
Towards Realizing Intelligent Coordinated Controllers for Multi-USV Systems Using Abstract Training Environments


Abstract
:1. Introduction
- A generic framework for an autonomous unmanned systems training system design that supports operational data collection in a closed-loop was developed;
- We present a realistic abstract digital maritime environment for interactive multi-USV systems that can be used for multi-agent reinforcement learning;
- A behavior-driven immunized fuzzy classifier system approach for multi-USV coordinated intelligent control and decision-making is presented;
- We demonstrate the feasibility of our approach in realizing improved decision-making in multi-USV missions.
2. Background and Motivation
3. Multi-USVs Training System Design
System Architecture
4. Multi-USV Interactive Environment Design
4.1. USV Physical Engine
- is a vector of position and euler angles in the m-frame;
- is a vector of linear and angular velocities in the d-frame;
- is the hydrodynamic terms of relative velocities vector, i.e., the difference between the vessel velocity relative to the fluid velocity and of the velocity of marine currents expressed in the reference frame;
- is the forces and moments of environmental disturbances of superimposed wind, currents and waves;
- The parameters J, M, D, C are the rotational transformation, inertia, damping and the coriolis and centric fugal matrices, respectively.
4.1.1. Modeling Buoyancy
4.1.2. Actuator and Sensor Modelling
4.1.3. Wave, Wind and Current Modeling
5. Multi-USV Training Algorithm Design
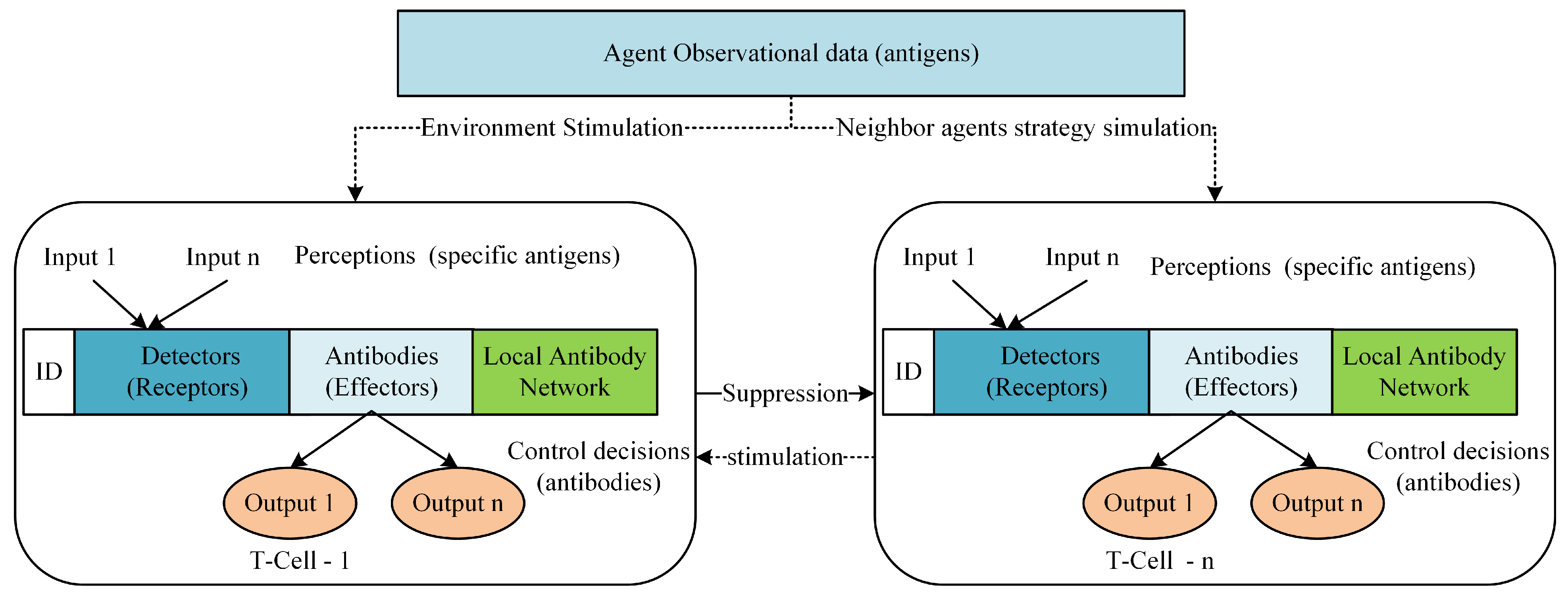
5.1. Agent Knowledge Modelling and Representation
5.2. Decision-Making and Evaluation Mechanism
- At each decision step, the agent activates behaviors according to the environmental stimulation;
- For every activated behavior, we generate a set of strategies or determine the match set of strategies (B-Cells). When multiple tasks are detected within the behavior, a match set is formed for each task. For example, when a track behavior is activated after USV detects multiple targets, the behavior model generates a strategy for each target using the attributes of each task (target);
- Then, the agent establishes connections between B-Cells based on the selected task. Connections between B-Cells are established based on the tasks and behavior under which they are generated or activated.
