand | 232 | Silty sand | 231 | ||||
| Total | 873 | 89.7% | 58.2% | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Zhai, J.; Zou, B.; Shao, Q.; Hou, G. A Novel Acoustic Sediment Classification Method Based on the K-Mdoids Algorithm Using Multibeam Echosounder Backscatter Intensity. J. Mar. Sci. Eng. 2021, 9, 508. https://doi.org/10.3390/jmse9050508
Yu X, Zhai J, Zou B, Shao Q, Hou G. A Novel Acoustic Sediment Classification Method Based on the K-Mdoids Algorithm Using Multibeam Echosounder Backscatter Intensity. Journal of Marine Science and Engineering. 2021; 9(5):508. https://doi.org/10.3390/jmse9050508
Chicago/Turabian StyleYu, Xiaochen, Jingsheng Zhai, Bo Zou, Qi Shao, and Guangchao Hou. 2021. "A Novel Acoustic Sediment Classification Method Based on the K-Mdoids Algorithm Using Multibeam Echosounder Backscatter Intensity" Journal of Marine Science and Engineering 9, no. 5: 508. https://doi.org/10.3390/jmse9050508