- To coordinate with nearby agents, the same is done by the agent with respect to nearby agents and the detected targets. Agents can also communicate with nearby agents within a communication range to obtain the strategy concentration for shared behaviors’ activation to select the best strategy with respect to a task and submit to a behavior learner;
- Apply immune network dynamics to update the concentration of each B-Cell;
- The final actions of the environment are emitted from the classifiers (B-Cells) with a higher concentration after interacting with other classifiers.
- N is the number of B-Cells that have an inhibitory or stimulating effect on the B-Cell;
- is the affinity between B-Cell a and current stimuli (antigens);
- is the mutual stimulus coefficient of antibody j into B-Cell a;
- represents the inhibitory effect of B-Cell k into B-Cell a;
- is the rate of the natural death rate of B-Cell a;
- is the bounded concentrations imposed on a B-Cell modeled as a squashing function for normalized concentration values [53];
- The coefficients , and are weight factors that determine the significance of the individual terms.
5.3. Evolution Mechanism: Clonal and Negative Selection
- At the beginning of training, T-Cell receptors must undergo the rearrangement process for the recombination of genes that express T-Cell receptors to form the knowledge base of all encoded behaviors;
- Initialize a non-self database to empty or using prior knowledge where the designer encodes inconsistent antibody (control action) mapping as the antibody set for individual behaviors (T-Cells);
- Randomly initialize an N population of the antibody set for each T-Cell by assigning an antibody from the valid antibodies of the respective T-Cell to each B-Cell to form the initial controllers;
- Compare the current generated antibodies with those in the non-self database to remove/modify inconsistent antibody-sets;
- Next, the simulator is run with the current generation of antibodies for each behavior N times to test each set in the population. In each run, we apply the decision-making mechanism described above to select the classifiers whose actions are posted to the environment;
- At the end of each episode, we apply the evaluation mechanism to evaluate the antibody set of each behavior;
- At the end of each generation of the population of antibodies, the concentration level of classifiers (B-Cells) based on the performance of individual behaviors’ entire antibody set is used to determine the n best antibody sets;
- Clone and store the classifiers of the elite antibody sets that were triggered and re-compose the global cure database with these classifiers. Submit the population of clones to a hyper-mutation scheme by randomly selecting and changing the antibodies of classifiers to form temporary antibody sets to be evaluated next;
- Add the set of antibodies that results in the poor performance of the behavior to the non-self database. After the B-Cell undergoes mutation by changing the action (antibody) parts of the B-Cells, the resulted antibody set is compared with those in the non-self database and modified if the similarities between them is below a predefined threshold;
- On the other hand, elite B-Cells resulting from other agents are cloned by other agents when other agents succeed in finding more optimal actions for a behavior execution;
- Repeat Steps 5 to 10 until a termination condition is met.
6. Experiments
6.1. General System Setup
6.2. Case 1: Multi-USV Target Escort
6.3. Case 2: Cooperative Islands Conquering
6.4. Results and Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Dong, Y.; Zou, Q.; Zhang, R.; Kang, L.; Ren, C. An USV controlling autonomy level algorithm based on PROMMETHEE. In Proceedings of the 2016 12th World Congress on Intelligent Control and Automation (WCICA), Guilin, China, 12–15 June 2016; pp. 2460–2465. [Google Scholar] [CrossRef]
- Von Ellenrieder, K.D. Development of a USV-based bridge inspection system. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–10. [Google Scholar]
- Zhang, J.; Xiong, J.; Zhang, G.; Gu, F.; He, Y. Flooding disaster oriented USV UAV system development demonstration. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016; pp. 1–4. [Google Scholar]
- Shriyam, S.; Shah, B.; Gupta, S. Online Task Decomposition for Collaborative Surveillance of Marine Environment by a Team of Unmanned Surface Vehicles. J. Mech. Robot. 2018, 10. [Google Scholar] [CrossRef]
- Peng, Y.; Yang, Y.; Cui, J.; Li, X.; Pu, H.; Gu, J.; Xie, S.; Luo, J. Development of the USV ‘JingHai-I’ and sea trials in the Southern Yellow Sea. Ocean Eng. 2017, 131, 186–196. [Google Scholar] [CrossRef]
- Simetti, E.; Turetta, A.; Casalino, G.; Storti, E.; Cresta, M. Protecting Assets within a Civilian Harbour through the Use of a Team of USVs: Interception of Possible Menaces. In Proceedings of the IARP workshop on Robots for Risky Interventions and Environmental Surveillance-Maintenance (RISE’10), Sheffield, UK, 20–21 January 2010. [Google Scholar]
- Corfield, S.; Young, J. Unmanned Surface Vehicles—Game Changing Technology for Naval Operations. In Advances in Unmanned Marine Vehicles; IET: London, UK, 2006; pp. 311–328. [Google Scholar] [CrossRef]
- Pinko, E. Unmanned Vehicles in the Maritime Domain Missions, Capabilities, Technologies and Challenges. 2019. Available online: https://www.researchgate.net/publication/332420996 (accessed on 19 April 2021).
- Jakuba, M.V.; Kinsey, J.C.; Partan, J.W.; Webster, S.E. Feasibility of low-power one-way travel-time inverted ultra-short baseline navigation. In Proceedings of the OCEANS 2015—MTS/IEEE Washington, Washington, DC, USA, 19–22 October 2015; pp. 1–10. [Google Scholar] [CrossRef]
- Suzuki, N.; Kitajima, H.; Kaba, H.; Suzuki, T.; Suto, T.; Kobayashi, A.; Ochi, F. An experiment of real-time data transmission of sonar images from cruising UUV to distant support vessel via USV: Development of underwater real-time communication system (URCS) by parallel cruising. In Proceedings of the OCEANS 2015—Genova, Genova, Italy, 18–21 May 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Claus, B.; Kinsey, J.; Girdhar, Y. Towards persistent cooperative marine robotics. In Proceedings of the 2016 IEEE/OES Autonomous Underwater Vehicles (AUV), Tokyo, Japan, 6–9 November 2016; pp. 416–422. [Google Scholar] [CrossRef]
- Mitra, S.; Hayashi, Y. Neuro-fuzzy rule generation: Survey in soft computing framework. IEEE Trans. Neural Netw. 2000, 11, 748–768. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ernest, N. Genetic Fuzzy Trees for Intelligent Control of Unmanned Combat Aerial Vehicles. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2015. [Google Scholar] [CrossRef]
- Sabra, A.; Fung, W.K. A Fuzzy Cooperative Localisation Framework for Underwater Robotic Swarms. Sensors 2020, 20, 5496. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.; Xia, L.; Zhao, Q. Air-Combat Strategy Using Deep Q-Learning. In Proceedings of the 2018 Chinese Automation Congress (CAC), Xi’an, China, 30 November–2 December 2018; pp. 3952–3957. [Google Scholar] [CrossRef]
- Raboin, E.; Svec, P.; Nau, D.; Gupta, S. Model-predictive target defense by team of unmanned surface vehicles operating in uncertain environments. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3517–3522. [Google Scholar]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Garg, A.; Hasan, Y.A.; Yañez, A.; Tapia, L. Defensive Escort Teams via Multi-Agent Deep Reinforcement Learning. arXiv 2019, arXiv:1910.04537. [Google Scholar]
- Han, W.; Zhang, B.; Wang, Q.; Luo, J.; Ran, W.; Xu, Y. A Multi-Agent Based Intelligent Training System for Unmanned Surface Vehicles. Appl. Sci. 2019, 9, 1089. [Google Scholar] [CrossRef] [Green Version]
- Torres-Torriti, M.; Arredondo, T.; Castillo-Pizarro, P. Survey and comparative study of free simulation software for mobile robots. Robotica 2014, 1, 1–32. [Google Scholar] [CrossRef]
- Paravisi, M.; dos Santos, D.H.; Jorge, V.A.M.; Heck, G.; Gonçalves, L.M.G.; Amory, A.M. Unmanned Surface Vehicle Simulator with Realistic Environmental Disturbances. Sensors 2019, 19, 1068. [Google Scholar] [CrossRef] [Green Version]
- Velasco, O.; Valente, J.; Alhama Blanco, P.J.; Abderrahim, M. An Open Simulation Strategy for Rapid Control Design in Aerial and Maritime Drone Teams: A Comprehensive Tutorial. Drones 2020, 4, 37. [Google Scholar] [CrossRef]
- Borreguero, D.; Velasco, O.; Valente, J. Experimental Design of a Mobile Landing Platform to Assist Aerial Surveys in Fluvial Environments. Appl. Sci. 2019, 9, 38. [Google Scholar] [CrossRef] [Green Version]
- Bingham, B.; Agüero, C.; McCarrin, M.; Klamo, J.; Malia, J.; Allen, K.; Lum, T.; Rawson, M.; Waqar, R. Toward Maritime Robotic Simulation in Gazebo. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; pp. 1–10. [Google Scholar] [CrossRef]
- Garg, S.; Quintas, J.; Cruz, J.; Pascoal, A.M. NetMarSyS–A Tool for the Simulation and Visualization of Distributed Autonomous Marine Robotic Systems. In Proceedings of the 2020 IEEE/OES Autonomous Underwater Vehicles Symposium (AUV), St. Johns, NL, Canada, 30 September–2 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Smith, R.; Dike, B.; Mehra, R.; Ravichandran, B.; El-Fallah, A. Classifier systems in combat: Two-sided learning of maneuvers for advanced fighter aircraft. Comput. Methods Appl. Mech. Eng. 2000, 186, 421–437. [Google Scholar] [CrossRef]
- Studley, M.; Bull, L. X-TCS: Accuracy-based learning classifier system robotics. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–5 September 2005; Volume 3, pp. 2099–2106. [Google Scholar]
- Wang, C.; Wiggers, P.; Hindriks, K.; Jonker, C.M. Learning Classifier System on a humanoid NAO robot in dynamic environments. In Proceedings of the 2012 12th International Conference on Control Automation Robotics Vision (ICARCV), Guangzhou, China, 5–7 December 2012; pp. 94–99. [Google Scholar]
- Smith, R.E.; Dike, B.A.; Ravichandran, B.; El-Fallah, A.; Mehra, R.K. Two-Sided, Genetics-Based Learning to Discover Novel Fighter Combat Maneuvers. In Applications of Evolutionary Computing; Boers, E.J.W., Ed.; Springer: Berlin/Heidelberg, Germany, 2001; pp. 233–242. [Google Scholar]
- Tosik, T.; Maehle, E. MARS: A simulation environment for marine robotics. In Proceedings of the 2014 Oceans—St. John’s, St. John’s, NL, Canada, 14–19 September 2014; pp. 1–7. [Google Scholar]
- Bonarini, A. An Introduction to Learning Fuzzy Classifier Systems. In Proceedings of the IWLCS 1999, Orland, FL, USA, 13 July 1999; pp. 83–106. [Google Scholar] [CrossRef]
- Booker, L. Classifier Systems that Learn Internal World Models. Mach. Learn. 1988, 3, 161–192. [Google Scholar] [CrossRef]
- Booker, L.; Goldberg, D.; Holland, J. Classifier systems and genetic algorithms. Artif. Intell. 1989, 40, 235–282. [Google Scholar] [CrossRef]
- Nantogma, S.; Ran, W.; Yang, X.; Xiaoqin, H. Behavior-based Genetic Fuzzy Control System for Multiple USVs Cooperative Target Protection. In Proceedings of the 2019 3rd International Symposium on Autonomous Systems (ISAS), Shanghai, China, 29–31 May 2019; pp. 181–186. [Google Scholar] [CrossRef]
- Hunt, J.E.; Cooke, D.E. Learning using an artificial immune system. J. Netw. Comput. Appl. 1996, 19, 189–212. [Google Scholar] [CrossRef]
- Farmer, J.; Packard, N.H.; Perelson, A.S. The immune system, adaptation, and machine learning. Phys. D Nonlinear Phenom. 1986, 22, 187–204. [Google Scholar] [CrossRef]
- Jerne, N. Towards a network theory of the immune system. Ann. Immunol. 1974, 125 C, 373–389. [Google Scholar]
- Burnet, F.M.F.M. The Clonal Selection Theory of Acquired Immunity; Vanderbilt University Press: Nashville, TN, USA, 1959; p. 232. Available online: https://www.biodiversitylibrary.org/bibliography/8281 (accessed on 6 February 2021).
- Matzinger, P. The danger model: A renewed sense of self. Science 2002, 296, 301–305. [Google Scholar] [CrossRef] [Green Version]
- Kong, X.; Liu, D.; Xiao, J.; Wang, C. A multi-agent optimal bidding strategy in microgrids based on artificial immune system. Energy 2019, 189, 116154. [Google Scholar] [CrossRef]
- De Castro, L.; Von Zuben, F. The Clonal Selection Algorithm with Engineering Applications. Artif. Immune Syst. 2001, 8, 36–39. [Google Scholar]
- Youssef, A.; Osman, M.; Aladl, M. A Review of the Clonal Selection Algorithm as an Optimization Method. Leonardo J. Sci. 2017, 16, 1–4. [Google Scholar]
- Michel, O. Webots: Professional Mobile Robot Simulation. J. Adv. Robot. Syst. 2004, 1, 39–42. [Google Scholar]
- Koenig, N.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Sendai, Japan, 28 September–2 October 2004; Volume 3, pp. 2149–2154. [Google Scholar] [CrossRef] [Green Version]
- Prats, M.; Pérez, J.; Fernández, J.J.; Sanz, P.J. An open source tool for simulation and supervision of underwater intervention missions. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 2577–2582. [Google Scholar] [CrossRef]
- McCue, L. Handbook of Marine Craft Hydrodynamics and Motion Control [Bookshelf]. IEEE Control Syst. Mag. 2016, 36, 78–79. [Google Scholar] [CrossRef]
- Velueta, M.; Rullan, J.; Ruz-Hernandez, J.; Alazki, H. A Strategy of Robust Control for the Dynamics of an Unmanned Surface Vehicle under Marine Waves and Currents. Math. Probl. Eng. 2019, 2019, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Xiao, L.; Jouffroy, J. Modeling and Nonlinear Heading Control of Sailing Yachts. IEEE J. Ocean. Eng. 2014, 39, 256–268. [Google Scholar] [CrossRef]
- Tosik, T.; Schwinghammer, J.; Feldvoß, M.J.; Jonte, J.P.; Brech, A.; Maehle, E. MARS: A simulation environment for marine swarm robotics and environmental monitoring. In Proceedings of the OCEANS 2016, Shanghai, China, 10–13 April 2016. [Google Scholar] [CrossRef]
- Hinsinger, D.; Neyret, F.; Cani, M.P. Interactive Animation of Ocean Waves. In Proceedings of the ACM-SIGGRAPH/EG Symposium on Computer Animation (SCA), San Antonio, TX, USA, 21–22 July 2002. [Google Scholar] [CrossRef] [Green Version]
- Thon, S.; Dischler, J.; Ghazanfarpour, D. Ocean waves synthesis using a spectrum-based turbulence function. In Proceedings of the Computer Graphics International 2000, Geneva, Switzerland, 19–24 June 2000; pp. 65–72. [Google Scholar] [CrossRef]
- Nantogma, S.; Xu, Y.; Ran, W. A Coordinated Air Defense Learning System Based on Immunized Classifier Systems. Symmetry 2021, 13, 271. [Google Scholar] [CrossRef]
- Raza, A.; Fernandez, B.R. Immuno-inspired robotic applications: A review. Appl. Soft Comput. 2015, 37, 490–505. [Google Scholar] [CrossRef] [Green Version]
- Holland, J.H. Escaping Brittleness: The Possibilities of General-Purpose Learning Algorithms Applied to Parallel Rule-Based Systems. In Machine Learning: An Artificial Intelligence Approach; Michalski, R.S., Carbonell, J.G., Mitchell, T.M., Eds.; Morgan Kaufmann: Los Altos, CA, USA, 1986; Volume 2. [Google Scholar]
- Smith, S.F. A Learning System Based on Genetic Adaptive Algorithms. Ph.D. Thesis, University of Pittsburgh, Pittsburgh, PA, USA, 1980. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Item | Description | Examples |
|---|---|---|
| Internal state | These data consist of information that is internal to the USV | Rudder angle, radar range, engine power, weapon type, number of ammunition, etc. |
| External state | This consists of USV external information in relation to the environment coordinates | position, orientation, speed, heading, etc. |
| Observation | These data include the external state information of objects detected by USV sensors | distance, relative heading, relative position, dimension, etc. |
| Weather | This data model holds the environment data contents of wind, currents and waves data | wind speed, wind direction, waves height, currents speed, etc. |
| Simulation info | The information and data pertaining to the abstract environment of the USV | simulation mode, simulation time steps, and configuration data |
| Behavior Module (T-Cell) | Control Actions (Antibodies) | Description |
|---|---|---|
| Alignment | Speed, direction | Align with other agents or an object |
| Avoid collision | speed, direction | Avoid colliding with a static or dynamic object |
| Pursue | Speed, direction | Chase a target |
| Detour | Speed, direction | Get behind a target as soon as possible |
| Track | Speed, direction | Follow a target at a specific distance |
| Search | Speed, direction | Search an area |
| Attack | Weapon angle, salvo | fire at a target with an appropriate number of salvos |
| Assist teammate | Speed, direction | Move to a teammate performing a task |
| Conquer | Speed, direction | Move to an island location |
| Attribute (Antigen or Input Variable) | Description |
|---|---|
| V | The current velocity of usv |
| V | The velocity of a detected threat usv |
| V | The velocity of the protected target |
| H | Current heading of usv |
| H | Current heading of detected threat usv |
| H | Heading of protected target. |
| D | Distance to task (enemy usv or island to be conqured) |
| D | Distance to protected target |
| H | Heading difference of task and current usv |
| D | Distance to the assigned neighbor |
| N | Number of threats detected by this usv |
| N | Number of threats detected by neighbor USVs |
| T | Number of available neighbors |
| C | Number of un-responded calls |
| C | Number of objects or agents in collision region |
| DC | distance to potential collision point |
| W | Speed of wind |
| W | Direction of wind |
| C | Speed of water current |
| C | Direction of water current |
| W | Wave height |
| Type | Primitive Fuzzy Terms (Antibodies) |
|---|---|
| Steer control | straightAhead, turnSlightlyLeft, turnVeryLeft, turnLeft, turnExtremelyLeft, |
| turnVeryRight, turnRight, turnSlightlyLeft, turnExtremelyRight, | |
| Throttle control | reverseSpeed, verySlowSpeed, lowSpeed, normalSpeed, fastSpeed |
| Gun and radar control | fire(angle), performDetection |
| Scenario/ Settings | B6vsR3 (Scene 1) | B10vsR7 (Scene 2) | B10vsR10 (Scene 4) | B7vsR10 (Scene 3) | ||||
|---|---|---|---|---|---|---|---|---|
| Blue | Red | Blue | Red | Blue | Red | Blue | Red | |
| Radar range | 300 m | 300 m | 200m | 300 m | 300 m/s | 250 m/s | 250 m/s | 300 m/s |
| Firing range | 95 m | 95 m | 75 m | 95 m | 75 m | 90 m | 70 m | 80 m |
| Max gun turn | 30 | 30 | 25 | 30 | 25 | 25 | 20 | 30 |
| Max turn angle | 30 | 30 | 25 | 30 | 25 | 25 | 20 | 30 |
| Max speed | 30 m/s | 30 m/s | 30 m/s | 25 m/s | 25 m/s | 30 m/s | 30 m/s | 30 m/s |
| Wind speed | 3 m/s | 3 m/s | 5 m/s | 8 m/s | ||||
| current speed | 2 m/s | 1.5 m/s | 3 m/s | 6 m/s | ||||
| Protected Target | Enemy Detected | Behavior Output |
|---|---|---|
| Destroyed | Is none | Retreat |
| Destroyed | Is more | Intercept closest enemy |
| Destroyed | Is behind me | Perform detour |
| Is alive | Is many | Intercept closest enemy |
| Is alive | Not attacking | Attack target |
| Is alive | Is behind me | Perform detour |
| Is in firing range | - | Fire at target |
| Is alive or dead | Is in firing range | fire at enemy |
| Is alive | Is none | Attack target |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nantogma, S.; Pan, K.; Song, W.; Luo, R.; Xu, Y. Towards Realizing Intelligent Coordinated Controllers for Multi-USV Systems Using Abstract Training Environments. J. Mar. Sci. Eng. 2021, 9, 560. https://doi.org/10.3390/jmse9060560
Nantogma S, Pan K, Song W, Luo R, Xu Y. Towards Realizing Intelligent Coordinated Controllers for Multi-USV Systems Using Abstract Training Environments. Journal of Marine Science and Engineering. 2021; 9(6):560. https://doi.org/10.3390/jmse9060560
Chicago/Turabian StyleNantogma, Sulemana, Keyu Pan, Weilong Song, Renwei Luo, and Yang Xu. 2021. "Towards Realizing Intelligent Coordinated Controllers for Multi-USV Systems Using Abstract Training Environments" Journal of Marine Science and Engineering 9, no. 6: 560. https://doi.org/10.3390/jmse9060560